1. Introduction
With the advancement of deep learning, particularly convolutional neural networks (CNNs), a breakthrough was achieved in 2012 at the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [
1]. Since then, CNNs have been widely adopted in various computer vision tasks, including image classification, object detection, and image segmentation. The subsequent introduction of architectures such as VGGNet [
2], GoogLeNet [
3], and ResNet [
4] led to significant success in image classification. However, as convolutional neural networks become more and more complex, their multilayered and diverse architectures have led to black-box characteristics in the internal operation of the model. Therefore, the explainability of the model becomes more and more important. To address this issue, Explainable Artificial Intelligence (XAI) methods have been developed to improve the transparency and explainability of deep learning models to help researchers and users better understand the decision-making process of the model.
To solve the problem of black-box properties of deep learning models, researchers have proposed various XAI methods, which can be broadly classified into two categories: (a) non-Class Activation Mapping (non-CAM) methods and (b) Class Activation Mapping (CAM) and its derivatives. In non-CAM methods, researchers [
5,
6,
7,
8,
9] have explored different techniques to interpret the decision-making processes of deep learning models. For instance, Zeiler et al. [
7] introduced Deconvolutional Networks, which reverse convolutional layer operations to project activations back to the input space, revealing the model’s response patterns. Springenberg et al. [
8] proposed Guided Backpropagation, which refines feature visualization by combining forward propagation with gradient-based backpropagation. Meanwhile, Sundararajan et al. [
9] developed Integrated Gradients, a mathematically grounded approach that quantifies the importance of features using linear interpolation and integration, generating saliency maps. Despite their advantages, these methods exhibit several limitations. They often involve high computational complexity and instability in the interpretation results, particularly in deep networks, where vanishing or exploding gradients can degrade the quality of the explanation. Furthermore, their implementation frequently requires setting critical parameters such as baselines and reference points. The lack of standardized selection criteria for these parameters makes the interpretability results highly dependent on expert heuristics, compromising reproducibility and reliability. These challenges hinder the practical applicability of non-CAM methods, limiting their effectiveness in real-world scenarios.
To overcome the aforementioned limitations and provide more stable and intuitive explanation results, research focus has gradually shifted towards methods based on the theory of CAM. CAM-based methods focus on directly visualizing the decision-making rationale behind a model’s predictions in visual interpretability tasks. CAM proposed by Zhou et al. [
10] is a pioneering work in this field, which generates saliency maps for specific categories by mapping the model’s decision outcomes back to the input image. This breakthrough is not only technically significant but also demonstrates significant value in real-world applications, such as medical imaging diagnosis, enabling professionals with nontechnical backgrounds to understand the decision basis of the model while providing model developers with an effective tool for model bias identification and performance optimization. To address this issue, Selvaraju et al. [
11] proposed Grad-CAM, which enhances CAM by weighting feature maps from specific convolutional layers. The method performs gradient backpropagation on each convolutional layer’s feature map to obtain the weights of each feature. After applying gradient weighting to the activation maps, the method progressively aggregates them into a comprehensive saliency map, allowing the heatmap to intuitively display the regions of the image that the model focuses on. This improvement laid a crucial foundation for subsequent research and spurred a series of advances. Among these, Chattopadhyay et al. [
12] introduced Grad-CAM++, which refines the weight calculation by considering the second derivative of each pixel’s contribution to the classification score, improving localization accuracy in multi-instance scenarios. Jiang et al. [
13] proposed Layer-CAM, which incorporates shallow convolutional feature maps and fuses multilayer feature maps to generate more granular visualizations of saliency maps. Meanwhile, Fu et al. [
14] introduced XGrad-CAM, which combines an expected gradient approach to calculate the expected gradient values of the output predictions with respect to the activation maps, thus reducing the impact of gradient fluctuations on the saliency maps. However, some derivative methods argue that using gradient information to compute linear coefficients is unreliable and propose alternative approaches. For example, Muhammad et al. [
15] introduced Eigen-CAM, which applies Principal Component Analysis (PCA) to feature weighting based on the activation maps. Wang et al. [
16] developed Score-CAM, which determines weights by calculating the contribution of each activation map to the predicted class score. Ramaswamy [
17] proposed Ablation-CAM, which uses a feature masking strategy to iteratively assess the impact of each feature map on model predictions, determining their importance. The evolution of these methods reflects the transition from simple gradient calculations to more complex mathematical models, continually enhancing the ability to handle multiple-instance scenarios and fine-grained details, thus producing more stable and reliable explanations.
Although CAM-based methods have achieved significant results, most of these techniques were originally developed for image classification tasks and are limited to providing image-level explanations. These approaches typically generate coarse heatmaps to highlight the most influential regions for a single predicted class. Object detection networks, which require both classification and localization capabilities, represent an intermediate level of granularity between classification and segmentation tasks. Although detection methods can benefit from region-level CAM explanations to understand bounding-box predictions, they still do not require the fine-grained pixel-level interpretability demanded by semantic segmentation. Segmentation tasks present unique challenges, as they require dense and pixel-accurate explanations that preserve spatial relationships and boundary details. Consequently, directly applying conventional CAM methods to segmentation models often leads to spatial detail loss and reduced localization accuracy.
Therefore, the development of explainability methods that can be applied to a broader range of visual tasks remains an important research direction in this field. Recently, researchers have begun to propose specialized XAI methods for image segmentation tasks. For example, Seg-Grad-CAM, introduced by Vinogradova et al. [
18], extends the Grad-CAM framework to interpret segmentation models, generating saliency maps that indicate the relevance of individual pixels or regions through masking. Furthermore, Seg-XRes-CAM, presented by Hasany et al. [
19], improves this approach by combining feature maps with residual connections and fine-grained spatial information, further enhancing the accuracy of segmentation region explanations. As emphasized by Draelos et al. [
20], the retention of spatial information is crucial to accurately reflecting the decision-making process of pixel-level localization models. This can be achieved by improving the weight computation and avoiding the effects of global pooling.
Despite significant advances in existing methods, several notable limitations remain. Gradient-based methods (e.g., Seg-Grad-CAM or Seg-XRes-CAM) are often susceptible to noise interference. Moreover, when dealing with complex backgrounds or high-density objects, these methods tend to highlight irrelevant background areas inappropriately. These limitations are particularly pronounced in multiple-object tasks requiring precise target localization, such as image segmentation and object detection, where the interpretability results often fail to accurately reflect the model’s decision-making process, lacking sufficient focus on local regions. On the other hand, while non-gradient-based methods (e.g., Eigen-CAM) effectively mitigate noise interference, they also face challenges when dealing with complex backgrounds or dense targets in multi-objective tasks due to insufficient consideration of spatial information. Additionally, the sign ambiguity in the Singular Value Decomposition (SVD) process in Eigen-CAM can lead to unstable explanation results, especially when handling scenes with multiple target classes. This instability significantly affects the reliability of the explanation results.
Therefore, this study aims to propose a novel XAI method to avoid the impact of noise on gradient information and provide a more stable and accurate explanation for segmentation models. Specifically, we first obtain spatial information by performing gradient backpropagation on feature maps and use it as a weighted sum in an element-wise product with the activation map to generate a weighted activation map. Then, following the approach of Eigen-CAM, we perform SVD on the weighted activation map and use the first principal component as the weight vector to generate the class-discriminative localization map. Finally, in the post-processing stage, we employ an innovative sign correction strategy designed to optimize the representation direction of saliency maps by selecting and preserving the contributions of the most relevant information directions. Furthermore, in response to the shortcomings of existing evaluation metrics for assessing the performance of different explanation methods, we also propose a new evaluation framework to objectively compare the performance of various explanation methods. In summary, the main contributions of this study can be summarized as follows:
We propose a completely new XAI method, extending the widely used Eigen-CAM method to make it more suitable for semantic segmentation models. By applying a gradient weighting strategy, we can obtain more precise spatial information, thus generating fine-grained explanation results.
We perform SVD on the weighted activation map to extract its main feature representations and introduce a sign correction strategy to optimize the direction of the saliency map. This approach not only effectively suppresses noise issues but also enhances the stability of explanation results.
We introduce an evaluation framework specifically designed for the interpretation of multiple-object task models, allowing for a more objective assessment of the performance of different XAI methods and quantifying their explanatory effectiveness.
3. Methods
3.1. Problem Setup
Given a CNN designed for semantic segmentation, let the input image I have dimensions , . The network generates a prediction output Y, and the objective of the class-discriminative localization map is to provide a visual explanation of the prediction Y for the target class c. This explanation approach typically uses a trained CNN model with fixed parameters, analyzing feature maps from specific convolutional layers to extract relevant information. By applying different weighting mechanisms, a saliency map is generated, highlighting the most influential regions. Finally, the saliency map is overlaid on the input image for visualization.
3.2. Methodology Overview
To illustrate our proposed method and its enhancements over the original Eigen-CAM framework, we present a comparative flowchart in
Figure 3. The diagram outlines the processing pipelines of both Eigen-CAM and our method, clearly highlighting the key differences. Our method introduces two critical modifications: a gradient weighting strategy applied before SVD to enhance spatial sensitivity and a sign correction module to address the directional ambiguity inherent in SVD decomposition. These enhancements generate more stable saliency maps for semantic segmentation tasks. The following subsections detail each component of our approach.
3.2.1. Gradient Weighting Strategy for Spatial Information
In deep learning interpretability models, effectively capturing spatial information and integrating weighting mechanisms for saliency map generation remains a significant challenge. Furthermore, the choice of interpretability methods should be tailored to specific application scenarios to ensure that explanations align with practical needs. As observed in the study by Samek et al. [
33], in linear cases, different applications require different attribution methods, and selecting an appropriate attribution strategy is crucial to revealing the internal workings of a model. The choice of an attribution method should be guided by the specific question we aim to answer: for instance, whether we seek to determine which input features have the most significant impact on the overall model output or whether we are interested in understanding the contribution of each input feature to a specific data point.
Consider a linear regression model
, where
represents the attribution value for the
i-th feature
, and
denotes the target variable. For global interpretation, the regression coefficients
and
directly indicate the impact of each feature on the target variable, as they correspond to the partial derivatives of the target variable with respect to the independent variables. Thus, the attribution value in global interpretation can be defined as:
On the other hand, local interpretation focuses on the input features of a specific data point, emphasizing the contribution of
and
to the prediction at that point. The attribution value in local interpretation can be defined as:
Although both approaches rely on gradient computations of the model function, their scope and objectives differ. In computer vision tasks, the interpretability of image classification and image segmentation models exhibits notable differences. Classification models produce a single label or probability score as output, making global interpretation valuable for identifying the most influential input features for classification. In contrast, segmentation models generate pixel-wise classification results, requiring an understanding of how the classification of each pixel is influenced by input features. In this context, local interpretability becomes crucial. To generate more fine-grained explanations, we established direct correlations between pixel activations and their corresponding gradient variations. This approach precisely quantifies the impact of individual features on pixel-wise classification, shifting the focus from global feature contributions to localized feature importance.
To address this issue, we propose a method that integrates gradient information with activation maps, providing a more comprehensive representation of the significance of the feature. Specifically, given an input image
I and a target class
c, we compute the gradient matrix of the class score with respect to an intermediate convolutional feature map
, capturing the influence of class
c on
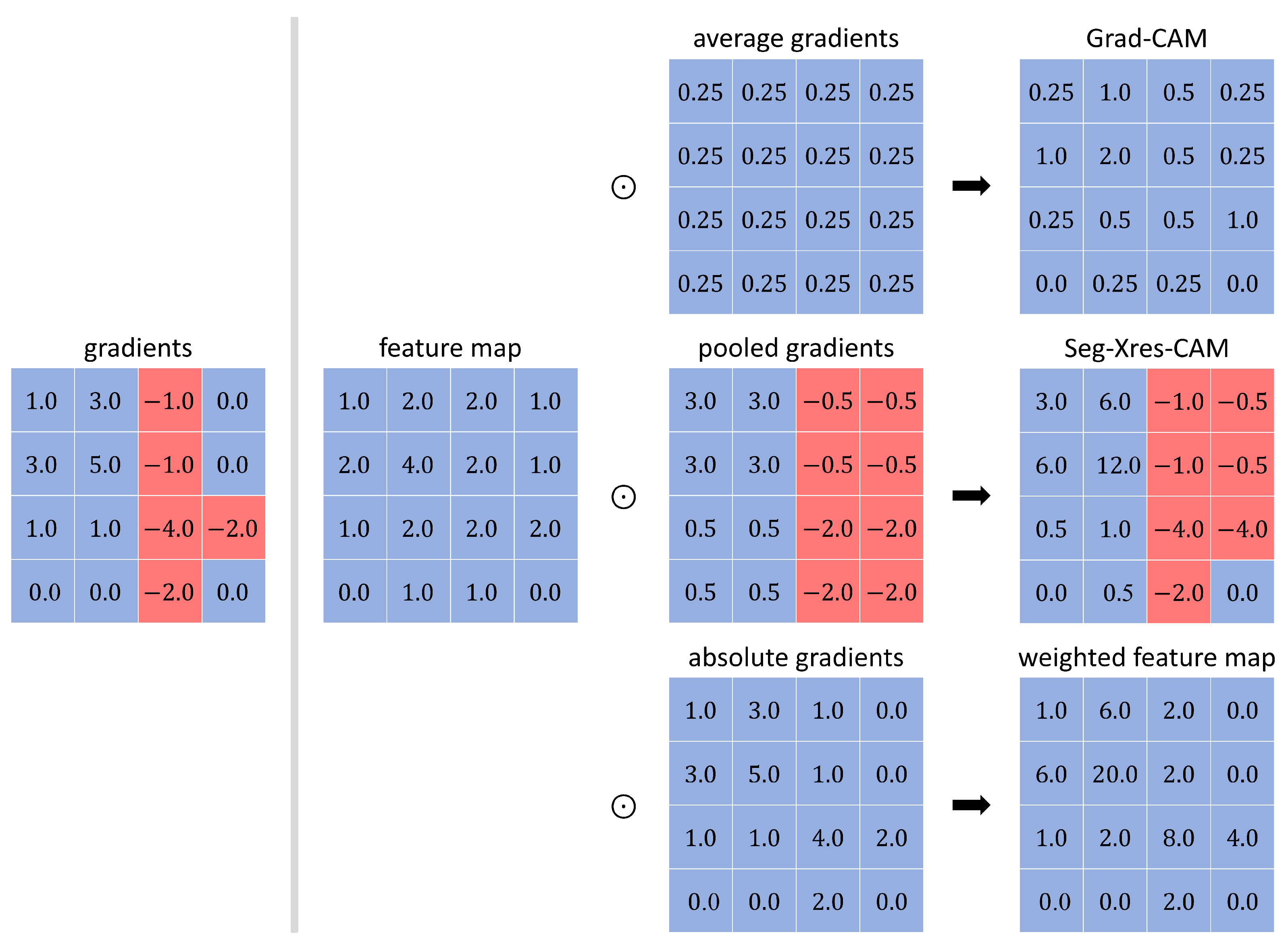
. Traditional gradient-based methods, such as Grad-CAM, primarily focus on positive gradients, which may overlook features that have a significant negative impact on the loss function. To mitigate this, we employ the absolute values of gradients to measure their contribution to the loss function rather than considering only their direction. Subsequently, we perform an element-wise product between the absolute gradients and the activation map, effectively using the pixel-wise gradient contributions as weights to integrate activation maps with their spatial information. The computation process is defined as follows:
Here, ⊙ represents element-wise product. In addition, is replaced with , indicating the generation of a localized explanation for the region of interest.
When interpreting the behavior of deep learning models, gradients provide a natural way to quantify the influence of features on the model’s output. According to Wang et al. [
34], who reviewed and synthesized existing gradient-based methods, gradients reflect the sensitivity of predictions to changes in input, making them a local approximation of feature coefficients. This offers a reasonable starting point for analyzing the decision-making process of models. However, direct use of gradients can be affected by noise, especially when unrelated features contribute to noise. Researchers have pointed out that such noise primarily arises from imperfections in the method design rather than from the model relying on noise for predictions. This study emphasizes the necessity of evaluating the magnitudes of the gradients in absolute terms, as both negative and positive gradients can significantly impact the results. Considering only positive gradients can underestimate the contributions of certain critical features and potentially introduce noise through low-intensity responses.
As shown in
Figure 4, Grad-CAM emphasizes understanding which input features contribute most to the overall classification result, using the global average pooling of gradients to capture a global interpretation of features. In contrast, Seg-Xres-CAM adopts a local pooling approach, allowing it to capture the variations in the gradients within specific regions. Although this method preserves more spatial information, it may still introduce additional noise, particularly in edge regions, where larger gradient variations can lead to overestimating the influence of features near the boundaries, causing the activation of non-target areas to increase and affecting the accuracy of the visualizations. To address these limitations, we propose a method that focuses on gradient magnitude values, which not only reduces noise interference but also provides a more accurate quantification of feature importance. By multiplying absolute gradient values with activation maps, we obtain a weighted activation map with high spatial resolution that more faithfully represents pixel-wise contributions. For further analysis of this weighted activation map, we employ SVD in subsequent steps to extract key information.
3.2.2. Sign Correction Strategy
Next, our approach follows the same procedure as Eigen-CAM: we perform SVD on
and extract its principal components, capturing the most significant variance in the feature activation. The localization map
is then obtained by projecting
onto the first principal component. The computation process is defined as follows:
However, a fundamental mathematical property of SVD results in the issue of sign ambiguity: When a matrix
A is decomposed as
, the column vectors of
U and
V can change signs simultaneously without affecting the final decomposition. This is because
. This phenomenon, known as sign ambiguity [
21,
22,
23,
24], poses challenges in feature extraction and visualization by potentially changing the representation of salient regions, thereby affecting the stability, consistency, and interpretability of feature maps.
To address this issue, we propose a Dynamic Sign Correction Mechanism as a post-processing step for the localization map. Specifically, we perform a directional analysis by comparing the absolute values of the extrema in the localization map, dynamically adjusting its overall sign. The correction mechanism is defined as follows:
This mechanism is based on the optimization principle of feature representation, which assumes that in a well-optimized saliency map, class-discriminative information should contribute positively. When the absolute value of the negative extrema significantly exceeds that of the positive extrema, it often indicates a suboptimal assignment of signs. By dynamically correcting the sign, our method ensures that the primary feature information remains aligned with the positive direction, thereby enhancing the consistency and interpretability of the localization map. Furthermore, this correction strategy not only rectifies potential directional bias but also enhances feature representation stability through a simple linear transformation.
3.3. Evaluation Metrics and Performance Indicators
One of the key challenges in developing XAI methods for deep convolutional neural networks is how to objectively evaluate their effectiveness in a rigorous and standardized manner. A major difficulty in this process lies in determining appropriate evaluation metrics that can effectively measure the relevance, fidelity, and overall quality of an explanation.
To comprehensively assess the effectiveness of the proposed method, this study adopts the experimental framework established by Hasany et al. [
19], using the relevance-based element retention approach as the primary evaluation strategy. The evaluation procedure follows a series of steps. First, the generated saliency map
is binarized to retain only the highlighted regions, with the remaining areas masked out. Next, the resulting masked image
is fed back into the model for prediction. Finally, the relevance of the explanation is measured by comparing the model predictions for the original image, denoted as
Y, with those for the masked image, denoted as
. The comparison is performed using the Dice score
, which quantifies the similarity between the two sets of predictions. The computation process is defined as follows:
Here, represents the binarized mask, , and is the threshold to preserve the highlighted regions. In this study, we set to ensure the integrity of the highlighted regions, thereby preserving fine-grained details in the explanation results.
However, this study does not adopt the relevance-based element masking approach as an evaluation metric. This decision is based on experimental observations. When the saliency map exhibits high-intensity activations in the background, the highlighted regions tend to be excessively large. In such cases, extensive masking removes critical information required for the prediction, leading to prediction failures and causing the Dice score to approach zero. Although this metric can reveal the sensitivity of the model, when the masked area is too large, performance differences between explanation methods become less distinguishable, reducing the discriminatory power and effectiveness of the evaluation. In light of these considerations, this study chooses to exclude this metric in order to ensure the reliability of the evaluation results.
Recognizing the limitations of a single metric, this study proposes a novel metric of “Preserved Effectiveness” (
), which integrates the Dice score with the proportion of retained salient regions (
), which is defined as follows:
This metric aims to balance the trade-off between effectiveness and efficiency in evaluating explanation methods. Specifically, an ideal saliency map should focus on regions that are most relevant to the model’s decision rather than irrelevant or distracting background regions. Although retaining larger salient regions may help maintain a higher Dice score, this approach often compromises the precision of the explanation. Thus, serves as a comprehensive evaluation measure, incorporating the following key aspects:
Relevance—An ideal explanation method should accurately identify the key regions that influence the prediction. The Dice score directly reflects whether the explanation method captures areas crucial to the decision-making process of the model.
Low Complexity—A complex explanation incorporates all relevant regions to identify features critical for predictions. However, excessive complexity can diminish interpretability, even when the explanation faithfully represents the model’s behavior. metric quantifies this complexity by measuring the proportion of regions retained, providing an objective assessment of the explanation density.
Synergistic Performance—This metric ensures that the evaluation measures operate in a complementary and synergistic manner, enabling explanations to precisely highlight critical regions while maintaining appropriate conciseness. This balance optimizes the overall effectiveness and improves the trustworthiness of the interpretations.
4. Experiments
To evaluate the effectiveness and robustness of the proposed Seg-Eigen-CAM method, we conducted extensive experiments on semantic segmentation models. This section presents comprehensive quantitative and qualitative analyses to assess the interpretability and stability of our approach. We begin by describing the experimental setup and evaluation protocols, followed by systematic ablation studies and quantitative comparative analyses with existing methods. In addition, we provide visual evaluations of local interpretability, qualitative assessments in complex scenarios, and detailed case studies to demonstrate the practical effectiveness of our method.
4.1. Datasets and Models
This study uses the val2017 subset of the COCO dataset (Common Objects in Context) [
35]. This subset contains 5000 high-quality annotated images across 80 object categories, covering a diverse range of natural scene images. The variety in the image data provides a comprehensive and representative basis for evaluation.
The experimental framework in this study is based on OpenMMLab’s MMSegmentation [
36] toolkit. This open source image segmentation toolkit is well regarded for its modular design, flexibility, and ease of use. It also utilizes pre-trained models trained on several public benchmark datasets, providing a solid technical foundation for our research. In the experiments, we selected three different semantic segmentation models: DeepLabV3 [
24], PSPNet [
37], and BiSeNetV1 [
38]. All models employ ResNet-50 as the backbone network and are pre-trained on the COCO-Stuff 164K dataset. Detailed configuration parameters and performance comparisons for each model are shown in
Table 1. In all experiments, we extracted saliency maps from the model bottleneck.
4.2. Data Preprocessing
During the data preprocessing stage, we performed filtering and cleaning on the val2017 dataset. Initially, a preliminary inspection revealed that 48 of the 5000 images in the original dataset were unlabeled. To ensure data integrity and eliminate potential sources of bias, we removed these images, retaining a final set of 4952 images.
Next, for each image, we selected the annotated category that occupies the largest area of pixels as the target class. This decision was guided by several key considerations. Attempting to interpret all small objects within an image could lead to unreliable and less meaningful results. For instance, when a category occupies only a minimal pixel area, the region contains insufficient features, making it difficult for the model to learn effective discriminative information. Consequently, explanations for such regions are more susceptible to local noise, image compression artifacts, or annotation errors, which could cause discrepancies between the explanation and the actual predictive features. Furthermore, when the model explanation slightly expands or contracts such a region, evaluation metrics may exhibit nonlinear variations due to changes in pixel count, making it challenging to consistently assess the effectiveness of the explanation method. This could reduce the reliability of the metric values and potentially lead to misleading conclusions.
Finally, to ensure the reliability of the statistical analysis, we retained only categories with more than 40 samples. In this process, we removed 44 categories, accounting for 541 images, to prevent statistical bias due to insufficient sample sizes and to avoid extreme fluctuations in evaluation results that could compromise the trustworthiness of the overall experiment. After these filtering steps, the final dataset consisted of 4411 images. The distribution of target categories and their corresponding counts is summarized in
Table 2.
4.3. Evaluation Framework
In XAI research, the effective and reliable evaluation of explanation methods remains a critical challenge. To address this issue, this study proposes a comprehensive multi-metric evaluation framework that assesses various explanation methods from multiple perspectives. The core evaluation strategy of this framework is the relevance-based element retention approach, which measures whether an explanation method can accurately identify and capture the crucial factors that influence model decisions. In addition, we introduce the Preserved Effectiveness as a complement to the Dice score. Unlike purely numerical performance metrics, emphasizes both the precision and interpretability of the explanations, thus enhancing the credibility and practical value of the model interpretations.
Furthermore, this study incorporates the M3 metric proposed by Gizzini et al. [
31] as a supplementary evaluation criterion. This metric evaluates the stability of explanation methods by analyzing the uncertainty of the prediction, providing an alternative perspective on the behavior of the model when key regions are preserved, which is defined as follows:
Here, represents the total pixel-level entropy of the input image X, , and denotes the softmax output of the model in the l-th feature map. refers to the masked image that retains only the salient and target regions.
In summary, this study evaluates explanation methods from multiple dimensions and adopts , , and as the primary metrics within the proposed multi-metric evaluation framework. These metrics provide an effective and reliable means to assess the performance of explanation methods.
4.4. Ablation Study
4.4.1. Gradient Weighting Strategy Experiments
In this section, we conduct an ablation study on gradient weighting strategies to compare different approaches and analyze their impact on model interpretability.
Table 3 presents the detailed results of this experiment. Specifically,
refers to multiplying the gradient by the activation map, while
involves multiplying the absolute value of the gradient by the activation map. From the results in
Table 3, we observe that both strategies yield comparable performance across most categories, indicating that our approach does not introduce a significant negative impact on the Dice score. However, in certain categories,
slightly outperforms
by ensuring a consistent directional input, thus emphasizing the numerical significance of the features. This suggests that
may offer greater stability in certain feature recognition tasks.
In general, while the performance differences between the two strategies are relatively minor, we hypothesize that this may be attributed to the limitations of the evaluation metrics. Purely numerical assessments may not fully capture the characteristics and implications of different methods. To gain deeper insights into the interpretability advantages of our approach, we further explore this aspect in the subsequent qualitative analysis.
4.4.2. Sign Correction Strategy Experiments
In this section, we conduct an ablation study to analyze the effect of the sign correction strategy on the interpretability of the model.
Table 4 presents the detailed results of this experiment. As shown in
Figure 5, we select a scene image that contains both the target class (person) and various background regions for analysis. Without sign correction, the model exhibits a strong negative response in the target class region while displaying a weaker positive response in non-target background areas. This contradicts intuitive explanations. In contrast, after applying sign correction, the model’s attention is more effectively concentrated on the person, producing a visual explanation that aligns with human perception.
The experimental results indicate that, due to the inherent symbolic ambiguity in the feature space, uncorrected saliency maps may lead to instability and inconsistency in explanation results. Specifically, this can cause the model to overemphasize background regions while suppressing truly important areas. By incorporating the sign correction strategy, we successfully mitigate this issue, enabling the model to generate more stable and intuitive explanations.
4.4.3. Evaluation Metrics Experiments
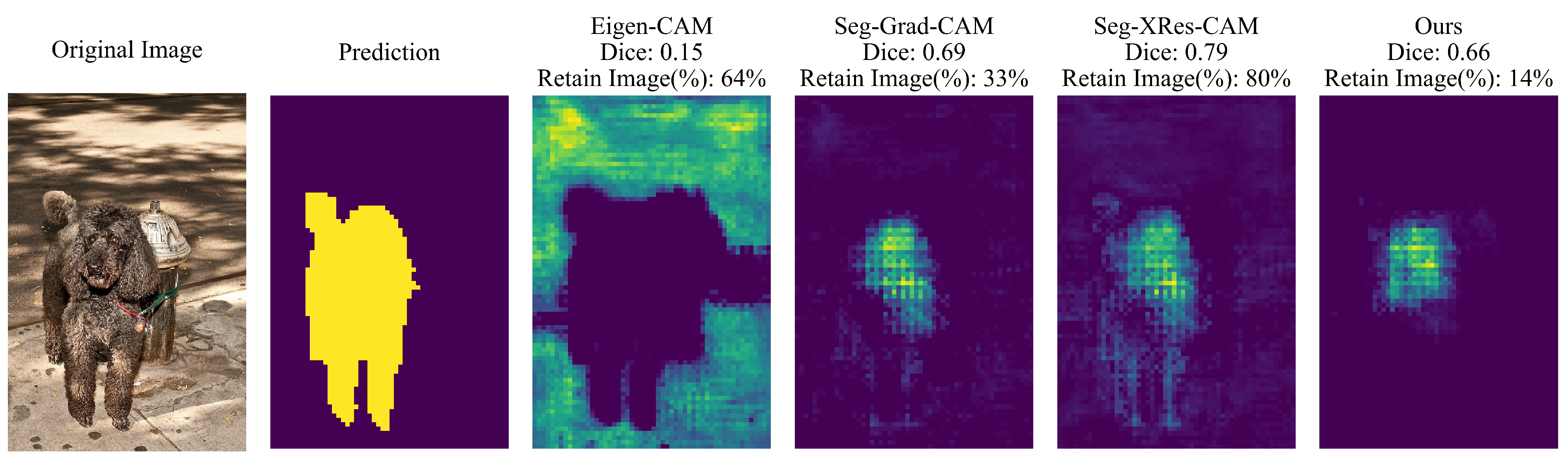
In this section, we conduct a case study to examine the reliability and interpretability of evaluation metrics. As shown in
Figure 6, we analyze an image containing a single target class (dog). The experimental results indicate that although Seg-XRes-CAM achieves the highest Dice score (0.79), effectively preserving the overall contour of the target object, it also retains a substantial portion of the background. This phenomenon is reflected in its relatively high image retention rate. In contrast, both Seg-Grad-CAM and our proposed method focus primarily on the head region of the target object, aligning more closely with human visual perception. Although these methods yield a comparatively lower Dice score, their explanations are more precise and intuitively understandable. In particular, our approach demonstrates the highest interpretability by accurately localizing the key decision-influencing regions while maintaining the lowest image retention rate. Meanwhile, Seg-Grad-CAM retains some irrelevant background regions due to noise interference.
To further quantify the quality of the XAI method, we introduce the Preserved Effectiveness metric and compute the value for each method: Eigen-CAM (0.23), Seg-Grad-CAM (2.09), Seg-XRes-CAM (0.99), and our proposed method (4.71). The results clearly demonstrate the superiority of our approach in terms of the quality of the explanation. The metric effectively captures the spatial precision of the explanations, revealing the critical regions that influence the model decisions. A higher PE value indicates that the method provides a more refined and focused explanation, avoiding the inclusion of extensive background areas or weakly relevant regions, thus more accurately reflecting the core basis of the model’s decision-making process. This multidimensional evaluation framework mitigates the limitations of relying on a single metric, ensuring that the explanation results are both interpretable and reliable, ultimately enhancing their practical value.
4.5. Quantitative Analysis
In this section, we evaluate the effectiveness of various interpretability methods using a comprehensive evaluation framework to quantitatively assess their explanation performance. This framework enables a multidimensional evaluation of explanation capabilities, providing an in-depth analysis of the advantages and limitations of different methods.
Table 5 presents the results of the comprehensive evaluation of different explanation methods in three semantic segmentation models applied to all images in the dataset.
The experimental results indicate that Seg-XRes-CAM exhibits the best performance in
, achieving the highest scores in most categories in all three models. This demonstrates its ability to accurately capture the regions of interest influencing the model’s decision, effectively utilizing spatial information to generate local explanations. This results in high consistency and fidelity, with the attention regions aligning closely with the predicted regions. However, even less precise XAI methods often produce large highlighted areas in the image, which may overlap with the predicted regions, thus preventing extremely low
scores. This phenomenon is observable in Eigen-CAM: although its explanations may not align with intuitive human judgments and may even be deemed incorrect, it still maintains a certain level of
. In addition, all methods perform poorly on BiSeNetV1 in terms of
, probably due to the lower baseline performance of BiSeNetV1 as a lightweight semantic segmentation model, as shown in
Table 1. This highlights the impact of the performance of the underlying model on the explanation results.
For the metric, Seg-XRes-CAM and our proposed method demonstrate superior performance in individual class evaluations, with lower values of . This suggests that these methods are more effective in identifying key features that influence the model’s segmentation decisions, excelling in local interpretability. However, our method also faces challenges: By retaining only the primary directional information in the image regions, some details may be overlooked. When the masked image is re-predicted, this may lead to prediction failure, with some classes exhibiting a higher increase in entropy. This phenomenon reflects the instability that can arise under low image retention rates, which also explains why our overall average performance is lower than Seg-XRes-CAM.
For the
metric, our proposed method outperforms all other methods in all models and classes. As shown in
Table 6, our method achieves significantly lower image retention rates while maintaining stable performance
, demonstrating its ability to effectively identify the core decision-making regions. In contrast, Seg-XRes-CAM shows a higher
, indicating that it can faithfully present the rationale of the model decision. However, because the explanation is coarser and the influence of gradient weighting and gradient noise, Seg-XRes-CAM exhibits comparatively poorer performance in the
metric. Although Eigen-CAM
is similar to other methods, it is important to note that
can only effectively reflect the quality of the explanations when
is sufficiently high.
To visualize the performance of each explanation method, we present the distribution of the Dice score and the image retention rate in a two-dimensional histogram, as shown in
Figure 7. The analysis reveals that Eigen-CAM’s samples are concentrated in the bottom-left region, indicating suboptimal explanation performance. Gradient-based methods demonstrate higher image retention rates, with their high
values indicating an effective representation of the model’s decision rationale. In comparison, samples from our proposed approach cluster in the bottom-right region, suggesting superior capability in identifying critical regions that influence model decisions while minimizing the impact of irrelevant areas. The distribution pattern in the two-dimensional plane demonstrates both the correlation and stability characteristics of each method, highlighting their respective reliability. Optimally, an attribution map should preserve maximum prediction information within a minimal image area; therefore, distributions closer to the bottom-right quadrant represent more effective explanation outcomes.
4.6. Performance of Local Interpretability
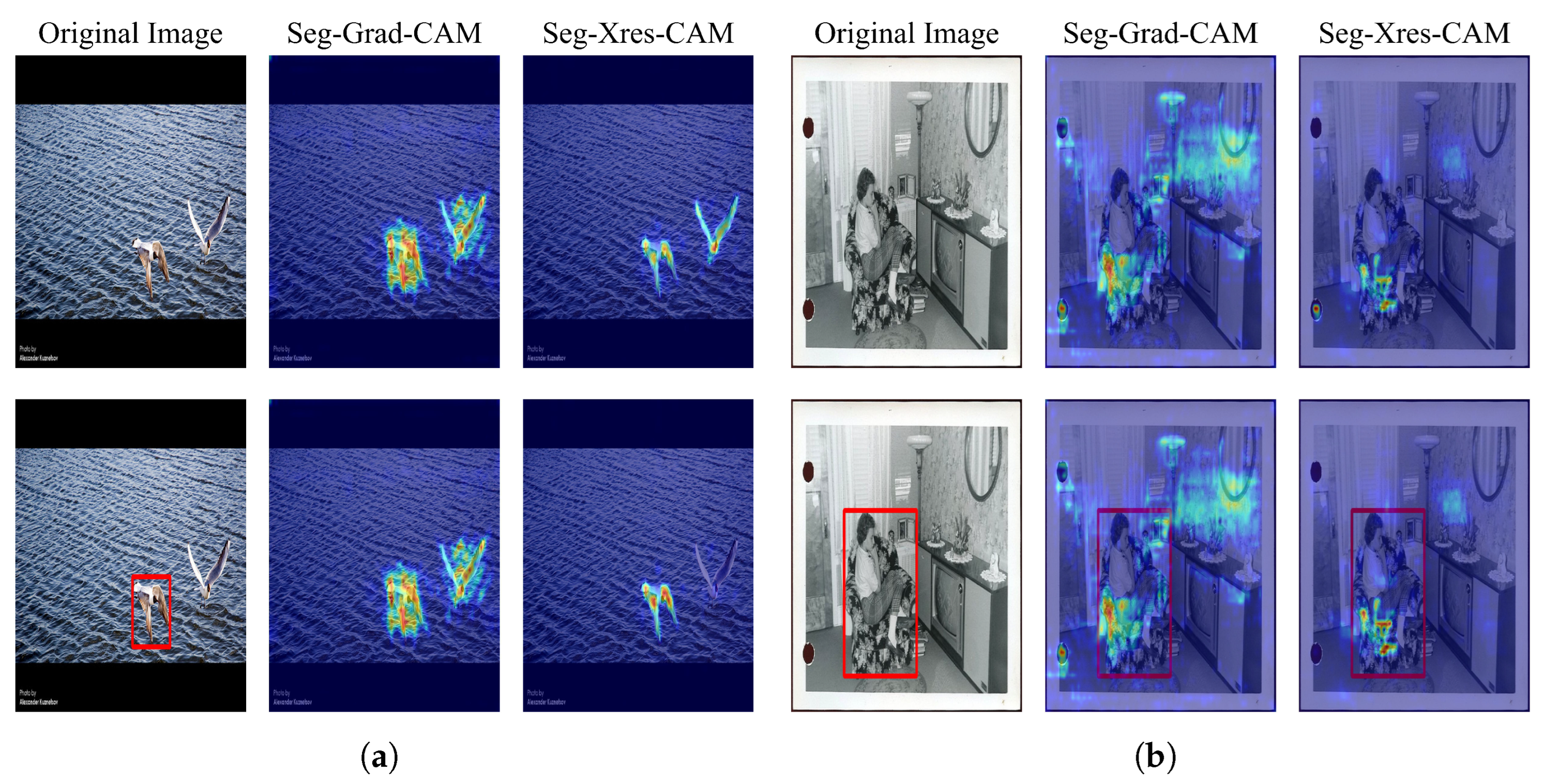
To evaluate the performance of different methods in generating localized explanations, we analyzed an image containing the target class (bird), as shown in
Figure 8. Since Seg-Grad-CAM, Seg-XRes-CAM, and our method all employ similar mechanisms to focus on regions of interest, comparing their respective heatmap distributions allows us to directly assess their ability to preserve spatial information and accurately locate target objects.
From the figure, it is evident that Eigen-CAM and Seg-Grad-CAM struggle to accurately localize target regions because of their inability to fully incorporate the spatial information. As a result, their heatmaps display significant background interference, with strong activations appearing in non-target areas such as branches and leaves. In contrast, Seg-XRes-CAM and our method effectively leverage spatial information, allowing more precise identification and interpretation of the model focus areas. This advantage is particularly noticeable in multi-objective scenarios; for example, in the second example in
Figure 8, both methods clearly highlight the location of the bird and generate the corresponding localized explanations.
The experimental results highlight the importance of retaining and utilizing spatial information when generating localized explanations. By effectively integrating spatial context with feature representations, our proposed method ultimately improved the precision and reliability of model explanations.
4.7. Performance in Complex Scenarios
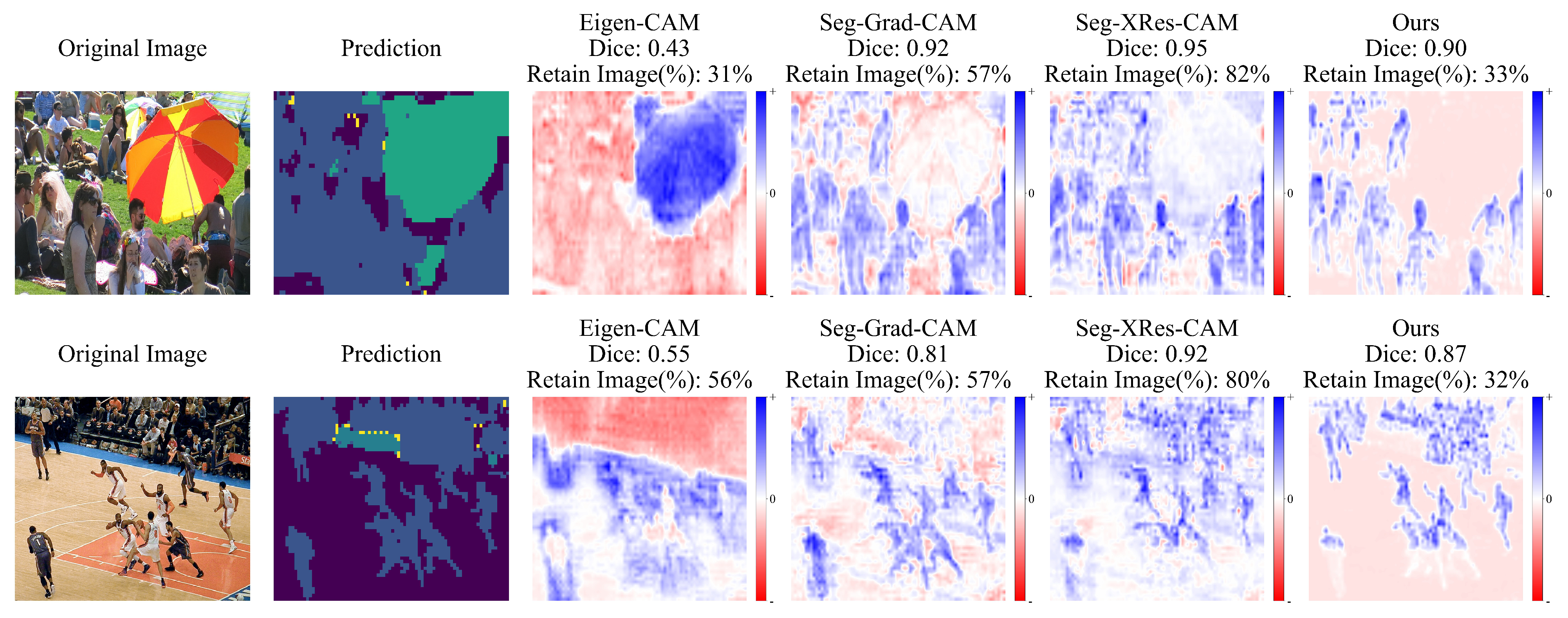
To investigate how different methods perform in complex scenarios, we analyzed images containing multiple densely distributed instances of the same target category (person), as shown in
Figure 9. The figure reveals notable issues with Seg-XRes-CAM. For example, in the first scene, weak positive responses appear along the edges of umbrellas and at the boundaries of the crowd, causing the activation regions (blue areas) to extend into non-target regions such as umbrellas and the ground. This validates our previous discussion, highlighting how local pooling mechanisms can overestimate the influence of features at boundaries, leading to excessive activation in irrelevant areas.
In contrast, our method achieves more accurate target localization. In the same scene, it clearly distinguishes between relevant and non-relevant regions, generating heatmaps with more concentrated activation regions primarily focused on the human figures. This indicates that our approach is capable of preserving semantic consistency even in visually cluttered environments. A similar trend is observed in the basketball court scene, where our method maintains robust identification performance even under lower image retention rates, effectively filtering out irrelevant visual information and producing more precise and concise explanations.
The experimental results confirm the importance of precise spatial information utilization in enhancing the interpretability of the model in complex scenes. Using a more refined feature processing approach, our method effectively mitigates background interference commonly observed in gradient-based methods and generates more detailed and reliable explanations.
4.8. Case Study and Limitation Analysis
To further explore the potential limitations of evaluation metrics, this study selected several cases in which our method performed relatively poorly in quantitative metrics within images containing the target class (person). These cases help uncover biases and misconceptions that may arise from relying solely on quantitative metrics for evaluation.
As shown in
Figure 10, in the first two scenes, although our method achieved relatively low Dice scores, the visual results reveal that Seg-Grad-CAM and Seg-XRes-CAM, despite achieving higher Dice scores, retained a larger retention of the image area. Specifically, Seg-XRes-CAM produced visual results similar to ours but retained a large amount of low-intensity responses in the background. This suggests that higher Dice scores may not necessarily reflect the quality of the explanation accurately. In the third scene, our method retained only 3% of the image area while still achieving a Dice score of 0.87. This further corroborates the fact that low-intensity responses generated by gradient-based methods may originate from gradient noise rather than key factors influencing the decision-making process of the model. Furthermore, in the fourth scene, our method not only identified the crowd in the stands but also accurately captured the head region of the players on the field. This aligns with the experimental conclusion in
Section 4.4.3, showing that the model’s attention is typically focused on the head region of the target objects. This characteristic is consistent with the Human Visual System, indicating that the explanations generated by our method are more intuitive and interpretable.
However, these cases also highlight the limitations of relying solely on quantitative metrics for evaluation. When the pixel area of the target class is extremely small, even if the explanation effectively reflects the model’s decision-making process and aligns with human intuition, the limited features in that area may cause prediction failures when the masked image is re-predicted, leading to inaccurate conclusions from the evaluation metrics. Although evaluation metrics can assess the overall performance of XAI methods and provide insight into the characteristics of the method through 2D histograms, the black-box nature of deep learning models makes it difficult to accurately distinguish between errors in the model itself and biases in the attribution method. Therefore, relying solely on quantitative metrics to evaluate the quality of the explanation, especially in individual cases, can lead to erroneous conclusions.
To further investigate the explanation characteristics of different methods, we performed analyses in three cases with different scene characteristics, as shown in
Figure 11. The experimental results demonstrate that our method exhibits a unique attention distribution pattern. Specifically, in the first scene, our method accurately captures the model’s focus on facial regions; in the second scene, it effectively highlights the hair regions; and in the third scene, it clearly delineates the subject’s edge contours. In contrast, while other methods achieved higher scores in evaluation metrics, their explanation contained substantial background regions that may be irrelevant to the decision-making process. This observation raises the crucial question of whether high evaluation metric scores truly reflect the actual effectiveness of explanation methods. Overly complex or coarse explanations may fail to accurately represent the model’s decision-making process, and it remains challenging to verify whether these non-target regions substantially influence the model’s decisions. Although our method generates explanations that align more closely with human visual perception and offer better interpretability, the inherent black-box nature of deep learning models prevents us from fully validating the faithfulness of these explanations.
5. Conclusions and Future Work
In this study, we have proposed an improved interpretability method for convolutional neural networks in semantic segmentation tasks. Building upon the Eigen-CAM framework, our approach incorporates spatial information and class-relevance scores from gradients, resulting in weighted activation maps that better capture region-specific attention. Furthermore, we introduced a dynamic sign correction mechanism to optimize feature representations derived from the singular value decomposition of weighted activation maps, effectively addressing the sign ambiguity issues that commonly arise in multi-class segmentation scenarios.
Our experimental results, comparing against established interpretability methods including Eigen-CAM, Seg-Grad-CAM, and Seg-XRes-CAM, demonstrate several significant findings. Although our method may not consistently outperform Seg-XRes-CAM in individual quantitative metrics, it exhibits superior performance in the Preserved Effectiveness metric. This high PE score substantiates that our method effectively identifies the critical regions necessary for class recognition without relying on complete target pixels or extensive background information. The method generates refined local explanations that align more closely with human visual perception, effectively highlighting object contours and key regions while filtering out low-relevance areas.
However, through a detailed qualitative analysis, we identified certain limitations in traditional evaluation metrics. Although our highly refined explanations may occasionally lead to prediction failures during re-prediction tests, they effectively reflect the model’s decision-making process. The visual results, while similar to Seg-XRes-CAM in some aspects, provide users with more concise and intuitive visual explanations, which is the core objective of interpretability methods.
Looking ahead, several promising research directions emerge from our findings. First, while our current dynamic sign correction mechanism effectively handles sign ambiguity, there is room for improvement in complex scenes. Future research could explore the integration of adaptive feature weight adjustment with multiscale feature analysis to enhance interpretation accuracy across varying target scales and scene complexities. Second, the method’s applicability could be extended to broader domains, such as medical image analysis and remote sensing, to evaluate its generalization capabilities comprehensively. Third, investigating the extensibility of the method to other deep learning architectures, including instance segmentation and object detection models, would validate its versatility.
A particularly crucial area for future work lies in developing more comprehensive evaluation frameworks. Given that the ultimate goal of interpretability methods is to provide intuitive and meaningful explanations to users, there is a need to establish human-centric evaluation standards. These standards should effectively assess how well the explanations aid human understanding and align with human visual cognition patterns. Such evaluation frameworks should combine both quantitative metrics and qualitative analyses to provide a more complete assessment of interpretability methods.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}