

Retrieval-Augmented Generation to Generate Knowledge Assets and Creation of Action Drivers



Abstract
1. Introduction
2. Related Works
- Enhanced Accuracy and Reduced Hallucination. By grounding responses in verifiable external data, RAG significantly mitigates the tendency of LLMs to generate factually incorrect information. This is particularly vital in business domains where accuracy is paramount, such as finance, legal, and healthcare [12].
- Domain-Specific and Up-to-Date Knowledge. RAG enables LLMs to access and utilise current specialised information from enterprise-specific databases or real-time data feeds. This overcomes the static knowledge limitation of pretrained LLMs, allowing businesses to deploy AI solutions that are conversant with their unique operational context and the latest developments [11].
- Improved Traceability and Trust. Responses generated by RAG systems can often be linked back to the source documents used for retrieval. This traceability improves user trust and allows verification, which is essential for compliance and critical decision-making processes [11].
- Cost-Effective Customisation. Compared to the extensive resources required to fine-tune or retrain an entire LLM with new or proprietary data, RAG offers a more cost-effective and agile way to customise LLM outputs for specific business needs by updating the external knowledge base [12].
3. Materials and Methods
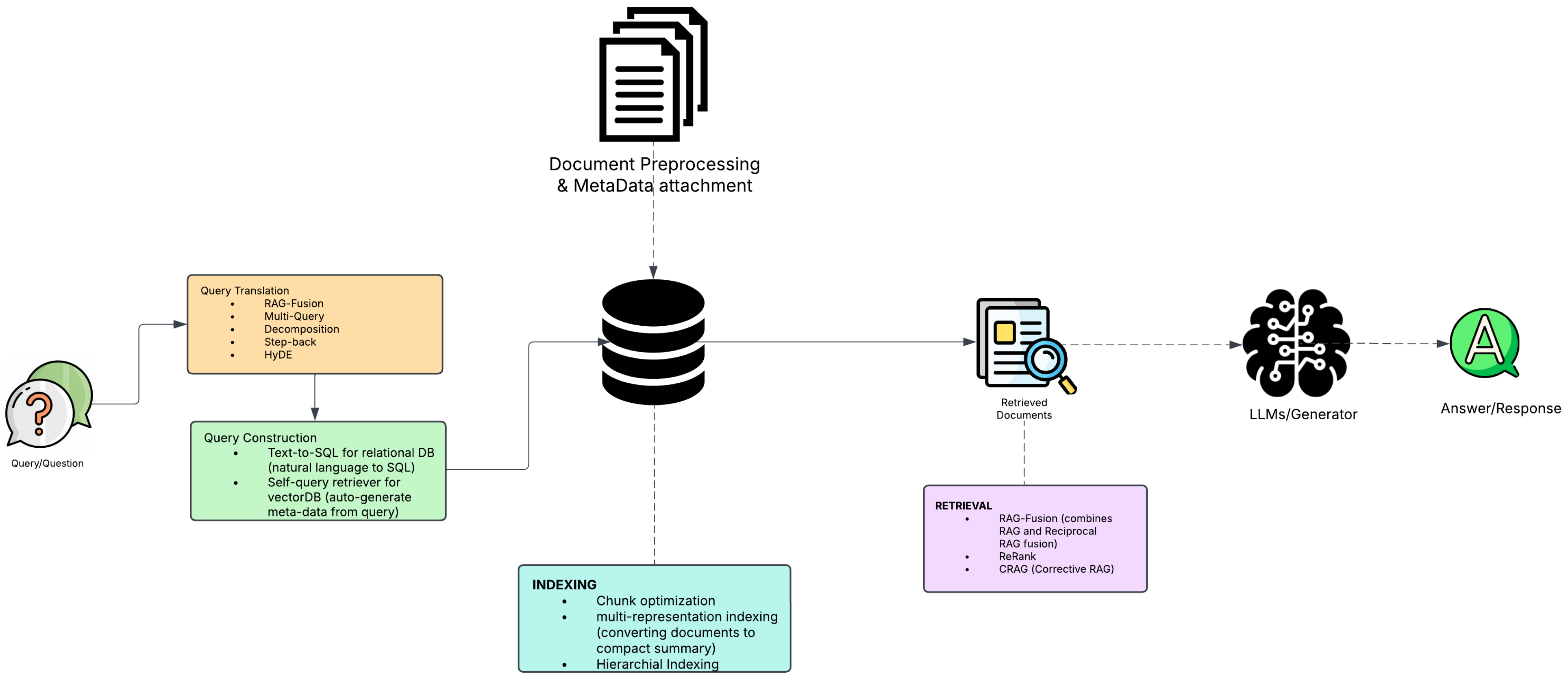
3.1. Retrieval Augmented Generation
3.2. Näive RAGs
3.2.1. Indexing
3.2.2. Retrieval
3.2.3. Generation
3.2.4. Challenges
- Splitting into different chunks of data removes the relevant context and breaks the semantic structure of the data. When we query the data, we retrieve the closest−k (top k documents) similarity document, which causes many documents to be omitted, even if they were relevant to the query. Hence, it does not provide a concrete answer.
- The chunking parameters (chunk size and chunk overlap) are highly data-dependent, and hence, we may not be able to generalise these variables for the entire data. Different RAG models need to be defined for different datasets.
- Naïve RAG (and RAG in general) works best for continuous textual data that can be broken into chunks to query about a particular question. For textual summarisation or for querying information regarding the complete data, it fails considerably.
3.3. Advanced RAG
3.4. Indexing
- Chunk Strategy: Documents are divided into fixed-size chunks (for example, 100–512 tokens). Larger chunks provide more context but increase noise and cost, while smaller ones reduce noise but risk losing meaning. Advanced methods like recursive splits, sliding windows, and Small2Big improve retrieval by balancing semantic completeness and context, with sentences as retrieval units and surrounding sentences as additional context.
- Metadata Attachments: Chunks are enriched with metadata (e.g., page number, author, timestamp) for filtered and time-aware retrieval, ensuring updated knowledge. Artificial metadata, such as paragraph summaries or hypothetical questions (Reverse HyDE), reduces semantic gaps by aligning document content with user queries.
- Structural Index: Hierarchical indexing organises documents in parent–child structures, linking chunks with summaries for efficient traversal. Knowledge Graphs (KG) [17] further enhance retrieval by mapping relationships between concepts and structures, improving reasoning, and reducing inconsistencies in multidocument environments.
3.5. Query Optimisation
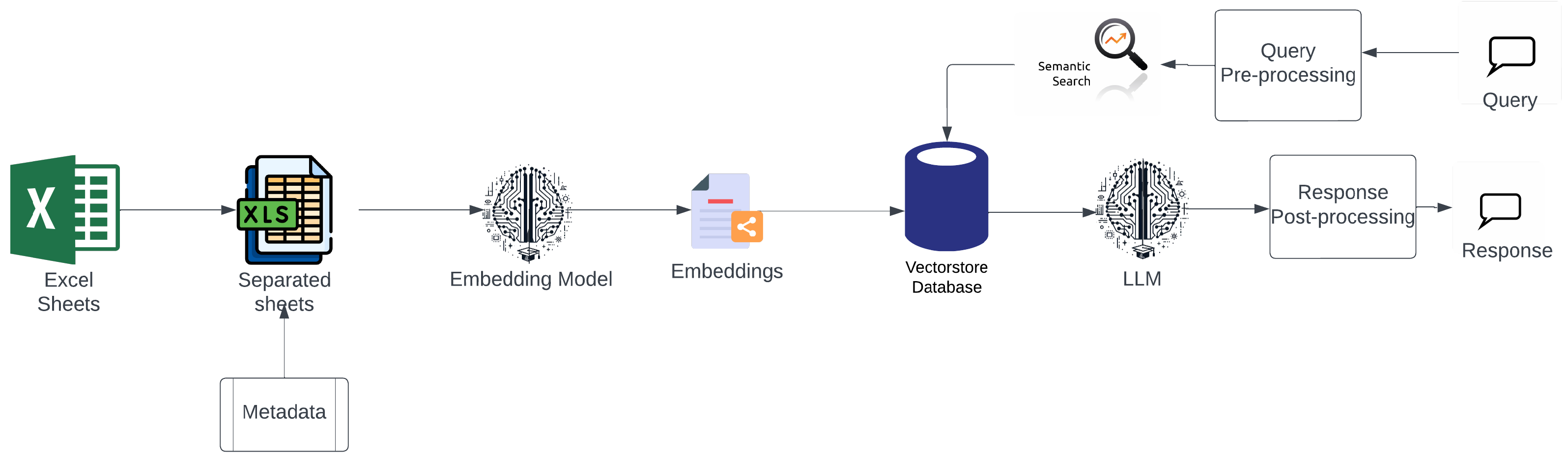
3.6. Metadata Utilisation
- Row-level metadata: Add tags or labels for each row according to its content.
- Sheet-level metadata: Annotate each sheet with the descriptive metadata.
- Hierarchical metadata: Organise the metadata hierarchically for better filtering.
3.7. Retrieval Techniques
- Contextual retrieval: Retrieval of not just the top row but also related rows and columns that provide context.
- Multihop Retrieval: For complex queries, retrieve data from multiple sheets and combine results.
- Reranking: Using a reranking model to prioritise retrieved rows based on relevance.
- Prompt Engineering: Designing prompts that clearly instruct the language model on how to use retrieved tabular data.
- Template-Based Responses: Using templates for predictable queries and to get specific responses.
- Error handling: Including instructions in the prompts to handle exceptional cases where no relevant data are found so that the generator does not hallucinate.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Techniques |
|---|---|
| Preprocessing | Data cleaning, chunking, metadata annotation |
| Indexing | Vectorisation, column-specific indexing, hybrid indexing |
| Query Optimisation | Query parsing, column filtering, semantic matching |
| Metadata Utilisation | Row-level tags, sheet-level metadata, hierarchical organisation |
| Retrieval | Contextual retrieval, multihop retrieval, reranking |
| Post-Retrieval | Answer extraction, aggregation, formatting |
| Generator Optimisation | Prompt engineering, template-based responses, error handling |
| Automation | Automated updates, API integration, version control |
3.8. Tools and Frameworks Used
3.9. Preprocessing
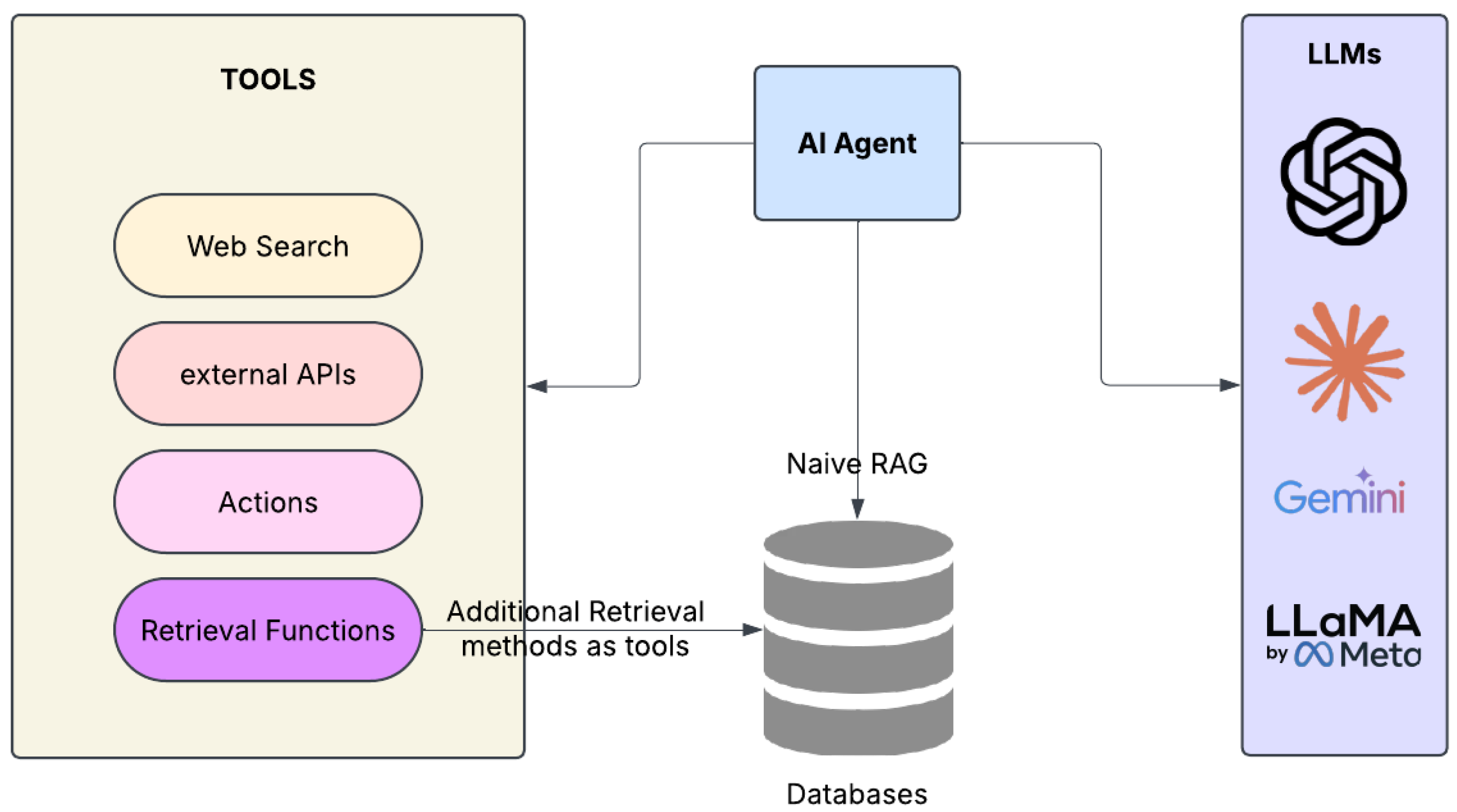
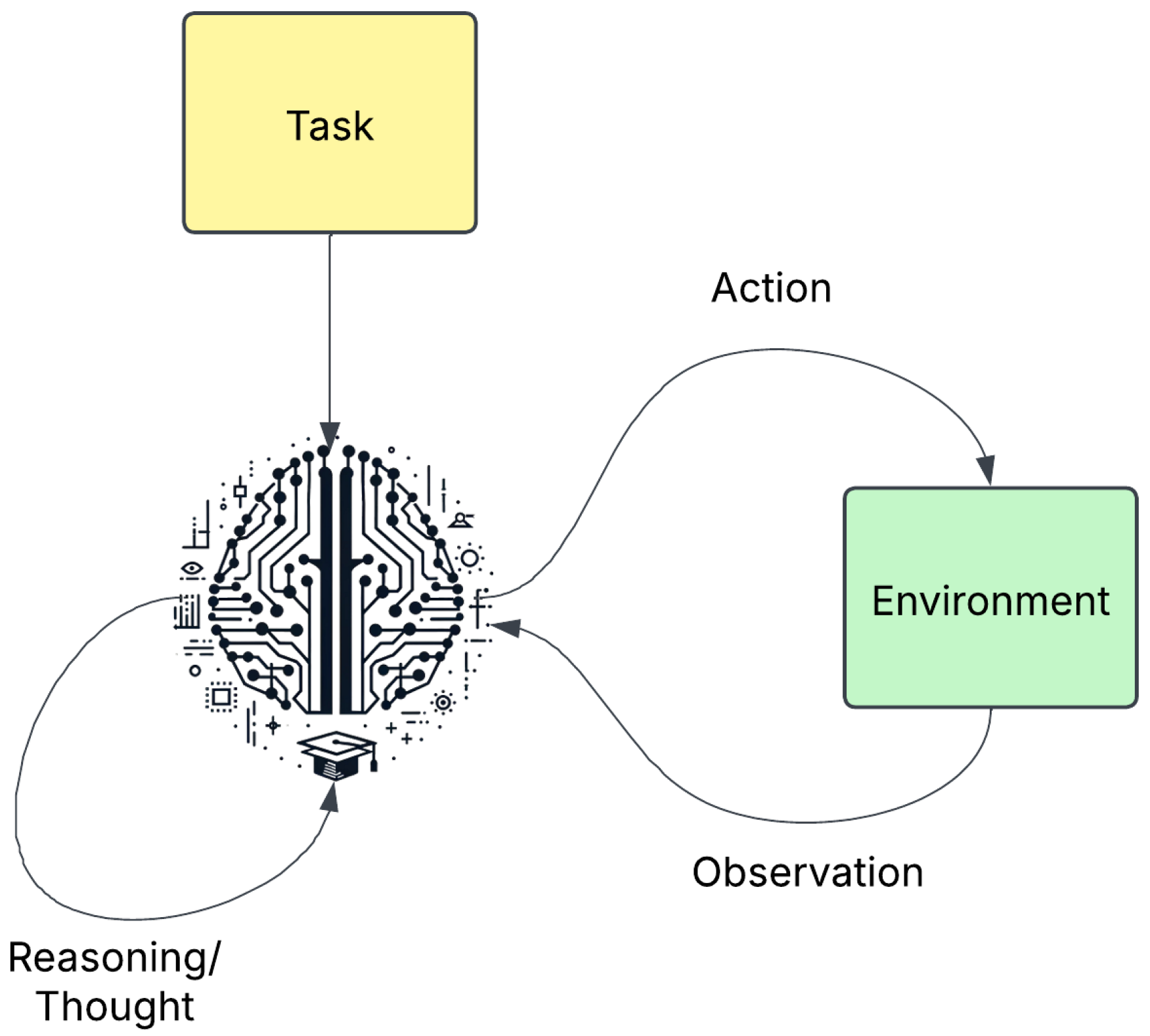
3.10. Agentic RAG
- Reflection: Agents evaluate retrieved information and self-critique their outputs;
- Planning: Systems break down complex queries into manageable subtasks;
- Tool use: Agents can access external resources beyond the initial knowledge base;
- Multiagent collaboration: Networks of specialised agents work together, checking each other’s work.
- Autonomous Agent Integration: Agentic Retrieval-Augmented Generation (RAG) [23] integrates autonomous AI agents capable of reflection, planning, tool use, and multiagent collaboration. These agents operate beyond static retrieval pipelines by dynamically adapting retrieval strategies based on intermediate outputs and evolving task demands. This agentic control enables complex reasoning, improved interpretability, and task-specific optimisation, making the system more responsive and intelligent in handling diverse and evolving information needs.
- Iterative Refinement: A key differentiator of Agentic RAG is its iterative approach to information retrieval. Rather than relying on a single retrieval step, the system performs multiple refinement cycles, progressively improving both the relevance and diversity of retrieved documents. For example, Vendi-RAG [25] introduced a new diversity metric—the Vendi Score—alongside large language model (LLM) judges to evaluate and enhance the quality of responses across iterations. This iterative refinement mechanism leads to more robust and contextually nuanced outputs.
- Context-Aware Retrieval:Agentic RAG systems place significant emphasis on semantic and structural context. Frameworks such as Citation Graph RAG [26] (CG-RAG) leverage citation graphs to model interdocument relationships, thereby improving contextual grounding and retrieval precision. Similarly, systems like Golden-Retriever [27] improve retrieval quality by preprocessing queries to resolve domain-specific terminology and jargon, ensuring better alignment between user intent and retrieved content. These strategies collectively improve the depth and relevance of the knowledge retrieved, particularly in technical or specialised domains.
4. RAG for Knowledge Asset Generation
5. Knowledge Asset Generation
6. Case Study: Challenges of Using LLMs to Analyse Complex Datasets
6.1. Data Structuring Issues
- Inconsistent Formats: Data from sources such as CSVs, databases, and APIs often contain mismatched fields, naming conventions, or missing values. For example, the report had to standardise SIC codes and reconcile data across LCR boroughs, tasks that require robust preprocessing pipelines.
- Unstructured Data Complexity: Although the review primarily used quantitative data, qualitative insights (e.g., growth needs and strategic support plans) required transformation techniques such as tokenisation or embedding before AI models could process them meaningfully.
- Noise and redundancy: Duplicated or outdated company records can mislead AI models during analysis. The report noted potential oversimplification risks when using SIC codes.
- Scalability: Processing datasets for over 12,000 firms across various lifecycle stages demands scalable AI systems in terms of both computational power and data governance.
6.2. Prompt Development Issues
- Ambiguity in prompts: Vague prompts such as “what do scale-ups need in LCR?” yield generic results. Tailored prompts are necessary to address specific business lifecycle stages (e.g., scale-up vs. repeat scale-up).
- Overfitting to Context: Customised prompts for the LCR context may not generalise well to other regions, limiting their utility for national benchmarking.
- Context Limitations: Token limits in AI models like GPT can truncate or lose critical information when attempting to include sectoral comparisons, borough-level insights, and lifecycle requirements in a single prompt.
- Skill Gap in Prompt Engineering: Creating effective prompts requires expertise in both AI behaviour and domain knowledge. Without domain-aware developers, replicating expert analysis becomes risky.
6.3. Testing and Retesting for Consistency
- Non-Determinism of AI Models: Generative AI can produce different results for identical inputs, complicating the task of generating repeatable recommendations.
- Version Drift: Updates to AI models (for example, new GPT versions) may alter the output over time. For studies spanning multiple years, version control is essential.
- Validation Difficulty: Defining "correct" AI analysis is challenging without ground-truth benchmarks, especially when forecasting economic outcomes.
- Feedback loops: Refining of prompts based on AI-generated insights risks confirming user bias rather than uncovering objective findings.
- Implement robust data structuring practices to standardise input and maintain accuracy.
- Design clear and context-sensitive prompts that reflect the complexity of business lifecycles, regional variations, and sector interdependencies.
- Establish thorough testing and validation protocols to ensure repeatability and reliability of AI outputs.
7. RAG vs. Large Context Window LLMs
8. Experiments, Results, and Evaluation
- Retriever Component: Context Precision, Context Recall;
- Generator Component: Faithfulness, Answer Relevancy.
- Ground Truth and Reference Data: For our evaluation, we used a curated set of representative queries about council data (as shown in Table 5). The ground truth for Context Recall was established based on the complete dataset knowledge, allowing RAGAS to determine what relevant information should ideally be retrieved for each query.
- Limitations and Human Evaluation: While our current evaluation relies on automated metrics through RAGAS, we acknowledge that human evaluation would provide additional validation of our results. The relatively low Context Precision and Context Recall scores (particularly for queries 1–4) reflect the challenge of retrieving relevant information from council-specific documents when k = 3 documents are retrieved per query. Future work will incorporate human evaluation to validate these automated assessments and provide qualitative analysis of answer quality.
9. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RAG | Retrieval-Augmented Generation |
| LLM | Large language models |
| MTEB | Text Embedding Benchmark |
References
- Ferreira Barros, C.; Borges Azevedo, B.; Graciano Neto, V.V.; Kassab, M.; Kalinowski, M.; do Nascimento, H.A.D.; Bandeira, M.C. Large Language Model for Qualitative Research—A Systematic Mapping Study. arXiv 2024, arXiv:2411.14473. [Google Scholar]
- Fischer, T.; Biemann, C. Exploring Large Language Models for Qualitative Data Analysis. In Proceedings of the 4th International Conference on Natural Language Processing for Digital Humanities, Miami, FL, USA, 15–16 November 2024; pp. 423–437. [Google Scholar]
- Xu, Z.; Jain, S.; Kankanhalli, M. Hallucination is inevitable: An innate limitation of large language models. arXiv 2024, arXiv:2401.11817. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Es, S.; James, J.; Espinosa-Anke, L.; Schockaert, S. Ragas: Automated evaluation of retrieval augmented generation. arXiv 2023, arXiv:2309.15217. [Google Scholar]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 17754–17762. [Google Scholar]
- Li, X.; Ouyang, J. A Systematic Investigation of Knowledge Retrieval and Selection for Retrieval Augmented Generation. arXiv 2024, arXiv:2410.13258. [Google Scholar]
- Hoshi, Y.; Miyashita, D.; Ng, Y.; Tatsuno, K.; Morioka, Y.; Torii, O.; Deguchi, J. Ralle: A framework for developing and evaluating retrieval-augmented large language models. arXiv 2023, arXiv:2308.10633. [Google Scholar]
- Liverpool Chamber of Commerce. Baseline Review 2024: Professional Business Services—Identifying Future Growth Potential Liverpool City Region—Executive Summary; Technical Report; Liverpool Chamber of Commerce: Liverpool, NY, USA, 2024. [Google Scholar]
- Arslan, M.; Munawar, S.; Cruz, C. Business insights using RAG–LLMs: A review and case study. J. Decis. Syst. 2024. [Google Scholar] [CrossRef]
- Arslan, M.; Cruz, C. Business-RAG: Information Extraction for Business Insights. In 21st International Conference on Smart Business Technologies; SCITEPRESS-Science and Technology Publications: Setúbal, Portugal, 2024; pp. 88–94. [Google Scholar]
- Ramalingam, S. RAG in Action: Building the Future of AI-Driven Applications; Libertatem Media Private Limited: Ahmedabad, India, 2023. [Google Scholar]
- Lovtsov, V.A.; Skvortsova, M.A. Automated Mobile Operator Customer Service Using Large Language Models Combined with RAG System. In Proceedings of the 2025 7th International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE), Cairo, Egypt, 8–10 April 2025; pp. 1–6. [Google Scholar]
- Hang, C.N.; Yu, P.D.; Tan, C.W. TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking. IEEE Trans. Artif. Intell. 2025. [Google Scholar] [CrossRef]
- Bruckhaus, T. Rag does not work for enterprises. arXiv 2024, arXiv:2406.04369. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Wang, Y.; Lipka, N.; Rossi, R.A.; Siu, A.; Zhang, R.; Derr, T. Knowledge graph prompting for multi-document question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2024; Volume 38, pp. 19206–19214. [Google Scholar]
- Dhuliawala, S.; Komeili, M.; Xu, J.; Raileanu, R.; Li, X.; Celikyilmaz, A.; Weston, J. Chain-of-Verification Reduces Hallucination in Large Language Models. In Findings of the Association for Computational Linguistics: ACL 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 3563–3578. [Google Scholar]
- Ma, X.; Gong, Y.; He, P.; Zhao, H.; Duan, N. Query Rewriting in Retrieval-Augmented Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023. [Google Scholar]
- Peng, W.; Li, G.; Jiang, Y.; Wang, Z.; Ou, D.; Zeng, X.; Xu, D.; Xu, T.; Chen, E. Large Language Model based Long-tail Query Rewriting in Taobao Search. In Proceedings of the ACM Web Conference, Singapore, 13–17 May 2024; pp. 20–28. [Google Scholar]
- Gao, L.; Ma, X.; Lin, J.; Callan, J. Precise Zero-Shot Dense Retrieval without Relevance Labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Toronto, ON, Canada; pp. 1762–1777. [Google Scholar]
- Zheng, H.S.; Mishra, S.; Chen, X.; Cheng, H.T.; Chi, E.H.; Le, Q.V.; Zhou, D. Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Singh, A.; Ehtesham, A.; Kumar, S.; Khoei, T.T. Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG. arXiv 2025, arXiv:2501.09136. [Google Scholar]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. React: Synergizing reasoning and acting in language models. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Rezaei, M.R.; Dieng, A.B. Vendi-rag: Adaptively trading-off diversity and quality significantly improves retrieval augmented generation with llms. arXiv 2025, arXiv:2502.11228. [Google Scholar]
- Hu, Y.; Lei, Z.; Dai, Z.; Zhang, A.; Angirekula, A.; Zhang, Z.; Zhao, L. CG-RAG: Research Question Answering by Citation Graph Retrieval-Augmented LLMs. arXiv 2025, arXiv:2501.15067. [Google Scholar]
- An, Z.; Ding, X.; Fu, Y.C.; Chu, C.C.; Li, Y.; Du, W. Golden-Retriever: High-Fidelity Agentic Retrieval Augmented Generation for Industrial Knowledge Base. arXiv 2024, arXiv:2408.00798. [Google Scholar]
- Geetha, M.; Thirukumaran, G.; Pradakshana, C.; Sudharsana, B.; Ashwin, T. Conversational AI Meets Documents Revolutionizing PDF Interaction with GenAI. In Proceedings of the 2024 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, 12–14 December 2024; pp. 1–6. [Google Scholar]
- Kang, B.; Kim, J.; Yun, T.R.; Kim, C.E. Prompt-rag: Pioneering vector embedding-free retrieval-augmented generation in niche domains, exemplified by korean medicine. arXiv 2024, arXiv:2401.11246. [Google Scholar]
- An, H.; Narechania, A.; Wall, E.; Xu, K. VITALITY 2: Reviewing Academic Literature Using Large Language Models. arXiv 2024, arXiv:2408.13450. [Google Scholar]
- Gopi, S.; Sreekanth, D.; Dehbozorgi, N. Enhancing Engineering Education Through LLM-Driven Adaptive Quiz Generation: A RAG-Based Approach. In Proceedings of the 2024 IEEE Frontiers in Education Conference (FIE), Washington, DC, USA, 13–16 October 2024; pp. 1–8. [Google Scholar]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. MTEB: Massive Text Embedding Benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; pp. 2014–2037. [Google Scholar]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. MTEB Leaderboard. Hugging Face Spaces. 2023. Available online: https://huggingface.co/spaces/mteb/leaderboard (accessed on 20 March 2025).
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Ding, Y.; Zhang, L.L.; Zhang, C.; Xu, Y.; Shang, N.; Xu, J.; Yang, F.; Yang, M. Longrope: Extending llm context window beyond 2 million tokens. arXiv 2024, arXiv:2402.13753. [Google Scholar]
- Li, X.; Cao, Y.; Ma, Y.; Sun, A. Long Context vs. RAG for LLMs: An Evaluation and Revisits. arXiv 2024, arXiv:2501.01880. [Google Scholar]
- Wan, D.; Vig, J.; Bansal, M.; Joty, S. On Positional Bias of Faithfulness for Long-form Summarization. arXiv 2024, arXiv:2410.23609. [Google Scholar]

| Component | Techniques/Approaches |
|---|---|
| Data Extraction & Preprocessing | Data cleaning, normalisation, handling missing values, chunking rows/columns, metadata annotation |
| Indexing | Dense vectorisation (e.g., using language model embeddings), column-specific indexing, hybrid indexing (combining dense and sparse retrieval) |
| Query Optimisation | Query parsing, query expansion (e.g., synonyms), column filtering, semantic matching |
| Metadata Utilisation | Adding row-level and sheet-level metadata, hierarchical metadata organisation for filtering and context |
| Retrieval | Contextual retrieval (extracting related rows/columns), multihop retrieval across sheets, reranking using graph or similarity models |
| Post-Retrieval Processing | Answer extraction (cell or range selection), data aggregation (sums, averages, counts), formatting before passing to the generator |
| Generator Optimisation | Prompt engineering, using templates for predictable responses, building in error handling for missing or ambiguous data |
| Automation & Integration | Automated data syncing when Excel updates occur, API integration (e.g., using Python libraries such as pandas and openpyxl), version control, and external tool integration |
| Component | Metrics |
|---|---|
| Context Relevance | Precision, Recall, |
| MRR (Mean Reciprocal Rank), MAP (Mean Average) | |
| Faithfulness | Factual consistency |
| Answer Relevance | BLEU, ROUGE, embedding similarity |
| No. | Question/Query | Naive RAG Answer/Response | RAG (With Preprocessing Using LlamaParse) Retrieval k = 7 |
|---|---|---|---|
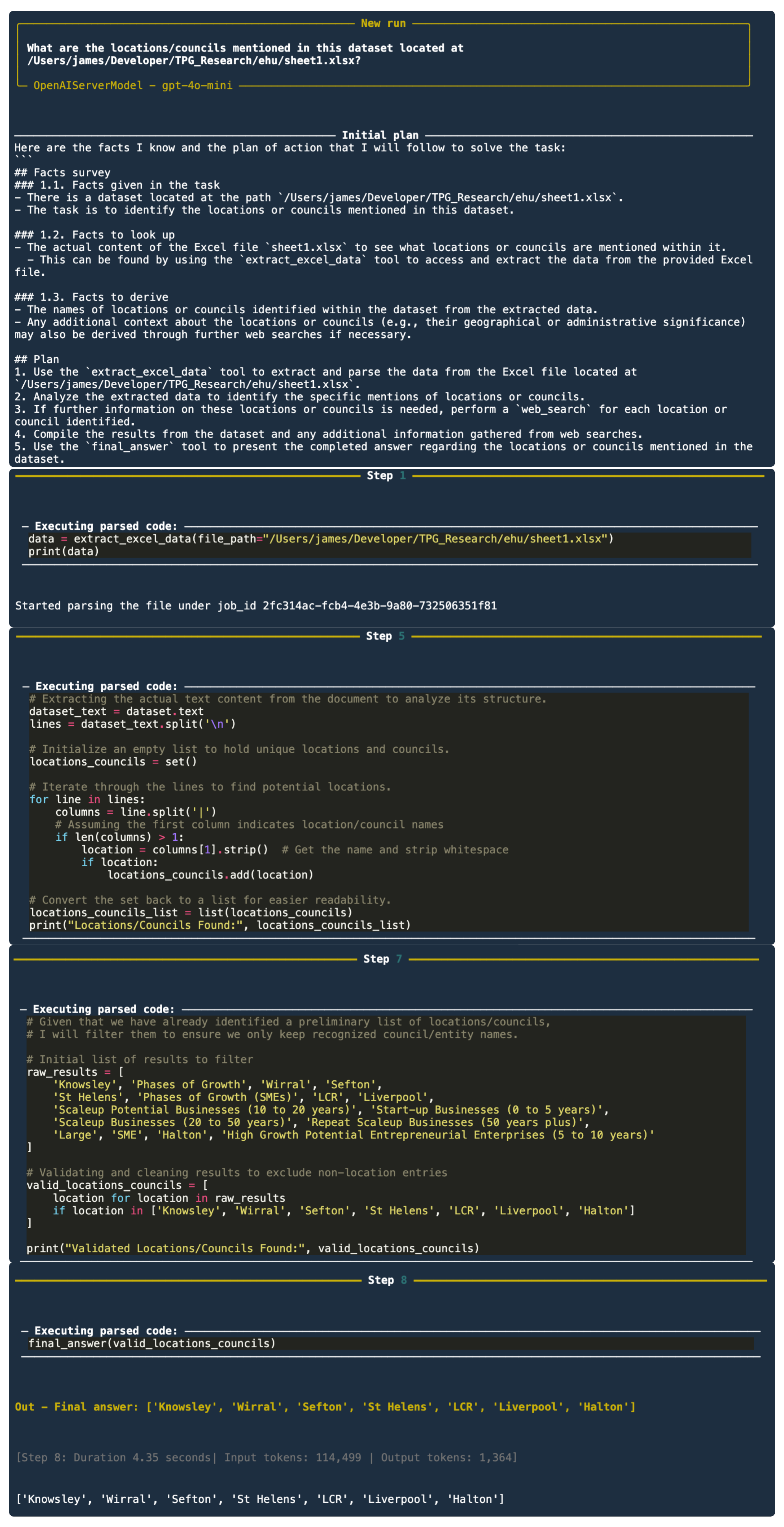
| 1 | Tell me all the locations mentioned in this data? | The location mentioned in the data are Liverpool | The locations mentioned in the data are LCR, Wirral, Liverpool, Knowsley, St Helens, Halton, and Sefton. |
| 2 | What are the total companies and scale-ups in Sefton? | In Sefton, there are a total of 793 companies and 32 visible scale-ups. | In Sefton, there are a total of 2095 companies. Among these, there are 81 visible scale-ups. |
| 3 | What are the total companies and scale-ups in Liverpool? | Liverpool has a total of 1833 companies and 72 visible scale-ups. | In Liverpool, there are a total of 5142 companies. Among these, there are 185 visible scale-ups. |
| S No. | Questions | Context Precision | Context Recall | Faithfulness | Answer Relevancy |
|---|---|---|---|---|---|
| 1 | Tell me the number of the Scale-up Potential SMEs in Sefton | 0 | 0 | 0 | 0.98 |
| 2 | Tell me the number of the Visible Scale-ups businesses in Wirral | 0.5 | 0 | 0 | 0.97 |
| 3 | Tell me the number of the Scale-up Potential SMEs in Wirral | 0.5 | 0 | 0 | 0.98 |
| 4 | Which council has the highest number of Scale-up Potential SMEs? | 0.33 | 0 | 0 | 0.94 |
| 5 | Tell me all the councils mentioned | 1 | 1 | 1 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
James, A.; Trovati, M.; Bolton, S. Retrieval-Augmented Generation to Generate Knowledge Assets and Creation of Action Drivers. Appl. Sci. 2025, 15, 6247. https://doi.org/10.3390/app15116247
James A, Trovati M, Bolton S. Retrieval-Augmented Generation to Generate Knowledge Assets and Creation of Action Drivers. Applied Sciences. 2025; 15(11):6247. https://doi.org/10.3390/app15116247
Chicago/Turabian StyleJames, Antony, Marcello Trovati, and Simon Bolton. 2025. "Retrieval-Augmented Generation to Generate Knowledge Assets and Creation of Action Drivers" Applied Sciences 15, no. 11: 6247. https://doi.org/10.3390/app15116247
APA StyleJames, A., Trovati, M., & Bolton, S. (2025). Retrieval-Augmented Generation to Generate Knowledge Assets and Creation of Action Drivers. Applied Sciences, 15(11), 6247. https://doi.org/10.3390/app15116247