


A Method for Grading Failure Rates Within the Dynamic Effective Space of Integrated Circuits After Testing

 ,
,
Abstract
1. Introduction
2. Algorithm Description
2.1. Calculate the Failure Rate of the Evaluated Die
2.1.1. Determination of Effective Space
- Processing of evaluated dies with sufficient number of surrounding dies
- Set a minimum radius (r = 3) as the initial radius and calculate the failure rate within the current radius:where the “Number of Faulty Dies within r” is the number of faulty dies within the current radius, and the “Total Number of Dies within r” is the total number of dies within the current radius.
- Set a maximum threshold R and dynamically adjust the evaluation radius until the final radius is obtained:Within the range of , if the Fault Rate is less than , expand the radius to . If the Fault Rate is still less than when the evaluation radius is 4, then extend it to , choosing as the final radius (if the maximum range of the evaluated die is less than 7, choose the current r as the final r).In the range where , if the Fault Rate is less than , expand the radius to , meaning that the evaluated radius is 4; if it exceeds , expand r outward three times, while each time the Fault Rate is less than , select this time r for subsequent calculation. If the Fault Rate is greater than , expand r outward three times, and each time, if the Fault Rate is greater than total, select for subsequent calculation.Otherwise, extend to .
- Processing of edge partsDuring the expansion of the radius, it is necessary to evaluate whether the number of dies within the current radius is sufficient to determine if there are missing dies in certain directions or if the evaluated die is located at the edge of the wafer. For dies located at the edge of the wafer and missing dies in certain directions, the average failure rate of neighboring points is used as virtual data to estimate the average failure rate of a missing part.
- Starting from radius 1, gradually check the actual number of neighboring dies within each radius range. If the data in a certain direction of the edge die are insufficient, calculate the average failure rate (afr) of the currently available neighboring die radius range:
- Dynamically adjust the radius and fill in data. Dynamically calculate and update the average failure rate of neighboring dies according to the evaluation radius at each step. Each time the evaluation radius is expanded, recalculate the average failure rate of all actual neighboring dies within that radius and use these data to fill in the virtual neighboring dies.
- If sufficient neighboring die data are already included within a certain radius range, or further expansion of the radius does not add new actual neighboring dies, expand and judge according to the above steps, determine the final evaluation space, and fill in the missing die data for different radius.
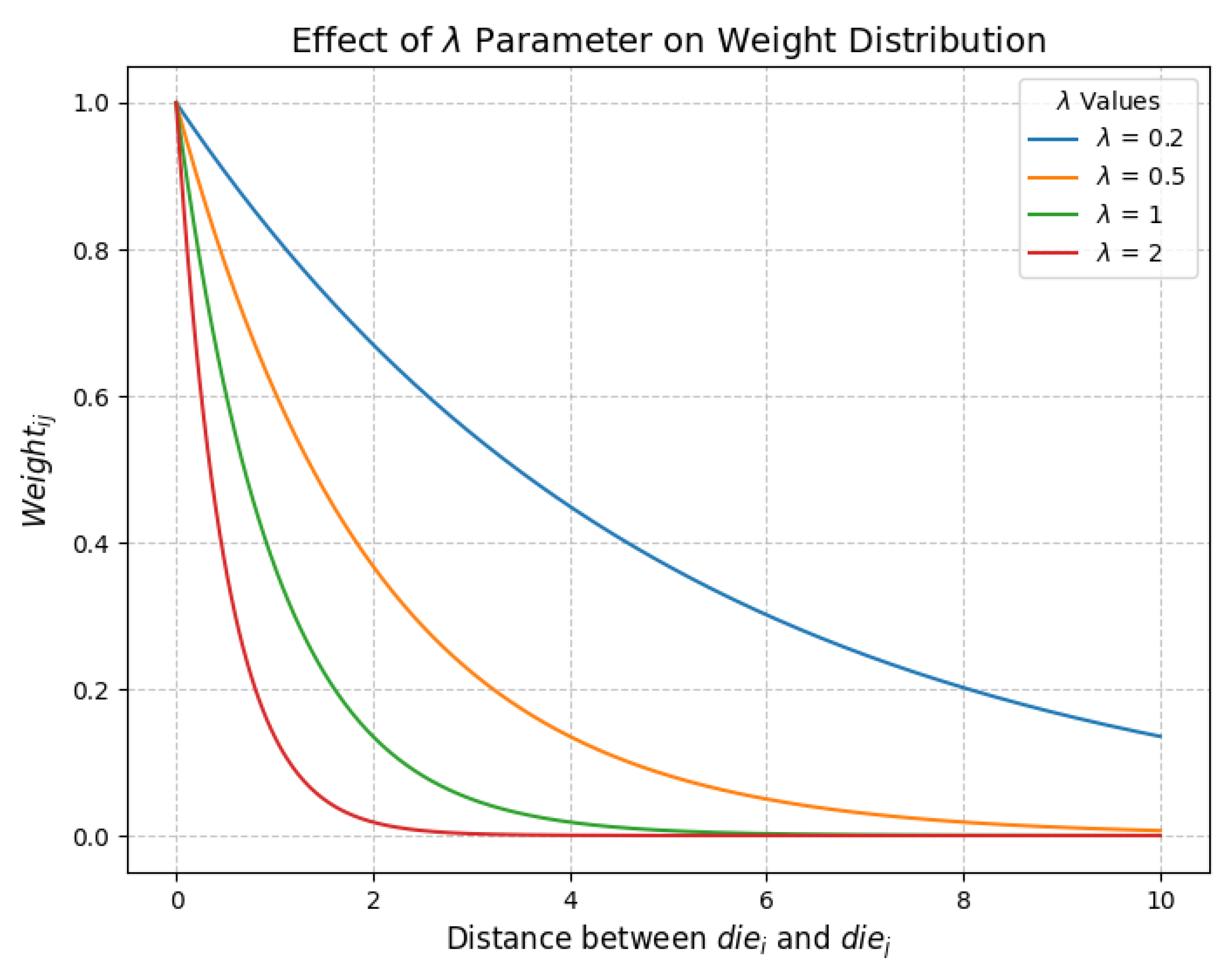
2.1.2. Calculate Impact Weight
2.1.3. Calculation of Final Weighted Failure Rate
2.2. Performance Evaluation by Parameters
2.2.1. Calculation of the Score of Each Parameter Item
2.2.2. Calculation of the Test Total Score of the Test Item
2.3. Rank Division
2.3.1. Calculation of the Total Score
2.3.2. Result Optimization
2.3.3. Grade Definition
- Calculate the average score of all dies.
- Calculate the standard deviation of the scores.
- Set multiple quality levels as shown in Table 1:
3. Experimental Procedure
3.1. Description of the Data Set
3.2. Data Cleaning
3.3. Specific Experimental Procedure
3.4. Experiment for Comparison
- Use other parameter items in the wafer test for calculation to obtain the test item scores for each chip (the parameter item OSN_DCIN was selected for this experiment).
- Calculate the total score for each chip and perform grade classification, and save the results to the database (Grade_Test).
- A comparative analysis of the results was made: compare the grading results of this method (Grade) with the traditional method (Grade_Test), and calculate the accuracy and confusion matrix to evaluate the performance of both methods.
- Obtain Grade and Grade_Test column data from the database.
- Accuracy calculation: Use the accuracy_score function in sklearn.metrics to calculate the accuracy of Grade and Grade_Test, evaluating the grading accuracy of this method compared to the traditional method.
- Calculation of confusion matrix: Use the confusion_matrix function in sklearn. metrics to calculate the confusion matrix of Grade and Grade_Test, analyzing the classification performance for each category (A, B, C, D).
- Analyze and interpret the results: Calculate precision, recall, and F1 scores to show the model’s performance in each category.
3.5. Experimental Result
3.5.1. Partial Experimental Results
3.5.2. Comparative Experimental Results
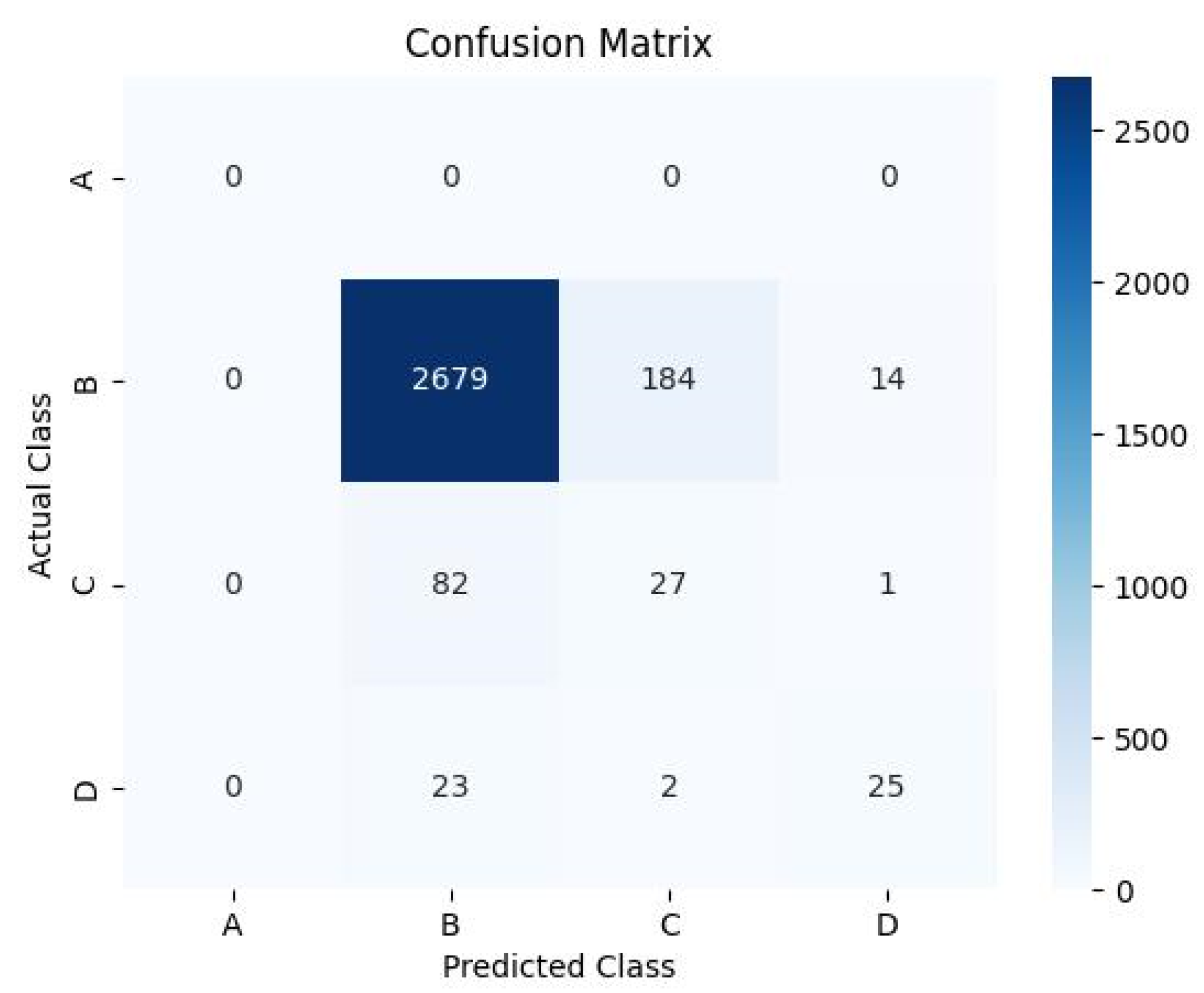
- Accuracy: 0.899, indicating that 89.9% of the samples in all test samples were correctly classified by this method.
- Each piece of data of the confusion matrix represents the classification between different categories, which is explained as follows:
- First row (samples with actual category A): No actual category A samples were correctly or incorrectly classified (all values are 0).
- Second row (samples with actual category B): 2679 actual category B samples were correctly classified as B. A total of 184 actual category B samples were incorrectly classified as C. A total of 14 actual category B samples were incorrectly classified as D.
- Third row (samples with actual category C): 82 actual category C samples were correctly classified as B. One actual category C sample was incorrectly classified as D.
- Fourth row (samples with actual category D): 23 actual category D samples were correctly classified as B. Two actual category D samples were incorrectly classified as C.
3.5.3. Algorithm Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Name | Meaning |
|---|---|---|
| PPAT | Parameter Parts Average Testing | A chip quality evaluation method based on parameter average. |
| SYA | Statistical Yield Analysis | A statistically based method for analyzing chip yield. |
| ATE | Automatic Test Equipment | |
| PCA | Principal Components Analysis | Dimensionality reduction to transform multiple indicators into a few comprehensive ones. |
| I-PAT | Inline Part Average Testing | |
| CNN | Convolutional Neural Network |
| Abbreviation | Full Name | Meaning |
|---|---|---|
| Average | The average score | |
| SD | standard deviation | |
| afr | Average failure rate | Used to measure the average failure rate of neighboring chips. |
| W_score() | Weighted failure rate | The weighted failure rate of the evaluated die (i). |
| Parameter score of test item k | ||
| T_score | Total score of test items for the evaluated chip (i). | |
| Weight of parameter item k | ||
| F_score | The final score of the evaluated chip (i). | |
| OSN_TCK(V) | Open Short Net Test Clock Voltage |
References
- Gerling, W.H.; Preussger, A.; Wulfert, F.W. Reliability qualification of semiconductor devices based on physics-of-failure and risk and opportunity assessment. Qual. Reliab. Eng. Int. 2002, 18, 81–98. [Google Scholar] [CrossRef]
- Yan, H.; Feng, X.; Hu, Y.; Tang, X. Research on chip test method for improving test quality. In Proceedings of the 2019 IEEE 2nd International Conference on Electronics and Communication Engineering (ICECE), Xi’an, China, 9–11 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 226–229. [Google Scholar]
- Hu, X. Application of Moore’s law in semiconductor and integrated circuits intelligent manufacturing. In Proceedings of the 2022 IEEE 2nd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 21–23 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 964–968. [Google Scholar]
- Wang, Q.; Tian, Z.; He, X.; Xu, Z.; Tang, M.; Cai, S. Universal Semiconductor ATPG Solutions for ATE Platform under the Trend of AI and ADAS. In Proceedings of the 2021 China Semiconductor Technology International Conference (CSTIC), Shanghai, China, 14–15 March 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Huang, A.C.; Meng, S.H.; Huang, T.J. A survey on machine and deep learning in semiconductor industry: Methods, opportunities, and challenges. Clust. Comput. 2023, 26, 3437–3472. [Google Scholar] [CrossRef]
- Mitra, S.; McCluskey, E.J.; Makar, S. Design for testability and testing of IEEE 1149.1 TAP controller. In Proceedings of the 20th IEEE VLSI Test Symposium (VTS 2002), Monterey, CA, USA, 28 April–2 May 2002; pp. 247–252. [Google Scholar] [CrossRef]
- Yeh, C.H.; Chen, J.E. Unbalanced-tests to the improvement of yield and quality. Electronics 2021, 10, 3032. [Google Scholar] [CrossRef]
- Burkacky, O.; Patel, M.; Sergeant, N.; Thomas, C. Reimagining Fabs: Advanced Analytics in Semiconductor Manufacturing. Article. Available online: https://www.mckinsey.com/industries/semiconductors/our-insights/reimagining-fabs-advanced-analytics-in-semiconductor-manufacturing (accessed on 30 March 2017).
- Shen, J.P.; Maly, W.; Ferguson, F.J. Inductive fault analysis of MOS integrated circuits. IEEE Des. Test Comput. 1985, 2, 13–26. [Google Scholar] [CrossRef]
- Hutner, M.; Sethuram, R.; Vinnakota, B.; Armstrong, D.; Copperhall, A. Special session: Test challenges in a chiplet marketplace. In Proceedings of the 2020 IEEE 38th VLSI Test Symposium (VTS), San Diego, CA, USA, 5–8 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–12. [Google Scholar]
- Fan, S.K.S.; Cheng, C.W.; Tsai, D.M. Fault diagnosis of wafer acceptance test and chip probing between front-end-of-line and back-end-of-line processes. IEEE Trans. Autom. Sci. Eng. 2021, 19, 3068–3082. [Google Scholar] [CrossRef]
- Pateras, S.; Tai, T.P. Automotive semiconductor test. In Proceedings of the 2017 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 24–27 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Sunter, S.K.; Nadeau-Dostie, B. Complete, contactless I/O testing reaching the boundary in minimizing digital IC testing cost. In Proceedings of the International Test Conference, Baltimore, MD, USA, 7–10 October 2002; IEEE: Piscataway, NJ, USA, 2002; pp. 446–455. [Google Scholar]
- Krasniewski, A.; Pilarski, S. Circular self-test path: A low-cost BIST technique for VLSI circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1989, 8, 46–55. [Google Scholar] [CrossRef]
- Chou, P.B.; Rao, A.R.; Sturzenbecker, M.C.; Wu, F.Y.; Brecher, V.H. Automatic defect classification for semiconductor manufacturing. Mach. Vis. Appl. 1997, 9, 201–214. [Google Scholar] [CrossRef]
- Wu, T.; Li, B.; Wang, L.; Huang, Y. Study on path-optimization by grade for sorting dies. In Proceedings of the 2010 IEEE International Conference on Mechatronics and Automation, Xi’an, China, 4–7 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 876–880. [Google Scholar]
- Robinson, J.C.; Sherman, K.; Price, D.W.; Rathert, J. Inline Part Average Testing (I-PAT) for automotive die reliability. In Metrology, Inspection, and Process Control for Microlithography XXXIV; SPIE: Paris, France, 2020; Volume 11325, pp. 50–59. [Google Scholar]
- Malozyomov, B.V.; Martyushev, N.V.; Bryukhanova, N.N.; Kondratiev, V.V.; Kononenko, R.V.; Pavlov, P.P.; Romanova, V.V.; Karlina, Y.I. Reliability Study of Metal-Oxide Semiconductors in Integrated Circuits. Micromachines 2024, 15, 561. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Navaraj, W.T.; Lorenzelli, L.; Dahiya, R. Ultra-thin chips for high-performance flexible electronics. NPJ Flex. Electron. 2018, 2, 8. [Google Scholar] [CrossRef]
- Shen, W.W.; Chen, K.N. Three-dimensional integrated circuit (3D IC) key technology: Through-silicon via (TSV). Nanoscale Res. Lett. 2017, 12, 56. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Sarkar, P. A Comprehensive Review of Machine Learning Applications in VLSI Testing: Unveiling the Future of Semiconductor Manufacturing. In Proceedings of the 2023 7th International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 18–20 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Ghosh, A.; Ho, C.N.M.; Prendergast, J. A cost-effective, compact, automatic testing system for dynamic characterization of power semiconductor devices. In Proceedings of the 2019 IEEE Energy Conversion Congress and Exposition (ECCE), Baltimore, MD, USA, 29 September–3 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2026–2032. [Google Scholar]
- Donzella, O.; Robinson, J.C.; Sherman, K.; Lach, J.; von den Hoff, M.; Saville, B.; Groos, T.; Lim, A.; Price, D.W.; Rathert, J.; et al. The emergence of inline screening for high volume manufacturing. In Metrology, Inspection, and Process Control for Semiconductor Manufacturing XXXV; SPIE: Paris, France, 2021; Volume 11611, p. 1161107. [Google Scholar]
- Deshpande, P.; Epili, V.; Ghule, G.; Ratnaparkhi, A.; Habbu, S. Digital Semiconductor Testing Methodologies. In Proceedings of the 2023 4th International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 6–8 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 316–321. [Google Scholar]
- Dawn, Y.C.; Yeh, J.C.; Wu, C.W.; Wang, C.C.; Lin, Y.C.; Chen, C.H. Flash Memory Die Sort by a Sample Classification Method. In Proceedings of the 14th Asian Test Symposium (ATS’05), Calcutta, India, 18–21 December; IEEE: Piscataway, NJ, USA, 2005; pp. 182–187. [Google Scholar]
- Zhang, X.; Zhang, J.; Xu, X. An efficient image-elm-based chip classification algorithm. In Proceedings of the 2018 VII International Conference on Network, Communication and Computing, Taipei, Taiwan, 14–16 December 2018; pp. 283–287. [Google Scholar]
- Hsieh, Y.; Tzeng, G.; Lin, G.T.R.; Yu, H.C. Wafer sort bitmap data analysis using the PCA-based approach for yield analysis and optimization. IEEE Trans. Semicond. Manuf. 2010, 23, 493–502. [Google Scholar] [CrossRef]
- Milewicz, R.; Pirkelbauer, P. 10th IEEE International Conference on Software Testing, Verification and Validation; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Ting, H.W.; Hsu, C.M. An overkill detection system for improving the testing quality of semiconductor. In Proceedings of the 2012 International Conference on Information Security and Intelligent Control, Yunlin, Taiwan, 14–16 August 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 29–32. [Google Scholar]
- Pandey, R.; Pandey, S.; Shaul Hammed, C.S.M. Security in Design for Testability (DFT). In Proceedings of the 2017 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Coimbatore, India, 14–16 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Pandey, C.; Bhat, K.G. An Efficient AI-Based Classification of Semiconductor Wafer Defects using an Optimized CNN Model. In Proceedings of the 2023 IEEE IAS Global Conference on Emerging Technologies (GlobConET), London, UK, 19–21 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–9. [Google Scholar]
- St-Pierre, R.; Tuv, E. Robust, Non-Redundant Feature Selection for Yield Analysis in Semiconductor Manufacturing. In Advances in Data Mining. Applications and Theoretical Aspectsr; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Liu, M.; Chakrabarty, K. Adaptive methods for machine learning-based testing of integrated circuits and boards. In Proceedings of the 2021 IEEE International Test Conference (ITC), Anaheim, CA, USA, 10–15 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 153–162. [Google Scholar]
- Afacan, E.; Lourenço, N.; Martins, R.; Dündar, G. Machine learning techniques in analog/RF integrated circuit design, synthesis, layout, and test. Integration 2021, 77, 113–130. [Google Scholar] [CrossRef]
- Stratigopoulos, H.G. Machine learning applications in IC testing. In Proceedings of the 2018 IEEE 23rd European Test Symposium (ETS), Bremen, Germany, 28 May–1 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–10. [Google Scholar] [CrossRef]



| Grade | Score Range | Description |
|---|---|---|
| A | > | Excellent |
| B | Good | |
| C | Fair | |
| D | < | Poor |
| Id | W_Score | T_Score | F_Score | Grade |
|---|---|---|---|---|
| 139 | 0.994552 | 0.595353 | 0.994552 | B |
| 140 | 0.986764 | 0.597397 | 0.986764 | C |
| 141 | 0.966017 | 0.596029 | 0.966017 | C |
| 142 | 0.913740 | 0.597999 | 0.913740 | D |
| 143 | 0.991467 | 0.595927 | 0.991467 | B |
| 145 | 0.991294 | 0.595037 | 0.991294 | C |
| 146 | 0.992589 | 0.596689 | 0.992589 | B |
| 147 | 0.976132 | 0.588751 | 0.976132 | C |
| 148 | 0.914109 | 0.595905 | 0.914109 | D |
| 149 | 0.966588 | 0.595990 | 0.966588 | C |
| 150 | 0.987443 | 0.596877 | 0.987443 | C |
| 151 | 0.995343 | 0.594699 | 0.995343 | B |
| 152 | 0.986764 | 0.597397 | 0.986764 | C |
| Actual\Predicted | Grade A | Grade B | Grade C | Grade D |
|---|---|---|---|---|
| Grade A | 0 | 0 | 0 | 0 |
| Grade B | 0 | 2679 | 184 | 14 |
| Grade C | 0 | 82 | 27 | 1 |
| Grade D | 0 | 23 | 2 | 25 |
| Method\Test Content | Time | Memory |
|---|---|---|
| Proposed Method | 0.69 s | 62.88 MiB |
| Traditional Method [15] | 1.52 s | 63.90 MiB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, W.; Zhou, Y.; Zheng, J.; Cai, X.; Zhang, Q.; Wen, X. A Method for Grading Failure Rates Within the Dynamic Effective Space of Integrated Circuits After Testing. Appl. Sci. 2025, 15, 2009. https://doi.org/10.3390/app15042009
Zhan W, Zhou Y, Zheng J, Cai X, Zhang Q, Wen X. A Method for Grading Failure Rates Within the Dynamic Effective Space of Integrated Circuits After Testing. Applied Sciences. 2025; 15(4):2009. https://doi.org/10.3390/app15042009
Chicago/Turabian StyleZhan, Wenfa, Yangxinzi Zhou, Jiangyun Zheng, Xueyuan Cai, Qingping Zhang, and Xiaoqing Wen. 2025. "A Method for Grading Failure Rates Within the Dynamic Effective Space of Integrated Circuits After Testing" Applied Sciences 15, no. 4: 2009. https://doi.org/10.3390/app15042009
APA StyleZhan, W., Zhou, Y., Zheng, J., Cai, X., Zhang, Q., & Wen, X. (2025). A Method for Grading Failure Rates Within the Dynamic Effective Space of Integrated Circuits After Testing. Applied Sciences, 15(4), 2009. https://doi.org/10.3390/app15042009