
A Tile-Based Multi-Core Hardware Architecture for Lossless Image Compression and Decompression



Abstract
1. Introduction
- A novel high-throughput, lossless compression and decompression system is proposed, which employs a tile-based approach to enhance parallel processing capabilities. By distributing images across multiple compression and decompression cores within a specially developed multi-core architecture, the system significantly improves processing efficiency while building on previously introduced algorithms.
- A four-stage pipeline is implemented for the compression algorithm to maximize clock frequency, further increasing throughput.
- Dynamic state machines are utilized in the decompression algorithm, significantly improving throughput.
2. Compression and Decompression Algorithms Based on Hybrid Strategies
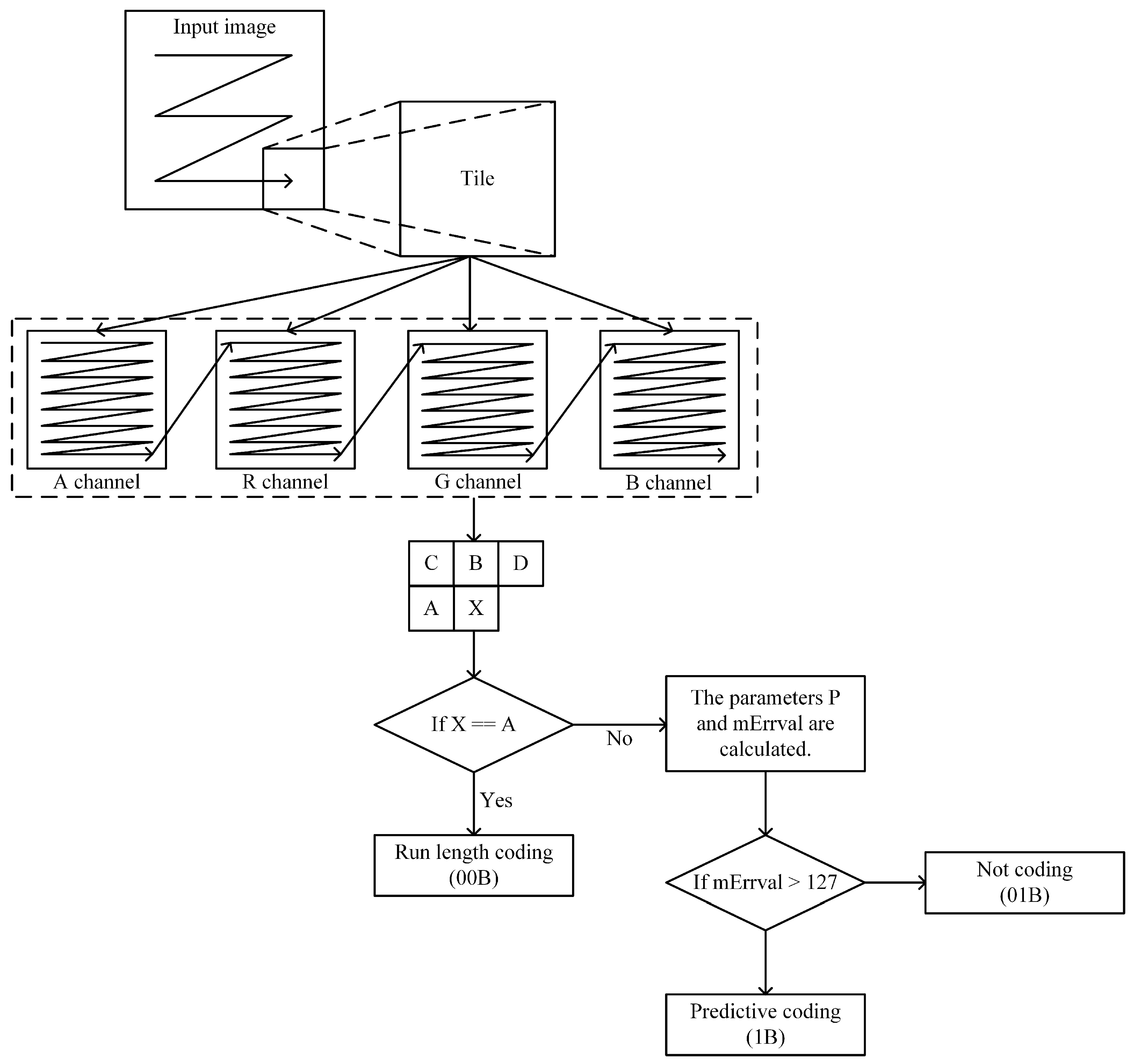
2.1. Compression Workflow
2.2. Decompression Workflow
2.3. Strategies
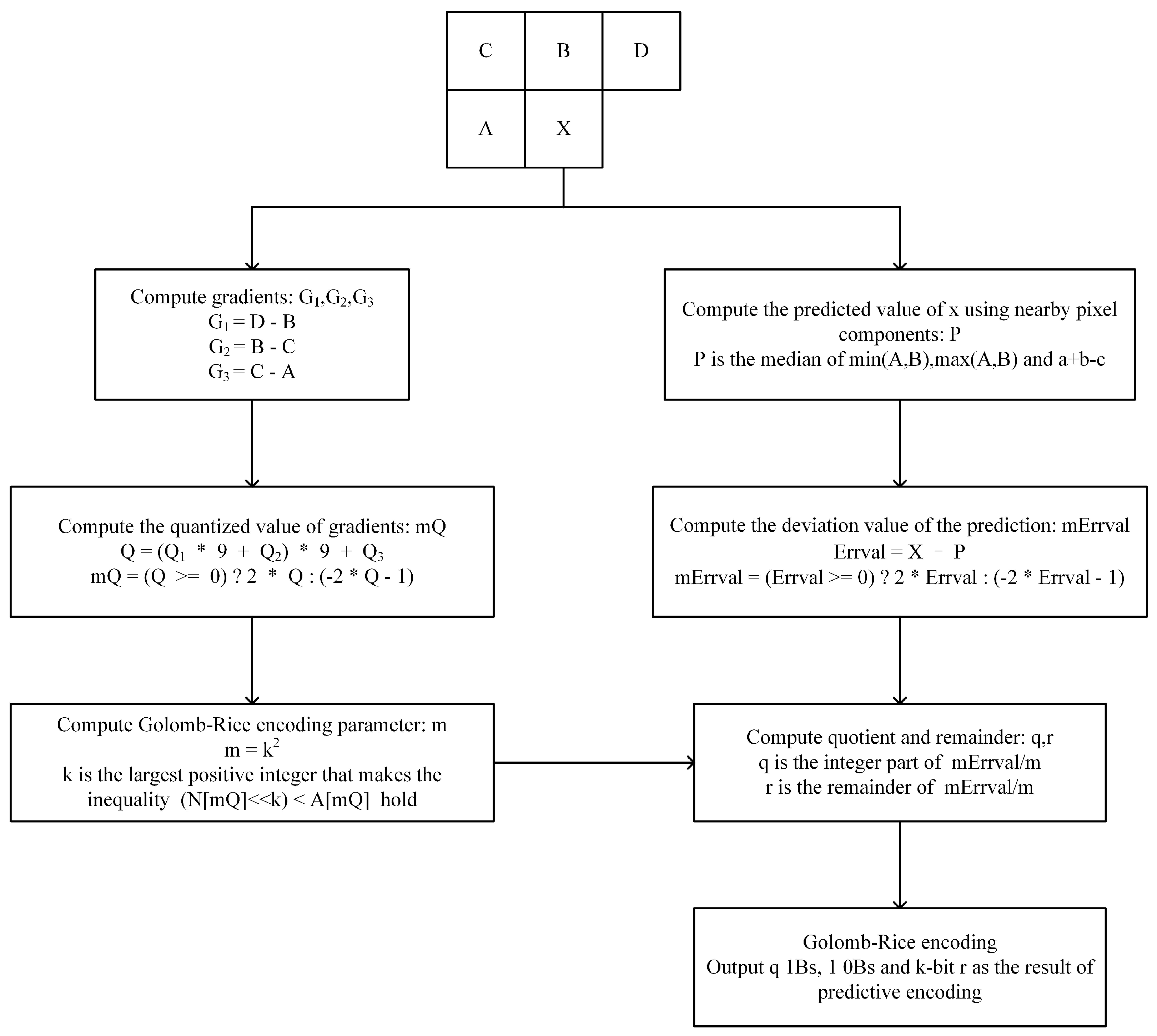
2.3.1. Predictive Coding
2.3.2. Run-Length Coding
2.3.3. Non-Coding
3. High-Efficiency Parallel Processing Architecture
3.1. Four-Stage Pipeline-Based Compression Architecture
3.2. Dynamic State Machine-Based Decompression Architecture
4. Validation and Analysis
4.1. Settings
- ImageNet64 [25]: A downsampled variant of the ImageNet dataset with 50,000 images at 64 × 64 pixels.
- DIV2K [26]: Contains 100 high-resolution images from diverse scenes.
- CLIC.p [27]: Comprises 41 high-quality color images, mainly in 2K resolution.
- CLIC.m [27]: Includes 612K images captured with mobile devices, at predominantly 2K resolution.
- Kodak [28]: Contains 24 uncompressed color images at 768 × 512 resolution.
4.2. Performance of Proposed System
- Throughput: Significant improvements were achieved by the proposed architecture. The compression module operates at a clock frequency of 300 MHz, with a maximum throughput of 480 Msubpixel/s. Pipelining is utilized in the implementation, ensuring that runtime throughput is not affected by the data themselves. One compression core processes a subpixel every five clock cycles. Throughput is calculated based on the clock frequency and the number of compression cores. Latency varies depending on the type of pixel data. When run-length coding is applied, latency is 7 clock cycles. When non-coding is applied, latency increases to 11 cycles. When predictive coding is used, latency reaches 25 cycles. Under conditions of full-speed pipelined operation, latency is effectively masked by continuous processing. The execution time is estimated using the throughput and image size. Specifically, the total data size of the image is divided by the throughput to approximate the processing duration. However, the actual processing time is influenced by the content of the image. The decompression module operates at a clock frequency of 400 MHz, achieving a maximum throughput of 372 Msubpixel/s, which is more than three times that of naive implementations. The throughput of the decompression module is influenced by the data, with varying numbers of clock cycles required for processing by different decompression cores.
- Other resources: The system effectively minimized memory consumption by employing FIFO for tile buffering and DDR3 SDRAM for tile and parameter storage, optimized for various tile sizes. In total, four AXI-STREAM interfaces with widths of 128 bits, 256 bits, and 512 bits were utilized in both the compression and decompression modules. Additionally, an extra AXI-STREAM interface FIFO was implemented for the transmission of compressed information. At least 512 MB of high-speed memory, such as DDR2 or higher, is required for the implementation of this system. FLASH memory cards were selected as the external storage medium for data retention.
- Energy consumption: The system power consumption was measured to be 2.585 W at room temperature. Under extreme low temperatures of −35 °C, power consumption was reduced to 2.37 W. At an extreme high temperature of 125 °C, power consumption was increased to 3.441 W.
- Impact of image patterns: The smoothness of images notably influenced the compression performance. Images with minimal grayscale variation yielded better compression ratios, while those with high variability performed less effectively.
- Effect of tile size: Testing various tile sizes indicated a moderate increase in compression ratio with larger sizes. An optimal tile size of 16 × 16 was identified, balancing compression efficiency with resource constraints.
- Consistency: Since the proposed system is implemented using a lossless compression algorithm, the images before compression and after decompression are expected to be completely identical—that is, consistency should be preserved. Therefore, the decompressed images were compared with the original images on a one-to-one basis. Upon inspection, it was confirmed that the decompressed images were completely consistent with the original ones.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mentzer, F.; Agustsson, E.; Tschannen, M.; Timofte, R.; Gool, L.V. Practical full resolution learned lossless image compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10629–10638. [Google Scholar]
- Si, Z.; Shen, K. Research on the WebP image format. In Advanced Graphic Communications, Packaging Technology and Materials; Springer: Berlin/Heidelberg, Germany, 2016; pp. 271–277. [Google Scholar]
- Miaou, S.G.; Ke, F.S.; Chen, S.C. A Lossless Compression Method for Medical Image Sequences Using JPEG-LS and Interframe Coding. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 818–821. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Yang, M.; Tao, J.; Wang, Y.; Liu, B.; Bukhari, D. Extraction of tongue contour in real-time magnetic resonance imaging sequences. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 937–941. [Google Scholar] [CrossRef]
- Tong, L.Y.; Lin, J.B.; Deng, Y.Y.; Ji, K.F.; Hou, J.F.; Wang, Q.; Yang, X. Lossless Compression Method for the Magnetic and Helioseismic Imager (MHI) Payload. Res. Astron. Astrophys. 2024, 24, 045019. [Google Scholar] [CrossRef]
- Rane, S.; Sapiro, G. Evaluation of JPEG-LS, the new lossless and controlled-lossy still image compression standard, for compression of high-resolution elevation data. IEEE Trans. Geosci. Remote. Sens. 2001, 39, 2298–2306. [Google Scholar] [CrossRef]
- Verstockt, S.; De Bruyne, S.; Poppe, C.; Lambert, P.; Van de Walle, R. Multi-view Object Localization in H.264/AVC Compressed Domain. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genoa, Italy, 2–4 September 2009; pp. 370–374. [Google Scholar] [CrossRef]
- Albalawi, U.; Mohanty, S.P.; Kougianos, E. A Hardware Architecture for Better Portable Graphics (BPG) Compression Encoder. In Proceedings of the 2015 IEEE International Symposium on Nanoelectronic and Information Systems, Didcot, UK, 8–10 October 2015; pp. 291–296. [Google Scholar] [CrossRef]
- Wu, X.; Choi, W.K.; Bao, P. L/sub /spl infin//-constrained high-fidelity image compression via adaptive context modeling. In Proceedings of the DCC ’97. Data Compression Conference, Snowbird, UT, USA, 25–27 March 1997; pp. 91–100. [Google Scholar] [CrossRef]
- Öztürk, E.; Mesut, A. Performance Evaluation of JPEG Standards, WebP and PNG in Terms of Compression Ratio and Time for Lossless Encoding. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 15–20. [Google Scholar] [CrossRef]
- Weinberger, M.; Seroussi, G.; Sapiro, G. The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS. IEEE Trans. Image Process. 2000, 9, 1309–1324. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Chen, X.; Liao, Z.; Yang, C. Adaptive Pipeline Hardware Architecture Design and Implementation for Image Lossless Compression/Decompression Based on JPEG-LS. IEEE Access 2024, 12, 5393–5403. [Google Scholar] [CrossRef]
- Dong, X.; Li, P. Implementation of A Real-Time Lossless JPEG-LS Compression Algorithm Based on FPGA. In Proceedings of the 2022 14th International Conference on Signal Processing Systems (ICSPS), Zhenjiang, China, 18–20 November 2022; pp. 523–528. [Google Scholar] [CrossRef]
- Wang, X.; Gong, L.; Wang, C.; Li, X.; Zhou, X. UH-JLS: A Parallel Ultra-High Throughput JPEG-LS Encoding Architecture for Lossless Image Compression. In Proceedings of the 2021 IEEE 39th International Conference on Computer Design (ICCD), Virtual, 24–27 October 2021; pp. 335–343. [Google Scholar] [CrossRef]
- Ferretti, M.; Boffadossi, M. A parallel pipelined implementation of LOCO-I for JPEG-LS. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 23–26 August 2004; Volume 1, pp. 769–772. [Google Scholar] [CrossRef]
- Klimesh, M.; Stanton, V.; Watola, D. Hardware implementation of a lossless image compression algorithm using a field programmable gate array. Mars 2001, 4, 5–72. [Google Scholar]
- Merlino, P.; Abramo, A. A Fully Pipelined Architecture for the LOCO-I Compression Algorithm. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2009, 17, 967–971. [Google Scholar] [CrossRef]
- Mert, Y.M. FPGA-based JPEG-LS encoder for onboard real-time lossless image compression. In Proceedings of the Satellite Data Compression, Communications, and Processing XI, Baltimore, MD, USA, 23–24 April 2015; Volume 9501, pp. 45–52. [Google Scholar]
- Varshney, A.; Suneetha, K.; Yadav, D.K. Analyzing the Performance of Different Compactor Techniques in Data Compression Source Coding. In Proceedings of the 2024 International Conference on Optimization Computing and Wireless Communication (ICOCWC), Debre Tabor, Ethiopia, 29–30 January 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Akhtar, M.B.; Qureshi, A.M.; ul Islam, Q. Optimized run length coding for jpeg image compression used in space research program of IST. In Proceedings of the International Conference on Computer Networks and Information Technology, Paphos, Cyprus, 31 August–2 September 2011; pp. 81–85. [Google Scholar] [CrossRef]
- Golomb, S. Run-length encodings (Corresp.). IEEE Trans. Inf. Theory 1966, 12, 399–401. [Google Scholar] [CrossRef]
- xilinx. Vivado Design Suite User Guide Using Constraints (UG903). 2022. Available online: https://docs.amd.com/r/en-US/ug903-vivado-using-constraints (accessed on 20 December 2024).
- xilinx. ZC706 Evaluation Board for the Zynq-7000 XC7Z045 SoC User Guide (UG954). 2019. Available online: https://docs.amd.com/v/u/en-US/ug954-zc706-eval-board-xc7z045-ap-soc (accessed on 6 August 2019).
- xilinx. Zynq-7000 SoC Data Sheet: Overview (DS190). 2018. Available online: https://docs.amd.com/v/u/en-US/ds190-Zynq-7000-Overview (accessed on 2 July 2018).
- Chrabaszcz, P.; Loshchilov, I.; Hutter, F. A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets. arXiv 2017, arXiv:1707.08819. [Google Scholar]
- Chen, S.; Han, Z.; Dai, E.; Jia, X.; Liu, Z.; Liu, X.; Zou, X.; Xu, C.; Liu, J.; Tian, Q. Unsupervised Image Super-Resolution with an Indirect Supervised Path. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1924–1933. [Google Scholar] [CrossRef]
- Ma, G.; Chai, Y.; Jiang, T.; Lu, M.; Chen, T. TinyLIC-High efficiency lossy image compression method. arXiv 2024, arXiv:2402.11164. [Google Scholar]
- Minnen, D.; Toderici, G.; Covell, M.; Chinen, T.; Johnston, N.; Shor, J.; Hwang, S.J.; Vincent, D.; Singh, S. Spatially adaptive image compression using a tiled deep network. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2796–2800. [Google Scholar]
- Skodras, A.; Christopoulos, C.; Ebrahimi, T. The JPEG 2000 still image compression standard. IEEE Signal Process. Mag. 2001, 18, 36–58. [Google Scholar] [CrossRef]
- Chen, L.; Yan, L.; Sang, H.; Zhang, T. High-Throughput Architecture for Both Lossless and Near-lossless Compression Modes of LOCO-I Algorithm. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3754–3764. [Google Scholar] [CrossRef]
- Savakis, A.; Piorun, M. Benchmarking and hardware implementation of JPEG-LS. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 2, p. II. [Google Scholar] [CrossRef]
- Deng, L.; Huang, Z. The FPGA design of JPEG-LS image lossless decompression IP core. In Proceedings of the 2015 Chinese Automation Congress (CAC), Wuhan, China, 27–29 November 2015; pp. 2199–2203. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ImageNet64 | DIV2K | CLIC.p | CLIC.m | Kodak |
|---|---|---|---|---|---|
| PNG [10] | 1.22 | 1.30 | 1.34 | 1.34 | 1.29 |
| JPEG-LS [11] | 1.28 | 1.50 | 1.54 | 1.65 | 1.46 |
| CALIC [9] | 1.26 | 1.48 | 1.53 | 1.62 | 1.45 |
| JPEG2000 [29] | 1.26 | 1.47 | 1.51 | 1.58 | 1.45 |
| WebP [2] | 1.29 | 1.47 | 1.52 | 1.57 | 1.45 |
| BPG [8] | 1.29 | 1.43 | 1.48 | 1.54 | 1.42 |
| Proposed (4 × 4) | 1.09 | 1.27 | 1.38 | 1.41 | 1.27 |
| Proposed (8 × 8) | 1.27 | 1.47 | 1.50 | 1.62 | 1.44 |
| Proposed (16 × 16) | 1.28 | 1.50 | 1.52 | 1.64 | 1.45 |
| Proposed (full) | 1.28 | 1.50 | 1.53 | 1.64 | 1.45 |
| Work | Technology | Resource | Frequency (MHz) | Throughput (Mpixel/s) | Algorithm |
|---|---|---|---|---|---|
| 2009 [17] | Spartan-3 | 36k equivalent gates | 21 | 21 | LOCO-I |
| 2018 [30] | Virtex-6 XC6VCX75T | 8354 slices | 51.684 | 51.684 | LOCO-I |
| 2021 [14] | Virtex-7 XC7VX485 | 18.7k LUT | 264 | 263.98 | JPEG-LS |
| 2022 [13] | Kintex-7 XC7K70T | 10.25k LUT | 103 | 100 | JPEG-LS |
| 2024 [12] | Zynq-7000 XC7Z020 | 1.3k LUT | 108.6 | 43.03 | JPEG-LS |
| Proposed | Zynq-7000 XC7Z045 | 8437 slices | 300 | 480 | - |
| Work | Technology | Resource | Frequency (MHz) | Throughput (Mpixel/s) | Algorithm |
|---|---|---|---|---|---|
| 2002 [31] | - | 20k equivalent gates | - | 7.14 | JPEG-LS |
| 2015 [32] | Virtex-6 XC6VSX315T | 1.4k LUT | 66.66 | 21.07 | JPEG-LS |
| 2024 [12] | Zynq-7000 XC7Z020 | 1.1k LUT | 128.5 | 37.02 | JPEG-LS |
| Proposed | Zynq-7000 XC7Z045 | 7422 slices | 400 | 372 | - |
| Name | System | Compression Module | Decompression Module |
|---|---|---|---|
| Slice LUTs | 88754 | 21147 | 20268 |
| Block RAM | 310.5 | 226.5 | 50.5 |
| Bonded IOPADS | 130 | 0 | 0 |
| BUFGCTRL | 4 | 0 | 0 |
| MMCME2_ADV | 2 | 0 | 0 |
| Slice Registers | 85156 | 5035 | 3974 |
| F7 Muxes | 1718 | 314 | 264 |
| F8 Muxes | 225 | 72 | 95 |
| Slice | 29850 | 8437 | 7422 |
| LUT as Logic | 84069 | 20995 | 19848 |
| LUT as Memory | 4685 | 152 | 420 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhou, L.; Zhu, Y. A Tile-Based Multi-Core Hardware Architecture for Lossless Image Compression and Decompression. Appl. Sci. 2025, 15, 6017. https://doi.org/10.3390/app15116017
Li X, Zhou L, Zhu Y. A Tile-Based Multi-Core Hardware Architecture for Lossless Image Compression and Decompression. Applied Sciences. 2025; 15(11):6017. https://doi.org/10.3390/app15116017
Chicago/Turabian StyleLi, Xufeng, Li Zhou, and Yan Zhu. 2025. "A Tile-Based Multi-Core Hardware Architecture for Lossless Image Compression and Decompression" Applied Sciences 15, no. 11: 6017. https://doi.org/10.3390/app15116017
APA StyleLi, X., Zhou, L., & Zhu, Y. (2025). A Tile-Based Multi-Core Hardware Architecture for Lossless Image Compression and Decompression. Applied Sciences, 15(11), 6017. https://doi.org/10.3390/app15116017