


Fusion of Computer Vision and AI in Collaborative Robotics: A Review and Future Prospects




Abstract
1. Introduction
1.1. Motivation and Scope
1.2. Definitions and Interdisciplinary Scope
1.3. Contributions of the Review
- Comprehensive Survey of Vision–AI Synergy: We synthesize the literature across various domains—robotic vision, AI planning, human activity recognition, and multimodal perception—into a unified taxonomy tailored to collaborative robotics.
- Technology Landscape Mapping: We provide a structured overview of key methods including visual object detection, human pose estimation, and scene understanding.
- Simultaneous Localization and Mapping (SLAM), and deep learning architectures for HRC [12].
- Evaluation and Benchmarking: We discuss performance metrics, benchmark datasets, and simulation environments for vision–AI-enabled cobots, emphasizing the need for reproducibility and standardization [13].
1.4. Methodology and Literature Selection Criteria
1.5. Outline of the Paper
2. Foundations and Evolution
2.1. Overview of Collaborative Robotics (Cobots)
2.2. Historical Evolution of Computer Vision in Robotics
2.3. Progression of Artificial Intelligence (AI) in Robotic Applications
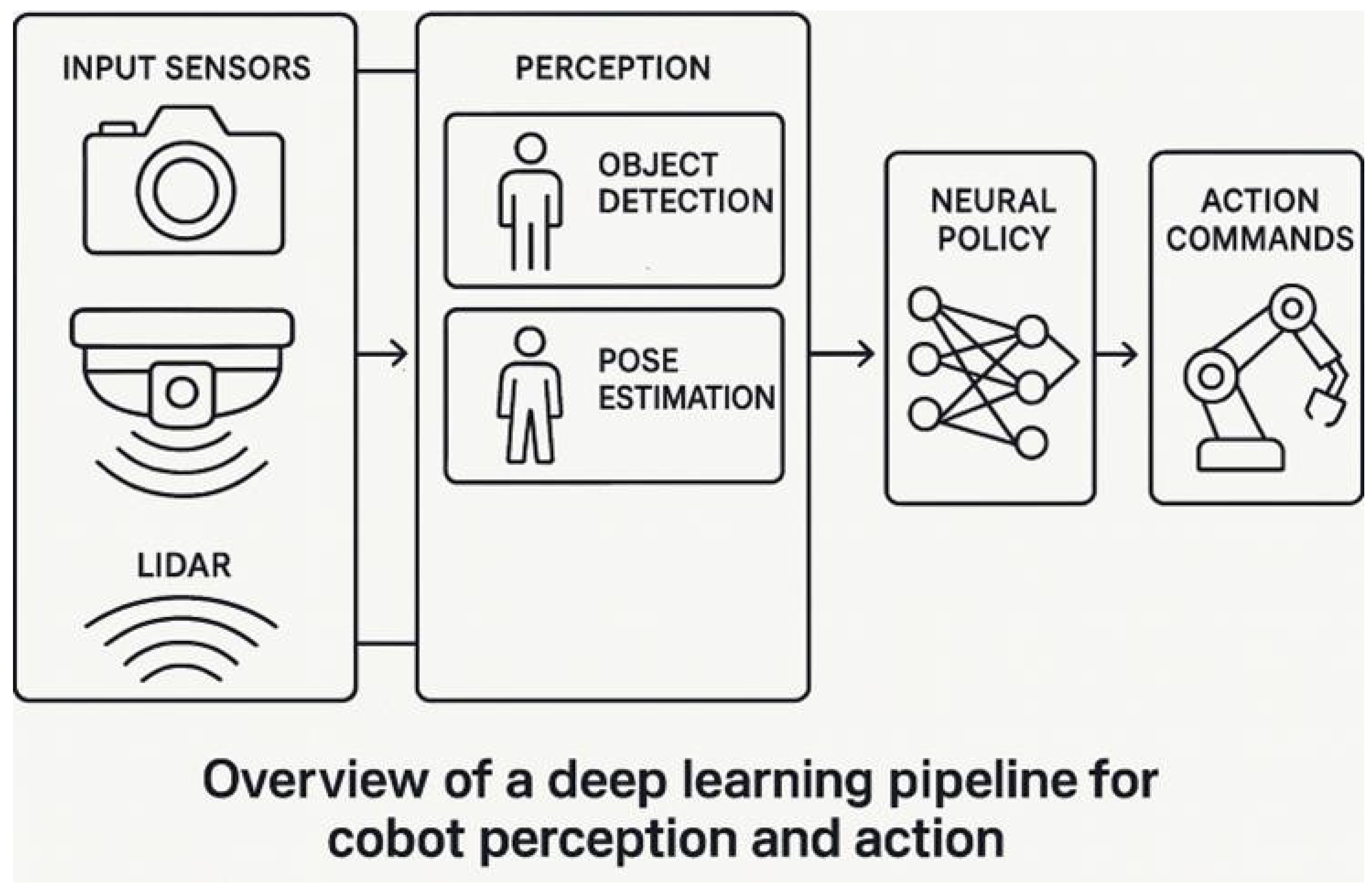
3. Core Technologies in Vision-Based Collaborative Robotics
3.1. Visual Perception and Object Detection
3.2. Human Pose Estimation and Activity Recognition
3.3. Scene Understanding and Environmental Modeling
3.4. SLAM and Spatial Awareness for Shared Workspaces
4. AI-Driven Autonomy and Decision-Making
4.1. Deep Learning Architectures for Perception and Planning
4.2. Reinforcement Learning for Adaptive Behavior
4.3. Explainable AI (XAI) and Ethical Autonomy
4.4. Cognitive Architectures for Human-like Interaction
5. Technological Trends and Challenges
5.1. Vision Technologies Integration and Deployment Challenges
5.2. Real-Time Adaptation and Learning
- NVIDIA leveraged its Isaac Lab and ROS frameworks to develop a contact-rich gear assembly task on the UR10e robot. This system achieved zero-shot transfer—the model was trained entirely in a simulation and directly deployed on real hardware without additional tuning [103]. The robot successfully picked, transported, and inserted multiple gears in random poses—demonstrating remarkable robustness and adaptability directly from a simulation.
- Researchers from Karlsruhe Institute of Technology and Heidelberg University Hospital trained in simulation for robotic tissue manipulation in surgery. They applied pixel-level domain adaptation (unpaired image translation) to bridge visual differences, enabling zero-shot deployment in a real surgical environment. This is one of the first successful sim-to-real transfers involving deformable tissues in a surgical robotic context, marking a significant milestone toward clinical-world deployment.
5.3. Trends in Cobots’ Hardware Related Capabilities
5.4. Trends Based on Technological Convergence
6. Cobot Considerations in System Architecture, AI, and Algorithms
6.1. Advanced System Architectures and Integration
6.2. Evolving AI Paradigms: From Deep Learning to Foundation Models
6.3. Role of Neural Policy Architectures
6.4. Algorithmic Frameworks for Dynamic Environments
7. Human Related Challenges and Trends
7.1. Trust Calibration in Collaborative Robotics
7.2. Socio-Cognitive Models and HRI
7.3. Ethical and Societal Considerations
8. Discussion
- Manufacturing and Industry: Cobots are central to the evolution of flexible, human-centric production lines. By combining foundation models with multimodal sensing, industrial robots are executing complex tasks in real time. The focus on safety, sustainability, and seamless human–machine collaboration aligns with the principles of Industry 5.0 [1,4,81,109,124,126,137].
- Healthcare and Assistive Robotics: Cobots are increasingly supporting hospital operations—from delivery and cleaning to patient monitoring [89,133]. Emotion-aware and trust-sensitive designs are improving safety and acceptance. In surgical settings, vision-guided robots are enhancing tool precision, while rehabilitation robots are using pose estimation for adaptive therapy delivery [151,152].
- Education and Training: Educational robots are leveraging vision and affective computing to create adaptive, emotionally intelligent learning environments. These systems promote student engagement, they personalize instruction, and help educators monitor cognitive and emotional states to improve learning outcomes [148].
8.1. Perceptual Awareness to Intent Understanding
- Sparse Contextual Data: Existing datasets rarely capture labeled human intentions over time, making supervised learning of intent inference difficult.
- Ambiguous Visual Cues: Similar gestures may signal different intentions depending on task context, making disambiguation hard from vision alone.
- Limited Multimodal Integration: Audio, gaze, force sensing, and verbal cues are critical for intent inference but remain challenging to fuse robustly in real time.
- Poor Generalization: Models often overfit to specific tasks or environments, failing to adapt to new users, layouts, or cultural practices.
- Real-Time and Safety Constraints: Predicting intent must happen quickly and reliably to avoid errors that compromise trust and safety.
8.2. Adaptive Interaction in Shared Workspaces
8.3. Challenges in Real-Time and Scalable Machine Learning
8.4. Human Trust, Transparency, and Ethical AI
- Stakeholder Analysis:
- Engage operators, designers, and ethicists early.
- Identify potential biases, vulnerabilities, and social impacts.
- Data Privacy and Minimization:
- Collect only necessary visual data.
- Apply on-device processing when possible to reduce cloud exposure.
- Anonymize human data (e.g., blur faces, remove identifiers).
- Bias and Fairness Auditing:
- Evaluate training datasets for representation gaps.
- Test models across diverse user groups to avoid discriminatory performance.
- Retrain with balanced data if disparities emerge.
- Explainable AI (XAI) Integration:
- Provide human-understandable reasons for vision-driven decisions.
- Use visual overlays or verbal cues to explain robot intentions.
- Safety and Consent:
- Implement opt-in/opt-out mechanisms for visual monitoring.
- Ensure clear signaling when cameras are active.
- Provide manual overrides for emergency stops.
- Continuous Monitoring and Feedback:
- Track system performance and ethical compliance post-deployment.
- Gather operator feedback to refine policies.
- Establish accountability lines for failures or breaches.
8.5. Toward Seamless and Proactive Collaboration
8.6. Interoperability Challenges and Open Robotic Architectures
8.7. Limitations in Real-World Deployability
9. Conclusions and Future Directions
9.1. Proactive Human–Robot Collaboration
- Spatiotemporal Transformers for predicting human motion and intent from video sequences, enabling anticipatory planning.
- Graph Neural Networks to fuse multimodal inputs (vision, force, and audio) for relational reasoning about humans, objects, and tasks.
- Real-Time 3D Semantic Mapping using neural implicit representations for a detailed, dynamic workspace understanding.
- Uncertainty-Aware Trajectory Prediction with probabilistic models to ensure safe and cautious planning around humans.
- Explainable Reinforcement Learning to make robot policies interpretable and trustworthy.
- Few-Shot and Meta-Learning for rapid adaptation to new tasks and collaborators with minimal data.
- Edge AI Deployment to deliver low-latency perception and planning for responsive and safe interaction.
9.2. Few-Shot and Continual Learning at the Edge
9.3. Interoperability and Open Robotic Architectures
9.4. Explainability, Safety, and Human Trust
9.5. Multimodal and Semantic Sensor Fusion
9.6. Need for Standardization and Unified Evaluation Frameworks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Patil, Y.H.; Patil, R.Y.; Gurale, M.A.; Karati, A. Industry 5.0: Empowering Collaboration through Advanced Technological Approaches. In Intelligent Systems and Industrial Internet of Things for Sustainable Development; Chapman and Hall/CRC: New York, NY, USA, 2024; pp. 1–23. [Google Scholar]
- George, A.S.; George, A.H. The cobot chronicles: Evaluating the emergence, evolution, and impact of collaborative robots in next-generation manufacturing. Partn. Univers. Int. Res. J. 2023, 2, 89–116. [Google Scholar]
- Palanisamy, C.; Perumal, L.; Chin, C.W. A comprehensive review of collaborative robotics in manufacturing. Eng. Technol. Appl. Sci. Res. 2025, 15, 21970–21975. [Google Scholar] [CrossRef]
- Rahman, M.M.; Khatun, F.; Jahan, I.; Devnath, R.; Bhuiyan, M.A.A. Cobotics: The Evolving Roles and Prospects of Next-Generation Collaborative Robots in Industry 5.0. J. Robot. 2024, 2024, 2918089. [Google Scholar] [CrossRef]
- Weidemann, C.; Mandischer, N.; van Kerkom, F.; Corves, B.; Hüsing, M.; Kraus, T.; Garus, C. Literature review on recent trends and perspectives of collaborative robotics in work 4.0. Robotics 2023, 12, 84. [Google Scholar] [CrossRef]
- De Magistris, G.; Caprari, R.; Castro, G.; Russo, S.; Iocchi, L.; Nardi, D.; Napoli, C. Vision-based holistic scene understanding for context-aware human-robot interaction. In International Conference of the Italian Association for Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2021; pp. 310–325. [Google Scholar]
- Borboni, A.; Reddy, K.V.V.; Elamvazuthi, I.; AL-Quraishi, M.S.; Natarajan, E.; Ali, S.S.A. The expanding role of artificial intelligence in collaborative robots for industrial applications: A systematic review of recent works. Machines 2023, 11, 111. [Google Scholar] [CrossRef]
- Scheutz, C.; Law, T.; Scheutz, M. Envirobots: How human–robot interaction can facilitate sustainable behavior. Sustainability 2021, 13, 12283. [Google Scholar] [CrossRef]
- Buyukgoz, S.; Grosinger, J.; Chetouani, M.; Saffiotti, A. Two ways to make your robot proactive: Reasoning about human intentions or reasoning about possible futures. Front. Robot. AI 2022, 9, 929267. [Google Scholar] [CrossRef] [PubMed]
- Semeraro, F.; Griffiths, A.; Cangelosi, A. Human–robot collaboration and machine learning: A systematic review of recent research. Robot. Comput.-Integr. Manuf. 2023, 79, 102432. [Google Scholar] [CrossRef]
- Mendez, E.; Ochoa, O.; Olivera-Guzman, D.; Soto-Herrera, V.H.; Luna-Sánchez, J.A.; Lucas-Dophe, C.; Lugo-del-Real, E.; Ayala-Garcia, I.N.; Alvarado Perez, M.; González, A. Integration of deep learning and collaborative robot for assembly tasks. Appl. Sci. 2024, 14, 839. [Google Scholar] [CrossRef]
- Riedelbauch, D.; Höllerich, N.; Henrich, D. Benchmarking teamwork of humans and cobots—An overview of metrics, strategies, and tasks. IEEE Access 2023, 11, 43648–43674. [Google Scholar] [CrossRef]
- Addula, S.R.; Tyagi, A.K. Future of Computer Vision and Industrial Robotics in Smart Manufacturing. Artif. Intell.-Enabled Digit. Twin Smart Manuf. 2024, 22, 505–539. [Google Scholar]
- Soori, M.; Dastres, R.; Arezoo, B.; Jough, F.K.G. Intelligent robotic systems in Industry 4.0: A review. J. Adv. Manuf. Sci. Technol. 2024, 4, 2024007. [Google Scholar] [CrossRef]
- Cohen, Y.; Shoval, S.; Faccio, M.; Minto, R. Deploying cobots in collaborative systems: Major considerations and productivity analysis. Int. J. Prod. Res. 2022, 60, 1815–1831. [Google Scholar] [CrossRef]
- Faccio, M.; Cohen, Y. Intelligent cobot systems: Human-cobot collaboration in manufacturing. J. Intell. Manuf. 2024, 35, 1905–1907. [Google Scholar] [CrossRef]
- Cohen, Y.; Faccio, M.; Rozenes, S. Vocal Communication Between Cobots and Humans to Enhance Productivity and Safety: Review and Discussion. Appl. Sci. 2025, 15, 726. [Google Scholar] [CrossRef]
- Cohen, Y.; Gal, H.C.B. Digital, Technological and AI Skills for Smart Production Work Environment. IFAC-Pap. 2024, 58, 545–550. [Google Scholar] [CrossRef]
- D’Avella, S.; Avizzano, C.A.; Tripicchio, P. ROS-Industrial based robotic cell for Industry 4.0: Eye-in-hand stereo camera and visual servoing for flexible, fast, and accurate picking and hooking in the production line. Robot. Comput.-Integr. Manuf. 2023, 80, 102453. [Google Scholar] [CrossRef]
- Wang, J.; Li, L.; Xu, P. Visual sensing and depth perception for welding robots and their industrial applications. Sensors 2023, 23, 9700. [Google Scholar] [CrossRef] [PubMed]
- Malhan, R.; Jomy Joseph, R.; Bhatt, P.M.; Shah, B.; Gupta, S.K. Algorithms for improving speed and accuracy of automated three-dimensional reconstruction with a depth camera mounted on an industrial robot. J. Comput. Inf. Sci. Eng. 2022, 22, 031012. [Google Scholar] [CrossRef]
- Thakur, U.; Singh, S.K.; Kumar, S.; Singh, A.; Arya, V.; Chui, K.T. Multi-Modal Sensor Fusion With CRNNs for Robust Object Detection and Simultaneous Localization and Mapping (SLAM) in Agile Industrial Drones. In AI Developments for Industrial Robotics and Intelligent Drones; IGI Global Scientific Publishing: New York, NY, USA, 2025; pp. 285–304. [Google Scholar]
- Raj, R.; Kos, A. An Extensive Study of Convolutional Neural Networks: Applications in Computer Vision for Improved Robotics Perceptions. Sensors 2025, 25, 1033. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Zheng, P.; Li, S. Vision-based holistic scene understanding towards proactive human–robot collaboration. Robot. Comput.-Integr. Manuf. 2022, 75, 102304. [Google Scholar] [CrossRef]
- Sado, F.; Loo, C.K.; Liew, W.S.; Kerzel, M.; Wermter, S. Explainable goal-driven agents and robots-a comprehensive review. ACM Comput. Surv. 2023, 55, 1–41. [Google Scholar] [CrossRef]
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. Explainable reinforcement learning: A survey and comparative review. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Brawer, J. Fusing Symbolic and Subsymbolic Approaches for Natural and Effective Human-Robot Collaboration. Ph.D. Dissertation, Yale University, New Haven, CT, USA, 2023. [Google Scholar]
- Baduge, S.K.; Thilakarathna, S.; Perera, J.S.; Arashpour, M.; Sharafi, P.; Teodosio, B.; Shringi, A.; Mendis, P. Artificial intelligence and smart vision for building and construction 4.0: Machine and deep learning methods and applications. Autom. Constr. 2022, 141, 104440. [Google Scholar] [CrossRef]
- Chen, H.; Li, S.; Fan, J.; Duan, A.; Yang, C.; Navarro-Alarcon, D.; Zheng, P. Human-in-the-Loop Robot Learning for Smart Manufacturing: A Human-Centric Perspective. IEEE Trans. Autom. Sci. Eng. 2025, 22, 11062–11086. [Google Scholar] [CrossRef]
- Mahajan, H.B.; Uke, N.; Pise, P.; Shahade, M.; Dixit, V.G.; Bhavsar, S.; Deshpande, S.D. Automatic robot manoeuvres detection using computer vision and deep learning techniques: A perspective of Internet of Robotics Things (IoRT). Multimed. Tools Appl. 2023, 82, 23251–23276. [Google Scholar] [CrossRef]
- Manakitsa, N.; Maraslidis, G.S.; Moysis, L.; Fragulis, G.F. A review of machine learning and deep learning for object detection, semantic segmentation, and human action recognition in machine and robotic vision. Technologies 2024, 12, 15. [Google Scholar] [CrossRef]
- Adebayo, R.A.; Obiuto, N.C.; Olajiga, O.K.; Festus-Ikhuoria, I.C. AI-enhanced manufacturing robotics: A review of applications and trends. World J. Adv. Res. Rev. 2024, 21, 2060–2072. [Google Scholar] [CrossRef]
- Angulo, C.; Chacón, A.; Ponsa, P. Towards a cognitive assistant supporting human operators in the Artificial Intelligence of Things. Internet Things 2023, 21, 100673. [Google Scholar] [CrossRef]
- Jiang, N.; Liu, X.; Liu, H.; Lim, E.T.K.; Tan, C.W.; Gu, J. Beyond AI-powered context-aware services: The role of human–AI collaboration. Ind. Manag. Data Syst. 2023, 123, 2771–2802. [Google Scholar] [CrossRef]
- Gallagher, J.E.; Oughton, E.J. Surveying You Only Look Once (YOLO) Multispectral Object Detection Advancements, Applications And Challenges. IEEE Access 2025, 13, 7366–7395. [Google Scholar] [CrossRef]
- Aboyomi, D.D.; Daniel, C. A Comparative Analysis of Modern Object Detection Algorithms: YOLO vs. SSD vs. Faster R-CNN. ITEJ Inf. Technol. Eng. J. 2023, 8, 96–106. [Google Scholar] [CrossRef]
- Amjoud, A.B.; Amrouch, M. Object detection using deep learning, CNNs and vision transformers: A review. IEEE Access 2023, 11, 35479–35516. [Google Scholar] [CrossRef]
- Shah, S.; Tembhurne, J. Object detection using convolutional neural networks and transformer-based models: A review. J. Electr. Syst. Inf. Technol. 2023, 10, 54. [Google Scholar] [CrossRef]
- Liu, S.; Yao, S.; Fu, X.; Shao, H.; Tabish, R.; Yu, S.; Yun, H.; Sha, L.; Abdelzaher, T.; Bansal, A.; et al. Real-time task scheduling for machine perception in intelligent cyber-physical systems. IEEE Trans. Comput. 2021, 71, 1770–1783. [Google Scholar] [CrossRef]
- Hussain, M.; Ali, N.; Hong, J.E. Vision beyond the field-of-view: A collaborative perception system to improve safety of intelligent cyber-physical systems. Sensors 2022, 22, 6610. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Li, J.; Zeng, T. A Review of Environmental Perception Technology Based on Multi-Sensor Information Fusion in Autonomous Driving. World Electr. Veh. J. 2025, 16, 20. [Google Scholar] [CrossRef]
- Duan, J.; Zhuang, L.; Zhang, Q.; Zhou, Y.; Qin, J. Multimodal perception-fusion-control and human–robot collaboration in manufacturing: A review. Int. J. Adv. Manuf. Technol. 2024, 132, 1071–1093. [Google Scholar] [CrossRef]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Dubey, S.; Dixit, M. A comprehensive survey on human pose estimation approaches. Multimed. Syst. 2023, 29, 167–195. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Z.; Wang, L.; Li, M.; Wang, X.V. Data-efficient multimodal human action recognition for proactive human–robot collaborative assembly: A cross-domain few-shot learning approach. Robot. Comput.-Integr. Manuf. 2024, 89, 102785. [Google Scholar] [CrossRef]
- Kwon, H.; Wang, B.; Abowd, G.D.; Plötz, T. Approaching the real-world: Supporting activity recognition training with virtual imu data. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 1–32. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose++: Vision transformer for generic body pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 1212–1230. [Google Scholar] [CrossRef] [PubMed]
- Papanagiotou, D.; Senteri, G.; Manitsaris, S. Egocentric gesture recognition using 3D convolutional neural networks for the spatiotemporal adaptation of collaborative robots. Front. Neurorobot. 2021, 15, 703545. [Google Scholar] [CrossRef] [PubMed]
- Matin, A.; Islam, M.R.; Wang, X.; Huo, H. Robust Multimodal Approach for Assembly Action Recognition. Procedia Comput. Sci. 2024, 246, 4916–4925. [Google Scholar] [CrossRef]
- Delitzas, A.; Takmaz, A.; Tombari, F.; Sumner, R.; Pollefeys, M.; Engelmann, F. SceneFun3D: Fine-grained functionality and affordance understanding in 3D scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 14531–14542. [Google Scholar]
- Hoque, S.; Arafat, M.Y.; Xu, S.; Maiti, A.; Wei, Y. A comprehensive review on 3D object detection and 6D pose estimation with deep learning. IEEE Access 2021, 9, 143746–143770. [Google Scholar] [CrossRef]
- Yarovoi, A.; Cho, Y.K. Review of simultaneous localization and mapping (SLAM) for construction robotics applications. Autom. Constr. 2024, 162, 105344. [Google Scholar] [CrossRef]
- Zheng, C.; Du, Y.; Xiao, J.; Sun, T.; Wang, Z.; Eynard, B.; Zhang, Y. Semantic map construction approach for human-robot collaborative manufacturing. Robot. Comput.-Integr. Manuf. 2025, 91, 102845. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, Y.; Tong, K.; Chen, H.; Yuan, Y. Review of visual simultaneous localization and mapping based on deep learning. Remote Sens. 2023, 15, 2740. [Google Scholar] [CrossRef]
- Pu, H.; Luo, J.; Wang, G.; Huang, T.; Liu, H. Visual SLAM integration with semantic segmentation and deep learning: A review. IEEE Sens. J. 2023, 23, 22119–22138. [Google Scholar] [CrossRef]
- Merveille, F.F.R.; Jia, B.; Xu, Z.; Fred, B. Enhancing Underwater SLAM Navigation and Perception: A Comprehensive Review of Deep Learning Integration. Sensors 2024, 24, 7034. [Google Scholar] [CrossRef] [PubMed]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Servières, M.; Renaudin, V.; Dupuis, A.; Antigny, N. Visual and Visual-Inertial SLAM: State of the Art, Classification, and Experimental Benchmarking. J. Sens. 2021, 2021, 2054828. [Google Scholar] [CrossRef]
- Schmidt, F.; Blessing, C.; Enzweiler, M.; Valada, A. Visual-Inertial SLAM for Unstructured Outdoor Environments: Benchmarking the Benefits and Computational Costs of Loop Closing. J. Field Robot. 2025, 1–22. [Google Scholar] [CrossRef]
- Tao, Y.; Liu, X.; Spasojevic, I.; Agarwal, S.; Kumar, V. 3d active metric-semantic slam. IEEE Robot. Autom. Lett. 2024, 9, 2989–2996. [Google Scholar] [CrossRef]
- Rahman, S.; DiPietro, R.; Kedarisetti, D.; Kulathumani, V. Large-scale Indoor Mapping with Failure Detection and Recovery in SLAM. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 12294–12301. [Google Scholar]
- Peng, H.; Zhao, Z.; Wang, L. A review of dynamic object filtering in SLAM based on 3D LiDAR. Sensors 2024, 24, 645. [Google Scholar] [CrossRef] [PubMed]
- Arshad, S.; Kim, G.W. Role of deep learning in loop closure detection for visual and lidar slam: A survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef] [PubMed]
- Ebadi, K.; Palieri, M.; Wood, S.; Padgett, C.; Agha-mohammadi, A.A. DARE-SLAM: Degeneracy-aware and resilient loop closing in perceptually-degraded environments. J. Intell. Robot. Syst. 2021, 102, 1–25. [Google Scholar] [CrossRef]
- Ni, J.; Chen, Y.; Tang, G.; Shi, J.; Cao, W.; Shi, P. Deep learning-based scene understanding for autonomous robots: A survey. Intell. Robot. 2023, 3, 374–401. [Google Scholar] [CrossRef]
- Farkh, R.; Alhuwaimel, S.; Alzahrani, S.; Al Jaloud, K.; Quasim, M.T. Deep Learning Control for Autonomous Robot. Comput. Mater. Contin. 2022, 72. [Google Scholar] [CrossRef]
- Firoozi, R.; Tucker, J.; Tian, S.; Majumdar, A.; Sun, J.; Liu, W.; Zhu, Y.; Song, S.; Kapoor, A.; Hausman, K.; et al. Foundation models in robotics: Applications, challenges, and the future. Int. J. Robot. Res. 2024, 44, 701–739. [Google Scholar] [CrossRef]
- Huang, C.I.; Huang, Y.Y.; Liu, J.X.; Ko, Y.T.; Wang, H.C.; Chiang, K.H.; Yu, L.F. Fed-HANet: Federated visual grasping learning for human robot handovers. IEEE Robot. Autom. Lett. 2023, 8, 3772–3779. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, L.; Zhang, Y.; Han, X.; Deveci, M.; Parmar, M. A review of convolutional neural networks in computer vision. Artif. Intell. Rev. 2024, 57, 99. [Google Scholar] [CrossRef]
- Wu, F.; Wu, J.; Kong, Y.; Yang, C.; Yang, G.; Shu, H.; Carrault, G.; Senhadji, L. Multiscale low-frequency memory network for improved feature extraction in convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, WC, Canada, 20–27 February 2024; Volume 38, pp. 5967–5975. [Google Scholar]
- Ma, R.; Liu, Y.; Graf, E.W.; Oyekan, J. Applying vision-guided graph neural networks for adaptive task planning in dynamic human robot collaborative scenarios. Adv. Robot. 2024, 38, 1690–1709. [Google Scholar] [CrossRef]
- Ding, P.; Zhang, J.; Zhang, P.; Lv, Y. A Spatial-Temporal Graph Neural Network with Hawkes Process for Temporal Hypergraph Reasoning towards Robotic Decision-Making in Proactive Human-Robot Collaboration. In Proceedings of the 2024 IEEE 20th International Conference on Automation Science and Engineering (CASE), Bari, Italy, 28 August–1 September 2024; pp. 514–519. [Google Scholar]
- Ding, P.; Zhang, J.; Zhang, P.; Lv, Y.; Wang, D. A stacked graph neural network with self-exciting process for robotic cognitive strategy reasoning in proactive human-robot collaborative assembly. Adv. Eng. Inform. 2025, 63, 102957. [Google Scholar] [CrossRef]
- Ding, P.; Zhang, J.; Zheng, P.; Fei, B.; Xu, Z. Dynamic scenario-enhanced diverse human motion prediction network for proactive human–robot collaboration in customized assembly tasks. J. Intell. Manuf. 2024. [Google Scholar] [CrossRef]
- Hou, W.; Xiong, Z.; Yue, M.; Chen, H. Human-robot collaborative assembly task planning for mobile cobots based on deep reinforcement learning. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2024, 238, 11097–11114. [Google Scholar] [CrossRef]
- Qiu, Y.; Jin, Y.; Yu, L.; Wang, J.; Wang, Y.; Zhang, X. Improving sample efficiency of multiagent reinforcement learning with nonexpert policy for flocking control. IEEE Internet Things J. 2023, 10, 14014–14027. [Google Scholar] [CrossRef]
- Salvato, E.; Fenu, G.; Medvet, E.; Pellegrino, F.A. Crossing the reality gap: A survey on sim-to-real transferability of robot controllers in reinforcement learning. IEEE Access 2021, 9, 153171–153187. [Google Scholar] [CrossRef]
- Ju, H.; Juan, R.; Gomez, R.; Nakamura, K.; Li, G. Transferring policy of deep reinforcement learning from simulation to reality for robotics. Nat. Mach. Intell. 2022, 4, 1077–1087. [Google Scholar] [CrossRef]
- Zhu, X.; Zheng, X.; Zhang, Q.; Chen, Z.; Liu, Y.; Liang, B. Sim-to-real transfer with action mapping and state prediction for robot motion control. In Proceedings of the 2021 6th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Tokyo, Japan, 16–18 July 2021; pp. 1–6. [Google Scholar]
- Amirnia, A.; Keivanpour, S. Real-time sustainable cobotic disassembly planning using fuzzy reinforcement learning. Int. J. Prod. Res. 2025, 63, 3798–3821. [Google Scholar] [CrossRef]
- Langås, E.F.; Zafar, M.H.; Sanfilippo, F. Exploring the synergy of human-robot teaming, digital twins, and machine learning in Industry 5.0: A step towards sustainable manufacturing. J. Intell. Manuf. 2025, 1–24. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, R.; Zhang, L.; Wang, J.; Wang, S. Embodied intelligence in RO/RO logistic terminal: Autonomous intelligent transportation robot architecture. Sci. China Inf. Sci. 2025, 68, 1–17. [Google Scholar] [CrossRef]
- Laukaitis, A.; Šareiko, A.; Mažeika, D. Facilitating Robot Learning in Virtual Environments: A Deep Reinforcement Learning Framework. Appl. Sci. 2025, 15, 5016. [Google Scholar] [CrossRef]
- Li, C.; Zheng, P.; Zhou, P.; Yin, Y.; Lee, C.K.; Wang, L. Unleashing mixed-reality capability in Deep Reinforcement Learning-based robot motion generation towards safe human–robot collaboration. J. Manuf. Syst. 2024, 74, 411–421. [Google Scholar] [CrossRef]
- Gonzalez-Santocildes, A.; Vazquez, J.I.; Eguiluz, A. Adaptive Robot Behavior Based on Human Comfort Using Reinforcement Learning. IEEE Access 2024, 12, 122289–122299. [Google Scholar] [CrossRef]
- Walker, J.C.; Vértes, E.; Li, Y.; Dulac-Arnold, G.; Anand, A.; Weber, T.; Hamrick, J.B. Investigating the role of model-based learning in exploration and transfer. In Proceedings of the ICML’23: 40th International Conference on Machine Learning, Honolulu, HA, USA, 23–29 July 2023; pp. 35368–35383. [Google Scholar]
- Thalpage, N. Unlocking the black box: Explainable artificial intelligence (XAI) for trust and transparency in ai systems. J. Digit. Art Humanit 2023, 4, 31–36. [Google Scholar] [CrossRef] [PubMed]
- Gunning, D.; Aha, D. DARPA’s explainable artificial intelligence (XAI) program. AI Mag. 2019, 40, 44–58. [Google Scholar]
- Saraswat, D.; Bhattacharya, P.; Verma, A.; Prasad, V.K.; Tanwar, S.; Sharma, G.; Bokoro, P.N.; Sharma, R. Explainable AI for healthcare 5.0: Opportunities and challenges. IEEE Access 2022, 10, 84486–84517. [Google Scholar] [CrossRef]
- Oviedo, J.; Rodriguez, M.; Trenta, A.; Cannas, D.; Natale, D.; Piattini, M. ISO/IEC quality standards for AI engineering. Comput. Sci. Rev. 2024, 54, 100681. [Google Scholar] [CrossRef]
- Lewis, D.; Hogan, L.; Filip, D.; Wall, P.J. Global challenges in the standardization of ethics for trustworthy AI. J. ICT Stand. 2020, 8, 123–150. [Google Scholar] [CrossRef]
- Ali, J.A.H.; Lezoche, M.; Panetto, H.; Naudet, Y.; Gaffinet, B. Cognitive architecture for cognitive cyber-physical systems. IFAC-Pap. 2024, 58, 1180–1185. [Google Scholar]
- Ogunsina, M.; Efunniyi, C.P.; Osundare, O.S.; Folorunsho, S.O.; Akwawa, L.A. Cognitive architectures for autonomous robots: Towards human-level autonomy and beyond. Int. J. Frontline Res. Eng. Technol. 2024, 2, 41–50. [Google Scholar] [CrossRef]
- Gurney, N.; Pynadath, D.V. Robots with Theory of Mind for Humans: A Survey. In Proceedings of the 2022 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Napoli, Italy, 29 August–1 September 2022. [Google Scholar]
- Taesi, C.; Aggogeri, F.; Pellegrini, N. COBOT applications—Recent advances and challenges. Robotics 2023, 12, 79. [Google Scholar] [CrossRef]
- Liu, Y.; Caldwell, G.; Rittenbruch, M.; Belek Fialho Teixeira, M.; Burden, A.; Guertler, M. What affects human decision making in human–robot collaboration?: A scoping review. Robotics 2024, 13, 30. [Google Scholar] [CrossRef]
- Sun, J.; Mao, P.; Kong, L.; Wang, J. A Review of Embodied Grasping. Sensors 2025, 25, 852. [Google Scholar] [CrossRef] [PubMed]
- Karbouj, B.; Al Rashwany, K.; Alshamaa, O.; Krüger, J. Adaptive Behavior of Collaborative Robots: Review and Investigation of Human Predictive Ability. Procedia CIRP 2024, 130, 952–958. [Google Scholar] [CrossRef]
- Ebert, N.; Mangat, P.; Wasenmuller, O. Multitask network for joint object detection, semantic segmentation and human pose estimation in vehicle occupancy monitoring. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 637–643. [Google Scholar]
- Yalcinkaya, B.; Couceiro, M.S.; Pina, L.; Soares, S.; Valente, A.; Remondino, F. Towards Enhanced Human Activity Recognition for Real-World Human-Robot Collaboration. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 7909–7915. [Google Scholar]
- Carissoli, C.; Negri, L.; Bassi, M.; Storm, F.A.; Delle Fave, A. Mental workload and human-robot interaction in collaborative tasks: A scoping review. Int. J. Hum.-Comput. Interact. 2024, 40, 6458–6477. [Google Scholar] [CrossRef]
- Huang, S.; Chen, Z.; Zhang, Y. An Algorithm for Standing Long Jump Distance Measurement Based on Improved YOLOv11 and Lightweight Pose Estimation. In Proceedings of the 2025 4th International Symposium on Computer Applications and Information Technology (ISCAIT), Xi’an, China, 21–23 March 2025; pp. 914–918. [Google Scholar]
- Salimpour, S.; Peña-Queralta, J.; Paez-Granados, D.; Heikkonen, J.; Westerlund, T. Sim-to-Real Transfer for Mobile Robots with Reinforcement Learning: From NVIDIA Isaac Sim to Gazebo and Real ROS 2 Robots. arXiv 2025, arXiv:2501.02902. [Google Scholar]
- Scheikl, P.M.; Tagliabue, E.; Gyenes, B.; Wagner, M.; Dall’Alba, D.; Fiorini, P.; Mathis-Ullrich, F. Sim-to-real transfer for visual reinforcement learning of deformable object manipulation for robot-assisted surgery. IEEE Robot. Autom. Lett. 2022, 8, 560–567. [Google Scholar] [CrossRef]
- Véronneau, C.; Denis, J.; Lhommeau, P.; St-Jean, A.; Girard, A.; Plante, J.S.; Bigué, J.P.L. Modular magnetorheological actuator with high torque density and transparency for the collaborative robot industry. IEEE Robot. Autom. Lett. 2022, 8, 896–903. [Google Scholar] [CrossRef]
- Feng, H.; Zhang, J.; Kang, L. Key Technologies of Cobots with High Payload-Reach to Weight Ratio: A Review. In International Conference on Social Robotics; Springer Nature: Singapore, 2024; pp. 29–40. [Google Scholar]
- Rojas, R.A.; Garcia, M.A.R.; Gualtieri, L.; Rauch, E. Combining safety and speed in collaborative assembly systems–An approach to time optimal trajectories for collaborative robots. Procedia CIRP 2021, 97, 308–312. [Google Scholar] [CrossRef]
- Guida, R.; Bertolino, A.C.; De Martin, A.; Sorli, M. Comprehensive Analysis of Major Fault-to-Failure Mechanisms in Harmonic Drives. Machines 2024, 12, 776. [Google Scholar] [CrossRef]
- Zafar, M.H.; Langås, E.F.; Sanfilippo, F. Exploring the synergies between collaborative robotics, digital twins, augmentation, and industry 5.0 for smart manufacturing: A state-of-the-art review. Robot. Comput.-Integr. Manuf. 2024, 89, 102769. [Google Scholar] [CrossRef]
- Hua, H.; Liao, Z.; Wu, X.; Chen, Y.; Feng, C. A back-drivable linear force actuator for adaptive grasping. J. Mech. Sci. Technol. 2022, 36, 4213–4220. [Google Scholar] [CrossRef]
- Pantano, M.; Blumberg, A.; Regulin, D.; Hauser, T.; Saenz, J.; Lee, D. Design of a collaborative modular end effector considering human values and safety requirements for industrial use cases. In Human-Friendly Robotics 2021: HFR: 14th International Workshop on Human-Friendly Robotics; Springer International Publishing: Cham, Switzerland, 2022; pp. 45–60. [Google Scholar]
- Li, S.; Xu, J. Multi-Axis Force/Torque Sensor Technologies: Design Principles and Robotic Force Control Applications: A Review. IEEE Sens. J. 2024, 25, 4055–4069. [Google Scholar] [CrossRef]
- Elfferich, J.F.; Dodou, D.; Della Santina, C. Soft robotic grippers for crop handling or harvesting: A review. IEEE Access 2022, 10, 75428–75443. [Google Scholar] [CrossRef]
- Zaidi, S.; Maselli, M.; Laschi, C.; Cianchetti, M. Actuation technologies for soft robot grippers and manipulators: A review. Curr. Robot. Rep. 2021, 2, 355–369. [Google Scholar] [CrossRef]
- Fernandez-Vega, M.; Alfaro-Viquez, D.; Zamora-Hernandez, M.; Garcia-Rodriguez, J.; Azorin-Lopez, J. Transforming Robots into Cobots: A Sustainable Approach to Industrial Automation. Electronics 2025, 14, 2275. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.; Huang, Y.; Wu, Y.; Ota, J. Kinematics optimization of a novel 7-DOF redundant manipulator. Robot. Auton. Syst. 2023, 163, 104377. [Google Scholar] [CrossRef]
- Zheng, P.; Wieber, P.B.; Baber, J.; Aycard, O. Human arm motion prediction for collision avoidance in a shared workspace. Sensors 2022, 22, 6951. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wang, R.; Zheng, P.; Wang, L. Towards proactive human–robot collaboration: A foreseeable cognitive manufacturing paradigm. J. Manuf. Syst. 2021, 60, 547–552. [Google Scholar] [CrossRef]
- Sampieri, A.; di Melendugno, G.M.D.A.; Avogaro, A.; Cunico, F.; Setti, F.; Skenderi, G.; Cristani, M.; Galasso, F. Pose forecasting in industrial human-robot collaboration. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 51–69. [Google Scholar]
- Hao, Z.; Zhang, D.; Honarvar Shakibaei Asli, B. Motion Prediction and Object Detection for Image-Based Visual Servoing Systems Using Deep Learning. Electronics 2024, 13, 3487. [Google Scholar] [CrossRef]
- Vosniakos, G.C.; Stathas, E. Exploring collaboration of humans with industrial robots using ROS-based simulation. Proc. Manuf. Syst. 2023, 18, 33–38. [Google Scholar]
- Freire, I.T.; Guerrero-Rosado, O.; Amil, A.F.; Verschure, P.F. Socially adaptive cognitive architecture for human-robot collaboration in industrial settings. Front. Robot. AI 2024, 11, 1248646. [Google Scholar] [CrossRef] [PubMed]
- Ciccarelli, M.; Forlini, M.; Papetti, A.; Palmieri, G.; Germani, M. Advancing human–robot collaboration in handcrafted manufacturing: Cobot-assisted polishing design boosted by virtual reality and human-in-the-loop. Int. J. Adv. Manuf. Technol. 2024, 132, 4489–4504. [Google Scholar] [CrossRef]
- Jabrane, K.; Bousmah, M. A new approach for training cobots from small amount of data in industry 5.0. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 634–646. [Google Scholar] [CrossRef]
- Ranasinghe, N.; Mohammed, W.M.; Stefanidis, K.; Lastra, J.L.M. Large Language Models in Human-Robot Collaboration with Cognitive Validation Against Context-induced Hallucinations. IEEE Access 2025, 13, 77418–77430. [Google Scholar] [CrossRef]
- Trivedi, C.; Bhattacharya, P.; Prasad, V.K.; Patel, V.; Singh, A.; Tanwar, S.; Sharma, R.; Aluvala, S.; Pau, G.; Sharma, G. Explainable AI for Industry 5.0: Vision, architecture, and potential directions. IEEE Open J. Ind. Appl. 2024, 5, 177–208. [Google Scholar] [CrossRef]
- Świetlicka, A. A Survey on Artificial Neural Networks in Human-Robot Interaction. Neural Comput. 2025, 37, 1–63. [Google Scholar] [CrossRef] [PubMed]
- Moezzi, M. Towards Sample-Efficient Reinforcement Learning Methods for Robotic Manipulation Tasks. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2024. [Google Scholar]
- Liu, Y.; Xu, H.; Liu, D.; Wang, L. A digital twin-based sim-to-real transfer for deep reinforcement learning-enabled industrial robot grasping. Robot. Comput.-Integr. Manuf. 2022, 78, 102365. [Google Scholar] [CrossRef]
- Trentsios, P.; Wolf, M.; Gerhard, D. Overcoming the sim-to-real gap in autonomous robots. Procedia CIRP 2022, 109, 287–292. [Google Scholar] [CrossRef]
- Rothert, J.J.; Lang, S.; Seidel, M.; Hanses, M. Sim-to-Real Transfer for a Robotics Task: Challenges and Lessons Learned. In Proceedings of the 2024 IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETFA), Padova, Italy, 10–13 September 2024; pp. 1–8. [Google Scholar]
- Lettera, G.; Costa, D.; Callegari, M. A Hybrid Architecture for Safe Human–Robot Industrial Tasks. Appl. Sci. 2025, 15, 1158. [Google Scholar] [CrossRef]
- Tulk Jesso, S.; Greene, C.; Zhang, S.; Booth, A.; DiFabio, M.; Babalola, G.; Adegbemijo, A.; Sarkar, S. On the potential for human-centered, cognitively inspired AI to bridge the gap between optimism and reality for autonomous robotics in healthcare: A respectful critique. In Proceedings of the International Symposium on Human Factors and Ergonomics in Health Care, Chicago, IL, USA, 24–27 March 2024; SAGE Publications; Sage CA: Los Angeles, CA, USA, 2024; Volume 13, pp. 106–112. [Google Scholar]
- Swarnkar, N.; Rawal, A.; Patel, G. A paradigm shift for computational excellence from traditional machine learning to modern deep learning-based image steganalysis. In Data Science and Innovations for Intelligent Systems; CRC Press: Boca Raton, FL, USA, 2021; pp. 209–240. [Google Scholar]
- Wang, S.; Zhang, J.; Wang, P.; Law, J.; Calinescu, R.; Mihaylova, L. A deep learning-enhanced Digital Twin framework for improving safety and reliability in human–robot collaborative manufacturing. Robot. Comput.-Integr. Manuf. 2024, 85, 102608. [Google Scholar] [CrossRef]
- Robinson, N.; Tidd, B.; Campbell, D.; Kulić, D.; Corke, P. Robotic vision for human-robot interaction and collaboration: A survey and systematic review. ACM Trans. Hum.-Robot Interact. 2023, 12, 1–66. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Maddikunta, P.K.R.; Boopathy, P.; Deepa, N.; Chengoden, R.; Victor, N.; Wang, W.; Wang, W.; Zhu, Y.; Dev, K. Xai for industry 5.0-concepts, opportunities, challenges and future directions. IEEE Open J. Commun. Soc. 2024, 6, 2706–2729. [Google Scholar] [CrossRef]
- Li, J.; Cai, M.; Xiao, S. Reinforcement learning-based motion planning in partially observable environments under ethical constraints. AI Ethics 2024, 5, 1047–1067. [Google Scholar] [CrossRef]
- Hostettler, D.; Mayer, S.; Albert, J.L.; Jenss, K.E.; Hildebrand, C. Real-time adaptive industrial robots: Improving safety and comfort in human-robot collaboration. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025; pp. 1–16. [Google Scholar]
- Conlon, N.J. Robot Competency Self-Assessments to Improve Human Decision-Making in Uncertain Environments. Ph.D. Dissertation, University of Colorado at Boulder, Boulder, CO, USA, 2024. [Google Scholar]
- Kluy, L.; Roesler, E. Working with industrial cobots: The influence of reliability and transparency on perception and trust. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; SAGE Publications: Los Angeles, CA, USA, 2021; Volume 65, pp. 77–81. [Google Scholar]
- Pinto, A.; Duarte, I.; Carvalho, C.; Rocha, L.; Santos, J. Enhancing cobot design through user experience goals: An investigation of human–robot collaboration in picking tasks. Hum. Behav. Emerg. Technol. 2024, 2024, 7058933. [Google Scholar] [CrossRef]
- Hancock, P.A.; Billings, D.R.; Schaefer, K.E.; Chen, J.Y.C.; De Visser, E.J.; Parasuraman, R. A meta-analysis of factors affecting trust in human-robot interaction. Hum. Factors 2011, 53, 517–527. [Google Scholar] [CrossRef] [PubMed]
- Desai, M.; Stubbs, K.; Steinfeld, A.; Yanco, H.A. Creating trustworthy robots: Lessons and inspirations from automated systems. In Proceedings of the 2013 ACM/IEEE International Conference on Human-Robot Interaction, Tokyo, Japan, 3–6 March 2013; pp. 409–416. [Google Scholar] [CrossRef]
- Robinette, P.; Howard, A.M.; Wagner, A.R. Timing is key for robot trust repair. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction, Portland, OR, USA, 2–5 March 2015; pp. 205–212. [Google Scholar]
- Gervasi, R.; Barravecchia, F.; Mastrogiacomo, L.; Franceschini, F. Applications of affective computing in human-robot interaction: State-of-art and challenges for manufacturing. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2023, 237, 815–832. [Google Scholar] [CrossRef]
- Toaiari, A.; Murino, V.; Cristani, M.; Beyan, C. Upper-Body pose-based gaze estimation for privacy-preserving 3D gaze target detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2025; pp. 359–376. [Google Scholar]
- Pourmirzaei, M.; Montazer, G.A.; Mousavi, E. ATTENDEE: An AffecTive Tutoring system based on facial EmotioN recognition and heaD posE Estimation to personalize e-learning environment. J. Comput. Educ. 2025, 12, 65–92. [Google Scholar] [CrossRef]
- Tsumura, T.; Yamada, S. Making a human’s trust repair for an agent in a series of tasks through the agent’s empathic behavior. Front. Comput. Sci. 2024, 6, 1461131. [Google Scholar] [CrossRef]
- Esterwood, C.; Robert, L.P. Repairing Trust in Robots?: A Meta-analysis of HRI Trust Repair Studies with A No-Repair Condition. In Proceedings of the 2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Melbourne, Australia, 4–6 March 2025; pp. 410–419. [Google Scholar]
- Wong, S.W.; Crowe, P. Cognitive ergonomics and robotic surgery. J. Robot. Surg. 2024, 18, 110. [Google Scholar] [CrossRef] [PubMed]
- Min, Z.; Lai, J.; Ren, H. Innovating robot-assisted surgery through large vision models. Nat. Rev. Electr. Eng. 2025, 2, 350–363. [Google Scholar] [CrossRef]
- Chen, H.; Alghowinem, S.; Breazeal, C.; Park, H.W. Integrating flow theory and adaptive robot roles: A conceptual model of dynamic robot role adaptation for the enhanced flow experience in long-term multi-person human-robot interactions. In Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, Boulder, CO, USA, 11–15 March 2024; pp. 116–126. [Google Scholar]
- Pelikan, H.; Hofstetter, E. Managing delays in human-robot interaction. ACM Trans. Comput.-Hum. Interact. 2023, 30, 1–42. [Google Scholar] [CrossRef]
- Tuncer, S.; Gillet, S.; Leite, I. Robot-mediated inclusive processes in groups of children: From gaze aversion to mutual smiling gaze. Front. Robot. AI 2022, 9, 729146. [Google Scholar] [CrossRef] [PubMed]
- Ricciardi Celsi, L.; Zomaya, A.Y. Perspectives on Managing AI Ethics in the Digital Age. Information 2025, 16, 318. [Google Scholar] [CrossRef]
- Bourgais, A.; Ibnouhsein, I. Ethics-by-design: The next frontier of industrialization. AI Ethics 2022, 2, 317–324. [Google Scholar] [CrossRef]
- Kolvig-Raun, E.S.; Hviid, J.; Kjærgaard, M.B.; Brorsen, R.; Jacob, P. Balancing Cobot Productivity and Longevity Through Pre-Runtime Developer Feedback. IEEE Robot. Autom. Lett. 2024, 10, 1617–1624. [Google Scholar] [CrossRef]
- Zia, A.; Haleem, M. Bridging Research Gaps in Industry 5.0: Synergizing Federated Learning, Collaborative Robotics, and Autonomous Systems for Enhanced Operational Efficiency and Sustainability. IEEE Access 2025, 13, 40456–40479. [Google Scholar] [CrossRef]
- Ramírez, T.; Mora, H.; Pujol, F.A.; Maciá-Lillo, A.; Jimeno-Morenilla, A. Management of heterogeneous AI-based industrial environments by means of federated adaptive-robot learning. Eur. J. Innov. Manag. 2025, 28, 50–64. [Google Scholar] [CrossRef]
- Govi, E.; Sapienza, D.; Toscani, S.; Cotti, I.; Franchini, G.; Bertogna, M. Addressing challenges in industrial pick and place: A deep learning-based 6 Degrees-of-Freedom pose estimation solution. Comput. Ind. 2024, 161, 104130. [Google Scholar] [CrossRef]
- Pan, Z.; Zhuang, B.; Liu, J.; He, H.; Cai, J. Scalable vision transformers with hierarchical pooling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 377–386. [Google Scholar]
- Liu, R.; Wang, L.; Yu, Z.; Zhang, H.; Liu, X.; Sun, B.; Huo, X.; Zhang, J. SCTNet-NAS: Efficient semantic segmentation via neural architecture search for cloud-edge collaborative perception. Complex Intell. Syst. 2025, 11, 365. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, B.; Chen, Z.; Zhang, J. Progress and Thinking on Self-Supervised Learning Methods in Computer Vision: A Review. IEEE Sens. J. 2024, 24, 29524–29544. [Google Scholar] [CrossRef]
- Shaw, A. Self-Supervised Learning For Robust Robotic Grasping In Dynamic Environment. arXiv 2024, arXiv:2410.11229. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector | Accuracy (mAP) | Inference Speed | Real-Time Suitability | Strengths | Limitations |
|---|---|---|---|---|---|
| YOLOv6-N/S/S-Quant | 35.9–43.5% | 1234–495 FPS (T4 GPU) | Very High | Very fast, ideal for edge deployment | Moderate accuracy, dataset-dependent |
| YOLOv7 | ~56.8% @30 FPS (V100 GPU) | 30–160 FPS | High | Best-in-class real-time balance | GPU-dependent, less mobile-friendly |
| Faster R-CNN (with VGG16) | ~55% mAP | ~5 FPS (GPU) | Moderate | High precision, good for small objects | Too slow for real-time use with light hardware |
| AT-LI-YOLO (home service robots) | +3.2% over YOLOv3 (≈40%+ mAP) | ~34 FPS (29 ms) | High | Great for small/blurred/occluded indoor objects | Still task-specific, needs deblurring add-ons |
| YOLOv3 vs. YOLOv4 (robot arm) | YOLOv4 better than YOLOv3 (no data) | YOLOv4 has best speed | High | YOLOv4 has faster speed + accuracy over v3 | Context-specific performance |
| Technology | Purpose | Representative Methods | Application Examples |
|---|---|---|---|
| Object Detection [36,37,38,39] | Identify and locate task-relevant objects | YOLOv8, Faster R-CNN, DETR | Tool identification, obstacle recognition |
| Human Pose Estimation [43,44,45,46,47,48,49] | Capture human body landmarks and movement | OpenPose, HRNet, Vision Transformers | Gesture recognition, safety monitoring |
| Scene Understanding [6,24,50,51] | Semantic labeling and spatial reasoning | DeepLabv3+, DenseFusion, Semantic SLAM | Workspace mapping, affordance detection |
| Visual SLAM [52,53,54,55,56,63,64] | Localization and environment reconstruction | ORB-SLAM3, DeepFactors, SemanticFusion | Navigation, shared workspace adaptation |
| Method | Description | Key Advantages | Example Applications |
|---|---|---|---|
| Deep Learning Architectures [65,66,67,68,69,70,71,72,73,74] | End-to-end models for perception and planning | High accuracy; handles complex scenes | Visual part detection; semantic mapping |
| Reinforcement Learning (RL) [75,76,77,78,79,80,81,82,83,84,85,86] | Learning adaptive policies via trial-and-error | Handles dynamic, changing tasks | Adaptive path planning; force-sensitive assembly |
| Explainable AI (XAI) and Ethical Autonomy [87,88,89,90] | Interpretable, safe decision-making | Improves trust and safety | Visual feedback; regulatory compliance |
| Cognitive Architectures [91,92,93,94] | Human-like integration of perception and planning | Enables proactive, intuitive interaction | Intention prediction; shared task handover |
| Topic | Description | Key Challenges/Notes |
|---|---|---|
| General Trends [95,96,97,98] | Advances in CV–AI fusion for perception, reasoning, and multimodal interaction | Need for seamless, real-time, and trustworthy HRC |
| Vision Integration Challenges [99,100,101,102] | Deploying object detection, segmentation, and pose estimation in real-world cobots | Performance drops in unstructured, dynamic settings; real-time latency issues |
| Real-Time Adaptation and Learning [24,75,76,77] | Reinforcement learning and anticipatory AI for dynamic task adjustment | Stability, transparency, and sample efficiency |
| Hardware Capabilities Trends [105,106,107,108,109,110,111,112,113,114,115,116,117] | Advanced sensors, compliant actuators, soft robotics, and lightweight structures | Complexity, cost, and safety compliance |
| Technological Convergence [24,118,119,120] | Holistic scene understanding and proactive HRC via multi-level visual cognition | Need for cognitive empathy and context awareness |
| Topic | Description | Key Challenges/Notes |
|---|---|---|
| Advanced System Architectures [19,121,122] | Integrated perception, planning, control via middleware (e.g., ROS-Industrial) | Real-time sensor fusion; latency-sensitive tasks |
| Evolving AI Paradigms [67,124,125,126] | From task-specific models to foundation models and vision transformers | Explainability, computational demands |
| Neural Policy Architectures [127,128,129,130,131,132] | DRL, imitation learning, end-to-end visuomotor control | Data intensity; sim-to-real gap; overfitting |
| Algorithmic Frameworks for Dynamic Environments [53,133,134,135] | Probabilistic planning (POMDPs), semantic mapping, digital twins | Adapting under uncertainty; safe pre-validation |
| Topic | Description | Key Challenges/Notes |
|---|---|---|
| Trust Calibration in HRC [39,84,139,140,141,142,143,144,145] | Systems that monitor and adapt to human trust levels | Avoiding over-reliance or under-utilization; trust repair mechanisms |
| Socio-Cognitive Models and HRI [6,122,146,147,148,149,150,151,152,153,154,155] | Cognitive architectures for intention, emotion, and social cues | Theory of Mind; joint attention; real-time adaptation |
| Ethical and Societal Considerations [126,137,138] | Ensuring privacy, fairness, and transparency in vision–AI | Ethical safeguards; bias mitigation; regulatory compliance |
| Aspect | Laboratory Demonstrations | Real-World Deployment | Representative References |
|---|---|---|---|
| Environment | Controlled, static, well-lit | Dynamic, cluttered, variable lighting and occlusion | [24,100,101] |
| Data Distribution | Limited variation; curated datasets | Diverse, unpredictable, domain shifts | [24,77,99,101] |
| Task Definition | Predefined, repetitive, scripted | Variable tasks, unplanned changes | [16,19,75,124] |
| Sensor Conditions | Calibrated, noise-free | Sensor degradation, misalignment, interference | [99,100,101] |
| Human Behavior | Cooperative, predictable | Variable, ambiguous, culturally diverse | [24,139,146,147] |
| Latency Requirements | Often relaxed, offline processing possible | Strict real-time constraints for safety and trust | [19,100,102,121] |
| Generalization Need | Low (task-specific tuning acceptable) | High (must adapt to new users, objects, settings) | [24,75,76,124,126] |
| Safety Concerns | Simulated or with fail-safe barriers | Shared workspace with humans; legal compliance needed | [84,90,91,138,140] |
| Performance Metrics | Accuracy-focused benchmarks | Robustness, reliability, human acceptance | [77,99,126,137] |
| Explainability | Often not emphasized | Essential for user trust and regulatory approval | [87,90,126,137] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cohen, Y.; Biton, A.; Shoval, S. Fusion of Computer Vision and AI in Collaborative Robotics: A Review and Future Prospects. Appl. Sci. 2025, 15, 7905. https://doi.org/10.3390/app15147905
Cohen Y, Biton A, Shoval S. Fusion of Computer Vision and AI in Collaborative Robotics: A Review and Future Prospects. Applied Sciences. 2025; 15(14):7905. https://doi.org/10.3390/app15147905
Chicago/Turabian StyleCohen, Yuval, Amir Biton, and Shraga Shoval. 2025. "Fusion of Computer Vision and AI in Collaborative Robotics: A Review and Future Prospects" Applied Sciences 15, no. 14: 7905. https://doi.org/10.3390/app15147905
APA StyleCohen, Y., Biton, A., & Shoval, S. (2025). Fusion of Computer Vision and AI in Collaborative Robotics: A Review and Future Prospects. Applied Sciences, 15(14), 7905. https://doi.org/10.3390/app15147905