
A Human–Robot Skill Transfer Strategy with Task-Constrained Optimization and Real-Time Whole-Body Adaptation



Abstract
1. Introduction
- 1.
- Considering basic-level MPs learning, to facilitate human–robot skill transfer, we develop the via-point trajectory generalization method enabling the robot to learn and generalize smooth trajectories from only one human demonstration. To incrementally incorporate multiple human skill variations, we encode initial distributions for each skill with Joint ProMPs by generalizing the template trajectory with discrete via-points and deriving corresponding inverse kinematics (IK) solutions.
- 2.
- Considering core-level MPs adaptation, given initial Joint ProMPs, we propose an effective task-constrained probabilistic optimization method integrating multiple task constraints in Joint and Cartesian space via a double-loop optimization. We decouple the ProMPs into Gaussians at each timestep, only optimizing those timesteps violating task constraints, and update ProMPs independently. Given optimized ProMPs, we propose the analytical movement adaptation method to utilize ProMPs directly for task execution with a threshold.
- 3.
- Considering real-time movement adaptation, during task execution, we propose an improved robot whole-body movement adaptation method, combining offline task-constrained optimization. For the robot end-effector, we incorporate an offline-optimized trajectory for dynamic modulation and develop DSM by performing multiple modulation iterations until safe; for the robot non-end-effector, we integrate the offline-optimized Joint ProMPs to improve the real-time null space velocity control method to ensure collision-free joint configurations through iterations.
- 4.
- We conduct both offline and online movement adaptation experiments with comparative results to validate the effectiveness of the proposed strategy.
2. Via-Point Trajectory Generalization and Initial Distributions Encoding
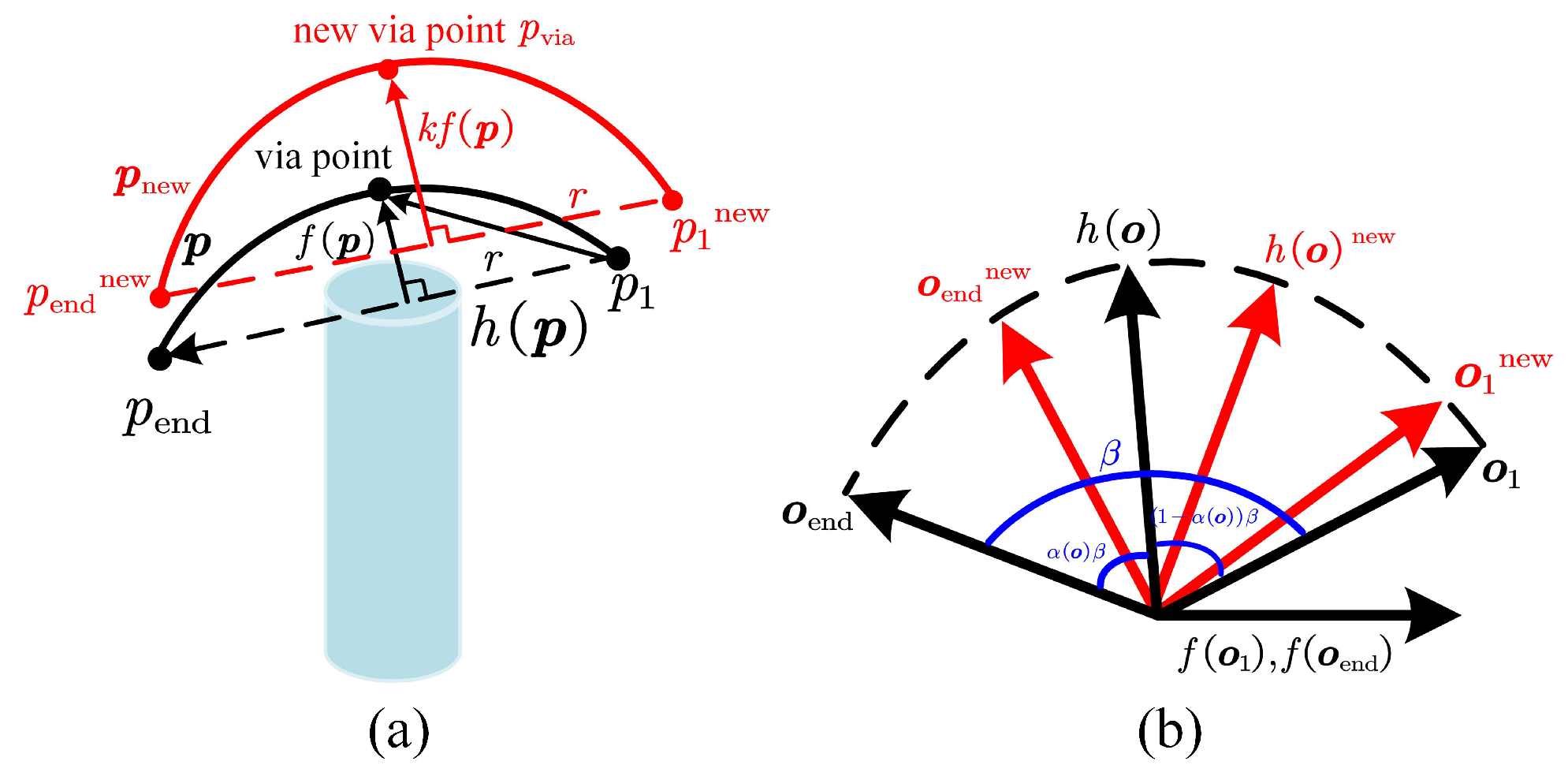
2.1. Learning New Skills in Cartesian Space with Via-Point Trajectory Generalization
2.2. Model Joint Space Distributions with Probabilistic Movement Primitives
3. Offline Optimization and Adaptation Under Nonlinear Task Constraints
3.1. Problem Formulation
3.2. Constraints Definitions in Joint Space and Cartesian Space
3.2.1. Joint Range Limit
3.2.2. Waypoints
3.2.3. Hyperplane
3.2.4. Repellers
3.3. Optimization and Adaptation Procedure
3.3.1. Optimization Procedure
3.3.2. Adaptation Procedure
| Algorithm 1 Robotic offline task constrained optimization and adaptation algorithm. |
Input:
|
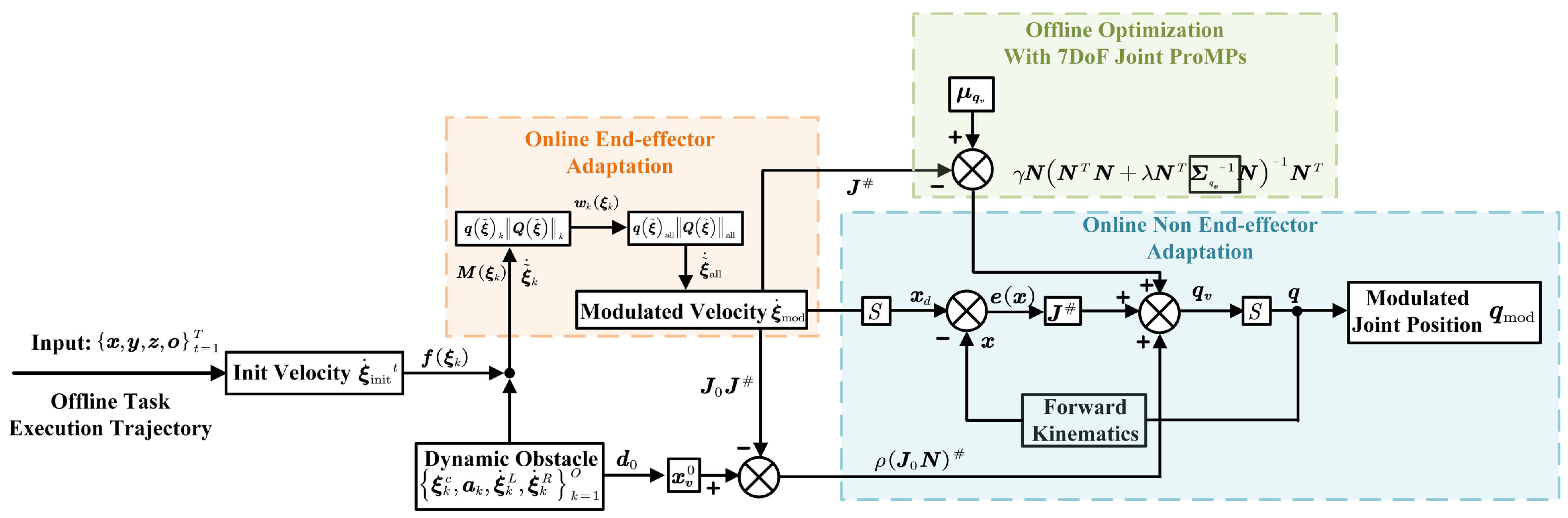
4. Real-Time Whole-Body Movement Adaptation
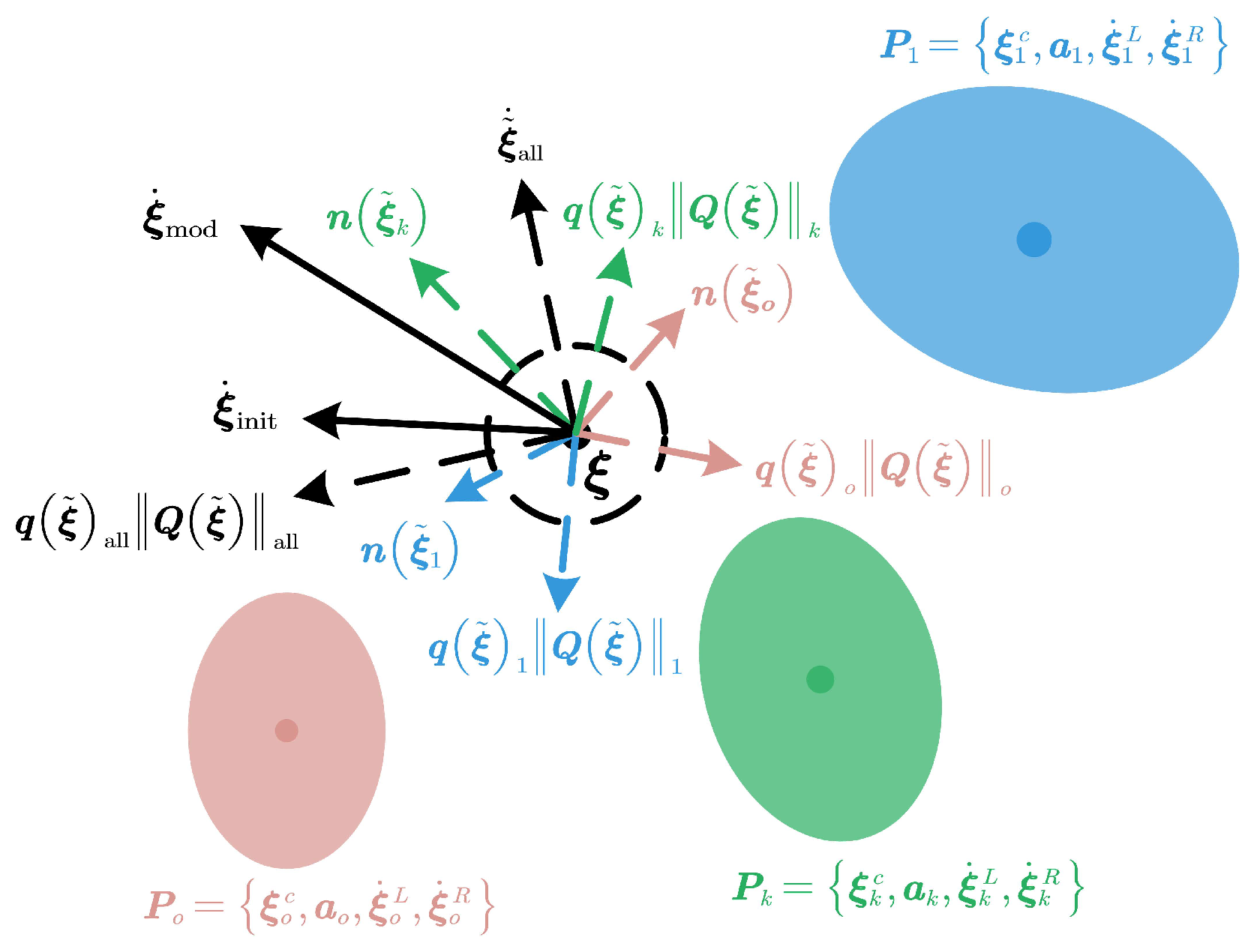
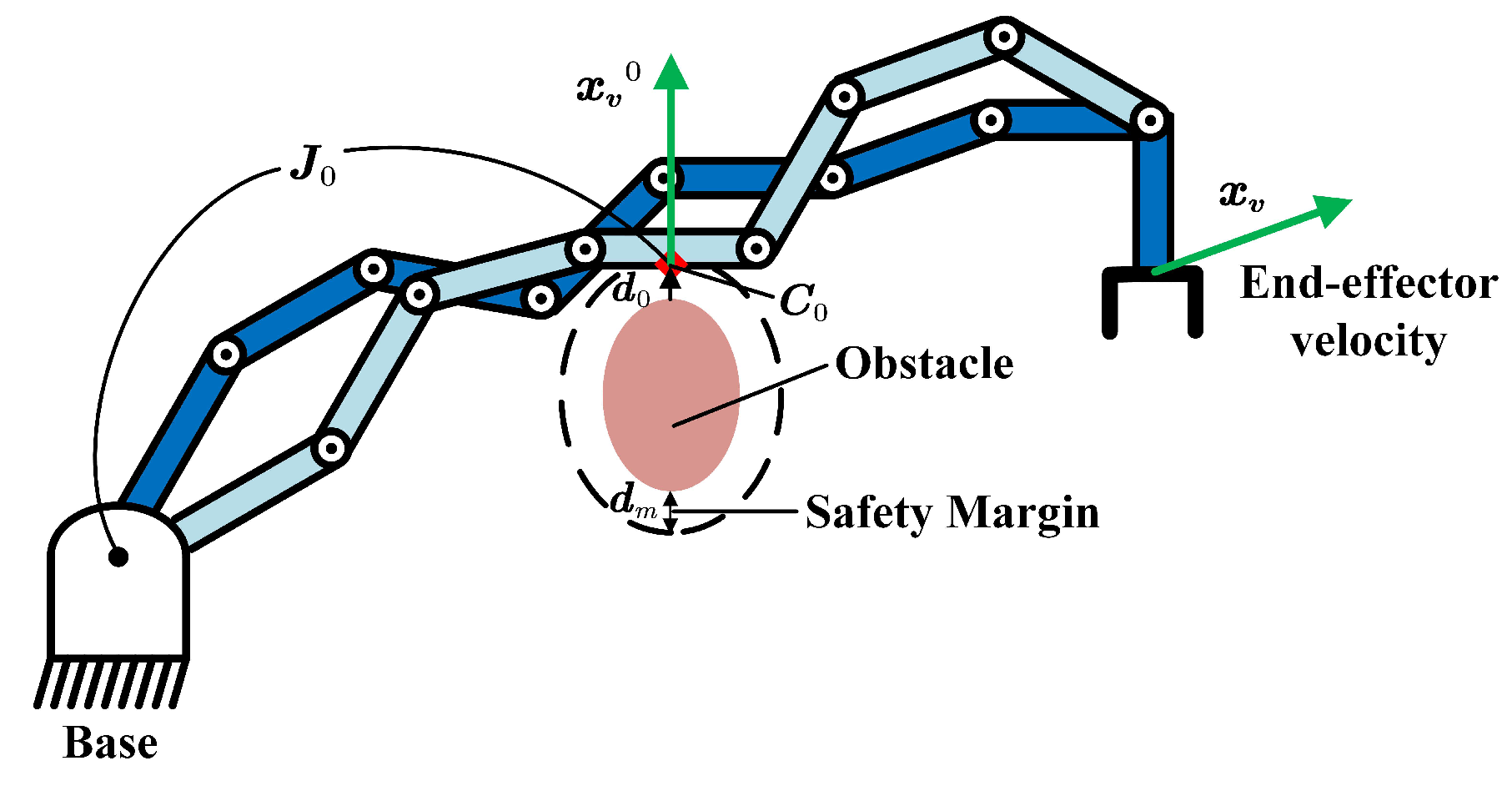
4.1. Real-Time End-Effector Adaptation
4.2. Real-Time Non-End-Effector Adaptation
5. Experimental Validation
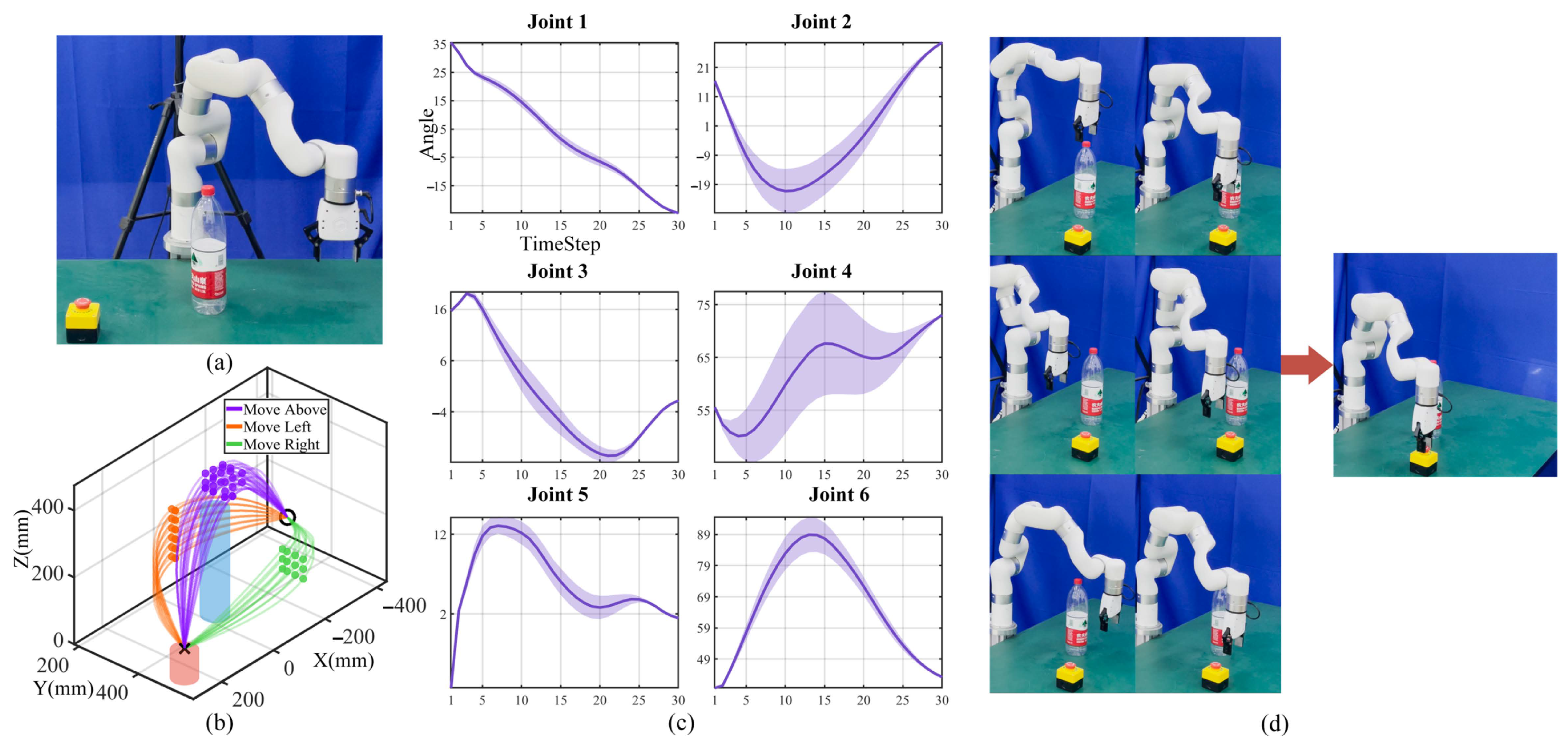
5.1. Template Trajectory Generalization from Only One Human Demonstration
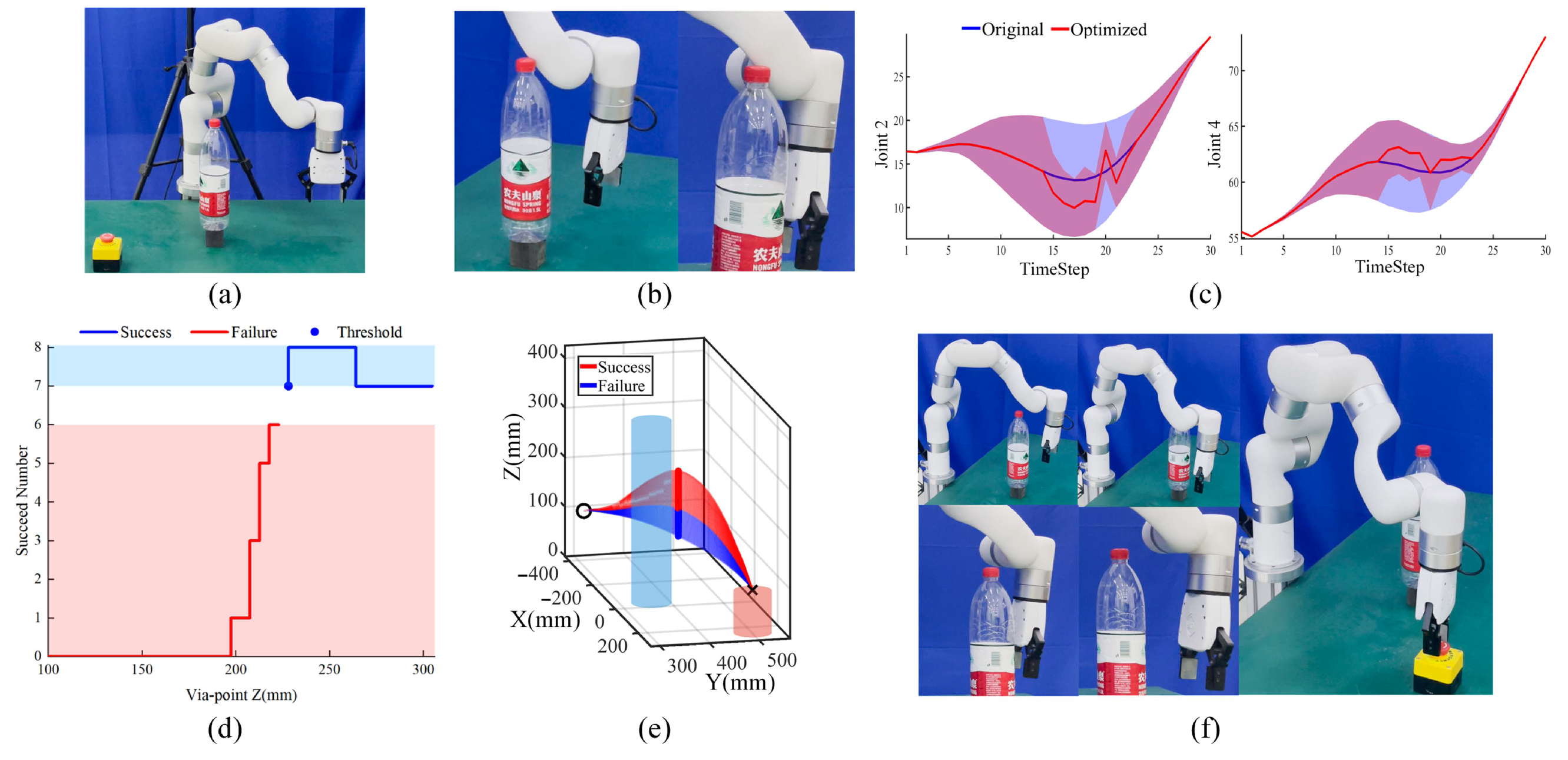
5.2. Offline Movement Adaptation
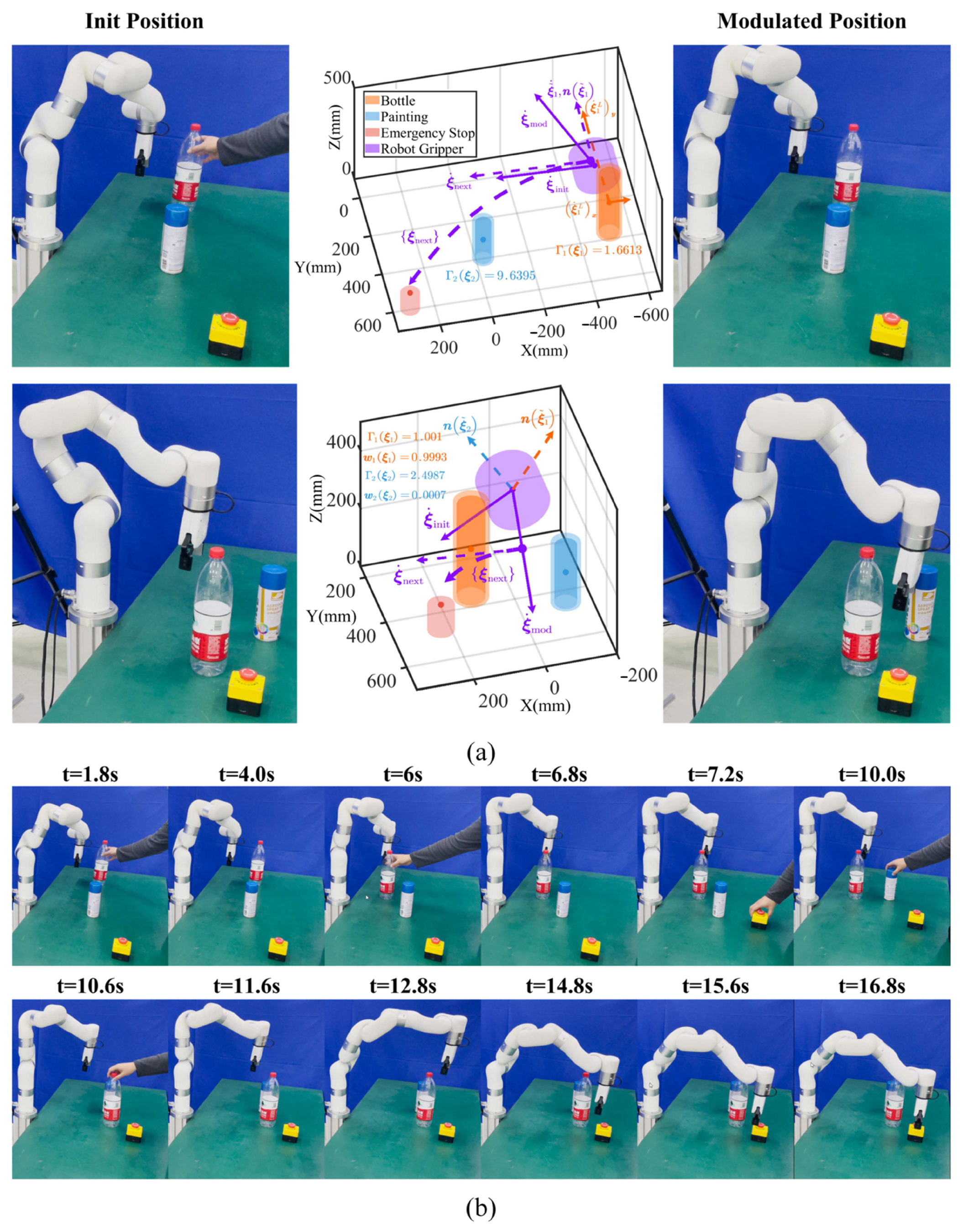
5.3. Real-Time Whole-Body Movement Adaptation
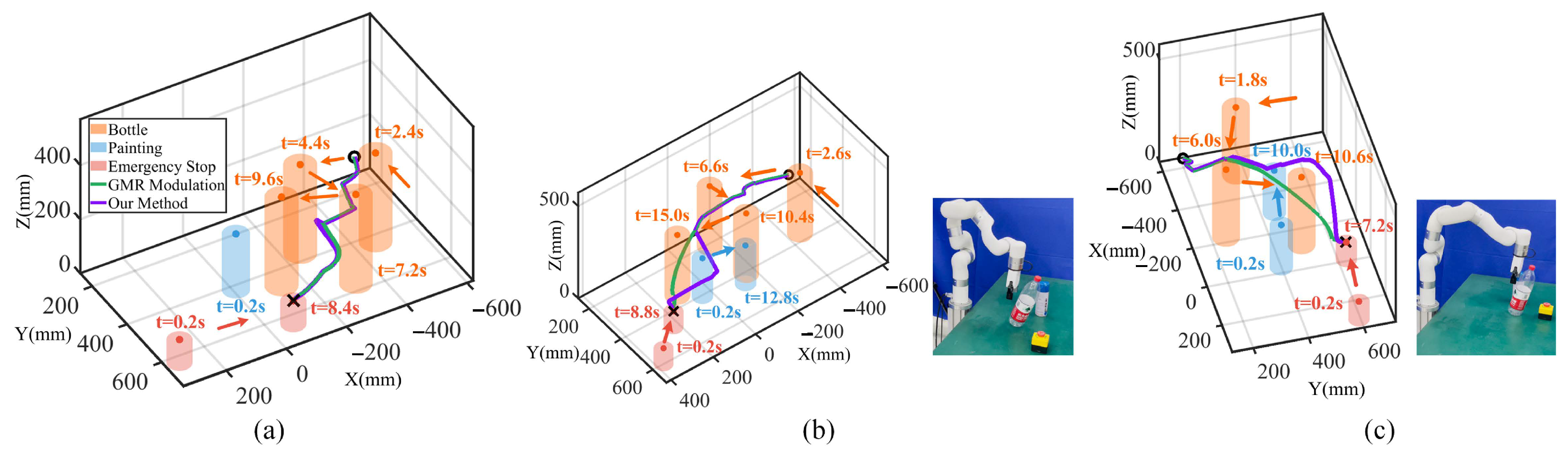
5.4. Comparative Experiments
5.4.1. Offline Movement Adaptation
5.4.2. Real-Time Movement Adaptation
6. Discussion
6.1. Comparison to Previous Work
6.2. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mukherjee, D.; Gupta, K.; Chang, L.H.; Najjaran, H. A survey of robot learning strategies for human-robot collaboration in industrial settings. Robot. Comput.-Integr. Manuf. 2022, 73, 102231. [Google Scholar] [CrossRef]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef]
- Zhu, Z.; Hu, H. Robot learning from demonstration in robotic assembly: A survey. Robotics 2018, 7, 17. [Google Scholar] [CrossRef]
- Calinon, S. Learning from demonstration (programming by demonstration). Encycl. Robot. 2018, 1–8. [Google Scholar] [CrossRef]
- Correia, A.; Alexandre, L.A. A survey of demonstration learning. Robot. Auton. Syst. 2024, 182, 104812. [Google Scholar] [CrossRef]
- Zare, M.; Kebria, P.M.; Khosravi, A.; Nahavandi, S. A survey of imitation learning: Algorithms, recent developments, and challenges. IEEE Trans. Cybern. 2024, 54, 7173–7186. [Google Scholar] [CrossRef] [PubMed]
- Jaquier, N.; Zhou, Y.; Starke, J.; Asfour, T. Learning to sequence and blend robot skills via differentiable optimization. IEEE Robot. Autom. Lett. 2022, 7, 8431–8438. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef]
- Calinon, S.; Guenter, F.; Billard, A. On learning, representing, and generalizing a task in a humanoid robot. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2007, 37, 286–298. [Google Scholar] [CrossRef]
- Paraschos, A.; Daniel, C.; Peters, J.; Neumann, G. Using probabilistic movement primitives in robotics. Auton. Robot. 2018, 42, 529–551. [Google Scholar] [CrossRef]
- Huang, Y.; Rozo, L.; Silvério, J.; Caldwell, D.G. Kernelized movement primitives. Int. J. Robot. Res. 2019, 38, 833–852. [Google Scholar] [CrossRef]
- Li, G.; Jin, Z.; Volpp, M.; Otto, F.; Lioutikov, R.; Neumann, G. ProDMP: A Unified Perspective on Dynamic and Probabilistic Movement Primitives. IEEE Robot. Autom. Lett. 2023, 8, 2325–2332. [Google Scholar] [CrossRef]
- Lauretti, C.; Cordella, F.; Zollo, L. A hybrid joint/Cartesian DMP-based approach for obstacle avoidance of anthropomorphic assistive robots. Int. J. Soc. Robot. 2019, 11, 783–796. [Google Scholar] [CrossRef]
- Pairet, È.; Ardón, P.; Mistry, M.; Petillot, Y. Learning generalizable coupling terms for obstacle avoidance via low-dimensional geometric descriptors. IEEE Robot. Autom. Lett. 2019, 4, 3979–3986. [Google Scholar] [CrossRef]
- Duan, A.; Camoriano, R.; Ferigo, D.; Calandriello, D.; Rosasco, L.; Pucci, D. Constrained DMPs for feasible skill learning on humanoid robots. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; pp. 1–6. [Google Scholar]
- Dahlin, A.; Karayiannidis, Y. Adaptive trajectory generation under velocity constraints using dynamical movement primitives. IEEE Control Syst. Lett. 2019, 4, 438–443. [Google Scholar] [CrossRef]
- Paraschos, A.; Lioutikov, R.; Peters, J.; Neumann, G. Probabilistic prioritization of movement primitives. IEEE Robot. Autom. Lett. 2017, 2, 2294–2301. [Google Scholar] [CrossRef]
- Koert, D.; Maeda, G.; Lioutikov, R.; Neumann, G.; Peters, J. Demonstration based trajectory optimization for generalizable robot motions. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 515–522. [Google Scholar]
- Izadi, N.H.; Palhang, M.; Safayani, M. Layered Relative Entropy Policy Search. Knowl.-Based Syst. 2021, 223, 107025. [Google Scholar] [CrossRef]
- Koert, D.; Pajarinen, J.; Schotschneider, A.; Trick, S.; Rothkopf, C.; Peters, J. Learning intention aware online adaptation of movement primitives. IEEE Robot. Autom. Lett. 2019, 4, 3719–3726. [Google Scholar] [CrossRef]
- Frank, F.; Paraschos, A.; van der Smagt, P.; Cseke, B. Constrained probabilistic movement primitives for robot trajectory adaptation. IEEE Trans. Robot. 2021, 38, 2276–2294. [Google Scholar] [CrossRef]
- Huang, Y.; Caldwell, D.G. A linearly constrained nonparametric framework for imitation learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4400–4406. [Google Scholar]
- Huang, Y. Ekmp: Generalized imitation learning with adaptation, nonlinear hard constraints and obstacle avoidance. arXiv 2021, arXiv:2103.00452. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Zucker, M.; Ratliff, N.; Dragan, A.D.; Pivtoraiko, M.; Klingensmith, M.; Dellin, C.M.; Bagnell, J.A.; Srinivasa, S.S. Chomp: Covariant hamiltonian optimization for motion planning. Int. J. Robot. Res. 2013, 32, 1164–1193. [Google Scholar] [CrossRef]
- Bhardwaj, M.; Sundaralingam, B.; Mousavian, A.; Ratliff, N.D.; Fox, D.; Ramos, F.; Boots, B. Storm: An integrated framework for fast joint-space model-predictive control for reactive manipulation. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 750–759. [Google Scholar]
- Cai, M.; Aasi, E.; Belta, C.; Vasile, C.I. Overcoming exploration: Deep reinforcement learning for continuous control in cluttered environments from temporal logic specifications. IEEE Robot. Autom. Lett. 2023, 8, 2158–2165. [Google Scholar] [CrossRef]
- Tulbure, A.; Khatib, O. Closing the loop: Real-time perception and control for robust collision avoidance with occluded obstacles. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 5700–5707. [Google Scholar]
- Szulczyński, P.; Pazderski, D.; Kozłowski, K. Real-time obstacle avoidance using harmonic potential functions. J. Autom. Mob. Robot. Intell. Syst. 2011, 5, 59–66. [Google Scholar]
- Khansari-Zadeh, S.M.; Billard, A. A dynamical system approach to realtime obstacle avoidance. Auton. Robot. 2012, 32, 433–454. [Google Scholar] [CrossRef]
- Huber, L.; Billard, A.; Slotine, J.J. Avoidance of convex and concave obstacles with convergence ensured through contraction. IEEE Robot. Autom. Lett. 2019, 4, 1462–1469. [Google Scholar] [CrossRef]
- Huber, L.; Slotine, J.J.; Billard, A. Fast obstacle avoidance based on real-time sensing. IEEE Robot. Autom. Lett. 2022, 8, 1375–1382. [Google Scholar] [CrossRef]
- Huber, L.; Slotine, J.J.; Billard, A. Avoidance of Concave Obstacles through Rotation of Nonlinear Dynamics. IEEE Trans. Robot. 2023, 40, 1983–2002. [Google Scholar] [CrossRef]
- Seraji, H.; Bon, B. Real-time collision avoidance for position-controlled manipulators. IEEE Trans. Robot. Autom. 1999, 15, 670–677. [Google Scholar] [CrossRef]
- Petrič, T.; Žlajpah, L. Smooth continuous transition between tasks on a kinematic control level: Obstacle avoidance as a control problem. Robot. Auton. Syst. 2013, 61, 948–959. [Google Scholar] [CrossRef]
- Zheng, D.; Wu, X.; Pang, J. Real-time whole-body obstacle avoidance for 7-DOF redundant manipulators. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 2626–2631. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Efficient model-based 3D tracking of hand articulations using Kinect. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; Volume 1, p. 3. [Google Scholar]
- Carpentier, J.; Mansard, N. Analytical derivatives of rigid body dynamics algorithms. In Proceedings of the Robotics: Science and Systems (RSS 2018), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- McDonald, G.C. Ridge regression. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 93–100. [Google Scholar] [CrossRef]
- Wan, E.A.; Van Der Merwe, R. The unscented Kalman filter for nonlinear estimation. In Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No. 00EX373), Lake Louise, AB, Canada, 4 October 2000; pp. 153–158. [Google Scholar]
- Bertsekas, D.P. Nonlinear programming. J. Oper. Res. Soc. 1997, 48, 334. [Google Scholar] [CrossRef]
- Berahas, A.S.; Takáč, M. A robust multi-batch L-BFGS method for machine learning. Optim. Methods Softw. 2020, 35, 191–219. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Kronander, K.; Khansari, M.; Billard, A. Incremental motion learning with locally modulated dynamical systems. Robot. Auton. Syst. 2015, 70, 52–62. [Google Scholar] [CrossRef]
- Barata, J.C.A.; Hussein, M.S. The Moore–Penrose pseudoinverse: A tutorial review of the theory. Braz. J. Phys. 2012, 42, 146–165. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Khansari-Zadeh, S.M.; Billard, A. Learning stable nonlinear dynamical systems with gaussian mixture models. IEEE Trans. Robot. 2011, 27, 943–957. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Offline Adaptation | Description |
|---|---|
| Trajectory shape modulation for 3D positions | |
| The obstacle radius | |
| The 3D position sets for via-points range | |
| The threshold for fine-tuning via-points | |
| T | The forward kinematics function |
| The distance threshold to represent task constraints probability | |
| The hyperplane normal and bias vectors for the maximum Z | |
| The obstacle safe radius | |
| The confidence level to represent the task constraints probability | |
| The initial Lagrange multiplier | |
| Initial Gaussian distributions of ProMPs | |
| Optimized Gaussian distributions of ProMPs | |
| The initial mean and standard deviation of each timestep | |
| The optimized mean and standard deviation of each timestep | |
| The optimized joint limit range | |
| Gaussian basis functions | |
| The initial joint value for Jacobian IK | |
| The interval between adjacent timesteps | |
| The ellipsoid-shaped distance function | |
| The curvature parameter and the center of the distance function | |
| The linear and angular velocities of dynamic obstacles | |
| Real-Time Adaptation | Description |
| The normal vector of the deflection hyperplane at point | |
| The basis and the diagonal eigenvalue matrix | |
| The safety magnitude and reactivity parameter for | |
| Tail-effect definition for | |
| The modulation matrix and weighted coefficient for each dynamic obstacle | |
| The weighted magnitude and directions for all dynamic obstacles | |
| The initial and modulated velocity in Cartesian space | |
| The closest point between the robot links and the obstacle | |
| The retreat velocity and the Jacobian matrix at point | |
| The minimum detected distance between robot links 1 to 6 and the obstacle | |
| The safety margin for dynamic obstacles | |
| The weight term and weighted relative velocity | |
| The next generalized trajectory sets and the next velocity computed | |
| The distance at which the obstacle begins to affect the manipulator | |
| The scalar velocity | |
| The modulated joint configuration |
| Algorithm in [21] | EKMPs in [23] | Our Method | |
|---|---|---|---|
| Parameters for Optimization | 665 | 512 | 777 |
| Constraints Formulas Numbers | 512 | 512 | 136 |
| Total Iteration Numbers | 265 | 36 | 64 |
| Optimization Time (s) | 853.36 | 728.58 | 126.45 |
| Distribution Loss | 76.48% | 70.32% | 84.36% |
| Task Success Rate | 92% | 91% | 99% |
| SEDS-GMR Modulation [30,31] | Our Method | |
|---|---|---|
| Task Success Rate | 73.33% | 93.33% |
| Offline Parameters Learning Time (s) | 24.6856 ± 0.1546 | 0.0904 ± 0.0148 |
| Average Real-time Modulation Time (s) | 0.1238 ± 0.0167 | 0.1465 ± 0.0285 |
| Total Task Execution Time (s) | 23.2 ± 1 | 16.8 ± 0.4 |
| Collison Rate | 26.67% | 6.67% |
| Final Position Error (mm) | 0.52 ± 0.13 | 0.55 ± 0.09 |
| Convergence TimeSteps | 116 ± 5 | 84 ± 2 |
| CHOMP | Null Space Control in [36] | Our Method | |
|---|---|---|---|
| Success Rate | 93.33% | 76.67% | 96.67% |
| Average Modulation Time (s) | 0.1434 ± 0.0563 | 0.1654 ± 0.0146 | 0.1757 ± 0.0086 |
| Joint Configurations Iterations | 126 ± 24 | 10 ± 2 | 20 ± 1 |
| Modulation Path (m) | 9.8829 ± 1.2368 | 0.8204 ± 0.0046 | 0.8232 ± 0.0024 |
| Total Task Execution Time (s) | 232.8 | 13.2 | 13.8 ± 0.4 |
| Collision Rate | 6.67% | 23.33% | 3.33% |
| Final Position Error (mm) | 0.83 ± 0.16 | 0.66 ± 0.14 | 0.59 ± 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, G.; Zang, X.; Zhang, X.; Li, C.; Zhu, Y.; Zhao, J. A Human–Robot Skill Transfer Strategy with Task-Constrained Optimization and Real-Time Whole-Body Adaptation. Appl. Sci. 2025, 15, 3171. https://doi.org/10.3390/app15063171
Ding G, Zang X, Zhang X, Li C, Zhu Y, Zhao J. A Human–Robot Skill Transfer Strategy with Task-Constrained Optimization and Real-Time Whole-Body Adaptation. Applied Sciences. 2025; 15(6):3171. https://doi.org/10.3390/app15063171
Chicago/Turabian StyleDing, Guanwen, Xizhe Zang, Xuehe Zhang, Changle Li, Yanhe Zhu, and Jie Zhao. 2025. "A Human–Robot Skill Transfer Strategy with Task-Constrained Optimization and Real-Time Whole-Body Adaptation" Applied Sciences 15, no. 6: 3171. https://doi.org/10.3390/app15063171
APA StyleDing, G., Zang, X., Zhang, X., Li, C., Zhu, Y., & Zhao, J. (2025). A Human–Robot Skill Transfer Strategy with Task-Constrained Optimization and Real-Time Whole-Body Adaptation. Applied Sciences, 15(6), 3171. https://doi.org/10.3390/app15063171