1. Introduction
Visual simultaneous localization and mapping (SLAM) utilizes images as the primary source of environmental perception, estimating camera pose and trajectory through feature extraction and matching while reconstructing a map of the surrounding scene. Edge computing offloads computationally intensive steps, enhancing accessibility and expanding the applications of visual SLAM. Edge-assisted visual SLAM is essential for autonomous driving [
1], robot navigation [
2], and virtual/augmented reality (AR/VR) [
3]. However, transmitting images to edge servers introduces privacy risks [
4], as their leakage could lead to significant and unpredictable consequences [
5]. Moreover, the generated three-dimensional (3D) point cloud can reconstruct the original scene [
6,
7], further exacerbating privacy concerns. Thus, privacy protection remains a critical challenge in edge-assisted visual SLAM.
To address this challenge, researchers have proposed various privacy-preserving methods to protect the privacy of images, such as introducing noise or applying image blurring [
8,
9]. However, these approaches degrade global and local feature descriptors, and processed images can still be restored using image deblurring techniques [
4,
10]. Other methods focus on encrypting images [
11,
12], but encrypted images require decryption for pose estimation, increasing the transmission overhead in visual SLAM. Image inpainting is an image processing technique that fills or repairs missing or requested areas in an image to make it look visually natural and coherent. This technology is considered promising for alleviating the privacy protection issues of visual SLAM.
For point clouds, Speciale et al. [
13] proposed lifting 2D/3D feature points into random 2D/3D lines during visual localization, preserving privacy while ensuring accurate camera pose estimation. Building on this idea, Shibuya et al. [
14] developed a visual SLAM framework that integrates hybrid point-line features. It realizes efficient relocation and tracking while maintaining privacy during computations. However, this method [
14] primarily protects point clouds during processing. After computation, line clouds are discretized into point clouds, leaving the generated 3D point cloud map unprotected. Additionally, it does not safeguard input images.
Existing privacy protection schemes for visual SLAM primarily safeguard point clouds during runtime but overlook the privacy-sensitive information in incoming images and the output 3D map. This gap underscores the need for a method that protects both while maintaining SLAM pose estimation performance. To address this, this paper introduces a dual-component approach that combines the inpainting of privacy-sensitive areas in images with the encryption of 3D point clouds. This method aims to enhance privacy preservation in edge-assisted visual SLAM. The main contributions of this paper are as follows:
We propose a dual-component privacy protection scheme for visual SLAM, which integrates the protection of both image and point cloud data.
We propose an image inpainting method for privacy-sensitive areas. This method integrates object detection based on multi-scale feature fusion with two-stage image inpainting based on edge prediction and image inpainting. It conceals privacy-sensitive information from input images and accurately restores the affected areas.
We introduce an encryption algorithm for point clouds based on the concept of dimensionality lifting. By randomly determining the direction and normalizing the length, each 3D point can be encrypted into a 3D line to obtain a 3D line cloud, improving the anti-attack ability of the visual SLAM output map.
2. Related Work
2.1. Visual SLAM
Visual SLAM can be broadly categorized into direct-based [
15,
16] and feature-based approaches [
17,
18]. Direct methods estimate camera motion by tracking pixel intensity variations between consecutive frames. Since they do not require keypoint detection or descriptor computation, they are computationally efficient. However, they are highly sensitive to image noise and uncertainty, limiting their effectiveness in complex environments. In contrast, feature-based methods rely on multi-view geometry principles. They first detect feature points in images, then match them with 2D or 3D points to compute camera poses and reconstruct scenes. These methods provide more distinctive and stable features, enhancing adaptability to diverse lighting conditions and environments, including indoor and outdoor settings. A notable example in this category is oriented fast and rotated brief (ORB)-SLAM [
17]. This paper employs ORB-SLAM3 [
18] as the operational framework for implementing the proposed privacy-preserving approach.
2.2. Edge-Assisted Visual SLAM
To enable visual SLAM on resource-constrained devices such as mobile devices and robots, Cao et al. [
19] proposed edgeSLAM, an edge-assisted mobile semantic visual SLAM system. This method integrates an efficient computational offloading strategy into ORB-SLAM2 and improves localization and mapping accuracy through semantic segmentation. Similarly, Ben Ali et al. [
20] introduced Edge-SLAM, which ensures long-term, accurate operation under limited computational resources by offloading local mapping and loop-closing computations to edge servers.
These edge-assisted visual SLAM approaches require transmitting image frames to edge servers, which then return point clouds and poses after processing. However, this transmission process poses significant privacy risks [
6,
7,
10].
2.3. Privacy-Preserving for Edge-Assisted Visual SLAM
The transmission data in edge-assisted visual SLAM contain privacy-sensitive information. Input images may include personal details such as faces, license plates, and location data, which, if exposed, could lead to unforeseen consequences [
5]. Moreover, the output 3D point clouds have been shown to be invertible, allowing the reconstruction of original scenes [
6,
7], thereby compromising user privacy.
Shibuya et al. [
14] proposed a privacy-preserving method for visual SLAM that lifts 3D points into 3D lines during computation. This approach assumes that privacy can be preserved simply by transforming points into lines during processing. However, the 3D line cloud is discretized into a 3D point cloud during relocalization. Thus, the map generated by SLAM still has the risk of being attacked and leaking privacy [
6,
7].
Despite the growing adoption of edge-assisted visual SLAM, no existing privacy-preserving approach addresses both input data and generated outputs. Given that these data serve as potential vectors for privacy breaches, effective protection mechanisms are essential. This paper proposes a dual-component approach for privacy preservation in edge-assisted visual SLAM. By combining image inpainting for sensitive areas with point cloud encryption, the proposed method aims to safeguard user privacy while maintaining the accuracy of pose estimation.
3. Method
A dual-component approach for edge-assisted visual SLAM to preserve privacy is proposed. ORB-SLAM3 is applied as the application environment for our approach.
To protect the transmission data in ORB-SLAM3, the privacy-sensitive areas in the input image are realistically inpainted, and each point of the output point cloud is encrypted into a line. To provide more detail, firstly, the approach presents a method by combining object detection and image inpainting. By inpainting the privacy-sensitive areas in the image based on the surrounding scene, it is ensured that private information is invisible and the inpainted area is natural. Secondly, the output 3D point cloud is encrypted into a 3D line cloud, where each line has a random direction and normalized length. This increases the difficulty of restoring the original 3D point clouds, making it challenging to reconstruct the original scenes. Moreover, the privacy-preserved SLAM maintains accurate pose estimation.
This section illustrates our approach by describing the framework and workflow. The theoretical basis, algorithm workflow, and models are also introduced in detail.
3.1. Approach Overview
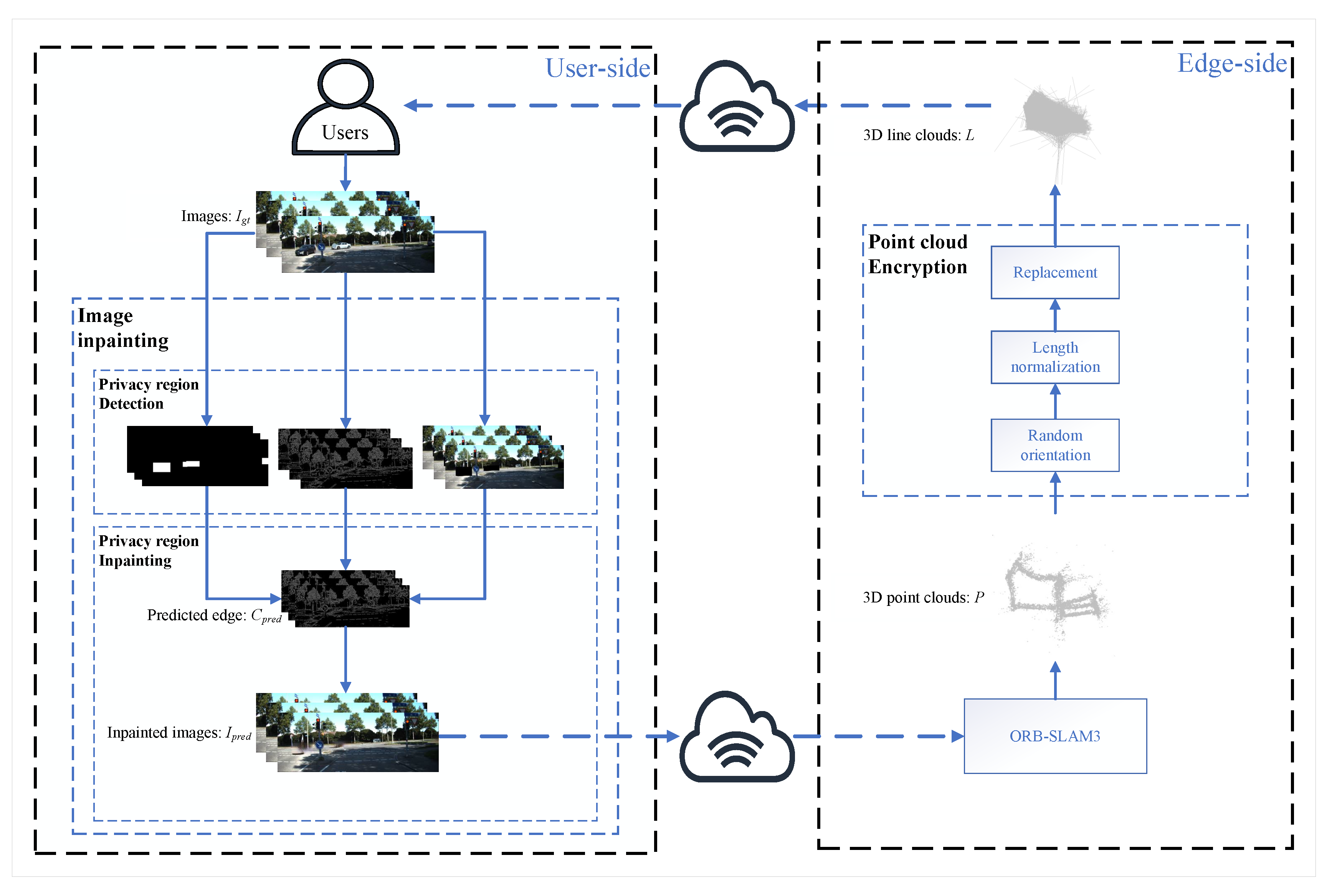
Our approach comprises an image inpainting method and a point cloud encryption algorithm, as illustrated in
Figure 1. After privacy preservation, each uploaded video frame
is first processed by the image inpainting method to inpaint privacy-sensitive areas. The method initially performs object detection using the you only look once (YOLO)v8 network to identify the location of privacy-sensitive areas within
. Compared to two-stage detectors such as Mask R-CNN [
21], single-stage detectors like the YOLO series models offer better real-time performance and lower computational resource requirements. Therefore, YOLOv8 is more suitable for tasks such as SLAM, which demand real-time processing and can be deployed in resource-constrained environments, such as mobile devices. The resulting image with privacy-sensitive areas masked is then passed to the EdgeConnect network. The EdgeConnect network first generates the contour prediction
of privacy-sensitive areas using the contour generator
and then generates the image
after inpainting privacy-sensitive areas using the image complementation network
. Compared to DeepFill v2 [
22], EdgeConnect leverages image edge information to generate more stable results for the areas to be repaired. Moreover, in contrast to Stable Diffusion [
23], which focuses more on stylized creation, EdgeConnect is better suited for generating content that aligns with the original image style. Additionally, EdgeConnect requires fewer computational resources, making it more suitable for integration with SLAM tasks. The privacy-protected image is then inputted into ORB-SLAM3, which generates a 3D point cloud
P of the scene. In order to protect
P, it is processed by the point cloud encryption algorithm, which generates a 3D line
with a random direction and normalized length for each 3D point
. Finally, the encrypted 3D line cloud
L is obtained by replacing each 3D point
with the corresponding 3D line
, and then returned to the user.
3.2. Image Inpainting
3.2.1. Network Model
The method consists of two networks: YOLOv8, and EdgeConnect. The former utilizes multi-size feature fusion to identify privacy-sensitive areas in images, and the latter utilizes two-stage image generation to inpaint those privacy-sensitive areas.
The structure of YOLOv8 is shown in
Figure 2. Inspired by the cross-stage partial (CSP) idea [
24], the backbone network implements the Feature Pyramid Network (FPN) concept and consists of six components: P1 through P5, along with a Spatial Pyramid Pooling Fast (SPPF) module. P1 incorporates a CBS convolution module, while the subsequent four components feature both a CBS convolution module and a C2f residual module. These five components gradually reduce the spatial resolution of the input image, while increasing the number of feature channels. As a result, YOLOv8 can obtain feature maps at various resolutions.
Following the processing of these components, the SPPF module extracts and encodes features from images at different scales. Additionally, it resizes input images of any size to a fixed size, generating a fixed-length feature vector. This backbone network conveys strong semantic features in a top-down manner and aggregates feature maps across different scales for multi-scale feature fusion.
In the neck component of the network, YOLOv8 utilizes the Path Aggregation Network (PAN) concept, which combines features of varying resolutions through concatenation and upsampling. This approach enhances the bottom-up transmission of robust localization features and facilitates further multi-scale feature fusion. Consequently, this multi-scale feature fusion enables YOLOv8 to detect objects of various sizes, ranging from individuals to vehicles. Finally, YOLOv8 utilizes three detection heads to analyze images at different resolutions, allowing for the effective identification of privacy-sensitive objects.
As illustrated in
Figure 3, EdgeConnect comprises two generative adversarial networks (GANs), namely, EdgeGenerator and InpaintGenerator. These networks are designed to predict contours and inpaint privacy-sensitive areas detected by YOLOv8, respectively. Each network consists of a generator and a discriminator.
The generator is primarily divided into three components: the encoder, residual module, and decoder. In the encoder, the spatial resolution of the image is downsampled twice through three convolutional layers, effectively extracting various features from the image. The residual module includes eight ResNet residual blocks, which enhance the model’s feature extraction capability, ensuring that the deep network retains more information. Subsequently, the decoder performs upsampling through two deconvolution modules to restore the image to its original resolution. Additionally, by employing upsampling in conjunction with instance normalization, the decoder achieves a balance between global information and local details, thereby improving the quality of both edge and image generation.
Notably, both the convolutional and residual blocks in EdgeGenerator incorporate Spectral Normalization to enhance the stability of the generated edges. The discriminator utilized is a
PatchGAN [
27], which assesses whether overlapping image blocks of size
are real.
3.2.2. Algorithm Details
Firstly, the original image
is passed into the YOLOv8 network for the detection of privacy-sensitive areas. The objects that appear in the street view dataset, including people, bicycles, cars, motorcycles, buses, and trucks, are defined as to be detected due to the presence of sensitive information like faces and license plates. The detection threshold is mainly used to filter the prediction results. By retaining the results with prediction confidence higher than the threshold, a balance is achieved between reducing false positives and improving recall. In this paper, the detection threshold is set to 0.4 to ensure that as many privacy objects as possible are detected while avoiding false detections. Then, the areas
S where the privacy objects are located are detected through multi-scale feature fusion, and the mask image
M is generated. Moreover, the original image is grayscaled to obtain a grayscale image
and is also subjected to an algorithm of contour detection called Canny to generate a contour image
. Secondly,
,
, and
M are used to generate
and
by the Hadamard product. The purpose of this step is to ensure that privacy-sensitive information is invisible. Then, a contour image
is generated, where the privacy-sensitive areas are missing. After completing the above steps,
,
, and
M are passed into the contour generator of the EdgeConnect network, generating the contour prediction
for masked privacy-sensitive areas. Thirdly, the contour
of the inpainted image is generated using
,
, and
M. Finally,
and
are passed to the image completion network of the EdgeConnect network, and the inpainted image
is obtained and then inputted to ORB-SLAM3 for localization and mapping. The specific process of our method is presented in Algorithm 1.
| Algorithm 1 Image inpainting method |
- 1:
Input: Original image , The YOLOv8 , Generators of the EdgeConnect , , The algorithm of contours detection , and The algorithm of grayscale conversion - 2:
Output: Inpainted image - 3:
Privacy-sensitive areas detection: - 4:
Detection of privacy-sensitive areas S: - 5:
- 6:
Generation of a mask image M: - 7:
if , otherwise 0 - 8:
Grayscale conversion: - 9:
- 10:
Contours detection: - 11:
Canny() - 12:
Privacy-sensitive areas masking: - 13:
- 14:
- 15:
- 16:
Privacy-sensitive areas inpainting: - 17:
Contours prediction: - 18:
- 19:
Contours combination: - 20:
- 21:
Image inpainting: - 22:
|
Differently from EdgeConnect [
26], which aims to restore the original image, our method ensures that the generated image does not contain privacy-sensitive objects. The inpainted area should blend naturally with the surrounding areas to minimize the impact on the subsequent localization accuracy of ORB-SLAM3.
3.3. Point Cloud Encryption
3.3.1. Theoretical Basis
Considering the point cloud
and the dimensionally lifted line cloud
as random variables, the posterior distribution
can be obtained according to the Bayesian rule expressed in Equation (
1):
Since all line directions are determined independently and randomly,
. The probability
that a line
corresponds to a given point
is zero if
is not on
; otherwise, the probability is constant since all line directions are equally likely. Consequently, the likelihood function
is a piece-wise constant. As long as each point
lies on its corresponding line
, the original point cloud
and the restored point cloud
share the same likelihood
. To obtain the maximum a posteriori, the prior
must be maximized, assuming that all points lie on their lines. Nevertheless, it is challenging to define or learn a general prior distribution
, which makes it difficult to reason about the original point cloud.
3.3.2. Algorithm Details
Based on the above theory, our encryption algorithm for point cloud proceeded as follows: For each point in the point cloud , a line was generated to replace it. Firstly, the direction vector of was randomly generated with components randomly decided from a standard normal distribution (mean 0; standard deviation 1). Secondly, the direction vector was normalized to ensure that the length of each line was 1. Finally, was replaced by to generate the line cloud . The advantage of the algorithm is that it introduces an additional degree of freedom for each point, as any point on the lifted line could be the original point, thus complicating the accurate restoration of the original 3D point cloud. Moreover, the generated line cloud is difficult for humans to understand, and no information about the original scene can be directly derived from it.
4. Results
This section evaluates the privacy-preserving performance of the proposed image inpainting method. The evaluations include the effectiveness of the sensitive object detection algorithm, along with the re-detection rate of privacy-sensitive objects after image restoration. Additionally, the point cloud encryption algorithm is assessed for its resilience against inversion attacks. The impact of privacy protection methods on the pose estimation accuracy of ORB-SLAM3 is also assessed. Finally, the running time of ORB-SLAM3 before and after incorporating privacy-preserving methods is compared. Experiments are conducted on the Oxford Robocar, KITTI, and KITTI SLAM Evaluation 2012 datasets. These are taken in real urban environments that include moving pedestrians or vehicles, as well as changes in lighting, to effectively simulate autonomous driving scenarios.
4.1. Performance of Object Detection
The performance of the privacy region detection algorithm was evaluated on KITTI’s Object Detection Evaluation dataset. It contains 7481 training images and 7518 test images, with 80,256 labeled cars and pedestrians. Evaluation metrics included Precision (P), Recall (R), Mean Average Precision at a 50% Intersection over Union (IoU) threshold (mAP@50), and Mean Average Precision averaged over IoU thresholds from 50% to 95% (mAP@50-95), along with the number of model parameters. The formula for mAP@50, computed across n categories, is given as:
where P and R denote Precision and Recall, respectively, defined as:
where TP, FP, and FN represent the number of true positives, false positives, and false negatives, respectively.
RT-DETR [
28], YOLOv3 [
29], YOLOv5, YOLOv6, and YOLOv11 were used as comparison models. All experimental results of these models are obtained in the same experimental environment as the proposed method.
The experimental results on the KITTI object detection dataset are summarized in
Table 1. The applied model outperforms existing models across several key performance metrics. Despite having only 2.7 M parameters, significantly fewer than most other models, it achieves strong Precision, Recall, and mAP. Notably, it attains 92.4% Precision, second only to YOLOv3 (92.9%). Given that it uses just 2.6% of YOLOv3’s parameters, this result highlights its efficiency. Moreover, it surpasses RT-DETR, which achieves only 41.0% Precision while using more parameters, further demonstrating its effectiveness.
In terms of Recall, the applied model achieves the highest value of 87.8%, surpassing YOLOv5 (86.2%), YOLOv6 (83.5%), and YOLOv11 (85.6%), demonstrating its ability to correctly detect more positive samples. Regarding mAP@50 and mAP@50-95, it attains 93.7% and 70.7%, respectively, outperforming all other models. These results highlight its superior detection performance and overall effectiveness while maintaining a compact model size.
Figure 4 presents a visual comparison of the detection results from the applied model and the YOLOv11 model on the test set of the KITTI Object Detection Evaluation. The upper subfigure shows a scenario with numerous pedestrians, while the lower subfigure focuses on vehicle detection. In pedestrian detection, the applied model identifies more correct instances than YOLOv11, ensuring better coverage of sensitive areas and enhancing privacy protection. This also demonstrates its superior ability to detect objects in crowded environments, which is crucial for privacy-preserving applications. For vehicle detection, the applied model accurately identifies vehicles without false positives, unlike YOLOv11. This reduces the need for subsequent image inpainting processing, minimizing computational overhead. Moreover, accurate detection reduces interference with visual SLAM performance, ensuring reliable pose estimation. These results validate the model’s effectiveness in balancing privacy protection and practical usability in real-world scenarios.
4.2. Performance of Image Inpainting
Privacy-sensitive object detection was conducted on both the original and inpainted images. The re-detection rate was defined as the proportion of privacy-sensitive objects detected in the original image that were re-detected in the inpainted image. This metric assessed the performance of the inpainting methods in preserving privacy, with a lower re-detection rate indicating better privacy protection. For comparison, masking and noise addition algorithms were applied to privacy-sensitive areas. The masking algorithms used black, gray, and white pixels to cover these areas.
Additionally, three types of noise addition algorithms were compared. The first method introduces Gaussian noise into the privacy-sensitive area, defined as:
where
I represents the original image,
M is the mask indicating the privacy-sensitive region, ⊙ is the Hadamard product, and
N(0, 25) denotes Gaussian noise with a mean of 0 and a variance of 25. The other two methods randomly insert noise into 25% and 50% of the area, respectively.
Table 2 shows that the proposed image inpainting method outperforms masking algorithms in most sequences, remaining competitive across the others. It also surpasses noise addition algorithms in all sequences. These results demonstrate that the method is more effective in handling privacy-sensitive areas, providing more robust privacy preservation for visual SLAM. Masking algorithms perform better than noise addition algorithms because they render privacy-sensitive objects invisible, whereas noise addition may still allow some sensitive areas to be identified.
Figure 5 visualizes the generated images protected by different privacy-preservation algorithms alongside the original image. While masking algorithms offer a degree of privacy protection, they struggle to accurately restore privacy-sensitive areas. In contrast, the proposed method can accurately identify privacy-sensitive objects and realistically inpaint these regions while concealing their locations. Moreover, compared to noise addition algorithms, which introduce noise in the area where the privacy-sensitive objects are located, the proposed method can more thoroughly remove all privacy-sensitive information. This is because it first masks the area to ensure that the privacy-sensitive objects are invisible, and then realistic inpainting is performed on the masked area. The above processing not only enhances SLAM’s privacy protection capabilities but also makes the restored image more conducive to subsequent SLAM positioning tasks.
4.3. Effectiveness of Point Cloud Lifting
Section 3.3 introduces a 3D point cloud encryption algorithm into SLAM, which is based on point dimensionality lifting. In this section, the 3D point clouds generated by the original ORB-SLAM3 [
18] and ORB-SLAM3 with various image privacy preservation algorithms are first encrypted into 3D line clouds. These encrypted line clouds are then attacked by the Line2Point [
30] algorithm, which is divided into two stages: neighborhood estimation and peak finding. In the neighborhood estimation stage, the algorithm first finds the nearest neighboring lines for each line and then uses these neighboring lines to generate candidate 3D points on the line. The peak finding stage determines the final point locations by analyzing the distribution of these candidate points and identifying high-density areas. The algorithm aims to restore the original 3D point clouds. To evaluate the effectiveness of the point cloud encryption algorithm, a k-dimensional tree is used to match the original and restored point clouds. The average point-to-point Euclidean distance error between the original and restored point clouds, for the same sequence, is employed as an evaluation metric. Euclidean distance represents the straight-line distance between two points in three-dimensional space and can be used to measure the positional difference between corresponding points in two different point clouds. The larger the Euclidean distance error, the greater the difference between corresponding points, indicating poorer alignment between the two point clouds. In this experiment, this means that the point cloud restored by the Line2Point [
30] algorithm differs more from the original point cloud.
Table 3 shows the average point cloud error results across different sequences. Even in the 54 sequences with the smallest error, the average point-to-point Euclidean distance error reached 0.579 m, while errors in the remaining sequences were generally greater than 1m. This indicates that the point cloud encryption algorithm effectively preserves privacy, as evidenced by the significant error between the restored and original point clouds. The primary factor behind the robust privacy preservation lies in the transformation of the point cloud into a line cloud. This transformation increases the complexity of accurately reconstructing the original point cloud, as any point along the line could represent the original location. Additionally, the outdoor test scenario leads to a more scattered point cloud, which makes it harder for the Line2Point algorithm to restore the original point clouds accurately.
Figure 6 visualizes the original point cloud, the lifted line cloud, and the restored point cloud for 58 sequences. Although the Line2Point attack approximates the general shape of the point cloud, the reconstruction lacks fine details and exhibits mismatched point cloud density.
The preceding experimental results demonstrate that the point cloud encryption algorithm generates a line cloud that is difficult for humans to interpret, effectively concealing the original scene. Moreover, following the Line2Point attack, accurately reconstructing the 3D point cloud of the original scene proves challenging, highlighting the algorithm’s effectiveness in privacy preservation.
4.4. Accuracy of Pose Estimation
Experiments were conducted on the original image datasets from KITTI and Oxford Robotcar. Specifically, we compared the pose estimation performance of three kinds of approaches: the original ORB-SLAM3, ORB-SLAM3 with various image privacy protection methods, and ORB-SLAM3 integrated with the privacy protection method proposed in this paper. This comparison allowed us to evaluate the impact of the proposed method on pose estimation accuracy in visual SLAM. Since the KITTI and Oxford Robotcar datasets do not provide ground truth for ORB-SLAM3, the pose estimation results from the original ORB-SLAM3 were used as the evaluation benchmark. To quantify the impact of different privacy protection methods, the root mean square error (RMSE) of the absolute trajectory error across different sequences was compared. The reported results represent the median values obtained from 10 independent trials.
Additionally, experiments were conducted on the KITTI SLAM Evaluation 2012 dataset, which contains long-range sequences that effectively assess the pose estimation performance of SLAM. This dataset is particularly valuable as trajectory visualization helps identify anomalies such as drift errors and pose outliers, enabling a more comprehensive analysis of SLAM performance. Unlike the previous datasets, the KITTI SLAM Evaluation 2012 dataset provides ground truth trajectories for each sequence, which were used as the evaluation benchmark. All other experimental settings remained consistent with the previous experiments.
As shown in
Table 4, on the KITTI and Oxford Robotcar datasets, the dual-component approach enables ORB-SLAM3 to achieve more accurate pose estimation with lower RMSE across all sequences, compared to other privacy-preservation methods. This indicates that our approach better maintains localization accuracy in visual SLAM. By considering the surrounding scenes when inpainting privacy-sensitive areas, our method generates more natural inpainted images. In contrast to other methods, the inpainted areas produced by our approach offer more feature points, enhancing ORB-SLAM3’s pose estimation capability. In comparison, other methods hindered feature extraction due to their handling of privacy-sensitive areas. Complete masking with uniform pixels made it difficult to extract useful feature points, while noise addition interfered with feature point detection, reducing pose estimation performance. However, in sequence 58, the performance of the dual-component approach declined due to significant illumination variations, as shown in
Figure 7, which affected ORB-SLAM3’s accuracy. Other methods also experienced performance degradation in this sequence. Compared to other privacy-preserving methods, our approach reduces the average RMSE by 58% on the Oxford Robotcar dataset and 69.18% on the KITTI dataset, highlighting its effectiveness in maintaining localization accuracy.
The experimental results on the KITTI SLAM Evaluation 2012 dataset are presented in
Table 5. Compared to other privacy protection methods, the approach proposed in this paper effectively guarantees the positioning accuracy of ORB-SLAM3, with the smallest RMSE increase in absolute pose error. Moreover, the pose estimation accuracy of ORB-SLAM3 with privacy protection remains close to that of the original ORB-SLAM3. Notably, in certain sequences, ORB-SLAM3 integrated with our method even outperforms the original version. Given that this dataset represents large outdoor scenes with moving pedestrians and vehicles, these results demonstrate the potential and practicality of the proposed method for real-world autonomous driving scenarios and augmented reality applications.
To evaluate the impact of the proposed dual-component privacy protection method on ORB-SLAM3’s positioning accuracy,
Figure 8 compares the pose trajectories of the original and protected versions of ORB-SLAM3.
Figure 8a,c compare pose estimation results for sequence 12 of the Oxford Robotcar dataset and sequence 001 of the KITTI dataset.
Figure 8b,d display changes in absolute pose errors for these two sequences. The results indicate that our method introduces minimal deviation from the original pose, guaranteeing the performance of visual SLAM.
Figure 9 presents a comparison of pose estimation results obtained by the original ORB-SLAM3 and the proposed method, alongside the ground truth trajectories for sequences 00 and 05 of the KITTI SLAM Evaluation 2012 dataset.
Figure 9a,c compare our method with ORB-SLAM3, and the ground truth trajectory on the xz plane for sequences 00 and 05, respectively.
Figure 9b,d display trajectory changes along the xyz axes. As shown, the proposed method maintains high positioning accuracy. Notably, in certain corners, such as those on the left side of
Figure 9a,c, our method produces a trajectory even closer to the ground truth. This demonstrates that privacy-preserving visual SLAM can achieve excellent positioning accuracy while protecting privacy-sensitive information.
4.5. Comparison of Running Time
The runtimes of the proposed method and ORB-SLAM3 were compared under the same environment configuration, as shown in
Table 6, using the KITTI SLAM Evaluation 2012 dataset. Although the runtime of our method is slightly higher than that of ORB-SLAM3, primarily due to the detection of privacy-sensitive objects and their subsequent repair to ensure confidentiality, the increase is considered acceptable. Enhancing privacy protection in visual SLAM is a key contribution of this research. Furthermore, this modest runtime increase still meets the real-time requirements of SLAM.
In practical applications, the improved privacy protection significantly supports the broader adoption of visual SLAM in autonomous driving and augmented reality scenarios, which is crucial for the further development and deployment of the technology.
5. Discussion
Compared to previous privacy-preserving schemes for visual SLAM, the proposed method effectively removes sensitive information from image data, thereby ensuring security in visual SLAM without compromising pose estimation accuracy. Furthermore, it also protects 3D point cloud maps. This method has real-world applicability because, in autonomous driving scenarios or augmented reality applications, cameras inevitably capture privacy-sensitive information. Protecting this information can make SLAM applications more acceptable to users. Additionally, the models used in this paper have small model sizes and fewer parameters, which makes them well suited for deployment in resource-constrained environments.
However, this approach has certain limitations. For instance, in environments with less sensitive information, such as low-texture or unmanned indoor spaces, the frequent detection of privacy-sensitive objects in incoming images may unnecessarily increase the running time of the SLAM system.
In future work, we will focus on adapting our method for computationally constrained environments, such as mobile and wearable devices. Additionally, we aim to make the related models lightweight to enhance efficiency. As our experimental resources improve, we plan to evaluate these methods in real-world application scenarios, including autonomous driving and drone navigation, to comprehensively assess their practical effectiveness and limitations.
6. Conclusions
This paper proposes a novel privacy protection method that can improve the privacy protection performance of visual SLAM. Our method can automatically identify and realistically restore privacy-sensitive areas. In addition, point cloud data can be effectively converted into an unrecognizable line cloud form. Experimental results demonstrate that, first, after combining the methods, visual SLAM can accurately identify privacy-sensitive objects and restore the corresponding areas. Compared with other image privacy protection methods, this method makes privacy-sensitive information completely invisible, and the restored image is more conducive to subsequent positioning tasks. Secondly, the protected SLAM still guarantees excellent positioning accuracy. Finally, the encryption algorithm makes it difficult for attackers to recover accurate point cloud maps from line clouds.
We noticed that the running time of the protected visual SLAM is slightly increased. However, the improvement in privacy protection performance is not negligible, which is conducive to broadening the application scope of visual SLAM. In future research, we intend to further improve our method, e.g., by making the detection model lightweight and deploying it in computationally constrained environments.
Author Contributions
Conceptualization, M.Y. and C.H.; methodology, M.Y. and C.H.; software, M.Y.; validation, M.Y.; formal analysis, M.Y.; investigation, M.Y. and X.H.; resources, S.H.; data curation, M.Y.; writing—original draft preparation, M.Y. and X.H.; writing—review and editing, M.Y. and C.H.; visualization, M.Y. and X.H.; supervision, M.Y. and C.H.; project administration, M.Y. and C.H.; funding acquisition, C.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant number 62162007) and the Natural Science Foundation of Guizhou Province (grant number QianKeHeJiChu-ZK[2024]YiBan079).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SLAM | Simultaneous localization and mapping |
| AR | Augmented reality |
| VR | Virtual reality |
| 2D | Two-dimensional |
| 3D | Three-dimensional |
| ORB | Oriented fast and rotated brief |
| YOLO | You only look once |
| FPN | Feature Pyramid Network |
| SPPF | Spatial Pyramid Pooling Fast |
| PAN | Path Aggregation Network |
| GAN | Generative adversarial networks |
| IoU | Intersection over Union |
| RMSE | Root mean square error |
References
- Lu, Y.; Ma, H.; Smart, E.; Yu, H. Real-time performance-focused localization techniques for autonomous vehicle: A review. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6082–6100. [Google Scholar] [CrossRef]
- Yarovoi, A.; Cho, Y.K. Review of simultaneous localization and mapping (SLAM) for construction robotics applications. Autom. Constr. 2024, 162, 105344. [Google Scholar] [CrossRef]
- Saeedi, S.; Bodin, B.; Wagstaff, H.; Nisbet, A.; Nardi, L.; Mawer, J.; Melot, N.; Palomar, O.; Vespa, E. Navigating the landscape for real-time localization and mapping for robotics and virtual and augmented reality. Proc. IEEE 2018, 106, 2020–2039. [Google Scholar] [CrossRef]
- Himmi, S.; Ilter, O.; Pailleau, F.; Siegwart, R.; Bescos, B.; Cadena, C. Don’t Share My Face: Privacy Preserving Inpainting for Visual Localization. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 12506–12511. [Google Scholar]
- Kuang, Z.; Guo, Z.; Fang, J.; Yu, J.; Babaguchi, N.; Fan, J. Unnoticeable synthetic face replacement for image privacy protection. Neurocomputing 2021, 457, 322–333. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Brox, T. Inverting visual representations with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4829–4837. [Google Scholar]
- Pittaluga, F.; Koppal, S.J.; Kang, S.B.; Sinha, S.N. Revealing scenes by inverting structure from motion reconstructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 145–154. [Google Scholar]
- Yang, K.; Yau, J.H.; Fei-Fei, L.; Deng, J.; Russakovsky, O. A study of face obfuscation in imagenet. In Proceedings of the 39th International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2022; pp. 25313–25330. [Google Scholar]
- McPherson, R.; Shokri, R.; Shmatikov, V. Defeating image obfuscation with deep learning. arXiv 2016, arXiv:1609.00408. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2737–2746. [Google Scholar]
- Alawida, M. A novel chaos-based permutation for image encryption. J. King Saud-Univ.-Comput. Inf. Sci. 2023, 35, 101595. [Google Scholar] [CrossRef]
- Bian, S.; Wang, T.; Hiromoto, M.; Shi, Y.; Sato, T. Ensei: Efficient secure inference via frequency-domain homomorphic convolution for privacy-preserving visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9403–9412. [Google Scholar]
- Speciale, P.; Schonberger, J.L.; Kang, S.B.; Sinha, S.N.; Pollefeys, M. Privacy preserving image-based localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5493–5503. [Google Scholar]
- Shibuya, M.; Sumikura, S.; Sakurada, K. Privacy preserving visual slam. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 102–118. [Google Scholar]
- Von Stumberg, L.; Usenko, V.; Cremers, D. Direct sparse visual-inertial odometry using dynamic marginalization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2510–2517. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Cao, H.; Xu, J.; Li, D.; Shangguan, L.; Liu, Y.; Yang, Z. Edge assisted mobile semantic visual slam. IEEE Trans. Mob. Comput. 2022, 22, 6985–6999. [Google Scholar] [CrossRef]
- Ben Ali, A.J.; Kouroshli, M.; Semenova, S.; Hashemifar, Z.S.; Ko, S.Y.; Dantu, K. Edge-SLAM: Edge-assisted visual simultaneous localization and mapping. ACM Trans. Embed. Comput. Syst. 2022, 22, 1–31. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 10684–10695. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Architecture of yolov8. Available online: https://github.com/ultralytics/ultralytics/issues/189 (accessed on 30 March 2024).
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.; Ebrahimi, M. Edgeconnect: Structure guided image inpainting using edge prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Chelani, K.; Kahl, F.; Sattler, T. How privacy-preserving are line clouds? recovering scene details from 3d lines. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15668–15678. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}