
Fault Detection Method Using Auto-Associative Shared Nearest Neighbor Kernel Regression for Industrial Processes



Abstract
1. Introduction
- By weighting the training data according to their shared neighbors, the significance of fault data is enhanced.
- The method is robust to outliers, including faulty data.
- By weighting neighbors based on their distances, the method can effectively detect faults in data that are close to healthy data.
- It can improve the limitations of conventional AAKR and distance-based methods that rely on simple distance measurements.
- Effective fault detection can be performed even when healthy and faulty data are close together.
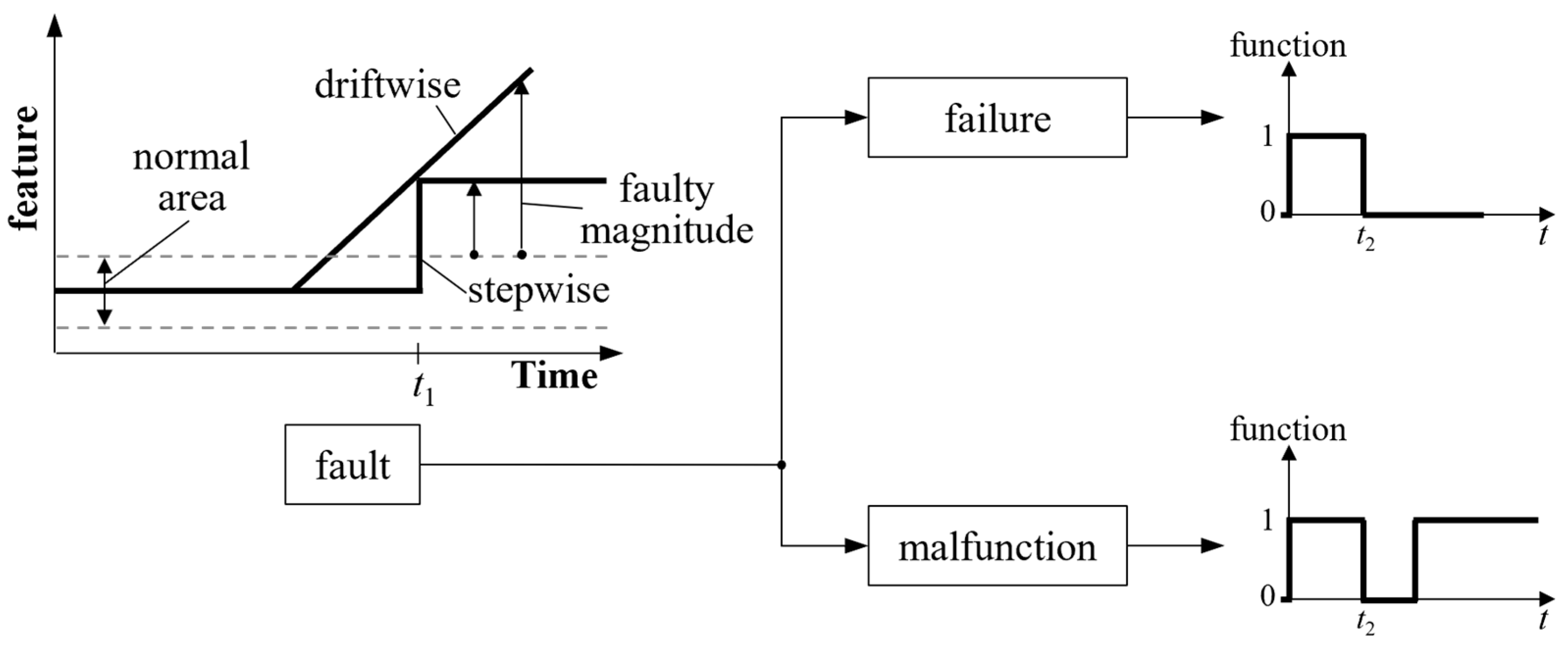
2. AAKR-Based Method for Fault Detection
3. Detection Index Using Kernel Density Estimation
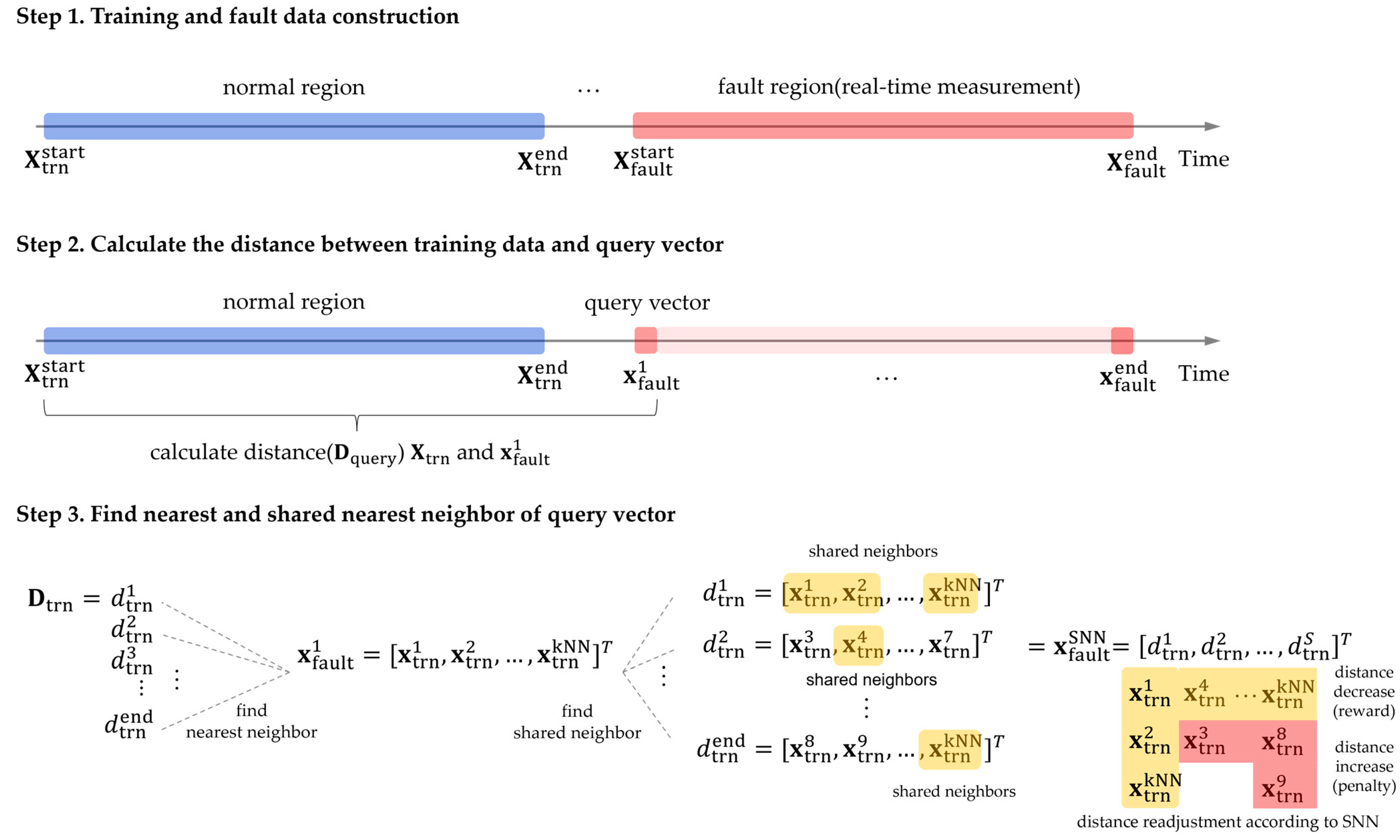
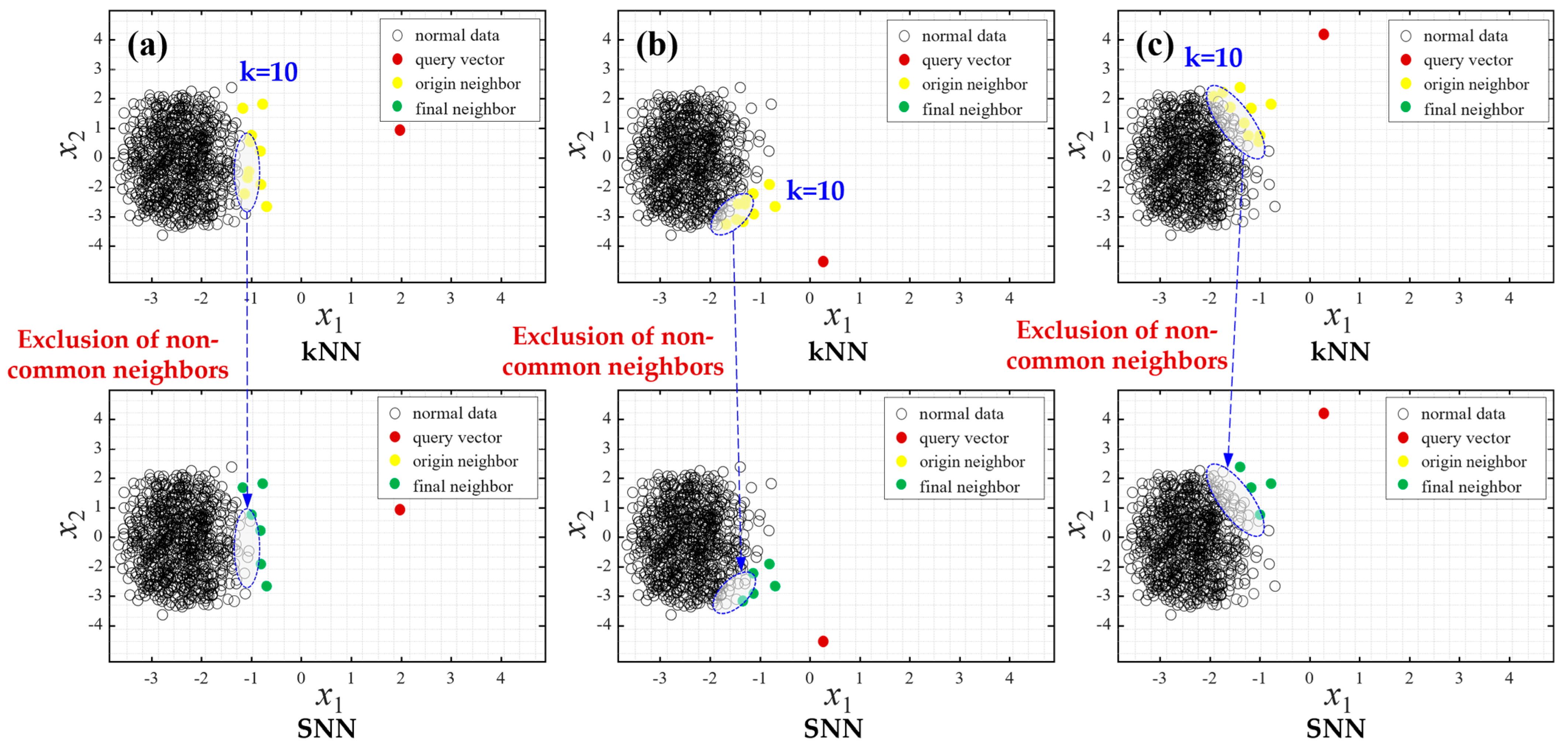
4. Auto-Associative Shared Nearest Neighbor Kernel Regression
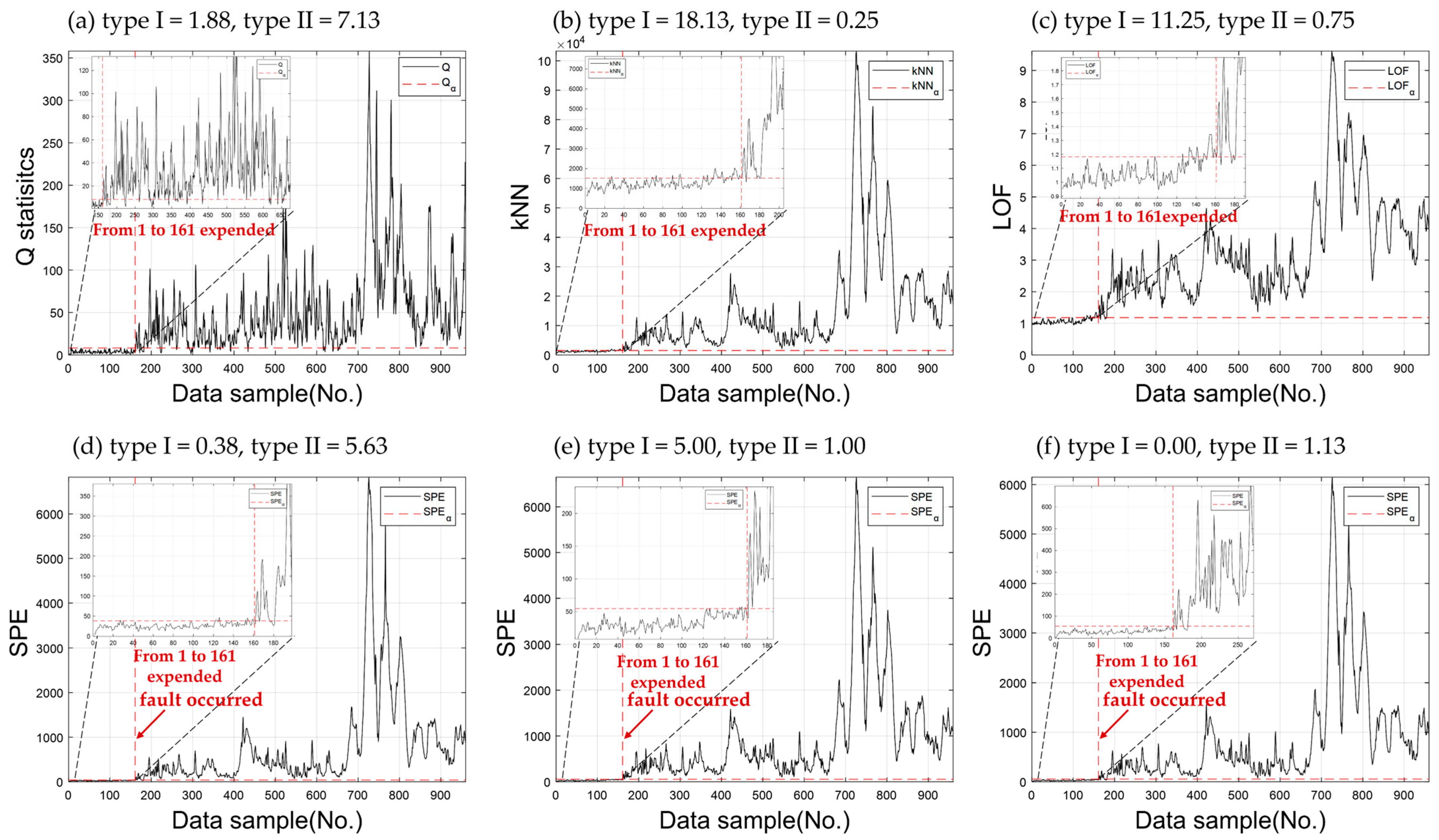
5. Experimental Results and Discussion
5.1. Benchmark Simulation Data: Tennessee Eastman Process
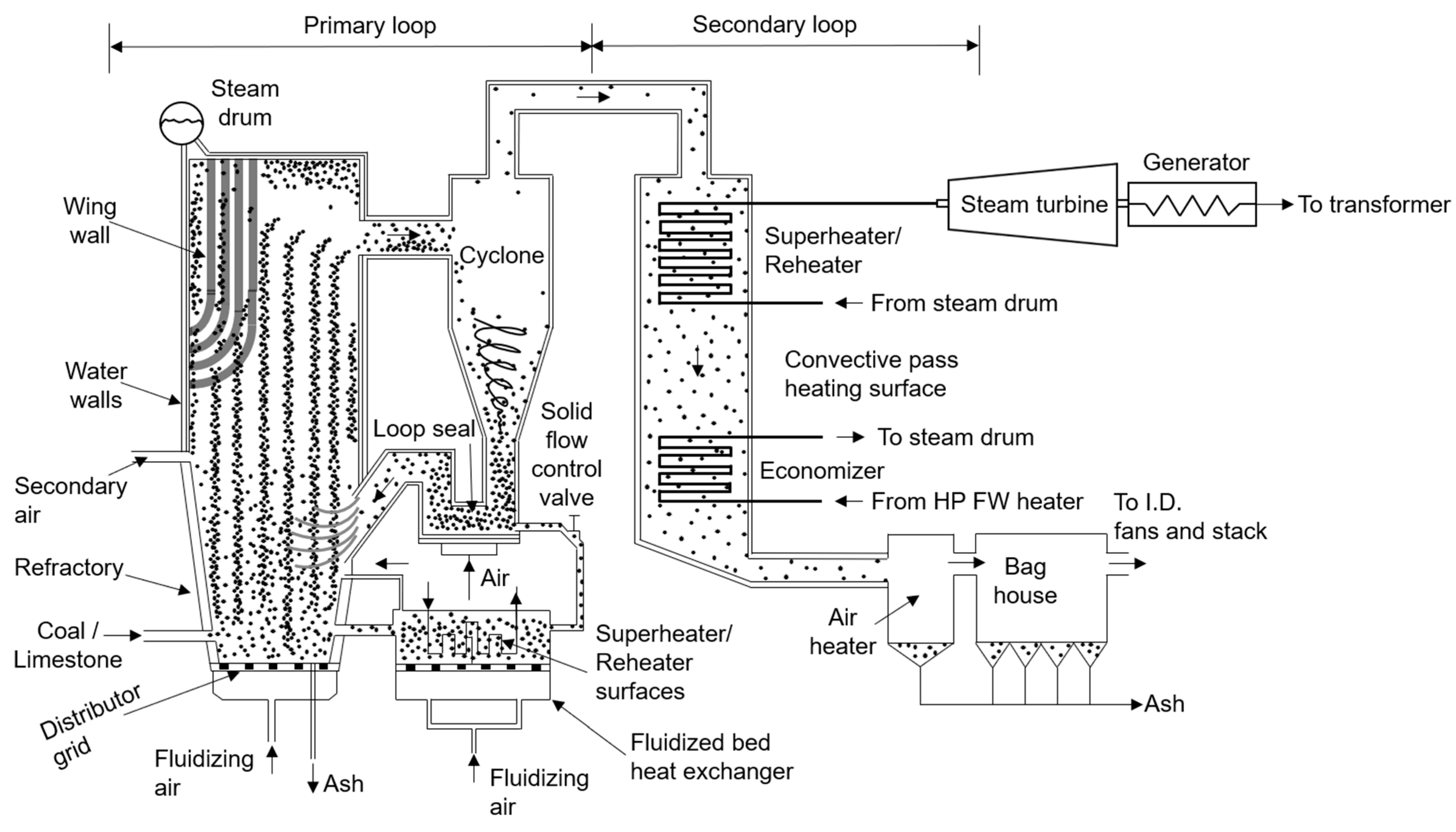
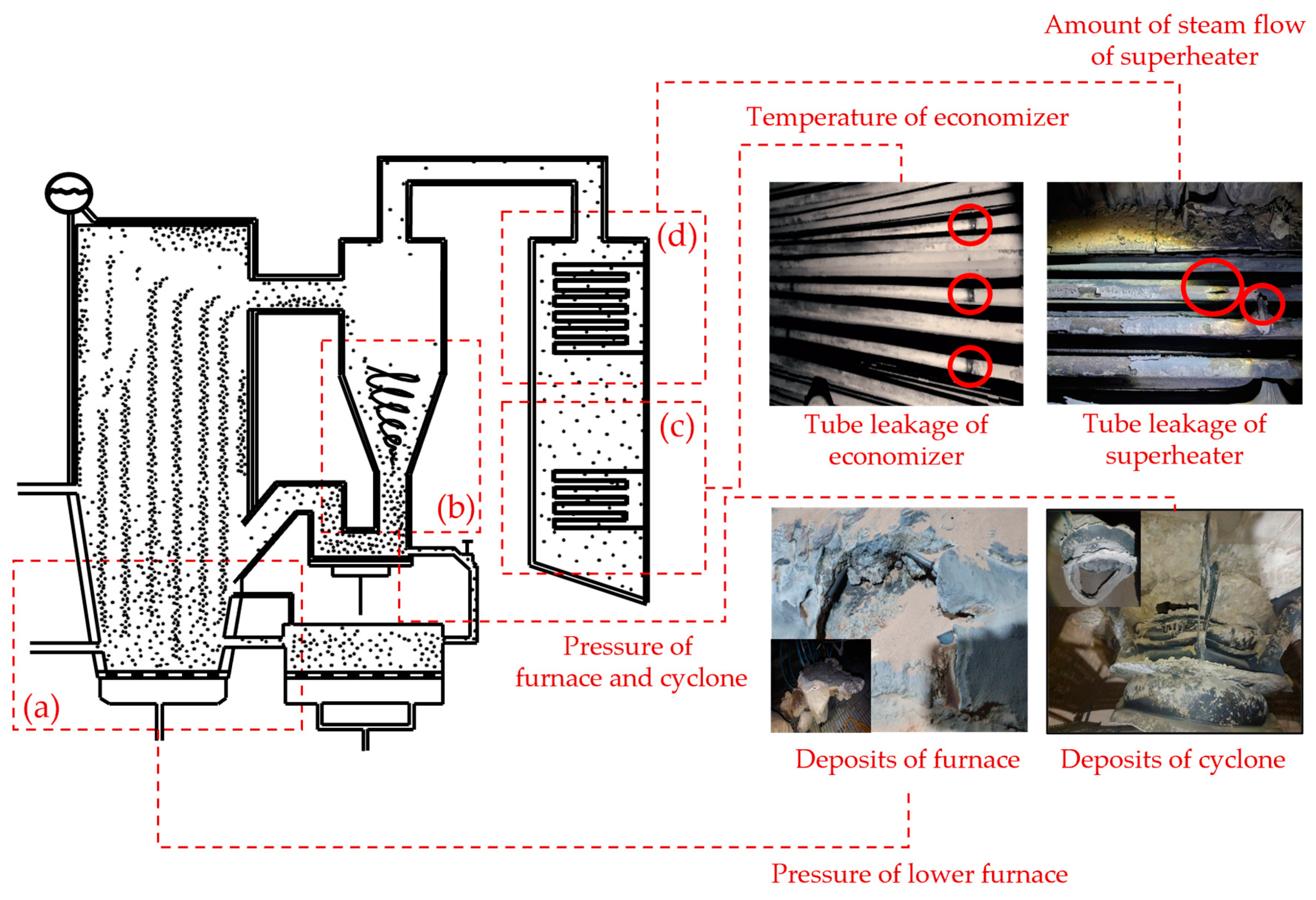
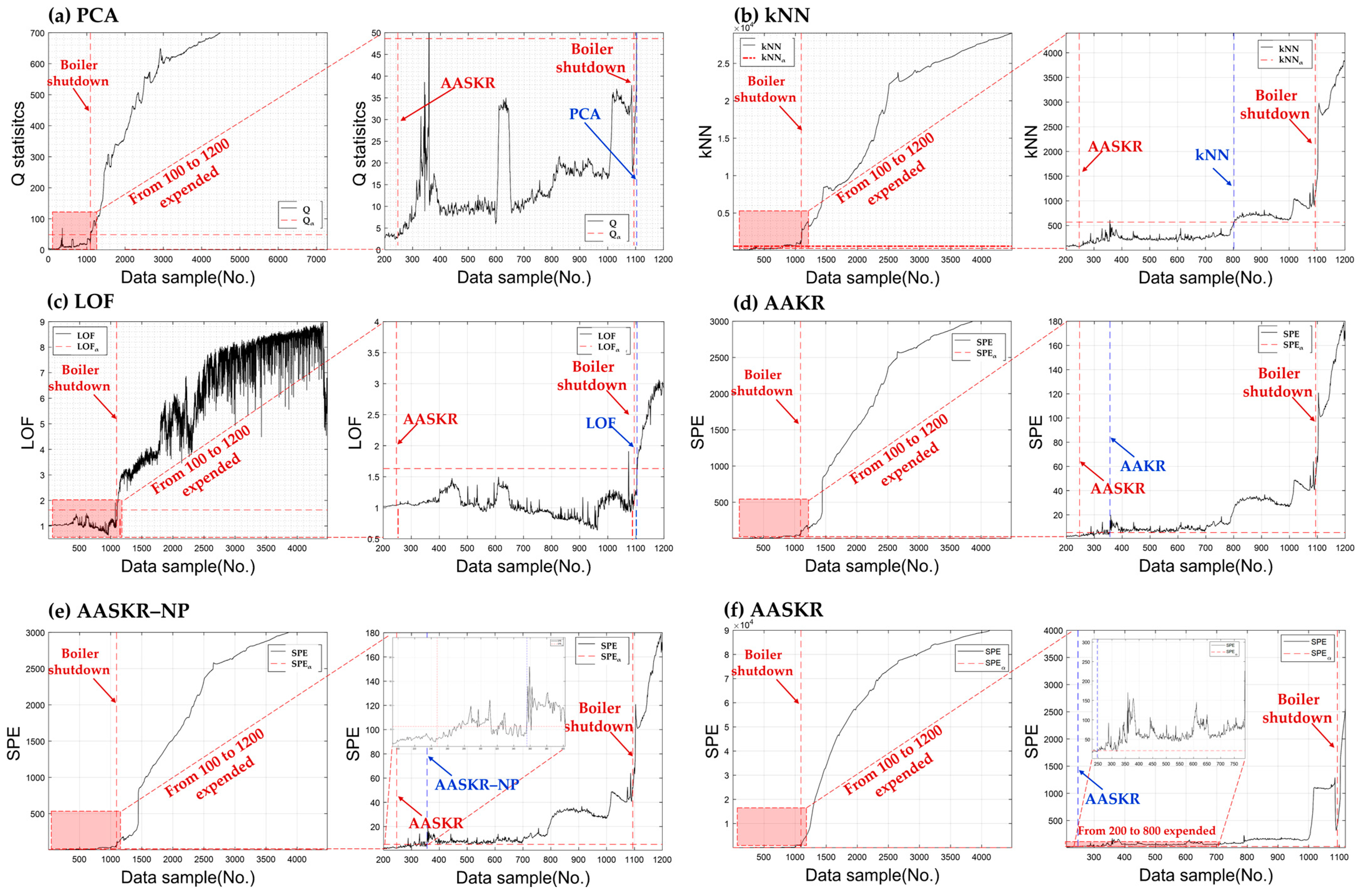
5.2. Real-World Application: Circulating Fluidized Bed Boiler
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, G.; Liu, J.; Zhang, Y.; Li, Y. A novel multi-mode data processing method and its application in industrial process monitoring. J. Chemom. 2015, 29, 126–138. [Google Scholar] [CrossRef]
- Barszcz, T.; Czop, P. A feedwater heater model intended for model-based diagnostics of power plant installations. Appl. Therm. Eng. 2011, 31, 1357–1367. [Google Scholar] [CrossRef]
- Lang, F.D.; Rodgers, D.A.; Mayer, L.E. Detection of tube leaks and their location using input/loss methods. In Proceedings of the ASME Power Conference, Baltimore, MD, USA, 30 March–1 April 2004; Volume 41626, pp. 143–150. [Google Scholar]
- Sun, X.; Chen, T.; Marquez, H.J. Efficient model-based leak detection in boiler steam-water systems. Comput. Chem. Eng. 2002, 26, 1643–1647. [Google Scholar] [CrossRef]
- Guo, J.; Yuan, T.; Li, Y. Fault detection of multimode process based on local neighbor normalized matrix. Chemom. Intell. Lab. Syst. 2016, 154, 162–175. [Google Scholar] [CrossRef]
- Ge, Z.; Gao, F.; Song, Z. Two-dimensional Bayesian monitoring method for nonlinear multimode processes. Chem. Eng. Sci. 2011, 66, 5173–5183. [Google Scholar] [CrossRef]
- Yu, J. A nonlinear kernel Gaussian mixture model based inferential monitoring approach for fault detection and diagnosis of chemical processes. Chem. Eng. Sci. 2012, 68, 506–519. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, H.; Chen, Y.; Yang, L.; Bi, W. Deep learning GAN-based fault detection and diagnosis method for building air-conditioning systems. Sustain. Cities Soc. 2025, 118, 106068. [Google Scholar] [CrossRef]
- Ahmed, I.; Maaruf, M.; Khalid, M. Detection of Cracks in the Industrial System Using Adaptive Principal Component Analysis and Wavelet Denoising. In Proceedings of the 2024 IEEE International Conference on Industrial Technology (ICIT), Bristol, UK, 25–27 March 2024; pp. 1–6. [Google Scholar]
- Ma, H.; Hu, Y.; Shi, H. A novel local neighborhood standardization strategy and its application in fault detection of multimode processes. Chemom. Intell. Lab. Syst. 2012, 118, 287–300. [Google Scholar] [CrossRef]
- Isermann, R. Fault-Diagnosis Applications: Model-Based Condition Monitoring: Actuators, Drives, Machinery, Plants, Sensors, and Fault-Tolerant Systems; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Hines, J.W.; Dustin, G. Process and equipment monitoring methodologies applied to sensor calibration monitoring. Qual. Reliab. Eng. Int. 2007, 23, 123–135. [Google Scholar] [CrossRef]
- Lee, J.M.; Yoo, C.; Choi, S.W.; Vanrolleghem, P.A.; Lee, I.B. Nonlinear process monitoring using kernel principal component analysis. Chem. Eng. Sci. 2004, 59, 223–234. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Zhang, D.; Zhao, W.; Wang, L.; Chang, X.; Li, X.; Wu, P. Evaluation of the state of health of lithium-ion battery based on the temporal convolution network. Front. Energy Res. 2022, 10, 929235. [Google Scholar] [CrossRef]
- Shams, M.B.; Budman, H.M.; Duever, T.A. Fault detection, identification and diagnosis using CUSUM based PCA. Chem. Eng. Sci. 2011, 66, 4488–4498. [Google Scholar] [CrossRef]
- Garcia-Alvares, D.; Fuente, M.J.; Sainz, G.I. Fault detection and isolation in transient states using principal component analysis. J. Process Control 2012, 22, 551–563. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, F. Fault-relevant principal component analysis (FPCA) method for multivariate statistical modeling and process monitoring. Chemom. Intell. Lab. Syst. 2014, 133, 1–16. [Google Scholar] [CrossRef]
- Gajjar, S.; Palazoglu, A. A data-driven multidimensional visualization technique for process fault detection and diagnosis. Chemom. Intell. Lab. Syst. 2016, 154, 122–136. [Google Scholar] [CrossRef]
- Guo, J.; Wang, X.; Li, Y.; Wang, G. Fault detection based on weighted difference principal component analysis. J. Chemom. 2017, 31, e2926. [Google Scholar] [CrossRef]
- Zhu, Z.; Song, Z.; Palazoglu, A. Process pattern construction and multi-mode monitoring. J. Process Control 2012, 22, 247–262. [Google Scholar] [CrossRef]
- Ng, Y.S.; Srinivasan, R. An adjoined multi-model approach for monitoring batch and transient operations. Comput. Chem. Eng. 2009, 33, 887–902. [Google Scholar] [CrossRef]
- Lu, N.; Gao, F.; Wang, F. Sub-PCA modeling and on-line monitoring strategy for batch processes. AIChE J. 2004, 50, 255–259. [Google Scholar] [CrossRef]
- Hwang, D.H.; Han, C. Real-time monitoring for a process with multiple operating modes. Control Eng. Pract. 1999, 7, 891–902. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, F.; Lu, N.; Jia, M. Stage-based soft-transition multiple PCA modeling and on-line monitoring strategy for batch processes. J. Process Control 2007, 17, 728–741. [Google Scholar] [CrossRef]
- Kazemi, P.; Masoumian, A.; Martin, P. Fault Detection and Isolation for Time-Varying Processes Using Neural-Based Principal Component Analysis. Processes 2024, 12, 1218. [Google Scholar] [CrossRef]
- Feng, X.; Kong, X.; Du, B.; Luo, J. Adaptive LII-RMPLS based data-driven process monitoring scheme for quality-relevant fault detection. J. Control Decis. 2022, 9, 477–488. [Google Scholar] [CrossRef]
- Ali, H.; Zhang, Z.; Safdar, R.; Rasool, M.H.; Yao, Y.; Yao, L.; Gao, F. Fault detection using machine learning based dynamic ICA-distributed CCA: Application to industrial chemical process. Digit. Chem. Eng. 2024, 11, 100156. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Z.; Fu, A.W.-c.; Cheung, D.W. Enhancing effectiveness of outlier detections for low density patterns. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 6th Pacific-Asia Conference, Taiwan, 6–8 May 2002. [Google Scholar]
- Tong, C.; Palazoglu, A.; Yan, X. An adaptive multimode process monitoring strategy based on mode clustering and mode unfolding. J. Process Control 2013, 23, 1497–1507. [Google Scholar] [CrossRef]
- Chiu, A.L.M.; Fu, A.W.C. Enhancements on local outlier detection. In Proceedings of the Seventh International Database Engineering and Applications Symposium, Hong Kong, China, 18 July 2003. [Google Scholar]
- Yu, J.; Jang, J.; Yoo, J.; Park, J.H.; Kim, S. Bagged auto-associative kernel regression-based fault detection and identification approach for steam boilers in thermal power plants. J. Electr. Eng. Technol. 2017, 12, 1406–1416. [Google Scholar]
- Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Yu, J.; Yoo, J.; Jang, J.; Park, J.H.; Kim, S. A novel hybrid of auto-associative kernel regression and dynamic independent component analysis for fault detection in nonlinear multimode processes. J. Process Control 2018, 68, 124–144. [Google Scholar] [CrossRef]
- Rosenblatt, M. Curve estimates. Ann. Math. Stat. 1971, 42, 1815–1842. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Odiowei, P.E.P.; Cao, Y. Nonlinear dynamic process monitoring using canonical variate analysis and kernel density estimations. IEEE Trans. Ind. Inform. 2009, 6, 36–45. [Google Scholar] [CrossRef]
- Zhao, S.; Duan, Y.; Roy, N.; Zhang, B. A novel fault diagnosis framework empowered by LSTM and attention: A case study on the Tennessee Eastman process. Can. J. Chem. Eng. 2024. [Google Scholar]
- Van Caneghem, J.; Brems, A.; Lievens, P.; Block, C.; Billen, P.; Vermeulen, I.; Vandecasteele, C. Fluidized bed waste incinerators: Design, operational and environmental issues. Prog. Energy Combust. Sci. 2012, 38, 551–582. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, Z. Leakage Failure Analysis in a Power Plant Boiler. IERI Procedia 2013, 5, 107–111. [Google Scholar] [CrossRef]
- Kim, M.; Jung, S.; Kim, E.; Kim, B.; Kim, J.; Kim, S. A Fault Detection and Isolation Method via Shared Nearest Neighbor for Circulating Fluidized Bed Boiler. Processes 2023, 11, 3433. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PCA | kNN | LOF | AAKR | AASKR–NP | AASKR | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type I | Type II | Type I | Type II | Type I | Type II | Type I | Type II | Type I | Type II | Type I | Type II | |
| 1 | 3.75 | 0.25 | 6.25 | 0.25 | 3.75 | 0.50 | 1.25 | 0.38 | 1.25 | 0.38 | 0.00 | 0.50 |
| 2 | 0.63 | 1.38 | 5.00 | 1.25 | 1.88 | 1.25 | 1.88 | 1.38 | 1.25 | 1.38 | 0.00 | 1.38 |
| 3 * | 2.50 | 95.25 | 28.13 | 58.13 | 1.25 | 94.75 | 6.25 | 92.50 | 5.00 | 92.88 | 0.00 | 98.38 |
| 4 | 1.88 | 0.00 | 5.63 | 2.75 | 1.25 | 20.13 | 1.25 | 0.88 | 0.63 | 1.13 | 3.13 | 1.25 |
| 5 | 1.88 | 64.13 | 5.63 | 48.25 | 0.63 | 65.88 | 1.25 | 64.63 | 0.63 | 64.75 | 1.88 | 57.38 |
| 6 | 2.50 | 0.00 | 1.88 | 0.00 | 3.75 | 0.00 | 0.63 | 0.00 | 0.63 | 0.00 | 0.00 | 0.00 |
| 7 | 3.13 | 0.50 | 1.88 | 0.00 | 0.63 | 0.00 | 0.00 | 0.00 | 0.63 | 0.00 | 0.00 | 0.00 |
| 8 | 4.38 | 4.38 | 20.63 | 1.38 | 5.00 | 2.50 | 0.00 | 2.25 | 0.00 | 2.13 | 0.00 | 1.88 |
| 9 * | 3.75 | 94.50 | 51.88 | 48.13 | 11.25 | 86.88 | 10.63 | 91.75 | 8.13 | 91.75 | 14.38 | 90.13 |
| 10 | 1.88 | 51.00 | 14.38 | 30.88 | 5.00 | 40.13 | 0.63 | 41.25 | 0.63 | 42.25 | 4.38 | 31.75 |
| 11 | 3.75 | 34.13 | 13.75 | 19.38 | 1.25 | 35.75 | 1.25 | 25.00 | 1.25 | 25.63 | 3.75 | 22.50 |
| 12 | 1.88 | 7.13 | 18.13 | 0.25 | 11.25 | 0.75 | 5.63 | 1.00 | 5.00 | 1.00 | 0.00 | 1.13 |
| 13 | 0.00 | 4.25 | 5.00 | 3.63 | 3.75 | 3.75 | 1.88 | 4.50 | 1.88 | 4.63 | 0.00 | 5.25 |
| 14 | 2.50 | 6.63 | 7.50 | 0.00 | 2.50 | 0.00 | 2.50 | 0.00 | 2.50 | 0.00 | 0.00 | 0.13 |
| 15 * | 3.75 | 94.38 | 6.88 | 69.25 | 1.88 | 84.13 | 1.88 | 88.13 | 1.88 | 87.88 | 0.00 | 99.13 |
| 16 | 2.50 | 50.88 | 53.13 | 29.25 | 15.63 | 71.50 | 16.25 | 55.00 | 16.88 | 55.88 | 5.00 | 73.13 |
| 17 | 1.88 | 2.88 | 3.13 | 5.38 | 0.00 | 4.38 | 3.13 | 6.00 | 3.75 | 6.00 | 1.88 | 5.13 |
| 18 | 6.88 | 9.50 | 11.88 | 6.25 | 1.25 | 10.13 | 2.50 | 9.88 | 3.13 | 9.63 | 0.00 | 10.38 |
| 19 | 3.75 | 71.13 | 3.13 | 67.13 | 0.63 | 93.50 | 1.88 | 77.63 | 3.13 | 76.75 | 8.75 | 53.63 |
| 20 | 1.25 | 41.75 | 2.50 | 29.38 | 0.00 | 45.13 | 0.63 | 40.00 | 0.63 | 40.88 | 4.38 | 29.63 |
| 21 | 8.75 | 54.75 | 18.75 | 49.63 | 10.63 | 56.88 | 7.50 | 51.75 | 9.38 | 52.00 | 1.88 | 57.50 |
| Average | 2.95 | 22.48 | 11.01 | 16.39 | 3.82 | 25.12 | 2.78 | 21.19 | 2.95 | 21.35 | 1.94 | 19.58 |
| Total | 12.72 | 13.70 | 14.47 | 11.99 | 12.15 | 10.76 | ||||||
| Variable | Description | Unit |
|---|---|---|
| x1 | Steam output of feedwater pipe 1(sensor A) | t/h |
| x2 | Steam output of feedwater pipe 1(sensor B) | t/h |
| x3 | Steam output of feedwater pipe 2(sensor C) | t/h |
| x4 | Steam output of fluidized bed material supply | t/h |
| x5 | Aux steam output of lower feedwater pipe | t/h |
| x6 | Steam flow between feedwater pipe 1 and 2 | t/h |
| x7 | Steam flow between feedwater pipe 1 and 2 (x2, x3, and x4) | t/h |
| x8 | Steam flow of fluidized bed material supply | t/h |
| x9 | Furnace pressure of feedwater pipe 2 | mmH2O |
| x10 | Furnace pressure of feedwater pipe 2 (sensor A) | mmH2O |
| x11 | Furnace pressure of feedwater pipe (sensor B) | mmH2O |
| x12 | Combustor bed pressure of lower furnace feedwater (sensor A) | mmH2O |
| x13 | Combustor bed pressure of lower furnace feedwater (sensor B) | mmH2O |
| x14 | Sum of steam output of feedwater pipe 1 and 2 | mmH2O |
| x15 | Pressure of fluidized bed material supply | mmH2O |
| x16 | Pressure of lower place furnace | mmH2O |
| x17 | Pressure of middle place furnace | mmH2O |
| x18 | Pressure of upper place furnace | mmH2O |
| x19 | Pressure between cyclone and boiler | mmH2O |
| x20 | Pressure of 1st superheater | mmH2O |
| x21 | Pressure of 2nd superheater | mmH2O |
| x22 | Pressure of steam supplied of upper place furnace | MPa |
| x23 | Pressure of 2nd economizer | mmH2O |
| x24 | Pressure of lower supply cyclone (sensor A) | mmH2O |
| x25 | Pressure of lower supply cyclone (sensor B) | mmH2O |
| x26 | Pressure of middle place cyclone | mmH2O |
| x27 | Pressure of middle place furnace | mmH2O |
| x28 | Pressure of lower place furnace | mmH2O |
| x29 | Steam pressure of selective catalytic reduction | mmH2O |
| x30 | Pressure of air pre-heater | mmH2O |
| x31 | Pressure of air pre-heater and dry reactor | mmH2O |
| x32 | Pressure of dry reactor and bag filter | mmH2O |
| x33 | difference pressure between dry reactor and bag filter | mmH2O |
| x34 | Pressure of upper place combustor | mmH2O |
| x35 | Pressure of selective catalytic reduction terminal | mmH2O |
| x36 | Difference pressure between feedwater pipe 1 | mmH2O |
| x37 | Inlet temperature of feedwater pipe 1 (sensor A) | °C |
| x38 | Inlet temperature of feedwater pipe 1 (sensor B) | °C |
| x39 | Inlet temperature of feedwater pipe 2 (sensor A) | °C |
| x40 | Inlet temperature of feedwater pipe 2 (sensor B) | °C |
| x41 | Outlet temperature of feedwater pipe 1 | °C |
| x42 | Outlet temperature of feedwater pipe 2 | °C |
| x43 | Inlet temperature inlet of fluidized bed material supply | °C |
| x44 | Inlet temperature inlet of lower place furnace (sensor A) | °C |
| x45 | Inlet temperature inlet of lower place furnace (sensor B) | °C |
| x46 | Inlet temperature inlet of middle place furnace (sensor A) | °C |
| x47 | Inlet temperature inlet of middle place furnace (sensor B) | °C |
| x48 | Outlet temperature inlet of cyclone and boiler | °C |
| x49 | Inlet temperature inlet of upper place furnace | °C |
| x50 | Outlet temperature of upper place furnace | °C |
| x51 | Inlet temperature inlet of furnace 2-1 | °C |
| x52 | Inlet temperature inlet of cyclone and boiler front-end | °C |
| x53 | Inlet temperature inlet of cyclone and boiler terminal | °C |
| x54 | Inlet temperature inlet of 1st superheater | °C |
| x55 | Inlet temperature inlet of 2nd superheater | °C |
| x56 | Inlet temperature inlet of 1st economizer | °C |
| x57 | Inlet temperature inlet of 2nd economizer | °C |
| x58 | Outlet temperature of upper place boiler | °C |
| x59 | Inlet temperature of cyclone fluidized bed material supply | °C |
| x60 | Inlet temperature of dry reactor and bag filter | °C |
| x61 | Inlet temperature of selective catalytic reduction and stack gas recovery | °C |
| x62 | Inlet temperature of stack gas recovery and combustor | °C |
| x63 | Inlet temperature of feedwater pipe 1 | °C |
| x64 | Inlet temperature of feedwater pipe 2 | °C |
| x65 | Outlet temperature of dry reactor front-end | °C |
| x66 | Outlet temperature of air pre-heater terminal | °C |
| x67 | Difference of temperature 2nd and 1st superheater | °C |
| x68 | Difference of temperature 1st S/H and 2nd economizer | °C |
| x69 | Difference of temperature 1st and 2nd economizer | °C |
| x70 | Difference of temperature 1st superheater and new economizer | °C |
| x71 | Difference of temperature between the new economizer and bag filter | °C |
| x72 | Difference of temperature cyclone and boiler | °C |
| x73 | Amount of O2 in economizer | % |
| x74 | Inlet output of feedwater pipe 1 | % |
| x75 | Outlet output of feedwater pipe 2 | % |
| x76 | Output of feedwater ratio (sensor A) | % |
| x77 | Output of feedwater ratio (sensor B) | % |
| x78 | Output of steam ratio (sensor A) | % |
| x79 | Output of steam ratio (sensor B) | % |
| x80 | Output of steam ratio (sensor C) | % |
| x81 | Amount of H2O | % |
| x82 | Inlet pressure of feedwater pipe 2 | mmH2O |
| x83 | Difference pressure outlet between feedwater pipe 2 | mmH2O |
| x84 | Steam flow of air pre-heater and dry reactor | mmH2O |
| x85 | Difference of pressure furnace and top of cyclone | mmH2O |
| x86 | Difference of pressure 2nd and 1st superheater | mmH2O |
| x87 | Difference of pressure 1st superheater and 2nd economizer | mmH2O |
| x88 | Difference of pressure 2nd and 1st economizer | mmH2O |
| x89 | Difference of pressure of 1st and new economizer | mmH2O |
| x90 | Difference of pressure of new economizer | mmH2O |
| x91 | Metering bin an outlet conveyor | rpm |
| x92 | Steam flow of feedwater pipe 1 | t/h |
| x93 | Outlet output of feedwater pipe 2 | % |
| x94 | Inlet temperature inlet of lower place furnace (sensor C) | °C |
| x95 | Inlet temperature of lower place furnace (sensor C) | °C |
| x96 | Outlet temperature of 1st superheater | °C |
| x97 | Outlet temperature of 1st superheater | °C |
| x98 | Inlet temperature of 2nd superheater (sensor A) | °C |
| x99 | Inlet temperature of 2nd superheater (sensor B) | °C |
| x100 | Temperature of steam supplied of boiler silencer | °C |
| x101 | Inlet temperature of 1st superheater (sensor A) | °C |
| x102 | Inlet temperature of 1st superheater (sensor B) | °C |
| x103 | Steam drum level of feedwater tank | mm |
| x104 | Outlet pressure 2nd superheater | MPa |
| x105 | Outlet pressure steam supplied of 2nd superheater | MPa |
| x106 | Inlet pressure 2nd superheater | MPa |
| x107 | Amount of outlet steam flow 2nd superheater | t/h |
| x108 | Amount of inlet steam flow 2nd superheater | t/h |
| x109 | Steam output of steam drum | t/h |
| PCA | kNN | LOF | AAKR | AASKR–NP | AASKR | |
|---|---|---|---|---|---|---|
| Boiler shutdown | 2020. 09. 09. 14:35 | |||||
| Detection time | 14:53 | 13:36 | 14:36 | 12:32 | 12:32 | 12:13 |
| Early detection time | −18 m | 59 m | -26 s | 2 h 3 m | 2 h 3 m | 2 h 21 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Kim, E.; Jung, S.; Kim, B.; Kim, J.; Kim, S. Fault Detection Method Using Auto-Associative Shared Nearest Neighbor Kernel Regression for Industrial Processes. Appl. Sci. 2025, 15, 2251. https://doi.org/10.3390/app15052251
Kim M, Kim E, Jung S, Kim B, Kim J, Kim S. Fault Detection Method Using Auto-Associative Shared Nearest Neighbor Kernel Regression for Industrial Processes. Applied Sciences. 2025; 15(5):2251. https://doi.org/10.3390/app15052251
Chicago/Turabian StyleKim, Minseok, Eunkyeong Kim, Seunghwan Jung, Baekcheon Kim, Jinyong Kim, and Sungshin Kim. 2025. "Fault Detection Method Using Auto-Associative Shared Nearest Neighbor Kernel Regression for Industrial Processes" Applied Sciences 15, no. 5: 2251. https://doi.org/10.3390/app15052251
APA StyleKim, M., Kim, E., Jung, S., Kim, B., Kim, J., & Kim, S. (2025). Fault Detection Method Using Auto-Associative Shared Nearest Neighbor Kernel Regression for Industrial Processes. Applied Sciences, 15(5), 2251. https://doi.org/10.3390/app15052251