Abstract
In the context of cybersecurity digital twin environments, the ability to simulate realistic network traffic is critical for validating and training intrusion detection systems. However, generating synthetic data that accurately reflects the complex, time-dependent nature of network flows remains a significant challenge. This paper presents an AI-based data generation approach designed to generate multivariate temporal network flow data that accurately reflects adversarial scenarios. The proposed method integrates a Long Short-Term Memory (LSTM) architecture trained to capture the temporal dynamics of both normal and attack traffic, ensuring the synthetic data preserves realistic, sequence-aware behavioral patterns. To further enhance data fidelity, a combination of deep learning-based generative models and statistical techniques is employed to synthesize both numerical and categorical features while maintaining the correct proportions and temporal relationships between attack and normal traffic. A key contribution of the framework is its ability to generate high-fidelity synthetic data that supports the simulation of realistic, production-like cybersecurity scenarios. Experimental results demonstrate the effectiveness of the approach in generating data that supports robust machine learning-based detection systems, making it a valuable tool for cybersecurity validation and training in digital twin environments.
1. Introduction
Keeping pace with the detection of increasingly sophisticated cyberattacks, while simultaneously ensuring that the underlying systems and technologies remain up to date, is a significant challenge. A critical enabler for advancing cybersecurity defences lies in the development of realistic adversarial environments for testing and validation. However, creating such environments requires specialized expertise, access to resources for emulating emerging threats, and the ability to replicate critical system assets without disrupting normal operations. In this context, digital twin technology has emerged as a transformative tool, offering virtual replicas of physical systems to mirror their behaviors, communications, and vulnerabilities.
Digital twins in cybersecurity demand high-fidelity synthetic data that preserves both the statistical and temporal characteristics of real-world network traffic. Preserving temporal characteristics in synthetic network data is essential for accurately modeling user and system behaviors over time, which is fundamental for effective cybersecurity analysis [1,2]. Maintaining these temporal dependencies ensures that the generated data reflects realistic patterns of network activity, such as attack sequences or normal usage trends. This fidelity is crucial for developing, testing, and validating security solutions, as it enables the detection of sophisticated threats and supports the evaluation of defense mechanisms in environments that closely resemble real-world conditions like digital twins [3]. In the context of cybersecurity, digital twins and replicas rely on high-fidelity data to accurately simulate network behaviors and attack scenarios. Without realistic data that preserves temporal dependencies and multivariate relationships, digital twins may fail to capture the complexity of real-world threats, limiting their utility for forensic analysis.
Despite recent advances, current methods for generating attack-related data remain limited. Deep generative models, in particular, struggle to effectively capture the complex interplay between temporal dynamics and their associated statistical distributions [4,5,6]. These limitations are especially critical in digital-twin-based cybersecurity simulations, where accurately modeling both the evolution of attacks and their statistical realism is essential for reproducing sophisticated adversarial behaviors [7]. Consequently, existing approaches hinder the ability to simulate truly realistic adversarial scenarios within digital twin environments.
1.1. Research Contribution
To address these challenges, this work proposes a novel hybrid AI-based framework for multivariate temporal network flow data generation, specifically tailored for cybersecurity digital twin environments. The proposed method combines the strengths of LSTM networks and state-of-the-art generative models, enabling the simultaneous preservation of temporal dynamics and statistical realism across diverse feature types.
The main contributions of this work are as follows:
- Hybrid multivariate temporal generation method: We introduce a modular hybrid framework that leverages LSTM networks to model temporal features, capturing sequential dependencies across network flows and ensuring temporal coherence in attack patterns. For non-temporal features, the framework employs complementary generative models, with the best-performing technique selected based on dataset characteristics. Experimental results demonstrate that TVAE achieves the best performance on the CICFlowMeter dataset, while Gaussian Copula performs best on OCPPFlowMeter, both outperforming CTGAN. This adaptive strategy enables the joint preservation of temporal dynamics and multivariate statistical distributions.
- Decoupled temporal and static feature modeling: A key innovation of the proposed method is its architectural decoupling of sequence-aware pattern modeling from the modeling of static or non-temporal feature values. By isolating the temporal dimension and assigning it to a dedicated LSTM-based module, the framework ensures that the sequential nature of network flows is learned independently of the statistical modeling of other features. This modular design enhances scalability and flexibility, allowing for targeted optimization of each component. It also enables the system to be easily adapted to different network environments and attack scenarios.
- Comprehensive Experimental Validation: The proposed framework is evaluated using multiple network flow datasets, including CICFlowMeter [8] and OCPPFlowMeter [9], both containing labeled traffic data for various cyberattack types. The evaluation assesses the statistical fidelity, temporal realism, and overall utility of the generated data. A combination of quantitative metrics is used to measure the realism and generalization capacity of the synthetic data. The results demonstrate the effectiveness of the hybrid approach in generating high-quality, temporally coherent synthetic network flows that are suitable for training, testing, and validating AI-driven cybersecurity systems, including intrusion detection system (IDS) solutions.
1.2. Article Structure
The remainder of this paper is organized as follows. Section 2 introduces a brief overview of the generative methods used in this research. Section 3 reviews related work on synthetic data generation methods and cybersecurity simulation approaches, as well as their current limitations. Section 4 presents the identified limitations in the literature and the motivation behind our research, and the formal definition of our method for generating multivariate temporal synthetic network flow attack data. Section 5 details the implementation, including the infrastructure and resources used for validation, as well as the validation methodology employed. This section also presents and analyses the experimental results. Section 6 offers a discussion of the findings, and Section 7 concludes the paper with a summary and outlines directions for future research.
2. Background: Synthetic Data Generation Techniques
This section provides a brief overview of the generative techniques used in this research.
2.1. Long Short-Term Memory (LSTM)-Based Models
LSTM networks are a class of recurrent neural networks (RNNs) designed to model long-range temporal dependencies using gated memory cells [10]. During training, LSTMs learn to predict the next probable value in a time series, making them suitable for generating synthetic sequences with autoregressive or periodic behavior. Their ability to retain contextual information over long time horizons supports the creation of temporally coherent data.
In this work, sequences are constructed using a fixed window size and a defined stride to capture relevant temporal patterns for learning. However, pure LSTM-based generators can suffer from mode collapse and instability, especially with complex or inconsistent temporal dynamics.
2.2. Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs), introduced by [11], consist of a generator–discriminator deep learning network pair trained in an adversarial configuration to produce synthetic data that is identical to real samples. For time series, approaches like TimeGAN [4] extend GANs by incorporating recurrent networks to better preserve temporal relationships. GAN-based methods are powerful for generating high-fidelity synthetic data and modeling complex distributions. However, they often struggle with training stability and preserving temporal dependencies, especially in high-dimensional, multivariate datasets such as network flows with attack patterns.
In this work, we complement GANs with LSTM-based temporal modelling and other statistical generators to address these limitations and ensure both temporal coherence and statistical realism in synthetic network data.
2.3. Tabular Variational Autoencoder (TVAE)
Variational autoencoders (VAEs) generate synthetic data by learning a probabilistic latent space from which new samples can be drawn [12]. The Tabular VAE (TVAE) variant [13] builds upon the VAE framework by incorporating flexible likelihood functions and latent space constraints, enabling it to effectively model heterogeneous tabular data. TVAE is particularly effective at reproducing feature-level statistical distributions, making it well-suited for structured datasets such as network flow logs. However, both VAEs and TVAEs often struggle to capture rare or complex patterns, which limits their effectiveness in terms of modeling adversarial behaviors such as those seen in APT-like attacks.
In this work, we address these limitations by combining TVAE with LSTM-based temporal modeling to enable more realistic and attack-aware synthetic data generation, while also incorporating additional generative techniques to enhance performance and adaptability.
2.4. Statistical Methods: Gaussian Copula Models
Statistical methods like the Gaussian Copula generate synthetic data by first estimating the distribution of each feature and then modelling how they are related using a copula function [14,15]. This approach is computationally efficient, especially for capturing linear correlations between variables. It works well for static datasets where relationships can be described using correlation matrices. However, it assumes a Gaussian (normal) distribution, which theoretically makes it less effective for modeling nonlinear, temporal, or complex dependencies, as these are essential features for simulating realistic network attacks in cybersecurity digital twins.
In this work, we use Gaussian Copula as one of the components in our hybrid synthetic data generation framework, particularly for modeling non-temporal features where it performs well. To overcome its limitations in capturing attack patterns and temporal dynamics, we combine it with LSTM-based models and other generative techniques, ensuring a more accurate and behaviorally rich synthetic dataset.
3. Related Work
Faleiro et al. [16] emphasize the transformative potential of digital twins in cybersecurity, noting their ability to virtualize physical systems and provide real-time visibility into system status, processes, and functions through data integration from their physical counterparts. They identify two primary use cases: (i) intrusion detection systems (IDSs), where digital twins enhance security through advanced monitoring and historical data analysis, and (ii) simulation, testing, and training, where digital twins enable the creation of emulated environments for attack simulation and security preparedness. Furthermore, the authors highlight that future research should focus on exploring more complex network environments and systems of systems, rather than isolated assets, to fully realize the benefits of digital twins in cybersecurity.
Homaei et al. [17] review the application of digital twins in the cybersecurity domain, focusing on the use of Artificial Intelligence (AI) technologies for this purpose. The paper discusses several limitations related to integrating AI and machine learning (ML) with digital twins, such as challenges in incorporating real-time data, maintaining data integrity, and adapting to changes in the physical environment. The most significant issue identified is the integration of dynamic, real-time data, along with maintaining both data integrity and reliable data flow.
Epiphaniou et al. [18] present a proof-of-concept for critical infrastructure, demonstrating how digital twins can enhance the resilience of cyber-physical systems (CPSs) by simulating attacks and evaluating resilience metrics. They note that model-based approaches often lack precise representations of adversarial behaviors in complex attacks. Additionally, they highlight the inherent ambiguity in modern cyber infrastructures, where modeling incomplete observations poses a significant challenge when characterizing threat sources.
Dietz and Pernul [19] identify three modes of operation for a security-focused digital twin: data analysis and optimization, simulation, and replication. The replication-based model of digital twins is particularly noteworthy, as it enables digital tracing of real-world events by replicating temporal dependencies and utilizing specification data from the physical twin. However, this approach introduces additional complexity and demands specialized knowledge and expertise.
Acquaah and Roy [20] utilize DoppelGANger, a model based on GANs, to generate synthetic data for cyber-physical systems across various domains, with potential applications in cybersecurity. Their work emphasizes the need for further research to enhance the realism of synthetic data and to address challenges in modeling complex environments. One key limitation of their approach is its difficulty in capturing intricate temporal dependencies within the data.
Gatta et al. [21] conducted a study comparing four neural network-based generative methods for multivariate time series generation: Recurrent Conditional GAN (RCGAN), TimeGAN, Conditional Sig-Wasserstein GAN (SigCWGAN), and Generative Moment Matching Networks (GMMNs). Their research spans various domains, including electricity, finance, and industrial production. One of the main challenges they encountered was the instability of GANs during training, often resulting in non-convergence. The authors also emphasize the need to explore alternative models for data generation.
Xu et al. [22] introduce STAN (Synthetic network Traffic generation with Autoregressive Neural models), a tool designed to generate realistic synthetic network traffic. The authors emphasize the importance of validating the model’s ability to capture long-term dependencies and suggest experimenting with larger filters to better model these temporal relationships. For their experiments, they selected a large, publicly available network flow dataset, which includes typical attributes such as timestamps, flow duration, packet and byte counts, source and destination IP addresses and ports, flags, and transport protocol; in summary, ten features commonly found in flow data.
Li et al. [23] introduced Multivariate Anomaly Detection-GAN (MAD-GAN), a model designed for multivariate anomaly detection in time series data. While its primary purpose is detection, MAD-GAN which is built on LSTM-recurrent neural network (RNN) architectures, can also generate multivariate temporal sequences that capture both inter-variable and sequential dependencies, making it suitable for simulating complex attack scenarios in industrial settings. However, the model’s main limitation is its reduced efficiency when handling longer sub-sequences, as using these with LSTM-RNNs significantly increases computational load and slows performance.
Ammara et al. [24] present a comparative study of twelve synthetic network traffic data generation methods. Their analysis shows that GAN-based models, particularly Conditional Tabular GAN (CTGAN) [13] and CopulaGAN, outperform others, while statistical methods like SMOTE (Synthetic Minority Oversampling Technique), are effective at maintaining class balance but fail to capture the complexity of real network traffic. TVAE also demonstrates strong overall performance. The authors note that many synthetic data generation methods struggle to accurately replicate the statistical and temporal characteristics of real network traffic, which limits their practical use. They also observe that non-AI statistical methods are effective for simple traffic patterns and class balance, with low computational cost. The experiments were conducted using the CIC-IDS2017 [25] and NSL-KDD [26] datasets, selecting 26 features from NSL-KDD and 21 from CIC-IDS2017 for data generation.
4. Method for Multivariate Temporal Synthetic Network Flow Data Generation
4.1. Limitations of Existing Approaches and the Rationale of Our Method
Recent reviews of time series analysis for cybersecurity [27] and comparative studies of synthetic data generation methods [21,24] consistently highlight two major gaps in the state of the art: (i) limited ability of existing models to jointly capture temporal dependencies and statistical distributions, and (ii) narrow coverage of network traffic features that reduces the realism of generated data. While deep learning approaches such as GANs and LSTM-RNNs have achieved promising results, they remain computationally demanding and often unstable during training, whereas statistical and variational approaches like TVAE and Gaussian Copula exhibit better stability but lack temporal awareness.
Motivated by these limitations, this work proposes a hybrid AI-based framework for multivariate time series synthetic network flow data generation tailored to cybersecurity digital twins. The hybrid framework was designed to overcome the trade-offs observed in prior approaches between temporal fidelity and statistical realism. The proposed approach leverages the strengths of multiple paradigms:
- LSTM networks are employed to model and generate temporal features, capturing sequential dependencies across flows and ensuring temporal coherence of attack patterns;
- Complementary generative models are selectively applied to non-temporal features, choosing the best-performing technique among GAN, TVAE, and Gaussian Copula according to dataset characteristics. Experimental results show that TVAE achieves the best performance for the CICFlowMeter dataset, while Gaussian Copula performs best for OCPPFlowMeter, both outperforming CTGAN;
- This adaptive hybrid strategy combines LSTM-based temporal modeling with data-driven selection of statistical generators, enabling the joint preservation of temporal dynamics and multivariate statistical distributions across heterogeneous feature types.
A key innovation of the proposed method lies in its architectural decoupling of sequence-aware pattern modeling from the modeling of static or non-temporal feature values. By isolating the temporal dimension and assigning it to a dedicated LSTM-based module, the framework ensures that the sequential nature of network flows is learned independently of the statistical modeling of other features. This separation not only enhances the interpretability and modularity of the system but also allows for more targeted optimization of each component.
This design rationale directly addresses the challenges identified in prior work. Unlike GAN-only generators (e.g., DoppelGANger) [20] or single-architecture frameworks (e.g., STAN or MAD-GAN) [22,23], our hybrid system decomposes the data generation process according to feature type and dependency structure. Furthermore, we extend the feature scope beyond the 21–26 variables used in [24] to 93 features for CICFlowMeter and 53 for OCPPFlowMeter, offering a more comprehensive representation of network behavior.
To strengthen the experimental validation and respond to the need for comparative evidence, we additionally perform a Train on Real, Test on Synthetic (TRTS) evaluation. This assessment quantitatively measures the generalization of machine learning models trained on real traffic when tested on synthetic samples, providing a formal measure of realism. The combination of hybrid design and TRTS validation demonstrates the innovation and robustness of our proposed framework compared to existing state-of-the-art methods.
4.2. Method Formulation
This study introduces a novel hybrid method for generating synthetic network flow data that faithfully replicates the behavior of cyber-attacks across heterogeneous formats, specifically those generated by CICFlowMeter and OCPPFlowMeter. The method is designed to preserve both the temporal dynamics and the statistical properties of real-world traffic, ensuring high fidelity and utility for cybersecurity digital twins.
The proposed approach follows a modular architecture that decouples the modeling of temporal and non-temporal features. Temporal dependencies, which are crucial for capturing the evolution of attack behaviors, are learned using a sequential LSTM model trained on time-ordered network flows. This component captures the temporal distribution of normal and malicious traffic, including multi-class attack scenarios.
In parallel, the modeling of non-temporal features is executed using a combination of deep generative models (e.g., CTGAN and TVAE) and statistical techniques (e.g., Gaussian Copula). These models are applied selectively based on the nature of the features and the characteristics of the dataset. Importantly, the non-temporal modeling is divided by class, resulting in the training of independent synthesizers for each class label. This class-specific synthesis ensures that the generated data is not only statistically accurate but also semantically consistent with the behavioral patterns of each traffic type.
While the primary goal is to reconstruct network flow data that mirrors the original in both structure and behavior, the modular design also supports alternative use cases. Particularly, the class-specific synthesizers can be used to inject synthetic attack flows into real traffic captured from the physical twin. This enables controlled augmentation of benign datasets with realistic, class-labeled adversarial behaviors, facilitating the development and stress-testing of intrusion detection systems under diverse threat conditions.
To preserve the contextual integrity of network interactions, the synthetic data generation process is organized around a tuple of key attributes: source IP, source port, destination IP, destination port, and protocol. These identifiers are used to group the data into subsets that represent specific asset-level communication patterns. Each subset is treated as a behavioral unit, allowing the model to learn the contextual dynamics of individual assets and their associated services during attack scenarios. This grouping strategy ensures that the generated data reflects realistic interactions between network entities, maintaining the structural coherence necessary for effective digital twin simulations.
Figure 1 provides a comprehensive overview of the training pipeline for generating realistic synthetic network flow data using the proposed hybrid framework. The process is structured into a series of well-defined stages, each contributing to the generation of high-quality, temporally coherent, and statistically realistic synthetic data.
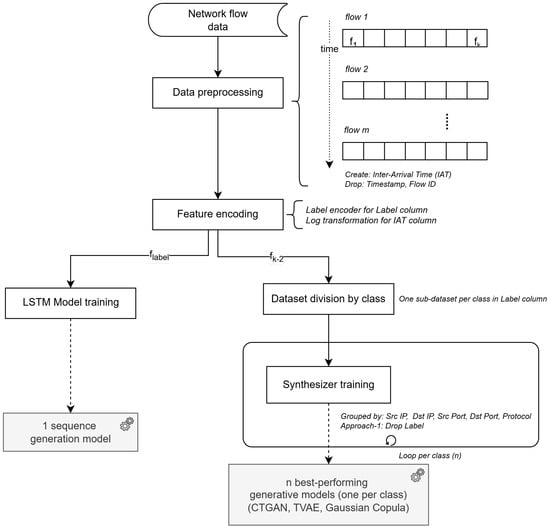
Figure 1.
Training process of generating realistic synthetic network flow data.
The process begins with the ingestion of raw network flow data, sourced from either the CICFlowMeter or OCPPFlowMeter datasets, both of which include labeled traffic data for a range of network behaviors and attack types.
Several preprocessing steps are applied to prepare the data for model training. First, the flows are sorted by timestamp to ensure temporal order. The Inter-Arrival Time (IAT) is computed to capture the temporal spacing between packets, a key indicator of traffic behavior. The timestamp and Flow ID columns are excluded, as they are not relevant to modeling behavioral patterns. The Label column is processed using label encoding to convert categorical class labels into numerical format. Additionally, the IAT column is transformed using a logarithmic transformation to stabilize its distribution and improve model convergence.
An LSTM-based sequence modeling approach is employed to capture temporal dependencies in the data. The training process involves multiple iterations with varied hyperparameters, including window size, stride, and sequence length, tailored to the specific dataset and attack scenario. Appendix A provides details on the LSTM architecture, hyperparameters, and scenario-specific settings used in the experiments presented in the validation section. These parameters were selected based on empirical evaluation and are tailored to the characteristics of each attack type and dataset. The window size defines the number of previous time steps considered for sequence prediction, while the stride determines the step size for sliding the window during training. These settings were optimized to ensure that the model captures both short-term and long-term temporal dependencies in the data.
The dataset is partitioned into class-specific subsets, where each subset corresponds to a unique network behavior (e.g., normal traffic, denial-of-service, flooding, etc.). This class-based division enables targeted training of the synthesizer for each behavior type. For each class, multiple generative models, including both deep learning (e.g., CTGAN and TVAE) and statistical (e.g., Gaussian Copula) approaches, are trained to determine the best-performing synthesizer for that class.
The synthesizer is trained on data grouped by a tuple of key network attributes:
This grouping enables the model to focus on the behavior of specific assets and their associated services within the network, capturing both normal and attack scenarios at a granular level. The selected tuple serves as a unique identifier for each subset, ensuring that asset-level interactions and contextual communication patterns are preserved in the synthetic data.
At this point, one sequence generation model and multiple generative synthesizers per class are implemented. This allows for a comparative evaluation to identify the most effective synthesizer for each class combination, as the optimal generative technique may vary depending on the specific characteristics and relationships present in each subset of the data.
Figure 2 illustrates the reverse process of generating synthetic network flow data from the trained models, focusing on how the synthetic data is sampled and reconstructed to emulate realistic network traffic.
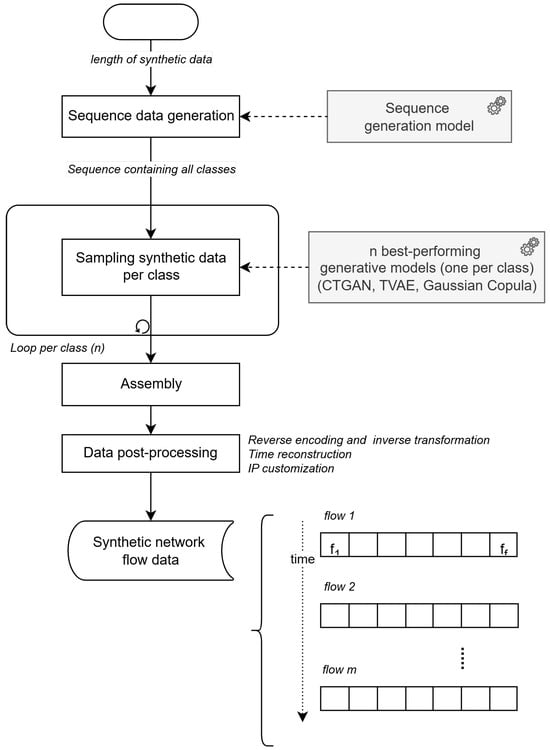
Figure 2.
Sampling and reconstruction process of realistic synthetic network flow data.
The process begins with defining the length of the synthetic sequence to be generated. Using the trained LSTM model, a sequence of class labels is generated, reflecting the distribution of classes present in the original dataset. The LSTM-based approach allows for flexible and context-aware generation of label sequences. Furthermore, optionally, the model can be fine-tuned during inference to adapt the weights and biases of specific classes, enabling customization for particular use cases or scenarios. During the experimental validation no bias has been introduced.
For each class in the generated sequence, the corresponding synthetic data is sampled using the best-performing synthesizer. The sampling process is repeated iteratively for each class in the sequence, maintaining both statistical realism and temporal coherence.
The sampled data is then assembled into a coherent sequence, aligning the generated class labels with their corresponding synthetic flow features. This step reconstructs a complete synthetic network flow that follows the temporal order and behavioral patterns of the original data.
The synthetic data undergoes a series of post-processing steps to reverse the transformations applied during training. These include inverse label encoding to restore the original class names, inverse log transformation to return numerical features to their original scale, and timestamp reconstruction using the generated IAT values to simulate realistic packet timing. At this stage, the base start time can be optionally customized, either set to the current system time or defined by the user of the cybersecurity digital twin. Once the sequence of events is generated, the start time serves as a reference point from which all subsequent timestamps are calculated, ensuring temporal consistency and realism in the synthetic network flow data.
Optionally, IP address attributes can be updated to reflect specific values from the physical twin environment, allowing the synthetic data to be aligned with the actual infrastructure being simulated in the digital twin. This step enhances the operational relevance of the synthetic data in real-world cybersecurity applications.
The result is a fully reconstructed synthetic dataset that closely mimics real network flow behavior, including accurate timing, realistic class distribution, original feature format, and asset-level interactions.
5. Experimental Validation
5.1. Infrastructure
For the experimental validation of the proposed method, we utilized the Katea Computing Platform (KCP) [28], a shared high-performance computing (HPC) infrastructure operated by Tecnalia. KCP was selected not only for its computational capabilities but also because it is a collaborative research platform, specifically designed to support experimentation and innovation across multiple research projects. KCP provides a robust and scalable environment for data-intensive and compute-heavy task. These resources are particularly well-suited for training deep learning models and executing large-scale synthetic data generation workflows.
The software environment was carefully configured to ensure reproducibility and compatibility with the hardware. Python 3.11.6 was used as the primary programming language, managed through a module system. GPU acceleration was enabled via the CUDA Toolkit version 12.2.1, fully leveraging the capabilities of the NVIDIA GPUs. Deep learning tasks were implemented using PyTorch 2.7.1 and TensorFlow 2.16.1.
For synthetic data generation, we employed the Synthetic Data Vault (SDV) framework, version 1.21.0 [15]. SDV was selected due to its comprehensive suite of state-of-the-art generative models, including CTGAN, TVAE, and Gaussian Copula, which are particularly well-suited for tabular data with mixed data types (numerical and categorical). SDV also offers a robust evaluation metrics, making it a practical and reliable choice for research-oriented synthetic data generation.
5.2. Validation Methodology
To experimentally evaluate the proposed method for realistic network flow data generation, the Federated OCPP 1.6 Intrusion Detection Dataset [29] was selected. This dataset is specifically designed for the development and benchmarking of AI-based intrusion detection systems in Industrial Control Systems (ICS), with a focus on the OCPP 1.6 protocol, which is widely used in Electric Vehicle Charging Station (EVCS) communications. The dataset contains labelled network traffic data related to cyberattacks targeting the OCPP 1.6 protocol, and includes a variety of realistic attack scenarios, such as charging profile manipulation, denial of charge, heartbeat flooding (Denial of Service, DoS), and unauthorized access. These scenarios are highly representative of the types of threats faced in ICS environments and are therefore particularly suitable for validating synthetic data generation methods in the context of cybersecurity digital twins.
In addition to the attack-specific data, the dataset includes a comprehensive README file, which provides clear descriptions of all features, their data types, and their relevance to network flow and attack context, enhancing the reproducibility and interpretability of the experimental setup.
The primary objective of the evaluation is to assess the ability of the proposed method to replicate this dataset with high fidelity, generating synthetic data that is statistically and temporally realistic, and suitable for integration into a cybersecurity digital twin environment. Specifically, the evaluation focuses on three representative attack scenarios: charging profile manipulation, denial of charge, and heartbeat flooding, as well as two balanced datasets that include multiple attack classes. This allows for a comprehensive assessment of the method’s performance across both individual attack types and mixed traffic environments.
To quantify the contribution of temporal modeling, we define a baseline in which the same datasets are used to train synthesizers without incorporating temporal dependencies. In this baseline, all features are modeled jointly using statistical or deep generative models, with the data sorted chronologically but without leveraging sequence-aware architectures. The results from our proposed hybrid method, which integrates LSTM-based temporal modelling with class-specific statistical synthesis, are then compared against this baseline. This comparative analysis enables a rigorous assessment of the impact of temporal modelling on the quality, realism, and class fidelity of the generated synthetic data.
5.2.1. Sequence Modeling Evaluation
While LSTM accuracy can indicate predictive performance, it does not adequately reflect how well the generated label sequences replicate real-world event patterns. To evaluate sequence fidelity, token-level Levenshtein similarity has been used, which compares sequences of categorical labels (e.g., “normal”, “attack”) as discrete tokens rather than character strings.
Each substitution, insertion, or deletion was counted as one edit, and the total distance was normalized by the maximum length of the two sequences. This normalization provides an interpretable score representing the proportion of aligned events and is especially suitable for categorical data where partial matches are not meaningful.
Definition 1 (Token-level Levenshtein Similarity (TKS)). Given two sequences of categorical labels a and b, the token-level Levenshtein distance is the minimum number of insertions, deletions, or substitutions needed to transform a into b.
The normalized similarity is defined as:
This metric measures how closely two sequences align, treating each label as an atomic token. A similarity of 1 indicates identical sequences, while lower values reflect greater differences.
This approach is supported by prior work in sequence modelling and symbolic data evaluation [30,31], and allows us to rigorously assess how well the generated sequences preserve the structure and transitions of real attack scenarios.
5.2.2. Synthesizers Evaluation
To evaluate the performance of the synthetic data generation process, several AI-based synthesizers were compared, following the recommendations in [32]:
- Gaussian Copula, which models the joint distribution of variables using Gaussian mathematical functions, capturing statistical dependencies between features.
- CTGAN, which uses a conditional GAN architecture tailored for tabular data.
- TVAE, which leverages a variational autoencoder to learn and sample from the latent distribution of mixed-type tabular data.
The evaluation was conducted using the SDV quality metrics suite [33], which provides standardized tools to assess the fidelity of synthetic tabular data. The following metrics were used:
- Column Shapes (CS): Measures how well the distribution of each individual column in the synthetic data matches the real data.
- Column Pair Trends (CPT): Assesses the preservation of relationships between pairs of columns.
- Overall Score (OS): Represents the average of the previous metric scores.
These metrics provide a comprehensive view of how well the synthetic data captures both the patterns and distributions of the original dataset per class.
To quantify the overall quality of the adversarial data generated prior to sequence modeling, we define the following metric:
Definition 2
(). The mean Overall Score (OS) across the best-performing synthesizers used in a given scenario:
where N is the number of selected synthesizers.
This metric provides a concise summary of the synthetic data quality before temporal dependencies are introduced.
5.2.3. Train-on-Real–Test-on-Synthetic (TRTS) Evaluation
To assess the realism and utility of the generated data, the Train-on-Real–Test-on-Synthetic (TRTS) [34,35] evaluation strategy is employed. In this approach, a machine learning model is first trained on real-world data and subsequently evaluated on synthetic data generated by different methods. If the model maintains comparable performance across both datasets, this indicates that the synthetic samples preserve the key statistical properties, feature dependencies, and relevant relationships present in the real data.
This evaluation method provides an indirect but robust measure of fidelity, particularly relevant in cybersecurity contexts where synthetic data is intended to support tasks such as intrusion detection. By simulating real-world deployment conditions TRTS offers a practical benchmark for assessing the usability of synthetic data.
5.2.4. Evaluation Strategy
For each adversarial scenario included in the demonstration, two complementary metrics are reported: the TKS and the synthetic data quality score (). These metrics are computed for both the proposed hybrid method and the baseline (non-sequential) approach. TKS evaluates the fidelity of the generated label sequences, while quantifies the statistical realism of the synthetic data prior to sequencing. By jointly analyzing these metrics, we assess the impact of temporal modelling on both the structural alignment of event sequences and the statistical quality of the generated data. This dual-metric comparison enables a comprehensive evaluation of the method’s effectiveness in replicating realistic network flow behavior for cybersecurity applications.
In addition to these core metrics, a TRTS evaluation is conducted as a complementary analysis. This approach assesses the utility of the synthetic data in AI-based learning tasks by training classifiers on real data and testing them on synthetic samples. Consistent performance across real and synthetic data serves as further evidence of the data’s realism and applicability in cybersecurity scenarios.
5.3. Results
To provide a comprehensive evaluation, we first present baseline performance metrics for widely used synthesizer models (CTGAN, TVAE, and Gaussian Copula) across the CICFlowMeter and OCPPFlowMeter datasets in Table 1. These results serve as a benchmark for evaluating the performance of our proposed method.

Table 1.
Baseline performance comparison of synthesizer models (CTGAN, TVAE, Gaussian Copula) and sequence modelling (TLS) across CICFlowMeter and OCPPFlowMeter datasets for different attack types.
Appendix B presents the training parameters for the generative models used in the experiments.
The Gaussian Copula model excels in preserving column pair trends, particularly in capturing the relationships between features, although it tends to exhibit lower shape fidelity in certain cases. In contrast, TVAE consistently achieves the highest performance when replicating the CICFlowMeter data type, especially for attack-specific scenarios such as Flooding Heartbeat and charging profile manipulation. CTGAN also performs well in attack-specific datasets but shows reduced effectiveness in balanced, multi-class settings. Sequence modelling, as measured by the TKS, is most effective in attack-specific datasets, where the synthetic sequences closely align with real-world patterns. In contrast, TLS scores drop significantly in multi-class datasets, reaching as low as 0.2689 and 0.2146, indicating that the increased complexity of these datasets hinders the synthesizers’ ability to accurately preserve the temporal structure of the data.
As shown in Table 2, the proposed method demonstrates strong synthetic data generation capabilities across a range of network-based attack scenarios on the CICFlowMeter dataset. The , defined as the average of the best-performing synthesizers per class, ranges from 0.8700 to 0.8879 across the tested attack types. This indicates that the method consistently produces high-quality synthetic data that closely matches the real data in terms of both feature value shape and pair trend preservation.
Table 2.
Comparison of synthesizer performance and sequence modeling performance (TLS) on CICFlowMeter data-based attack scenarios using the proposed method.
The TLS further highlights the method’s ability to preserve sequence realism, with scores ranging from 0.6340 to 0.9266, depending on the complexity of the attack scenario. Notably, Flooding Heartbeat and Charging Profile Manipulation achieve TLS values above 0.90, suggesting that the LSTM-based temporal modelling component is particularly effective in replicating the label sequence patterns of these attacks. In contrast, the balanced multi-class scenario, which involves multiple attack classes and the normal class, shows a lower TLS of 0.6340, likely due to the increased complexity and variability in the data. Nevertheless, this is a significant improvement over the baseline results.
When compared to the baseline models in Table 1, the proposed method demonstrates consistent improvements in both data fidelity and sequence modelling performance. The values for the proposed method are 2–4% higher than those of the best-performing baseline models across all attack types. More significantly, the TLS results show that the proposed method dramatically outperforms the baseline in sequence modeling, particularly in complex and multi-class scenarios. In the balanced dataset, where the baseline TLS was as low as 0.27, the proposed method achieves a TLS of 0.63, a 133% improvement.
Table 3 shows the performance results of the proposed method on the OCPPFlowMeter dataset. The ranges from 0.8965 to 0.9183 across different attack types, indicating high fidelity in comparison to real data. A key observation is that the Gaussian Copula model consistently outperforms CTGAN and TVAE in most attack classes, particularly in Flooding Heartbeat, Charging Profile Manipulation, and Denial of Charge. For instance, in the Flooding Heartbeat attack class, Gaussian Copula achieves an OS of 0.9247, significantly outperforming CTGAN (0.8182) and TVAE (0.8396). Similarly, in the Charging Profile Manipulation class, Gaussian Copula scores 0.9037, compared to CTGAN (0.8161) and TVAE (0.8585). These results suggest that the Gaussian Copula is particularly effective in capturing the statistical shape of features in OCPPFlowMeter data, which is crucial for accurately modelling the behaviour of specific attack types where OCPP protocol is present, like Electric Vehicle Changing Systems (EVCSs).
Table 3.
Comparison of synthesizer performance and sequence modeling performance (TLS) on OCPPFlowMeter data-based attack scenarios using the proposed method.
In the balanced scenario, which includes multiple attack classes and the normal class, Gaussian Copula continues to perform well in most classes. The only exception is the Unauthorized Access class, where CTGAN achieves the highest OS of 0.9438, closely followed by Gaussian Copula with 0.9394. Notably, both models achieve near-perfect CS (Column Shapes) scores, with CTGAN at 0.9890 and Gaussian Copula at 0.9903, indicating that they are highly effective in replicating the distributions of individual features in this class.
The TLS scores further highlight the effectiveness of the LSTM-based temporal modelling component in preserving the realistic structure of attack sequences. The TLS values for OCPPFlowMeter data range from 0.71 to 0.98, with particularly high scores in Flooding Heartbeat (0.9835) and Charging Profile Manipulation (0.9199). These results indicate that the proposed method is capable of accurately replicating the temporal dynamics of attack patterns.
Compared to baseline results, the most significant improvements are observed in the sequence modeling performance (TLS). In the Charging Profile Manipulation scenario, the TLS improves from 0.5410 (baseline) to 0.9199 (proposed method), a 70% increase, indicating a drastic enhancement in temporal alignment. Similarly, in the balanced scenario, the TLS improves from 0.2146 to 0.7109, a 231% increase, showing that the LSTM-based temporal modelling is highly effective in capturing the complex temporal structure of multi-class attack sequences. These improvements are particularly important for realistic adversarial testing, where the ability to simulate real-world attack dynamics is critical.
In the evaluation of the proposed method, the total number of features presents both a challenge and an opportunity for improvement compared to existing approaches in the literature. For the CICFlowMeter dataset, the total number of features is 93, while for the OCPPFlowMeter dataset, it is 53. These totals are obtained by summing the features generated by the deep generative models (CTGAN, TVAE, and Gaussian Copula) and the LSTM-based temporal model, with the Flow ID excluded from the count.
Interestingly, the OCPPFlowMeter dataset consistently achieves higher synthetic data quality scores than CICFlowMeter across all attack scenarios. This may be attributed to its lower feature dimensionality, which allows the synthesizers to generalize more effectively and capture the underlying data structure with greater accuracy. In contrast, the higher feature count in CICFlowMeter introduces increased complexity, making it more challenging for the models to maintain high fidelity in both feature distributions and temporal dynamics.
The proposed method supports data augmentation by incorporating bias attributes into the LSTM model, allowing for controlled adjustment of class representation in the generated sequences. This feature enables users to intentionally amplify the presence of specific attack classes, if needed, to better align with custom simulation scenarios or validation requirements in cybersecurity digital twin applications.
To evaluate the fidelity of the generated data, we applied the TRTS evaluation procedure. Using the proposed hybrid method, LSTM models were trained with the hyperparameters specified in Appendix A to generate label sequences capturing the temporal structure of network flows. For each attack scenario, the best-performing synthesizers, as identified in Table 2 and Table 3, were used to generate high-fidelity synthetic data across both CICFlowMeter and OCPPFlowMeter formats. The generated data was then used to conduct a TRTS evaluation, a standard benchmark for assessing the realism of synthetic data in machine learning tasks.
In this evaluation, the entire synthetic dataset was used for testing, and it was matched in length to the real dataset used for training, ensuring a direct and fair comparison of model performance. This evaluation was conducted using Support Vector Machine (SVM) classifiers, with performance measured in terms of accuracy, precision, recall, and F1-score across the eight attack scenarios, as shown in Table 4.
Table 4.
TRTS Evaluation Results using SVM Classifier.
These results confirm the effectiveness of the proposed method in generating realistic synthetic network flow data that supports robust machine learning model training and assessment.
6. Discussion
This method enables the generation of realistic and temporally coherent adversarial network flow data without being constrained by a fixed time range or dataset size. Unlike traditional static datasets, which are limited in scope and require regeneration, or complex attack emulation processes that is time-consuming, this approach allows this approach offers a scalable and flexible solution for synthesizing network traffic data across diverse adversarial scenarios. A key advantage of this method is its ability to generate continuous, on-demand data, which is particularly valuable in digital twin environments where realistic and dynamic data streams are essential for training and evaluating AI-driven cybersecurity systems.
However, achieving full convergence and closed-loop adaptation in digital twins remains an open challenge. While the proposed framework does not directly address closed-loop control, it provides a foundational step by enabling the synthesis of high-quality, attack-specific network flows that can be integrated and injected into digital twin systems for simulation, validation, and training.
By enabling the realistic injection of adversarial scenarios, the synthetic datasets produced by our model enhance the operational relevance of AI-driven cybersecurity systems such as IDS and Security Information and Event Management (SIEM) solutions. These systems rely heavily on rich, diverse, and representative data to detect evolving and previously unseen attacks.
The method also facilitates the creation of custom synthetic datasets tailored to specific digital twin instances or system configurations, thereby reducing the dependence on costly and often incomplete real-world data collection. Furthermore, through TRTS and TSTR evaluations, the realism and generalization capacity of the generated data can be quantitatively assessed, ensuring that it aligns closely with the statistical and temporal characteristics of real system behaviours.
While the method supports the application of data augmentation techniques, such as introducing bias attributes into the LSTM model to increase the representation of specific classes, it is equally important to preserve the original flow ratios to ensure realism. Maintaining the natural distribution of attack and normal traffic is critical when streaming synthetic data into a cybersecurity digital twin. This enables accurate assessment of how cybersecurity mechanisms perform under realistic conditions, particularly in detecting complex, multi-stage attacks involving multiple and often rare attack classes. Preserving key characteristics such as temporal sequencing is essential to avoid distorting the behavioral patterns that these systems rely on for detection and response.
In addition, other attributes that are not critical to sequence integrity, such as LAN-based IP addresses, can be adapted to match the real assets in the physical twin. This flexibility allows the synthetic data to be aligned with the actual infrastructure being simulated, enhancing the relevance and applicability of the digital twin environment. Importantly, this customization capability is intended as a post-generation tailoring mechanism that enables users to adapt the synthetic data to their specific network topology or asset configuration, rather than a direct component of the generative process itself. In the present work, all generative models were trained exclusively on publicly available and anonymized datasets, ensuring that no private identifiers or confidential network information are ever introduced or replicated. Consequently, there is no risk of identifier leakage or disclosure of sensitive endpoint structures within the generated data. In future applications, if this methodology is applied to proprietary or organization-specific datasets, it is essential that developers implement privacy-preserving preprocessing steps, such as IP anonymization, before applying our method. This ensures that the generated synthetic data remains free of IP identifiers while still maintaining statistical and structural fidelity.
In addition to privacy challenges, the adversarial robustness of AI-based solutions must also be considered. In the current landscape of cybersecurity, adversarial testing frameworks such as the Adversarial Robustness Toolbox (ART) provide essential tools for evaluating and improving the resilience of deep learning models as part of a broader threat assessment process within the software development lifecycle. While the focus of this work is on synthetic data generation for digital twin environments, these considerations are increasingly relevant for the secure deployment of AI-driven cybersecurity systems.
Previous research has highlighted that using pure LSTM models for synthetic data generation can be computationally intensive and time-consuming, especially for long temporal sequences or large datasets. To address this, the proposed method strategically limits the use of LSTM to temporal feature generation, where its strengths are most effective. For other feature types, such as categorical and numerical attributes, the best-performing generative models for each class are selected based on their efficiency and statistical fidelity, such as TVAE and Gaussian Copula, as demonstrated in Section 5.3.
While this hybrid approach still demands considerable computational resources, particularly for high-dimensional or complex datasets, it optimizes resource use compared to relying solely on LSTM networks. Moreover, it allows for flexible adaptation to the unique characteristics of different datasets and attack scenarios. Notably, Gaussian Copula, while requiring significant memory at training time for complex datasets, has low inference-time computational demands, making it a promising candidate for real-time or near-real-time synthetic data generation in network flow applications.
7. Conclusions
This work presents a scalable, flexible, and realistic approach to generating synthetic network flow data for adversarial scenarios in digital twin environments. By combining LSTM-based temporal modeling with class-specific deep generative models, it ensures both statistical accuracy and temporal coherence in the synthetic data. The ability to customize and align data with real-world infrastructure, makes this approach particularly suitable for cybersecurity training, validation, and simulation.
A key finding is the importance of maintaining the natural ratio and sequencing of attack and normal traffic, as this directly impacts the realism and utility of synthetic data when used in digital twin environments. The method’s flexibility allows for the adaptation of non-critical attributes, such as LAN-based IP addresses, to match the real assets in the physical twin, thereby enhancing the relevance and applicability of the synthetic data to specific infrastructures.
Given that pure LSTM-RNN models for synthetic data generation can be computationally intensive and time-consuming, the approach in this study adopts a hybrid solution: LSTM networks are used specifically to replicate temporal dependencies, while the remaining features are generated using the best-performing statistical or AI methods suited to the characteristics of each dataset. Moreover, our hybrid approach incorporates best-performing generative techniques to maximize fidelity and efficiency.
By interlinking tabular and multivariate aspects while preserving temporal relationships, the usability and reliability of synthetic data for cybersecurity applications are significantly enhanced. Furthermore, the ability to generate realistic and representative synthetic data lays a strong foundation for the development of robust cybersecurity solutions and the effective use of digital twins in threat detection and response.
Future research may explore the generation of additional data types and the simultaneous modeling of multiple system layers to create a more comprehensive digital twin of the physical counterpart. This includes not only network flow data but also application-layer logs, host-based telemetry, and other relevant sources that contribute to a holistic view of system behavior. By synthesizing diverse data streams in parallel, digital twins can more accurately reflect the complexity and interdependencies present in real-world environments. Such advancements will further enhance the realism, applicability, and effectiveness of synthetic data for cybersecurity testing, threat detection, and response in increasingly sophisticated and layered infrastructures.
Future work may explore optimization and model compression techniques to further reduce computational overhead without compromising generation quality.
Author Contributions
Conceptualization, E.I. and J.A.; methodology, E.I.; software, E.I., J.A. and G.G.; validation, E.I. and J.A.; investigation, E.I. and J.A.; resources, E.I., G.G., J.A. and E.R.; data curation, E.I.; writing—original draft preparation, E.I.; writing—review and editing, E.I., J.A., E.R. and N.T.; supervision, E.R. and N.T.; project administration, E.R.; funding acquisition, E.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work has received funding from the European Union’s Horizon Europe research and innovation program under grant agreement No 101070455 (DYNABIC).
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. LSTM Model Architecture and Hyperparameters
This appendix provides information on the LSTM-based model architecture used for temporal sequence generation in the proposed hybrid framework.
The model architecture is summarized in Table A1, where the following notations are used:
- B denotes the batch size, which is the number of sequences processed in parallel during training or inference. In the experiments, a batch size of 64 was used.
- W denotes the sequence length or window size, which is the number of time steps in each input sequence. The values of W are specified per attack type in Table A2.
Table A1.
Overview of the label sequence generator model layers.
Table A1.
Overview of the label sequence generator model layers.
| Layer | Input/Output Size | Function |
|---|---|---|
| Input Layer | (B, W) | Accepts label indices as input |
| Embedding Layer | (B, W, 32) | Maps labels to dense vectors of size 32 |
| LSTM Layer | (B, W, 256) | Captures temporal dependencies |
| Dropout Layer | (B, 256) | Regularization to reduce overfitting |
| Dense Output Layer | (B, n) | Outputs class probabilities over n classes |
In addition to the model architecture, Table A2 summarizes the dataset-specific hyperparameters used for training the LSTM model across different attack types. These include the window size, stride, and dataset type (CICFlowMeter or OCPPFlowMeter).
Table A2.
Attack-specific hyperparameters for LSTM sequence generation.
Table A2.
Attack-specific hyperparameters for LSTM sequence generation.
| Attack | Dataset Type | Window | Stride |
|---|---|---|---|
| Flooding Heartbeat | CICFlowMeter | 28 | 0.1 |
| Flooding Heartbeat | OCPPFlowMeter | 16 | 0.2 |
| DoCharge | CICFlowMeter | 16 | 0.3 |
| DoCharge | OCPPFlowMeter | 16 | 0.4 |
| Charging Profile Manipulation | CICFlowMeter | 16 | 0.3 |
| Charging Profile Manipulation | OCPPFlowMeter | 32 | 0.01 |
| Balanced | CICFlowMeter | 32 | 0.01 |
| Balanced | OCPPFlowMeter | 32 | 0.06 |
Appendix B. Generative Model Training Parameters
This appendix provides the training parameters used for the generative models in the synthetic network flow data generation process. These parameters were empirically selected to balance model performance and training stability.
- CTGAN
- –
- Epochs: 400–700 (with model checkpoints saved periodically)
- –
- Batch size: 500
- –
- Embedding size: 64
- –
- Generator network dimensions: [128, 128]
- –
- Discriminator network dimensions: [128, 128]
- TVAE
- –
- Epochs: 400–700 (with model checkpoints saved periodically)
- –
- Batch size: 500
- –
- Embedding size: 64
- Gaussian copula: gaussian_kde distribution has been used (kernel density estimation with gaussian kernel)
CTGAN and TVAE were trained for a similar number of epochs, with checkpoints used to select the best-performing model. The embedding dimensions and network layer sizes were tuned based on the complexity of the dataset. The Gaussian Copula model uses a non-parametric distribution.
References
- Li, G.; Jung, J.J. Deep learning for anomaly detection in multivariate time series: Approaches, applications, and challenges. Inf. Fusion 2023, 91, 93–102. [Google Scholar] [CrossRef]
- Schmidl, S.; Wenig, P.; Papenbrock, T. Anomaly detection in time series: A comprehensive evaluation. Proc. VLDB Endow. 2022, 15, 1779–1797. [Google Scholar] [CrossRef]
- Pokhrel, A.; Katta, V.; Colomo-Palacios, R. Digital twin for cybersecurity incident prediction: A multivocal literature review. In Proceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, Seoul, Republic of Korea, 27 June–19 July 2020; pp. 671–678. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Alzahrani, N.; Cała, J.; Missier, P. Experience: A comparative analysis of multivariate time-series generative models: A case study on human activity data. ACM J. Data Inf. Qual. 2024, 16, 18. [Google Scholar] [CrossRef]
- Brophy, E.; Wang, Z.; She, Q.; Ward, T. Generative adversarial networks in time series: A survey and taxonomy. arXiv 2021, arXiv:2107.11098. [Google Scholar] [CrossRef]
- Empl, P.; Koch, D.; Dietz, M.; Pernul, G. Digital twins in security operations: State of the art and future perspectives. ACM Comput. Surv. 2024, 58, 18. [Google Scholar] [CrossRef]
- Engelen, G.; Rimmer, V.; Joosen, W. Troubleshooting an intrusion detection dataset: The CICIDS2017 case study. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), Piscataway, NJ, USA, 27–27 May 2021; IEEE: New York, NY, USA, 2021; pp. 7–12. [Google Scholar]
- Dalamagkas, C.; Radoglou-Grammatikis, P.; Bouzinis, P.; Papadopoulos, I.; Lagkas, T.; Argyriou, V.; Goudos, S.; Margounakis, D.; Fountoukidis, E.; Sarigiannidis, P. Federated detection of open charge point protocol 1.6 cyberattacks. arXiv 2025, arXiv:2502.01569. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Patki, N.; Wedge, R.; Veeramachaneni, K. The synthetic data vault. In Proceedings of the 2016 IEEE international conference on data science and advanced analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; IEEE: New York, NY, USA, 2016; pp. 399–410. [Google Scholar]
- Faleiro, R.; Pan, L.; Pokhrel, S.R.; Doss, R. Digital twin for cybersecurity: Towards enhancing cyber resilience. In Proceedings of the International Conference on Broadband Communications, Networks and Systems, Melbourne, Australia, 28–29 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 57–76. [Google Scholar]
- Homaei, M.; Mogollón-Gutiérrez, Ó.; Sancho, J.C.; Ávila, M.; Caro, A. A review of digital twins and their application in cybersecurity based on artificial intelligence. Artif. Intell. Rev. 2024, 57, 201. [Google Scholar] [CrossRef]
- Epiphaniou, G.; Hammoudeh, M.; Yuan, H.; Maple, C.; Ani, U. Digital twins in cyber effects modelling of IoT/CPS points of low resilience. Simul. Model. Pract. Theory 2023, 125, 102744. [Google Scholar] [CrossRef]
- Dietz, M.; Pernul, G. Unleashing the digital twin’s potential for ics security. IEEE Secur. Priv. 2020, 18, 20–27. [Google Scholar] [CrossRef]
- Acquaah, Y.; Roy, K. Realistic synthetic dataset generation for cyber-physical systems: A performance evaluation. Discov. Appl. Sci. 2025, 7, 719. [Google Scholar] [CrossRef]
- Gatta, F.; Giampaolo, F.; Prezioso, E.; Mei, G.; Cuomo, S.; Piccialli, F. Neural networks generative models for time series. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 7920–7939. [Google Scholar] [CrossRef]
- Xu, S.; Marwah, M.; Arlitt, M.; Ramakrishnan, N. Stan: Synthetic network traffic generation with generative neural models. In Proceedings of the International Workshop on Deployable Machine Learning for Security Defense, Virtual Event, 15 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 3–29. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 703–716. [Google Scholar]
- Ammara, D.A.; Ding, J.; Tutschku, K. Synthetic Network Traffic Data Generation: A Comparative Study. arXiv 2024, arXiv:2410.16326. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; IEEE: New York, NY, USA, 2009; pp. 1–6. [Google Scholar]
- Landauer, M.; Skopik, F.; Stojanović, B.; Flatscher, A.; Ullrich, T. A review of time-series analysis for cyber security analytics: From intrusion detection to attack prediction. Int. J. Inf. Secur. 2025, 24, 3. [Google Scholar] [CrossRef]
- KATEA Blue Prints. Available online: https://katea.digital.tecnalia.dev/docs/hpc/overview/ (accessed on 23 September 2025).
- Dalamagkas, C.; Radoglou-Grammatikis, P.; Bouzinis, P.; Papadopoulos, I.; Lagkas, T.; Argyriou, V.; Sarigiannidis, P. Federated OCPP 1.6 Intrusion Detection Dataset. IEEE Dataport 2025. [Google Scholar] [CrossRef]
- Yujian, L.; Bo, L. A normalized Levenshtein distance metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef] [PubMed]
- Navarro, G. A guided tour to approximate string matching. ACM Comput. Surv. (CSUR) 2001, 33, 31–88. [Google Scholar] [CrossRef]
- Miletic, M.; Sariyar, M. Challenges of using synthetic data generation methods for tabular microdata. Appl. Sci. 2024, 14, 5975. [Google Scholar] [CrossRef]
- DataCebo, Inc. Synthetic Data Metrics; DataCebo, Inc.: Boston, MA, USA, 2016. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar] [CrossRef]
- Stenger, M.; Leppich, R.; Foster, I.; Kounev, S.; Bauer, A. Evaluation is key: A survey on evaluation measures for synthetic time series. J. Big Data 2024, 11, 66. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).