
Signal Super Prediction and Rock Burst Precursor Recognition Framework Based on Guided Diffusion Model with Transformer

 ,
,  ,
,
Abstract
1. Introduction
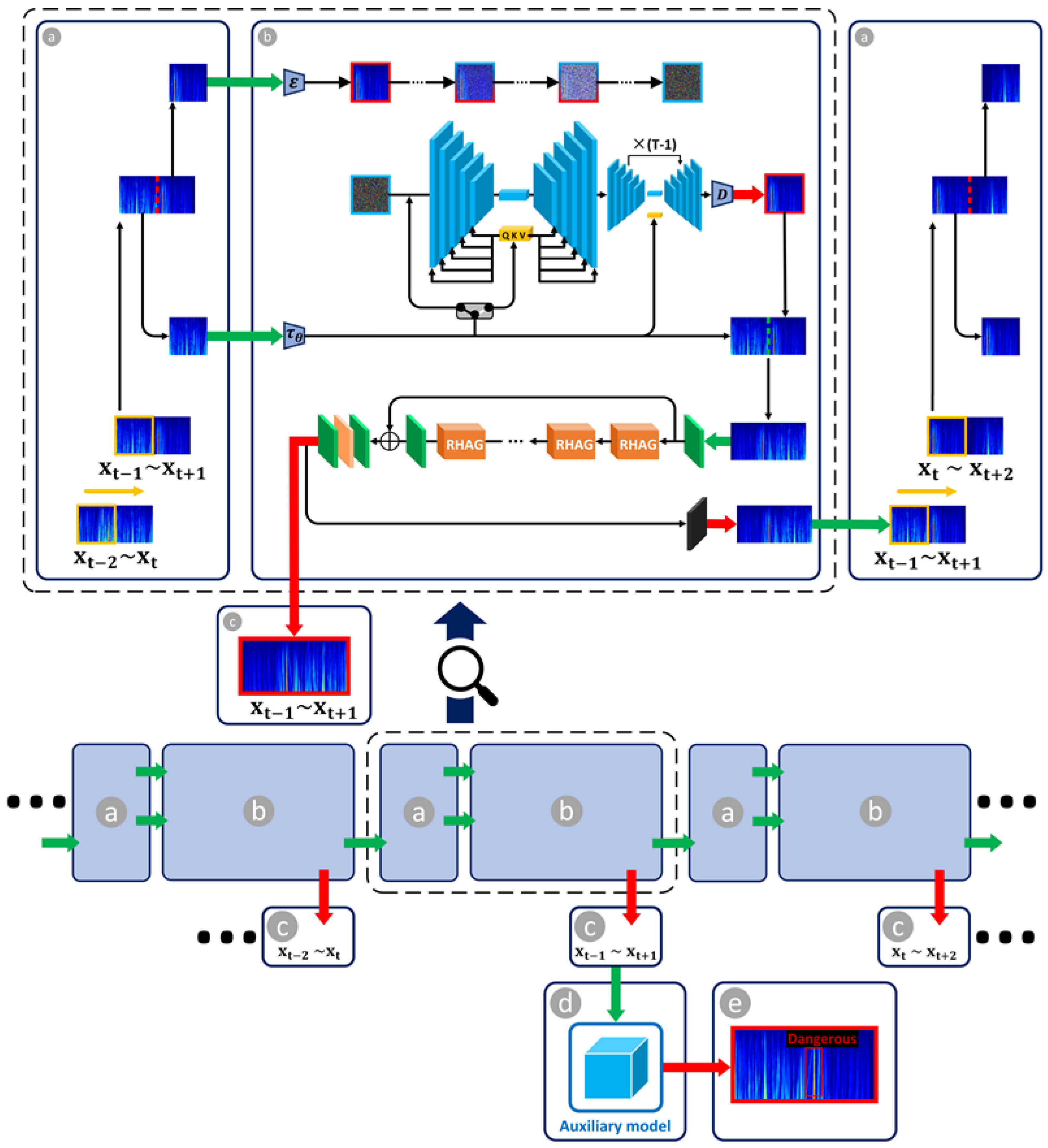
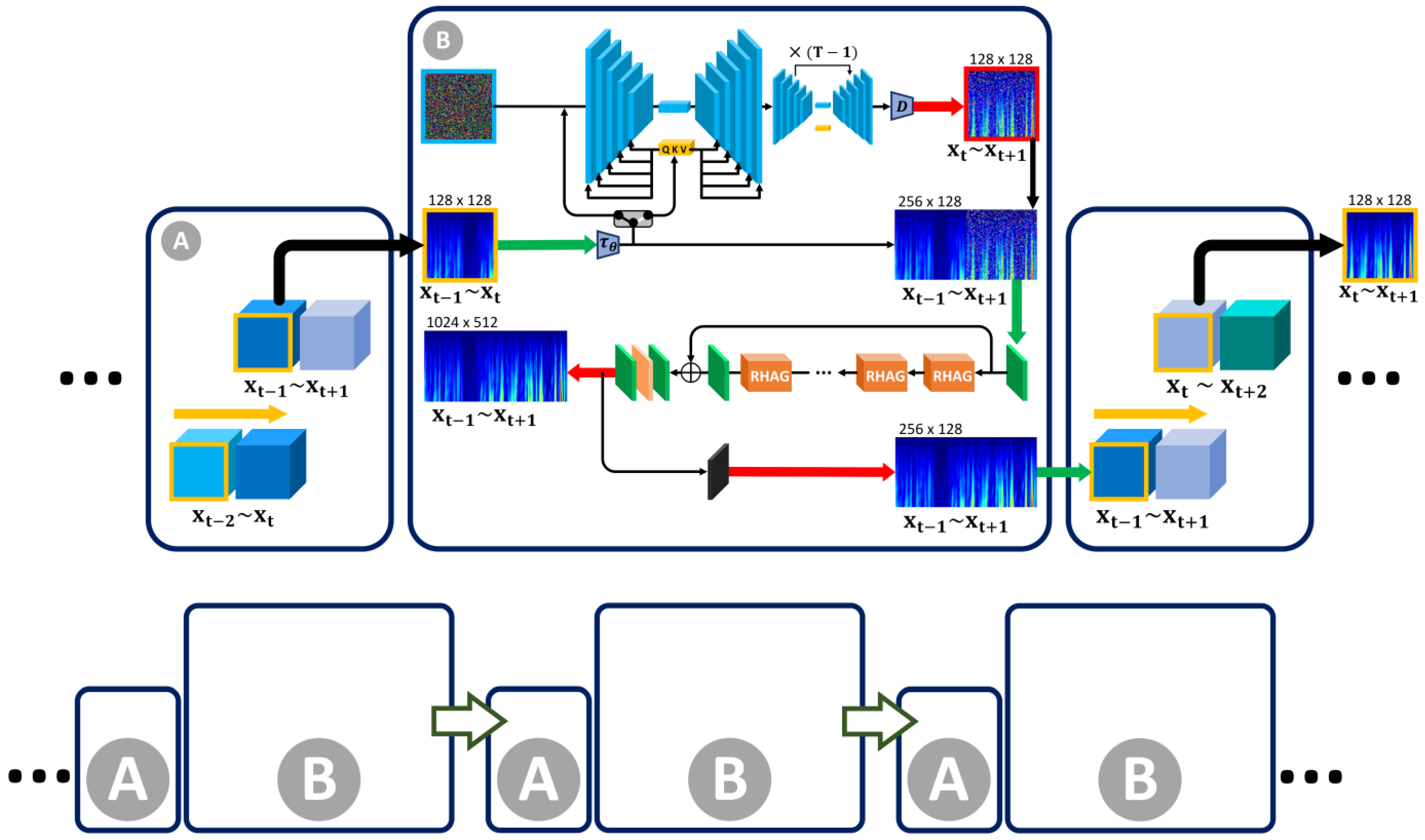
2. Methodology
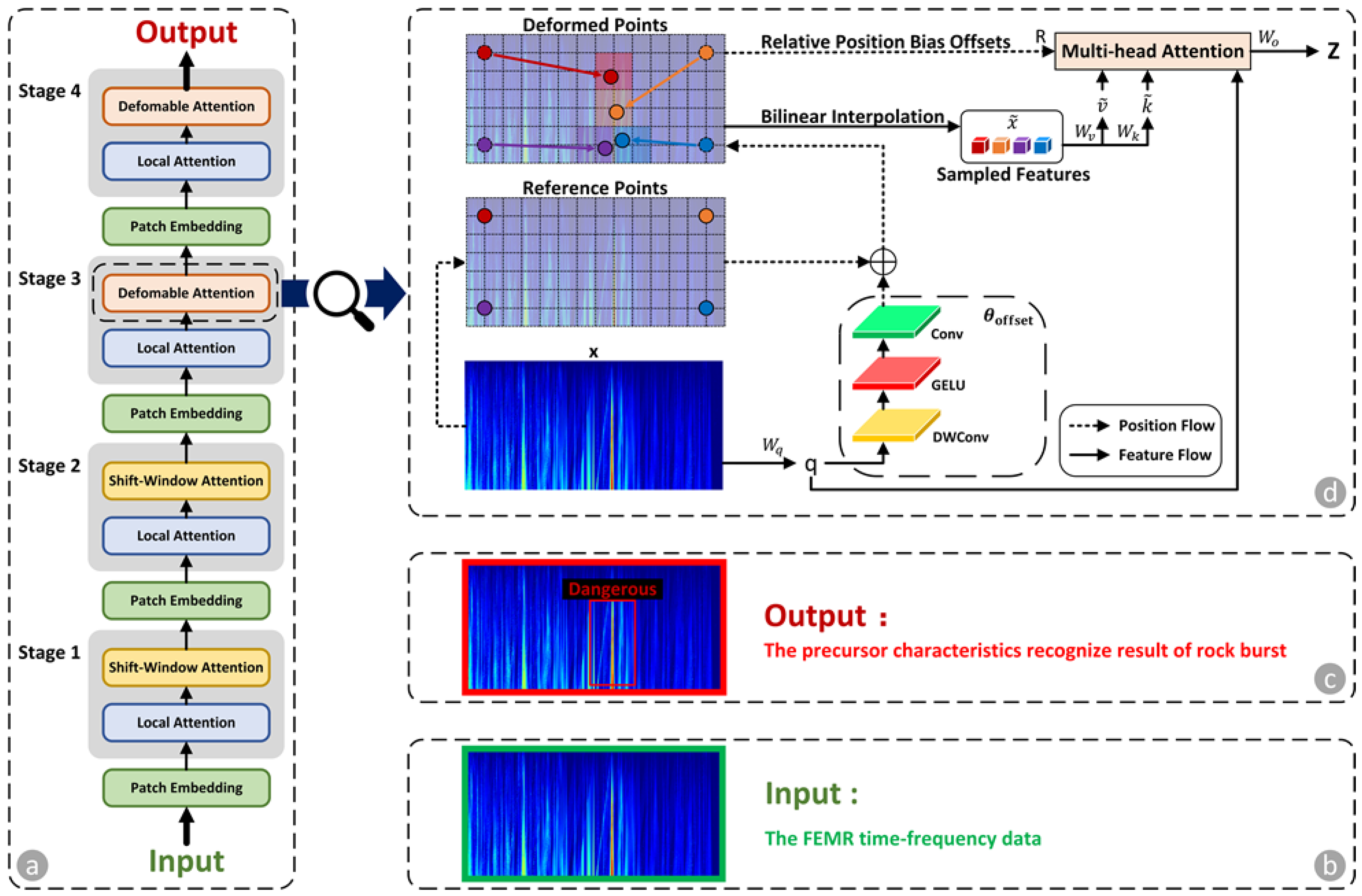
2.1. Auxiliary Model
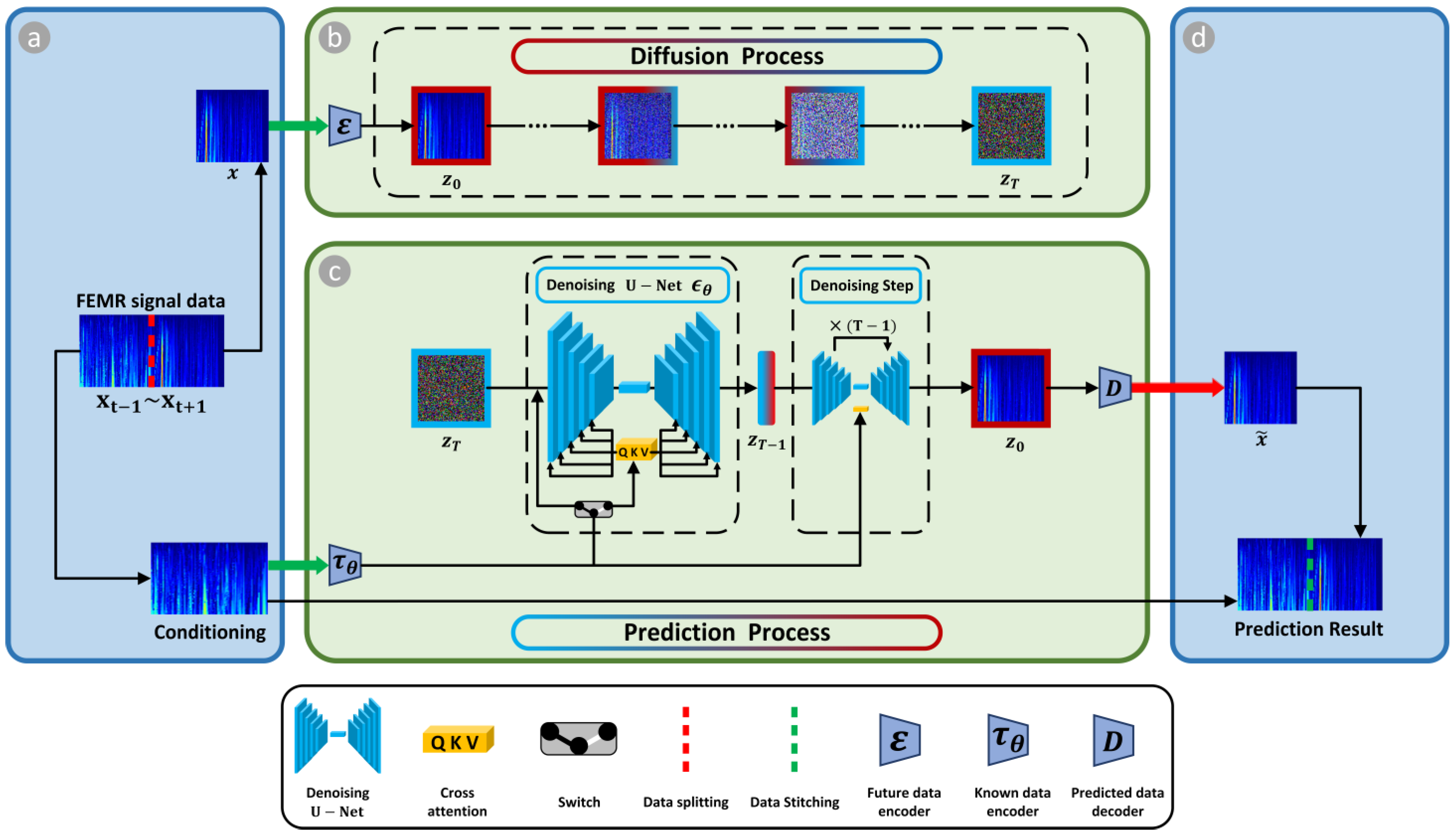
2.2. Guided Diffusion Model with Transformer
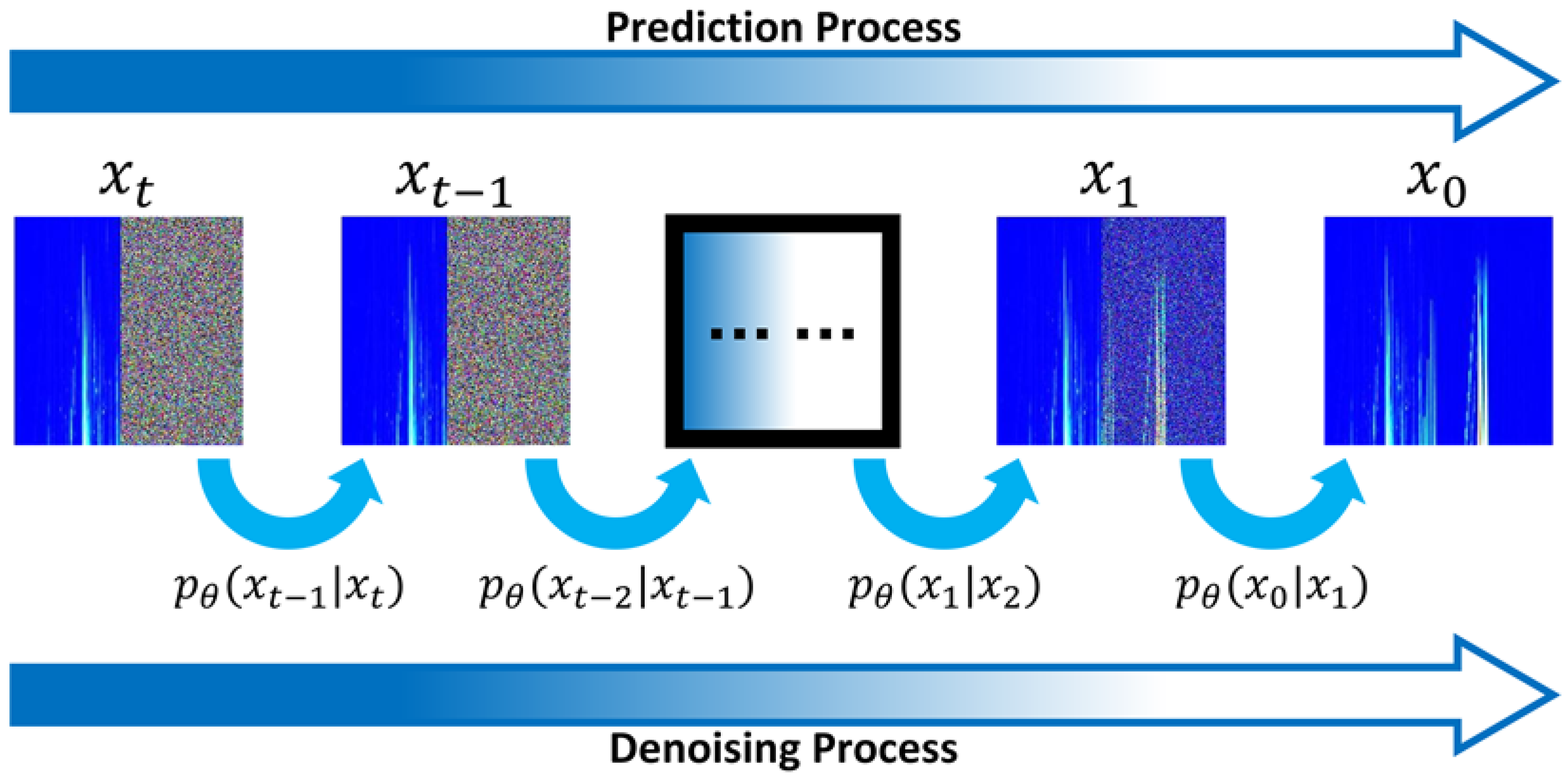
2.2.1. Guided Diffusion Model
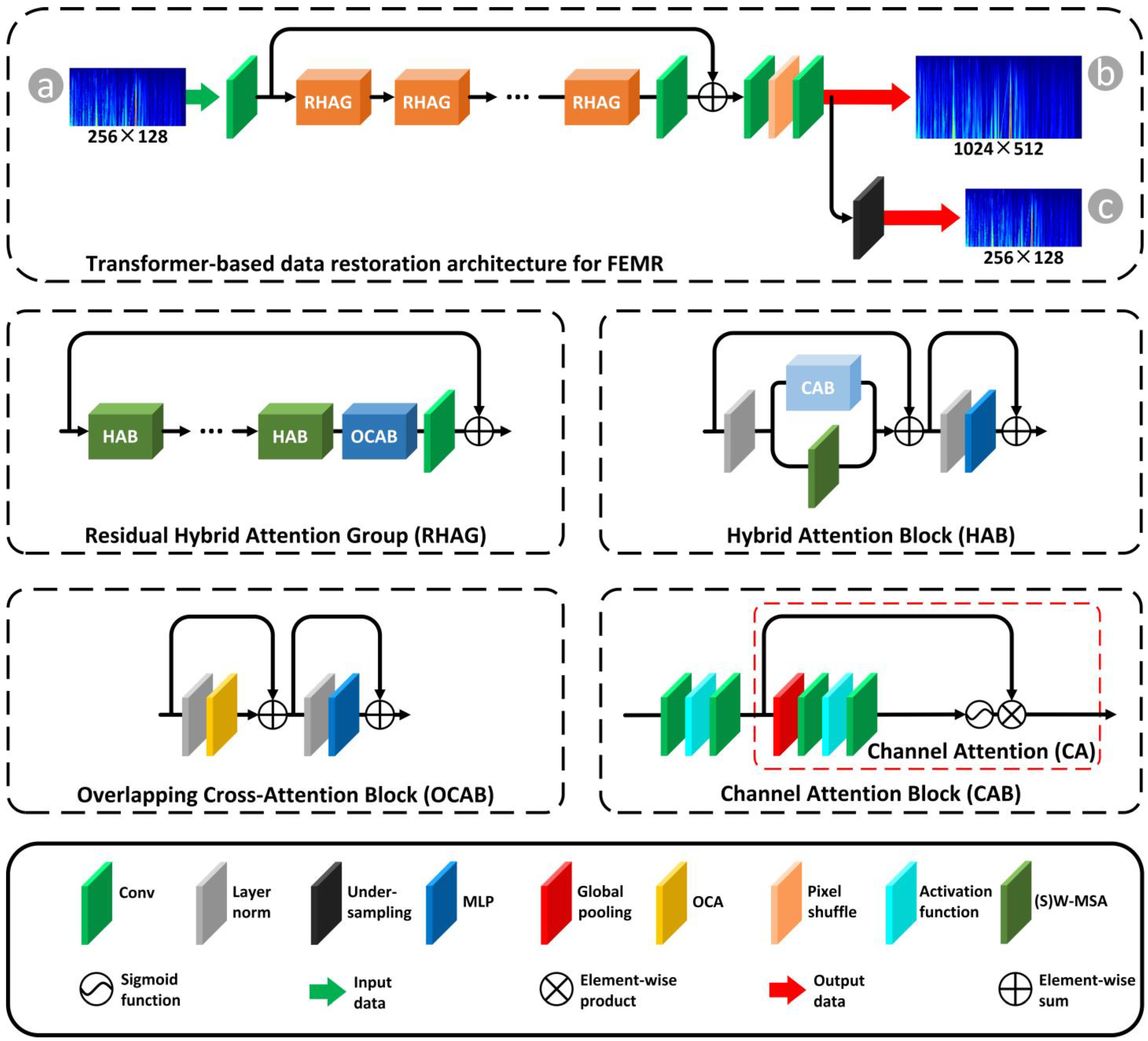
2.2.2. Transformer-Based Data Restoration Architecture
2.2.3. Recurrent Structure for Super Prediction
2.3. Dataset Preparation
2.3.1. Acquisition of FEMR Data
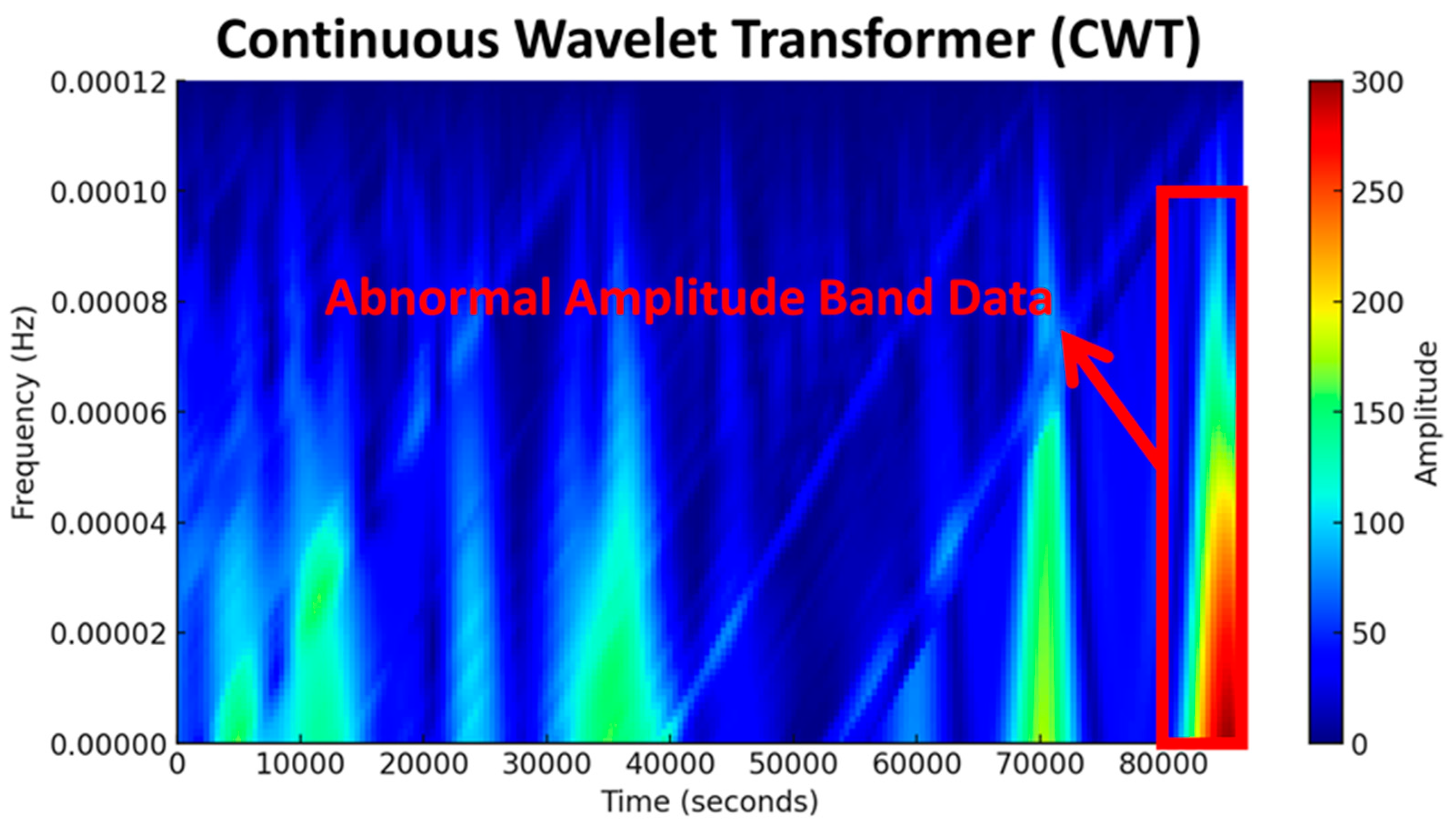
2.3.2. Principle of Continuous Wavelet Transform (CWT)
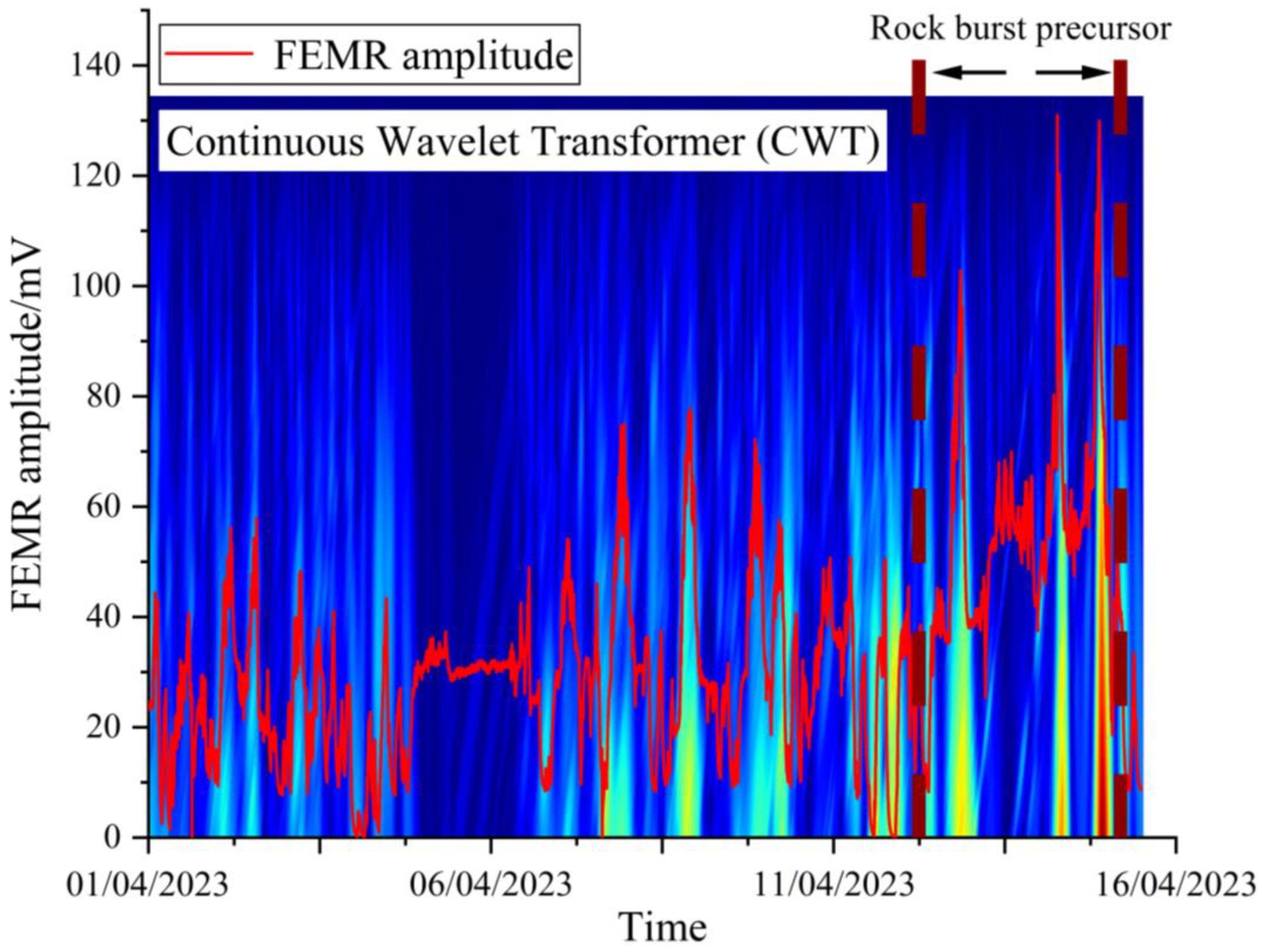
2.3.3. Time–Frequency Analysis of FEMR
3. Results
3.1. Dataset Creation and Enhancement
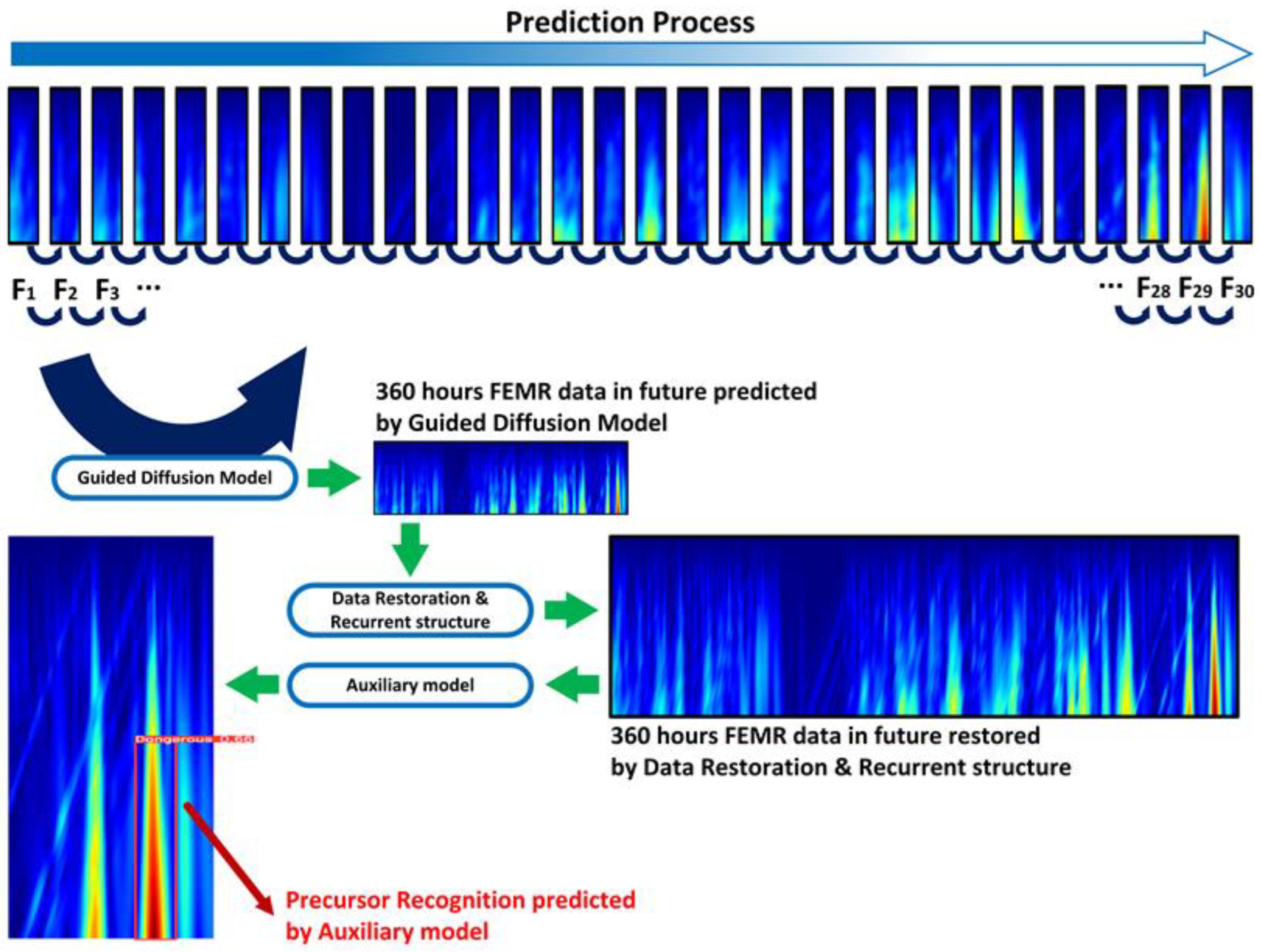
3.2. Signal Super Prediction and Precursor Recognition Framework Based on Guided Diffusion Model with Transformer
3.2.1. The Guided Diffusion Model
3.2.2. Transformer-Based Data Restoration and Recurrent Structure for Super Prediction
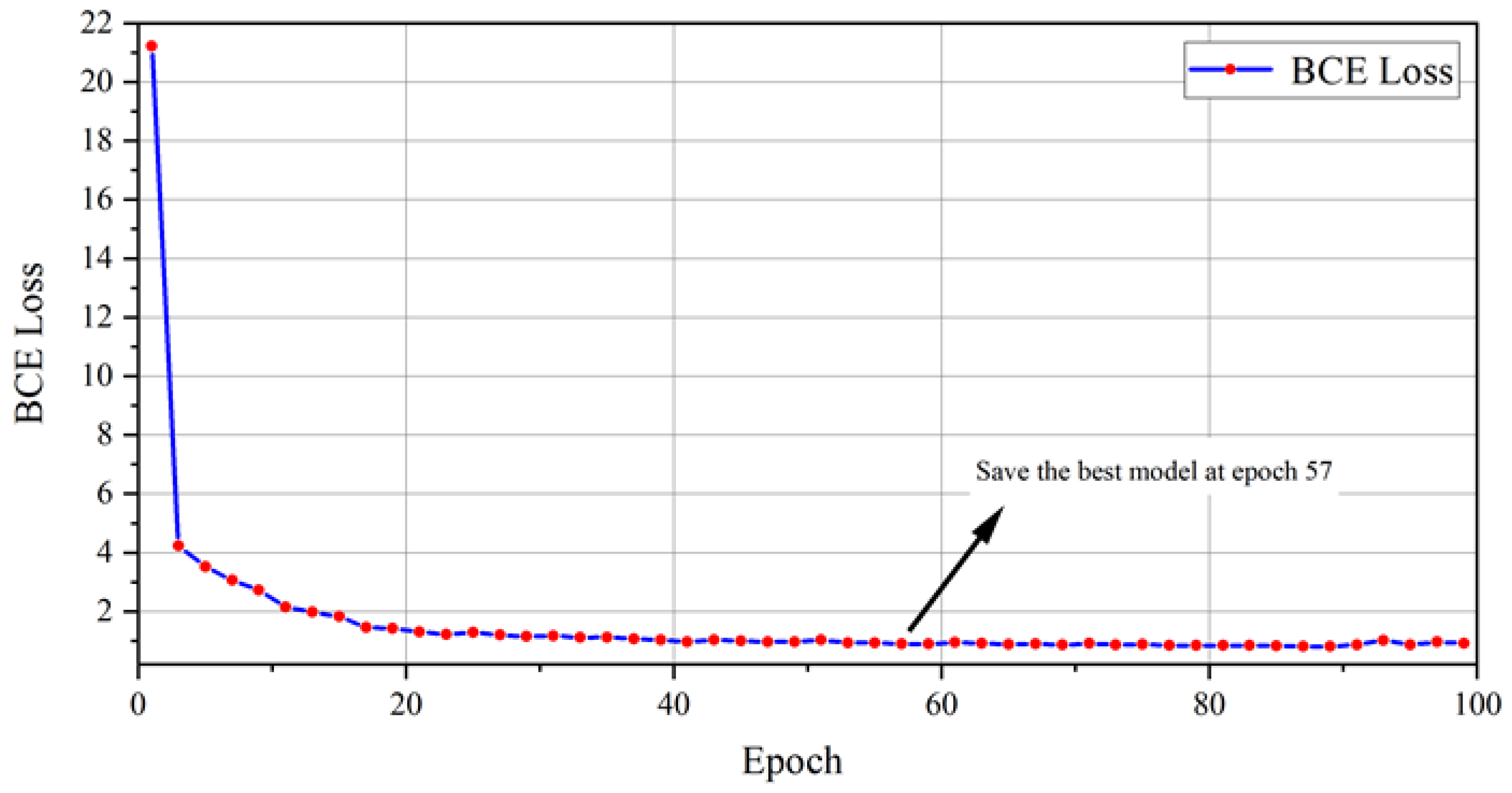
3.2.3. Auxiliary Model for Recognizing Rock Burst Precursor Characteristics
3.3. Early Warning Results for Rock Burst Using Signal Super Prediction and Precursor Recognition Framework
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, G.; Wang, E. Risk identification for coal and gas outburst in underground coal mines: A critical review and future directions. Gas Sci. Eng. 2023, 118, 205106. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, W.; Jiang, B.; Hu, C. Case of rock burst danger and its prediction and prevention in tunneling and mining period at an irregular coal face. Geotech. Geol. Eng. 2019, 37, 2545–2564. [Google Scholar] [CrossRef]
- Yin, S.; Wang, E.; Li, Z.; Zang, Z.; Liu, X.; Zhang, C.; Ding, X.; Aihemaiti, A. Multifractal and b-value nonlinear time-varying characteristics of acoustic emission for coal with different impact tendency. Measurement 2025, 248, 116896. [Google Scholar] [CrossRef]
- Li, X.; Wang, E.; Li, Z.; Liu, Z.; Song, D.; Qiu, L. Rock burst monitoring by integrated microseismic and electromagnetic radiation methods. Rock Mech. Rock Eng. 2016, 49, 4393–4406. [Google Scholar] [CrossRef]
- Di, Y.; Wang, E. Rock burst precursor electromagnetic radiation signal recognition method and early warning application based on recurrent neural networks. Rock Mech. Rock Eng. 2021, 54, 1449–1461. [Google Scholar] [CrossRef]
- Das, S.; Frid, V.; Rabinovitch, A.; Bahat, D.; Kushnir, U. Insights into the Dead Sea Transform Activity through the study of fracture-induced electromagnetic radiation (FEMR) signals before the Syrian-Turkey earthquake (Mw-6.3) on 20.2.2023. Sci. Rep. 2024, 14, 4579. [Google Scholar] [CrossRef]
- Bai, W.; Shu, L.; Sun, R.; Xu, J.; Silberschmidt, V.V.; Sugita, N. Mechanism of material removal in orthogonal cutting of cortical bone. J. Mech. Behav. Biomed. Mater. 2020, 104, 103618. [Google Scholar] [CrossRef]
- Frid, V.; Rabinovitch, A.; Bahat, D.; Kushnir, U. Fracture electromagnetic radiation induced by a seismic active zone (in the Vicinity of Eilat City, Southern Israel). Remote Sens. 2023, 15, 3639. [Google Scholar] [CrossRef]
- Wang, X.; Yu, S.; Yin, D. Time-frequency Characteristics of Micro-seismic Signals Before and after Rock Burst. In Proceedings of the 9th China-Russia Symposium “Coal in the 21st Century: Mining, Intelligent Equipment and Environment Protection” (COAL 2018), Qingdao, China, 18–21 October 2018; Atlantis Press: Amsterdam, The Netherlands, 2018; pp. 9–12. [Google Scholar]
- Ma, T.; Lin, D.; Tang, L.; Li, L.; Tang, C.; Yadav, K.P.; Jin, W. Characteristics of rockburst and early warning of microseismic monitoring at qinling water tunnel. Geomat. Nat. Hazards Risk 2022, 13, 1366–1394. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, Y.; Luo, B.; Chen, G.; Wu, M. Investigation of microseismic signal denoising using an improved wavelet adaptive thresholding method. Sci. Rep. 2022, 12, 22186. [Google Scholar] [CrossRef]
- Wu, M.; Ye, Y.; Wang, Q.; Hu, N. Development of rockburst research: A comprehensive review. Appl. Sci. 2022, 12, 974. [Google Scholar] [CrossRef]
- Zhang, S.; Tang, C.; Wang, Y.; Li, J.; Ma, T.; Wang, K. Review on early warning methods for rockbursts in tunnel engineering based on microseismic monitoring. Appl. Sci. 2021, 11, 10965. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Ahmed, S.; Nielsen, I.E.; Tripathi, A.; Siddiqui, S.; Ramachandran, R.P.; Rasool, G. Transformers in time-series analysis: A tutorial. Circuits Syst. Signal Process. 2023, 42, 7433–7466. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Du, Z.; Liu, X.; Wang, J.; Jiang, G.; Meng, Z.; Jia, H.; Xie, H.; Zhou, X. Response characteristics of gas concentration level in mining process and intelligent recognition method based on bi-lstm. Min. Metall. Explor. 2023, 40, 807–818. [Google Scholar] [CrossRef]
- Zhang, S.; Mu, C.; Feng, X.; Ma, K.; Guo, X.; Zhang, X. Intelligent dynamic warning method of rockburst risk and level based on recurrent neural network. Rock Mech. Rock Eng. 2024, 57, 3509–3529. [Google Scholar] [CrossRef]
- Wojtecki, Ł.; Iwaszenko, S.; Apel, D.B.; Cichy, T. An attempt to use machine learning algorithms to estimate the rockburst hazard in underground excavations of hard coal mine. Energies 2021, 14, 6928. [Google Scholar] [CrossRef]
- Mahmood, M.R.; Matin, M.A.; Sarigiannidis, P.; Goudos, S.K. A comprehensive review on artificial intelligence/machine learning algorithms for empowering the future IoT toward 6G era. IEEE Access 2022, 10, 87535–87562. [Google Scholar] [CrossRef]
- Basnet, P.M.S.; Mahtab, S.; Jin, A. A comprehensive review of intelligent machine learning based predicting methods in long-term and short-term rock burst prediction. Tunn. Undergr. Space Technol. 2023, 142, 105434. [Google Scholar] [CrossRef]
- Prasad, S.C.; Prasad, P. Deep recurrent neural networks for time series prediction. arXiv 2014, arXiv:1407.5949. [Google Scholar]
- Huang, L.; Xiang, L. Method for meteorological early warning of precipitation-induced landslides based on deep neural network. Neural Process. Lett. 2018, 48, 1243–1260. [Google Scholar] [CrossRef]
- Deb, S.; Chanda, A.K. Comparative analysis of contextual and context-free embeddings in disaster prediction from Twitter data. Mach. Learn. Appl. 2022, 7, 100253. [Google Scholar] [CrossRef]
- Jiao, H.; Song, W.; Cao, P.; Jiao, D. Prediction method of coal mine gas occurrence law based on multi-source data fusion. Heliyon 2023, 9, e17117. [Google Scholar] [CrossRef]
- Kiziroglou, M.E.; Boyle, D.E.; Yeatman, E.M.; Cilliers, J.J. Opportunities for sensing systems in mining. IEEE Trans. Ind. Inform. 2016, 13, 278–286. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2016; Volume 29. [Google Scholar]
- Adler, J.; Lunz, S. Banach wasserstein gan. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2018; Volume 31. [Google Scholar]
- Brock, A. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Mirza, M. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X.; Chen, X. Improved techniques for training gans. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2016; Volume 29. [Google Scholar]
- Radford, A. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Nagpal, S.; Verma, S.; Gupta, S.; Aggarwal, S. A guided learning approach for generative adversarial networks. In Proceedings of the 2020 IEEE International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Karras, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2019, arXiv:1812.04948. [Google Scholar]
- Younesi, A.; Ansari, M.; Fazli, M.; Ejlali, A.; Shafique, M.; Henkel, J. A Comprehensive Survey of Convolutions in Deep Learning: Applications, Challenges, and Future Trends. IEEE Access 2024, 12, 41180–41218. [Google Scholar] [CrossRef]
- Panariello, M. Low-Complexity Neural Networks for Robust Acoustic Scene Classification in Wearable Audio Devices; Politecnico di Torino: Turin, Italy, 2022. [Google Scholar]
- Peng, J.; Liu, Y.; Wang, M.; Li, Y.; Li, H. Zero-Shot Self-Consistency Learning for Seismic Irregular Spatial Sampling Reconstruction. arXiv 2024, arXiv:2411.00911. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2014; Volume 27. [Google Scholar]
- Cao, H.; Tan, C.; Gao, Z.; Xu, Y.; Chen, G.; Heng, P.-A.; Li, S.Z. A survey on generative diffusion models. IEEE Trans. Knowl. Data Eng. 2024, 36, 2814–2830. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.-H. Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2021; Volume 34, pp. 8780–8794. [Google Scholar]
- Srivastava, A.; Sutton, C. Autoencoding variational inference for topic models. arXiv 2017, arXiv:1703.01488. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Zhu, L.; Zheng, Y.; Zhang, Y.; Wang, X.; Wang, L.; Huang, H. Temporal Residual Guided Diffusion Framework for Event-Driven Video Reconstruction. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2025; pp. 411–427. [Google Scholar]
- Huang, Y.; Huang, J.; Liu, Y.; Yan, M.; Lv, J.; Liu, J.; Xiong, W.; Zhang, H.; Chen, S.; Cao, L. Diffusion model-based image editing: A survey. arXiv 2024, arXiv:2402.17525. [Google Scholar] [CrossRef] [PubMed]
- Fuest, M.; Ma, P.; Gui, M.; Schusterbauer, J.; Hu, V.T.; Ommer, B. Diffusion models and representation learning: A survey. arXiv 2024, arXiv:2407.00783. [Google Scholar]
- Blattmann, A.; Rombach, R.; Ling, H.; Dockhorn, T.; Kim, S.W.; Fidler, S.; Kreis, K. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 22563–22575. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 10684–10695. [Google Scholar]
- Avrahami, O.; Fried, O.; Lischinski, D. Blended latent diffusion. ACM Trans. Graph. (TOG) 2023, 42, 1–11. [Google Scholar] [CrossRef]
- Lovelace, J.; Kishore, V.; Wan, C.; Shekhtman, E.; Weinberger, K.Q. Latent diffusion for language generation. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2024; Volume 36. [Google Scholar]
- Xu, M.; Powers, A.S.; Dror, R.O.; Ermon, S.; Leskovec, J. Geometric latent diffusion models for 3d molecule generation. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 38592–38610. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2019; Volume 32. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2256–2265. [Google Scholar]
- Kingma, D.P. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ahmed, D.M.; Hassan, M.M.; Mstafa, R.J. A review on deep sequential models for forecasting time series data. Appl. Comput. Intell. Soft Comput. 2022, 2022, 6596397. [Google Scholar] [CrossRef]
- Mavrogiorgos, K.; Kiourtis, A.; Mavrogiorgou, A.; Gucek, A.; Menychtas, A.; Kyriazis, D. Mitigating Bias in Time Series Forecasting for Efficient Wastewater Management. In Proceedings of the 2024 7th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 17–18 July 2024; IEEE: New York, NY, USA, 2024; pp. 185–190. [Google Scholar]
- Nguyen, H.P.; Liu, J.; Zio, E. A long-term prediction approach based on long short-term memory neural networks with automatic parameter optimization by Tree-structured Parzen Estimator and applied to time-series data of NPP steam generators. Appl. Soft Comput. 2020, 89, 106116. [Google Scholar] [CrossRef]
- Rahman, M.; Shakeri, M.; Khatun, F.; Tiong, S.K.; Alkahtani, A.A.; Samsudin, N.A.; Amin, N.; Pasupuleti, J.; Hasan, M.K. A comprehensive study and performance analysis of deep neural network-based approaches in wind time-series forecasting. J. Reliab. Intell. Environ. 2023, 9, 183–200. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2017. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 3202–3211. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 12009–12019. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Newry, UK, 2020; Volume 33, pp. 6840–6851. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Buertai Coal Mine Database |
|---|---|
| Rock Burst Precursor | |
| Train | 2080 |
| Test | 520 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weng, M.; Du, Z.; Cai, C.; Wang, E.; Jia, H.; Liu, X.; Wu, J.; Su, G.; Liu, Y. Signal Super Prediction and Rock Burst Precursor Recognition Framework Based on Guided Diffusion Model with Transformer. Appl. Sci. 2025, 15, 3264. https://doi.org/10.3390/app15063264
Weng M, Du Z, Cai C, Wang E, Jia H, Liu X, Wu J, Su G, Liu Y. Signal Super Prediction and Rock Burst Precursor Recognition Framework Based on Guided Diffusion Model with Transformer. Applied Sciences. 2025; 15(6):3264. https://doi.org/10.3390/app15063264
Chicago/Turabian StyleWeng, Mingyue, Zinan Du, Chuncheng Cai, Enyuan Wang, Huilin Jia, Xiaofei Liu, Jinze Wu, Guorui Su, and Yong Liu. 2025. "Signal Super Prediction and Rock Burst Precursor Recognition Framework Based on Guided Diffusion Model with Transformer" Applied Sciences 15, no. 6: 3264. https://doi.org/10.3390/app15063264
APA StyleWeng, M., Du, Z., Cai, C., Wang, E., Jia, H., Liu, X., Wu, J., Su, G., & Liu, Y. (2025). Signal Super Prediction and Rock Burst Precursor Recognition Framework Based on Guided Diffusion Model with Transformer. Applied Sciences, 15(6), 3264. https://doi.org/10.3390/app15063264