
Integrating Financial Knowledge for Explainable Stock Market Sentiment Analysis via Query-Guided Attention

Abstract
1. Introduction
- We propose a hierarchical BERT-GRU model that integrates financial domain knowledge for sentiment classification of stock market documents via a novel Query-Guided Dual Attention (QGDA) mechanism. This mechanism effectively directs attention based on domain-specific conceptual queries.
- We design a query set derived from securities knowledge and utilize the attention weights distributed by the QGDA mechanism among these queries to provide an entirely new and interpretable form of concept-level explainability for stock-related document classification that reveals the ’why’ behind predictions.
- Crucially, we quantitatively validate our model’s explainability. Our case study demonstrates that predictions guided by dominant query categories identified through QGDA exhibit statistically significant higher consistency with actual stock market fluctuations (p-value = 0.0368). This not only confirms the utility of our explanations but also identifies which conceptual drivers are more indicative of market movements.
2. Related Work
2.1. Sentiment Analysis for Financial Articles
2.2. Explainable Sentiment Analysis Network
3. Preliminaries and Problem Definition
3.1. Preliminaries
3.2. Problem Definition
4. Methodology
4.1. Algorithm Description
| Algorithm 1: Hierarchical BERT-GRU Model with Query-Guided Dual Attention (QGDA) for Financial Sentiment Analysis |
 |
4.2. BERT Word Encoder

4.3. Query-Guided Dual Attention (QGDA)
4.4. Output Layer
5. Experimental Results and Evaluation
5.1. Datasets and Query Construction
5.2. Experimental Setup
- (1)
- How does BERT affect the performance of hierarchical structure in the document-level SA task?
- (2)
- Is our Query-Guided Dual Attention (QGDA) mechanism leveraging manually-defined financial queries able to improve model performance?
- (3)
- How does the concept-level explainable basis derived from the QGDA mechanism (specifically, the dominant query categories) affect the analysis of stock market predictions and their consistency with actual market fluctuations?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Query Symbol | Query Aspects | Content Example |
|---|---|---|
| Macroeconomic Analysis | Economy, Cycle, Price, International, Finance, Currency, Policy, Politics, Macro, etc. | |
| Industry Analysis | Industry, Market, Industry, Product, Innovation, Shipment, Sales Volume, Business, Peers, etc. | |
| Business Analysis | Personnel, Executives, Management, Law, Litigation, Cases, Resignation, Complaints, Stepping down, etc. | |
| Financial Analysis | Revenue, Profit, Sales, Loan, Cost, Loss, Debt, Liability, Arrears, etc. | |
| Technical Analysis | Candlestick chart, Tangent line, Pattern, Trend, Market index, Indicator, Technical analysis, Share, Equity capital, etc. |
5.3. Baselines
- HAN [50]: This method adopts a hierarchical structure with GRU based word-level and sentence-level attention mechanisms. The original paper demonstrated that deep learning-based methods can outperform lexicon-based methods.
- FISHQA [6]: A novel attention mechanism that incorporates user-specified queries to spotlight texts on different levels and provide explainability through the distribution of attention weights.
- BERT-Attention [5]: We designed a hierarchical BERT with a standard GRU attention mechanism without queries in order to evaluate the performance of BERT and the impact of queries.
- BERT-GRU-QA (BQGA): We conducted an ablation experiment by removing the dual attention mechanism from the sentence-level encoder in our full model in order to evaluate the performance of our proposed QGDA mechanism.
- FISHDQA: We conducted an ablation experiment by adding the dual attention mechanism to FISHQA in order to evaluate its performance within the hierarchical GRU structure.
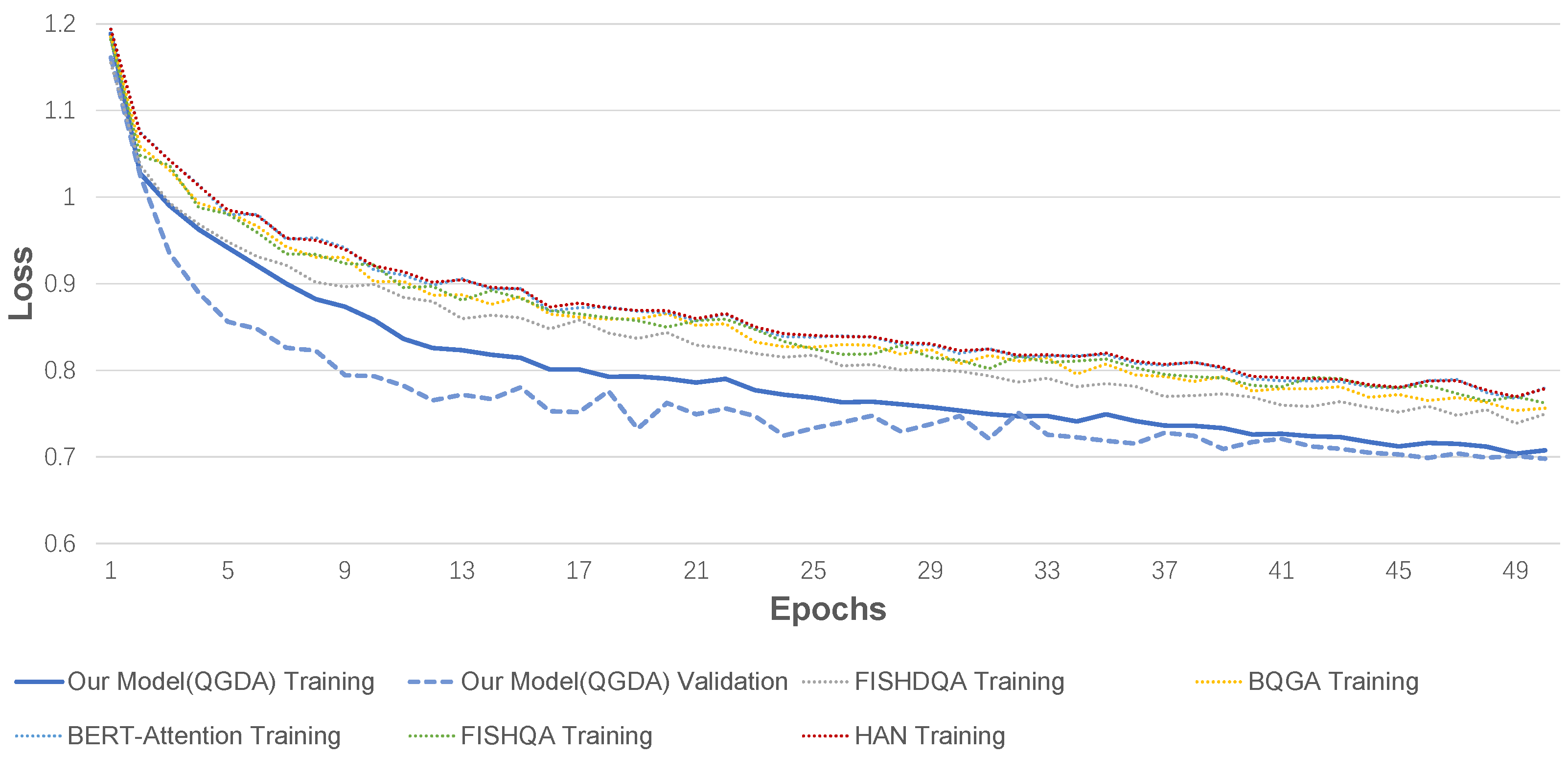
5.4. Results Analysis
| Class | QGDA | FISHQDA | BQGA | BERT-Att | FISHQA | HAN | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | Prec. | Recall | ||||||
| Buying | 0.763 | 0.784 | 0.724 | 0.823 | 0.674 | 0.817 | 0.710 | 0.769 | 0.743 | 0.790 | 0.659 | 0.820 | |||||
| Selling | 0.900 | 0.862 | 0.927 | 0.867 | 0.882 | 0.868 | 0.889 | 0.829 | 0.847 | 0.897 | 0.925 | 0.843 | |||||
| Holding | 0.832 | 0.626 | 0.864 | 0.599 | 0.758 | 0.581 | 0.770 | 0.588 | 0.884 | 0.567 | 0.745 | 0.633 | |||||
| Following | 0.725 | 0.817 | 0.705 | 0.724 | 0.686 | 0.765 | 0.657 | 0.781 | 0.652 | 0.756 | 0.677 | 0.712 | |||||
| Others | 0.598 | 0.679 | 0.534 | 0.645 | 0.590 | 0.544 | 0.546 | 0.564 | 0.518 | 0.558 | 0.548 | 0.514 | |||||
5.5. Effect of Explainable Basis
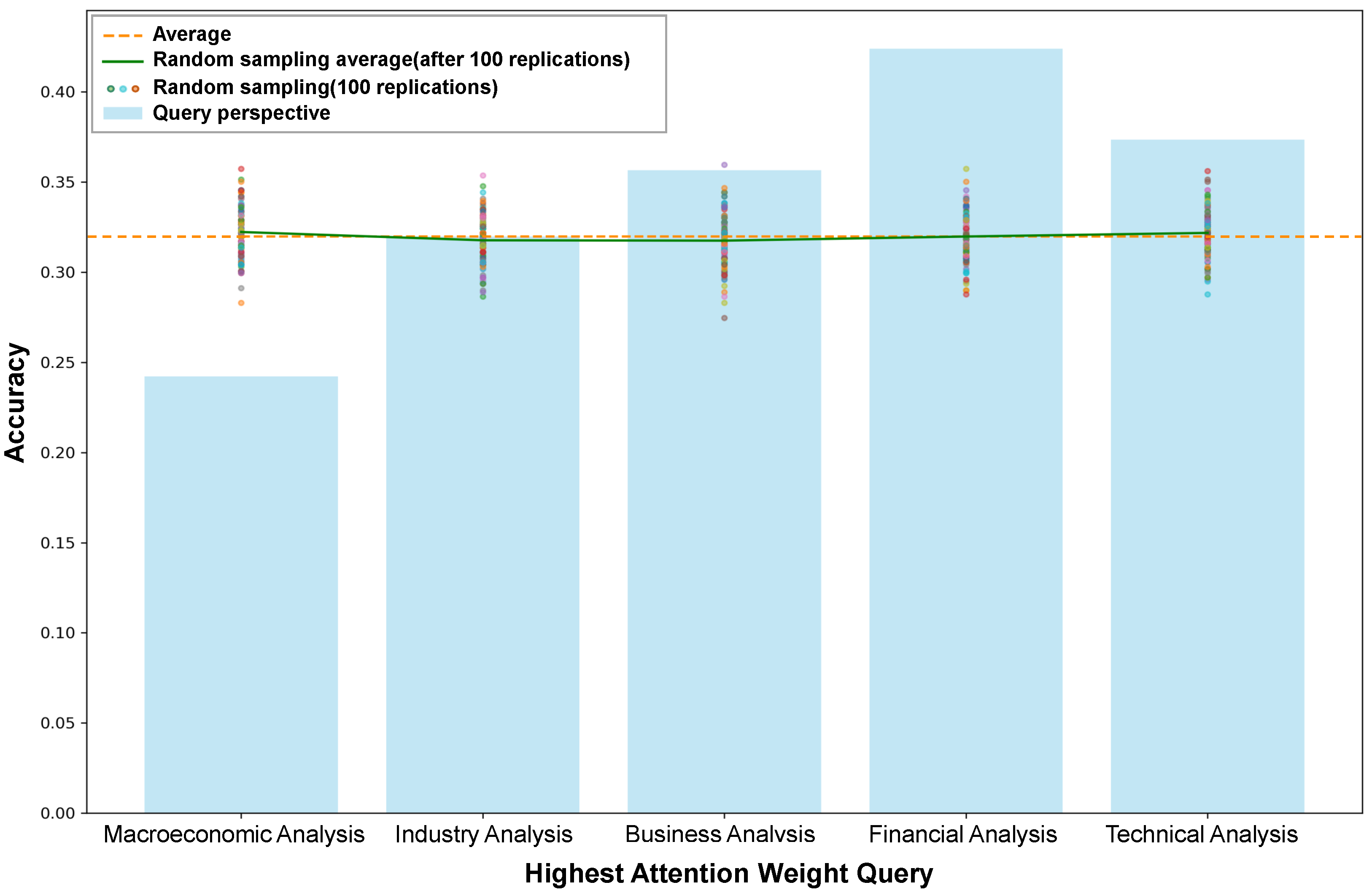
- For financial analysts, it allows for rapid verification of a prediction’s rationale. An analyst can see whether the model’s decision was based on relevant financial concepts (e.g., `profit margin’, `debt ratio’) or spurious correlations, thereby building trust and facilitating human-in-the-loop validation.
- For model auditing and debugging, it provides a transparent lens to diagnose model failures. If a prediction is wrong, the concept-level explanations can reveal whether the model misinterpreted a key financial term or focused on irrelevant information.
- For future AI integration, this structured and verifiable explainability provides a powerful asset for integration with large language models (LLMs). The identified dominant query concepts can serve as high-quality reliable context in retrieval-augmented generation (RAG) systems, guiding LLMs to generate more accurate and factually grounded financial summaries or reports in order to mitigate the risk of hallucination.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Chen, Y.; Wang, J.; Chen, Y.; Chen, H. Web media and stock markets: A survey and future directions from a big data perspective. IEEE Trans. Knowl. Data Eng. 2017, 30, 381–399. [Google Scholar] [CrossRef]
- Engle, R.F.; Ng, V.K. Measuring and testing the impact of news on volatility. J. Financ. 1993, 48, 1749–1778. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Sousa, M.G.; Sakiyama, K.; de Souza Rodrigues, L.; Moraes, P.H.; Fernandes, E.R.; Matsubara, E.T. Bert for stock market sentiment analysis. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1597–1601. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Luo, L.; Ao, X.; Pan, F.; Wang, J.; Zhao, T.; Yu, N.; He, Q. Beyond polarity: Interpretable financial sentiment analysis with hierarchical query-driven attention. In Proceedings of the International Joint Conference on Artificial Intelligence—IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4244–4250. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Fama, E.F. The behavior of stock-market prices. J. Bus. 1965, 38, 34–105. [Google Scholar] [CrossRef]
- De Long, J.B.; Shleifer, A.; Summers, L.H.; Waldmann, R.J. Noise trader risk in financial markets. J. Political Econ. 1990, 98, 703–738. [Google Scholar] [CrossRef]
- Shleifer, A.; Vishny, R.W. The limits of arbitrage. J. Financ. 1997, 52, 35–55. [Google Scholar] [CrossRef]
- Chan, W.S. Stock price reaction to news and no-news: Drift and reversal after headlines. J. Financ. Econ. 2003, 70, 223–260. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Do, H.H.; Prasad, P.; Maag, A.; Alsadoon, A. Deep learning for aspect-based sentiment analysis: A comparative review. Expert Syst. Appl. 2019, 118, 272–299. [Google Scholar] [CrossRef]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl.-Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Joloudari, J.H.; Hussain, S.; Nematollahi, M.A.; Bagheri, R.; Fazl, F.; Alizadehsani, R.; Lashgari, R.; Talukder, A. Bert-deep cnn: State of the art for sentiment analysis of covid-19 tweets. Soc. Netw. Anal. Min. 2023, 13, 99. [Google Scholar] [CrossRef]
- Hussain, S.; Muhammad, L.; Yakubu, A. Mining social media and dbpedia data using gephi and r. J. Appl. Comput. Sci. Math. 2018, 12, 14–20. [Google Scholar] [CrossRef]
- Creamer, G.G.; Sakamoto, Y.; Nickerson, J.V.; Ren, Y. Hybrid human and machine learning algorithms to forecast the european stock market. Complexity 2023, 2023, 5847887. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Li, Q.; Wang, T.; Li, P.; Liu, L.; Gong, Q.; Chen, Y. The effect of news and public mood on stock movements. Inf. Sci. 2014, 278, 826–840. [Google Scholar] [CrossRef]
- Shahi, T.B.; Shrestha, A.; Neupane, A.; Guo, W. Stock price forecasting with deep learning: A comparative study. Mathematics 2020, 8, 1441. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Shirai, K. Topic modeling based sentiment analysis on social media for stock market prediction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1354–1364. [Google Scholar]
- Chen, Y.; Xie, Z.; Zhang, W.; Xing, R.; Li, Q. Quantifying the effect of real estate news on chinese stock movements. Emerg. Mark. Financ. Trade 2021, 57, 4185–4210. [Google Scholar] [CrossRef]
- Li, Y.; Lv, S.; Liu, X.; Zhang, Q. Incorporating transformers and attention networks for stock movement prediction. Complexity 2022, 2022, 7739087. [Google Scholar] [CrossRef]
- Tang, X.; Lei, N.; Dong, M.; Ma, D. Stock price prediction based on natural language processing. Complexity 2022, 2022, 9031900. [Google Scholar] [CrossRef]
- OpenAI. Openai: Introducing Chatgpt. 2022. Available online: https://openai.com/blog/chatgpt (accessed on 12 March 2025).
- OpenAI. Openai: Gpt-4. 2023. Available online: https://openai.com/research/gpt-4 (accessed on 12 March 2025).
- Ramjee, P.; Chhokar, M.; Sachdeva, B.; Meena, M.; Abdullah, H.; Vashistha, A.; Nagar, R.; Jain, M. ASHABot: An LLM-Powered Chatbot to Support the Informational Needs of Community Health Workers. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, New York, NY, USA; 2025; pp. 1–22. [Google Scholar]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Metropolitansky, D.; Ness, R.O.; Larson, J. From local to global: A graph rag approach to query-focused summarization. arXiv 2024, arXiv:2404.16130. [Google Scholar]
- Hang, C.N.; Yu, P.D.; Tan, C.W. TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking. IEEE Trans. Artif. Intell. 2025, 1–15. [Google Scholar] [CrossRef]
- Jo, Y.; Oh, A.H. Aspect and sentiment unification model for online review analysis. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 815–824. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–4 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 80–89. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Müller, K.-R. Explaining deep neural networks and beyond: A review of methods and applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4765–4774. [Google Scholar]
- Smilkov, D.; Thorat, N.; Kim, B.; Viégas, F.; Wattenberg, M. Smoothgrad: Removing noise by adding noise. arXiv 2017, arXiv:1706.03825. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Serrano, S.; Smith, N.A. Is attention interpretable? arXiv 2019, arXiv:1906.03731. [Google Scholar]
- Wiegreffe, S.; Pinter, Y. Attention is not not explanation. arXiv 2019, arXiv:1908.04626. [Google Scholar]
- Cheng, Z.; Zhou, J.; Wu, W.; Chen, Q.; He, L. Learning intrinsic dimension via information bottleneck for explainable aspect-based sentiment analysis. arXiv 2024, arXiv:2402.18145. [Google Scholar]
- Rizinski, M.; Peshov, H.; Mishev, K.; Jovanovik, M.; Trajanov, D. Sentiment analysis in finance: From transformers back to explainable lexicons (xlex). IEEE Access 2024, 12, 7170–7198. [Google Scholar] [CrossRef]
- Anoop, V.; Krishna, C.S.; Govindarajan, U.H. Graph embedding approaches for social media sentiment analysis with model explanation. Int. J. Inf. Manag. Data Insights 2024, 4, 100221. [Google Scholar] [CrossRef]
- Pruthi, D.; Gupta, M.; Dhingra, B.; Neubig, G.; Lipton, Z.C. Learning to deceive with attention-based explanations. arXiv 2019, arXiv:1909.07913. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Philadelphia, PA, USA, 2018; pp. 2227–2237. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Philadelphia, PA, USA, 2020; pp. 38–45. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2019; pp. 194–206. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Jain, S.; Wallace, B.C. Attention is not explanation. arXiv 2019, arXiv:1902.10186. [Google Scholar]

| Methods | Accuracy | F1-Score |
|---|---|---|
| HAN | 70.44 | 70.48 |
| FISHQA | 71.32 | 71.37 |
| BERT-Attention | 70.63 | 70.61 |
| BQGA | 71.34 | 71.51 |
| FISHDQA | 73.45 | 73.16 |
| Our Model(QGDA) | 75.38 | 75.47 |
| Category | p-Value (ANOVA) | p-Value (t-test) |
|---|---|---|
| Macroeconomic Analysis | 0.0368 | <0.0001 |
| Industry Analysis | 0.0368 | 0.1390 |
| Business Analysis | 0.0368 | <0.0001 |
| Financial Analysis | 0.0368 | <0.0001 |
| Technical Analysis | 0.0368 | <0.0001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, C.; He, Q. Integrating Financial Knowledge for Explainable Stock Market Sentiment Analysis via Query-Guided Attention. Appl. Sci. 2025, 15, 6893. https://doi.org/10.3390/app15126893
Hong C, He Q. Integrating Financial Knowledge for Explainable Stock Market Sentiment Analysis via Query-Guided Attention. Applied Sciences. 2025; 15(12):6893. https://doi.org/10.3390/app15126893
Chicago/Turabian StyleHong, Chuanyang, and Qingyun He. 2025. "Integrating Financial Knowledge for Explainable Stock Market Sentiment Analysis via Query-Guided Attention" Applied Sciences 15, no. 12: 6893. https://doi.org/10.3390/app15126893
APA StyleHong, C., & He, Q. (2025). Integrating Financial Knowledge for Explainable Stock Market Sentiment Analysis via Query-Guided Attention. Applied Sciences, 15(12), 6893. https://doi.org/10.3390/app15126893