1. Introduction
Information and Communication Technologies (ICTs) play a critical role in the delivery of health services and are commonly referred to as components of digital health [
1]. These technologies provide a range of administrative benefits, including increased efficiency and cost reduction, as well as clinical benefits, such as the implementation of electronic prescriptions and electronic health records [
2]. Among the various digital health tools, Artificial Intelligence (AI) has emerged as a valuable resource for supporting clinical decision-making by healthcare teams [
3]. Within the field of AI, Natural Language Processing (NLP) stands out as a key area focused on developing methods that enable computers to understand, interpret, and generate human language in a natural and contextually relevant manner [
4].
Large Language Models (LLMs) are advanced AI systems based on the transformer architecture [
5] and trained using Natural Language Processing (NLP) techniques on vast amounts of textual data. This foundation enables them to learn complex language patterns and generate coherent, contextually appropriate responses [
6]. Examples of LLMs include proprietary models such as OpenAI’s ChatGPT, Microsoft’s Copilot, and Google’s Gemini, as well as open-source alternatives like Meta’s LLaMA and Alibaba’s Qwen. These generative models are designed to produce meaningful and relevant text based on a given input [
6], and they are widely applied in tasks such as chatbots, virtual assistants, content creation, and machine translation.
Generative LLMs have significant potential for application in the healthcare domain [
7,
8,
9], particularly in areas such as clinical decision support and health education. Clinical decision support systems are tools designed to assist healthcare professionals in making informed decisions related to diagnosis, treatment, and patient management [
10]. Within these systems, generative LLMs can produce contextually relevant text that helps clinicians access accurate, up-to-date information on medical conditions, treatment options, and clinical guidelines. In the context of medical education, generative LLMs can support learning by generating tailored educational content for students and non-specialist health professionals [
11,
12].
The work of health professionals is multifaceted and challenging, involving health promotion, disease prevention, diagnosis, patient treatment, and contributing to the management of health services. For this reason, the Brazilian Ministry of Health annually applies the National Exam for the Revalidation of Medical Diplomas Issued by Foreign Higher Education Institutions (a.k.a., Revalida). It was established by Law number 13,959, 18 December 2019, and is periodically applied by the Anísio Teixeira National Institute for Educational Studies and Research (INEP). The purpose of the exam is to “increase the provision of medical services in the national territory and guarantee the regularity of the revalidation of foreign medical diplomas” [
13].
LLMs have demonstrated the ability to process and generate text related to a variety of technical domains, including in medical licensing examinations worldwide [
14]. Based on this, we hypothesize that generative LLMs can produce relevant and contextually appropriate answers to domain-specific questions in Brazilian Portuguese (PT-BR). To explore this hypothesis, we selected the Revalida as the evaluation context. This exam is conducted in PT-BR and includes questions that require familiarity with specialized medical vocabulary, clinical guidelines, and public health concepts. The use of Revalida offers a realistic and linguistically appropriate benchmark to investigate how well current generative LLMs perform in a demanding healthcare context.
This study aimed to comparatively evaluate the performance of various generative LLMs on the multiple-choice questions from six editions (2017 to 2024) of the Revalida exam. The evaluation focuses on models capable of processing content in PT-BR, the official language of the exam. The LLMs assessed include open-source models, specifically LLaMA 3.1 (8B parameters) [
15] and Qwen 2.5 (7B parameters) [
16], as well as open-access commercial models (GPT-3.5, GPT-4o, and Gemini). In addition, we evaluated distilled reasoning-oriented variants based on the DeepSeek-R1 [
17] architecture, using the same LLaMA and Qwen model versions. This design enables a comparative analysis of both general-purpose and reasoning-optimized LLMs in a high-stakes, domain-specific context.
Another key objective of this study was to assess the ability of the top-performing model to justify its answers. The LLM that achieved the highest performance in the initial evaluation was tasked with answering the 2024 Revalida exam and generating explanations for its responses. These answers and justifications were then independently reviewed by three licensed physicians to qualitatively evaluate the alignment of LLM’s reasoning with medical knowledge and practice. Additionally, we constructed a domain-specific knowledge base by prompting GPT-4o to generate justifications for questions from five Revalida editions (2017–2023). These justifications were later used to enhance GPT-4o via retrieval-augmented generation (RAG) [
18,
19] and to fine-tune LLaMA. Both enhanced models were subsequently evaluated on the 2024 edition of the Revalida exam.
The remainder of the article is organized as follows.
Section 2 reviews related work and highlights the contributions of this study.
Section 3 describes materials and methods used in our study.
Section 4 presents the results of the study.
Section 5 follows with an analysis of the findings, including a discussion of their implications and the study’s limitations. Finally,
Section 6 offers the concluding remarks.
2. Related Work
Recent studies have investigated the performance of generative LLMs in medical licensing examinations across different countries [
14]. ChatGPT, particularly in its GPT-3.5 and GPT-4 versions, has been the subject of growing interest in the context of medical education. One of the early benchmarks was the study by Kung et al. [
20], which assessed ChatGPT using the GPT-3.5 model on the United States Medical Licensing Examination (USMLE), a multistep exam required for medical licensure in the U.S. The results indicated that GPT-3.5 achieved a score sufficient to pass the exam, demonstrating the potential of LLMs to handle complex, domain-specific assessments in the medical field.
Wang, X. et al. [
21] evaluated the performance of ChatGPT using the GPT-3.5 model on the Chinese National Medical Licensing Examination (CNMLE), a mandatory exam for practicing medicine in China. The study compared ChatGPT’s responses with the performance of medical students who took the exam between 2020 and 2022, and found that GPT-3.5 performed worse than the students. In a similar study, Wang H. et al. [
22] assessed ChatGPT using both GPT-3.5 and GPT-4 on the CNMLE and its English-translated version (ENMLE). Their findings showed that GPT-4 passed the exam in both Chinese and English, whereas GPT-3.5 failed to pass the CNMLE but succeeded in the English version. The authors concluded that LLMs, particularly GPT-4, could support the understanding of medical knowledge in the Chinese context and contribute to the advancement of medical education in China.
Roos et al. [
23] evaluated the performance of ChatGPT (GPT-3.5 Turbo and GPT-4) and Microsoft Bing (an earlier version of Copilot) on the 2022 German Medical State Examination, a mandatory test conducted in German for obtaining a medical license in Germany. The study also compared the performance of these models with that of medical students. Results showed that GPT-4 achieved the highest accuracy, correctly answering 88.1% of the questions, followed by Bing with 86.0%, and GPT-3.5 Turbo with 65.7%. In comparison, the average score among students was 74.6%.
Gobira et al. [
24] conducted the first study to assess the performance of a LLM on the Revalida. Using ChatGPT powered by GPT-4, the authors assessed its responses to the multiple-choice questions from the 2022 second-semester edition. Two independent physicians reviewed and classified the model’s answers as adequate, inadequate, or indeterminate, resolving any disagreements through consensus. Excluding discursive and image-based items, the model achieved an overall accuracy of 87.7% on the non-nullified questions. Although performance varied slightly across medical domains, no statistically significant differences were found. Accuracy dropped to 71.4% on questions later annulled by the exam authority (i.e., INEP), suggesting lower clarity or quality in those items. The authors concluded that GPT-4 performed satisfactorily and could be useful for evaluating exam quality while noting its limitations in handling ethically complex or public health-related content.
This study offers several key contributions to the evaluation of generative LLMs in the medical domain, with a specific focus on the Brazilian context. Unlike previous research that often centers on a single model or exam edition, our work evaluates three major commercial LLMs and four open-source models (both in their original and reasoning-optimized versions) across six editions of the Revalida exam. This represents one of the most comprehensive benchmarking efforts conducted to date using a real, high-stakes medical licensing exam administered in PT-BR. By leveraging a standardized and government-administered assessment as the evaluation framework, our study provides a replicable, policy-relevant, and linguistically appropriate benchmark for future research. The inclusion of both proprietary and open-source models enables a broad comparative analysis. Another distinctive contribution lies in the qualitative evaluation of GPT-4o’s explanations, allowing for the assessment of not just answer correctness, but also the clinical relevance of the model’s reasoning. Additionally, domain adaptation strategies are investigated by using GPT-4o-generated justifications from previous exams to construct a knowledge base, which is then used to enhance GPT-4o through RAG and fine-tune LLaMA.
3. Materials and Methods
This study was conducted in six sequential phases. First, the Revalida exams from 2017 to 2024 were collected. Next, the questions were prepared as input for LLMs. In the third phase, questions from the 2017 to 2023 exams were submitted to seven LLMs using zero-shot prompt engineering, and the generated answers were recorded in CSV files. These responses were then compared with the official answer keys to evaluate the models’ performance using quantitative metrics. In the fifth phase, the LLM that had achieved the highest performance in the previous comparison was also tasked with answering the 2024 Revalida exam and generating explanations for its answers (i.e., answer justifications). The responses and explanations were then independently reviewed by three physicians. In the final phase, answer justifications generated by GPT-4o for correctly answered questions from the 2017 to 2023 exams were curated and compiled into a structured knowledge base. This knowledge base was used in two downstream approaches: RAG with GPT-4o and fine-tuning of the LLaMA model. Both enhanced models were then evaluated on the 2024 Revalida exam to assess performance gains. Each of these phases is described in detail in the subsections that follow.
3.1. Data Collection
The objective tests from the last six editions of the Revalida exam (2017 to 2024) were collected from the official Inep website, which provides access to all exam editions along with their respective answer keys. Revalida is typically held annually and consists of two stages. The first stage includes both an objective and a subjective test. The objective test comprises 100 multiple-choice questions, each with a single correct answer worth 1 point, for a maximum score of 100 points. The subjective (i.e., discursive) test usually includes five questions, each valued at 10 points. The second stage assesses various clinical skills. To advance from one stage to the next, applicants must meet the minimum score established in the exam’s official guidelines. For this study, we focused exclusively on the objective tests from the following years:
In 2017: Two versions of the exam were administered, distinguished by colour (blue and red);
In 2020: Two editions were held, labelled 2020.01 and 2020.02.
In 2021: Only one version of the exam was administered.
In 2022: Two editions were conducted, identified as 2022.01 and 2022.02.
In 2023: Two editions were conducted, labelled 2023.01 and 2023.02.
In 2024: The exam used was the version identified as 2024.01.
In total, the tests collected for this study comprised 1000 multiple-choice questions.
3.2. Data Preparation
Two filters were applied to select the objective questions suitable for inclusion in the study. The first filter excluded any questions containing images or tables (often embedded as images). This step ensured a fair comparison across the LLMs, as not all models are capable of multimodal analysis, that is, interpreting inputs in formats other than plain text. The second filter removed questions that had been annulled by the exam board due to the absence of a correct answer in the official answer key.
After applying these filters, a total of 771 objective questions from the 2017 to 2023 exams were retained for the quantitative analysis. Additionally, 86 questions from the 2024 exam were selected for the analysis involving answer explanations. All selected questions were organized into a CSV file for processing, with appropriate identifiers for each exam version.
3.3. Assessing Models
We evaluated a total of seven models: four open-source small LLMs (i.e., from 7 to 8 billion parameters [
25]) and three open-access commercial LLMs. Open-access commercial LLMs are developed by private companies and made available to the public, typically through web interfaces or APIs. While users can interact with these models, sometimes for free, the underlying code and training data are not openly shared, and their use is governed by specific terms of service. Open-source LLMs, on the other hand, are released with open licenses, allowing broader access to their architecture, weights, and in some cases, their training datasets [
26]. This openness facilitates transparency, customization, and reproducibility in research. Among the four open-source models evaluated, two were specifically designed as reasoning models. These models are fine-tuned or architecturally optimized to enhance their ability to handle tasks that require multi-step reasoning, logical inference, or complex problem-solving [
27]. These capabilities are particularly important in answering medical exam questions that go beyond surface-level recall.
The third phase of the study involved submitting the 771 previously selected questions (from the 2017 to 2023 exams) as input to the following LLMs:
The open-source LLMs utilized in this study were executed within Google Colaboratory (Colab), a cloud-based platform offering accessible computational resources for machine learning tasks. Specifically, the models ran on a virtual machine equipped with an NVIDIA Tesla T4 GPU, which features 16 GB of RAM. To optimize resource utilization and enable the execution of large models within Colab’s memory constraints, we employed 4-bit quantization using the Unsloth library [
31]. This quantization technique reduces the precision of model weights from the standard 32-bit floating-point format to 4 bits, significantly decreasing memory usage and computational load. While lower precision can introduce some loss in model accuracy, 4-bit quantization has been shown to maintain performance levels close to full-precision models for many tasks [
32]. Regarding hyperparameters, Unsloth’s default settings [
31] were utilized to maintain consistency and reproducibility across experiments.
Prompt engineering refers to the process of crafting optimized inputs to effectively leverage LLMs across various applications and research domains [
33]. A systematic approach to input design is essential to guide LLM responses in a coherent and contextually appropriate manner, while also ensuring consistent performance [
34,
35]. To fully harness the capabilities of LLMs, prompt engineering plays a critical role [
36]. One commonly used approach within prompt engineering is zero-shot prompting [
28,
37]. In this method, the model is given a task without any prior examples. The LLM generates its response based solely on the task description, relying on its internal knowledge, the language of the prompt, and any contextual cues provided [
38].
Zero-shot prompt engineering was adopted to place the LLMs under conditions similar to those of Revalida applicants, who must answer the exam questions based solely on their prior knowledge and without additional guidance. This approach also helps minimize potential biases introduced by fine-tuning or prompt adaptations tailored specifically for the study. As a result, it enables a more authentic and objective assessment of each model’s capabilities, relying exclusively on the robustness and comprehensiveness of the data used to train the LLMs.
For open-source LLMs, we utilized a pure zero-shot strategy by directly inputting the Revalida exam questions without any preceding instructions or contextual information. For commercial LLMs, we initiated each session with a brief instruction: “Can you answer health questions in the medical field?” (
Figure 1). This initial prompt served to orient the models toward the medical domain, ensuring that subsequent responses were contextually relevant to healthcare topics. Despite this preliminary instruction, the models were not provided with specific examples or additional guidance, maintaining the essence of zero-shot prompting.
To mitigate potential bias and ensure objectivity in the evaluation of commercial LLMs, two researchers independently submitted the questions to these models without access to the official answer keys. The responses were recorded separately in individual CSV files, allowing for cross-verification and minimizing transcription errors. In contrast, the evaluation of open-source models was fully automated through code execution using the Unsloth library and saved as a CSV file. This automation enabled direct batch input of all questions and systematic extraction of responses, eliminating human interaction during inference and ensuring consistency and reproducibility in the evaluation process.
3.4. Performance Measures
The data extracted from the CSV files was analyzed to assess the performance of the LLMs. Two key performance metrics were used in this study: hit rate (i.e., accuracy) and the fallback index. The hit rate represents the proportion of correct answers (based on the official answer key), relative to the total number of questions (as shown in Equation (
1)). In addition to calculating this metric, we conducted a descriptive statistical analysis to summarize the results and highlight patterns in model performance.
A fallback trigger occurs when an LLM fails to understand the input and provides a response that does not match any of the answer options presented in the question [
39]. This type of response can also be interpreted as a form of hallucination [
40,
41], where the model generates information that is irrelevant or inconsistent with the prompt. A fallback trigger may also take the form of a task rejection [
42], where the model explicitly states that it cannot answer the question or lacks the necessary knowledge (i.e., honesty). The fallback index is defined as the proportion of fallback triggers relative to the total number of questions (as shown in Equation (
2)).
Cohen’s Kappa coefficient [
43] was used to assess the level of agreement between the responses generated by the LLMs when the same questions were independently submitted by two researchers. This analysis was performed only for the commercial LLMs, as they were the ones evaluated through manual input by both researchers. Cohen’s Kappa is a widely used statistical measure that quantifies the degree of agreement between two raters or methods while accounting for agreement that may occur by chance. Data analysis and result visualization were performed using both Python 3.11.13 and R 4.5.0 languages.
3.5. Assessment of Answer Justifications
The fifth phase of the study focused on analyzing the explanations provided by GPT-4o for its responses to the 2024 Revalida exam. GPT-4o was selected for this analysis because it achieved the highest scores in the quantitative evaluation. This stage aimed to examine how the model justified each objective answer, offering insights into its underlying reasoning. The goal was not only to assess the accuracy of its responses but also to determine whether its justifications aligned with clinical reasoning and accepted medical practices. By evaluating the clarity and validity of these explanations, the study aimed to confirm that GPT-4o’s strong performance was grounded in coherent reasoning rather than random guesses.
For this qualitative analysis, a zero-shot prompt engineering approach (similar to the one used in the initial phase) was employed. However, this time the language model was instructed not only to select an answer but also to explain the reasoning behind its choice. At the beginning of each session, the prompt used was: “Can you answer health questions in the medical field? Present the line of reasoning used to answer each question.” Out of the 86 questions from the 2024 Revalida exam, GPT-4o correctly answered 76.
Three physicians (authors A.C., C.S., and R.A.) from different medical specialities (clinical oncology, geriatrics, and radiology), all of whom also teach medicine at the university level in Brazil, participated in this phase of the study. The answers and explanations generated by GPT-4o for the 76 questions it answered correctly were transcribed and made available to the physicians via Google Forms. For each question, they were asked to indicate whether they agreed with the explanation provided. This allowed the physicians to assess the alignment of GPT-4o’s reasoning with accepted medical knowledge and practice.
3.6. Knowledge Base Construction and Model Enhancement via RAG and Fine-Tuning
In the final phase of the study, domain adaptation techniques were applied to improve the performance of LLMs on the Revalida exam. These techniques included the construction of a knowledge base, RAG, and fine-tuning. The knowledge base was constructed using GPT-4o via the OpenAI API. Specifically, multiple-choice questions from the 2017 to 2023 Revalida exams were submitted to GPT-4o, which was prompted to generate a justification for its chosen answer. Only responses in which GPT-4o correctly identified the answer (matching the official answer key) were retained. The resulting justifications were compiled into a structured file representing a domain-specific knowledge base.
To evaluate the impact of RAG, this file was uploaded and used as an external knowledge source via the OpenAI API. GPT-4o was then prompted to answer the 2024 Revalida exam with RAG enabled, allowing the model to retrieve relevant information from the uploaded file during inference. This approach leveraged OpenAI’s native support for RAG through file-based retrieval, requiring no additional infrastructure for indexing or querying.
In parallel, a fine-tuning procedure was conducted to evaluate the benefits of integrating the same knowledge base into an open-source model. The fine-tuning of LLMs was performed on Google Colab. The training of the models was conducted using the Unsloth library [
31], which enables efficient fine-tuning of LLMs on GPUs with support for 4 bits. The fine-tuning was implemented using the parameter-efficient fine-tuning (PEFT) methodology [
44]. To optimize the fine-tuning process, the quantized low-rank adaptation (QLoRA) technique was employed [
45]. This method combines 4-bit quantization with low-rank matrix adaptations to the original model weights, significantly reducing memory consumption and computational costs while preserving model performance [
45].
The fine-tuning process was applied exclusively to the instruction-tuned version of LLaMA 3.1 (8B parameters). Instruction-tuned models are pre-trained on instruction-response datasets, which improves their ability to follow user prompts and align with intended tasks. Fine-tuning an instruction-tuned model, rather than a base model, offers several advantages, including reduced data requirements, better generalization, lower computational costs, and improved safety and reliability in downstream applications.
The configuration of QLoRA followed the default hyperparameters provided by the Unsloth library. The model was trained with a maximum sequence length of 2048, ensuring internal support for Rotary Position Embedding (RoPE) scaling. The training loop was executed with a per-device batch size of 2, alongside gradient accumulation steps set to 4 to balance computational load and stability. A total of 60 training steps were conducted, with a learning rate of 2 and 5 warm-up steps, allowing a measured adaptation of weight updates to ensure optimal convergence. The optimization process leveraged the 8-bit AdamW to enhance efficiency, complemented by a linear learning rate scheduler to moderate learning dynamics smoothly. Furthermore, a weight decay of 0.01 was incorporated to mitigate overfitting risks.
The classification model was fine-tuned using the following prompt format (
Figure 2):
Finally, model performance was evaluated on the 2024 edition of the Revalida exam. Accuracy was also used as the primary metric to assess the effectiveness of both the RAG-enhanced GPT-4o and the fine-tuned LLaMA 3.1 model.
5. Discussion
5.1. Principal Findings
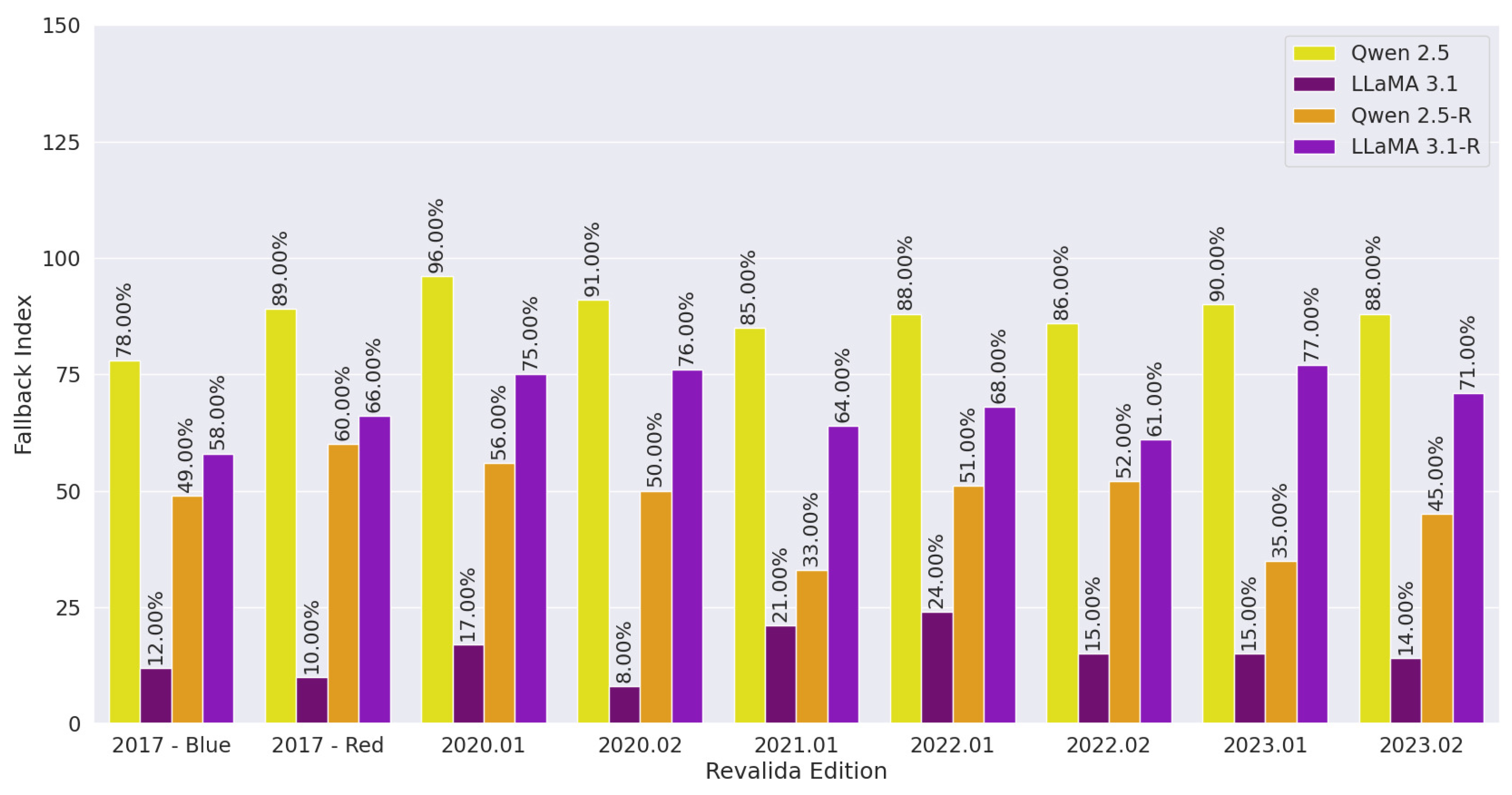
The evaluation of small LLMs reveals both performance and reliability challenges when applied to complex medical exam tasks. Among the models tested, Llama 3.1 consistently achieved the highest accuracy, although the absolute values remained low, never exceeding 22%. This indicates a significant gap between the reasoning demands of the Revalida exam and the current capabilities of these models. The reasoning-augmented versions of the models did not show substantial gains in accuracy, suggesting that simply prompting for more explicit reasoning is not sufficient to improve outcomes. Furthermore, these reasoning variants exhibited higher fallback rates, often producing hallucinations or off-topic responses, or explicitly rejecting the task. Llama 3.1 maintained a more favourable balance, combining the best accuracy with relatively lower fallback behaviour. These findings suggest that while reasoning prompts may increase caution or refusal in model responses, they do not yet translate into improved correctness.
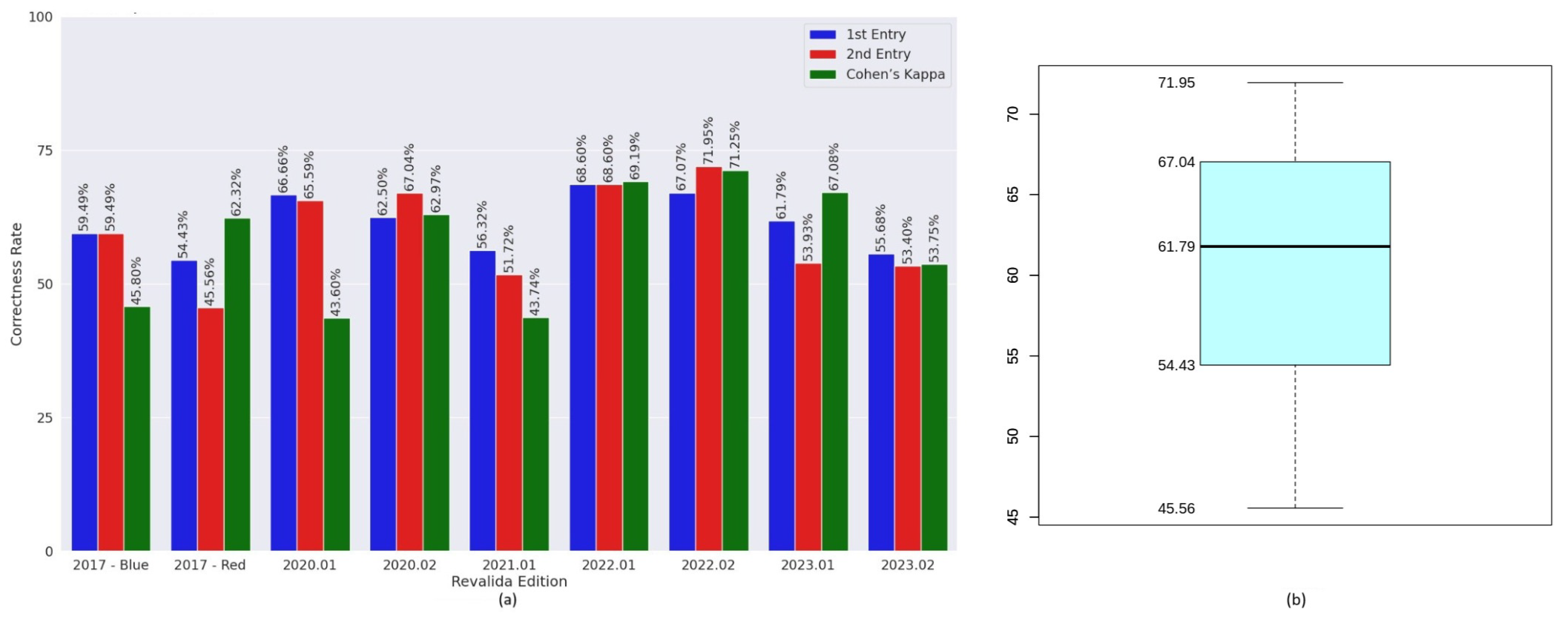
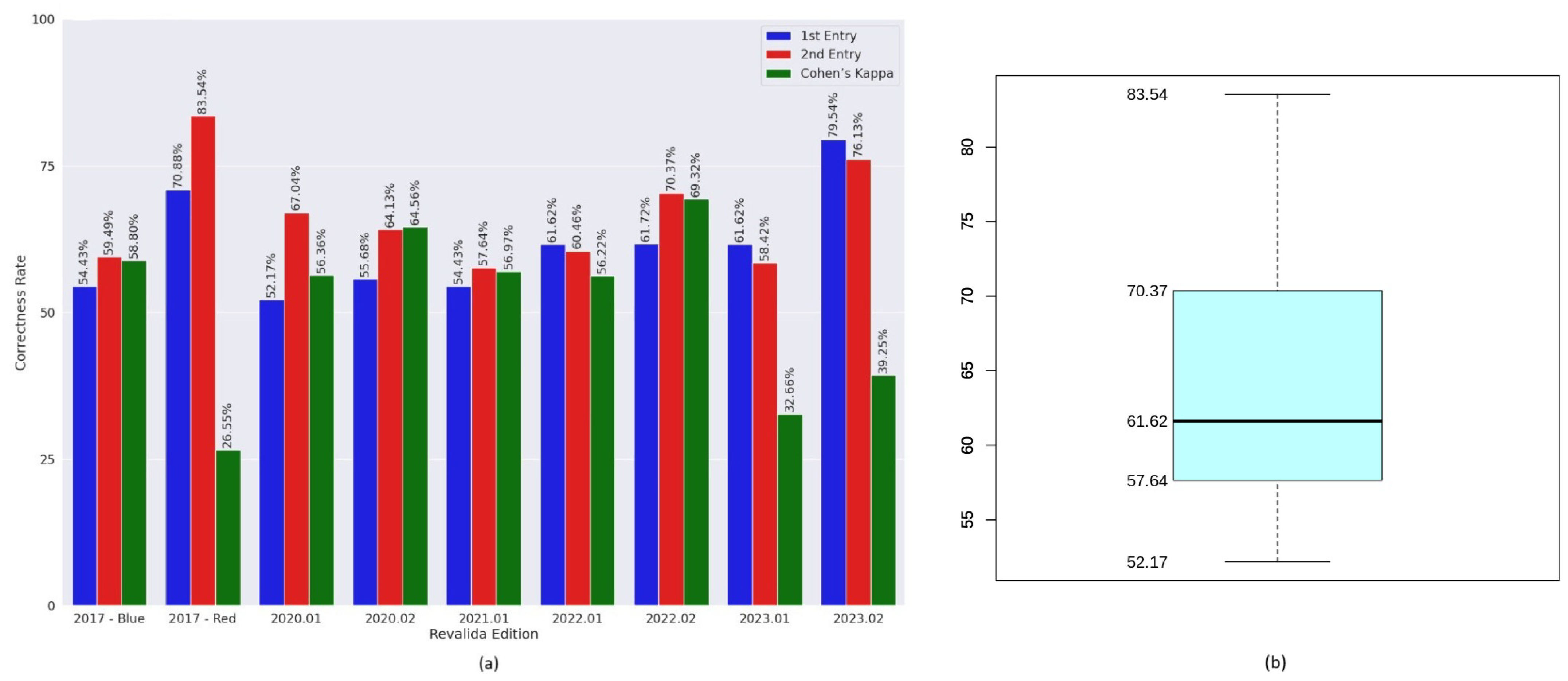
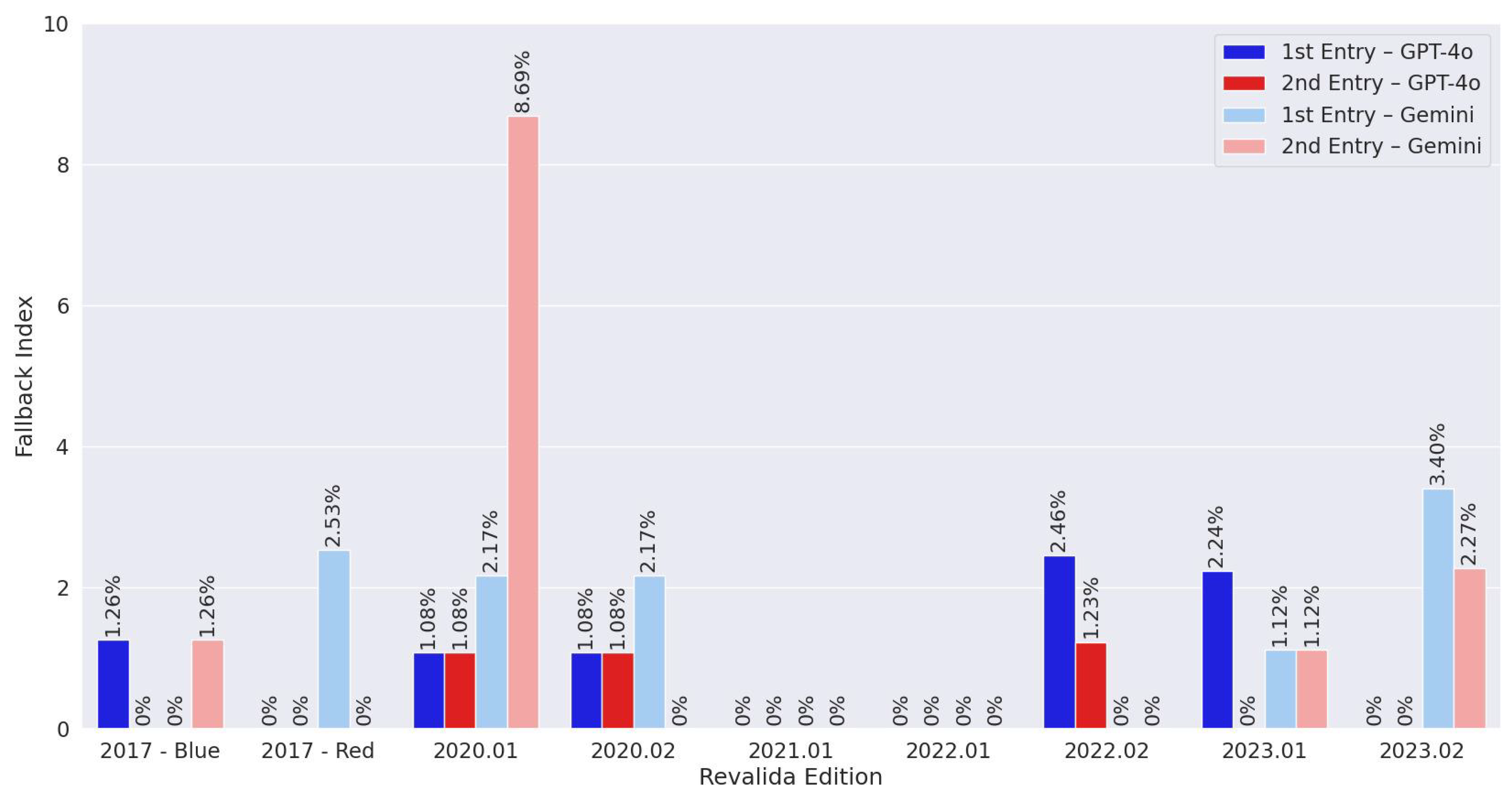
Regarding commercial LLMs, GPT-4o achieved the best performance on the Revalida objective questions and also maintained a low fallback rate. In comparison, GPT-3.5 showed lower accuracy but did not produce any fallback responses. Gemini had the weakest overall performance among the models evaluated. These results highlight the variation in capabilities across the commercial LLMs used in this study. The superior performance of GPT-4o can likely be attributed to its more advanced architecture and greater number of parameters—it is a newer, more powerful iteration of GPT-3.5, which has 175 billion parameters, while GPT-4 is estimated to exceed one trillion. In contrast, Gemini’s lower performance may be explained by the use of its earlier version (1.0 Pro), which is less capable than more recent releases from Google, such as versions 2.0 and 2.5.
Among the models evaluated, GPT-3.5 was the only one that did not exhibit fallback responses, which may indicate a tendency to generate contextualized answers even when uncertain. In contrast, GPT-4o and Gemini produced fallback responses that contributed to a reduction in their overall performance. However, this behaviour can also be interpreted positively, as it reflects a cautious stance in avoiding incorrect answers, demonstrating a form of honesty that may increase user trust in high-stakes scenarios. Performance variability was also observed between the two entries of the same exam for some models. Moreover, statistical analysis using Cohen’s Kappa revealed low agreement between entries in certain cases, indicating instability in the models’ ability to produce consistent answers. This inconsistency may reflect limitations in reasoning or a higher likelihood of random guessing in some responses.
The qualitative analysis provided deeper insight into GPT-4o’s performance, extending beyond traditional metrics such as accuracy and fallback rate. By examining the explanations generated for the objective questions of the 2024 Revalida exam, the analysis revealed a strong alignment between the model’s reasoning and the participants’ medical expertise. The justifications were assessed by three physicians, who reported 100% agreement with the content provided. This outcome suggests that the GPT-4o’s explanations were well-structured, clinically coherent, and consistent with accepted medical reasoning.
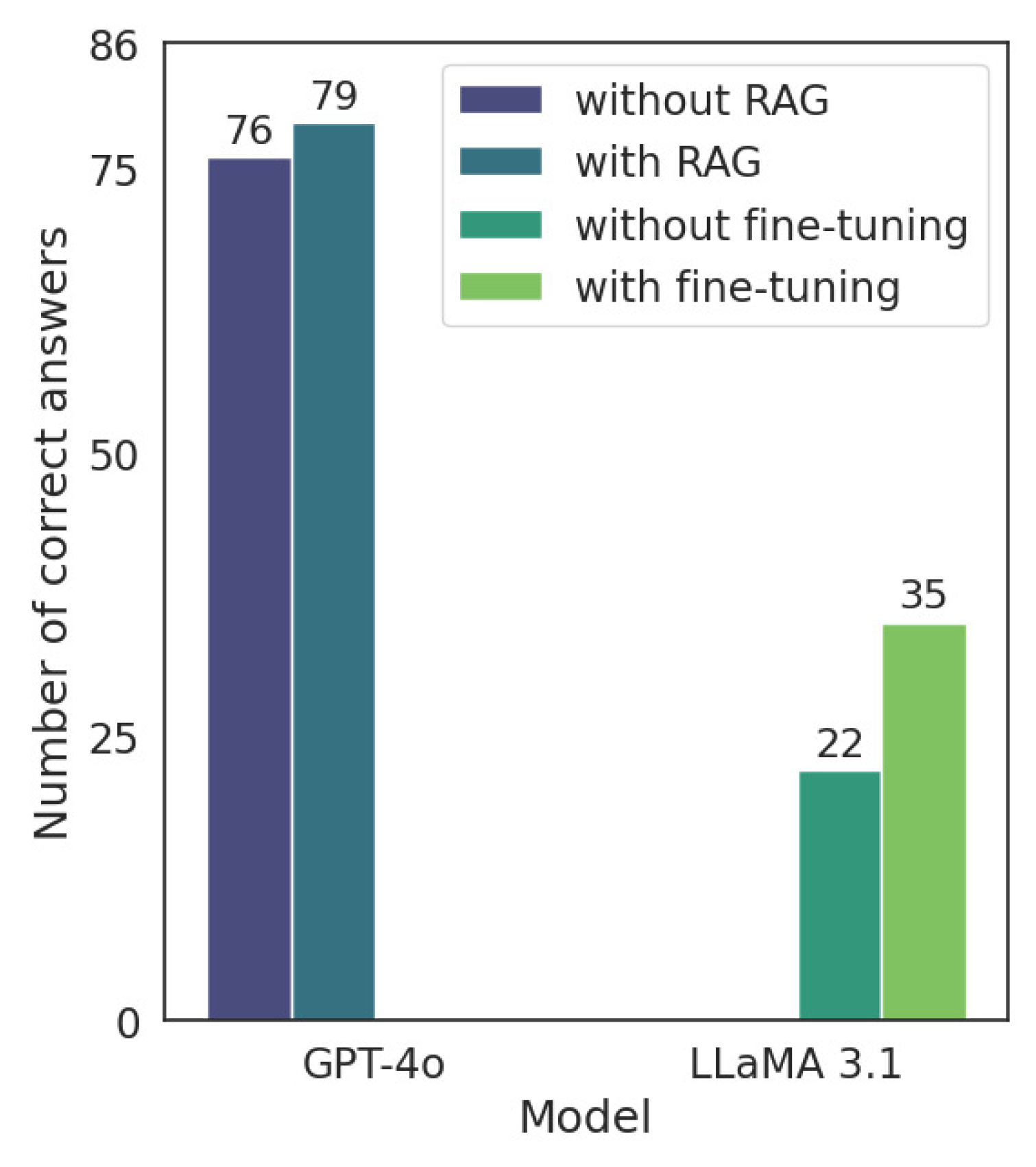
Another key finding of this study is that both RAG and fine-tuning with domain-specific justifications contributed to measurable improvements in LLM performance on the 2024 Revalida exam. GPT-4o, despite already achieving a high baseline accuracy, benefited from the integration of external knowledge via RAG, increasing its number of correct answers from 76 to 79 out of 86. While modest in absolute terms, this gain is notable given the model’s proximity to the performance ceiling. In contrast, LLaMA 3.1 exhibited a more substantial improvement (from 22 to 35 correct answers) following fine-tuning, underscoring the effectiveness of targeted adaptation when there is greater room for enhancement. These findings suggest that commercial models may still benefit from external context, while open-source models can achieve considerable gains through domain-informed fine-tuning.
5.2. Implications
The implications of this study are particularly relevant for two key audiences: (i) medical students and international graduates preparing for licensing exams (particularly the Revalida), and (ii) healthcare professionals interested in exploring the use of LLMs in clinical decision support systems. For the former, LLMs may serve as valuable educational tools by reinforcing knowledge and offering structured justifications aligned with clinical reasoning. For the latter, although the current results highlight the potential of LLMs to process complex medical content in PT-BR, their application should remain strictly assistive, with outputs subject to professional review and validation.
The findings demonstrate that some LLMs, particularly GPT-4o (79 out of 86 correct answers when using RAG; refer to
Section 4.4), are capable of performing reasonably well on the objective questions of the Revalida exam. This level of performance suggests that these models have the potential as supportive tools in medical education, particularly for knowledge reinforcement [
46,
47]. The qualitative analysis further revealed that GPT-4o’s explanations were well-aligned with expert medical reasoning, offering structured and clinically coherent justifications. These results are consistent with prior studies with language models [
48,
49], reinforcing the idea that LLMs could serve as valuable resources for healthcare.
The ability of LLMs to perform well on licensing exam questions (particularly those that integrate clinical reasoning) suggests a foundational alignment with the types of decisions encountered in practice. While answering multiple-choice questions is not equivalent to practicing medicine, these tasks do reflect core knowledge and judgment processes that AI systems may eventually support in real-world clinical workflows.
Despite this promising outlook, LLMs, especially when used in PT-BR language contexts, are not yet ready for autonomous integration into clinical workflows. The inconsistencies observed between test entries, the presence of fallback responses, and the risk of hallucinated content highlight ongoing limitations in reliability, accuracy, and contextual understanding. Moreover, medical knowledge and policies vary across countries, further complicating the applicability of LLMs in diverse clinical and educational settings [
14]. In high-stakes domains like healthcare, even minor errors can have significant consequences, underscoring the need for careful validation and oversight.
Therefore, LLMs should be regarded as complementary tools in clinical decision support, not as replacements for the expertise and judgment of healthcare professionals. While their performance in objective assessments is encouraging, human competence remains essential, particularly for tasks involving clinical judgment, ethical considerations, and patient-centered care. Any outputs generated by these models must be critically evaluated and validated by qualified professionals before being used in practice. With proper oversight, LLMs may help streamline access to information and support clinical reasoning, but their integration into healthcare must be approached cautiously and responsibly.
The final phase of the study demonstrated that LLM performance can be further enhanced through domain adaptation strategies grounded in prior exam content. By leveraging justifications generated from previous Revalida editions, it was possible to improve model accuracy through both RAG and fine-tuning. This mirrors common practices among medical students and exam candidates, who frequently study past questions to reinforce learning and recognize patterns. The effectiveness of this strategy highlights a promising avenue for aligning LLM outputs with real-world reasoning expectations. As such, incorporating curated historical content may represent a practical and scalable approach to improving the relevance and trustworthiness of LLMs in medical education and assessment contexts.
In addition to supporting medical education, LLMs show potential for aiding in the comprehension of ethically complex and high-stakes clinical scenarios. Several questions in the Revalida exam implicitly address domains in which decision-making carries significant clinical and legal implications, such as contraindications, public health ethics, and patient safety. These may also involve sensitive topics like abortion, blood transfusion, gender identity, and racism. These questions often integrate multiple dimensions of reasoning, requiring not only factual knowledge but also sound ethical judgment. The ability of LLMs to navigate such nuanced content has important implications for their use in both educational and clinical support settings. Ensuring that models can reliably process and respond to ethically sensitive material is essential for building trust in their outputs.
5.3. Limitations
This study has limitations that may affect the interpretation of results. Although zero-shot prompting was used, commercial models received a brief initial instruction to establish context, potentially giving them an advantage over open-source models that received no prompt. Additionally, platform-specific variability in commercial LLMs could lead to non-deterministic responses. Another limitation was the exclusion of questions containing images [
50]. Since not all the evaluated LLMs are multimodal, only text-based questions were used to ensure a fair comparison. Including image-based questions could have unfairly advantaged multimodal models, as unimodal LLMs would not be capable of analyzing visual content. Another limitation is that the study focused exclusively on the first phase of the Revalida exam, which consists of objective questions. It did not include the discursive section or the second phase of the exam, both of which are essential components for fully assessing medical knowledge and certifying physicians in Brazil.
In the qualitative analysis, one limitation was that the participants were aware that the explanations being evaluated corresponded only to questions that GPT-4o had answered correctly, based on the official answer key. This prior knowledge may have influenced the physicians’ assessments, potentially introducing bias into the evaluation of the explanations. Nonetheless, this was an intentional strategy, as the goal of the study was to evaluate the model’s reasoning, not the participants’ medical knowledge.
Another limitation of this study lies in the reliance on GPT-4o-generated justifications from past Revalida exams (2017–2023) as the source of domain knowledge. Although only correct answers were retained, no formal expert validation was performed for the justifications used in the knowledge base. This leaves open the possibility that subtle inaccuracies or context-specific reasoning patterns from justifications may have influenced model adaptation. Lastly, the fine-tuning process was limited to a single open-source model (LLaMA 3.1), and further investigation is needed to assess whether similar gains can be achieved across different open-source models.
6. Conclusions
This study aimed to comparatively evaluate the performance of various generative LLMs on multiple-choice questions from six editions (2017–2024) of the Revalida exam, focusing on models that process content in PT-BR. Among the models evaluated, GPT-4o achieved the highest accuracy, followed by GPT-3.5 and Gemini, while open-source models such as LLaMA 3.1 and Qwen 2.5 showed limited performance. Although reasoning-optimized variants slightly improved fallback behaviour, overall accuracy remained low. The best-performing model, GPT-4o, was also assessed qualitatively, and its explanations were found to be aligned with clinical reasoning, according to independent evaluations by three licensed physicians. In the final phase of the study, we demonstrated that domain-specific justifications derived from previous Revalida editions can be effectively used to enhance model performance. Both GPT-4o, through RAG, and LLaMA 3.1, through fine-tuning, achieved improved results on the 2024 exam, highlighting the value of targeted adaptation using curated historical content.
Despite these promising results, LLMs still exhibit inconsistencies (answer variability), occasional hallucinations, and limited reliability, especially in high-stakes contexts such as healthcare. Therefore, while they hold future potential as educational and decision-support tools, their integration into clinical practice must remain supervised and cautious. Human expertise continues to be essential, and LLM-generated outputs should be validated by professionals before informing any clinical decisions. Nonetheless, this study suggests that incorporating curated historical content (e.g., justifications from prior exams) via RAG or fine-tuning may represent a practical approach to improving the relevance and trustworthiness of LLMs.
Future work will focus on expanding the scope of the evaluation to include discursive questions and the second phase of the Revalida exam, allowing for a more comprehensive assessment of the models’ clinical reasoning and interpretive skills. We also plan to evaluate multimodal LLMs by incorporating questions that include images, graphs, and tables, which were excluded in the current study.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}