

Prevention Is Better than Cure: Exposing the Vulnerabilities of Social Bot Detectors with Realistic Simulations

Abstract
1. Introduction
- The heuristic used in previous studies was falsified, and the first bot influence and user engagement models were proposed by analyzing a large real-world dataset.
- An adversarially trained profile editor and a preselection mechanism based on user clustering were proposed to enable the simulation of various novel bots that have evolved in different aspects within a large social network.
- Novel bots were trained to function as fake accounts and influencers, and both RF-based and GNN-based detectors that utilized the bots’ profile data, user-generated content, and graph information were deployed to identify them. The results demonstrated that the improvements helped the bots to evade detection, rendering the adversary detectors ineffective.
- We found that certain types of bots outperform others in the ablation experiments, which proves the existence of the detectors’ vulnerabilities.
2. Related Works
2.1. Feature-Based Social Bot Detection
2.2. Text-Based Social Bot Detection
2.3. Graph-Based Social Bot Detection
2.4. Social Bot Imitation
3. Materials and Methods
3.1. Threat Model
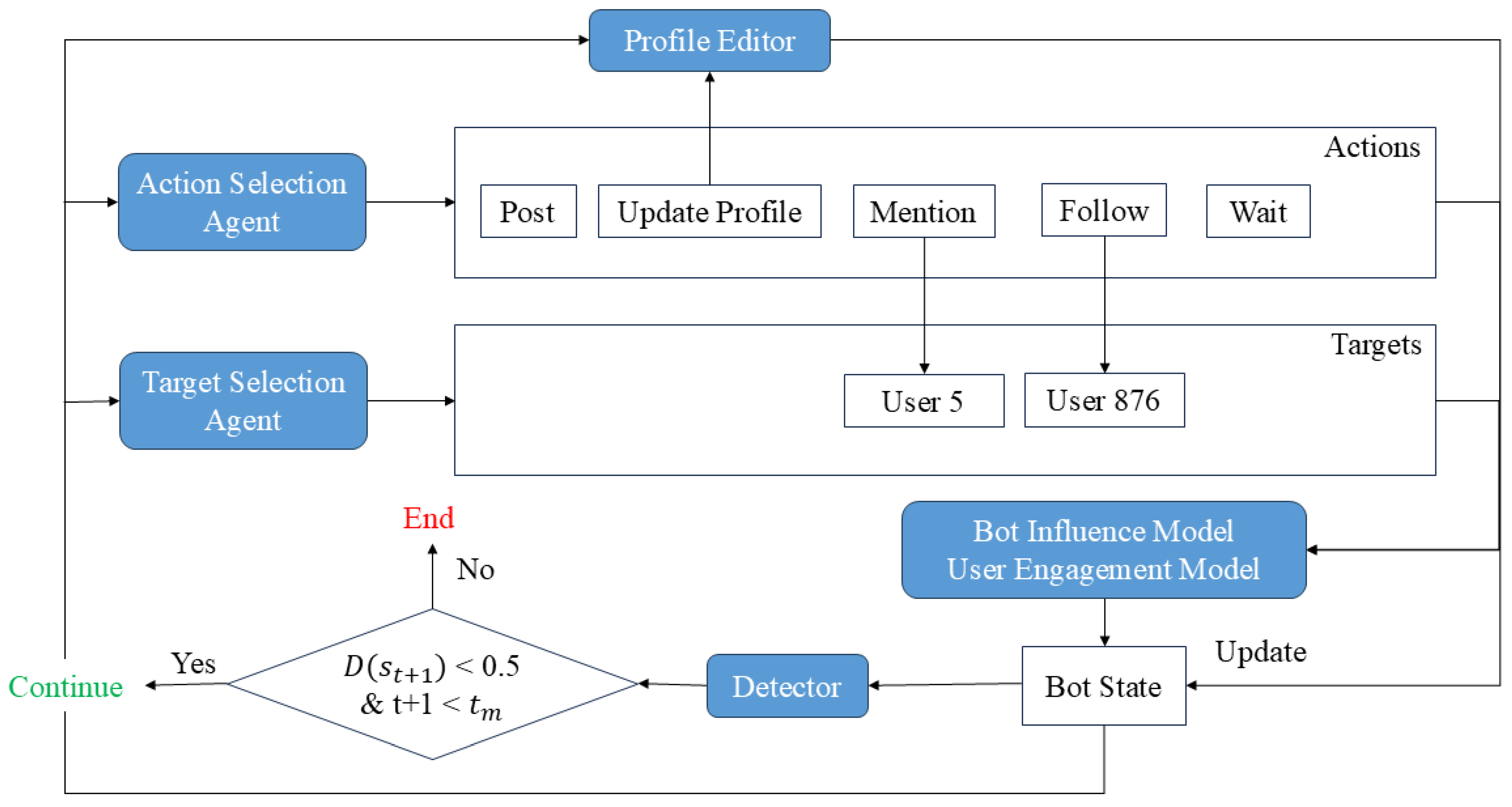
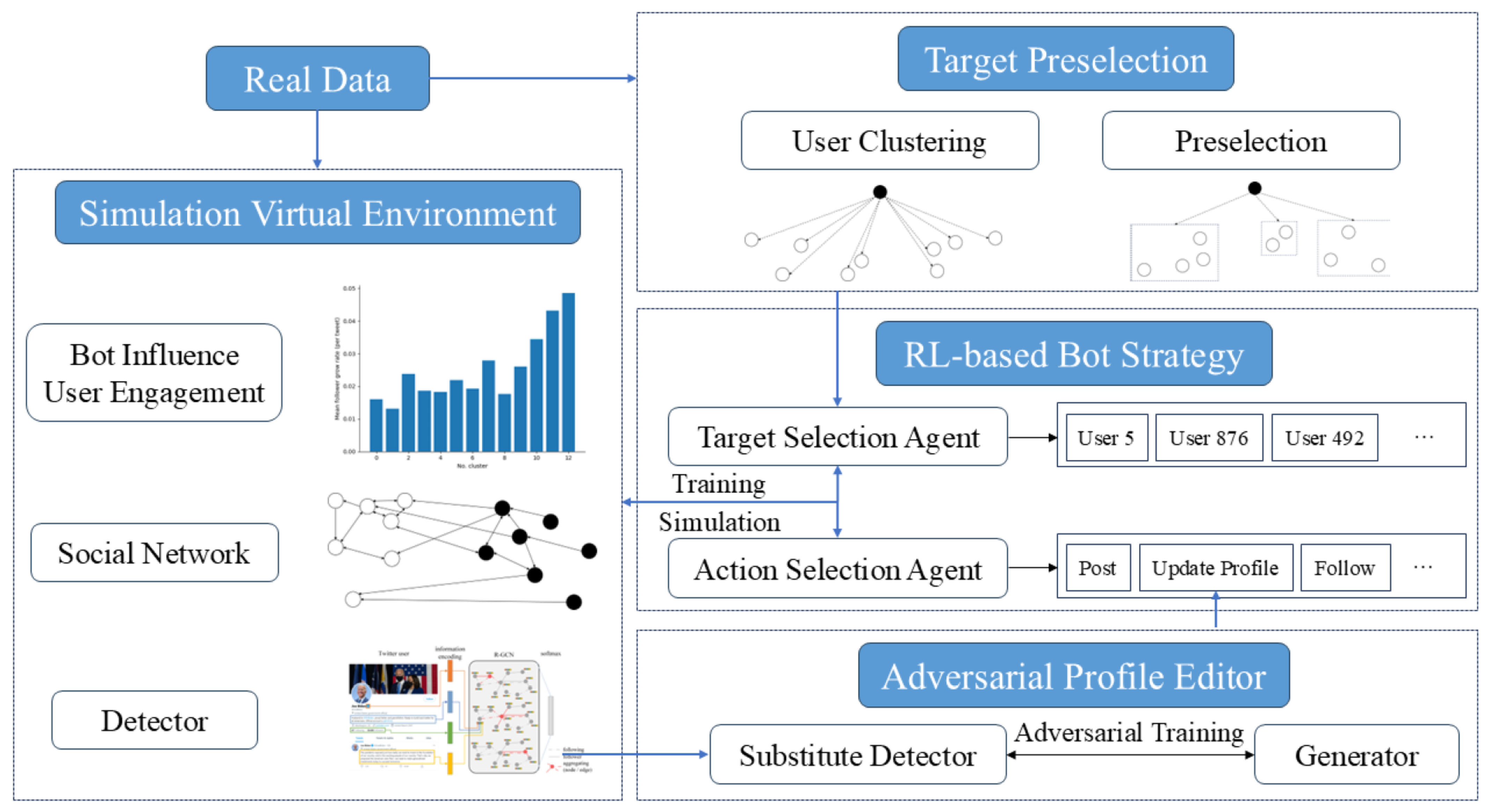
3.2. Framework
3.3. Virtual Environment
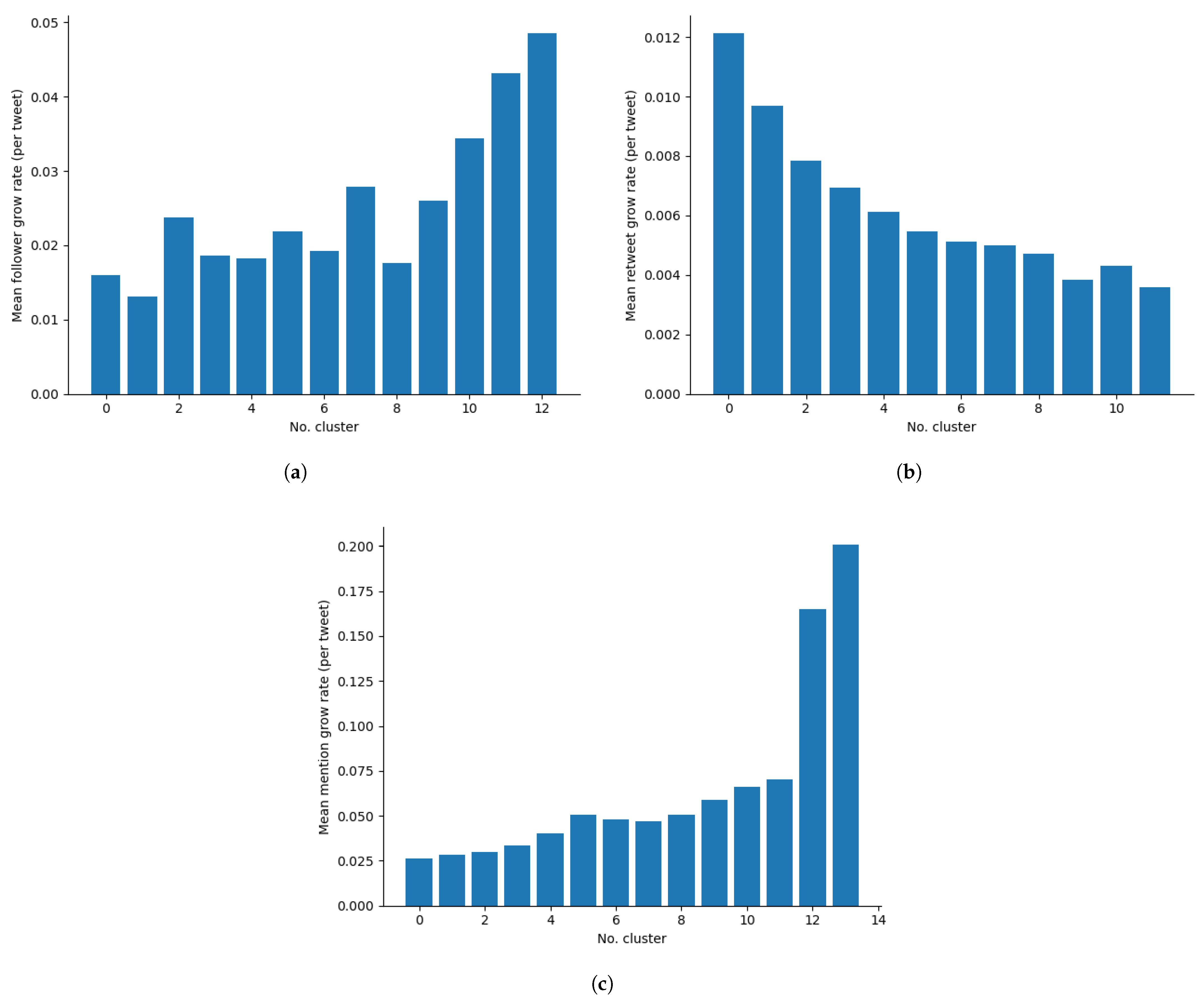
3.3.1. Influence Simulation
3.3.2. User Engagement Simulation
3.3.3. Bot Detection Model
- Profile features, such as user name length, account age, and follower count.
- Friend features, such as the mean account age of friends and the maximum number of followers of friends.
- Network features, such as the number of nodes and edges of the user’s retweet graph.
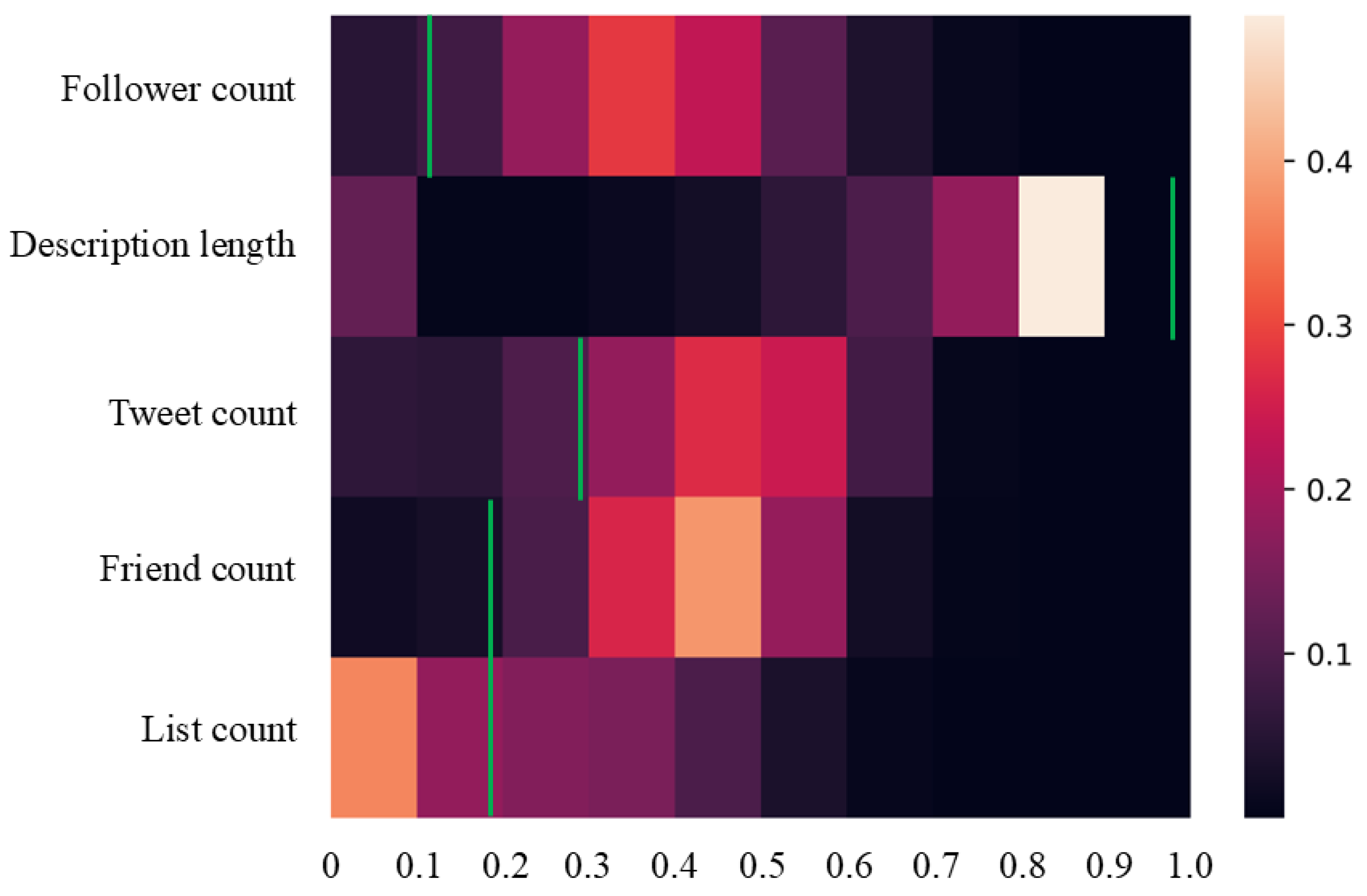
3.4. User Clustering
3.5. Profile Edition
- Username length: Considering Twitter’s rules (the username must be more than 4 characters long and can be up to 15 characters or less. It can contain only letters, numbers, and underscores—no spaces are allowed) and the requirement of the flexibility of the digits of numbers in the username, we assume that only letters and underscores are allowed, resulting in 27 options for each digit. Given that usernames cannot be duplicated and Twitter has over 300 million users, the range of username length is set to [7, 15].
- Number of digits in username length: The maximum value is the bot’s username length.
- Display name length: The display name can be up to 50 characters long and can be duplicated. Thus, the range is [1, 50].
- Whether the default profile picture is used.
- Description length: The bot’s description is randomly copied from the dataset. The length range is [0, 274].
- Whether the description includes URLs.
3.6. Bot Strategy Model
- Posting a tweet;
- Updating the profile;
- Retweeting, mentioning, or following an account;
- Creating or deleting a list;
- Waiting for a day.
3.7. Complexity Analysis
4. Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Implementation
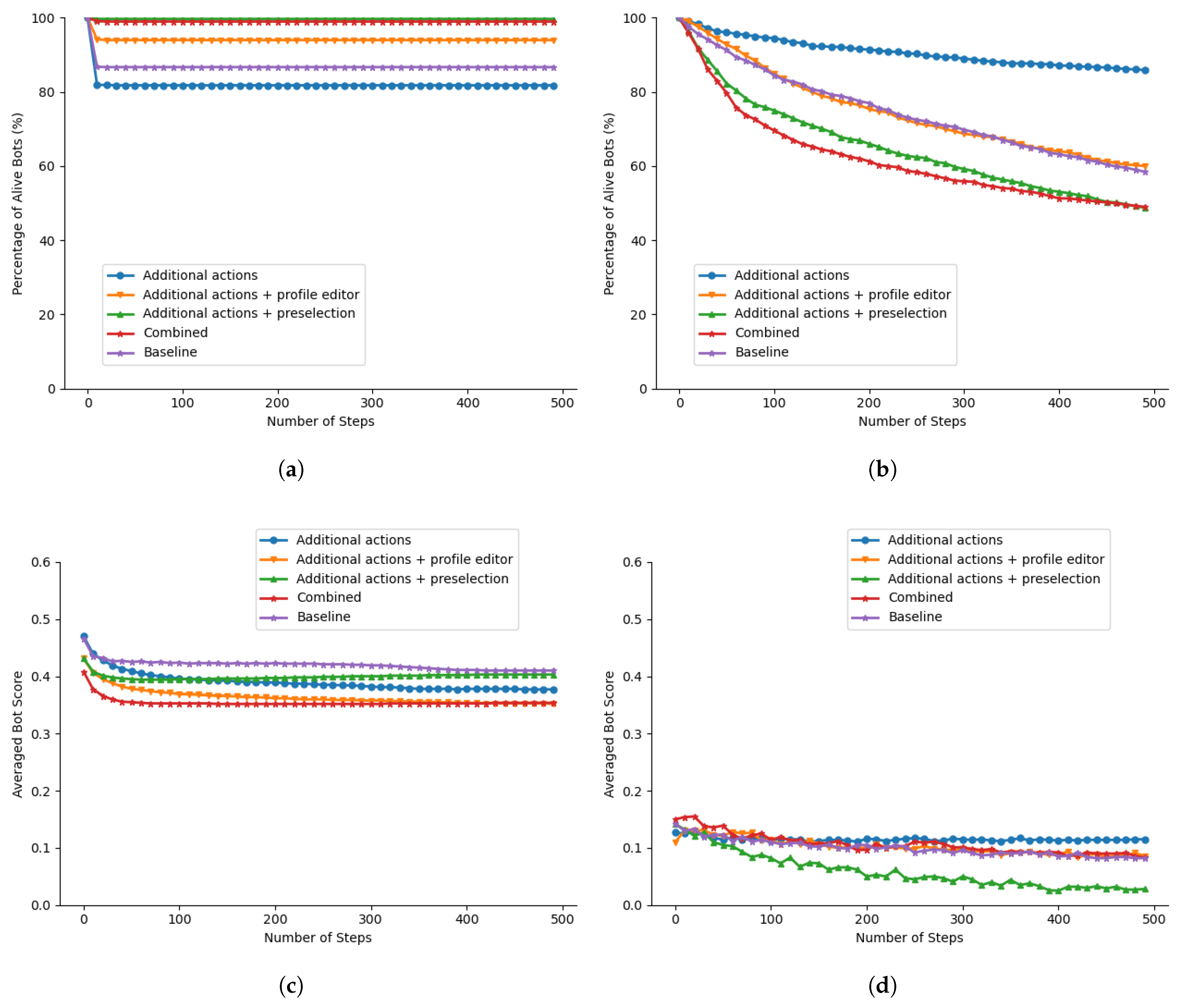
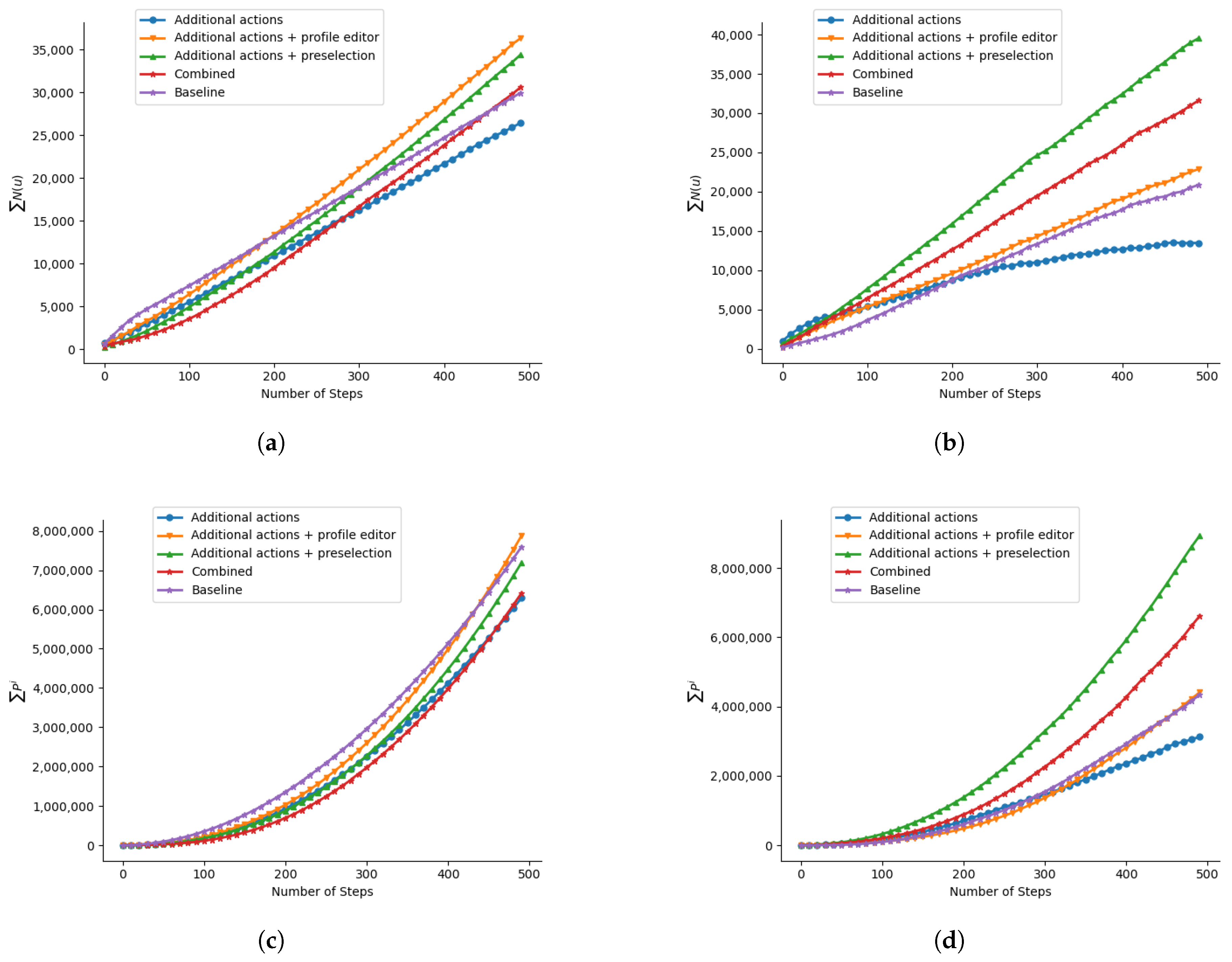
- Baseline: Since this study is based on the work of Le et al., the baseline is based on ACORN (SISAM uses an adjacency matrix to represent the relation between users, leading to a space complexity of . Since this would cause severe scaling problems when applying SISAM on Twibot-22, SISAM was not used as a baseline) [10]. The bot strategy model is similar to the proposed model but with a different action selection agent and a target selection agent. Possible actions are posting, retweeting, mentioning, and following. The discrete target selection action space is mapped into randomly selected users.
- Additional actions: Except for the actions in the baseline, the action selection agent’s action space includes three new actions: creating/deleting a list and waiting for a day.
- Additional actions + profile editor: The action selection agent’s action space further includes updating the profile with the proposed profile editor.
- Additional actions + preselection: The target selection agent’s action space is mapped to the preselected users.
- Combined: All proposed enhancements are applied.
4.2. Influence and Engagement Model
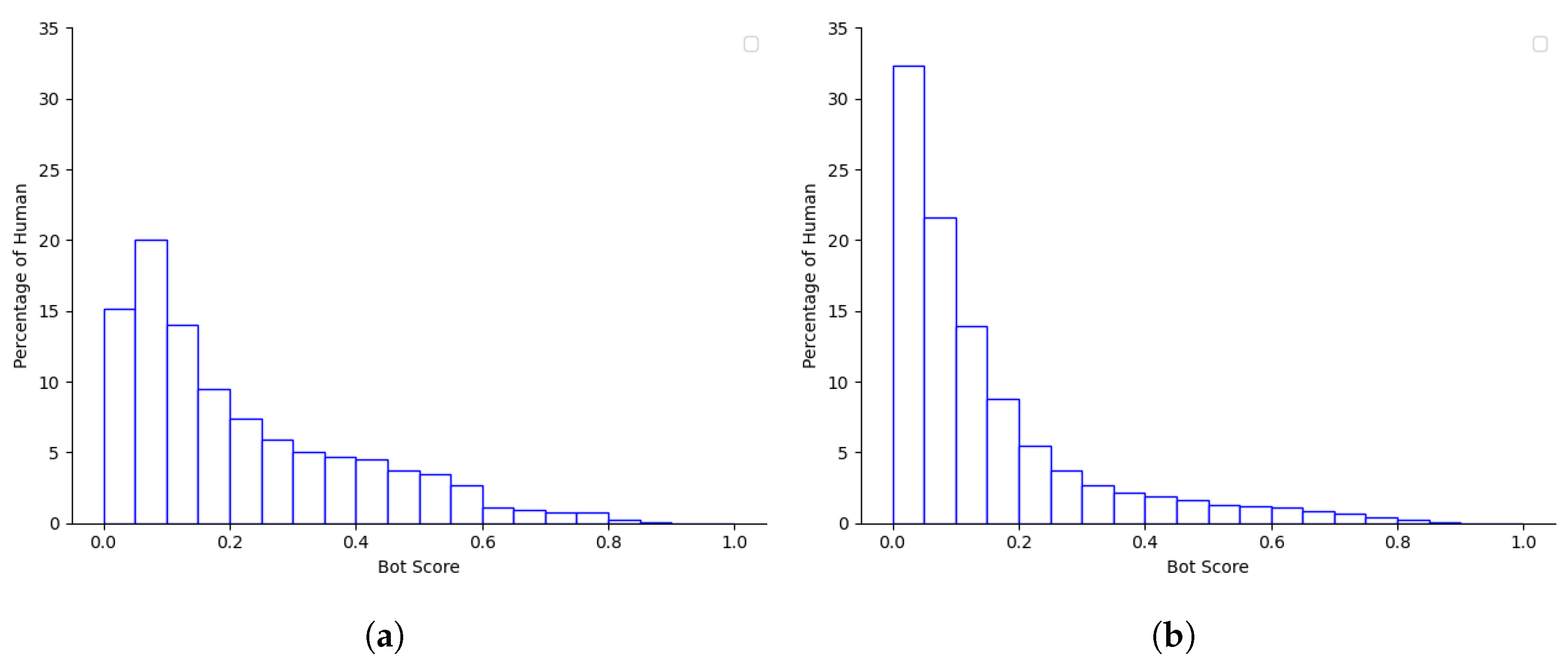
4.3. Fake Account Simulation
4.4. Influencer Simulation
4.5. Discovery of Unrecognized Bots: An Example
5. Limitation and Future Work
- The virtual environment is still much simplified. More actions can be introduced. The recommender engines of social media platforms are not considered. With more realistic simulation come more valuable samples.
- The bots would be more realistic if they cooperated. Only one bot was active during simulations. Thus, the bot strategy model was not optimized to control multiple bots simultaneously. However, there is increasing evidence that novel bots act in coordination.
- The bot strategy models presented in this study successfully bypassed the adversary detectors, but there is still room for improvement, such as in the observation space and the reinforcement learning algorithm.
6. Conclusions
- Aside from the structure of the detector, other information, such as the utilized account data and the output bot score of given accounts, can also be used against it. Social media platforms should think twice before releasing any information relevant to their bot detector.
- The impact of evaluation on different aspects of bots is interconnected. A highly developed bot may not necessarily deliver the best performance, and conversely, a bot detector may not effectively detect certain types of bots, even if it can detect bots that are generally considered more advanced. It is advisable to create and test various types of bots to identify vulnerabilities before they can be exploited for malicious purposes.
- RF-based detectors may have a higher recall for identifying new social bots compared to GNN-based detectors, although this may come at the expense of precision. It could be worthwhile to conduct further research on using an RF-based detector with a low-pass threshold to screen users before additional analysis or for ensemble learning.
- The detectors should undergo separate evaluations using bots with varying account ages, numbers of followers, and number of views. Bots that don’t attempt to increase their influence are usually more challenging to identify. Also, it is crucial to discover and suspend influencer bots as soon as possible. This way, they will have fewer followers or views, helping to reduce their impact.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The paradigm-shift of social spambots: Evidence, theories, and tools for the arms race. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 963–972. [Google Scholar]
- Hajli, N.; Saeed, U.; Tajvidi, M.; Shirazi, F. Social bots and the spread of disinformation in social media: The challenges of artificial intelligence. Br. J. Manag. 2022, 33, 1238–1253. [Google Scholar] [CrossRef]
- Hagen, L.; Neely, S.; Keller, T.E.; Scharf, R.; Vasquez, F.E. Rise of the machines? Examining the influence of social bots on a political discussion network. Soc. Sci. Comput. Rev. 2022, 40, 264–287. [Google Scholar] [CrossRef]
- Feng, S.; Tan, Z.; Wan, H.; Wang, N.; Chen, Z.; Zhang, B.; Zheng, Q.; Zhang, W.; Lei, Z.; Yang, S.; et al. TwiBot-22: Towards graph-based Twitter bot detection. arXiv 2022, arXiv:2206.04564. [Google Scholar]
- Kwon, H. AudioGuard: Speech Recognition System Robust against Optimized Audio Adversarial Examples. Multimed. Tools Appl. 2024, 83, 57943–57962. [Google Scholar] [CrossRef]
- Van Der Walt, E.; Eloff, J. Using machine learning to detect fake identities: Bots vs humans. IEEE Access 2018, 6, 6540–6549. [Google Scholar] [CrossRef]
- Wang, L.; Qiao, X.; Xie, Y.; Nie, W.; Zhang, Y.; Liu, A. My brother helps me: Node injection based adversarial attack on social bot detection. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 6705–6714. [Google Scholar]
- Abreu, J.V.F.; Fernandes, J.H.C.; Gondim, J.J.C.; Ralha, C.G. Bot development for social engineering attacks on Twitter. arXiv 2020, arXiv:2007.11778. [Google Scholar]
- Cresci, S.; Petrocchi, M.; Spognardi, A.; Tognazzi, S. Better safe than sorry: An adversarial approach to improve social bot detection. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 47–56. [Google Scholar]
- Le, T.; Tran-Thanh, L.; Lee, D. Socialbots on fire: Modeling adversarial behaviors of socialbots via multi-agent hierarchical reinforcement learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 545–554. [Google Scholar]
- Zeng, X.; Peng, H.; Li, A. Adversarial socialbots modeling based on structural information principles. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 392–400. [Google Scholar]
- Davis, C.A.; Varol, O.; Ferrara, E.; Flammini, A.; Menczer, F. Botornot: A system to evaluate social bots. In Proceedings of the 25th International Conference Companion on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 273–274. [Google Scholar]
- Varol, O.; Ferrara, E.; Davis, C.; Menczer, F.; Flammini, A. Online human-bot interactions: Detection, estimation, and characterization. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 280–289. [Google Scholar]
- Yang, K.C.; Varol, O.; Davis, C.A.; Ferrara, E.; Flammini, A.; Menczer, F. Arming the public with artificial intelligence to counter social bots. Hum. Behav. Emerg. Technol. 2019, 1, 48–61. [Google Scholar] [CrossRef]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Heidari, M.; Jones, J.H.; Uzuner, O. Deep contextualized word embedding for text-based online user profiling to detect social bots on twitter. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020; pp. 480–487. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. Satar: A self-supervised approach to twitter account representation learning and its application in bot detection. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual, 1–5 November 2021; pp. 3808–3817. [Google Scholar]
- Cardaioli, M.; Conti, M.; Di Sorbo, A.; Fabrizio, E.; Laudanna, S.; Visaggio, C.A. It’s a matter of style: Detecting social bots through writing style consistency. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021; pp. 1–9. [Google Scholar]
- Loyola-González, O.; Monroy, R.; Rodríguez, J.; López-Cuevas, A.; Mata-Sánchez, J.I. Contrast pattern-based classification for bot detection on twitter. IEEE Access 2019, 7, 45800–45817. [Google Scholar] [CrossRef]
- Wei, F.; Nguyen, U.T. Twitter bot detection using bidirectional long short-term memory neural networks and word embeddings. In Proceedings of the 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Los Angeles, CA, USA, 12–14 December 2019; pp. 101–109. [Google Scholar]
- Dukić, D.; Keča, D.; Stipić, D. Are you human? Detecting bots on Twitter Using BERT. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, Australia, 6–9 October 2020; pp. 631–636. [Google Scholar]
- Jia, J.; Wang, B.; Gong, N.Z. Random walk based fake account detection in online social networks. In Proceedings of the 2017 47th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Denver, CO, USA, 26–29 June 2017; pp. 273–284. [Google Scholar]
- Breuer, A.; Eilat, R.; Weinsberg, U. Friend or faux: Graph-based early detection of fake accounts on social networks. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1287–1297. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Luo, M. BotRGCN: Twitter bot detection with relational graph convolutional networks. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Virtual, 8–11 November 2021; pp. 236–239. [Google Scholar]
- Feng, S.; Tan, Z.; Li, R.; Luo, M. Heterogeneity-aware twitter bot detection with relational graph transformers. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 3977–3985. [Google Scholar]
- Liu, Y.; Tan, Z.; Wang, H.; Feng, S.; Zheng, Q.; Luo, M. Botmoe: Twitter bot detection with community-aware mixtures of modal-specific experts. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 485–495. [Google Scholar]
- Pham, P.; Nguyen, L.T.; Vo, B.; Yun, U. Bot2Vec: A general approach of intra-community oriented representation learning for bot detection in different types of social networks. Inf. Syst. 2022, 103, 101771. [Google Scholar] [CrossRef]
- Dehghan, A.; Siuta, K.; Skorupka, A.; Dubey, A.; Betlen, A.; Miller, D.; Xu, W.; Kamiński, B.; Prałat, P. Detecting bots in social-networks using node and structural embeddings. J. Big Data 2023, 10, 119. [Google Scholar] [CrossRef] [PubMed]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Social fingerprinting: Detection of spambot groups through DNA-inspired behavioral modeling. IEEE Trans. Dependable Secur. Comput. 2017, 15, 561–576. [Google Scholar] [CrossRef]
- Gao, C.; Lan, X.; Lu, Z.; Mao, J.; Piao, J.; Wang, H.; Jin, D.; Li, Y. S3: Social-network Simulation System with Large Language Model-Empowered Agents. arXiv 2023, arXiv:2307.14984. [Google Scholar] [CrossRef]
- Feng, S.; Wan, H.; Wang, N.; Tan, Z.; Luo, M.; Tsvetkov, Y. What Does the Bot Say? Opportunities and Risks of Large Language Models in Social Media Bot Detection. arXiv 2024, arXiv:2402.00371. [Google Scholar]
- Edwards, A.L. The relationship between the judged desirability of a trait and the probability that the trait will be endorsed. J. Appl. Psychol. 1953, 37, 90. [Google Scholar] [CrossRef]
- Varol, O.; Davis, C.A.; Menczer, F.; Flammini, A. Feature engineering for social bot detection. In Feature Engineering for Machine Learning and Data Analytics; CRC Press: Boca Raton, FL, USA, 2018; p. 311. [Google Scholar]
- Ratner, A.; Bach, S.H.; Ehrenberg, H.; Fries, J.; Wu, S.; Ré, C. Snorkel: Rapid training data creation with weak supervision. In Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, Munich, Germany, 28 August–1 September 2017; Volume 11, p. 269. [Google Scholar]
- Terry, J.; Black, B.; Grammel, N.; Jayakumar, M.; Hari, A.; Sullivan, R.; Santos, L.S.; Dieffendahl, C.; Horsch, C.; Perez-Vicente, R.; et al. Pettingzoo: Gym for multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2021, 34, 15032–15043. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Bot Strategy | Survival Rate | Avg. Bot Score (SD) |
|---|---|---|---|
| Fake account and RF detector | Baseline | 86.7% | 0.410 (0.014) |
| Additional actions | 81.8% | 0.377 (0.011) | |
| Additional actions + profile editor | 94.0% | 0.352 (0.014) | |
| Additional actions + preselection | 99.7% | 0.403 (0.006) | |
| Combined | 99.0% | 0.354 (0.013) | |
| Fake account and BotRGCN | Baseline | 58.5% | 0.082 (0.084) |
| Additional actions | 85.9% | 0.115 (0.063) | |
| Additional actions + profile editor | 60.0% | 0.086 (0.066) | |
| Additional actions + preselection | 48.8% | 0.028 (0.128) | |
| Combined | 49.0% | 0.083 (0.079) |
| Scene | Bot Strategy | Survival Rate | Avg. Bot Score (SD) | (SD) | (SD) | |
|---|---|---|---|---|---|---|
| Influencer & RF detector | 0.003 | Baseline | 65.4% | 0.382 (0.015) | 29,942 (8.057) | 7,595,250 (1845.121) |
| 0.003 | Additional actions | 59.5% | 0.401 (0.018) | 26,426 (7.706) | 6,292,190 (1950.827) | |
| 0.0025 | Additional actions + profile editor | 97.9% | 0.359 (0.014) | 36,320 (8.042) | 7,878,764 (2016.605) | |
| 0.0025 | Additional actions + preselection | 98.6% | 0.408 (0.014) | 34,392 (8.782) | 7,188,792 (2302.556) | |
| 0.0025 | Combined | 84.2% | 0.389 (0.017) | 30,584 (7.687) | 6,416,062 (1990.133) | |
| Influencer & BotRGCN | 0.003 | Baseline | 34.1% | 0.009 (0.054) | 20,874 (7.366) | 4,335,142 (2374.298) |
| 0.003 | Additional actions | 18.8% | 0.011 (0.103) | 13,470 (6.789) | 3,119,952 (1957.740) | |
| 0.003 | Additional actions + profile editor | 37.2% | 0.011 (0.057) | 22,884 (5.877) | 4,408,418 (1721.843) | |
| 0.004 | Additional actions + preselection | 60.0% | 0.002 (0.041) | 39,542 (8.030) | 8,932,088 (2629.436) | |
| 0.003 | Combined | 34.1% | 0.002 (0.043) | 31,620 (6.562) | 6,610,018 (1997.801) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, R.; Liao, Y. Prevention Is Better than Cure: Exposing the Vulnerabilities of Social Bot Detectors with Realistic Simulations. Appl. Sci. 2025, 15, 6230. https://doi.org/10.3390/app15116230
Jin R, Liao Y. Prevention Is Better than Cure: Exposing the Vulnerabilities of Social Bot Detectors with Realistic Simulations. Applied Sciences. 2025; 15(11):6230. https://doi.org/10.3390/app15116230
Chicago/Turabian StyleJin, Rui, and Yong Liao. 2025. "Prevention Is Better than Cure: Exposing the Vulnerabilities of Social Bot Detectors with Realistic Simulations" Applied Sciences 15, no. 11: 6230. https://doi.org/10.3390/app15116230
APA StyleJin, R., & Liao, Y. (2025). Prevention Is Better than Cure: Exposing the Vulnerabilities of Social Bot Detectors with Realistic Simulations. Applied Sciences, 15(11), 6230. https://doi.org/10.3390/app15116230