


A Novel Method for Traffic Parameter Extraction and Analysis Based on Vehicle Trajectory Data for Signal Control Optimization


Abstract
1. Introduction
1.1. Research Background
1.2. Research Significance
1.3. Literature Review
1.4. Contributions
- (1)
- Established a systematic trajectory data processing methodology framework. This study designs a complete processing workflow including data preprocessing, basic feature processing, exploratory data analysis, key feature extraction, and data visualization. Each module has been carefully designed and optimized to ensure data processing quality and efficiency. The framework exhibits excellent modular characteristics with clear interfaces between modules, facilitating customization and extension according to specific requirements.
- (2)
- Proposed a trajectory point “labeling” algorithm based on regular polygon coverage. This effectively solves the technical challenge of mapping discrete trajectory points to road network nodes. By constructing regular polygon coverage areas centered on nodes and utilizing geometric determination algorithms to assign trajectory points, high-precision vehicle path identification is achieved. The algorithm demonstrates excellent stability and efficiency when processing large-scale data.
- (3)
- Established a multi-source data fusion method for traffic parameter calculation. Addressing the uncertainty in trajectory data, this study adopts a dual calculation method based on vehicle instantaneous speed and arrival time differences, improving parameter extraction accuracy and reliability through multi-source information fusion. This method effectively reduces errors that may arise from single data sources and enhances the robustness of parameter estimation.
- (4)
- Developed a highly reusable and automated data processing toolchain. Based on Python and MATLAB platforms, a series of comprehensive data processing functions and modules have been developed, including automated data cleaning, feature extraction, parameter calculation, and result visualization. These highly reusable and automated tools not only serve this research but can also provide technical support for other researchers and engineering practices.
- (5)
- Validated the effectiveness of the method through actual data. Using actual trajectory data containing over 2.48 million records, the performance of the proposed method was comprehensively validated. Experimental results demonstrate that the method can effectively process large-scale data, and the extracted traffic parameters accurately reflect the operational status of the road network, providing a reliable data foundation for signal control optimization.
2. Methodology
2.1. Overall Framework
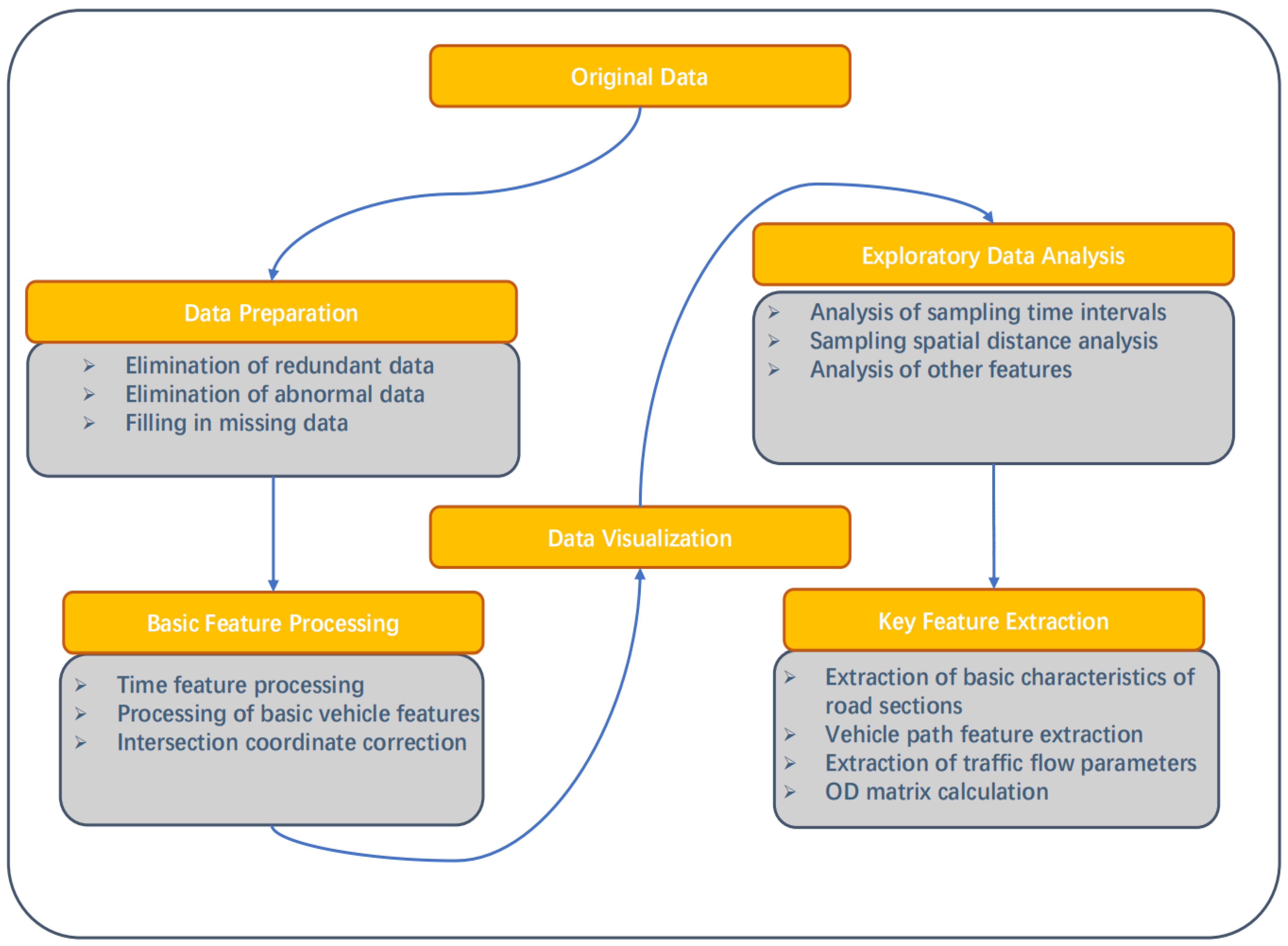
2.2. Data Preprocessing
2.2.1. Redundant Data Removal
2.2.2. Anomalous Data Removal

2.2.3. Missing Data Imputation
2.3. Basic Feature Processing
2.3.1. Temporal Feature Processing
2.3.2. Vehicle Basic Feature Processing
2.3.3. Intersection Coordinate Calibration

2.4. Vehicle Path Feature Extraction
2.4.1. OD Point Addition Strategy
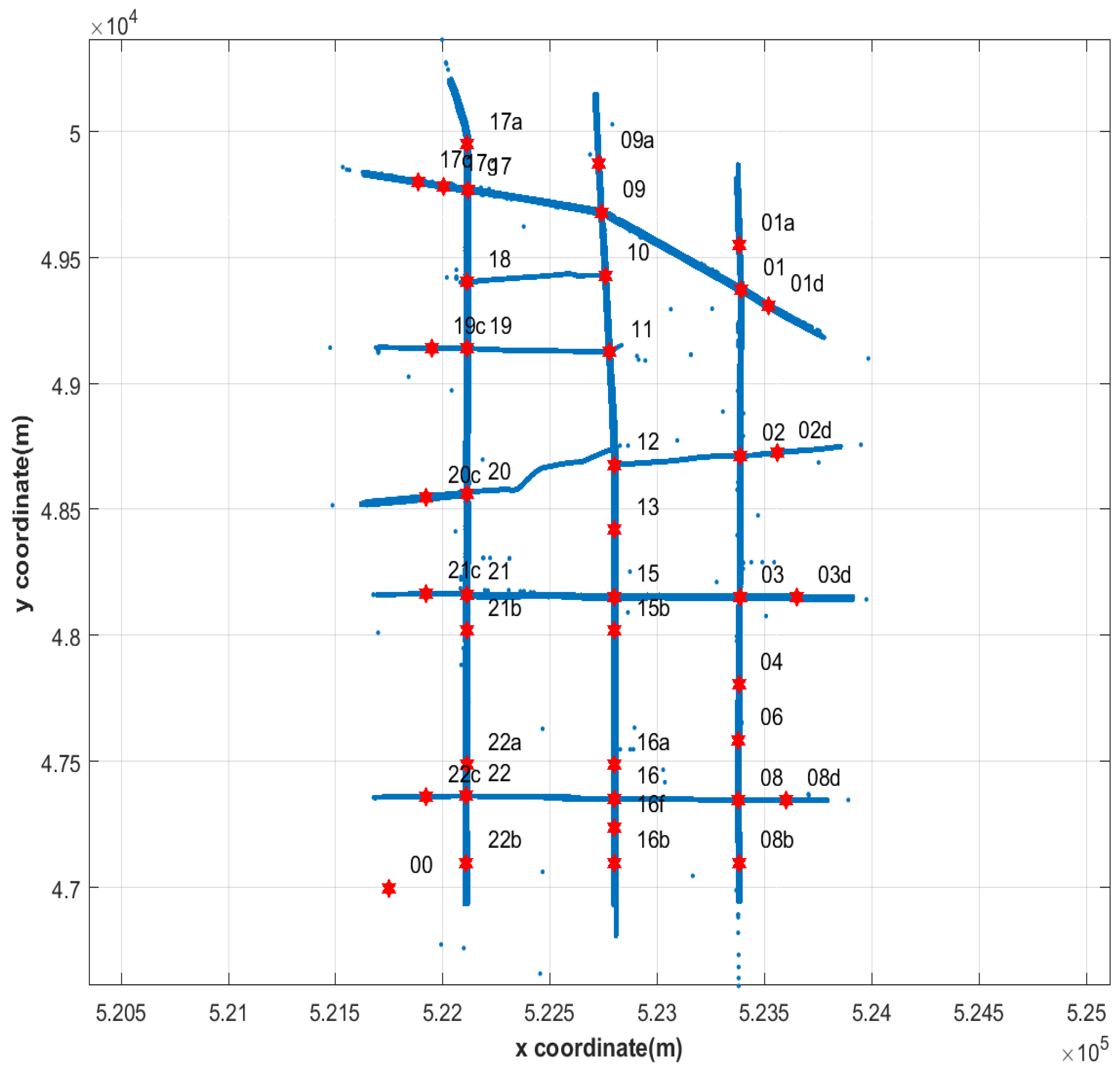
2.4.2. Trajectory Point-Labeling Algorithm Based on Regular Polygons
- (1)
- Regular polygon construction: Using the makePolygon2() function, a regular hexadecagon (with an adjustable number of sides) is generated for each node. The circumscribed circle radius of the regular polygon is a key parameter requiring optimization based on road network characteristics.
- (2)
- Trajectory point assignment determination: Using MATLAB’s inpolygon() function to determine whether each trajectory point lies within a regular polygon. This function, based on the ray casting principle, offers high computational efficiency and accuracy.
- (3)
- Path compression and organization: Merging consecutive trajectory points at the same node, removing trajectory points on road segments (marked as ‘00’), ultimately obtaining the sequence of nodes traversed by the vehicle.
2.4.3. Vehicle Path Identification and Feature Extraction
3. Experimental Design and Implementation
3.1. Experimental Data
3.1.1. Data Scale and Temporal Scope
3.1.2. Spatial Coverage and Road Network Structure
- (1)
- Grid layout: Intersections exhibit a regular grid distribution, conforming to modern urban planning characteristics.
- (2)
- Clear hierarchy: There are distinct arterial roads (such as the arterial formed by intersections 1–8) and secondary roads.
- (3)
- Clear boundaries: The road network has explicit spatial boundaries, facilitating OD analysis.
- (4)
- Intersection coordinate data is provided in text file format, containing each intersection’s number and precise geographic coordinates. This coordinate information forms the foundation for spatial analysis and path identification.
3.1.3. Data Attributes and Quality
- (1)
- Vehicle identifier (vid): Uniquely identifies each floating car
- (2)
- Timestamp (time): Unix timestamp format, accurate to the second
- (3)
- Spatial coordinates (xcoord, ycoord): Real-time vehicle position
- (4)
- Instantaneous speed (speed): Vehicle’s instantaneous speed in meters per second
- (5)
- Passenger status: Indicates whether the vehicle is carrying passengers
3.1.4. Data Representativeness and Validation
3.2. Development Environment
3.2.1. Python Development Environment
- (1)
- Rich data processing libraries: pandas provides powerful dataframe manipulation capabilities, numpy supports efficient numerical computation, and matplotlib and seaborn offer flexible visualization functions.
- (2)
- Excellent extensibility: Python’s modular design makes code easy to maintain and extend, facilitating the construction of reusable processing workflows.
- (3)
- Active community support: Python has widespread application in data science, making it easy to find solutions when encountering problems.
3.2.2. MATLAB Development Environment
- (1)
- Powerful geometric computation capabilities: MATLAB’s built-in functions such as inpolygon() provide efficient and reliable solutions for geometric determination.
- (2)
- Interactive visualization: MATLAB’s graphical interface supports interactive operations such as zooming, panning, and other interactions, facilitating detailed visual analysis.
- (3)
- Matrix computation advantages: MATLAB excels when handling matrix operations on large-scale data.
3.2.3. Development Tool Integration
3.3. Experimental Procedure
3.3.1. Data Import and Initial Processing
- (1)
- Data type conversion: Ensuring correct data types for each column, such as converting timestamps to integer type.
- (2)
- Index setting: Establishing appropriate indices to improve query efficiency.
- (3)
- Basic statistics: Computing basic statistical information to understand overall data characteristics.
3.3.2. Data Cleaning Workflow
- (1)
- Redundant data removal: Executing the dropDuplicated() function to remove duplicate records based on the combined uniqueness of vehicle ID, timestamp, and coordinates. During processing, the number of removed records is tracked in real time to assess the degree of data redundancy.
- (2)
- Anomalous data identification: Generating road network visualization through the plotRoadnet() function for manual identification of anomalous points obviously deviating from the road network. Based on identification results, spatial range thresholds are set for automatic anomalous data screening.
- (3)
- Anomalous data removal: Executing the removeOutlier() function to delete trajectory points with abnormal spatial positions and vehicles with only single trajectory points. Simultaneously, using the sortVidbyTime() function to sort vehicles by time, facilitating subsequent temporal analysis.
- (4)
- Data integrity check: Checking processed data for missing values and verifying data completeness.
3.3.3. Feature Engineering Implementation
- (1)
- Temporal feature extraction: Using the addTime() function to convert Unix timestamps to a readable time format, identifying time periods contained in the data through the timeSegment() function, and adding time period identifiers to each record using the addTimesegNo() function.
- (2)
- Vehicle feature construction: Generating vehicle basic feature data tables through the getVid() function, adding derived features such as time periods and start–end row numbers using the vinfoAdd() function, and constructing structured vehicle information tables to support rapid querying and analysis.
- (3)
- Spatial coordinate calibration: Importing processed data into the MATLAB environment, visualizing the relationship between intersection positions and trajectories using the plotRoad() function, manually adjusting intersection coordinates to trajectory convergence centers based on visualization results, and verifying calibration effects to ensure accurate positioning of all intersections.
3.3.4. Path Identification Experiment
- (1)
- OD point addition: Adding original OD points at road network edges based on network topology, adding supplementary OD points for anomalous flow segments, and generating a complete node (intersection + OD point) list.
- (2)
- Parameter optimization experiment: Determining regular polygon radius candidate values (25 m and 49 m) based on sampling spatial distance distribution, running the path identification algorithm for each parameter setting, counting anomalous vehicle numbers, and selecting optimal parameters.
- (3)
- Path extraction execution:Running the routeInferMain() main function, including the following sub-processes:· makePolygon2(): Generating regular polygons for each node· nodeDigger(): Determining node assignment for each trajectory point· routeInfer(): Extracting vehicle path sequences· routeDiagnose(): Diagnosing and processing anomalous paths
- (4)
- Result validation: Checking the reasonableness of path identification results, analyzing the distribution of nodes traversed by vehicles, and analyzing causes of anomalous paths. Quantitative evaluation of path inference accuracy was conducted by analyzing the proportion of successfully identified vehicle paths. With the optimal 49-m polygon radius, 7252 out of 7317 vehicles (99.1%) had their paths successfully identified, while 65 vehicles (0.9%) contained only single trajectory points and were excluded from analysis due to insufficient trajectory information for meaningful path reconstruction.
3.3.5. Traffic Parameter Calculation
- (1)
- Link flow calculation: Defining the list of links to be analyzed, calling the selectVinfoMain() function with the parameter set to ‘volume’, counting vehicle numbers passing through each link in each time period, and calculating the mean and standard deviation of flow.
- (2)
- Speed and travel time calculation: Using dual calculation methods (based on instantaneous speed and time difference), extracting speed and time parameters simultaneously through the selectVinfoMain() function, fusing results from both methods to improve estimation accuracy.
- (3)
- Approach flow analysis: Identifying turning relationships at each intersection, calculating left-turn flow using the tpVolume3() function, and generating intersection-level flow statistics tables.
- (4)
- OD matrix construction: Counting OD pairs based on vehicle path data, generating both basic and detailed OD matrices, and calculating time period averages of OD flows.
3.3.6. Result Visualization
- (1)
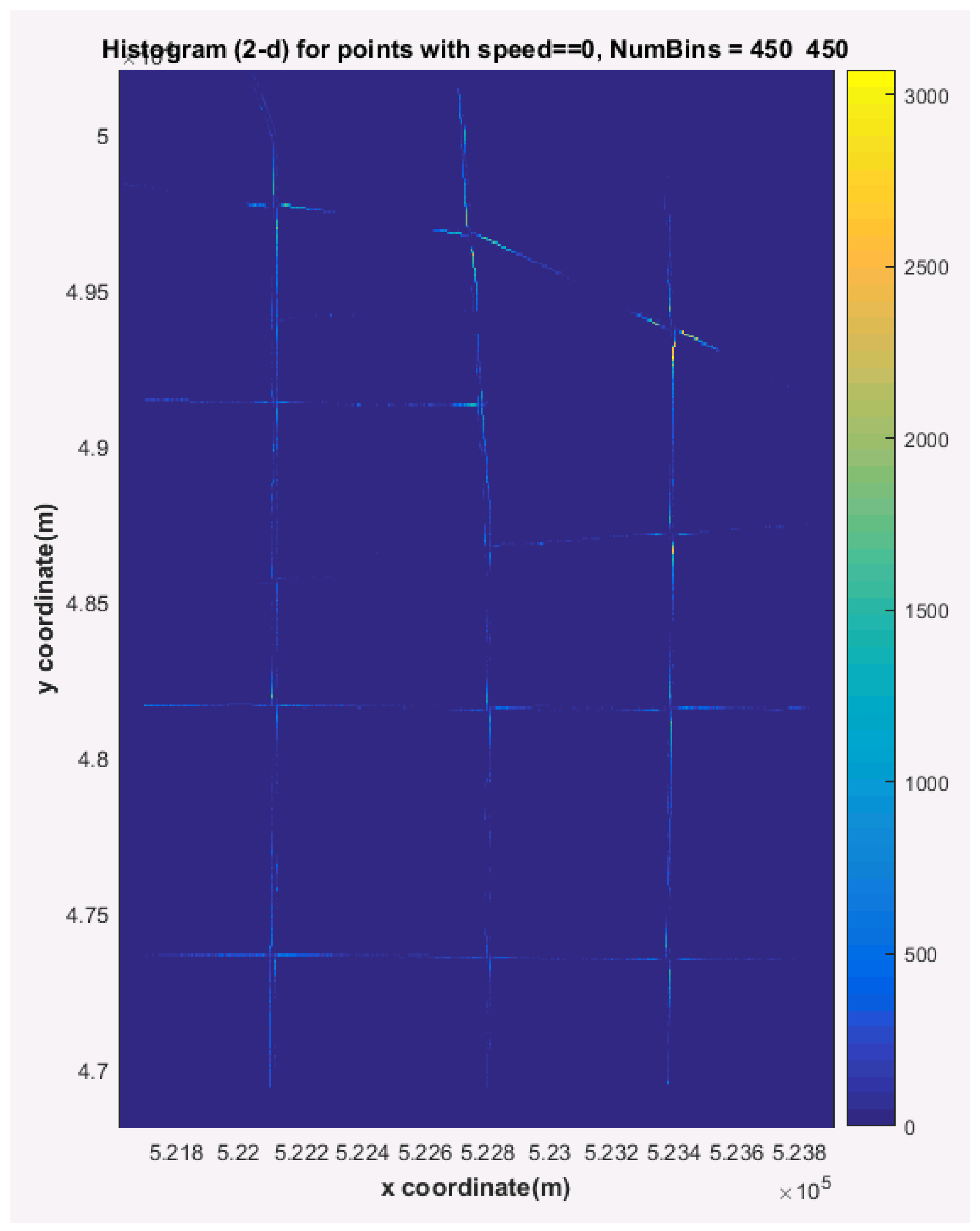
- Stop point density visualization: Extracting trajectory points with zero speed, using 2D histograms to analyze spatial distribution, and generating heat maps to display congestion distribution.
- (2)
- Traffic parameter visualization: Using box plots to display distributions of speed, travel time, and flow, generating time series plots to show temporal variation characteristics of parameters, and creating spatial distribution maps to show spatial differences in parameters.
- (3)
- Comprehensive analysis charts: OD matrix heat maps, road network flow distribution maps, and key indicator comparison charts.
3.4. Experimental Parameter Setting and Optimization
3.4.1. Spatial Parameter Settings
- (1)
- Regular polygon sides: Selecting hexadecagons as the shape for node coverage areas. This choice is based on the following considerations: too few sides (e.g., quadrilaterals) result in significant differences between coverage areas and actual road shapes; too many sides increase computational complexity with limited accuracy improvement. Hexadecagons achieve a good balance between accuracy and efficiency.
- (2)
- Circumscribed circle radius: The polygon radius selection was based on analysis of the spatial sampling characteristics of the trajectory data. Specifically, sampling spatial distances (excluding zero distances and sampling intervals ≥5 s) were analyzed, and the 99th percentile distance was calculated as 49 m. The second candidate radius of 25 m represents half of the 99th percentile value, allowing comparison of algorithm performance under different coverage scales to determine the optimal parameter setting.
- (3)
- Anomalous data threshold: Based on road network visualization results, setting determination thresholds for abnormal spatial positions to ensure removal of trajectory points obviously deviating from the road network while retaining normal data in edge areas.
3.4.2. Temporal Parameter Settings
- (1)
- Time window division: Each time period is set to 2 h, matching the actual morning peak duration, ensuring sufficient data volume while avoiding confusion from cross-period traffic patterns.
- (2)
- Sampling interval threshold: When analyzing sampling characteristics, sampling time intervals are divided into two categories: less than 10 s and greater than or equal to 10 s. This threshold selection is based on data distribution characteristics and can effectively distinguish normal sampling from anomalous intervals.
3.4.3. Algorithm Parameter Optimization
- (1)
- Data storage format: Providing two storage options, ‘manytable’ and ‘onetable’, where the former is suitable for detailed segment-by-segment analysis and the latter facilitates overall comparison and statistics.
- (2)
- Parallel processing settings: When processing large-scale data, reasonably setting the number of parallel processing threads to balance computational resources and processing efficiency.
- (3)
- Visualization parameters: Including histogram bin numbers, chart color schemes, and annotation detail levels. These parameter settings must ensure sufficient information display while avoiding visual clutter.
4. Experimental Results and Analysis
4.1. Traffic Parameter Extraction Results
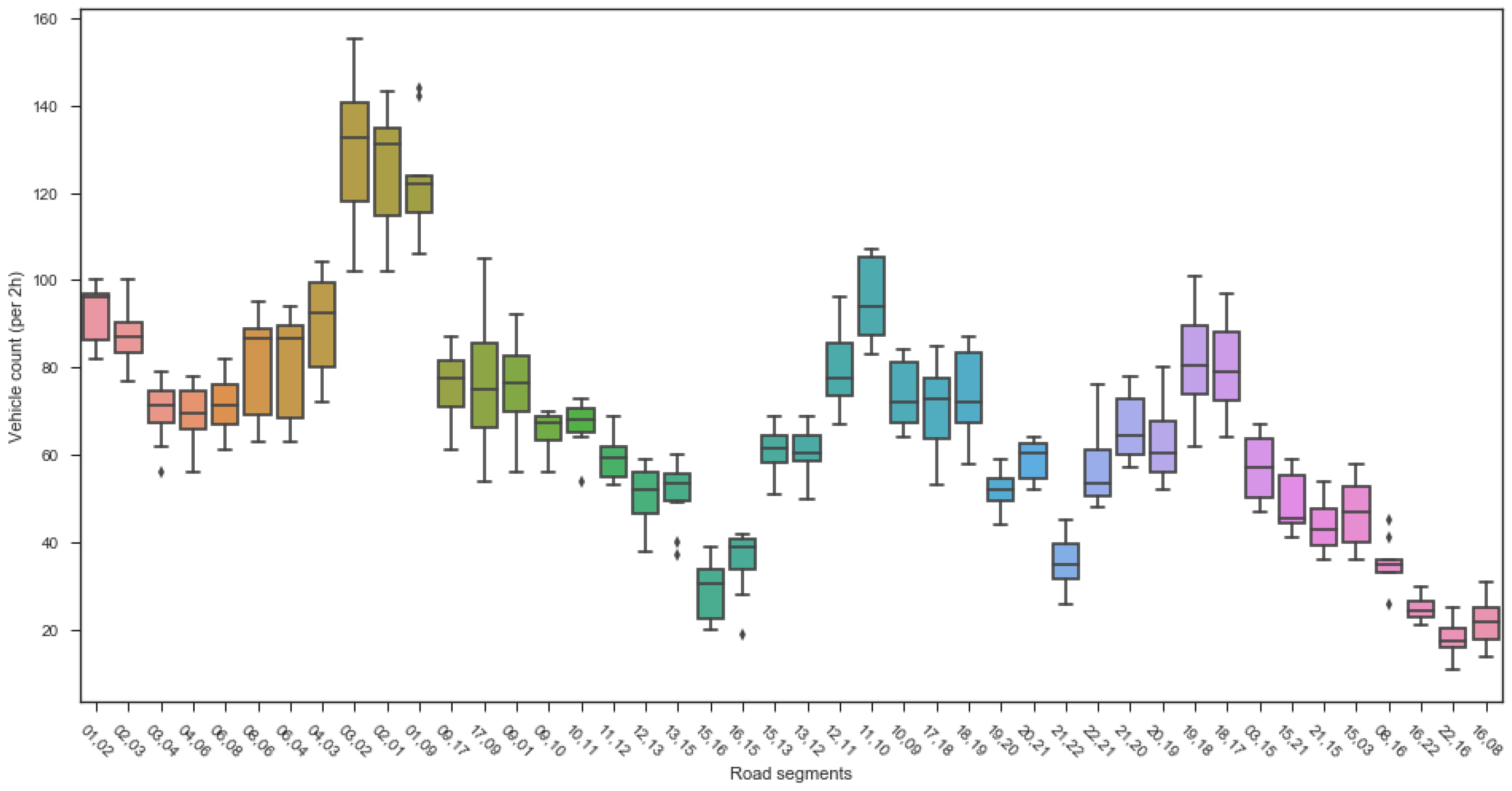
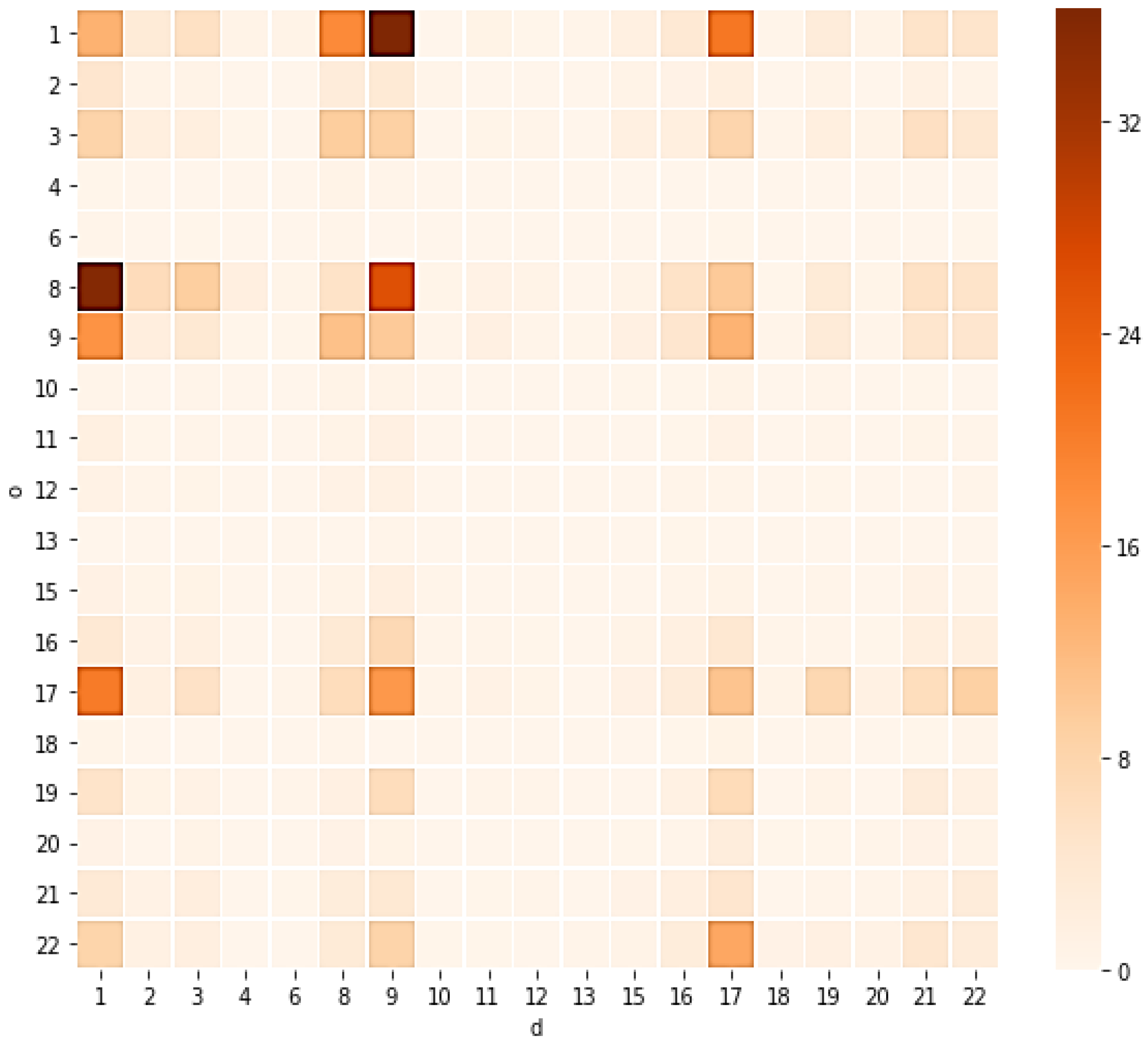
4.1.1. Link Flow Characteristics
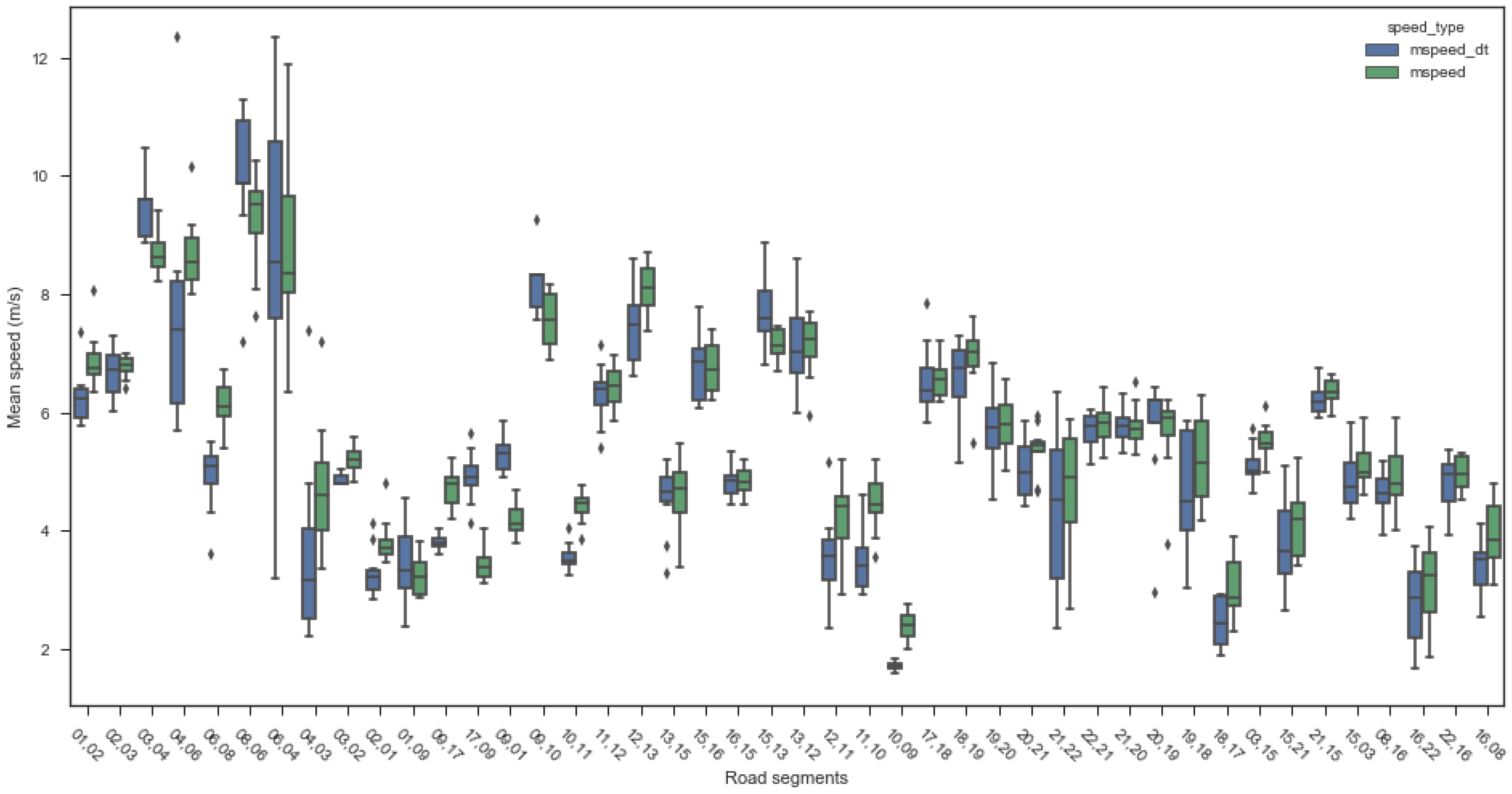
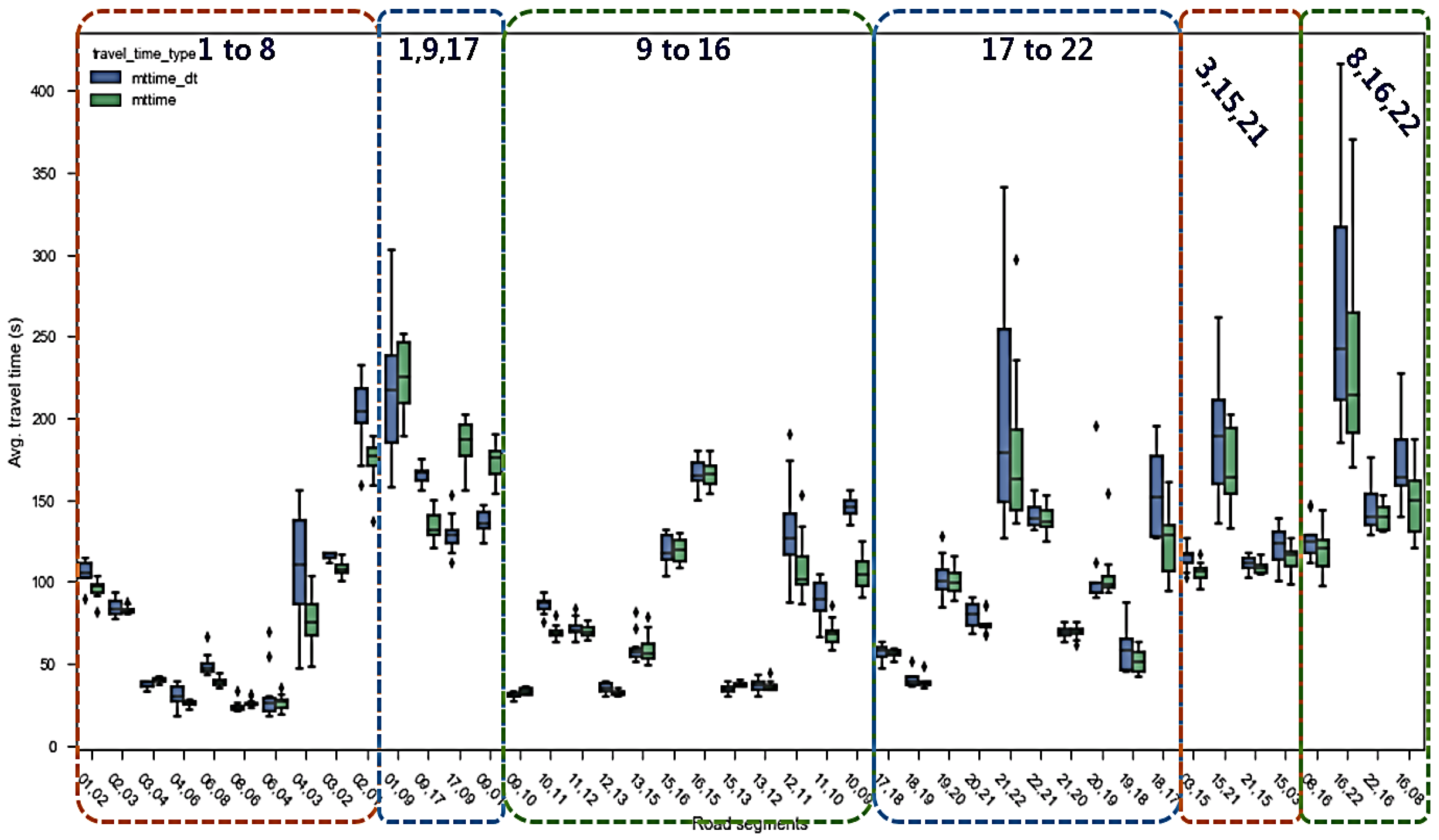
4.1.2. Link Average Speed
4.1.3. Average Travel Time
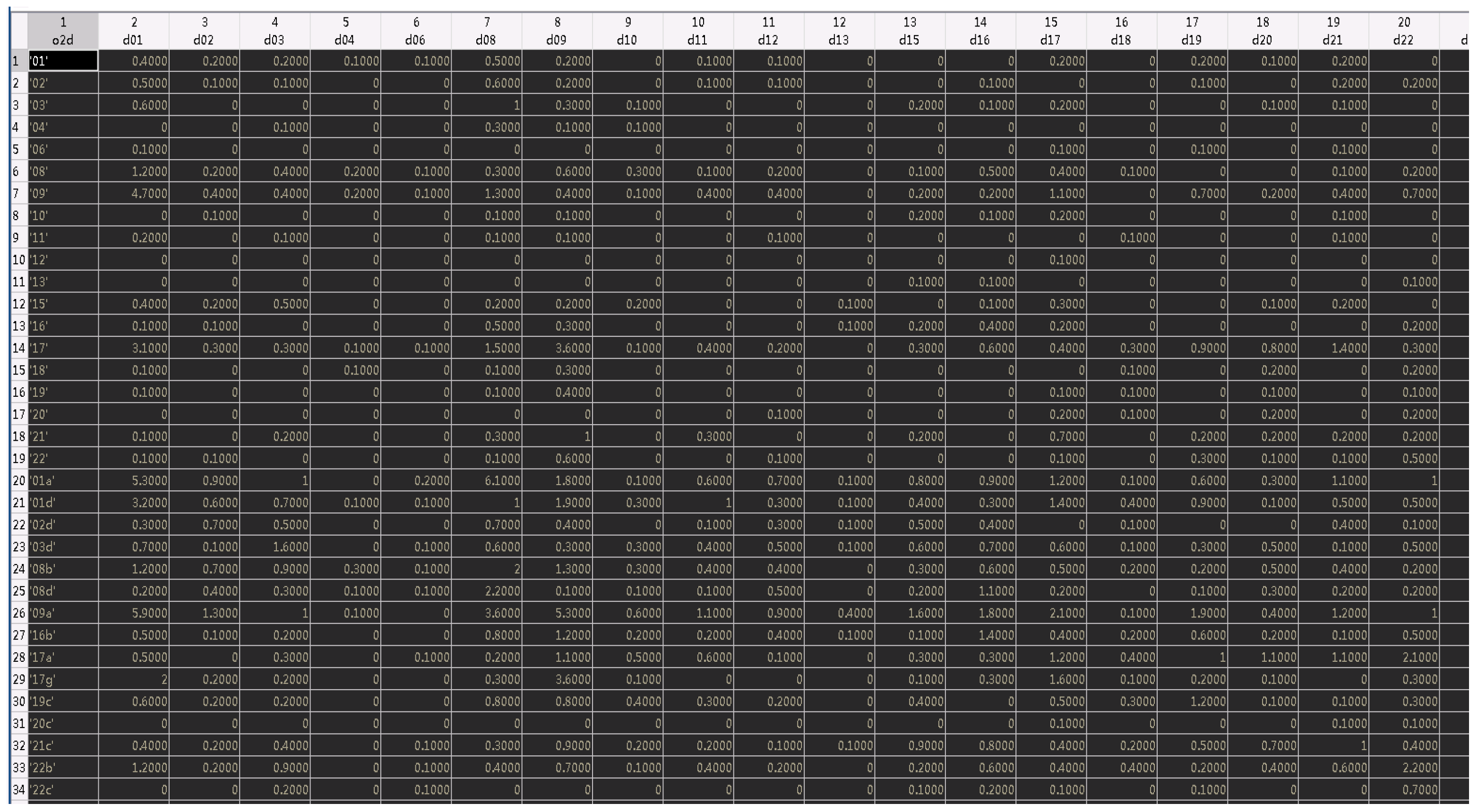
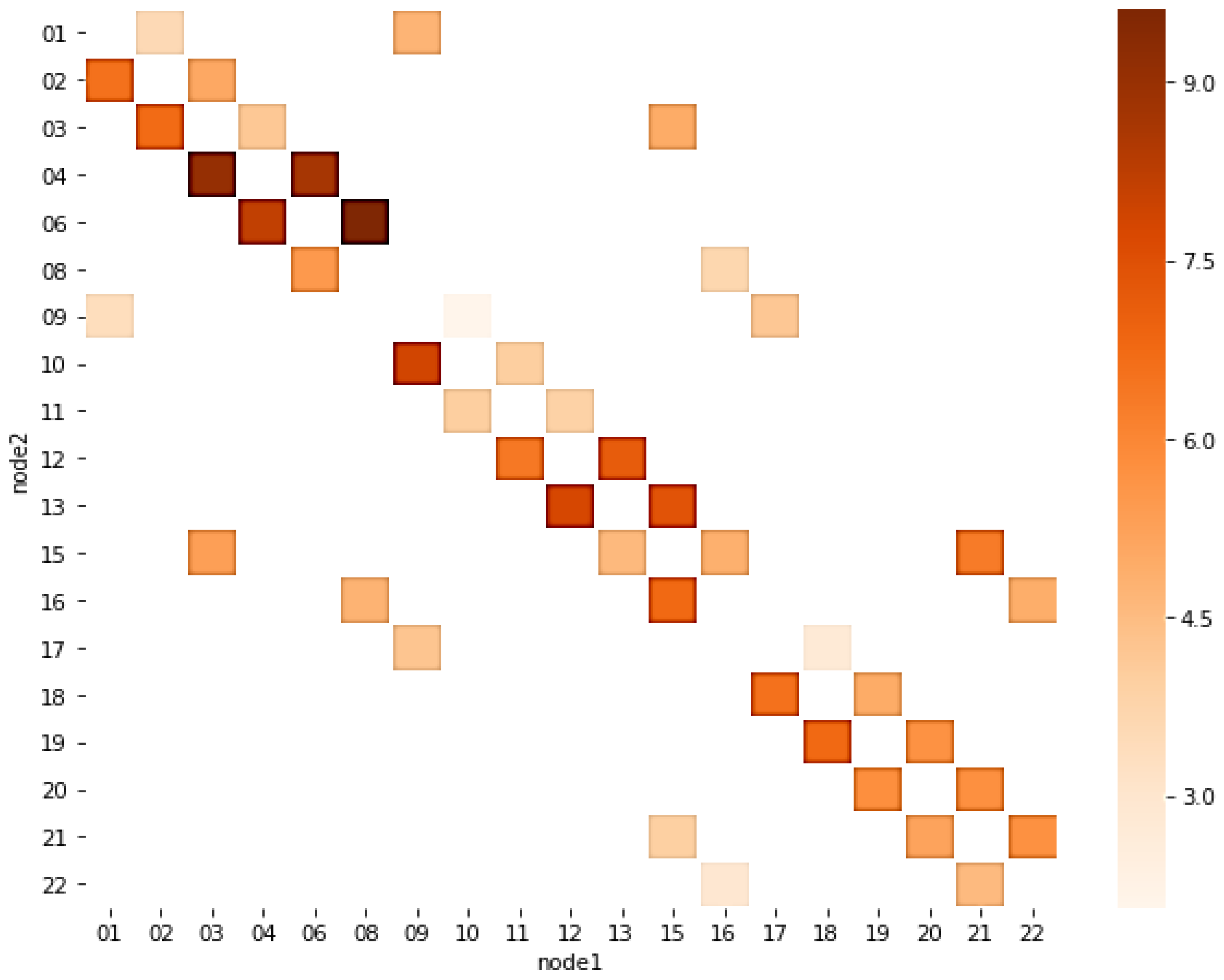
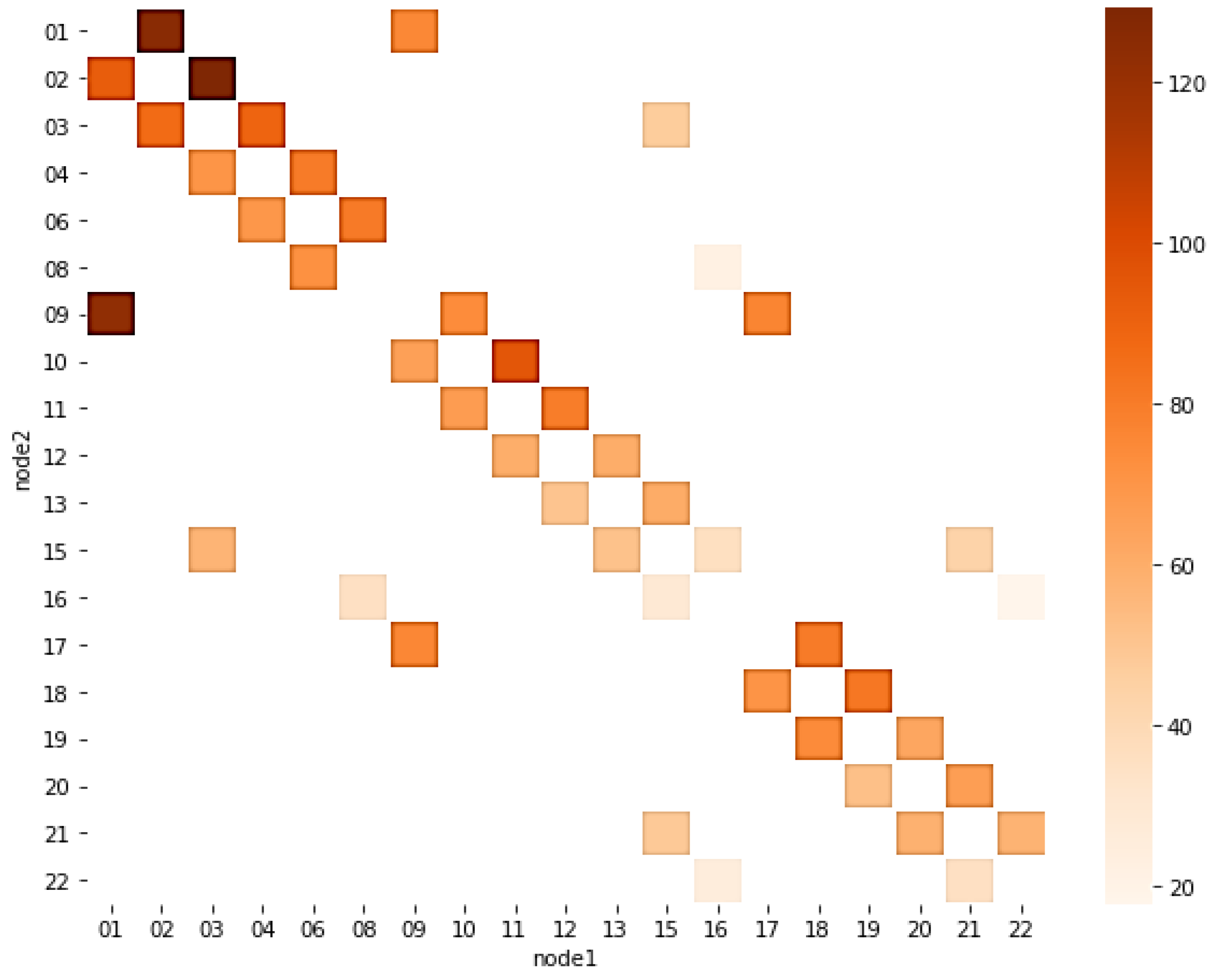
4.1.4. OD Matrix Analysis
4.2. Visualization Analysis
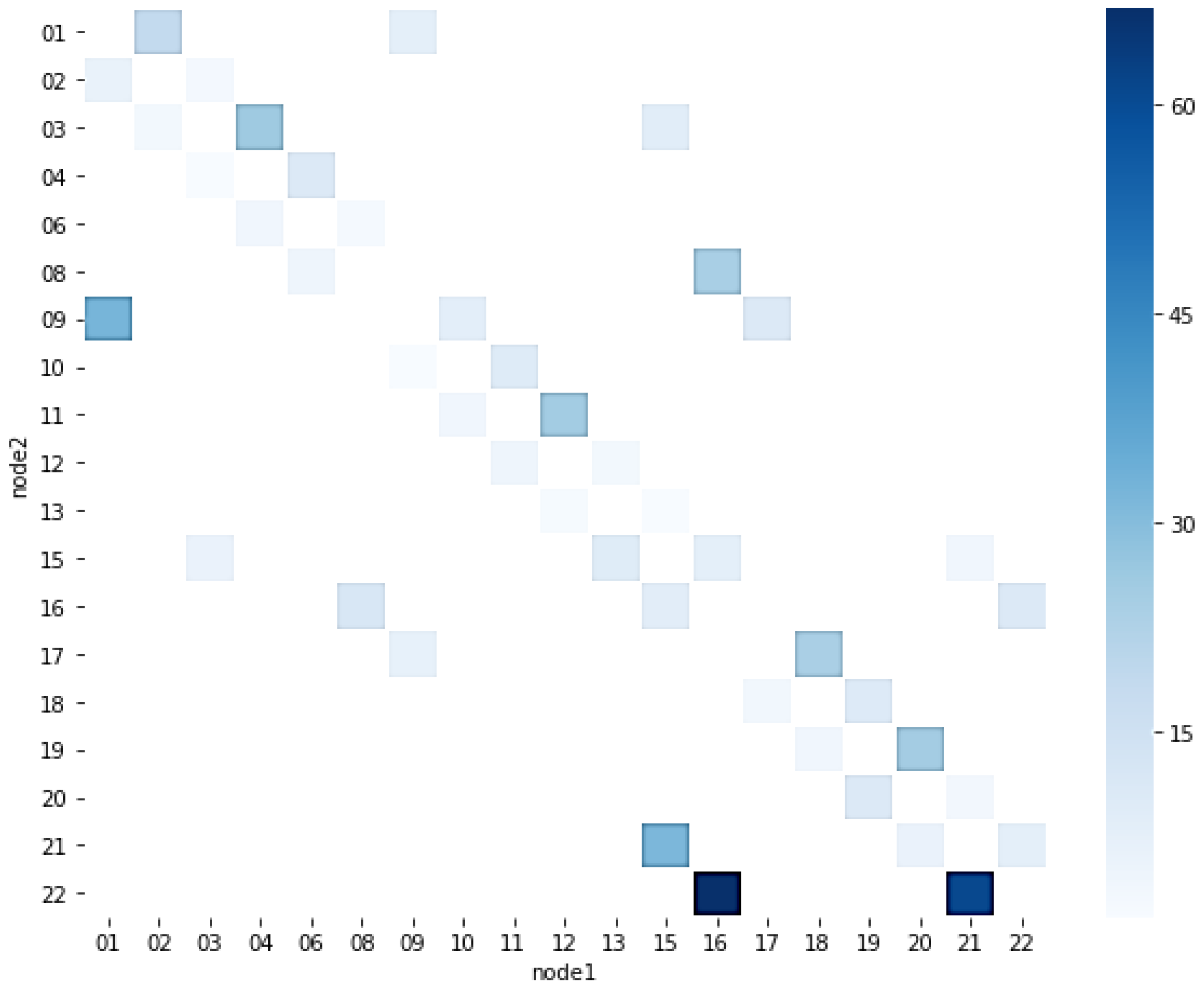
4.2.1. Stop Point Density Analysis
4.2.2. Link Traffic Flow Direction Characteristic Analysis
4.2.3. OD Distribution Visualization Analysis
4.2.4. Traffic Parameter Volatility Analysis
5. Guidance of Traffic Parameters for Signal Control Optimization
5.1. Guidance for Coordination Control Subarea Division
- (1)
- Intersections 1, 9, 17 subarea: forming an east–west arterial coordination system
- (2)
- Intersections 2–8 subarea: constituting a north–south major arterial coordination system
- (3)
- Intersections 10–16 subarea: covering the central area network
- (4)
- Intersections 18–22 subarea: controlling peripheral area traffic flows
5.2. Decision Support for Offset Optimization
- (1)
- Basic offset determination: Calculate typical travel times between adjacent intersections based on link average travel times. For instance, if a link’s average travel time is 45 s, the basic offset should be set as an integer multiple of 45 s to ensure vehicles can pass through downstream intersections during green phases.
- (2)
- Dynamic adjustment strategy: For links with high speed fluctuations (such as link ‘4,6’ and links ‘21,22’ and ‘16,22’ in the experimental results), offsets need fine-tuning based on speed distribution standard deviations. When standard deviations are large, safety margins for offsets should be appropriately increased to prevent vehicles from missing green phases due to speed fluctuations.
- (3)
- Tidal phenomenon response: Pronounced directional imbalances exist during morning peak periods. Through analyzing bidirectional flow ratios and speed differences, offsets can be optimized accordingly. Experimental data indicates that directions 8–1, 16–9, and 22–17 (reverse green waves) carry substantial flows during morning peaks, warranting increased green wave bandwidth in these directions with corresponding offset adjustments to match actual demands.
- (4)
- Multi-path coordination: Based on OD matrix analysis, identify primary traffic flow paths and ensure offset settings along critical paths can form continuous green wave effects. This multi-path offset optimization approach can enhance overall network operational efficiency.
5.3. Oversaturation State Identification and Control
- (1)
- Stop point density identification: Through analyzing the spatial distribution of vehicle stop points, congestion hotspots can be intuitively identified. Experimental results indicate that intersections 1, 2, 3, 9, and 17 exhibit significantly higher stop densities than other areas, with the northbound approaches at intersections 1 and 2 being most severe.
- (2)
- Travel time volatility analysis: Standard deviations of link travel times reflect traffic flow stability. Large standard deviations indicate that links are prone to cycles of congestion formation and dissipation, representing potential bottleneck segments.
- (3)
- Queue length estimation: Based on stop point density and vehicle trajectories, queue lengths at various approaches can be estimated. When queue lengths approach link lengths, queue spillback risks exist.
- (1)
- Travel time reduction: In offset optimization, apply travel time reductions for links prone to queue spillback, reserving buffer space to absorb queue fluctuations.
- (2)
- Gating control: When links experience oversaturation, appropriately shorten green times for traffic entering the area, preventing or gating large vehicle volumes from entering to avoid regional gridlock.
- (3)
- Evacuation priority: Appropriately extend green times at congested area exits to accelerate vehicle evacuation from the area, alleviating internal congestion.
5.4. Signal Control Scheme Evaluation System
- (1)
- Microscopic level: Vehicle-level indicators including number of stops, travel times, and speed fluctuations, reflecting individual travel experiences
- (2)
- Mesoscopic level: Link average speeds, flows, densities, and other indicators, evaluating link operational efficiency
- (3)
- Macroscopic level: Network average speeds, total delays, system throughput, and other indicators, measuring overall performance
5.5. Data Support for Intelligent Control Algorithms
- (1)
- Feature engineering for machine learning models: Extracted parameters including link flows, speeds, densities, and travel times can directly serve as feature inputs for machine learning models. Compared with traditional single-flow data, multi-dimensional features can more comprehensively describe traffic states, improving model prediction accuracy and generalization capability. Features include:
- Temporal features: Flow and speed variations across different time periods
- Spatial features: Correlation parameters of upstream and downstream links
- State features: Indicators reflecting saturation levels such as density and queue lengths
- (2)
- Application of Bayesian optimization: Average travel time parameters can be combined with Gaussian process-based Bayesian optimization methods to achieve intelligent offset optimization. Advantages of Bayesian optimization include:
- Capability to handle nonlinear and non-convex optimization problems
- High sample efficiency, suitable for computationally expensive scenarios
- Ability to quantify uncertainty, providing robust optimization results
- (3)
- State space for reinforcement learning: For more complex adaptive signal control, extracted traffic parameters can constitute the state space for reinforcement learning:
- Current state: Real-time density, speed, and queue lengths for each link
- Historical state: Parameter change trends over the past several cycles
- Predicted state: Future flow predictions based on OD matrices
6. Conclusions and Future Directions
6.1. Main Conclusions
6.1.1. Method Effectiveness Validated
6.1.2. Technical Innovations Hold Significant Value
6.1.3. Parameter Extraction Results Accurately Reflect Network State
6.1.4. Practical Value Fully Demonstrated
6.1.5. Research Limitations and Assumptions
6.2. Future Directions
6.2.1. Algorithm Optimization Directions
6.2.2. Accuracy Enhancement Strategies
6.2.3. Application Extension Directions
6.3. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GPS | Global Positioning System |
| ID | Identifier |
| OD | Origin–Destination |
References
- Ni, D.; Wang, H. Trajectory reconstruction for travel time estimation. J. Intell. Transp. Syst. 2008, 12, 113–125. [Google Scholar] [CrossRef]
- Cao, Q.; Zhao, Z.; Zeng, Q.; Wang, Z.; Long, K. Real-Time Vehicle Trajectory Prediction for Traffic Conflict Detection at Unsignalized Intersections. J. Adv. Transp. 2021, 2021, 8453726. [Google Scholar] [CrossRef]
- Shang, Y.; Li, X.; Jia, B.; Yang, Z.; Liu, Z. Freeway traffic state estimation method based on multisource data. J. Transp. Eng. Part A Syst. 2022, 148, 04022005. [Google Scholar] [CrossRef]
- Lai, W.K.; Kuo, T.H.; Chen, C.H. Vehicle speed estimation and forecasting methods based on cellular floating vehicle data. Appl. Sci. 2016, 6, 47. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Zhang, X.; Lv, M. Estimation and Reliability Research of Post-Earthquake Traffic Travel Time Distribution Based on Floating Car Data. Appl. Sci. 2022, 12, 9129. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, L.; Wang, L.; Xie, X. Learning transportation mode from raw GPS data for geographic applications on the web. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 247–256. [Google Scholar]
- Li, J.; Pei, X.; Wang, X.; Yao, D.; Zhang, Y.; Yue, Y. Transportation mode identification with GPS trajectory data and GIS information. Tsinghua Sci. Technol. 2021, 26, 403–416. [Google Scholar] [CrossRef]
- Sadeghian, P.; Håkansson, J.; Zhao, X. Review and evaluation of methods in transport mode detection based on GPS tracking data. J. Traffic Transp. Eng. Engl. Ed. 2021, 8, 467–482. [Google Scholar] [CrossRef]
- Zeng, J.; Yu, Y.; Chen, Y.; Yang, D.; Zhang, L.; Wang, D. Trajectory-as-a-sequence: A novel travel mode identification framework. Transp. Res. Part C Emerg. Technol. 2023, 146, 103957. [Google Scholar] [CrossRef]
- James, J.Q. Travel mode identification with GPS trajectories using wavelet transform and deep learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1093–1103. [Google Scholar]
- Sadeghian, P.; Golshan, A.; Zhao, M.X.; Håkansson, J. A deep semi-supervised machine learning algorithm for detecting transportation modes based on GPS tracking data. Transportation 2024, 52, 1745–1765. [Google Scholar] [CrossRef]
- Ma, Y.; Guan, X.; Cao, J.; Wu, H. A multi-stage fusion network for transportation mode identification with varied scale representation of GPS trajectories. Transp. Res. Part C Emerg. Technol. 2023, 150, 104088. [Google Scholar] [CrossRef]
- Zhou, X.; Mahmassani, H.S. Dynamic origin-destination demand estimation using automatic vehicle identification data. IEEE Trans. Intell. Transp. Syst. 2006, 7, 105–114. [Google Scholar] [CrossRef]
- Rao, W.; Wu, Y.J.; Xia, J.; Ou, J.; Kluger, R. Origin-destination pattern estimation based on trajectory reconstruction using automatic license plate recognition data. Transp. Res. Part C Emerg. Technol. 2018, 95, 29–46. [Google Scholar] [CrossRef]
- Shi, C.; Zou, W.; Wang, Y.; Zhu, Z.; Chen, T.; Zhang, Y.; Wang, N. Enhancing Travel Time Prediction for Intelligent Transportation Systems: A High-Resolution Origin–Destination-Based Approach with Multi-Dimensional Features. Sustainability 2025, 17, 2111. [Google Scholar] [CrossRef]
- Sun, S.; Chen, J.; Sun, J. Traffic congestion prediction based on GPS trajectory data. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719847440. [Google Scholar] [CrossRef]
- Kong, X.; Xu, Z.; Shen, G.; Wang, J.; Yang, Q.; Zhang, B. Urban traffic congestion estimation and prediction based on floating car trajectory data. Future Gener. Comput. Syst. 2016, 61, 97–107. [Google Scholar] [CrossRef]
- Qu, D.; Liu, H.; Song, H.; Meng, Y. Extraction of Catastrophe Boundary and Evolution of Expressway Traffic Flow State. Appl. Sci. 2022, 12, 6291. [Google Scholar] [CrossRef]
- Ranjan, S.; Kim, Y.C.; Ranjan, N.; Bhandari, S.; Kim, H. Large-scale road network traffic congestion prediction based on recurrent high-resolution network. Appl. Sci. 2023, 13, 5512. [Google Scholar] [CrossRef]
- Kumar, N.; Raubal, M. Applications of deep learning in congestion detection, prediction and alleviation: A survey. Transp. Res. Part C Emerg. Technol. 2021, 133, 103432. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Category | Parameter Name | Type | Input Function | Output Function | Description |
|---|---|---|---|---|---|
| Input Parameters | gon_radius | double | makePolygon2; routeDiagnose | - | Circumscribed circle radius of the regular polygon representing node entry/exit range (referred to as node regular polygon) |
| gon_nvert | double | makePolygon2 | - | Number of vertices (i.e., sides) of the node regular polygon | |
| traj | table | plotRoad; nodeDigger | - | Trajectory data | |
| inter_origin | table | makePolygon2; plotRoad; routeInfer | - | Node data | |
| vinfo | table | routeInfer | - | Vehicle basic feature data | |
| figurepath | char | - | - | Parent path for image storage | |
| route_dialog | Empty matrix or table | routeDiagnose | - | Abnormal path vehicle statistical data | |
| Temporary Parameters | gonxy | cell | nodeDigger | makePolygon2 | Vertex coordinates of all node regular polygons |
| roadfig | figure | - | plotRoad | Visualization of nodes and node regular polygons | |
| node | double | routeInfer | nodeDigger | Index of nodes to which vehicle trajectory points belong | |
| route2 | table | routeDiagnose | routeInfer | Vehicle path data (without ‘00’ nodes, adjacent nodes not merged for individual vehicles) | |
| route3 | table | routeDiagnose | routeInfer | Vehicle path data (without ‘00’ nodes, adjacent nodes merged as strings and vectors for individual vehicles) | |
| route_diag_0 | table | - | routeDiagnose | Vehicle path data passing through 0 nodes | |
| route_diag_1 | table | - | routeDiagnose | Vehicle path data passing through 1 node | |
| Output Parameters | route_dialog_out | table | - | routeDiagnose | Statistics of vehicles passing through 0 and 1 nodes |
| route_struct | struct | - | - | Final output of vehicle path data, containing gon_radius, gon_nvert, roadfig, node, route2, route3, route_diag_0, route_diag_1, gonxy |
| Function Name | Main Input Parameters | Output Parameters | Description |
|---|---|---|---|
| makePolygon2 | inter_origin; gon_radius; gon_nvert | gonxy | Given a set of centers, circumscribed circle radii, and corresponding regular polygon sides, outputs a set of regular polygon coordinates |
| plotRoad | traj; inter_origin | roadfig | Road network visualization function; besides this application scenario, inputting more parameters can satisfy various visualization requirements |
| nodeDigger | traj; gonxy | node | Input trajectory data and regular polygon coordinates, output regular polygon numbers corresponding to trajectory points |
| routeInfer | node, vinfo, mode; inter_origin | route2, route3 | Output various vehicle path data |
| routeDiagnose | route3, mode, route2, gon_radius, route_dialog | route_diag_0; route_diag_1; route_diag_out | Input vehicle path data and content requiring diagnosis or supplementation (mode), output required features or data |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Liu, Y.; Yang, X. A Novel Method for Traffic Parameter Extraction and Analysis Based on Vehicle Trajectory Data for Signal Control Optimization. Appl. Sci. 2025, 15, 7155. https://doi.org/10.3390/app15137155
Wang Y, Liu Y, Yang X. A Novel Method for Traffic Parameter Extraction and Analysis Based on Vehicle Trajectory Data for Signal Control Optimization. Applied Sciences. 2025; 15(13):7155. https://doi.org/10.3390/app15137155
Chicago/Turabian StyleWang, Yizhe, Yangdong Liu, and Xiaoguang Yang. 2025. "A Novel Method for Traffic Parameter Extraction and Analysis Based on Vehicle Trajectory Data for Signal Control Optimization" Applied Sciences 15, no. 13: 7155. https://doi.org/10.3390/app15137155
APA StyleWang, Y., Liu, Y., & Yang, X. (2025). A Novel Method for Traffic Parameter Extraction and Analysis Based on Vehicle Trajectory Data for Signal Control Optimization. Applied Sciences, 15(13), 7155. https://doi.org/10.3390/app15137155