1. Introduction
Natural disasters such as earthquakes, floods, hurricanes, and landslides often cause significant damage to critical infrastructure, including road networks [
1]. Roads play a vital role in disaster response logistics, serving as essential corridors for search and rescue operations, relief supply delivery, and post-disaster recovery activities. However, transportation infrastructure is particularly vulnerable during disasters as access is frequently obstructed by debris, landslides, or collapsed structures [
2].
Traditional road damage assessment methods primarily rely on field surveys or the manual interpretation of aerial imagery. While effective in small-scale areas, these approaches are labor-intensive, time-consuming, and potentially hazardous for field personnel [
3,
4]. In large-scale disaster zones, it is nearly impossible to conduct exhaustive on-site inspections within a short period. These limitations underscore the urgent need for an automated and scalable approach to road damage assessment.
Recent advancements in remote sensing and the increasing availability of high-resolution satellite imagery have opened new possibilities for rapid disaster assessment [
5,
6,
7]. Satellite images can provide timely, wide-area coverage immediately after a disaster, enabling situational awareness without requiring physical access to the site [
8,
9,
10,
11]. When combined with deep learning techniques, such imagery can facilitate the automated detection and quantification of infrastructure damage [
12,
13], thereby accelerating decision-making in disaster response and recovery planning. However, achieving reliable automated assessment is a formidable technical challenge. The visual signatures of road damage can be subtle, and more importantly, the severe class imbalance—where damaged areas constitute a tiny fraction of the total area—poses a significant hurdle to robust model training [
5,
9].
Most existing deep learning-based research in this domain has focused on building damage assessment [
14,
15,
16,
17,
18,
19,
20], which is supported by datasets such as xBD and xView2 [
21,
22,
23,
24,
25]. In contrast, despite the critical operational role of road networks during emergencies, studies targeting road infrastructure remain limited [
26,
27]. The lack of reliable road damage detection and evaluation techniques introduces a significant gap in current disaster response systems.
To address this issue, this study aims to propose a deep learning framework that automatically detects and classifies road damage using pre- and post-disaster satellite imagery. Unlike building-focused approaches, the proposed method segments road infrastructure into three categories—background, undamaged, and damaged roads—allowing for more refined and timely infrastructure assessments. The proposed model leverages change detection techniques to capture structural variations in road segments and provides quantitative information that can support disaster response activities, such as prioritizing road restoration and estimating accessible routes.
The remainder of this study is organized as follows:
Section 2 provides an informative summary of the related works.
Section 3 describes the research methodology with the underlying concepts and algorithms for road damage detection, which is followed by experimental designs with specific processes and parameters in
Section 4. Lastly,
Section 5 and
Section 6 contain quantitative and qualitative results of three approaches and conclusions, research limitations, and future research issues.
2. Related Works
This section reviews the progression and limitations of image-based approaches for road damage assessment in disaster scenarios and positions the proposed study within this context. Specifically, this study examines prior research from three perspectives: (1) remote sensing-based techniques for road damage assessment, (2) applications of the xBD dataset, and (3) recent advances in image segmentation with change detection method.
2.1. Road Damage Detection, Assessment, and Classification
Assessing road infrastructure damage is critical for disaster response and recovery. Numerous deep learning-based approaches have been proposed in recent years, which can be broadly classified based on the type of data used and the architectural frameworks employed.
Karimzadeh et al. [
28] developed a multi-layer perceptron model that integrates post-earthquake Synthetic Aperture Radar (SAR) imagery and field-based International Roughness Index (IRI) data from the 2016 Kumamoto earthquake in Japan, achieving a detection accuracy of 87.1%. Zhang et al. [
29] applied a segmentation model based on the Segment Anything Model (SAM) to high-resolution satellite images and reported a pixel-level F1-score of 76.09% using the precisely annotated CAU-RoadDamage dataset.
Kopiika et al. [
20] quantified bridge damage in Ukraine after disaster events using remote sensing and multi-layer deep learning models, while Rastiveis et al. [
30] proposed a hybrid CNN model with Gabor filters for the simultaneous detection of damage to both roads and buildings. Arya et al. [
31] leveraged the RDD2022 dataset, which comprises road damage images from six countries, and applied a YOLO ensemble model to achieve a maximum F1-score of 76.9%. Zhao et al. [
27] and Jiang [
32] utilized CNN models to detect and classify road damage from satellite and smartphone images, yielding improved efficiency and accuracy. Zeng and Zhong [
33], Doshi and Yilmaz [
34], and Guo and Zhang [
35] proposed enhanced YOLO-based models, achieving higher F1-scores up to 0.636 and improved mAP (mean average precision) by 2.5%.
Sakamoto [
36] exploited elevation data to identify flooded road segments. Wei and Zhang [
3] investigated road continuity, and Gheidar-Kheljani and Nasiri [
37] supported the deep learning process with optimization techniques, resulting in more robust identification of road damage from disasters.
However, existing studies exhibit two primary limitations: (i) the lack of explicit change detection mechanisms within model architectures, and (ii) optimization for specific object types (e.g., buildings or roads), which hinders generalization across other infrastructure types. To address these gaps, this study introduces a change detection-centered framework utilizing temporally aligned satellite imagery to quantitatively evaluate road damage.
2.2. Use Cases of xBD Dataset
The xBD dataset, developed jointly by Maxar Technologies and DARPA, is a publicly available large-scale satellite imagery dataset designed for multi-disaster building damage analysis. It includes over 850,000 annotated building footprints across 15 countries and eight disaster types, including earthquakes, floods, hurricanes, and wildfires [
21,
22,
23,
38,
39,
40].
Weber and Kan [
24] proposed a multi-temporal fusion CNN using xBD image pairs, and Bai et al. [
38] combined a semi-Siamese network with a pyramid pooling module to enhance classification performance, achieving an F1-score of up to 0.90. Xia et al. [
39] applied self-supervised learning to the unlabeled portion of xBD images, obtaining better performance comparable to fully supervised models. Chen et al. [
25] introduced a state-space model architecture using Visual Mamba for building damage assessment, outperforming CNN- and Transformer-based methods. Ma et al. [
41] and Melamed et al. [
42] developed extended and augmented versions of xBD to assess damage to not only buildings but also electrical infrastructure.
Despite these research efforts, there remain inherent limitations. While most of these studies focus on building-level damage assessment, applications to linear infrastructure (i.e., roads) are still rare. Therefore, this study repurposes the temporally aligned satellite imagery in xBD for road-specific training, presenting a novel use case of the dataset for road damage detection.
2.3. Image Segmentation with Change Detection Method
Change detection is a key technique that quantifies differences between temporally distinct image pairs, making it highly suitable for extracting disaster-induced infrastructure damage, as demonstrated by Weber and Kan [
24] and Li et al. [
43].
Daudt et al. [
44] introduced the Fully Convolutional Siamese Network (FC-Siamese), which internally resolves image alignment issues across pre- and post-disaster imagery, offering significant improvements in computational efficiency. Zhong and Wu [
45] utilized a Triplet U-Net architecture to fuse spatial and spectral features for high-resolution remote sensing imagery. Wang et al. [
46] improved the Siamese U-Net by incorporating a flow alignment module, resulting in a gain of 7. 32% in the F1-score. More recently, Tang et al. [
47] and Zhou and Hu [
48] developed lightweight models such as the Siamese Swin-U-Net using a Swin Transformer, achieving a precision of 94.67% with minimal parameters.
These developments reflect a paradigm shift from object-based detection toward change-focused frameworks. In the context of road infrastructure, which is linear, structured and topologically constrained, difference-based segmentation and Siamese architectures offer promising strategies. Based on this rationale, this study introduces and theoretically contrasts three types of models with differing algorithmic structures. The first is a baseline single-timeframe segmentation model, which performs standard semantic segmentation using only post-disaster imagery. The second is a difference-based model that explicitly computes pixel-wise differences between pre- and post-disaster images before feeding the result into a segmentation network. The third is a Siamese-based model, which processes paired images through dual-branch networks to learn temporal change representations via feature similarity and implicit alignment.
A detailed comparison of the advantages and limitations of these three approaches is summarized in
Table 1.
3. Methodology
This section presents the analytical framework and detailed model architectures used for road damage detection based on pre- and post-disaster satellite imagery. Focusing on change detection techniques applied to temporally aligned image pairs, this study systematically designs, implements, and compares three distinct approaches: single-timeframe overlay segmentation, difference image-based segmentation, and a Siamese network for feature-level fusion.
3.1. Overlay-Based Approach: Post Hoc Comparison
The first approach establishes a baseline by treating damage assessment as a post-processing step following independent semantic segmentation. As described in the project’s experimental design, a standard U-Net model, denoted as with trainable parameters , is trained to perform semantic segmentation on individual images.
Let the pre- and post-disaster images be . The process is as follows:
3.1.1. Independent Segmentation
The trained segmentation model
is applied to both images separately to generate binary road masks. The output logits are passed through an ‘argmax’ function to yield class predictions.
where
are the predicted binary masks with 1 representing roads and 0 representing background.
3.1.2. Overlay and Damage Labeling
A rule-based overlay function,
, is applied to the two masks to generate the final 3-class damage assessment map,
. This logic is implemented in the project’s ‘utils/labeling.py’ utility. For each pixel
,
This approach is computationally simple and allows for the reuse of existing segmentation models but is highly susceptible to image misalignment and may fail to capture subtle damages not significant enough to alter the binary segmentation outcome.
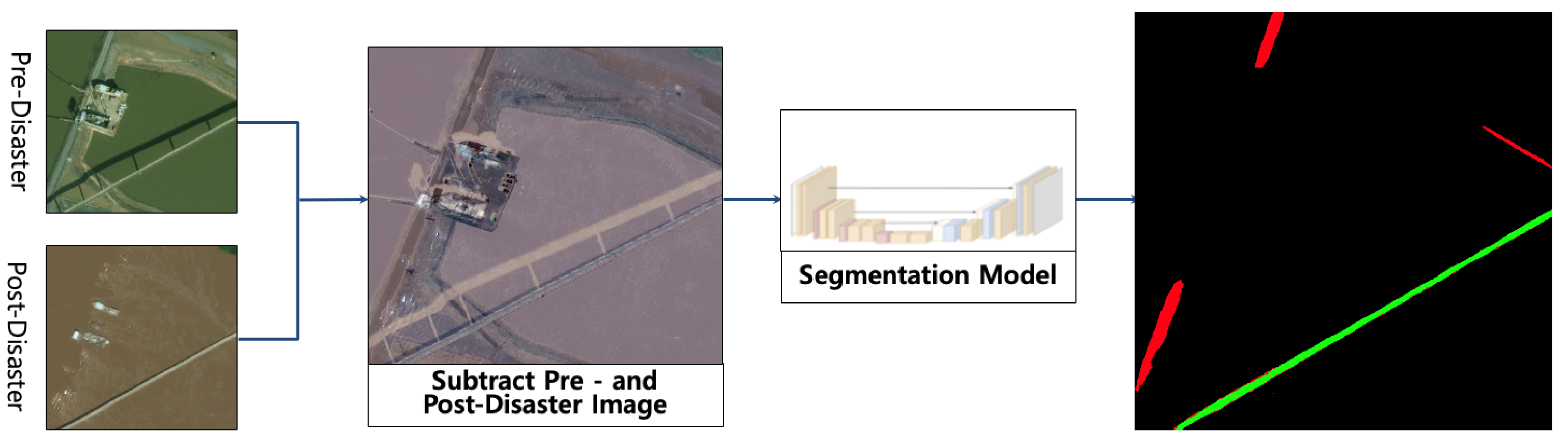
3.2. Difference-Based Approach: Change-Enhanced Segmentation
This approach directly models the change between the two time points by using a difference image as the input to the segmentation network. This strategy is designed to force the model to learn features from temporal changes explicitly. The process, as implemented in the ‘SingleDiffDataset’ class, is as follows.
3.2.1. Image Differencing
First, standard transformations and normalizations, denoted by
, are applied to both images. Then, a single difference image,
, is created by computing the element-wise subtraction of the pre-disaster image tensor from the post-disaster image tensor.
3.2.2. Direct 3-Class Segmentation
A standard U-Net model,
(identical in architecture to the one in 3.1 but trained differently), takes the 3-channel difference image
as its sole input. The network is trained end-to-end to directly output a 3-class segmentation map.
By feeding the network with explicit change information, this method is highly sensitive to alterations between images. However, it risks losing context present in the original images and can be sensitive to noise or non-damage-related changes like illumination or seasonal variations.
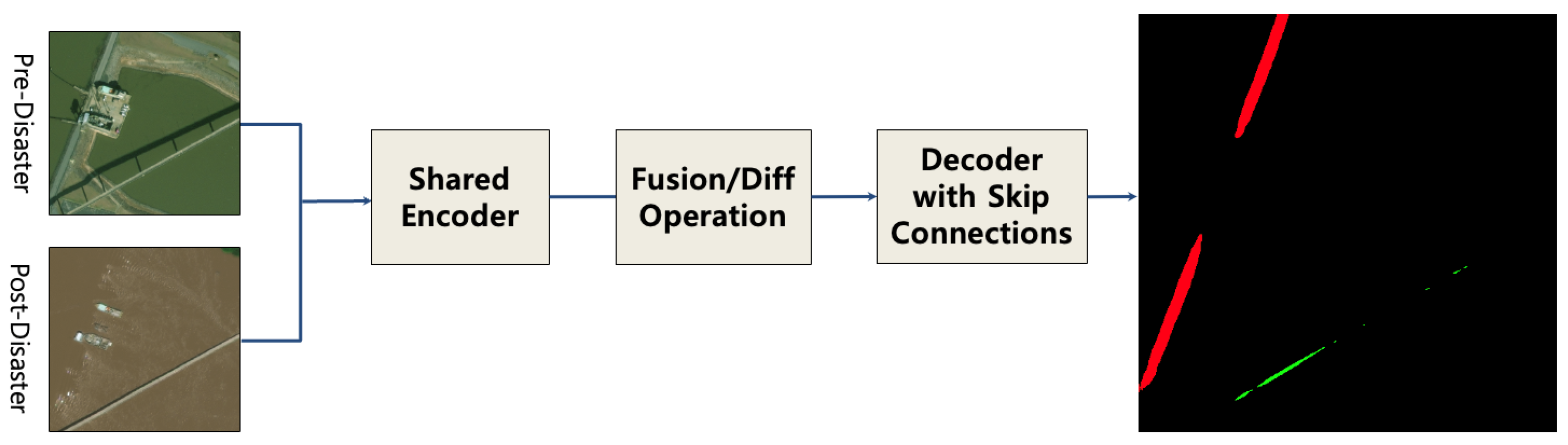
3.3. Siamese-Based Approach: Feature-Level Change Detection
This approach, implemented as the ‘SiameseDiffUNet’, provides the most sophisticated fusion mechanism by comparing features at multiple semantic levels within the network. It uses a U-Net architecture with a shared-weight encoder to ensure that features from both images are extracted in a consistent manner.
3.3.1. Siamese Encoder Path
A shared-weight encoder
, composed of
L levels, processes both
and
. Each level
i consists of convolutional blocks
and a downsampling operator
. The feature maps
generated at each level are defined as
(and identically for
using
).
3.3.2. Feature Differencing for Skip Connections
Instead of using the encoder features directly for skip connections, their element-wise absolute difference is calculated. This creates a set of “difference maps”
that explicitly represent the magnitude of change at each spatial scale.
3.3.3. Decoder Path with Fused Skip Connections
The decoder reconstructs the segmentation map hierarchically. The process begins at the deepest level L using the difference map . For all subsequent levels down to 1, the decoder block receives the concatenated input of the upsampled features from the level below and the difference map from the corresponding encoder level.
Let
be the output of the decoder at level
i.
where
is the upsampling operator and
is the concatenation operator.
3.3.4. Final Prediction
The output of the final decoder layer,
, is passed through a final convolutional layer
to produce the 3-class segmentation map.
This architecture forces the network to learn from the magnitude of feature changes across multiple scales, making it robust to global shifts (e.g., lighting) while remaining sensitive to local, structural disruptions indicative of damage.
4. Experimental Design
The proposed framework aims to automatically detect and quantify road damage using high-resolution satellite image pairs captured before and after a disaster. This section describes the experimental design of the study including datasets, labeling methodology, model implementation, training parameters, and computing environment. To ensure a fair and rigorous comparison despite architectural differences among the three proposed models, a strictly controlled experimental environment was established. For example, all models were trained, validated, and tested on identical data splits. Key hyperparameters such as the optimizer (Adam), learning rate (0.0001), and batch size were held constant. For each model, training proceeded for up to 100 epochs, but the final version used for evaluation was selected based on the checkpoint that achieved the lowest validation loss rather than the final epoch. This approach ensures that each model is evaluated at its optimal generalization state. All experiments were conducted on the same hardware and software environment. Finally, a unified evaluation framework (F1b, F1d, F1s) was employed to enable direct performance comparison across all models. These controls ensure that any observed differences in performance are attributable to the models’ intrinsic architectures rather than experimental variation.
4.1. Dataset Introduction and Labeling
The primary dataset used in this study is xBD, consisting of a total of 9330 high-resolution satellite image pairs (i.e., pre- and post-disaster). Individual images were resized to 1024 × 1024 resolution. The dataset is split into training, validation, and test sets at a 7.0:1.5:1.5 ratio, that is, 5598 images, 1866 images, and 1866 images, respectively. In addition, pre-processing includes three steps such as radiometric normalization to standardize brightness levels, histogram matching to improve temporal consistency between image pairs. To prepare the images for the model input, each original 1024 × 1024 image was divided into four non-overlapping 512 × 512 patches via cropping. To address the challenge of non-disaster-related changes (e.g., road repaving) occurring between image acquisition dates, a specific labeling methodology was adopted. For each post-disaster image, the corresponding ground-truth mask was created by starting with the pre-disaster road mask as a template. Annotators then specifically marked only the sections that showed clear evidence of disaster-induced damage. Consequently, a repaved but structurally intact road would appear different in the imagery but remain labeled as ‘undamaged’ in the ground truth of this study. This process implicitly teaches the model to associate only labeled structural changes with the ‘damaged’ class while learning to tolerate mere appearance variations. While this strategy mitigates the issue, it is acknowledged that extreme non-disaster changes could still present a challenge, which remains a topic for future investigation.
Hybrid Labeling Strategy for Ground-Truth Generation
As the xBD dataset lacks official road annotations, a hybrid labeling strategy was developed to generate high-quality ground-truth masks. This approach consists of three sequential steps:
Baseline Generation via Transfer Learning: A U-Net segmentation model was first trained using the DeepGlobe Road Extraction dataset, which provides manually annotated, high-fidelity road masks. This pre-trained model was then applied to the pre-disaster images from the xBD dataset to infer baseline road labels.
Semi-Automated Labeling Pipeline: Concurrently, a semi-automated labeling process was implemented, combining YOLOv9 for initial road detection and the Segment Anything Model (SAM) for pixel-level refinement. This enabled large-scale label generation across xBD imagery.
Hybrid Validation and Quality Enhancement: To ensure label quality, the outputs from both pipelines were compared. Cases with significant discrepancies were flagged for manual expert review, wherein the label was either corrected manually or selected based on fidelity (e.g., choosing the DeepGlobe-informed mask when SAM results were noisy). This hybrid pipeline allowed us to construct a reliable, large-scale road mask dataset for training damage detection models while minimizing annotation noise.
The final ground-truth masks generated through this process consist of three distinct classes at the pixel level: background (class 0), undamaged road (class 1), and damaged road (class 2). This three-class definition serves as the foundational ground truth for the training and evaluation of all models presented in this study.
4.2. Model Implementation and Parameter Settings
Table 2 shows that three distinct deep learning models are designed and implemented based on the U-Net architecture with variations in input format and feature fusion strategies.
All models were implemented using the deep learning framework Pytorch 2.1.0 (CUDA-enabled). The training epoch of all models and the initial learning rate were set to 100 and 0.0001 with the SetpLR scheduler, respectively. The Adam optimizer with the categorical cross-entropy loss function was applied to update the weights of the model parameters to speed up the convergence of the network, and the batch size for image processing was set to 12 for all models.
To ensure that each model was evaluated at its optimal point and to prevent overfitting, a best-checkpoint saving strategy was implemented. While all models were trained for up to 100 epochs, the final model selected for evaluation was not taken from the last epoch. Instead, the validation loss was monitored after each epoch, and a checkpoint was saved only if the loss improved upon the previous minimum. The final model used for testing was the one that achieved the lowest validation loss during training.
Furthermore, to establish the statistical robustness and reproducibility of the results, the entire training and evaluation process was conducted four times using different random seeds. The performance metrics reported in the Results section represent the mean and standard deviation of these multiple runs. The source code, including the specific configurations and random seeds used for each run, is publicly available (refer to Data Availability Statement).
4.3. Computing Environment
To ensure scientific consistency of the experiment, all the experiments in this study were trained and tested under a unified hardware environment such as the Intel(R) Core(TM) i9-13900K CPU with 128 GB RAM and NVIDIA GeForce RTX 4090 GPU with 24 GB of memory. Also, the operating system and the development environment are Ubuntu 22.04 LTS and Python3.10 on Jupyter Lab, respectively.
4.4. Evaluation Metrics
Quantitative evaluation was performed using F1-score-based metrics for both localization and damage assessment [
31], which is defined as
where
TP,
FP, and
FN denote the number of true-positive, false-positive, and false-negative pixels of segmentation results, respectively.
The quantitative performance of the proposed models is evaluated using metrics such as localization
, damage assessment
in a similar manner with
, and overall
scores. More specifically, the first one (
) measures the accuracy of detecting road boundaries and positions, and the second one (
) assesses the model’s ability to capture detailed damage within detected roads. The last one (
) is a weighted average defined as
, highlighting the importance of precise damage assessment in disaster response [
22,
23,
40,
42]. This design enables fair comparison across models with respect to both spatial accuracy and semantic damage identification, allowing for a quantitative comparison of the proposed models with a particular focus on accurately identifying damage rather than merely locating roads.
In addition to the F1-score, to provide a more detailed diagnostic of model performance, this study also reports on other standard metrics. These include precision, which measures the accuracy of positive predictions (i.e., what proportion of pixels predicted as a certain class were actually that class), and recall (or sensitivity), which measures the model’s ability to find all relevant instances (i.e., what proportion of actual positive pixels were correctly identified). The analysis is further supplemented by intersection over union (IoU), which is a standard metric for segmentation tasks that evaluates the degree of overlap between the predicted and ground-truth regions.
For generating the final segmentation maps, a class is assigned to each pixel by applying an argmax function to the model’s output logits; therefore, an explicit segmentation threshold (e.g., 0.5) was not used. As a general strategy to ensure model generalization and mitigate potential overfitting to the majority classes, this study employed the standard cross-entropy loss function and selected the model checkpoint with the minimum validation loss for final evaluation.
5. Results and Analysis
This section presents both quantitative and qualitative performance results for the three proposed models. A comparative analysis highlights the superior performance of the difference-based model while also providing a deep dive into its inherent limitations to establish a valuable benchmark for future research. Furthermore, this study discusses the applicability of the proposed models in real-world disaster response scenarios.
5.1. Quantitative Performance Comparison
All three models were evaluated using the same test dataset (i.e., 1866 images), and the results were assessed based on F1-score metrics. To ensure statistical robustness, the evaluation was conducted over four separate runs with different random seeds. The primary
F1-score results, reported as mean ± standard deviation, are summarized in
Table 3. The data clearly indicate that the difference-based model achieved the highest and most stable overall performance with an overall
F1-score (
) of 0.594 ± 0.025. In contrast, the Siamese model exhibited significant performance variance, with a high standard deviation of 0.083 for its
score, indicating inconsistent results across different runs. While the overlay model attained the highest localization F1-score (
), its inability to perform damage classification (
) rendered it unsuitable for the primary objective of this study.
To diagnose the performance behind these F1-scores, a detailed breakdown of precision, recall, and intersection over union (IoU) is presented in
Table 4. This diagnostic analysis provides deeper insights into the specific behaviors and limitations of each model.
For the difference model, the superior overall score is achieved despite a significant weakness in its damage assessment recall (0.445 ± 0.051). This indicates that it consistently fails to identify more than half of the actual damaged road areas, highlighting the difficulty of this task due to class imbalance.
The Siamese model exhibits a different flaw. For damage assessment, it achieves a high precision (0.770 ± 0.041) but suffers from an extremely low and inconsistent recall (0.225 ± 0.090). This suggests the model is very conservative, making high-confidence predictions on a very small subset of damage while missing the vast majority of it. This trade-off results in a poor overall score.
5.2. Qualitative Comparison of Results
The visual outputs in
Figure 1,
Figure 2 and
Figure 3 support our quantitative findings. The numerous false positives produced by the Siamese model (
Figure 3) when confusing background features with damage are consistent with its high-precision, low-recall profile seen in
Table 4. In contrast, the difference-based model (
Figure 2) provides the clearest segmentation with minimal noise, aligning with its more balanced, albeit imperfect performance metrics.
5.3. Structural Analysis and Comparative Insights
The superior performance of the difference-based model can be attributed to the inherent compatibility between road features and change detection techniques. Roads are continuous, linear structures, and disruptions such as fractures or disconnections appear distinctly in difference images. This structural clarity enhances the effectiveness of change-enhanced segmentation.
This observation is consistent with findings from previous studies, which demonstrated that change detection-based models such as FC-Siamese [
44] and improved Siamese U-Net [
46] architectures are particularly effective in capturing structural damage in linear infrastructures like roads and railways. These studies reinforce the reliability of difference-based segmentation for damage assessment in structured environments.
In contrast, while the Siamese model is designed to capture rich contextual features, its complexity can lead to overfitting or confusion with background textures (e.g., agricultural field boundaries), resulting in a higher false-positive rate as seen in
Figure 3. This tendency is exacerbated by the severe class imbalance in the dataset, where the model can achieve a lower overall loss by prioritizing the majority background class over the minority damage class.
5.4. Case Analysis Using the Difference-Based Model
Damage distribution maps generated by the difference-based model can support the prioritization of emergency road repairs in disaster-affected areas.
Figure 4 shows an example of damage visualization for a specific urban area, enabling the identification of potentially isolated zones at risk of delayed access. While the model’s quantified recall of 0.445 ± 0.051 indicates that a significant portion of damage may be missed, these maps provide a critical “first-pass” assessment that is substantially more rapid and scalable than manual methods.
Such outputs can be leveraged as quantitative and automated resources for disaster response planning, including traffic control, rescue route optimization, and infrastructure inspection prioritization. Compared to manual assessment methods, the proposed approach substantially improves both the speed and accuracy of field response.
In conclusion, while acknowledging its quantified limitations, the difference-based road damage assessment model demonstrates the most practical and effective performance among the evaluated change detection strategies.
6. Conclusions and Future Works
This study proposed a deep learning-based framework for detecting and quantifying road damage using high-resolution pre- and post-disaster satellite imagery. Specifically, three change detection approaches (i.e., the overlay approach, difference-based approach, and Siamese-based approach) were evaluated under a strictly controlled experimental environment to identify the most effective strategy.
Quantitative results of this study, validated over multiple runs, demonstrated that the difference-based model achieved the most effective and stable performance with the highest overall F1-score (). However, the detailed analysis revealed that even this best-performing model is constrained by a low detection recall for the ‘damaged road’ class. This highlights that the severe class imbalance inherent in such real-world datasets remains a critical and unresolved challenge for which standard training strategies are insufficient. Despite this limitation, the damage distribution maps generated by the framework can serve as a valuable tool for practical disaster response, enabling the prioritization of infrastructure restoration efforts.
6.1. Model Selection Guidelines for Practical Application
Based on the comparative results and model characteristics, the following guidelines are proposed to assist practitioners in selecting the most appropriate model for specific disaster response scenarios:
Overlay-Based Approach (Approach 1): This method is computationally light and offers the fastest inference speed. It is particularly suitable for rapid situational awareness in the early phase of a disaster, where quick mapping of the road network is more important than precise damage identification.
Difference-Based Approach (Approach 2): This model offers the best overall balance between performance and stability among the evaluated approaches. While its low detection recall for damaged segments remains a significant limitation, its superior overall F1-score () makes it the most practical choice for generating a first-pass assessment in detailed damage analysis. It is best used for prioritizing areas for on-site inspection rather than as a definitive tool for damage identification.
Siamese-Based Approach (Approach 3): This model demonstrated a high-precision, low-recall profile, making it suitable for applications where ensuring high precision is the top priority. However, due to its heavier computational requirements and performance instability, it is less efficient for time-sensitive damage assessment.
This operational guideline suggests that the difference-based model is optimal for real-world road infrastructure damage detection tasks, especially when considering the balance between inference time and segmentation accuracy.
6.2. Limitations and Future Works
While this study provides a valuable benchmark, several limitations and avenues for future research must be acknowledged.
A key limitation of this study is its reliance on high-resolution optical imagery which is susceptible to performance degradation from low-resolution data and adverse weather conditions such as cloud cover. As such, the performance of the proposed models is expected to degrade when fine-grained damage indicators such as surface cracks or small debris may become undetectable.
Based on the underlying finding, the most critical area for future research is directly addressing the class imbalance and low recall for damage detection. Future work should prioritize the implementation of advanced techniques such as weighted loss functions (e.g., focal loss) or sophisticated data sampling strategies to force the model to learn the features of rare ‘damaged’ instances more effectively.
Further enhancements can be achieved by exploring more advanced model architectures and feature fusion strategies. Future work will include a comprehensive ablation study to dissect the contributions of the model components, such as systematically evaluating different feature fusion mechanisms (e.g., concatenation, attention) for the Siamese architecture. Furthermore, this study plans to compare the U-Net backbone against other state-of-the-art segmentation architectures and integrate next-generation change detection backbones (e.g., SChanger, ChangeMamba) to further validate and potentially improve the framework.
Another avenue for improvement is the fusion of multimodal data. Combining optical imagery with other sensors, such as Synthetic Aperture Radar (SAR) or LiDAR, could create a robuster all-weather disaster response solution. The development of large-scale multimodal datasets such as BRIGHT signifies a growing trend toward this direction, which will be a key focus of subsequent research [
49]. Additionally, a quantitative analysis of the computational costs, including training and inference times for each model, was beyond the scope of this study but represents an important direction for future work to provide practitioners with a comprehensive performance–efficiency trade-off analysis.
Finally, to improve real-world applicability, future work should incorporate post-processing techniques such as road connectivity analysis to identify completely isolated areas and damage length quantification to better estimate repair costs and timelines.
Through these enhancements, the proposed framework can evolve into an automated and scalable road damage assessment system, serving as a core infrastructure for urban disaster response planning.
Author Contributions
Conceptualization, S.L. and H.-K.K.; methodology, S.L. and H.-K.K.; software, S.L.; validation, J.C., S.L. and H.-K.K.; formal analysis, J.C. and S.L.; investigation, J.C. and S.L.; writing—original draft preparation, J.C. and H.-K.K.; visualization, S.L.; supervision, H.-K.K.; project administration, H.-K.K.; funding acquisition, H.-K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Dong-A University in the Republic of Korea.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The source code, which includes all configurations, hyperparameters, and the specific random seeds used for each experimental run, is available at
https://github.com/seunghyeokleeme/xBD_road_damage_assessment, accessed on 29 June 2025. The curated road mask dataset generated through the hybrid labeling strategy is publicly available via the same repository. Details on access and usage are provided in the README file. For further inquiries, contact the corresponding author.
Conflicts of Interest
The authors declare no competing interests.
References
- Zhang, S.; Li, S.; Zhai, C.; Xiao, J. An Integrated Seismic Assessment Method for Urban Buildings and Roads. Int. J. Disaster Risk Sci. 2024, 15, 935–953. [Google Scholar] [CrossRef]
- Seydi, S.T.; Rastiveis, H. A Deep Learning Framework for Roads Network Damage Assessment Using Post-Earthquake LiDAR Data. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Karaj, Iran, 12–14 October 2019; Copernicus Publications: Enschede, The Netherlands, 2019; Volume XLII-4/W18, pp. 955–961. [Google Scholar] [CrossRef]
- Wei, Z.; Zhang, Z. Remote Sensing Image Road Extraction Network Based on MSPFE-Net. Electronics 2023, 12, 1713. [Google Scholar] [CrossRef]
- Salaudeen, H.; Çelebi, E. Pothole Detection Using Image Enhancement GAN and Object Detection Network. Electronics 2022, 11, 1882. [Google Scholar] [CrossRef]
- Liu, R.; Wu, J.; Lu, W.; Miao, Q.; Zhang, H.; Liu, X.; Lu, Z.; Li, L. A Review of Deep Learning-Based Methods for Road Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 2056. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2022: A Multi-National Image Dataset for Automatic Road Damage Detection. Geosci. Data J. 2022, 11, 846–862. [Google Scholar] [CrossRef]
- Gupta, A.; Watson, S.; Yin, H. Deep Learning-based Aerial Image Segmentation with Open Data for Disaster Impact Assessment. Neurocomputing 2021, 439, 22–33. [Google Scholar] [CrossRef]
- Akhyar, A.; Zulkifley, M.A.; Lee, J.; Song, T.; Han, J.; Cho, C.; Hyun, S.; Son, Y.; Hong, B.-W. Deep artificial intelligence applications for natural disaster management systems: A methodlogical review. Ecol. Indic. 2024, 163, 112067. [Google Scholar] [CrossRef]
- Adegun, A.A.; Fonou Dombeu, J.V.; Viriri, S.; Odindi, J. State-of-the-Art Deep Learning Methods for Objects Detection in Remote Sensing Satellite Images. Sensors 2023, 23, 5849. [Google Scholar] [CrossRef]
- Emrah, A.; Yıldırım, Ö. Detection of Road Extraction from Satellite Images with Deep Learning Method. Clust. Comput. 2025, 28, 72. [Google Scholar] [CrossRef]
- Swapandeep, K.; Sheifali, G.; Swati, S.; Vinh Truong, H.; Sultan, A.; Turki, A.; Asadullah, S. Transfer Learning-Based Automatic Hurricane Damage Detection Using Satellite Images. Electronics 2022, 11, 1448. [Google Scholar] [CrossRef]
- Vasileios, L.; Maria, D.; Panagiotis, T.; Karnavas, Y.L. Machine Learning in Disaster Management: Recent Developments in Methods and Applications. Mach. Learn. Knowl. Extr. 2022, 4, 446–473. [Google Scholar] [CrossRef]
- Sheikh Kamran, A.; Noralfishah, S.; Shiau Wei, C.; Umber, N.; Muhammad, A.; Heesup, H.; Antonio, A.M.; Alejandro, V.M. Toward an Integrated Disaster Management Approach: How Artificial Intelligence Can Boost Disaster Management. Sustainability 2021, 13, 12560. [Google Scholar] [CrossRef]
- Mirsalar, K.; Youngjib, H. AI-based risk assessment for construction site disaster preparedness through deep learning-based digital twinning. Autom. Constr. 2022, 134, 104091. [Google Scholar] [CrossRef]
- Xia, H.; Wu, J.; Yao, J.; Zhu, H.; Gong, A.; Yang, J.; Hu, L.; Mo, F. A Deep Learning Application for Building Damage Assessment Using Ultra-High-Resolution Remote Sensing Imagery in Turkey Earthquake. Int. J. Disaster Risk Sci. 2023, 14, 947–962. [Google Scholar] [CrossRef]
- Wheeler, B.J.; Karimi, H.A. Deep Learning-Enabled Semantic Inference of Individual Building Damage Magnitude from Satellite Images. Algorithms 2020, 13, 195. [Google Scholar] [CrossRef]
- Kim, D.; Won, J.; Lee, E.; Park, K.R.; Kim, J.; Park, S.; Yang, H.; Cha, M. Disaster Assessment Using Computer Vision and Satellite Imagery: Applications in Detecting Water-Related Building Damages. Environ. Sci. 2022, 10, 969758. [Google Scholar] [CrossRef]
- Masoud, M.; Reza, S.H. Earthquake Damage Assessment Based on Deep Learning Method Using VHR Images. Environ. Sci. Proc. 2021, 5, 16. [Google Scholar] [CrossRef]
- Sultan Al, S.; Da, H. Integrating Machine Learning and Remote Sensing in Disaster Management: A Decadal Review of Post-Disaster Building Damage Assessment. Buildings 2024, 14, 2344. [Google Scholar] [CrossRef]
- Kopiika, N.; Karavias, A.; Krassakis, P.; Ye, Z.; Ninic, J.; Shakhovska, N.; Koukouzas, N.; Argyroudis, S.; Mitoulis, S.A. Rapid Post-Disaster Infrastructure Damage Characterisation Enabled by Remote Sensing and Deep Learning Technologies—A Tiered Approach. Autom. Constr. 2025, 170, 105955. [Google Scholar] [CrossRef]
- Ritwik, G.; Bryce, G.; Nirav, P.; Richard, H.; Sandra, S.; Eric, H.; Jigar, D.; Keane, L.; Howie, C.; Matthew, G. Creating xBD: A Dataset for Assessing Building Damage from Satellite Imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019; pp. 10–17. [Google Scholar] [CrossRef]
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C.; Pan, D.; Chen, J.; Xiao, L.; Du, Q. BDANet: Multiscale Convolutional Neural Network with Cross-directional Attention for Building Damage Assessment from Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 3082797. [Google Scholar] [CrossRef]
- Shen, Y.; Zhu, S.; Yang, T.; Chen, C. Cross-directional Feature Fusion Network for Building Damage Assessment from Satellite Imagery. arXiv 2020, arXiv:2010.14014. [Google Scholar]
- Weber, E.; Kané, H. Building Disaster Damage Assessment in Satellite Imagery with Multi-Temporal Fusion. arXiv 2020, arXiv:2004.05525. [Google Scholar]
- Chen, H.; Song, J.; Han, C.; Xia, J.; Yokoya, N. ChangeMamba: Remote Sensing Change Detection with Spatio-Temporal State Space Model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4409720. [Google Scholar]
- Dogu, I.; Iban, M.C.; Seker, D. Deep Learning-Based Scene Classification of Very High-Resolution Satellite Imagery for Post-Earthquake Damage Assessment: A Case Study of the 2023 Kahramanmaraş Earthquakes; Copernicus Publications: Enschede, The Netherlands, 2024; Volume XLVIII-4/W9-2024, pp. 249–256. [Google Scholar] [CrossRef]
- Zhao, K.; Liu, J.; Wang, Q.; Wu, X.; Tu, J. Road Damage Detection from Post-Disaster High-Resolution Remote Sensing Images Based on TLD Framework. IEEE Access 2022, 10, 43552–43564. [Google Scholar] [CrossRef]
- Karimzadeh, S.; Ghasemi, M.; Matsuoka, M.; Yagi, K.; Zulfikar, A.C. A Deep Learning Model for Road Damage Detection After an Earthquake Based on Synthetic Aperture Radar (SAR) and Field Datasets. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5753–5764. [Google Scholar] [CrossRef]
- Zhang, S.; He, X.; Xue, B.; Wu, T.; Ren, K.; Zhao, T. Segment-anything embedding for pixel-level road damage extraction using high-resolution satellite images. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103985. [Google Scholar] [CrossRef]
- Rastiveis, H.; Seydi, S.T.; Chen, Z.; Li, J. Seismic urban damage map generation based on satellite images and Gabor convolutional neural networks. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103450. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Kumar Ghosh, S.; Toshniwal, D.; Omata, H.; Takehiro, K.; Yoshihide, S. Global Road Damage Detection: State-of-the-Art Solutions. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5533–5539. [Google Scholar] [CrossRef]
- Jiang, Y. Road damage detection and classification using deep neural networks. SN Appl. Sci. 2024, 6, 421. [Google Scholar] [CrossRef]
- Zeng, J.; Zhong, H. YOLOv8-PD: An Improved Road Damage Detection Algorithm Based on YOLOv8n Model. Sci. Rep. 2024, 14, 12052. [Google Scholar] [CrossRef]
- Doshi, K.; Yilmaz, Y. Road Damage Detection using Deep Ensemble Learning. arXiv 2020, arXiv:2011.00728. [Google Scholar]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef]
- Sakamoto, J. Proposal of a flood damage road detection method based on deep learning and elevation data. Geomat. Nat. Hazards Risk 2024, 15, 2375545. [Google Scholar] [CrossRef]
- Gheidar-Kheljani, J.; Nasiri, M.M. A Deep Learning Method for Road Extraction in Disaster Management to Increase the Efficiency of Health Services. Adv. Ind. Eng. 2024, 58, 1–12. [Google Scholar] [CrossRef]
- Bai, Y.; Hu, J.; Su, J.; Liu, X.; Liu, H.; He, X.; Meng, S.; Mas, X.; Koshimura, S. Pyramid Pooling Module-Based Semi-Siamese Network: A Benchmark Model for Assessing Building Damage from xBD Satellite Imagery Datasets. Remote Sens. 2020, 12, 4055. [Google Scholar] [CrossRef]
- Xia, Z.; Li, Z.; Bai, Y.; Yu, J.; Adriano, B. Self-Supervised Learning for Building Damage Assessment from Large-Scale xBD Satellite Imagery Benchmark Datasets. In Proceedings of the33rd International Conference on Database and Expert Systems Applications (DEXA 2022), Vienna, Austria, 29 August–2 September 2022; pp. 373–386. [Google Scholar] [CrossRef]
- Gerard, S.; Borne-Pons, P.; Sullivan, J. A Simple, Strong Baseline for Building Damage Detection on the xBD Dataset. arXiv 2024, arXiv:2401.17271. [Google Scholar]
- Ma, Y.; Zhou, F.; Wen, G.; Gen, H.; Huang, R.; Liu, G.; Pei, L. Assessment of Buildings and Electrical Facilities Damaged by Flood and Earthquake from Satellite Imagery. In Proceedings of the 7th International Conference on Ubiquitous Positioning, Indoor Navigation and Location-Based Services (UPINLBS 2022), Wuhan, China, 18–19 March 2022; Volume XLVI-3/W1-2022, pp. 133–139. [Google Scholar] [CrossRef]
- Melamed, D.; Johnson, C.; Zhao, C.; Blue, R.; Morrone, P.; Hoogs, A.; Clipp, B. xFBD: Focused Building Damage Dataset and Analysis. arXiv 2022, arXiv:2212.13876. [Google Scholar]
- Li, X.; Li, Z.; Zhang, Y.; Li, C. Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami. Remote Sens. 2019, 11, 1123. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef]
- Zhong, H.; Wu, C. T-UNet: Triplet UNet for Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 372. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Y.; Xu, T.; Yao, Y.; Ma, C. High-Resolution Remote Sensing Image Change Detection Method Based on Improved Siamese U-Net. Remote Sens. 2023, 15, 3517. [Google Scholar] [CrossRef]
- Tang, Y.; Cao, Z.; Guo, N.; Jiang, M. A Siamese Swin-Unet for Image Change Detection. Sci. Rep. 2024, 14, 4577. [Google Scholar] [CrossRef]
- Zhou, Z.; Hu, K.; Fang, Y.; Rui, X. SChanger: Change Detection from a Semantic Change and Spatial Consistency Perspective. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 10186–10203. [Google Scholar] [CrossRef]
- Chen, H.; Song, J.; Dietrich, O.; Broni-Bediako, C.; Xuan, W.; Wang, J.; Shao, X.; Wei, Y.; Xia, J.; Lan, C.; et al. BRIGHT: A Globally Distributed Multimodal Building Damage Assessment Dataset with Very-High-Resolution for All-Weather Disaster Response. arXiv 2025, arXiv:2501.06019. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}