
An Analysis of the Training Data Impact for Domain-Adapted Tokenizer Performances—The Case of Serbian Legal Domain Adaptation


Abstract
1. Introduction
2. Related Work
2.1. Language Models—From Large to Small and Back
2.2. Domain-Adapted Tokenizers and Tokenization Efficiency Metrics
3. Tokenizer Performance—Models, Dataset, and Performance Measure Insights
3.1. State-of-the-Art Multilingual, Slavic or Serbian-Specific Models
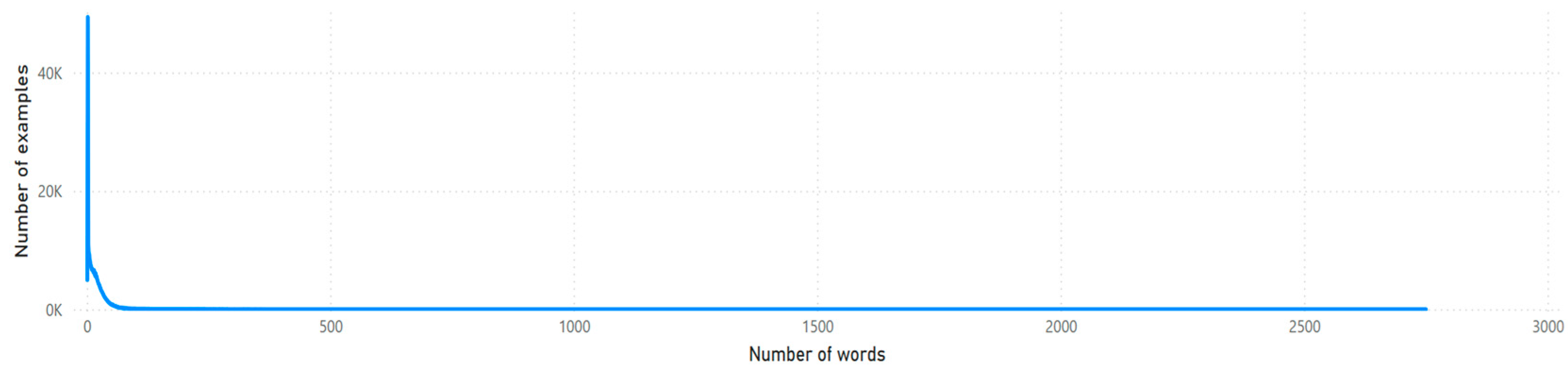
3.2. Dataset and Performance Measure Insights
- Number of tokens used to represent a sequence,
- Fertility measure, and
- Number of tokens in relation to the word frequency measure.
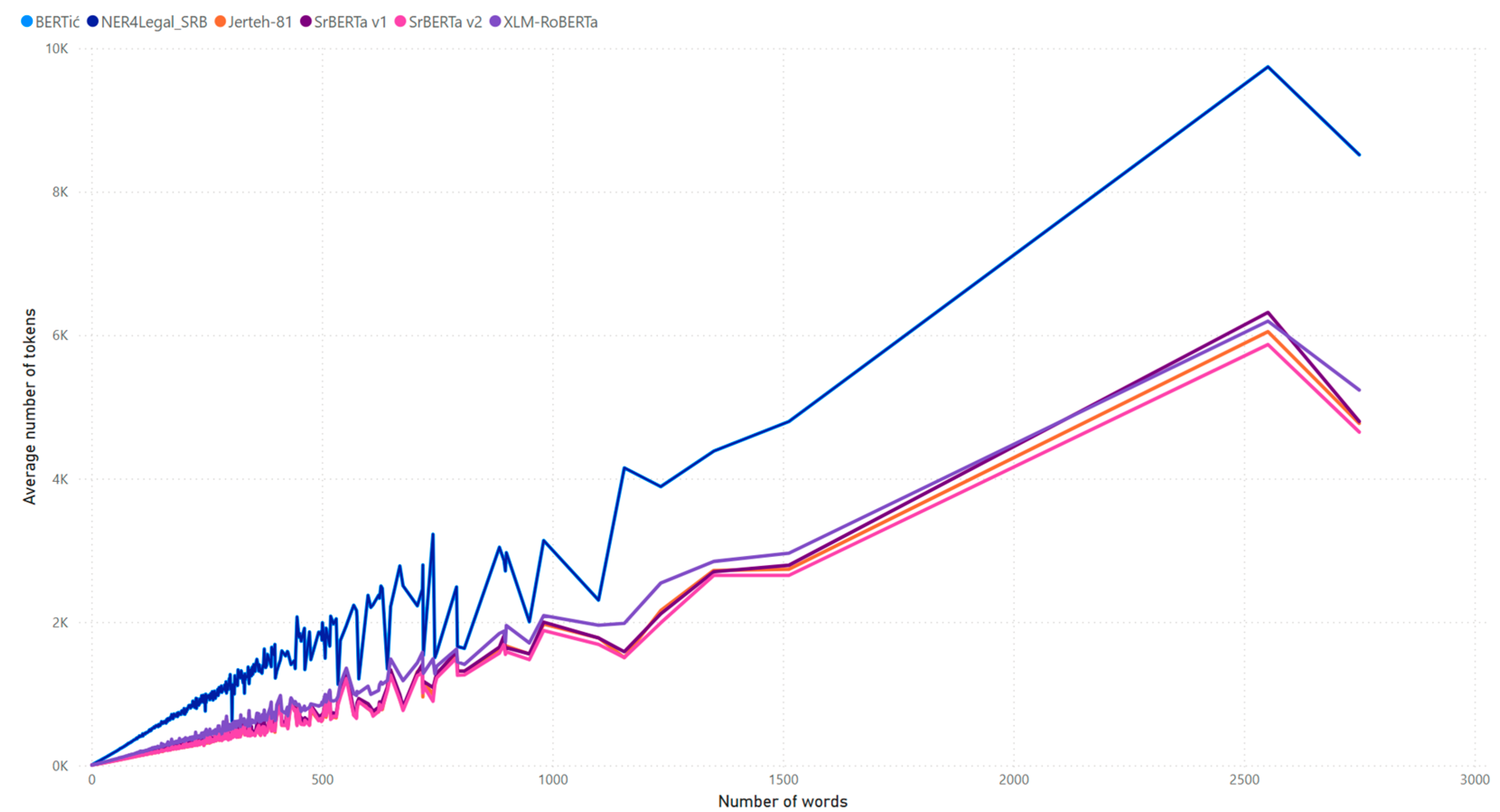
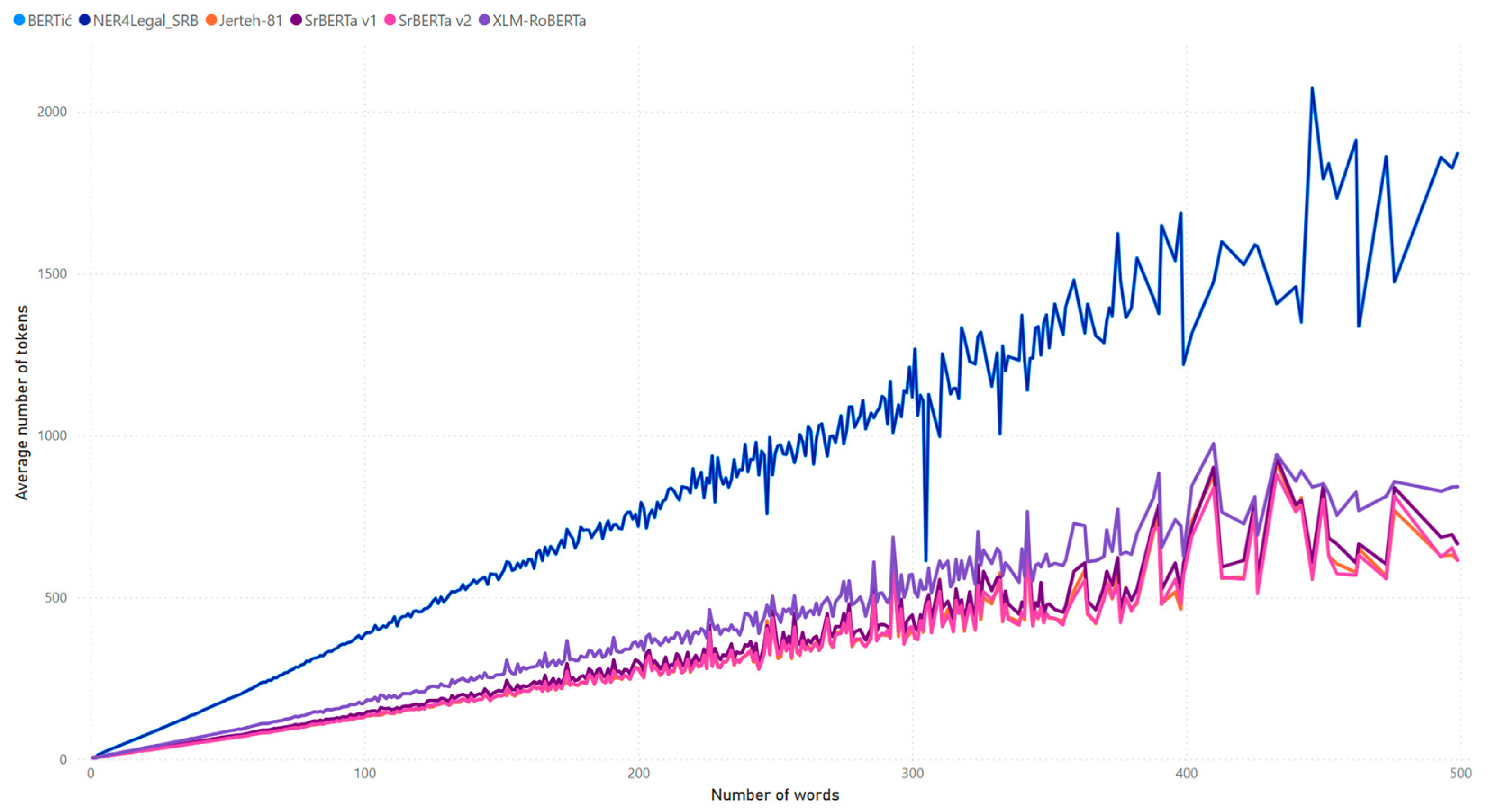
3.3. Number of Tokens Used to Represent a Sequence
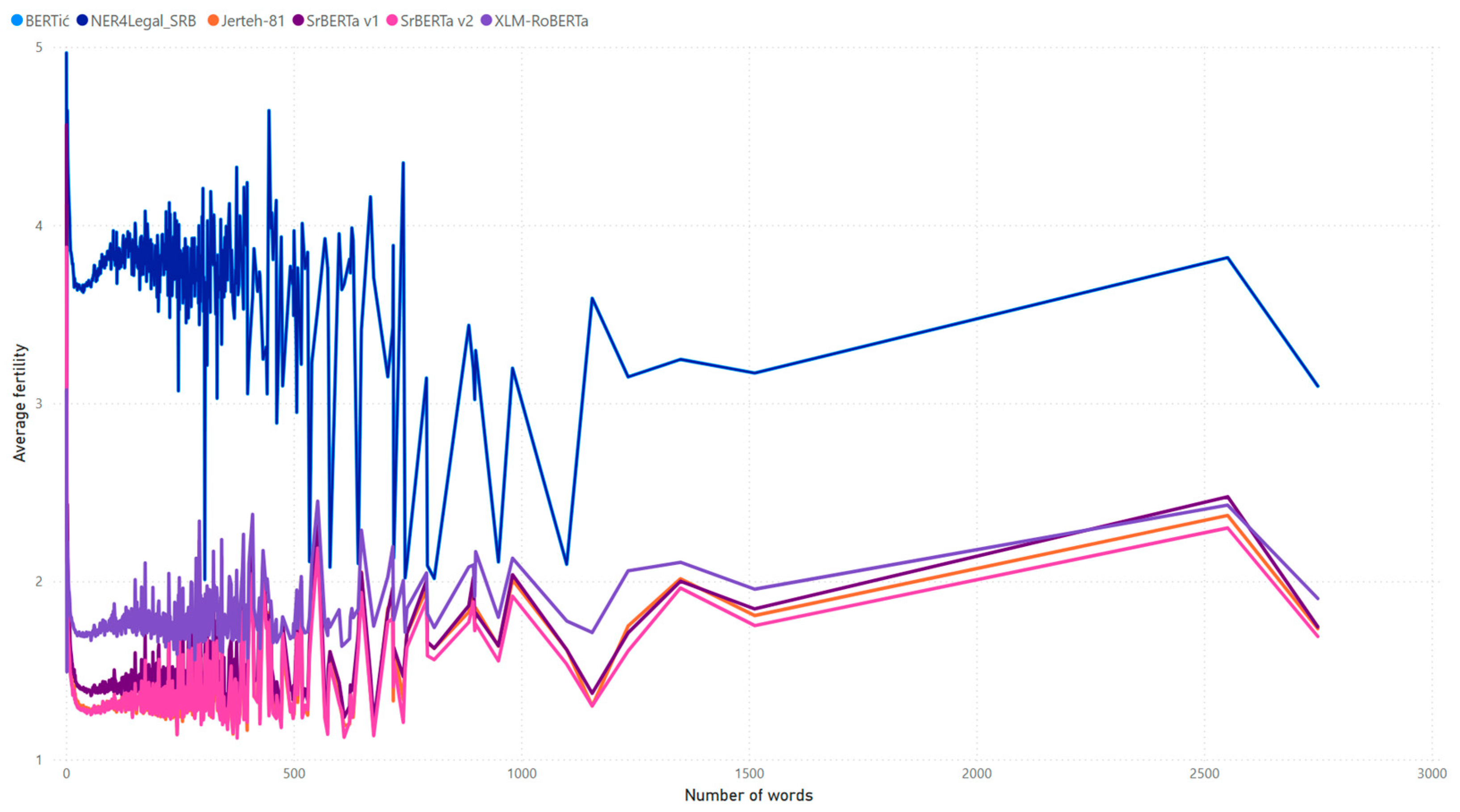
3.4. Fertility Measure
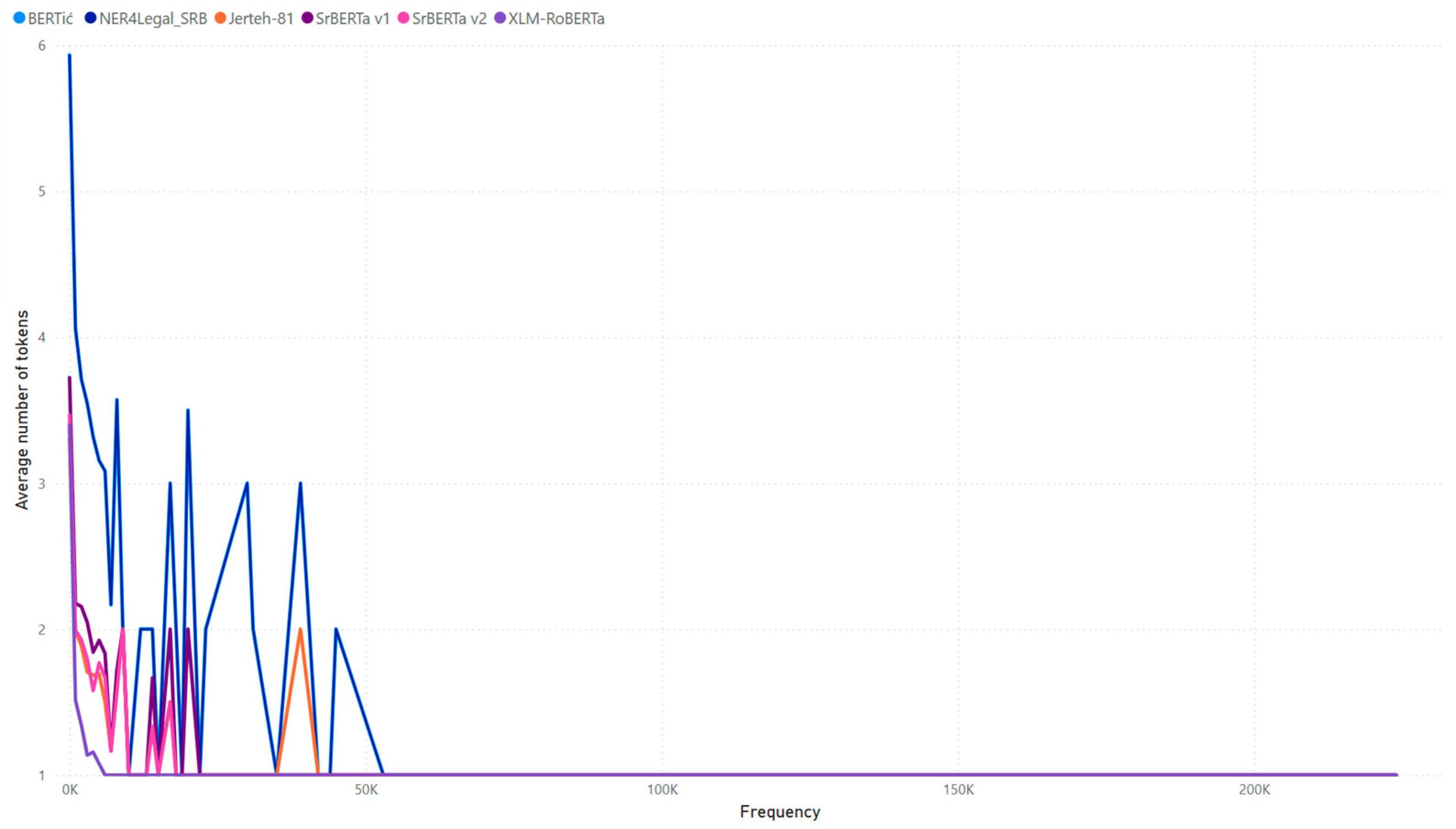
3.5. Number of Tokens in Relation to the Word Frequency Measure
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020. ISBN 9781713829546. [Google Scholar]
- Peng, B.; Alcaide, E.; Anthony, Q.; Albalak, A.; Arcadinho, S.; Biderman, S.; Cao, H.; Cheng, X.; Chung, M.; Grella, M.; et al. Rwkv: Reinventing rnns for the transformer era. arXiv 2023, arXiv:2305.13048. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model.Part of Advances in neural information processing systems. In Proceedings of the 2000 Neural Information Processing Systems (NIPS) Conference, Denver, CO, USA, 10–16 December 2023; The MIT Press: Cambridge, MA, USA, 2000. ISBN 9780262526517. [Google Scholar]
- Schwenk, H.; Dechelotte, D.; Gauvain, J.-L. Continuous space language models for statistical machine translation. In Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, Sydney, Australia, 17–21 July 2006; pp. 723–730. [Google Scholar]
- Mikolov, T.; Deoras, A.; Povey, D.; Burget, L.; Černocky, J. Strategies for training large scale neural network language models. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition & Understanding, Waikoloa, HI, USA, 11–15 December 2011; pp. 196–201. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning–based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 (NIPS’14), Vol. 2. MIT Press, Cambridge, MA, USA; pp. 3104–3112.
- Cho, K.; Van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Goldman, O.; Caciularu, A.; Eyal, M.; Cao, K.; Szpektor, I.; Tsarfaty, R. Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance. arXiv 2024. [Google Scholar] [CrossRef]
- Kong, Z.; Li, Y.; Zeng, F.; Xin, L.; Messica, S.; Lin, X.; Zhao, P.; Kellis, M.; Tang, H.; Zitnik, M. Token Reduction Should Go Beyond Efficiency in Generative Models—From Vision, Language to Multimodality. arXiv 2025. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8440–8451. [Google Scholar]
- Ljubešić, N.; Lauc, D. BERTić—The Transformer Language Model for Bosnian, Croatian, Montenegrin and Serbian. In Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing, Online, 20 April 2021; Association for Computational Linguistics: Kiyv, Ukraine, 2021; pp. 37–42. [Google Scholar]
- Škorić, M. Novi jezički modeli za srpski jezik. arXiv 2024. (In Serbian) [Google Scholar] [CrossRef]
- Bogdanović, M.; Kocić, J.; Stoimenov, L. SRBerta—A Transformer Language Model for Serbian Cyrillic Legal Texts. Information 2024, 15, 74. [Google Scholar] [CrossRef]
- Kalušev, V.; Brkljač, B. Named entity recognition for Serbian legal documents: Design, methodology and dataset development. arXiv 2025. [Google Scholar] [CrossRef]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, E.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. arXiv 2022, arXiv:2210.11416. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Scao, T.L.; Bari, M.S.; Shen, S.; Yong, Z.X.; Schoelkopf, H.; et al. Crosslingual generalization through multitask finetuning. arXiv 2022, arXiv:2211.01786. [Google Scholar]
- Zeng, W.; Ren, X.; Su, T.; Wang, H.; Liao, Y.; Wang, Z.; Jiang, X.; Yang, Z.; Wang, K.; Zhang, X.; et al. Pangu-α: Large-scale autoregressive pretrained chinese language models with auto parallel computation. arXiv 2021, arXiv:2104.12369. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Roziere, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2022, arXiv:2302.13971. [Google Scholar]
- Almazrouei, E.; Alobeidli, H.; Alshamsi, A.; Cappelli, A.; Cojocaru, R.; Debbah, M.; Goffinet, E.; Heslow, D.; Launay, J.; Malartic, Q.; et al. Falcon-40B: An Open Large Language Model with State-of-the-Art Performance. 2023. Available online: https://huggingface.co/tiiuae/falcon-40b (accessed on 21 May 2025).
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Facebook. facebook/opt-125m. Available online: https://huggingface.co/facebook/opt-125m (accessed on 25 May 2022).
- Facebook. facebook/galactica-125m. Available online: https://huggingface.co/facebook/galactica-125m (accessed on 22 November 2022).
- BigScience. bigscience/bloom-560m. Available online: https://huggingface.co/bigscience/bloom-560m (accessed on 22 November 2022).
- Bisk, Y.; Zellers, R.; Le Bras, R.; Gao, J.; Choi, Y. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Microsoft. microsoft/phi-2. Available online: https://huggingface.co/microsoft/phi-2 (accessed on 10 December 2023).
- Microsoft. microsoft/phi-3-mini. Available online: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct (accessed on 25 June 2025).
- Tinyllama. Available online: https://huggingface.co/tinyllama (accessed on 10 December 2023).
- Meituan. Mobilellama. Available online: https://huggingface.co/mtgv/MobileLLaMA-1.4B-Base (accessed on 25 June 2025).
- Alibaba. Qwen 2.5. Available online: https://qwenlm.github.io/blog/qwen2.5/ (accessed on 14 September 2024).
- Google. Gemma. Available online: https://huggingface.co/google/gemma-3-4b-it (accessed on 25 June 2025).
- Apple. Openelm. Available online: https://huggingface.co/apple/OpenELM (accessed on 28 April 2024).
- HuggingFace. Smollm. Available online: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct (accessed on 25 June 2025).
- DataBricks. databricks/dolly-v2-3b. Available online: https://huggingface.co/databricks/dolly-v2-3b (accessed on 28 April 2023).
- H2O.ai. h2o-danube3-4b-base. Available online: https://huggingface.co/h2oai/h2o-danube3-4b-base (accessed on 10 January 2025).
- Padiu, B.; Iacob, R.; Rebedea, T.; Dascalu, M. To What Extent Have LLMs Reshaped the Legal Domain So Far? A Scoping Literature Review. Information 2024, 15, 662. [Google Scholar] [CrossRef]
- Tagarelli, A.; Simeri, A. LamBERTa: Law Article Mining Based on Bert Architecture for the Italian Civil Code. In IRCDL; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Siino, M.; Falco, M.; Croce, D.; Rosso, P. Exploring LLMs Applications in Law: A Literature Review on Current Legal NLP Approaches. IEEE Access 2025, 13, 18253–18276. [Google Scholar] [CrossRef]
- Mellinkoff, D. The Language of the Law; Wipf and Stock Publishers: Eugene, OR, USA, 2004. [Google Scholar]
- Mertz, E. The Language of Law School: Learning to “Think Like a Lawyer”; Oxford University Press: Cary, NC, USA, 2007. [Google Scholar]
- Tiersma, P.M. Legal Language; University of Chicago Press: Chicago, IL, USA, 1999. [Google Scholar]
- Guarasci, R.; Silvestri, S.; De Pietro, G.; Fujita, H.; Esposito, M. BERT syntactic transfer: A computational experiment on Italian, French and English languages. Comput. Speech Lang. 2022, 71, 101261. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Healthc. 2021, 3, 1–23. [Google Scholar] [CrossRef]
- Sachidananda, V.; Kessler, J.; Lai, Y.A. Efficient Domain Adaptation of Language Models via Adaptive Tokenization. In Proceedings of the Second Workshop on Simple and Efficient Natural Language Processing, Virtual, 10 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 155–165. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8342–8360. [Google Scholar]
- Dagan, G.; Synnaeve, G.; Rozière, B. Getting the most out of your tokenizer for pre-training and domain adaptation. arXiv 2024, arXiv:2402.01035. [Google Scholar] [CrossRef]
- Occiglot. EU Tokenizer Performance. Available online: https://occiglot.eu/posts/eu_tokenizer_perfomance/ (accessed on 22 May 2025).
- Byte-Pair Encoding tokenization. Available online: https://huggingface.co/learn/llm-course/en/chapter6/5 (accessed on 26 May 2025).
- Summary of the Tokenizers. Available online: https://huggingface.co/docs/transformers/tokenizer_summary#byte-pairencoding (accessed on 26 May 2025).
- Bogdanović, M.; Frtunić Gligorijević, M.; Kocić, J.; Stoimenov, L. Improving Text Recognition Accuracy for Serbian Legal Documents Using BERT. Appl. Sci. 2025, 15, 615. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tokenizer | Average | Median |
|---|---|---|
| SrBERTa v1 | 1.77 | 1.53 |
| SrBERTa v2 | 1.61 | 1.40 |
| Jerteh-81 | 1.72 | 1.44 |
| XLM-RoBERTa | 1.77 | 1.67 |
| BERTić | 3.73 | 3.65 |
| NER4Legal_SRB | 3.73 | 3.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bogdanović, M.; Frtunić Gligorijević, M.; Kocić, J.; Stoimenov, L. An Analysis of the Training Data Impact for Domain-Adapted Tokenizer Performances—The Case of Serbian Legal Domain Adaptation. Appl. Sci. 2025, 15, 7491. https://doi.org/10.3390/app15137491
Bogdanović M, Frtunić Gligorijević M, Kocić J, Stoimenov L. An Analysis of the Training Data Impact for Domain-Adapted Tokenizer Performances—The Case of Serbian Legal Domain Adaptation. Applied Sciences. 2025; 15(13):7491. https://doi.org/10.3390/app15137491
Chicago/Turabian StyleBogdanović, Miloš, Milena Frtunić Gligorijević, Jelena Kocić, and Leonid Stoimenov. 2025. "An Analysis of the Training Data Impact for Domain-Adapted Tokenizer Performances—The Case of Serbian Legal Domain Adaptation" Applied Sciences 15, no. 13: 7491. https://doi.org/10.3390/app15137491
APA StyleBogdanović, M., Frtunić Gligorijević, M., Kocić, J., & Stoimenov, L. (2025). An Analysis of the Training Data Impact for Domain-Adapted Tokenizer Performances—The Case of Serbian Legal Domain Adaptation. Applied Sciences, 15(13), 7491. https://doi.org/10.3390/app15137491