1. Introduction
With the continuous advancement of technology, intelligent manufacturing has emerged as a key approach to improving production efficiency, optimizing resource allocation, and enhancing market competitiveness—thereby promoting high-quality development in the manufacturing industry. As a core component of intelligent manufacturing, the job shop scheduling problem (JSP) [
1] plays a crucial role in optimizing resource allocation, shortening production cycles, and controlling manufacturing costs.
Driven by increasingly customized and diversified production demands, flexible job shops have gained prominence. As an extension of traditional job shop scheduling, the flexible job shop scheduling problem (FJSP) allows operations to be assigned to multiple machines, each capable of processing different tasks [
2]. This flexibility enables dynamic resource allocation and improves the shop’s ability to handle uncertain order requirements. However, this increased flexibility also introduces new challenges, particularly frequent job transfers between machines, thereby giving rise to complex intra-shop transportation issues. Traditionally, production scheduling and logistics scheduling in FJSPs have been addressed independently, overlooking the intricate coupling between processing machines and transport equipment.
As logistics technology evolves, AGVs have been widely adopted in manufacturing systems due to their high flexibility and operational stability. According to recent statistics, the global AGV market reached approximately USD 2.74 billion by the end of 2023, up from USD 1.86 billion in 2018, with a compound annual growth rate (CAGR) of 8.02%. In the same year, the global shipment of forklift AGVs—commonly used in manufacturing workshops—reached around 30,700 units, marking a year-over-year increase of 46.19% [
3].
In real-world manufacturing scenarios, once an operation is completed on a machine, it must be transferred—often via AGVs—to the next designated machine or a storage buffer [
4]. The subsequent operation can only commence once the processed part has been delivered to the area. This creates a strong interdependence between production scheduling and logistics scheduling. Therefore, production scheduling and logistics scheduling are intricately coupled in flexible job shops. However, most existing studies tend to ignore this coupling by investigating production scheduling [
5,
6,
7] and logistics scheduling [
3,
8,
9,
10] independently, which often results in infeasible scheduling solutions in real-world applications [
11].
In recent years, some researchers have begun exploring collaborative scheduling approaches that jointly consider production and logistics in FJSP environments. Nonetheless, most of these studies assume either unlimited transportation resources [
12,
13,
14], like a sufficient number of AGVs or mobile robots, or fixed transfer times [
15]. A few works have attempted to address limited AGV availability by designing case-specific AGV configurations for different problem scales [
16,
17]. Moreover, current research on the collaborative scheduling of production and logistics in flexible job shops is still in its infancy. Many practical factors have not been thoroughly addressed, such as the power consumption of AGVs, variations in transportation speed, charging strategies, and the availability of charging stations. In fact, such issues have already been well considered in other AGV-related application domains, such as port handling systems [
18,
19,
20,
21].
To fill these research gaps, this study investigates a flexible job shop production-logistics collaborative scheduling problem with limited transportation resources and charging constraints (FJSPLSP-LTCC). On top of machine and operation selection, the proposed model integrates AGV assignment for each transport task, taking into account battery depletion, in-transit charging requirements, and charger constraints. To ensure alignment with practical conditions, multiple scenarios with different shop sizes have been designed, each with limited AGV and charger resources. In addition, this study introduces the “deterioration” effect of AGVs: as the battery level decreases, the transportation efficiency declines, resulting in prolonged handling time. This assumption is based on engineering observations of AGV operation in industrial scenarios, where AGVs typically reduce their operating speed at lower battery levels to conserve energy or ensure operational safety. Although comprehensive empirical modeling data are currently lacking, the incorporation of this effect enhances the practical applicability of the proposed scheduling model and reflects the actual operating characteristics of AGVs. Future research will focus on collecting empirical data to further validate and optimize the model.
Heuristic algorithms [
22,
23,
24] and Deep Reinforcement Learning (DRL) approaches [
17,
25] are commonly used to solve collaborative scheduling problems in flexible job shops. However, the problem addressed in this paper incorporates several additional decision dimensions—such as charging constraints—compared with traditional models, making it a high-dimensional scheduling problem. DRL, as a fully reactive scheduling method, leverages data to learn the correlation between data distributions and decision behaviors, and has demonstrated superior optimization performance in solving such high-dimensional and complex scheduling tasks [
17,
26,
27]. Among DRL methods, PPO and its variants have gained significant attention in recent years for their robustness, stability, and ease of implementation [
28,
29,
30,
31,
32]. Accordingly, this study develops a customized PPO-based DRL algorithm named CRGPPO-TKL to solve the FJSPLSP-LTCC. The algorithm samples candidate actions and computes candidate probability ratios to better evaluate policy divergence. Furthermore, it introduces a target KL divergence mechanism to dynamically adjust the clipping range, thus maintaining a balance between exploration and policy stability.
In summary, the main contributions of this study are as follows:
- (1)
A comprehensive modeling framework for collaborative production-logistics scheduling in flexible job shops is proposed, which incorporates limited AGV resources, AGV charging constraints, and the deterioration effect between battery level and transportation speed, thereby enhancing the practical applicability of the scheduling model.
- (2)
Multiple flexible job shop scenarios with varying workshop scales are designed, and a systematic analysis is conducted to determine the optimal AGV configuration for each layout, providing valuable guidance for resource allocation in practical applications.
- (3)
An improved PPO algorithm—CRGPPO-TKL—is developed, which enhances action evaluation through candidate probability ratio sampling and dynamically adjusts the clipping range based on the target KL divergence, thereby improving learning stability and performance in solving complex collaborative scheduling problems.
The remainder of this paper is organized as follows:
Section 2 reviews related literature on production-logistics collaborative scheduling in flexible job shops.
Section 3 defines the proposed FJSPLSP-LTCC problem.
Section 4 describes the developed DRL framework.
Section 5 presents experimental results and analysis. Finally,
Section 6 concludes the paper and outlines future research directions.
2. Literature Review
This section presents a comprehensive literature review to contextualize the problem addressed in this paper. We organize the discussion into three thematic areas: (1) Flexible Job Shop Scheduling Problems (FJSPs) assuming unlimited transportation resources, (2) Job Shop Scheduling Problems (JSPs) under transport resource constraints, and (3) applications of Deep Reinforcement Learning (DRL) in solving complex scheduling problems. This structure allows us to clarify the research gap and highlight the novelty of our proposed approach in integrating production-logistics scheduling with intelligent decision making under limited AGV resources and charging constraints.
2.1. FJSP with Unlimited Transport Resources
Integrating job transportation into the FJSP and solving it by assuming unlimited transport resources has been a common approach in earlier research. Karimi et al. [
33] identified the unrealistic omission of transportation time in traditional FJSP models. To address this, they introduced multiple transport devices into the system, where transportation time depended solely on the distance between machines, excluding other disturbances. This study was among the first to incorporate transportation time into FJSP and applied a novel imperialist competitive algorithm to solve the model. Dai et al. [
4] and Li et al. [
34] formulated a multi-objective FJSP aiming to minimize energy consumption and makespan. They demonstrated that transportation not only affects makespan but also generates additional energy consumption, impacting total shop floor energy usage. Dai proposed an enhanced genetic algorithm, while Li applied an improved gray wolf optimization algorithm to tackle the problem. Jiang et al. [
35] extended this line of research by introducing the concept of machine deterioration, where prolonged machine operation leads to decreased efficiency and increased processing time. This notion laid a foundation for the deterioration effect of AGVs proposed in this study. Further complexity was introduced by Sun et al. [
36], Zhang et al. [
24], and Pai et al. [
37], who considered setup times and job transportation times. Sun and Zhang also accounted for transportation energy consumption and employed multi-objective optimization algorithms, while Pai focused on minimizing makespan through a multi-agent system. In all of these studies, the assumption of unlimited transport resources remained prevalent, with transportation time modeled merely as a function of machine distance. However, such assumptions diverge significantly from real manufacturing environments, where transportation time is closely tied to the number and operational state of transport devices, like battery levels. As a result, the practical feasibility of these scheduling strategies is limited.
2.2. JSP with Limited Transport Resources
Compared with the assumption of unlimited transport resources, the assumption of limited transport resources is more in line with real-world production environments and has therefore attracted increasing attention from researchers. Nouri et al. [
16] studied the FJSP involving transport time and a limited number of robots, and proposed a clustering-based hybrid metaheuristic multi-agent model to minimize makespan. Ham et al. [
12] pointed out that, unlike traditional JSPs, the target workstation for subsequent operations in FJSP is not predetermined, and each transport device has a fixed capacity. They proposed two constraint programming-based methods to minimize makespan. Homayouni et al. [
13], Meng et al. [
14], and Amirteimoori et al. [
23] improved traditional genetic algorithms to solve the FJSP under limited transport resources with the objective of minimizing makespan. Yan et al. [
38] further refined the modeling of the transport process by considering four states of AGVs: idle, unloaded transport, loaded transport, and return transport. They proposed an improved genetic algorithm validated through a digital twin system, enhancing the practical feasibility of the scheduling results. Pan et al. [
25] addressed the high complexity and NP-hard nature of FJSP under limited transport resources by proposing a learning-based multi-population evolutionary optimization algorithm to tackle large-scale and complex instances. Li et al. [
17] investigated a dynamic FJSP scenario with limited transport resources, aiming to minimize both makespan and total energy consumption. They incorporated disruptions such as machine breakdowns and proposed a hybrid deep Q-network (DQN) algorithm. Zhang et al. [
39] presented a memetic algorithm combined with DQN for solving energy-aware FJSPs involving multiple AGVs, also targeting makespan and energy consumption minimization. Lei et al. [
40] addressed the often-overlooked assumption of infinite buffer capacity in previous research. They analyzed the impact of buffer size on job waiting time and makespan, and further explored scheduling optimization in zero buffer capacity settings using a memetic algorithm. Chen et al. [
41] also applied a DQN algorithm to solve multi-AGV FJSPs with objectives of minimizing makespan, total energy consumption, and their combination. Furthermore, Shi et al. [
11] introduced a novel nested hierarchical reinforcement learning framework that coordinates “production agents” and “logistics agents” to simultaneously minimize makespan and energy consumption. This framework also considers AGV breakdowns, a factor rarely addressed in prior studies.
In summary, under the constraint of limited transport resources, the FJSP commonly aims to minimize makespan and total energy consumption. Solution approaches include linear programming, heuristic algorithms, and machine learning methods. Most studies consider AGVs as the primary transport resource. Although some have accounted for AGV status, energy consumption, and failure events, few have considered AGV charging behavior, and most assume unlimited battery capacity—an unrealistic simplification. Additionally, most studies assume a fixed number of AGVs, ignoring the real-world variability in AGV availability, which can lead to scheduling solutions that are impractical in actual production environments. In contrast, this study further refines the load modeling by, for the first time, jointly considering AGV transportation status, charging constraints, speed degradation, and dynamic variation in AGV quantity, thereby enhancing the model’s adaptability and scalability to real industrial scenarios. A detailed literature comparison is shown in
Table 1.
2.3. DRL for Solving JSP
DRL has become a powerful tool for tackling high-dimensional scheduling and combinatorial optimization problems. With its capabilities in autonomous learning and real-time decision making, DRL has been widely applied to job shop scheduling. To address dynamic events such as machine breakdowns and job insertions, Liu et al. [
42] proposed a hierarchical and distributed framework using the Double Deep Q-Network (Double DQN) algorithm to train scheduling agents, capturing the complex relationships between production information and scheduling objectives, thereby enabling real-time scheduling decisions in flexible job shops. Luo et al. [
43] developed a hierarchical multi-agent DRL approach based on PPO, which incorporates multiple types of agents, including objective agents, job agents, and machine agents. Zhang et al. [
44] modeled manufacturing equipment as agents and employed an improved contract net protocol to guide agent cooperation and competition, training the agents via the PPO algorithm. Wu et al. [
45] proposed a PPO-based hybrid prioritized experience replay strategy to effectively reduce training time. In static job shop scheduling scenarios, Chen et al. [
46] used a disjunctive graph embedding method to learn graph representations containing JSSP features, enhancing the model’s generalization ability. They employed a modified Transformer architecture with multi-head attention to solve large-scale scheduling problems efficiently. Similarly, Huang et al. [
27] represented solutions to distributed Job Shop Scheduling Problems using disjunctive graphs and combined graph neural networks with reinforcement learning to solve the problem. Wen et al. [
47] proposed a heterogeneous graph neural network framework to capture intricate relationships between jobs and machines, and designed a novel DRL-based method to learn priority scheduling rules in an end-to-end manner. Wang et al. [
48] introduced a new DRL algorithm that utilizes Long Short-Term Memory (LSTM) networks to capture the temporal dependencies within scheduling state sequences. Pan et al. [
49] focused on the permutation flow shop problem (PFSP) and developed a dedicated PFSPNet, trained using the actor-critic reinforcement learning approach. In summary, the application of DRL in solving Job Shop Scheduling Problems has demonstrated high efficiency and the ability to quickly generate effective scheduling strategies. Moreover, DRL’s generalization capabilities make it suitable for handling systems of varying sizes and complexities.
Although existing studies have demonstrated that Deep Reinforcement Learning (DRL) methods perform well in solving scheduling problems, there remain inherent limitations when applied to flexible Job Shop Scheduling Problems (FJSPs): (1) the state space of FJSP is complex, involving large-scale matching relationships among jobs, operations, and machines. Current state encoding methods struggle to comprehensively represent the scheduling environment, thus affecting model generalization; (2) scheduling problems have sparse rewards, typically only provided at the final makespan, which leads to low training efficiency and policies prone to local optima; (3) most studies focus on static FJSP and lack dynamic adaptive scheduling capabilities for practical disturbances such as machine failures and order insertions; and (4) in the collaborative optimization of production and logistics scheduling, existing research mostly assumes sufficient logistics resources or treats logistics scheduling independently, without systematically considering practical issues such as limited AGV resources, AGV charging and charging station constraints, and AGV speed degradation effects, limiting their industrial applicability.
Currently, research on production-logistics collaborative scheduling is limited. Some studies employ rule-based methods, heuristic algorithms, or traditional optimization models for joint optimization but lack DRL methods designed for high-dimensional, dynamic, and complex environments. To address these shortcomings, this paper designs a flexible DRL framework that fully integrates production and logistics scheduling processes, jointly considers limited AGV transportation resources, charging constraints, and AGV speed degradation effects, thereby enhancing the practicality and intelligence level of scheduling systems in complex real-world environments.
3. Problem Description and Modeling
This section details the formulation of the collaborative production and logistics scheduling problem in a flexible job shop setting with limited transportation resources and charging constraints (FJSPLSP-LTCC). It begins with a formal description of the problem and presents a motivating example to illustrate the problem characteristics. Then, we develop a mathematical model that captures the scheduling objectives and system constraints. This foundational modeling work serves as the basis for the algorithmic solution described in the subsequent chapter.
3.1. Problem Description
The traditional FJSP with AGVs (FJSP-AGV) is described as follows: In a flexible job shop, there are n jobs to be processed, m machines, and x AGVs. Each job consists of multiple operations, and each operation can be assigned to one machine selected from a set of eligible machines. The processing time for each operation is known and deterministic, and every operation can be processed by at least one machine. Initially, all jobs and AGVs are located at the loading/unloading (L/U) station. AGVs operate in three states: idle, unloaded running, and loaded running. For the first operation of a job, the AGV transports the job from the L/U station to the assigned machine in the loaded state. For subsequent operations, the AGV first travels in the unloaded state to the machine where the job was last processed, and then transports the job in the loaded state to the next assigned machine. Building upon this, this study incorporates AGV charging constraints into the problem formulation, resulting in the FJSPLSP-LTCC model. Specifically, the workshop is equipped with y AGV charger. AGVs, when in the unloaded state, may choose to proceed to a charger for battery replenishment. If the charger is occupied, the AGV must wait until it becomes available. To better reflect practical manufacturing scenarios, three types of AGV charging actions are defined: no charging (NC), opportunity charging (OC), and full charging (FC). OC refers to short-term charging during AGV idle periods to partially replenish battery levels, while FC involves longer charging durations that restore the battery to full capacity. Moreover, to prevent AGV shutdowns due to complete battery depletion, a mandatory maintenance battery change (MBC) policy is introduced, wherein maintenance personnel manually replace the battery for the AGV.
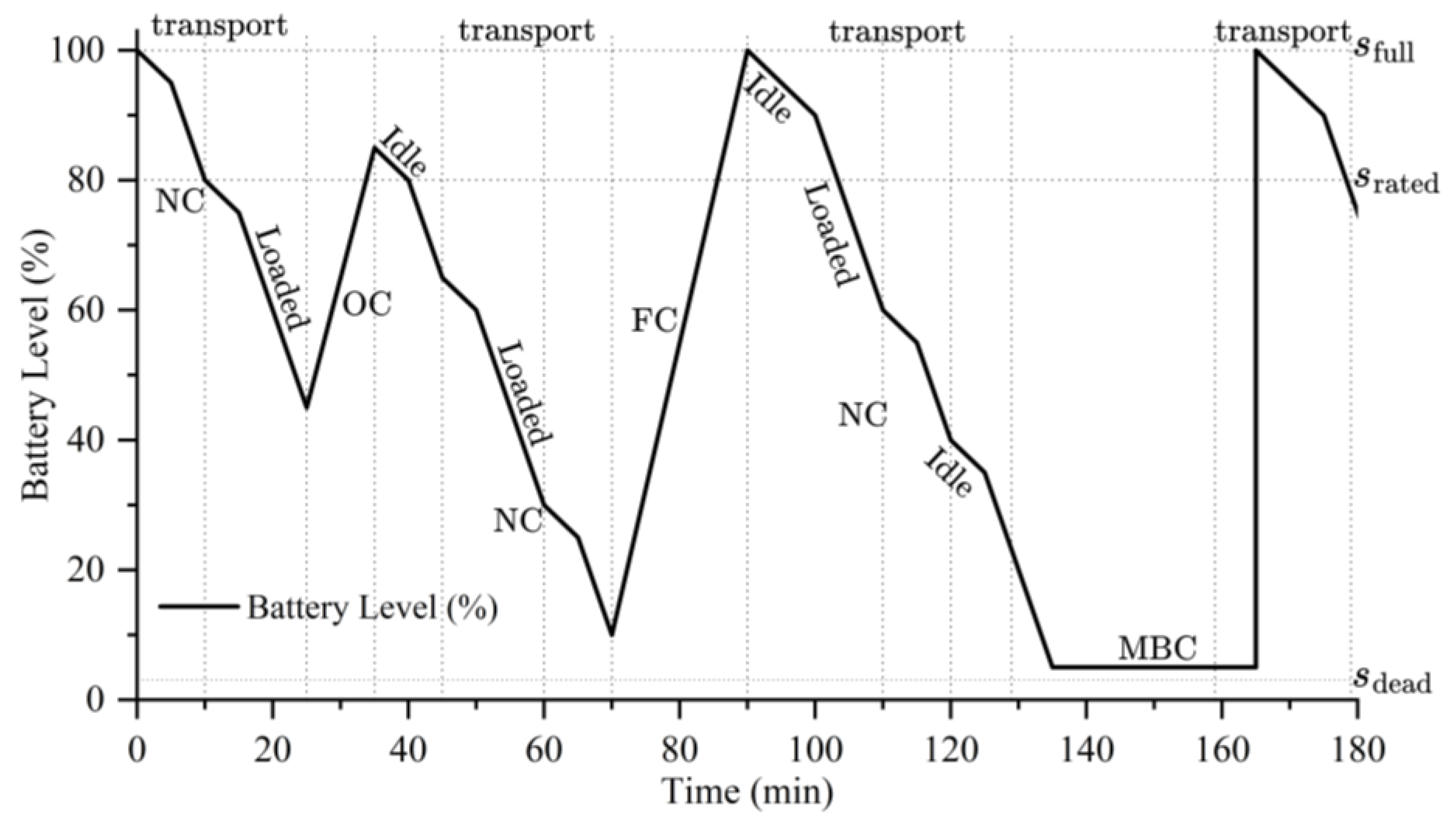
Different strategies are suitable for different practical scenarios: the OC strategy is mainly applied when AGVs have short idle windows; the FC strategy is used when AGVs experience longer idle times or when future tasks are expected to have high energy demands; the MBC strategy serves as an emergency backup, automatically triggered by the system monitoring when AGV battery levels approach depletion. The effects of different charging strategies on AGV battery levels are illustrated in
Figure 1. It should be noted that battery degradation effects are not considered in
Figure 1; it only reflects the improvements in battery level under different charging strategies.
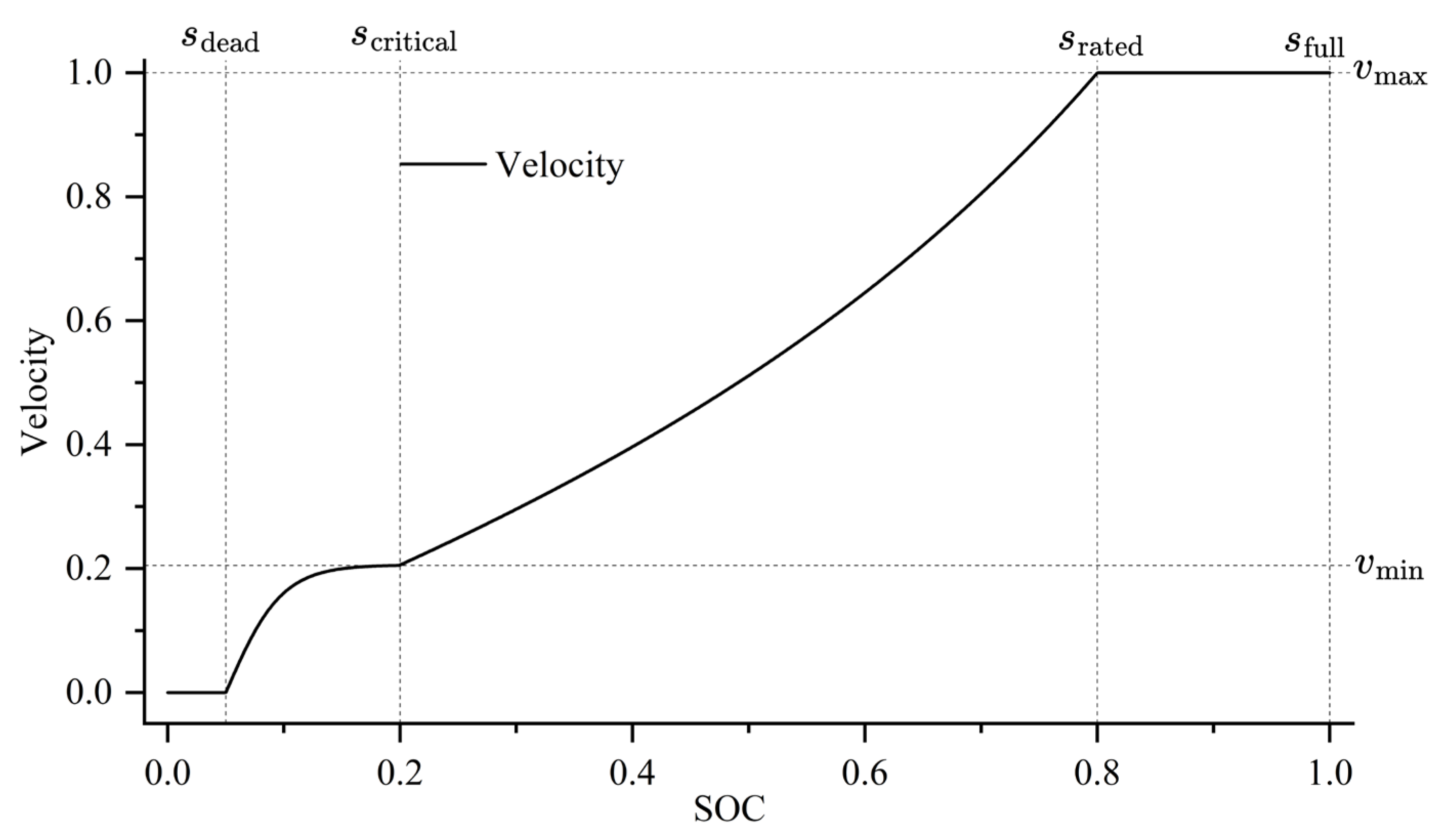
In addition, the FJSPLSP-LTCC model incorporates the battery degradation effect of AGVs, characterized by a nonlinear decline in travel speed as the remaining battery level decreases. This study models the degradation through a four-phase velocity control function, described as follows: Saturation Zone (
): When energy supply is sufficient, the AGV operates at its rated maximum speed. Decay Zone (
): The velocity is determined by a combination of a linear term
and an exponential decay term
, reflecting the effects of increased internal resistance and polarization that lead to compounded energy losses. Sustainment Zone (
): A smooth deceleration trend is modeled using
. Failure Zone (
: A deep discharge protection mechanism is triggered, forcing the AGV to shut down in order to prevent battery damage. The corresponding mathematical formulation is given in Equation (1), and the velocity profile under different battery levels is illustrated in
Figure 2. Here,
= 0.5,
= 0.8,
= 2.5.
The FJSPLSP-LTCC problem studied in this paper involves several interdependent decision subproblems, including: (1) selecting a processing machine for each operation; (2) determining the processing sequence of operations on each machine; (3) assigning AGV resources to each operation; and (4) scheduling charging actions for each AGV.
To facilitate the modeling of the FJSPLSP-LTCC, the following assumptions are made:
- (1)
All jobs, machines, AGVs, and chargers are initially available;
- (2)
The sequence of operations within each job is predetermined and must be followed;
- (3)
Each operation can only be processed on one machine at a time;
- (4)
Each machine and each AGV can process/transport only one job at a time.
- (5)
Once an operation (processing, transportation, or charging) starts, it cannot be interrupted until completion;
- (6)
AGVs can only travel along predefined paths;
- (7)
AGV speed is updated prior to each movement based on the current battery level and remains constant during the trip;
- (8)
Jobs do not need to be returned to the L/U station after the final operation;
- (9)
AGVs can only be charged prior to transporting jobs; after each transport task, a forced battery swap is evaluated;
- (10)
Each charging station can serve only one AGV at a time;
- (11)
Machine failures, job insertions, and AGV path conflicts are not considered.
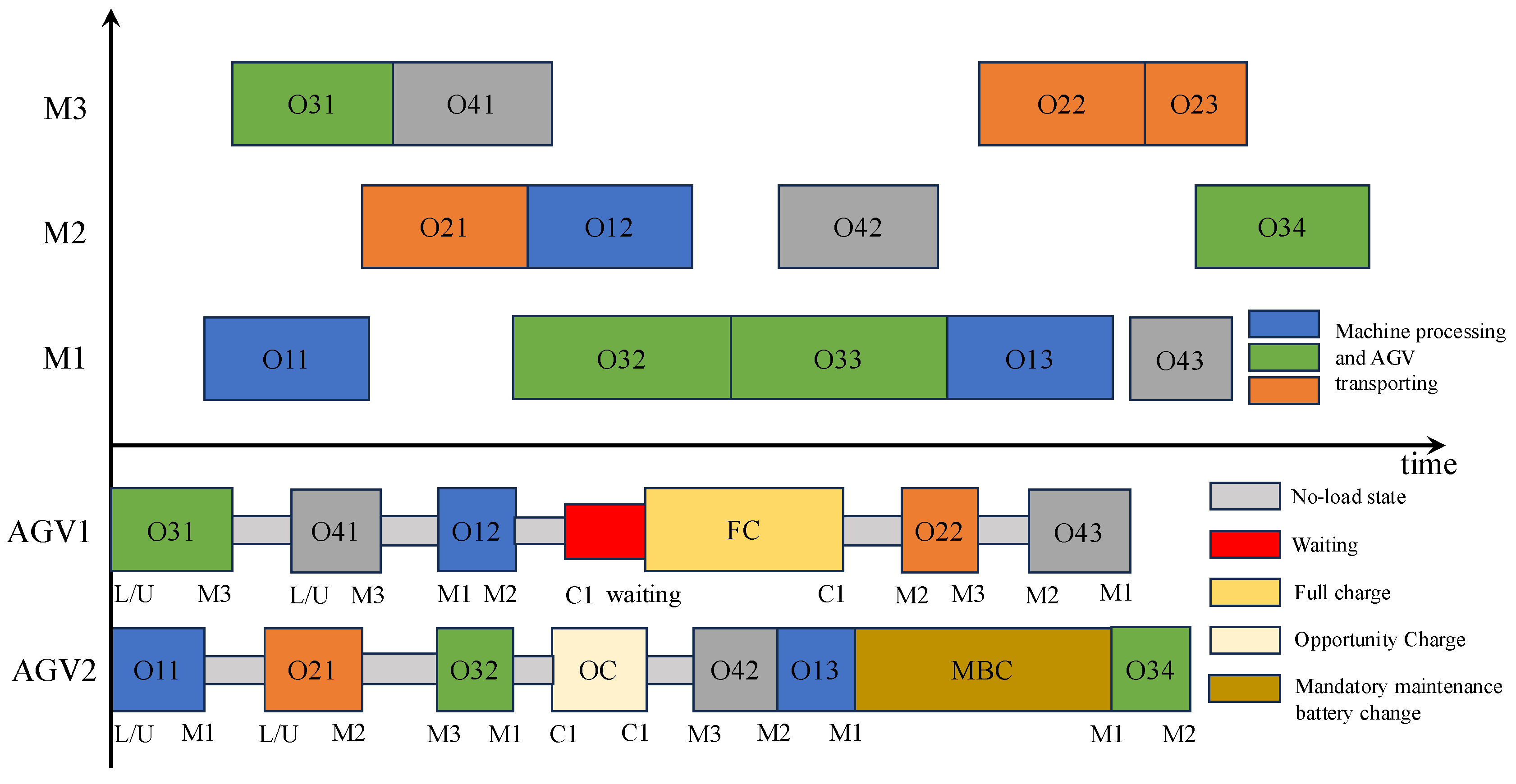
3.2. An Example for FJSPLSP-LTCC
Figure 3 illustrates an instance of the FJSPLSP-LTCC, comprising four jobs, three machines, two AGVs, and one charger. From the AGV perspective, AGV1 initially transports Job 3 from the L/U station to machine M3. Upon completion, it returns to the L/U station in no-load state, picks up Job 4, and transports it to M3. Since M3 is still occupied with Job 3, Job 4 must wait until the machine becomes available before proceeding. Next, AGV1 carries Job 1 from machine M1 to M2. After this transfer, AGV1’s battery level falls below the threshold, selecting an FC operation: it travels to charger C1. However, C1 is occupied by AGV2, so AGV1 remains idle at the charger (highlighted in red in
Figure 3) until AGV2 finishes charging. In contrast, after AGV2 transports Job 1 from M2 back to M1, its battery level drops below the maintenance threshold, invoking an MBC procedure. This procedure is performed in situ without relocating the AGV, so AGV2 remains stationary during the process. Finally, note that when consecutive operations of the same job are processed on the same machine—such as Operations 2 and 3 of Job 2 and of Job 3—no AGV transport is required.
3.3. Problem Modeling
Before constructing the mathematical model, it is essential to define the parameters and decision variables used in the formulation.
Table 2 lists the notations and decision variables involved in the FJSPLSP-LTCC. The objective of this study is to minimize the makespan (the maximum completion time among all jobs). The objective function is formulated as follows:
Constraints to be considered include the following modules:
Workpiece processing-related constraints, including
1. Precedence constraint.
2. Uniqueness of processing.
3. Machine assignment constraint.
AGV transportation related constraints, including:
4. Transportation constraint: each operation must be transported only once.
5. AGV assignment constraint.
6. Complete transportation time constraint: includes transportation, charging, and battery change time.
AGV charging and energy management related constraints, including:
7. Charging decision logic constraint.
8. Mandatory maintenance battery change constraint.
9. Charging time linkage constraint: charging actions must be recorded with corresponding time and charger availability.
10. AGV battery update rule: AGV battery levels are updated based on consumption models.
11. Charger exclusivity constraint: each charger can serve only one AGV at a time.
4. Solving FJSPLSP-LTCC Using DRL
As described in
Section 3.1, the FJSPLSP-LTCC problem is a complex scheduling problem characterized by sequential decision making, involving several interdependent subtasks: operation assignment, sequencing, AGV scheduling, and charging decision making. DRL is an effective tool for solving such problems.
To mitigate the inherent combinatorial explosion risk in this multi-stage scheduling problem, this study adopts a structured decision-making process by partitioning the overall action space into staged and hierarchical local subspaces. Specifically, machine allocation, operation sequencing, AGV assignment, and charging decisions are conducted separately within their respective stages, significantly reducing the effective action space at each stage. Additionally, within the PPO algorithm framework, a candidate action sampling strategy is designed to eliminate infeasible or evidently inferior action combinations, thereby enhancing learning efficiency and solution quality.
4.1. MDP Formulation
A Markov Decision Process (MDP) is typically defined by a five-tuple: , where is the state space, including machine states, job statuses, and AGV states. is the action space, covering job selection, machine assignment, AGV selection, charging decisions, and charging station assignment. is the state transition probability, denoting the likelihood of transitioning from state to upon taking action . is the immediate reward function, representing the feedback received from the environment based on state-action pairs. is the discount factor that determines the impact of future rewards on current decision-making. The objective of reinforcement learning is to maximize the expected total discounted reward: . To evaluate the effectiveness of a given policy , the following value functions are defined: State Value Function (), Action Value Function (), Advantage Function (measuring the benefit of an action over the average, ). The formulation above lays the foundation for the DRL-based solver using the PPO algorithm presented in the subsequent section.
4.1.1. State
At each decision step , a total of 13 state features are designed to capture the key aspects of the FJSPLSP-LTCC system, including the statuses of machines, jobs, and AGVs. These features form the state vector observed by the agent. The definitions are as follows:
(1) Average utilization rate of machines, denoted as
.
where
is the utilization rate of machine
m, calculated as the total processing time of all operations on machine
divided by its total running time up to time
.
(2) Standard deviation of machine utilization rate, denoted as
.
(3) Average completion rate of jobs, denoted as
.
where
denotes the completion rate of job
, defined as the ratio of completed operations to total operations.
(4) Standard deviation of job completion rate, denoted as
.
(5) Average remaining processing time of unfinished jobs, denoted as
.
where
denotes the remaining processing time of job
, and is set to 0 if the job is already completed;
is the number of unfinished jobs.
(6) Total number of operations remaining for unfinished jobs, denoted as
.
where
is the number of remaining operations for job
.
(7) Average current power level of AGVs, denoted as
.
where
is the current power level of AGV
.
(8) Standard deviation of AGVs current power level, denoted as
.
(9) Average utilization rate of AGVs, denoted as
.
where
is the utilization rate of AGV
, calculated as the total material handling time divided by its running time.
(10) Standard deviation of AGV utilization rate, denoted as
.
(11) Average number of charges for AGVs, denoted as
.
where
denotes the number of times AGV
has charged up to time
.
(12) Standard deviation of AGV charge counts, denoted as
.
(13) Total number of AGVs with power below
, denoted as
.
The 13 state features designed in this subsection are based on a systematic approach, aiming to comprehensively characterize the dynamic characteristics of the FJSPLSP-LTCC system from both operational status and energy management perspectives. Metrics such as the mean and variance of machine utilization and job completion rates quantify production progress and load distribution, aiding the agent in identifying potential bottlenecks and resource allocation inefficiencies. Indicators including the average remaining processing time and the total number of unfinished operations reflect workload intensity and scheduling complexity, providing a basis for reasonable task prioritization to enhance overall scheduling efficiency. Energy-related features encompass the mean and fluctuation of AGV battery levels, the number of low-battery AGVs, and charging frequency, integrating AGV energy status into the scheduling decision framework to effectively coordinate AGV dispatch and charging actions, thereby reducing downtime risks. The comprehensive construction of these features forms a systematic yet concise state representation, equipping the agent with the necessary information to navigate the large decision space and achieve balanced and efficient scheduling decisions.
4.1.2. Action Design
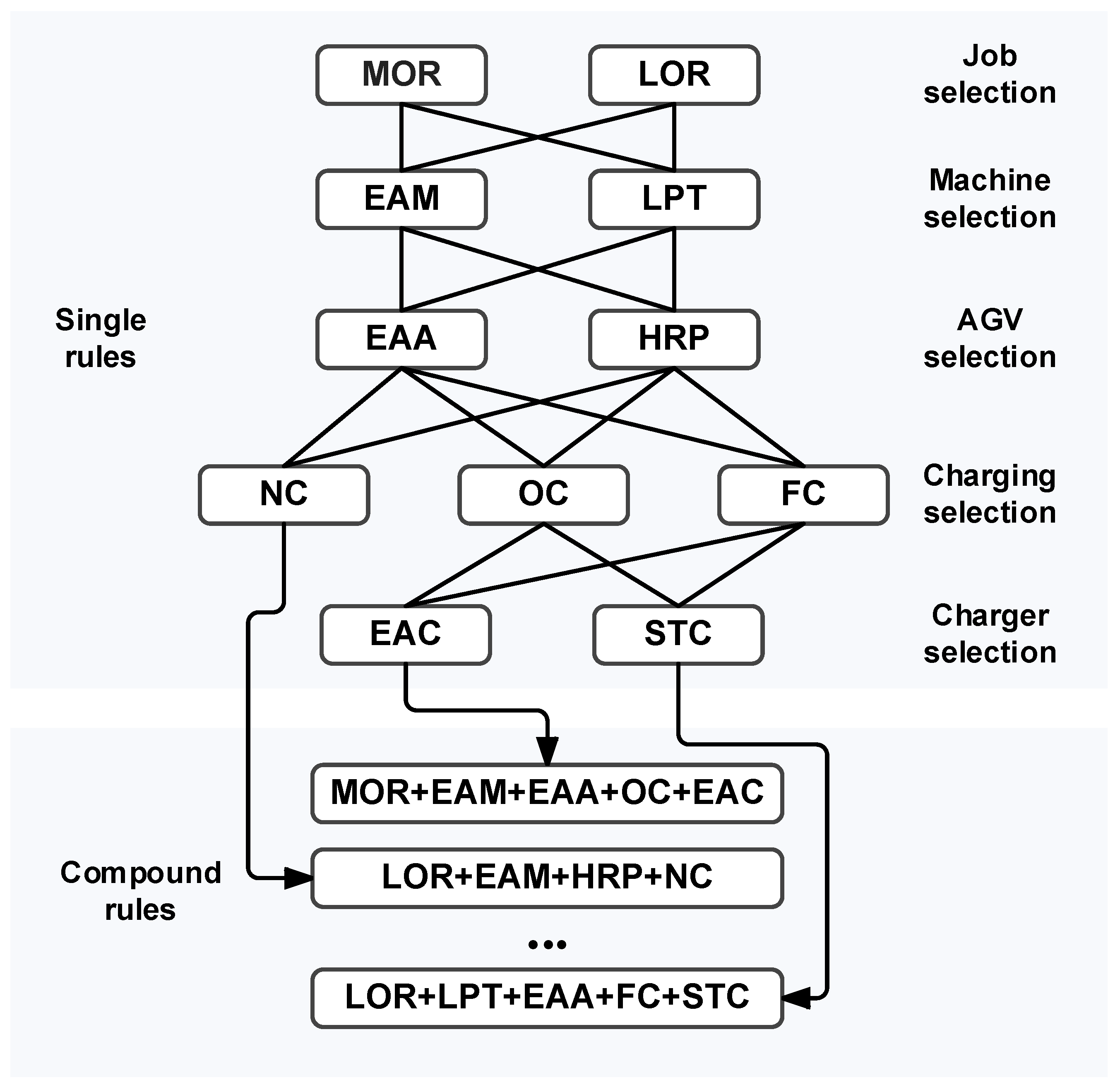
In the proposed FJSPLSP-LTCC model, the agent needs to solve the following sub-problems at each decision point: operation sequencing, machine selection, AGV selection, charging decision, and charger selection. Therefore, each action is essentially a multi-dimensional decision involving the overall scheduling of jobs to resources. To handle this, we design specific action rules at different levels as follows:
Two rules are designed for selecting the job: MOR (Most Operations Remaining), which selects the job with the highest number of remaining unprocessed operations. LOR (Least number of Operations Remaining), which selects the job with the fewest remaining operations.
- 2.
Machine selection rules
Two machine selection strategies are proposed, both based on the set of machines capable of processing the selected operation: EAM (Earliest Available Machine), which selects the machine that becomes available the earliest. LPT (Lowest Processing Time of Machines), which selects the machine with the lowest processing time for the selected operation.
- 3.
AGV selection rules
Since AGV selection is not constrained by the production process, the following two rules are proposed: EAA (Earliest Available AGV), which selects the AGV that finishes its last transport task earliest. HRP (Highest Remaining Power of AGV), which selects the AGV with the highest remaining battery power.
- 4.
Charge selections rules
Considering the dynamic battery level of AGVs, three charging options are introduced: NC (Not Charging, no charging is performed). OC (Opportunity Charging), performing opportunity-based partial charging. FC (Full Charge, charging the AGV to full capacity). It should be noted that mandatory maintenance battery change (MBC) is not included in the action space, as it is automatically executed after each transport and is not influenced by state variables.
- 5.
Charger selections rules
Two rules are proposed for selecting chargers: EAC (Earliest Available Charger) which selects the charger that becomes available first. STC (Shortest Transport Time of Chargers) which selects the charger with the shortest transport time from the current AGV location. Note that if NC is selected, charger selection is not required.
It should be noted that although the proposed action space is constructed through a combination of five hierarchical decision rules, the independence among these rules has been fully considered during the design process. The job selection, machine selection, and AGV selection rules are mutually independent—decisions made in one dimension do not constrain the feasible options in the others. For instance, adopting the MOR or LOR rule for job selection does not restrict the subsequent selection of machines or AGVs. Similarly, the charging decision is designed to remain independent, allowing the agent to autonomously choose among NC, OC, or FC based on the current battery state without relying on prior decision outcomes. To ensure the validity of the action space, the charging station selection rule is activated only when OC or FC is selected. This conditional dependency is explicitly modeled to prevent invalid action combinations. Overall, this structured design guarantees both the validity and expressiveness of the composite action space, facilitating efficient learning while preserving scheduling flexibility. Thus, by combining the decision rules across all five levels above, we construct a set of 40 compound scheduling actions, as shown in
Figure 4. Each compound action represents a complete scheduling strategy that spans from job selection to resource allocation and charging operations, forming the action space for reinforcement learning.
4.1.3. Reward
This study adopts minimizing the makespan as the primary scheduling objective. As the goal of reinforcement learning agents is to maximize the expected cumulative reward, the reward function is defined as follows:
where
denotes the maximum completion time of all finished operations at state
.
The core idea behind this reward design is to encourage the agent to reduce the makespan through each scheduling decision. A decrease in the makespan results in a positive reward, while an increase results in a negative reward. This drives the agent to iteratively improve the scheduling policy toward a globally or near-globally optimal solution.
It is important to note that during the early stages of training, the agent has limited knowledge of the environment, and the reward based on the makespan difference may exhibit high variance due to extensive random exploration, potentially hindering training stability. To mitigate this issue, we employ a reward normalization strategy that dynamically tracks the observed changes in makespan and scales the reward into a bounded range. This normalization facilitates more stable policy updates during the initial training phase. Moreover, the PPO framework inherently includes a clipped surrogate objective and an entropy regularization term, both of which help stabilize learning under high-reward-variance conditions. These mechanisms jointly ensure that the agent can progressively learn effective scheduling behaviors even when starting from a tabula rasa (no prior policy).
4.2. CRGPPO-TKL
This study adopts an enhanced PPO algorithm, named CRGPPO-TKL, to train the collaborative scheduling agent. PPO is a policy gradient method that collects data through interaction with the environment and updates the agent’s policy using stochastic gradient ascent [
50]. By employing a clipped surrogate objective and importance sampling, PPO maintains stable policy updates even in high-dimensional combinatorial optimization problems such as machine assignment, AGV selection, charging decisions, and charger selection in the proposed FJSPLSP-LTCC. Unlike value-based methods that only handle discrete action spaces, PPO’s actor-critic architecture allows separate policy heads to process both discrete and continuous actions. As one of the most widely used RL algorithms, PPO has proven its effectiveness in various manufacturing scenarios.
However, PPO still suffers from several limitations. The clipping mechanism, while central to PPO, is sensitive to its clipping range: A narrow clip range may discard many samples due to out-of-range probability ratios (gradient truncation), reducing data efficiency. A wide clip range may lead to policy updates that exceed the trust region, violating the principle of monotonic improvement. To address these issues, Li and Tan [
51] proposed Candidate Ratio Guided PPO (CRGPPO), which introduces candidate actions sampled with Gaussian noise. By computing candidate ratios, CRGPPO enables a better assessment of policy divergence and adjusts the clip range adaptively for more stable learning. However, the method is designed for continuous action spaces and introduces randomness that may destabilize training. To address these issues for the discrete decision space of FJSPLSP-LTCC, we propose a modified version called CRGPPO-TKL, with two key enhancements:
Since all actions designed in
Section 4.1.2 are discrete, we replace the Gaussian noise-based sampling used in CRGPPO with stochastic sampling from the policy’s discrete distribution, making it suitable for the current action space.
To balance exploration capability and computational efficiency, we preset the number of candidate actions sampled from the policy distribution to 5 per decision step. This fixed sampling size ensures sufficient coverage of the action space while avoiding excessive computational overhead. Although categorical sampling lacks continuous perturbation mechanisms such as Gaussian noise, the PPO framework incorporates an entropy regularization term to preserve policy stochasticity. This is particularly beneficial in the early training phase, as it promotes diverse action sampling and mitigates the risk of premature convergence to suboptimal policies.
- 2.
Dynamic Adjustment of the Clipping Range
To reduce training instability, we introduce a target KL divergence mechanism to adjust the clip range dynamically. The update is based on the deviation between the actual KL divergence and the target KL threshold, as follows:
Equations (32) and (33) compute the probability ratios for the current action and sampled candidates, respectively. These ratios quantify how much the policy has changed for a given action after the latest update. Equation (34) computes the average of these ratios across all N sampled candidates. This average serves as a proxy for the policy shift in the local neighborhood of the current action, making the clipping mechanism more robust to action sampling noise.
Equations (35) and (36) generate binary indicators (0 or 1) based on whether the probability ratio of the action or its candidates exceeds the clipping range [, ]. Equation (37) computes the deviation between the observed clipping violations and . A positive suggests excessive policy changes, indicating that the clipping range should be narrowed in the next iteration.
4.3. Training Details
The training process is shown in
Figure 5. The notations used and their descriptions are shown in
Table 3. The specific training steps are as follows:
Step 1: Initialize the actor network parameters , the critic network parameters , and the experience replay buffer. Set the initial clipping range , entropy coefficient , and target KL divergence threshold .
Step 2: Use the current policy
to interact with the environment and collect transitions in the following form:
Store these samples in the replay buffer for batch learning.
Step 3: Calculate the advantage estimate using Generalized Advantage Estimation (GAE):
Step 4: For each state , generate N candidate actions using the policy (Equations (30) and (31)). Compute the average ratio of current to old policy probabilities over the candidates (Equation (34)).
Step 5: Evaluate the current action’s ratio (Equation (32)) to determine whether the current action and candidate ratios exceed the clipping range (Equations (35) and (36)).
Step 6: Calculate the current KL divergence and adjust the clipping range accordingly (Equation (34)).
Step 7: Update the actor by maximizing the clipped surrogate objective with entropy regularization.
Use gradient ascent to update .
Step 8: Update the critic network by minimizing the value loss:
where
is the empirical return. Use gradient descent to update
.
Step 9: Repeat Steps 2–8 for multiple iterations until convergence.
The pseudo-code of the CRGPPO-TKL algorithm is shown in Table ‘Algorithm 1’.
| Algorithm 1: CRGPPO-TKL training mechanism |
| Input: Initial actor parameters , critic parameters , replay buffer B, clipping range , entropy coefficient , target KL threshold , learning rates , , minimum/maximum clipping ,, candidate sample size N, clipping update speed |
| 1: while not converged do |
| 2: Collect trajectories using current policy |
| 3: Store transitions in replay buffer B |
| 4: Compute advantages using GAE |
| 5: for each mini-batch from B do |
| 6: for each in mini-batch do |
| 7: Sample N candidate actions |
| 8: Compute ratio = / |
| 9: Compute = (1/N) ∑/ |
| 10: Compute = 1 if else 0 |
| 11: Compute = 1 if else 0 |
| 12: end for |
13: Update clipping range:
|
14: Compute policy loss:
|
| 15: Update actor: |
| 16: Compute value loss: |
| 17: Update critic: |
| 18: |
| 19: end for |
| 20: end while |
5. Experiments
In this section, we first utilize the proposed method to determine the optimal number of AGVs under different shop-floor layouts. Then, we compare its performance with compound scheduling rules and other DRL frameworks. Specifically,
Section 5.1 describes the benchmark datasets used in the experiments, the layout configurations, and the hyperparameter settings;
Section 5.2 applies the proposed CRGPPO-TKL approach to determine the optimal number of AGVs for each layout;
Section 5.3 compares the scheduling performance of various methods, assuming the optimal AGV configuration for each layout is fixed.
To compare optimization performance across different methods, we adopt the Optimality Deviation Ratio (ODR), which is calculated as follows:
where
represents the objective value obtained by algorithm
on a given instance, and
is the minimum objective value obtained among all competing methods for that instance. A lower ODR indicates better performance and is closer to the optimal result.
In addition to the ODR metric, this study also employs the independent two-sample t-test to evaluate the statistical significance of performance differences between the proposed CRGPPO-TKL method and baseline approaches, including composite dispatching rules and other DRL-based methods. For each test instance, the ODR values obtained from multiple independent runs are used as input data for the t-test. A significance level of 0.05 is set to determine whether the performance differences are statistically significant.
5.1. Instance Design and Hyperparameter Setting
This section utilizes a public benchmark dataset proposed by Brandimarte [
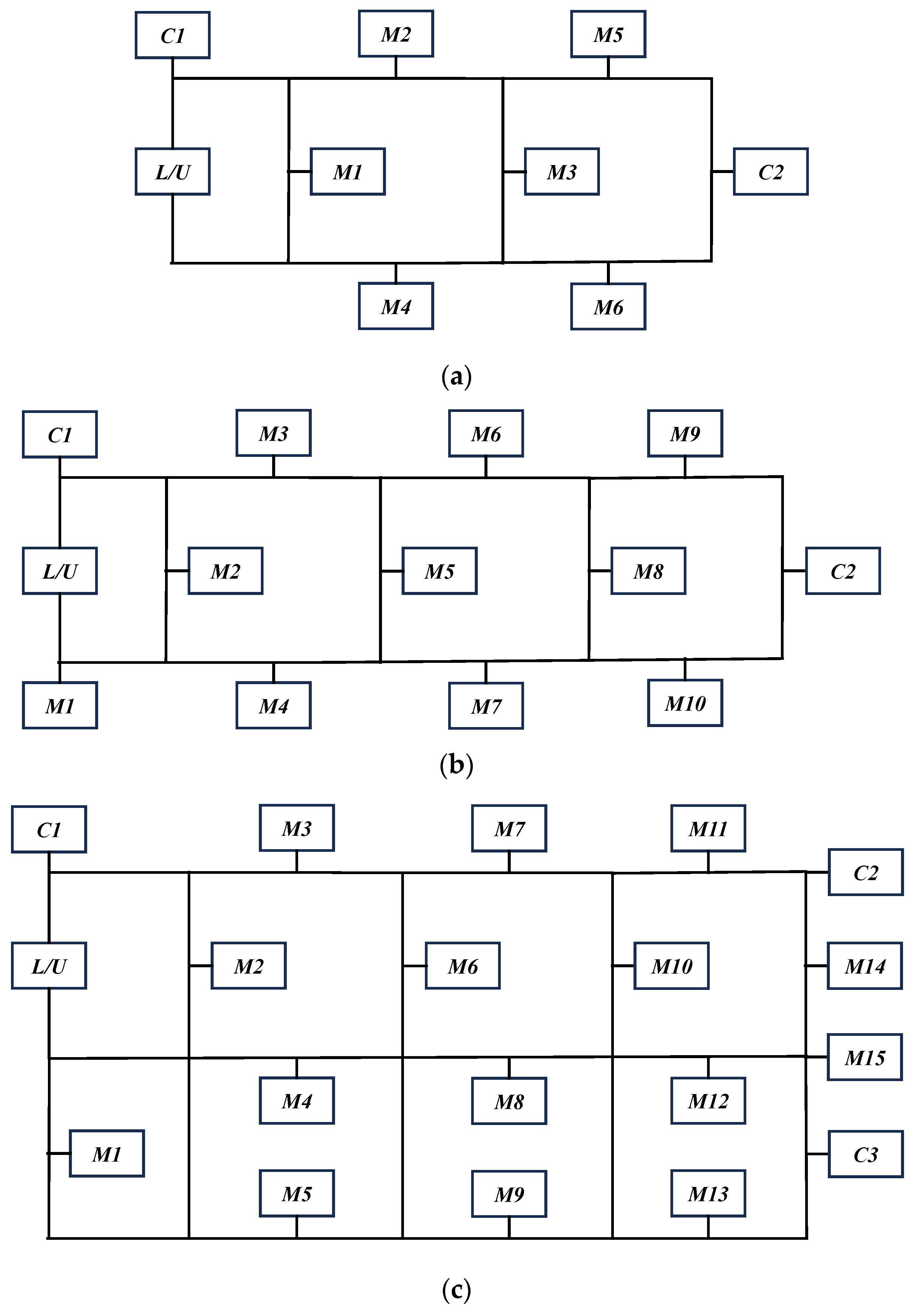
2], which includes 10 instances in total (MK01–MK10). To ensure that the proposed method can be evaluated under varying levels of scheduling complexity, this study designs three shop floor layouts by integrating practical manufacturing system scales and benchmark testing considerations. Specifically, the small-scale layout (6 machines) and medium-scale layout (10 machines) reflect typical shop floor sizes found in small to medium-sized manufacturing enterprises, while the large-scale layout (15 machines) is used to simulate more complex large-scale industrial production environments. The ratio of charging stations to machines (approximately one charging station per 5 to 6 machines) is based on commonly observed industrial configurations, aiming to balance AGV availability and mitigate the risk of charging station congestion. Furthermore, the use of varying layout scales facilitates a progressive increase in the decision space of the scheduling problem, thereby enabling a systematic assessment of the proposed scheduling method’s scalability and robustness. These layouts are illustrated in
Figure 6, reflecting a progressive increase in shop-floor complexity. Each dataset is assigned to its most suitable layout based on its size and processing requirements, as summarized in
Table 4. The other parameters used in this paper are set as follows: the initial power of the AGV is a full power of 43,200, the AGV charging power is 1440, the load power is 1200, the no-load power is 600, and the distance between the two locations is equal to the AGV transporting time, and since the FJSP time is dimensionless, the dimensionless data is also used here along with the uniformity of the time scale. For OC, the charging time set in this paper is 10, and for MBC, the time set in this paper is 60.
The proposed algorithm, CRGPPO-TKL, is built on the PPO framework and adopts an Actor-Critic dual-network architecture. The architecture and hyperparameter settings are as follows: The Actor network consists of three fully connected layers that map the input state (including machine status, AGV battery levels, and task queues) to a joint action space. The Tanh activation function is employed to ensure gradient stability, and Softmax is used to generate the policy distribution. The Critic network shares the first two layers of the Actor and outputs the value estimate of the current state.
The parameter settings in this study are based on a combination of established practices in the PPO literature and empirical tuning results specific to the FJSPLSP-LTCC problem. The discount factor
, GAE coefficient
, entropy regularization coefficient
, and learning rates
and
are selected according to commonly adopted configurations in prior PPO studies [
52]. For the newly introduced parameters in the proposed CRGPPO-TKL algorithm—such as the number of candidate actions
, the target KL divergence threshold
, and the clipping range parameters
, and the initial clipping value
—the values are determined with reference to related literature [
51] and experimental experience, aiming to ensure effective policy optimization while maintaining stable and efficient learning.
Additionally, the minimum batch size
, number of update epochs
, and total training time
are set based on trade-off analysis between training efficiency and policy performance during preliminary experiments. The complete hyperparameter settings are summarized in
Table 5.
The algorithm is implemented in Python 3.9 using the PyCharm 2023 development environment. The experiments are run on a laptop system with an Intel Core™ i5-13500HX processor (2.5 GHz) and 16 GB DDR4 RAM.
5.2. Determination of the Optimal Number of AGVs Under Different Layouts
In the FJSPLSP-LTCC problem, the configuration of transport resources is one of the key factors affecting the overall system performance. There exists a significant correlation between the number of AGVs and the system’s makespan: when the number of AGVs is insufficient, the material transport capacity of the system is limited, which tends to increase the waiting time between operations and thus prolong the overall production cycle. Conversely, an excessive number of AGVs may lead to resource waste, increased idle travel rates, and higher operational costs. Therefore, based on the three workshop layouts proposed in
Section 5.1, this section conducts a systematic analysis of the performance of each layout under different AGV configurations using the proposed CRGPPO-TKL algorithm, aiming to determine the optimal transport resource configuration for each layout. Each configuration was subjected to 20 independent experimental runs, and the results are presented in
Table 6 where bold indicates the best performance and
Figure 7.
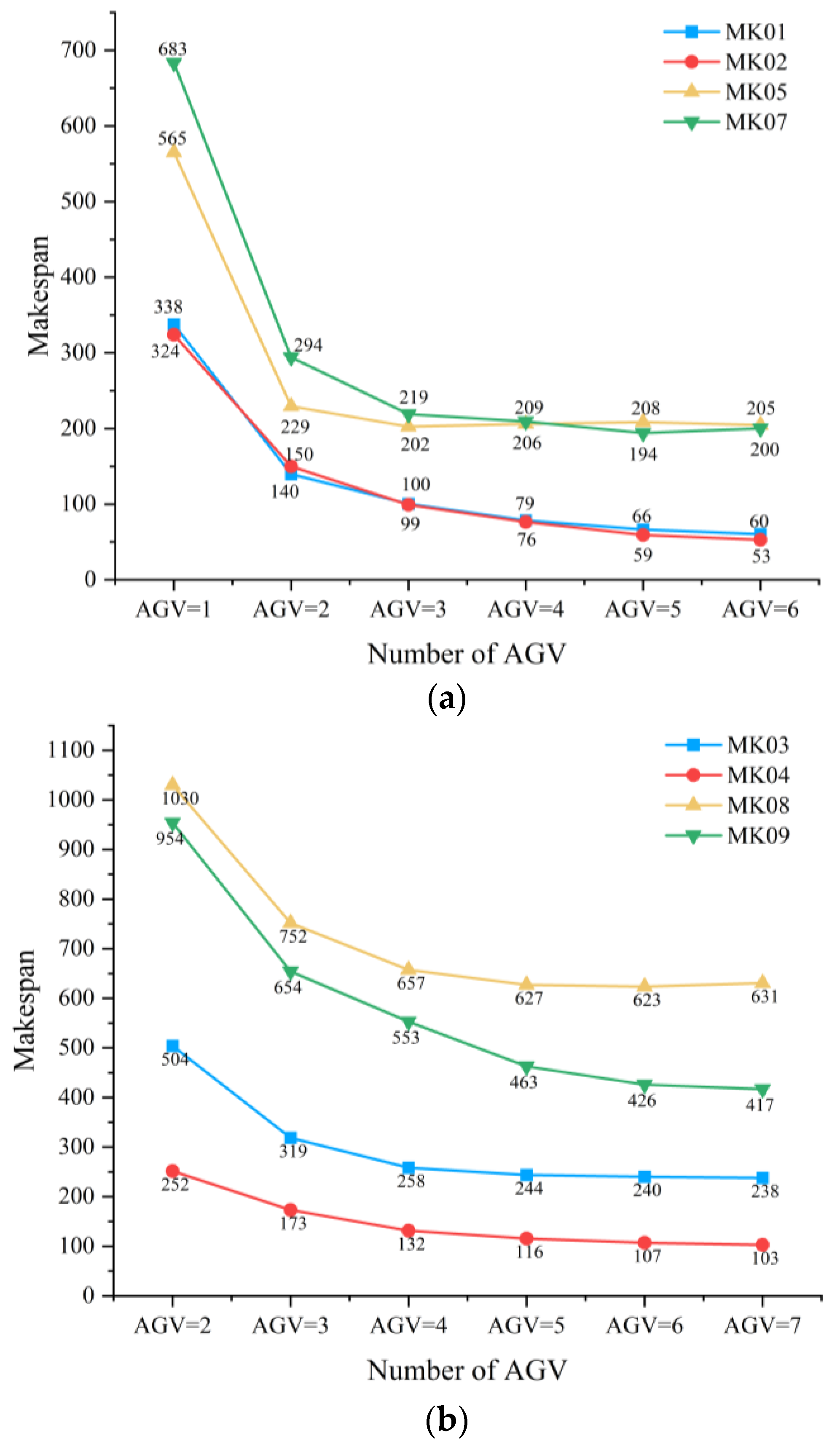
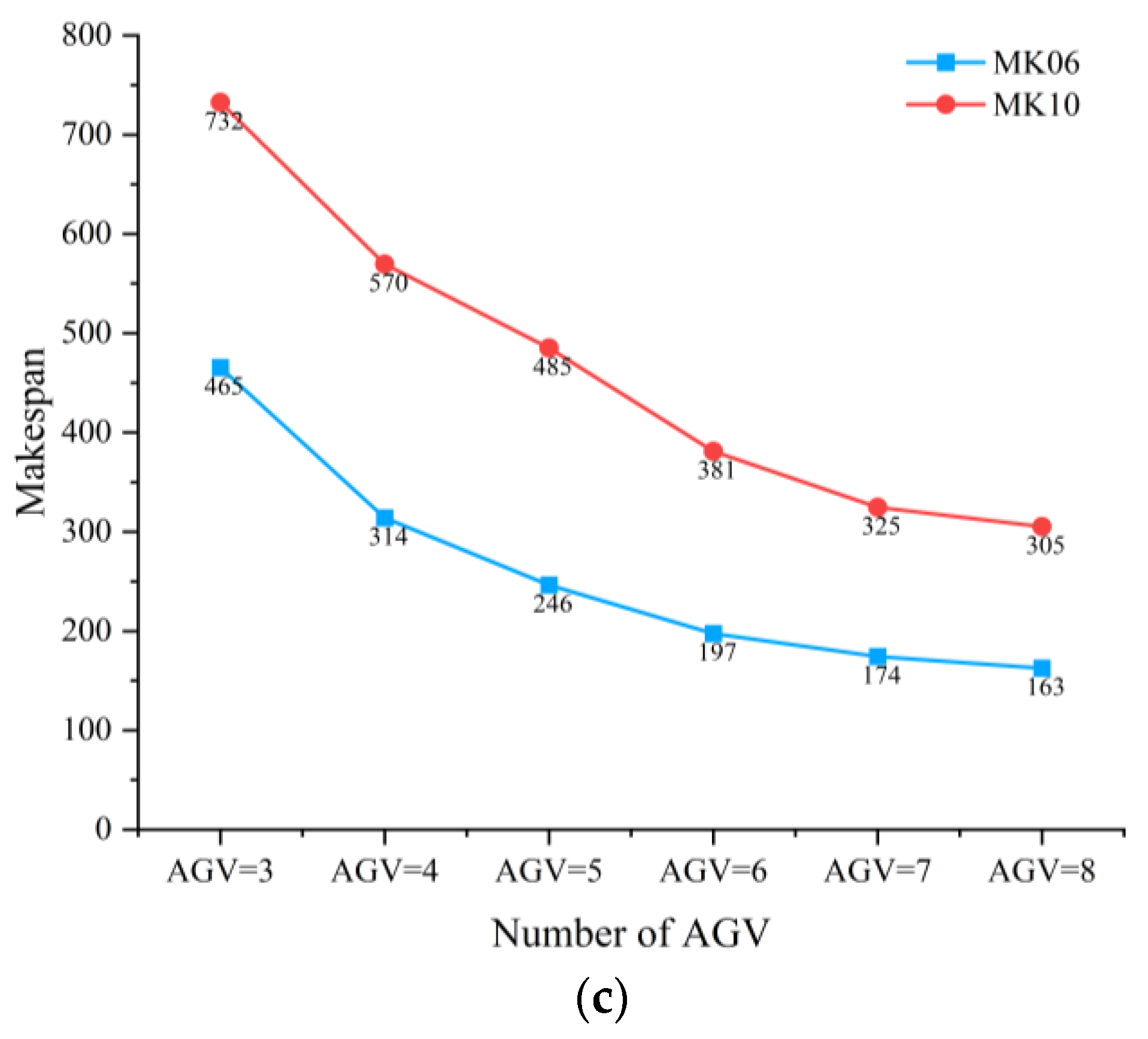
Figure 7 illustrates the significant impact of AGV quantity on the makespan across the three layouts. In Layout 1, when the number of AGVs increases from 1 to 6, the average makespan of test sets MK01, MK02, MK05, and MK07 decreases by 227.4, 271.2, 360.7, and 483.1, corresponding to reductions of 82.2%, 83.7%, 63.8%, and 70.7%, respectively. In Layout 2, when the AGV number increases from 2 to 7, the average makespan of test sets MK03, MK04, MK08, and MK09 decreases by 266.2, 148.7, 399.3, and 537.2, with reduction rates of 52.8%, 59.1%, 38.8%, and 56.3%, respectively. In Layout 3, increasing AGVs from 3 to 8 leads to makespan reductions of 302.8 and 427.4 for MK06 and MK10, corresponding to 65.1% and 58.4%, respectively. Furthermore, it can be observed from
Figure 6 that as the number of AGVs increases, the improvement in system makespan gradually diminishes. In some test sets, like MK05 and MK07, the shortest makespan is not achieved with the maximum number of AGVs, indicating that the transport capacity has reached saturation. Therefore, to achieve an optimal balance between transport efficiency and resource cost, it is crucial to determine the optimal AGV quantity for each layout. A detailed analysis of the results for the three layouts is presented below:
In Layout 1, the shortest makespan for test sets MK01, MK02, MK05, and MK07 corresponds to AGV quantities of 6, 6, 3, and 5, respectively. Using these shortest makespans as benchmarks, the ODR for other configurations is calculated, and the same method is applied for Layouts 2 and 3. When the number of AGVs increases from 1 to 2, the ODRs for the respective test sets reach 328.8%, 329.6%, 165.9%, and 200.6%, with an average of 256.2%, indicating that the system efficiency is severely constrained under extreme AGV shortages. As the number of AGVs gradually increases from 2 to 6, the average ODRs decrease to 53.3%, 20.6%, 14.9%, and 5.2%, demonstrating a diminishing marginal benefit. Notably, from
Figure 7, it is observed that when AGV quantity exceeds 3, the makespans of MK05 and MK07 tend to stabilize, suggesting that the transport capacity is sufficient for system demands. Therefore, the AGV quantity in Layout 1 is configured as 3 units.
As shown in
Figure 7, during the increase in AGV quantity from 4 to 7 in Layout 2, only MK09 exhibits a significant reduction in makespan, while the other three test sets show relatively stable performance. Specifically, when AGVs increase from 4 to 5, the ODR of MK09 is 21.6%, while MK03, MK04, and MK08 have ODRs of only 6.1%, 15.5%, and 4.9%, respectively. Further increasing the number of AGVs from 5 to 7 leads to a further decrease in overall ODR to 4.8%, 1.5%, and even a reverse increase in MK08, indicating that the system has reached its transport saturation. Therefore, the AGV quantity in Layout 2 is configured as 4 units.
In Layout 3, the variation in AGV quantity from 3 to 8 continuously impacts the makespan. The average ODRs for each AGV quantity level are 73.2%, 34.7%, 32.1%, 16.3%, and 6.8%, respectively. Even when AGVs increase from 7 to 8, there is still a 6.8% reduction in makespan, indicating that AGV resources in this layout still contribute to system performance enhancement. However, considering resource utilization efficiency and diminishing marginal returns, to avoid resource waste, the AGV quantity in Layout 3 is configured as 6 units.
5.3. Performance Comparison of CRGPPO-TKL
In this section, we evaluate the effectiveness and generalizability of the proposed CRGPPO-TKL algorithm through comparative experiments conducted under various test scenarios. The comparison includes 40 composite production-logistics scheduling rules designed for the FJSP, two DRL–based scheduling algorithms (including DQN-based and PPO-based methods), as well as a randomized version of CRGPPO-TKL (denoted as RN), in which the agent randomly selects actions at each decision level. Each method was executed over 20 independent runs on each test instance.
5.3.1. Comparison with Composite Scheduling Rules
The 40 composite rules were structured into a two-level hierarchy: the first level involves four machine–job assignment strategies, while the second includes ten AGV charging strategies. The composite actions were indexed sequentially: Actions 1–10 represent the first machine–job pairing combined with each of the ten AGV charging strategies; Actions 11–20 represent the second pairing, and so on. To streamline the analysis, only the best-performing AGV charging strategies under each machine–job rule are presented here; the results of the remaining combinations are provided in
Appendix A.
Table 7 summarizes the mean completion times and ODR of CRGPPO-TKL and the selected composite actions across all test instances.
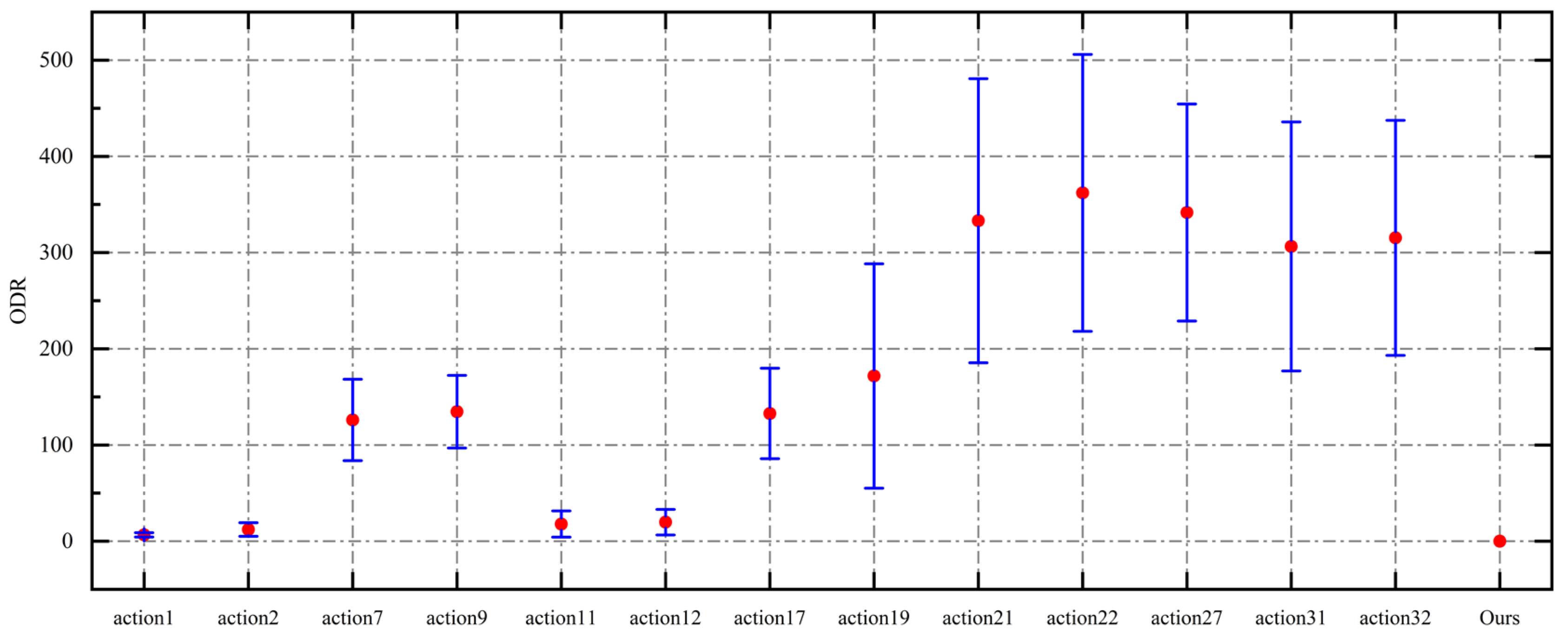
Figure 8 visualizes the mean ODR and variance for the selected rules. The results show that CRGPPO-TKL consistently achieved the best completion times across all 10 test instances. The most competitive composite actions were Actions 1, 2, 11, and 12, with average ODRs of 6.6%, 12.2%, 17.9%, and 19.8%, and variances of 2.26, 7.05, 13.64, and 13.28, respectively. Among AGV charging strategies, the 7th and 9th showed superior performance, primarily because the opportunity charging mechanism uses a fixed time duration—AGVs continue charging even if fully charged—while the full-charging strategy terminates once fully charged. As a result, full charging tends to require less time, contributing to shorter completion times. These findings suggest that strategies such as “EAA + STC” and “EAA + EAC”—both of which involve no charging—outperform others, independent of the specific charging policy.
To further validate the performance differences, we conducted independent two-sample t-tests between CRGPPO-TKL and each selected composite scheduling rule across all test instances. The results show that the performance differences are statistically significant (p < 0.05) in all comparisons, confirming that CRGPPO-TKL consistently outperforms composite rule-based methods.
5.3.2. Comparison with Other DRL Algorithms
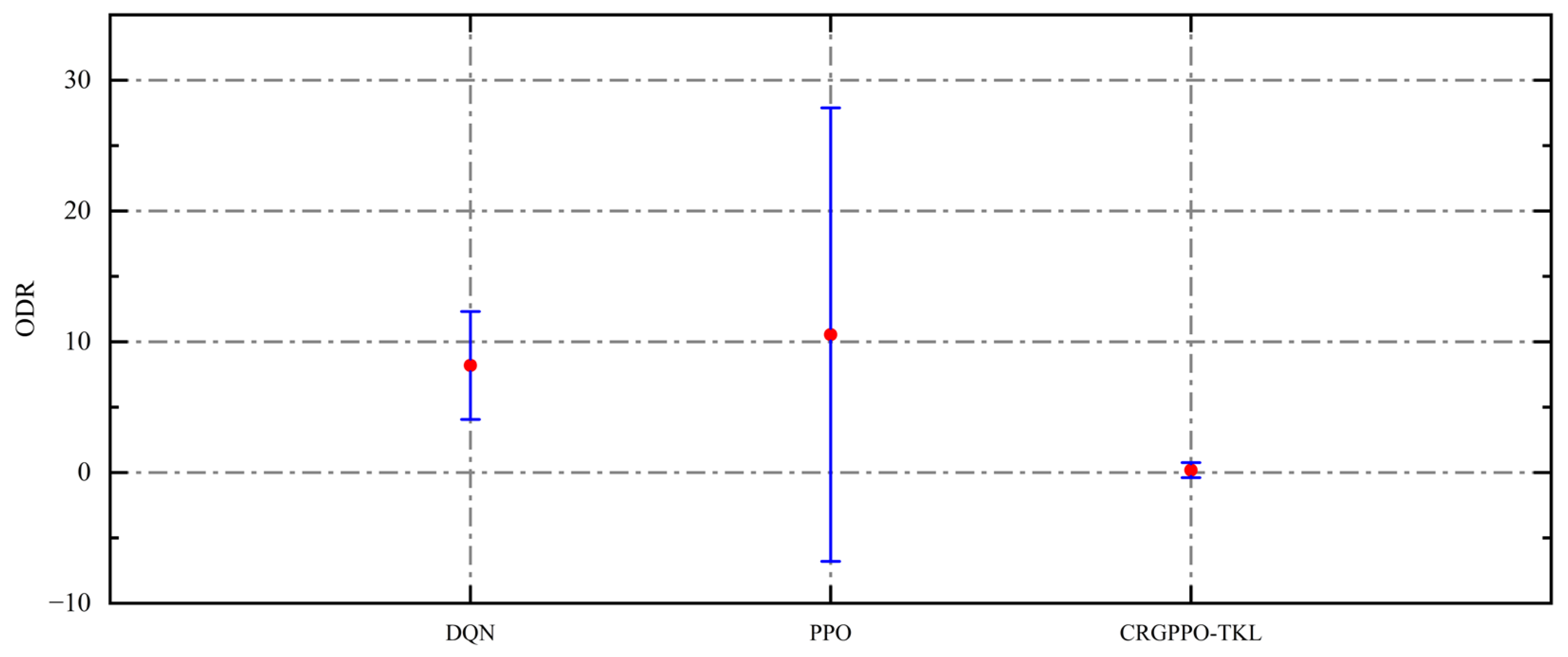
This subsection evaluates the performance of CRGPPO-TKL against other DRL-based scheduling methods. As shown in
Table 8, CRGPPO-TKL significantly outperforms both the DQN-based and PPO-based methods across 10 MK benchmark instances. It achieves the best performance in 9 out of 10 instances, with MK06 being the only case where PPO slightly outperforms CRGPPO-TKL (ODR = 1.8%). As shown in
Figure 9, on average, CRGPPO-TKL achieves an ODR of 0.18%, compared to 8.19% and 10.54% for DQN and PPO, respectively. Furthermore, CRGPPO-TKL exhibits a lower standard deviation of 11.9, in contrast to 10.1 for DQN and a much higher 140.7 for PPO, indicating improved stability alongside superior performance. Notably, PPO exhibits large performance fluctuations on the larger and more complex instances MK08 and MK09, which are characterized by longer completion times. In contrast, CRGPPO-TKL stabilizes performance by dynamically adjusting its clipping range based on the candidate action set, thereby enhancing robustness in complex scenarios. Layout-based statistics (
Table 9) further reveal that CRGPPO-TKL achieves the lowest average completion time under all three workshop layouts. In contrast, DQN and PPO record average ODRs of 8.5% and 13.3%, and standard deviations of 10.59 and 127.2, respectively. These results underscore the overall performance and robustness of CRGPPO-TKL.
Additionally, independent two-sample t-tests were performed between CRGPPO-TKL and the baseline DRL methods (DQN, PPO) across the 10 MK benchmark instances. The results indicate that the observed improvements of CRGPPO-TKL over DQN and PPO are statistically significant (p < 0.05) in all cases except for MK06, where the difference is not significant. These findings further support the robustness and superior performance of CRGPPO-TKL in complex flexible job shop scheduling scenarios.
5.3.3. Comparison with RN and Action Analysis
As shown in
Table 8, CRGPPO-TKL significantly outperforms the random version (RN) in both average completion time and standard deviation. For example, in the MK08 instance, RN records a mean completion time of 2951.2 with a standard deviation of 1315.7, whereas CRGPPO-TKL achieves a mean of 653.6 and a standard deviation of only 14—demonstrating a substantial performance gap. These results confirm that the proposed method does not rely on random action selection but rather learns to make near-optimal decisions at each step, thereby reducing overall system completion time.
To further validate the policy learning capability of CRGPPO-TKL, a detailed action-selection analysis is conducted on MK08, the most challenging instance in terms of average makespan. We conduct 20 independent runs on this instance and record all action selections at each decision point throughout the scheduling process. Actions are then classified and statistically analyzed.
Table 10 presents frequency statistics based on charging action types,
Table 11 shows results grouped by job–machine combinations, and
Figure 10 displays actions that occurred more than 20 times across experiments.
As shown in
Table 10, the agent strongly favors the NC action. OC occurs more frequently than FC, while FC actions are rarely chosen. This strategy reflects real-world operational logic: once the optimal number of AGVs is fixed, each vehicle typically performs continuous transport tasks. When battery levels drop, the agent prefers OC during idle gaps, which minimally disrupts production. In contrast, FC often incurs longer delays and is only selected when necessary.
Table 11 indicates that the majority of job–machine combination decisions fall into the MOR + EAM and MOR + LPT categories, accounting for 55.29% and 42.44%, respectively. This suggests that the MOR rule outperforms the LOR in job sequencing, while the EAM heuristic slightly outperforms the LPT rule for machine assignment.
Figure 10 shows that, aside from high-frequency non-charging actions like EAA + NC and HRP + NC, the most frequently selected and best-performing actions are EAA + OC + EAC and EAA + OC + STC. This implies that, when minimizing makespan is the sole objective, choosing the EAA and EAM leads to better performance. Meanwhile, EAC and STC perform similarly in charger selection, as both are closely related to completion time. The high frequency of OC further supports earlier conclusions about the efficiency of opportunistic charging.
In summary, CRGPPO-TKL successfully learns to differentiate the effectiveness of different scheduling and charging strategies. It consistently selects actions that accelerate task completion and mitigate resource conflicts and congestion. CRGPPO-TKL not only significantly outperforms the random baseline in overall performance but also demonstrates strong policy learning capabilities and adaptability to complex dynamic environments, confirming its effectiveness and practicality in intelligent industrial scheduling.
5.4. Sensitivity Analysis
To further assess the robustness of the proposed CRGPPO-TKL algorithm with respect to critical hyperparameters and enhance the credibility of our findings, we conducted a sensitivity analysis to evaluate how different parameter settings influence scheduling performance and to validate the rationality of the default configurations.
5.4.1. Experimental Design
The analysis was performed on a medium-scale shop layout (comprising 10 machines and 2 charging stations) using benchmark instances MK03 and MK04 from the MK dataset. Three key hyperparameters were examined: , , and . Specifically, was tested with values of 3, 5, and 7; with 0.1, 0.2, and 0.3; and with 0.1, 0.2, and 0.3, each with a clipping range of ±0.1. While holding other parameters constant, we systematically varied one parameter at a time and evaluated performance based on the mean Optimality Deviation Rate (ODR), ODR standard deviation, and the number of training epochs required for convergence.
5.4.2. Results and Discussion
The results of the experiment are shown in
Table 12, which indicate that the impact of these hyperparameters on performance varies considerably. The number of candidate actions had minimal influence; ODR and makespan remained relatively stable across different values, suggesting strong robustness under the default setting of
= 3, 5, 7. In contrast, both
and
significantly affected performance. Increasing
from 0.1 to 0.3 resulted in a substantial rise in ODR—particularly in MK03, where ODR rose from 0% to 32.1%—indicating that an excessively high KL target can destabilize policy updates. Similarly, smaller values of
(e.g., 0.1) slowed convergence and introduced greater variability, whereas larger values (e.g., 0.3) yielded better stability and convergence speed.
Based on these findings, we tested a combined setting using the most favorable individual values:
5,
= 0.1, and
= 0.3 with a clipping range of [0.2, 0.4]. The results are shown in
Table 13. Compared to the original setting (
= 0.3,
= 0.2), performance improvements were marginal. For instance, in MK03, ODR slightly increased from 0.0% to 0.1%, while MK04 remained unchanged. This suggests that, although individual parameters may influence performance, the algorithm remains stable under reasonable parameter configurations, demonstrating strong robustness.
5.4.3. Summary
This sensitivity analysis reveals the varying effects of key hyperparameters on convergence and scheduling performance, and confirms the robustness and generalizability of the proposed algorithm under well-tuned settings. These findings provide a solid foundation for future research on adaptive parameter control and large-scale deployment in dynamic production environments.
5.5. Complexity Analysis
To comprehensively evaluate the proposed CRGPPO-TKL algorithm, we analyze its computational and structural complexity, as well as its scalability in practical scheduling scenarios.
5.5.1. Computational Complexity
In each training step, the algorithm samples actions from the discrete policy distribution , computes the probability ratios , evaluates the clipping conditions and adjusts the clipping range based on the estimated KL divergence. Given that these operations are repeated for each state in a mini-batch, the computational complexity per training iteration can be expressed as: , denotes the batch size and represents the cost of a single forward/backward pass through the actor-critic network. Although this adds slight overhead compared to standard PPO, the small fixed number of candidates ensures tractability and maintains computational efficiency.
5.5.2. Structural Complexity
The algorithm introduces two enhancements to the standard PPO framework: Candidate action evaluation, which assesses multiple discrete actions before selection, and A dynamic clipping mechanism guided by a target KL divergence.
These modules are implemented independently and plugged into the original PPO structure without altering the core optimization logic. Such modularity improves interpretability, facilitates debugging, and allows for future extension (e.g., adapting to multi-agent or hierarchical settings).
5.5.3. Scalability and Performance Under Different Settings
To assess scalability, we evaluated the algorithm on a range of FJSPLSP-LTCC benchmark instances (MK01–MK10), covering small to large-scale problems with varying machine numbers, transportation resources, and energy constraints. Experimental results confirm that CRGPPO-TKL maintains stable performance and convergence behavior across different problem sizes. This indicates that the proposed method is well-suited for real-world flexible job shop environments with limited transport and energy resources.
5.6. Discussion
The proposed reinforcement learning-based collaborative scheduling method effectively integrates limited transportation resources and AGV charging strategies, addressing challenges such as energy constraints and logistics bottlenecks. Simulation results confirm its ability to reduce makespan, improve scheduling stability, and dynamically adapt to environmental changes. The opportunity charging strategy further enhances AGV utilization under limited transport capacity. Despite its strengths, the method has several limitations, including assumptions of deterministic parameters, simplified battery models, sensitivity to reward design, and the lack of real-world validation. Nonetheless, the approach shows strong potential for smart manufacturing by supporting energy-aware, multi-resource coordination, improving operational efficiency, and offering scalability. Future work will focus on enhancing model realism and deploying the method in digital twin platforms for practical application.
6. Conclusions and Future Research
This paper investigates the production and logistics collaborative scheduling problem in a flexible job shop scheduling environment with limited transport resources and charging constraints. To solve this problem, we introduce CRGPPO-TKL, a novel variant of the PPO algorithm. CRGPPO-TKL samples multiple candidate actions to compute a more comprehensive probability ratio, thereby evaluating policy deviations more thoroughly. Furthermore, it incorporates target scatter KL to dynamically adjust the clipping range, balancing exploration and stability. A 13-dimensional state representation capturing the operational status of machines and AGVs is designed, along with an action space comprising 40 composite scheduling rules. A reward function is formulated to maximize makespan reduction. Using CRGPPO-TKL, the optimal number of AGVs is determined for three facility layouts of different scales. Comparative experiments demonstrate superior learning speed and generalization compared to baseline methods.
Despite these achievements, some limitations remain. The current model assumes deterministic AGV path planning and does not consider path conflicts or dynamic traffic congestion common in high-density shop floors. Additionally, real-world disturbances such as machine breakdowns, order insertions, and stochastic transport delays have not been incorporated into the scheduling framework. Future work will focus on modeling these disturbances and optimizing scheduling accordingly. More accurate nonlinear battery models, including temperature effects, will also be incorporated to improve simulation realism.
Future research will extend the applicability of the proposed method to diverse manufacturing scenarios, such as multi-variety small-batch production and inter-workshop collaboration, enhancing the adaptability and generalization of scheduling algorithms. With the rapid development of Industrial Internet of Things (IIoT) and edge computing, we plan to investigate deploying scheduling strategies on edge devices to enable real-time response and intelligent coordination, providing more efficient and reliable solutions for flexible manufacturing systems.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}