1. Introduction
Defocus blurring is a common image distortion phenomenon that occurs when a camera or the human eye fails to focus accurately. Specifically, when the captured object is not aligned with the camera’s focal point, the in-focus object appears sharp, while out-of-focus objects become blurred [
1]. This blurring effect significantly degrades image quality and negatively impacts the subsequent tasks that rely on these images, such as image segmentation, object detection, and depth estimation. Therefore, researching effective methods for defocus deblurring is of considerable practical importance.
As a fundamental research area in computer vision, image restoration encompasses tasks such as denoising, super-resolution, and deblurring. Among these, deblurring aims to recover sharp images from degraded observations, which is crucial for improving the quality of images in various applications, including medical imaging, autonomous driving, and photography. Defocus deblurring, as a specific type of deblurring, focuses on addressing the spatially varying blur caused by incorrect focal settings. Unlike motion blur or uniform blur, defocus blur exhibits unique characteristics, such as varying blur levels depending on the distance from the focal plane, making it a particularly challenging problem within the broader field of image restoration.
Traditional defocus blur kernel estimation methods typically follow a two-stage approach. In the first stage, the blur kernel is obtained through blind estimation as proposed in [
2,
3,
4], or by leveraging known prior information as described in [
5,
6]. In the second stage, the blur kernel is used to recover the clear image through deconvolution or other inverse algorithms. While these methods rely on accurate blur kernel estimation, their effectiveness is limited, and their computational complexity is high, particularly when handling complex defocus blur. In recent years, deep learning-based approaches have improved the accuracy of blur kernel estimation as shown in [
7,
8]. However, accurately estimating the blur kernel and using it for image recovery remains challenging.
The complexity and diversity of defocus blur kernels have prompted researchers to explore non-kernel estimation approaches. In [
9], an end-to-end convolutional neural network (CNN) is designed to directly learn the mapping between blurry and clear images using a large dataset of real defocus blur images, eliminating the need for kernel estimation. In [
10], an iterative filtering adaptive network is employed to handle spatially varying and large defocus blur. In [
11], a non-overlapping window self-attention mechanism is used to focus image features, enhancing detail recovery and demonstrating the remarkable potential of Transformer [
12] in image restoration. The key feature of defocus blur is that the sharpness of the focal region and the blurriness of the foreground or background vary with distance. This spatially varying blur requires models to have strong local feature extraction capabilities to handle details under different blur levels, as well as global information modeling abilities to correctly process complex blur patterns. However, CNN-based deblurring methods are limited by the receptive field of the convolution kernels, making it difficult to capture sufficient global information. In contrast, Transformers excel at handling long-range dependencies and modeling complex blur patterns, but their local detail extraction capabilities are not as strong as those of CNNs. In addition, the quadratic complexity of the self-attention mechanism makes the computational complexity on high-resolution images very high. Although improvements to attention mechanisms have mitigated this to some extent, the demand for computational resources remains significant as the image resolution increases.
The recently introduced Mamba [
13] has an impressive linear complexity in long-range modeling, making it more suitable for handling high-resolution images with spatially varying defocus blur, compared to the quadratic complexity of Transformer. Its linear complexity makes it possible to conduct efficient global modeling with limited computational resources. Based on this, this paper proposes a CNN-Mamba hybrid architecture for defocus deblurring, named CNN-Mamba Defocusing Deblurring Network (CMDDNet). CMDDNet adopts a parallel structure that combines the advantages of CNNs in local detail recovery with Mamba’s ability to model long-range dependencies. This approach enhances the accuracy of local detail restoration in defocused images and effectively handles complex blur patterns, achieving competitive deblurring results with low resource consumption (see
Figure 1), making it highly efficient for practical applications.
The main contributions of this paper are as follows:
To overcome the limitations of a single structure in handling defocus blur tasks, particularly in local detail recovery and global dependency modeling, we propose a hybrid architecture for defocus deblurring, called CMDDNet. This network enables the simultaneous modeling and processing of local features and global context in different blurred regions of defocused images.
To address the high computational complexity of Transformers on high-resolution defocus images, we introduce Mamba as a replacement for the Transformer. Its linear complexity design significantly reduces both computational and memory costs, while retaining the ability to model global dependencies when handling complex spatially varying defocus blur.
To enhance defocus deblurring performance, we design a CNN–Mamba parallel feature extraction structure that fully leverages fine-grained image features. Combined with a multi-scale training strategy, this structure improves the model’s adaptability and generalization ability.
2. Related Work
2.1. Defocus Deblurring
The task of defocus deblurring can be divided into two main categories based on whether the defocus blur kernel is estimated: one is kernel-based estimation methods, and the other is kernel-free methods.
In kernel-based estimation methods, Bai et al. [
14] utilized a skeleton image (an image that preserves strong gradients while smoothing out details) as the foundation for estimating the blur kernel. By alternately solving for the skeleton image and blur kernel, blind image deblurring was achieved. Karaali et al. [
15] proposed estimating spatially variant defocus blur kernels by calculating the reblurred gradient magnitude in edge features. They extended the estimated result to the entire image using edge-connective filters and fast guided filters. In more recent methods, Son et al. [
7] introduced a deep learning-based defocus deblurring method for single images using inverse convolution kernels. By incorporating kernel-sharing parallel atrous convolution (KPAC) blocks, they leveraged the invariance of inverse convolution kernel shapes to efficiently handle blur kernels at different scales. Quan et al. [
8] proposed a pixel-based Gaussian Kernel Mixture (GKM) model, which effectively represents spatially variant defocus blur kernels in a linear parameterized form.
The precise estimation of the blur kernel directly impacts the effectiveness of defocus deblurring. However, achieving such precise estimation is often quite challenging. Some researchers have further explored methods that do not rely on blur kernel estimation. Shi et al. [
16] proposed a simple yet effective blur feature based on sparse representation and image decomposition. Through sparse edge representation, they directly established a correspondence with blur intensity estimation. Lee et al. [
4] introduced DMENet, an end-to-end convolutional neural network that directly estimates the defocus degree of each pixel in the image, thereby avoiding the blur kernel estimation step. Abuolaim et al. [
9] designed a deep neural network architecture, DPDNet, which uses two sub-aperture view data captured by dual-pixel sensors on modern cameras to reduce defocus blur. In 2021, Abuolaim et al. [
17] proposed a synthetic dual-pixel data approach to overcome the challenges of acquiring real dual-pixel data and introduced a recursive convolutional network architecture, MDPNet, which enhanced defocus deblurring performance.
These methods, by utilizing data-driven strategies or neural network self-learning, perform blur processing directly without manual design or estimation of the blur kernel, simplifying the process and adapting to complex blur patterns and diverse scenarios in real-world applications. This improves both the effectiveness and flexibility of deblurring. In this paper, we adopt a similar approach, leveraging a large dataset to further enhance the performance of the defocus deblurring model. By training the model on various types of blur scenarios, it effectively removes blur under complex conditions, improving its generalization capability and ensuring its broad applicability in real-world applications.
2.2. CNN-Based Defocus Deblurring
In defocus deblurring tasks, issues such as blurred edges and artifact removal often arise, making local fine-grained feature extraction crucial. With its strong local feature extraction capabilities, CNN has achieved remarkable success in various computer vision fields [
18,
19,
20,
21,
22], and has shown significant potential in addressing defocus blur.
In [
23], CNNs were used to estimate the blur kernel from a blurred image, which was then used for non-blind deconvolution to recover a sharp image. In [
4], the blur kernel estimation step was omitted, and an end-to-end neural network model was proposed to directly learn the defocus degree of each pixel, thus simplifying the deblurring process. A dual-pixel alignment network for defocus deblurring was introduced in [
24], which significantly improved the restoration of sharp images from defocus-blurred ones by employing a novel encoder–decoder alignment module. These methods are primarily based on CNN architectures, aiming to learn the mapping between defocus-blurred and sharp images.
However, CNNs mainly rely on 2D convolution kernels for local feature extraction, which presents clear limitations when dealing with spatially varying defocus blur. As shown in
Figure 2a, local feature extraction fails to capture the global information of blurred region effectively, the transition between blurred region and clear region may be unnatural. To compensate for this, multiple convolutional layers are often stacked to deepen the network structure in an attempt to extract higher-level global information, but this significantly increases the complexity of the model, resulting in higher computational costs and longer training times. In addition, deep convolutional networks are prone to problems such as gradient disappearance or explosion, which will affect the convergence of the model.
To address these issues, this paper proposes a more efficient network architecture based on a parallel branch design: one convolutional branch focuses on capturing local fine-grained details, while the other global feature extraction branch simultaneously model long-range dependencies. This dual-branch structure effectively balances the need for local detail recovery and global blur modeling, significantly improving the overall sharpness restoration of defocus-blurred images.
2.3. State Space Model
Defocus-blurred images often exhibit significant variations in blur intensity across different regions, necessitating robust global feature extraction capabilities to capture long-range dependencies and restore global consistency. However, global modeling typically incurs high computational complexity, requiring a careful balance between accuracy and efficiency. While Transformers have achieved remarkable success in global modeling tasks due to their self-attention mechanism, their quadratic computational complexity () limits their applicability in high-resolution image processing, particularly in deblurring tasks, where image resolution is typically high.
To address this limitation, the State Space Models (SSMs), represented by Mamba [
13], have emerged as a promising alternative. SSMs exhibit linear computational complexity (
) when modeling global dependencies, making them more suitable for processing high-resolution images. SSMs have already demonstrated significant potential in various vision tasks [
25,
26,
27,
28,
29].
A State Space Model (SSM) describes a set of states and predicts the next state based on input data, governed by state and output equations. Early SSMs were designed for continuous data and faced challenges in parallel processing and memory capacity. However, advancements such as discretization, cyclic or convolutional representations, and HiPPO techniques [
30] led to the development of the S4 model [
31]. The S4 model supports parallel training and can model longer dependencies, but its fixed coefficient matrices limit its ability to adapt to varying input importance. Mamba, or the Selective State Space Model (S6), addresses this limitation by introducing selective information processing, enabling dynamic adjustment based on input relevance.
Similar to how Transformers were adapted for vision tasks through Vision Transformer (VIT) [
32], Mamba has been adapted for vision tasks through models like Vision Mamba (VIM) [
33] and Visual State Space Model (VMamba) [
34]. These models divide images into patches, convert 2D images into 1D sequences, and employ bidirectional or cross-scan mechanisms to capture 2D structural information. The cross-scan mechanism, in particular, scans feature maps along four directions, ensuring each element integrates information from all positions without increasing computational complexity. This approach is especially beneficial for defocus deblurring, as it enhances the recovery of complex and irregular blur boundaries while reducing errors caused by insufficient local feature extraction.
Therefore, we adopt Mamba’s cross-scanning mechanism (
Figure 2c) for global feature modeling instead of Transformer’s self-attention mechanism (
Figure 2b). Mamba’s linear computational complexity (
) significantly reduces computational costs, making it more suitable for high-resolution defocus-blurred images and promoting its application in this field.
3. Method
This paper aims to design an efficient and effective single-image defocus deblurring model by cleverly leveraging the complementary advantages of CNN and Mamba. We propose a hybrid architecture model, CMDDNet. The following sections describe the overall process of the model and provide a detailed explanation of the core component, the CNN–Mamba parallel structure block in CMDDNet.
3.1. Overall Pipeline
Figure 3 shows the framework of the proposed CMDDNet. The input is a degraded image
. First, the PatchEmbed module is used to mix and increase the dimensionality of the channels, obtaining the initial feature
, where
represents the spatial dimensions, and
C is the number of channels. These shallow features are then processed through a U-shaped network structure, with each layer consisting of stacked CNN–Mamba parallel blocks. After three encoding and downsampling steps, the features are passed through latent layers, followed by three decoding and upsampling steps to generate the feature representation. Subsequently, a refinement block further processes these features to obtain the final feature representation
. Finally, the output layer (OutputLayer) uses convolutional blocks to generate a residual image
, which is added to the input degraded image to produce the restored image
.
3.2. CNN–Mamba Parallel Structure
By combining convolutional neural networks (CNNs) and Transformers, the complementary advantages of both can be utilized. For example, CNN can introduce inductive bias into the Transformer, thereby improving its generalization ability. Furthermore, the local feature extraction capability of CNN, combined with the global feature extraction ability of Transformer, enables more detailed and comprehensive feature extraction from defocused images. However, traditional Vision Transformers (ViTs), despite having global receptive fields, suffer from high computational costs. To address this, many ViT variants reduce the initial global receptive field and use local attention and other techniques to reduce computational burden. Although these methods effectively lower the computational complexity to some extent, they also sacrifice the ability to capture global information initially.
Mamba, a current research hotspot, achieves global feature extraction with linear complexity and serves as a good alternative structure. This approach not only retains the ability to extract global features but also significantly reduces the computational overhead, thus balancing performance and efficiency.
Based on this, we propose a lightweight feature extractor called the CNN–Mamba parallel structure block. This method considers both extensive global information and specific local information when processing input data, enabling better feature extraction.
The overall workflow of the CNN–Mamba parallel structure is shown in
Figure 3. Specifically, for a feature map
, it is processed through both the Mamba branch and the CNN branch. Prior to the two branches, the dimension order is adjusted, followed by channel normalization. It is important to note that the CNN branch undergoes two adjustments in dimension order to facilitate convolution operations. The fusion module combines the results of the two branches using addition fusion, followed by a learnable residual connection with the original input to obtain the final output. The entire processing flow can be summarized as
where
and
represent global perception and local capture operations, respectively. Fusion denotes the feature fusion operation, and
represents the learnable skip connection operation.
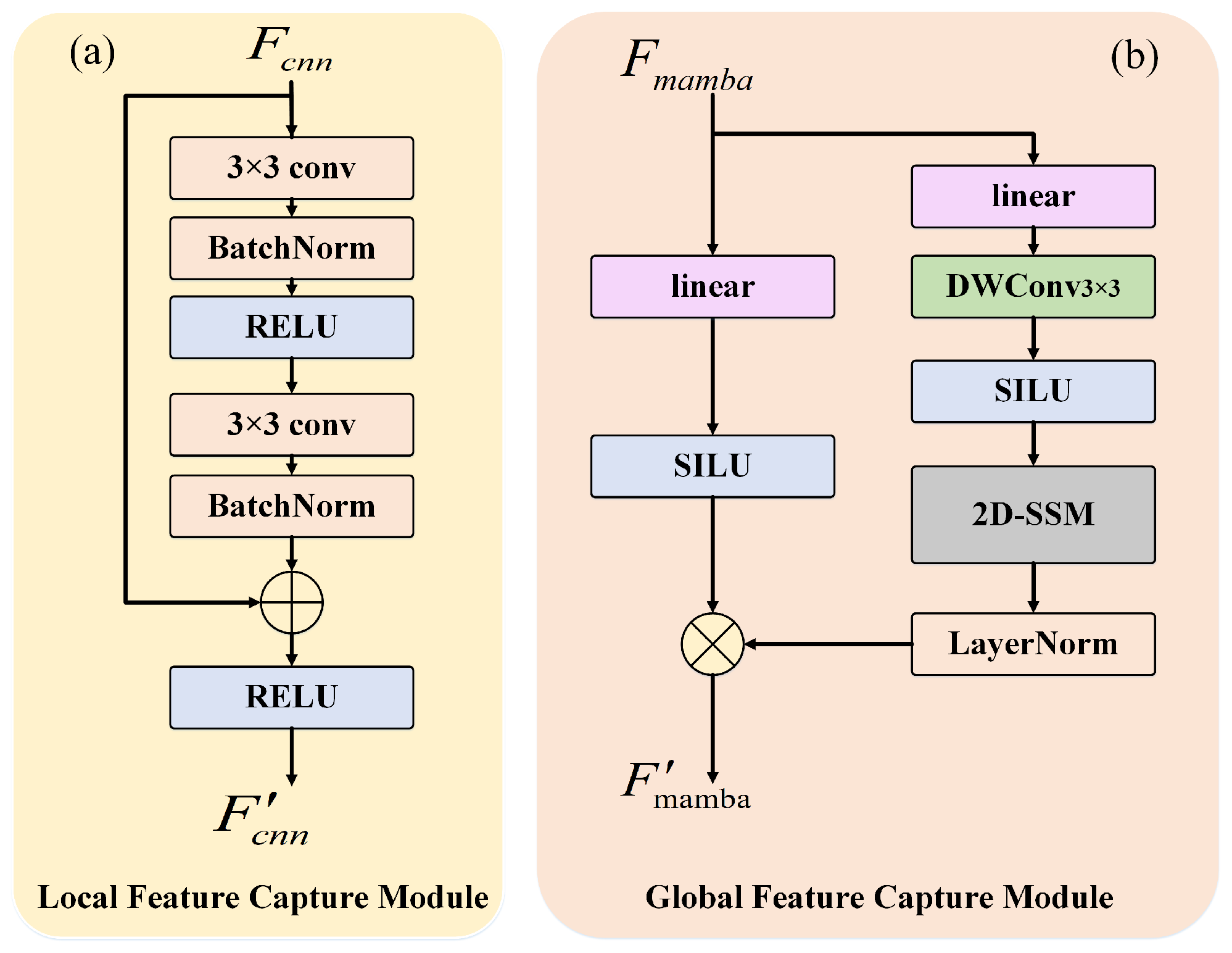
3.3. Convolution Branch
The convolution branch structure is shown in
Figure 4a. The convolution branch is the local detail feature capture branch in the CNN–Mamba parallel structure block. In this paper, a simple residual block is used in the convolution branch. The design of this residual block is inspired by ResNet [
35], which effectively alleviates the vanishing gradient problem in deep networks and helps improve the training efficiency and performance of the network.
First, the input feature map is passed through the first convolutional layer to extract local features from the defocused image. The output of the convolutional layer is then processed by Batch Normalization (BN) and a ReLU activation function, which introduces non-linearity and enhances the feature representation ability.
Next, after processing by the first convolutional layer, the feature map passes through a second convolutional layer, which further extracts features while keeping the number of channels unchanged. After the second convolutional layer, Batch Normalization is applied again. At this point, the output feature map of the network is added element-wise to the input feature map , forming a residual connection.
After the residual connection, the processed result is passed through the ReLU activation function again to generate the final output feature map. This design enables the network to effectively learn and optimize deep features while alleviating the vanishing gradient problem through residual connections. The specific operations can be represented as
where Conv1 and Conv2 are two
convolution operations, ReLU is the Leaky ReLU activation function, and BN1 and BN2 are the two Batch Normalization operations.
3.4. Mamba Branch
The Mamba branch structure is shown in
Figure 4b. The Mamba branch is the global feature extraction branch in the CNN–Mamba parallel structure block. The input data are first divided into two information streams, each passing through a linear embedding layer. In the linear embedding layer, the input data
undergo a linear transformation to generate embedding representations as shown in Equation (
4):
where
and
are the weight matrices of the linear embedding layer,
and
are the bias terms, and
and
are the linear embedding representations of the two information streams.
In the first information stream, the embedded representation
is passed through a
depthwise convolutional layer to extract the initial features. The output is then processed by a SiLU activation function to introduce non-linearity as shown in Equation (
5):
The activated output is then passed through the core 2D-SSM module, which processes it and outputs
as shown in Equation (
6):
To stabilize the training process, the output of the 2D-SSM module is processed by layer normalization as shown in Equation (
7):
Meanwhile, the second information stream’s embedded representation is directly passed through the SiLU activation function as shown in Equation (
8):
Finally, the outputs from the two information streams are added together to generate the final output of the Mamba branch module,
, as shown in Equation (
9):
3.5. Cross-Scan Mechanism
The key to the success of the Mamba method lies in its use of the Selective State Space Model (S6 model), originally designed for natural language processing (NLP) tasks. The S6 model reduces quadratic complexity to linear by enabling each 1D vector element to interact with previously scanned information. However, since visual signals lack the inherent order of text sequences, the S6 model cannot be directly applied to visual tasks.
To address this, we introduce the cross-scanning module proposed in VMamba, which adapts the S6 model for extracting global feature information from images. As illustrated in
Figure 4b, this module is implemented as the 2D-SSM block. To process visual images in the S6 block, we propose a four-direction scanning strategy. Taking the one direction as an example, the 2D feature map is flattened into a 1D sequence of
L blocks. The State Space Model (SSM) updates the state
at each block
k according to the following equation:
where
is the state vector at block
k,
is the state vector at the previous block
,
is the input feature at block
k, and
and
are the discretized parameters (refer to Equation (
2) in the VMamba paper).
At each block
k, the output
is computed as follows:
where
is the output at block
k, and
and
are the discretized parameters.
In the horizontal direction, all outputs
for blocks
are concatenated to form the output feature
:
where
is the output feature in the horizontal direction,
is the output at block
k, and
L is the number of blocks in the horizontal direction.
The cross-scan mechanism simultaneously scans the feature map from four directions. The outputs from these directions are then combined to construct the final 2D feature map as shown in
Figure 5. This strategy ensures that each feature element integrates information from different directions, forming a global receptive field while maintaining the linear computational complexity.
4. Experiments and Analysis
4.1. Datasets
The experiment in this paper uses two publicly available datasets DPDD [
9] and RealDOF [
10]. We use the training set of the DPDD dataset to train, and the DPDD test set and the RealDOF test set to evaluate the model. The DPDD dataset consists of 500 pairs of images, with a 1:1 ratio of indoor and outdoor images. Each image pair includes a defocused blurry image, two corresponding dual-pixel sub-aperture views, and a corresponding sharp image, with all images having a resolution of 1680 × 1120. The RealDOF dataset contains 50 scenes. For each scene, the dataset provides a defocused image and its corresponding sharp image. Depending on the training data, defocus deblurring models can be categorized into dual-pixel image defocus deblurring and single-image defocus deblurring. The former uses the left and right sub-aperture views of the dual-pixel blurry image for defocus processing, while the latter only uses a single blurry image for processing. This paper adopts the single-image defocus deblurring method, using only the defocused blurry images and their corresponding sharp images from the DPDD dataset.
4.2. Data Preprocessing
For model training, the dataset is divided into 70% for training, 15% for validation, and 15% for testing, following the partitioning method used in DPDNet. This division ensures that the ratio of indoor to outdoor images remains 1:1. However, due to the high resolution of the original images and the relatively small number of images, in order to speed up model training, the training and validation images are cropped into smaller patches. Specifically, a sliding window of size 512 × 512 with a 60% overlap is used. Additionally, to augment the dataset, horizontal and vertical flipping are applied. For the validation set, the processed data are further filtered, and ultimately, 74 image pairs with large inter-group similarity differences are retained.
As a result, the final training set consists of 7000 pairs of 512 × 512 images, the validation set contains 74 pairs of 512 × 512 images, and the test set includes 76 pairs of 1680 × 1120 full-resolution images.
4.3. Evaluation Metrics
To comprehensively evaluate the performance, this paper uses PSNR, SSIM, and MAE as the evaluation metrics. PSNR (Peak Signal-to-Noise Ratio) is used to quantify the absolute difference between the restored image and the original image, with higher values indicating better image quality. SSIM (Structural Similarity Index) assesses the fidelity of the image structure and texture, with values closer to 1 indicating better similarity. The MAE (Mean Absolute Error) calculates the average absolute difference between the predicted and ground truth values for each pixel position, with smaller values indicating more accurate restoration.
4.4. Implementation Details
The proposed CMDDNet model adopts an encoder–decoder architecture to process blurry images. Each level consists of two structural blocks, and the feature map dimensions are shown in
Figure 3. Unlike the traditional U-Net architecture, the CMDDNet model omits the skip connections in the middle part of the network to simplify the model structure and improve training efficiency. The model is trained for a total of 300,000 iterations, with no warm-up iterations and gradient clipping enabled. To enhance the model’s generalization ability, a staged progressive training strategy is employed. Different stages use input images of different scales to improve generalization. The input image sizes at different stages are 128 × 128, 192 × 192, and 256 × 256, with corresponding batch sizes of 8, 4, and 1, respectively. The training epochs for each stage are set to [192,000, 148,000, 60,000] iterations. The learning rate scheduler used is a cosine annealing restart scheduler, with the minimum learning rates set to [0.0003, 0.000001]. The Adam optimizer is employed, with a learning rate of 3 × 10
−4, weight decay of 1 × 10
−4, and beta parameters set to [0.9, 0.999]. The loss function used is L1 loss, with a loss weight of 1, and dimensionality reduction is performed using the average method.
4.5. Comparison with Existing Methods
The proposed model is compared with several classical defocus image deblurring methods on the DPDD and RealDOF datasets, with the experimental results shown in
Table 1 and
Table 2. Additionally,
Figure 1 presents a scatter plot comparing the model’s parameters and FLOPs against other methods, highlighting its superior efficiency in terms of computational resource utilization. In addition to the methods mentioned in [
4,
8,
9,
11], Ref. [
15] proposed an approach that estimates spatially varying defocus blur kernels by reblurring edge features and gradient magnitude, which are then extended to the entire image using a filter. Ref. [
16] utilized sparse representation and image decomposition to directly estimate blur intensity using sparse edge estimation. Ref. [
17] introduced a method for synthesizing dual-pixel data and designed a recursive convolutional network, MDPNet, to enhance the deblurring effect. Ref. [
36] proposed a realistic dual-pixel defocus model and a recursive network to address the defocus deblurring problem.
On the DPDD dataset, the proposed model achieves PSNR, SSIM, and MAE scores of 25.54 dB, 0.778, and 0.039, respectively. As shown in
Table 1, compared to the end-to-end convolutional neural network DPDNet-S, the proposed algorithm shows significant improvements in both PSNR and SSIM, with the indoor and outdoor comprehensive test results increasing by 1.2 dB and 0.032, respectively. The model’s parameter count is reduced from 34.52 M to 9.74 M. This demonstrates that the proposed method, which combines parallel feature extraction through the CNN branch for local feature information and the Mamba branch for global information, effectively improves image quality.
In the comparison, although the Uformer-B model slightly outperforms in certain metrics, such as in the outdoor scenes, the proposed model exhibits more balanced performance across several key aspects. In terms of model parameters, the proposed model has only 9.74 M parameters, representing an 80.9% reduction compared to Uformer-B. Additionally, the FLOPs decrease from 89.46 G to 39.39 G, significantly reducing the computational complexity and resource consumption. These improvements make the model more efficient and suitable for a wider range of applications. In addition, in indoor scenes, the model performs well in PSNR (28.37 dB) and MAE (0.025), which indicates that the model has a good defocusing ability of indoor images. In the combined scenario, the model has a PSNR of 25.54 dB, which is slightly lower than the 25.65 dB of the Uformer-B. However, the significant reduction in the number of parameters indicates that the method can greatly improve the operation efficiency while maintaining good performance. Therefore, compared with Uformer-B, the proposed method achieves a better balance between performance and computational complexity.
The experimental results on the RealDOF dataset show that the index numbers of PSNR, SSIM and MAE are 24.62 dB, 0.726 and 0.405, respectively. (Due to the small difference between the MAE indicators in the RealDOF dataset, the value is expanded by ten times to reflect the difference.) Compared with Gaussian hybrid blur kernel estimation network (GKMNet), the PSNR value and SSIM value of this model are increased by 0.32 dB and 0.01. The effectiveness of the model in removing defocusing blur in real scenes is proved. In addition, compared with the traditional defocusing blur kernel estimation method, this model overcomes the limitation of kernel estimation and turns to the data-driven deep learning method, showing significantly better performance.
4.6. Ablation Study
This section describes detailed ablation experiments to verify the effectiveness of different modules in the CMDDNet model. These experiments include model structure reduction, initial feature dimension size, and global feature extraction methods.
4.6.1. Ablation of the Structure
In order to verify the effectiveness of the double-branch design, the double-branch structure is split, the single-branch model is used for training, and the data are compared with the double-branch training results. The experimental results are shown in
Table 3. The experimental results show that the PSNR of DPDD dataset and RealDOF dataset are reduced by 0.4 dB and 0.44 dB by removing the CNN branch and keeping only the Mamba branch. In contrast, when only the CNN branch is retained for full-channel data processing, the PSNR and SSIM values on both datasets are significantly reduced. This shows that a single branch cannot fully meet the needs of defocus deblurring task by relying only on local or global feature capture, and the joint modeling of local and global features has important practical value for effectively restoring defocus images. Therefore, the parallel fusion feature extraction structure not only better preserves and restores image details but also achieves higher-quality deblurring results, effectively validating the effectiveness of the dual-branch design.
4.6.2. Ablation Study on Dimension Size
The data in
Table 4 demonstrate the impact of feature dimension on model performance. On the DPDD dataset, increasing the feature dimension from 24 to 36 channels improves PSNR by 0.12 dB but at the cost of a 5.25 M increase in parameters. Further increasing the dimension to 48 channels only yields a marginal PSNR improvement of 0.03 dB, while requiring an additional 7.25 M parameters.
On the RealDOF dataset, models with 36 and 48 channels show significant performance gains over the 24-channel model. However, the difference between the 36-channel and 48-channel models is negligible, despite the latter’s substantial increase in parameters.
Considering the trade-off between performance and computational cost, this study sets the initial channel dimension to 36, achieving an optimal balance between model effectiveness and resource efficiency.
4.6.3. Ablation of Global Feature Extraction Module
To compare the global feature extraction capabilities of Mamba and Transformer, a comparative experiment was conducted on the RealDOF dataset. Specifically, the Mamba branch in the global feature extraction module of the parallel block was replaced with a window attention module to observe the differences between the two approaches. Compared to traditional attention, window attention is more efficient and can maintain a similar parameter count to the Mamba branch, facilitating subsequent analysis. Additionally, due to computational resource limitations, it was challenging to test the high-resolution (2320 × 1520) images from the original RealDOF dataset in the window attention-based structure. Therefore, the original images were uniformly cropped to a size of 640 × 640, and the test metrics for both methods at this resolution were recorded. The final results are presented in
Figure 6. As shown in the table, Mamba, as the global feature extraction module, outperforms the window attention, indicating that although the modified attention module reduces computational resource consumption to some extent, it also impacts the effectiveness of global feature extraction, weakening the ability to capture global information. In contrast, Mamba demonstrates superior performance with much lower resource consumption. Furthermore, in terms of memory usage for inference on a single image, Mamba significantly reduces the required GPU memory, needing only 4.97 GB, while the window attention-based method requires 16.38 GB. This shows that although window attention reduces the parameter count of traditional Transformer models to some extent, the proposed model offers a significant advantage in terms of memory consumption during actual inference.
4.6.4. Qualitative Comparison of Different Deblurring Methods
A qualitative comparison was performed on the DPDD public dataset, selecting representative indoor and outdoor blurred images for visualization of the restoration results. The results are shown in
Figure 7, where panels (b), (d), (f), and (h) are zoomed-in views of the local details of panels (a), (c), (e), and (g), respectively. The first column shows the input images with spatially varying blur (Input), and the last column displays the corresponding ground truth sharp images (Sharp). The middle rows present the restoration results of different methods, including the proposed CMDDNet.
Through visual comparison, CMDDNet demonstrates superior deblurring performance, producing results closer to the ground truth. Specifically, MDPNet [
20] exhibits significant color distortion and over-sharpening artifacts, while RPDP+ [
32] generates noticeable visual noise in detail regions. In contrast, CMDDNet excels in handling complex blurring scenes, particularly under light variations and spatially inconsistent blur as evidenced by sharper edges and more natural textures in the red-boxed zoomed-in areas.
Similarly, a qualitative comparison was conducted on the RealDOF public dataset as shown in
Figure 8. Since RealDOF contains only a test set, the model was trained on the DPDD dataset and tested on the RealDOF dataset, thereby reflecting the model’s generalization capability to some extent. Similar to
Figure 7, the results are presented in the form of original images and locally magnified views, with a focus on comparing the proposed method with GKMNet [
8], which exhibits the closest performance to our approach.
From the figure, it can be observed that the restoration results of GKMNet and CMDDNet are visually similar. However, GKMNet exhibits varying degrees of tone overflow, such as yellow or green artifacts, particularly in edge details or regions with bright lighting in the original images. This phenomenon may be attributed to factors such as blur kernel estimation errors, over-enhancement by attention modules, and insufficient dynamic range processing. Although GKMNet employs a pixel-wise Gaussian Kernel Mixture (GKM) model to represent spatially varying defocus blur kernels with high precision, its blur kernel estimation may still incur errors under inconsistent blur conditions, leading to color distortion in the restored results. In contrast, CMDDNet adopts a data-driven approach by learning the mapping between defocused and sharp images, thereby overcoming the limitations of traditional blur kernel estimation methods under inconsistent blur conditions. This enables more natural color consistency and detail restoration.
In summary, the visual results demonstrate the significant advantages of CMDDNet in handling image blur, avoiding tone overflow, and preserving natural textures. Its data-driven approach not only addresses the shortcomings of traditional blur kernel estimation but also exhibits superior generalization capability and robustness, making it highly promising for practical applications.
5. Conclusions
This paper proposes a lightweight hybrid architecture model named CMDDNet to address the defocus deblurring problem. By combining the strengths of CNN and Mamba, the model provides an efficient solution for image deblurring. The convolutional branch in CMDDNet alleviates the vanishing gradient problem by introducing residual connections, allowing the network to capture finer details in the image more effectively. The Mamba branch, on the other hand, leverages a cross-scanning mechanism to perform comprehensive global feature extraction of the feature maps. This mechanism enables the Mamba branch to capture long-range dependencies and global structural information in the image, compensating for the convolutional branch’s limitations in modeling global dependencies. CMDDNet uses parallel feature extraction modules that combine the ability of CNN to extract local features with Mamba’s capacity to capture global features, enabling the model to extract fine-grained and coarse-grained fused features simultaneously, thereby improving the deblurring performance. In current popular benchmark tests, CMDDNet demonstrates outstanding deblurring performance while maintaining a relatively low parameter count.
However, the restoration performance of the proposed method still exhibits a certain gap compared to full-resolution high-definition images, particularly in the clarity and detail recovery of complex texture regions. To address this issue, we plan to improve the method from the following aspects: First, we will optimize the network architecture and training strategies to enhance the model’s feature extraction capability and detail recovery performance. Second, based on global feature extraction and local detail capture, we will introduce a classification mechanism for blurry and clear regions, enabling more targeted restoration of details in blurry areas. Furthermore, we will incorporate more challenging data augmentation techniques during training, such as Gaussian noise and random texture occlusion, to further improve the model’s robustness and generalization ability in complex environments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}