
MT-SiamNet: A Multi-Scale Attention Network for Reducing Missed Detections in Farmland Change Detection

Abstract
1. Introduction
- A multi-scale channel information mixing module is designed within the convolutional network, which emphasizes local contours in remote sensing images and focuses on the denoising of farmland remote sensing images. Information loss across different scales and channels is also addressed.
- A multi-head channel interaction and attention encoder is designed, enabling global context modeling based on key local contour information.
- A multi-scale and attention-based spatial decoder is designed, which maps the one-dimensional vectors of local contour features and global semantic information—processed by the CNN feature mixing module and encoder—back into the spatial dimension.
- The model is developed by combining the strengths of Convolutional Neural Networks (CNNs), Transformers, multi-scale modules, and attention mechanisms, effectively integrating attention mechanisms with Transformers. The model’s performance is evaluated on two benchmark datasets: the Cropland Change Detection (CLCD) dataset [39], a high-resolution dataset specifically designed for cropland change monitoring, and the High-Resolution Semantic Change Detection (HRSCD) dataset [40], which focuses on general semantic change detection across diverse land cover types. A more detailed discussion of these datasets is provided in a later section of this paper.
2. Materials and Methods
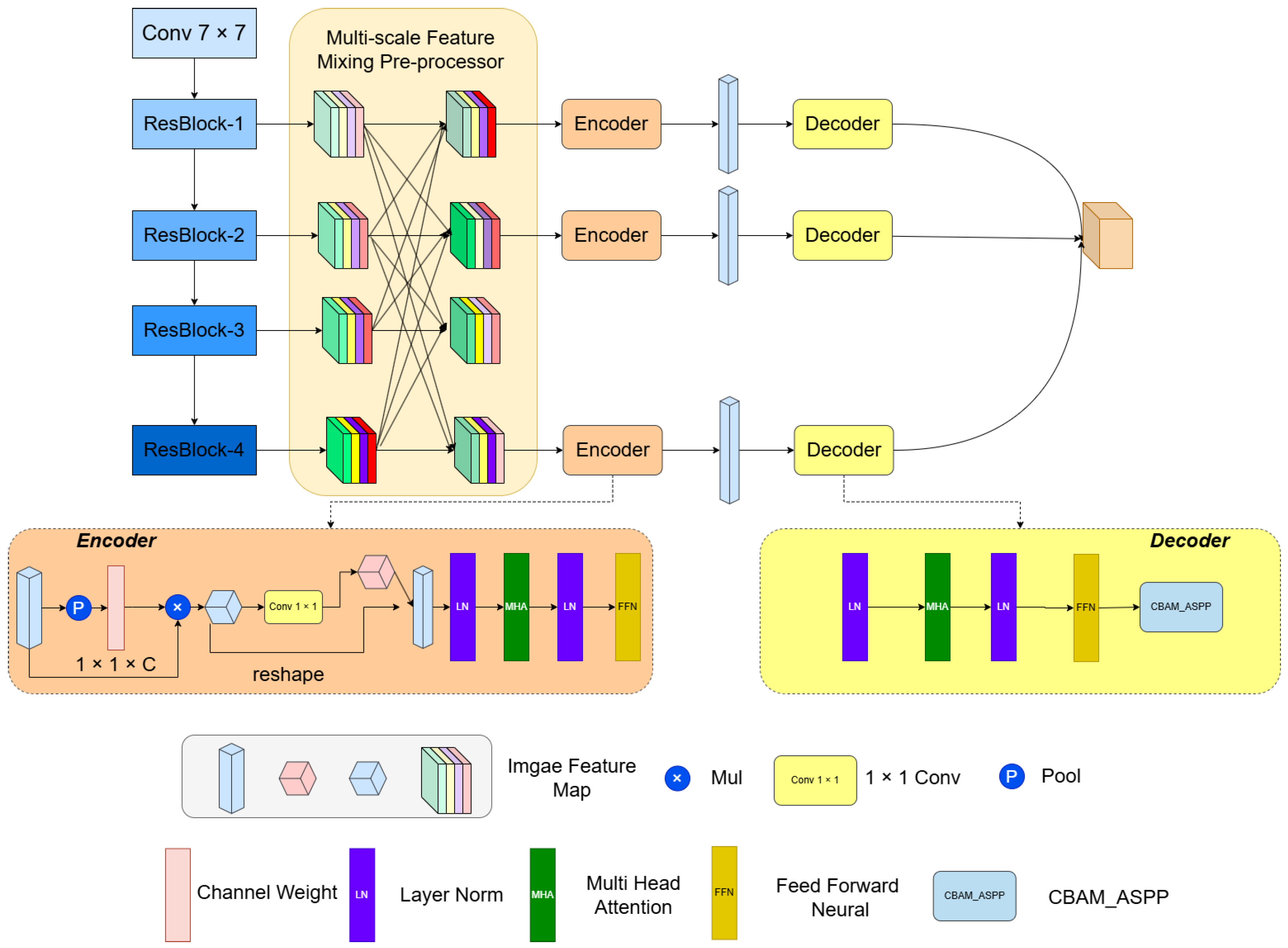
2.1. Multi-Scale Feature Mixing Preprocessor
2.2. Cross-Channel Spatial Attention Encoder
2.3. Multi-Scale Spatial Decoder
2.4. Loss Function
3. Experimental Setup
3.1. Datasets
3.2. Evaluation Metrics
- Precision: This indicates how well the areas of change correctly detected by the model match the actual areas of change. A high precision means that the model has a low false alarm rate, i.e., that most of the detected change areas are actual changes.
- Recall: This is a measure of how well the model covers the areas of change that it detects versus the actual areas of change. A high recall means that the model is able to detect more of the actual change area. A high recall is especially important in the task of change detection in agricultural fields, because omission (failure to detect an actual area of change) often has more serious consequences than misdetection (misclassifying an unchanged area as a change). Change detection in farmland is important for agricultural management and decision-making, and ensuring that all areas of change are detected can help farmers and agricultural managers take timely action.
- F1-score: This is a metric that combines precision and recall, and it is their reconciled average. A high F1-score indicates that the model performs well in terms of both accuracy and completeness, being a balance between precision and recall.
- Intersection and Union Ratio (IoU): This measures the degree of overlap between the region of change detected by the model and the actual region of change. A high IoU indicates that the region of change predicted by the model highly overlaps with the actual region of change, reflecting the overall detection performance of the model.
3.3. Comparison Methods
- FC-EF [35]: This model is based on the U-Net architecture and utilizes a pure Convolutional Neural Network for image-level fusion. The network takes as input a concatenation of a pair of dual-temporal images.
- FC-Siam-conc [35]: A variant of the FC-EF network, FC-Siam-conc employs a Siamese network structure to extract multi-layer image features, which are then concatenated using two fully connected layers.
- DTCDSCN [36]: This model is a variant of the FCN network that incorporates semantic-level and attention mechanisms. By focusing on channel and spatial features, it captures additional contextual information to discern changes in the images.
- MFPNet [30]: A Siamese network based on attention mechanisms, MFPNet uses multi-path fusion and adaptive weighted fusion strategies to integrate features effectively.
- DSIFN [29]: This model employs a differential discriminative network for change detection and integrates multi-layer features with image differential maps through attention mechanisms.
- BiT [38]: Designed with a Transformer-based encoder–decoder architecture, BiT models contextual information and effectively captures important features from the global feature space.
- MSCANet [39]: This model combines CNNs and Transformers in a multi-scale change detection network. It utilizes CNNs to capture local contour features at different scales and employs Transformers to encode and decode contextual information. These models represent some of the most advanced approaches in the field, each contributing unique methodologies for enhancing change detection performance.
3.4. Implementation Details
4. Results
4.1. HRSCD Results
4.2. CDLD Results
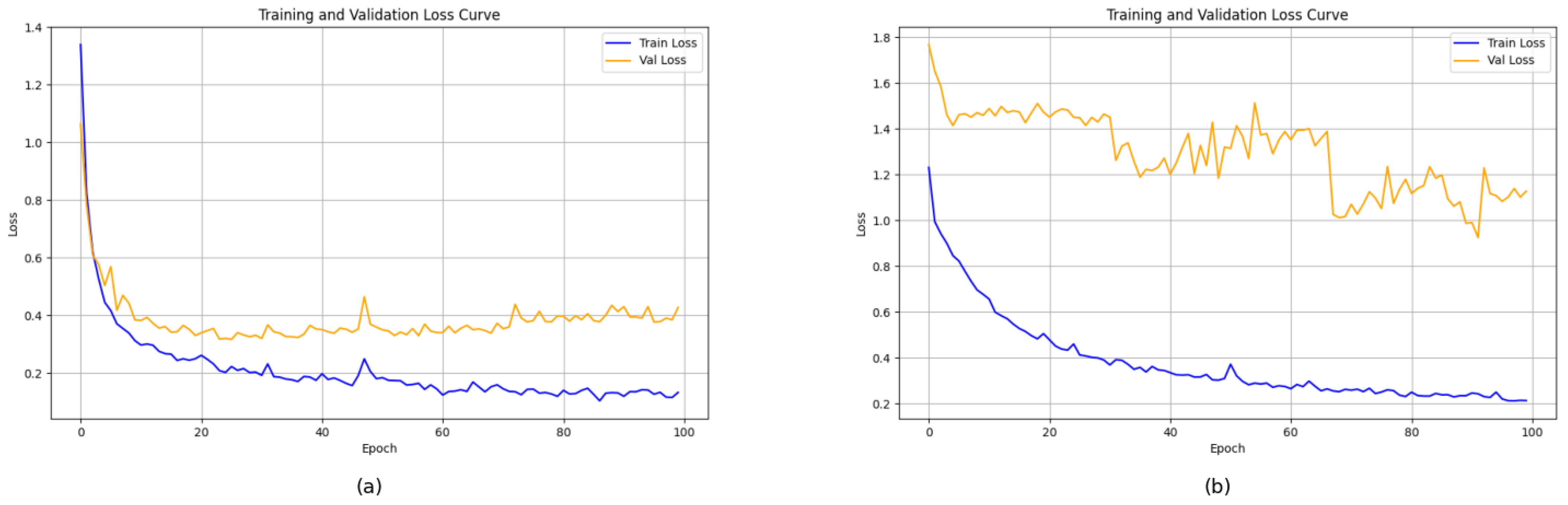
4.3. Ablation Experiments and Loss Curves
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, A.; Yue, W.; Yang, J.; Xue, B.; Xiao, W.; Li, M.; He, T.; Zhang, M.; Jin, X.; Zhou, Q. Cropland abandonment in China: Patterns, drivers, and implications for food security. J. Clean. Prod. 2023, 418, 138154. [Google Scholar] [CrossRef]
- Tian, Z.; Ji, Y.; Xu, H.; Qiu, H.; Sun, L.; Zhong, H.; Liu, J. The potential contribution of growing rapeseed in winter fallow fields across Yangtze River Basin to energy and food security in China. Resour. Conserv. Recycl. 2021, 164, 105159. [Google Scholar] [CrossRef]
- Ye, S.; Wang, J.; Jiang, J.; Gao, P.; Song, C. Coupling input and output intensity to explore the sustainable agriculture intensification path in mainland China. J. Clean. Prod. 2024, 442, 140827. [Google Scholar] [CrossRef]
- Du, B.; Ye, S.; Gao, P.; Ren, S.; Liu, C.; Song, C. Analyzing spatial patterns and driving factors of cropland change in China’s National Protected Areas for sustainable management. Sci. Total Environ. 2024, 912, 169102. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change detection based on artificial intelligence: State-of-the-art and challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef]
- Jing, Q.; He, J.; Li, Y.; Yang, X.; Peng, Y.; Wang, H.; Yu, F.; Wu, J.; Gong, S.; Che, H.; et al. Analysis of the spatiotemporal changes in global land cover from 2001 to 2020. Sci. Total Environ. 2024, 908, 168354. [Google Scholar] [CrossRef]
- Cheng, G.; Huang, Y.; Li, X.; Lyu, S.; Xu, Z.; Zhao, H.; Zhao, Q.; Xiang, S. Change detection methods for remote sensing in the last decade: A comprehensive review. Remote Sens. 2024, 16, 2355. [Google Scholar] [CrossRef]
- Chen, S.; Shi, W.; Zhou, M.; Zhang, M.; Yu, Y.; Sun, Y.; Guan, L.; Li, S. CDasXORNet: Change detection of buildings from bi-temporal remote sensing images as an XOR problem. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103836. [Google Scholar] [CrossRef]
- Pan, Y.; Lin, H.; Zang, Z.; Long, J.; Zhang, M.; Xu, X.; Jiang, W. A new change detection method for wetlands based on Bi-Temporal Semantic Reasoning UNet++ in Dongting Lake, China. Ecol. Indic. 2023, 155, 110997. [Google Scholar] [CrossRef]
- Ok, A.O.; Senaras, C.; Yuksel, B. Automated detection of arbitrarily shaped buildings in complex environments from monocular VHR optical satellite imagery. IEEE Trans. Geosci. Remote Sens. 2012, 51, 1701–1717. [Google Scholar] [CrossRef]
- Johnson, R.D.; Kasischke, E.S. Change vector analysis: A technique for the multispectral monitoring of land cover and condition. Int. J. Remote Sens. 1998, 19, 411–426. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef]
- Doxani, G.; Karantzalos, K.; Tsakiri-Strati, M. Monitoring urban changes based on scale-space filtering and object-oriented classification. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 38–48. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Thapa, A.; Horanont, T.; Neupane, B.; Aryal, J. Deep learning for remote sensing image scene classification: A review and meta-analysis. Remote Sens. 2023, 15, 4804. [Google Scholar] [CrossRef]
- Adegun, A.A.; Viriri, S.; Tapamo, J.-R. Review of deep learning methods for remote sensing satellite images classification: Experimental survey and comparative analysis. J. Big Data 2023, 10, 93. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Venugopal, N. Automatic semantic segmentation with DeepLab dilated learning network for change detection in remote sensing images. Neural Process. Lett. 2020, 51, 2355–2377. [Google Scholar] [CrossRef]
- Ke, Q.; Zhang, P. CS-HSNet: A cross-Siamese change detection network based on hierarchical-split attention. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9987–10002. [Google Scholar] [CrossRef]
- Yew, A.N.J.; Schraagen, M.; Otte, W.M.; van Diessen, E. Transforming epilepsy research: A systematic review on natural language processing applications. Epilepsia 2023, 64, 292–305. [Google Scholar] [CrossRef] [PubMed]
- Islam, S.; Elmekki, H.; Elsebai, A.; Bentahar, J.; Drawel, N.; Rjoub, G.; Pedrycz, W. A comprehensive survey on applications of transformers for deep learning tasks. Expert Syst. Appl. 2023, 241, 122666. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Jin, Y.; Hou, L.; Chen, Y. A time series transformer based method for the rotating machinery fault diagnosis. Neurocomputing 2022, 494, 379–395. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, C.; Bai, H.; Zhang, R.; Zhao, Y. Cross-part learning for fine-grained image classification. IEEE Trans. Image Process. 2021, 31, 748–758. [Google Scholar] [CrossRef]
- Guo, D.; Terzopoulos, D. A transformer-based network for anisotropic 3D medical image segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8857–8861. [Google Scholar]
- Chen, D.-J.; Hsieh, H.-Y.; Liu, T.-L. Adaptive image transformer for one-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 12247–12256. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Xu, J.; Luo, C.; Chen, X.; Wei, S.; Luo, Y. Remote sensing change detection based on multidirectional adaptive feature fusion and perceptual similarity. Remote Sens. 2021, 13, 3053. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Marinoni, A.; He, D.; Liu, X.; Zhang, L. Super-resolution-based change detection network with stacked attention module for images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4403718. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban change detection for multispectral earth observation using convolutional neural networks. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, W. A feature difference convolutional neural network-based change detection method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Liu, M.; Chai, Z.; Deng, H.; Liu, R. A CNN-transformer network with multiscale context aggregation for fine-grained cropland change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4297–4306. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask learning for large-scale semantic change detection. In Computer Vision and Image Understanding; Elsevier: Amsterdam, The Netherlands, 2019; Volume 187, p. 102783. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| FC-EF | 72.75 | 50.3 | 59.48 | 42.33 |
| FC-Siam-conc | 72.23 | 47.53 | 57.34 | 40.19 |
| DTCDSCN | 75.79 | 48.83 | 59.39 | 42.24 |
| BiT | 71.30 | 52.23 | 60.30 | 43.16 |
| MFPNet | 76.42 | 54.98 | 63.95 | 47.01 |
| DSIFN | 77.00 | 54.27 | 63.66 | 46.70 |
| MSCANet | 70.17 | 59.97 | 64.67 | 47.79 |
| The Proposed Method | 62.18 | 69.16 | 65.48 | 48.68 |
| Method | Pre(%) | Rec(%) | F1(%) | IoU(%) |
|---|---|---|---|---|
| FC-EF | 71.70 | 47.60 | 57.22 | 40.07 |
| FC-Siam-conc | 73.27 | 52.91 | 61.45 | 44.35 |
| DTCDSCN | 54.49 | 66.23 | 59.79 | 42.64 |
| BiT | 61.42 | 62.75 | 62.08 | 45.01 |
| MFPNet | 83.20 | 60.74 | 70.22 | 54.11 |
| DSIFN | 79.09 | 63.79 | 70.61 | 54.58 |
| MSCANet | 75.36 | 67.64 | 71.29 | 55.39 |
| The Proposed Method | 72.80 | 77.37 | 75.02 | 60.02 |
| Method | CLCD | HRSCD | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre (%) | Rec (%) | F1 (%) | IoU (%) | Pre (%) | Rec (%) | F1 (%) | IoU (%) | ||
| Base | 75.36 | 67.64 | 71.29 | 55.39 | 70.17 | 59.97 | 64.67 | 47.79 | |
| +MSM | 68.35 | 79.08 | 73.32 | 57.88 | 63.89 | 64.56 | 64.22 | 47.81 | |
| +CCSE | 70.24 | 78.35 | 74.07 | 58.82 | 63.92 | 65.59 | 64.32 | 47.89 | |
| OURS | 72.80 | 77.37 | 75.02 | 60.02 | 62.18 | 69.16 | 65.48 | 48.68 | |
| Method | HRSCD | CLCD | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre (%) | Rec (%) | F1 (%) | IoU (%) | Pre (%) | Rec (%) | F1 (%) | IoU (%) | ||
| 62.65 | 64.84 | 63.74 | 46.78 | 71.73 | 76.73 | 74.14 | 58.91 | ||
| 59.10 | 69.36 | 63.82 | 46.80 | 69.25 | 81.20 | 74.75 | 59.68 | ||
| 62.18 | 69.16 | 65.48 | 48.68 | 72.80 | 77.37 | 75.02 | 60.02 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Tian, J.; Zheng, L.; Xie, J.; Xia, M.; Li, S.; Chen, P. MT-SiamNet: A Multi-Scale Attention Network for Reducing Missed Detections in Farmland Change Detection. Appl. Sci. 2025, 15, 3061. https://doi.org/10.3390/app15063061
Wang J, Tian J, Zheng L, Xie J, Xia M, Li S, Chen P. MT-SiamNet: A Multi-Scale Attention Network for Reducing Missed Detections in Farmland Change Detection. Applied Sciences. 2025; 15(6):3061. https://doi.org/10.3390/app15063061
Chicago/Turabian StyleWang, Jiangqing, Juanjuan Tian, Lu Zheng, Jin Xie, Meng Xia, Shuangyang Li, and Pingting Chen. 2025. "MT-SiamNet: A Multi-Scale Attention Network for Reducing Missed Detections in Farmland Change Detection" Applied Sciences 15, no. 6: 3061. https://doi.org/10.3390/app15063061
APA StyleWang, J., Tian, J., Zheng, L., Xie, J., Xia, M., Li, S., & Chen, P. (2025). MT-SiamNet: A Multi-Scale Attention Network for Reducing Missed Detections in Farmland Change Detection. Applied Sciences, 15(6), 3061. https://doi.org/10.3390/app15063061