
Dynamic Classifier Auditing by Unsupervised Anomaly Detection Methods: An Application in Packaging Industry Predictive Maintenance

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Literature Review
3. Expert System Description and Objective of the Work
4. Methods
4.1. Data Preprocessing
4.2. Classifier
4.3. Anomaly Detection Methods
4.3.1. OCSVM
- is the weight vector in the feature space;
- are the slack variables representing margin violations;
- is the offset term (the decision function’s threshold);
- is the feature mapping function;
- controls the fraction of outliers and the margin (a value between 0 and 1).
- If , the point is classified as “normal”.
- If , the point is classified as an “anomaly”.
4.3.2. MCD
4.3.3. AD Ensembles
4.4. Streaming Framework
4.5. Performance Metric
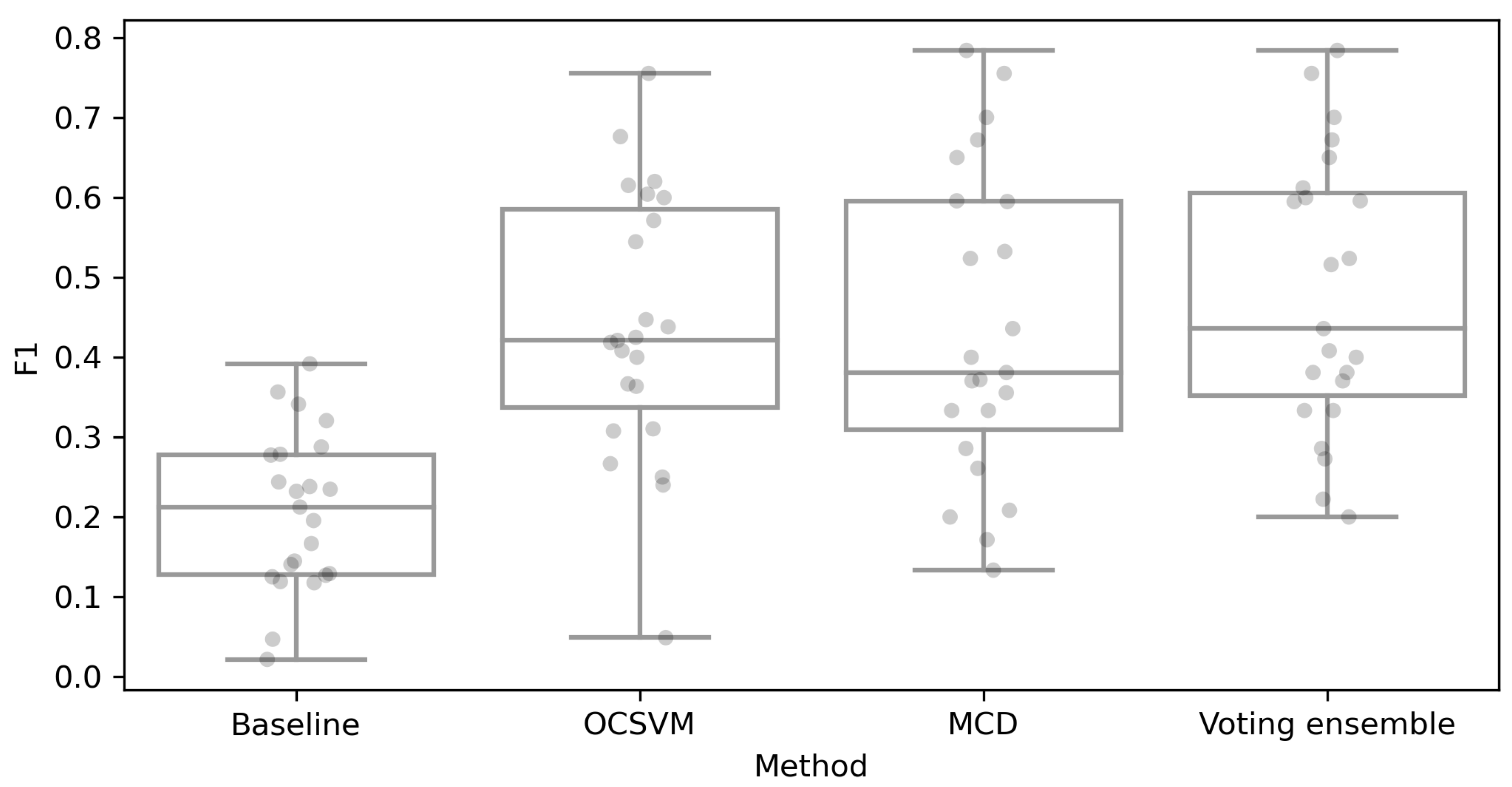
5. Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ayvaz, S.; Alpay, K. Predictive Maintenance System for Production Lines in Manufacturing: A Machine Learning Approach Using IoT Data in Real-Time. Expert Syst. Appl. 2021, 173, 114598. [Google Scholar] [CrossRef]
- Froger, A.; Gendreau, M.; Mendoza, J.E.; Pinson, E.; Rousseau, L.M. Maintenance scheduling in the electricity industry: A literature review. Eur. J. Oper. Res. 2016, 251, 695–706. [Google Scholar] [CrossRef]
- Stock, T.; Seliger, G. Opportunities of sustainable manufacturing in industry 4.0. Procedia CIRP 2016, 40, 536–541. [Google Scholar] [CrossRef]
- Yin, S.; Li, X.; Gao, H.; Kaynak, O. Data-Based Techniques Focused on Modern Industry: An Overview. IEEE Trans. Ind. Electron. 2015, 62, 657–667. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Yu, Z.; Zeng, M. Incremental supervised locally linear embedding for machinery fault diagnosis. Eng. Appl. Artif. Intell. 2016, 50, 60–70. [Google Scholar] [CrossRef]
- Lee, S.S. Noisy replication in skewed binary classification. Comput. Stat. Data Anal. 2000, 34, 165–191. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; da Rosa Righi, R.; de Lima, M.J.; da Trindade, E.S.; Li, G.P. Predictive maintenance in the Industry 4.0: A systematic literature review. Comput. Ind. Eng. 2020, 150, 106889. [Google Scholar] [CrossRef]
- O’Donovan, P.; Leahy, K.; Bruton, K.; O’Sullivan, D.T. Big data in manufacturing: A systematic mapping study. J. Big Data 2015, 2, 20. [Google Scholar] [CrossRef]
- Muhuri, P.K.; Shukla, A.K.; Abraham, A. Industry 4.0: A bibliometric analysis and detailed overview. Eng. Appl. Artif. Intell. 2019, 78, 218–235. [Google Scholar] [CrossRef]
- Lee, J.; Bagheri, B.; Kao, H.A. Recent advances and trends of cyber-physical systems and big data analytics in industrial informatics. In Proceedings of the International Conference on Industrial Informatics (INDIN), Porto Alegre, Brazil, 27–30 July 2014; pp. 1–6. [Google Scholar]
- Rodríguez-Mazahua, L.; Rodríguez-Enríquez, C.A.; Sánchez-Cervantes, J.L.; Cervantes, J.; García-Alcaraz, J.L.; Alor-Hernández, G. A general perspective of Big Data: Applications, tools, challenges and trends. J. Supercomput. 2016, 72, 3073–3113. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Lu, B.; Durocher, D.B.; Stemper, P. Predictive maintenance techniques. IEEE Ind. Appl. Mag. 2009, 15, 52–60. [Google Scholar] [CrossRef]
- Chouikhi, H.; Khatab, A.; Rezg, N. A condition-based maintenance policy for a production system under excessive environmental degradation. J. Intell. Manuf. 2014, 25, 727–737. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Duan, L.; Gao, R. A new paradigm of cloud-based predictive maintenance for intelligent manufacturing. J. Intell. Manuf. 2015, 28, 1125–1137. [Google Scholar] [CrossRef]
- Cucurull, J.; Martí, R.; Navarro-Arribas, G.; Robles, S.; Overeinder, B.; Borrell, J. Agent mobility architecture based on IEEE-FIPA standards. Comput. Commun. 2009, 32, 712–729. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.; Vita, R.; Francisco, R.d.P.; Basto, J.P.; Alcalá, S.G. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-driven methods for predictive maintenance of industrial equipment: A survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Susto, G.A.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine learning for predictive maintenance: A multiple classifier approach. IEEE Trans. Ind. Inform. 2014, 11, 812–820. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Prytz, R.; Nowaczyk, S.; Rögnvaldsson, T.; Byttner, S. Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data. Eng. Appl. Artif. Intell. 2015, 41, 139–150. [Google Scholar]
- Vapnik, V.N. Support Vector Machines. In Encyclopedia of Biometrics; Li, S.Z., Jain, A.K., Eds.; Springer: Boston, MA, USA, 2009; pp. 1365–1368. [Google Scholar] [CrossRef]
- Gryllias, K.; Antoniadis, I. A Support Vector Machine approach based on physical model training for rolling element bearing fault detection in industrial environments. Eng. Appl. Artif. Intell. 2012, 25, 326–344. [Google Scholar] [CrossRef]
- Li, H.; Parikh, D.; He, Q.; Qian, B.; Li, Z.; Fang, D.; Hampapur, A. Improving rail network velocity: A machine learning approach to predictive maintenance. Transp. Res. Part C Emerg. Technol. 2014, 45, 17–26. [Google Scholar] [CrossRef]
- Langone, R.; Alzate, C.; Ketelaere, B.D.; Vlasselaer, J.; Meert, W.; Suykens, J.A. LS-SVM based spectral clustering and regression for predicting maintenance of industrial machines. Eng. Appl. Artif. Intell. 2015, 37, 268–278. [Google Scholar] [CrossRef]
- Erhan, L.; Ndubuaku, M.; Di Mauro, M.; Song, W.; Chen, M.; Fortino, G.; Bagdasar, O.; Liotta, A. Smart anomaly detection in sensor systems: A multi-perspective review. Inf. Fusion 2021, 67, 64–79. [Google Scholar] [CrossRef]
- Nunes, P.; Santos, J.; Rocha, E. Challenges in predictive maintenance—A review. CIRP J. Manuf. Sci. Technol. 2023, 40, 53–67. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10. [Google Scholar]
- Morselli, F.; Bedogni, L.; Mirani, U.; Fantoni, M.; Galasso, S. Anomaly Detection and Classification in Predictive Maintenance Tasks with Zero Initial Training. IoT 2021, 2, 590–609. [Google Scholar] [CrossRef]
- Kulanuwat, L.; Chantrapornchai, C.; Maleewong, M.; Wongchaisuwat, P.; Wimala, S.; Sarinnapakorn, K.; Boonya-aroonnet, S. Anomaly Detection Using a Sliding Window Technique and Data Imputation with Machine Learning for Hydrological Time Series. Water 2021, 13, 1862. [Google Scholar] [CrossRef]
- Zhong, Z.; Zhao, Y.; Yang, A.; Zhang, H.; Qiao, D.; Zhang, Z. Industrial Robot Vibration Anomaly Detection Based on Sliding Window One-Dimensional Convolution Autoencoder. Shock Vib. 2022, 2022, 1179192. [Google Scholar] [CrossRef]
- Li, Z.; Li, G.; Liu, Y.; Li, Z.; Li, G.; Liu, Y. Network traffic anomaly detection based on sliding window. In Proceedings of the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 1820–1823. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Int. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. Artic. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. Adv. Neural Inf. Process. Syst. 1999, 12, 582–588. [Google Scholar]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. J. Mach. Learn. Res. 2019, 20, 1–7. [Google Scholar]
- Rousseeuw, P.J.; Driessen, K.V. A fast algorithm for the minimum covariance determinant estimator. Technometrics 1999, 41, 212–223. [Google Scholar] [CrossRef]
- Croux, C.; Haesbroeck, G. Influence function and efficiency of the minimum covariance determinant scatter matrix estimator. J. Multivar. Anal. 1999, 71, 161–190. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, L.; Ding, L.; Huang, Z.; Sui, H.; Wang, S.; Song, Y. Selective ensemble method for anomaly detection based on parallel learning. Sci. Rep. 2024, 14, 1420. [Google Scholar] [CrossRef] [PubMed]
- Grunova, D.; Bakratsi, V.; Vrochidou, E.; Papakostas, G.A. Machine Learning for Anomaly Detection in Industrial Environments. Eng. Proc. 2024, 70, 25. [Google Scholar] [CrossRef]
- Yilmaz, S.F.; Kozat, S.S. PySAD: A Streaming Anomaly Detection Framework in Python. arXiv 2020, arXiv:2009.02572. [Google Scholar]
- Manzoor, E.; Lamba, H.; Akoglu, L. xstream: Outlier detection in feature-evolving data streams. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1963–1972. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alarm | Description |
|---|---|
| A1 | Pulley failure |
| A2 | Arm engine failure |
| A3 | Maximum intensity in arm engine failure |
| A4 | Offset position failure |
| A5 | Communication failure |
| A6 | Minimum battery level failure |
| A7 | Maximum battery level failure |
| A8 | Emergency button |
| A9 | Pulley failure |
| A10 | Carriage failure |
| A11 | Carriage engine failure |
| A12 | Vertical bar failure |
| A13 | Horizontal bar failure |
| A14 | Maintenance failure 1 |
| A15 | Maintenance failure 2 |
| A16 | Latch failure |
| A17 | Brake communication system failure |
| A18 | Plastic film broken |
| A19 | Brake off |
| A20 | Excess strain on plastic film |
| A200 | Communication error with remote board |
| A201 | Extended time without communication failure |
| Machine | Baseline | OCSVM | MCD | Ensemble | Max. % Change |
|---|---|---|---|---|---|
| 25ARE2200:2AB-0118 | 0.277 | 0.600 | 0.784 | 0.784 | +182.7% |
| 25ARE2200:2AB-0140 | 0.244 | 0.615 | 0.650 | 0.650 | +166.6% |
| 25ARE22V2:2BC-0248 | 0.022 | 0.049 | 0.133 | 0.222 | +933.3% |
| 25ARE22V2:2BC-0264 | 0.235 | 0.620 | 0.533 | 0.612 | +164.3% |
| 25ARE22V2:2BC-0268 | 0.321 | 0.545 | 0.596 | 0.596 | +85.9% |
| 25ARF2200:101-0020 | 0.167 | 0.408 | 0.208 | 0.408 | +144.9% |
| 25ARF2200:101-0027 | 0.047 | 0.240 | 0.261 | 0.273 | +481.8% |
| 25ARF2200:101-0035 | 0.288 | 0.756 | 0.756 | 0.756 | +162.6% |
| 25ARF22V2:1AA-0042 | 0.119 | 0.267 | 0.286 | 0.286 | +140.0% |
| 25ARF22V2:1AA-0083 | 0.129 | 0.250 | 0.333 | 0.333 | + 158.3% |
| 25ARF22V2:1AA-0094 | 0.232 | 0.447 | 0.595 | 0.595 | +156.5% |
| 25ARF22V2:1AA-0098 | 0.125 | 0.571 | 0.171 | 0.600 | +380.0% |
| 25ARF22V2:1AA-0099 | 0.278 | 0.425 | 0.436 | 0.436 | +56.5% |
| 25ARF22V2:1AA-0108 | 0.392 | 0.419 | 0.372 | 0.381 | +6.9% |
| 25ARF22V2:1AA-0109 | 0.238 | 0.308 | 0.370 | 0.370 | +55.6% |
| 25ARF22V2:1AA-0110 | 0.212 | 0.310 | 0.333 | 0.333 | +56.9% |
| 25ARF22V2:1AA-0113 | 0.140 | 0.421 | 0.356 | 0.516 | +267.7% |
| 25ARF22V2:1AA-0173 | 0.195 | 0.438 | 0.524 | 0.524 | +167.9% |
| 25ARF22V2:1AA-0176 | 0.145 | 0.367 | 0.200 | 0.200 | +153.2% |
| 25ARF22V3:1BB-0184 | 0.118 | 0.400 | 0.400 | 0.400 | +240.0% |
| 25ARF22V3:1BB-0188 | 0.127 | 0.364 | 0.381 | 0.381 | +200.0% |
| 25ARF22V3:1BB-0189 | 0.341 | 0.604 | 0.672 | 0.672 | +97.0% |
| 25ARF22V4:1CC-0308 | 0.357 | 0.676 | 0.701 | 0.701 | +96.5% |
| Average ± std | 0.21 ± 0.01 | 0.44 ± 0.17 | 0.44 ± 0.19 | 0.48 ± 0.17 | +198.0% |
| Machine | Baseline | OCSVM | MCD | Ensemble | Max. % Change |
|---|---|---|---|---|---|
| 25ARE2200:2AB-0118 | 1.000 | 0.875 | 0.833 | 0.833 | −12.5% |
| 25ARE2200:2AB-0140 | 0.891 | 0.673 | 0.653 | 0.653 | −24.4% |
| 25ARE22V2:2BC-0248 | 0.125 | 0.125 | 0.125 | 0.125 | 0.0% |
| 25ARE22V2:2BC-0264 | 0.888 | 0.613 | 0.563 | 0.563 | −36.6% |
| 25ARE22V2:2BC-0268 | 0.889 | 0.711 | 0.656 | 0.656 | −26.3% |
| 25ARF2200:101-0020 | 0.895 | 0.526 | 0.526 | 0.526 | −41.2% |
| 25ARF2200:101-0027 | 0.375 | 0.375 | 0.375 | 0.375 | 0.0% |
| 25ARF2200:101-0035 | 0.872 | 0.723 | 0.723 | 0.723 | −17.1% |
| 25ARF22V2:1AA-0042 | 0.714 | 0.571 | 0.571 | 0.571 | −20.0% |
| 25ARF22V2:1AA-0083 | 0.286 | 0.286 | 0.286 | 0.286 | 0.0% |
| 25ARF22V2:1AA-0094 | 0.806 | 0.581 | 0.581 | 0.581 | −28.0% |
| 25ARF22V2:1AA-0098 | 0.571 | 0.571 | 0.429 | 0.429 | −25.0% |
| 25ARF22V2:1AA-0099 | 0.957 | 0.739 | 0.739 | 0.739 | −22.7% |
| 25ARF22V2:1AA-0108 | 0.905 | 0.429 | 0.381 | 0.381 | −57.9% |
| 25ARF22V2:1AA-0109 | 1.000 | 1.000 | 1.000 | 1.000 | 0.0% |
| 25ARF22V2:1AA-0110 | 0.750 | 0.563 | 0.563 | 0.563 | −25.0% |
| 25ARF22V2:1AA-0113 | 0.727 | 0.727 | 0.727 | 0.727 | 0.0% |
| 25ARF22V2:1AA-0173 | 0.839 | 0.742 | 0.710 | 0.710 | −15.4% |
| 25ARF22V2:1AA-0176 | 0.889 | 0.611 | 0.167 | 0.167 | −31.3% |
| 25ARF22V3:1BB-0184 | 0.500 | 0.500 | 0.500 | 0.500 | 0.0% |
| 25ARF22V3:1BB-0188 | 1.000 | 1.000 | 1.000 | 1.000 | 0.0% |
| 25ARF22V3:1BB-0189 | 0.915 | 0.894 | 0.851 | 0.851 | −7.0% |
| 25ARF22V4:1CC-0308 | 1.000 | 0.841 | 0.841 | 0.841 | −15.9% |
| Average ± std | 0.77 ± 0.24 | 0.64 ± 0.22 | 0.60 ± 0.24 | 0.60 ± 0.24 | −15.5% |
| Machine | Baseline | OCSVM | MCD | Ensemble | Max. % Change |
|---|---|---|---|---|---|
| 25ARE2200:2AB-0118 | 0.161 | 0.457 | 0.741 | 0.741 | 359.9% |
| 25ARE2200:2AB-0140 | 0.141 | 0.567 | 0.647 | 0.647 | 358.0% |
| 25ARE22V2:2BC-0248 | 0.012 | 0.030 | 0.143 | 1.000 | 8400.0% |
| 25ARE22V2:2BC-0264 | 0.135 | 0.628 | 0.506 | 0.672 | 396.6% |
| 25ARE22V2:2BC-0268 | 0.196 | 0.441 | 0.546 | 0.546 | 179.3% |
| 25ARF2200:101-0020 | 0.092 | 0.333 | 0.130 | 0.333 | 262.7% |
| 25ARF2200:101-0027 | 0.025 | 0.176 | 0.200 | 0.214 | 757.1% |
| 25ARF2200:101-0035 | 0.172 | 0.791 | 0.791 | 0.791 | 359.0% |
| 25ARF22V2:1AA-0042 | 0.065 | 0.174 | 0.190 | 0.190 | 193.3% |
| 25ARF22V2:1AA-0083 | 0.083 | 0.222 | 0.400 | 0.400 | 380.0% |
| 25ARF22V2:1AA-0094 | 0.136 | 0.364 | 0.610 | 0.610 | 350.3% |
| 25ARF22V2:1AA-0098 | 0.070 | 0.571 | 0.107 | 1.000 | 1325.0% |
| 25ARF22V2:1AA-0099 | 0.163 | 0.298 | 0.309 | 0.309 | 89.7% |
| 25ARF22V2:1AA-0108 | 0.250 | 0.409 | 0.364 | 0.381 | 63.6% |
| 25ARF22V2:1AA-0109 | 0.135 | 0.182 | 0.227 | 0.227 | 68.2% |
| 25ARF22V2:1AA-0110 | 0.124 | 0.214 | 0.237 | 0.237 | 91.4% |
| 25ARF22V2:1AA-0113 | 0.078 | 0.296 | 0.235 | 0.400 | 415.0% |
| 25ARF22V2:1AA-0173 | 0.111 | 0.311 | 0.415 | 0.415 | 275.2% |
| 25ARF22V2:1AA-0176 | 0.079 | 0.262 | 0.250 | 0.250 | 232.3% |
| 25ARF22V3:1BB-0184 | 0.067 | 0.333 | 0.333 | 0.333 | 400.0% |
| 25ARF22V3:1BB-0188 | 0.068 | 0.222 | 0.235 | 0.235 | 247.1% |
| 25ARF22V3:1BB-0189 | 0.210 | 0.456 | 0.513 | 0.513 | 144.8% |
| 25ARF22V4:1CC-0308 | 0.196 | 0.629 | 0.704 | 0.704 | 258.2% |
| Average ± std | 0.12 ± 0.06 | 0.36 ± 0.18 | 0.38 ± 0.20 | 0.48 ± 0.24 | 675.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mateo, F.; Vila-Francés, J.; Soria-Olivas, E.; Martínez-Sober, M.; Gómez-Sanchis, J.; Serrano-López, A.J. Dynamic Classifier Auditing by Unsupervised Anomaly Detection Methods: An Application in Packaging Industry Predictive Maintenance. Appl. Sci. 2025, 15, 882. https://doi.org/10.3390/app15020882
Mateo F, Vila-Francés J, Soria-Olivas E, Martínez-Sober M, Gómez-Sanchis J, Serrano-López AJ. Dynamic Classifier Auditing by Unsupervised Anomaly Detection Methods: An Application in Packaging Industry Predictive Maintenance. Applied Sciences. 2025; 15(2):882. https://doi.org/10.3390/app15020882
Chicago/Turabian StyleMateo, Fernando, Joan Vila-Francés, Emilio Soria-Olivas, Marcelino Martínez-Sober, Juan Gómez-Sanchis, and Antonio José Serrano-López. 2025. "Dynamic Classifier Auditing by Unsupervised Anomaly Detection Methods: An Application in Packaging Industry Predictive Maintenance" Applied Sciences 15, no. 2: 882. https://doi.org/10.3390/app15020882
APA StyleMateo, F., Vila-Francés, J., Soria-Olivas, E., Martínez-Sober, M., Gómez-Sanchis, J., & Serrano-López, A. J. (2025). Dynamic Classifier Auditing by Unsupervised Anomaly Detection Methods: An Application in Packaging Industry Predictive Maintenance. Applied Sciences, 15(2), 882. https://doi.org/10.3390/app15020882