
Study on Few-Shot Object Detection Approach Based on Improved RPN and Feature Aggregation


Abstract
1. Introduction
- (1)
- Few-shot object detection network based on improved RPN and feature aggregation (IFA-FSOD) was proposed using Faster R-CNN as the backbone, achieving efficient performance improvement in FSOD.
- (2)
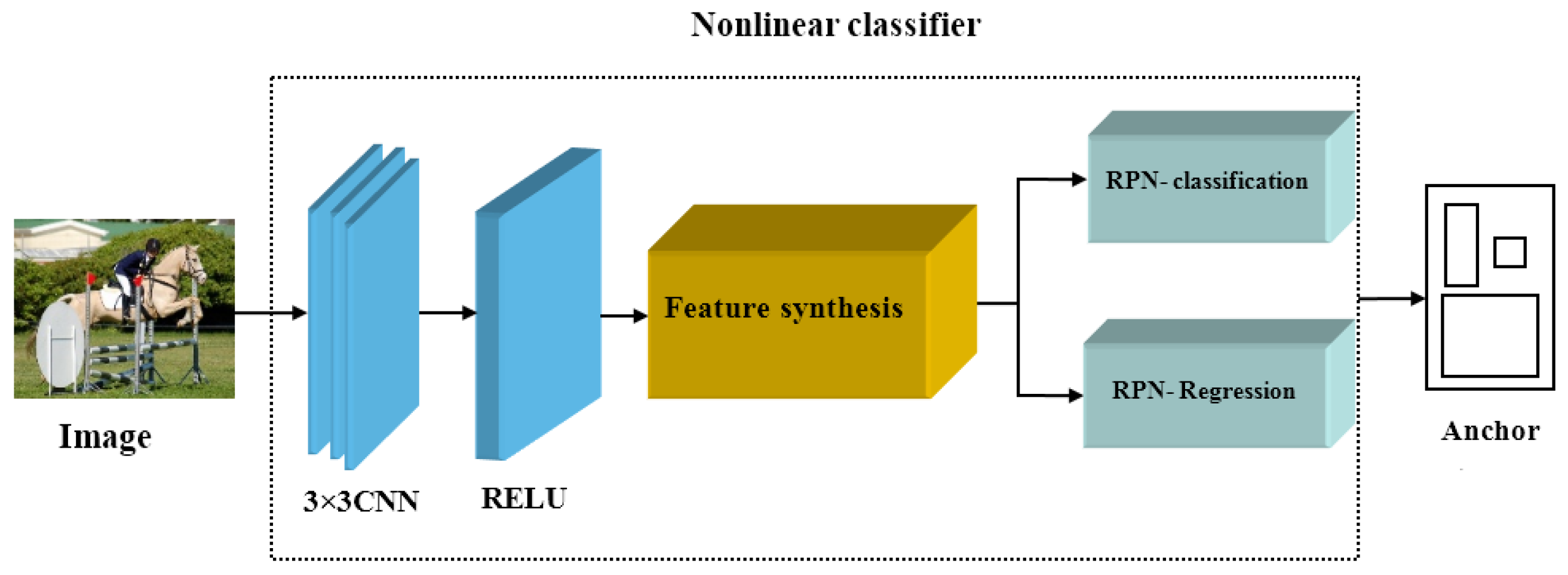
- The original RPN has been improved by introducing a nonlinear classifier to calculate the similarity between the features extracted by the backbone network and the new class features, thereby increasing the detection precision of new class candidate boxes and screening out high IoU candidate boxes, improving the detection performance of object detection.
- (3)
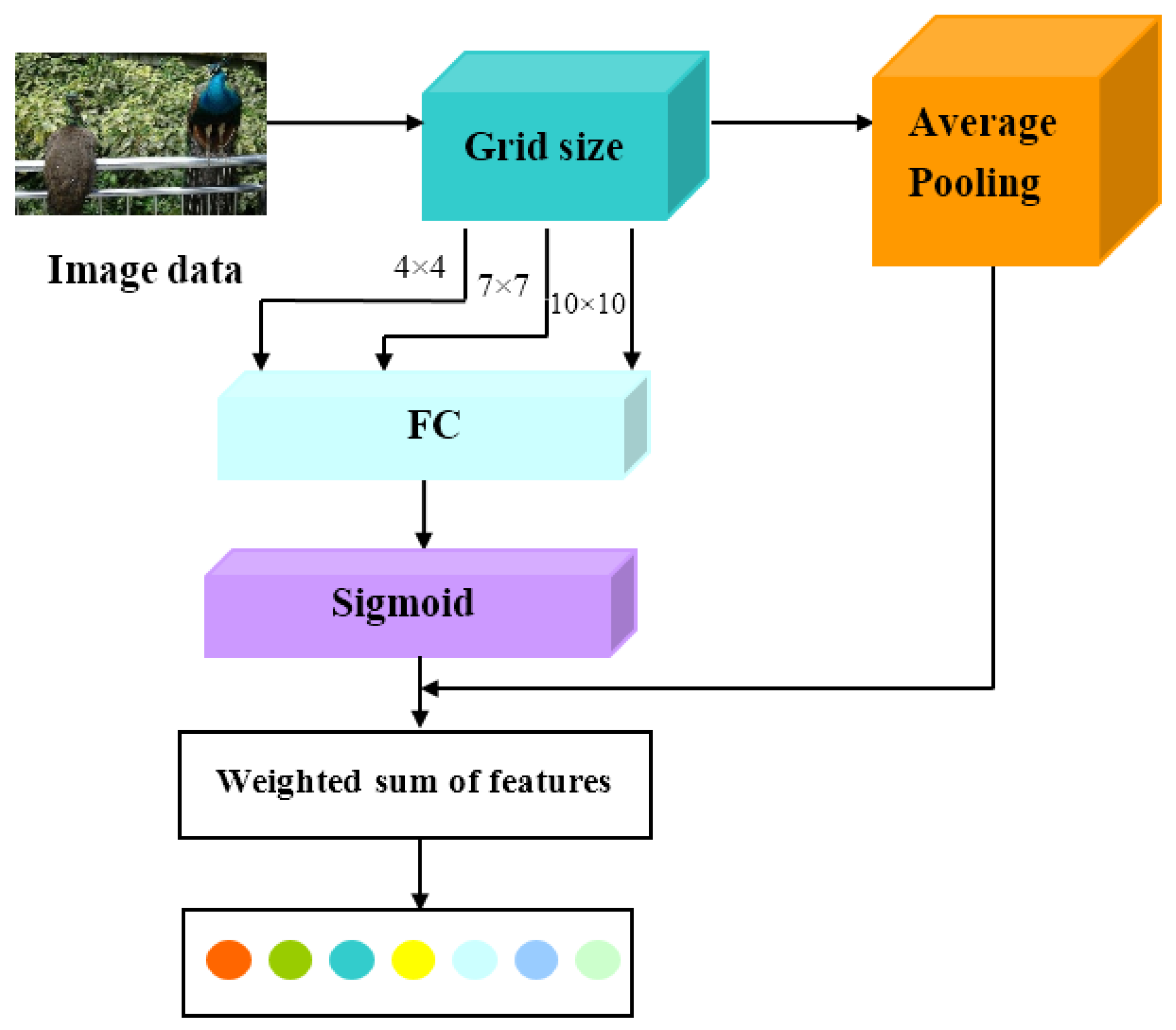
- Utilizing attention mechanism to enhance feature aggregation, aggregating feature information from different levels, obtaining more comprehensive information and feature representations, solving the problem of information loss, and improving the model’s generalization ability and detection performance for new classes.
2. Related Work
2.1. Few-Shot Learning
2.2. Few-Shot Object Detection
3. Definitions and Improved Network Framework
3.1. Related Definitions
3.2. Basic Network Framework
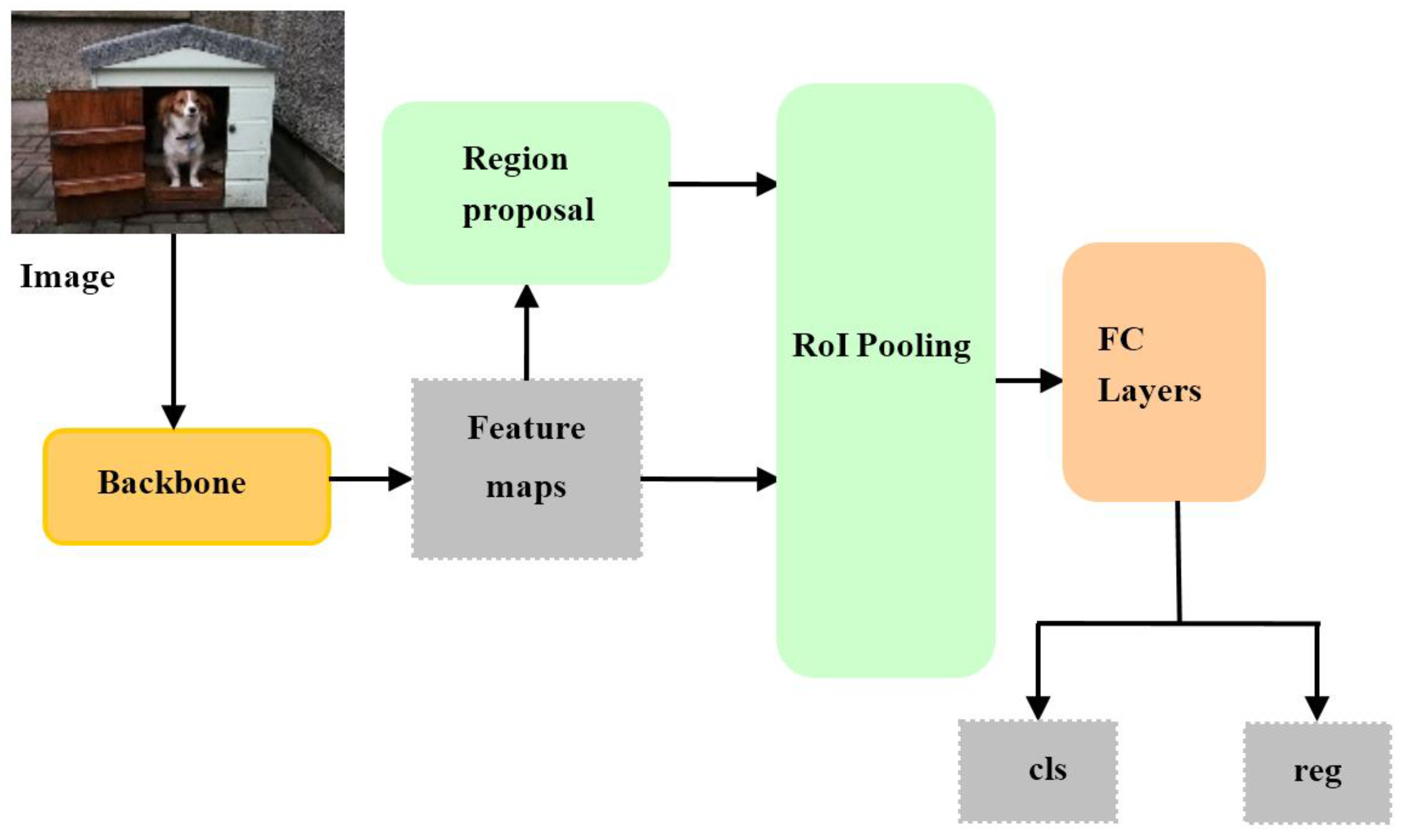
3.2.1. Feature Extractor
3.2.2. Improved RPN Module
3.2.3. Feature Aggregation Module
4. Experiment and Results Analysis
4.1. Dataset Selection
4.2. Training Steps
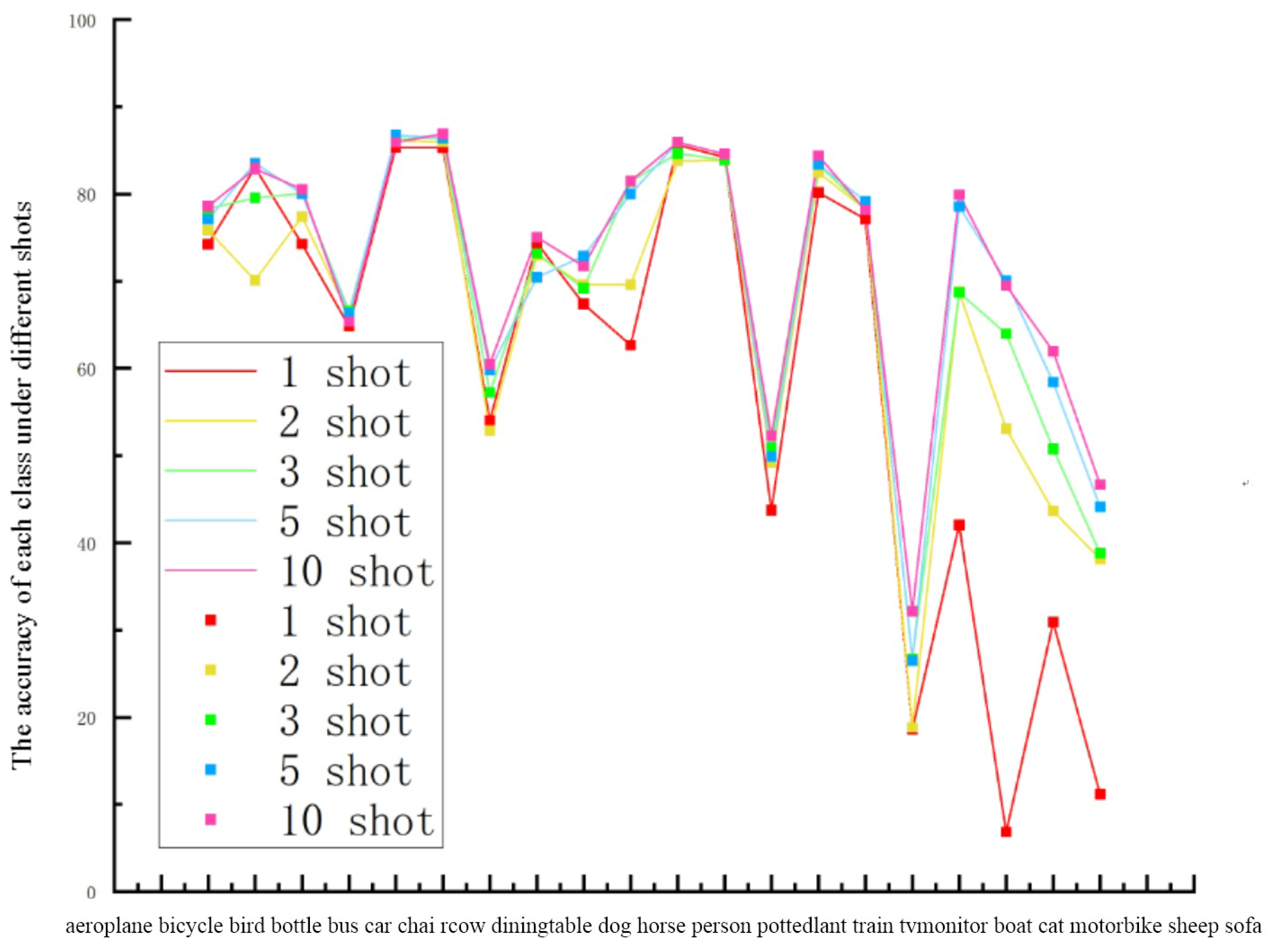
4.3. Experimental Results and Analysis
4.4. Ablation Experiments
5. Conclusions and Further Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shi, Y.; Shi, D.; Qiao, Z.; Zhang, Y.; Liu, Y.; Yang, S. A review of research on small sample object detection. J. Comput. Sci. 2023, 46, 1753–1780. [Google Scholar]
- Xin, Z.; Chen, S.; Wu, T.; Shao, Y.; Ding, W.; You, X. Few-shot object detection: Research advances and challenges. Inf. Fusion 2024, 107, 102307. [Google Scholar]
- Huang, Y.; Dou, H.; Xiao, G. Small Sample Object Detection Combining Classification Correction and Sample Amplification. Computer Engineering and Applications: 1-10 2023 [2022-11-20]. Available online: http://kns.cnki.net/kcms/detail/11.2127.TP.20221104.1529.020.html (accessed on 15 June 2024).
- Kohler, M.; Eisenbach, M.; Gross, H.-M. Few-Shot Object Detection: A Comprehensive Survey. [EB/OL]. [2023-11-10]. Available online: https://arxiv.org/pdf/2112.11699v2.pdf (accessed on 15 June 2024).
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8420–8429. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. In Proceedings of the 2020 International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 9919–9928. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 9577–9586. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [PubMed]
- Hu, H.; Bai, S.; Li, A.; Cui, J.; Wang, L. Dense relation distillation with context—Aware aggregation for few-shot object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 10185–10194. [Google Scholar]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the 2022 AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; AAAI: Menlo Park, CA, USA, 2022; Volume 36, pp. 780–789. [Google Scholar]
- Jeune, P.L.; Mokraoui, A. A Comparative Attention Framework for Better Few-Shot Object Detection on Aerial Images. [EB/OL]. [2023-11-10]. Available online: https://arxiv.org/pdf/2210.13923.pdf (accessed on 15 June 2024).
- Li, Y.; Feng, W.; Lyu, S.; Zhao, Q. Feature reconstruction and metric based network for few-shot object detection. Comput. Vis. Image Underst. 2023, 227, 103600. [Google Scholar] [CrossRef]
- Li, A.; Li, Z. Transformation Invariant Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3094–3102. [Google Scholar]
- Li, B.; Yang, B.; Liu, C.; Liu, F.; Ji, R.; Ye, Q. Beyond Max-Margin: Class Margin Equilibrium for Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7363–7372. [Google Scholar]
- Han, G.; Ma, J.; Huang, S.; Chen, L.; Chang, S.F. Few-shot object detection with fully cross-transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 5321–5330. [Google Scholar]
- Xiao, Y.; Lepetit, V.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3090–3106. [Google Scholar] [CrossRef] [PubMed]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with Attention-RPN and multi-relation detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 4012–4021. [Google Scholar]
- Zhang, L.; Zhou, S.; Guan, J.; Zhang, J. Accurate few-shot object detection with support-query mutual guidance and hybrid loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 14424–14432. [Google Scholar]
- Han, G.; He, Y.; Huang, S.; Ma, J.; Chang, S.F. Query adaptive few-shot object detection with heterogeneous graph convolutional networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3263–3272. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2117–2125. [Google Scholar]
- Fan, Z.; Ma, Y.; Li, Z.; Sun, J. Generalized few-shot object detection without forgetting. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4527–4536. [Google Scholar]
- Han, J.; Ren, Y.; Ding, J.; Yan, K.; Xia, G.S. Few-Shot Object Detection via Variational Feature Aggregation. In Proceedings of the 2023 AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 203; AAAI: Menlo Park, CA, USA, 2023; pp. 755–763. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7352–7362. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8782–8791. [Google Scholar]
- Qiao, L.; Zhao, Y.; Li, Z.; Qiu, X.; Wu, J.; Zhang, C. DeFRCN: Decoupled Faster R-CNN for few-shot object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8681–8690. [Google Scholar]
- Kaul, P.; Xie, W.; Zisserman, A. Label, verify, correct: A simple few shot object detection method. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 14237–14247. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) challenge. Int. J. Comput. Vis. 2009, 88, 303–308. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part V 13; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 9925–9934. [Google Scholar]
- Yao, J.; Shi, T.; Che, X.; Yao, J.; Wu, L. DA-FSOD:A Novel Augmentation Scheme for Few-Shot Object Detection. IEEE Access 2023, 11, 92100–92110. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the 2020 European Conference on Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XVI 16; Springer: Cham, Switzerland, 2020; pp. 456–472. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mAP50% for Different VOC Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Split | Shot |
FSRW
[5] | Meta R-CNN [7] |
MetaDet
[31] |
TFA
[6] |
SRR
-FSD [24] |
QA
-FewDet [19] |
DA
-FSOD [32] |
FSCE
[23] |
IFA-
FSOD (Ours) |
| Set 1 | 1 | 14.8 | 19.9 | 18.9 | 39.8 | 47.8 | 42.4 | 33.4 | 32.9 | 30.1 |
| 2 | 15.5 | 25.5 | 20.6 | 36.1 | 50.5 | 51.9 | 45.1 | 44.0 | 52.3 | |
| 3 | 26.7 | 35.0 | 30.2 | 44.7 | 51.3 | 55.7 | 47.1 | 46.8 | 58.7 | |
| 5 | 33.9 | 45.7 | 36.8 | 55.7 | 55.2 | 62.6 | 53.1 | 52.9 | 62.4 | |
| 10 | 47.2 | 51.5 | 49.6 | 56.0 | 56.8 | 63.4 | 60.0 | 59.7 | 65.4 | |
| Set 2 | 1 | 15.7 | 10.4 | 21.8 | 23.5 | 32.5 | 25.9 | 24.2 | 23.7 | 27.7 |
| 2 | 15.3 | 19.4 | 23.1 | 26.9 | 35.3 | 37.8 | 31.4 | 30.6 | 37.9 | |
| 3 | 22.7 | 29.6 | 27.8 | 34.1 | 39.1 | 46.6 | 39.5 | 38.4 | 38.0 | |
| 5 | 30.1 | 34.8 | 31.7 | 35.1 | 40.8 | 48.9 | 43.9 | 38.4 | 42.5 | |
| 10 | 40.5 | 45.4 | 43.0 | 39.1 | 43.8 | 51.1 | 49.0 | 48.5 | 48.6 | |
| Set 3 | 1 | 21.3 | 14.3 | 20.6 | 30.8 | 40.1 | 35.2 | 24.5 | 22.6 | 21.9 |
| 2 | 25.6 | 18.2 | 23.9 | 34.8 | 41.5 | 42.9 | 36.1 | 33.4 | 44.5 | |
| 3 | 28.4 | 27.5 | 29.4 | 42.8 | 44.3 | 47.8 | 42.3 | 39.5 | 49.8 | |
| 5 | 42.8 | 41.2 | 43.9 | 49.5 | 46.9 | 54.8 | 49.2 | 47.3 | 55.5 | |
| 10 | 45.9 | 48.1 | 44.1 | 49.8 | 46.4 | 53.5 | 54.5 | 54.0 | 58.0 | |
| Different COCO Methods Have mAP50% at 10 and 30 Shots | ||||||
|---|---|---|---|---|---|---|
| 10-shot | 30-shot | |||||
| Method | mAP | mAP50 | mAP75 | mAP | mAP50 | mAP75 |
| TFAw/fc [6] | 10.0 | 19.2 | 9.2 | 13.4 | 24.7 | 13.2 |
| TFAw/cos [6] | 10.0 | 19.1 | 9.3 | 13.7 | 24.9 | 13.4 |
| FSRW [5] | 5.6 | 12.3 | 4.6 | 9.1 | 19.0 | 7.6 |
| MetaDet [31] | 7.1 | 14.6 | 6.1 | 11.3 | 21.7 | 8.1 |
| Meta R-CNN [7] | 8.7 | 19.1 | 6.6 | 12.4 | 25.3 | 10.8 |
| MPSR [33] | 9.8 | 17.9 | 9.7 | 14.1 | 25.4 | 14.2 |
| FSCE [23] | 11.9 | - | 10.5 | 15.3 | - | 14.2 |
| FsDetView [16] | 12.5 | 27.3 | 9.8 | 14.7 | 30.6 | 12.2 |
| IFA-FSOD (ours) | 12.8 | 25.5 | 10.7 | 15.5 | 31.0 | 15.6 |
| Method | PASCAL VOC Novel Set 1 | |||||
|---|---|---|---|---|---|---|
| Metric RPN | AFM | 1-shot | 2-shot | 3-shot | 5-shot | 10-shot |
| mAP50 | mAP50 | mAP50 | mAP50 | mAP50 | ||
| × | × | 29.1 | 50.5 | 58.0 | 60.2 | 62.8 |
| × | √ | 29.4 | 50.9 | 57.9 | 60.8 | 63.3 |
| √ | × | 29.9 | 51.5 | 58.5 | 61.4 | 64.1 |
| √ | √ | 30.1 | 52.3 | 58.7 | 62.4 | 65.4 |
| Method | MSCOCO | ||
|---|---|---|---|
| Metric RPN | AFM | 10 shot mAP50 | 30 shot mAP50 |
| × | × | 23.8 | 29.7 |
| × | √ | 24.1 | 30.1 |
| √ | × | 24.7 | 30.8 |
| √ | √ | 25.5 | 31.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Q.; Fu, K.; Wang, G. Study on Few-Shot Object Detection Approach Based on Improved RPN and Feature Aggregation. Appl. Sci. 2025, 15, 3734. https://doi.org/10.3390/app15073734
Pan Q, Fu K, Wang G. Study on Few-Shot Object Detection Approach Based on Improved RPN and Feature Aggregation. Applied Sciences. 2025; 15(7):3734. https://doi.org/10.3390/app15073734
Chicago/Turabian StylePan, Qiyu, Keyi Fu, and Gaocai Wang. 2025. "Study on Few-Shot Object Detection Approach Based on Improved RPN and Feature Aggregation" Applied Sciences 15, no. 7: 3734. https://doi.org/10.3390/app15073734
APA StylePan, Q., Fu, K., & Wang, G. (2025). Study on Few-Shot Object Detection Approach Based on Improved RPN and Feature Aggregation. Applied Sciences, 15(7), 3734. https://doi.org/10.3390/app15073734