
Resource-Efficient Traffic Classification Using Feature Selection for Message Queuing Telemetry Transport-Internet of Things Network-Based Security Attacks
 ,
,  ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
- -
- We propose Statistical Moments Difference Thresholding (SMDT), a feature selection method that leverages four statistical central moments (mean, standard deviation, skewness, and kurtosis) to select the most significant features. To our knowledge, this is the first approach to leverage these specific statistical moments for FS, particularly in the context of IoT network security. The aim is to reduce feature dimensionality while maintaining a decent detection accuracy, particularly in resource-constrained environments.
- -
- We validate the proposed FS method on the MQTTset [20] dataset and evaluate the performance of seven ML models in detecting malicious traffic using the selected features, demonstrating its practicality and effectiveness.
- -
- We compare the effectiveness of binary and multiclass classification approaches, providing a comprehensive analysis of each method’s advantages and limitations.
- -
- We analyze the trade-offs between model accuracy, computational cost, and feature dimensionality, highlighting the balance between performance and efficiency.
2. Related Work
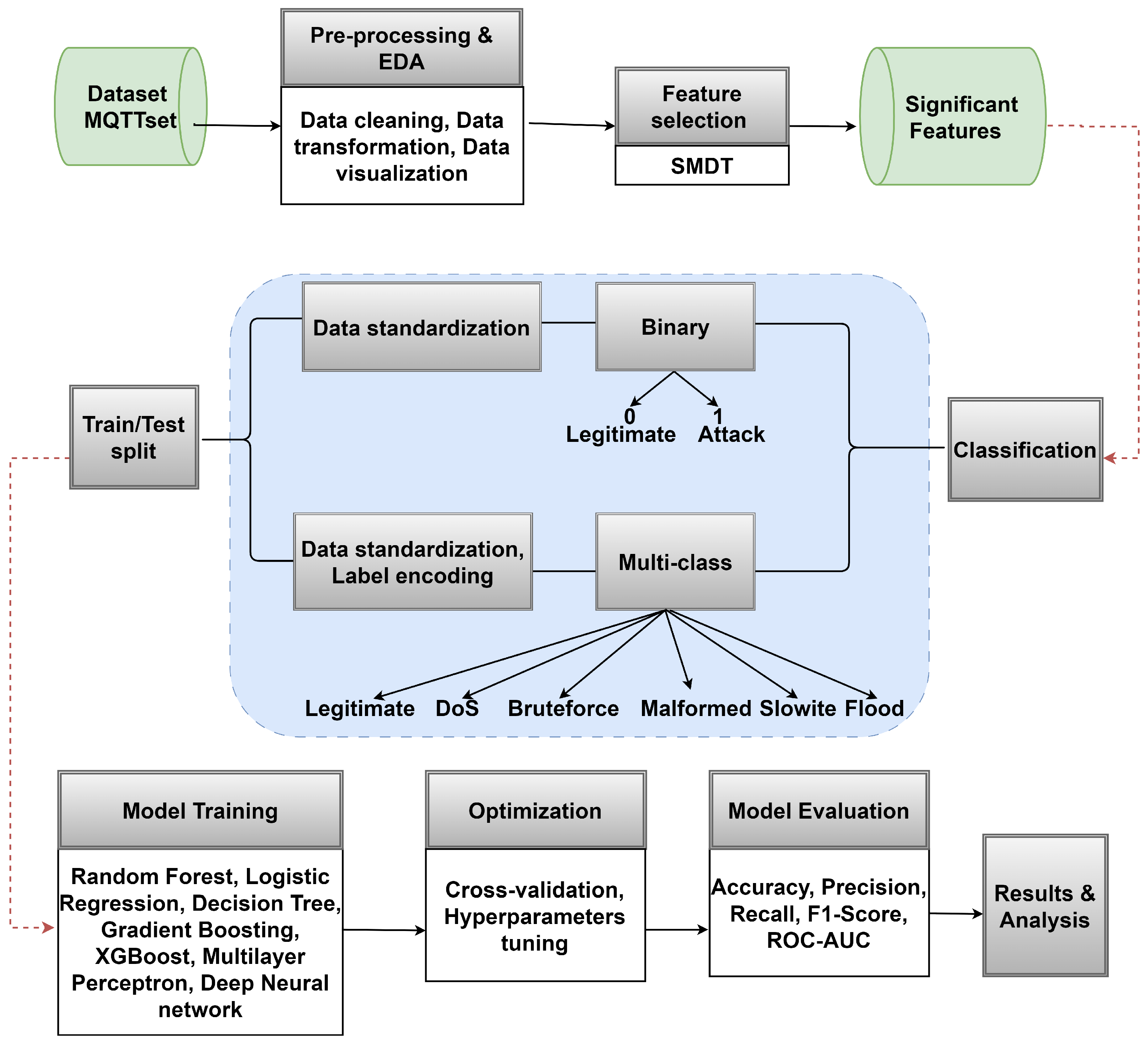
3. Materials and Methods
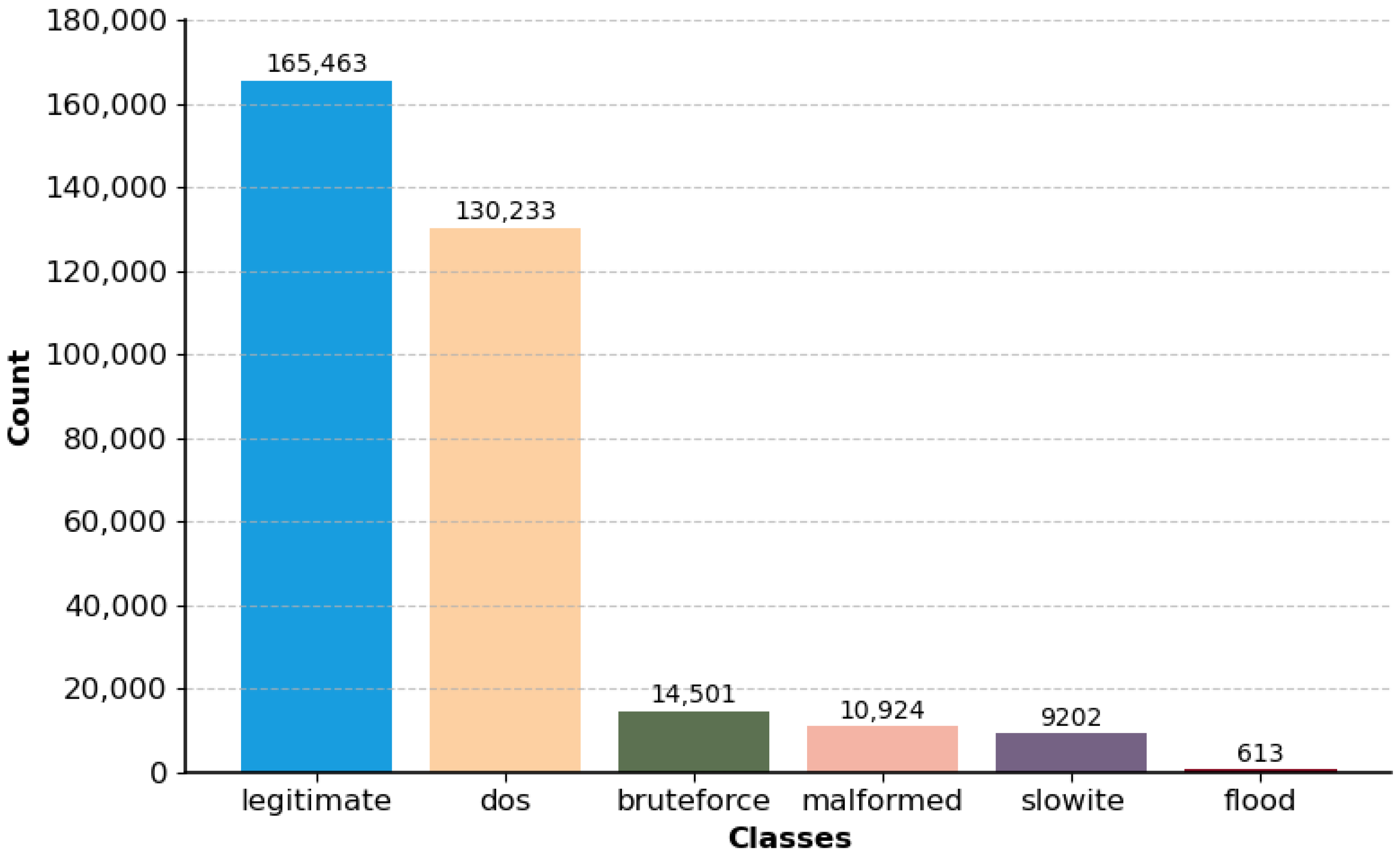
3.1. Employed Dataset
- Flooding Denial of Service (DoS): This attack targets the MQTT broker by establishing numerous connections and sending a high volume of messages using the MQTT-malaria tool (https://github.com/etactica/mqtt-malaria accessed on 13 March 2025), aiming to prevent the broker from serving legitimate clients.
- MQTT Publish Flood (flood): A single malicious device sends large amounts of MQTT data to exhaust server resources. This attack is implemented using the IoT-Flock tool.
- SlowITe (slowite): A slow DoS attack that initiates many connections to the MQTT broker with minimal bandwidth, using the MQTT service’s connection slots and causing a denial of service. This attack demonstrates efficiency in resource usage while achieving the attack’s objectives.
- Malformed Data (malformed): This attack sends malformed CONNECT or PUBLISH packets to the MQTT broker using the MQTTSA tool, aiming to trigger exceptions and disrupt normal operations.
- Brute Force Authentication (brute force): This attack attempts to crack MQTT user credentials using the MQTTSA tool and the rockyou.txt word list, simulating real-world brute force attacks to test the security of the MQTT authentication process.
3.2. Preprocessing and Exploratory Data Analysis
3.3. Tools and Environment
3.4. Feature Selection for Malicious Traffic Classification
- -
- The first moment, referred to as mean (µ), measures the central tendency that represents the average value of the feature. It is computed as follows:where µ is the mean, Xi presents the feature’s value for the i-th instance, and n is the total number of instances.
- -
- The second central moment, referred to as variance (σ2), quantifies the extent to which each data point in the feature deviates from the mean, revealing the dispersion or variability in the feature values. Analysis of variance (ANOVA) is a widely utilized technique for data mining in various scientific and engineering disciplines [31]. However, in this study, we employed standard deviation, the square root of the variance, as it provides a more interpretable measure of dispersion [32]. The standard deviation (σ) is computed as follows:
- -
- The third central moment, skewness (γ1), quantifies the asymmetry of a distribution. A skewness coefficient of zero signifies a perfectly symmetrical distribution. A positive skewness indicates that the distribution has a longer tail on the right side (right-skewed), whereas a negative skewness suggests a longer tail on the left side (left-skewed) [33,34]. However, skewness and kurtosis are interpreted differently across various studies and statistical software. As a result, different definitions and formulas can affect the interpretation of these measures. Therefore, our study uses the definitions and formulas provided by Python’s scientific statistics (SciPy. stats) module to ensure clarity. Precisely, skewness is calculated using the Fisher–Pearson coefficient, and kurtosis is measured as excess kurtosis, Fisher’s definition of kurtosis [33]. Hence, skewness is computed as follows:
- -
- The fourth central moment, kurtosis (γ2), quantifies the “tailedness” of the distribution of the feature values. It indicates whether the data distribution has heavier tails (positive kurtosis) or lighter tails (negative kurtosis) compared to a normal distribution [35]. Kurtosis is computed as follows:As previously highlighted, if excess kurtosis (Fisher’s definition) [33] is utilized, the subtraction of 3 adjusts the kurtosis of a normal distribution to zero.
| Algorithm 1: Feature Selection |
 |
4. Experiment and Results
4.1. Binary Classification
4.1.1. Model Training and Selection
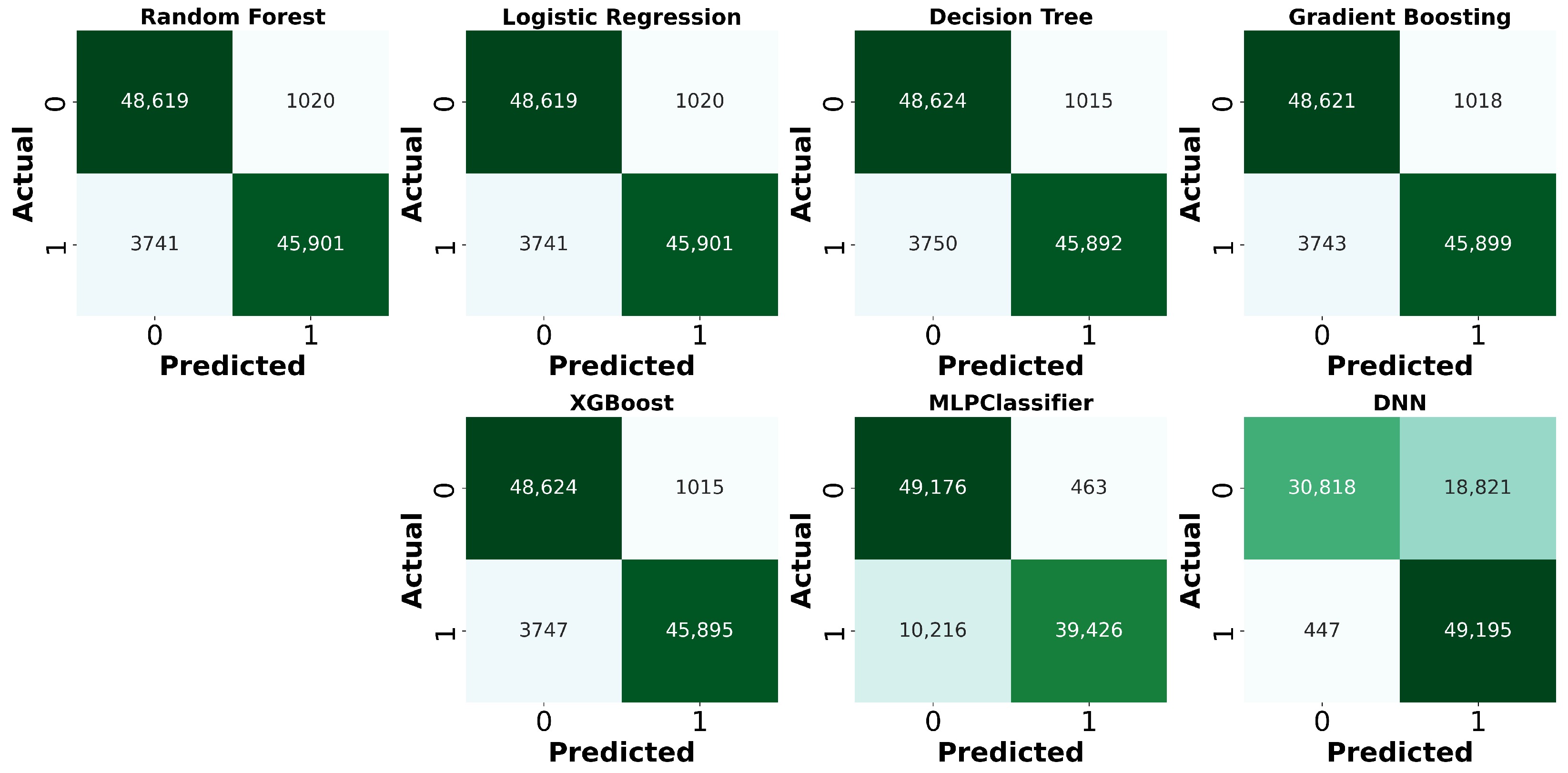
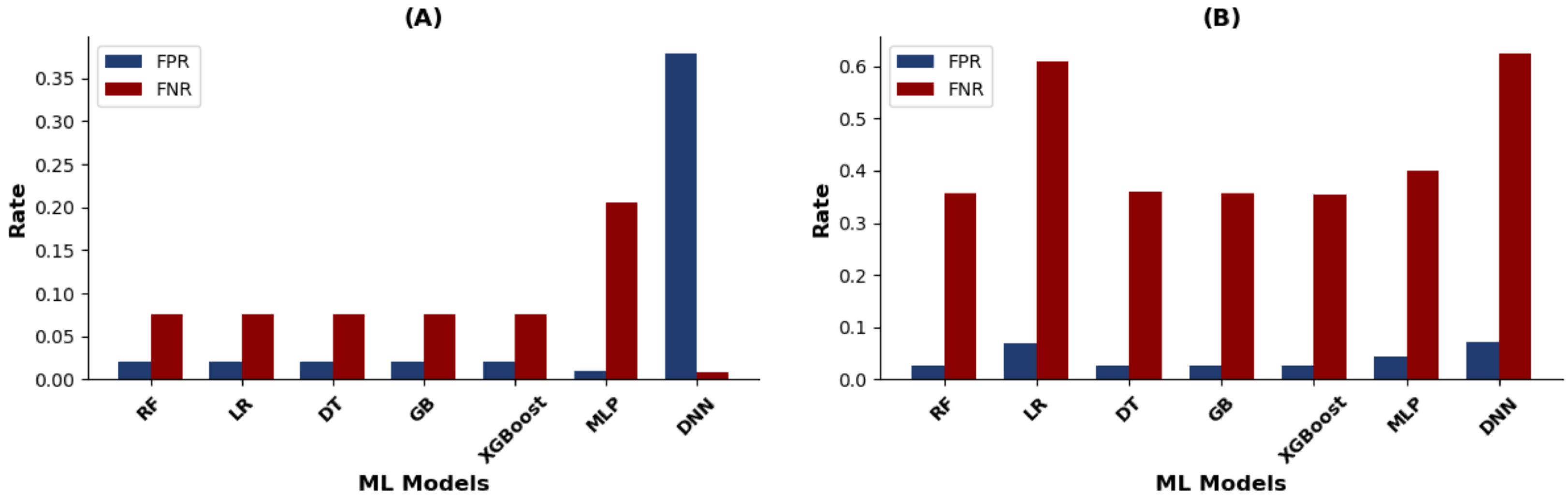
4.1.2. Performance Evaluation
- –
- True Positive (TP): The model correctly predicts attack traffic.
- –
- False Negative (FN): The model incorrectly predicts attack traffic as legitimate traffic.
- –
- False Positive (FP): The model incorrectly predicts legitimate traffic as attack traffic.
- –
- True Negative (TN): The model correctly predicts legitimate traffic.
- –
- –
- –
- –
- F1-score represents the harmonic mean of precision (P) and recall (R), providing a single metric that balances both precision and recall [50]:
- –
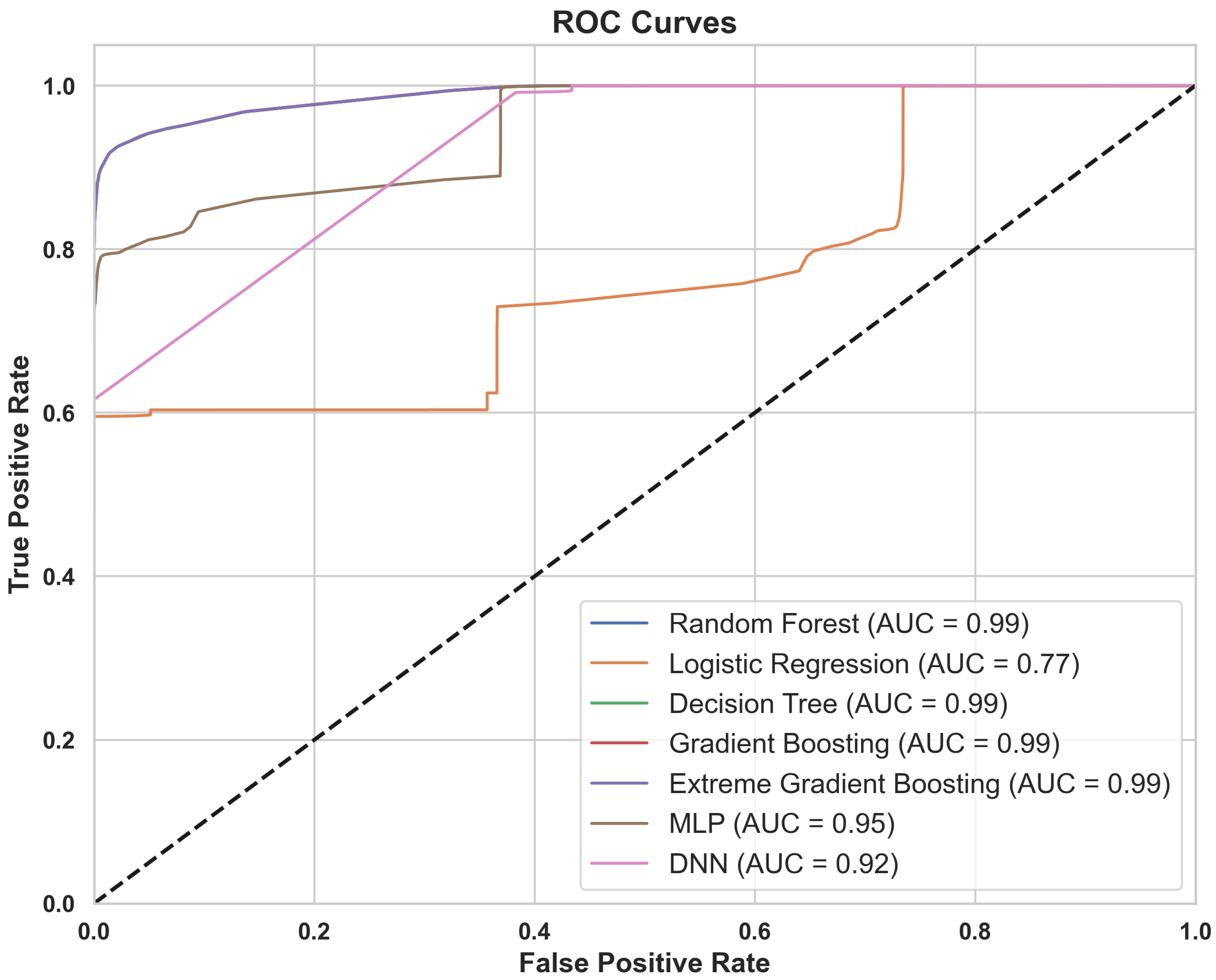
- ROC-AUC score is a performance measurement for classification problems across various threshold settings [50]. The AUC score, which ranges from 0 to 1, quantifies the classifier’s ability to discriminate between positive (attack) and negative (legitimate) classes. A higher AUC value indicates better model performance. The ROC curve is created by plotting the true positive rate (TPR) against the false positive rate (FPR) at different threshold levels [51].
4.2. Multiclass Classification
- (a)
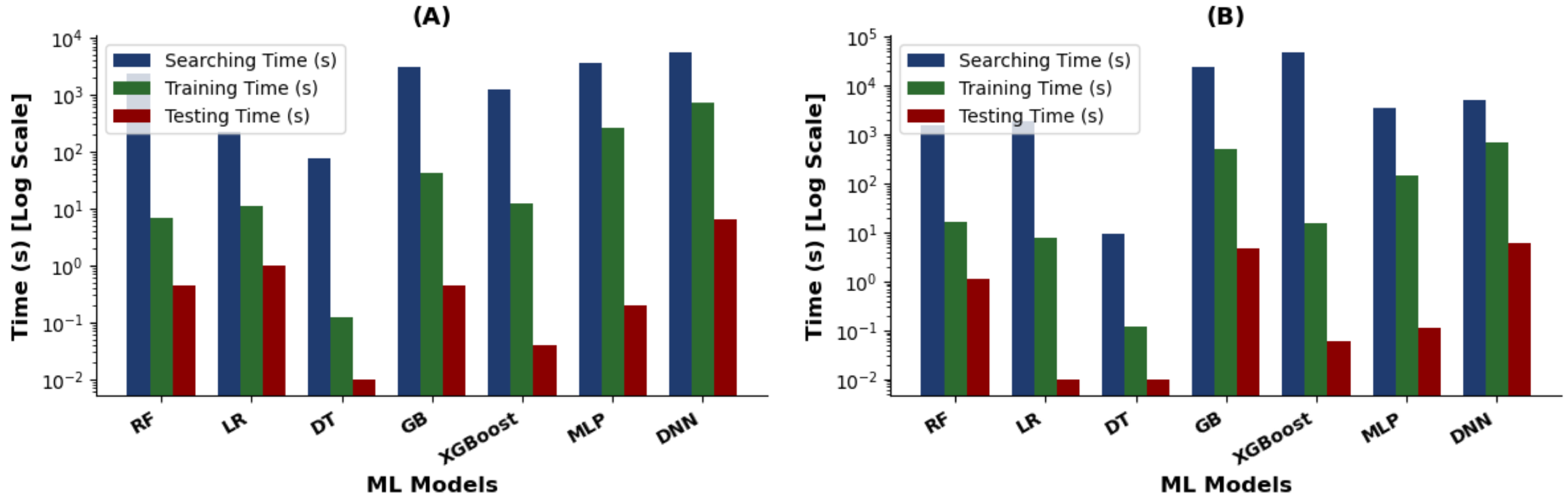
- Classification report: This includes accuracy, precision, recall, and F1-score. Table 8 summarizes the obtained results for these metrics. As previously defined, the “Searching Time (s)” reported in Table 8 refers to the computational time required by hyperparameter optimization procedures to identify the optimal hyperparameter combinations used for subsequent model training.
- (b)
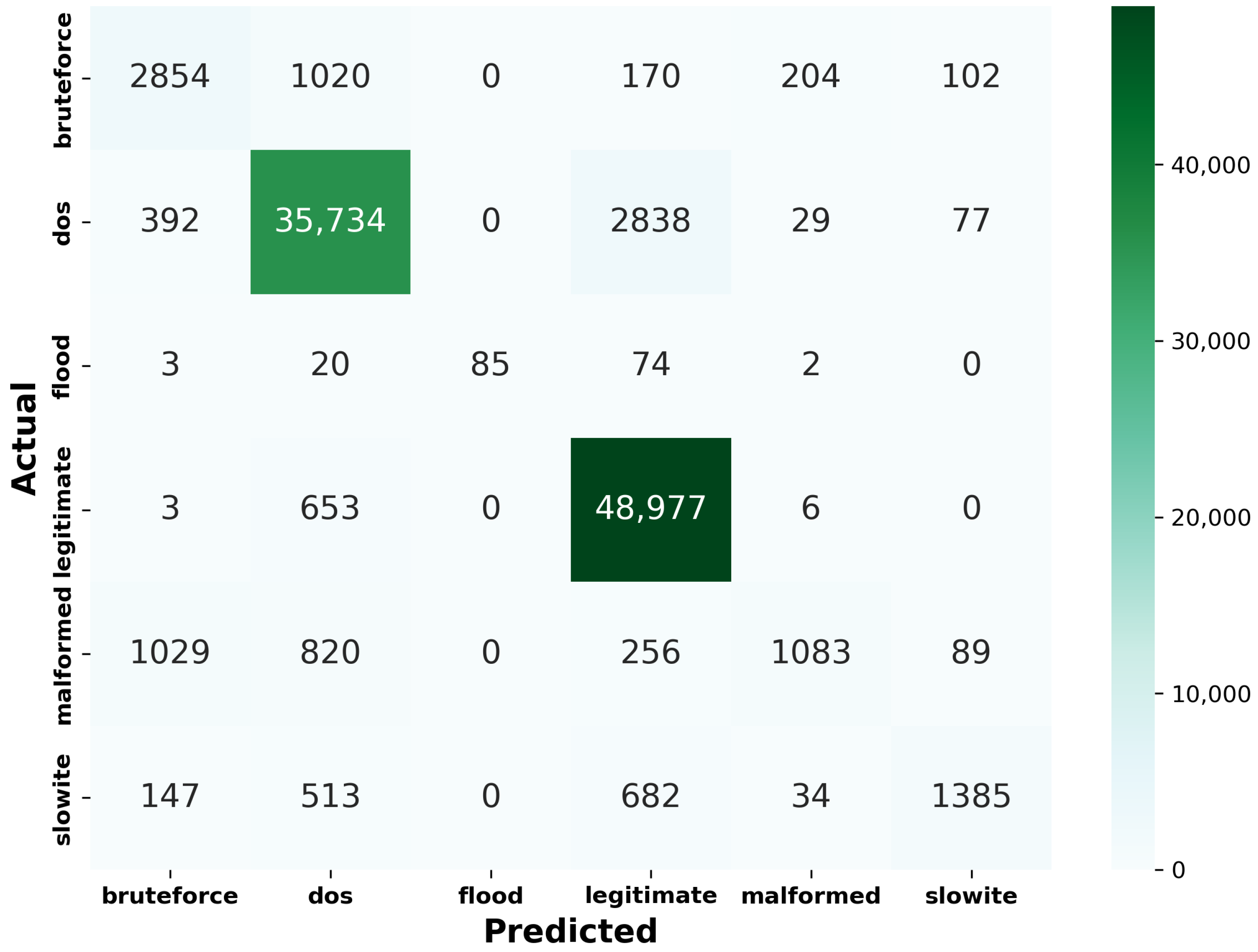
- Confusion matrix: As previously discussed, the confusion matrix highlights the frequency of correct and incorrect predictions made by a model by comparing actual classifications to predicted classifications. Multiclass classification becomes more complex than binary classification. Instead of a simple 2 × 2 grid, the matrix expands to an N × N grid, where N represents the number of classes. Each cell in this grid represents the count of instances for each actual/predicted class pair, thus helping us to understand the model’s performance across all six classes, showing how many instances of each class are correctly or incorrectly predicted. Table 9 is provided to facilitate the interpretation of the confusion matrix for each model, where the following definitions apply:
- –
- TP (XX): True positive for class X.
- –
- FP (XY): False positive, predicted as class Y but actual class is X.
- –
- FN (YX): False negative, actual class Y but predicted as class X.
For the sake of brevity, we present Figure 5, the confusion matrix for the RF model. The confusion matrices for the other six models are provided in the Appendix A (see Figure A1). - (c)
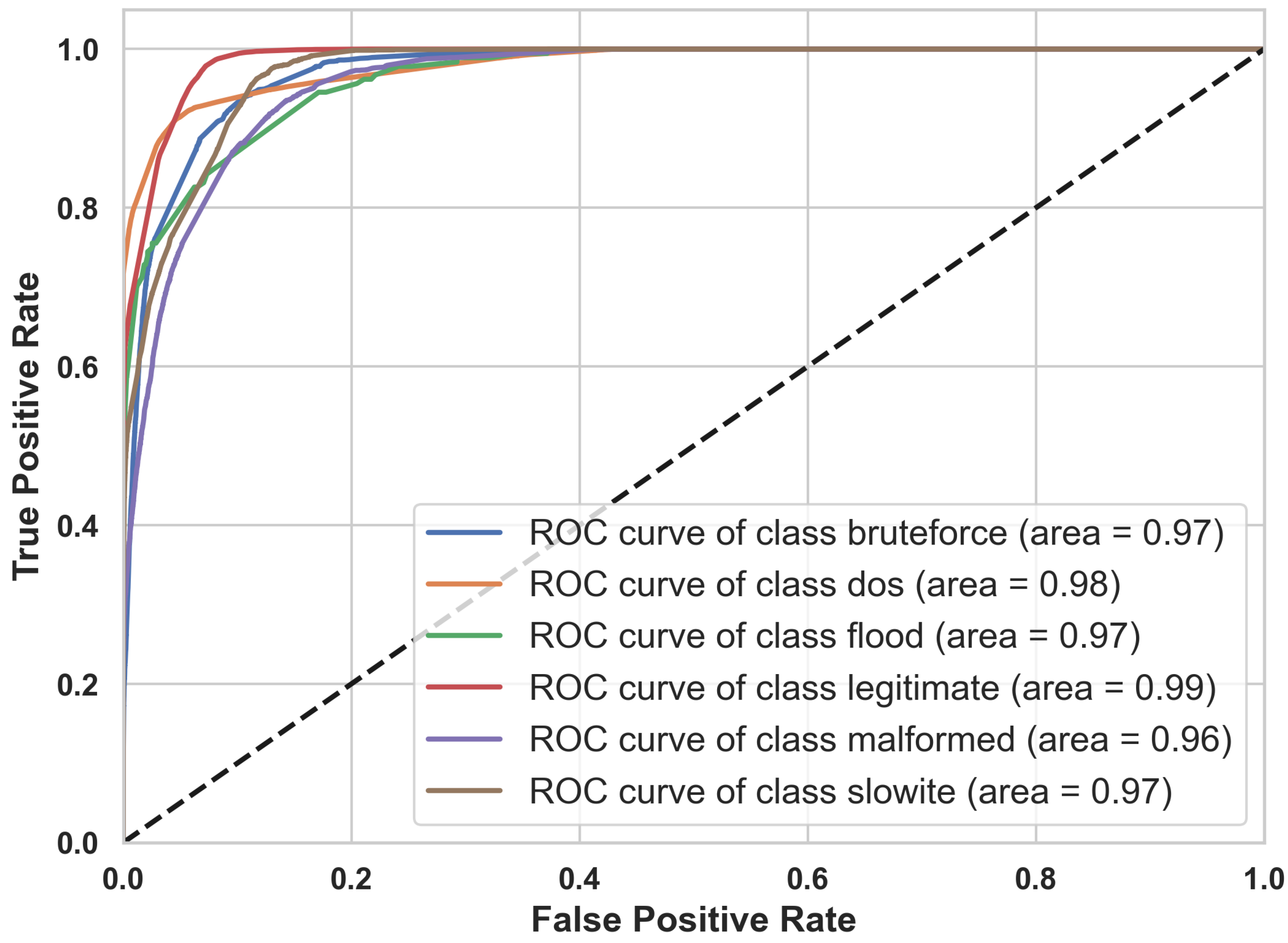
- ROC-AUC: The approach used to compute ROC-AUC in the multiclass case differs from that in binary classification. A standard method in the literature is to produce one ROC curve for each class, treating each class as the positive class and all others as negative [51]. We computed the ROC-AUC using the One-vs.-Rest (OvR) approach for the multiclass classification. The AUC was evaluated and reported as a weighted average to account for class imbalances. For the sake of brevity, we present Figure 6, the ROC-AUC scores for the RF model. The ROC-AUC scores for the other six models are provided in the Appendix A (see Figure A2).
5. Discussion
5.1. Performance Analysis
5.2. Comparative Analysis with Previous Studies Using MQTTset Dataset
5.3. Analysis and Selection of Models
5.4. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AMQP | Advanced Message Queuing Protocol |
| ANN | Artificial Neural Networks |
| ANOVA | Analysis of Variance |
| APTs | Advanced Persistent Threats |
| AUC | Area Under the Curve |
| CoAP | Constrained Application Protocol |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DoS | Denial of Service |
| DT | Decision Tree |
| DTC | Decision Tree Classifier |
| EDA | Exploratory Data Analysis |
| EL | Ensemble Learning |
| FN | False Negative |
| FP | False Positive |
| FPR | False Positive Rate |
| FS | Feature Selection |
| GB | Gradient Boosting |
| HTTP/HTTPS | Hypertext Transfer Protocol/Secure |
| IDS | Intrusion Detection System |
| IoT | Internet of Things |
| KNN | k-nearest Neighbor |
| LR | Logistic Regression |
| LR-DDoS | Low-Rate Distributed Denial of Service |
| MCC | Matthew’s Correlation Coefficient |
| MitM | Man-in-The-Middle |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MQTT | Message Queuing Telemetry Transport |
| MQTTSA | MQTT Security Assistant |
| NB | Naive Bayes |
| NBC | Naive Bayes Classifier |
| OvR | One-vs.-Rest |
| PCC | Pearson Correlation Coefficient |
| ReLU | Rectified Linear Unit |
| RF | Random Forest |
| RNNs | Recurrent Neural Network |
| ROC | Receiver Operating Characteristic |
| SMDT | Statistical Moments Difference Thresholding |
| SSL | Secure Sockets Layer |
| SVM | Support Vector Machine |
| TLS | Transport Layer Security |
| TN | True Negative |
| TP | True Positive |
| TPR | True Positive Rate |
| XGBoost | Extreme Gradient Boosting |
Appendix A
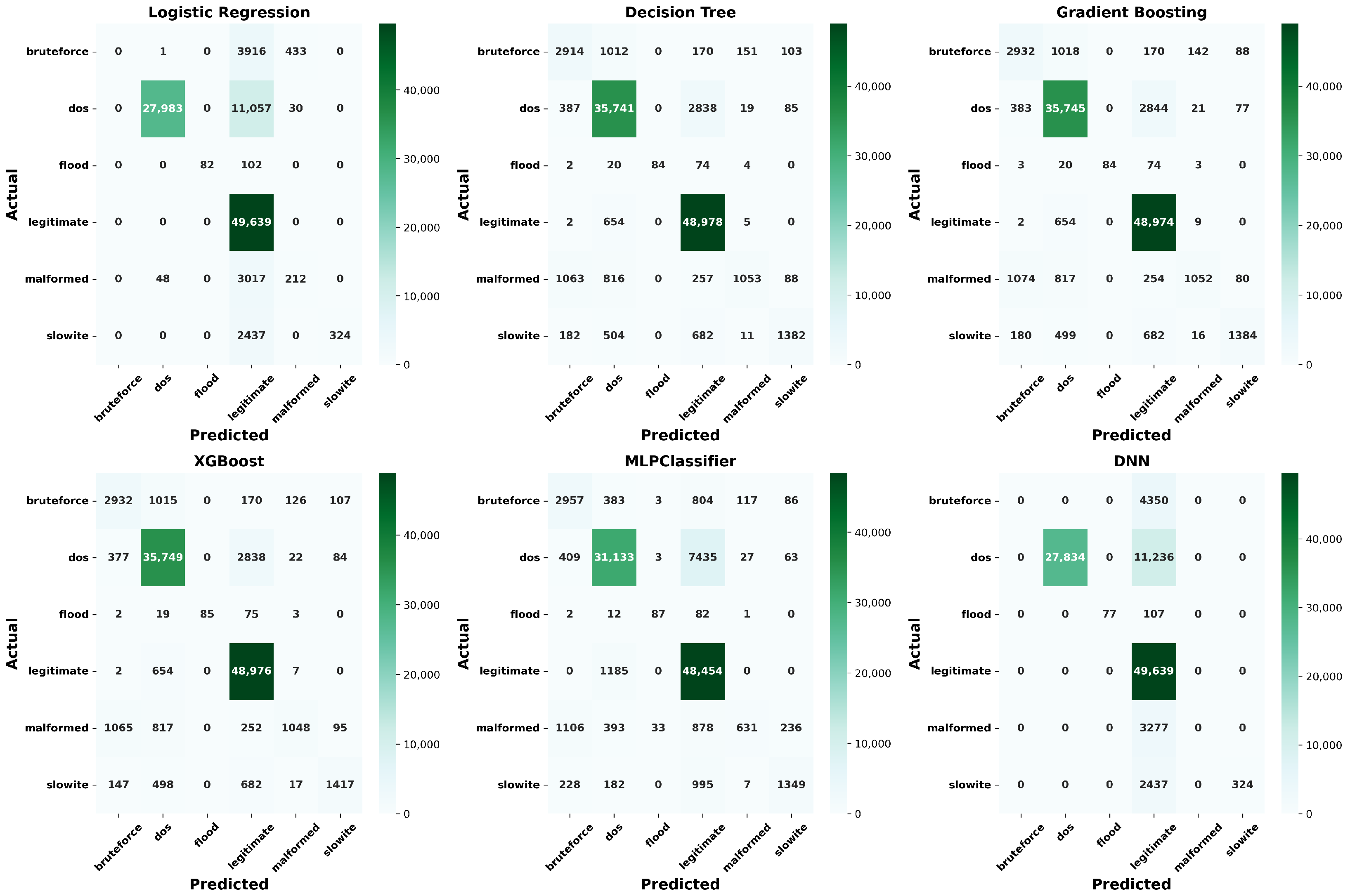
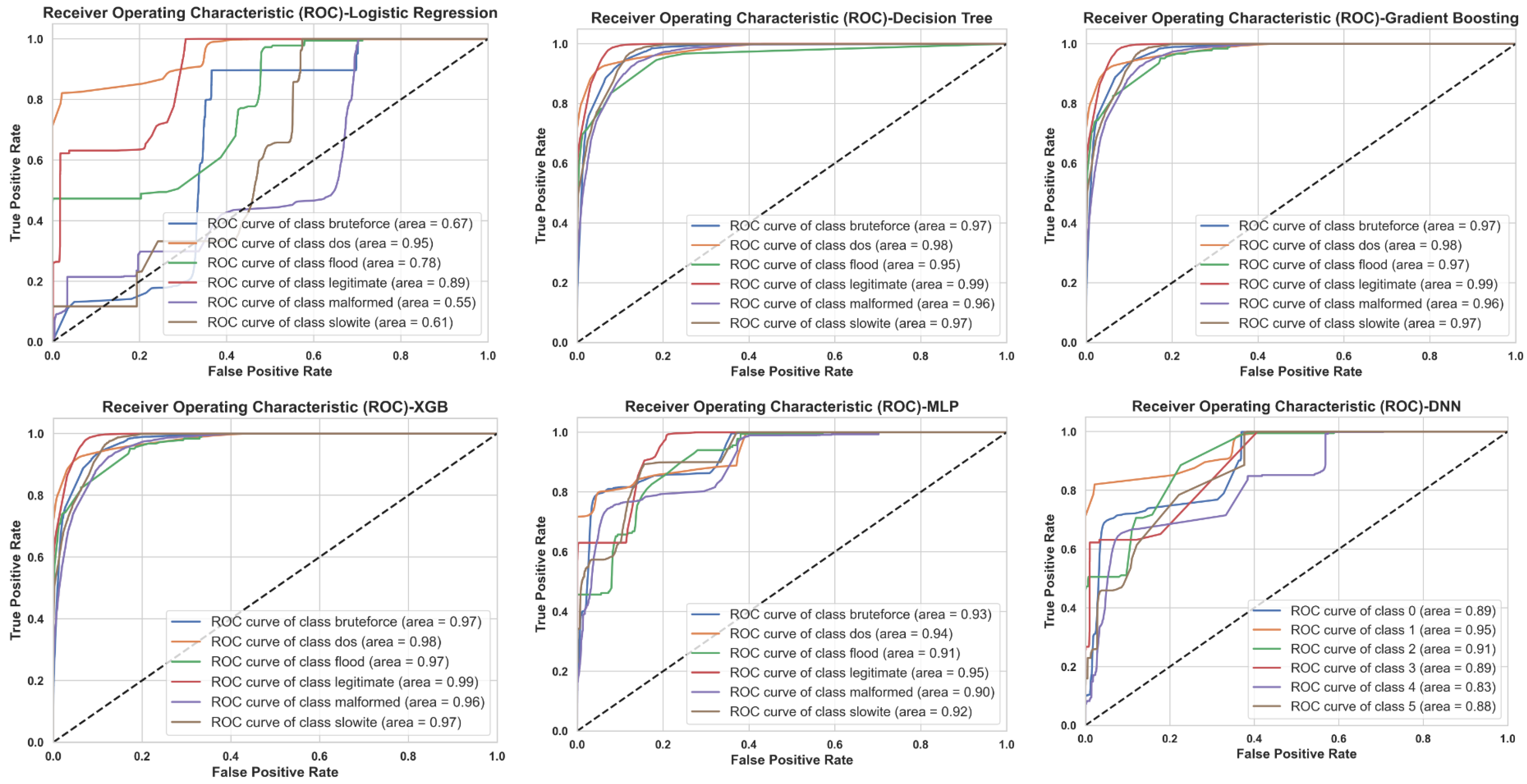
References
- Georgios, L.; Kerstin, S.; Theofylaktos, A. Internet of things in the context of industry 4.0: An overview. Int. J. Entrep. Knowl. 2019, 7, 4–19. [Google Scholar] [CrossRef]
- Naik, N. Choice of effective messaging protocols for IoT systems: MQTT, CoAP, AMQP and HTTP. In Proceedings of the 2017 IEEE International Systems Engineering Symposium (ISSE), Vienna, Austria, 11–13 October 2017; pp. 1–7. [Google Scholar]
- Al-Masri, E.; Kalyanam, K.R.; Batts, J.; Kim, J.; Singh, S.; Vo, T.; Yan, C. Investigating Messaging Protocols for the Internet of Things (IoT). IEEE Access 2020, 8, 94880–94911. [Google Scholar] [CrossRef]
- Al Hanif, A.; Ilyas, M. Effective Feature Engineering Framework for Securing MQTT Protocol in IoT Environments. Sensors 2024, 24, 1782. [Google Scholar] [CrossRef] [PubMed]
- Zeghida, H.; Boulaiche, M.; Chikh, R. Securing MQTT protocol for IoT environment using IDS based on ensemble learning. Int. J. Inf. Secur. 2023, 22, 1075–1086. [Google Scholar] [CrossRef]
- Sadio, O.; Ngom, I.; Lishou, C. Lightweight Security Scheme for MQTT/MQTT-SN Protocol. In Proceedings of the 2019 Sixth International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Granada, Spain, 22–25 October 2019; pp. 119–123. [Google Scholar]
- Chen, F.; Huo, Y.; Zhu, J.; Fan, D. A Review on the Study on MQTT Security Challenge. In Proceedings of the 2020 IEEE International Conference on Smart Cloud (SmartCloud), Washington, DC, USA, 6–8 November 2020; pp. 128–133. [Google Scholar]
- Lakshminarayana, S.; Praseed, A.; Thilagam, P.S. Securing the IoT Application Layer from an MQTT Protocol Perspective: Challenges and Research Prospects. IEEE Commun. Surv. Tutor. 2024, 26, 2510–2546. [Google Scholar] [CrossRef]
- MQTT Organization. MQTT—The Standard for IoT Messaging. 2025. Available online: https://mqtt.org/ (accessed on 25 January 2025).
- Bouzidi, M.; Gupta, N.; Cheikh, F.A.; Shalaginov, A.; Derawi, M. A Novel Architectural Framework on IoT Ecosystem, Security Aspects and Mechanisms: A Comprehensive Survey. IEEE Access 2022, 10, 101362–101384. [Google Scholar] [CrossRef]
- HiveMQ. Securing MQTT Systems—MQTT Security Fundamentals. 2024. Available online: https://www.hivemq.com/blog/mqtt-security-fundamentals-securing-mqtt-systems/ (accessed on 26 January 2025).
- ul A. Laghari, S.; Li, W.; Manickam, S.; Nanda, P.; Al-Ani, A.K.; Karuppayah, S. Securing MQTT Ecosystem: Exploring Vulnerabilities, Mitigations, and Future Trajectories. IEEE Access 2024, 12, 139273–139289. [Google Scholar]
- Husnain, M.; Hayat, K.; Cambiaso, E.; Fayyaz, U.U.; Mongelli, M.; Akram, H.; Abbas, S.G.; Shah, G.A. Preventing MQTT Vulnerabilities Using IoT-Enabled Intrusion Detection System. Sensors 2022, 22, 567. [Google Scholar] [CrossRef]
- Tuyishime, E.; Radu, F.; Cotfas, P.; Cotfas, D.; Balan, T.; Rekeraho, A. Online Laboratory Access Control with Zero Trust Approach: Twingate Use Case. In Proceedings of the 2024 16th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Iasi, Romania, 27–28 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- SANS Institute. Exposed Industrial Control System Remote Services: A Threat to Critical Infrastructure|SANS Webcast. 2023. Available online: https://www.sans.org/webcasts/exposed-industrial-control-system-remote-services-a-threat-to-critical-infrastructure/ (accessed on 13 January 2025).
- Alaiz-Moreton, H.; Aveleira-Mata, J.; Ondicol-Garcia, J.; Muñoz-Castañeda, A.L.; García, I.; Benavides, C. Multiclass Classification Procedure for Detecting Attacks on MQTT-IoT Protocol. Complexity 2019, 2019, 6516253. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Kornaros, G. Hardware-Assisted Machine Learning in Resource-Constrained IoT Environments for Security: Review and Future Prospective. IEEE Access 2022, 10, 58603–58622. [Google Scholar] [CrossRef]
- Fatima, M.; Rehman, O.; Ali, S.; Niazi, M.F. ELIDS: Ensemble Feature Selection for Lightweight IDS against DDoS Attacks in Resource-Constrained IoT Environment. Future Gener. Comput. Syst. 2024, 159, 172–187. [Google Scholar] [CrossRef]
- CNR IEIIT. MQTTset. 2021. Available online: https://www.kaggle.com/datasets/cnrieiit/mqttset (accessed on 5 January 2025).
- Al-Fayoumi, M.; Abu Al-Haija, Q. Capturing low-rate DDoS attack based on MQTT protocol in software Defined-IoT environment. Array 2023, 19, 100316. [Google Scholar] [CrossRef]
- Hindy, H.; Bayne, E.; Bures, M.; Atkinson, R.; Tachtatzis, C.; Bellekens, X. Machine Learning Based IoT Intrusion Detection System: An MQTT Case Study (MQTT-IoT-IDS2020 Dataset). arXiv 2020, arXiv:2006.15340. [Google Scholar]
- Vaccari, I.; Chiola, G.; Aiello, M.; Mongelli, M.; Cambiaso, E. MQTTset, a New Dataset for Machine Learning Techniques on MQTT. Sensors 2020, 20, 6578. [Google Scholar] [CrossRef]
- Ramasubramanian, K.; Singh, A. Data Preparation and Exploration. In Machine Learning Using R: With Time Series and Industry-Based Use Cases in R; Ramasubramanian, K., Singh, A., Eds.; Apress: Berkeley, CA, USA, 2019; pp. 35–77. [Google Scholar]
- Wongsuphasawat, K.; Liu, Y.; Heer, J. Goals, Process, and Challenges of Exploratory Data Analysis: An Interview Study. arXiv 2019, arXiv:1911.00568. [Google Scholar]
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 9. [Google Scholar] [CrossRef]
- Tuyishime, E. Traffic Classification for MQTT IoT Network-Based Security Attacks. 2025. Available online: https://github.com/emmanuel-tuyishime/Traffic-Classification-for-MQTT-IoT-Network-Based-Security-Attacks- (accessed on 4 April 2025).
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Li, T. Robust estimations from distribution structures: II. Central Moments. arXiv 2024, arXiv:2403.14570. [Google Scholar] [CrossRef]
- Ulrych, T.J.; Velis, D.R.; Woodbury, A.D.; Sacchi, M.D. L-moments and C-moments. Stoch. Environ. Res. Risk Assess. 2000, 14, 50–68. [Google Scholar] [CrossRef]
- Kaufmann, J.; Schering, A. Analysis of Variance ANOVA. In Wiley Encyclopedia of Clinical Trials; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2007. [Google Scholar]
- Ivie, J.; MacKay, A. Measures of Variability; Tulsa Community College: Tulsa, OK, USA, 2021. [Google Scholar]
- Zwillinger, D.; Kokoska, S. CRC Standard Probability and Statistics Tables and Formulae; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Guo, Y.; Kibria, B.G. On Some Statistics for Testing the Skewness in a Population: An Empirical Study. Appl. Appl. Math. Int. J. AAM 2017, 12, 6. [Google Scholar]
- Yusoff, S.b.; Bee Wah, Y. Comparison of conventional measures of skewness and kurtosis for small sample size. In Proceedings of the 2012 International Conference on Statistics in Science, Business and Engineering (ICSSBE), Langkawi, Malaysia, 10–12 September 2012; pp. 1–6. [Google Scholar]
- Raju, V.N.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the Influence of Normalization/Transformation process on the Accuracy of Supervised Classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 729–735. [Google Scholar]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2020, arXiv:1811.12808. [Google Scholar]
- GridSearchCV. 2024. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html (accessed on 9 January 2025).
- Stapor, K.; Ksieniewicz, P.; García, S.; Woźniak, M. How to design the fair experimental classifier evaluation. Appl. Soft Comput. 2021, 104, 107219. [Google Scholar] [CrossRef]
- O’Malley, T.; Bursztein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L. KerasTuner. 2019. Available online: https://github.com/keras-team/keras-tuner (accessed on 9 April 2025).
- Joshi, S.; Owens, J.A.; Shah, S.; Munasinghe, T. Analysis of Preprocessing Techniques, Keras Tuner, and Transfer Learning on Cloud Street image data. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 4165–4168. [Google Scholar]
- Shawki, N.; Nunez, R.R.; Obeid, I.; Picone, J. On Automating Hyperparameter Optimization for Deep Learning Applications. In Proceedings of the 2021 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 4 December 2021; pp. 1–7. [Google Scholar]
- Joseph, F.J.J.; Nonsiri, S.; Monsakul, A. Keras and TensorFlow: A Hands-On Experience. In Advanced Deep Learning for Engineers and Scientists: A Practical Approach; Prakash, K.B., Kannan, R., Alexander, S.A., Kanagachidambaresan, G.R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 85–111. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hara, K.; Saito, D.; Shouno, H. Analysis of function of rectified linear unit used in deep learning. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2019, arXiv:1803.08375. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2020, 8, 4806–4813. [Google Scholar] [CrossRef]
- Raschka, S. An Overview of General Performance Metrics of Binary Classifier Systems. arXiv 2014, arXiv:1410.5330. [Google Scholar]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]
- Goli, Y.D.; Ambika, R. Network Traffic Classification Techniques—A Review. In Proceedings of the 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belgaum, India, 21–22 December 2018; pp. 219–222. [Google Scholar]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation functions in neural networks. Int. J. Eng. Appl. Sci. Technol. 2020, 4, 310–316. [Google Scholar] [CrossRef]
- Mercioni, M.A.; Holban, S. The Most Used Activation Functions: Classic Versus Current. In Proceedings of the 2020 International Conference on Development and Application Systems (DAS), Suceava, Romania, 21–23 May 2020; pp. 141–145. [Google Scholar]
- Höhn, M.; Wunderlich, M.; Ballweg, K.; von Landesberger, T. Width-Scale Bar Charts for Data with Large Value Range. In Proceedings of the EuroVis (Short Papers), Norrköping, Sweden, 25–29 May 2020; pp. 103–107. [Google Scholar]
- Alsoufi, M.A.; Razak, S.; Siraj, M.M.; Nafea, I.; Ghaleb, F.A.; Saeed, F.; Nasser, M. Anomaly-Based Intrusion Detection Systems in IoT Using Deep Learning: A Systematic Literature Review. Appl. Sci. 2021, 11, 8383. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Year | Classifi- cation | ML Method | DL Method | Evaluation Metrics | FS Method | Retained Features | Hyperpara- meter Tuning | Cross- Validation |
|---|---|---|---|---|---|---|---|---|---|
| [23] | 2020 | Multi- class | RF, NB, DT, GB, MLP | DNN | Accuracy, F1-score | ✗ | 33 | ✗ | ✗ |
| [5] | 2023 | Binary | DT, RF, NB, MLP, Bagging, Adaboost, HGBoost, XGBoost, stacking | ✗ | Accuracy, F1-score, MCC | ✗ | 33 | ✗ | ✗ |
| [4] | 2024 | Binary | DT, KNN, RF, Adaboost, XGBoost | ✗ | Accuracy, Precision, Recall, F1-score, ROC | PCC | 10 | ✓ | ✓ |
| This study | 2025 | Binary and Multi- class | RF, LR, DT, GB, XGBoost, MLP | DNN | Accuracy, Precision, Recall, F1-score, ROC-AUC | SMDT | 5 | ✓ | ✓ |
| Tools/Software/Library | Version | Role |
|---|---|---|
| Anaconda | 4.14.0 | Package management and environment management |
| Jupyter Notebook | 6.4.8 | Interactive development environment |
| Python | 3.9.12 | Programming language |
| Pandas | 1.4.4 | For data manipulation and analysis |
| NumPy | 1.22.4 | For numerical operations |
| Scikit-Learn | 1.0.2 | For machine learning tasks including preprocessing, model training, and evaluation |
| Seaborn | 0.11.2 | For statistical data visualization |
| Matplotlib | 3.5.1 | For data visualization |
| TensorFlow | 2.10.1 | For building and training neural networks |
| No. | Name | Description | Protocol Layer |
|---|---|---|---|
| 1 | tcp.time_delta | Time TCP stream | TCP |
| 2 | tcp.len | TCP Segment Len | TCP |
| 3 | mqtt.kalive | Keep-Alive | MQTT |
| 4 | mqtt.msgid | Message Identifier | MQTT |
| 5 | mqtt.retain | Retain | MQTT |
| Algorithm | Identified Best Parameters (Based on the Defined Parameter Grid) |
|---|---|
| RF | bootstrap: True, criterion: gini, max_features: auto, min_samples_leaf: 1, min_samples_split: 2, n_estimators: 100 |
| LR | fit_intercept: True, max_iter: 100, penalty: l2, solver: sag, tol: 0.0001 |
| DT | criterion: gini, max_depth: 10, max_features: None, max_leaf_nodes: None, min_impurity_decrease: 0.0, min_samples_leaf: 5, min_samples_split: 2, splitter: best |
| GB | learning_rate: 0.1, max_depth: 5, min_samples_leaf: 1, min_samples_split: 10, n_estimators: 300 |
| XGBoost | colsample_bytree: 0.8, gamma: 0, learning_rate: 0.1, max_depth: 5, n_estimators: 300, subsample: 0.8 |
| MLP | activation: tanh, alpha: 0.0001, hidden_layer_sizes: (50, 50), learning_rate: constant, solver: adam |
| Actual Traffic Class | Predicted as Attack | Predicted as Legitimate |
|---|---|---|
| Attack | TP | FN |
| Legitimate (Normal) | FP | TN |
| Model | Accuracy | Precision | Recall | F1-Score | ROC-AUC | Searching Time (s) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|---|
| RF | 0.95 | 0.95 | 0.95 | 0.95 | 0.99 | 2280.81 | 6.96 | 0.45 |
| LR | 0.95 | 0.95 | 0.95 | 0.95 | 0.99 | 221.58 | 11.27 | 0.99 |
| DT | 0.95 | 0.95 | 0.95 | 0.95 | 0.99 | 74.98 | 0.12 | 0.01 |
| GB | 0.95 | 0.95 | 0.95 | 0.95 | 0.99 | 3051.20 | 43.08 | 0.45 |
| XGBoost | 0.95 | 0.95 | 0.95 | 0.95 | 0.99 | 1252.83 | 12.38 | 0.04 |
| MLP | 0.89 | 0.91 | 0.89 | 0.89 | 0.95 | 3551.45 | 264.61 | 0.20 |
| DNN | 0.81 | 0.85 | 0.81 | 0.80 | 0.92 | 5602.99 | 722.57 | 6.44 |
| Algorithm | Identified Best Parameters (Based on the Defined Parameter Grid) |
|---|---|
| RF | bootstrap: True, max_depth: 20, min_samples_leaf: 2, min_samples_split: 5, n_estimators: 200 |
| LR | C: 1.0, max_iter: 100, penalty: l2, solver: liblinear |
| DT | criterion: entropy, max_depth: 10, min_samples_leaf: 1, min_samples_split: 10, splitter: best |
| GB | learning_rate: 0.01, max_depth: 7, min_samples_leaf: 10, min_samples_split: 2, n_estimators: 300 |
| XGBoost | colsample_bytree: 1.0, gamma: 0.1, learning_rate: 0.1, max_depth: 7, min_child_weight: 3, n_estimators: 100, subsample: 0.8 |
| MLP | activation: tanh, alpha: 0.0001, hidden_layer_sizes: (100, 100), learning_rate: constant, solver: adam |
| Model | Accuracy | Precision | Recall | F1-Score | Searching Time (s) | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|---|
| RF | 0.91 | 0.90 | 0.91 | 0.90 | 1547.43 | 16.21 | 1.15 |
| LR | 0.79 | 0.79 | 0.79 | 0.75 | 1834.67 | 8.00 | 0.01 |
| DT | 0.91 | 0.91 | 0.91 | 0.90 | 9.24 | 0.12 | 0.01 |
| GB | 0.91 | 0.91 | 0.91 | 0.90 | 24,489.46 | 505.96 | 4.80 |
| XGBoost | 0.91 | 0.91 | 0.91 | 0.90 | 49,323.92 | 15.75 | 0.06 |
| MLP | 0.82 | 0.85 | 0.82 | 0.80 | 3573.60 | 141.93 | 0.11 |
| DNN | 0.78 | 0.77 | 0.78 | 0.74 | 5081.92 | 702.20 | 6.03 |
| Actual/Predicted | Brute Force (B) | DoS (D) | Flood (F) | Legitimate (L) | Malformed (M) | SlowITe (S) |
|---|---|---|---|---|---|---|
| Brute Force (B) | TP (BB) | FP (BD) | FP (BF) | FN (BL) | FP (BM) | FP (BS) |
| DoS (D) | FP (DB) | TP (DD) | FP (DF) | FN (DL) | FP (DM) | FP (DS) |
| Flood (F) | FP (FB) | FP (FD) | TP (FF) | FN (FL) | FP (FM) | FP (FS) |
| Legitimate (L) | FP (LB) | FP (LD) | FP (LF) | TP (LL) | FP (LM) | FP (LS) |
| Malformed (M) | FP (MB) | FP (MD) | FP (MF) | FN (ML) | TP (MM) | FP (MS) |
| SlowITe (S) | FP (SB) | FP (SD) | FP (SF) | FN (SL) | FP (SM) | TP (SS) |
| Ref | Year | Features | Best Accuracy | Best F1-Score | Training Time (s) | Testing Time (s) |
|---|---|---|---|---|---|---|
| [23] | 2020 | 33 | (multiclass) RF, DT: 91.59% | RF, DT: 91.40% | 2298.2762 | 125.8504 |
| [5] | 2023 | 33 | (binary classes) Stacking: 95.42% | Stacking: 95.42% | 250.05 | 0.94 |
| [4] | 2024 | 10 | (binary classes) RF: 96.33% | RF: 96.32% | 4.0888 | 0.1686 |
| Our study | 2025 | 5 | (binary classes) RF, LR, DT, GB, XGBoost: 95% (multiclass) RF, DT, GB, XGBoost: 91% | (binary classes) RF, LR, DT, GB, XGBoost: 95% (multiclass) RF, DT, GB, XGBoost: 90% | (binary classes) 6.96, 11.27, 0.12, 43.08, 12.38 (multiclass) 16.21, 0.12, 505.96, 15.75 | (binary classes) 0.45, 0.99, 0.01, 0.45, 0.04 (multiclass) 1.15, 0.01, 4.80, 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tuyishime, E.; Martalò, M.; Cotfas, P.A.; Popescu, V.; Cotfas, D.T.; Rekeraho, A. Resource-Efficient Traffic Classification Using Feature Selection for Message Queuing Telemetry Transport-Internet of Things Network-Based Security Attacks. Appl. Sci. 2025, 15, 4252. https://doi.org/10.3390/app15084252
Tuyishime E, Martalò M, Cotfas PA, Popescu V, Cotfas DT, Rekeraho A. Resource-Efficient Traffic Classification Using Feature Selection for Message Queuing Telemetry Transport-Internet of Things Network-Based Security Attacks. Applied Sciences. 2025; 15(8):4252. https://doi.org/10.3390/app15084252
Chicago/Turabian StyleTuyishime, Emmanuel, Marco Martalò, Petru A. Cotfas, Vlad Popescu, Daniel T. Cotfas, and Alexandre Rekeraho. 2025. "Resource-Efficient Traffic Classification Using Feature Selection for Message Queuing Telemetry Transport-Internet of Things Network-Based Security Attacks" Applied Sciences 15, no. 8: 4252. https://doi.org/10.3390/app15084252
APA StyleTuyishime, E., Martalò, M., Cotfas, P. A., Popescu, V., Cotfas, D. T., & Rekeraho, A. (2025). Resource-Efficient Traffic Classification Using Feature Selection for Message Queuing Telemetry Transport-Internet of Things Network-Based Security Attacks. Applied Sciences, 15(8), 4252. https://doi.org/10.3390/app15084252