
Reactive Power Optimization of a Distribution Network Based on Graph Security Reinforcement Learning



Abstract
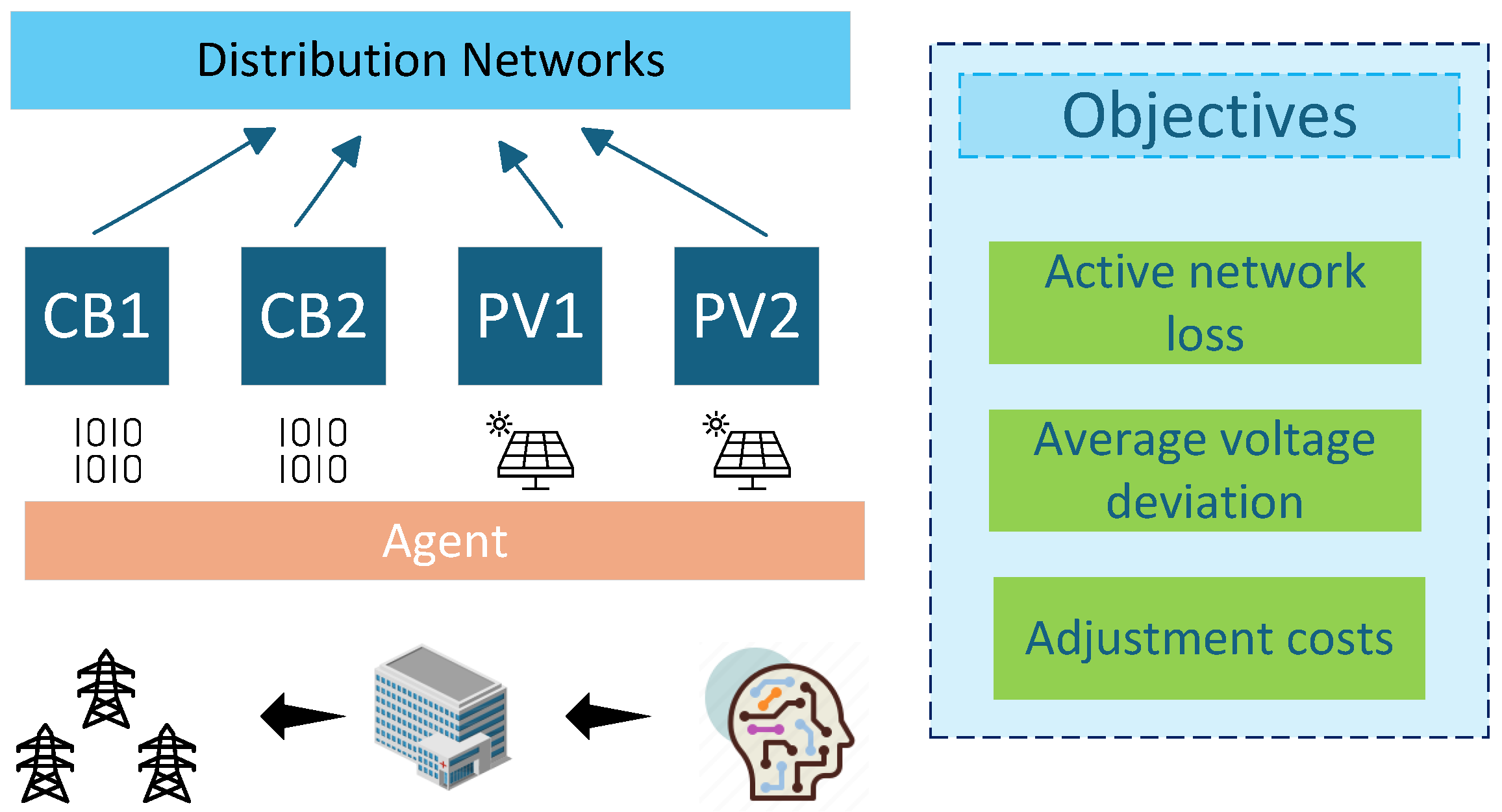
1. Introduction
- We model Secure Reactive Power Optimization under DER fluctuations as a Constrained Markov Decision Process, explicitly incorporating voltage security limits.
- A graph-enhanced neural network extracts both topological and nodal features, improving agent awareness of spatial dependencies.
- We introduce a cost critic network alongside the reward critic, using a primal-dual update to enforce safety constraints without manual penalty weight tuning.
- On an improved IEEE 33-bus test case with real load and PV data, our method outperformed standard DDPG and TD3 in both safety (no voltage violations) and efficiency (lower network losses).
2. Problem Description and System Models
2.1. Problem Formulation
2.2. Distribution Network Models and Equipment Models
2.3. Safety Constraints for Reactive Power Optimization
2.4. Constrained Markov Decision Process
2.4.1. State Space
2.4.2. Action Space
2.4.3. Transition Probability
2.4.4. Reward Function
2.4.5. Constraints
3. Reactive Power Optimization Method Based on Graph Security Reinforcement Learning
3.1. Security Graph DDPG Algorithm
| Algorithm 1 Safe graph DDPG algorithm. |
Require: Hyperparameters: EPISODES, STEPS, TEST, LR_ACTOR, LR_CRITIC, dual_variable, dual_variable_lr, obs_dim, act_dim, memory_capacity, batch_size, var, , , constraint_limit
|
3.2. Graph Convolutional Network
3.3. Actor Network
3.4. Reward Critic and Cost Critic Networks
3.5. Dual Variable
4. Case Study
4.1. Introduction to Testing System
4.2. Result and Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| The 1st and 2nd capacitor banks installed in the distribution network | |
| The 1st and 2nd photovoltaic inverters installed in the distribution network | |
| Branch current magnitude between node i and j | |
| Voltage magnitude at node i at time t | |
| Reference voltage value |
| Resistance of the branch between node i and j | |
| Switching cost of the a-th mechanical device | |
| Action sets of PV inverters and capacitor banks | |
| Discount factor at time t | |
| Reward value at time t | |
| Cost value at time t | |
| d | Predefined constraint threshold |
| Policy network parameterized by trainable parameters | |
| Parameters of the online policy network | |
| Gradient with respect to the online policy network parameters | |
| Soft update parameter | |
| Critic network parameters for reward and cost | |
| Dual variable for constraint handling | |
| Gradient of the dual variable |
References
- Singh, B.; Das, S. Adaptive Control for Undisturbed Functioning and Smooth Mode Transition in Utility-Interactive Wind–Solar Based AC/DC Microgrid. IEEE Trans. Power Electron. 2024, 39, 15011–15020. [Google Scholar] [CrossRef]
- Andersson, G.; Donalek, P.; Farmer, R.; Hatziargyriou, N.; Kamwa, I.; Kundur, P.; Martins, N.; Paserba, J.; Pourbeik, P.; Sanchez-Gasca, J.; et al. Causes of the 2003 major grid blackouts in North America and Europe, and recommended means to improve system dynamic performance. IEEE Trans. Power Syst. 2005, 20, 1922–1928. [Google Scholar] [CrossRef]
- Wang, C.; Mishra, C.; Centeno, V.A. A Scalable Method of Adaptive LVRT Settings Adjustment for Voltage Security Enhancement in Power Systems with High Renewable Penetration. IEEE Trans. Sustain. Energy 2022, 13, 440–451. [Google Scholar] [CrossRef]
- Naseem, H.; Seok, J.-K. Reactive Power Controller for Single Phase Dual Active Bridge DC–DC Converters. IEEE Access 2023, 11, 141537–141546. [Google Scholar] [CrossRef]
- Adegoke, S.A.; Sun, Y.; Wang, Z.; Stephen, O. A mini review on optimal reactive power dispatch incorporating renewable energy sources and flexible alternating current transmission system. Electr. Eng. 2024, 106, 3961–3982. [Google Scholar] [CrossRef]
- Naseem, H.; Seok, J.-K. Reactive Power Control to Minimize Inductor Current for Single Phase Dual Active Bridge DC/DC Converters. In Proceedings of the 2021 IEEE Energy Conversion Congress and Exposition (ECCE), Vancouver, BC, Canada, 10–14 October 2021; pp. 3261–3266. [Google Scholar]
- Mohammed, A.; Sakr, E.K.; Abo-Adma, M.; Elazab, R. A comprehensive review of advancements and challenges in reactive power planning for microgrids. Energy Inform. 2024, 7, 63. [Google Scholar] [CrossRef]
- Jabr, R.A.; Džafić, I. Sensitivity-Based Discrete Coordinate-Descent for Volt/VAr Control in Distribution Networks. IEEE Trans. Power Syst. 2016, 31, 4670–4678. [Google Scholar] [CrossRef]
- Dutta, A.; Ganguly, S.; Kumar, C. MPC-Based Coordinated Voltage Control in Active Distribution Networks Incorporating CVR and DR. IEEE Trans. Ind. Appl. 2022, 58, 4309–4318. [Google Scholar] [CrossRef]
- Liu, H.; Wu, W.; Wang, Y. Bi-Level Off-Policy Reinforcement Learning for Two-Timescale Volt/VAR Control in Active Distribution Networks. IEEE Trans. Power Syst. 2023, 38, 385–395. [Google Scholar] [CrossRef]
- Farivar, M.; Low, S.H. Branch Flow Model: Relaxations and Convexification—Part I. IEEE Trans. Power Syst. 2013, 28, 2554–2564. [Google Scholar] [CrossRef]
- Gholizadeh-Roshanagh, R.; Zare, K.; Marzband, M. An A-Posteriori Multi-Objective Optimization Method for MILP-Based Distribution Expansion Planning. IEEE Access 2020, 8, 60279–60292. [Google Scholar] [CrossRef]
- Kaur, S.; Kumbhar, G.; Sharma, J. A MINLP technique for optimal placement of multiple DG units in distribution systems. Int. J. Electr. Power Energy Syst. 2014, 63, 609–617. [Google Scholar] [CrossRef]
- Byeon, G.; Kim, K. Distributionally Robust Decentralized Volt-Var Control with Network Reconfiguration. IEEE Trans. Smart Grid 2024, 15, 4705–4718. [Google Scholar] [CrossRef]
- Anilkumar, R.; Devriese, G.; Srivastava, A.K. Voltage and Reactive Power Control to Maximize the Energy Savings in Power Distribution System with Wind Energy. IEEE Trans. Ind. Appl. 2018, 54, 656–664. [Google Scholar] [CrossRef]
- Padilha-Feltrin, A.; Rodezno, D.A.Q.; Mantovani, J.R.S. Volt-VAR Multiobjective Optimization to Peak-Load Relief and Energy Efficiency in Distribution Networks. IEEE Trans. Power Deliv. 2015, 30, 618–626. [Google Scholar] [CrossRef]
- Qiu, W.; Yadav, A.; You, S.; Dong, J.; Kuruganti, T.; Liu, Y.; Yin, H. Neural Networks-Based Inverter Control: Modeling and Adaptive Optimization for Smart Distribution Networks. IEEE Trans. Sustain. Energy 2024, 15, 1039–1049. [Google Scholar] [CrossRef]
- Alonso, A.M.S.; Arenas, L.D.O.; Brandao, D.I.; Tedeschi, E.; Marafao, F.P. Integrated Local and Coordinated Overvoltage Control to Increase Energy Feed-In and Expand DER Participation in Low-Voltage Networks. IEEE Trans. Sustain. Energy 2022, 13, 1049–1061. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, X.; Wang, J.; Zhang, Y. Deep Reinforcement Learning Based Volt-VAR Optimization in Smart Distribution Systems. IEEE Trans. Smart Grid 2021, 12, 361–371. [Google Scholar] [CrossRef]
- Gu, Y.; Cheng, Y.; Chen, C.L.P.; Wang, X. Proximal Policy Optimization with Policy Feedback. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4600–4610. [Google Scholar] [CrossRef]
- Cao, D.; Zhao, J.; Hu, W.; Yu, N.; Ding, F.; Huang, Q.; Chen, Z. Deep Reinforcement Learning Enabled Physical-Model-Free Two-Timescale Voltage Control Method for Active Distribution Systems. IEEE Trans. Smart Grid 2022, 13, 149–165. [Google Scholar] [CrossRef]
- Wang, R.; Bi, X.; Bu, S. Real-Time Coordination of Dynamic Network Reconfiguration and Volt-VAR Control in Active Distribution Network: A Graph-Aware Deep Reinforcement Learning Approach. IEEE Trans. Smart Grid 2024, 15, 3288–3302. [Google Scholar] [CrossRef]
- Guo, C.; Luk, W. FPGA-Accelerated Sim-to-Real Control Policy Learning for Robotic Arms. IEEE Trans. Circuits Syst. II Express Briefs 2024, 71, 1690–1694. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Huang, C.-Y. DDPG-Based Adaptive Robust Tracking Control for Aerial Manipulators with Decoupling Approach. IEEE Trans. Cybern. 2022, 52, 8258–8271. [Google Scholar] [CrossRef] [PubMed]
- Kou, P.; Liang, D.; Wang, C.; Wu, Z.; Gao, L. Safe deep reinforcement learning-based constrained optimal control scheme for active distribution networks. Appl. Energy 2020, 264, 114772. [Google Scholar] [CrossRef]
- Li, C.; Jin, C.; Sharma, R. Coordination of PV smart inverters using deep reinforcement learning for grid voltage regulation. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Raton, FL, USA, 16–19 December 2019; pp. 1930–1937. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Volume 4, pp. 2587–2601. [Google Scholar]
- Liang, Q.; Que, F.; Modiano, E. Accelerated primal-dual policy optimization for safe reinforcement learning. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 1–7. [Google Scholar]
- Khalaf, M.; Ayad, A.; Tushar, M.H.K.; Kassouf, M.; Kundur, D. A Survey on Cyber-Physical Security of Active Distribution Networks in Smart Grids. IEEE Access 2024, 12, 29414–29444. [Google Scholar] [CrossRef]
- Liu, X.; Wang, X.; Fan, B.; Xiao, G.; Wen, S.; Chen, B.; Wang, P. Multi-Agent Primal Dual DDPG based Reactive Power Optimization of Active Distribution Networks via Graph Reinforcement Learning. IEEE Internet Things J. 2025. [Google Scholar] [CrossRef]
- Liu, X.; Wang, X.; Fan, B.; Li, B.; Deng, R.; Kong, M. DDPG-based Reactive Power Optimization Strategy For Active Distribution Network. In Proceedings of the 2024 7th International Conference on Intelligent Robotics and Control Engineering (IRCE), Xi’an, China, 7–9 August 2024; pp. 220–225. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Actor Network | Reward Critic Network | Cost Critic Network |
|---|---|---|---|
| Layer number | 3 | 3 | 3 |
| Learning rate | |||
| Discount factor | 0.9 | 0.9 | 0.9 |
| Safe update factor | 0.002 | 0.002 | 0.002 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Gui, X.; Sun, P.; Li, X.; Zhang, Y.; Wang, X.; Dang, C.; Liu, X. Reactive Power Optimization of a Distribution Network Based on Graph Security Reinforcement Learning. Appl. Sci. 2025, 15, 8209. https://doi.org/10.3390/app15158209
Zhang X, Gui X, Sun P, Li X, Zhang Y, Wang X, Dang C, Liu X. Reactive Power Optimization of a Distribution Network Based on Graph Security Reinforcement Learning. Applied Sciences. 2025; 15(15):8209. https://doi.org/10.3390/app15158209
Chicago/Turabian StyleZhang, Xu, Xiaolin Gui, Pei Sun, Xing Li, Yuan Zhang, Xiaoyu Wang, Chaoliang Dang, and Xinghua Liu. 2025. "Reactive Power Optimization of a Distribution Network Based on Graph Security Reinforcement Learning" Applied Sciences 15, no. 15: 8209. https://doi.org/10.3390/app15158209
APA StyleZhang, X., Gui, X., Sun, P., Li, X., Zhang, Y., Wang, X., Dang, C., & Liu, X. (2025). Reactive Power Optimization of a Distribution Network Based on Graph Security Reinforcement Learning. Applied Sciences, 15(15), 8209. https://doi.org/10.3390/app15158209