3.1. Experimental Settings
This study aims to derive an optimal ambulance deployment strategy for 119 emergency centers through artificial intelligence-based predictive modeling, adopting a quantitative empirical research design. The research framework consists of predictive modeling and simulation analysis using observation-based panel data, structured to enable multivariate analysis that comprehensively incorporates a variety of factors influencing ambulance allocation. The dataset integrates emergency dispatch records with a wide range of contextual information to reflect both static and dynamic variables relevant to deployment decisions.
As summarized in
Table 1, data were collected over a 9-month period, from January to September 2024, covering all 229 emergency centers nationwide. This yielded a total of 2061 center-month observations (229 centers × 9 months), forming a panel data structure that captures both temporal and cross-sectional variations. Such a structure enhances the generalizability of the model and enables control for regional heterogeneity. The dataset includes variables such as ambulance dispatch frequency, patient transport times, patient severity levels, center-level operational statistics, population density, traffic congestion, hospital locations and capacities, and road infrastructure conditions. These data were compiled from administrative records of the National Fire Agency, Statistics Korea, the Ministry of Health and Welfare, and national traffic information systems.
To address discrepancies in data formats across multiple sources, the collected datasets underwent a comprehensive integration and standardization process. Reverse geocoding was applied using a normalized address system aligned with administrative district boundaries. Following the integration of all sources, preprocessing procedures were conducted to manage outliers and missing values. Data consistency and structural validity were further verified through spatial comparative analysis at the city and county (Si/Gun/Gu) level. Throughout the dataset construction process, administrative district codes were employed as the primary mapping key to reduce mismatches and minimize data loss across heterogeneous regional datasets.
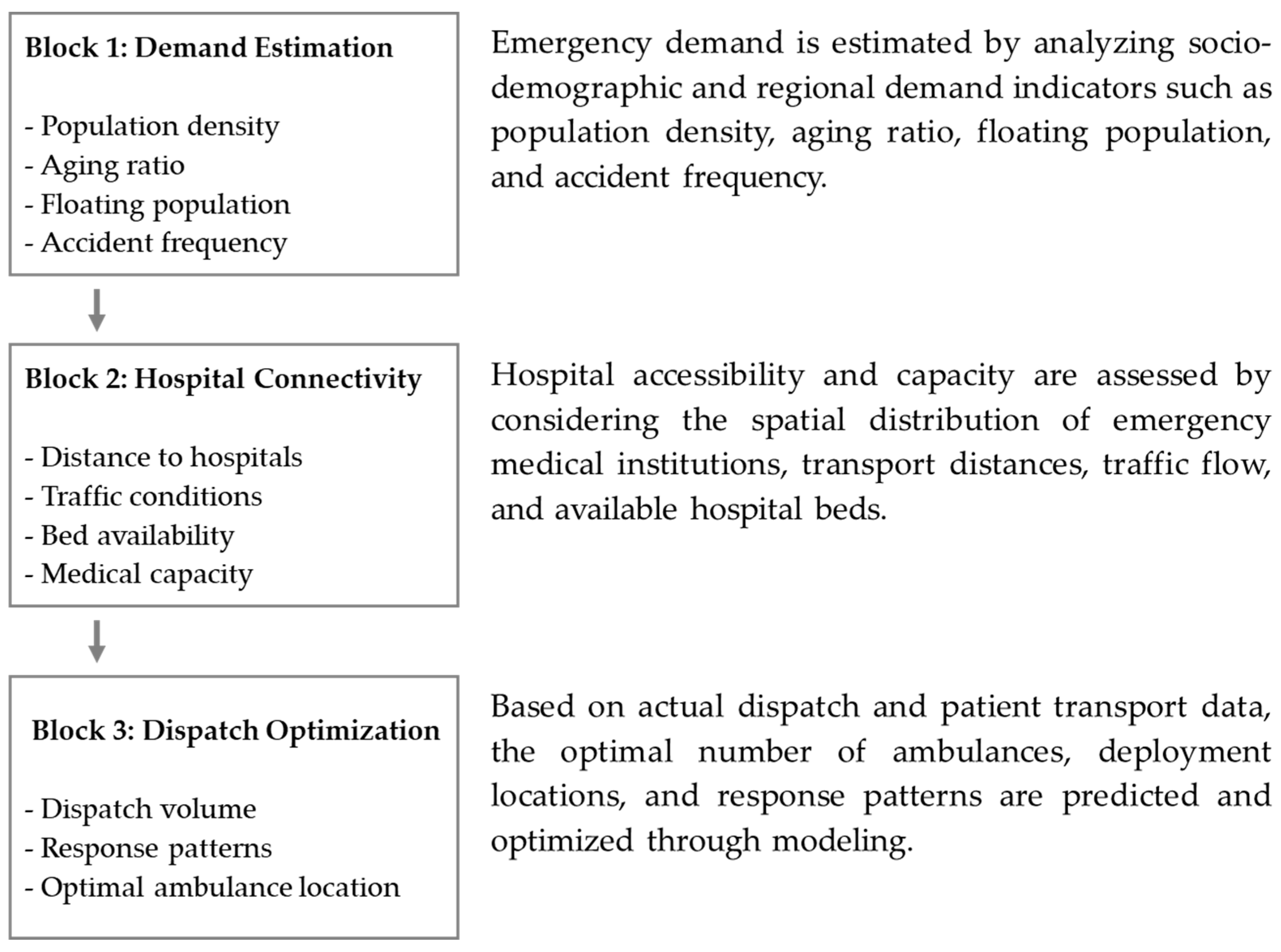
The model development framework was structured around three major analytical pillars (
Figure 2). First, a demand estimation phase was implemented to quantitatively predict regional emergency demand based on sociodemographic variables and location-specific factors, including population density, aging rates, floating population size, and accident occurrence rates. Second, an accessibility-based hospital connectivity analysis was conducted, evaluating the practical accessibility to emergency medical institutions by considering geographic distribution, patient transport distances, traffic flow conditions, and hospital bed capacities. Third, a dispatch and deployment optimization phase was developed to predict ambulance demand for each emergency center and to optimize the allocation of ambulances and dispatch patterns within their jurisdictions, based on historical dispatch records and patient transport data.
Each analytical block was designed as an independent module while maintaining interoperability to allow for integrated simulation-based cross-validation. Since factors influencing ambulance deployment arise from multiple domains—including demographic characteristics, socio-environmental conditions, hospital accessibility, traffic dynamics, and patient severity—variables were organized using a multidimensional taxonomy. This structure enhanced model interpretability and minimized multicollinearity during the machine learning-based variable weighting process. Key features were selected through a combination of expert Delphi surveys and Lasso regression–based importance estimation. By adopting this architecture, this study advances beyond simple statistical analysis to develop a predictive model grounded in real-world structured data that captures the heterogeneity of regional ambulance demand and the complexity of operational environments. Incorporating spatial and temporal data diversity further improves the scalability of the model and its applicability to practical policy design and implementation.
3.2. Variable Design and Data Preprocessing
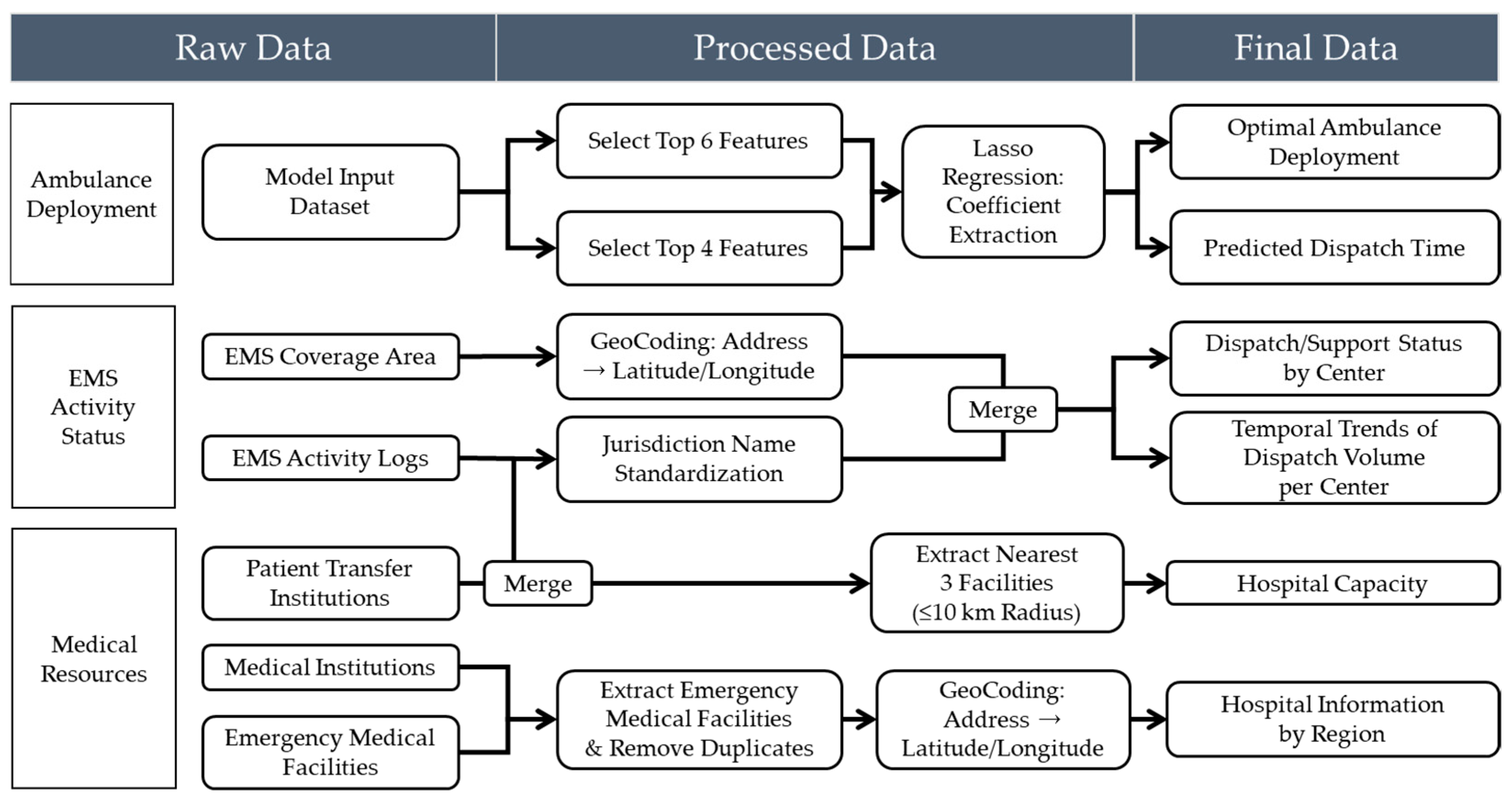
This study aims to construct a highly reliable predictive model by implementing a rigorous data preprocessing and validation framework to ensure data consistency and integrity. Rather than merely eliminating basic errors, the validation process is treated as a core component throughout the analytical workflow, serving to ensure both the statistical reliability and logical validity of the variables. These efforts directly contribute to the model’s robustness and generalizability. Specific preprocessing steps included identifying and handling missing and outlier values, removing duplicate records, resolving merge conflicts between datasets, standardizing variable formats, and ensuring spatial coherence. All procedures were designed in consultation with the National Fire Agency and regional emergency management agencies to support policy-relevant interpretations. To optimize the predictive performance of the ambulance deployment model while ensuring policy applicability, two distinct datasets were constructed based on the analytical objective. The first dataset was used for training the machine learning models, while the second was designed to support visualization and spatial policy analysis. Both datasets were developed through a systematic pipeline involving raw data collection, preprocessing, variable transformation, and final integration. The overall data processing workflow is illustrated in
Figure 3.
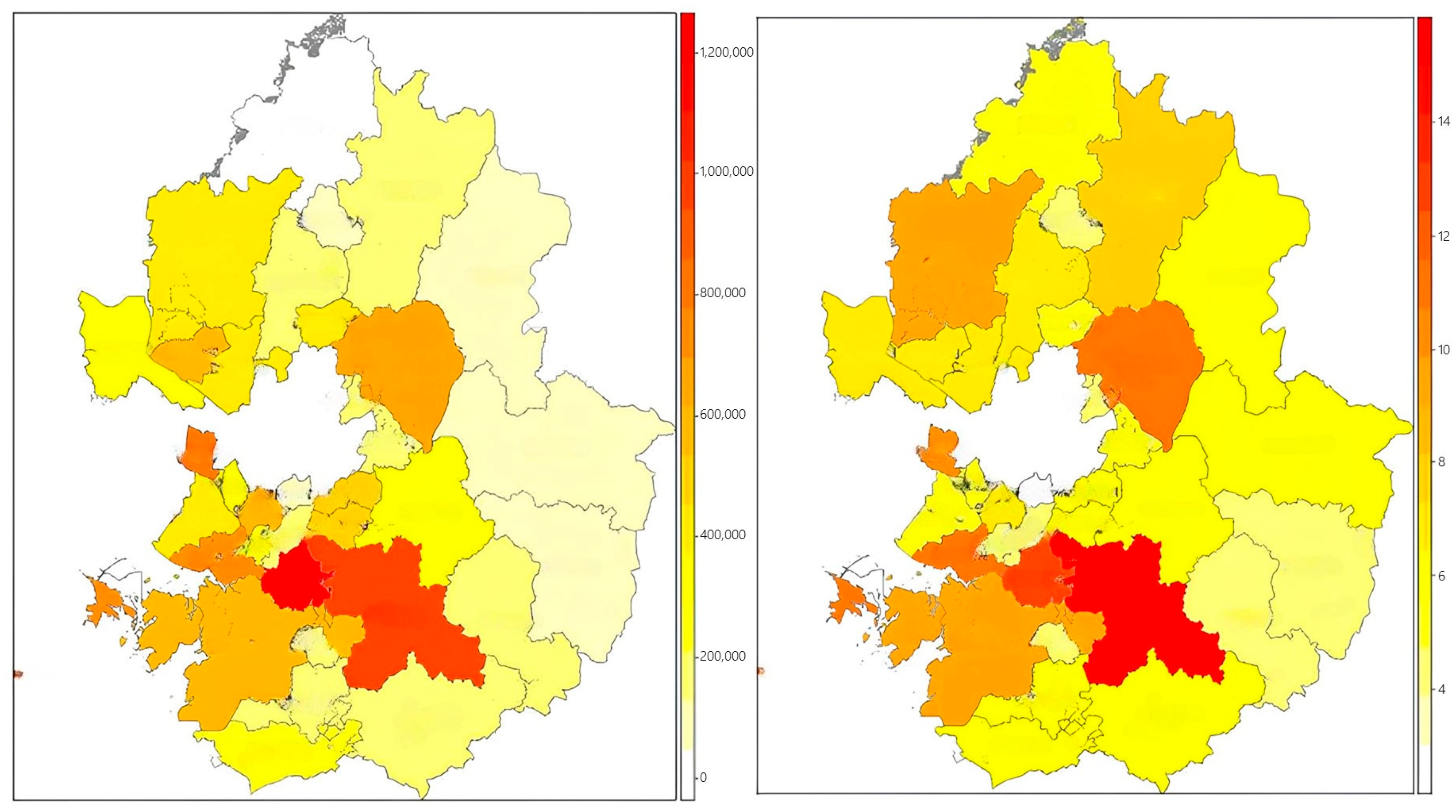
The training dataset was constructed based on operational and demographic data from 229 emergency response centers across South Korea. The collected raw data included ambulance dispatch records, monthly dispatch counts, patient transport times, total and elderly population ratios, daily floating population figures, road traffic volume, and congestion indices, as well as environmental indicators such as alcohol consumption rates and food establishment density. Variable selection was guided by both theoretical relevance—derived from prior studies—and empirical validity, confirmed through expert consultations. To further validate the practical impact of each variable, we incorporated results from a field survey administered to 311 frontline emergency medical personnel affiliated with the National Fire Agency. In response to the question, “Which factor most significantly affects your on-site workload?”, 87.0% of respondents identified the number of dispatches as the primary determinant. Additional influential factors included “distance or time to the hospital” (5.1%), “availability of medical resources” (3.3%), and “proportion of high-acuity emergency cases” (2.2%). These findings are highly consistent with the variable importance rankings derived from the model, supporting the construct validity of the selected features. Furthermore, frequent inter-jurisdictional ambulance deployments were observed, with certain centers reporting over 100 outbound emergency responses per month. This suggests that structural resource shortages are occurring in specific areas. An analysis of hourly traffic volumes on major roads in 2023 (
Figure 4) also revealed recurrent congestion patterns during morning and evening peak periods, highlighting traffic delays as a critical factor contributing to prolonged emergency response times.
There was also considerable variation in the frequency of high-acuity emergency dispatches across centers, with some facilities recording over 60 such cases per month. This finding highlights the potential value of implementing severity-based deployment strategies. These statistics align not only with the observed operational data but also with the field experiences reported by emergency personnel, thereby reinforcing the construct validity of the selected variables and the practical relevance of the training dataset. To ensure data quality and integrity, we collaborated with the National Fire Agency to identify and remove outliers and missing values based on domain expert assessments. Where appropriate, statistical imputation techniques were applied to correct for missing data. In addition, reverse geocoding procedures were performed to convert geographic coordinates (latitude and longitude) into standardized administrative district codes and addresses. This process ensured spatial alignment across datasets from heterogeneous sources, thereby enhancing the consistency and reliability of the integrated dataset.
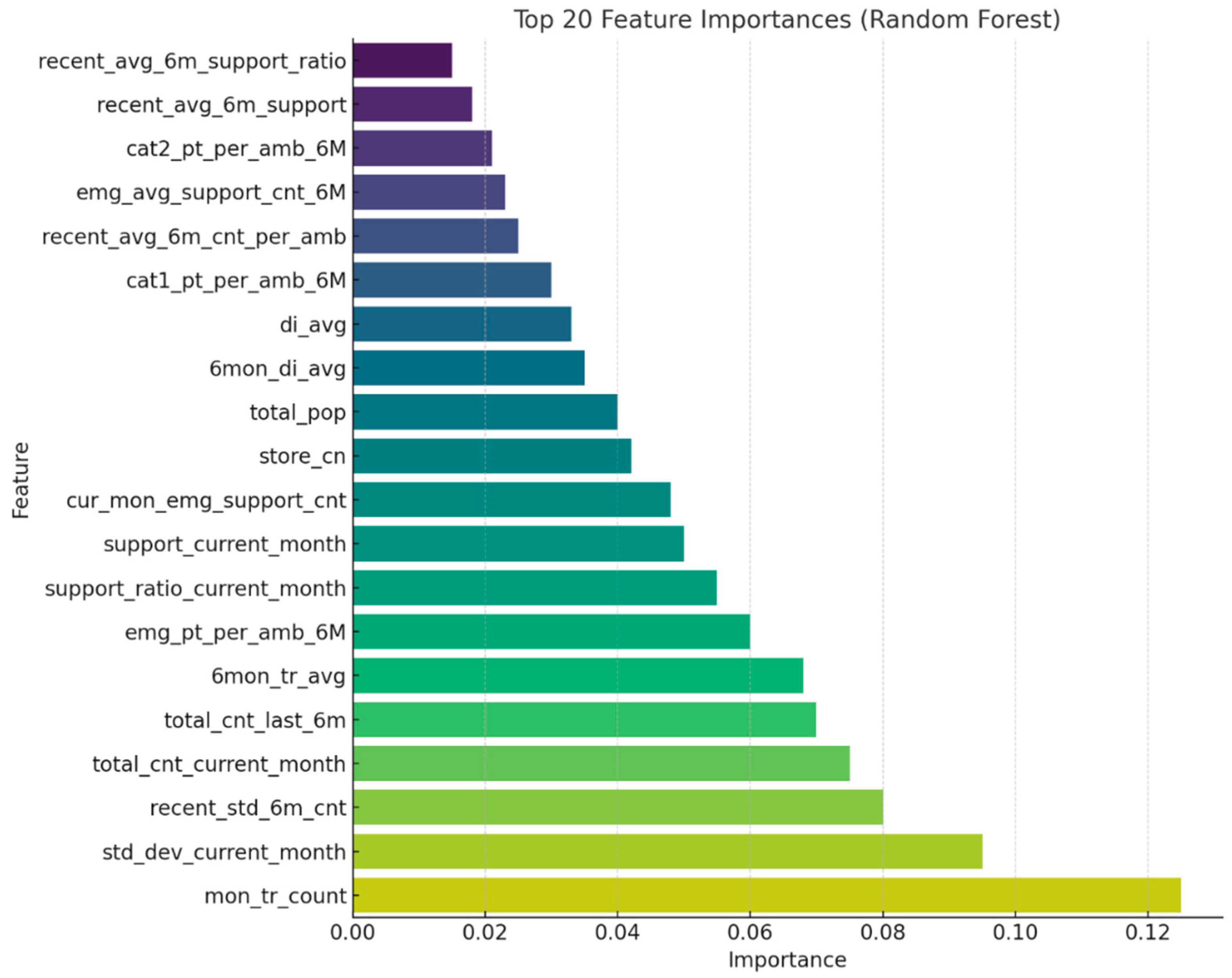
Numerical input variables used in the model were scaled using either min–max normalization or z-score standardization, depending on distribution characteristics. Categorical variables (e.g., urban vs. rural classification, hospital types) were converted into numeric form using one-hot encoding. An initial set of approximately 20 candidate variables was considered. To mitigate overfitting and multicollinearity, Lasso regression was applied, resulting in the selection of six key predictors with high explanatory power. These selected variables were subsequently used for training tree-based machine learning models, including Random Forest, XGBoost, and LightGBM. Considering the heterogeneous and dynamic nature of EMS data, characterized by spatial variability in population distribution, temporal fluctuations in emergency dispatch frequency, and complex nonlinear interactions among multiple explanatory variables, this study employed ensemble-based tree models including Random Forest, XGBoost, and LightGBM. These models are particularly well suited for high-dimensional structured data with intricate relationships, as they offer robustness against multicollinearity, capture nonlinear patterns without the need for extensive feature transformation, and provide interpretable metrics such as variable importance for policy-relevant insights [
29]. In parallel, a supplementary dataset was constructed to support visualization of prediction results and policy-oriented interpretation. This dataset incorporated spatial information on hospital capacity, emergency medical facility distribution, and regional accessibility. It was designed to help policymakers intuitively assess local resource allocation needs.
The jurisdiction of each 119 emergency center was standardized under a unified naming convention, and hospital information within a 10-kilometer radius of each center was collected. This process included the deduplication of medical facilities and geocoding of hospital locations. Additional filtering criteria—such as number of available beds, operating hours, and emergency service capability—were applied to refine the hospital dataset. Measures of distance and accessibility between centers and hospitals were then computed and merged into the final dataset. Using the results from the feature importance analysis, the top-ranked variables were employed to generate spatial weight maps and predicted response times, visualized at the administrative district level. This dual-dataset structure supports both predictive modeling and policy simulation on an empirical basis, moving beyond conventional experience-based decision-making toward data-driven ambulance deployment strategies.
Missing values were addressed through tailored strategies based on the characteristics and distribution patterns of each variable. When the missingness was determined to be completely at random or statistically predictable, appropriate imputation techniques such as mean substitution, median replacement, or linear interpolation were applied. For critical variables where missing values were logically implausible, the corresponding records were excluded entirely to ensure data integrity. In cases where missing data occurred for specific centers or time periods, the cause was investigated in collaboration with the Gyeonggi Fire and Disaster Headquarters, as such gaps were often due to administrative reporting delays or system transitions. The treatment methods were then adjusted accordingly, depending on the identified cause. Outlier detection followed both statistical and logical criteria. Statistically, values were considered outliers if they exceeded 3 standard deviations from the mean or fell outside 1.5 times the interquartile range. Logically implausible values, such as dispatch durations longer than 10 h or response times exceeding 1 h, were also excluded on the basis of operational infeasibility. The overall removal of outliers was kept below two percent of the dataset, in order to preserve the stability of model training and avoid distortion in inter-variable relationships. For extreme values that could plausibly occur during exceptional events such as large-scale disasters, removal decisions were made only after further review with the National Fire Agency. To ensure compliance with international and national data protection regulations, including the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA), rigorous data anonymization and de-identification procedures were applied prior to model training. All personally identifiable information (PII) and protected health information (PHI) were removed or transformed through a multi-step process in accordance with the guidelines provided by relevant authorities. Specifically, the dataset underwent structured de-identification using suppression, generalization, and pseudonymization techniques. Geolocation data were truncated to administrative units (e.g., district-level codes) to prevent re-identification of individuals or specific sites. Temporal data, such as timestamps of emergency incidents, were generalized to daily granularity to mitigate temporal linkage risks. In addition, all unique identifiers (e.g., patient IDs, call numbers) were replaced with random hashes and were not recoverable.
Duplicate values were identified not only based on exact record matches but also by accounting for partially blank fields and inconsistent formatting. In addition to identifying record-level duplicates, logical redundancies—such as repeated registration of the same hospital within a single jurisdiction—were carefully reviewed during the data integration process. Common issues such as mismatched key fields, typographical errors in location names, and inconsistencies in temporal granularity were resolved through the normalization of administrative district codes and the unification of jurisdictional naming conventions. For instance, geographic names such as “Jeongja-dong, Jangan-gu, Suwon-si, Gyeonggi-do” were sometimes confused with “Jeongja-dong” in Seongnam-si due to naming overlap. These cases were standardized using the Vworld administrative code system to ensure consistent merge keys across datasets. During the merging of each center’s jurisdictional boundaries with population data from Statistics Korea, several records were found to be missing. Further investigation revealed that these omissions were primarily due to historical changes in administrative boundaries and naming conventions. To address this issue, the temporal reference points for data aggregation were adjusted and historical administrative codes were matched to restore the missing data. After merging, any remaining logical duplicates were removed using key-based filtering, and an additional validation procedure was performed to ensure integrity. Following these refinement procedures, data formatting consistency and unit harmonization across variables were carried out. For example, traffic flow data, originally reported as vehicles per hour, were aggregated and converted into daily averages for model compatibility. In addition, potential multicollinearity between variables with high correlation, such as alcohol consumption rates and the number of food establishments, was addressed using correlation-based filtering and Lasso regression for variable selection. Through this process, 6 key predictive features were extracted from over 20 candidate variables, and these served as the core inputs for both model training and simulation.
As a result of these data preprocessing efforts, the proportion of missing values was maintained below 5 percent, the rate of outliers was kept under 2 percent, and no unresolved merge or mapping errors remained in the final dataset. This indicates that the data used in this study met rigorous statistical quality standards and were well-suited for both practical applications and policy-oriented analyses. Furthermore, this preprocessing approach contributed not only to improving the generalizability of the prediction model but also to enhancing the interpretability of its outputs. It ultimately supports evidence-based decision-making for future ambulance deployment planning.
As illustrated in
Figure 5, a dedicated visualization dataset was developed to enhance the interpretability of model outputs and support spatially informed policy decisions. The dataset was structured based on EMS service jurisdictions and incorporated key spatial features, such as the three nearest emergency medical institutions within a 10 km radius, regional population distributions, and the density of critical public facilities. To ensure consistency and accurate spatial matching, address information was converted into geographic coordinates via geocoding and reverse geocoding, then standardized using administrative district codes. Hospital-level data were collected from the Ministry of Health and Welfare’s national emergency facility registry and regional health information systems. Information on capacity indicators—such as bed availability, operating hours, and emergency care capabilities—was refined into structured variables. Accessibility between EMS centers and hospitals was assessed through both distance-based metrics and transportation infrastructure indicators, including average driving speed and congestion levels on major roads. The processed dataset enabled the generation of visual tools such as weighted resource allocation maps, hospital-to-center connectivity networks, and district-level response time heat maps. Variables identified as highly important by the prediction model were prioritized for visualization, serving as foundational elements for developing a policy dashboard. This system offers decision-makers an intuitive understanding of spatial disparities in EMS coverage and supports evidence-based adjustments in ambulance distribution and infrastructure planning.
3.3. Development of Predictive Models for Emergency Resource Allocation
The development of the proposed model was designed to optimize the nationwide deployment of 119 emergency ambulances in Korea, with an emphasis on achieving both high predictive accuracy based on empirical data and practical applicability for policy implementation. A supervised regression modeling framework was employed, integrating EMS dispatch records with variables such as population demographics, traffic metrics, and medical infrastructure to construct the learning dataset. The training dataset included preprocessed input variables such as the proportion of critical patients, the total and elderly population within each jurisdiction, the ratio of dispatches to available ambulances, traffic indices for general and express roads, average transfer time, alcohol consumption rate, and the density of food establishments. To enhance model efficiency, Lasso regression was applied to identify optimal variable combinations, mitigate multicollinearity, and extract sparsity-weighted coefficients for feature selection. Three tree-based ensemble regression models—Random Forest, XGBoost, and LightGBM—were implemented and comparatively evaluated. Random Forest offers strong resistance to overfitting, maintains high interpretability, and is relatively easy to implement. XGBoost provides superior generalization performance through L1 and L2 regularization and leverages sequential learning via gradient boosting, yielding high predictive accuracy. LightGBM, while structurally similar to XGBoost, is better suited for large-scale applications due to its high computational efficiency and ability to handle high-dimensional data using parallel processing, making it advantageous for real-time operational deployment.
From a mathematical perspective, the core algorithms used in this study are based on distinct learning principles. Random Forest is an ensemble method that aggregates the output of multiple decision trees trained on bootstrapped samples. Its predictive output is expressed as
where
represents the prediction from each individual decision tree, and
denotes the total number of trees in the ensemble [
30].
XGBoost, an advanced implementation of gradient boosting, optimizes a regularized objective function defined as follows:
This formulation enables robust regularization and efficient convergence through second-order gradient approximation, which is a key advantage of XGBoost over traditional boosting methods [
31].
Lasso regression employs L1-penalization to enforce sparsity in feature selection. Its optimization objective is
where
λ controls the strength of the penalty term. This formulation promotes model sparsity by shrinking less informative coefficients toward zero, thereby facilitating feature selection [
32].
Hyperparameters for each model were independently tuned to maximize learning stability and minimize overfitting. Detailed parameter configurations for each model are provided in
Section 4.1. For the Lasso regression, the regularization parameter alpha was set to 0.001, allowing for the extraction of sparse coefficients from the most relevant predictors while promoting model simplification.
Model training was conducted using Python 3.10, employing libraries such as Scikit-learn, LightGBM, and XGBoost. An 80:20 train–validation split was applied, followed by 5-fold cross-validation to assess both the average performance and variance across folds. The training and hyperparameter tuning were performed on a high-performance computing environment equipped with an Intel Xeon Gold 6248R 3.00 GHz CPU, 256 GB of RAM (Intel Corporation, Santa Clara, CA, USA), and an NVIDIA A100 GPU (40 GB) (NVIDIA Corporation, Santa Clara, CA, USA). While most operations were executed on the CPU, GPU acceleration was selectively utilized for large-scale matrix computations and hyperparameter optimization. This setup ensured sufficient computational capacity to handle spatiotemporally complex and high-volume datasets and to support the repeated training of ensemble-based models with high stability. Two separate target variables were modeled. The first was the optimal number of ambulances per EMS center, which serves as the foundation for demand-based resource allocation strategies. The second was the dispatch duration from scene to hospital, which is critical for evaluating emergency response performance in relation to geographic and traffic conditions. These outputs were subsequently used as core inputs in the simulation phase for generating region-specific weight factors and conducting scenario-based policy analyses.
The dependent variable for the first predictive model—namely, the optimal number of ambulances per EMS center—was defined based on empirical data from 100 EMS centers identified by the National Fire Agency as having achieved an appropriate level of deployment. This determination was made by comprehensively considering factors such as operational efficiency, responsiveness to local demand, population characteristics, dispatch frequency, response time, hospital accessibility, and environmental conditions. These centers were evaluated as benchmark cases where such variables were well-balanced and were therefore designated as a reference baseline within the training dataset. The selection criteria were established in consultation with policy officers and field-level administrators at the NFA to ensure both operational validity and policy relevance. Using this group of 100 reference centers, the model was trained to predict appropriate deployment levels for other regions by comparing their respective combinations of input features. This similarity-based approach enabled the model to account for structural and contextual heterogeneity across EMS centers and quantify relative deployment needs in a more nuanced and context-sensitive manner. This modeling approach thus departs from conventional methods that rely solely on historical dispatch volumes and offers a more rigorous and data-driven foundation for resource planning.
In conclusion, the modeling strategy adopted in this study integrates multiple strengths: objective feature selection using Lasso regression, structural diversity through ensemble tree-based algorithms, performance optimization via cross-validation and hyperparameter tuning, and practical applicability by balancing predictive accuracy and interpretability. This framework is designed not only to enhance short-term operational efficiency but also to serve as a robust quantitative foundation for long-term emergency medical service policy planning and infrastructure investment decisions.
3.4. Simulation-Based Weight Calibration
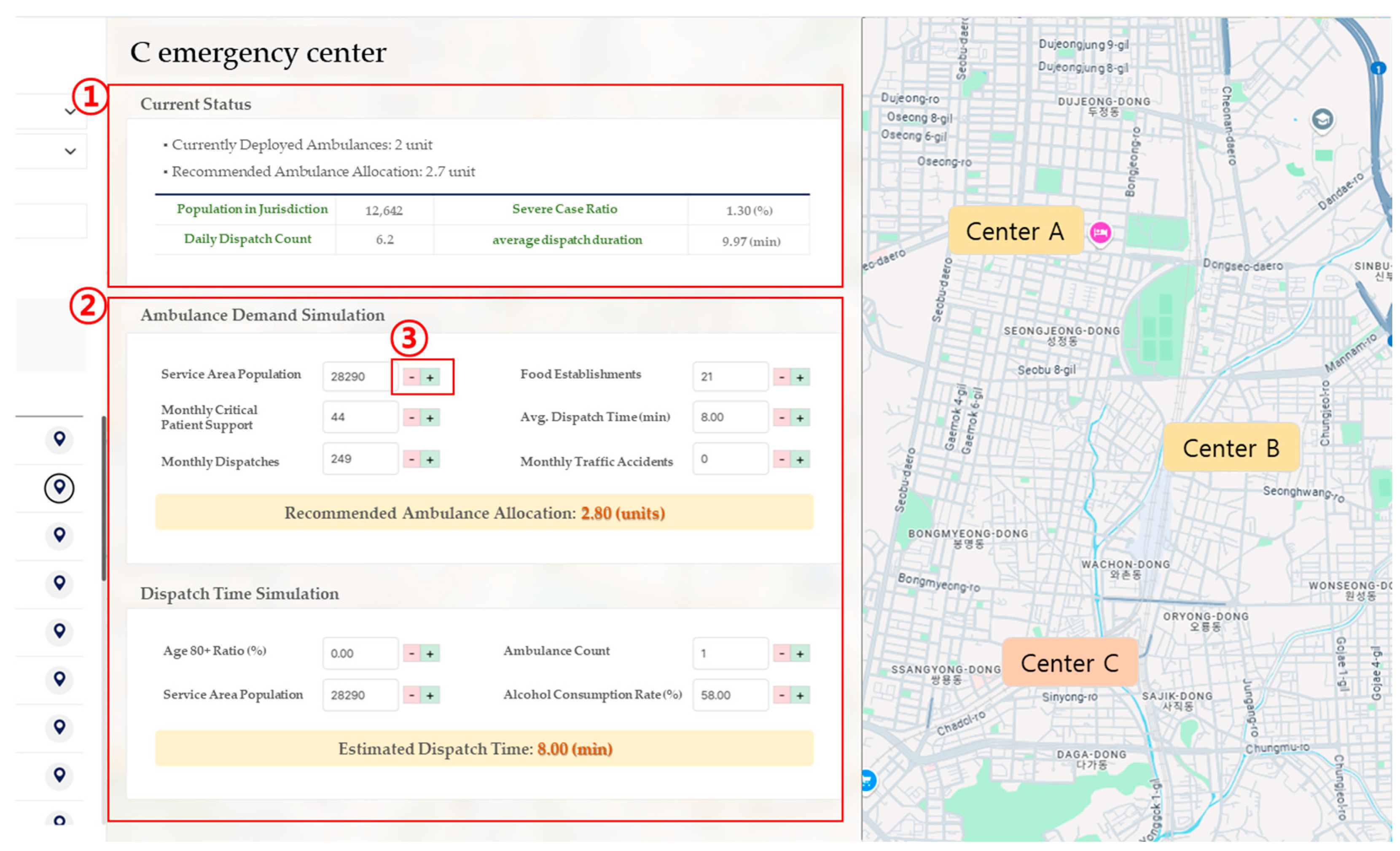
To facilitate the practical application of the machine learning model in real-world policy decision-making, a simulation-based weight calibration procedure was developed. This simulation system was designed with a dual focus on operational flexibility in the field and policy scalability. It allows users to dynamically adjust key input variables, after which the predictive results are automatically recalculated in real time. This design ensures that the model’s outputs function not merely as static forecasts but as adaptable tools for conducting sensitivity analyses and constructing policy scenarios. The simulation engine generates recommended ambulance deployment volumes or expected dispatch durations based on user-defined input variables at the EMS center level. These variables include population size within the jurisdiction, daily dispatch volume, number of inter-center critical patient transfers, average dispatch duration, number of local food establishments, and incidence of traffic accidents. Users can input values manually or adjust them via interactive controls. The simulation then compares these user-defined inputs with the model’s baseline values and recalculates the outcome by applying variable-specific weights that reflect each feature’s relative importance. The prediction mechanism is built upon a reference baseline, adjusting the predicted values by computing the weighted differences between user-provided inputs and their corresponding baseline values. This can be formally expressed as
where
is the adjusted prediction,
is the baseline value,
represents each user input variable,
is the corresponding baseline input value, and
is the weight assigned to the
variable based on its learned importance in the predictive model. For example, variables such as population size and the number of critically ill patients exert a strong influence on demand prediction and are therefore assigned relatively high weights. In contrast, indirect variables, such as the number of restaurants or local alcohol consumption rates, are given lower weights due to their weaker direct impact on emergency response needs. Rather than relying on a simple weighted average, the simulation model adopts a baseline-adjusted prediction mechanism based on the deviation of each input variable from its reference value. Each deviation is multiplied by a pre-defined weight, and the cumulative result is added to the baseline to produce the final output. This approach enhances both transparency and interpretability, allowing users to understand how changes in individual inputs affect the prediction. Moreover, the system is designed such that adjustments to input variables are immediately reflected in the visualized results, enabling intuitive exploration of scenario outcomes in real time. All simulation weights are calculated using a standardized reference framework across all EMS centers, ensuring consistency in comparative analyses. Based on these weights, the system can support policy scenario design, such as increasing or decreasing ambulance allocations, reassigning hospital linkages, or reconfiguring regional deployment strategies. Simulation results can be visualized either as temporal scenarios or spatial distribution maps, offering decision-makers a user-friendly interface through which they can explore center-specific recommendations, structural risk levels in emergency response, and the capacity of nearby hospitals based on weighted rankings.
This simulation framework provides a systematic basis for identifying not only areas with high emergency response demand but also regions where structural delays in response time are prevalent. Unlike static prediction models, the simulation weights are designed to support cumulative trend-based computations, enabling linkage with time-series analyses, such as trends in dispatch volume and duration or regional increases in the proportion of severe cases. Furthermore, the simulation architecture allows for flexible adjustment of weights depending on policy scenarios. For instance, in scenarios targeting elderly concentrated regions, a higher weight can be assigned to the elderly population ratio. In contrast, for urban areas characterized by severe traffic congestion, greater importance may be placed on average dispatch duration. Through this design, the simulation functions not only as a predictive tool but also as a policy sensitivity analysis instrument that reflects variations in contextual conditions. The weight system is implemented to allow for real-time automatic updates and is integrated with the National Fire Agency’s centralized platform via an API, playing a key role in establishing a field-responsive policy framework. As a result, the system facilitates not only demand-driven strategic ambulance deployment but also dynamic resource reallocation in emergency scenarios. Ultimately, this simulation structure can be applied across multiple decision-making domains, including ambulance resource allocation, deployment standard refinement, and mid-to-long-term emergency response planning. The weight-based prediction outputs can be regularly reported or synchronized in real time with central platforms. This represents a significant advancement from static model-based policymaking toward a dynamic, input-responsive decision-support simulation paradigm.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}