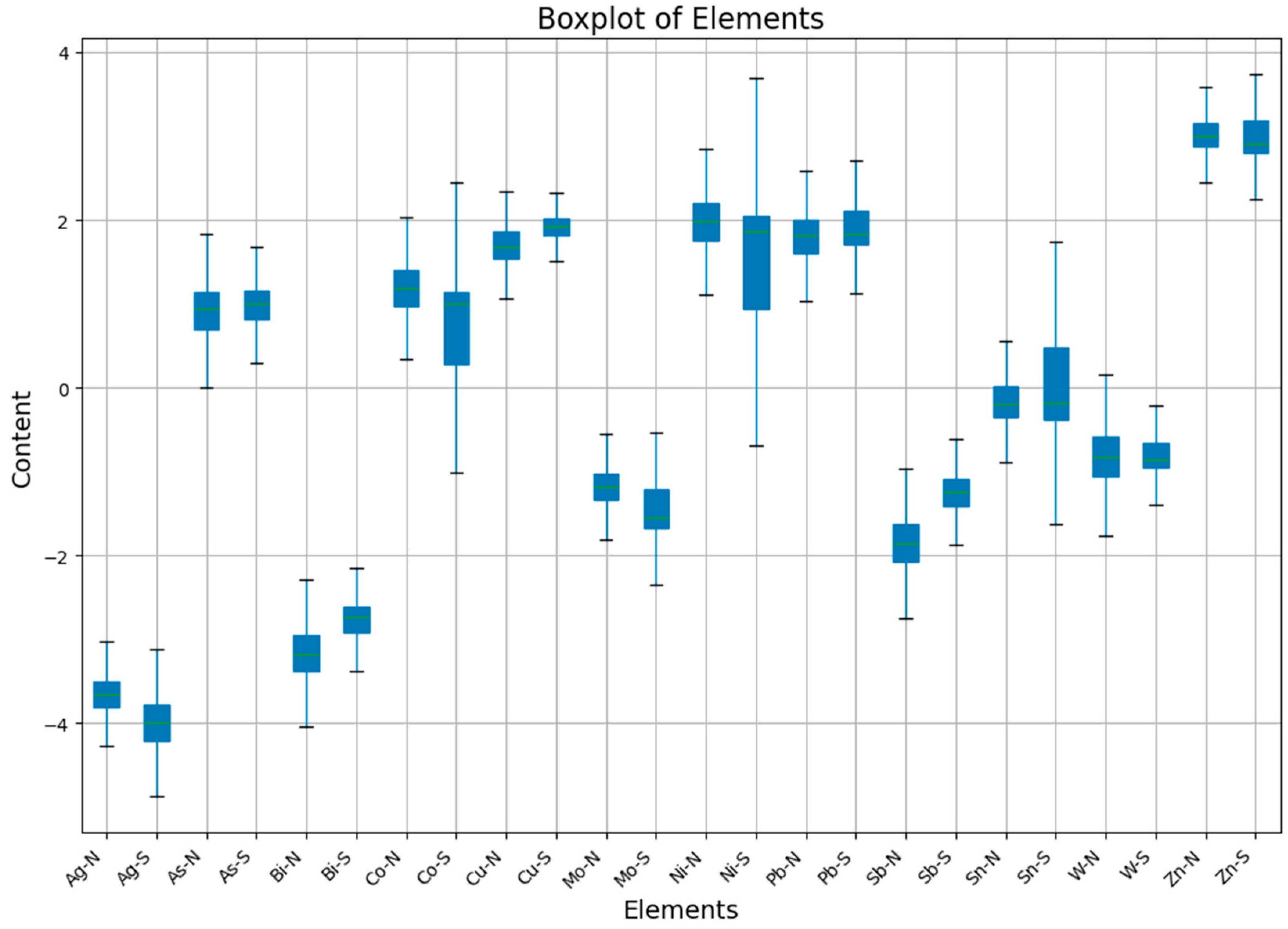
5.3.1. Results of the CR Method
Based on the compositional data analysis, data leveling for the northern and southern regions was performed using the CR method. The basic principle of the CR method is to perform overall data leveling based on the mean values between the map sheets.
After calculating the statistical parameters for the northern, southern, and entire regions, and using the mean values for the CR method, the leveled element parameters for the northern and southern regions are shown in
Table 6.
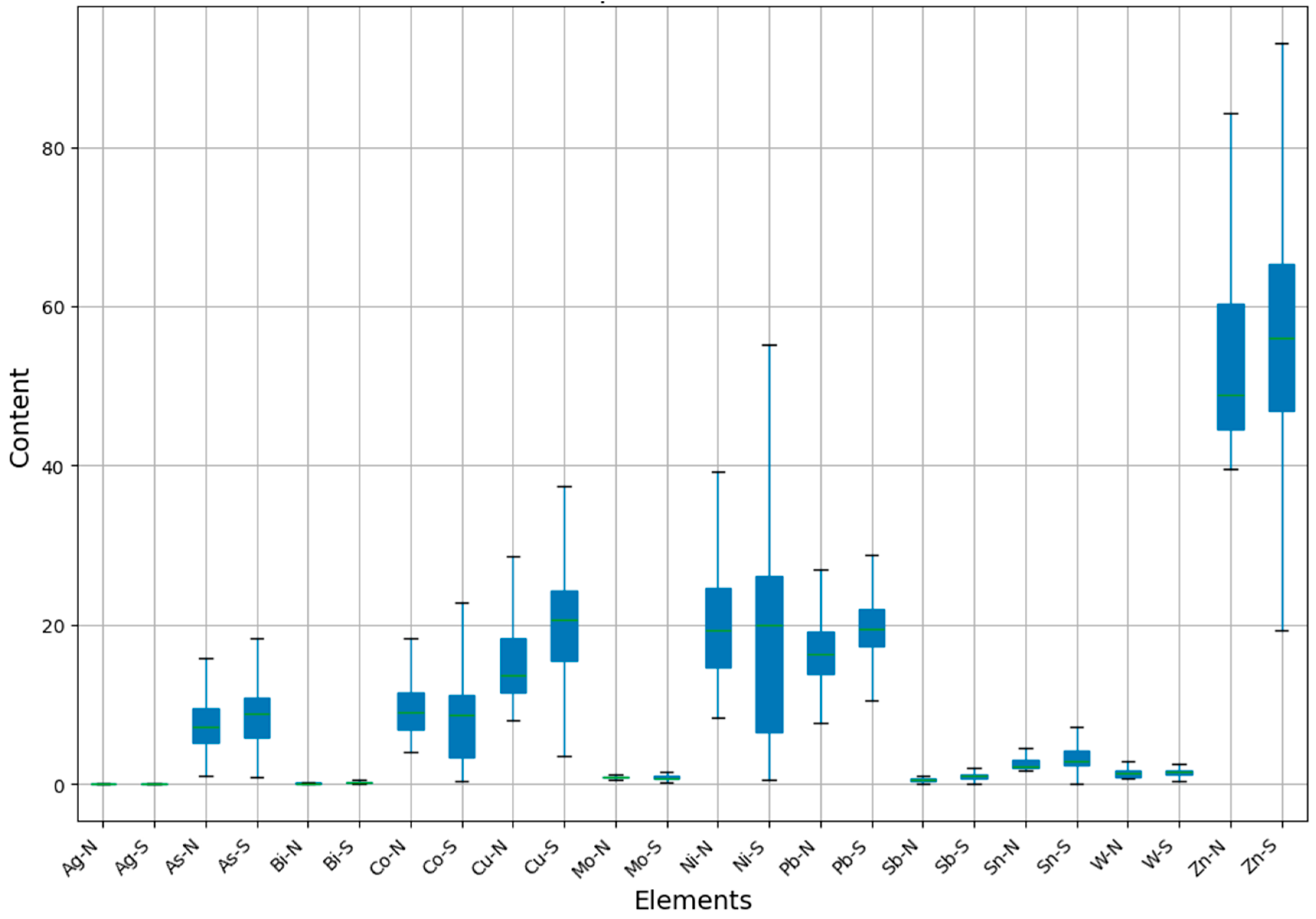
From
Table 6, it can be observed that after the CR method transformation using the median, the percentiles of each element are now much closer, and the kurtosis and skewness of all elements have not changed. When considering the corresponding geochemical maps (
Figure 10), the results show some improvement compared to the raw data (
Figure 7). The shift effect that was present in the raw data for Ag, Mo, and Sb elements has mostly been improved. Among them, Ag and Sb elements show the best results, with almost no shift between map sheets, and the distribution of geochemical anomalies is highly consistent with the distribution of faults, reflecting the fact that faults serve as migration channels for hydrothermal fluids.
Furthermore, although Mo elements have improved to some extent, there is still a noticeable shift at the boundaries. This may be due to the fact that the CR method levels the data as a whole for each map sheet, without considering the different geochemical backgrounds caused by the large area of the study region.
Additionally, a new issue emerged after applying the CR method: data that did not originally exhibit a shift now show one. This is most notable for Sn and Bi elements, followed by Co and Ni elements, which also exhibit a shift problem. Since Bi and Sn elements are mainly related to hydrothermal activity in the study area, and the southern region has a large number of faults, which are suitable migration channels for hydrothermal fluids, the anomalous distribution in the southern region should be more prominent than in the northern region, with a higher lower limit for the geochemical background. However, the CR method directly assumes that the northern and southern regions have the same background value, leading to data errors. For Co and Ni elements, which are related to basic rocks, and given that the upwelling of basic magma provides a heat source, similar to Sn and Bi elements, there are certain background value differences between the northern and southern regions.
5.3.2. Results of the BL Method
Theoretically, data that are closer to the boundary line should be more similar (since the data comes from the same geological unit). Therefore, data close to the boundary line should be selected as much as possible. However, it is also important to consider the statistical validity of the data. Too few data points may not adequately represent the true distribution characteristics, while too many data points may deviate from the similar background.
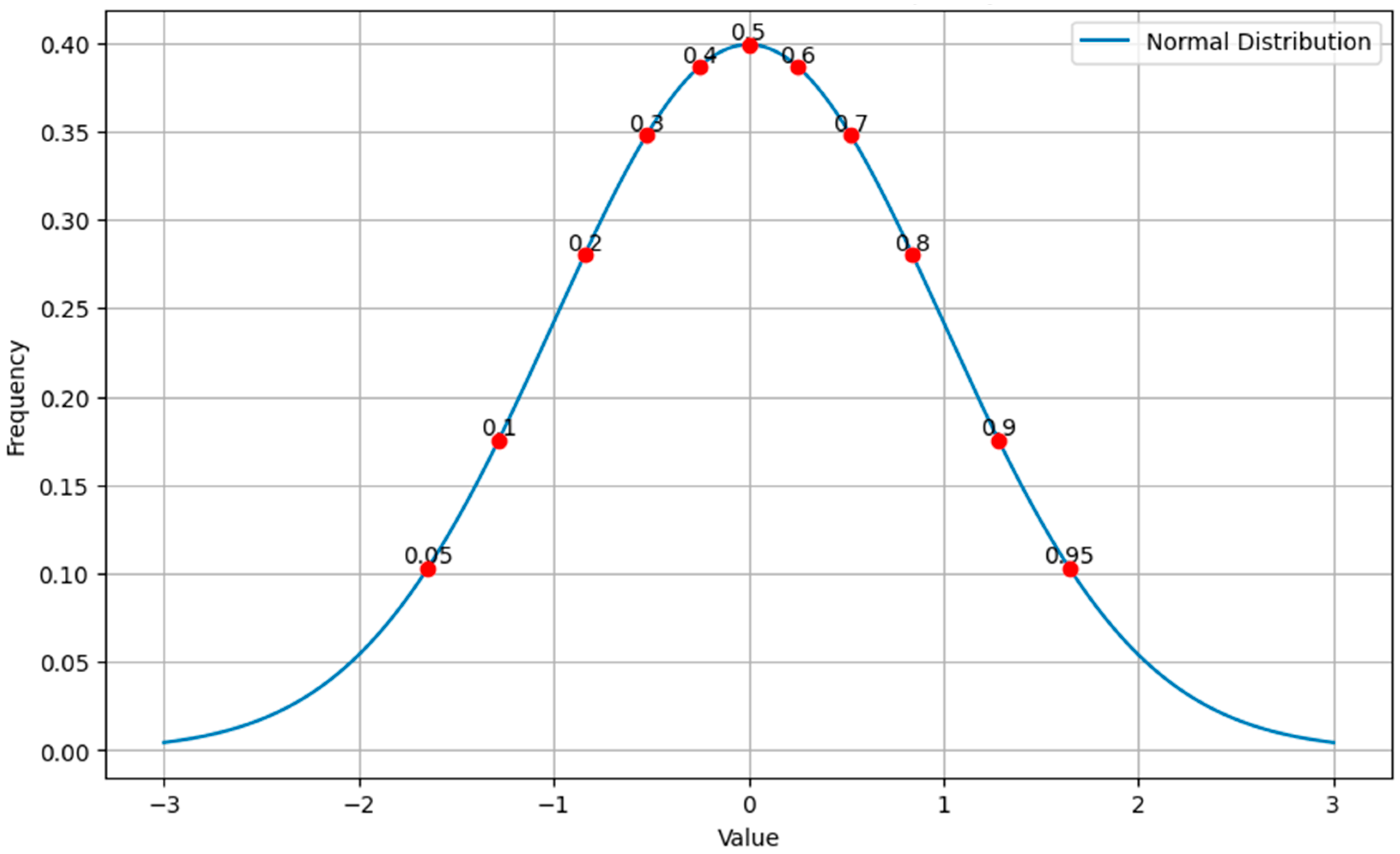
To address this, the southern and northern boundary lines were selected with distances ranging from 500 to 5000 meters, incrementing by 500 meters. The percentiles for different boundary ranges in the northern and southern regions were calculated, and the differences in percentiles were measured using a difference metric (D-value) and displayed in a line chart to assess the degree of difference in percentiles for different boundary ranges (
Figure 11).
From
Figure 11, it can be seen that at a 1000 m distance, the data difference between the northern and southern regions is the smallest, meaning the similarity is highest. Therefore, the data within this range is selected as the parameter for BL.
In the boundary-based leveling process, a certain area needs to be designated as the “standard area”, and the data from other areas are then leveled based on this “standard area” using the fitting function determined by the percentiles. Since the data for each map sheet follow sampling specifications, any area can be randomly selected as the “standard area”. In this study, the southern region was chosen as the standard area because its larger sample size helps effectively reduce errors caused by insufficient samples or data fluctuations, thus improving the reliability of the leveling results. Therefore, the southern region’s data is used to adjust the northern region’s data.
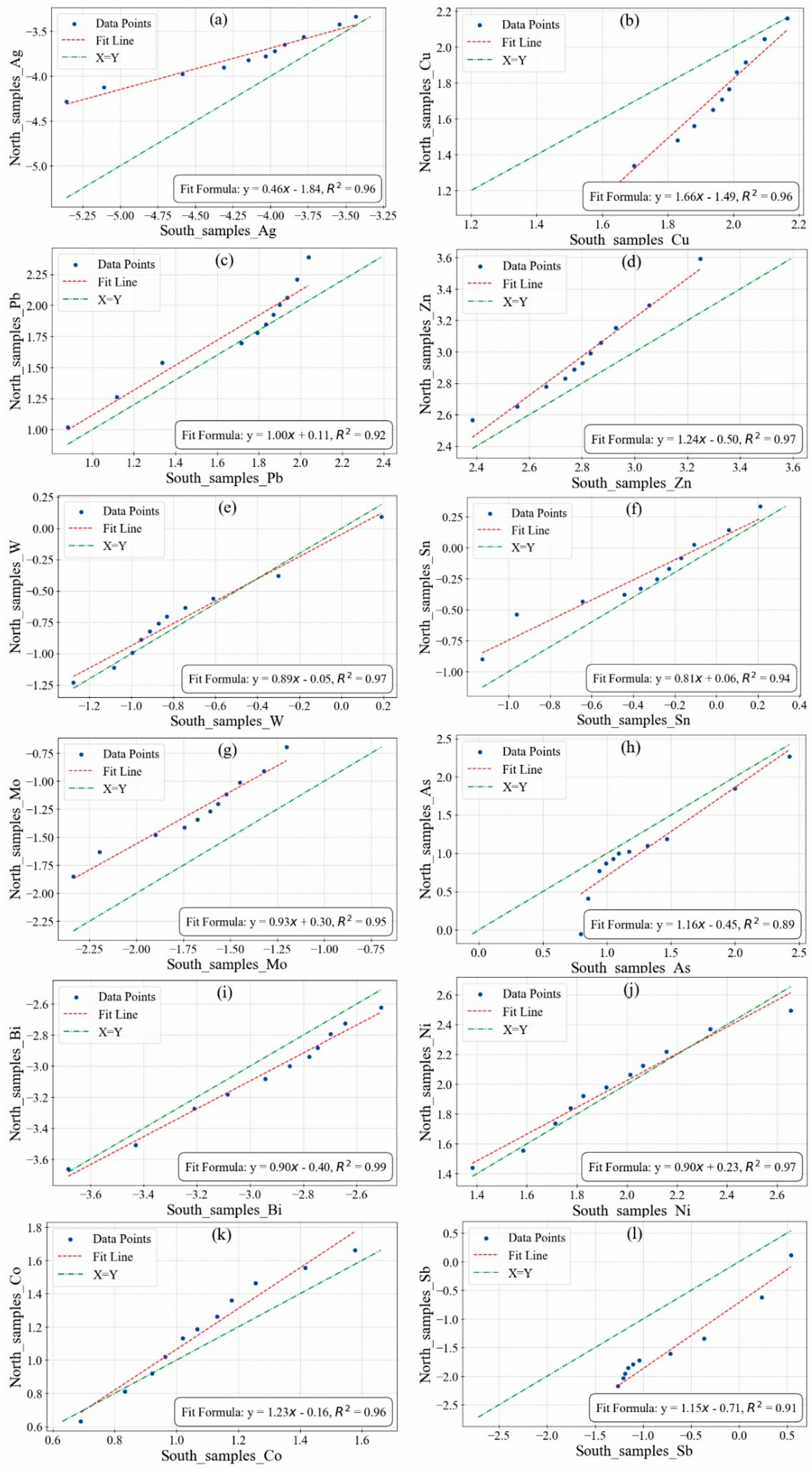
The leveling parameters are derived from the percentiles of the data within the 1000 m boundary range, and the fitting information can be seen in
Table 7 and
Figure 12. It is clearly evident that the element Ag requires the most leveling; theoretically, the distribution curve near the boundary line should be close to X = Y, but it deviates significantly, which is worth noting. Additionally, the R
2 values for the elements indicate that the fitting in both the northern and southern regions is quite good (all above 0.9), showing that the data for each element in both regions exhibit linear correlation, making boundary-based leveling a viable approach.
The leveling parameters determined through the boundary were extended to the entire region, with the data from the southern region used as the baseline to level the data from the northern region. The statistics of the leveled data parameters for each region are shown in
Table 8.
Similarly, the data leveled using the BL method was subjected to IDW interpolation, and the results are shown in
Figure 13.
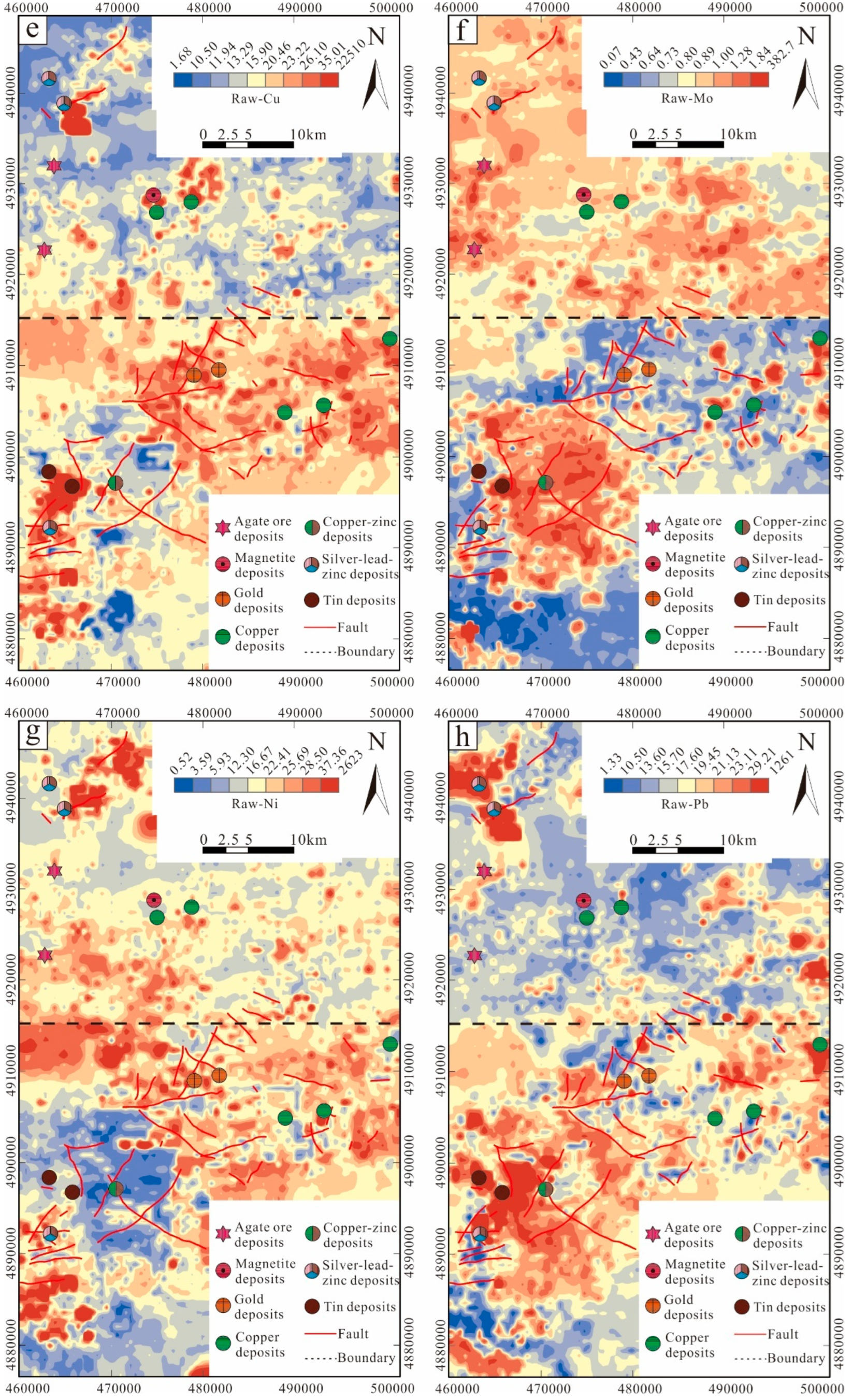
From
Figure 13, it can be seen that none of the element anomaly maps exhibit a shift effect. Taking the Sb element as an example, its geochemical distribution pattern is very similar to that of As, which is also a low-temperature element. Both exhibit a significant large-scale anomaly in the northern region, with relatively fewer anomalies in the southern region. On the other hand, elements such as W, Sn, Mo, and Bi, which are associated with high-temperature hydrothermal fluids, are mainly concentrated in the southern part of the study area, closely related to the positions of intrusive or extrusive rocks. Moreover, almost all the elements’ extension orientations are close to NE, consistent with the main fault orientations in the study area.
From the distribution of mineral points, the high-concentration anomalies of Cu in the geochemical map, after being leveled by the BL method, align well with the known mineral points. Compared to the CR method, there is almost no shift, indicating that the data leveling effect is good. For Sn, the improvement is most noticeable; in the raw data, no shift was observed for Sn, but after applying the CR method, a clear boundary appeared between the northern and southern regions. Clearly, this method is not suitable for this type of data. After processing with the BL method, the Sn element geochemical anomaly map performs well, with no shift and a large-scale anomaly in the southern region. This aligns with the geological background of widespread extrusive rocks in the southern region of the study area, confirming the good leveling effect of the BL method.
5.3.3. Results of MSC Method
Using the 1:200,000 geochemical data as the calibration medium, the sparsified 1:50,000 data for both the northern and southern regions were leveled to their corresponding levels. Then, the corrected relationships obtained from the sparsified data were applied to all the data, offering another approach to processing. Essentially, this method assumes that the 1:200,000 data serves as the baseline at the same or nearby sampling locations, and thus, the 1:50,000 data (including both the northern and southern regions) is leveled accordingly.
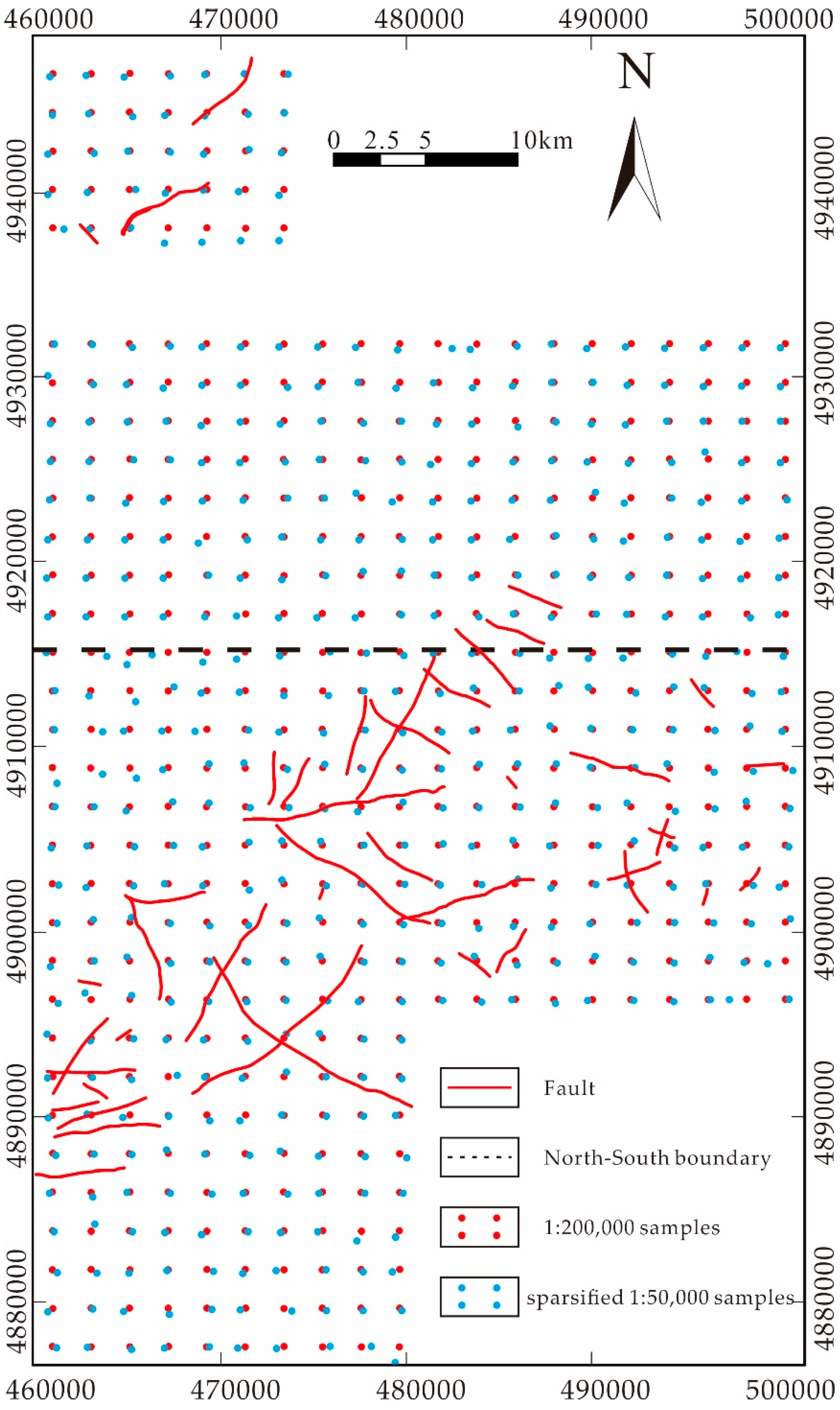
By calculating the Euclidean distance, the closest 1:50,000 sampling point to each 1:200,000 sampling point was selected. As shown in
Figure 14, the distributions of the sparsified 1:50,000 sampling points and 1:200,000 sampling points are nearly identical. Comparing the distribution of the sparsified samples, it can be concluded that the sampling locations are essentially the same. This means that for single elements, such as the Ag element in the northern region, the data from 1:200,000 should closely align with the data from 1:50,000, and the fitting curve of the percentiles should show a slope of 1, corresponding to the X = Y distribution.
However, in practice, there is still some systematic error. Therefore, we can correct this systematic error using the slope and intercept. Furthermore, the parameters for the slope and intercept apply to the entire northern 1:50,000 data set, and not just the sparsified data.
First, the fitting parameters between the sparsified 1:50,000 data and the 1:200,000 data were calculated. The fitting results are shown in the
Table 9 (since the table and figure provide the same information, they are not displayed here). From the R
2 values, which are consistently above 0.85, it is evident that the linear relationship is strong, and leveling based on the 1:200,000 data is valid.
Similar to the data after BL, the percentiles of all elements are also very close after the MSC method. The specific parameters are shown in
Table 10.
It should be emphasized that even though the 1:50,000 and 1:200,000 data were analyzed using different detection methods, it does not affect the leveling process. This is because, through linear regression, we focus on the trends or ratios between the data. As long as the data does not contain non-systematic errors, there will always be a clear linear relationship between the measurement values, and therefore, leveling can be performed using linear regression.
The results of the MSC method, as shown in
Figure 15, are essentially consistent with the BL method. Most of the elements are improved to some extent, and no issues similar to those in the CR method were observed. Since the geochemical map distribution is essentially consistent with that of the BL method, no further explanation is provided here.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}