1. Introduction
Manipulating objects at a distance is a fundamental interaction in virtual reality (VR) environments [
1]. Like in the real world, walking to a distant object and manipulating it is realistic, but this requires two steps of interactions and is hence considered inefficient. Therefore, researchers have explored more efficient methods for distant object manipulation, such as extending the virtual arm to reach objects [
2] or using controller-based raycasting [
3,
4]. These methods allow users to reach and manipulate distant objects, but they still have significant challenges. Extended virtual arm techniques result in imprecise hand control due to scaling up the input, while raycasting methods reduce the intuitiveness and naturalness of interaction.
Alternatively, gaze has been explored as a potential input modality for distant object manipulation, offering advantages such as rapid movement [
5,
6], easy indication of a distant object [
7], and reduced physical effort [
8]. However, a simple gaze interaction has notable limitations: (1) the Midas touch problem [
9], where simply looking at an object causes unintentional selection, and (2) limited interaction capabilities, as gaze primarily provides point information (i.e., indicating the point where the user is looking at).
Recent studies have demonstrated potential solutions to these problems by combining eye gaze and hand inputs. For the Midas touch problem, many studies have adopted the principle of ‘gaze indicates and hand confirms a selection’ [
10,
11,
12]. Combining hand input with gaze also addresses the issue of limited interaction by supporting diverse and sophisticated hand interactions [
13,
14]. An interesting recent trend in using gaze input is exploiting a gaze ray, a line from the user’s eye to the gaze point. Lystbæk et al. [
15] and Wagner et al. [
16] introduced Gaze Hand Alignment (GHA), a quick selection mechanism realized by placing a fingertip on the gaze ray. Bao et al. [
17] proposed Gaze Beam Guided interaction, which supports the translation of selected objects in the depth direction along the gaze ray.
Numerous previous studies combining eye gaze and hand interactions showed effective distant object manipulation, but most previous methods control 6 degrees-of-freedom (DOF) manipulation simultaneously, which may reduce the level of accuracy [
18]. Additionally, existing research has not thoroughly explored the potential of using the relative position between gaze and the hand for manipulation. Thus, this research aims to explore a method that leverages the relative position between the gaze ray and hand to support manipulation for each individual DOF.
We explore two manipulation techniques: GazeRayHand and GazeRayHand2. GazeRayHand relies on hand movements relative to the gaze ray allowing for handling one or two DOFs separately for 3D object manipulation. GazeRayHand2 additionally employs gaze interaction for coarse object translation but still supports hand interaction. To evaluate these two techniques, we conducted a user study by comparing them with existing techniques that combine gaze and hand interactions: Gaze&Pinch [
19] and modified Gaze Beam Guided [
17]. To the best of our knowledge, this research is the first to introduce and evaluate an object manipulation method based on the relative position between a hand and a gaze ray.
In summary, the contributions of this paper are as follows:
We utilize the relative position between the gaze ray and the hand for object manipulation.
We propose two novel techniques that combine gaze ray and hand interactions.
We evaluate our techniques by comparing them with other recent manipulation techniques that combine gaze and hand interactions.
2. Related Work
In this section, we review existing work for both precise and distant object manipulation. We first introduce previous work using a single modality for object manipulation. We then review how gaze and hand inputs were combined for manipulation. Lastly, we discuss the limitations of these approaches and present solution.
2.1. Object Manipulation in VR
A simple but natural way to accomplish object manipulation is to directly grasp and manipulate an object with a Simple Virtual Hand (SVH) [
1]. This method supports 6-DOF transformation (i.e., three for translation and three for rotation), similar to object manipulation in the physical world. However, this approach has two main limitations: (1) limited precision due to handling 6 DOFs simultaneously and (2) difficulty in manipulating out-of-reach objects.
To address the first issue of precise manipulation, researchers separated 6-DOF manipulation into multiple manipulations of one or two DOFs [
18,
20,
21]. For example, Hayatpur et al. [
22] employed three geometrical constraints (plane, ray, and point) to guide the object manipulation. These constraints allow users to manipulate restricted DOF at once: a plane only supports 2D translation on the plane, a ray supports 1D translation (i.e., linear movement along the ray) and 1D rotation (rotation around the ray), and a point supports 2D rotation and 1D translation anchored by the point. Another solution for precise manipulation is scaling the movement of the virtual object based on the speed of hand movements [
23,
24,
25]. For example, Frees et al. [
23] introduced PRISM (Precise and Rapid Interaction through Scaled Manipulation) where a user could perform fine-grained object manipulation with a scaled-down 6-DOF transformation by reducing the amount of manipulation according to the speed of hand movement.
To overcome the challenges of manipulating distant objects, many researchers have explored methods for extending the user’s reach [
2,
4,
24]. For instance, Poupyrev et al. [
2] proposed Go-Go interaction, which allows the user to lengthen a virtual arm to reach distant objects. When stretching user’s arm beyond a predefined distance, the virtual arm grows non-linearly proportional to reach, enabling the grasping of distant objects. Similarly, HOMER (Hand-centered Object Manipulation Extending Ray-casting) [
4] lengthens the user’s arm after a user selects a distant object by a ray-casting method first. Once the object is selected, the virtual arm grows to place the hand at the selected object, allowing the user to manipulate it directly as if the user’s body was in front of the object.
Another approach for distant object manipulation is providing a miniature copy of the environment and synchronizing the user’s manipulation of the miniature to the full-scale objects [
26,
27,
28]. For instance, Stoakley et al. [
26] proposed the World-In-Miniature (WIM) interface. The miniature is identical to the virtual space where a user is in but scaled-down and positioned nearby the user. This allows the user to manipulate full-size, distant objects by interacting with miniature objects as they are synchronized with each other. However, reducing the size of virtual objects could increase the difficulty of fine-grained manipulation because a small geometrical error in the miniature results in a larger geometrical error in the full-sized objects. Additionally, since the miniature is always in front of a user, it could sometimes occlude the full-size VR environment. As a solution, Scaled-World Grab [
27] was introduced. This method automatically scales down a virtual world when a user selects an object and scales it back up when the user releases the object.
Additionally, Lee et al. [
20] presented Unimanual Metaphor with Scaled Replica (UMSR), a method for precise and distant object manipulation. This method places a scaled replica of the distant object within the user’s near-field and allows the user to manipulate it. For precise manipulation, this method supports restricted DOF manipulation when selecting the face, edge, or vertex of the bounding box of a replica.
Nevertheless, performing hand manipulation for more than a few minutes leads to arm fatigue (a.k.a. the gorilla arm effect [
29]). Hence, recent studies have explored interfaces that combine hand and gaze interactions for distant object manipulation.
2.2. Combining Gaze and Hand for Object Manipulation
In daily life, humans naturally use their eyes to see a target object before selecting and manipulating it [
30,
31]. The gaze interaction is fast [
5,
6] and requires low effort [
7,
8], while the hand interaction is intuitive and allows for precise adjustments [
32]. Therefore, many researchers have adopted the combination of gaze and hand interactions and demonstrated its effectiveness [
19,
32,
33,
34].
For example, Chatterjee et al. [
10] proposed the Gaze+Gesture technique in a desktop environment. In this technique, a user’s gaze quickly sets the approximate initial position of a cursor, followed by fine adjustments using hand gestures. In their user study, the combination of gaze and gesture interaction outperformed gaze or gesture alone in terms of precision and time in a positioning-objects task using the cursor. Similarly, Pfeuffer et al. [
34] investigated a method for switching between direct and indirect hand manipulation based on the position of the gaze on a 2D touch display. If the hand input is within the gaze region, direct hand manipulation is applied to the target object. Conversely, if the hand input is outside the gaze region, indirect manipulation is activated for applying the hand input at the gaze position on the 2D touch display.
Extending the concept to 3D VR environments, Pfeuffer et al. [
19] introduced the Gaze&Pinch technique, where a user selects a distant object by looking at it with a gaze and confirms the selection with pinching. After the selection, the user can translate the object by moving the hand until the pinch is released. This technique also supports rotation by a two-hand interaction. The technique rotates the selected object in the direction which the movement of the two hands represents.
Some researchers have explored gaze manipulation after selecting an object [
13,
14,
17]. Yu et al. [
13] introduced 3DMagicGaze, which supports coarse translation based on gaze movement and fine hand manipulation. They established a circular region around the target object, and if the gaze point is within this region, hand manipulation is applied. Otherwise, if a user moves their gaze outside the region, the object is translated at the gaze direction. One significant limitation of this technique is depth translation by hand operation which is restricted by the arm’s reach.
Bao et al. [
17] proposed a method that extends gaze-based translation not only in the lateral or longitudinal directions but also in the depth direction. Their approach consists of three steps: selection, the first translation step in lateral and longitudinal direction, and then the second step for depth translation. Selection is confirmed by releasing a hand pinching when aligning a gaze ray with a target object. In the first translation step, the target object moves according to eye movements, and then fine translation is performed using the hand adjustment. When the first translation ends, the direction of the gaze ray is fixed, and moving the hand forward or backward makes the target object move forward or backward along the ray, respectively, for depth translation. While supporting translation in three dimensions, this method does not support object rotation.
2.3. Asynchronous and Synchronous Inputs of Gaze and Hand for Manipulation
Gaze and hand manipulation can be categorized into two types. In the first type, gaze and hand inputs are asynchronously performed in a sequential manner by switching the input mode between them [
19,
33,
34,
35]. Hence, the gaze and hand inputs are not performed and applied simultaneously. For example, Ryu et al. [
36] introduced the GG method that uses gaze to create a selected area for distant dense objects and then supports translation or rotation using a hand within the area without taking any input from the user’s gaze. Additionally, Kyto et al. [
32] proposed a method for object selection, and the gaze input is deactivated when the hand is used for object selection, and vice versa.
Recently, researchers have developed interaction techniques that simultaneously take gaze and hand inputs for object selection and manipulation [
14,
16,
17]. Lystbæk et al. [
15] proposed a method that selects an object which is gazed at when placing a hand on a gaze ray. In a user study, they found their selection method was faster and had fewer errors than hand-only and Gaze&Pinch [
19] techniques. Additionally, Jeong et al. [
14] introduced the GazeHand technique for object translation. This technique first creates a gaze ray to an object which a user is looking at and then places virtual hands nearby the object. The GazeHand takes gaze and hand inputs simultaneously and allows for concurrent gaze and hand manipulation after grabbing the object.
2.4. Limitations in Previous Work
According to our literature review, we found that hand manipulation is essential but has two main limitations: (1) handling 6-DOF at once causes difficulty in accurate manipulation, and (2) it is limited to arm-reachable area. As solutions, researchers have proposed handling one or two DOFs separately in a sequential manner for the 6-DOF manipulation [
18,
20] and combining gaze and hand interaction to reach a distant object [
13,
14,
17,
19]. However, there is no previous study using the relative position between the gaze ray and hand that could represent object manipulation in a 3D VR environment. We explore the benefits of using relative position between the gaze ray and hand for object manipulation by designing two interaction techniques that utilize the concept.
3. Design of GazeRayHand Techniques
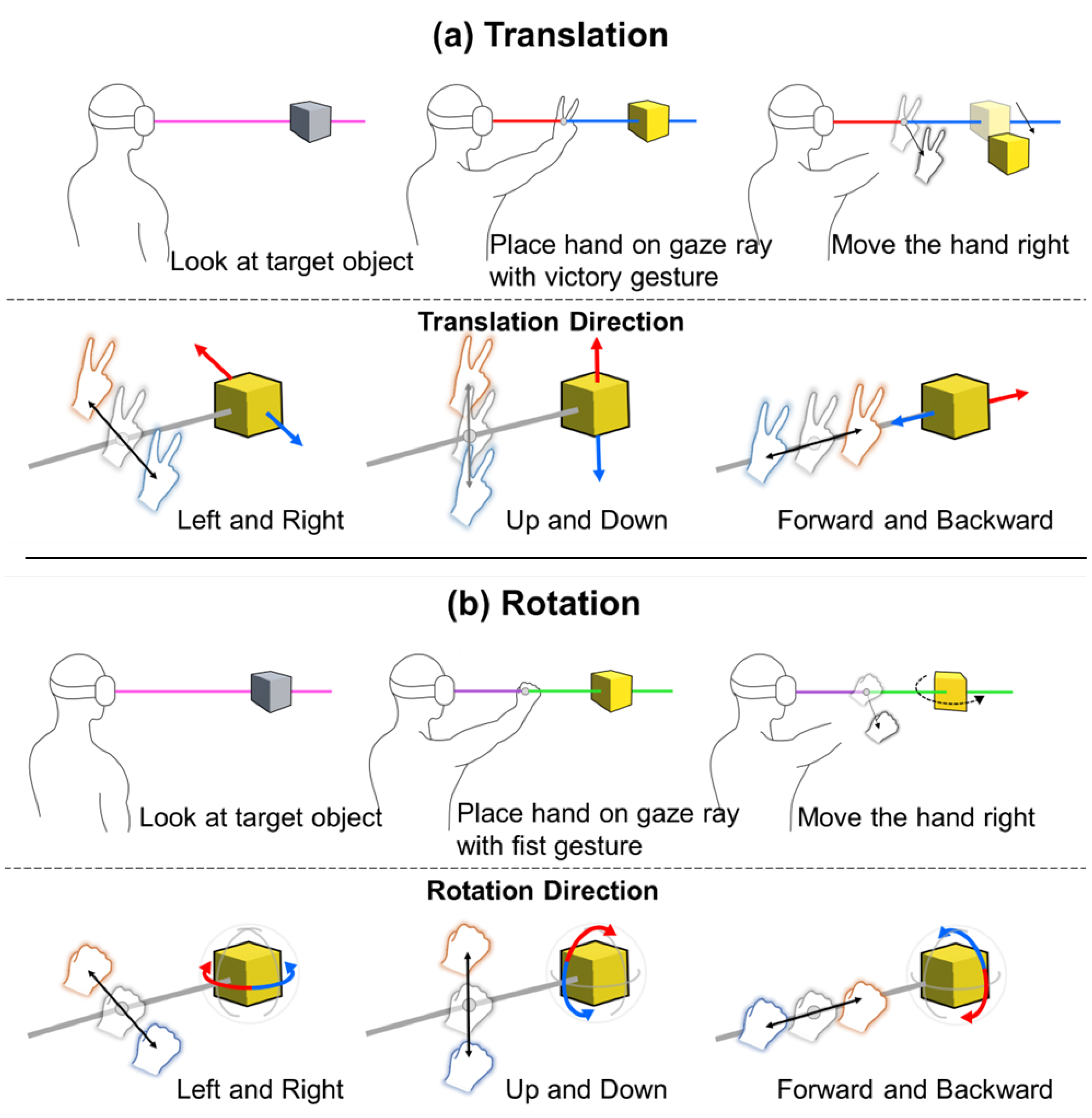
We propose the GazeRayHand manipulation which utilizes the relative position between a gaze ray and a hand. Before selecting an object, the magenta gaze ray starting from the user’s forehead to a gazing point is updated according to the gazing direction. The object that a user is looking at is selected when placing a hand on the gaze ray for more than 0.3 s, which is to prevent unintended selection. After selecting an object, the ray is fixed at the position to prevent fluctuating gaze movement during object manipulation. To provide visual feedback, the selected object color is changed to yellow and a small spherical indicator (radius: 0.015 m) appears on the gaze ray at the hand position when selection happens. This small indicator lets the user estimate how far the user’s hand moved for manipulation from the original position when selection took place.
The GazeRayHand translates or rotates the selected object in the direction of the hand is relative to the ray (see
Figure 1). Hence, moving a hand up, down, left, or right relative to the gaze ray translates or rotates the object in the corresponding directions. We differentiate translation and rotation interactions by two hand gestures: V gesture (stretching index and middle fingers while closing the others) for translation, and fist gesture (closing all five fingers) for rotation. Moving the hand forward or backward translates the selected object forward or backward with the V gesture or rotates the selected object clockwise and counter-clockwise (yawing at the depth axis) with the fist gesture.
To allow users to handle one or two DOFs separately for 3D manipulation, the GazeRayHand technique estimates which manipulation the hand interaction is for between depth and horizontal/vertical manipulations. If the hand moves more in the depth direction rather than in the horizontal/vertical direction, the hand movement results in depth manipulation but not horizontal/vertical manipulation, and vice versa.
The hand manipulation area was empirically decided through a pilot study with five VR-experienced participants. In the pilot study, we found that it was easy to move a hand 0.25 m away in any direction from the point where the user initially placed the hand on the gaze ray for object selection. Thus, we designed the hand manipulation area as a cube having 0.5 m sides with its center point at the hand position when selecting an object. For rate-based control, we also designed the range of the translation and rotation speeds through the pilot study. The basic idea of controlling the speeds was calculating them with the distance between the hand and gaze ray. As the hand moves farther from the gaze ray, the speed increases. The translation speed ranges from 0.05 m/s to 1.2 m/s, while the rotation speed changes from 0.05 rad/s to 1 rad/s. To prevent unintentional translation or rotation, the hand should be placed more than 0.05 m away from the initial position at selection. We mapped the maximum distance in the hand manipulation area (0.5 m) to the maximum speed and the starting point of manipulation (0.05 m) to the minimum speed.
A simple hand opening gesture stops the manipulation, and the object returns to its original color, and the gaze ray updates again according to the user’s gaze direction. The width of gaze ray was set to 0.03 m, and the hand model was visualized using Vive Hand Tracking SDK 1.0.0 [
37]. To mitigate the occlusion and detraction of the user’s view, we made the hands and gaze-ray semi-transparent.
Based on the GazeRayHand manipulation, we additionally implemented another variation, named GazeRayHand2. Both techniques work identically for selection, translation, and rotation using hands, but the GazeRayHand2 technique adds gaze-based translation to the GazeRayHand technique. To achieve this, the GazeRayHand2 creates a white, semi-transparent sphere around an object when it is selected. The radius of the sphere is 20 percent larger than the radius of the selected object’s bounding sphere. The GazeRayHand2 technique works in the same manner as the GazeRayHand technique while the user’s gaze point is within the sphere (see
Figure 2b). However, when the gaze moves out from the sphere, it additionally supports gaze based translation which repositions the selected object to the gaze point (see
Figure 2a). This gaze-based translation repositions not only the selected object but also the sphere representing the hand translation area. While the GazeRayHand2 technique uses gaze-based translation, it serves to mitigate the Midas touch problem [
9] by activating gaze translation only when the user’s gaze point is outside the defined sphere around the object. This conditional activation ensures that object movement is based on intentional gaze shifts. This approach is inspired by prior work such as Zhai et al.’s MAGIC Pointing [
33] and Yu et al.’s 3DMagicGaze [
13]. Both approaches employed explicit mode switching between gaze and hand input by using a designated area; gaze-based translation was activated when the gaze moved outside the area, thereby preventing unintended gaze-triggered translations.
4. User Study
We conducted a within-subject user study to evaluate our proposed techniques, GazeRayHand and GazeRayHand2, in comparison to existing techniques: Gaze&Pinch [
19] and modified Gaze Beam Guided [
17]. These four techniques take different approaches to using gaze and hand interactions for object manipulation. The objective of this study was to understand how different variations of combining gaze and hand interactions influence the user experience in distant object manipulation.
4.1. Conditions
4.1.1. Gaze&Pinch
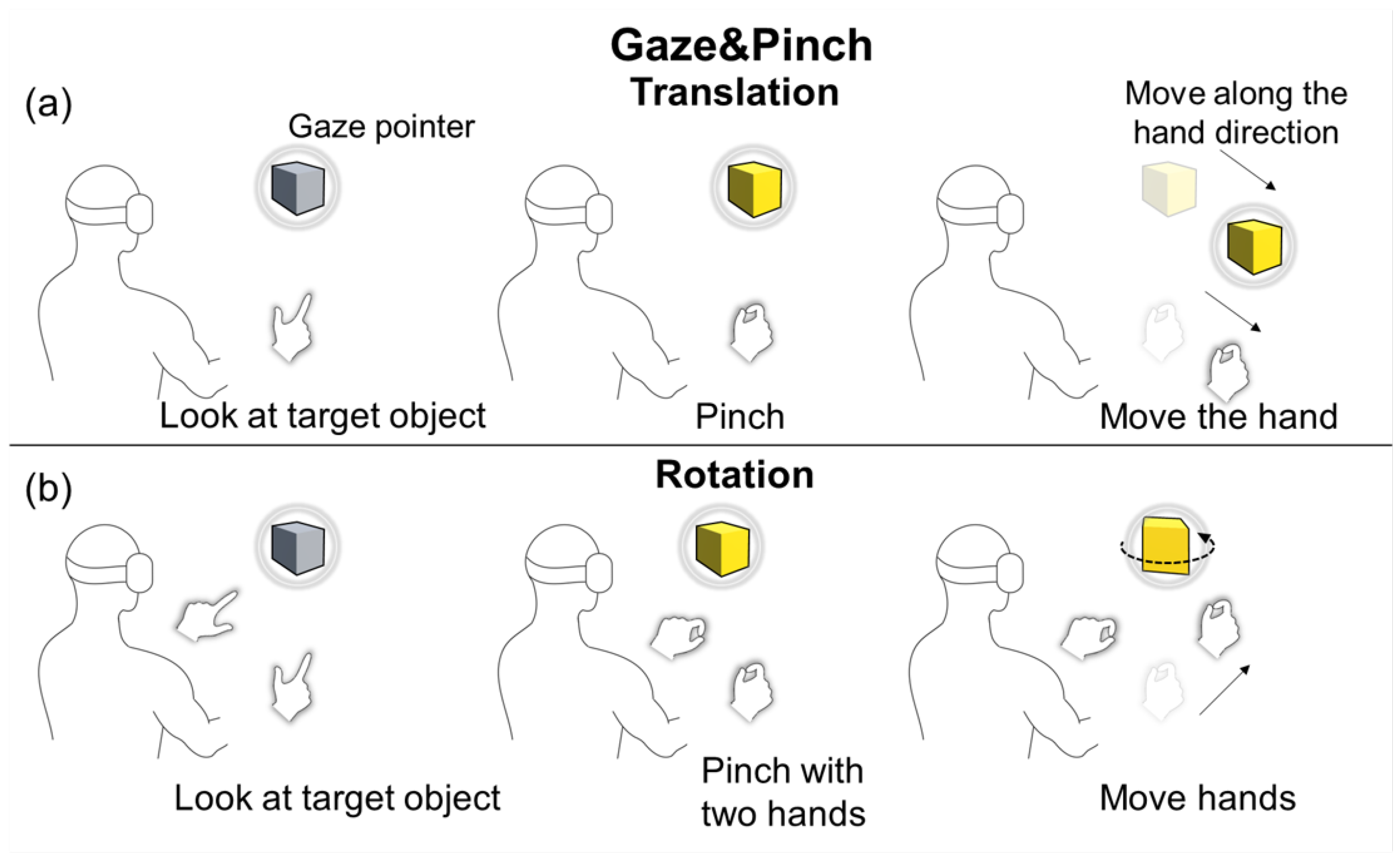
Gaze&Pinch [
19] exclusively employs gaze interaction for object selection. To select an object, a user looks at the object to place the gaze pointer at it and makes a pinch gesture with a hand. Same as our GazeRayHand technique, the selected object changes its color to yellow, indicating the confirmation of selection.
The translation of the pinched hand triggers the translation of the selected object in the direction in which that hand is moving until the pinch is released (see
Figure 3a). The distance of the translation is controlled using an equation:
. According to this equation, the amplification of object translation increases as the distance between the user and selected object grows. The translation stops when the pinch is released, and the object turns back to its original color.
Similar to our GazeRayHand technique, the Gaze&Pinch has a different input mode for object rotation. For the rotation mode, selection should be performed by a two-hand pinching gesture while the user is looking at an object. After selection, rotation is performed with a two-hand interaction which decides the rotating movement (see
Figure 3b). Similar to translation, rotation stops when the pinch is released.
4.1.2. Modified Gaze Beam Guided
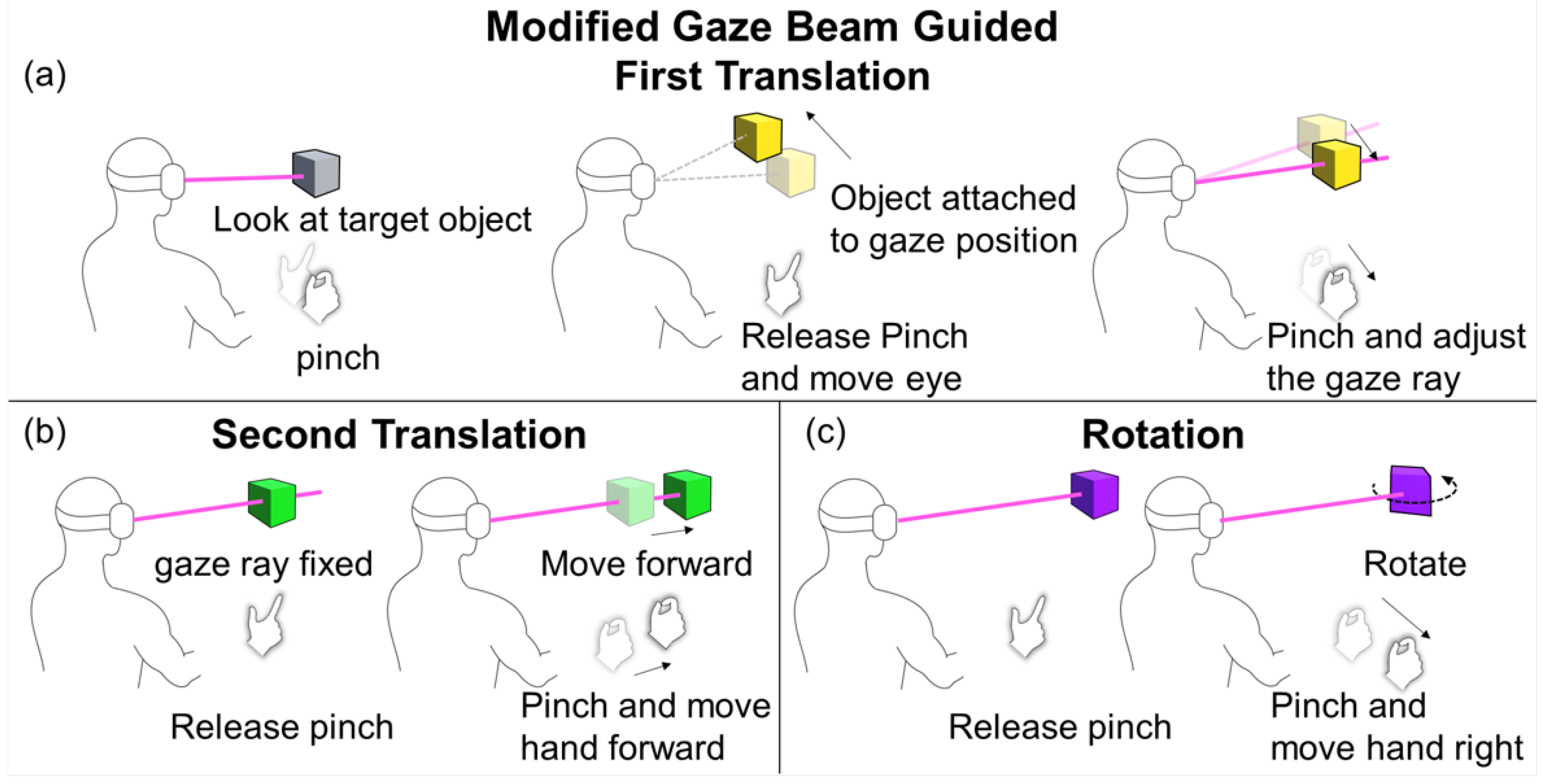
The Gaze Beam Guided [
17] technique selects an object that the gaze ray is pointing at when the user makes and releases a pinching gesture. Initially, an invisible gaze ray is used which starts from the user’s forehead and ends at a gazed point. The gaze ray becomes visible when a user makes a pinching gesture, and the ray is controlled by the pinching hand afterwards. This changes the end point of the ray according to the hand movement. Moving the hand up, down, left, or right makes the end point of the ray move up, down, left, or right, respectively. When releasing the pinching gesture, the object at the end point of the ray is selected and the ray becomes invisible again with being controlled by eyes, and the object turns yellow indicating that it is selected for manipulation.
There are two steps for object translation, allowing users to handle horizontal/vertical and depth translations separately. The first step is for horizontal/vertical translation. With another pinching gesture, the selected object instantly relocates to the point where a user is looking at, and the gaze ray becomes visible, being controlled by the pinching hand again (see
Figure 4a). The selected object is attached to the end of the ray; hence, moving the hand to control the end point, as in the selection, moves the object. Releasing the pinching gesture completes the first step of translation. The ray remains visible but fixed after this step is completed, and the object turns green.
Another pinching gesture triggers the second step in translation for a depth control. Moving the pinching hand further or closer makes the object move further or closer along the fixed ray (see
Figure 4b). The distance of depth translation is controlled in the same way as with Gaze&Pinch. Upon releasing the pinch, the second translation step finishes, and the object turns purple.
While the original Gaze Beam Guided technique does not support object rotation, we modified it to add the feature so it would be comparable to other techniques in this study. Since the Gaze Beam Guided technique repeatedly uses the pinching gesture, we also adopted it to start a rotation step. After the second translation step, the fixed ray remains visible, and it becomes a reference line for the rotation, like in our GazeRayHand technique. The user can rotate the object left, right, up, or down by moving the pinching hand in these directions. The rotation speed is controlled in the same way as in our techniques (see
Figure 4c). Releasing the pinching gesture completes all steps of object manipulation by the Gaze Beam Guided technique; so the gaze ray becomes invisible, and the object returns to its original color. We note that object manipulation with the Gaze Beam Guided technique is performed sequentially, and we modified it by adding a rotation step at the end of the sequence.
4.2. Hypothesis
We were interested in how GazeRayHand and GazeRayHand2, which leverage the relative position between the gaze ray and hand, affect task performance and user experience, compared to existing techniques that combine gaze and hand interactions (e.g., Gaze&Pinch and Gaze Beam Guided). Given that GazeRayHand and GazeRayHand2 support simple and one-handed manipulation using relative position, we formulated the following hypotheses:
H1: The GazeRayHand technique will reduce overall manipulation time compared to the Gaze&Pinch technique.
H2: The GazeRayHand techniques will reduce hand movement and perceived arm fatigue compared to Gaze&Pinch and modified Gaze Beam Guided techniques.
H3: Both the GazeRayHand and GazeRayHand2 techniques will lead to a greater perceived user experience compared to the modified Gaze Beam Guided technique.
4.3. Participants and Apparatus
We recruited 24 participants (8 males and 16 female) aged between 20 and 28 years (MD = 22.8, SD = 2.31). Three participants were left-handed, and the others were right-handed. Two thirds of the participants (n = 16) reported that they experienced VR rarely, seven reported experiencing VR less than once a month, and one reported experiencing VR more than once a week.
We developed the system using HTC Vive Pro HMD [
38] embedded with a Tobii Eye tracker. The HMD was connected to a desktop PC (3.8 GHz AMD Ryzen 7 5800X 8-Core, 32 GB of RAM, and an NVIDIA GeForce RTX 3060 graphics card). The software was implemented in C# with Unity game engine 2020.3.37f1. To get hand tracking information, Vive Hand Tracking SDK 1.0.0 [
37] was used.
4.4. Task Design
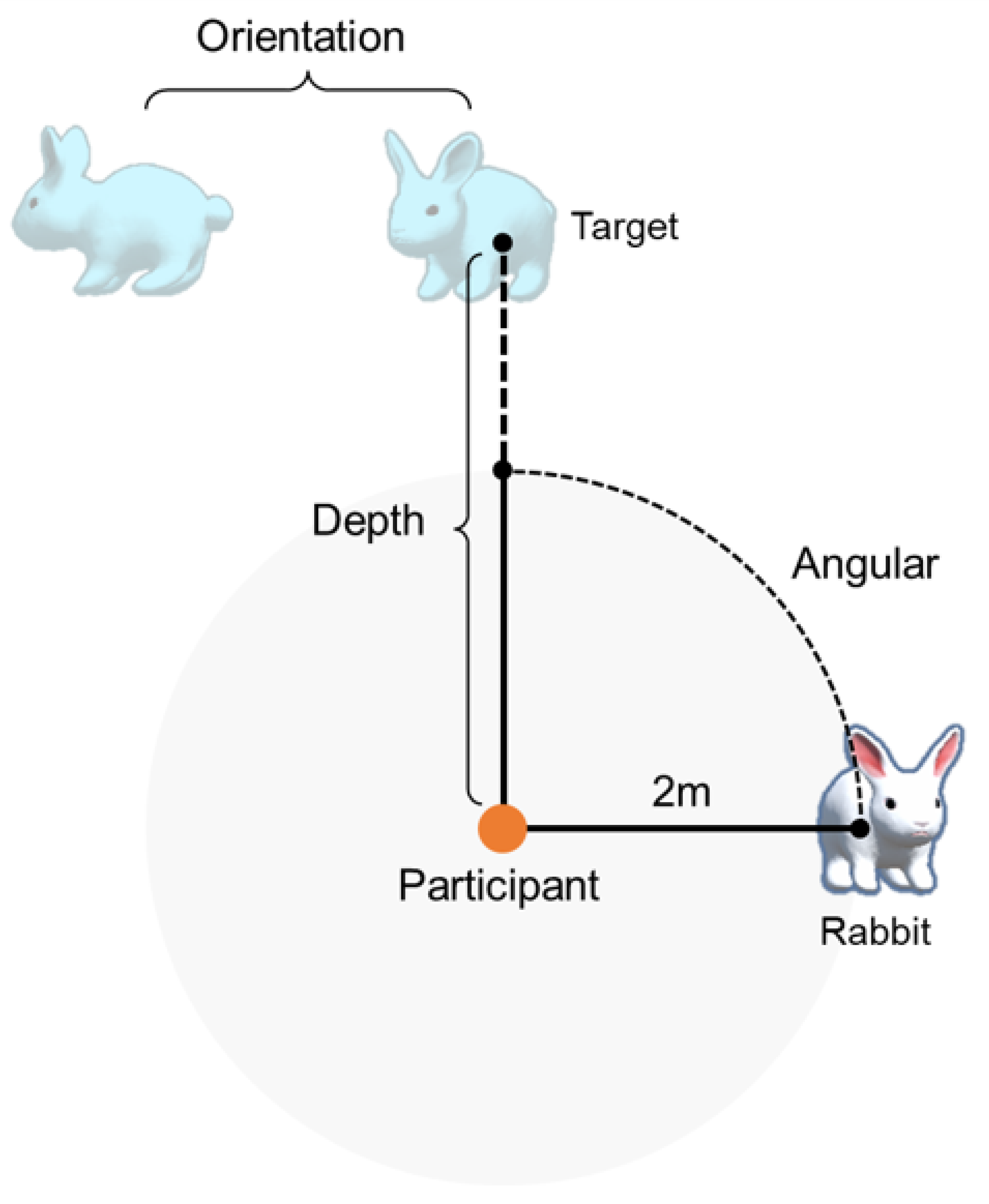
The task design is illustrated in
Figure 5. The task was to manipulate a rabbit-shaped virtual object to be fitted at the target position and orientation, as quickly and accurately as possible. Eight trials of manipulation were conducted in each condition, with the rabbit and target having different positions and orientations. The eight trials were designed with three factors of two values (2 × 2 × 2 = 8) that decided the target pose. The first factor was the positional difference between the rabbit and the target, with a
or
angular difference from the participant’s view, with the rabbit positioned two meters away. The second factor was the two levels of depth of the target: 3.5 m or 5 m. The third factor was the target orientation:
or
difference compared to the rabbit. For the user study, one set of eight trials was prepared for each experimental condition. The order of the eight trials was randomized, so the order will be different in each condition but balanced in difficulty level.
The target was represented as a semi-transparent blue rabbit. Each trial was completed when the difference between the rabbit and target was less than in rotation and 0.05 m in translation. When each trial was completed, the target disappears, the rabbit turns red, and the user can no longer control the rabbit. After three seconds, a new set of rabbit and target was displayed for the next trial.
4.5. Procedure and Evaluation Measures
On arrival, participants were given a written explanation of the purpose and procedure of this experiment. Once they agreed to participate, they filled out a demographic questionnaire asking about gender, age, hand dominance, and VR experience. They then received verbal instruction about the equipment and interaction techniques. Participants sat on a chair in a designated area and were asked to select their preferred hand and use only that hand. They wore an HMD and calibrated the eye tracker. Once ready, they practiced each experimental condition by translating and rotating three cubes (0.5 m width), located 3.5 away and 1 m above the user. After becoming familiar with them, they performed the experimental task.
In the experimental task, we adjusted the object height based on the height of the HMD worn by the participant. The order of the four experimental conditions was counter-balanced using a Balanced Latin Square design. During the experiment, we measured the following objective measures for each experimental condition:
Total Manipulation Time: total manipulation time (in seconds) that participants spent to complete a task with a given condition.
Coarse Manipulation Time: the time (in seconds) that participants spent for roughly matching the rabbit and target within and 0.1 m in rotation and translation, respectively.
Fine-grained Manipulation Time: the amount of time (in seconds) taken until completing a rabbit manipulation after the moment of roughly matching the rabbit and target (Total Manipulation Time = Coarse Manipulation Time + Fine-grained Manipulation Time).
Total Translation Distance: accumulated distance (in meters) that the object has been translated during the manipulation.
Total Rotation Degree: total amount of rotation (in degrees) that the object has been rotated during the manipulation.
Total Hand Translation: total translation distance (in meters) that the participant’s hand moved for the manipulation. For Gaze&Pinch, which uses both hands for object rotation, we accumulated the distances of both hands’ movements.
Total Hand Rotation: the total amount of hand rotation (in degrees) performed during manipulation. For Gaze&Pinch, we accumulated the amount of both hands’ rotation.
Total Head Translation: total translation distance (in meters) that the head moved during manipulation.
Total Head Rotation: total amount of head rotation (in degrees) that was performed during manipulation.
After completing the eight trials for each experimental condition, participants answered a set of questionnaires: Borg Category-Ratio 10 (Borg CR10) [
29,
39], System Usability Scale (SUS) [
40], NASA Task Load Index (NASA-TLX) [
41], and the short version of the User Experience Questionnaire (UEQ-S, measuring pragmatic and hedonic qualities) [
42]. Participants were allowed sufficient rest after completing a set of eight trials in each experimental condition. Upon completing all four experimental conditions, participants ranked their preference for the four conditions, from 1 (best) to 4 (worst), and were interviewed about the pros and cons of each condition. The entire experiment took about 70 min per participant. Participants received USD 10 as a reward and were free to withdraw at any time during the experiment.
5. Results
We present the results of the user study with objective and subjective measures. According to the Shapiro–Wilk test, our objective measures (total manipulation time, coarse manipulation time, fine-grained manipulation time, total translation distance, total rotation degree, total hand translation, total hand rotation, total head translation, and total head rotation) were not normally distributed, and subjective measures (Borg CR10, NASA-TLX, SUS, and UEQ-S) are in ordinal scales. We thus ran a Friedman test ( = 0.05) among the four experimental conditions, and for those showing a significant difference, we ran a post hoc test for pair-wise comparisons using Wilcoxon signed-rank tests with Bonferroni correction applied ( = 0.05/6 = 0.0083).
In this section, we use the following abbreviations: GRH, GRH2, GP, and GB for GazeRayHand, GazeRayHand2, Gaze&Pinch, and modified Gaze Beam Guided, respectively.
5.1. Objective Measures
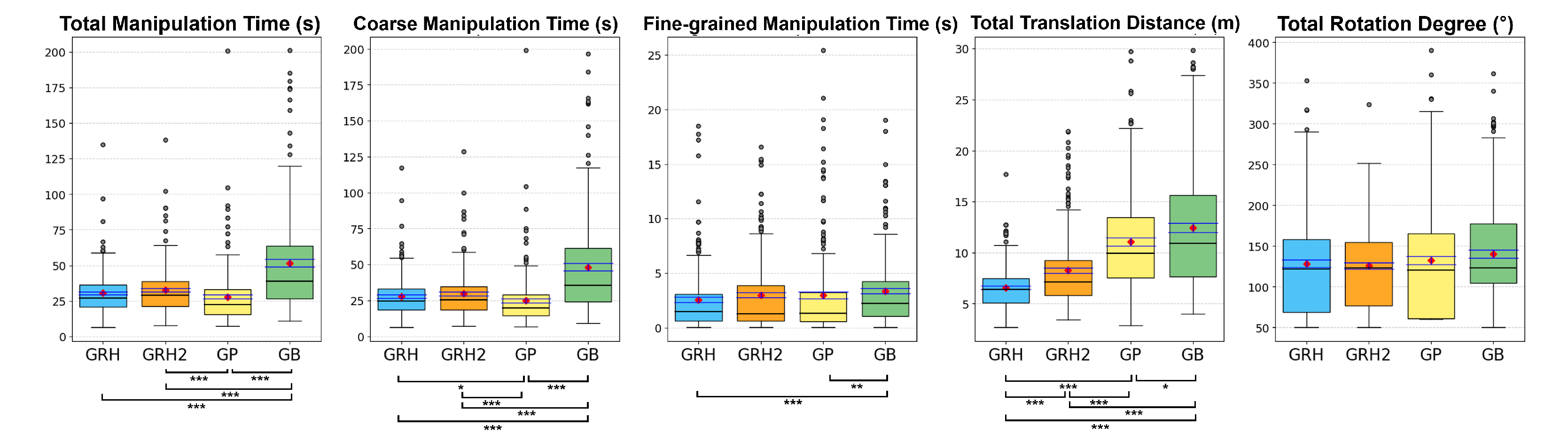
Results from objective measures are summarized in
Figure 6 and
Figure 7. Friedman tests found significant differences between the four experimental conditions in all measures except the object total rotation (all
p-values are less than 0.05, but the one for the object total rotation is 0.365).
5.1.1. Manipulation Time
In total manipulation time, the GB condition (M = 51.63, SD = 37.20) was significantly slower to complete the manipulations compared to the GRH condition (M = 30.44, SD = 15.38; GRH-GB: Z = −7.667, Z < 0.001), GRH2 condition (M = 32.69, SD = 17.83; GRH2-GB: Z = −6.931, p < 0.001), and GP condition (M = 27.89, SD = 20.43; GP-GB: Z = −8.507, p < 0.001). Additionally, participants completed faster when using the GP condition compared to the GRH2 condition (Z = −3.643, p < 0.001). In the other comparisons, there was no significant effect (GRH-GRH2: Z = −1.598, p = 0.110; GRH-GP: Z = −2.296, p = 0.022).
In coarse manipulation time, the GP condition (M = 24.90, SD = 19.32) was significantly faster than the GRH condition (M = 27.87, SD = 14.28; GRH-GP: Z = −2.881, p = 0.004), GRH2 condition (M = 29.69, SD = 17.02; GRH2-GP: Z = −4.163, p < 0.001), and GB condition (M = 48.25, SD = 36.07; GP-GB: Z =−8.782, p < 0.001). Furthermore, the GRH and GRH2 conditions were significantly faster than the GB condition (GRH-GB: Z = −7.501, p < 0.001; GRH2-GB: Z = −7.003, p < 0.001), but there was no significant effect between them (GRH-GRH2: Z = −1.101, p = 0.271).
Finally, in the results of fine-grained manipulation time, the GB condition (M = 3.38, SD = 3.41) was slower compared to the GRH condition (M = 2.57, SD = 3.16; GRH-GB: Z = −3.558, p < 0.001) and the GP condition (M = 2.98, SD = 4.25; GP-GB: Z = −3.312, p = 0.001). We found no significant difference in other pairwise comparisons (GRH2: M = 3.0, SD = 3.52; GRH-GRH2: Z = −1.527, p = 0.127; GRH-GP: Z = −0.211, p = 0.883; GRH2-GP: Z = −0.623, p = 0.553; GRH2-GB: Z = −1.883, p = 0.06).
5.1.2. Total Translation Distance and Total Rotation Degree
Participants translated object less when using the GRH condition (M = 6.56, SD = 2.26) than when using the GRH2 condition (M = 8.25, SD = 3.84; GRH-GRH2: Z = −4.949, Z < 0.001), GP condition (M = 11.09, SD = 5.37; GRH-GP: Z = −9.842, Z < 0.001), and GB condition (M = 12.42, SD = 6.28; GRH-GB: Z = −10.499, Z < 0.001). Additionally, the GRH2 condition helped participants make significantly less object translation than the GP condition (Z = −6.266, Z < 0.001) and the GB condition (Z = −7.569, Z < 0.001). The GP condition had significantly less object translation than the GB condition (Z = −2.668, p = 0.008).
Interestingly, we found that the sum of degrees by which the participants rotated objects did not show a significant effect among the four conditions ((3) = 3.181, p = 0.365; GRH: M = 128.43, SD = 62.74; GRH2: M = 125.77, SD = 54.20; GP: M = 132.48, SD = 71.18; GB: M = 140.54, SD = 68.13).
5.1.3. Total Hand Translation and Rotation
The GRH condition (M = 3.91, SD = 2.11) required less hand translation distance than the GP condition (M = 5.06, SD = 2.69; GRH-GP: Z = −5.488, p < 0.001) and GB condition (M = 5.25, SD = 3.55; GRH-GB: Z = −4.252, p < 0.001). However, there was no significant difference in other pairwise comparisons (GRH2: M = 4.44, SD = 2.43; GRH-GRH2 Z = −2.623, p = 0.009; GRH2-GP: Z = −2.486, p = 0.013; GRH2-GB: Z = −2.322, p = 0.020; GP-GB: Z = −0.595, p = 0.552).
Similarly, participants required less hand rotation when using the GRH condition (M = 165.59, SD = 106.01) compared to the GP condition (M = 214.04, SD = 157.94; GRH-GP: Z = −3.904, p < 0.001) and GB condition (M = 219.5, SD = 192.63; GRH-GB: Z = −2.922, p = 0.003). No significant difference was found in the comparison between GRH and GRH2 (GRH2: M = 181.26, SD = 118.19; GRH-GRH2: Z = −1.607, p = 0.108), GRH2 and GP (Z = −2.262, p = 0.024), GRH2 and GB (Z = −1.628, p = 0.104), and GP and GB (Z = −0.80, p = 0.424) conditions.
5.1.4. Total Head Translation and Rotation
The GB condition (M = 1.61, SD = 1.52) showed more head movement distance in comparison to the GRH condition (M = 0.94, SD = 0.6; GRH-GB: Z = −5.747, p < 0.001), GRH2 condition (M = 1.13, SD = 1.0; GRH2-GB: Z = −4.353, p < 0.001), and GP condition (M = 1.04, SD = 0.8; GP-GB: Z = −5.0, p < 0.001). On the contrary, no significant effect was found in other pairwise comparisons (GRH-GRH2: Z = −2.385, p = 0.017; GRH-GP: Z = −1.571, p = 0.116; GRH2-GP: Z = −1.687, p = 0.092).
The GB condition (M = 304.70, SD = 302.29) showed more head rotation compared to the GRH condition (M = 206.67, SD = 150.94; GRH-GB: Z = −4.547, p < 0.001) and GP condition (M = 234.68, SD = 203.06; GP-GB: Z = −2.843, p = 0.004), but no significant difference was found between GRH and GRH2 (GRH2: M = 257.42, SD = 254.57; GRH-GRH2: Z = −2.416, p = 0.016), GRH and GP (Z = −1.975, p = 0.048), GRH2 and GP (Z = −0.969, p = 0.33), and GRH2 and GB (Z = −2.165, p = 0.03) conditions.
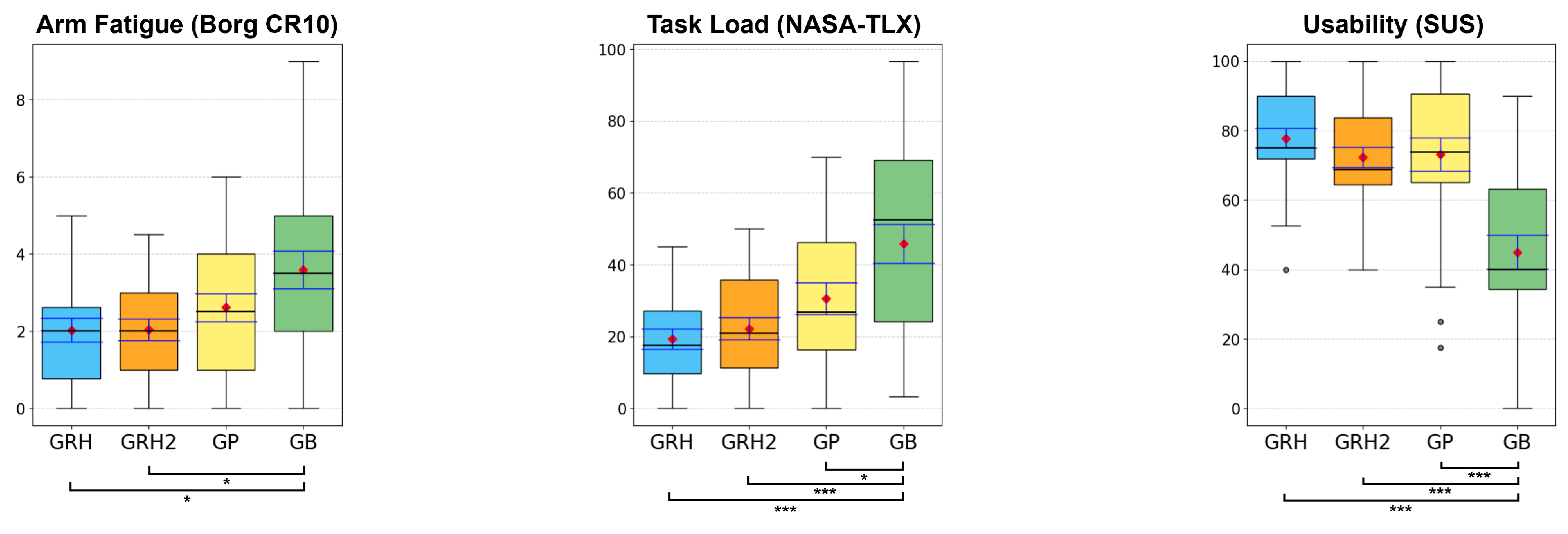
5.2. Subjective Measures
Results from participants’ rating scales are summarized in
Figure 8 and
Figure 9. A Friedman test found significant differences between all four conditions in all measurements (all
p-values are less than 0.05).
5.2.1. Arm Fatigue (Borg CR10)
Participants felt significantly higher arm fatigue with the GB condition (M = 3.6; SD = 2.36) compared to the GRH condition (M = 2.03, SD = 1.54; GRH-GB: Z = −3.065, p = 0.002;) and GRH2 condition (M = 2.05, SD = 1.36; GRH2-GB: Z = −2.735, p=0.006). However, there was no significant difference in their rating scales about arm fatigue between GRH and GRH2 (Z = −0.171, p=0.864), GRH and GP (M = 2.61, SD = 1.78; GRH-GP: Z = −1.709, p = 0.087), GRH2 and GP (Z = −1.181, p = 0.238), and GP and GB (Z = −2.322, p = 0.02) conditions.
5.2.2. Task Load (NASA-TLX)
The GB condition (M = 45.76, SD = 26.63) was significantly more demanding with respect to task load than the other three conditions: GRH condition (M = 19.38, SD = 13.57; GRH-GB: Z = −3.788, p < 0.001), GRH2 condition (M = 22.22, SD = 14.87; GRH2-GB: Z = −3.473, p < 0.001), and GP condition (M = 30.56, SD = 21.76; GP-GB: Z = −3.15, p = 0.002). However, we found no significant effect between GRH and GRH2 (Z = −1.065, p = 0.287), GRH and GP (Z = −2.307, p = 0.021), and GRH2 and GP (Z = −1.544, p = 0.123) conditions.
5.2.3. Usability (SUS)
Participants felt significantly higher usability when using the GRH condition (M = 77.81; SD = 14.05), GRH2 condition (M = 72.29, SD = 14.26), and GP condition (M = 73.13, SD = 23.21) rather than when using the GB condition (M = 45.0, SD = 23.48; GRH-GB: Z = −4.048, p < 0.001; GRH2-GB: Z = −3.743, p < 0.001; GP-GB: Z = −4.003, p < 0.001). However, there was no significant difference among other pairwise comparisons (GRH-GRH2: Z = −2.281, p = 0.023; GRH-GP: Z = −0.076, p = 0.939; GRH2-GP: Z = −0.837, p = 0.402).
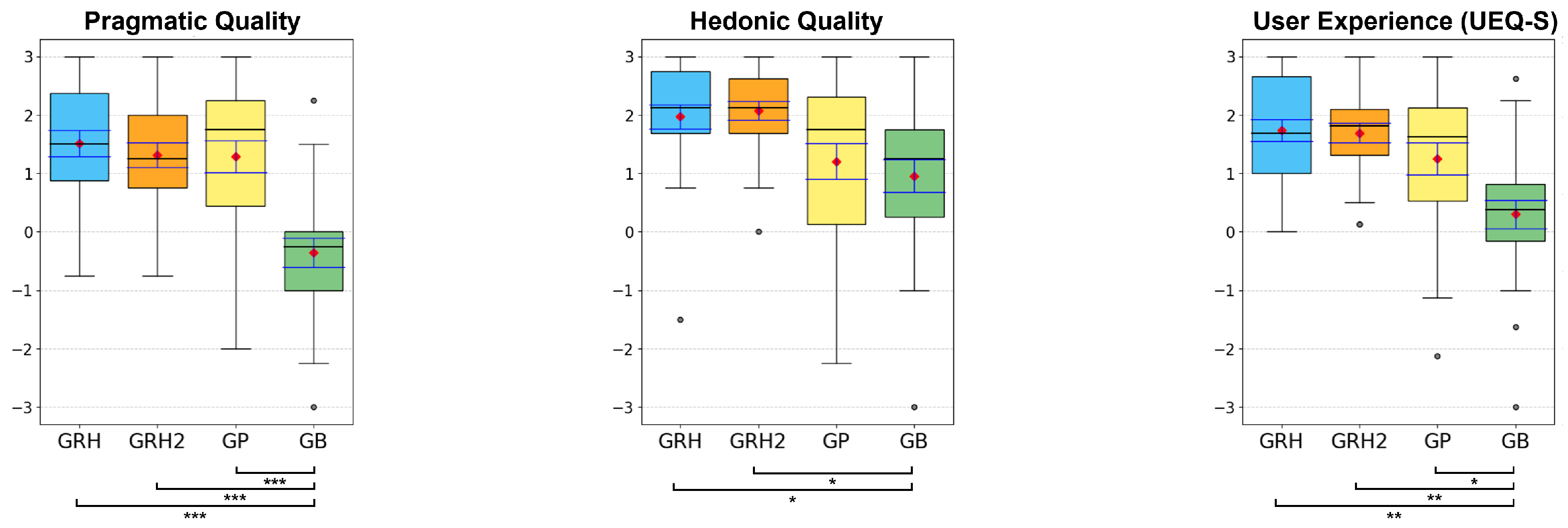
5.2.4. User Experience (UEQ-S)
Participants answered the short version of the UEQ (UEQ-S) that measured the overall user experience including pragmatic and hedonic qualities.
For pragmatic quality, the GRH (M = 1.51, SD = 1.11), GRH2 (M = 1.31, SD = 1.02), and GP (M = 1.29, SD =1.34) conditions scored significantly higher than the GB condition (M = −0.35, SD = 1.21; GRH-GB: Z = −3.721, p < 0.001; GRH2-GB: Z = −3.488, p < 0.001; GP-GB: Z = −3.753, p < 0.001). However, no significant difference was found in the comparisons between GRH and GRH2 (Z = −1.013, p = 0.311), GRH and GP (Z = −0.302, p = 0.762), and GRH2 and GP (Z = −0.049, p = 0.961) conditions.
Similarly, participants felt higher levels of hedonic quality when using the GRH (M = 1.97, SD = 1.0) and GRH2 (M = 2.07, SD = 0.8) conditions compared to the GB condition (M = 0.96, SD = 1.36; GRH-GB: Z = −2.749, p = 0.006; GRH2-GB: Z = −2.906, p = 0.004), but no significant difference was found in the other pairwise comparisons (GRH-GRH2: Z = −0.542, p = 0.588; GRH-GP: Z = −2.036, p = 0.042; GRH2-GP: Z = −2.508, p = 0.012; GP-GB: Z = −0.837, p = 0.403).
For the total score value reflecting the overall user experience, the GRH (M = 1.74, SD = 0.91), GRH2 (M = 1.69, SD = 0.84), and GP (M = 1.25, SD = 1.36) conditions scored significantly higher than the GB condition (M = 0.30, SD = 1.18; GRH-GB: Z = −3.408, p = 0.001; GRH2-GB: Z = −3.401, p = 0.001; GP-GB: Z = −2.974, p = 0.003). But there was no significant difference between GRH and GRH2 (Z = −0.227, p = 0.821), GRH and GP (Z = −1.084, p = 0.279), and GRH2 and GP (Z = −1.020, p = 0.308) conditions.
5.2.5. Preference
Table 1 summarizes the results of the user preference assessment. Participants preferred the GB condition less than the GRH (
Z = −3.43,
p = 0.001), GRH2 (
Z = −3.03,
p = 0.002), and GP (
Z =−2.69,
p = 0.007) conditions. There was no significant difference between GRH and GRH2 (
Z = −0.12,
p = 0.9), GRH and GP (
Z = −1.11,
p = 0.27), and GRH2 and GP (
Z = −0.82,
p = 0.411) conditions.
5.3. User Feedback
Three participants, P9 (the ninth participant; ‘P’ is the abbreviation for participant, and the number means the order of participation in the experiment), P14, and P23, reported arm fatigue when using two hands for object rotation with the GP condition. P11 noted the inconvenience of needing two hands for object rotation when using the GP condition (“I felt it was unnatural to switch from one hand to two hands just for rotating the object, which made it difficult to get used to”). P9 and P23 added, “using two hands for GP was complicated.” On the contrary, several participants (P1, P8, P15, and P22) reported that the GRH and GRH2 conditions reduced arm fatigue by requiring minimal movement and allowing one-handed operation.
The majority of participants (15 out of 24) preferred the GRH condition with its intuitiveness and ease of use. P5, P12, and P19 commented that “controlling direction simply by moving my hand relative to the ray was very easy.” This intuitiveness and easiness might have contributed to precise and accurate manipulation. P2 commented, “GRH allows for more precise control compared to other techniques.” P16 noted, “GRH has fewer errors and didn’t require multiple steps like GB.” Regarding the GRH2 condition, many participants (P1, P4, P6, P13, P18, P20, and P24) appreciated its convenience in translating an object with a simple gaze movement for a long distance: “GRH2 allows for quick object movement by eye, especially over long distances.” Additionally, in both the GRH and GRH2 conditions, the gaze ray serves as visual guidance, allowing users to verify the direction of manipulation. However, the GRH2 condition had an issue compared to the GRH condition. P17 reported “GRH2 was more complicated than GRH. After selection, if I accidentally looked somewhere else, the object would suddenly teleport there.” P7 mentioned that “After sufficient training, GRH2 could be the fastest and most convenient technique, but in the first impression it was more difficult to control compared to hand movement techniques.”
The GB condition was the worst among the conditions because of its lack of flexibility due to its multi-step manipulation. P3, P10, P21, and P24 stated, “GB’s step-based approach was difficult.” P20 added, “GB was difficult because it did not allow me revise what I have done in previous step.”
6. Discussion
In this study, we evaluated the two proposed methods for object manipulation, GRH and GRH2, that exploited the relative position between the gaze ray and hand. In our user study, we compared them to two previous methods, GP and GB, and found four main results: (1) the GRH and GRH2 techniques helped participants reduce the total distance of object translation compared to GP and GB, (2) the gaze ray in the GRH and GRH2 techniques was used as a reference line so it was easy and intuitive to conceptually shape the direction of translation and rotation by the hand position relative to the reference, (3) the GP technique had an issue of requiring two hands while generally showing similar results with the GRH and GRH2 techniques, and (4) the GB technique was the worst because it required users to follow the three compulsory steps (horizontal/vertical translation, depth translation, and rotation) even when not all of them were necessary.
Participants had a shorter object translation distance with the GRH and GRH2 techniques compared to the GP and GB techniques. With the GRH and GRH2 techniques, participants handled one or two DOFs translation individually. This individual handling reduced unnecessary translation while the participants had to perform some unnecessary translation with the GP technique that manipulated all three at once. Interestingly, this reduced manipulation distance did not lead to faster manipulation because at least two steps (1. horizontal/vertical translation and 2. depth translation) were required to complete translation in 3D while 3-DOF translation was performed with one step by the GP technique (H1 was not supported). However, we observed that although GRH was slower than GP during the coarse manipulation phase, it tended to be more efficient in the fine-grained manipulation phase. This suggests that GRH may offer advantages in tasks requiring fine control.
The GRH and GRH2 techniques were easy and intuitive because they employed the hand position relative to the gaze ray to determine the direction and speed of translation and rotation. The gaze ray worked as a reference line and mapped the left/right, up/down, and forward/backward hand motion for moving or rotating an object in these directions. This simple design offered a high level of affordance due to its ease of memorization and quick learning. Additionally, based on perceived effort (i.e., arm fatigue and task load) and total hand translation, GRH and GRH2 consistently resulted in lower fatigue and required fewer hand movements, particularly compared to GB. This suggests that GRH and GRH2 are more suitable for prolonged use in VR environments and may help mitigate the gorilla arm effect [
29] (
H2 partially supported).
Interestingly, the benefits described in the previous two paragraphs were less obvious with the GRH2 technique compared to the GRH technique. The main difference between them was whether they supported gaze-based translation or not, while the hand-based translation and rotation were consistently supported. This gaze based translation was fast, so some participants preferred it, but it had an issue of Midas touch which resulted in translating an object unintentionally.
The GP technique showed similar results with the GRH and GRH2 techniques in overall objective and subjective measurements (including total rotation degree, total head translation and rotation, arm fatigue, task load, usability, and pragmatic and hedonic qualities). However, the GP technique had a notable limitation: requiring two-handed manipulation for rotation. Since the experimental task did not include other tasks such as holding another object or shooting with a hand during manipulation, the issue was not clearly revealed. We note that the issue could be more prominent with the tasks requiring additional hand operation.
The GB technique was the worst among the four techniques. The GB technique included three compulsory steps for three types of manipulation: horizontal/vertical translation, depth translation, and rotation. However, some object manipulation could be completed with only one or two types of manipulations. Since the GB technique compulsorily required unnecessary interaction such as pinching and releasing gestures to start and end the unnecessary steps (i.e., turning on and off interactions with a pinching motion are required for the rotation step even when no rotation is required), the participant’s experience of using the GB technique was the worst. This suggests that the compulsory interaction structure not only affected performance but also negatively impacted user experience by preventing users from returning to previous manipulation phases or skipping unnecessary ones. As a result, the GB technique showed the lowest scores in all object measures, except total rotation degree, and all subjective measures (H3 supported).
While our study demonstrates the potential of the GRH and GRH2 techniques, it has a few limitations. First, our experimental manipulation task did not cover all possible object manipulations in a 3D VR world. We note that our task was designed based on the previous study [
13] and 6-DOF manipulation. Second, our interaction design for the GRH and GRH2 techniques did not cover all possible designs with the gaze ray and hand. For example, the distance between the gaze ray and hand determined the speed of object translation and rotation in our study, but the distance could also be used to decide the distance of object translation or the amount of rotation rather than the speed. Future work will explore other possible interaction desigsn with the gaze ray and hand inputs. Third, this study primarily focused on general task performance metrics—manipulation time, object movement, hand movement, and head movement—across the techniques, without explicitly measuring manipulation precision (e.g., overshooting rate or time for fine adjustments). Lastly, the participants in our study do not represent a diverse range of VR users. They were under 30 years old and mostly inexperienced with VR. Nonetheless, we believe that our findings are still generalizable to other VR applications. This is because our interaction techniques—moving the hand relative to the gaze ray to interact with distant objects—are simple and intuitive. This design allows users to learn and adopt the techniques quickly, regardless of their background.
7. Future Work
In the future, we will explore user experiences with GazeRayHand and GazeRayHand2 in more complex manipulation tasks. These will include scenarios involving occluded environments, objects of varying distances and sizes, precision tasks (e.g., tunneling and fine assembly), collaborative manipulation, and multi-object manipulation [
43,
44]. These scenarios will help assess the scalability of our techniques.
We also plan to expand our evaluation by incorporating explicit manipulation precision metrics, including overshooting rate, number of adjustments, and positional accuracy variance. These additional measures will enable a more comprehensive analysis of control accuracy and stability.
Additionally, We plan to extend our techniques for applications beyond general VR object manipulation [
45,
46,
47]. For instance, our techniques could be integrated into VR training systems (e.g., equipment operation; construction), where intuitive and low-fatigue interaction is essential. Another promising direction is multi-user remote collaboration, where gestures must be accurately interpreted across users and spaces. In such settings, we will study how our techniques affect communication and task efficiency, particularly by comparing them with indirect manipulation methods that are commonly used in collaborative VR.
8. Conclusions
In this paper, we introduced a novel 3D manipulation technique, named GazeRayHand, which combines gaze ray and hand interaction for distant object manipulation in VR. The GazeRayHand technique allows users to translate and rotate objects using the relative position between the gaze ray and hand with handling one or two DOFs separately. We additionally proposed a variation technique, named GazeRayHand2, supporting not only hand interaction for translation and rotation but also gaze interaction for translation. We evaluated them against existing manipulation techniques that combine gaze and hand interaction, namely Gaze&Pinch and modified Gaze Beam Guided techniques. The GazeRayHand and GazeRayHand2 techniques had similar results to the Gaze&Pinch technique, which is known for its high performance, in overall objective and subjective measures. The GazeRayHand and GazeRayHand2 techniques significantly reduced unnecessary translations compared to other techniques and were rated highly for intuitiveness and ease of use by using hand position relative to the gaze ray for controlling the direction and speed of translation and rotation. However, the Gaze&Pinch technique had a limitation of requiring two hands for rotation, leading to inconvenience. The modified Gaze Beam Guided technique performed the worst among the four techniques because of mandating the three compulsory steps for manipulation, even when not all steps were necessary.
Furthermore, our techniques have potential for practical applications. For example, our GazeRayHand and GazeRayHand2 techniques, which support intuitive and low-fatigue interaction, can be beneficial in industrial training scenarios where users are required to repeatedly manipulate virtual tools. Additionally, their one-handed operation and reduced physical effort make them suitable for rehabilitation systems aimed at patients with limited mobility. Finally, the ease of use and compatibility with gaze ray and hand inputs suggest their applicability in commercial AR/VR platforms, such as gaming or collaborative virtual environments.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}