
The Development of a Lane Identification and Assessment Framework for Maintenance Using AI Technology †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Literature Review
3. Data Preparation
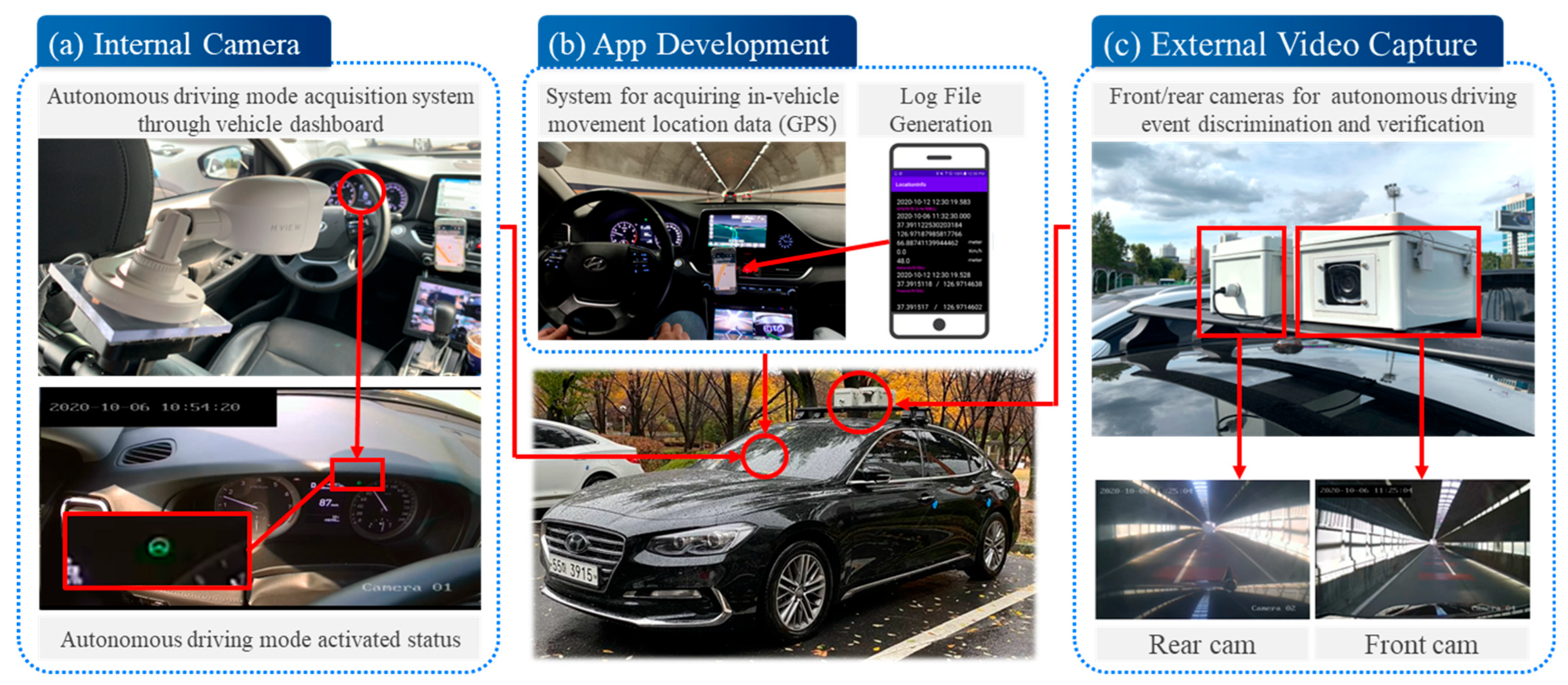
3.1. Data Collection Equipment
3.2. Field Data Collection
3.3. Data Pre-Processing
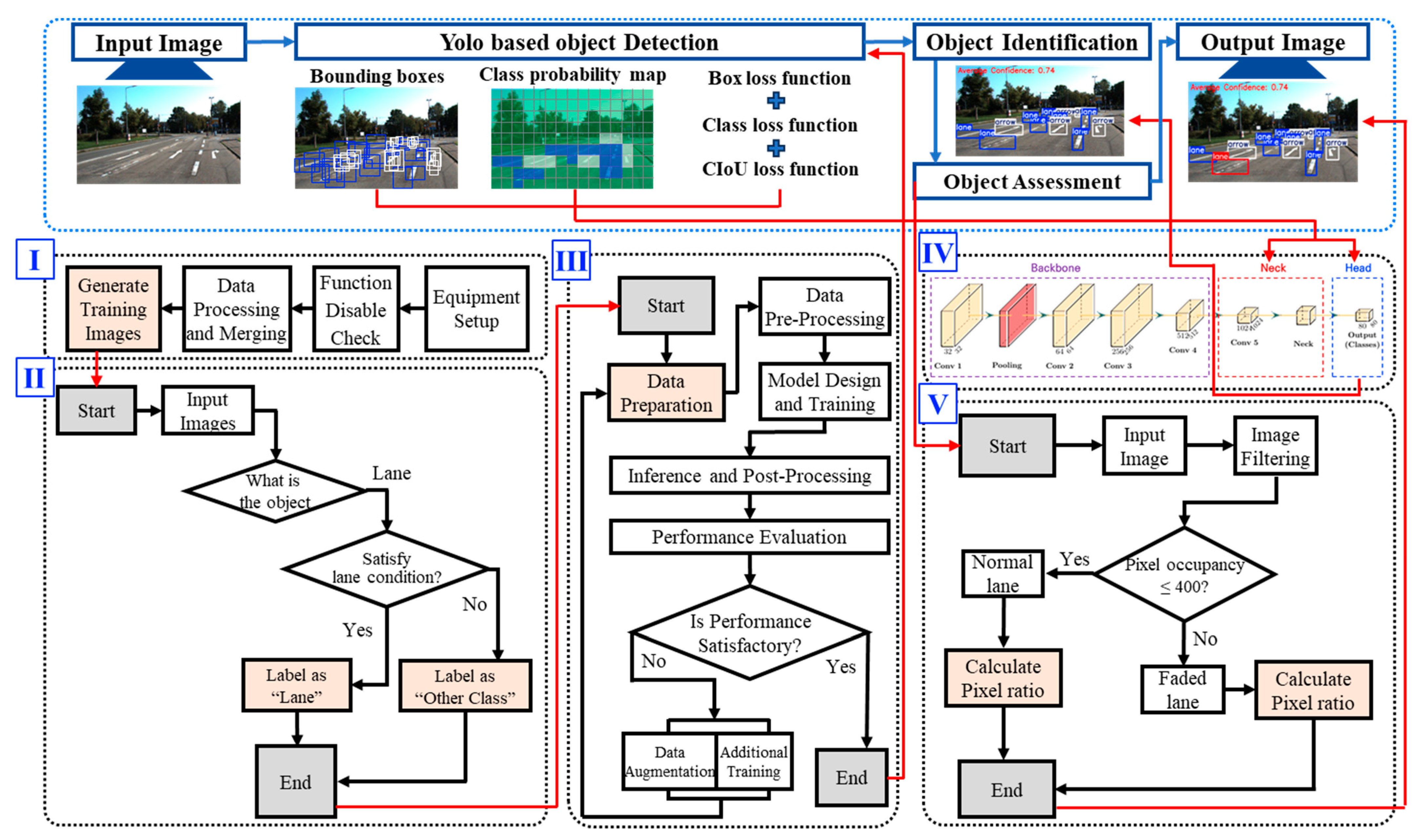
4. Framework Development and Validation
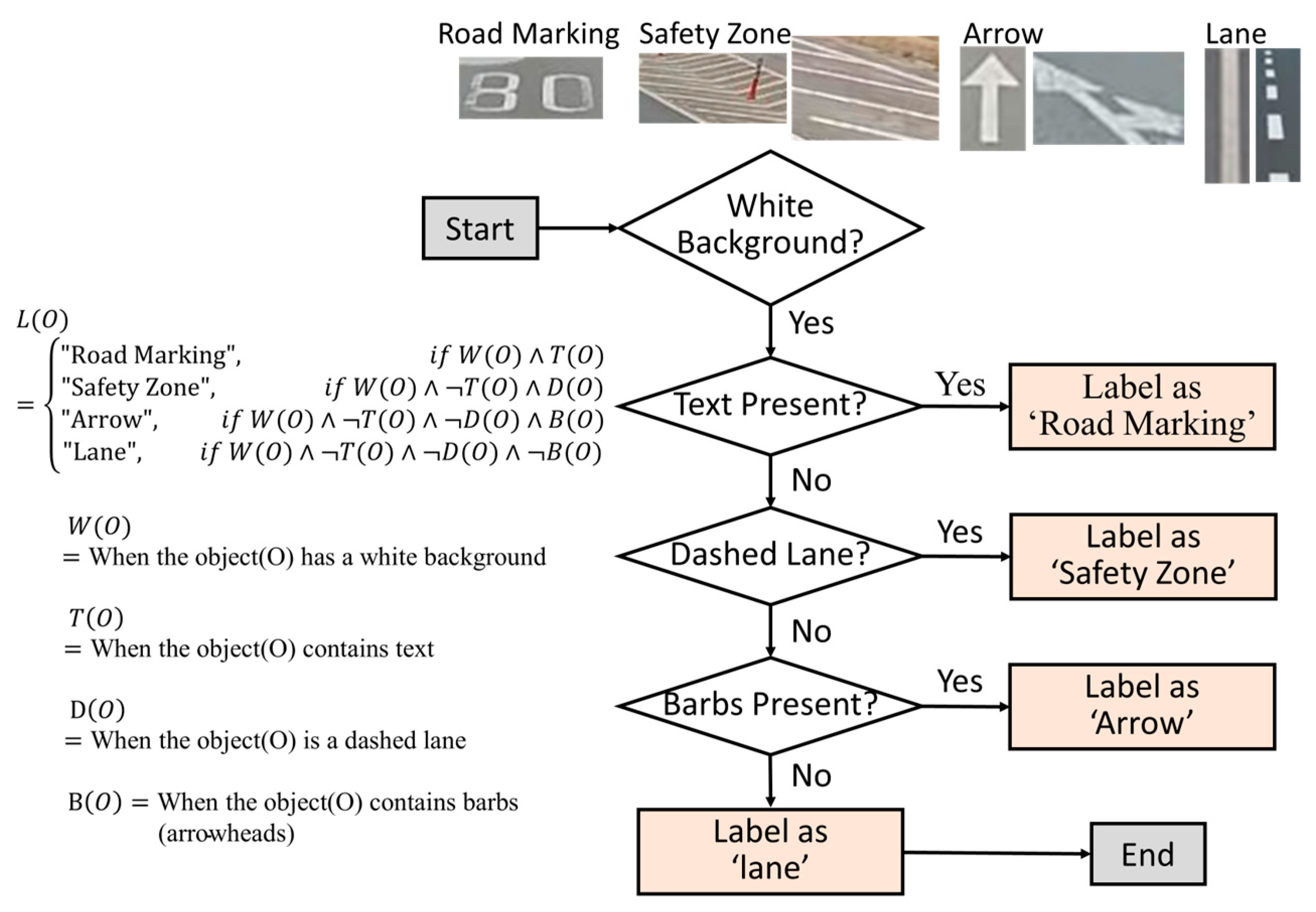
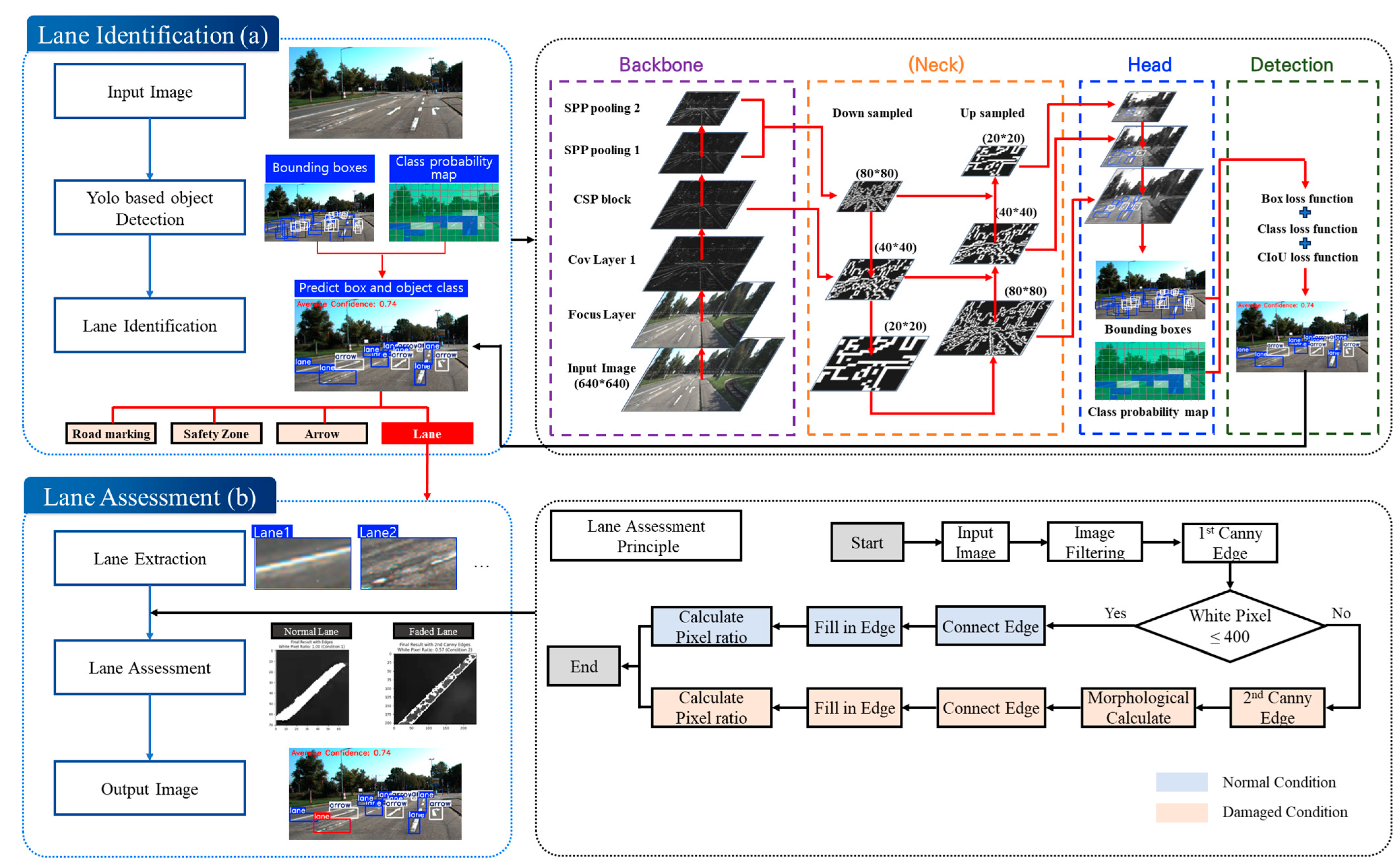
4.1. Lane Identification Algorithm Development
| Algorithm 1. Data Augmentation Algorithm |
function Load_Image(image_path)
function Apply_Augmentations (image, labels) 4. Define augmentation techniques 5. for each augmentation in list do 6. if augmentation is brightness_contrast then 7. Randomly adjust brightness and contrast 8. else if augmentation is blur then 9. Apply Gaussian blur to reduce detail 10. else if augmentation is noise then 11. Add random Gaussian noise to simulate camera noise 12. else if augmentation is horizontal_flip then 13. Flip image horizontally and adjust bounding boxes 14. else if augmentation is gamma_correction then 15. Randomly adjust gamma for varied lighting 16. else if augmentation is rotation then 17. Rotate image randomly and adjust bounding boxes 18. else if augmentation is crop then 19. Randomly crop image and rescale bounding boxes 20. else if augmentation is CLAHE then 21. Apply Contrast Limited Adaptive Histogram Equalization 22. else if augmentation is grayscale then 23. Convert image to grayscale 24. end if 25. end for 26. return augmented images and labels end function |
4.2. Lane Assessment Algorithm Development
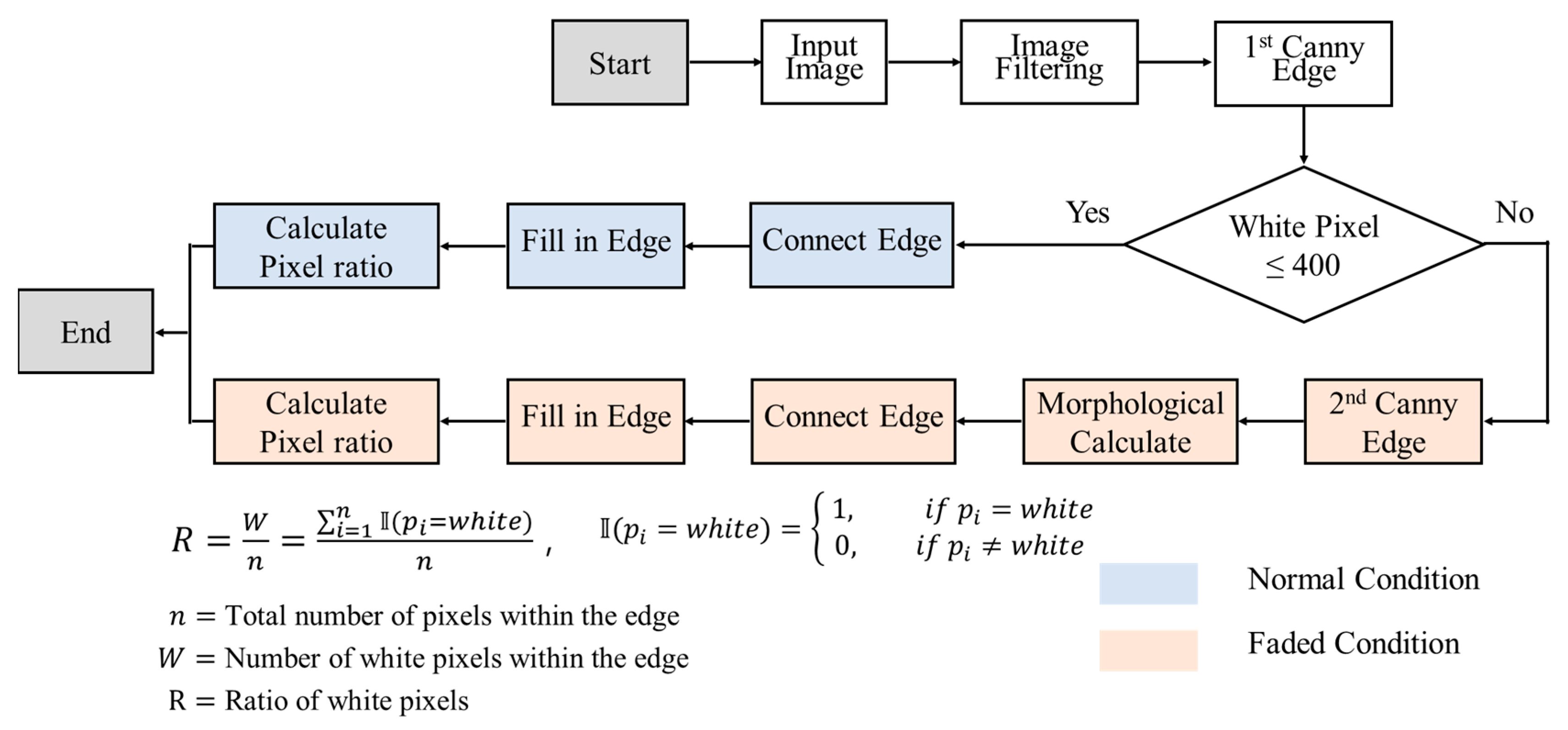
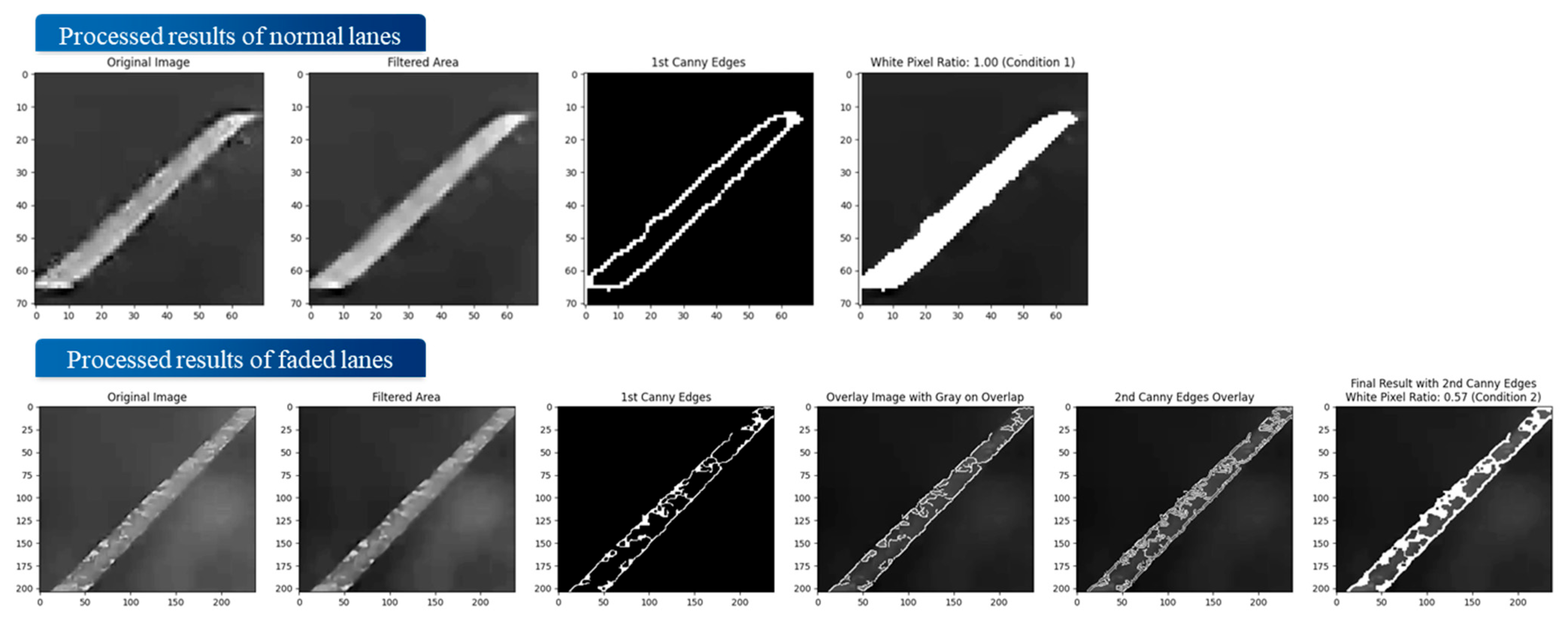
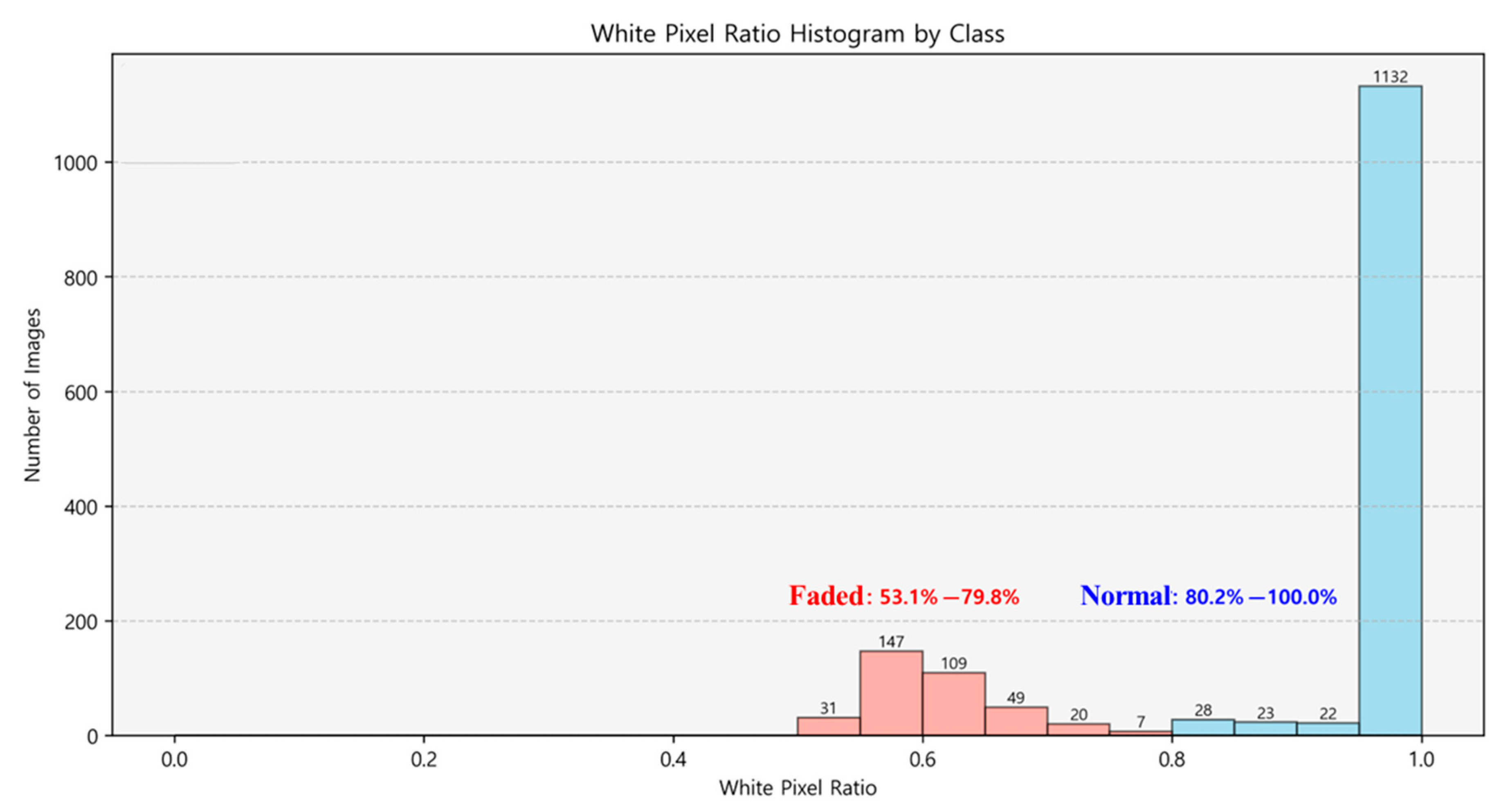
| Algorithm 2: Lane Assessment Process |
| Input: Image set , Hyperparameter CSV Output: White Pixel Ratio and Final Processed Images
|
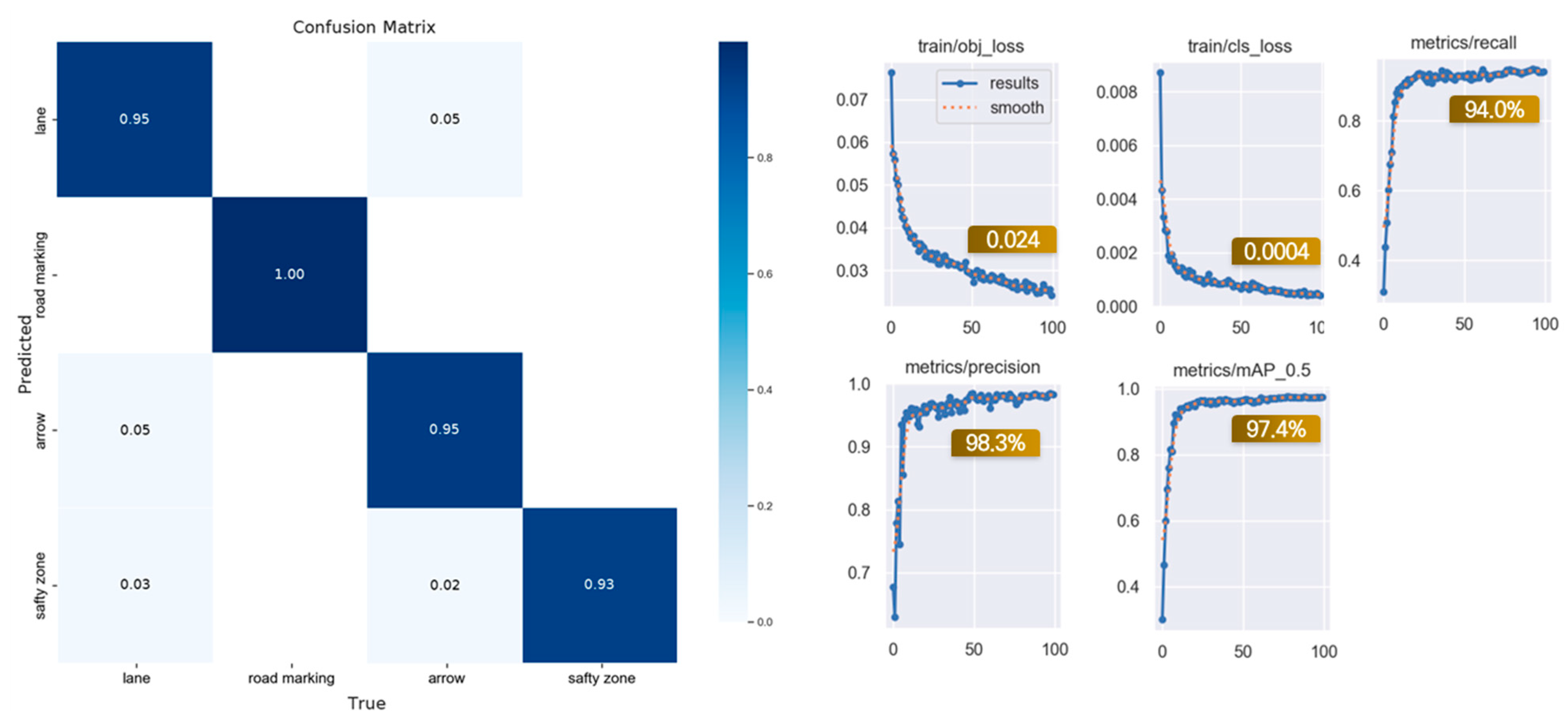
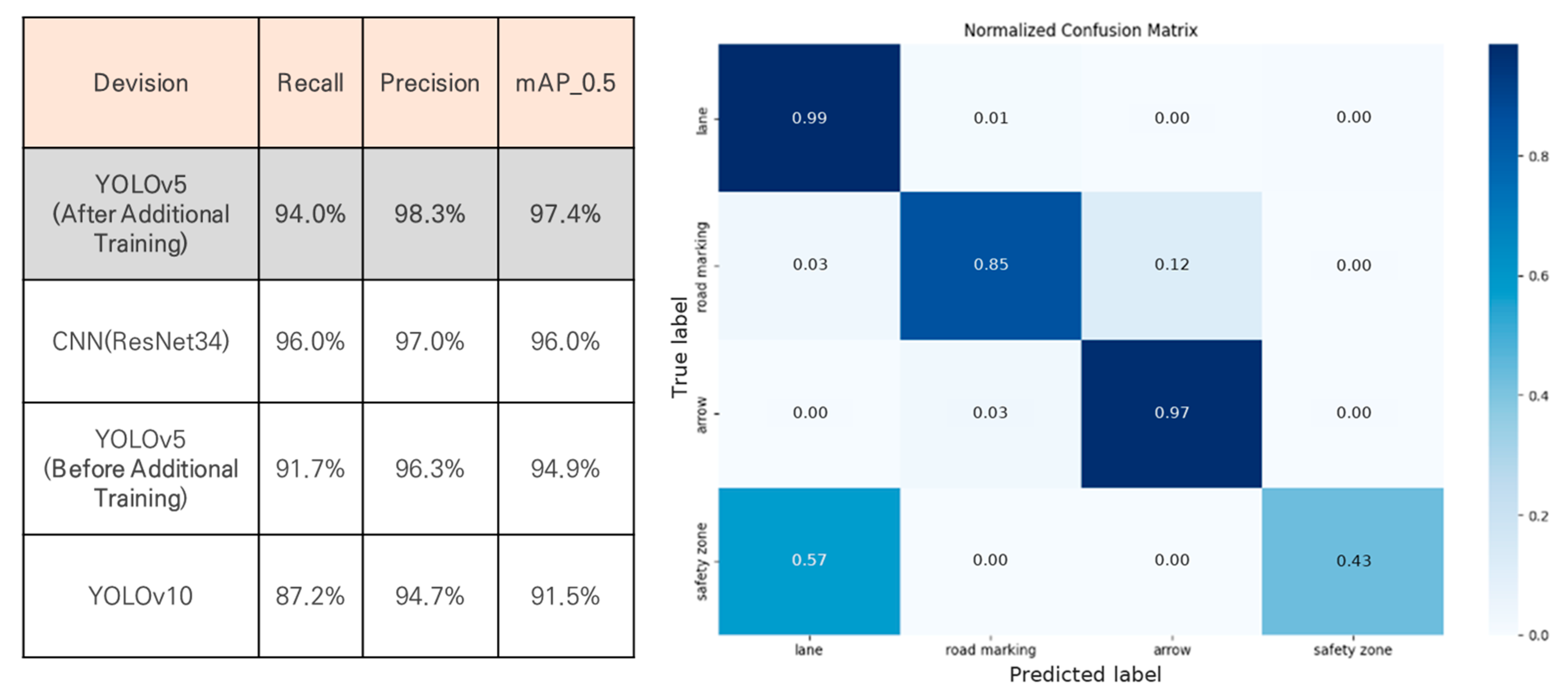
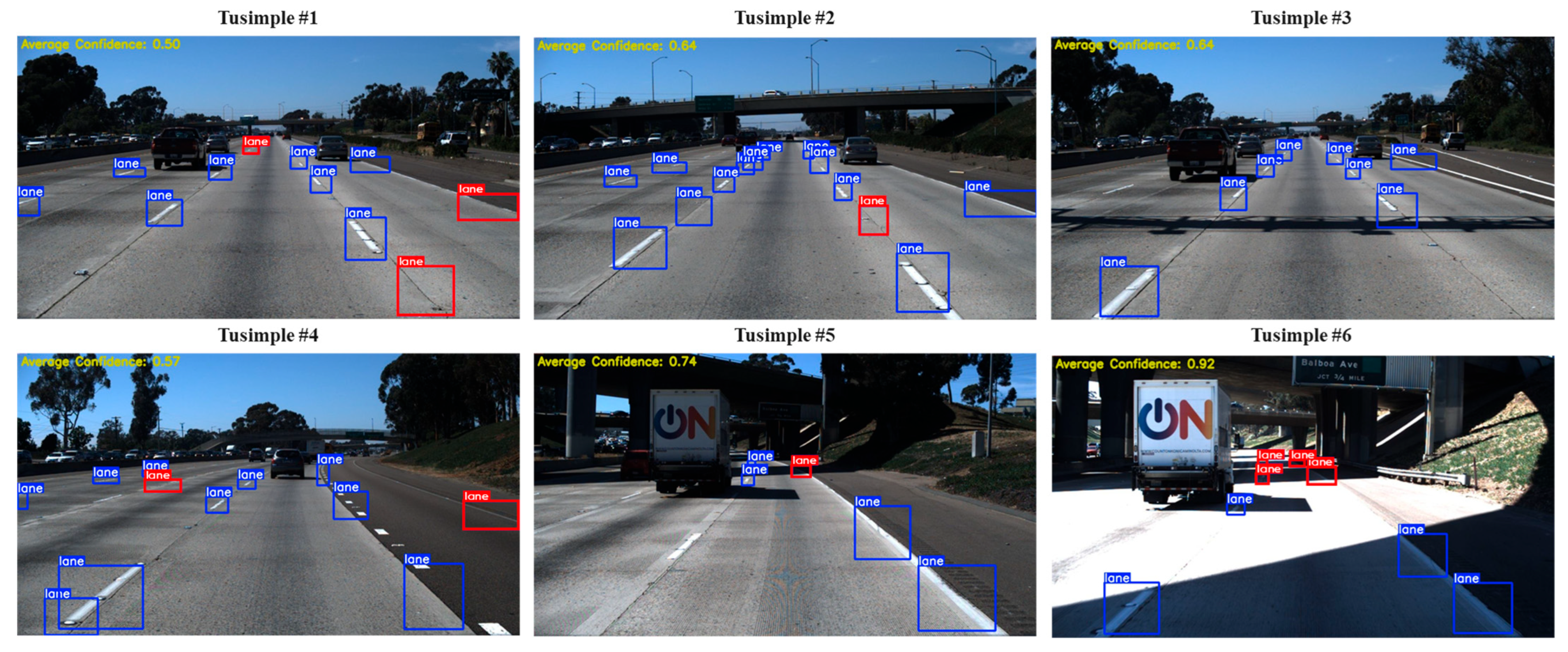
4.3. Performance Validation and Framework Development
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Road Association (PIARC). The Contribution of Road Transport to Sustainability and Economic Development: A PIARC Special Project; World Road Association (PIARC): Nanterre, France, 2020. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A Survey of Deep Learning Techniques for Autonomous Driving. J. Field Robot. 2019, 37, 362–386. [Google Scholar] [CrossRef]
- Em, P.P.; Hossen, J.; Fitrian, I.; Wong, E.K. Vision-Based Lane Departure Warning Framework. Heliyon 2019, 5, e02169. [Google Scholar] [CrossRef] [PubMed]
- Paek, D.; Kong, S.-H.; Wijaya, K.T. K-Lane: Lidar Lane Dataset and Benchmark for Urban Roads and Highways. arXiv 2021, arXiv:2110.11048. [Google Scholar] [CrossRef]
- Yadav, S.; Kumar, S.N.T.; Rajalakshmi, P. Vehicle Detection and Tracking Using Radar for Lane Keep Assist Systems. In Proceedings of the 2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), Florence, Italy, 20–23 June 2023. [Google Scholar] [CrossRef]
- Federal Highway Administration (FHWA). Manual on Uniform Traffic Control Devices for Streets and Highways, 11th ed.; USA Department of Transportation: Washington, DC, USA, 2023. [Google Scholar]
- California Department of Motor Vehicles (DMV). Disengagement Reports; 2024. Available online: https://www.dmv.ca.gov/portal/vehicle-industry-services/autonomous-vehicles/disengagement-reports/ (accessed on 29 July 2024).
- Tang, J.; Li, S.; Liu, P. A Review of Lane Detection Methods Based on Deep Learning. Pattern Recognit. 2021, 111, 107623. [Google Scholar] [CrossRef]
- Mamun, A.A.; Ping, E.P.; Hossen, J.; Tahabilder, A.; Jahan, B. A Comprehensive Review on Lane Marking Detection Using Deep Neural Networks. Sensors 2022, 22, 7682. [Google Scholar] [CrossRef] [PubMed]
- Na, H.; Kim, D.; Kang, J.; Lee, C. Development of a Lane Identification and Assessment Framework for Maintenance Using AI Techniques. In Proceedings of the 16th ITS European Congress, Seville, Spain, 19–21 May 2025. [Google Scholar]
- Aly, M. Real-Time Detection of Lane Markers in Urban Streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Bojarski, M.; Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Muller, U. End-to-End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial As Deep: Spatial CNN for Traffic Scene Understanding. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kim, J.; Lee, M. Robust Lane Detection Based on Convolutional Neural Network and Random Sample Consensus. In Neural Information Processing: 21st International Conference, Proceedings of the ICONIP 2014, Kuching, Malaysia, 3–6 November 2014; Springer: Cham, Switzerland, 2014; pp. 454–461. [Google Scholar] [CrossRef]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An Empirical Evaluation of Deep Learning on Highway Driving. arXiv 2015, arXiv:1504.01716. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J. A Computer Vision Enabled Damage Detection Model with Improved YOLOv5 Based on Transformer Prediction Head. arXiv 2023, arXiv:2303.04275. [Google Scholar] [CrossRef]
- Swain, S.; Tripathy, A.K. Real-Time Lane Detection for Autonomous Vehicles Using YOLOv5 Segmentation Model. J. Auton. Veh. Technol. 2024, 12, 718–728. [Google Scholar] [CrossRef]
- Yang, Z.; Shen, C.; Shao, W.; Xue, R. LDTR: Transformer-Based Lane Detection with Anchor-Chain Representation. Comput. Vis. Media 2024, 10, 753–769. [Google Scholar] [CrossRef]
- Wang, P.; Luo, Z.; Zha, Y.; Zhang, Y.; Tang, Y. End-to-End Lane Detection: A Two-Branch Instance Segmentation Approach. Electronics 2025, 14, 1283. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLabv3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection. arXiv 2018, arXiv:1806.05525. [Google Scholar] [CrossRef]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards End-to-End Lane Detection: An Instance Segmentation Approach. Mach. Vis. Appl. 2018, 29, 1281–1293. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar] [CrossRef]
- Zoljodi, A.; Abadijou, S.; Alibeigi, M.; Daneshtalab, M. Contrastive Learning for Lane Detection via Cross-Similarity (CLLD). Pattern Recognit. Lett. 2024, 185, 175–183. [Google Scholar] [CrossRef]
- Peng, J.; Bu, X.; Sun, M.; Zhang, Z.; Tan, T.; Yan, J. Large-Scale Object Detection in the Wild from Imbalanced Multi-Labels. arXiv 2020, arXiv:2005.08455. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar] [CrossRef]
- Zhang, J. Evolution of YOLO: A Comparative Analysis of YOLOv5, YOLOv8, and YOLOv10. In Proceedings of the 9th International Conference on Computing Innovation and Applied Physics (CONF-CIAP 2025), Singapore, 23–25 March 2025; pp. 185–192. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Na, H.; Kim, D.G.; Kang, J.M.; Lee, C. The Development of a Lane Identification and Assessment Framework for Maintenance Using AI Technology. Appl. Sci. 2025, 15, 7410. https://doi.org/10.3390/app15137410
Na H, Kim DG, Kang JM, Lee C. The Development of a Lane Identification and Assessment Framework for Maintenance Using AI Technology. Applied Sciences. 2025; 15(13):7410. https://doi.org/10.3390/app15137410
Chicago/Turabian StyleNa, Hohyuk, Do Gyeong Kim, Ji Min Kang, and Chungwon Lee. 2025. "The Development of a Lane Identification and Assessment Framework for Maintenance Using AI Technology" Applied Sciences 15, no. 13: 7410. https://doi.org/10.3390/app15137410
APA StyleNa, H., Kim, D. G., Kang, J. M., & Lee, C. (2025). The Development of a Lane Identification and Assessment Framework for Maintenance Using AI Technology. Applied Sciences, 15(13), 7410. https://doi.org/10.3390/app15137410