1. Introduction
Alien invasive species can cause a range of serious problems, including species extinction, degradation of natural ecosystems, and agricultural losses [
1,
2]. According to the United Nations Global Assessment Report on Biodiversity and Ecosystem Services, the number of alien invasive species in each country has increased by 70% since 1970, making it one of the five major drivers that have significantly impacted global ecosystems over the past 50 years. Due to its vast territory and diverse ecosystems, biological invasions have long affected China. These invasions have caused substantial losses to the agricultural and forest production of the country, and the associated costs of eradication and control are also considerable [
3,
4]. Many alien species have been introduced into new environments through international or regional trade. Exotic pets, in particular, may escape, be abandoned, or be intentionally released into the wild. In the absence of natural predators and due to their strong adaptability, such species may become invasive and cause severe damage to local ecosystems. China has launched the “4E Action Plan” to address this issue, which aims to combat species invasions effectively. The plan includes early-stage prevention, warning, monitoring, and detection; mid-stage eradication and interception; and late-stage joint control and disaster mitigation. Among these, detection and monitoring play a crucial role and involve techniques such as molecular identification, image-based recognition and diagnosis, remote intelligent monitoring, and regional tracking. At this stage, accurate species identification is essential. Introducing a classification model for exotic pet snakes can significantly improve operational efficiency at customs checkpoints. Real-time image-based analysis can help rapidly identify species and determine whether they are protected or prohibited from trade, thereby supporting efforts to combat illegal smuggling. Furthermore, such a classification model can help build a comprehensive species database, enabling customs to record information on each exotic pet that enters or leaves the country. This data-driven approach improves regulatory oversight and provides a scientific basis for developing more effective policies and preventive measures.
However, the current public datasets and image classification research of snakes, as well as the classification research mainly on venomous snake species, are used to assist in the diagnosis and treatment of snake bites [
5,
6]. In the past, fine-grained classification of snake images relied on expert classification and manual feature extraction on the dataset and did not develop [
7]. With the continuous advancement of deep learning technology, the research on snake image classification has gradually increased in recent years. The current classification methods are divided into data enhancement, transfer learning [
8,
9], and multimodal data fusion, including the combination of snake bite images and geographic information [
10,
11,
12,
13,
14].
Since 2019, there has been a growing focus on developing deep learning algorithms designed explicitly for snake image detection, which has been driven by continuous advancements in deep learning technology [
15]. Convolutional Neural Network (CNN) models have been widely applied in snake image classification, significantly contributing to progress in this field. In 2019, classical CNN architectures such as ResNet and VGG were used in the study by Fu et al. [
16], demonstrating a strong ability to extract deep image features and substantially improve classification performance. Fu and colleagues further enhanced the ResNet model by introducing the BRC module, achieving an accuracy of 89.1% on a self-constructed dataset with 10,336 images across 10 snake categories. Durso et al. observed that the EfficientNet model also performs well in snake image classification tasks, owing to its efficient use of parameters [
17]. In a more recent study in 2024, Naz et al. collected 400 images of four venomous snake species and several non-venomous species from the Indian region. They achieved an accuracy of 86% using the DenseNet121 model [
5].
In 2020, Alexey Dosovitskiy et al. introduced the Transformer architecture to the field of computer vision. The Vision Transformer (ViT) demonstrated remarkable performance in image classification tasks and was subsequently adapted for snake image classification [
18]. In 2021, He Can et al. proposed a twin network approach using a Swin Transformer as the backbone. They optimized feature extraction through contrastive learning, focusing on key visual features of snakes, such as scale texture and colour patterns. The backbone network was pre-trained through transfer learning on a fine-grained snake dataset and then used within the twin network framework. The two sets of feature vectors extracted by the twin network were compared and classified utilizing a metalearner, achieving 99.1% accuracy on a five-class dataset of 17,389 images [
19]. In recent years, the SnakeCLEF competition has become a prominent benchmark for fine-grained snake species identification, typically under real-world, geographically diverse conditions. The 2022 winning solution proposed a powerful multimodal framework combining image and geolocation metadata with customized loss functions and ensemble techniques to address data imbalance and long-tail distribution [
20]. In 2023, the top-ranked approach further integrated visual features with metadata priors using CLIP embeddings and employed seesaw loss and venom-focused post-processing to enhance safety-oriented classification [
21]. More recently, the 2024 solution explored the potential of self-supervised visual Transformers for feature extraction under limited supervision, showing promising results in embedding-based classification [
22].
Despite recent progress in snake image classification, several challenges remain unresolved in the specific context of exotic pet snake identification. First, publicly available datasets focused on exotic pet species are lacking. The limited number of images and high visual similarity among species make it difficult for models to learn discriminative features. Second, many images are captured in complex environments with significant background interference, significantly affecting recognition accuracy. The current snake classification methods heavily rely on multimodal data and large-scale training, which may not be feasible for small sample scenarios. Our work focuses on this under-explored environment, aiming to improve snake recognition performance and achieve fine-grained classification of exotic snakes using only image data optimized for small datasets and contrastive learning frameworks.
Specifically, the contributions of this paper are as follows:
1. We propose a novel method for small-scale image classification in complex scenes based on supervised contrastive learning. This approach offers an efficient technical solution for rapid unpacking inspection in environments such as customs and security screening. It improved classification accuracy by 6.63% compared to traditional deep learning models.
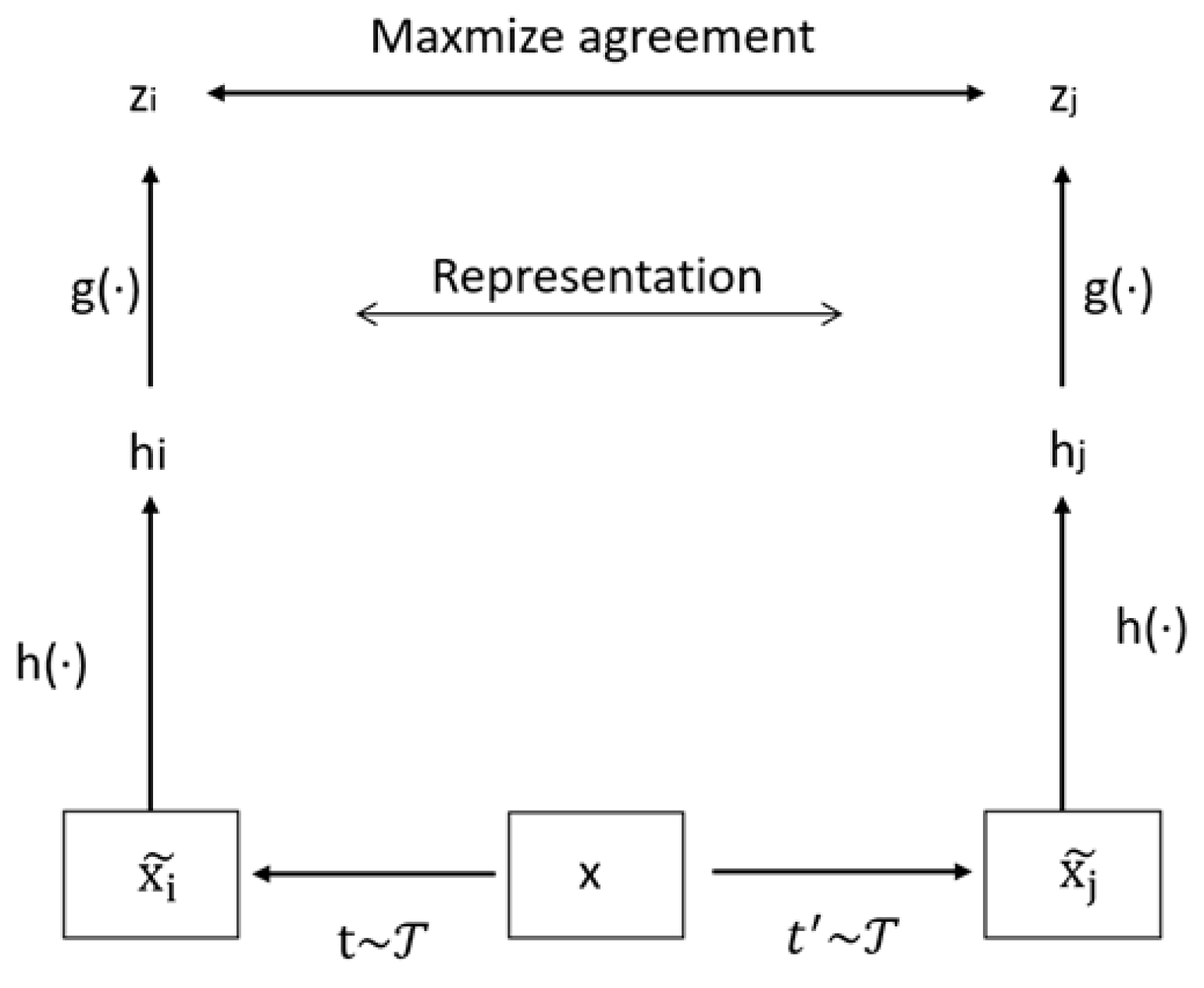
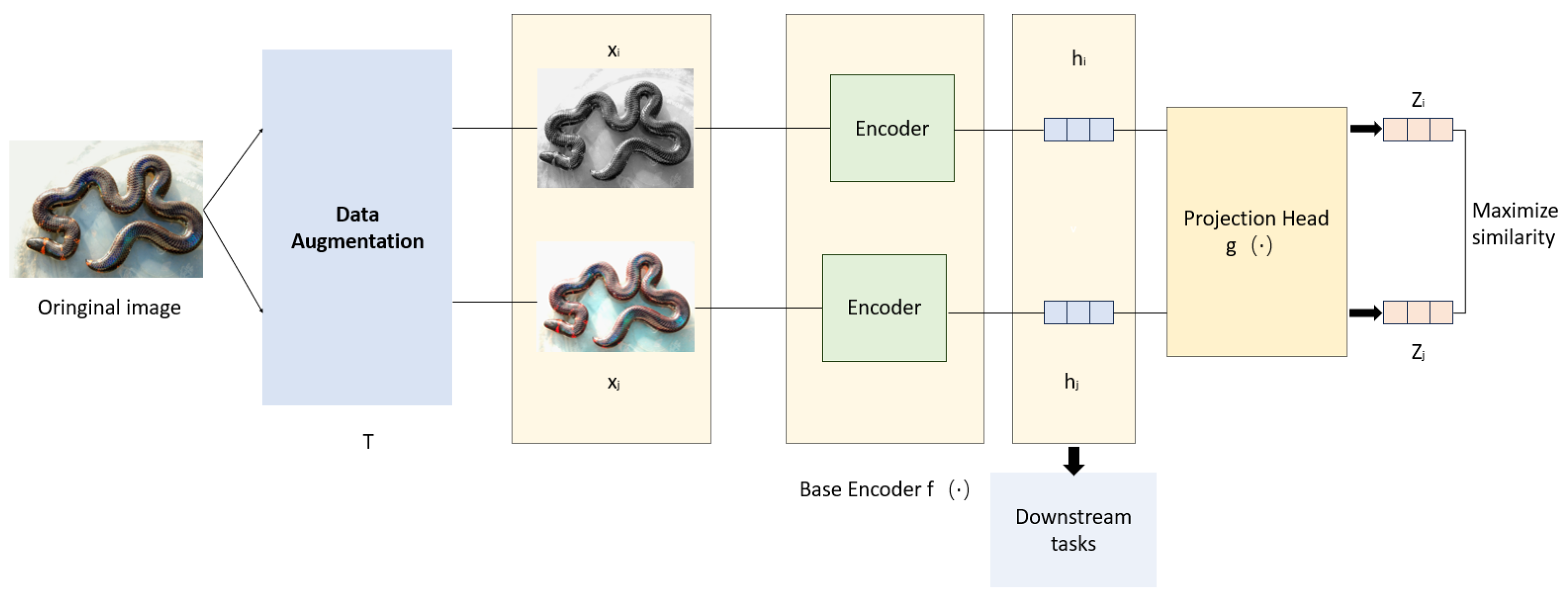
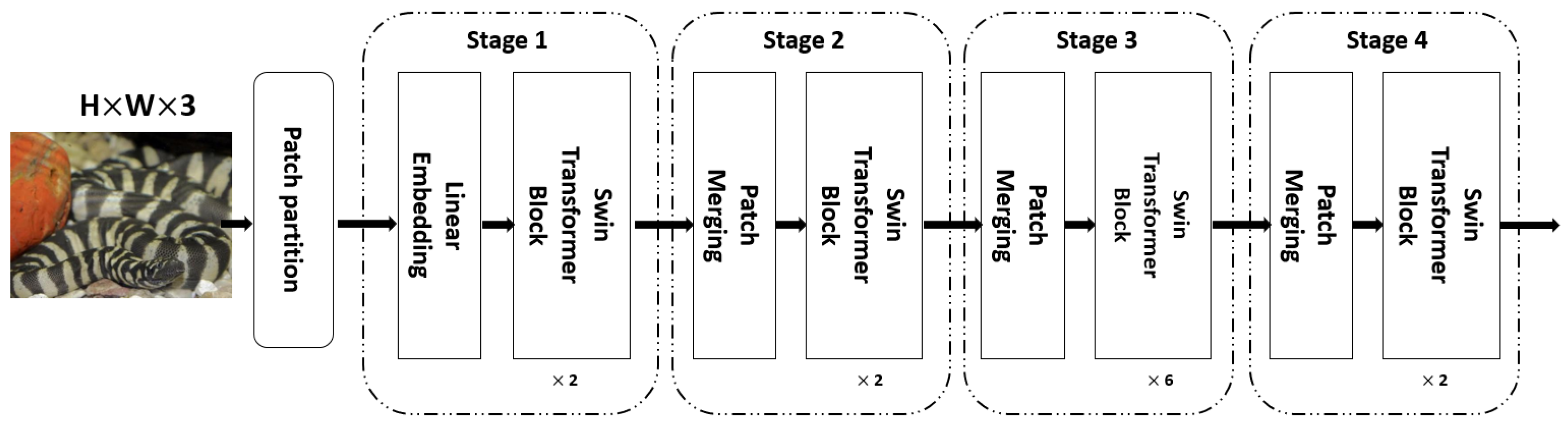
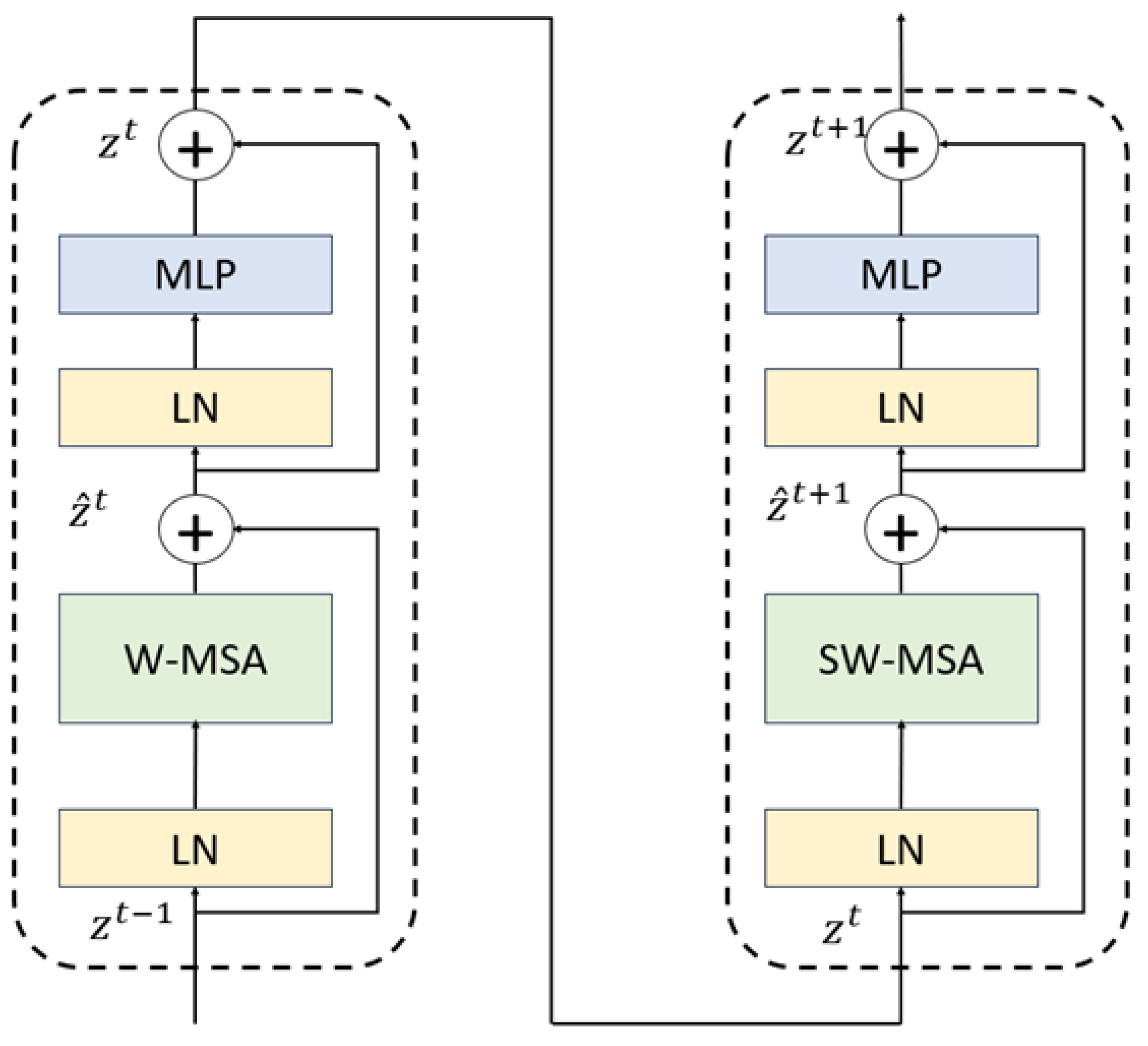
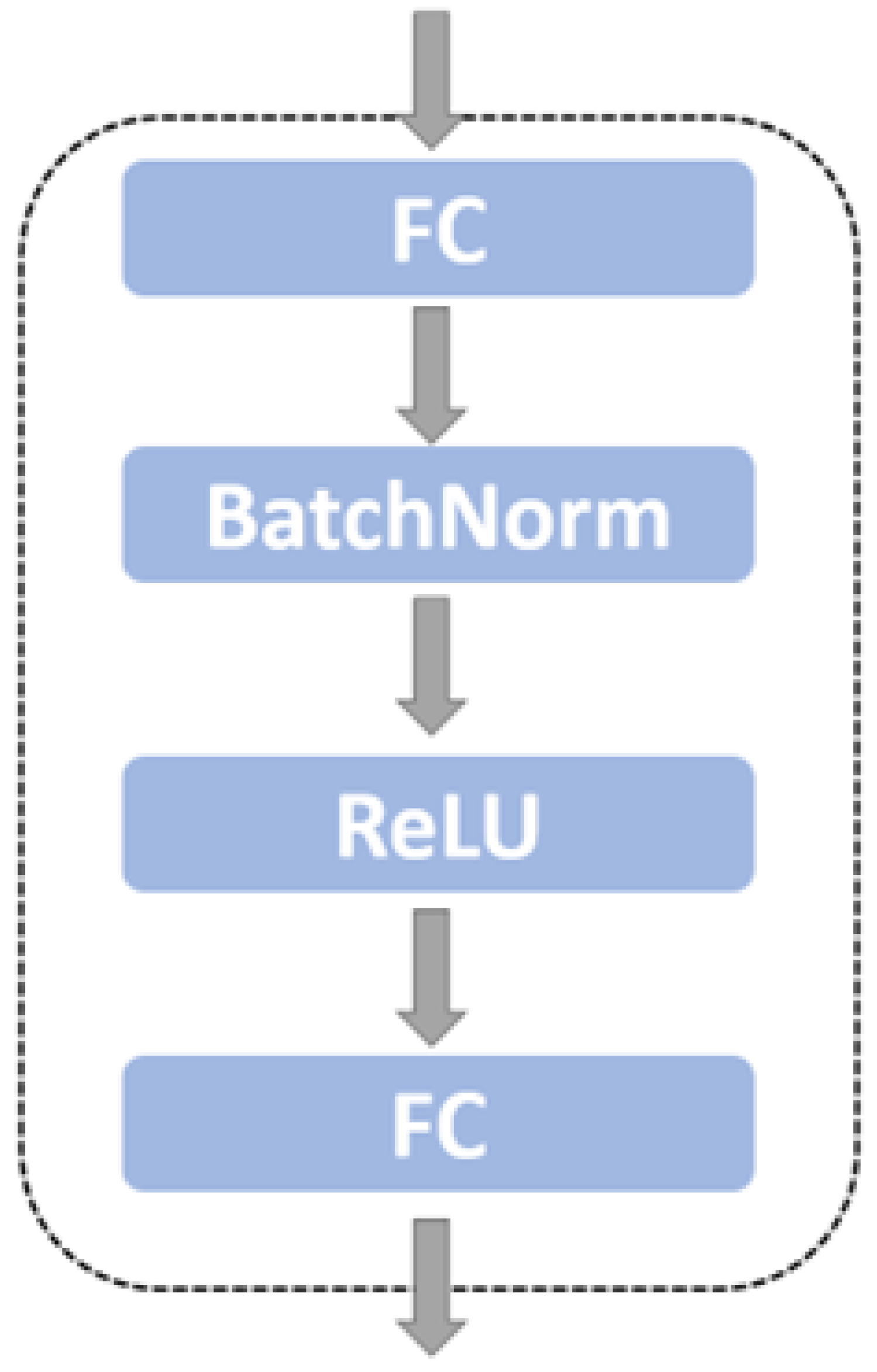
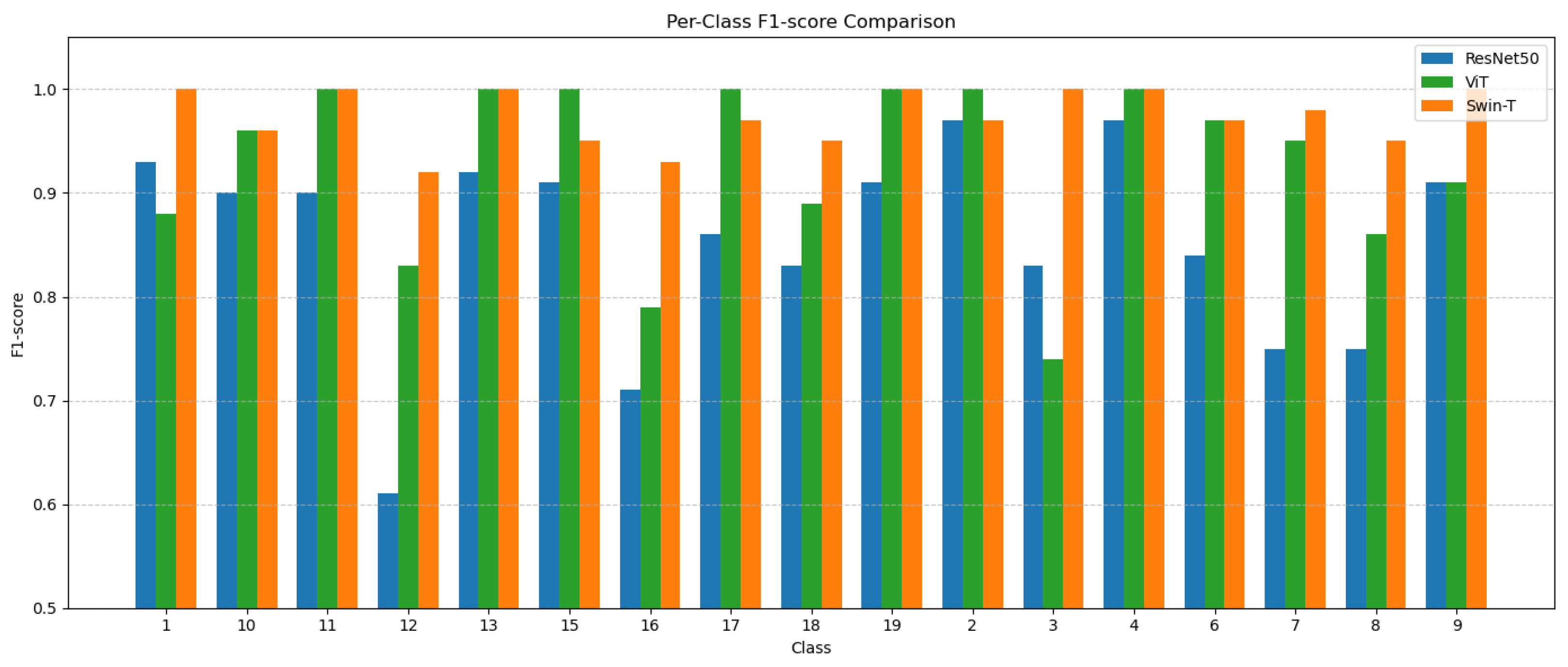
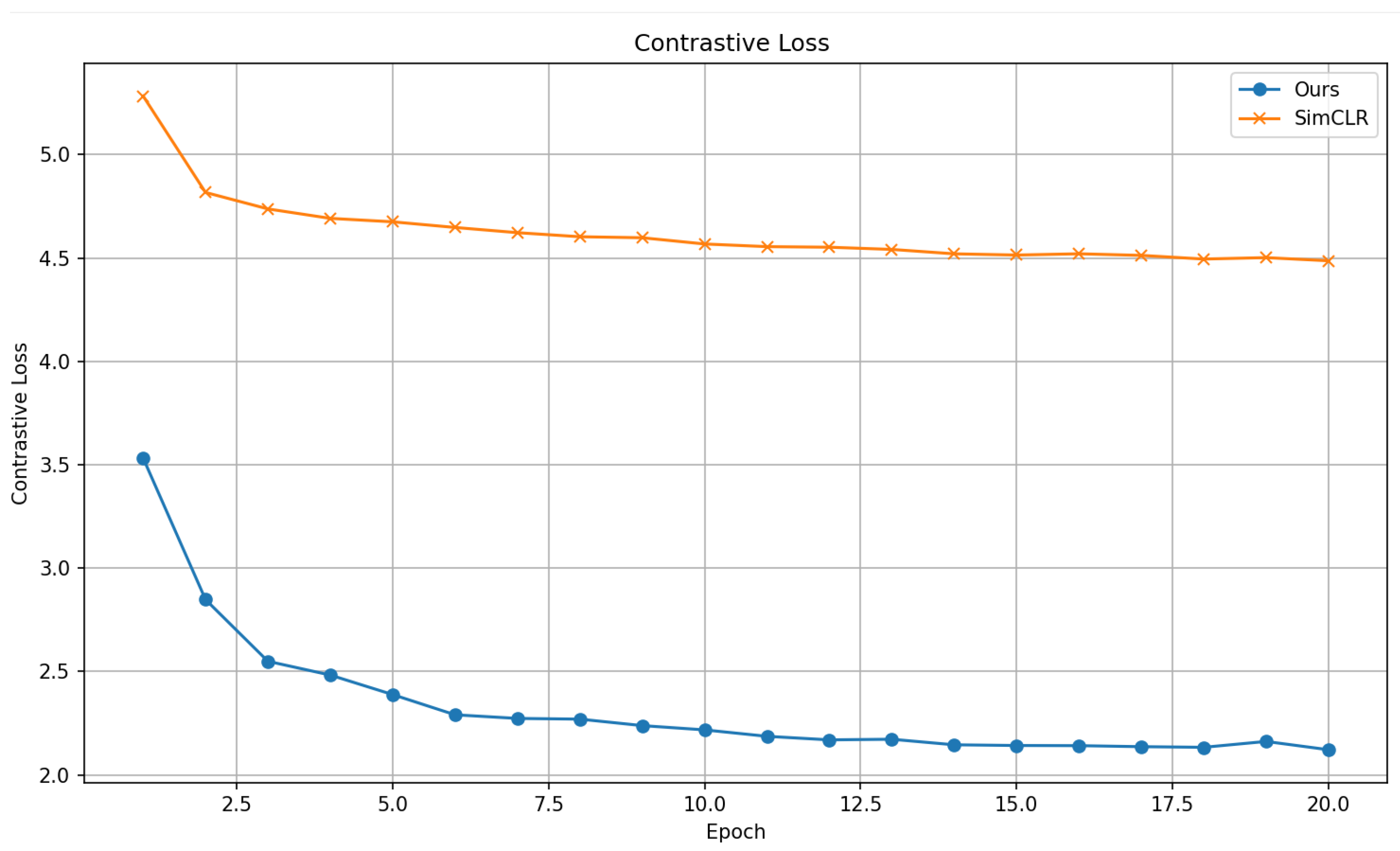
2. We improve the traditional SimCLR framework to better suit small-scale datasets with complex backgrounds. In the data augmentation module, in addition to basic image transformation strategies, we introduce grayscale enhancement and random erasure techniques. These strategies simulate complex background interference and significantly improve the model’s robustness to background noise. In the feature encoding module, we replace the traditional convolutional neural network with a Swin Transformer based on a shifted window multihead self-attention mechanism. This enables the model to leverage the advantages of global attention fully. The projection head is redesigned as a two-layer multilayer perceptron (MLP). For the loss function, a supervised contrastive mechanism is adopted. We employ the cosine annealing learning rate schedule and the AdamW optimizer regarding training strategy. This method achieved an accuracy of 97.48%, demonstrating superior performance in accuracy and relevance compared to other approaches in small-scale snake image classification.
3. We constructed a novel exotic pet snake image dataset comprising 17 species. Low-quality images are removed to ensure data clarity. This dataset can serve as a valuable reference for future research on exotic pet snakes or other tasks involving small-sample images with complex backgrounds.
4. Conclusions
This paper proposes an improved supervised contrastive learning model based on the SimCLR framework for fine-grained snake image classification under high-interference background conditions in a small-scale dataset. Our method introduces enhanced data augmentation strategies, including grayscale enhancement and random erasing, to simulate complex background interference and improve robustness. In the feature encoding module, we replace the traditional ResNet50 backbone with a Swin Transformer that leverages global self-attention for better spatial context modelling. Furthermore, a two-layer MLP projection head is designed to strengthen representation learning. The loss function adopts a supervised contrastive mechanism, and training uses cosine annealing scheduling with the AdamW optimizer.
Experimental results demonstrate that the proposed method achieved an accuracy of 97.48%, representing a significant improvement of 6.63% over traditional CNN models like EfficientNet-b4 while requiring fewer computational resources and no reliance on multimodal data or aggressive data augmentation. Additionally, we constructed a novel exotic pet snake image dataset of 17 species, providing a valuable benchmark for future research on small-sample, high-interference snake image classification.
Despite achieving good experimental results, we recognize that there are still directions for optimization in the current research. Firstly, due to the imbalance in the number of classes in the dataset, some classes contain as few as 30–40 images, which may limit the generalizability and robustness of the research results. Although data augmentation has somewhat alleviated this issue, more systematic class imbalance handling strategies can be explored in future work. Secondly, potential label errors in the dataset may affect the performance of supervised contrastive learning, and future research should consider incorporating anti-noise contrastive targets. Thirdly, although we assume this method may apply to other reptiles such as lizards and turtles, considering their similar data scarcity and complex image backgrounds, this hypothesis is still speculative and requires more experiments to verify.
In summary, our method offers an effective and efficient technical solution for fine-grained snake recognition in constrained and noisy environments, with potential applications in customs inspection, biosecurity, and exotic pet regulation. Future work will focus on expanding the dataset, improving robustness, and validating the method’s generalization to other species and domains.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}