1. Introduction
The recent advancements in Natural Language Processing (NLP) owe much to the introduction of the Transformer architecture by Vaswani et al. [
1], which revolutionized text analysis by leveraging attention mechanisms to extract meaningful information. This success has inspired the adaptation of Transformers to other domains, including computer vision. A pivotal development in this transition was the Vision Transformer (ViT) proposed by Dosovitskiy et al. [
2], which demonstrated that images could be processed similarly to text by segmenting them into non-overlapping patches and applying self-attention mechanisms. This innovation enabled Transformers, previously confined to text-based applications, to excel at image classification tasks, rivaling the long-standing dominance of Convolutional Neural Networks (CNNs).
CNNs have traditionally been the cornerstone of image classification due to their ability to capture spatial hierarchies through convolutional operations. Their hierarchical learning of features has made them a benchmark for many computer vision tasks [
3,
4]. However, Vision Transformers present a compelling alternative by capturing long-range dependencies in images without relying heavily on the inductive biases inherent to convolutional operations. This fundamental difference has sparked a competitive dynamic between the two architectures, each offering unique advantages and facing distinct challenges.
Building on previous research [
5,
6], where CNNs were employed to classify thermal images of volcanic activity captured by ground-based thermal cameras, this study explored whether Vision Transformers could provide additional benefits. Prior work [
7] demonstrated the effectiveness of various CNN architectures for analyzing volcanic images, but the potential of Vision Transformers to enhance the classification performance in this context remains unexamined. Given the complexity of thermal volcanic images, where both local and global feature dependencies are crucial, evaluating Transformers against CNNs is particularly pertinent.
The hypothesis of this study was that Vision Transformer models can outperform traditional CNNs in the classification of thermal images of volcanic activity, particularly in scenarios requiring the handling of complex and ambiguous classes.
The research questions addressed in this study were as follows:
Can Vision Transformer models achieve higher classification accuracies compared with CNNs for thermal images of volcanic activity?
How do Vision Transformer models perform in terms of efficiency and inference time compared with CNNs?
What are the specific strengths and weaknesses of Vision Transformer models versus CNNs in this application?
The objectives of this study were as follows:
To compare the classification performance of Vision Transformer models and CNNs on a dataset of thermal images of Mount Etna’s volcanic activity.
To evaluate the efficiency and inference time of both model types.
To identify the scenarios where Vision Transformer models provide significant benefits over CNNs.
The motivation behind this study was to improve the accuracy and reliability of volcanic-activity-monitoring systems. The accurate classification of thermal images is crucial for early warning systems and scientific research on volcanic phenomena. By exploring the potential of Vision Transformer models, we aimed to advance the state of the art in this field.
The novelty of this study lay in the extensive comparison between the most representative Convolutional Neural Networks (CNNs) and the latest Transformer networks for this specific application. Unlike previous studies that primarily focused on CNN-based techniques, our work provided new insights into the strengths and weaknesses of each approach. Our findings contribute to the broader field of computer vision by demonstrating the potential of Transformer networks in specialized applications, such as volcanic activity monitoring, where accurate and reliable image classification is crucial.
This study compared the performance of CNN and Vision Transformer models for classifying thermal images of Mount Etna’s volcanic activity. The dataset included 3000 images divided into six classes, where each represented distinct volcanic phenomena. The aim was to determine whether Transformer-based architectures, such as the Vision Transformer and Swin Transformer, can outperform CNNs, including AlexNet, in terms of classification accuracy and efficiency.
This paper is structured as follows. In
Section 2, we describe the dataset of thermal images used in this study, including the volcanic activity classes represented within it. In
Section 3, we outline the CNN and Transformer architectures evaluated in our experiments, detailing their structure and relevance to our classification task. Following this, in
Section 4, we introduce the evaluation metrics applied to objectively measure each classifier’s performance, providing a basis for comparison across different model types. The subsequent
Section 5 presents the findings of our comparative analysis, highlighting the strengths and limitations observed for each model. Finally, in
Section 6, we discuss the implications of our results and suggest directions for future work in applying these models to volcanic image classification and potentially other geophysical applications.
2. Materials
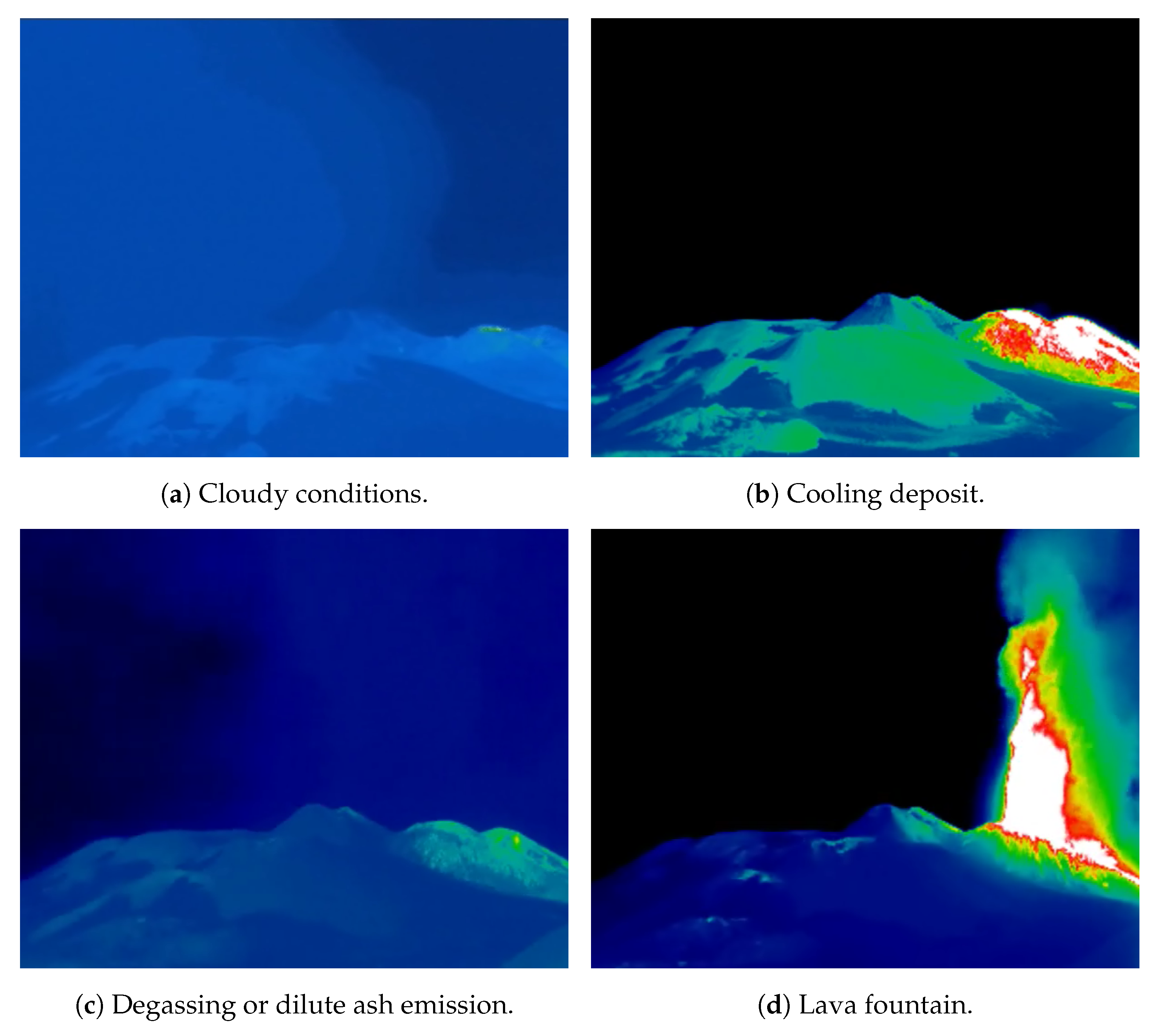
The images used in this study were extracted from the original .avi files recorded by thermal cameras for the surveillance of Etna’s activity. The current version of the dataset consisted of 3000 images, evenly distributed across six classes. The dataset was split into for training, for validation, and for testing. These images were subsequently labeled using six classes:
- Class 1:
Cloudy conditions: presence of atmospheric clouds obstructing observations.
- Class 2:
Cooling hot deposits: static volcanic deposits (lava flow, spatter, tephra) cooling down.
- Class 3:
Degassing or dilute ash emission: release of hot gases and dilute ash from summit craters.
- Class 4:
Lava fountain: steady ejection of spatter at medium or high height.
- Class 5:
No activity: absence of observable volcanic activity.
- Class 6:
Mild Strombolian explosion: low-height ejection of hot material with pulsating behavior.
Representative images for each class are shown in
Figure 1, while a more detailed description of the individual classes can be found in [
7].
3. Methods
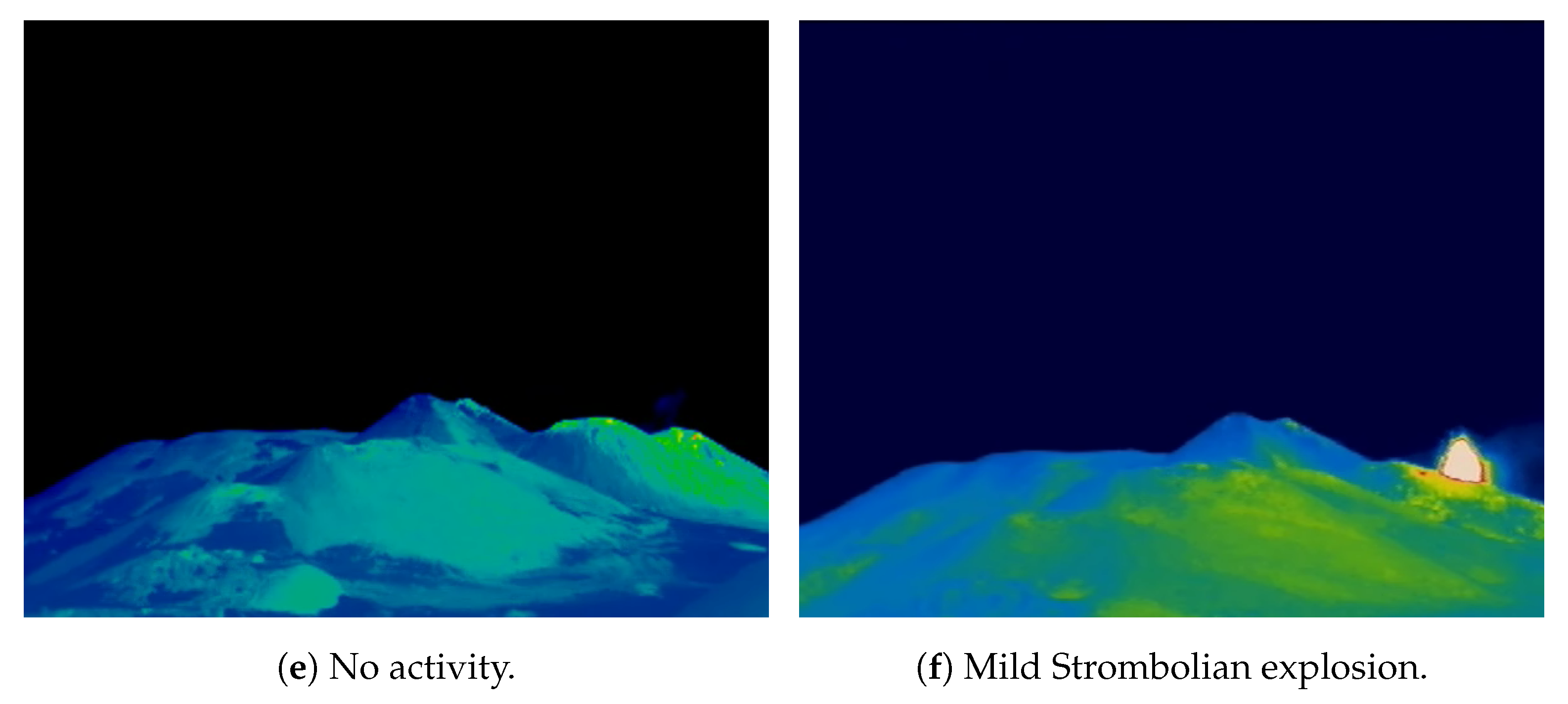
3.1. CNN Architectures
Convolutional Neural Networks (CNNs) are specifically engineered to handle grid-like data, such as images, with a high efficiency. For a more detailed discussion, interested readers can refer to specific papers [
4,
8] and/or textbooks [
9]. A typical CNN architecture comprises three primary types of layers: convolutional layers, pooling layers, and fully connected layers, as illustrated in
Figure 2.
The foundation of CNNs lies in the convolutional layers, which apply convolution operations to the input data using filters or kernels. This process allows the network to capture spatial hierarchies and learn local patterns. The convolution operation involves sliding the filter across the input, performing element-wise multiplications, and aggregating the results to generate feature maps.
Pooling layers play a crucial role in reducing the spatial dimensions of the input volume, thereby lowering the computational complexity of the network. Techniques such as max pooling and average pooling downsample the feature maps, preserving the most significant information while discarding less relevant details.
The final component of a CNN is the output layer, which produces the network’s predictions. The choice of activation function in this layer is task-dependent; for instance, softmax is commonly used for classification problems, while linear activation is suitable for regression tasks.
In the following section, we provide a comprehensive overview of selected CNN-based models, highlighting their unique features and contributions to the field of deep learning.
3.1.1. AlexNet
AlexNet, introduced by Krizhevsky et al. [
3], marked a significant milestone in image classification tasks when it was proposed in 2012. The architecture consists of 8 layers, namely, 5 convolutional layers followed by 3 fully connected layers, and encompasses approximately 57 million parameters. AlexNet’s groundbreaking innovations include the use of ReLU (Rectified Linear Unit) activations, which accelerate the training process, and dropout for regularization, which helps prevent overfitting. The integration of GPU acceleration further enhances the training speed and performance, particularly on large datasets, such as ImageNet [
10].
3.1.2. VGGNet
VGGNet, introduced in 2014 by Simonyan et al. [
11], showcases the potential of deeper architectures in neural networks. One of its popular variants, VGGNet-16, comprises 16 layers, namely, 13 convolutional layers and 3 fully connected layers, totaling around 138 million parameters. VGGNet’s modular design, characterized by the use of small
filters, provides a robust framework for visual recognition tasks. However, this depth came at the cost of high computational demands, making it resource intensive.
3.1.3. GoogleNet
GoogleNet, also known as Inception, was introduced in 2014 by Szegedy et al. [
12]. This model employs inception modules that apply convolutions of multiple sizes in parallel, enabling the network to capture features at various scales efficiently. With 22 layers and approximately 5.6 million parameters, GoogleNet achieves high accuracy while maintaining lower computational requirements compared with deeper architectures, like VGGNet. This efficiency makes it a preferred choice for applications requiring both performance and resource optimization.
3.1.4. SqueezeNet
SqueezeNet, introduced by Iandola et al. [
13], presents an efficient and lightweight architecture designed for resource-constrained environments. With only 1.2 million parameters spread across 18 layers, SqueezeNet utilizes
convolutions in bottleneck layers to achieve an accuracy comparable with larger models. This design made SqueezeNet particularly suitable for deployment on devices with limited computational power and memory.
3.1.5. ResNet
ResNet (Residual Network), introduced in 2015 by He et al. [
14], addresses the degradation problem in deep networks by incorporating residual connections. ResNet-50, featuring 50 layers and about 23 million parameters, allows for the effective training of very deep architectures by mitigating vanishing gradient issues. This innovation enables the network to learn more complex representations and achieve a higher performance in various tasks.
3.1.6. DenseNet
DenseNet, proposed in 2017 by Wang and Zhang [
15], introduces dense connections, where each layer receives input from all preceding layers. This architecture, exemplified by DenseNet-201 with 201 layers and approximately 18 million parameters, promotes feature reuse and improves the parameter efficiency. By alleviating the vanishing gradient problems, DenseNet enhances the flow of information and gradients through the network, leading to a better performance and reduced training time.
3.1.7. ShuffleNet
ShuffleNet, designed for mobile devices by Zhang et al. [
16], utilizes group convolutions and channel shuffling to balance efficiency and performance. ShuffleNetV1, with 50 layers and about 1.26 million parameters, is appropriate for low-memory, high-speed applications. This architecture ensures that the model remains lightweight and fast, making it suitable for real-time processing on mobile and embedded systems.
3.1.8. DarkNet
DarkNet, used in the YOLOv3 object detection framework and detailed by Redmon et al. [
17,
18], is exemplified by the DarkNet53 version, which features 53 layers and approximately 41 million parameters [
19]. Its efficient architecture is well suited for complex object detection tasks, providing a high accuracy and speed. DarkNet’s design allows it to handle a wide range of object detection scenarios, making it a versatile choice for various applications.
3.1.9. Summary of CNN Model Structures
The evolution of CNN architectures has focused on improving their depth, efficiency, and training stability.
Table 1 summarizes the key features of the CNN models considered in this study.
3.2. Vision Transformer (ViT)
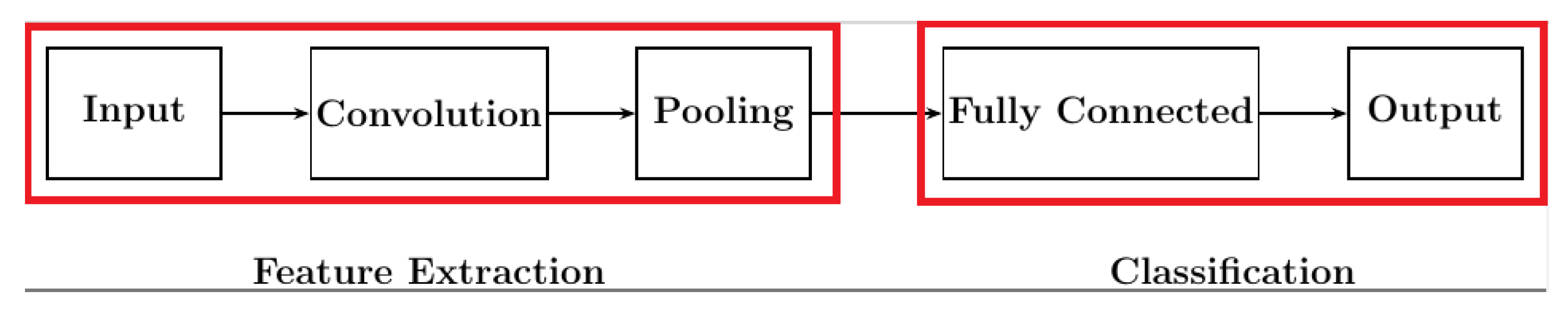
The Vision Transformer (ViT) introduced by Dosovitskiy et al. [
2] is a groundbreaking model in the field of computer vision that was designed to leverage the power of Transformer architectures originally developed for natural language processing tasks. ViTs are particularly effective in handling image classification and other vision-related tasks by processing images as sequences of patches, similar to how Transformers process sequences of words.
The architecture of a Vision Transformer, as illustrated in
Figure 3, consists of several key components:
Input image: the process begins with an input image, which is divided into fixed-size patches.
Patch + position embedding: each patch is then embedded into a vector space, and positional embeddings are added to retain spatial information.
Linear projection of flattened patches: the embedded patches are flattened and linearly projected to form a sequence of tokens.
Transformer Encoder: The core of the ViT architecture is the Transformer Encoder, which processes the sequence of tokens through multiple layers. Each layer includes the following:
- –
Normalization: normalization layers ensure stable training by standardizing the inputs.
- –
Multi-head attention: this mechanism allows the model to focus on different parts of the input sequence simultaneously, capturing complex relationships between patches.
- –
MLP (Multi-Layer Perceptron): a feed-forward neural network that further processes the attended features.
MLP head: the output from the Transformer Encoder is passed through an MLP head, which produces the final classification or regression output.
Output: the final output layer provides the predictions for the given task, such as class labels for image classification.
The Vision Transformer has demonstrated remarkable performance in various computer vision tasks, showcasing the versatility and effectiveness of Transformer architectures beyond their original application in natural language processing. An overview of key Vision Transformer (ViT) models, emphasizing their unique features, architectures, and parameter counts in the field of medical images can be found in Henry et al. [
20].
After the first version of the ViT transformer by Dosovitskiy et al. [
2], other versions have been proposed in the literature, some of which were used in this work and, for this reason, are briefly described in the following sections.
3.2.1. Data-Efficient Image Transformer (DeiT)
The Data-efficient Image Transformer (DeiT) by Touvron et al. [
21] is an advanced version of the Vision Transformer (ViT) that introduces several innovative features to potentially enhance the performance, especially on smaller datasets. Key characteristics of the DeiT include the following:
Distillation token: a distillation token designed to enhance the model’s learning process is utilized during training to capture and transfer knowledge from a teacher model to a student model, potentially improving the overall performance.
Efficiency on smaller datasets: One of the notable strengths of the DeiT is its ability to perform effectively on smaller datasets. This capability is particularly beneficial in situations where collecting large amounts of data is impractical or challenging.
Reduced computational requirements: By leveraging knowledge distillation and the distillation token, the DeiT can achieve high performance with fewer computational resources compared with traditional ViT models. This efficiency makes the DeiT more accessible for applications with limited computational power.
Robustness: the DeiT’s training methodology enhances the model’s robustness, making it more resilient to variations in the data and potentially improving its generalization capabilities.
3.2.2. Swin Transformer (SwT)
The Swin Transformer, introduced by Liu et al. [
22], considers a hierarchical architecture that leverages shifted windows to effectively capture multi-scale features. This design allows the model to generate a pyramid of feature maps, making it particularly well suited for tasks that require detailed spatial information, such as object detection and segmentation. The key innovations of the Swin Transformer include the following:
Hierarchical feature maps: Unlike traditional Vision Transformers that produce feature maps of a single scale, the Swin Transformer generates feature maps at multiple scales. This hierarchical structure enables the model to capture both fine-grained details and broader contextual information, enhancing its performance on complex vision tasks.
Shifted windows: The Swin Transformer employs a shifted window mechanism that allows for cross-window connections. This approach helps the model to capture dependencies between different regions of the image, improving its ability to understand spatial relationships and context.
Efficiency: By limiting self-attention computation to non-overlapping local windows and using shifted windows to introduce cross-window connections, the Swin Transformer achieves a good balance between computational efficiency and model capacity. This makes it more scalable and practical for high-resolution images and dense prediction tasks.
3.2.3. Convolutional Vision Transformer (CvT)
The Convolutional Vision Transformer (CvT), introduced by Wu et al. [
23], integrates convolutional layers within the Transformer architecture, combining the strengths of both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). This hybrid approach enhances local feature extraction while retaining the global representation capabilities of transformers.
The key features of the CvT include the following:
Local feature extraction: By incorporating convolutional layers, the CvT can effectively capture local patterns and textures within images. This is particularly beneficial for tasks that require detailed spatial information, such as object detection and segmentation.
Global representation: the transformer component of the CvT allows the model to capture long-range dependencies and global context, which is crucial for understanding the overall structure and relationships within an image.
Efficient computation: The integration of convolutional layers helps reduce the computational complexity associated with self-attention mechanisms in traditional transformers. This makes the CvT more efficient and scalable for high-resolution images and large-scale datasets.
3.2.4. Transformer in Transformer (TNT)
The Transformer in Transformer (TNT), introduced by Han et al. [
24], considers a nested Transformer design to model both intra-patch and inter-patch dependencies, enabling detailed and global feature representation. This innovative architecture enhances the model’s ability to capture fine-grained details within individual patches while also understanding the broader context across the entire image. The key features of the TNT include the following:
Intra-patch Transformer: The inner Transformer focuses on modeling dependencies within individual patches. This allows the model to capture detailed local features and textures, which are crucial for tasks that require high-resolution spatial information.
Inter-patch Transformer: The outer Transformer models dependencies between different patches, enabling the model to understand the global context and relationships across the entire image. This is essential for tasks that require a comprehensive understanding of the scene.
Enhanced feature representation: By combining intra-patch and inter-patch transformers, the TNT can effectively capture both local and global features, leading to a more robust and detailed feature representation. This dual-level approach improves the model’s performance on complex vision tasks.
3.2.5. LeViT
The LeViT, introduced by Graham et al. [
25], was designed to balance speed and accuracy, making it particularly suitable for real-time applications. This model combines convolutional layers with attention mechanisms to achieve efficient GPU inference, ensuring both high performance and computational efficiency. The key features of the LeViT include the following:
Hybrid architecture: The LeViT integrates convolutional layers with Transformer-based attention mechanisms. The convolutional layers capture local spatial features efficiently, while the attention mechanisms enable the model to understand the global context and long-range dependencies.
Efficient GPU inference: By leveraging the strengths of both convolutions and attention mechanisms, the LeViT optimizes the GPU inference, allowing for faster processing times. This efficiency is crucial for real-time applications where a rapid response is essential.
Balanced speed and accuracy: The LeViT was engineered to provide a good balance between speed and accuracy. This makes it an ideal choice for applications that require both high performance and quick processing, such as autonomous driving, video surveillance, and augmented reality.
3.2.6. Twins Transformer (Twins-SVT)
The Twins Transformer (Twins-SVT), introduced by Chu et al. [
26], leverages both local and global attention mechanisms to effectively handle image data at multiple scales. This dual-attention approach allows the model to capture detailed local features while also understanding the broader context of the entire image. The key features of the Twins-SVT include the following:
Local attention: The local attention mechanism focuses on capturing fine-grained details within smaller regions of the image. This is crucial for tasks that require precise spatial information, such as object detection and segmentation.
Global attention: The global attention mechanism enables the model to understand the overall structure and relationships across the entire image. This is essential for tasks that require a comprehensive understanding of the scene.
Multi-scale feature representation: By combining local and global attention mechanisms, the Twins-SVT can effectively capture features at multiple scales. This hierarchical representation enhances the model’s ability to handle complex vision tasks that require both detailed and contextual information.
Efficient computation: The dual-attention approach in the Twins-SVT allows for efficient computation by balancing the focus on local and global features. This makes the model more scalable and practical for high-resolution images and large-scale datasets.
Table 2 summarizes the main features of the selected ViT models.
4. Evaluation Metrics
In this section, we briefly describe the performance metrics used to objectively evaluate the classifiers implemented in this study. Let
and
represent the total numbers of actual positive and actual negative cases for the
i-th class, respectively. Additionally, let
,
,
, and
denote the numbers of true positives, true negatives, false positives, and false negatives, respectively, as identified by the classifier for the
i-th class. Based on these quantities, the following metrics can be defined:
These metrics can be interpreted as follows:
, also known as Recall or Sensitivity, represents the proportion of actual positives correctly classified as belonging to the i-th class. High values of indicate a good performance at identifying positive cases. For simplicity, the Recall for the i-th class is denoted as .
, or Specificity, represents the proportion of actual negatives correctly classified as not belonging to the i-th class. High values of indicate the effective exclusion of negatives.
indicates the proportion of false negatives in the i-th class with respect to all actual positives in the class. Lower values are desirable as they imply fewer missed positives.
represents the proportion of false positives in the i-th class relative to the total number of actual negatives in the class. Lower values are desirable as they indicate fewer incorrect positive classifications.
Based on these definitions, we can define the Positive Predictive Value (
PPV), or
Precision, for the
i-th class as follows:
In the following, the Precision for the i-th class is denoted as .
Together with
and
, we also consider the
-score, a combined metric that balances Precision and Recall for the
i-th class. It is defined as follows:
A useful tool for visualizing these performance metrics is the Confusion Matrix (CM), which provides a breakdown of classifier outcomes for each class. In a CM, rows correspond to the true classes (Target Classes), and columns correspond to the predicted classes (Output Classes). Diagonal cells represent correctly classified observations, while off-diagonal cells indicate misclassifications.
5. Results
In this section, we present the results following a structured approach. First, we compare the CNN-based classifiers considering the performance metrics averaged across all classes. Specifically, we analyze the average Precisions, Recalls, and f1-scores, along with the training time, which serves as a measure of the computational load required for each model. From this comparison, we identify the classifier that demonstrates the best performance, considering the four metrics mentioned above.
Next, we perform the same analysis for the models based on Vision Transformers, identifying the top-performing Transformer-based classifier. Subsequently, we compare the best CNN-based model with the best Transformer-based model. This comparison includes a detailed evaluation of their performance on individual classes using the respective confusion matrices to highlight the strengths and weaknesses. Finally, we assess the classifiers in terms of their average classification time for a single image after training, providing an estimate of their suitability for real-time applications. It is important to note that while CNNs and Transformers can benefit from the presence of a GPU, all experiments were conducted on a desktop computer without a GPU. The computer was equipped with an Intel(R) Core(TM) i5-10500 CPU running at 3.10 GHz and 16 GB of RAM. This approach was chosen to demonstrate the feasibility and performance of the models in a more accessible and widely available computing environment. For the parameters and hyperparameters, we used the standard settings of the models (see
Table 1 and
Table 2). The considered models, provided by the Torchvision library [
27], were pre-trained on the ImageNet dataset [
10] and fine-tuned for our specific classification task, which involved classifying six classes of volcanic activity. The final layers of the classifiers were modified to match the number of classes in our dataset. The number of training epochs was set to 4 for all models to ensure each model reached a steady state of learning, providing a fair and consistent comparison. All models were trained using the Adam optimizer with a learning rate of
and the CrossEntropyLoss function. The CNN models employed the ReLU (Rectified Linear Unit) activation function, while the Transformer models utilized the GELU (Gaussian Error Linear Unit) activation function.
5.1. Performances in Terms of Average Indices
For the CNN classifiers, the results in terms of average indices are reported in
Table 3.
It is possible to see that most of the CNN classifiers had average f1-score indices close to 0.9, and therefore, were able to solve the problem in a satisfactory way, with a slight advantage for GoogLeNet (0.92) and AlexNet (0.91). If we consider the average time required for training, the ranking would be DarkNet (4.18 min), ShuffleNet (4.49 min), and AlexNet (7.29 min).
Referring to the Transformer classifiers,
Table 4 shows that most of them had average f1-score indices close to 0.9, indicating their ability to solve the problem effectively. Notably, the CvT and Twins-SVT both achieved an f1-score of 0.91, followed closely by the SwinT, TNT, and DeiT, with scores of 0.90. If we consider the average time required for training, the LeViT was the fastest (10.77 min), followed by the SwinT (39.85 min) and PvT (35.70 min). However, the CvT required the longest training time (117.19 min).
Let us now consider in more detail the behavior of the classifiers with respect to the individual classes. For simplicity, we show the f1-score indices for the CNN classifiers and for the Vision Transformer classifiers.
The f1-scores for CNN-based classifiers across different classes and architectures are presented in
Table 5.
The f1-scores for the Transformer-based classifiers across the same classes are presented in
Table 6.
The results indicate that both the CNN and Transformer-based models were effective for the classification of volcanic activity. However, the following should be noted:
The Transformer-based models showed slightly better performance for challenging classes, like ‘Cooling or Lavaflow’ and ‘Degassing’, likely due to their global attention mechanism.
CNN-based models, like ‘DenseNet’ and ‘GoogLeNet’, excelled at simpler and more localized tasks, such as ‘Cloudy’ and ‘No Activity’.
5.2. Comparison of Confusion Matrices Between AlexNet and SwinT
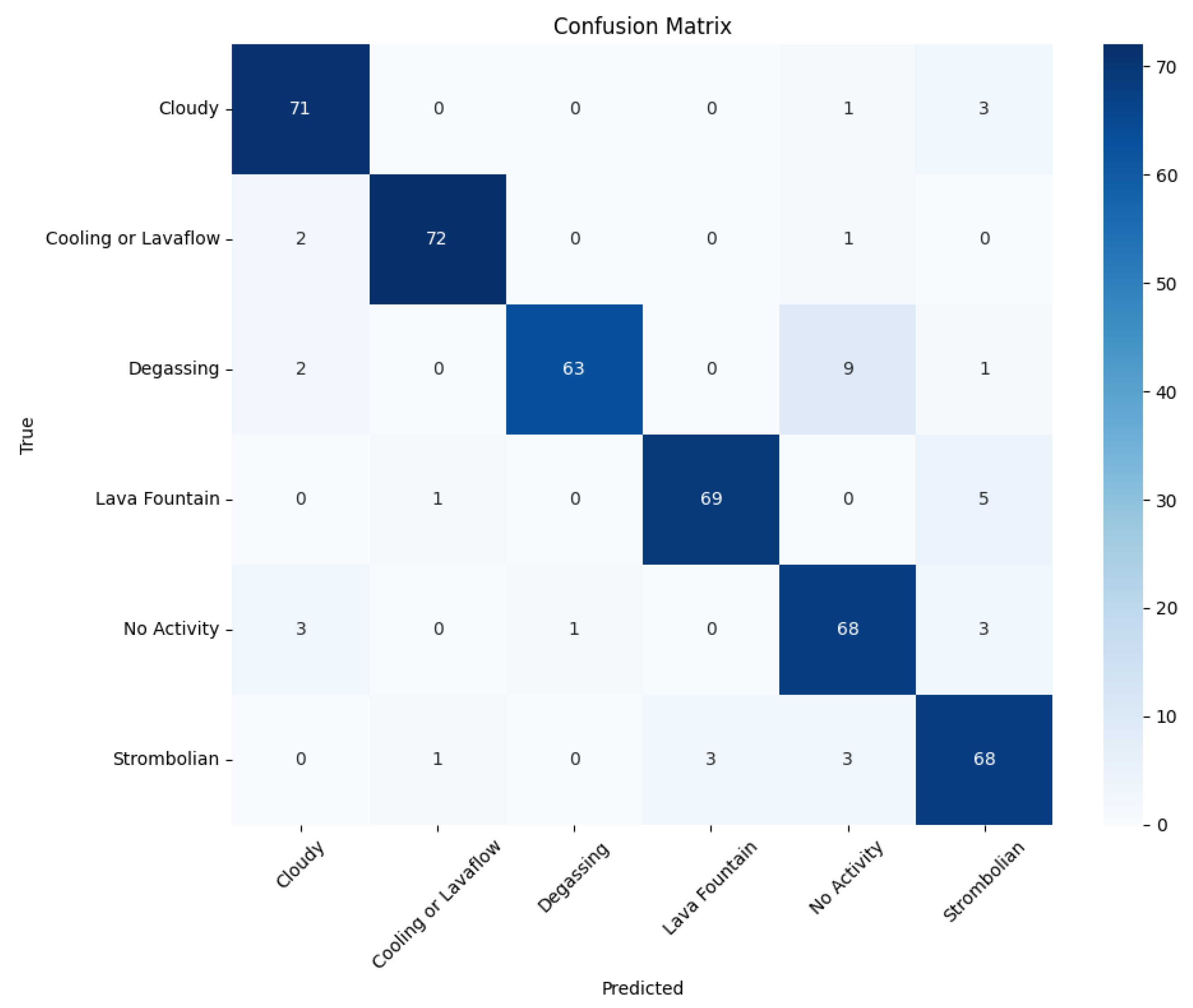
This section provides an analysis of the confusion matrices obtained from two representative classifiers: AlexNet (CNN-based) and the SwinT (Transformer-based). The test set contained 75 events per class. The rows in the matrices represent the true labels, while the columns represent the predicted labels.
The confusion matrix for AlexNet is presented in
Figure 4.
The following can be observed:
AlexNet performed well on the ‘Cloudy’, ‘Cooling or Lavaflow’, and ‘Lava Fountain’ classes, with minimal misclassifications. Notably, it correctly identified 71/75 events for ‘Cloudy’, 72/75 events for ‘Cooling or Lavaflow’, and 69/75 for ‘Lava Fountain’.
The ‘Degassing’ and ‘Strombolian’ classes showed higher rates of misclassification. For instance, nine events in the ‘Degassing’ class were misclassified as ‘No Activity’, and six events in the ‘Strombolian’ class were misclassified as ‘Cooling or Lavaflow’ and ‘No Activity’.
Misclassification often occurred between semantically similar classes, such as ‘Degassing’ and ‘No Activity’ or ‘Strombolian’ and ‘Lava Fountain’.
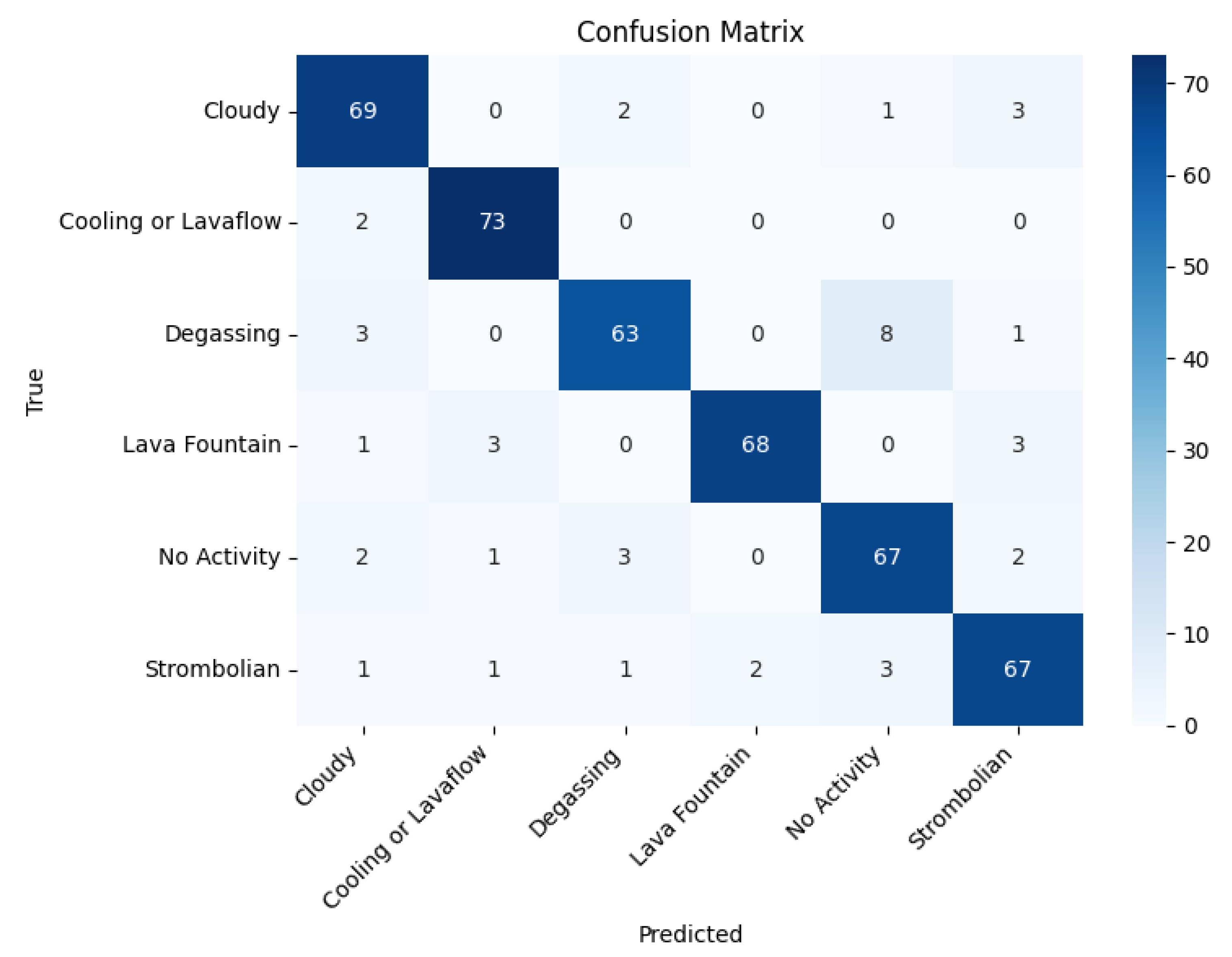
The confusion matrix for the Swin Transformer (SwinT) is shown in
Figure 5.
From the confusion matrix, we note the following:
A strong performance: the SwinT accurately classified ‘Cooling or Lavaflow’ in 73 out of 75 cases and performed well on ‘Lava Fountain’ and ‘Cloudy’.
Misclassifications: the ‘Strombolian’ class was often misclassified, primarily as ‘No Activity’ or ‘Lava Fountain’.
Similar errors to AlexNet: like AlexNet, the SwinT struggled with distinguishing ‘Degassing’ from ‘No Activity’ and ‘Lava Fountain’ from ‘Strombolian’.
5.3. Summary of Results
SwinT vs. AlexNet: both models classified most classes effectively, but the SwinT slightly outperformed AlexNet for ‘Cooling or Lavaflow’.
Challenges with similar classes: Both models found it difficult to distinguish the semantically close classes. For instance, ‘Degassing’ was often confused with ‘No Activity’, highlighting the need for additional data or finer-grained features.
Advantages of the SwinT: The SwinT’s Transformer-based architecture better resolved the inter-class confusion. This was evident from the confusion matrices, where the SwinT demonstrated superior performance when distinguishing between challenging classes, such as ‘Cooling or Lavaflow’ and ‘Degassing’. Specifically, the SwinT correctly classified 73 out of 75 instances of ‘Cooling or Lavaflow’ with minimal misclassifications, compared with AlexNet’s 72 out of 75. Additionally, the SwinT showed fewer misclassifications between ‘Degassing’ and ‘No Activity’ (eight misclassifications) compared with AlexNet (nine misclassifications). The global attention mechanism of SwinT allowed it to capture long-range dependencies and contextual information more effectively, leading to an improved classification accuracy regarding these complex scenarios.
Issues with Strombolian class: misclassifications of the ‘Strombolian’ class suggest a need for improved feature extraction or enhanced data augmentation to capture its unique characteristics.
5.4. Comparison of Average Classification Times Between CNN and Transformer-Based Classifiers
The average classification times for CNN-based classifiers are shown in
Table 7.
The following can be observed:
AlexNet, DarkNet53, and ShuffleNet were the fastest among the CNN-based classifiers, with an average classification time of 13.00 milliseconds.
VGG16 had the longest average classification time of 124.60 milliseconds, which was approximately 9 times slower than AlexNet.
Models like DenseNet201 and ResNet50 exhibited moderate classification times (108.00 and 69.10 milliseconds, respectively) but typically offered higher accuracies, as shown in previous analyses. This indicates a trade-off between computational efficiency and accuracy.
All models except VGG16 and DenseNet201 had classification times under 70 milliseconds, making them suitable for near-real-time applications.
The average classification times for the Transformer-based classifiers are shown in
Table 8.
The following can be seen:
The LeViT and CvT exhibited the lowest and the highest classification time, respectively.
Models like SwinT and PvT struck a balance between accuracy and computational efficiency.
The majority of the Transformer-based models, such as the TNT, ViT, and CvT, were computationally efficient and suitable for real-time applications.
In summary, the CNN-based models generally showed comparable or slightly better computational efficiencies than the Transformer-based models, with AlexNet, DarkNet53, and ShuffleNet being the fastest classifiers overall. Both AlexNet and ShuffleNet were strong candidates due to their low classification times and reliable performances.
6. Discussion and Conclusions
In this paper, we present a comprehensive comparison of CNN and Transformer-based models for the classification of volcanic activity. Our results indicate that both model families have their strengths and weaknesses, with Transformer-based models, like the SwinT, excelling in specific challenging categories, such as ‘Cooling or Lavaflow’. However, CNN models, like ‘VGG16’ and ‘GoogLeNet’, showed comparable or better performance in simpler and more localized tasks.
While there are no direct comparisons with other studies using Transformers for volcanic activity classification, our work can be contextualized within the broader literature on image classification. Previous studies using CNNs for volcanic activity classification showed promising results, but our study demonstrated that Transformer-based models can offer additional advantages. For instance, the Transformers’ ability to capture long-range dependencies and global context can be particularly beneficial for challenging classes where local features alone may not be sufficient.
The scientific novelty of our study lay in the extensive comparison between the most representative Convolutional Neural Networks (CNNs) and the latest Transformer networks. Unlike previous studies, our work highlighted the potential of Transformer networks in specialized applications, such as volcanic activity monitoring, where accurate and reliable image classification is crucial.
This study evaluated and compared the performance of CNN-based and Transformer-based classifiers for volcanic activity image classification. The results highlight key insights into the strengths and limitations of both approaches, offering a clearer perspective on their applicability to this specific task.
Overall, for a relatively straightforward classification problem, the Transformer-based models did not exhibit a significant advantage over CNNs. Both approaches demonstrated strong performances, albeit with distinct characteristics. CNNs, exemplified by models like ‘AlexNet’ and ‘ShuffleNet’, were computationally efficient, with faster training and inference times, making them particularly suitable for real-time applications. Transformers, such as the ‘SwinT’ and ‘ViT’, provided slightly improved accuracy in certain scenarios, particularly when dealing with more complex or ambiguous classes, showcasing their potential for tasks requiring greater handling of inter-class confusion.
An analysis of the confusion matrices indicated that while the Transformer-based models, such as the ‘SwinT’, excelled at specific challenging categories, like ‘Cooling or Lavaflow’, they did not consistently manage inter-class confusion more effectively than CNNs across all the classes. For instance, the CNN models showed comparable or better performance for classes such as ‘Cloudy’ and ‘No Activity’. Both model families struggled with visually similar classes, such as ‘Degassing’ vs. ‘No Activity’ or ‘Strombolian’ vs. other eruptive behaviors. These challenges underscore the need for expanding and diversifying the dataset to capture subtle distinctions between similar classes.
In terms of real-time monitoring, lightweight CNN architectures, like ‘AlexNet’ and ‘ShuffleNet’, excelled due to their speed and efficiency. Although the Transformer-based models were marginally slower, they remained competitive in terms of inference times while delivering high accuracies, making them a viable option for deployment in scenarios where accuracy is a higher priority.
In conclusion, while Transformer-based models show promise, their advantages over CNNs for this specific application remain modest. CNNs continue to be a reliable, efficient, and highly effective choice for volcanic activity classification. However, the benefits of Transformer-based models may become more evident in future work, particularly when addressing more complex tasks, such as developing a unified classifier for monitoring multiple volcanic activity stations. Such a system would need to address the challenges posed by varying perspectives and recording conditions, offering an opportunity to fully leverage the advanced capabilities of Transformer architectures for handling heterogeneous datasets.
Author Contributions
Conceptualization, G.N. and S.C.; methodology, G.N.; software, G.N.; validation, G.N. and S.C.; formal analysis, G.N. and S.C.; investigation, G.N. and S.C.; resources, G.N. and S.C.; data curation, G.N. and S.C.; writing—original draft preparation, G.N. and S.C.; writing—review and editing, G.N. and S.C.; visualization, G.N. and S.C.; supervision, G.N. and S.C.; project administration, G.N.; funding acquisition, G.N. and S.C. All authors read and agreed to the published version of this manuscript.
Funding
Supported by the Italian Research Center on High Performance Computing Big Data and Quantum Computing (ICSC), a project funded by the European Union—NextGenerationEU—and the National Recovery and Resilience Plan (PNRR)—Mission 4 Component 2 within the activities of Spoke 3 (Astrophysics and Cosmos Observations). Sonia Calvari also acknowledges the financial support of the Project FIRST—ForecastIng eRuptive activity at Stromboli volcano (Delibera n. 144/2020; Scientific Responsibility: S.C.). Vulcani 2019.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The images considered in this paper were extracted from videos of an eruptive activity paper belonging to the Istituto Nazionale di Geofisica e Vulcanologia, Osservatorio Etneo Sezione di Catania. Selected images can be made available upon request to Sonia Calvari of the INGV-OE.
Acknowledgments
We would like to thank the INGV-OE scientists and technicians for the monitoring and network maintenance.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Corradino, C.; Ganci, G.; Cappello, A.; Bilotta, G.; Herault, A.; Del Negro, C. Mapping recent lava flows at Mount Etna using multispectral Sentinel-2 images and machine learning techniques. Remote Sens. 2019, 11, 1916. [Google Scholar] [CrossRef]
- Corradino, C.; Ramsey, M.S.; Pailot-Bonnetat, S.; Harris, A.J.L.; Del Negro, C. Detection of subtle thermal anomalies: Deep learning applied to the ASTER Global Volcano Dataset. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000715. [Google Scholar] [CrossRef]
- Nunnari, G.; Calvari, S. Exploring Convolutional Neural Networks for the Thermal Image Classification of Volcanic Activity. Geomatics 2024, 4, 124–137. [Google Scholar] [CrossRef]
- Taye, M.M. Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions. Computation 2023, 11, 52. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning, 2nd ed.; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4500–4508. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, S.H.; Zhang, Y.D. DenseNet-201-Based Deep Neural Network with Composite Learning Factor and Precomputation for Multiple Sclerosis Classification. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 60. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, L.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Ahmadchoudhry, Z.; Shahid, H.; Naqvi, S.Z.H.; Aziz, S.; Khan, M.U. DarkNet-19 based Decision Algorithm for the Diagnosis of Ophthalmic Disorders. In Proceedings of the 2021 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 9–10 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Henry, E.U.; Emebob, O.; Omonhinmin, C.A. Vision Transformers in Medical Imaging: A Review. arXiv 2022, arXiv:2211.10043. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 17293–17304. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11912–11922. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L.; Hu, H.; Wang, Y.; Chen, L.; et al. CvT: Introducing Convolutions to Vision Transformers. IEEE Trans. Image Process. 2022, 31, 3752–3763. [Google Scholar]
- Han, X.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 12122–12132. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9478–9489. [Google Scholar]
- Torchvision Development Team. Pre-trained Models in Torchvision: Image and Video Datasets and Models for PyTorch. Available online: https://pytorch.org/vision/main/models.html (accessed on 25 November 2024).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}