

Deep-Learning-Based Cognitive Assistance Embedded Systems for People with Visual Impairment




Abstract
1. Introduction
2. Related Work
2.1. Face Recognition
2.2. Gender, Age, and Emotion Classifications
2.3. Object Detection
2.4. Smart Health Care
3. Multifunctional Embedded System
3.1. System Architecture
3.2. Function Selection
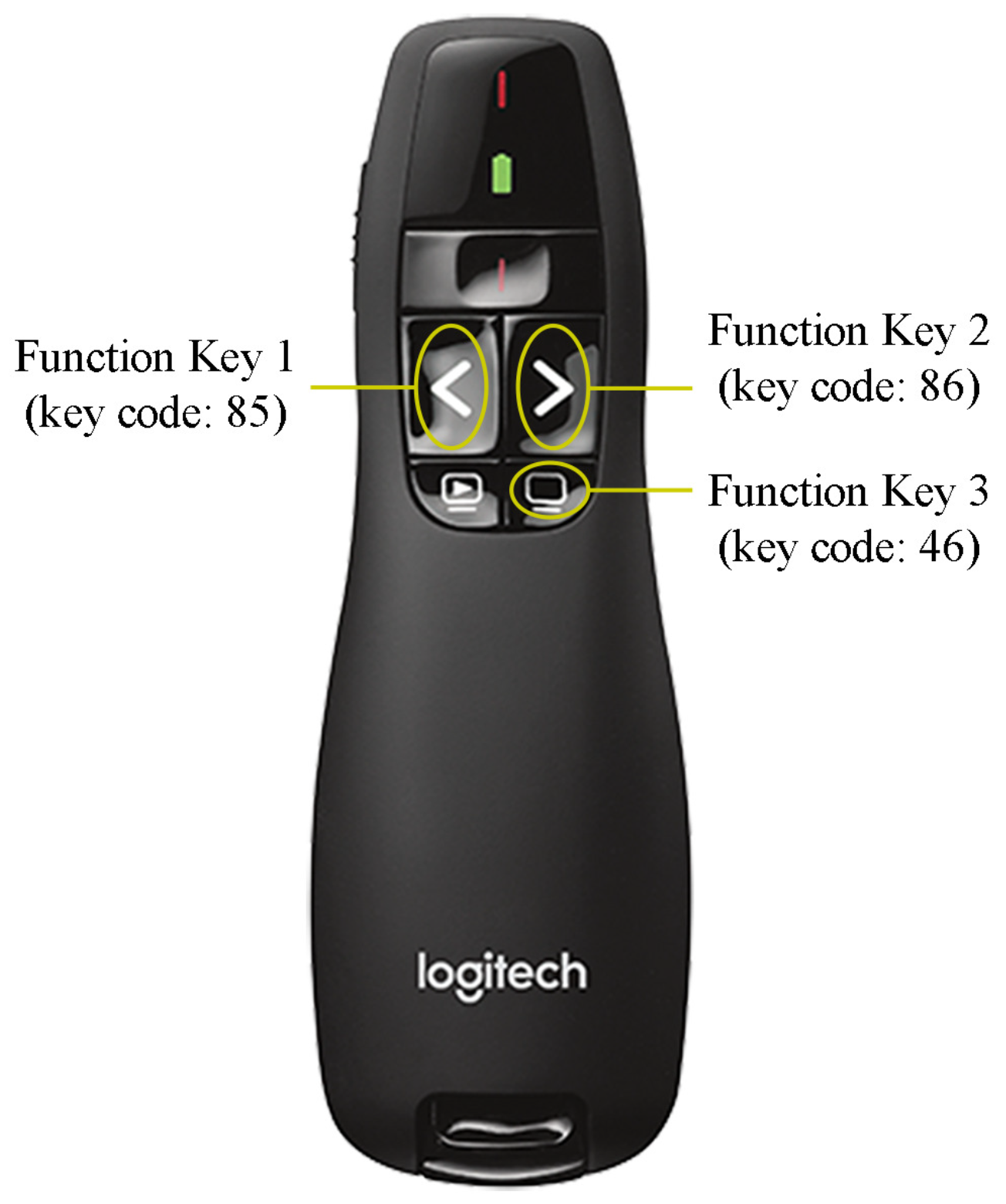
3.2.1. Remote Controller
3.2.2. Function Selection Process
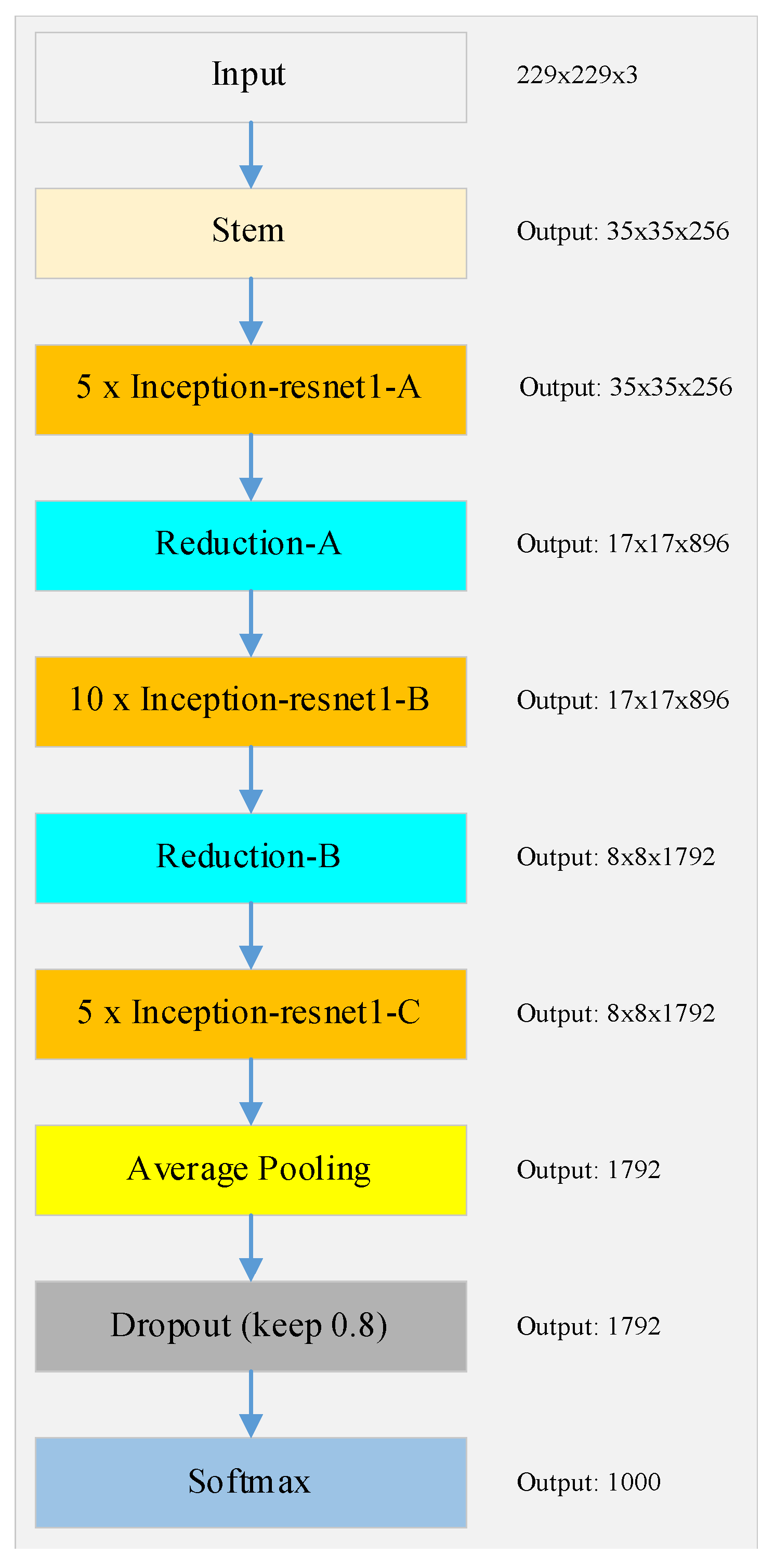
3.3. Face Recognition Model
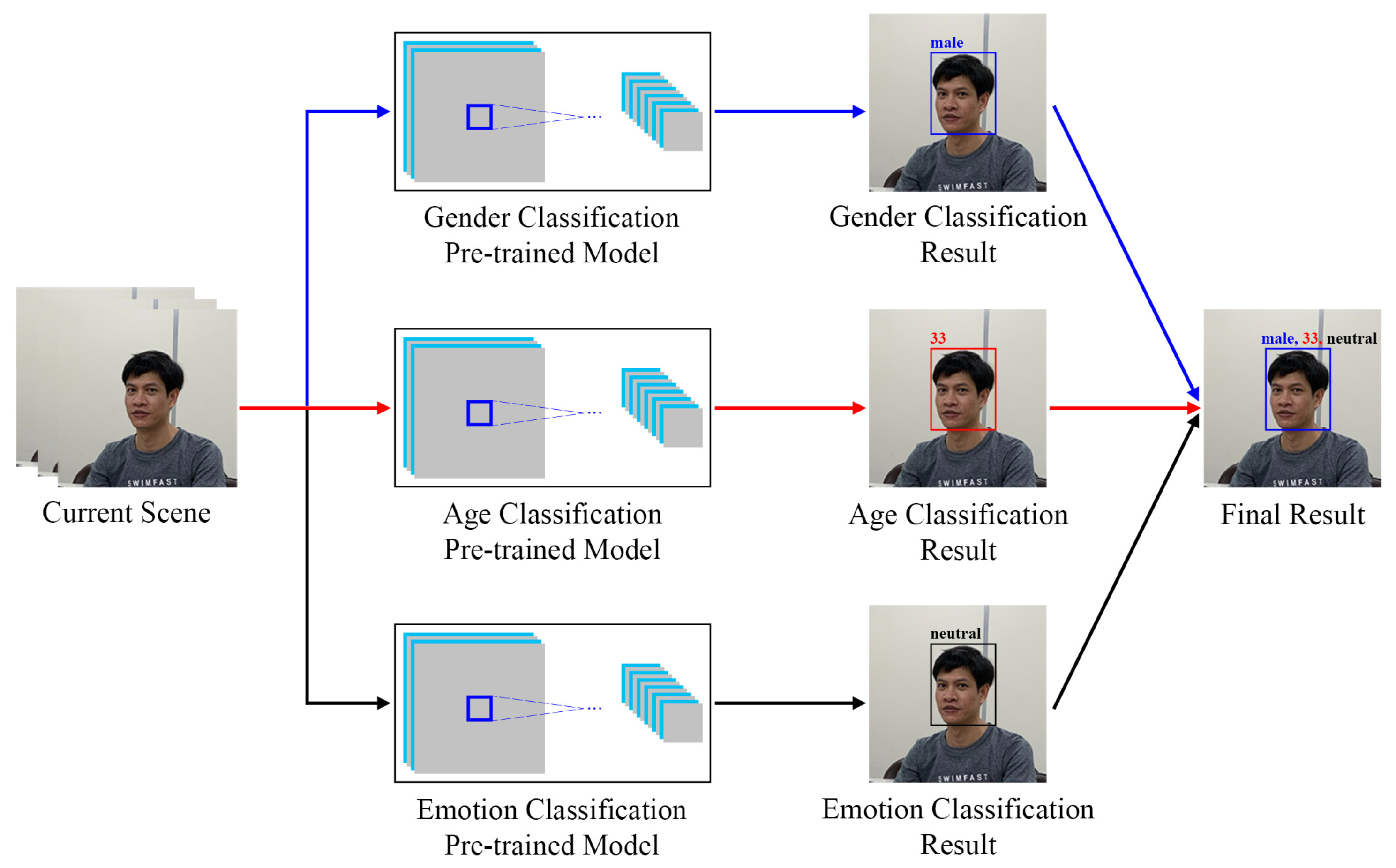
3.4. Gender, Age, and Emotion Classification Models
3.5. Object Detection Model
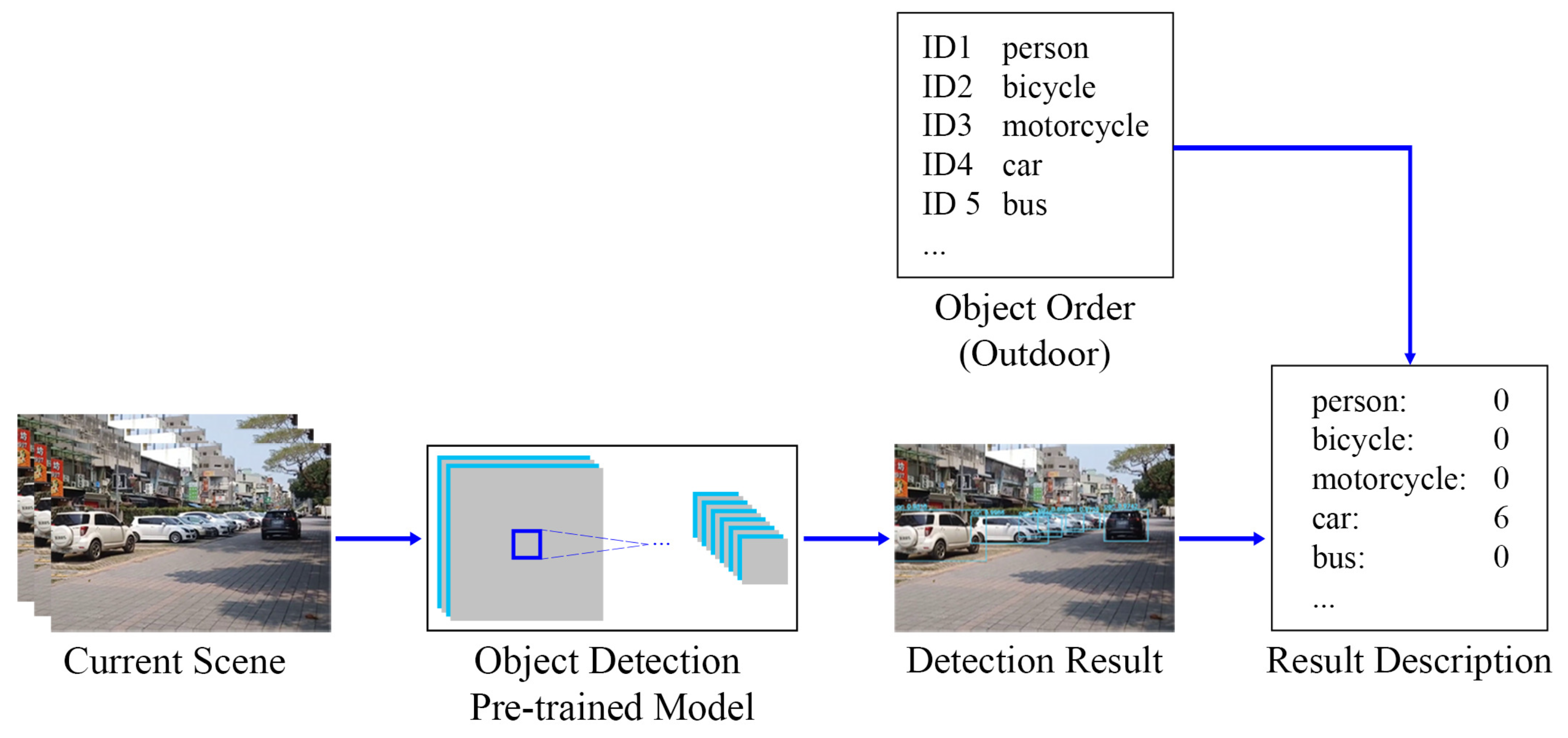
3.6. Arrangement of Result Description
4. System Implementation and Prototype
4.1. Devices Used in System Implementation
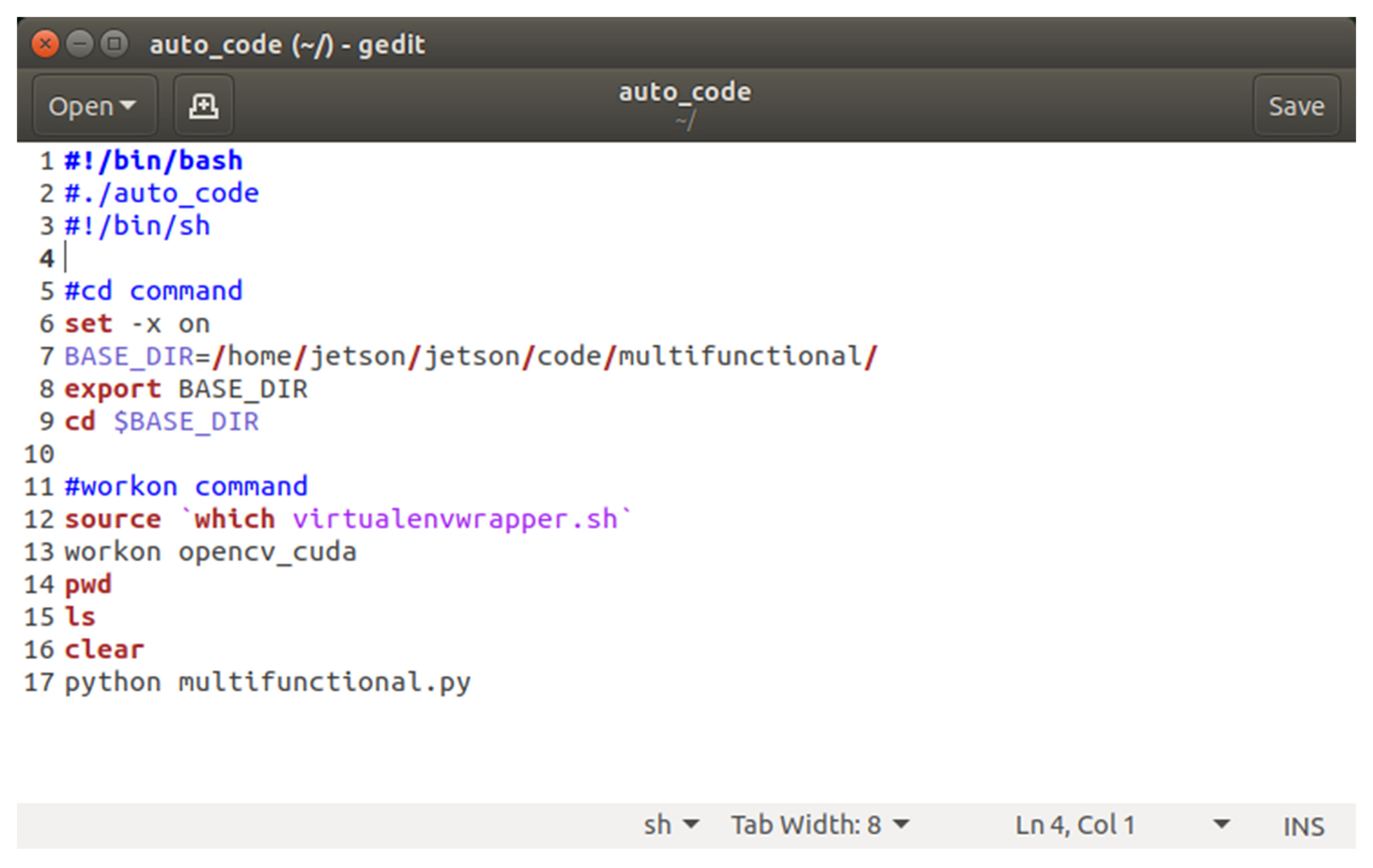
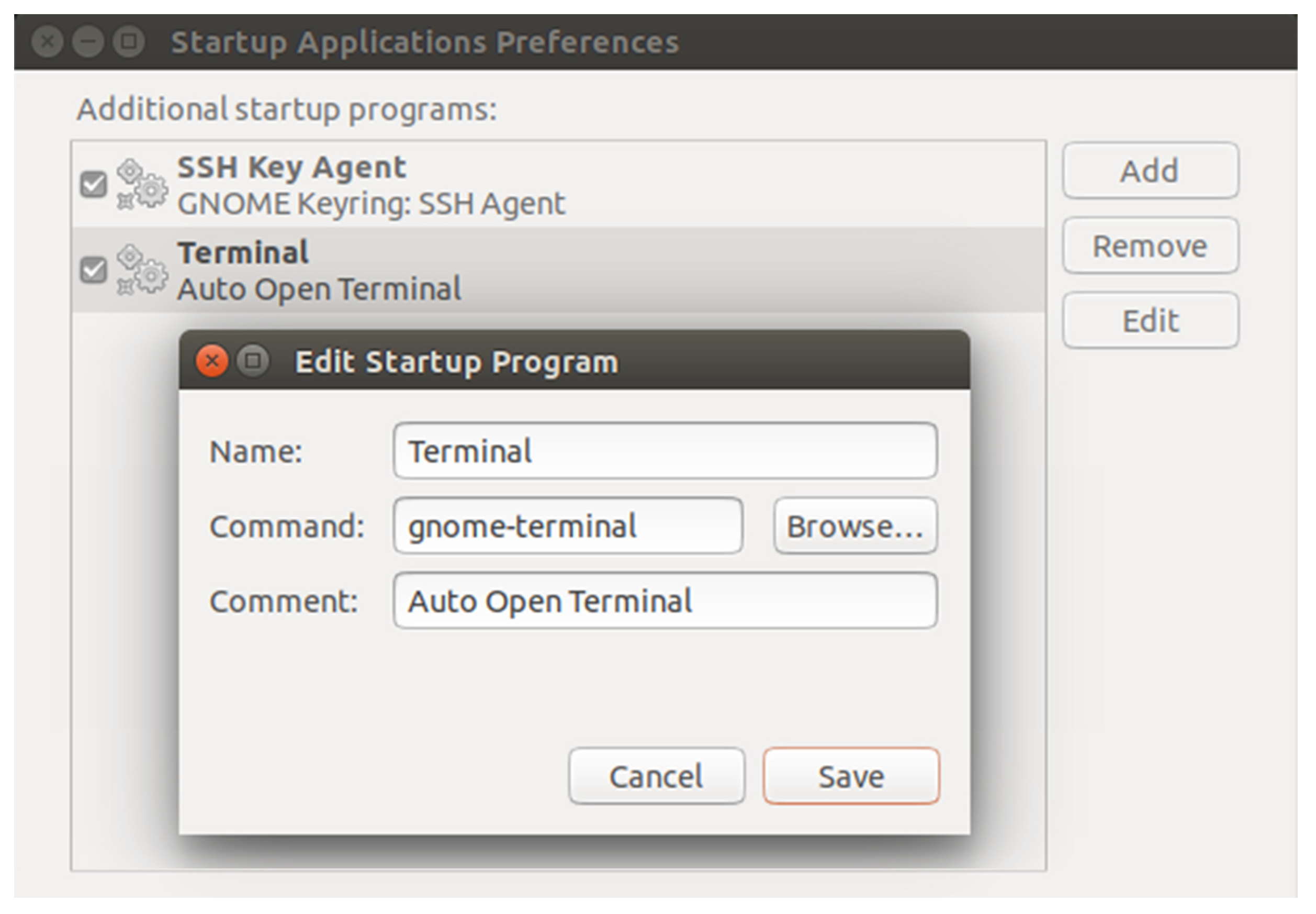
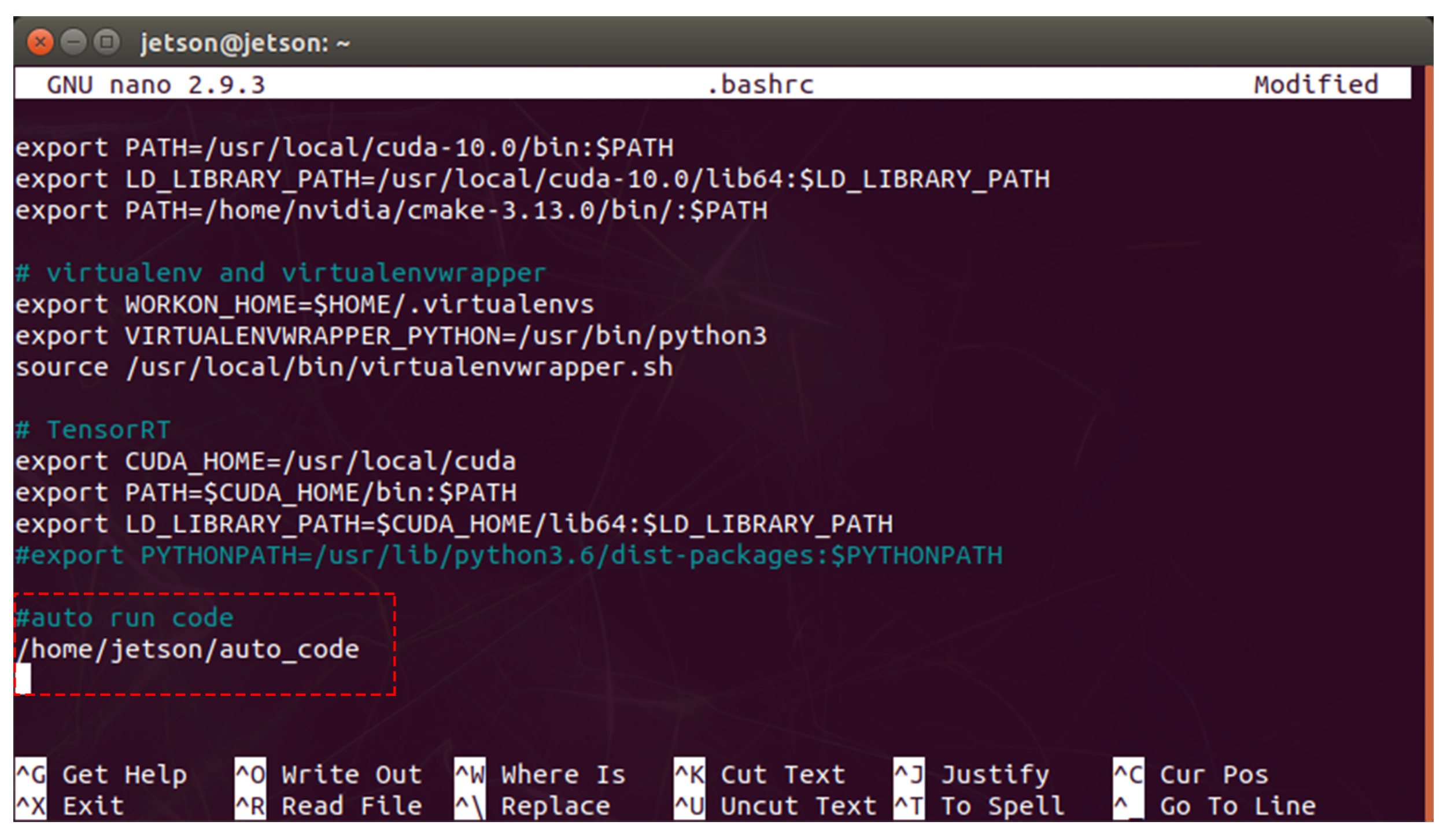
4.2. Initialization Program of the Embedded System
- Lines 6–9 implement the change from the current directory to the folder containing the main control program.
- Lines 12 and 13 activate a Python virtual environment called “opencv_cuda.”
- Line 17 performs the main control program called “multifunctional.py.”
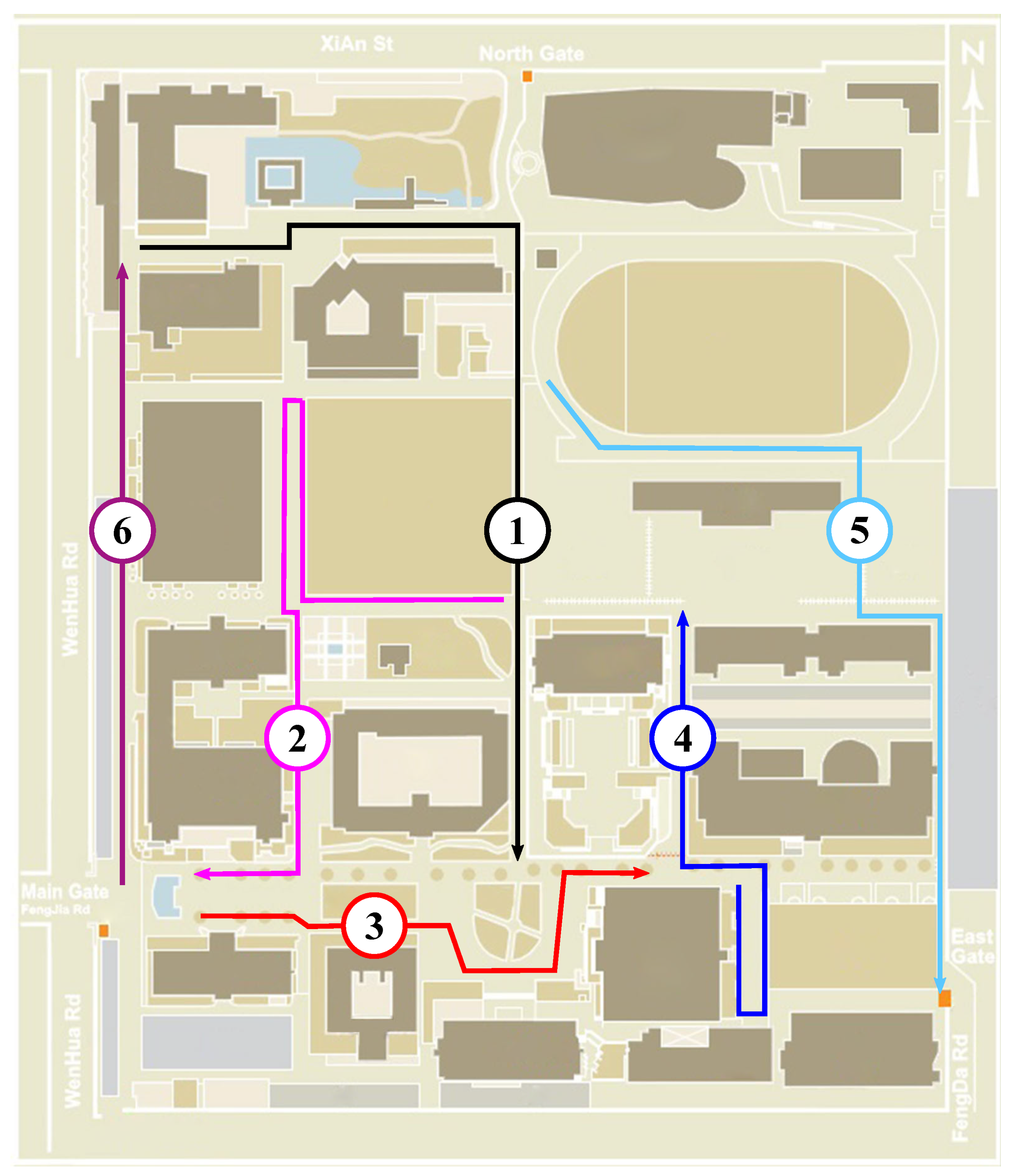
4.3. Data Set Collection
5. Experimental Results
5.1. Analysis Results for Face Recognition
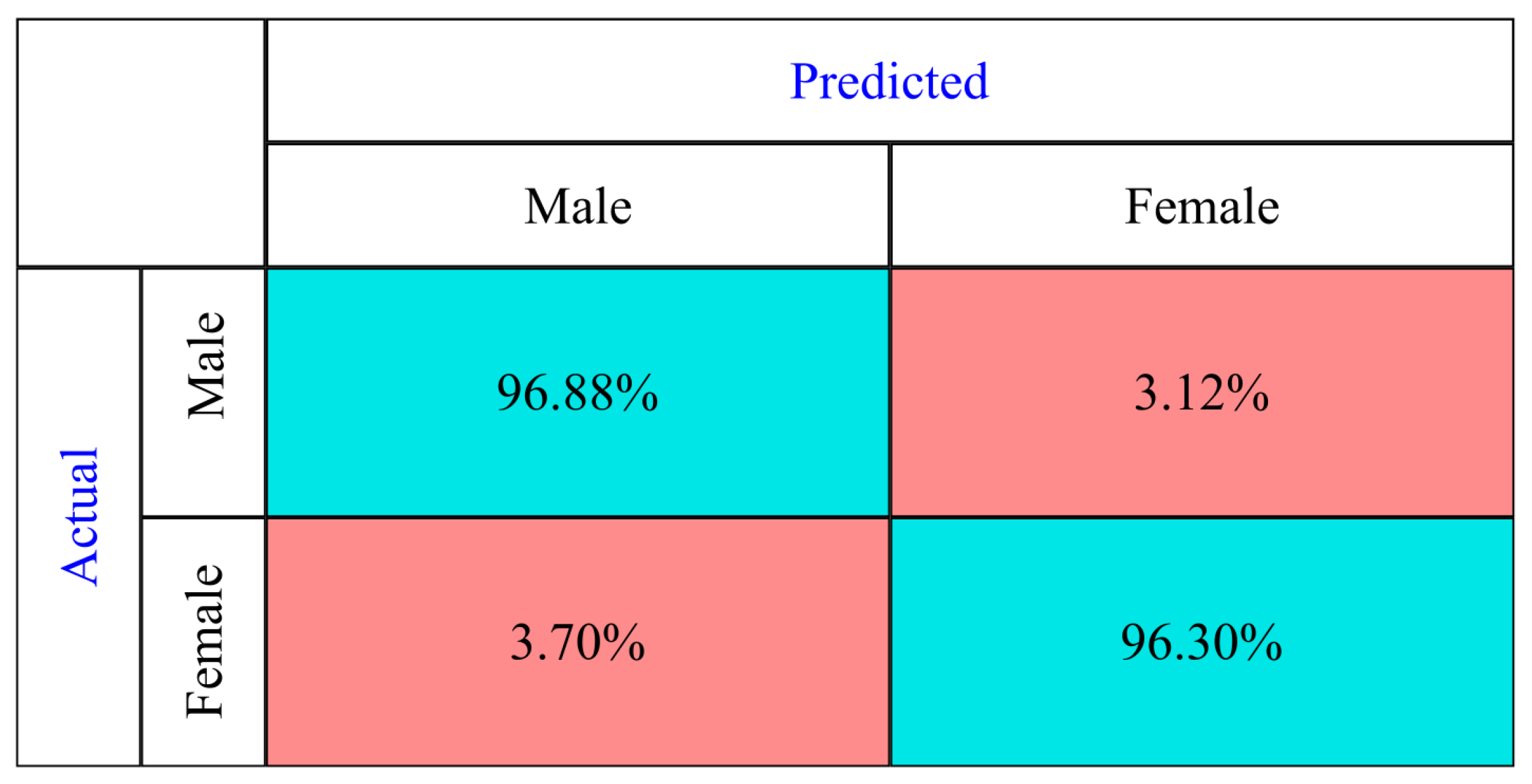
5.2. Gender Classification Results
5.3. Analysis Results of Age Classification
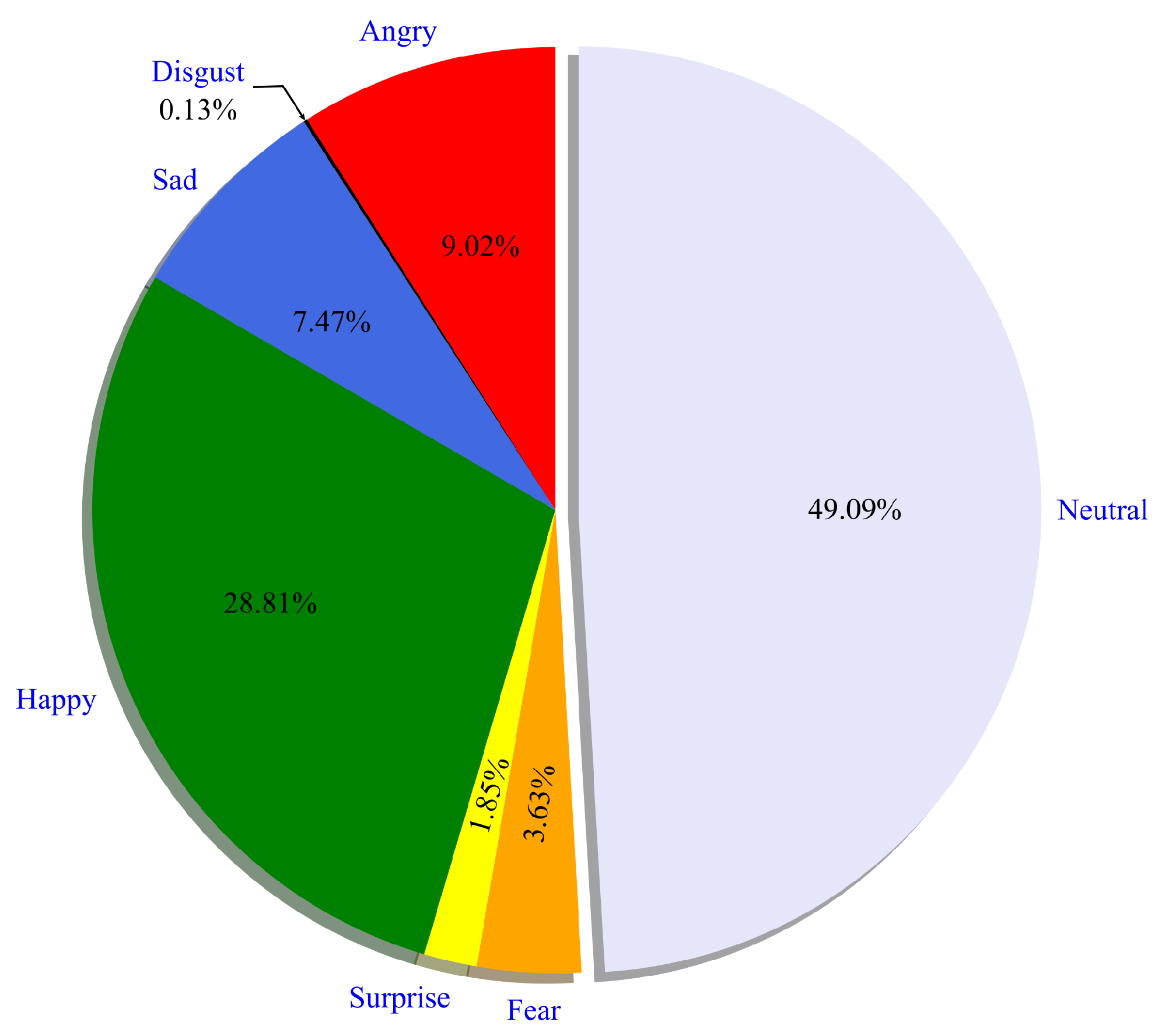
5.4. Emotion Classification Results
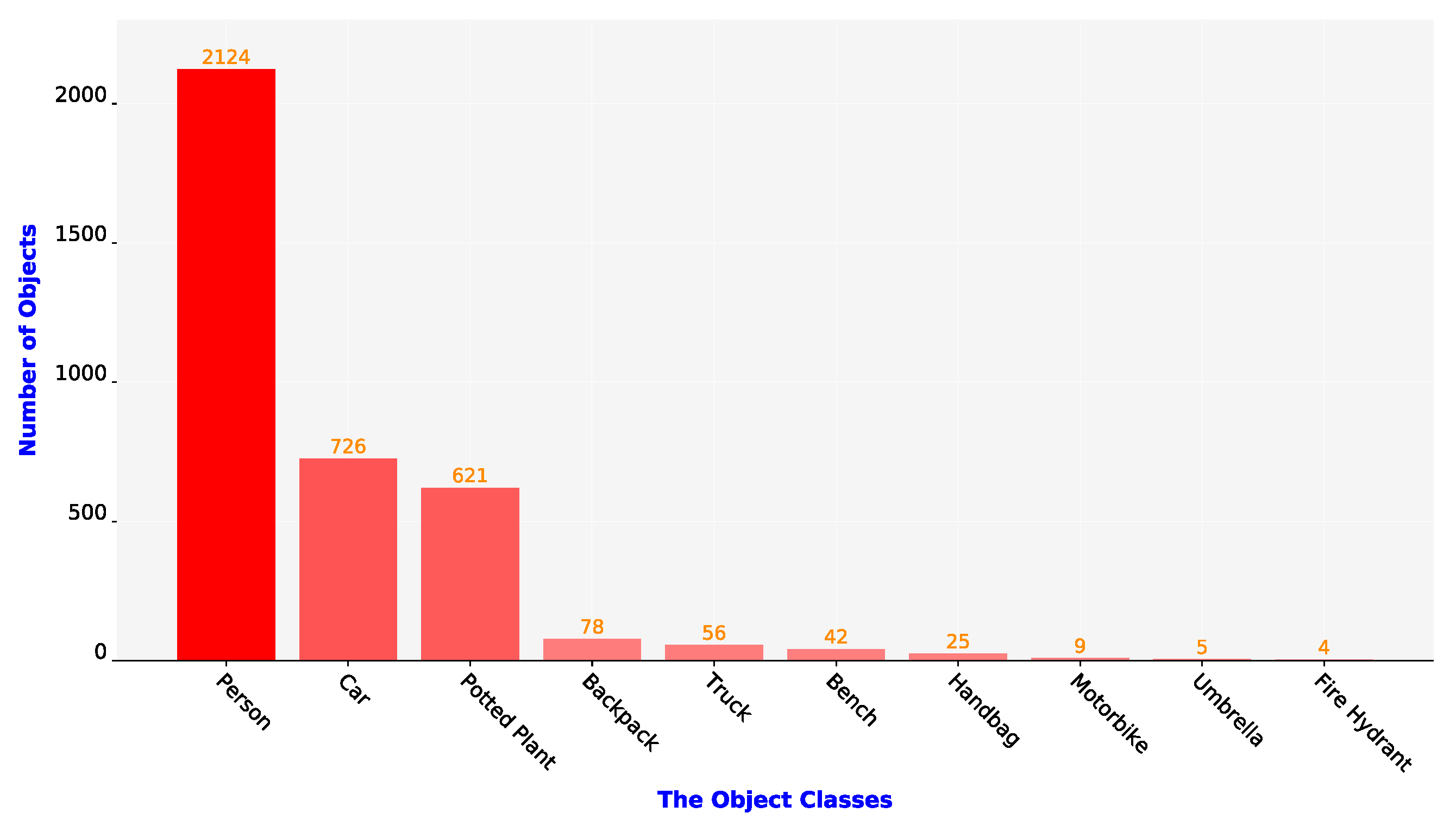
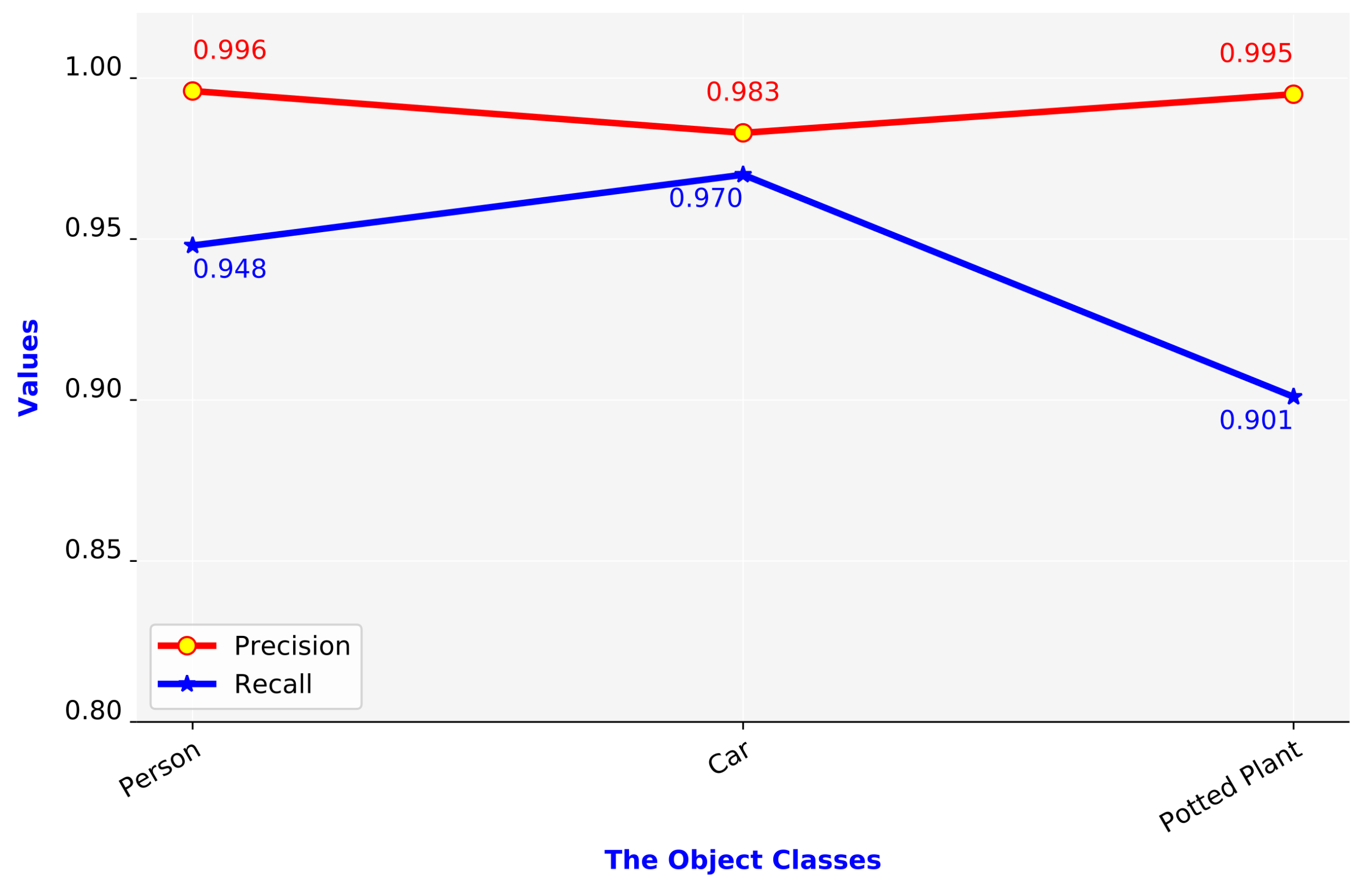
5.5. Analysis Results of Object Detection
5.6. Processing Time of System Functions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Capi, G. Development of a new robotic system for assisting and guiding visually impaired people. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; pp. 229–234. [Google Scholar]
- Katzschmann, R.K.; Araki, B.; Rus, D. Safe local navigation for visually impaired users with a time-of-flight and haptic feedback device. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 583–593. [Google Scholar] [CrossRef] [PubMed]
- Nada, A.A.; Fakhr, M.A.; Seddik, A.F. Assistive infrared sensor based smart stick for blind people. In Proceedings of the Science and Information Conference (SAI), London, UK, 28–30 July 2015; pp. 1149–1154. [Google Scholar]
- Kumar, D.; Sudha, K.; Gaur, A.; Sharma, A.; Vandana; Sharma, S. Assistive ultrasonic sensor based smart blind stick using fuzzy logic. J. Inf. Optim. Sci. 2022, 43, 233–237. [Google Scholar] [CrossRef]
- Șipoș, E.; Ciuciu, C.; Ivanciu, L. Sensor-based prototype of a smart assistant for visually impaired people—Preliminary results. Sensors 2022, 22, 4271. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.C.; Chae, S.H.; Sun, J.Y.; Yoo, J.W.; Ko, S.J. A novel obstacle detection method based on deformable grid for the visually impaired. IEEE Trans. Consum. Electron. 2015, 61, 376–383. [Google Scholar] [CrossRef]
- Mekhalfi, M.L.; Melgani, F.; Zeggada, A.; Natale, F.G.B.D.; Salem, M.A.M.; Khamis, A. Recovering the sight to blind people in indoor environments with smart technologies. Expert Syst. Appl. 2016, 46, 129–138. [Google Scholar] [CrossRef]
- Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying terrain awareness for the visually impaired through real-time semantic segmentation. Sensors 2018, 18, 1506. [Google Scholar] [CrossRef]
- Ashiq, F.; Asif, M.; Ahmad, M.B.; Zafar, S.; Masood, K.; Mahmood, T.; Mahmood, M.T.; Lee, I.H. CNN-based object recognition and tracking system to assist visually impaired people. IEEE Access 2022, 10, 14819–14834. [Google Scholar] [CrossRef]
- Li, G.; Xu, J.; Li, Z.; Chen, C.; Kan, Z. Sensing and navigation of wearable assistance cognitive systems for the visually impaired. IEEE Trans. Cogn. Dev. Syst. 2022, 15, 122–133. [Google Scholar] [CrossRef]
- Cheraghi, S.A.; Namboodiri, V.; Walker, L. Guidebeacon: Beacon-based indoor wayfinding for the blind, visually impaired, and disoriented. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom), Kona, HI, USA, 13–17 March 2017; pp. 121–130. [Google Scholar]
- Tanveer, M.S.R.; Hashem, M.M.A.; Hossain, M.K. Android assistant eyemate for blind and blind tracker. In Proceedings of the 18th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2015; pp. 266–271. [Google Scholar]
- Khan, A.; Khusro, S. An insight into smartphone-based assistive solutions for visually impaired and blind people: Issues, challenges and opportunities. Univers. Access Inf. Soc. 2021, 20, 265–298. [Google Scholar] [CrossRef]
- Ullah, M.; Khusro, S.; Khan, M.; Alam, I.; Khan, I.; Niazi, B. Smartphone-based cognitive assistance of blind people in room recognition and awareness. Mob. Inf. Syst. 2022, 2022, 6068584. [Google Scholar] [CrossRef]
- Islam, M.M.; Sadi, M.S.; Zamli, K.Z.; Ahmed, M.M. Developing walking assistants for visually impaired people: A review. IEEE Sens. J. 2019, 19, 2814–2828. [Google Scholar] [CrossRef]
- Han, J.; Kim, J.; Kim, S.; Wang, S. Effectiveness of image augmentation techniques on detection of building characteristics from street view images using deep learning. J. Constr. Eng. Manag. 2024, 150, 04024129. [Google Scholar] [CrossRef]
- Angin, P.; Bhargava, B.K. Real-time mobile-cloud computing for context-aware blind navigation. Int. J. Next Gener. Comput. 2011, 2, 405–414. [Google Scholar]
- Trabelsi, R.; Jabri, I.; Melgani, F.; Smach, F.; Conci, N.; Bouallegue, A. Indoor object recognition in RGBD images with complex-valued neural networks for visually-impaired people. Neurocomputing 2019, 330, 94–103. [Google Scholar] [CrossRef]
- Chaudary, B.; Pohjolainen, S.; Aziz, S.; Arhippainen, L.; Pulli, P. Teleguidance-based remote navigation assistance for visually impaired and blind people—Usability and user experience. Virtual Real. 2021, 27, 141–158. [Google Scholar] [CrossRef]
- Lo Valvo, A.; Croce, D.; Garlisi, D.; Giuliano, F.; Giarré, L.; Tinnirello, I. A navigation and augmented reality system for visually impaired people. Sensors 2021, 21, 3061. [Google Scholar] [CrossRef]
- Ngo, H.H.; Lin, F.C.; Sehn, Y.T.; Tu, M.; Dow, C.R. A room monitoring system using deep learning and perspective correction techniques. Appl. Sci. 2020, 10, 4423. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4690–4699. [Google Scholar]
- Chaudhry, S.; Chandra, R. Design of a mobile face recognition system for visually impaired persons. arXiv 2015, arXiv:1502.00756. [Google Scholar]
- Chen, S.; Yao, D.; Cao, H.; Shen, C. A novel approach to wearable image recognition systems to aid visually impaired people. Appl. Sci. 2019, 9, 3350. [Google Scholar] [CrossRef]
- Mocanu, B.; Tapu, R.; Zaharia, T. DEEP-SEE FACE: A mobile face recognition system dedicated to visually impaired people. IEEE Access 2018, 6, 51975–51985. [Google Scholar] [CrossRef]
- Neto, L.B.; Grijalva, F.; Maike, V.R.M.L.; Martini, L.C.; Florencio, D.; Baranauskas, M.C.C.; Rocha, A.; Goldenstein, S. A Kinect-Based Wearable Face Recognition System to Aid Visually Impaired Users. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 52–64. [Google Scholar] [CrossRef]
- Lin, F.; Wu, Y.; Zhuang, Y.; Long, X.; Xu, W. Human gender classification: A review. Int. J. Biom. 2016, 8, 275–300. [Google Scholar] [CrossRef]
- Agbo-Ajala, O.; Viriri, S. Deep learning approach for facial age classification: A survey of the state-of-the-art. Artif. Intell. Rev. 2020, 54, 179–213. [Google Scholar] [CrossRef]
- Punyani, P.; Gupta, R.; Kumar, A. Neural networks for facial age estimation: A survey on recent advances. Artif. Intell. Rev. 2020, 53, 3299–3347. [Google Scholar] [CrossRef]
- Ashok, A.; John, J. Facial expression recognition system for visually impaired. In Proceedings of the International Conference on Intelligent Data Communication Technologies and Internet of Things (ICICI), Coimbatore, Tamil Nadu, India, 7–8 August 2018; pp. 244–250. [Google Scholar]
- Das, S. A novel emotion recognition model for the visually impaired. In Proceedings of the IEEE 5th International Conference for Convergence in Technology (I2CT), Pune, India, 29–31 March 2019; pp. 1–6. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28, Montreal, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Islam, M.T.; Ahmad, M.; Bappy, A.S. Microprocessor-based smart blind glass system for visually impaired people. In Proceedings of the International Joint Conference on Computational Intelligence, Dhaka, Bangladesh, 28–29 December 2018; pp. 151–161. [Google Scholar]
- Joshi, R.C.; Yadav, S.; Dutta, M.K.; Travieso-Gonzalez, C.M. Efficient multi-object detection and smart navigation using artificial intelligence for visually impaired people. Entropy 2020, 22, 941. [Google Scholar] [CrossRef]
- Aza, V.; Indrabayu; Areni, I.S. Face recognition using local binary pattern histogram for visually impaired people. In Proceedings of the International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 21–22 September 2019; pp. 241–245. [Google Scholar]
- Arriaga, O.; Ploger, P.G.; Valdenegro, M. Real-time convolutional neural networks for emotion and gender classification. arXiv 2017, arXiv:1710.07557. [Google Scholar]
- Liew, S.S.; Hani, M.K.; Radzi, S.A.; Bakhteri, R. Gender classification: A convolutional neural network approach. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 1248–1264. [Google Scholar] [CrossRef]
- Yang, T.Y.; Huang, Y.H.; Lin, Y.Y.; Hsiu, P.C.; Chuang, Y.Y. SSR-Net: A compact soft stagewise regression network for age estimation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1078–1084. [Google Scholar]
- SSR-Net. GitHub. 2018. Available online: https://github.com/shamangary/SSR-Net (accessed on 15 October 2022).
- Dhomne, A.; Kumar, R.; Bhan, V. Gender recognition through face using deep learning. Procedia Comput. Sci. 2018, 132, 2–10. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Khan, K.; Attique, M.; Syed, I.; Gul, A. Automatic gender classification through face segmentation. Symmetry 2019, 11, 770. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 34–42. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Agbo-Ajala, O.; Viriri, S. Face-based age and gender classification using deep learning model. In Proceedings of the Image and Video Technology, Sydney, NSW, Australia, 18–22 November 2019; pp. 125–137. [Google Scholar]
- Nam, S.H.; Kim, Y.H.; Truong, N.Q.; Choi, J.; Park, K.R. Age estimation by super-resolution reconstruction based on adversarial networks. IEEE Access 2020, 8, 17103–17120. [Google Scholar] [CrossRef]
- Liao, H.; Yan, Y.; Dai, W.; Fan, P. Age estimation of face images based on CNN and divide-and-rule strategy. Math. Probl. Eng. 2018, 2018, 1712686. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, K.; Gao, C.; Guo, L.; Sun, M.; Yuan, X.; Han, T.X.; Zhao, Z.; Li, B. Age group and gender estimation in the wild with deep RoR architecture. IEEE Access 2017, 5, 22492–22503. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, P.; Cai, D.; Wang, S.; Yao, A.; Chen, Y. Learning supervised scoring ensemble for emotion recognition in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, New York, NY, USA, 13–17 November 2017; pp. 553–560. [Google Scholar]
- Cai, J.; Meng, Z.; Khan, A.S.; Li, Z.; O’Reilly, J.; Tong, Y. Island loss for learning discriminative features in facial expression recognition. In Proceedings of the 13th IEEE International Conference on Automatic Face Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 302–309. [Google Scholar]
- Bargal, S.A.; Barsoum, E.; Ferrer, C.C.; Zhang, C. Emotion recognition in the wild from videos using images. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 433–436. [Google Scholar]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef]
- Liu, M.; Li, S.; Shan, S.; Chen, X. AU-aware deep networks for facial expression recognition. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Long, N.; Wang, K.; Cheng, R.; Hu, W.; Yang, K. Unifying obstacle detection, recognition, and fusion based on millimeter wave radar and rgb-depth sensors for the visually impaired. Rev. Sci. Instrum. 2019, 90, 044102. [Google Scholar] [CrossRef]
- Khade, S.; Dandawate, Y.H. Hardware implementation of obstacle detection for assisting visually impaired people in an unfamiliar environment by using raspberry pi. In Proceedings of the Smart Trends in Information Technology and Computer Communications, Jaipur, Rajasthan, India, 6–7 August 2016; pp. 889–895. [Google Scholar]
- Wang, S.; Kim, M.; Hae, H.; Cao, M.; Kim, J. The development of a rebar-counting model for reinforced concrete columns: Using an unmanned aerial vehicle and deep-learning approach. J. Constr. Eng. Manag. 2023, 149, 04023111. [Google Scholar] [CrossRef]
- Eum, I.; Kim, J.; Wang, S.; Kim, J. Heavy equipment detection on construction sites using you only look once (YOLO-version 10) with transformer architectures. Appl. Sci. 2025, 15, 2320. [Google Scholar] [CrossRef]
- Yu, X.; Salimpour, S.; Queralta, J.P.; Westerlund, T. General-purpose deep learning detection and segmentation models for images from a lidar-based camera sensor. Sensors 2023, 23, 2936. [Google Scholar] [CrossRef]
- Alokasi, H.; Ahmad, M.B. Deep learning-based frameworks for semantic segmentation of road scenes. Electronics 2022, 11, 1884. [Google Scholar] [CrossRef]
- Jung, S.; Heo, H.; Park, S.; Jung, S.U.; Lee, K. Benchmarking deep learning models for instance segmentation. Appl. Sci. 2022, 12, 8856. [Google Scholar] [CrossRef]
- Lee, D.H.; Park, H.Y.; Lee, J. A review on recent deep learning-based semantic segmentation for urban greenness measurement. Sensors 2024, 24, 2245. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, X.; Yi, C.; Arditi, A. Toward a computer vision-based wayfinding aid for blind persons to access unfamiliar indoor environments. Mach. Vis. Appl. 2013, 24, 521–535. [Google Scholar] [CrossRef]
- Ko, E.; Kim, E.Y. A vision-based wayfinding system for visually impaired people using situation awareness and activity-based instructions. Sensors 2017, 17, 1882. [Google Scholar] [CrossRef]
- Tapu, R.; Mocanu, B.; Zaharia, T. Seeing without sight—An automatic cognition system dedicated to blind and visually impaired people. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1452–1459. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, F.C.; Ngo, H.H.; Dow, C.R. A cloud-based face video retrieval system with deep learning. J. Supercomput. 2020, 76, 8473–8493. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- FaceNet. GitHub. 2016. Available online: https://github.com/davidsandberg/facenet/ (accessed on 9 August 2022).
- Dow, C.R.; Ngo, H.H.; Lee, L.H.; Lai, P.Y.; Wang, K.C.; Bui, V.T. A crosswalk pedestrian recognition system by using deep learning and zebra-crossing recognition techniques. Softw. Pract. Exp. 2019, 50, 630–644. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common objects in context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Cheng, J.; Li, Y.; Wang, J.; Yu, L.; Wang, S. Exploiting effective facial patches for robust gender recognition. Tsinghua Sci. Technol. 2019, 24, 333–345. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1. | print(“Please press any key…”) |
| 2. | image = numpy.zeros([512,512,1],dtype=numpy.uint8) |
| 3. | while(True): |
| 4. | cv2.imshow(“The input key code testing (press Esc key to exit)”,image) |
| 5. | key_input = cv2.waitKey(1) & 0xFF |
| 6. | if (key_input != 0xFF): #press key |
| 7. | print(key_input) |
| 8. | if (key_input == 27): #press Esc key |
| 9. | break |
| 10. | cv2.destroyAllWindows() |
| No. | Device | Technical Specifications |
|---|---|---|
| 1 | Computer | Intel Core i7 CPU 3.70 GHz, 64-bit Windows operating system, 32 GB RAM, NVIDIA TITAN V GPU. |
| 2 | Jetson AGX Xavier | 8-core NVIDIA Carmel 64-bit CPU, 64-bit Ubuntu 18.04 operating system, 512-core NVIDIA Volta GPU with 64 Tensor Cores. |
| 3 | Power bank | Enerpad universal power bank, Input: DC 24 V/2 A, USB output: DC 5 V/2.4 A, AC output: AC 120 V/60 Hz. |
| 4 | Remote controller | Logitech R400 remote controller, Wireless operating distance: approx 10 m2, Wireless technology: 2.4 GHz. |
| 5 | Webcam | Logitech C920 webcam, Max resolution: 1080p/30 fps–720p/30 fps. |
| 6 | Headphone | E-books E-EPA184 Bluetooth headphone. |
| 7 | Audio transmitter adapter | RX-TX-10 transmitter and receiver Bluetooth adapter, Battery: 200 mAh, Power voltage: 3.7 V, Bluetooth 4.2. |
| 8 | HDMI to VGA/audio adapter | Mini HDMI to VGA video converter HD cable adapter, Input: Mini HDMI, Output: VGA and Audio. |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| An | 1 | 1 | 1 |
| Huy | 1 | 1 | 1 |
| Jason | 1 | 1 | 1 |
| Lam | 0.99 | 1 | 0.99 |
| Prof. Dow | 0.99 | 1 | 0.99 |
| Prof. Lin | 1 | 1 | 1 |
| Rich | 0.99 | 1 | 0.99 |
| Thanh | 0.99 | 1 | 0.99 |
| Tung | 0.96 | 1 | 0.98 |
| Wolf | 0.99 | 1 | 0.99 |
| Age Groups | 8–13 | 15–20 | 25–32 | 38–43 | 48–53 | 60+ | Average |
|---|---|---|---|---|---|---|---|
| Precision | 0.72 | 0.68 | 0.75 | 0.69 | 0.64 | 0.75 | 0.71 |
| Recall | 0.96 | 0.69 | 0.78 | 0.49 | 0.64 | 0.43 | 0.67 |
| F1 Score | 0.82 | 0.68 | 0.76 | 0.57 | 0.64 | 0.55 | 0.67 |
| Functions | Function 1 | Function 2 | Function 3 |
|---|---|---|---|
| Processing Time (frames per second) | 1.88 | 1.65 | 4.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, H.-H.; Le, H.L.; Lin, F.-C. Deep-Learning-Based Cognitive Assistance Embedded Systems for People with Visual Impairment. Appl. Sci. 2025, 15, 5887. https://doi.org/10.3390/app15115887
Ngo H-H, Le HL, Lin F-C. Deep-Learning-Based Cognitive Assistance Embedded Systems for People with Visual Impairment. Applied Sciences. 2025; 15(11):5887. https://doi.org/10.3390/app15115887
Chicago/Turabian StyleNgo, Huu-Huy, Hung Linh Le, and Feng-Cheng Lin. 2025. "Deep-Learning-Based Cognitive Assistance Embedded Systems for People with Visual Impairment" Applied Sciences 15, no. 11: 5887. https://doi.org/10.3390/app15115887
APA StyleNgo, H.-H., Le, H. L., & Lin, F.-C. (2025). Deep-Learning-Based Cognitive Assistance Embedded Systems for People with Visual Impairment. Applied Sciences, 15(11), 5887. https://doi.org/10.3390/app15115887