
Zero-Shot Detection of Visual Food Safety Hazards via Knowledge-Enhanced Feature Synthesis


Abstract
1. Introduction
- We introduce a specialized FSKG that models the relationships between food categories and visual safety attributes, providing structured prior knowledge for zero-shot hazard detection.
- We adapt and extend the Knowledge-Enhanced Feature Synthesizer framework to the food safety domain, addressing the unique challenges of fine-grained visual hazard detection through multi-source graph fusion and region feature diffusion.
- We present a new Food Safety Visual Hazards (FSVH) dataset with rich attribute annotations, establishing a benchmark for evaluating zero-shot food safety hazard detection.
2. Related Work
2.1. Food Safety Inspection and Visual Analysis
2.2. Zero-Shot Learning and Zero-Shot Detection
2.3. Knowledge Graphs for Computer Vision
2.4. Feature Synthesis for Zero-Shot Learning
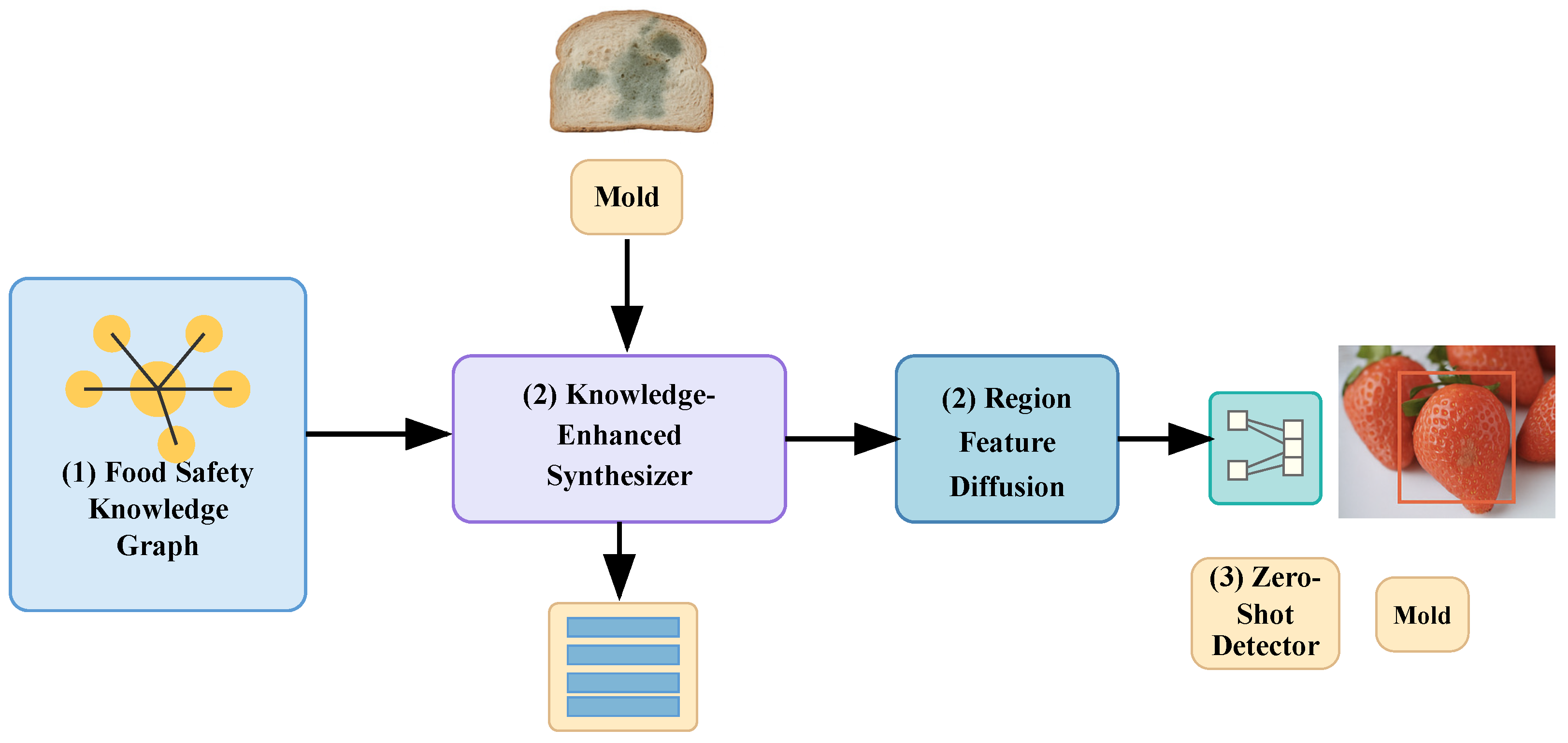
3. Methodology
3.1. Problem Formulation
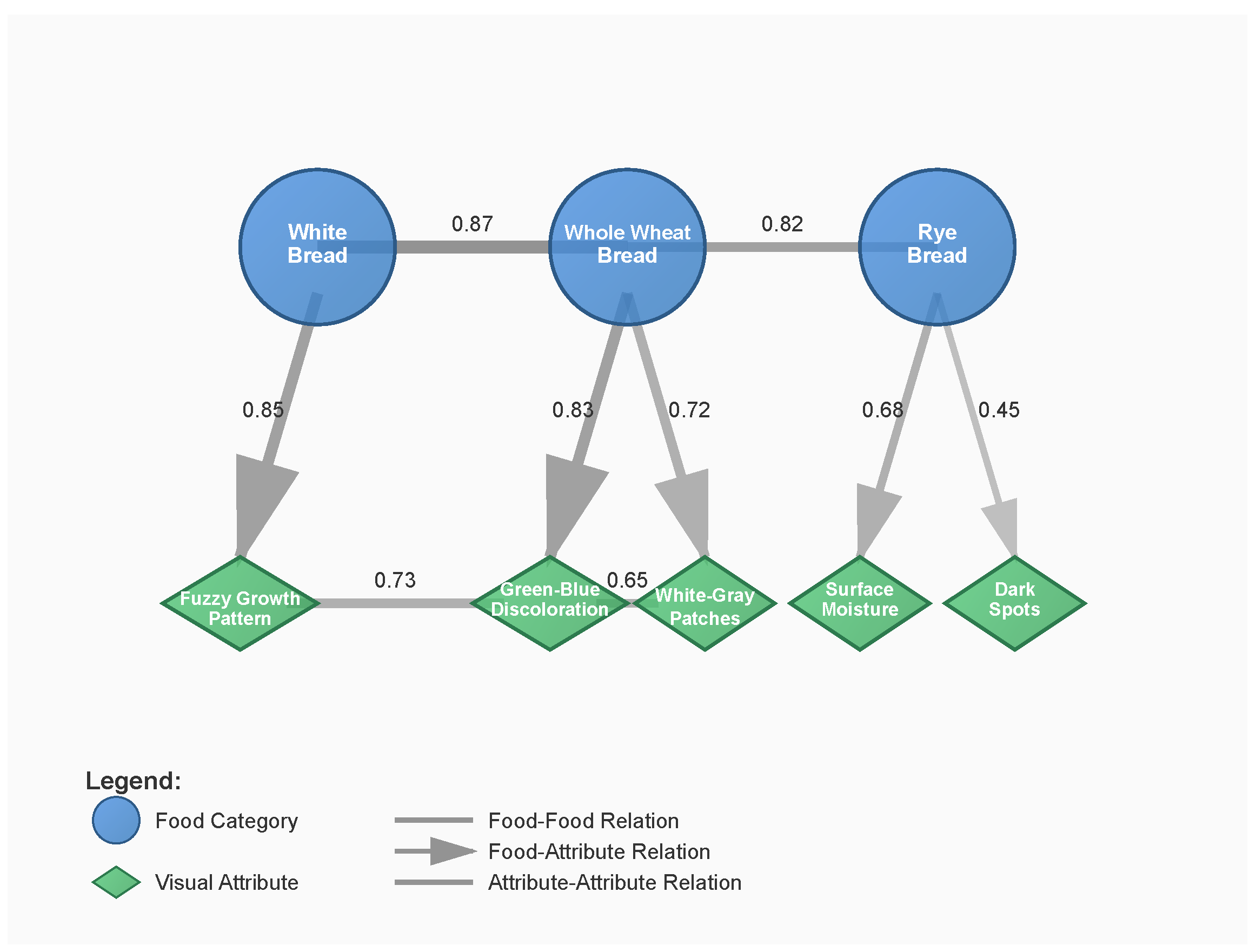
3.2. Food Safety Knowledge Graph
3.2.1. FSKG Construction
3.2.2. Knowledge Graph Embedding
3.3. Knowledge-Enhanced Feature Synthesizer
3.3.1. Multi-Source Graph Fusion Module
3.3.2. Region Feature Diffusion Model
3.4. Zero-Shot Detector Training
3.4.1. Detector Backbone Training
3.4.2. KEFS Training
3.4.3. Unseen Classifier Training
3.4.4. Detector Integration
| Algorithm 1 Training procedure for Zero-Shot Food Safety Hazard Detection |
| Require: Training set , semantic vectors and , food safety knowledge graph |
| Ensure: Zero-shot detector with parameters |
| 1: Train detector on with annotations |
| 2: Extract region features from using detector |
| 3: Initialize KEFS with knowledge graph |
| 4: Train KEFS on , , and by optimizing |
| 5: Synthesize region features for unseen classes using trained KEFS, |
| 6: Train unseen classifier using and labels |
| 7: Update detector parameters with unseen classifier |
| 8: return |
4. Experimental Evaluation
4.1. Datasets and Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Comparison with State-of-the-Art Methods
- Standard object detectors: Faster R-CNN [52], trained only on seen classes.
4.3. Ablation Studies
4.3.1. Effect of Food Safety Knowledge Graph
4.3.2. Effect of Multi-Source Graph Fusion
4.3.3. Effect of Region Feature Diffusion Model
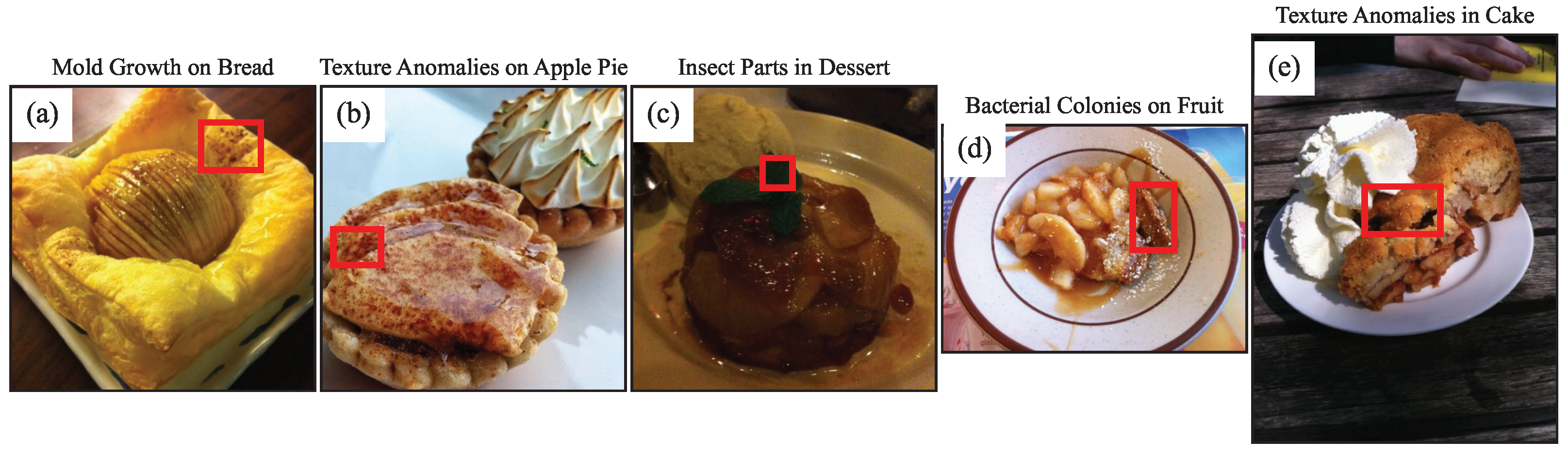
4.4. Feature Visualization and Qualitative Results
4.5. Computational Efficiency
4.6. Cross-Dataset Evaluation
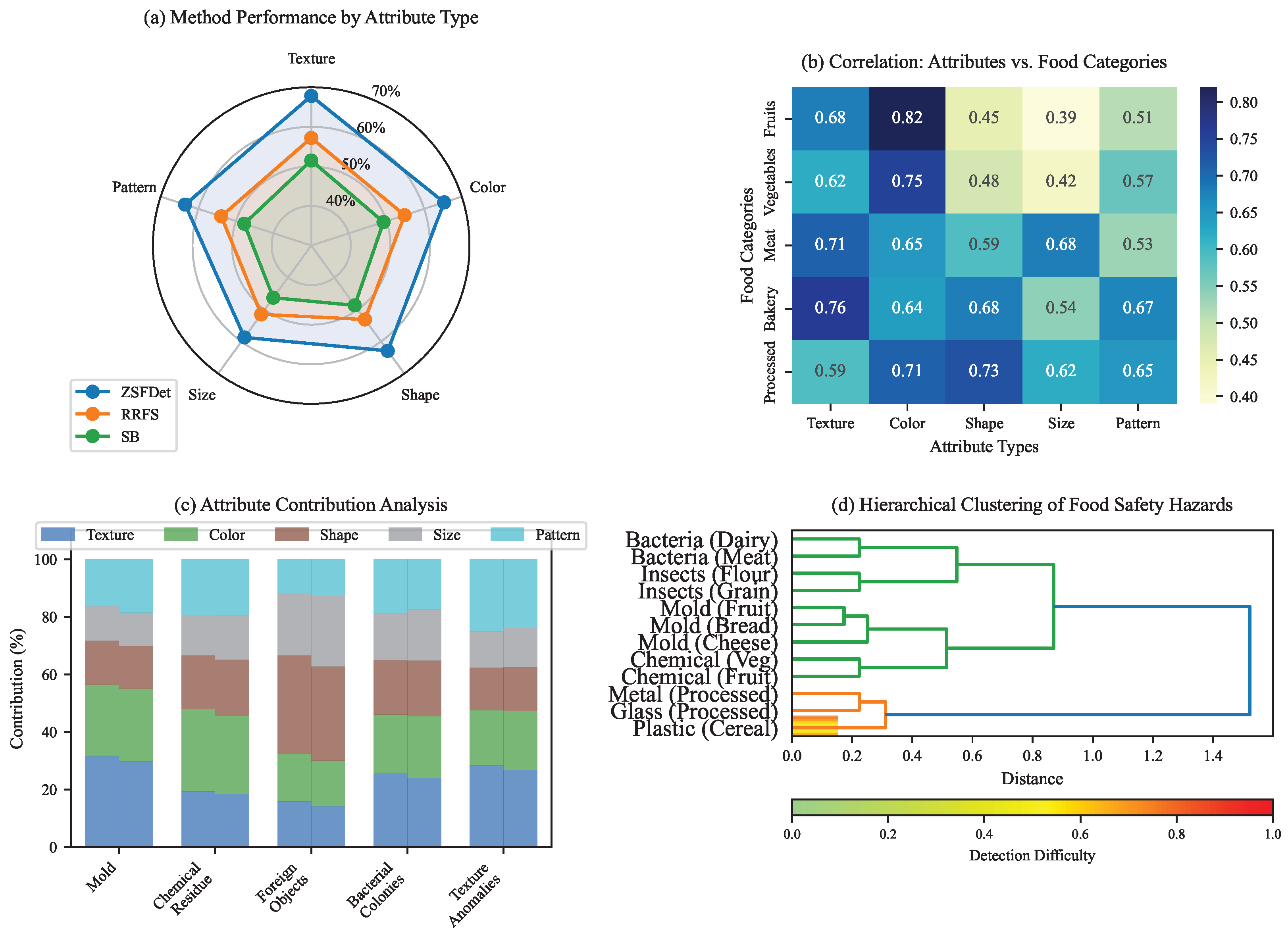
4.7. Analysis of Visual Attribute Influence on Detection Performance
4.8. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Borchers, A.; Teuber, S.S.; Keen, C.L.; Gershwin, M.E. Food safety. Clin. Rev. Allergy Immunol. 2010, 39, 95–141. [Google Scholar] [CrossRef] [PubMed]
- Kendall, H.; Clark, B.; Rhymer, C.; Kuznesof, S.; Hajslova, J.; Tomaniova, M.; Brereton, P.; Frewer, L. A systematic review of consumer perceptions of food fraud and authenticity: A European perspective. Trends Food Sci. Technol. 2019, 94, 79–90. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, H.; Song, G.; Huang, K.; Luo, Y.; Liu, Q.; He, X.; Cheng, N. Intelligent biosensing strategies for rapid detection in food safety: A review. Biosens. Bioelectron. 2022, 202, 114003. [Google Scholar] [CrossRef]
- He, H.J.; Sun, D.W. Hyperspectral imaging technology for rapid detection of various microbial contaminants in agricultural and food products. Trends Food Sci. Technol. 2015, 46, 99–109. [Google Scholar] [CrossRef]
- Ma, J.; Sun, D.W.; Qu, J.H.; Liu, D.; Pu, H.; Gao, W.H.; Zeng, X.A. Applications of computer vision for assessing quality of agri-food products: A review of recent research advances. Crit. Rev. Food Sci. Nutr. 2016, 56, 113–127. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Ma, J.; Wang, Q.; Sun, D.W. Applications of machine learning techniques for enhancing nondestructive food quality and safety detection. Crit. Rev. Food Sci. Nutr. 2023, 63, 1649–1669. [Google Scholar] [CrossRef]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-shot learning—A comprehensive evaluation of the good, the bad and the ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2251–2265. [Google Scholar] [CrossRef]
- Bansal, A.; Sikka, K.; Sharma, G.; Chellappa, R.; Divakaran, A. Zero-shot object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 384–400. [Google Scholar]
- Zhu, P.; Wang, H.; Saligrama, V. Don’t even look once: Synthesizing features for zero-shot detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11693–11702. [Google Scholar]
- Rahman, S.; Khan, S.; Barnes, N. Improved visual-semantic alignment for zero-shot object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11932–11939. [Google Scholar]
- Singh, R.; Nickhil, C.; Upendar, K.; Jithender, B.; Deka, S.C. A Comprehensive Review of Advanced Deep Learning Approaches for Food Freshness Detection. Food Eng. Rev. 2024, 17, 127–160. [Google Scholar] [CrossRef]
- Zhou, P.; Min, W.; Song, J.; Zhang, Y.; Jiang, S. Synthesizing knowledge-enhanced features for real-world zero-shot food detection. IEEE Trans. Image Process. 2024, 33, 1285–1298. [Google Scholar] [CrossRef]
- Kennett, C.A.; Stark, B. Automated ribotyping for the identification and characterization of foodborne clostridia. J. Food Prot. 2006, 69, 2970–2975. [Google Scholar] [CrossRef]
- Chen, T.C.; Yu, S.Y. The review of food safety inspection system based on artificial intelligence, image processing, and robotic. Food Sci. Technol. 2021, 42, e35421. [Google Scholar] [CrossRef]
- Sun, D.W. Computer Vision Technology for Food Quality Evaluation; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Magnus, I.; Virte, M.; Thienpont, H.; Smeesters, L. Combining optical spectroscopy and machine learning to improve food classification. Food Control 2021, 130, 108342. [Google Scholar] [CrossRef]
- Cho, B.K.; Chen, Y.R.; Kim, M.S. Multispectral detection of organic residues on poultry processing plant equipment based on hyperspectral reflectance imaging technique. Comput. Electron. Agric. 2007, 57, 177–189. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, J.; Deng, H.; Zeng, X. Food image recognition and food safety detection method based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 1268453. [Google Scholar] [CrossRef]
- Son, G.J.; Kwak, D.H.; Park, M.K.; Kim, Y.D.; Jung, H.C. U-Net-based foreign object detection method using effective image acquisition system: A case of almond and green onion flake food process. Sustainability 2021, 13, 13834. [Google Scholar] [CrossRef]
- Ma, L.; Guo, X.; Zhao, S.; Yin, D.; Fu, Y.; Duan, P.; Wang, B.; Zhang, L. Algorithm of strawberry disease recognition based on deep convolutional neural network. Complexity 2021, 2021, 6683255. [Google Scholar] [CrossRef]
- Dhal, S.B.; Kar, D. Leveraging artificial intelligence and advanced food processing techniques for enhanced food safety, quality, and security: A comprehensive review. Discov. Appl. Sci. 2025, 7, 75. [Google Scholar] [CrossRef]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Attribute-based classification for zero-shot visual object categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 453–465. [Google Scholar] [CrossRef]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Fu, Y.; Hospedales, T.M.; Xiang, T.; Gong, S. Transductive multi-view zero-shot learning. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2332–2345. [Google Scholar] [CrossRef]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature generating networks for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5542–5551. [Google Scholar]
- Schonfeld, E.; Ebrahimi, S.; Sinha, S.; Darrell, T.; Akata, Z. Generalized zero-and few-shot learning via aligned variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8247–8255. [Google Scholar]
- Rahman, S.; Khan, S.; Porikli, F. Zero-shot object detection: Learning to simultaneously recognize and localize novel concepts. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 547–563. [Google Scholar]
- Hayat, N.; Hayat, M.; Rahman, S.; Khan, S.; Zamir, S.W.; Khan, F.S. Synthesizing the unseen for zero-shot object detection. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Huang, P.; Han, J.; Cheng, D.; Zhang, D. Robust region feature synthesizer for zero-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7622–7631. [Google Scholar]
- Dong, X.; Huang, J.; Yang, Y.; Yan, S. More is less: A more complicated network with less inference complexity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5840–5848. [Google Scholar]
- Gu, J.; Zhao, H.; Lin, Z.; Li, S.; Cai, J.; Ling, M. Scene graph generation with external knowledge and image reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1969–1978. [Google Scholar]
- Wang, X.; Ye, Y.; Gupta, A. Zero-shot recognition via semantic embeddings and knowledge graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6857–6866. [Google Scholar]
- Kampffmeyer, M.; Chen, Y.; Liang, X.; Wang, H.; Zhang, Y.; Xing, E.P. Rethinking knowledge graph propagation for zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 11487–11496. [Google Scholar]
- Haussmann, S.; Seneviratne, O.; Chen, Y.; Ne’eman, Y.; Codella, J.; Chen, C.H.; McGuinness, D.L.; Zaki, M.J. FoodKG: A semantics-driven knowledge graph for food recommendation. In Proceedings of the Semantic Web–ISWC 2019: 18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Proceedings, Part II 18. Springer: Berlin/Heidelberg, Germany, 2019; pp. 146–162. [Google Scholar]
- Min, W.; Jiang, S.; Liu, L.; Rui, Y.; Jain, R. A survey on food computing. Acm Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Felix, R.; Reid, I.; Carneiro, G. Multi-modal cycle-consistent generalized zero-shot learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 21–37. [Google Scholar]
- Huang, H.; Wang, C.; Yu, P.S.; Wang, C.D. Generative dual adversarial network for generalized zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 801–810. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Andrews, W.H.; Wang, H.; Jacobson, A.; Hammack, T.; Food and Drug Administration. Bacteriological analytical manual (BAM) chapter 5: Salmonella. Bacteriol. Anal. Man. 2018, 110, 1–25. [Google Scholar]
- McNAMARA, A.; MAGEAU, R.; GREEN, S. Microbiology Laboratory Guidebook, 3rd ed.; United States Department of Agriculture Food Safety and Inspection Serviceoffice of Public Health and Science Microbiology Division: Washington, DC, USA, 1998; pp. 1–2.
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 9592–9600. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101–mining discriminative components with random forests. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VI 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 446–461. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Food, K.; Adminstration, D. Food code. 데 2017, 999, 542. [Google Scholar]
- Singla, A.; Yuan, L.; Ebrahimi, T. Food/non-food image classification and food categorization using pre-trained googlenet model. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 15–19 October 2016; pp. 3–11. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Norouzi, M.; Mikolov, T.; Bengio, S.; Singer, Y.; Shlens, J.; Frome, A.; Corrado, G.S.; Dean, J. Zero-shot learning by convex combination of semantic embeddings. arXiv 2013, arXiv:1312.5650. [Google Scholar]
- Changpinyo, S.; Chao, W.L.; Gong, B.; Sha, F. Synthesized classifiers for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5327–5336. [Google Scholar]
- Li, Z.; Yao, L.; Zhang, X.; Wang, X.; Kanhere, S.; Zhang, H. Zero-shot object detection with textual descriptions. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 8690–8697. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Count | Description |
|---|---|---|
| Food Categories | 26 | Meats, fruits, vegetables, etc. |
| Visual Attributes | 48 | Appearance, decomposition, etc. |
| Hazard Classes | 28 | Mold, foreign objects, etc. |
| Seen Classes | 20 | Used for training |
| Unseen Classes | 8 | Used for testing |
| Total Images | 18,326 | |
| Training Images | 12,854 | Seen hazards only |
| Testing Images | 5472 | Both seen and unseen hazards |
| Bounding Box Annotations | 32,741 |
| Food Type | Categories |
|---|---|
| Meats | Beef, Pork, Chicken, Fish |
| Dairy Products | Milk, Cheese, Yogurt |
| Fruits | Apples, Oranges, Berries, Bananas |
| Vegetables | Lettuce, Tomatoes, Potatoes, Carrots |
| Bakery Items | Bread, Cakes, Pastries |
| Grains | Rice, Wheat, Corn |
| Processed Foods | Canned Goods, Frozen Meals, Packaged Snacks |
| Attribute Category | Specific Attributes | Meat | Dairy | Fruits | Vegetables | Bakery | Processed |
|---|---|---|---|---|---|---|---|
| Appearance | Discoloration | 78.5 | 65.3 | 82.1 | 79.6 | 45.2 | 61.8 |
| Surface irregularities | 56.2 | 41.7 | 73.4 | 68.9 | 38.5 | 52.3 | |
| Abnormal shine/dullness | 62.8 | 58.9 | 45.6 | 42.3 | 31.7 | 48.5 | |
| Brown/black spots | 45.3 | 32.6 | 89.2 | 76.5 | 52.8 | 41.2 | |
| White/gray patches | 31.7 | 76.4 | 24.3 | 18.9 | 84.6 | 36.8 | |
| Unusual transparency | 72.4 | 15.2 | 31.8 | 28.6 | 8.3 | 21.5 | |
| Color fading | 58.9 | 42.3 | 76.5 | 71.2 | 35.6 | 54.7 | |
| Crystallization | 12.5 | 68.7 | 45.2 | 8.9 | 76.3 | 82.4 | |
| Oily residue | 84.6 | 52.3 | 15.7 | 12.4 | 28.9 | 65.8 | |
| Dried edges | 76.8 | 38.5 | 82.4 | 78.3 | 91.2 | 45.6 | |
| Bruising | 15.2 | 8.6 | 93.5 | 87.2 | 12.3 | 18.7 | |
| Swelling/bloating | 65.4 | 71.2 | 54.3 | 48.7 | 82.5 | 76.9 | |
| Decomposition | Mold (white) | 23.4 | 85.6 | 67.8 | 45.2 | 92.3 | 38.5 |
| Mold (green/blue) | 18.7 | 78.3 | 71.2 | 52.8 | 87.6 | 41.2 | |
| Mold (black) | 15.2 | 45.6 | 58.9 | 38.7 | 76.4 | 32.5 | |
| Visible bacteria | 68.5 | 52.3 | 31.8 | 28.4 | 15.6 | 45.8 | |
| Slime formation | 87.2 | 65.4 | 42.3 | 38.5 | 8.7 | 21.3 | |
| Rot/decay | 45.6 | 31.2 | 89.7 | 82.4 | 52.3 | 38.7 | |
| Fermentation bubbles | 12.3 | 76.8 | 65.4 | 15.8 | 84.2 | 52.6 | |
| Texture breakdown | 72.5 | 48.6 | 91.3 | 87.6 | 65.8 | 54.2 | |
| Liquefaction | 65.8 | 82.3 | 76.5 | 68.9 | 21.4 | 45.7 | |
| Spore formation | 31.2 | 68.5 | 52.4 | 41.8 | 78.6 | 35.2 | |
| Yeast growth | 8.5 | 71.2 | 48.6 | 12.3 | 91.5 | 28.4 | |
| Gas production | 52.3 | 85.6 | 31.8 | 28.7 | 76.4 | 68.5 | |
| Contamination | Plastic fragments | 25.6 | 31.2 | 42.8 | 48.5 | 52.3 | 78.6 |
| Metal shavings | 18.3 | 15.6 | 8.7 | 12.4 | 31.8 | 65.4 | |
| Glass pieces | 12.5 | 8.9 | 15.2 | 18.6 | 28.4 | 45.2 | |
| Hair/fibers | 42.3 | 38.7 | 31.5 | 35.2 | 48.6 | 52.8 | |
| Insect parts | 15.8 | 21.3 | 76.5 | 68.4 | 82.3 | 38.5 | |
| Rodent droppings | 8.6 | 12.4 | 31.8 | 28.5 | 45.2 | 21.6 | |
| Chemical stains | 31.5 | 28.6 | 52.4 | 48.7 | 18.3 | 68.9 | |
| Pesticide residue | 5.2 | 8.3 | 78.6 | 82.5 | 15.7 | 12.4 | |
| Oil contamination | 72.4 | 15.8 | 8.5 | 12.3 | 31.6 | 85.2 | |
| Dust/dirt | 38.5 | 42.6 | 65.8 | 71.2 | 52.3 | 48.7 | |
| Cleaning residue | 28.7 | 52.3 | 21.4 | 18.6 | 38.5 | 76.8 | |
| Cross-contamination | 85.6 | 68.4 | 45.2 | 41.8 | 31.5 | 52.7 | |
| Structural | Cracks/fissures | 31.2 | 78.5 | 52.6 | 48.3 | 85.6 | 65.4 |
| Holes/punctures | 18.5 | 12.3 | 68.7 | 65.2 | 42.8 | 71.2 | |
| Tears/rips | 52.8 | 8.7 | 31.4 | 38.6 | 15.2 | 82.3 | |
| Separation | 65.4 | 85.2 | 42.7 | 21.5 | 78.3 | 45.8 | |
| Deformation | 42.3 | 31.8 | 78.5 | 72.6 | 52.4 | 38.7 | |
| Freezer burn | 87.6 | 52.4 | 21.3 | 28.7 | 65.8 | 91.2 | |
| Dehydration | 78.3 | 45.6 | 85.2 | 82.4 | 71.5 | 31.8 | |
| Brittleness | 15.2 | 68.7 | 52.3 | 45.8 | 92.4 | 78.6 | |
| Collapse | 31.8 | 72.5 | 68.4 | 52.7 | 85.3 | 42.6 | |
| Blistering | 52.4 | 15.8 | 45.2 | 38.6 | 78.5 | 21.3 | |
| Warping | 8.7 | 21.4 | 31.8 | 28.5 | 65.2 | 85.6 | |
| Granulation | 45.6 | 82.3 | 15.7 | 12.4 | 52.8 | 68.7 |
| Method | ZSD | GZSD (mAP) | GZSD (Recall@100) | ||||
|---|---|---|---|---|---|---|---|
| S | U | HM | S | U | HM | ||
| Faster R-CNN [52] | - | 68.5 | - | - | 74.2 | - | - |
| ConSE [56] | 42.1 | 67.3 | 39.4 | 49.8 | 70.5 | 45.6 | 55.3 |
| SYNC [57] | 44.5 | 65.8 | 41.2 | 50.6 | 71.3 | 47.9 | 57.3 |
| DeViSE [23] | 46.2 | 64.9 | 43.1 | 51.8 | 68.7 | 48.3 | 56.7 |
| DSES [8] | 50.3 | 62.7 | 47.8 | 54.2 | 67.9 | 53.1 | 59.6 |
| SB [8] | 51.8 | 66.3 | 48.5 | 56.0 | 72.1 | 52.7 | 60.9 |
| ZSD-YOLO [58] | 53.4 | 63.5 | 50.1 | 56.0 | 70.8 | 54.3 | 61.5 |
| PL [10] | 54.9 | 67.1 | 51.6 | 58.4 | 72.6 | 56.8 | 63.7 |
| RRFS [29] | 56.8 | 68.3 | 52.7 | 59.5 | 73.5 | 58.4 | 65.1 |
| ZSFDet (Ours) | 63.7 | 68.9 | 53.5 | 60.2 | 74.6 | 63.2 | 68.4 |
| Method | Mold Growth | Glass Fragments | Insect Parts | Bacterial Colonies | Chemical Residue |
|---|---|---|---|---|---|
| ConSE [56] | 48.3 | 45.7 | 40.1 | 37.4 | 36.2 |
| SYNC [57] | 50.2 | 46.9 | 43.3 | 39.8 | 38.5 |
| DeViSE [23] | 51.6 | 49.5 | 44.8 | 41.2 | 37.9 |
| DSES [8] | 58.7 | 55.2 | 49.3 | 43.5 | 41.4 |
| SB [8] | 60.1 | 56.8 | 51.7 | 44.2 | 42.5 |
| ZSD-YOLO [58] | 61.3 | 58.5 | 52.9 | 46.8 | 43.1 |
| PL [10] | 62.5 | 60.3 | 54.1 | 47.9 | 44.7 |
| RRFS [29] | 65.2 | 62.8 | 56.5 | 48.3 | 45.9 |
| ZSFDet (Ours) | 73.6 | 69.5 | 63.4 | 54.7 | 50.2 |
| Model Configuration | ZSD | GZSD | ||
|---|---|---|---|---|
| S | U | HM | ||
| Baseline (RRFS [29]) | 56.8 | 68.3 | 52.7 | 59.5 |
| +Food Safety Attributes | 58.4 | 68.5 | 53.1 | 59.8 |
| +Knowledge Graph (w/o MSGF) | 60.3 | 68.6 | 53.8 | 60.3 |
| +MSGF (w/o RFDM) | 62.1 | 68.7 | 53.4 | 60.1 |
| +RFDM (Full ZSFDet) | 63.7 | 68.9 | 53.5 | 60.2 |
| ZSFDet w/GAN instead of RFDM | 61.8 | 68.6 | 53.0 | 59.8 |
| ZSFDet w/Only Word Vectors | 59.5 | 68.4 | 52.9 | 59.6 |
| ZSFDet w/Only Hyperclass Graph | 60.8 | 68.5 | 53.1 | 59.8 |
| ZSFDet w/Only Co-occurrence Graph | 61.2 | 68.6 | 53.2 | 59.9 |
| ZSFDet w/Only Food Safety Knowledge Graph | 62.5 | 68.7 | 53.3 | 60.0 |
| Method | Inference Time (ms) | Model Size (MB) |
|---|---|---|
| Faster R-CNN [52] | 85 | 235 |
| SB [8] | 92 | 248 |
| ZSD-YOLO [58] | 45 | 240 |
| RRFS [29] | 103 | 276 |
| ZSFDet (Ours) | 108 | 285 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, L.; Hu, X.; Liu, W.; Liu, Y. Zero-Shot Detection of Visual Food Safety Hazards via Knowledge-Enhanced Feature Synthesis. Appl. Sci. 2025, 15, 6338. https://doi.org/10.3390/app15116338
Guo L, Hu X, Liu W, Liu Y. Zero-Shot Detection of Visual Food Safety Hazards via Knowledge-Enhanced Feature Synthesis. Applied Sciences. 2025; 15(11):6338. https://doi.org/10.3390/app15116338
Chicago/Turabian StyleGuo, Lanting, Xiaoyu Hu, Wenhe Liu, and Yang Liu. 2025. "Zero-Shot Detection of Visual Food Safety Hazards via Knowledge-Enhanced Feature Synthesis" Applied Sciences 15, no. 11: 6338. https://doi.org/10.3390/app15116338
APA StyleGuo, L., Hu, X., Liu, W., & Liu, Y. (2025). Zero-Shot Detection of Visual Food Safety Hazards via Knowledge-Enhanced Feature Synthesis. Applied Sciences, 15(11), 6338. https://doi.org/10.3390/app15116338