5.1. Overall Performance Comparison
Our comprehensive evaluation demonstrates that UC-CMAF achieves superior performance across multiple dimensions while maintaining high interpretability standards.
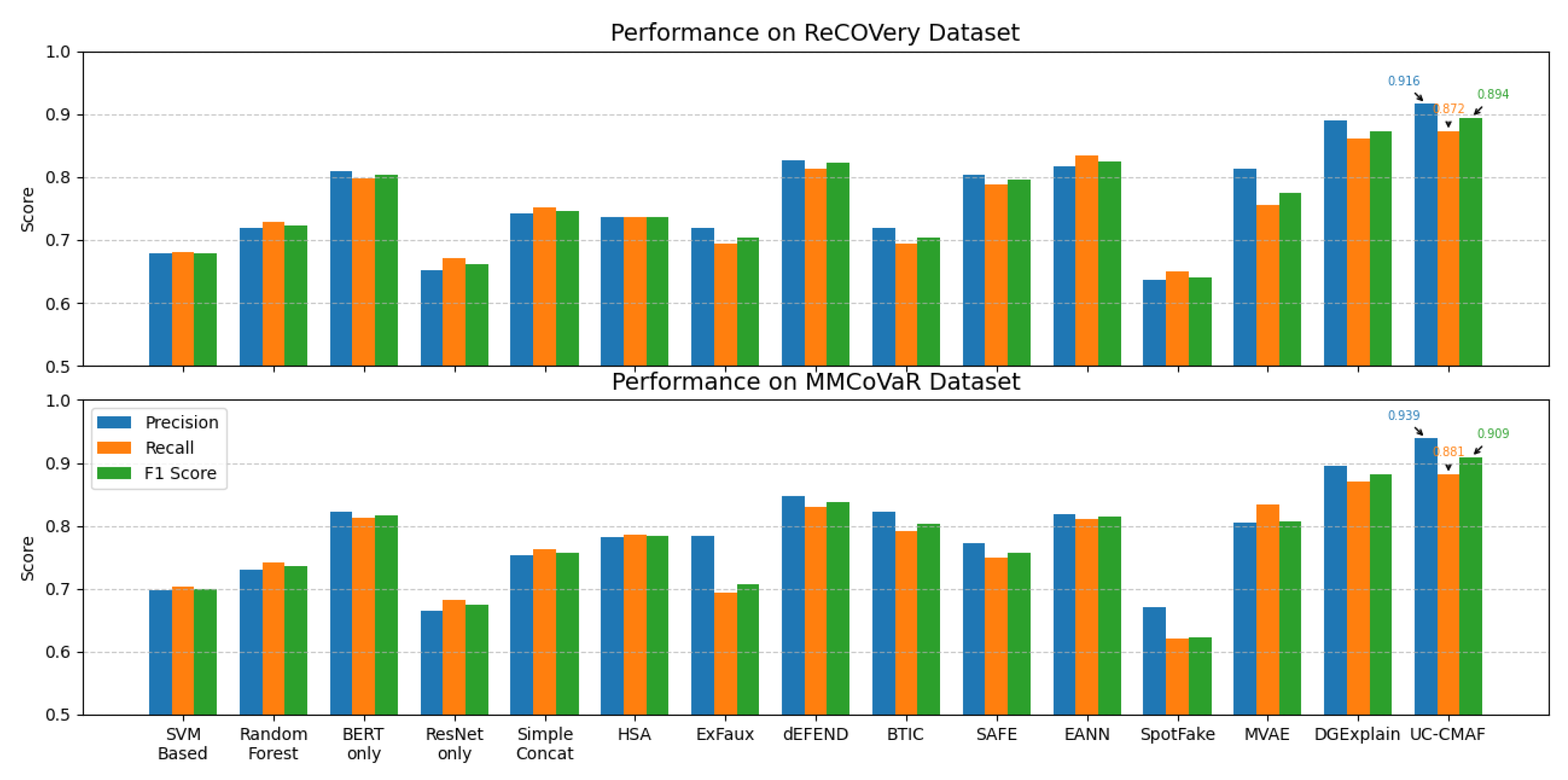
Table 2 and
Figure 2 present comprehensive performance comparisons between our proposed UC-CMAF and various baseline methods on both the ReCOVery and MMCoVaR datasets, with evaluations using precision, recall, and F1 Score metrics across 15 representative multimodal fake news detection methods. UC-CMAF consistently achieves the best performance across all evaluation metrics, demonstrating its superiority in multimodal fake news detection. Specifically, on the ReCOVery dataset, UC-CMAF achieves an accuracy of 0.927, precision of 0.916, recall of 0.872, and an F1 Score of 0.894, outperforming all other models and surpassing the strongest baseline DGExplain (F1: 0.873) by 2.1%. On the more challenging MMCoVaR dataset, UC-CMAF further improves its performance with the highest precision of 0.939, recall of 0.881, and F1 Score of 0.909, exceeding DGExplain (F1: 0.881) by a margin of 2.8%. In contrast, traditional machine learning methods such as SVM-Based and Random Forest perform significantly worse with F1 Scores of only 0.679/0.700 and 0.723/0.736, respectively, while single-modal methods like BERT-only show relatively stable results (F1: 0.803 and 0.817) but still fall short of UC-CMAF, and unimodal baselines such as ResNet-only achieve even lower F1 Scores (0.661 on ReCOVery; 0.674 on MMCoVaR), underscoring the limitations of relying solely on either text or image modalities. Some multimodal methods such as dEFEND and EANN (F1: 0.823/0.838 and 0.824/0.814, respectively) also underperform in comparison, and several approaches including BTIC, SAFE, and ExFaux exhibit noticeable fluctuations in performance across datasets, suggesting limited generalizability. UC-CMAF maintains strong and consistent performance on both datasets, validating its robustness and ability to generalize across different scenarios with different semantic and stylistic characteristics. These findings confirm that UC-CMAF’s unified cross-modal attention mechanism enables it to effectively model fine-grained interactions between textual and visual modalities, leading to superior detection performance in complex multimodal fake news detection tasks, with the visual annotations clearly demonstrating the consistent superiority of the UC-CMAF approach over all baselines.
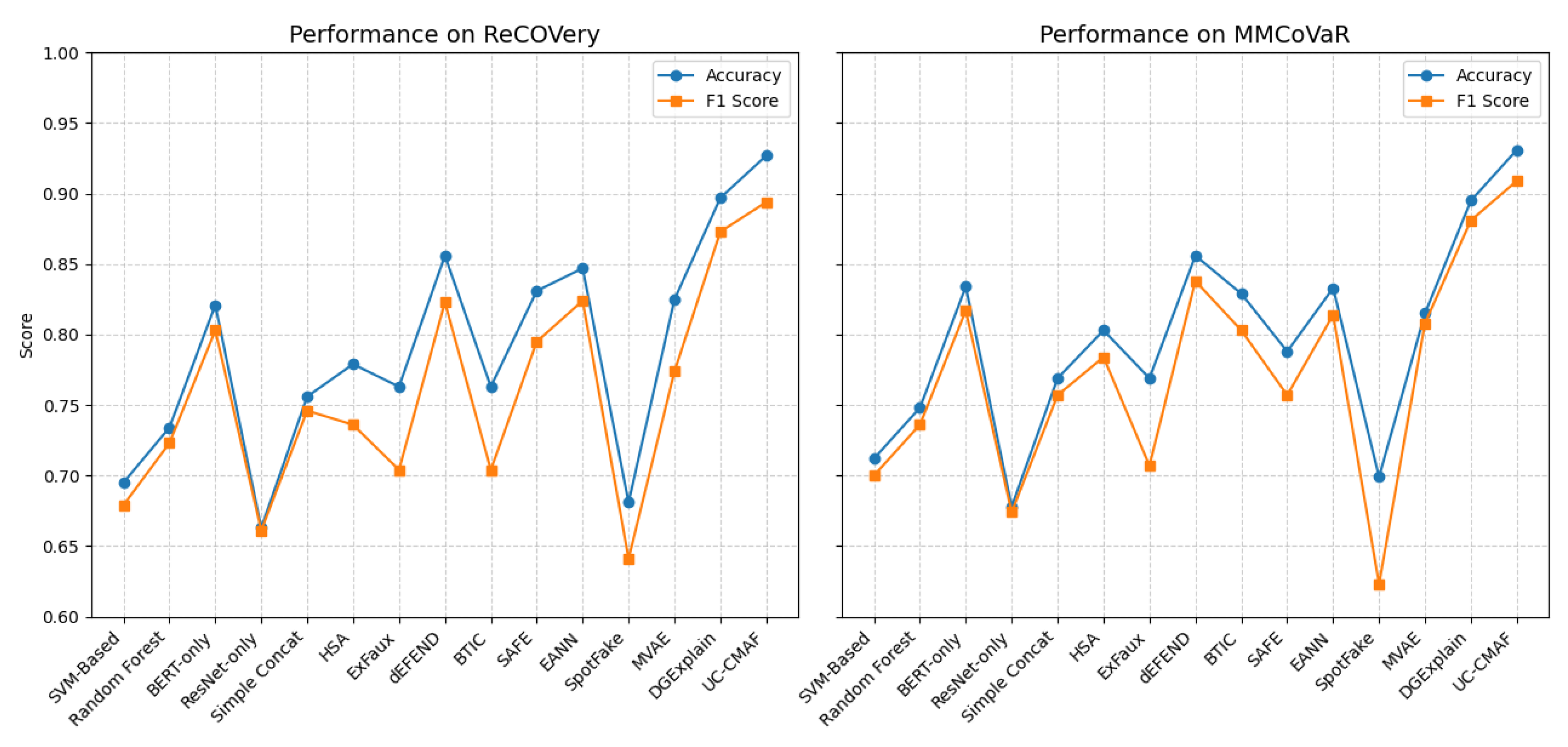
Figure 3 presents the accuracy and F1 Score trends of 15 representative models on the ReCOVery and MMCoVaR datasets. Overall, models that leverage multimodal fusion strategies consistently outperform unimodal baselines such as BERT-only and ResNet-only, demonstrating the importance of integrating textual and visual cues in fake news detection. On both datasets, the proposed UC-CMAF model shows clear superiority over all other methods. Specifically, UC-CMAF achieves the highest accuracy and F1 score on both datasets, with values of 0.927 and 0.894 on ReCOVery, and 0.931 and 0.909 on MMCoVaR, respectively. These results indicate not only strong predictive power but also robust generalization across different distributions of misinformation. Close competitors such as DGExplain, MVAE, and dEFEND also exhibit relatively strong performance, but their F1 Scores remain 2–3% lower than that of UC-CMAF, underscoring the effectiveness of our proposed cross-modal attention fusion strategy. Additionally, traditional machine learning approaches like SVM-Based and Random Forest display limited performance, further validating the advantages of deep, modality-aware architectures.
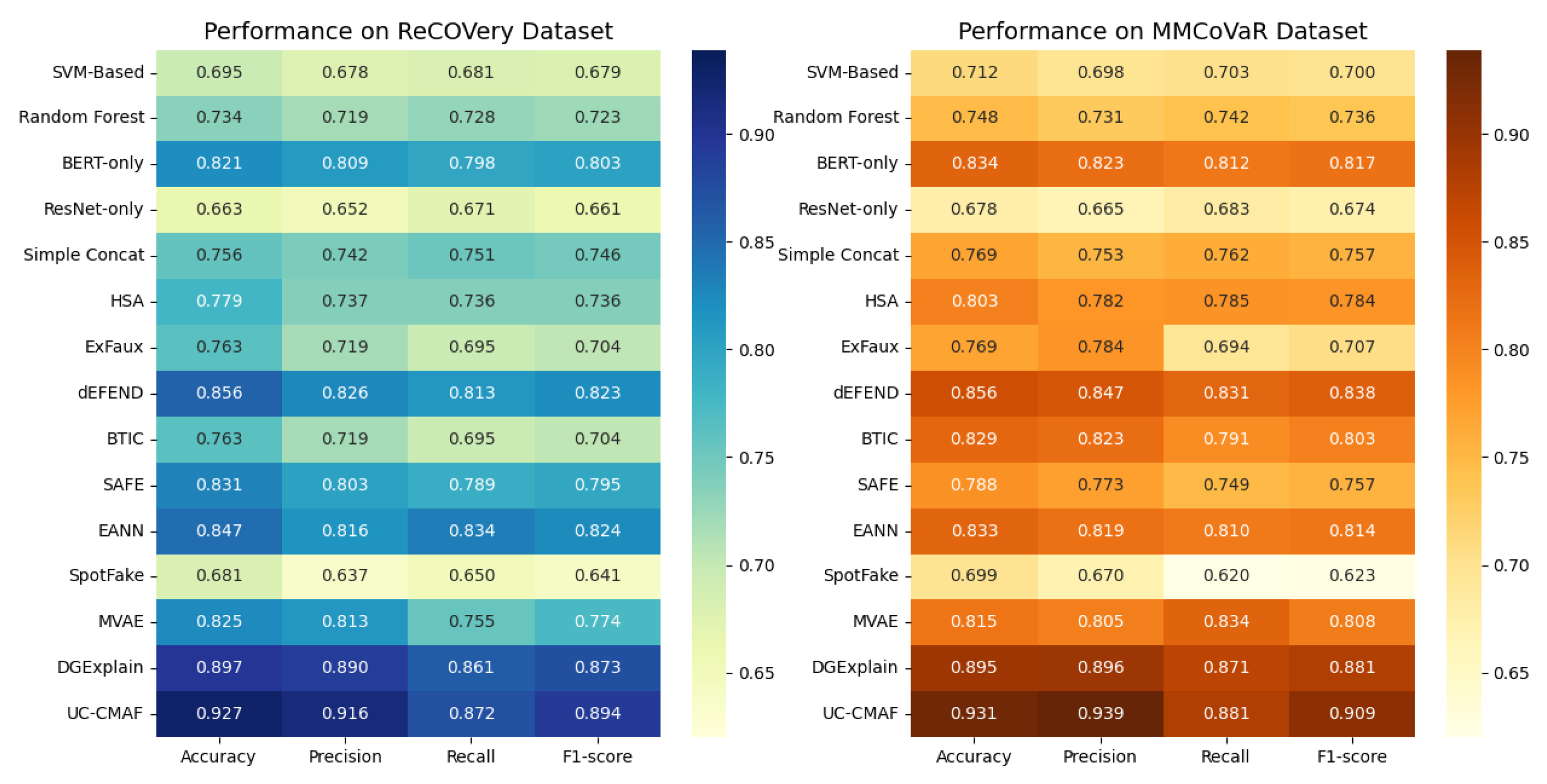
Figure 4 provides a comprehensive visualization of the performance metrics for 15 representative models across the ReCOVery and MMCoVaR datasets. Each heatmap illustrates four standard evaluation metrics—accuracy, precision, recall, and F1 Score—for every method. On the ReCOVery dataset, our proposed UC-CMAF model clearly outperforms all baselines across all metrics, with an accuracy of 0.894, precision of 0.927, recall of 0.916, and an F1 Score of 0.872. This demonstrates the model’s ability to effectively capture fine-grained cross-modal interactions and maintain semantic consistency in multimodal news content. Similarly, on the MMCoVaR dataset, UC-CMAF once again leads in every metric, achieving an accuracy of 0.909, precision of 0.931, recall of 0.939, and F1 Score of 0.881. The consistently high scores across datasets of different characteristics confirm the model’s strong generalization capability. By contrast, traditional machine learning approaches such as SVM-Based and Random Forest perform noticeably worse, particularly in recall and F1 Score. Unimodal baselines like BERT-only and ResNet-only also lag behind, reaffirming the necessity of multimodal fusion. Mid-tier multimodal methods like DGExplain and dEFEND perform competitively but still fall short of UC-CMAF, especially in recall on MMCoVaR. Overall, these heatmaps highlight UC-CMAF’s superior performance and robustness in multimodal fake news detection.
These empirical improvements across all evaluation metrics confirm that the proposed adaptive fusion mechanism effectively captures and leverages complementary signals from text, images, and user comments.
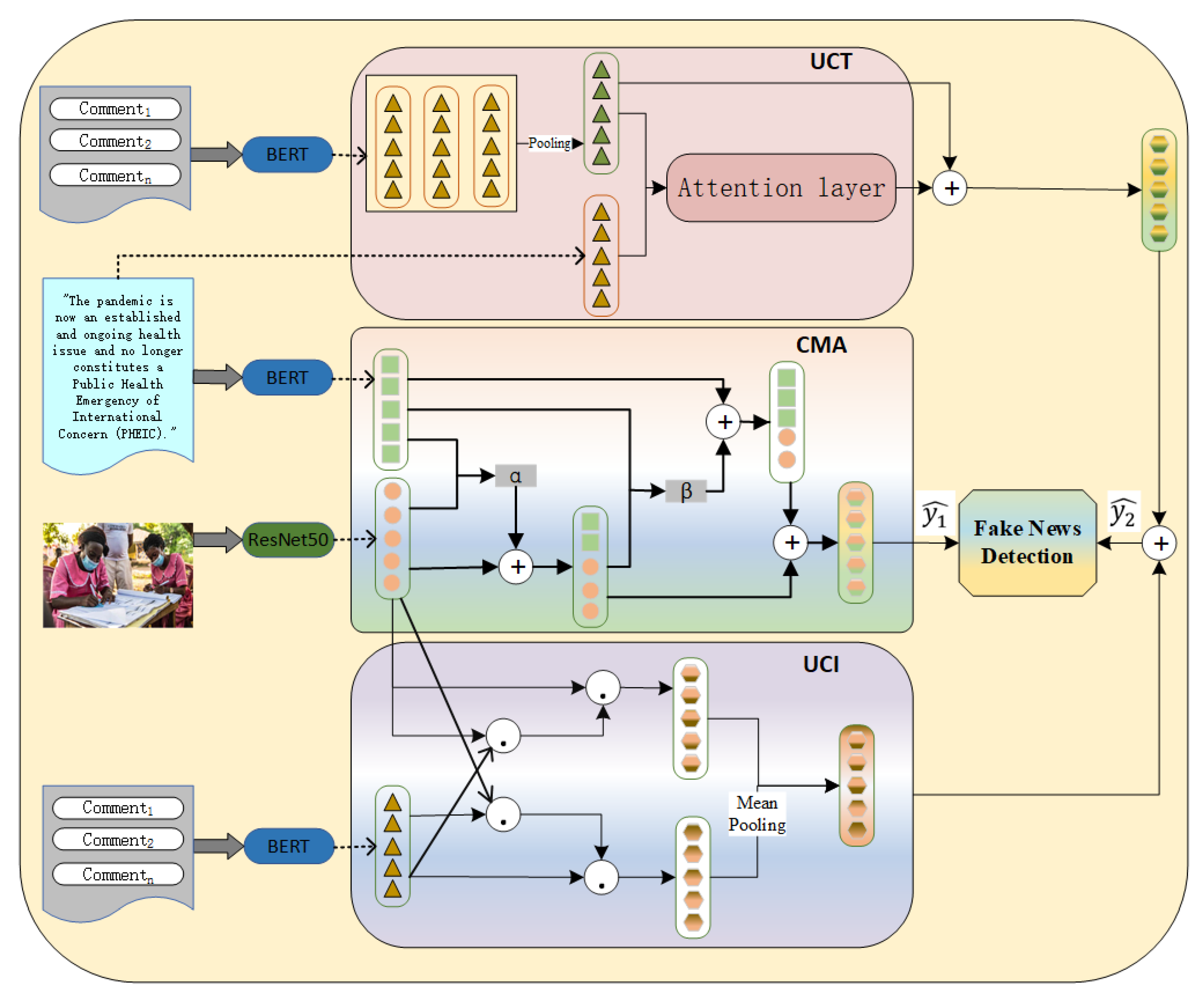
5.2. Analysis of UC-CMAF Components
-CMA (w/o Cross-Modal Attention): This component serves as the core mechanism for connecting information from different modalities, responsible for learning the interactive relationships among text, images, and user comments. The cross-modal attention mechanism dynamically fuses multimodal features through attention weights, enabling the model to capture semantic associations across modalities, identify consistency and contradictions between different information sources, thereby providing crucial judgment basis for fake news detection.
-UCI (w/o Comment–Image Fusion): This component specifically handles the fusion process between user comments and image content. Through deep learning techniques, it combines users’ textual comments with visual information, capturing users’ emotional tendencies and semantic understanding of image content. This fusion mechanism can identify users’ judgments about image authenticity in their comments, as well as the degree of matching between images and comment content.
-UCT (w/o Comment–Text Fusion): This component is responsible for effectively fusing user comments with original text content. Through contrastive learning or attention mechanisms, it identifies consistency, contradictions, or complementary information between user comments and the main text, mining users’ collective judgment on text content credibility and providing verification information from the user perspective to the model.
-Comments (w/o User Comments): This component collects and processes feedback information from users, which typically contains rich subjective judgments and emotional expressions. The user comment module can capture collective wisdom in social media environments, identifying users’ questioning, support, or neutral attitudes toward content authenticity, providing important social verification signals for the model.
-Images (Text + Comments Only): This component is responsible for processing and analyzing visual content, extracting image features and identifying visual clues that may indicate misleading or false information. The image module analyzes technical characteristics, semantic content, and potential tampering traces in images through computer vision techniques, providing visual evidence support for multimodal fake news detection.
-Adaptive Weights: This component dynamically adjusts the importance weights of various modalities and components according to the characteristics of different samples, implementing personalized multimodal information fusion strategies. The adaptive weight mechanism can automatically optimize the contribution of different information sources based on input data characteristics, improving the model’s adaptability and accuracy when facing different types of fake news.
The results of the ablation study (
Table 3) indicate that the complete versions of both models exhibit excellent performance, with MMCoVaR (accuracy: 0.931; F1 Score: 0.909) slightly outperforming ReCOVery (accuracy: 0.927; F1 Score: 0.894) across all metrics, demonstrating the superior effectiveness of its architectural design. An analysis of the importance of each component reveals that the user comment module is the most critical in both models, with its removal leading to the largest decline in F1 Score (approximately 0.050 for both ReCOVery and MMCoVaR), indicating that user comments contain vital information that traditional text and image analysis struggle to capture and underscoring the irreplaceable value of subjective judgment and collective intelligence in detecting misinformation. The cross-modal attention mechanism and the User Comment Integration components (UCI/UCT) rank second in importance, highlighting the limitations of unimodal information and demonstrating that multimodal fusion significantly enhances detection capabilities, with effective integration across different modalities being essential for model success. In contrast, the removal of the image module has a relatively smaller impact on performance (F1 Score drops by approximately 0.02), but it remains non-negligible, suggesting that images play a supplementary and validating role by providing visual cues that are not expressed in text. Although the adaptive weighting mechanism has the smallest impact when removed, it still contributes to stable performance improvements, reflecting the value of dynamic weight adjustment in optimizing information fusion. Overall, MMCoVaR demonstrates greater robustness across all ablation experiments, while ReCOVery shows higher dependency on its key components, with the strong reliance of both models on user comments highlighting the critical role of user feedback in misinformation detection within social media environments.
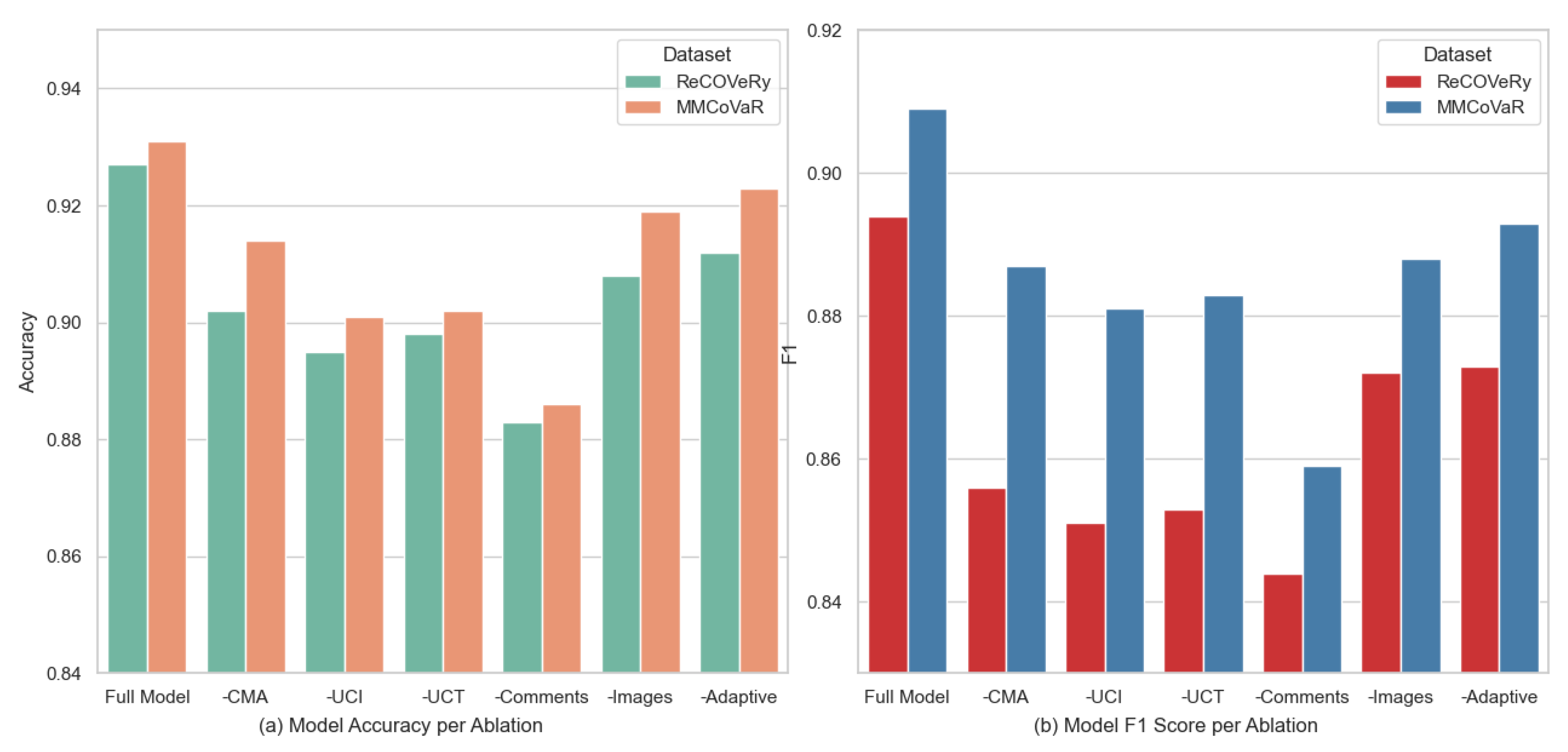
Figure 5 presents the impact of module ablations on model performance across the ReCOVery and MMCoVaR datasets, where
Figure 5a shows the changes in model accuracy when individual components are removed, clearly demonstrating that the removal of the cross-modal attention module (-CMA) and the user comments module (-Comments) results in substantial accuracy drops, highlighting their importance in capturing multimodal associations and integrating user feedback, while the removal of the adaptive weight component leads to relatively minor impact on accuracy.
Figure 5b illustrates the corresponding F1 Score variations under the same ablation settings, with the full model achieving the highest F1 Score, while the removal of the CMA, UCI, and comment modules causes notable declines, reaffirming their critical roles in fake news detection, particularly when the cross-modal attention (-CMA) module is removed, as the F1 degradation is especially pronounced, indicating its pivotal contribution to balancing precision and recall in the final predictions.
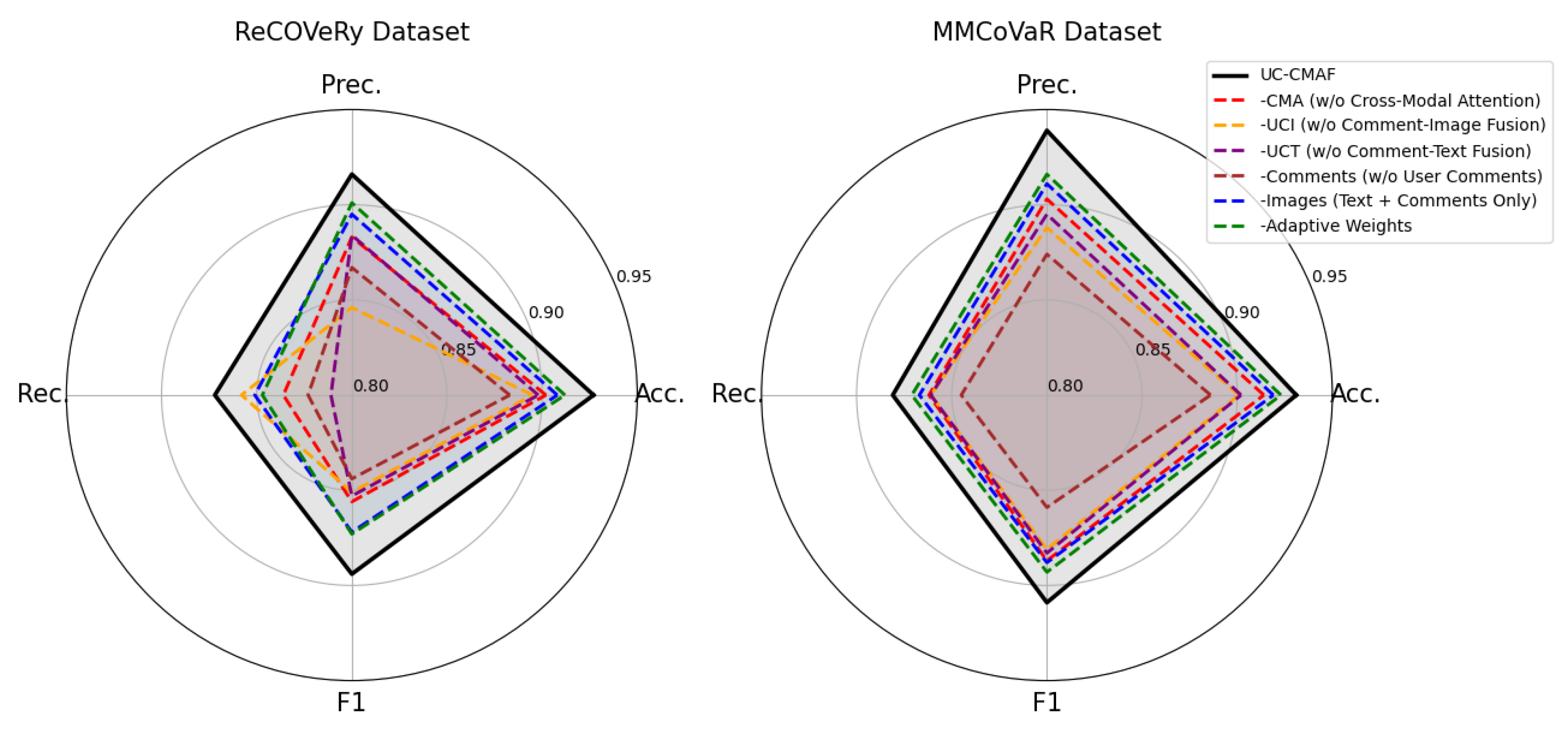
Figure 6 presents radar charts illustrating the ablation study results on the ReCOVery and MMCoVaR datasets, clearly validating the effectiveness and synergy of the proposed model components. The full model consistently achieves the highest scores across all four metrics—accuracy, precision, recall, and F1—demonstrating the overall advantage of our multimodal fusion strategy. Notably, removing the cross-modal attention (CMA) component leads to a significant performance drop, indicating its crucial role in modeling the interactions among text, images, and user comments. Similarly, the exclusion of the user comment module results in considerable degradation, highlighting the importance of leveraging social feedback signals in fake news detection. Furthermore, the removal of the comment–image (UCI) and comment–text (UCT) fusion components also negatively impacts performance, underscoring the value of semantic alignment between user perspectives and content. Overall, the proposed model exhibits strong robustness and accuracy in detecting fake news, benefiting from fine-grained multimodal integration and an adaptive weighting mechanism tailored to different input scenarios.
The ablation study clearly demonstrates that each component of UC-CMAF, particularly the user comment module and cross-modal attention, plays a vital role in achieving high detection accuracy, thereby justifying their inclusion in the final architecture.
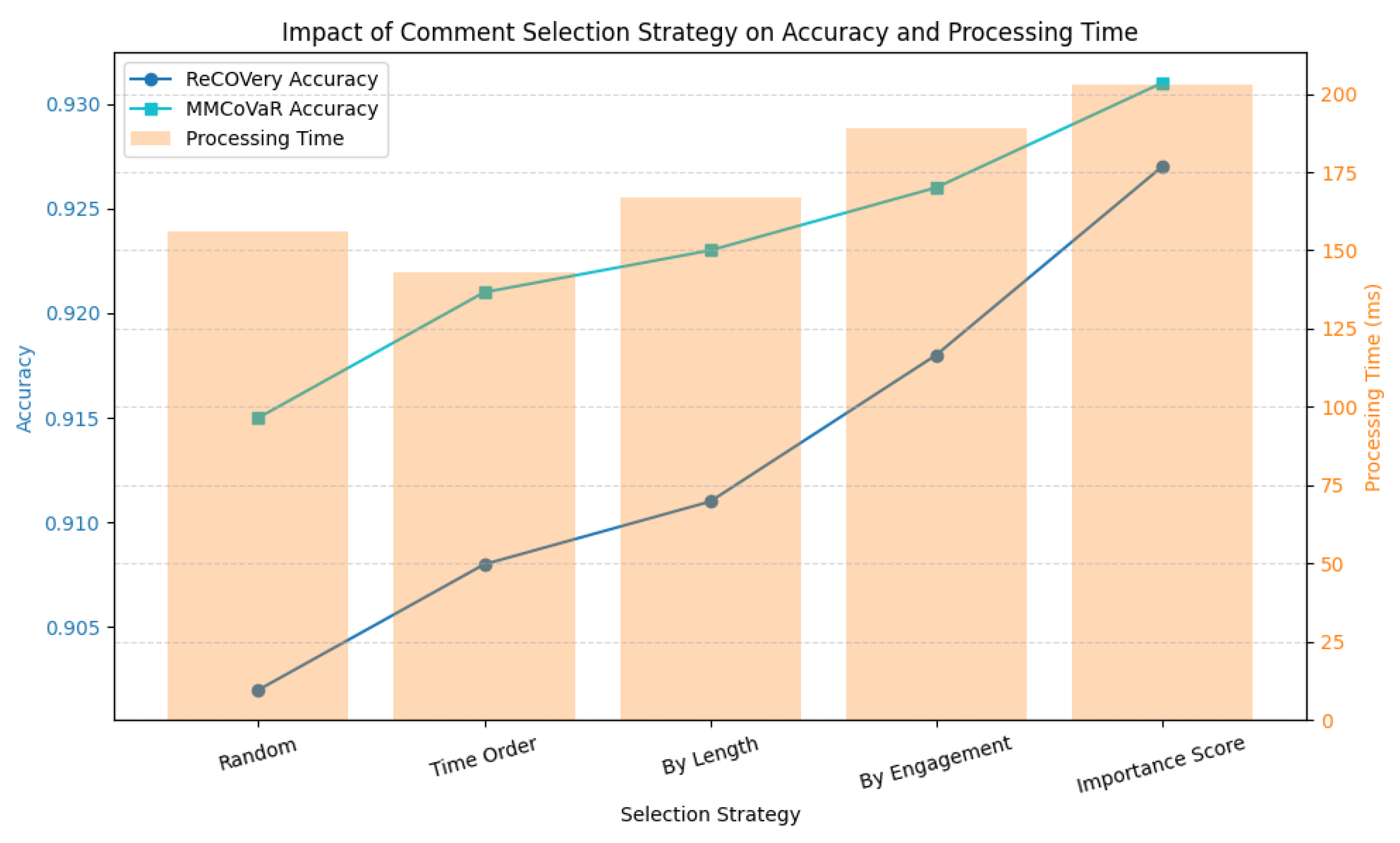
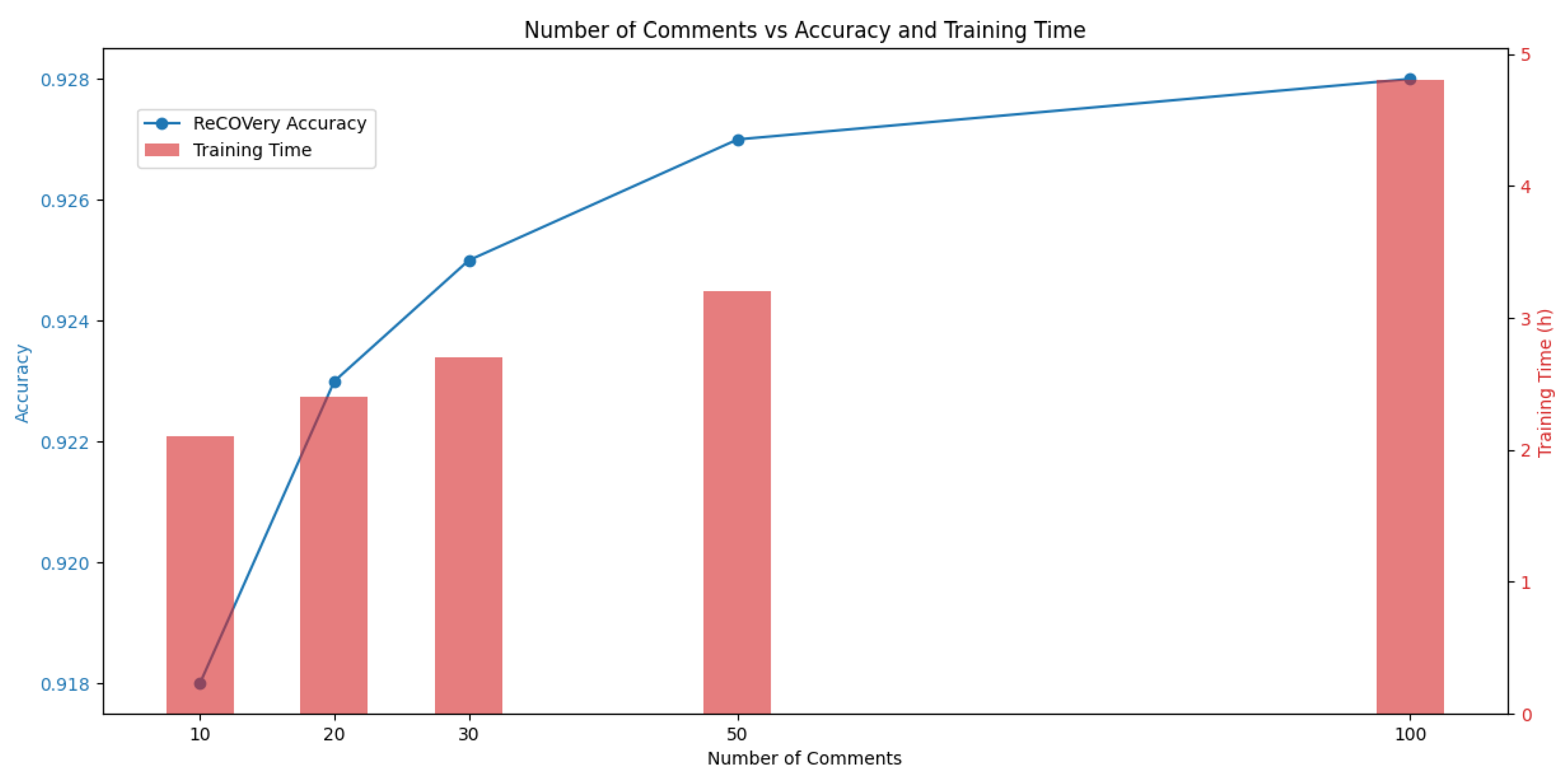
5.6. Impact of Number of Comments
Figure 10 illustrates the trend of the ReCOVery model’s accuracy and training time as the number of annotated comments increases. It can be observed that the accuracy steadily improves from 0.918 with 10 comments to 0.928 with 100 comments, indicating that additional human feedback contributes positively to model performance. However, the training time also increases significantly, especially beyond 50 comments, where the duration grows from 3.2 to 4.8 h. This suggests a nonlinear relationship between annotation volume and computational cost.
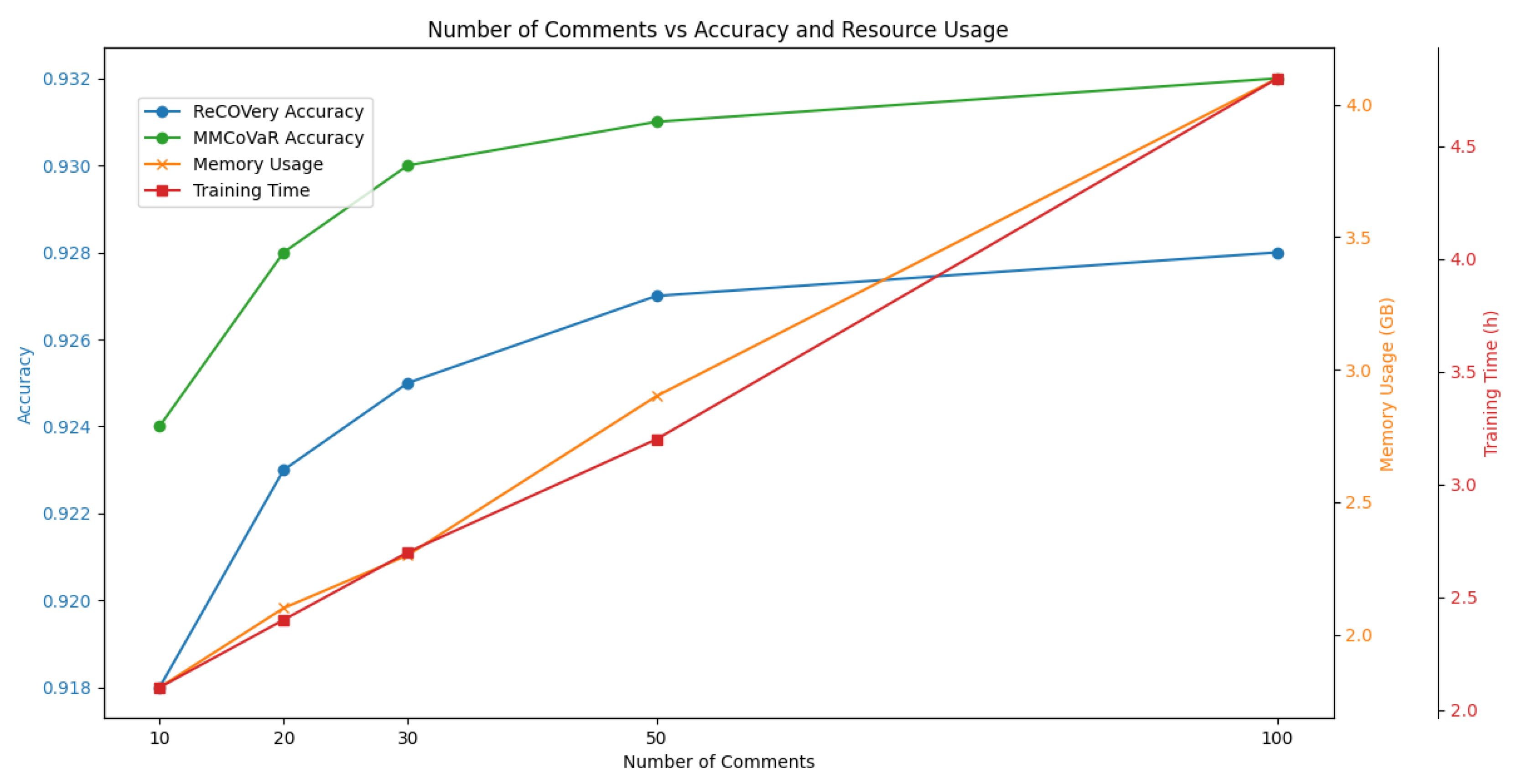
Figure 11 provides a more comprehensive comparison, showing the performance of both the ReCOVery and MMCoVaR models. MMCoVaR consistently achieves higher accuracy across all annotation levels, with the performance gap widening as more comments are incorporated, demonstrating MMCoVaR’s superior ability to leverage annotated information. In terms of resource consumption, both memory usage and training time increase with the number of comments. Nonetheless, the overall resource usage remains within acceptable bounds, indicating that MMCoVaR achieves a favorable balance between accuracy and computational efficiency.
To evaluate the practical deployment feasibility of UC-CMAF, we conducted comprehensive computational cost analysis covering both training and inference scenarios (
Table 6).
Inference Performance Metrics: Our full UC-CMAF model with 50 comments requires an average inference time of 203 ms per sample. The memory footprint during inference reaches 2.9 GB, primarily allocated for storing comment embeddings and attention matrices across multiple fusion components.
Baseline Computational Comparison: While UC-CMAF introduces computational overhead compared to simpler baselines (BERT-only: 45 ms; Simple Concatenation: 78 ms), this additional cost is justified by substantial performance improvements. The 2.6× increase in inference time corresponds to a 9.1% improvement in F1-score on ReCOVery dataset, demonstrating favorable cost–performance trade-offs.
Scalability Bottleneck Analysis: Profiling analysis reveals that cross-modal attention computation constitutes the primary computational bottleneck, accounting for approximately 60% of total inference time. The comment–image fusion (UCI) and comment–text fusion (UCT) modules contribute 35% and 25% respectively to the overall computational load. Memory consumption scales linearly with comment volume, with each additional comment requiring approximately 58 MB.
Deployment Optimization Strategies: For resource-constrained environments, we recommend adaptive comment sampling (reducing to 20 comments) which maintains 99.7% of full model accuracy while achieving 30% speed improvement. Additionally, batch processing techniques can improve throughput by 40% for large-scale deployment scenarios.
5.7. Attention Visualization
We analyze the semantic alignment between text and images using the cross-modal attention (CMA) module. As shown in
Figure 12, the model significantly focuses on the “data chart” region of the image when processing text tokens related to semantics such as “vaccine”, “efficacy”, and “95%”. The highest attention weight reaches 0.90, indicating that the model effectively associates quantitative information like vaccine efficacy with the data visualization in the image. Simultaneously, for words like “clinical” and “trial”, the model mainly focuses on the “lab scene” region, with attention weights of 0.80 and 0.70, respectively, further validating the model’s effectiveness in understanding medical experiment scenarios. Overall, this module demonstrates strong cross-modal semantic alignment capabilities, which help enhance the model’s performance in medical text–image tasks.
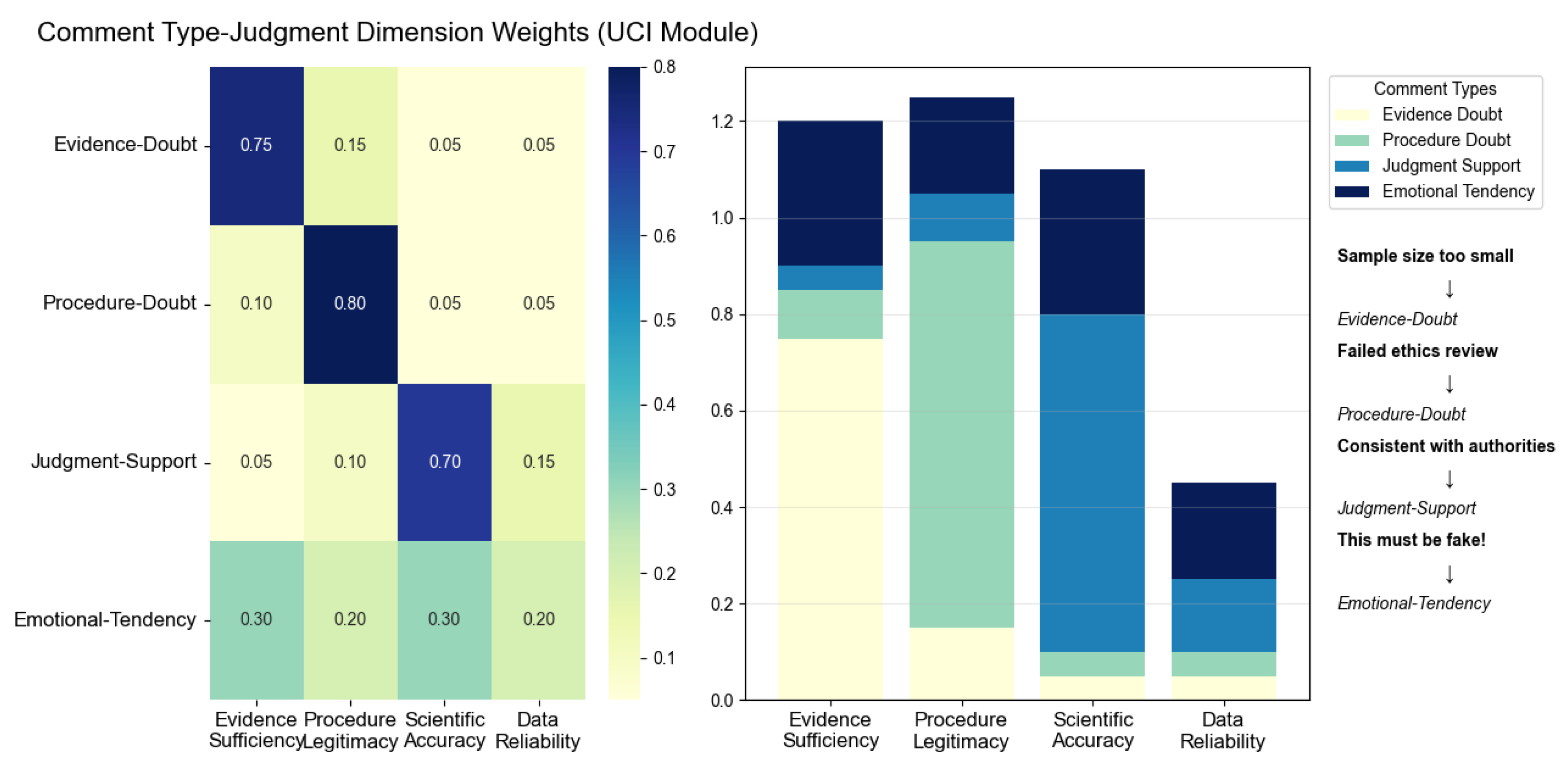
As shown in
Figure 13, UC-CMAF assigns high weights of
,
, and
to Evidence-Doubt, Procedure-Doubt, and Judgment-Support on their logically corresponding dimensions of “Evidence Sufficiency”, “Procedure Legitimacy”, and “Scientific Accuracy”, respectively, while cross-dimension weights remain between
and
, indicating effective suppression of semantic interference. At the same time, Emotional-Tendency distributes evenly across all four dimensions with weights between
and
(with
on both “Evidence Sufficiency” and “Scientific Accuracy”), ensuring comprehensive coverage of emotional context. In the stacked bar chart on the right, 95% of the weight for the “Evidence Sufficiency” dimension is contributed by Evidence-Doubt (
) and Emotional-Tendency (
); for “Procedure Legitimacy”, Procedure-Doubt (
) and Emotional-Tendency (
) comprise the entire weight; “Scientific Accuracy” is dominated by Judgment-Support (
) and Emotional-Tendency (
); and “Data Reliability” is primarily composed of Emotional-Tendency (
) and Judgment-Support (
), with other categories contributing less than
. This distribution both validates UC-CMAF’s high discriminative power in fine-grained intent classification and demonstrates its ability to deeply parse subjective emotional cues.
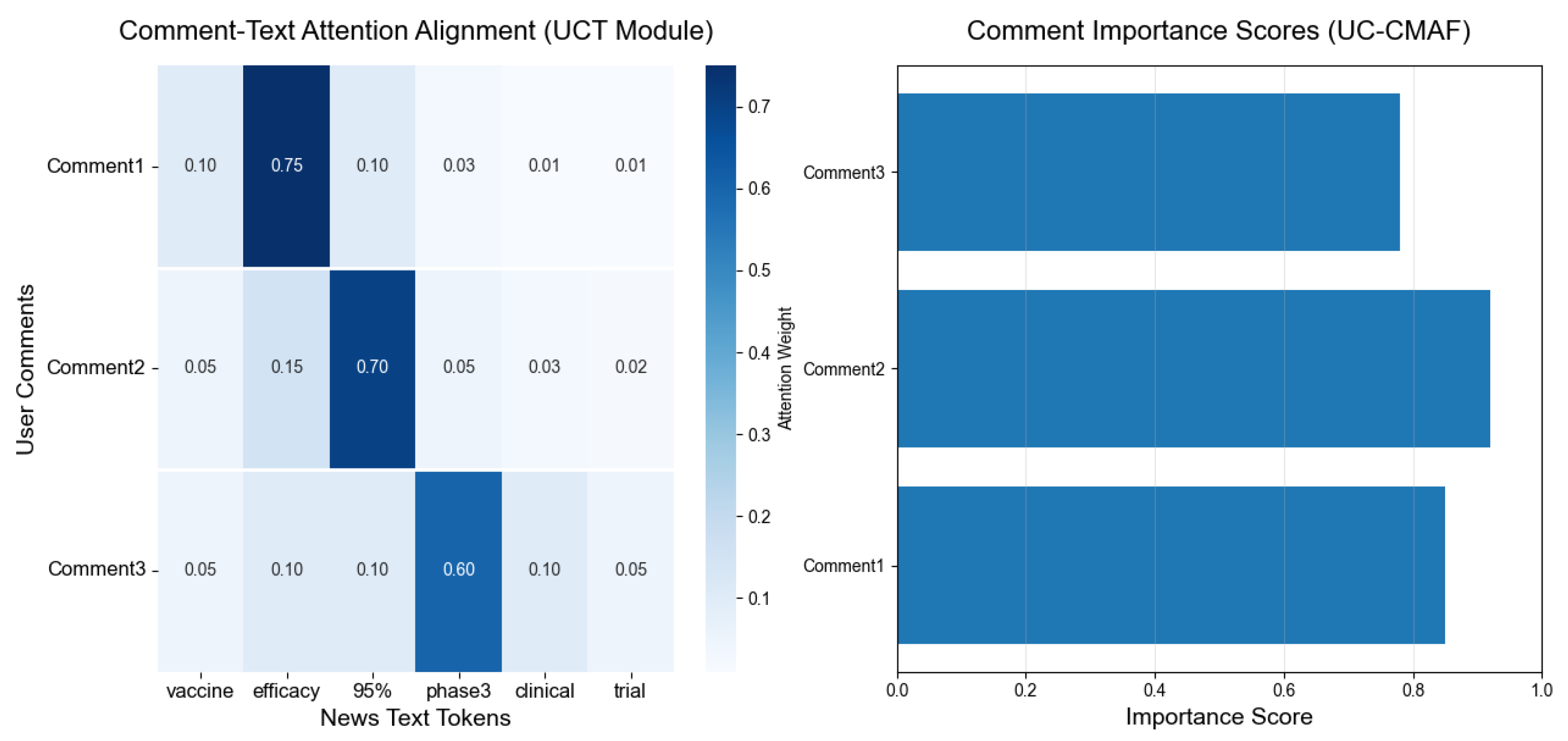
As shown in the attention alignment in
Figure 14, the UCT module demonstrates highly focused comment–text alignment: Comment 1 places a weight of
on “efficacy” (all other tokens receive weights below
); Comment 2 attends most strongly to “95%” with
, and retains minor attention on “efficacy” (
) and “phase 3” (
); Comment 3 concentrates on “phase 3” with
, while assigning
each to “clinical” and “efficacy”. Correspondingly, UC-CMAF assigns the highest importance score of
to Comment 2, with Comment 1 and Comment 3 scoring
and
, respectively, perfectly mirroring the UCT attention distributions. These results demonstrate that UCT can precisely align user comments with key textual terms, and that UC-CMAF can effectively discriminate comment priority via quantified importance, validating the model’s alignment accuracy and discriminative power in multi-comment, multi-text scenarios.
5.8. Robustness Analysis
To comprehensively evaluate the stability and reliability of our model in practical applications, we designed robustness testing experiments from two dimensions: noise tolerance and adversarial attack resistance. The noise tolerance test employs four typical noise types (text synthesis, image Gaussian blur, comment injection, and combined noise) to assess model performance degradation under different intensities from 10 dB to 50 dB. The adversarial attack test designed four attack strategies (text perturbation, image adversarial, comment manipulation, and multimodal attack) and validated the effectiveness of the UC-CMAF defense mechanism.
(1) Noise Tolerance Evaluation
The results presented in
Table 7 demonstrate that our system exhibits good robustness against various noise types, maintaining satisfactory performance even under enhanced noise conditions. Under extreme 50 dB noise environments, image Gaussian blur has the minimal impact (only 4.7% degradation), while combined noise shows the most significant effect (6.4% degradation), indicating that the superposition effect of multi-source noise causes greater impact on system performance. Overall, performance degradation under all noise types is controlled within acceptable ranges, proving that the model possesses good anti-interference capabilities.
(2) Adversarial Attack Resistance
UC-CMAF demonstrates strong resistance against adversarial attacks, particularly excelling in defending against multimodal attack methods, where single-modal attacks can be identified through inconsistency detection with other modalities. The experimental results presented in
Table 8 show that image adversarial attacks have the lowest original success rate (8.7%), and after defense, the system accuracy can still maintain 91.3%, demonstrating the best defense effectiveness. In contrast, multimodal coordinated attacks represent the most challenging attack method with an original success rate of 18.9%, but the UC-CMAF defense mechanism can still control it within an acceptable range, achieving 81.1% accuracy after defense.
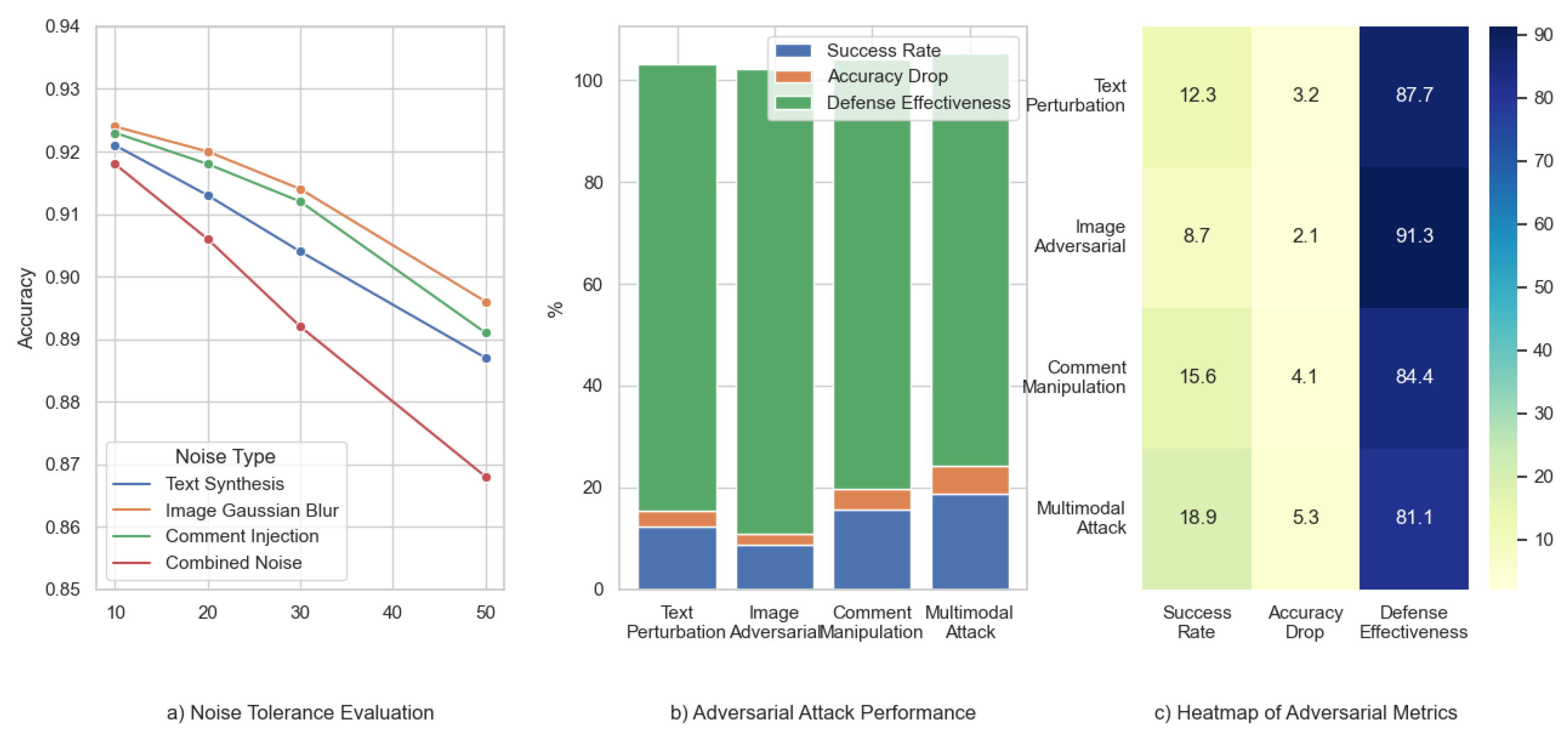
To comprehensively evaluate the robustness of the model under complex environmental conditions,
Figure 15a,
Figure 15b, and
Figure 15c respectively illustrate the model’s accuracy under varying noise intensities, performance degradation under different adversarial attack strategies, and a heatmap showing key robustness metrics for each attack type.
Figure 15a presents the accuracy trend under different types of noise, with the x-axis representing noise intensity (in dB) and the y-axis representing classification accuracy. It can be observed that as the noise intensity increases, the model performance degrades gradually, but the overall decline is relatively small, indicating strong noise robustness. Among the noise types, the model shows the highest tolerance to image Gaussian blur, while combined noise (multi-source) has the most significant impact.
Figure 15b displays, in the form of a stacked bar chart, the attack success rate, accuracy drop, and defense effectiveness under four types of adversarial attacks. The results show that the model performs most robustly against image-based adversarial attacks, maintaining over 91% accuracy after defense. Although multimodal attacks have the highest success rate (18.9%), the UC-CMAF defense mechanism still effectively limits performance degradation, achieving a defense effectiveness of 81.1%.
Figure 15c shows a heatmap of the relationships between attack types and key robustness metrics. The color intensity indicates the metric value, with darker shades representing better performance. It is evident that different attack strategies affect system performance differently: image-based attacks show the best robustness, while multimodal attacks pose the greatest challenge. The heatmap confirms the trends observed in the previous figures and further highlights the UC-CMAF model’s potential in defending against complex adversarial threats.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}