1. Introduction
In recent years, with the great progress of modern underwater acoustic signal processing technology and underwater acoustic equipment research and development technology, underwater imaging sonar simulation technology has become a research hotspot at home and abroad. Sonar simulation technology plays an important role in both military and civil fields. Especially in the military field, the detection and recognition of enemy military targets (submarines, torpedoes, dangerous obstacles), seafloor terrain matching navigation, and other fields urgently require the application of high-fidelity sonar image simulation technology in complex environments.
With the continuous enhancement of computers’ computing performance, sonar simulation technology also needs to be developed in the direction of intelligence. The data generated by computer sonar simulations can be used in image processing, underwater target detection, performance monitoring, fault detection, and other fields, which can greatly reduce the dependence of operators on sonar imaging hardware devices. At present, research using neural networks has made remarkable progress, and they can be combined with computer technology and signal processing technology to make sonar data simulation intelligent.
The traditional image simulation technology requires operators to have a high level of theoretical knowledge [
1,
2,
3,
4]. The simulation model needs to consider the contradiction between the simulation accuracy and simulation calculation efficiency in complex environments, which leads to the incomprehensive distribution of sonar images and low intelligence of the model. With the rapid improvement in computer hardware computing ability and the large-scale application of supercomputers, deep learning methods have developed rapidly, and have been applied to computer vision tasks in the fields of medicine, radar, sonar, etc. For example, convolutional neural network (CNN) has been applied to the analysis and feature extraction of static medical images and radar images, and has achieved good results. Since Goodfellow [
5] proposed the GAN method in 2014, it has become a hot research object in various fields. In recent years, generative adversarial networks (GANs) have been used for noise reduction and image simulation in medical imaging [
6,
7,
8]. In the field of radar, an image-to-image conversion technology using a GAN [
9,
10] has also been proposed, which can successfully transform low-resolution SAR imaging to high-resolution SAR imaging. In the sonar field, GANs have been applied to the underwater sonar image simulation task [
11,
12], but the network structure of these methods does not fuse the category condition information of the sonar image, and ignores the correlation between pixels and channels, resulting in poor controllability and low fidelity of the generated sonar images.
Based on the above analysis, sonar data generation faces significant challenges: The noise in sonar images is complex, the target signal is weak, and it is difficult to generate high-fidelity data without losing the target features. We pay more attention to the sonar target pixels in the image than other pixels in the image background. The convolution operation is limited by the receptive field, and it cannot extract the structural features of the image well [
13,
14]. Attention mechanisms can better calculate the degree of correlation between different positions, where a pixel-level attention mechanism calculates the proportion of each pixel point in all pixel points through the softmax operation, and then obtains the pixel weight matrix. The channel-level attention mechanism calculates the ratio of each channel to all channels in the feature map by using the softmax operation to obtain the channel weight matrix. In order to improve the efficiency and fidelity of sonar data simulation in complex environments, and solve the problems of low intelligence and low fidelity of simulation images in traditional sonar data simulation technology, this paper proposes a sonar data simulation technology based on a dual-branch attention feature fusion mechanism to achieve high-fidelity and condition-specific sonar data simulation in a complex environment. The main contributions of this manuscript are as follows:
We propose the conditional dual-branch attention generative adversarial network, which can generate high-fidelity sonar images with a high FID value.
We design a dual-branch attention feature fusion structure, which enables precise control over the generation of sonar images under specific conditions, improving the robustness.
Sufficient comparative experiments are designed, including different comparative methods, datasets, and evaluation metrics, which fully verify the effectiveness and robustness of our method.
2. Related Work
2.1. Traditional Methods for Simulation of Sonar Data
At present, there are a host of problems in the field of sonar data simulation, such as the difficulty in modeling sonar simulations, the lack of closed-form expressions, the need to consider the influence factors of various environments in the simulation model, and the conflict between the accuracy of the simulation results and the amount of calculations needed. Bell and Linnett [
1] presented the side-scan sonar simulation model using an underlying physical process modeling method; it can output a qualitative image generated by an actual side scan. Didier Guériot et al. [
2] simulated real sonar data through the selection of multiple underwater scene design and calculation methods, and this method can generate realistic sonar images in different underwater scenes. Yang et al. [
3] proposed a method of echo signal superposition to realize the simulation of multi-channel sonar reverberation signal. The experimental results were consistent with the empirical values, which proves the effectiveness of the simulation. Huang et al. [
4] proposed a 3D data simulation model of synthetic-aperture sonar based on sound-line-tracking technology with a moderate amount of calculations. Simulation data from point targets and body targets showed that the simulation model was feasible. The sonar image simulation method based on the traditional simulation model has strong interpretability and low computational complexity because it is constructed from a physical model. However, the real underwater environment is affected by numerous factors such as fish schools and ships, making it difficult to establish physical models and conduct data simulations. In particular, the simulation model is affected by the background environment, the type of target, and changes in location, which bring great challenges to the traditional image simulation technology.
2.2. Methods Based on Generative Adversarial Networks
2.2.1. Generative Adversarial Network Method Based on Unsupervised Learning
Goodfellow et al. [
5] first proposed the GAN in 2014, which achieves a balance state through confrontation training between a generator and discriminator. The generator deceives the discriminator by manufacturing virtual samples, and the discriminator is responsible for distinguishing the authenticity between the real sample and the generated sample. However, the original GAN model had some problems such as an unstable training process and model collapse. Later, Radford A et al. [
15] proposed a deep convolutional generative adversarial network (DCGAN), which replaced the multi-layer perceptron of the original GAN by introducing a convolutional neural network (CNN), thereby enhancing the feature extraction ability of the model and improving the quality of the synthesized image to a certain extent. However, the above methods do not fundamentally solve the problem of model training instability. Arjovskym et al. [
16] proposed the earth mover distance to measure the difference between the true and false distributions; this enhances the stability of model training and can better deal with training instability, model collapse, and other problems in original GAN model. Gulrajanii et al. [
17] presented weight clipping by adding a penalty term based on the gradient of the discriminator, which can train various GAN structures steadily.
GANs have a strong image generation and conversion ability. In recent years, GANs have been gradually applied to the field of medical image denoising, simulation [
6,
7,
8], and radar image conversion [
18]. In the field of sonar, some researchers have applied them to sonar image generation. Johnny L. Chen et al. [
11] proposed an unsupervised feature learning method for seafloor classification using synthetic-aperture sonar images; this could generate a small number of different types of seafloor synthetic-aperture sonar images. Marija jegorova et al. [
12] proposed a generative adversarial network method based on the Markov condition to generate sonar images with a high sense of reality, enhancing the quality and speed of model synthesis data to a certain extent. Jianqun Zhou et al. proposed the MFA-CycleGAN model, introducing the multi-granularity feature alignment mechanism into the CycleGAN framework, significantly improving the quality of cross-domain sonar image generation and providing a new idea for similar unpaired image transformation tasks [
19]. However, the images generated by the above methods have strong randomness, which cannot meet the sonar data simulation task with controllable conditions in complex environments.
2.2.2. Generative Adversarial Network Method Based on Supervised Learning
After the GAN network was proposed, Mirza M. et al. [
20] proposed a CGAN method based on the category condition, which guides the image data generation process by adding additional information to the input of the original generator and discriminator network structure; the model achieved preliminary results on the MNIST dataset. After CGAN used the category label as a condition, researchers used sentence descriptions [
21] and feature vectors [
22] as conditions to synthesize images. The model proposed in this paper integrates the encoded category information of sonar images into the input of the generative adversarial network, so as to control the image generation process.
2.2.3. Generative Adversarial Network Method Based on Attention Mechanism
In the field of computer vision, attention mechanisms can be divided into two categories: soft attention and hard attention. Soft attention is the proportion of a certain position in all positions, and its weight value is in the range 0–1. Vaswania et al. [
23] proposed the self-attention mechanism, and achieved good results in a machine translation model. Wang X. et al. [
24] took the lead in applying the self-attention mechanism to computer vision tasks, so as to establish the correlation between remote pixels. Han Zhang et al. [
25] introduced a self-attention mechanism in a GAN to establish the connection between pixels, and their experimental results achieved good results on the ImageNet dataset. Hard attention is based on the response of a single position, so as to enhance or weaken the position, and its weight value can only be 0 or 1. Hu J. et al. [
26] expressed the importance of channel features through the attention mechanism, and enhanced or suppressed useful or non-useful channel features. Hu J. et al. [
27] restored the channel-level feature map to the original size by an up-sampling operation.
Liang Li et al. designed a generative adversarial model with enhanced channel and spatial attention, and trained the model using the optical sonar pairing data of the physical model in a zero-shot scene. This can generate rich sonar images and significantly improve the quality of sonar images and the subsequent classification effect [
28]. Feihu Zhang et al. utilized a physically guided diffusion model, integrated the semantic vividness knowledge extracted by the Swin Transformer and the diffusion-generated features, and combined this with edge perception loss to improve the clarity of the target in the generated sonar data; this was conducive to the improvement of the accuracy of target detection and recognition [
29]. The dual-branch attention model proposed in this paper focuses on the correlation between pixels and channels, and is applied to the generation of sonar images under specific categories.
Overall, traditional methods overly rely on physical modeling and perform poorly in complex marine environments. The existing methods based on deep networks are vulnerable to environmental noise and have poor robustness. In response to the above problems, we propose a Conditional Dual-Branch Attention Generative Adversarial Network, which can generate high-fidelity sonar images of different environments and has strong robustness against environmental interference.
3. Proposed Method
3.1. Conditional Information Fusion Module
For some image generation tasks, especially sonar image simulation in complex environments, different types of sonar targets and background information should be considered to generate a condition-specific sonar image. A conditional GAN [
20] method based on multi-layer perceptron was proposed, but the image generated by the multi-layer perceptron structure had some problems [
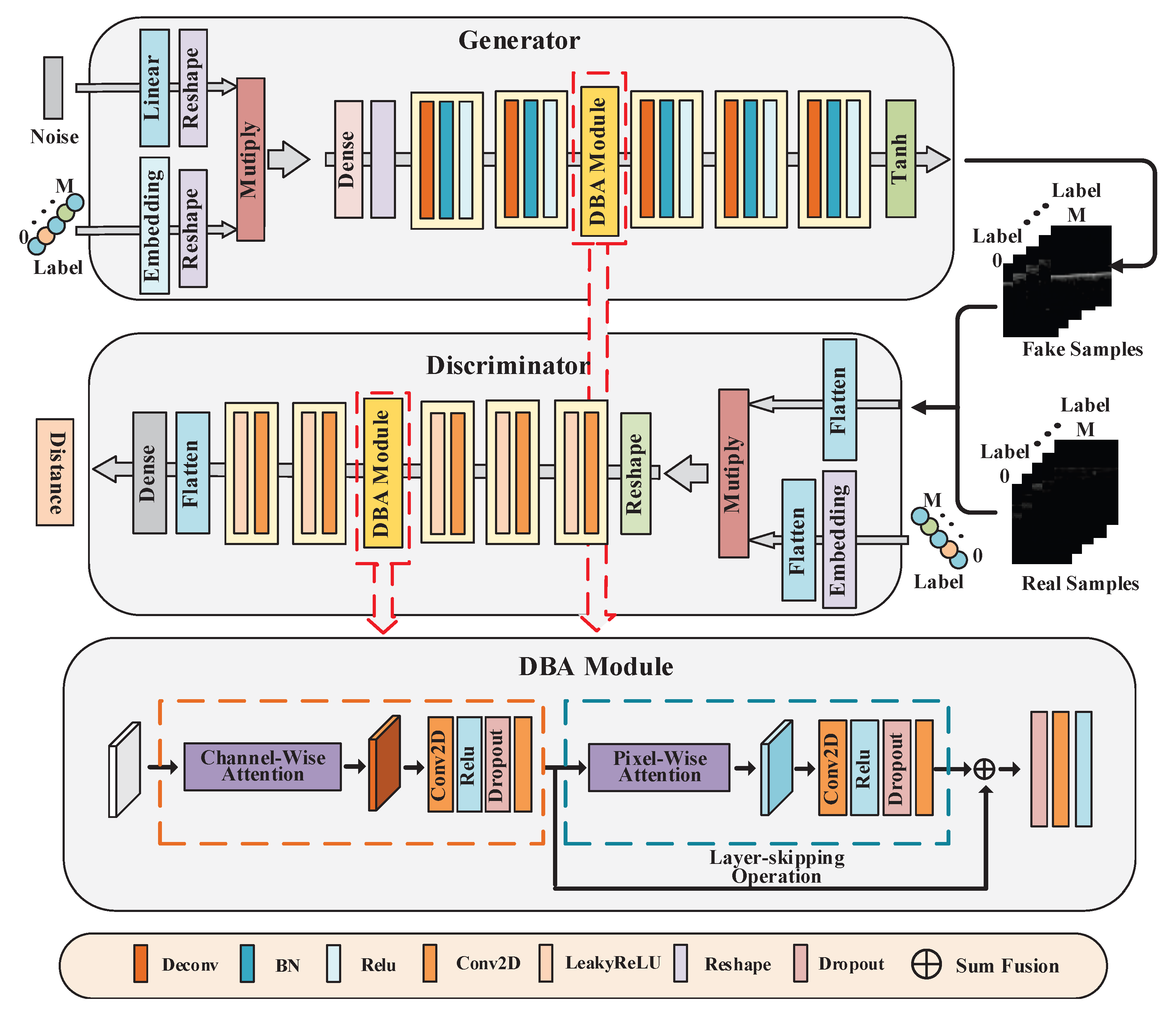
15], such as noise interference, low fidelity, and a strange structure. It could not cope with the task of high-fidelity sonar image generation in a complex environment. In this paper, a conditional information fusion module is designed to fuse the conditional information of the encoded sonar image with the original input of the network, and then the fused information is further input into the network. The overall framework of the method is shown in
Figure 1. The conditional information fusion module fuses the noise with the encoded conditional information of different categories, M represents the number of category conditions, and then transmits the fused information to the generator. The generator main network is composed of multiple deconvolution modules and a dual-branch attention feature fusion module. The feature map generated by the deconvolution module is processed by the dual-branch attention feature fusion module and then transferred to the next deconvolution module. The dual-branch attention feature fusion module completes the feature-level fusion operation through two different attention calculations combined with the layer-skipping operation. The conditional information fusion module fuses image information with category information and transmits it to the discriminator network. The discriminator main network is composed of multiple convolution modules and a dual-branch attention feature fusion module, that performs the difference measurement between the true and false distributions.
The conditional information fusion module is located on the input side of the generator and the discriminator. The fusion process is as follows:
In the discriminator network structure, given the input image A and label L , L is converted to L through the embedding operation, where represents the number of all pixels in the image, and the input sonar image A is tiled into A through the flatten operation; A and L are multiplied element-wise to obtain the vector B after the label and image information are fused, and the final input B of the discriminator is obtained by further performing the reshape operation.
In the generator network structure, given the input random noise Z and label L , L is converted to L through the embedding operation, where M is the size of the noise dimension, and then Z and L are multiplied element-wise to get the final input D of the generator.
3.2. Dual-Branch Attention Feature Fusion Mechanism
Sonar images are affected by complex underwater environments, and there are some problems such as overlap and difficulty in distinguishing between the sonar target and the background. As introduced in DBSAGAN [
30] and DBAA-CBB [
31], dual-branch attention can increase the richness of deep features, which may improve the network performance. This manuscript proposes a dual-branch attention feature fusion mechanism, which is composed of a channel-level attention module and a pixel-level attention module. Firstly, the correlation between different channels is calculated by the channel-level attention module, and then the correlation between target and background pixels is further calculated by the pixel-level attention module. The network can compensate for the problems of a limited receptive field and the insufficient ability of the image channel and structural feature extraction during the original convolution operation process, and enhance the structural information of the sonar feature image. Finally, through the layer-skipping operation, the channel attention features of the previous layer and the current layer are further fused to improve the expression ability of the features, so as to enhance the fidelity of the synthetic sonar image.
3.2.1. Channel-Level Attention Module
A pixel-level self-attention mechanism can enhance the correlation between distant pixels well, but the effect of channel information on the model is ignored. Reference [
26] proposed the SE network module, which enhances or suppresses the channel features by calculating the importance of each channel itself, but does not calculate the degree of correlation between channels. The channel attention designed in this paper pays more attention to the correlation between channels; this method calculates the proportion of each channel in all channels by using the softmax function, obtains the channel attention weight matrix of the sonar feature image, enhances the feature expression ability of the model, and improves the fidelity of the generated image. Our channel-level attention module is shown in
Figure 2, and the operation process is as follows.
Firstly, the input feature map X
is reshaped into X
, and the transposition of X is multiplied by X; then the channel attention weight matrix
is obtained by the softmax function, and
is multiplied by X to obtain the output result
of the channel-level attention mechanism layer:
We multiply the result by the scale parameter
, which is initialized as 0. The final output value of the channel-level attention layer is obtained by adding the input feature map:
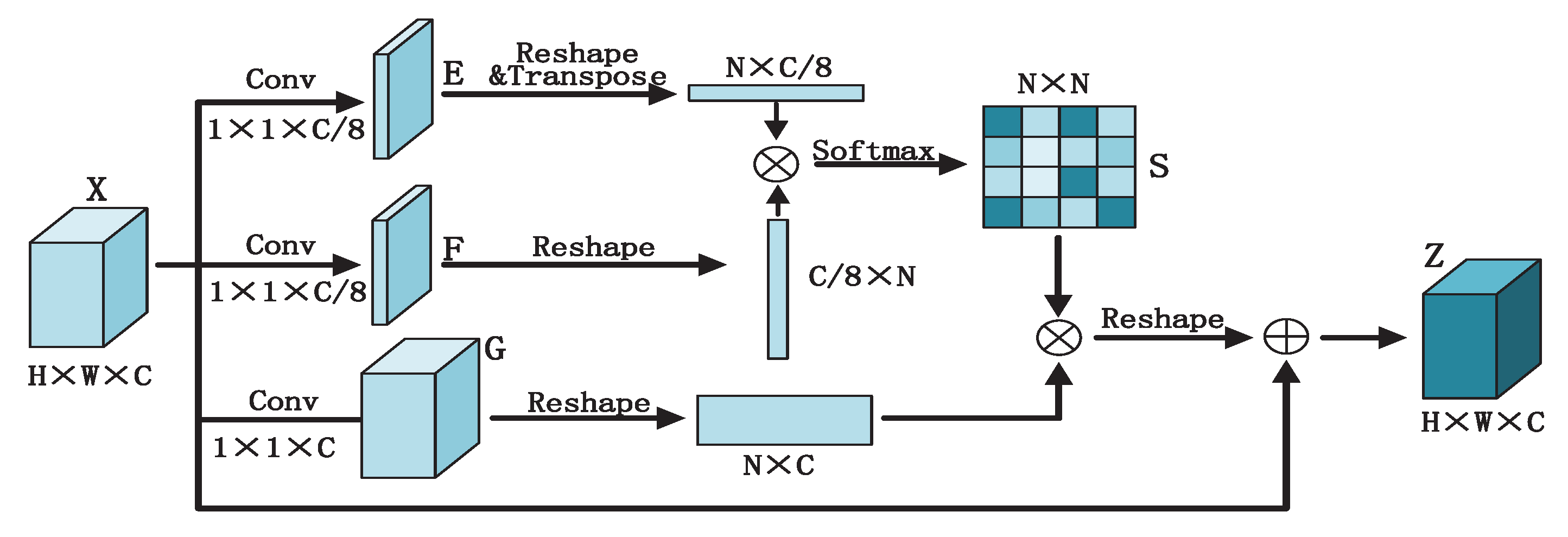
3.2.2. Pixel-Level Attention Module
The specific operation of the attention mechanism is illustrated in
Figure 3. This method performs a 1 × 1 convolution operation on the feature map obtained by the channel attention operation to reduce the dimensionality. and then obtains the feature maps, which can be expressed as
where H and W represent the height and width of the feature map, and C represents the channel.
,
,
,
,
, and
are the learned weight matrices, which are implemented as 1 × 1 convolutions.
After the feature map F is multiplied by the transpose of the feature map E, the pixel-level weight matrix is calculated by a softmax function, and then
is multiplied by
to obtain the output result of the self-attention mechanism layer:
We multiply the result by the scale parameter
, which is initialized as 0. The output of the channel attention mechanism layer is obtained by adding the input feature map:
Finally, the channel-level attention features of the previous layer and the features of the current layer are added at the pixel level by the layer-skipping operation to complete the feature-level fusion.
Here, represents the features generated by the channel attention module, and represents the features generated by the self-attention module; and are the learned weight matrices, which are implemented as 3 × 3 convolutions.
3.3. Loss Function
The discriminator in the traditional CGAN method [
20] is used to judge the authenticity of sonar samples in the generator. The model is prone to problems such as mode collapse and training instability during the training process. In this paper, the method of combining the Wasserstein distance and gradient penalty mechanism is used to enhance the stability of model training and improve the quality of the generated samples. The Wasserstein distance between the real sample distribution and the fake sample distribution is defined as follows:
In the formula, x and y represent the real sonar sample and the generated sample, respectively; represents all possible joint distributions , where the marginal distributions of each joint distribution are and .
According to the distance loss function, the loss functions of the discriminator and generator networks,
and
, can be expressed as the following forms, where
c represents the category condition information of the sonar image:
The overall model training process can be interpreted as a minimax confrontation game between the generator and the discriminator network. The training results are balanced by optimizing the discriminator and generator losses. The overall model training process is expressed as
On the basis of this loss function, the gradient of the discriminator is limited to a fixed range by introducing a gradient penalty mechanism. The improved loss function is expressed as follows:
Here, , is the gradient penalty coefficient, and is a random number that obeys a uniform distribution, that is, .
4. Experiments
For the sonar image generation model built above, the effectiveness of the method was verified on the sonar dataset. The original sonar data was provided by the Hangzhou Institute of Applied Acoustics. The running environment of the model was the Keras2.2.4 framework under Python 3.5, the Tensorflow-gpu version was 1.9.0, and the graphics card was the NVIDIA GeForce TITAN Xp.
4.1. Creation of the Sonar Dataset
The original sonar images of different categories and backgrounds were generated through the principle of front and background superimposition, and 411 sonar images required by the model were selected according to different category conditions (position, target or background type). The dataset includes sonar images in four categories. For the characteristics of a complex background and serious noise interference in underwater sonar images, this paper made a noise overlay on the dataset. The sonar images under label0, label1, and label2 conditions had no noise added. The sonar images under the label3 condition had added Gaussian noise with a mean value of 0 and a variance of 0.041.
4.2. Evaluation Metrics
The current metrics used for evaluating the quality of sonar images generated by the GAN model are mainly the inception score [
32] (IS) and Frechet inception distance [
33] (FID). The IS is obtained by pre-training the InceptionV3 network on the ImageNet dataset. Compared with the ImageNet dataset, the sonar dataset has a large difference in image distribution, so the IS cannot accurately measure the quality of the generated sonar image. In this paper, the Frechet inception distance (FID) [
33] was used to measure the similarity between the feature vectors of the generated sonar image and the real sonar image, which is the mean difference of features between the real images and the generated image and can measure the mean value of a batch of data. Compared with the IS [
32], the FID measures distance by extracting the feature vectors of the fully connected layer of the network under the real and generated sonar dataset, which can better measure the quality of the generated image, with stronger robustness and higher accuracy. The formula is as follows:
Here, u represents the mean value of the image features, represents the covariance matrix of the image features, and r and g represent the real sonar image and the generated sonar image.
4.3. Comparison with State-of-the-Art Models
In order to illustrate the effectiveness of the model for the sonar image synthesis problem under specific category conditions for different categories (square, columnar), positions, and noise value of sonar images, this method is compared with the most advanced image generation models (DCGAN [
15], WGAN [
16], SAGAN [
25]). These methods are based on unsupervised learning. In order to verify the effectiveness of the conditional information fusion module, this paper fused the category condition information on the basis of these models, calculated and compared the FID value of the sonar images generated by these methods; the smaller the FID value, the better the quality of the sonar image generated under the condition of this category. The sonar images generated under the different models are shown in
Figure 4, and the calculated FID values are shown in
Table 1.
Comparing the sonar images and their FID values under different category attributes, the qualitative results are shown in
Figure 4. Our method generates image details and an overall image quality that are more realistic, and has strong anti-interference ability under a background with a low signal-to-noise ratio. The sonar images generated by the DCGAN method are not clear enough and greatly affected by noise. WGAN adds the EM distance evaluation criterion on the basis of DCGAN, which can better measure the difference between the real and fake distribution, and the clarity of the generated images are better than DCGAN, but the ability in processing image details is not strong. SAGAN enhances the correlation between pixels by introducing a self-attention mechanism, but with the increase in noise intensity, the training ability of the model is limited by the noise interference problem, and some details are missing. As shown in
Table 1, the FID values of images generated by our method under the label0, label1, and label2 category labels are the lowest, achieving a reduction of more than 50 percent compared to the other four methods. In label3 with Gaussian noise, the FID value of our method is tied for the lowest with that of SAGAN, and it is more than 40 percent lower than the other three comparison methods. However, we observe that the target and background details of the SAGAN method are more blurred than our method, and there are greater differences compared to the real image, which shows the image quality of our method is best. The With-CAM method obtains the weight matrix between channels by calculating the channel-level self-attention, which strengthens the connection between channels, and improves the quality of the generated image compared with WGAN, and there is also the problem of poor model training under noise interference.
4.4. Dual-Branch Attention Mechanism
In order to verify the effect of the proposed dual-branch structure in this manuscript, we added the dual-branch attention mechanism to different positions in the model. Specifically, we added dual branches at positions of different sizes on the feature map, including feature map sizes of 16 × 16, 32 × 32, 64 × 64, and 128 × 128, and compared the FID evaluation metric, which is shown in
Table 2. It can be concluded from the experimental results that the dual-branch attention module can perform better in the middle and advanced feature maps. Among them, the FID value under the feature map size of 64 × 64 is better than the FID value under the small size of 16 × 16 and 32 × 32. This is because the method can fully calculate the dual-branch attention of the model under the larger size of the feature map, and feeds back the correlation between the elements in the channel and spatial dimensions to the original feature map better.
5. Conclusions
This paper proposes a Conditional Dual-Branch Attention Generative Adversarial Network (CDBA-GAN) for synthesizing high-fidelity sonar images under specific category conditions. The proposed framework introduces two core innovations. Conditional fusion architecture: Category-specific semantic information is encoded and fused with the generator’s input, enabling precise control over the generation of sonar images with predefined categorical attributes. Dual-branch attention mechanism: A hierarchical feature fusion strategy is implemented to simultaneously model channel-wise interdependencies and spatial correlations, thereby enhancing feature discriminability while preserving contextual coherence. To validate the effectiveness of CDBA-GAN, a comprehensive evaluation was conducted on a custom sonar dataset. Quantitative comparisons of the Fréchet inception distance (FID) metric across five methods—DCGAN, WGAN, SAGAN, CAM-enhanced GAN, and the proposed CDBA-GAN—demonstrate the superior fidelity of images generated by our method. Furthermore, the framework exhibits robustness against noise interference, outperforming state-of-the-art benchmarks by a significant margin. Sonar data were generated to solve the difficulty that the small amount of sonar data makes it hard to improve subsequent tasks such as detection and recognition. The experiments show that our method is better than several other methods on the FID. Subsequently, we will use the generated data for sonar target detection to verify the practical value of the generated data. While the proposed method achieves notable performance improvements, its computational complexity presents a practical limitation for real-time applications. Future work will prioritize model lightweighting through techniques such as network pruning or knowledge distillation. Additionally, we plan to extend this architecture to other conditional image generation tasks, including underwater optical image synthesis and multi-modal sensor data augmentation.
Author Contributions
All authors made significant contributions to this work. W.K. designed the research and analyzed the results. H.Y. assisted in the manuscript preparation work and validation work. M.J. and Z.C. provided advice for the preparation and revision of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Stable Supporting Fund of Acoustic Science and Technology Laboratory (JCKYS2024604SSJS00502), National Natural Science Foundation of China (U20B2074, 62471169).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Acknowledgments
This work was supported by the Stable Supporting Fund of Acoustic Science and Technology Laboratory (JCKYS2024604SSJS00502), which is gratefully acknowledged.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bell, J.M.; Linnett, L.M. Simulation and analysis of synthetic sidescan sonar images. IEE Proc.—Radar Sonar Navig. 1997, 144, 219–226. [Google Scholar] [CrossRef]
- Gueriot, D.; Sintes, C.; Garello, R. Sonar data simulation based on tube tracing. In Proceedings of the Oceans 2007-Europe, Aberdeen, UK, 18–21 June 2007; pp. 1–6. [Google Scholar]
- Yang, Z.; Zhao, J.; Yu, Y.; Huang, C. A Sample Augmentation Method for Side-Scan Sonar Full-Class Images That Can Be Used for Detection and Segmentation. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5908111. [Google Scholar] [CrossRef]
- Huang, C.; Zhao, J.; Zhang, H.; Yu, Y. Seg2Sonar: A Full-Class Sample Synthesis Method Applied to Underwater Sonar Image Target Detection, Recognition, and Segmentation Tasks. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5909319. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. Generative adversarial networks for noise reduction in low-dose CT. IEEE Trans. Med. Imaging 2007, 36, 2536–2545. [Google Scholar] [CrossRef]
- Dai, W.; Dong, N.; Wang, Z.; Liang, X.; Zhang, H.; Xing, E.P. Scan: Structure correcting adversarial network for organ segmentation in chest X-rays. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 263–273. [Google Scholar]
- Li, Z.; Wang, Y.; Yu, J. Reconstruction of thin-slice medical images using generative adversarial network. In Machine Learning in Medical Imaging; Springer: Cham, Switzerland, 2017; pp. 325–333. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Chen, J.L.; Summers, J.E. Deep neural networks for learning classification features and generative models from synthetic aperture sonar big data. Proc. Meet. Acoust. Acoust. Soc. Am. 2016, 29, 032001. [Google Scholar]
- Jegorova, M.; Karjalainen, A.I.; Vazquez, J.; Hospedales, T. Full-Scale Continuous Synthetic Sonar Data Generation with Markov Conditional Generative Adversarial Networks. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3168–3174. [Google Scholar]
- Hussain, A.; Hussain, T.; Ullah, W.; Khan, S.U.; Kim, M.J.; Muhammad, K. Big Data Analysis for Industrial Activity Recognition Using Attention-Inspired Sequential Temporal Convolution Network. IEEE Trans. Big Data 2024. [Google Scholar] [CrossRef]
- Munsif, M.; Khan, S.U.; Khan, N.; Hussain, A.; Kim, M.J.; Baik, S.W. Contextual visual and motion salient fusion framework for action recognition in dark environments. Knowl.-Based Syst. 2024, 304, 112480. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR. pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Ao, D.; Dumitru, C.O.; Schwarz, G.; Datcu, M. Dialectical GAN for SAR image translation: From Sentinel-1 to TerraSAR-X. Remote. Sens. 2018, 10, 1597. [Google Scholar] [CrossRef]
- Zhou, J.; Li, Y.; Qin, H.; Dai, P.; Zhao, Z.; Hu, M. Sonar Image Generation by MFA-CycleGAN for Boosting Underwater Object Detection of AUVs. IEEE J. Ocean. Eng. 2024, 49, 905–919. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; PMLR. pp. 1060–1069. [Google Scholar]
- Perarnau, G.; Van De Weijer, J.; Raducanu, B.; Álvarez, J.M. Invertible conditional gans for image editing. arXiv 2016, arXiv:1611.06355. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. arXiv 2018, arXiv:1810.12348. [Google Scholar]
- Li, L.; Li, Y.; Wang, H.; Yue, C.; Gao, P.; Wang, Y.; Feng, X. Side-Scan Sonar Image Generation Under Zero and Few Samples for Underwater Target Detection. Remote. Sens. 2024, 16, 4134. [Google Scholar] [CrossRef]
- Zhang, F.; Hou, X.; Wang, Z.; Cheng, C.; Tan, T. Side-Scan Sonar Image Generator Based on Diffusion Models for Autonomous Underwater Vehicles. J. Mar. Sci. Eng. 2024, 12, 1457. [Google Scholar] [CrossRef]
- Song, Y.; Li, J.; Hu, Z.; Cheng, L. DBSAGAN: Dual Branch Split Attention Generative Adversarial Network for Super-Resolution Reconstruction in Remote Sensing Images. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 6004705. [Google Scholar] [CrossRef]
- Huang, W.; Zhao, Z.; Su, L.; Ju, M. Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification. Remote Sens. 2022, 14, 6158. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Dowson, D.C.; Landau, B.V. The Fréchet distance between multivariate normal distributions. J. Multivar. Anal. 1982, 12, 450–455. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}