1. Introduction
The control of a single agent is no longer sufficient to meet the demands of complicated activities due to the recent rapid development of agent applications in a variety of industries. As a result, multi-agent systems (MASs) formation control has attracted significant attention from scholars and researchers. MASs are widely applied to collaboratively accomplish various complex tasks, such as target tracking [
1], UAV swarm missions [
2], and environmental detection [
3]. Formation control is one of the core functions of MASs, with the primary objective of controlling multiple agents to form a specific formation for cooperative operations. Currently, increasing research efforts have been directed toward formation control, leading to numerous achievements. For example, ref. [
4] studies formation control for quadrotor UAVs, while ref. [
5] discusses formation control for underwater vehicles.
It is worth noting that most existing studies adopt model-based control (MBC) methods to address such problems, requiring an accurate mathematical model of the MASs and assuming that all agents have identical structures. However, in practice, obtaining the plant’s accurate mathematical models is challenging, and MASs often consist of heterogeneous agents operating in complex environments with numerous uncertainties. Therefore, MBC methods are difficult to generalize and apply to practical systems. To address this challenge, data-driven control (DDC) methods have gained increasing attention, as they avoid the need for accurate data models. Various DDC approaches have emerged, such as reinforcement learning control [
6], model-free adaptive control (MFAC) [
7,
8,
9], and iterative learning control (ILC) [
10,
11,
12]. Among these methods, MFAC designs controllers are solely based on the input/output (I/O) data of the controlled system, without requiring implicit or explicit system models, making it particularly suitable for heterogeneous MASs.
The model-free adaptive iterative learning control (MFAILC) method combines MFAC and ILC and is effective for controlling unknown nonlinear non-affine systems with repetitive operations. This method ensures monotonic convergence of system output errors along the iteration axis. Ref. [
13] studies a bipartite formation event-triggered control scheme for single-input single-output (SISO) systems, introducing an observer to estimate outputs and designing event-triggered conditions based on the difference between observed and actual outputs. Ref. [
14] employs the matrix transformation and the property of the nonnegative matrix, guaranteeing the iterative asymptotic convergence of the error of the SISO-type MASs under the structurally balanced digraph with an oriented spanning tree.
Moreover, information exchange between agents relies on network communication. The stability and security of formation systems are now significantly impacted by network attacks due to the rapid growth of network technology. Information transmission channels between agents often experience instability and physical limitations, making MASs susceptible to various network attacks, such as denial-of-service (DoS) attacks, deception attacks, and replay attacks [
15,
16,
17]. Among these, DoS attacks are the most common, causing system instability or even loss of control. Therefore, addressing formation control problems under network attacks has become a research hotspot for MASs. Event-triggered mechanisms, which update the controller only when certain triggered conditions are met, can significantly reduce communication burdens and computational pressure [
18], thereby alleviating the impact of DoS attacks to some extent. However, they cannot entirely eliminate the adverse effects caused by DoS attacks. Ref. [
19] proposes a resilient event-triggered mechanism that effectively mitigates periodic DoS attacks while conserving network resources. In order to lessen the impact of DoS attacks, Zhao [
20] suggests a hierarchical resilient learning technique and creates a virtual reference signal for every agent to estimate the time-varying reference signal. Additionally, ref. [
21] presents an attack detection mechanism and buffer-based compensation strategies to address the adverse effects of DoS attacks. Designing more effective compensation strategies to minimize or eliminate the impact of DoS attacks remains an important research challenge.
The bipartite formation trajectory tracking problem for unknown non-affine nonlinear MASs that are subject to recurring DoS attacks is discussed in this study. The following is a summary of this work’s primary contributions:
- 1.
For MIMO heterogeneous multi-agent bipartite formation systems with unknown dynamics, a controller is designed based on the MFAILC method.
- 2.
To address the impact of periodic DoS attacks on MIMO heterogeneous MASs, a DoS attack compensation mechanism is introduced within the MFAILC framework to mitigate the effects of such attacks.
- 3.
An improved dynamic event-triggered mechanism is proposed, which incorporates both consensus error and tracking error into the dynamic triggered condition. Compared to the event-triggered conditions in ref. [
22], the proposed mechanism significantly reduces controller updates, alleviates communication and computational pressure, and further enhances the system’s resilience against DoS attacks.
This is how the remainder of the paper is structured: Graph theory and modeling of periodic DoS attacks are introduced in
Section 2. The controller design is detailed in
Section 3. The system stability analysis and dynamic event-triggered mechanism are discussed in
Section 4.
Section 5 reports the simulation experiments. Finally, the conclusions are summarized in
Section 6.
4. Proof of Convergence
The main goal of the section is to demonstrate that the algorithm suggested in this paper is convergent. Before proceeding with the convergence proof derivation, the following lemma should be considered:
Lemma 1 ([
9]).
The relationship between the parameters representing the information transmission relationship between neighbors in a directed graph, the parameters of the adjacency relationship, and the parameters of the subordinate subset of the agent is as follows:- (1)
;
- (2)
;
- (3)
here, W, A, , D, .
Lemma 2 ([
8]).
Let denote an irreducible sub-stochastic matrix with positive diagonal entries that changes with each iteration and P are P matrices arbitrarily selected from M. Then, we have:where . Theorem 2. Considering MIMO-type agents in BFMASs that satisfy the conditions of Assumptions 1 and 2. The parameter satisfies the following conditions: 4.1. Boundedness of the
In column vector form,
is first rewritten as follows:
where
,
. Rewriting Equation (
17) as below:
Defining
, and subtracting
from both sides of (
20), and combining with Equation (
4), we obtain:
Taking the norm of both sides of Equation (
21), it follows
from Theorem 1 that:
Squaring both sides of the norm in the above equation, we obtain:
Selecting
and
, then
From Equations (
23) and (
24), it follows that there exists a
such that:
From the above, is bounded; since is bounded, we obtain a conclusion that and are bounded.
4.2. Convergence Analysis of the Tracking Error for Agents
The parameters are defined as follows:
From Lemma 1, the consensus error can be rewritten in the following form:
Multiplying both sides of Equation (
26) by
, we obtain the following:
Rewriting (
27) as below:
where
, since
, and hence
is an invertible matrix. From Equation (
28), we have
Considering the two cases of event-triggered and non-event-triggered for BFMASs that is, when
and
hold, the control input is unchanged from the last triggered iteration. The following is obtained:
where
,
.
Since
, where
, and the desired distance
among each agent and the virtual leader is a time-invariant constant, it follows that:
When combined with (
30), we obtain the following:
where
. Taking the norm of both sides of Equation (
32), we have
where
,
.
For each block matrix in (
34), performing the decomposition yields (
35)
Rewriting
as below
Combining Equations (
36) and (
34), we can obtain
Taking the
norm of (
37)’s two sides, we obtain
Defining
and verifying the boundedness of
as the following part. Since
and
have the same sign,
.Therefore, when
, there is a
such that we have
From the above, the block matrix
. Theorem 2 states that
is a graph with strong connections. Combining Equation (
39), we select a
such that
is an irreducible sub-stochastic matrix that contains diagonal components that are positive, and at least one row of
is strictly less than 1. Thus, the conclusion is that
is bounded.
Since the matrix
has zero diagonal elements, by the Gerschgorin Circle Theorem, we have:
where
,
. The eigenvalues of
are
, and all eigenvalues lie within the union
and are less than or equal to the spectral radius, i.e.,
. Therefore, there exists a
such that
and
. We can obtain
From the above situation, it follows that by selecting , we obtain , where is an arbitrarily small positive number. Thus, we have .
Combining the boundedness of
and
, the boundedness of
is verified as follows:
where
The recursion relation for Equation (
42) is given as follows:
From Lemma 2, we have
where
is the floor function. For
, it is required that
, i.e.,
satisfies the following conditions:
From the above, it can be concluded that when
, we have
and converging. From Equation (
28), it follows that
is bounded.
4.3. Time-Varying Communication Switching Topology
The situation of time-varying communication topology in BFMASs control is discussed in this paper. The topology of BFMASs is represented by
, where
. Equation (
6) is revised as follows:
Considering that in the BFMASs, the agent (
1) is constrained by Assumptions 1 and 2, and the time-varying topology is constrained by Assumption 3, the following can be derived from Equation (
19):
Combining with (
47) and the below equation
By repeating the proof process in (2), it can be concluded that
is bounded in a time-varying communication topology system. From Equation (
28), it follows that
is bounded.
5. Simulation Examples
To confirm the efficacy of the proposed design in this study, this section conducts multi-agent bipartite formation control simulations from different perspectives and analyzes the results. In the experiments, the MIMO agents that form the multi-agent system are selected according to Equation (
49). It should be mentioned that Equation (
49) does not contribute to the controller architecture; rather, it exists solely to create the agents’ input-output data. The experimental environment is as follows: CPU—AMD Ryzen 7 5800H, RAM—16 GB, software version—MATLAB2022b.
where
, p=1,2,3,4,5,6,
,
,
.
The trajectory of the virtual leader: .
The desired distance between the virtual leader and each agent is selected as follows:
5.1. Simulation Experiment of BFMASs with a Fixed Topology
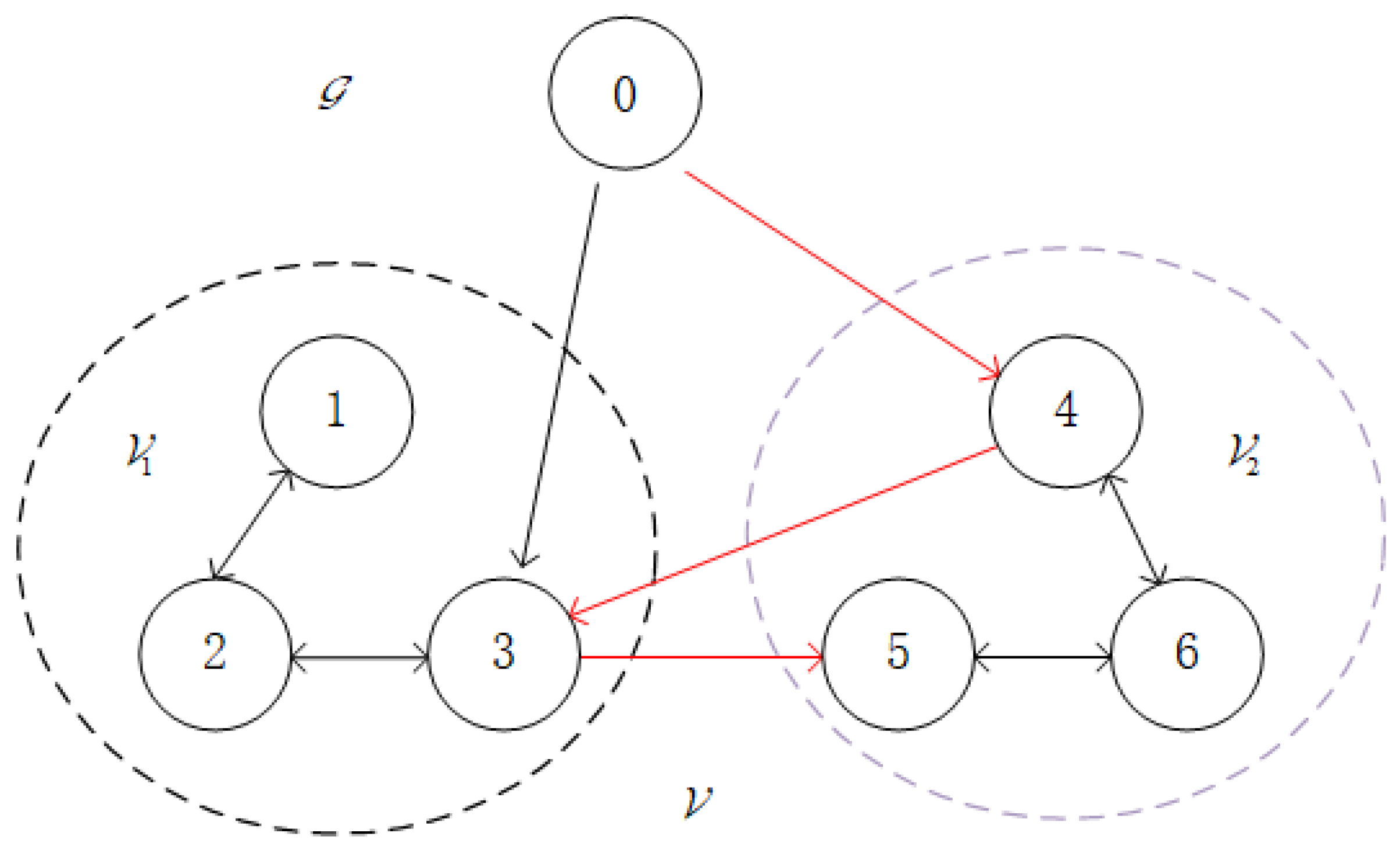
As illustrated in
Figure 1, the BFMASs in the experiment are composed of one virtual leader and six followers, with a communication topology structure. The union of two sets is the directed graph’s vertex set,
, where
and
are the sets of vertices corresponding to the virtual leader and followers, respectively. The agents in set
are assigned the formation control task with the desired trajectory
, while the agents in set
are assigned the formation control task with the desired trajectory
. The Laplacian matrix of this BFMAS is given by:
The matrix of relationships between the agents and the virtual leader is
.
Selecting the initial system output as
Selecting the initial system input as
and the related parameters
,
,
,
. The initial PJM is as
.
5.1.1. Simulation Experiment of BFMASs Under DoS Attacks
In order to confirm the effectiveness of the proposed scheme for BFMASs control under DoS attacks, simulation experiments are conducted using the traditional MFAILC scheme and the proposed DET-MFAILC scheme.
Figure 3 illustrates the periodic DoS attacks on the multi-agent system. The gray areas represent the active periods of the periodic DoS attacks, while the remaining areas represent the dormant periods. During the dormant periods of DoS attacks, the data transmission success rate between agents is set to 0.9, while during the active periods, the success rate is reduced to 0.7.
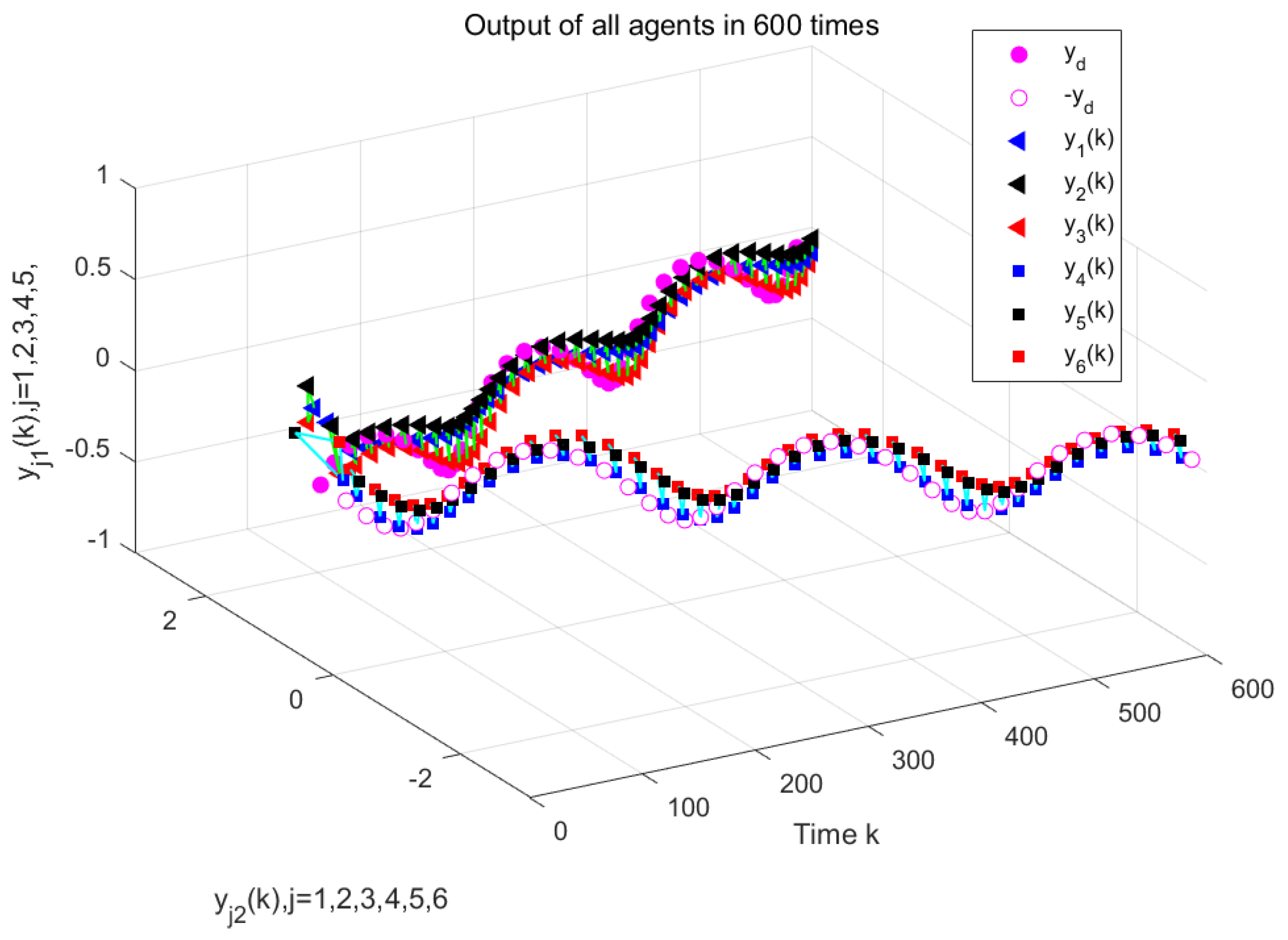
Figure 4 and
Figure 5 show the output results of the multi-agent formation at the 250th iteration and the output curves of each agent along the iteration axis, respectively, under periodic DoS attacks using the traditional MFAILC scheme. It is evident that due to the impact of DoS attacks, the agents do not track the trajectory of the virtual leader. The maximum tracking error of each agent along the iteration axis is shown in
Figure 6. It can be observed that the maximum tracking error of each agent cannot converge to an ideal range.
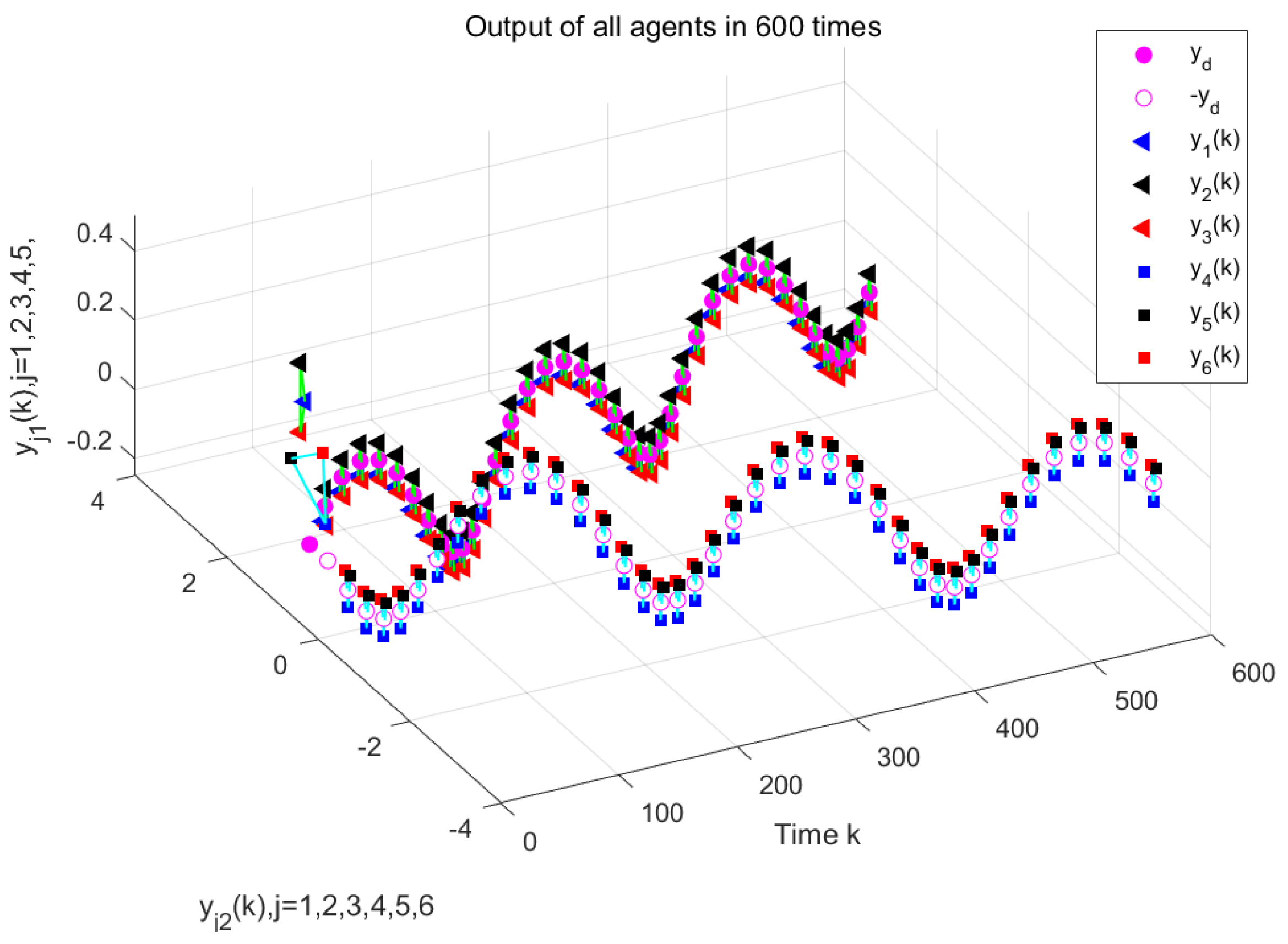
Figure 7 and
Figure 8 depict the output of the system under the MFAC algorithm with the same parameter conditions.
Figure 9 and
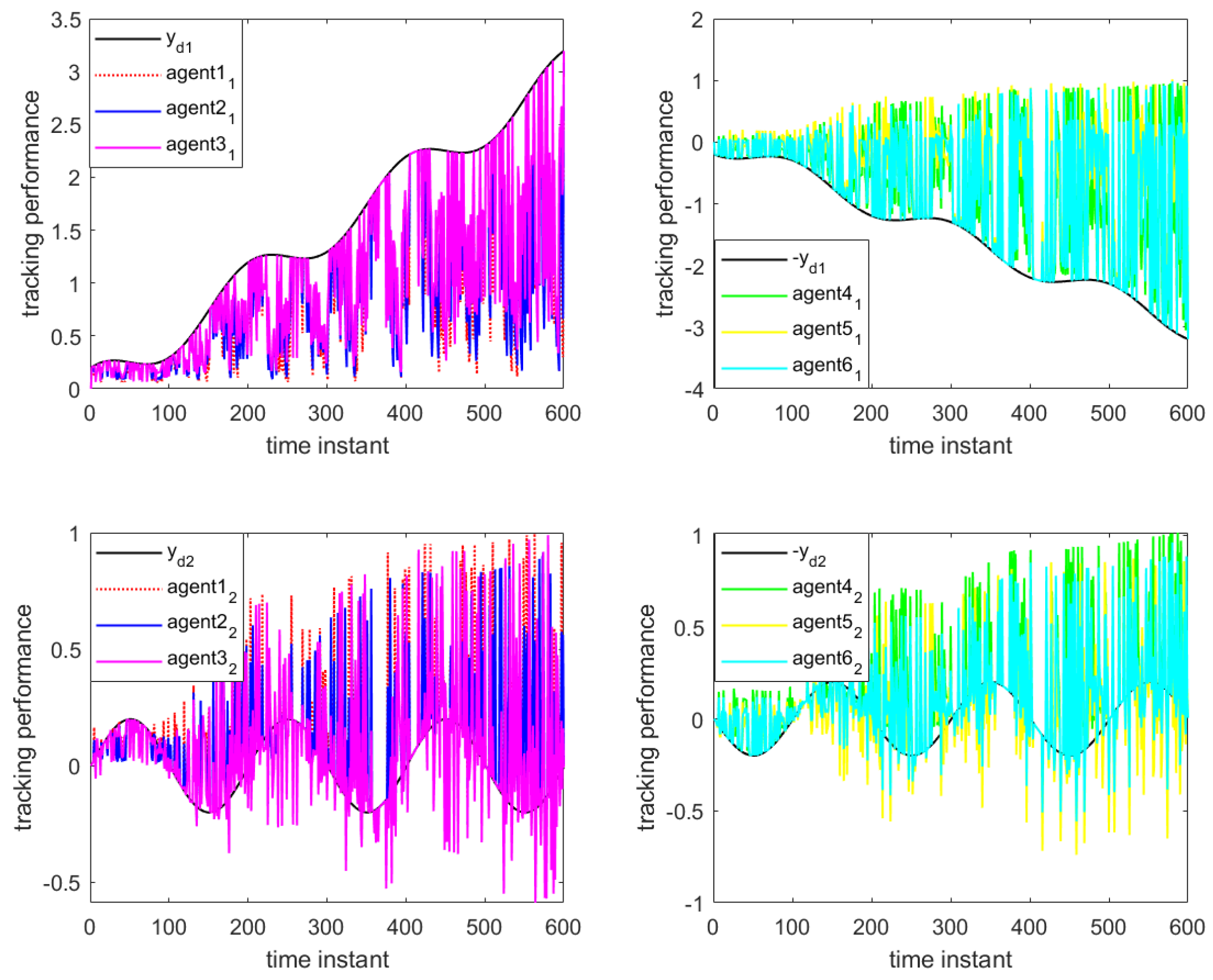
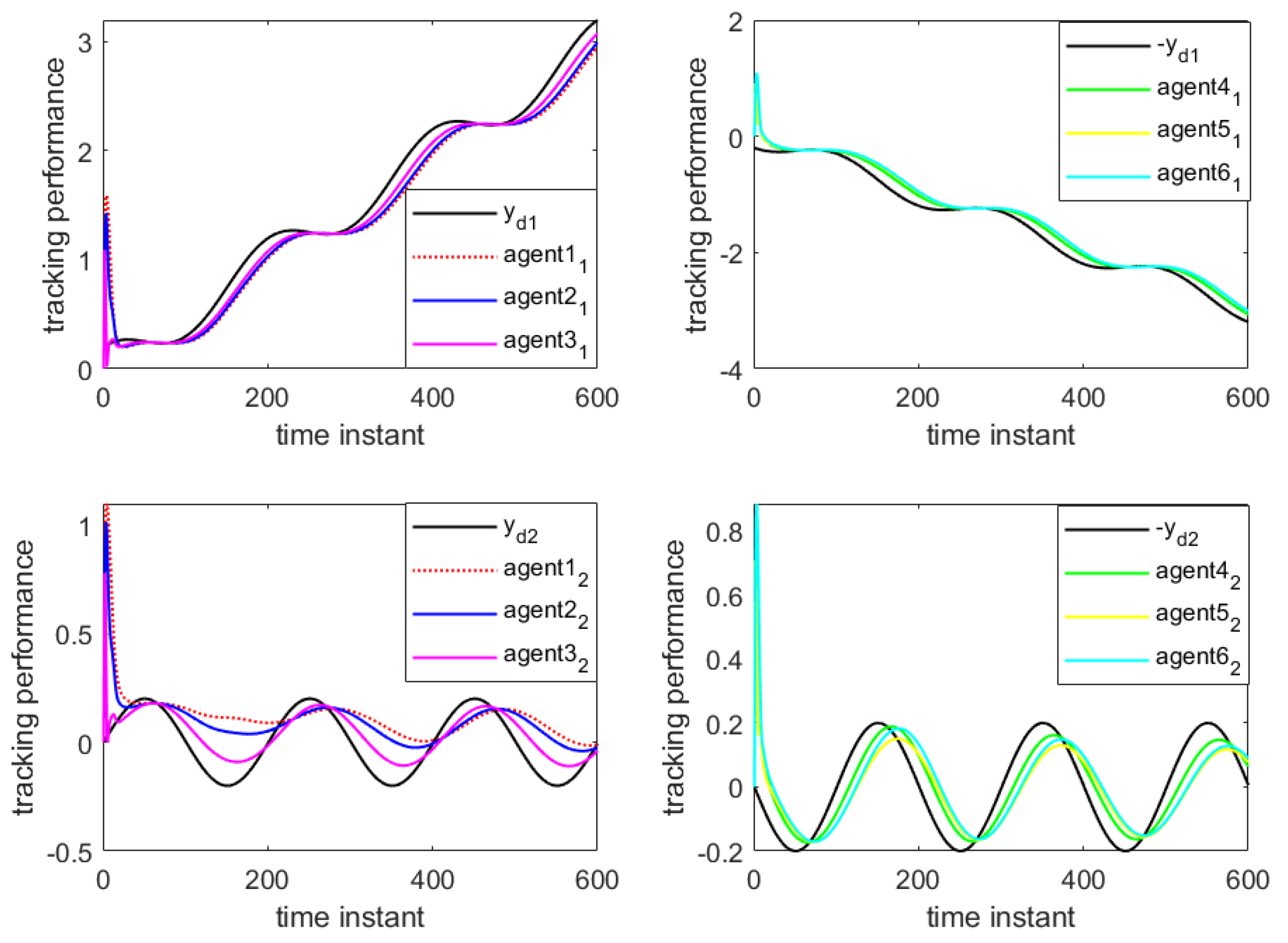
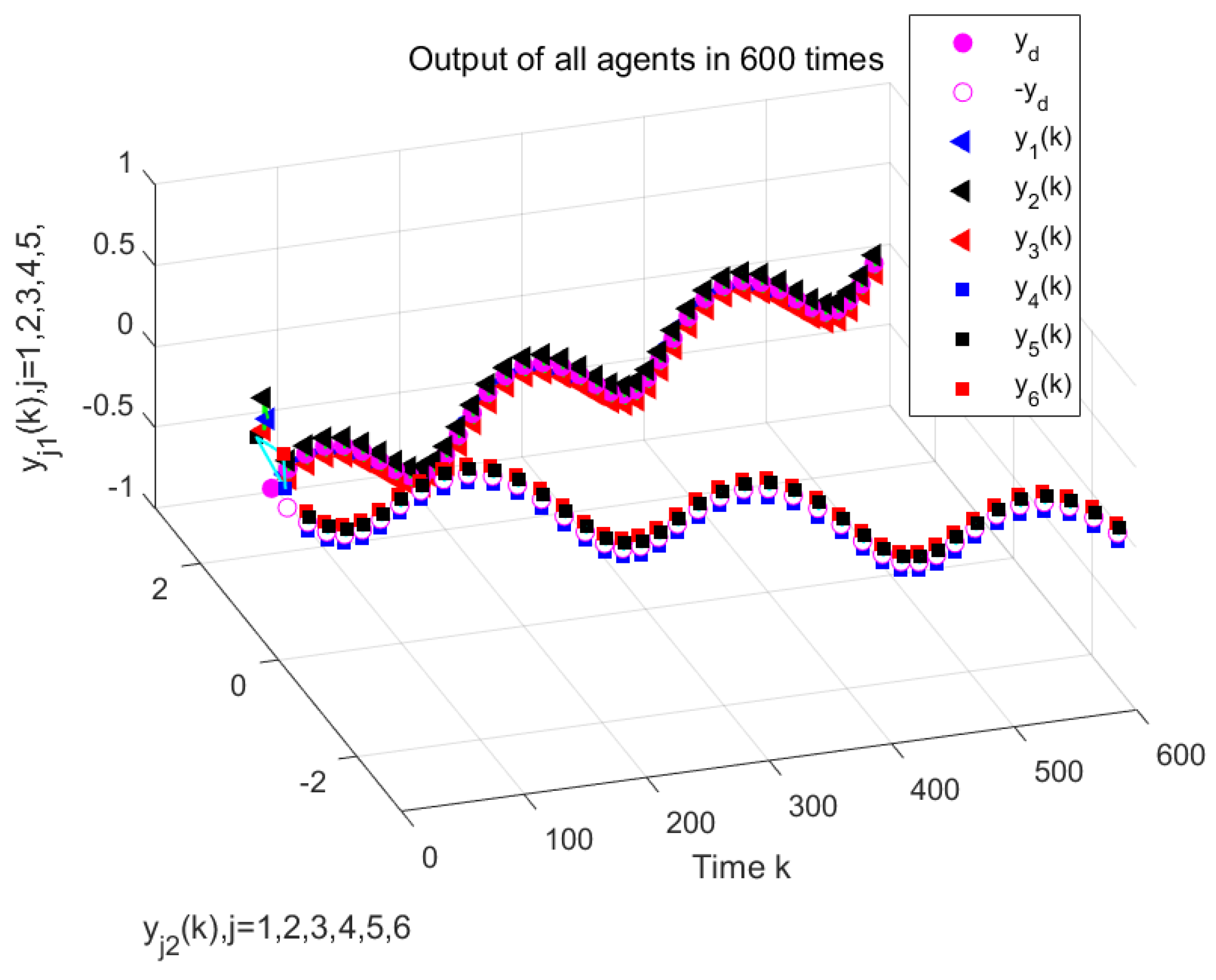
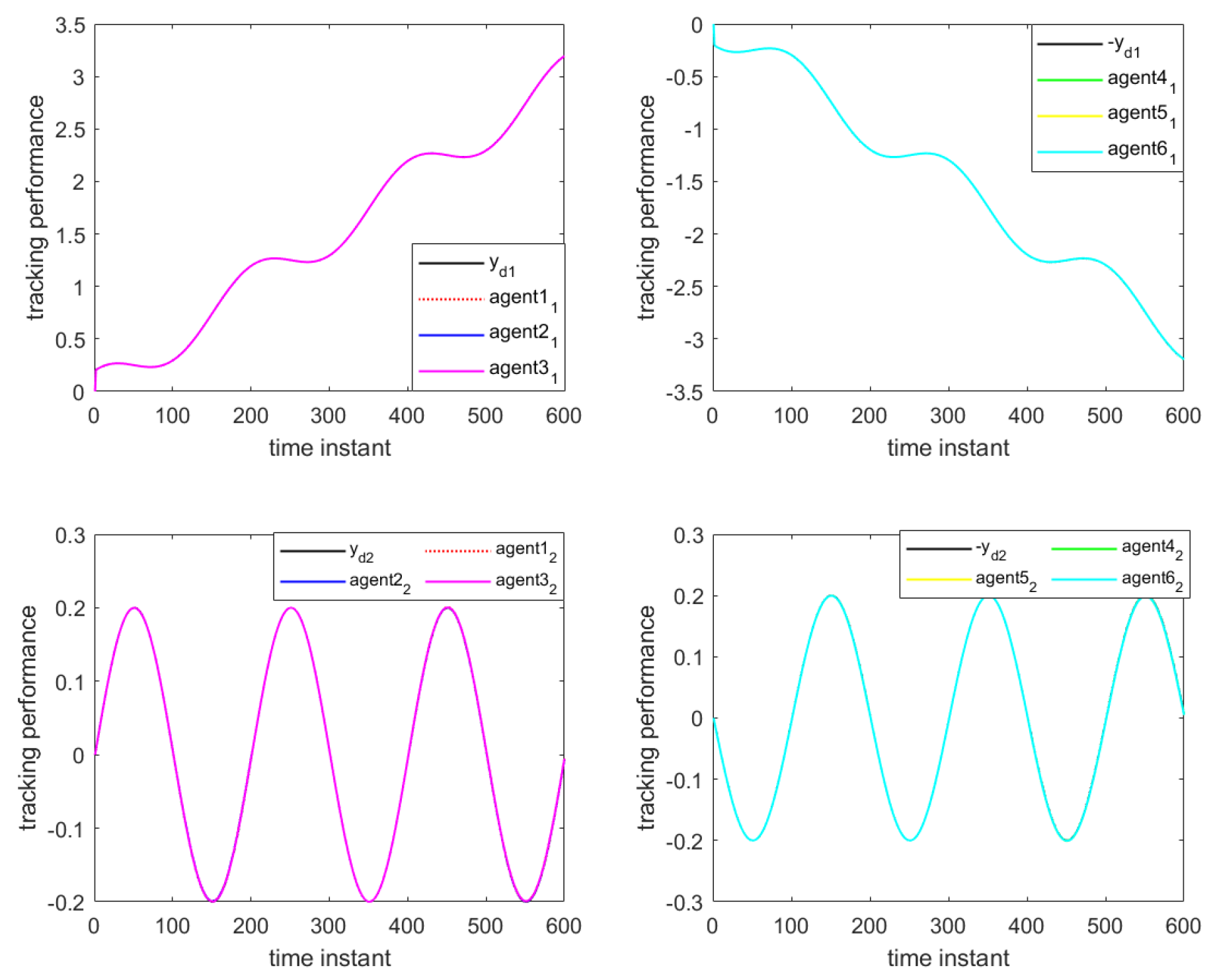
Figure 10 illustrate the formation control results at the 280th iteration and the output curves of each agent, respectively, using the proposed DET-MFAILC scheme with the DoS attack compensation mechanism under DoS attacks. It can be observed that the agents in the bipartite formation system effectively track the trajectory of the virtual leader.
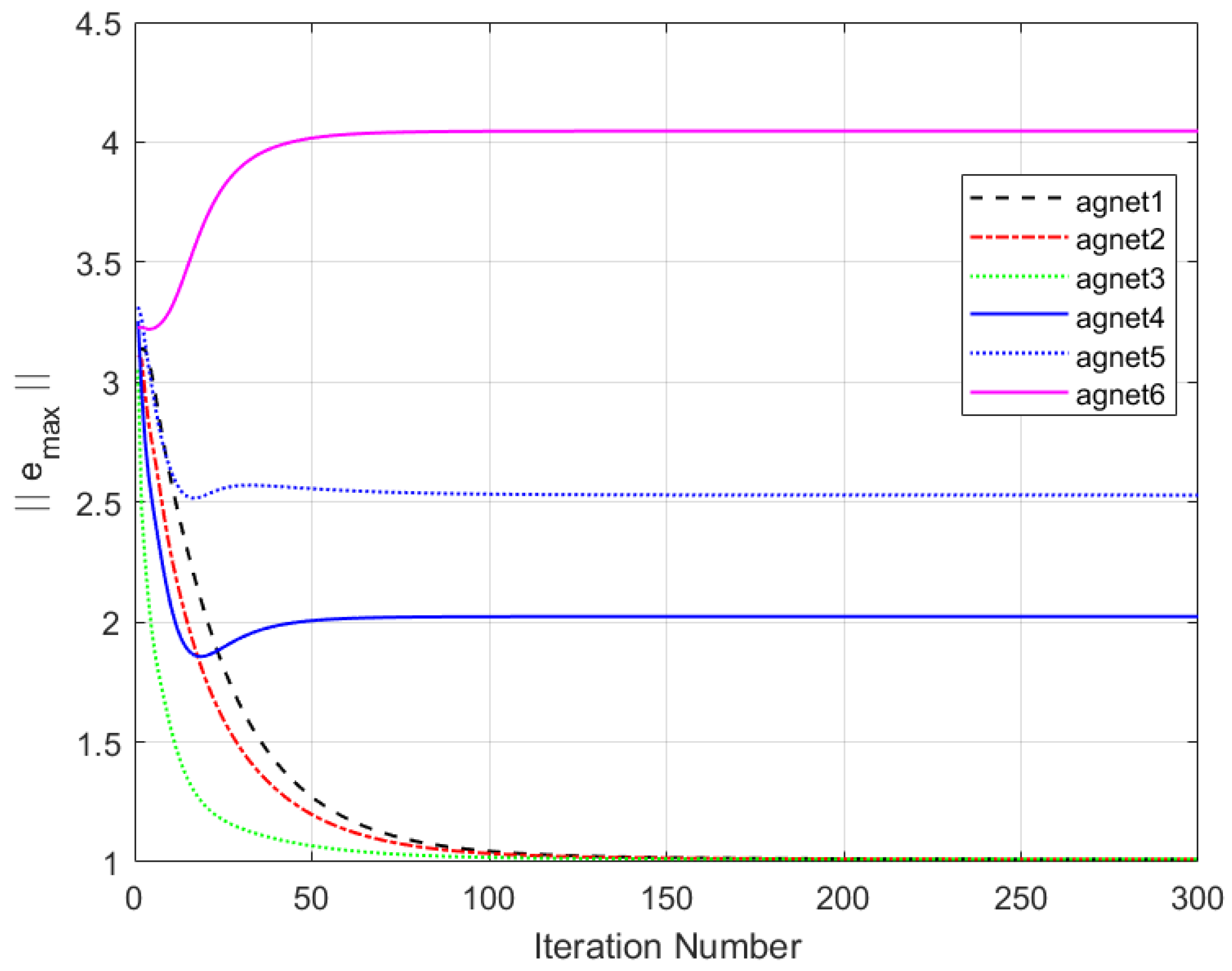
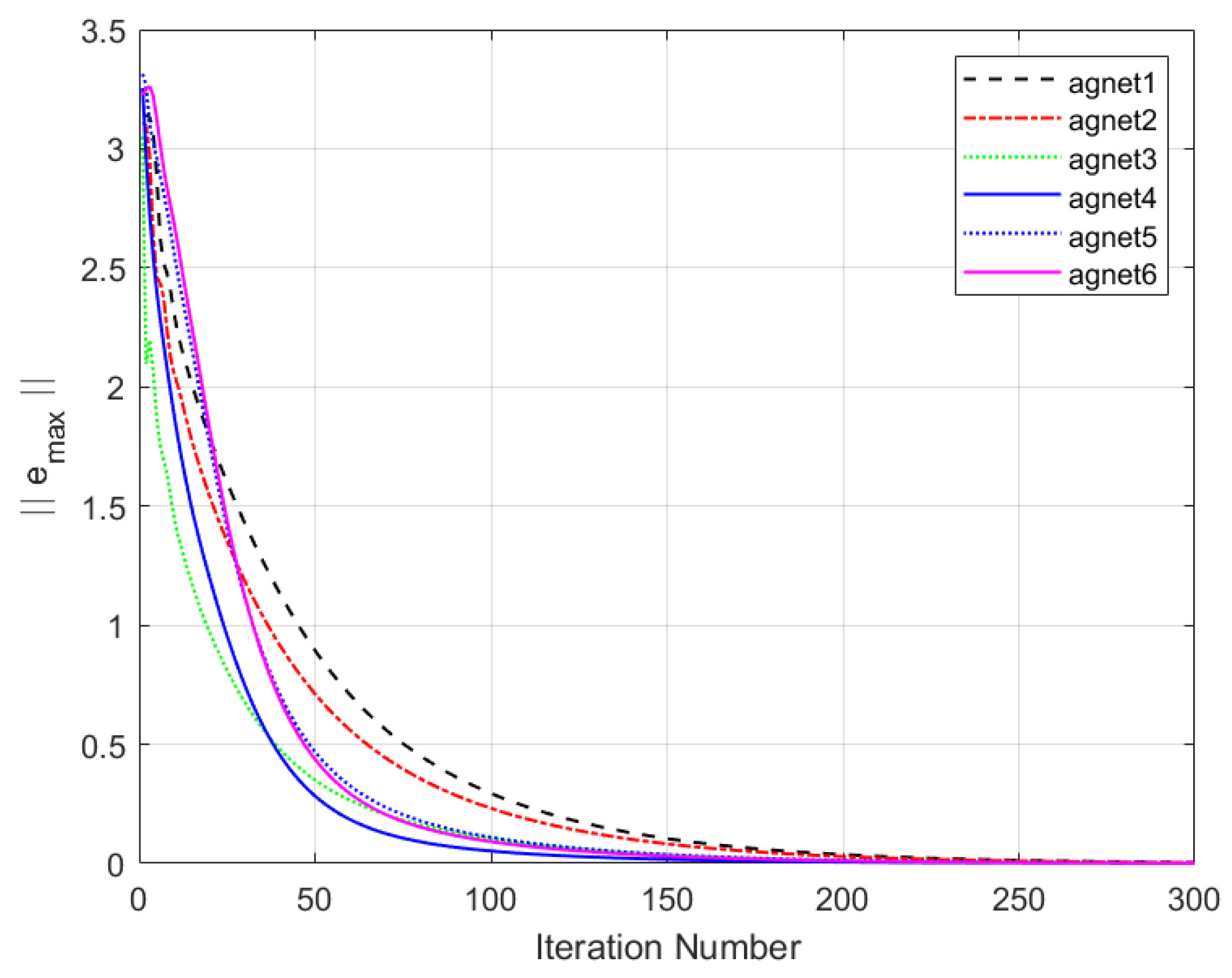
Figure 11 shows the maximum tracking error curves of the agents in this experiment. Despite the impact of DoS attacks, the maximum tracking errors of all agents converge stably and approach zero after 280 iterations. It can be seen that the tracking performance of the MFAC algorithm without the effect of DoS attacks is also significantly weaker than that of this paper.
Figure 12 shows the variation in the mean squared error of
with the number of iterations, showing that it gradually decreases with the number of iterations.
5.1.2. Simulation Experiment of BFMASs Under Different Event-Triggered Condition
Comparing with [
22], this paper incorporates both the consensus error and tracking error into the DET condition, resulting in a new DET condition, as shown in Equation (
9). To verify its effectiveness, simulation experiments are conducted within the DET-MFAILC scheme using the DET condition proposed in [
22] and the improved event-triggered condition proposed in this paper. The experimental results are shown in
Figure 13 and
Figure 14, respectively.
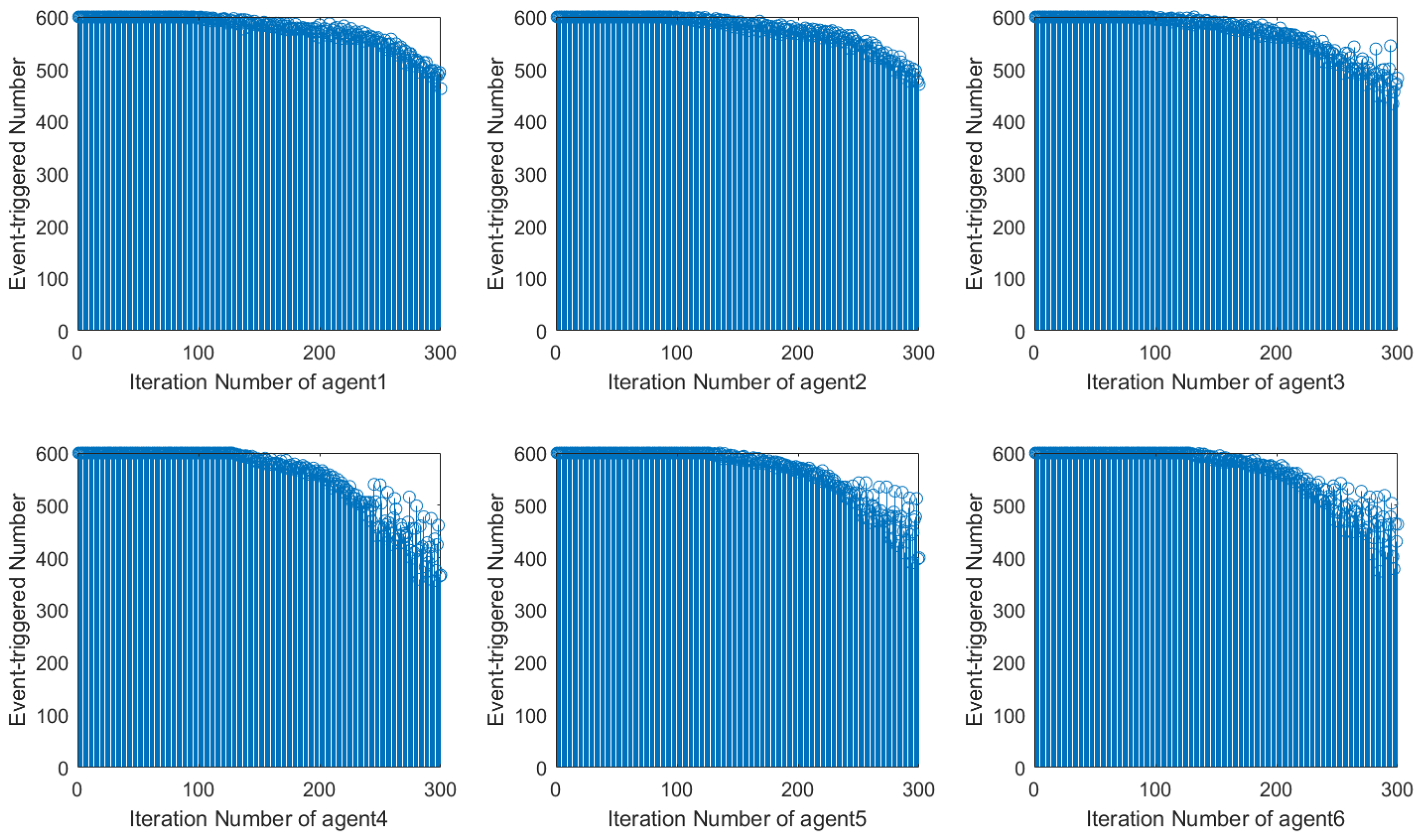
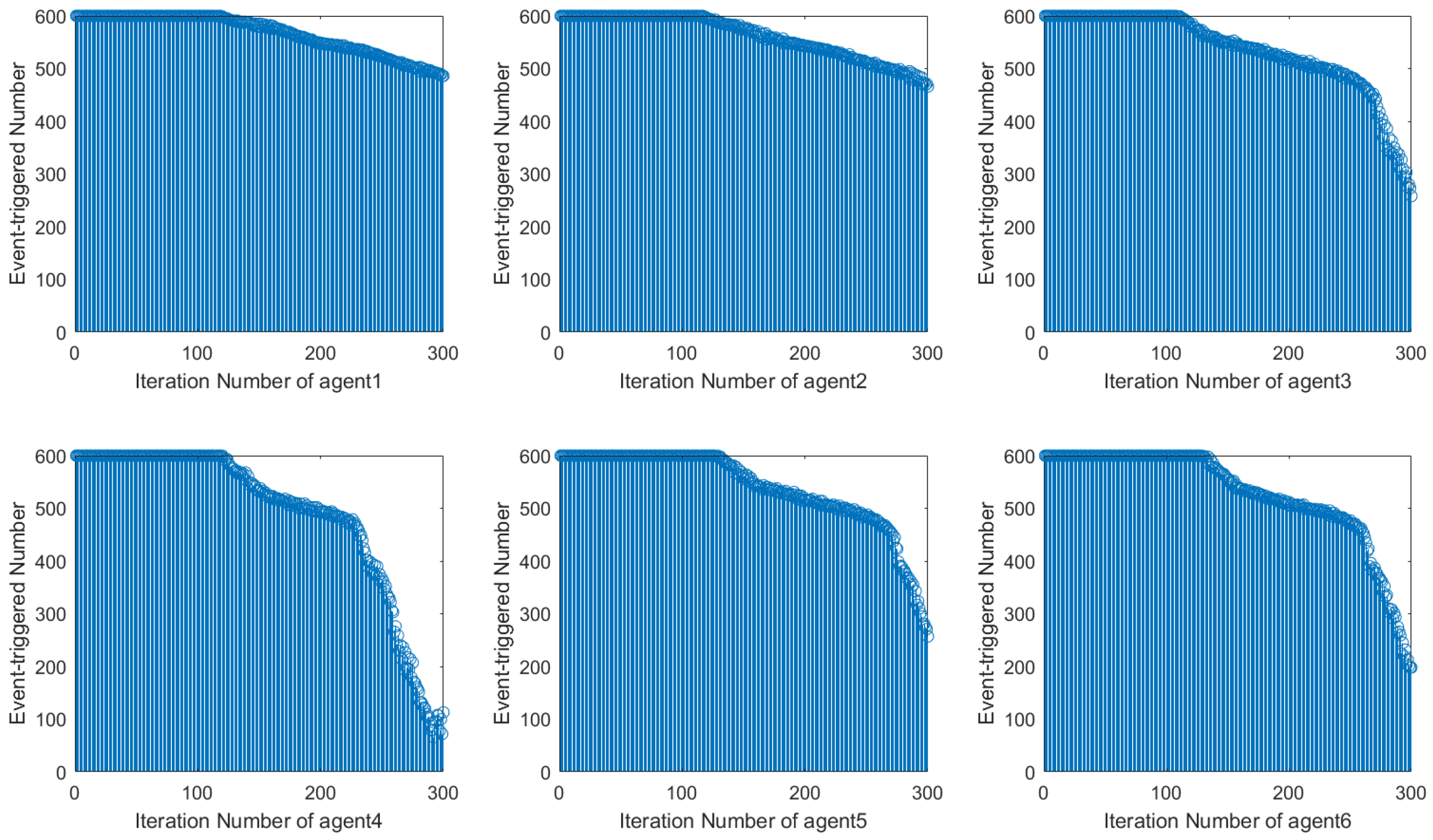
Using the DET condition from [
22], it is evident that the number of event triggers during system operation decreases along the iteration axis but exhibits instability with fluctuations. In contrast, when using the DET condition proposed in this paper, the number of event triggers during system operation stabilizes and decreases significantly after 120 iterations. This shows how the event-triggered condition designed in this paper can more efficiently save network resources by reducing the amount of controller updates.
5.2. Extension to Time-Vraying Topology
This experiment verifies the effectiveness of the proposed DET-MFAILC scheme for controlling the formation of BFMASs with time-varying topologies. In the experiment, all initialization parameters are the same as those for the BFMASs with a fixed topology. The difference lies in that the communication topology of the BFMASs in this experiment is time-varying, as shown in
Figure 15. The pattern of variation in the communication topology is as follows:
The simulation results are shown in
Figure 16,
Figure 17 and
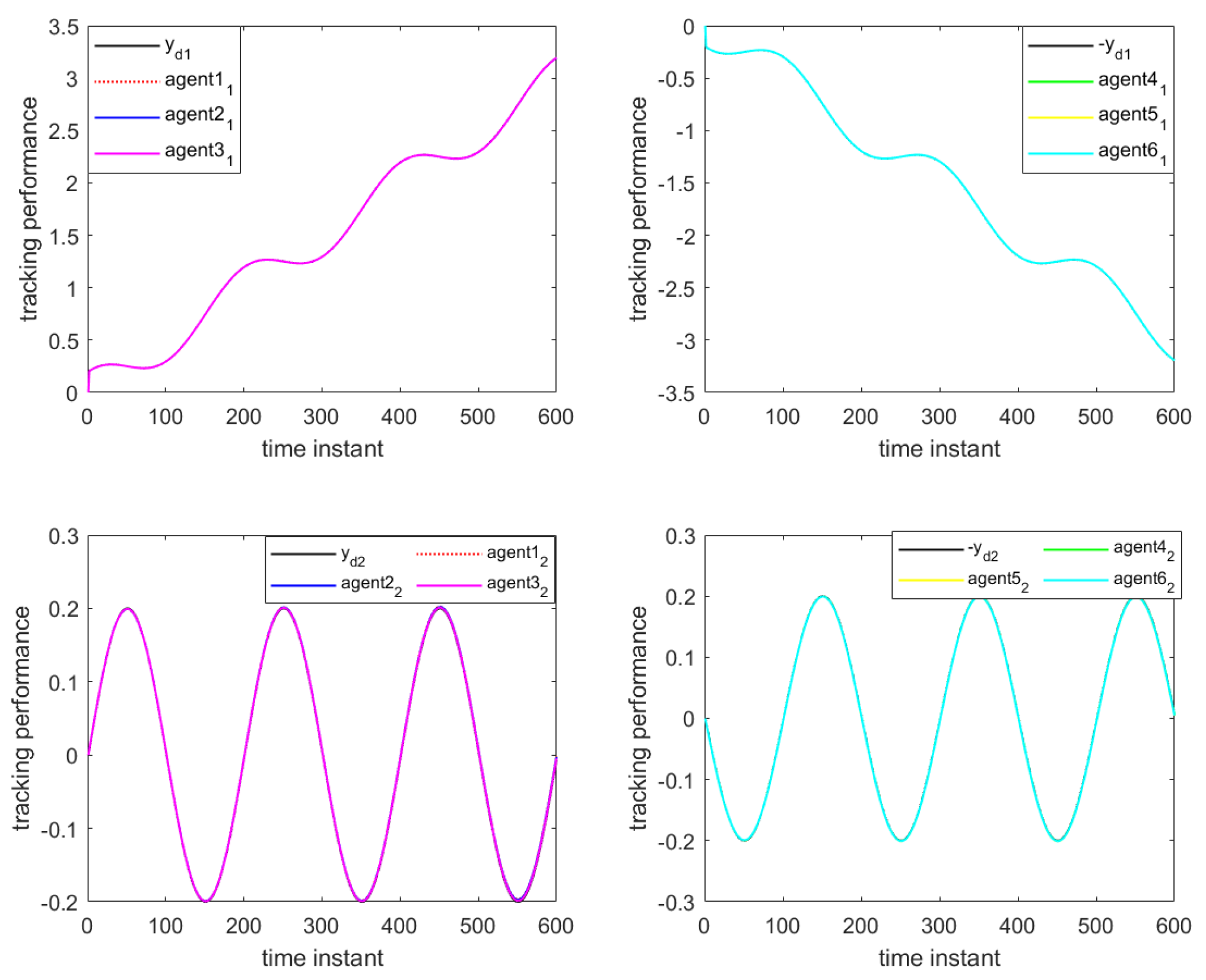
Figure 18. As can be seen in
Figure 16 and
Figure 17, all agents are able to effectively track the leader’s trajectory with good consensus. The tracking errors of the agents converge close to zero after 250 iterations, as shown in
Figure 18. Furthermore, the formation shape of the agents is well maintained, as illustrated in
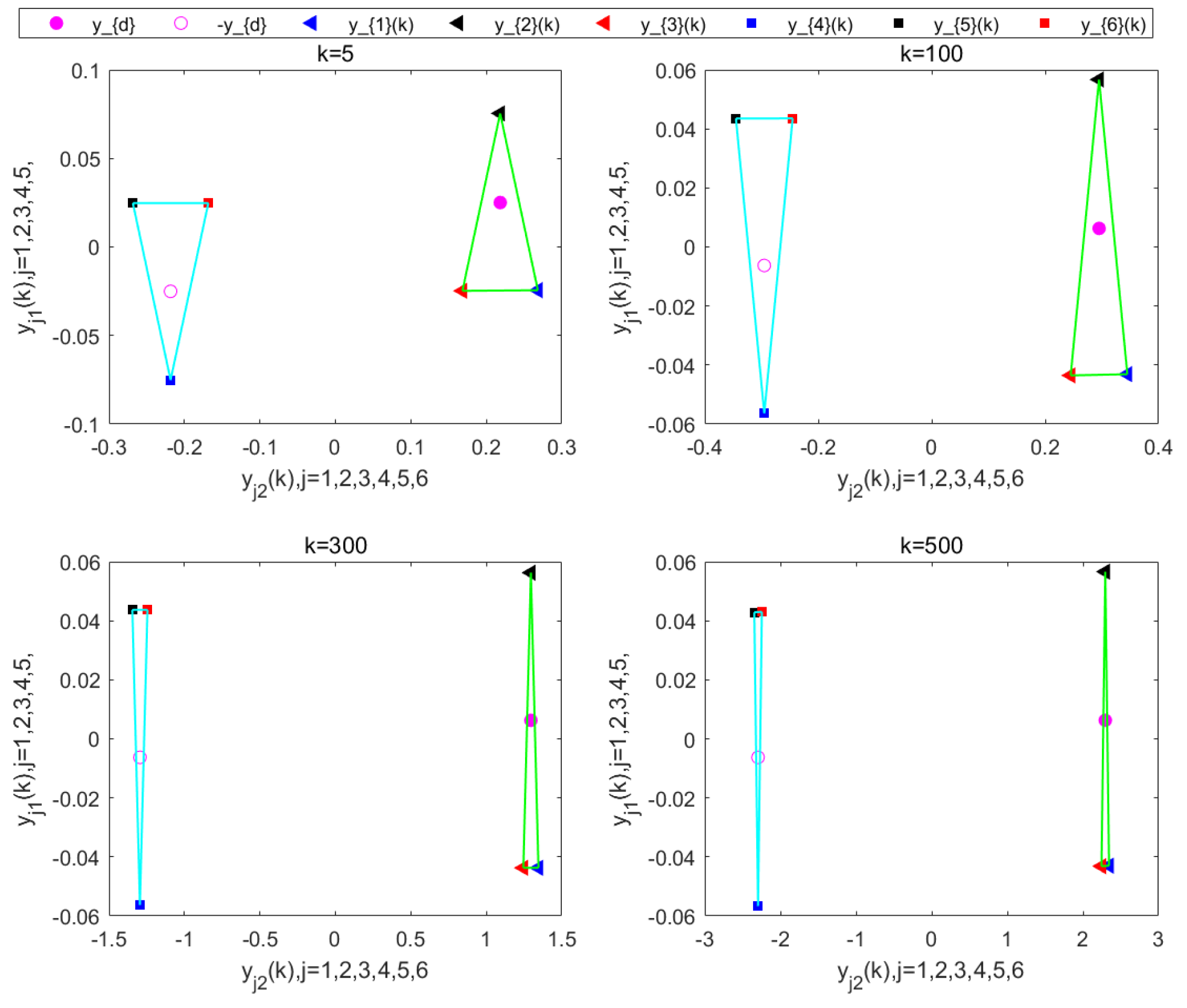
Figure 19. These results verify that the proposed DET-MFAILC scheme also achieves good control performance in the bipartite formation control task of BFMASs with time-varying switching topologies.
6. Conclusions
Unlike most studies that focus on MASs composed of SISO-type single agents, this paper investigates bipartite formation trajectory tracking control MASs composed of MIMO-type single agents, considering the impact of periodic DoS attacks. To mitigate the effects of DoS attacks on bipartite formation systems, a DoS attack compensation mechanism is introduced. To reduce the frequency of controller updates, conserve network resources, and alleviate computational pressure while further enhancing the system’s ability to resist DoS attacks, an event-triggered condition is designed to construct a DET mechanism. The DoS attack compensation algorithm and DET mechanism are combined with the MFAILC method for controller design. Furthermore, this algorithm is extended from fixed topology systems to time-varying topology systems, and the convergence of the system is proven.
The simulation results show that for MIMO-type bipartite formation systems under periodic DoS attacks, the proposed algorithm ensures that the tracking errors and consensus errors of the agents converge to an ideal range close to zero and the formation shape is well maintained. The algorithm effectively suppresses the impact of DoS attacks on the formation system and reduces the frequency of controller updates, thus conserving network resources. Future research will focus on further integrating predictive control to achieve faster system convergence.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}