1. Introduction
With the acceleration of industrialization, the demand for electric power continues to grow, and higher requirements are put forward for the reliability, safety, and stability of transmission lines. As critical components in power infrastructure, insulators perform the dual functions of mechanical support and electrical insulation. Subjected to prolonged exposure to extreme environmental conditions, these components face degradation risks, including spontaneous fracturing and surface flashover. Such failures will not only trigger power outages, but also may lead to conductor damage, fire, and other serious consequences, resulting in huge economic losses and security risks. Therefore, the regular inspection of insulators is absolutely necessary to ensure the stable operation of the power grid [
1,
2,
3,
4].
The traditional manual inspection method faces problems such as complicated terrain, low efficiency, and high personal risk [
5]. In recent years, with the development of drones and computer vision technology [
6], the use of drones carrying optical sensors to obtain images, and then through the vision algorithm to identify insulator defects, has gradually become the mainstream method [
7,
8,
9,
10].
Nowadays, with the continuous development of computer vision, a variety of computer vision-based methods have been applied to insulator image detection over the past few years, including image-processing-based and deep-learning-based ones, achieving remarkable results. Traditional methods such as Histogram of Oriented Gradients (HOG) [
11], Scale-Invariant Feature Transform (SIFT) [
12], and Local Binary Patterns (LBPs) [
13] rely on manual feature design, making them susceptible to shooting angles and lighting changes. Consequently, they have poor generalization ability and low detection accuracy. In contrast, deep-learning-based object detection methods like Faster R-CNN [
14], SSD [
15], and the YOLO series [
16,
17,
18,
19,
20,
21,
22,
23,
24] offer higher robustness and detection performance. While two-stage algorithms boast high accuracy, their computational complexity is significant. In comparison, single-stage algorithms, with their lighter structure and faster speed, are more suitable for deployment on resource-constrained drone platforms.
Although the above research work has addressed some of the difficulties in inspecting insulators by UAVs to a certain extent, there are still more challenges that have not been effectively addressed. Most of these problems arise from the practical engineering applications to which they are oriented.
The significant variation in insulator and defect sizes poses a major challenge to conventional detection algorithms. Drones, equipped with high-precision cameras, capture high-resolution images from afar, making the objects seem quite small relative to the overall image. Moreover, variations in shooting distance and angle further amplify these size discrepancies, thus undermining the effectiveness of standard detection methods. In existing research on power line insulator defects, a strategy of constructing a multi-scale fusion network is typically employed for multi-scale objects. Han et al. [
25] integrated an scSE attention mechanism with PA-Net to address multi-scale detection challenges. However, their approach merged features from only two levels and utilized numerous lightweight Ghost modules, which lessened the model’s overall detection performance. In contrast, He et al. [
26] put forward ResPANet, a multi-scale feature fusion framework that leverages residual jump connections to integrate high- and low-resolution features, thereby improving multi-scale detection capability without adding to the computational cost. Despite this progress, the method did not incorporate a 160 × 160 feature map that contains rich information, limiting its effectiveness for small objects. Similarly, Li et al. [
27] concentrated on large-scale feature maps through a Bi-PAN-FPN approach, enhancing the frequency and duration of multi-scale feature fusion to lower false and missed detections in aerial images. As can be seen from the above literature, employing the method of fusing features of different levels can boost the detection ability for multi-scale objects to a certain extent. These detection methods offer references for multi-scale object detection.
Current deep learning implementations face a critical efficiency–accuracy tradeoff, where computational complexity escalates alongside precision enhancement, severely impeding deployment feasibility on edge devices like UAVs with constrained resources. To address this challenge, Han et al. [
25] developed a context-streamlined convolutional framework (C2fGhost) that achieves 75.7% parametric compression through architectural pruning. Qu et al. [
28] developed a lightweight insulator feature pyramid network (LIFPN) alongside a compact insulator-oriented detection head (LIHead) to trim model parameters. Aiming to preserve accuracy while drastically cutting parameters, Li et al. [
29] created a new lightweight convolution module, EGC; built the backbone network around it; and employed a lightweight EGC-PANet in the neck section for efficient feature fusion and further parameter reduction. From the above reference, it is evident that the mainstream methods for reducing parameter volume generally involve modifications to network architecture, often at the expense of some degree of accuracy.
The detection accuracy of insulators is often limited by complex backgrounds and insufficient feature extraction capabilities.The extensive distribution of high-voltage power lines, along with varied terrain, causes a high degree of resemblance between objects and their backgrounds, posing a tough challenge for detection. Zhou et al. [
30] proposed a cascaded structure as the backbone network, yet this increased model complexity considerably. Zhao et al. [
31] enhanced the Faster R-CNN model by adding a feature pyramid network (FPN) to identify insulators in complex-background images. Nevertheless, combining the two-stage Faster R-CNN model with the FPN network further complicates the model, creating difficulties in both training and detection.
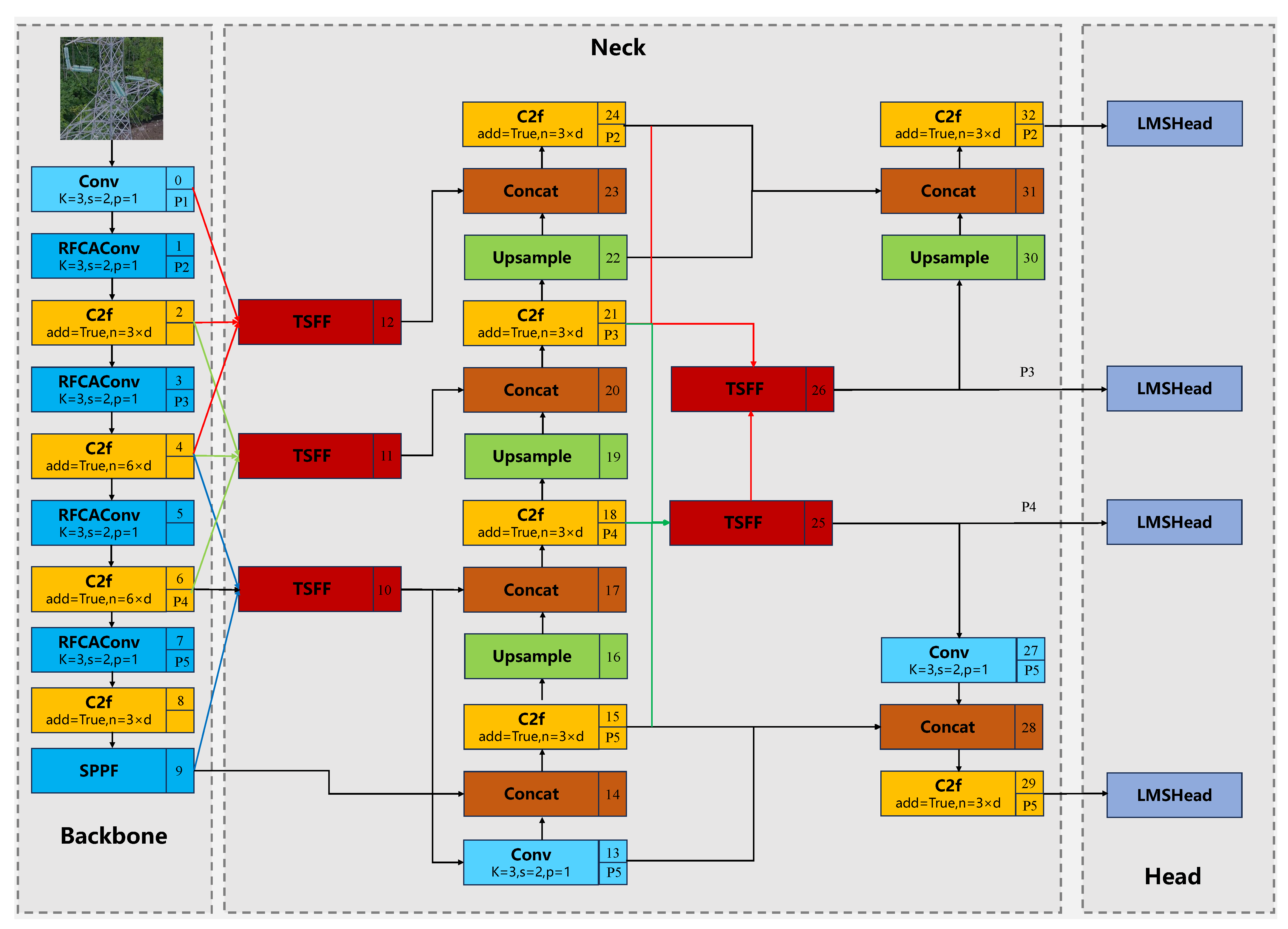
The referenced studies provide a foundation for our research. While existing detection algorithms address some challenges in drone-based insulator inspection, they fall short in handling issues like significant object size variation and high parameter volume. To address these challenges, this paper proposes RML-YOLO, a lightweight, multi-scale insulator defect detection method for drone-captured images. The core innovations are MSFENet and LMSHead, which enhance multi-scale object detection while reducing model parameters. The key contributions are as follows:
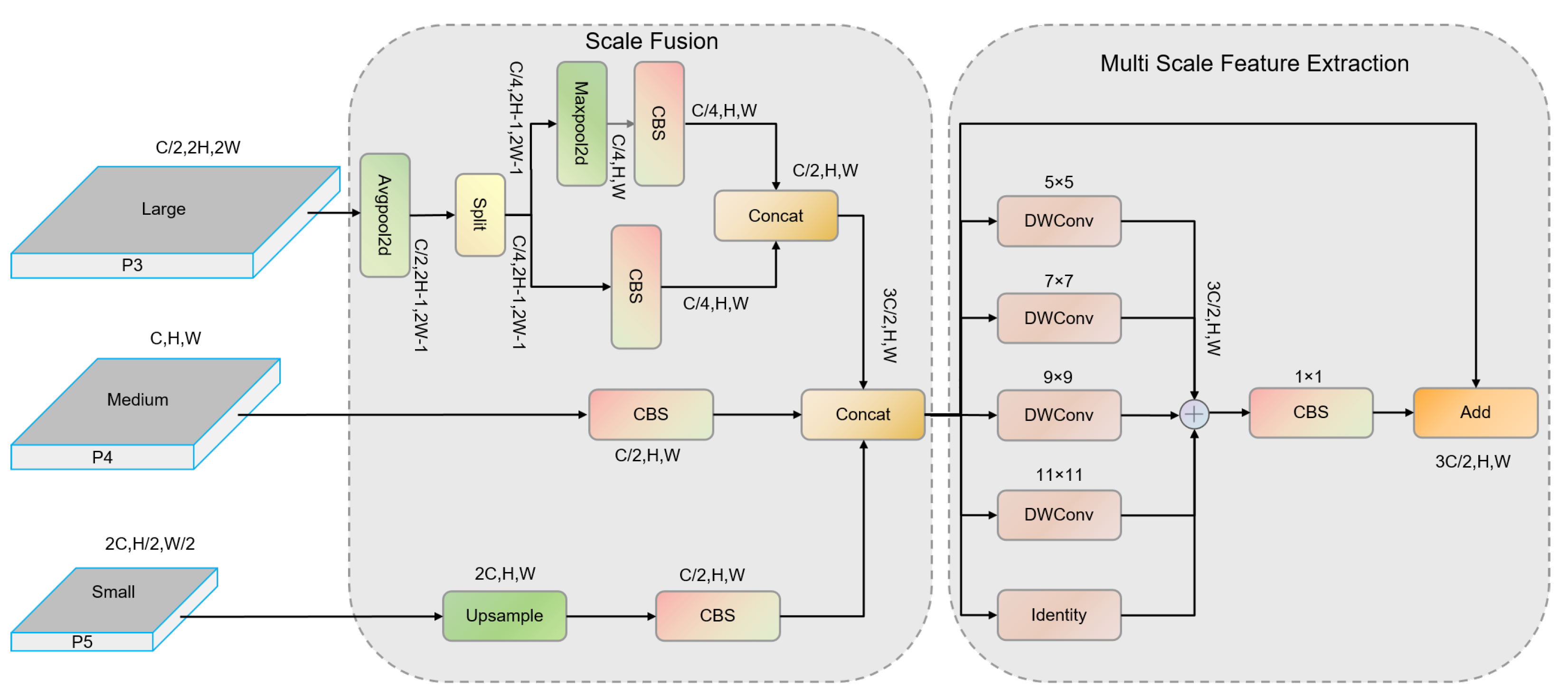
To address the challenges posed by the large variation in insulator and defect sizes, we propose MSFENet. This network improves upon traditional FPN by proposing a TSFF module to better fuse features across different layers. A multi-head detection strategy is employed to enhance the model’s ability to detect multi-scale objects.
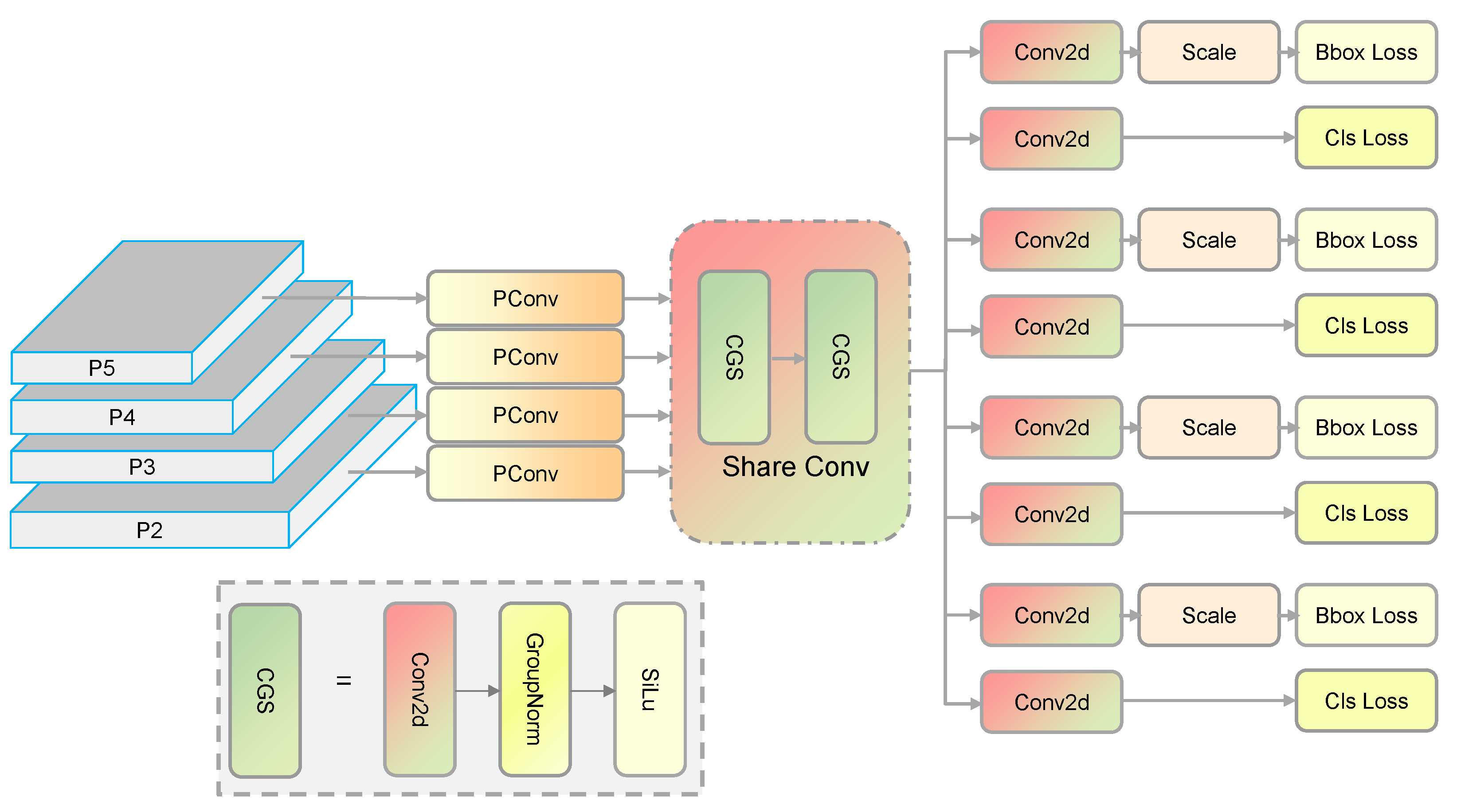
To mitigate the issue of high parameter volume in existing detection algorithms, we propose LMSHead, a lightweight multi-scale shared detection head. This head utilizes partial convolutions to extract features from various levels and applies shared convolutions to reduce model size and parameter count, while addressing the uneven distribution of objects across scales.
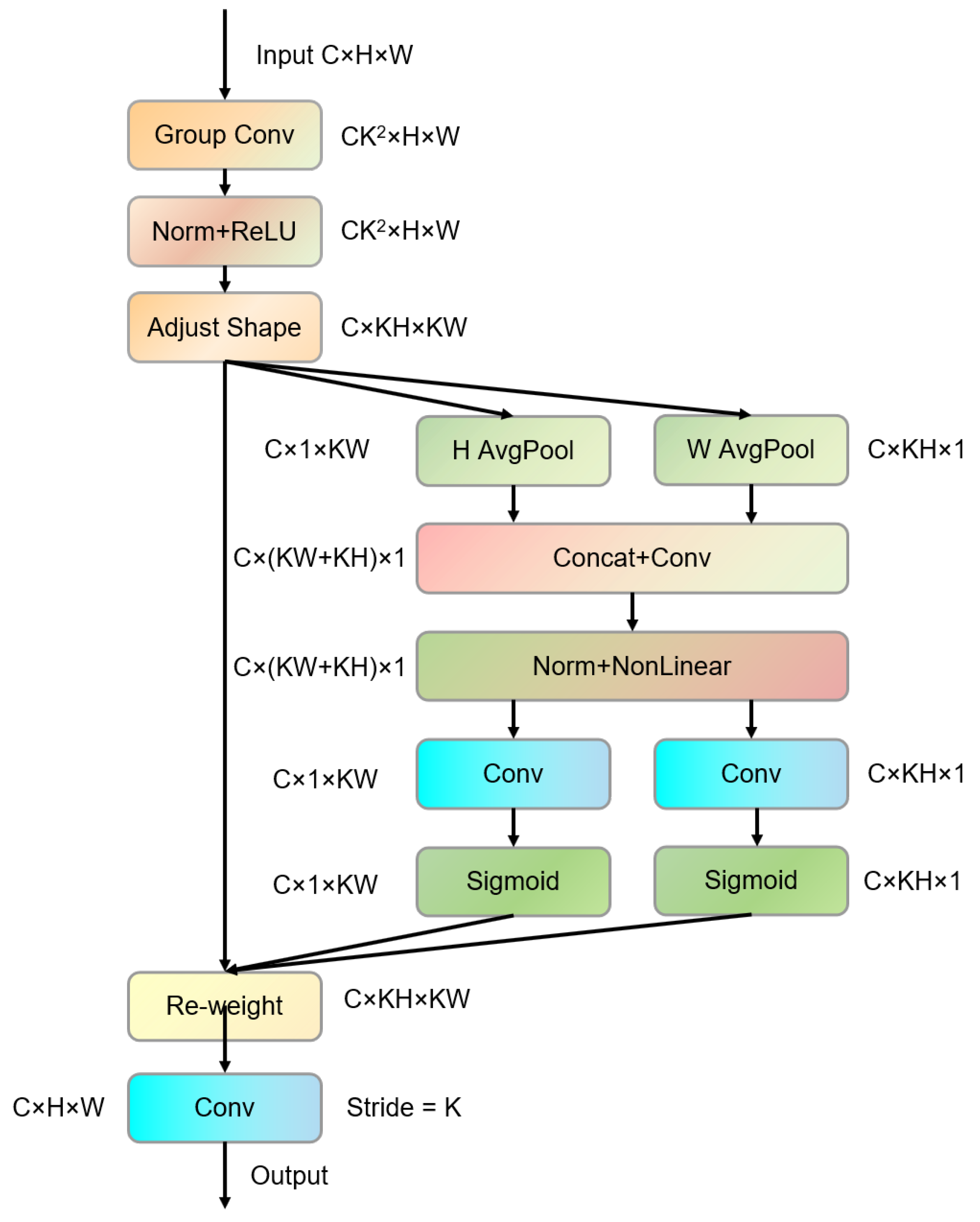
To improve detection performance in complex backgrounds, we incorporate RFCAConv, which enhances feature extraction by aggregating information from different receptive fields. This convolution, combined with CA attention mechanisms, allows the model to effectively capture features from various positions, overcoming the limitations of standard convolutions.
These innovations collectively improve detection accuracy, reduce computational complexity, and enhance the model’s robustness in challenging environments.
The remainder of this paper is organized as follows:
Section 2 of this paper provides a comprehensive overview of the methods employed in this study, with a detailed description of the proposed MSFENet and LMSHead architectures.
Section 3 introduces the datasets used in the research, along with the experimental environment, parameter settings, evaluation metrics, and experimental results, followed by an in-depth analysis of these results.
Section 4 discusses the strengths and limitations of the current study, explores the potential for applying the proposed improvements to other models, and outlines future research directions. Finally,
Section 5 presents a summary of the main research content and findings of this paper.
3. Results
3.1. Dataset
Tao et al. [
36] collected and constructed a public dataset of insulators called Chinese Power Line Insulator Dataset (CPLID). This dataset includes normal insulator images and synthesized defective insulator images acquired via UAVs, showcasing diverse backgrounds of overhead insulators such as urban, riverine, field, and mountainous environments. Later, Andrel et al. [
37] demonstrated the generalization capability of the proposed algorithm by means of stochastic affine transformation, Gaussian blurring, and lossless transformation to achieve further data enhancement for CPLID, which constructed the Unified Public Dataset for Insulators (UPID) with 6860 training and test images. Zhang et al. [
38] enhanced the UPID dataset by using stochastic luminance and fog thickness, which constructed a new Synthetic Foggy Insulator Dataset (SFID), which contains 13,718 images. The dataset is more comprehensive and complex.
However, there are still many shortcomings in the SFID dataset, because most of the insulators and defective objects in the SFID dataset are enhanced and synthesized, which are different from the real UAV inspection images, and the defective objects in SFID are often much larger than those in the real aerial images, so it is difficult to adapt the trained model on the SFID dataset to the real scene of the inspection. Therefore, in this paper, insulator defect data obtained from real UAV inspection aerial photography are collected.
In this paper, the dataset mainly uses DJI multi-rotor UAV series (such as DJI Royal 2, Royal 3, and DJI M300RTK), unmanned helicopters, etc. By carrying dual-optical pods and other low-altitude image acquisition equipment to obtain image data of the power lines, we collected 563 pictures containing defective insulators, and labeled the data through LabelImg software, which contains multiple detection objects for each picture. Each picture in the dataset contains multiple object detection objects, and the object labeling is divided into two types: normal insulators and defective insulators. Randomly partition the dataset in an 8:2 ratio, and obtain an initial training set containing 450 images and an initial validation set containing 113 images. Then the data are enhanced based on the 563 pictures by random rotation, random luminance, rain, snow, fog, etc.; the pictures are scaled in equal proportions; the widest or the highest side of the scaled pictures is 640 pixels; and the enhanced pictures have 2250 pictures in the training set. After the picture, there are 2250 pictures in the training set and 452 pictures in the validation set data; we named this dataset as UID. Since the dataset collected in this paper originates from real detection scenarios, compared with other publicly available insulator datasets, the UID features complex object backgrounds and a high number of small objects, making this dataset more challenging.
Figure 6 provides some UID dataset samples.
The detailed information of the dataset is shown in
Figure 7, where a represents the number of labels for normal and defective insulators in the dataset, with the number of normal insulators being much higher than the number of defective insulators; b represents the size of the bounding box, indicating that there are more small- and medium-sized target boxes; c represents the center coordinate distribution of the bounding box, indicating that the bounding box distribution is relatively uniform; and d represents the aspect ratio of the target relative to the entire image. It can be seen that the scattered points in the lower-left corner are denser, indicating that there are more small- and medium-sized targets in the dataset.
3.2. Experimental Environment and Configuration
All experiments were conducted on the Windows 10 system, which was equipped with Intel Xeon Bronze 3104 CPU@1.70 GHz, 12 GB NVIDIA GeForce RTX 3060 GPU, Python 3.9, CUDA 12.1, and PyTorch 2.1.0. YOLOv8 is used as the base model, and the optimizer defaults to SGD. Other parameter settings are the same.
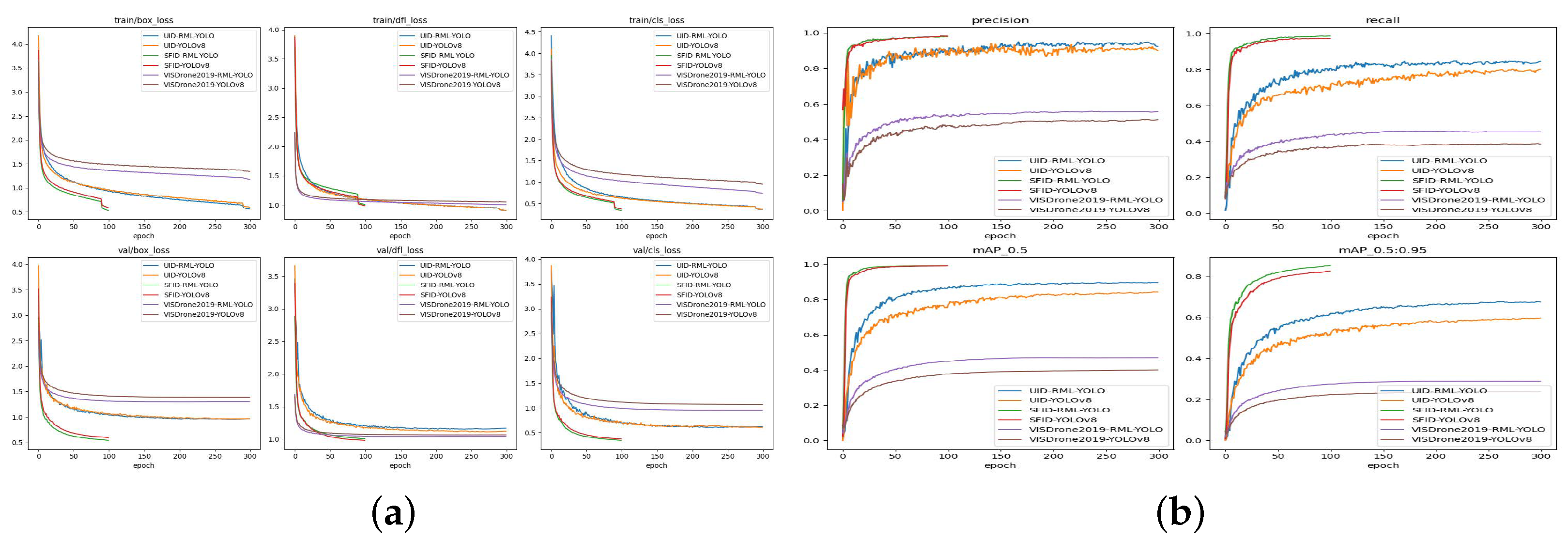
Figure 8a shows the loss plots of RML-YOLO and YOLOv8 trained on three different datasets. It can be seen that the training and validation losses of all models continue to decrease with the increase in iteration times. Among them, the SFID dataset has the fastest loss reduction rate and tends to stabilize at 100 epoch without overfitting problems.
Figure 8b shows the training results of RML-YOLO and YOLOv8 on three different datasets. It can be seen that, on the SFID dataset, mAP50 has become extremely stable and tends to approach 1 after 50 epoch, while mAP50-95 also tends to stabilize at 100 epoch without overfitting. Therefore, setting the training epoch of the SFID dataset to 100 is a more appropriate choice in the article. On the UID and VISDrone2019 datasets, accuracy and recall, as well as mAP50 and mAP50-95, begin to stabilize after 250 epoch, and no overfitting occurs at 300 epoch. Therefore, the training epoch on the UID and VISDrone2019 datasets are set to 300.
3.3. Evaluation Metrics
Object detection algorithms often use the competitive evaluation metrics of PASCAL VOC and MS COCO [
39]. Both VOC and COCO evaluation metrics use Mean Average Precision (mAP) to measure the detection performance of the model. The calculation of
involves the calculation of related indicators such as Precision and Recall. The following will introduce these evaluation metrics and parameters.
Unlike classification tasks, in object detection tasks, it is necessary not only to predict the category of the target, but also to accurately locate the position of the target. The commonly used evaluation parameter is the intersection to union ratio (IoU), which calculates the ratio of the intersection and union between the predicted box and the true box to measure the degree of overlap between the predicted result and the true result. The calculation formula is shown in Equation (
10). Among them,
represents the real bounding box,
represents the predicted bounding box by the model, and the higher the IoU threshold, the closer the predicted result is to the real result. When
reaches 1, it represents that the predicted result completely overlaps with the actual result.
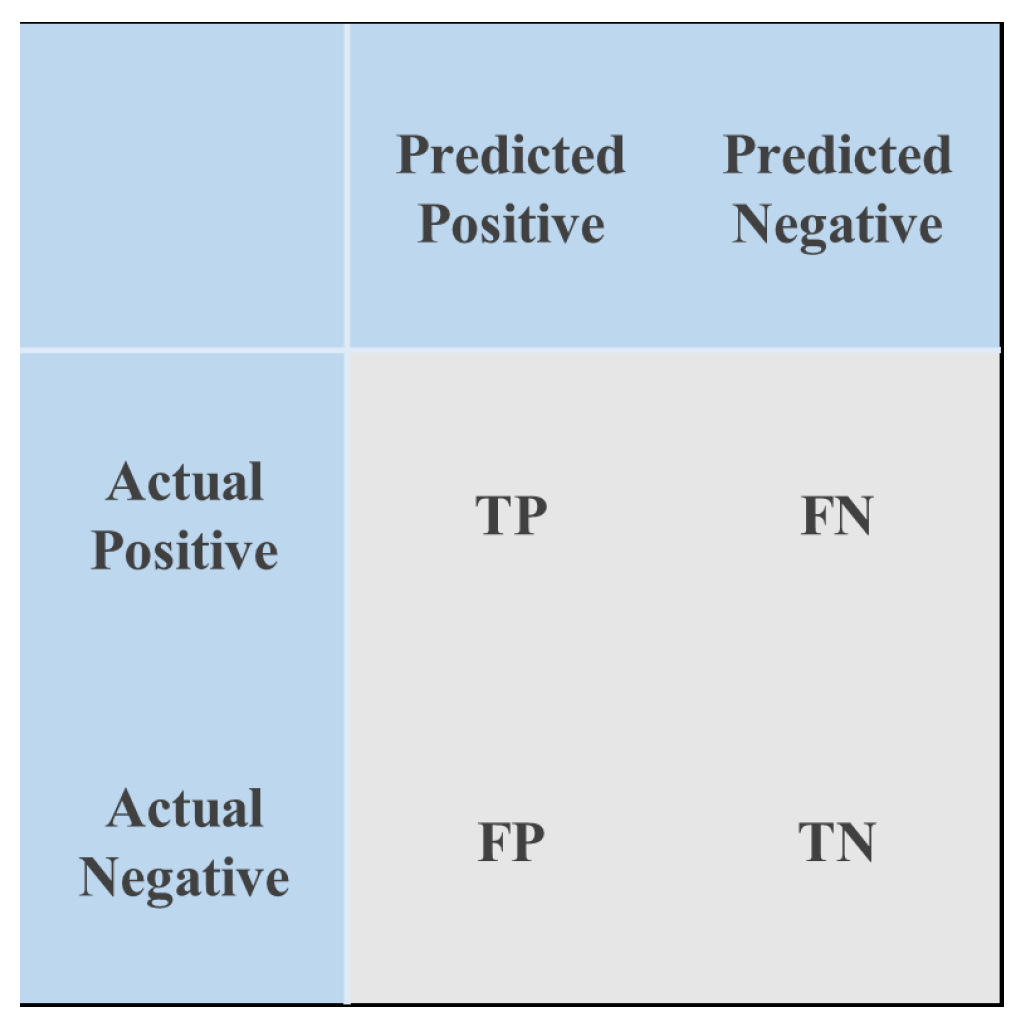
For the prediction of targets, it can be divided into four categories, as shown in
Figure 9. Precision refers to the proportion of true-positive cases predicted to be correct among all predictions, used to measure the probability of positive cases being correctly predicted in the prediction results. The calculation formula is shown in Equation (
11).
Recall refers to the proportion of predicted true-positive cases to the total number of actual positive samples, used to reflect missed detections. The calculation formula is shown in Equation (
12).
Through the formulas of Precision and Recall, it can be found that there is a certain degree of mutual exclusivity between Precision and Recall. When the IoU threshold is set high, the actual insulator may be predicted as the background, resulting in an increase in missed detections, an increase in FN, and a decrease in Recall. Similarly, when the IoU threshold is set low, false detections will increase, while missed detections will decrease, FP will increase, and therefore Precision will decrease. Therefore, evaluating network performance solely based on one evaluation metric is not comprehensive. Therefore, a PR curve is generally drawn to comprehensively evaluate detection performance. The horizontal axis of the PR curve represents the recall rate, the vertical axis represents the accuracy rate, and the area below the curve represents the AP value. The calculation formula for AP is shown Equation (
13).
In the VOC evaluation index, AP is the evaluation of a single category, while mAP represents the average AP of all categories in the dataset. The higher the mAP value, the better the detection performance of the model. The calculation method for mAP is shown in Equation (
14).
Compared with VOC evaluation metrics, COCO evaluation metrics adopt stricter standards and incorporate considerations for the average precision of targets at different scales. There are six commonly used COCO evaluation metrics: , , , , , and . AP50 and AP75 denote the evaluation results under different IoU thresholds, which correspond to at and in the PASCAL VOC evaluation metrics. The metric is defined as the calculated across IoU thresholds ranging from 0.5 to 0.95 in steps of 0.05, with the final result being the arithmetic mean of the values across these thresholds within the interval. , , and correspond to the mAP values for small-scale, medium-scale, and large-scale objects, respectively. Small-scale objects (S) refer to those with a pixel area smaller than , medium-scale objects (M) have a pixel area within the range of , and large-scale objects (L) refer to those with a pixel area larger than .
Due to the possible differences in the calculation methods of the evaluation indicators inherent in each object detection algorithm, while the COCO evaluation indicator has stricter standards, in order to ensure fairness in comparative experiments, this article will uniformly use the COCO evaluation indicator to evaluate the detection performance of the model.
For lightweight indicators, parameter quantity and model size are selected for evaluation. The number of model parameters and the model size together reflect the complexity of the model, where parameter quantity specifically refers to the total number of parameters that the model needs to optimize and learn during the training phase. The model size refers to the actual size of the model file in the storage space. Generally, models with fewer parameters and smaller models have relatively lower storage and computational costs, which is beneficial for running on resource-constrained devices. However, most lightweighting comes at the cost of sacrificing model performance, so when designing and selecting models, a balance between model complexity and performance needs to be comprehensively considered.
3.4. Ablation Experiment
In order to analyze the degree of influence of different modules on the model, we performed ablation analysis on the model proposed in this paper on the UID dataset. Among them, R is the RFCAConv module, M is MSFENet, and L is LMSSPH, and the experimental results are shown in
Table 1. In the article, the best results are shown in bold, and the second-best results are indicated with underline. After adding the RFCAConv module, the size of the model and the number of parameters increased slightly, and
,
, and
increased by 2.6%, 2.8%, and 2.6% respectively, which fully demonstrates the RFCAConv module’s feature extraction capability. After adding MSFENet,
increases by 3.9%, 2.2%, and 5.7% compared with the base model, and
,
, and
increase by 5.7%, 1.3%, and 3.2% compared with the base model, respectively, and the accuracy of object detection at the three scales is improved, with the effect of the detection of the small object being much better than that of the other scales, which proves the effect of the design for small object detection in MSFENet. Upon integrating the LMSHead module, a reduction of over 500,000 parameters and a model size decrease of 1.2 MB are achieved. Remarkably, these changes do not compromise performance; in fact,
,
, and
show further gains of 3.4%, 2.6%, and 5.3% respectively, underscoring LMSHead’s role in optimizing efficiency without sacrificing detection accuracy.
The algorithm designed in this paper, RML-YOLO, compared with the base model YOLOV8, has a drop of 500,000 in the number of participants. With the model size decreasing by 0.8 M, , , and increased by 7.8%, 5.5%, and 11.1%, respectively, while , , and increased by 10%, 2.7%, and 6.7%, respectively, which effectively proves the effectiveness of the improvements proposed in this paper.
3.5. UID Dataset Comparison Experiment
To demonstrate the superiority of the proposed algorithm, we conducted comparative experiments with several classic and state-of-the-art general-purpose object detection algorithms, including Faster R-CNN, YOLOv5, YOLOv7, YOLOv8, YOLOv9, YOLOv10, and Gold-YOLO. The YOLO series offers various versions of differing sizes (e.g., n, s, m, l, x). Given our focus on deployment in resource-constrained environments, we uniformly selected the most lightweight version of each model for comparison. All experimental codes were sourced from official implementations: YOLOv5 and YOLOv8 were obtained from the same version of Ultralytics, while Faster R-CNN was obtained from MMDetection (version: faster-rcnn_r50_fpn_1x). To ensure the fairness of the comparative experiments, all models were trained and evaluated on the same dataset, using identical hardware and experimental environments, and adhering strictly to the official model specifications and experimental settings.
As shown in
Table 2, although YOLOv5-n has 0.01 million fewer parameters and a model size 0.2 MB smaller than the proposed RML-YOLO, RML-YOLO demonstrates superior detection performance across all metrics. Specifically, RML-YOLO achieves
,
, and
values that are 7.45%, 4.87%, and 11.62% higher than those of YOLOv5-n, respectively, with
being 9.7% higher. YOLOv7-tiny exhibits strong performance in small object detection, achieving an
of 52.1%; however, this still falls 9.2% short of RML-YOLO. In terms of overall performance, YOLOv7-tiny ranks second to RML-YOLO. Compared with YOLOv7-tiny, RML-YOLO achieves improvements of 6.8%, 1.95%, and 10.82% in
,
, and
, respectively, despite having only 41.7% of YOLOv7-tiny parameters and 44.7% of its model size.
To further validate the performance of RML-YOLO, we also conducted comparisons with other algorithms that have performed well in the field of insulator defect detection, including LiteYOLO-ID proposed by Li et al. [
29] and CACS-YOLO proposed by CAO et al. [
40]. Since LiteYOLO-ID is an improvement based on YOLOv5s, and CACS-YOLO is an enhancement built upon YOLOv8-m, to ensure a fair comparison of the performance among these algorithms, we not only compared them with the versions used in the original papers but also evaluated their performance when improved upon the most lightweight versions of the models.
The experimental results are summarized in
Table 3. Both versions of the CACS-YOLO algorithm exhibit lower performance compared with RML-YOLO. RML-YOLO and CACS-YOLO are improvements based on YOLOv8. In the lightest
n version, RML-YOLO has 8% higher
and 11.1% higher
than CACS-YOLO-n, while RML-YOLO has 0.13 million fewer parameters than CACS-YOLO-n. Compared with CACS-YOLO-m,
is 2.2% higher. LiteYOLO-ID-m demonstrates greater success in lightweight improvements. LiteYOLO-ID-n has a parameter count of only 0.94 million and a model size of 2.14 MB, but its performance is subpar, with
,
, and
scores that are 16.7%, 11.7%, and 21.7% lower than those of RML-YOLO, respectively. In particular, LiteYOLO-ID-n performance in detecting small objects is 20.7% lower than that of RML-YOLO. Compared with its lighter
n version, LiteYOLO-ID-m shows improved performance with an
of 55.9%, but this comes at the cost of increased parameter count and model size, which are 1.25 million higher than those of RML-YOLO, while its
is still 9.8% lower than that of RML-YOLO.
These results demonstrate that our model, RML-YOLO, can maintain high detection accuracy at a lower computational cost, making it particularly suitable for applications on devices with limited resources.
3.6. SFID Dataset Comparison Experiment
In order to further demonstrate the ability of the algorithm proposed in this paper for insulator detection, comparative experiments were conducted on the public insulator dataset SFID.
The comparative results of general object detection algorithms on the SFID dataset are presented in
Table 4. Due to the relatively large object objects in the SFID dataset and the absence of tiny objects, the detection difficulty is comparatively low. Consequently, YOLOv7-tiny, which performs well on small object detection, achieves an
of only 76.02% on SFID. The
values across different models show minimal variation; however, the proposed RML-YOLO model remains superior to all other algorithms. On the SFID dataset, YOLOv8-n achieves the second-best
and
, which are 0.32% and 1.18% lower than those of RML-YOLO, respectively. Faster R-CNN also performs notably well, achieving an
of 83.1%, second only to RML-YOLO. However, Faster R-CNN comes with a significant drawback: its parameter count reaches 41.7 million, and its model size is 315 MB, which are several times larger than those of RML-YOLO. This substantial computational demand makes Faster R-CNN unsuitable for deployment on resource-constrained devices.
We also conducted comparisons with other algorithms that have performed well in the field of insulator defect detection. As shown in
Table 5, it can be observed that CACS-YOLO has an
that is 2.5% higher than that of RML-YOLO, and both models achieve an
of 99.3%. However, the number of parameters in CACS-YOLO is nearly eleven times that of RML-YOLO, and its model size is ten times larger. When comparing the lightweight n series models, it is evident that both CACS-YOLO and RML-YOLO have a model size of 5.5 MB, but the
of CACS-YOLO-n is 3.4% lower than that of RML-YOLO. Meanwhile, although LiteYOLO-ID-n has a smaller parameter count and model size, its performance decreases correspondingly, with an
that is 16.6% lower than that of RML-YOLO.
Overall, whether on the highly challenging UID dataset constructed in this study or on the publicly available large-scale insulator defect dataset SFID, RML-YOLO demonstrates excellent performance, ensuring high detection accuracy while maintaining a lightweight design. This makes it particularly suitable for applications on resource-constrained devices, such as drones, for the detection of insulator defects.
3.7. Comparative Experiments on Generalizability
In order to demonstrate that the algorithm proposed in this paper has some generalization ability, comparative experiments are conducted on the open-source insulator dataset SFID and the UAV dataset VISDrone 2019.
The VISDrone2019 dataset collects data from various drone cameras, including different cities, environments, and objects. Due to the effects of shooting angles, lighting, background, and other factors, detecting data from drones is more challenging than traditional computer vision tasks. The algorithm proposed in this paper will also be deployed on drones in the future; therefore, the VISDrone2019 dataset is chosen to further demonstrate the generality of the proposed algorithm.
As can be seen from
Table 6 experimental results, in terms of performance, RML-YOLO is a little bit weaker for large object detection, but it is in the lead in all other performance metrics. The algorithm proposed in this paper improves by 3.9% in AP compared with the base model YOLOV8 AP, 6.2% in AP50, 4.7% in AP75, 4.3% in detection accuracy for small objects, 3.9% for meso-scale objects, and 3.2% for large objects. RML-YOLO compares with YOLOv7-tiny with the second-best overall performance, AP compares with YOLOv7-tiny, and 3.2% for large objects. objects by 3.9%, and large-scale objects by 3.2%. RML-YOLO compares with YOLOv7-tiny, which has the next best overall performance, with 3.5% higher AP and 2.3% higher AP50 than YOLOv7-tiny. In addition, this paper also compares specialized object detection algorithms for UAV scenarios including HIC-YOLO proposed by Tang et al. [
41] and Drone-YOLO proposed by Zhang et al. [
42]. It can be seen that the accuracy of RML-YOLO still maintains the lead when compared with the specialized object detection algorithms for UAVs; and its AP, AP50, and AP75 are 2.1% higher than that of Drone-YOLO by 2.1%, 3.8%, and 2.4%, respectively; and its detection ability for small objects is slightly lower than HIC-YOLO but still ranks second; and its APS is 4.6% higher than the CACS-YOLO algorithm and 1.8% higher than Drone-YOLO. The excellent performance of RML-YOLO under the UAV aerial photography dataset demonstrates the generalization ability of the algorithm proposed in this paper. It not only is capable of detecting insulators, but also maintains detection performance on the VISDrone 2019 dataset in complex environments with different scenes, weather and lighting conditions. This further proves the possibility of promoting RML-YOLO on another drone aerial object.
3.8. Visual Comparative Experiment
In addition, in
Figure 10, this article compares the detection performances of mainstream object detection algorithms on an UID dataset. The figure shows various scene combinations, including noise, complex background, low light, rainy and snowy days, small objects, occlusion, etc.
In
Figure 10a, the main challenges are noise interference and complex background. From the visualization of detection results, it can be observed that RML-YOLO, LiteYOLO-ID, CACS-YOLO, YOLOv8, and Faster-RCNN successfully detected all objects. However, both YOLOv7 and Gold-YOLO exhibited false positives; YOLOv7 falsely identified weeds in the background as normal insulators and misclassified a normal insulator in the top-right corner as a defective one, failing to recognize both normal and defective insulators against the complex left background. Gold-YOLO successfully detected defective insulators but missed the normal insulator on the left and falsely detected background interference as normal insulators. YOLOv9 did not detect any objects in this image.
In
Figure 10b, the main challenges include complex backgrounds and small object. Ultimately, only RML-YOLO, YOLOv10, and CACS-YOLO successfully identified all object without false detections. Faster-RCNN, YOLOv7, YOLOv9, and Gold-YOLO all produced false positives by misclassifying background weeds as insulators.
In
Figure 10c, the key challenges are low illumination, partial occlusion, and small object. Due to partial occlusion affecting the second insulator from the right, Faster-RCNN, YOLOv8, YOLOv10, and LiteYOLO-ID failed to detect this partially occluded object. Only RML-YOLO, YOLOv5, and CACS-YOLO detected all object, though YOLOv5 yielded a low confidence score (0.27) for the occluded object.
In
Figure 10d, the main challenges are random rain interference and complex backgrounds. Faster-RCNN and YOLOv10 failed to detect defective insulators. YOLOv10 misclassified a normal insulator on the left, affected by random rain as a defective one. While YOLOv7 detected all object, it mistakenly identified leaves on the right as normal insulators.
In
Figure 10e, the challenges are small targets and complex backgrounds. The defective insulator is on the left, located at the image edge with indistinct features and susceptible to interference from surrounding wires. Only RML-YOLO correctly identified the object. The defective insulator above was more apparent: hence, all algorithms successfully recognized it.
In
Figure 10f, challenges arise from occlusion and complex backgrounds. The left insulator and its defective region are partially occluded. Only RML-YOLO and Faster-RCNN successfully recognized them, while YOLOv5, YOLOv9, and LiteYOLO-ID failed to detect the occluded normal insulator with background interference on the left.
Comprehensive analysis indicates that RML-YOLO maintains robust detection performance against challenges including complex backgrounds, occlusions, and small targets, making it suitable for object detection tasks in most scenarios.
4. Discussion
This paper proposes an insulator defect detection method for UAV aerial images, which enhances multi-scale target detection capabilities while reducing the model’s parameter count. The proposed algorithm introduces a multi-scale feature extraction network (MSFENet) that addresses the limitations of conventional FPNs, including insufficient information fusion and inadequate focus on large-scale feature layers. To overcome these issues, a Two-Stage Feature Fusion (TSFF) module is introduced, enabling the fusion of features from different levels and enhancing the model’s multi-scale detection performance through a multi-head detection strategy. To address the problem of excessive parameters in existing object detection algorithms, a lightweight Multi-Scale Shared Parameter Head (LMSSPH) is proposed. This detection head adopts a shared parameter design, effectively reducing the model’s size and parameter count while maintaining robust performance by leveraging a multi-head detection strategy. Considering the challenge of insufficient feature extraction in complex backgrounds, which often leads to degraded insulator detection performance, this study incorporates RFCAConv—a convolutional module that aggregates features with varying receptive fields. This design enables the model to effectively capture features from different spatial locations.
Experimental results on the UID and SFID datasets demonstrate that RML-YOLO achieves high detection accuracy for insulators and defects, with AP50 values of 88.3% and 99.3%, respectively, indicating that the model can effectively detect most insulator targets. Furthermore, experiments on the VISDrone2019 dataset confirm the algorithm’s generalization capability, achieving an AP that is 2.1% higher than that of Drone-YOLO, a dedicated target detection algorithm for UAV aerial scenarios. This result demonstrates that the model can accurately detect not only insulator targets but also other objects in UAV-captured scenes.
The YOLO series of algorithms has undergone continuous evolution and iteration. This study aims to develop improvements that can serve as plug-and-play modules, making them adaptable to other object detection algorithms. This article conducted an improvement experiment on YOLOv11 on the UID dataset, and the results are presented in
Table 7. The findings reveal that the improved algorithm achieves accuracy comparable to that of YOLOv8. However, despite the lightweight design of the detection head, the overall parameter count of RML-YOLOv11 is higher than that of YOLOv11 due to the integration of MSFENet and RFCAConv. This suggests that local model lightweighting may not be universally applicable to all algorithms. Future articles will conduct experiments and promote more methods.
Although RML-YOLO has demonstrated promising performance in insulator defect detection, certain limitations remain. Specifically, while the use of a shared parameter detection head effectively reduces the model’s parameter count, optimizing the detection head alone is insufficient for significantly reducing the overall model size. Therefore, future research could further optimize the model through the following directions: First, other lightweight technologies such as model pruning, quantization, and distillation could be considered to further compress model dimensions and enhance performance. Second, given that the purpose of lightweight design is to enable deployment on resource-constrained devices, future plans include directly deploying the optimized model on unmanned aerial vehicles (UAVs) equipped with edge computing devices after completing lightweight modifications. This implementation would achieve real-time detection while improving system response speed and stability in practical field applications.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}