

LogRESP-Agent: A Recursive AI Framework for Context-Aware Log Anomaly Detection and TTP Analysis


Abstract
1. Introduction
- (1)
- Integrate LLM-based anomaly detection with semantic explanation to unify diverse log formats and support interpretable, context-aware threat analysis.
- (2)
- Employ Retrieval-Augmented Generation (RAG) and a suite of internal tools for recursive, multi-step investigation across heterogeneous logs.
- (3)
- Integrate a planning-capable LLM agent that generates human-readable explanations, allowing transparent and autonomous threat interpretation.
1.1. Research Challenges
- (1)
- Analyzing Heterogeneous and Unstructured Logs (Q1)
- (2)
- Lack of Interpretability in Log Anomaly Detection (Q2)
- (3)
- Limits of Static and Passive Inference Models (Q3)
1.2. Contributions
- (a)
- Template-free Semantic Log Interpretation (C1)
- (b)
- Context-enriched Semantic Reasoning for Explanation (C2)
- (c)
- Autonomous and Recursive Threat Investigation (C3)
2. Related Works
2.1. Traditional and Deep Learning-Based Log Anomaly Detection
2.2. Transformer-Based Log Anomaly Detection
2.3. LLM-Based AI Agent
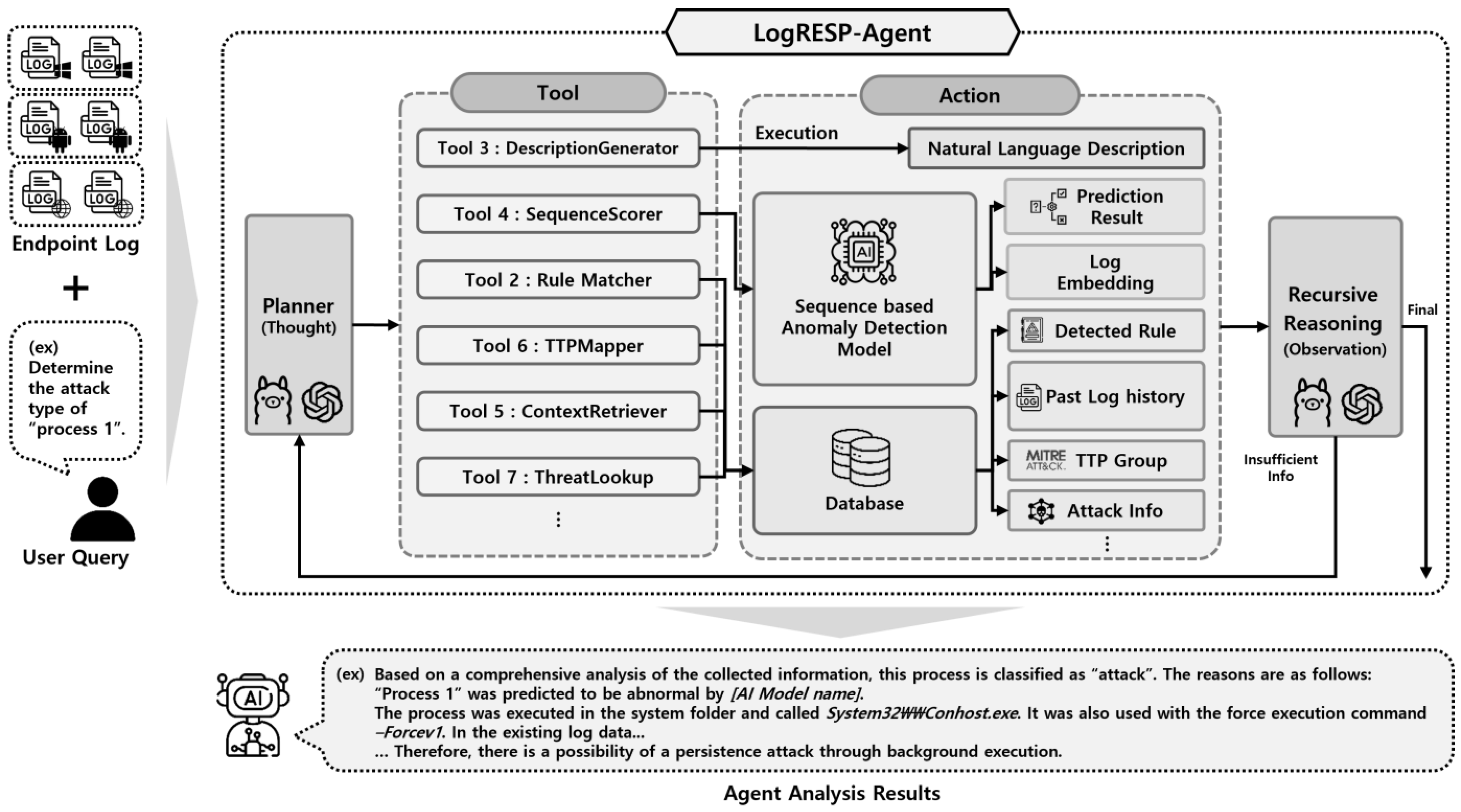
3. Proposed Method
3.1. Recursive Reasoning Framework for Log Analysis
| Algorithm 1: Recursive Anomaly Analysis Loop |
|
- (1)
- Planning Strategy Formulation
- (2)
- Context-Aware Execution
- (3)
- Reasoning via Recursive Threat Interpretation
- Autonomous Planning: The agent independently determines which tools to invoke and in what order.
- Dynamic Context Expansion: Relevant external information is retrieved as needed to fill knowledge gaps.
- Recursive Hypothesis Refinement: Each cycle incorporates new observations to update and improve its hypothesis.
- Goal-Directed Reasoning: All steps are explicitly tied to the initial analysis objective, ensuring coherence.
3.2. Tool-Oriented Semantic Transformation and Anomaly Detection
3.3. Dynamic Analysis Cycle and Final Reasoning Output
- (a)
- Summary: A high-level decision that characterizes the event as benign, suspicious, or indicative of an attack.
- (b)
- Evidence: A focused set of key observations that played a central role in guiding the agent’s assessment.
- (c)
- Reasoning Trace: A chronological outline of the agent’s investigative steps, detailing the sequence of tool invocations and the conclusions drawn at each stage.
- (d)
- Mapped Threat Context (if any): Behavioral correlations to known adversarial techniques, such as MITRE ATT&CK tactics, malware families, or threat actor patterns.
4. Implementation
4.1. Datasets
- (1)
- Monster-THC Endpoint Log
- (2)
- EVTX-ATTACK-SAMPLES [42]
4.2. Experimental Configuration: Agent Components and Baselines
- (1)
- AI Agent Architecture
- (2)
- Baseline Methods
- (a)
- Unsupervised anomaly detection models. We included an Autoencoder and LogBERT as representative unsupervised methods. The Autoencoder detects anomalies based on reconstruction error, while LogBERT leverages masked language modeling to identify sequence-level deviations in system logs.
- (b)
- Supervised machine learning classifiers. For multi-class classification, we trained standard classifiers including MLP, Random Forest, and XGBoost using structured log features. These models were selected for their widespread use in intrusion detection tasks and their strong performance on tabular data.
- (c)
- Agent-based ensemble variants. In addition to standalone models, we evaluated two configurations of the proposed AI Agent: one using LogBERT for binary anomaly detection, and the other using either Random Forest or XGBoost for multi-class classification. These variants retain the same modular reasoning structure, with only the scoring component replaced.
4.3. Detection Performance Evaluation
- (1)
- Anomaly Detection Performance on Monster-THC Dataset
- Chrome logs: LogRESP-Agent achieved full recall (TPR = 1.0, F1 = 1.0) with zero false positives, whereas LogBERT and Autoencoder recorded significantly lower F1-scores (0.81 and 0.73, respectively).
- Edge logs: The agent maintained strong performance (F1 = 0.94, TPR = 0.88), outperforming both baselines, which had comparable F1-scores (0.86) but lower recall.
- Hwp: On this more diverse process type, LogRESP-Agent again led with TPR 0.94 and F1-score 0.97, while LogBERT underperformed (TPR 0.68, F1 0.81), and Autoencoder plateaued at F1 0.86.
- (2)
- Multi-class Classification Performance on EVTX-ATTACK-SAMPLES
- Command and Control: All models performed well (F1 ≥ 0.98), but only the agent variant achieved full recall (TPR = 1.0, F1 = 1.0) with zero false positives.
- Credential Access: A challenging tactic for baselines—MLP and RF scored F1 ≤ 0.87. The agent variants improved this to 0.96 (RF) and 0.97 (XGBoost) with very low FPRs (≤0.002).
- Defense Evasion and Persistence: Involving stealthy or multi-stage behaviors, these classes saw consistent improvements from the agent variants, reaching F1 = 0.97 while keeping FPRs ≤ 0.003.
- Discovery and Execution: Easier to detect, all models performed well, but LogRESP-Agent again maintained near-perfect scores (F1 ≥ 0.99, FPR = 0.0).
- In Lateral Movement and Privilege Escalation: While some baselines showed reduced F1 (0.87–0.90), LogRESP-Agent sustained F1 = 0.99–1.0 with minimal false positives.
4.4. Explanation Analysis and Interpretability Evaluation
- (1)
- Case 1. Normal Chrome Execution (Monster-THC, Log ID: 1671)
“No malicious patterns were detected. The execution chain matches typical Chrome browser behavior.”
- (2)
- Case 2. Privilege Escalation via Chrome (Monster-THC, Log ID: 30048)
“Observed behavior includes indirect command execution, PowerShell in hidden mode, and multi-process escalation from Chrome to cmd.exe.”
- (3)
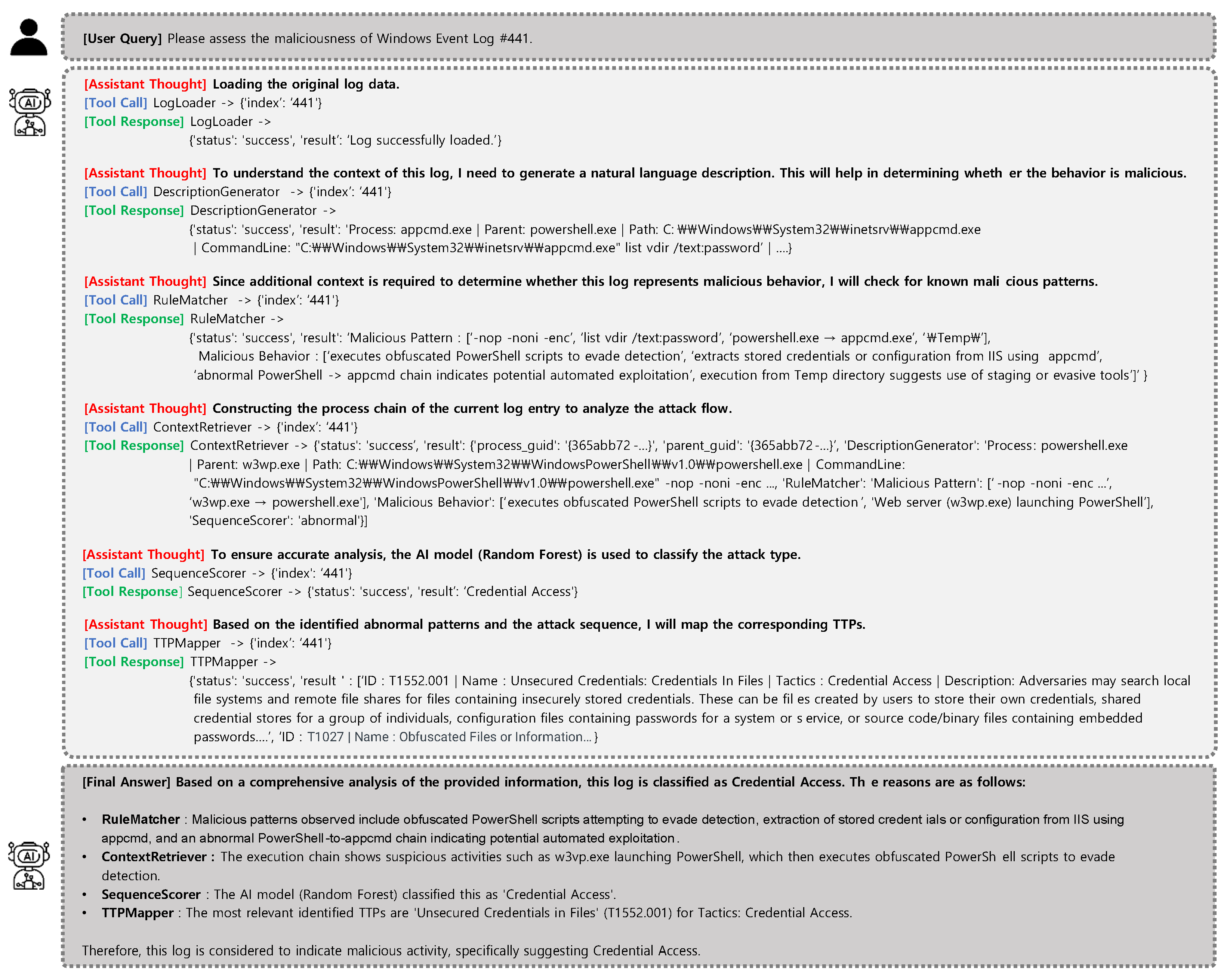
- Case 3. Credential Access via IIS Tooling (EVTX, Log ID: 441)
“The process appcmd.exe was launched by PowerShell with arguments suggesting credential enumeration via IIS.”
4.5. Ablation Study on Tool-Level Contributions to Detection Accuracy
5. Discussion
- (1)
- Practical Value and Comparative Advantages
- (2)
- Current Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mandru, S.K. Machine Learning and AI in Endpoint Security: Analyzing the use of AI and machine learning algorithms for anomaly detection and threat prediction in endpoint security. J. Sci. Eng. Res. 2021, 8, 264–270. [Google Scholar]
- Karantzas, G.; Patsakis, C. An empirical assessment of endpoint detection and response systems against advanced persistent threats attack vectors. J. Cybersecur. Priv. 2021, 1, 387–421. [Google Scholar] [CrossRef]
- Kara, I. Read the digital fingerprints: Log analysis for digital forensics and security. Comput. Fraud. Secur. 2021, 2021, 11–16. [Google Scholar] [CrossRef]
- Smiliotopoulos, C.; Kambourakis, G.; Kolias, C. Detecting lateral movement: A systematic survey. Heliyon 2024, 10, e26317. [Google Scholar] [CrossRef]
- Lee, W.; Stolfo, S.J. A framework for constructing features and models for intrusion detection systems. ACM Trans. Inf. Syst. Secur. 2000, 3, 227–261. [Google Scholar] [CrossRef]
- Hofmeyr, S.A.; Forrest, S.; Somayaji, A. Intrusion detection using sequences of system calls. J. Comput. Secur. 1998, 6, 151–180. [Google Scholar] [CrossRef]
- Hussein, S.A.; Sándor, R.R. Anomaly detection in log files based on machine learning techniques. J. Electr. Syst. 2024, 20, 1299–1311. [Google Scholar]
- Himler, P.; Landauer, M.; Skopik, F.; Wurzenberger, M. Anomaly detection in log-event sequences: A federated deep learning approach and open challenges. Mach. Learn. Appl. 2024, 16, 100554. [Google Scholar] [CrossRef]
- Wang, Z.; Tian, J.; Fang, H.; Chen, L.; Qin, J. LightLog: A lightweight temporal convolutional network for log anomaly detection on the edge. Comput. Netw. 2022, 203, 108616. [Google Scholar] [CrossRef]
- Lu, S.; Wei, X.; Li, Y.; Wang, L. Detecting anomaly in big data system logs using convolutional neural network. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; IEEE: New York, NY, USA; pp. 151–158. [Google Scholar] [CrossRef]
- Meng, W.; Liu, Y.; Zhu, Y.; Zhang, S.; Pei, D.; Liu, Y.; Chen, Y.; Zhang, R.; Tao, S.; Sun, P.; et al. Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; Volume 19, pp. 4739–4745. [Google Scholar]
- Zhang, X.; Xu, Y.; Lin, Q.; Qiao, B.; Zhang, H.; Dang, Y.; Xie, C.; Yang, X.; Cheng, Q.; Li, Z.; et al. Robust log-based anomaly detection on unstable log data. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Estonia, 26–30 August 2019; pp. 807–817. [Google Scholar] [CrossRef]
- Gu, S.; Chu, Y.; Zhang, W.; Liu, P.; Yin, Q.; Li, Q. Research on system log anomaly detection combining two-way slice GRU and GA-attention mechanism. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 28–31 May 2021; pp. 577–583. [Google Scholar] [CrossRef]
- Farzad, A.; Gulliver, T.A. Unsupervised log message anomaly detection. ICT Express 2020, 6, 229–237. [Google Scholar] [CrossRef]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar] [CrossRef]
- Wan, Y.; Liu, Y.; Wang, D.; Wen, Y. Glad-paw: Graph-based log anomaly detection by position aware weighted graph attention network. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Delhi, India, 11–14 May 2021; pp. 66–77. [Google Scholar]
- Guo, H.; Yuan, S.; Wu, X. Logbert: Log anomaly detection via bert. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Han, X.; Yuan, S.; Trabelsi, M. Loggpt: Log anomaly detection via gpt. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 1117–1122. [Google Scholar] [CrossRef]
- Almodovar, C.; Sabrina, F.; Karimi, S.; Azad, S. LogFiT: Log anomaly detection using fine-tuned language models. IEEE Trans. Netw. Serv. Manag. 2024, 21, 1715–1723. [Google Scholar] [CrossRef]
- Ma, X.; Li, Y.; Keung, J.; Yu, X.; Zou, H.; Yang, Z.; Sarro, F.; Barr, E.T. Practitioners’ Expectations on Log Anomaly Detection. arXiv 2024, arXiv:2412.01066. [Google Scholar]
- Zamanzadeh Darban, Z.; Webb, G.I.; Pan, S.; Aggarwal, C.; Salehi, M. Deep learning for time series anomaly detection: A survey. ACM Comput. Surv. 2024, 57, 1–42. [Google Scholar] [CrossRef]
- Zang, R.; Guo, H.; Yang, J.; Liu, J.; Li, Z.; Zheng, T.; Shi, X.; Zheng, L.; Zhang, B. MLAD: A Unified Model for Multi-system Log Anomaly Detection. arXiv 2024, arXiv:2401.07655. [Google Scholar]
- Yue, M. A Survey of Large Language Model Agents for Question Answering. arXiv 2025, arXiv:2503.19213. [Google Scholar]
- Masterman, T.; Besen, S.; Sawtell, M.; Chao, A. The landscape of emerging ai agent architectures for reasoning, planning, and tool calling: A survey. arXiv 2024, arXiv:2404.11584. [Google Scholar]
- Cemri, M.; Pan, M.Z.; Yang, S.; Agrawal, L.A.; Chopra, B.; Tiwari, R.; Keutzer, K.; Parameswaran, A.; Klein, D.; Ramchandran, K.; et al. Why Do Multi-Agent LLM Systems Fail? arXiv 2025, arXiv:2503.13657. [Google Scholar]
- Li, Y.; Xiang, Z.; Bastian, N.D.; Song, D.; Li, B. IDS-Agent: An LLM Agent for Explainable Intrusion Detection in IoT Networks. In NeurIPS 2024 Workshop on Open-World Agents; 2024; Available online: https://openreview.net/forum?id=iiK0pRyLkw (accessed on 30 May 2025).
- Kurnia, R.; Widyatama, F.; Wibawa, I.M.; Brata, Z.A.; Nelistiani, G.A.; Kim, H. Enhancing Security Operations Center: Wazuh Security Event Response with Retrieval-Augmented-Generation-Driven Copilot. Sensors 2025, 25, 870. [Google Scholar]
- Liang, Y.; Zhang, Y.; Xiong, H.; Sahoo, R. Failure prediction in ibm bluegene/l event logs. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, Nebraska, 28–31 October 2007; pp. 583–588. [Google Scholar] [CrossRef]
- Wang, J.; Tang, Y.; He, S.; Zhao, C.; Sharma, P.K.; Alfarraj, O.; Tolba, A. LogEvent2vec: LogEvent-to-vector based anomaly detection for large-scale logs in internet of things. Sensors 2020, 20, 2451. [Google Scholar] [CrossRef]
- Chen, M.; Zheng, A.X.; Lloyd, J.; Jordan, M.I.; Brewer, E. Failure diagnosis using decision trees. In Proceedings of the International Conference on Autonomic Computing, New York, NY, USA, 17–18 May 2004; pp. 36–43. [Google Scholar] [CrossRef]
- Dani, M.C.; Doreau, H.; Alt, S. K-means application for anomaly detection and log classification in hpc. In Proceedings of the Advances in Artificial Intelligence: From Theory to Practice: 30th International Conference on Industrial Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; Part 2; Volume 30, pp. 201–210. [Google Scholar]
- Mishra, A.K.; Bagla, P.; Sharma, R.; Pandey, N.K.; Tripathi, N. Anomaly Detection from Web Log Data Using Machine Learning Model. In Proceedings of the 2023 7th International Conference on Computer Applications in Electrical Engineering-Recent Advances (CERA), Roorkee, India, 27–29 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Karev, D.; McCubbin, C.; Vaulin, R. Cyber threat hunting through the use of an isolation forest. In Proceedings of the 18th International Conference on Computer Systems and Technologies, Ruse, Bulgaria, 23–24 June 2017; pp. 163–170. [Google Scholar] [CrossRef]
- Zhang, L.; Cushing, R.; de Laat, C.; Grosso, P. A real-time intrusion detection system based on OC-SVM for containerized applications. In Proceedings of the 2021 IEEE 24th International Conference on Computational Science and Engineering (CSE), Shenyang, China, 20–22 October 2021; pp. 138–145. [Google Scholar] [CrossRef]
- Kramer, M.A. Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Huang, S.; Liu, Y.; Fung, C.; He, R.; Zhao, Y.; Yang, H.; Luan, Z. Hitanomaly: Hierarchical transformers for anomaly detection in system log. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2064–2076. [Google Scholar] [CrossRef]
- Le, V.H.; Zhang, H. Log-based anomaly detection without log parsing. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021; pp. 492–504. [Google Scholar] [CrossRef]
- Chen, S.; Liao, H. Bert-log: Anomaly detection for system logs based on pre-trained language model. Appl. Artif. Intell. 2022, 36, 2145642. [Google Scholar] [CrossRef]
- Song, C.; Ma, L.; Zheng, J.; Liao, J.; Kuang, H.; Yang, L. Audit-LLM: Multi-Agent Collaboration for Log-based Insider Threat Detection. arXiv 2024, arXiv:2408.08902. [Google Scholar]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language agents with verbal reinforcement learning. Adv. Neural Inf. Process. Syst. 2023, 36, 8634–8652. [Google Scholar]
- Liu, X.; Yu, H.; Zhang, H.; Xu, Y.; Lei, X.; Lai, H.; Gu, Y.; Ding, H.; Men, K.; Yang, K.; et al. Agentbench: Evaluating llms as agents. arXiv 2023, arXiv:2308.03688. [Google Scholar]
- EVTX-ATTACK-SAMPLES. Available online: https://github.com/sbousseaden/EVTX-ATTACK-SAMPLES (accessed on 30 May 2025).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Log Format Flexibility | Recursive Planning | Recursive Reasoning | Autonomous Analysis Flow | Multi-Log Integration | Tool Integration + Automation | Inference Type | Explainability |
|---|---|---|---|---|---|---|---|---|
| HitAnomaly [36] | × | × | × | × | × | × | Static | ∆ |
| NeuralLog [37] | ∆ | × | × | × | × | × | Static | ∆ |
| LogBERT [17] | × | × | × | × | × | × | Static | ∆ |
| BERT-Log [38] | × | × | × | × | × | × | Static | ∆ |
| LogGPT [18] | × | × | × | × | × | × | Static | ∆ |
| LogFiT [19] | ◦ | × | × | × | × | × | Static | ∆ |
| IDS-Agent [26] | ∆ | ∆ | × | ∆ | ∆ | ∆ | Partially Dynamic | ◦ |
| SERC [27] | ∆ | ∆ | × | ∆ | ∆ | ◦ | Partially Dynamic | ◦ |
| Audit-LLM [39] | ∆ | ∆ | × | ∆ | ∆ | ∆ | Partially Dynamic | ∆ |
| LogRESP-Agent (Proposed) | ◦ | ◦ | ◦ | ◦ | ◦ | ◦ | Dynamic | ◦ |
| Tool | Function |
|---|---|
| LogLoader | Structures raw log data from system or endpoint sources for further analysis |
| RuleMatcher | Applies rules to identify known malicious signatures |
| DescriptionGenerator | Converts structured logs into natural language event summaries |
| SequenceScorer | Scores log sequences based on behavioral anomalies using pretrained models |
| ContextRetriever | Gathers related process logs (e.g., parent/child) to support correlation |
| TTPMapper | Maps observed behaviors to MITRE ATT&CK TTPs |
| ThreatLookup | Fetches background information on threats or attacker tools from threat intel |
| Scenario | Agent Behavior | Final Output |
|---|---|---|
| Attack |
| Identifies associated MITRE ATT&CK TTP(s) and describes supporting evidence in a structured explanation |
| Benign |
| Explains why the event is benign (e.g., scheduled task, admin script), referencing safe patterns or known whitelist behaviors |
| Ambiguous /Low Confidence |
| Continues reasoning or outputs “inconclusive” with explanation of missing context or low-confidence factors |
| Dataset | Category (Process/Tactic) | Benign | Malicious | Total |
|---|---|---|---|---|
| Monster-THC | Chrome | 30,036 | 150 | 30,186 |
| Edge | 1192 | 61 | 1253 | |
| Hwp | 2044 | 76 | 2120 | |
| EVTX-ATTACK-SAMPLE | Command and Control | - | 440 | 440 |
| Credential Access | - | 218 | 218 | |
| Defense Evasion | - | 283 | 283 | |
| Discovery | - | 146 | 146 | |
| Execution | - | 381 | 381 | |
| Lateral Movement | - | 1122 | 1122 | |
| Persistence | - | 163 | 163 | |
| Privilege Escalation | - | 414 | 414 |
| Tool Name | Role in Reasoning Loop | Function | Output Format |
|---|---|---|---|
| LogLoader | Data ingestion | Standardizes input logs into a unified format for downstream processing | Structured log in standard format |
| RuleMatcher | Signature-based detection (early stage) | Applies YARA/Sigma/custom rules to detect known suspicious patterns in process logs | Match result, rule metadata |
| Description Generator | Semantic summarization | Generates natural language summaries by pairing key log features with values to support semantic reasoning | Natural language sentence |
| SequenceScorer | Behavior modeling | Computes anomaly scores using LogBERT (anomaly detection) or classifies using RF/XGBoost (multi-class) | Score (0–1) or class label |
| ContextRetriever | Context expansion | Gathers related events (parent/child processes) to support behavioral correlation. | Related logs information (dict) |
| TTPMapper | Threat behavior mapping | Maps log behavior to MITRE ATT&CK techniques via cosine similarity between log descriptions and TTP embeddings (MiniLM-L12-v2). | Mapped TTP ID and label, Description |
| ThreatLookup | Intelligence enrichment | Provides concise descriptions of known TTPs and malware for enriched interpretation. | Textual threat summary |
| Process | Autoencoder | LogBERT | LogRESP-Agent (Proposed) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TPR | FPR | Acc | F1 | TPR | FPR | Acc | F1 | TPR | FPR | Acc | F1 | |
| Chrome | 0.79 | 0.002 | 0.99 | 0.73 | 0.71 | 0.0002 | 0.99 | 0.81 | 1.0 | 0.0 | 1.0 | 1.0 |
| Edge | 0.78 | 0.002 | 0.98 | 0.86 | 0.75 | 0.0 | 0.98 | 0.86 | 0.88 | 0.0 | 0.99 | 0.94 |
| Hwp | 0.78 | 0.002 | 0.99 | 0.86 | 0.68 | 0.0005 | 0.99 | 0.81 | 0.94 | 0.0 | 0.99 | 0.97 |
| All | 0.78 | 0.0002 | 0.98 | 0.82 | 0.71 | 0.0002 | 0.99 | 0.83 | 0.94 | 0.0 | 0.99 | 0.97 |
| Model | Mean F1-Score (%) | Std. Dev. |
|---|---|---|
| Autoencoder | 80.96 | ±1.10 |
| LogBERT | 83.52 | ±0.99 |
| LogRESP-Agent | 97.37 | ±0.57 |
| Tactic | MLP | RF | XGBoost | LogRESP-Agent + RF (Proposed) | LogRESP-Agent + XGBoost (Proposed) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TPR | FPR | Acc | F1 | TPR | FPR | Acc | F1 | TPR | FPR | Acc | F1 | TPR | FPR | Acc | F1 | TPR | FPR | Acc | F1 | |
| Command and Control | 0.98 | 0.004 | 0.99 | 0.98 | 0.97 | 0.0 | 0.99 | 0.98 | 0.99 | 0.0 | 0.99 | 0.99 | 0.99 | 0.0 | 0.99 | 0.99 | 1.0 | 0.0 | 1.0 | 1.00 |
| Credential Access | 0.81 | 0.017 | 0.97 | 0.80 | 0.81 | 0.003 | 0.98 | 0.87 | 0.96 | 0.003 | 0.99 | 0.96 | 0.96 | 0.002 | 0.98 | 0.96 | 0.97 | 0.002 | 0.99 | 0.97 |
| Defense Evasion | 0.87 | 0.007 | 0.98 | 0.90 | 0.91 | 0.008 | 0.98 | 0.91 | 0.95 | 0.003 | 0.99 | 0.95 | 0.94 | 0.001 | 0.98 | 0.95 | 0.97 | 0.003 | 0.99 | 0.97 |
| Discovery | 0.93 | 0.0 | 0.99 | 0.96 | 0.96 | 0.0 | 0.99 | 0.98 | 1.0 | 0.0 | 1.0 | 1.0 | 0.99 | 0.0 | 0.99 | 0.99 | 1.0 | 0.0 | 1.0 | 1.0 |
| Execution | 0.97 | 0.0 | 0.99 | 0.98 | 0.96 | 0.0 | 0.99 | 0.97 | 0.98 | 0.002 | 0.99 | 0.98 | 0.99 | 0.0 | 0.99 | 0.99 | 0.99 | 0.0 | 0.99 | 0.99 |
| Lateral Movement | 0.96 | 0.02 | 0.97 | 0.96 | 0.98 | 0.01 | 0.98 | 0.97 | 0.99 | 0.005 | 0.99 | 0.99 | 0.99 | 0.004 | 0.99 | 0.99 | 0.99 | 0.001 | 0.99 | 0.99 |
| Persistence | 0.75 | 0.008 | 0.97 | 0.79 | 0.78 | 0.003 | 0.98 | 0.85 | 0.94 | 0.002 | 0.99 | 0.95 | 0.97 | 0.0 | 0.98 | 0.97 | 0.99 | 0.002 | 0.99 | 0.99 |
| Privilege Escalation | 0.95 | 0.02 | 0.97 | 0.90 | 0.95 | 0.03 | 0.96 | 0.87 | 1.0 | 0.002 | 0.99 | 0.99 | 0.98 | 0.008 | 0.98 | 0.98 | 1.0 | 0.0 | 1.0 | 1.0 |
| All | 0.9 | 0.01 | 0.98 | 0.91 | 0.92 | 0.007 | 0.98 | 0.93 | 0.98 | 0.002 | 0.99 | 0.98 | 0.98 | 0.002 | 0.99 | 0.98 | 0.99 | 0.001 | 0.99 | 0.99 |
| Model | Mean F1-Score (%) | Std. Dev. |
|---|---|---|
| MLP | 91.00 | ±0.14 |
| RF | 93.00 | ±0.14 |
| XGBoost | 98.02 | ±0.13 |
| LogRESP-Agent + RF | 98.25 | ±0.12 |
| LogRESP-Agent + XGB | 98.96 | ±0.10 |
| Configuration | Anomaly Detection (LogRESP-Agent with LogBERT) | Multi-Class Classification (LogRESP-Agent with RF) | Multi-Class Classification (LogRESP-Agent with XGBoost) | |||
|---|---|---|---|---|---|---|
| F1-Score (%) | Change | F1-Score (%) | Change | F1-Score (%) | Change | |
| Full LogRESP-Agent | 97.00 | - | 98.25 | - | 99.47 | - |
| RuleMatcher removed | 93.08 | ↓ 3.92 | 94.18 | ↓ 4.07 | 95.43 | ↓ 4.04 |
| SequenceScorer removed | 94.43 | ↓ 2.57 | 95.42 | ↓ 2.83 | 96.75 | ↓ 2.72 |
| TTPMapper removed | 95.31 | ↓ 1.69 | 93.74 | ↓ 4.51 | 95.16 | ↓ 4.31 |
| ThreatLookup removed | 95.87 | ↓ 1.13 | 96.88 | ↓ 1.37 | 98.30 | ↓ 1.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Jeong, Y.; Han, T.; Lee, T. LogRESP-Agent: A Recursive AI Framework for Context-Aware Log Anomaly Detection and TTP Analysis. Appl. Sci. 2025, 15, 7237. https://doi.org/10.3390/app15137237
Lee J, Jeong Y, Han T, Lee T. LogRESP-Agent: A Recursive AI Framework for Context-Aware Log Anomaly Detection and TTP Analysis. Applied Sciences. 2025; 15(13):7237. https://doi.org/10.3390/app15137237
Chicago/Turabian StyleLee, Juyoung, Yeonsu Jeong, Taehyun Han, and Taejin Lee. 2025. "LogRESP-Agent: A Recursive AI Framework for Context-Aware Log Anomaly Detection and TTP Analysis" Applied Sciences 15, no. 13: 7237. https://doi.org/10.3390/app15137237
APA StyleLee, J., Jeong, Y., Han, T., & Lee, T. (2025). LogRESP-Agent: A Recursive AI Framework for Context-Aware Log Anomaly Detection and TTP Analysis. Applied Sciences, 15(13), 7237. https://doi.org/10.3390/app15137237