
Multi-Strategy-Improvement-Based Slime Mould Algorithm

Abstract
1. Introduction
2. Slime Mold Algorithm
2.1. Initialization
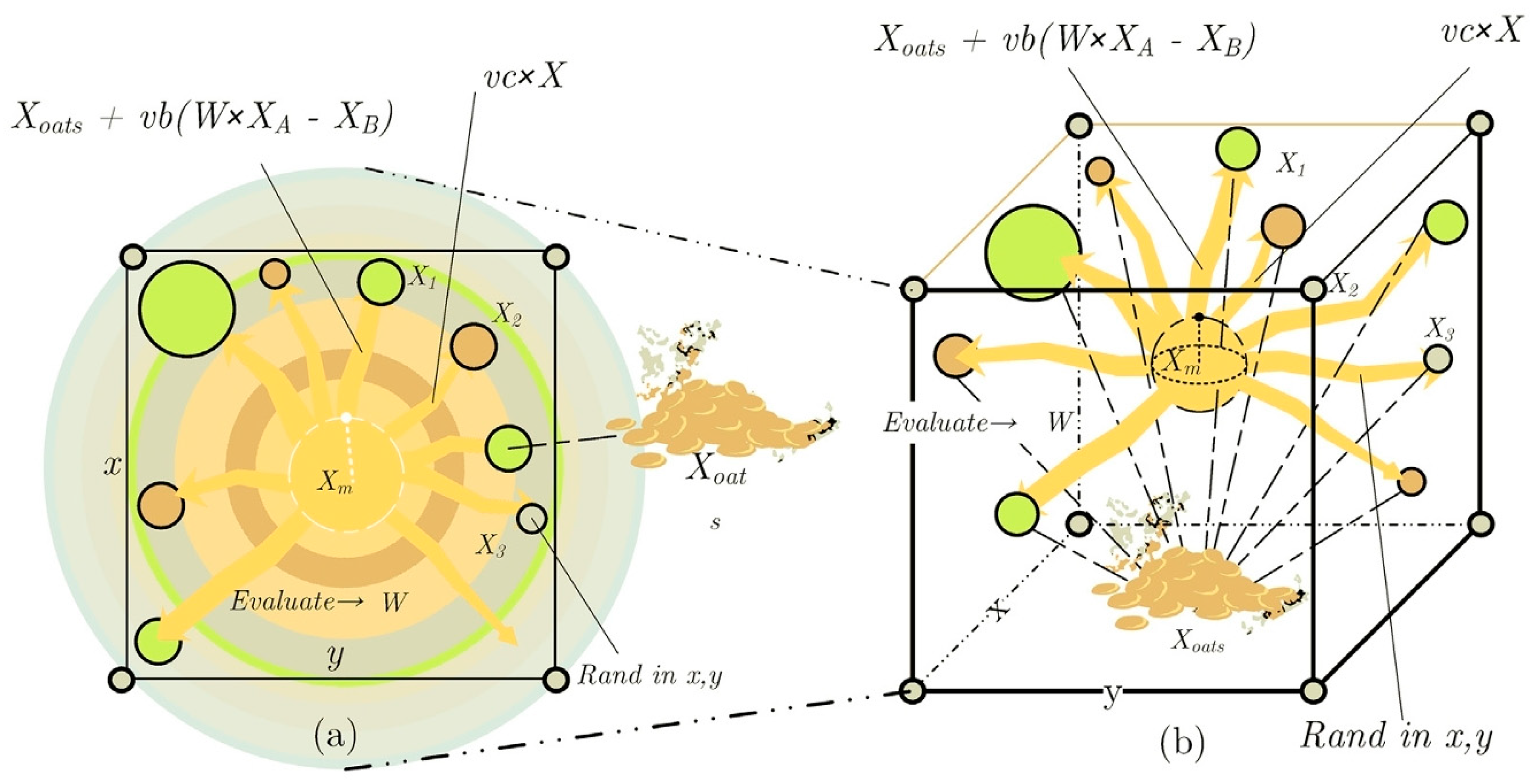
2.2. Exploration Phase
2.3. Exploitation Phase
2.4. Pseudo-Code of the SMA Algorithm
| Algorithm 1: Pseudo-Code of SMA |
| Initialize the parameters popsize, Max_iteraition, Dim. |
| Initialize the positions of slime mold Xinitial. |
| While(t ≤ ) |
| Calculate the fitness of all slime mold. |
| Update , . |
| Calculate the by Equation (9), (i = 1, 2,…, n). |
| For each search portion |
| Update , vb(t), vc(t). |
| Update position by Equation (10). |
| End For |
| t = t + 1 |
| End While |
| Return: , . |
3. MSSMA
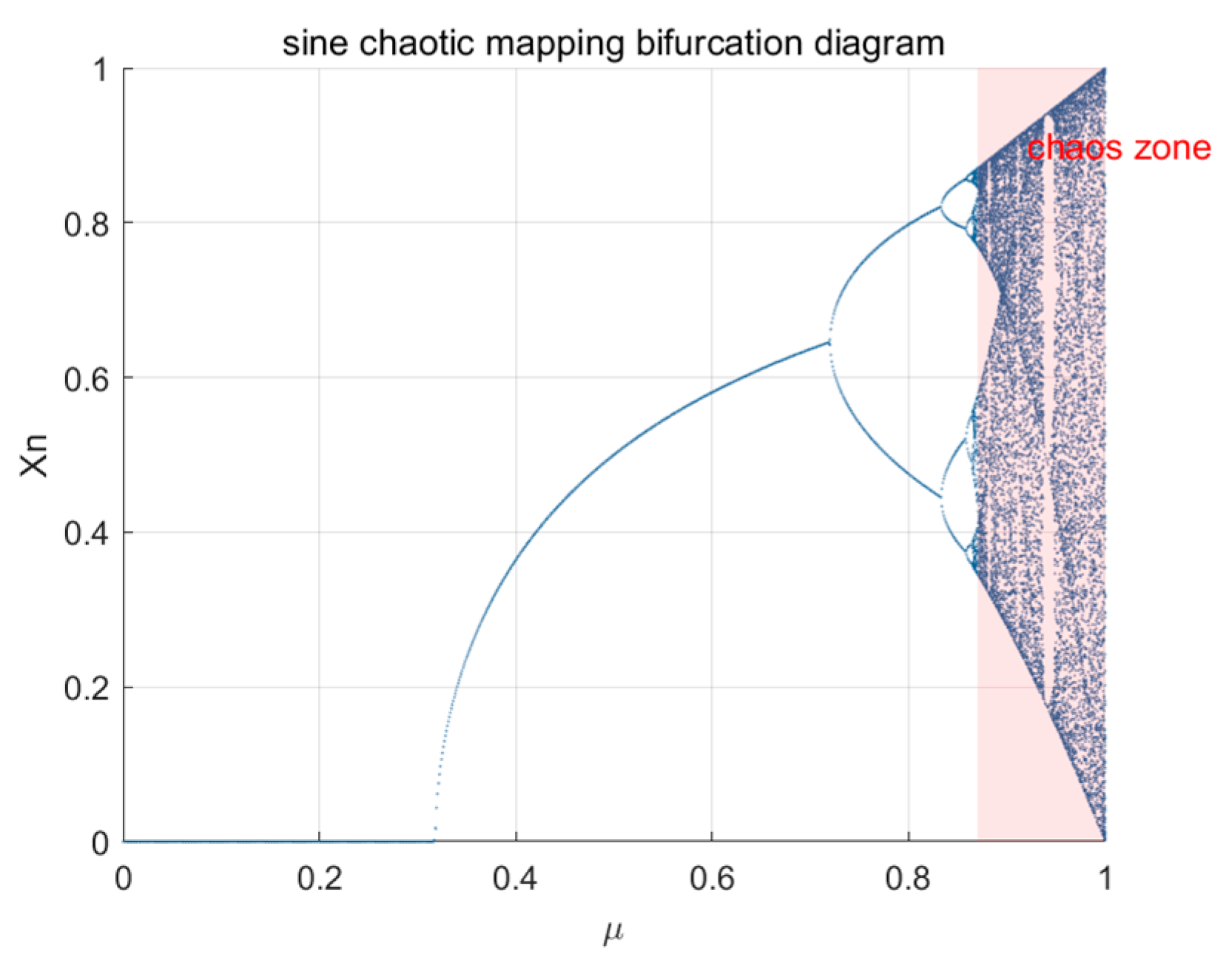
3.1. Chaotic Mapping and Reverse Learning
3.2. Balancing Factor B
3.3. Elite Tangent Search Strategy
3.4. Pseudo-Code of the MSSMA Algorithm
| Algorithm 2: MSSMA Pseudo-Code |
| Input: N,f,dim,T,LB,UB |
| Output: The global best solution and its fitness value |
| Initial populations are generated using chaotic mapping and reverse learning strategies, slime mold fitness values are calculated, and globally optimal solutions are recorded. |
| Population are sorted by fitness value to obtain sort(i), and slime mold weight information is updated by Equation (6) |
| While(t < T) |
| Calculate the value of B by Equation (13). |
| While(i < N) |
| Update position by Equation (22). |
| End While |
| Check if the location of the slime mold is within the search space and calculate the fitness value of the slime mold. |
| If a better solution is found in the current population, then update the global best solution and its fitness. |
| If (best(t) = best(t − L) && t > L) |
| Calculate the position of the slime molds that rank in the top half of the fitness values by Equation (19) |
| End If |
| Check if the location of the slime mold is within the search space and calculate the fitness value of the slime mold. |
| Update the optimal slime mold position and the optimal value. |
| Population are sorted by fitness value to obtain sort(i), and slime mold weight information is updated by Equation (6) |
| End While |
| Return: The global best solution and its fitness value. |
4. Experimentation and Application
4.1. Sensitivity Analysis of Parameter L
4.2. Ablation Experiment
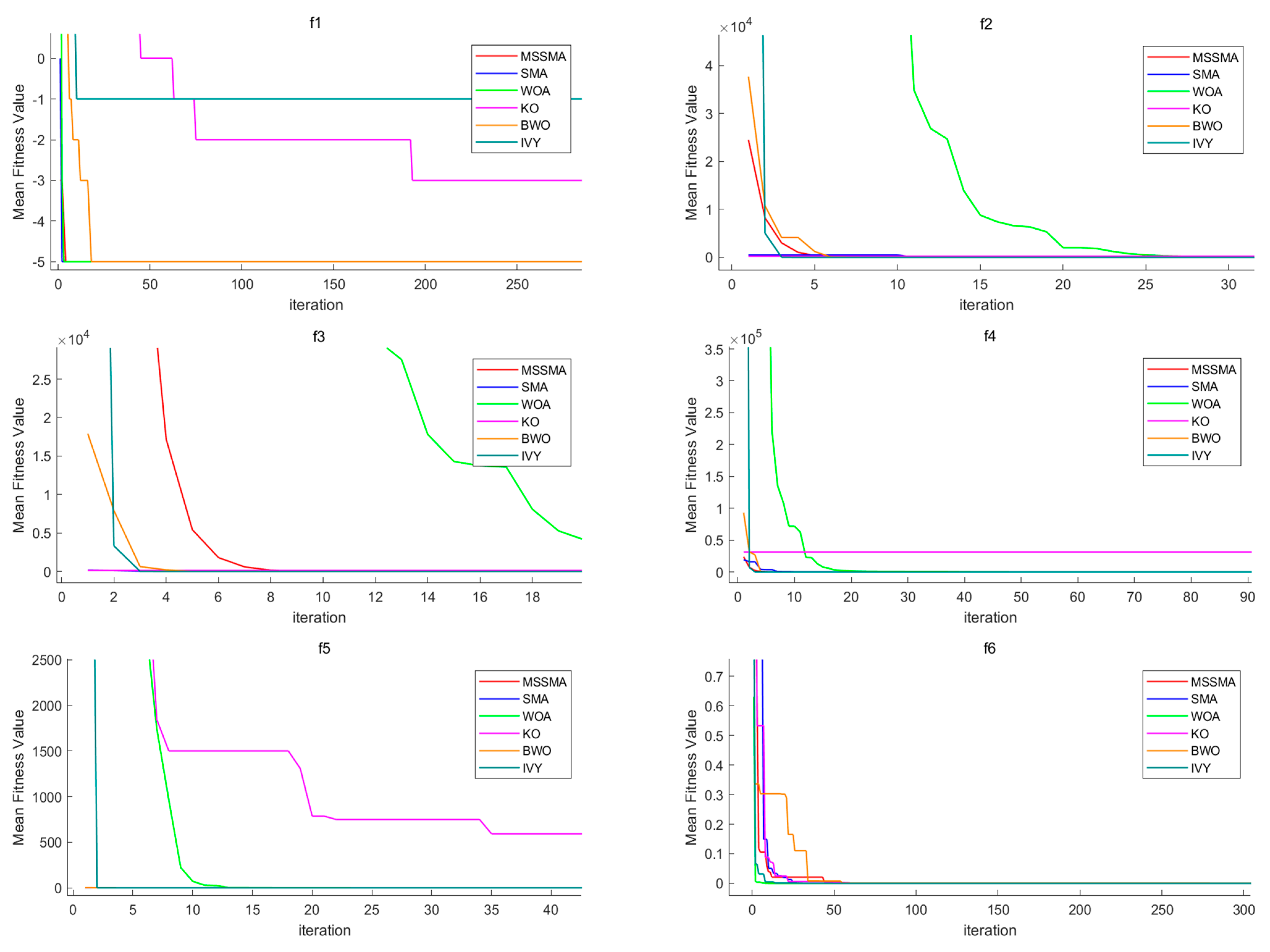
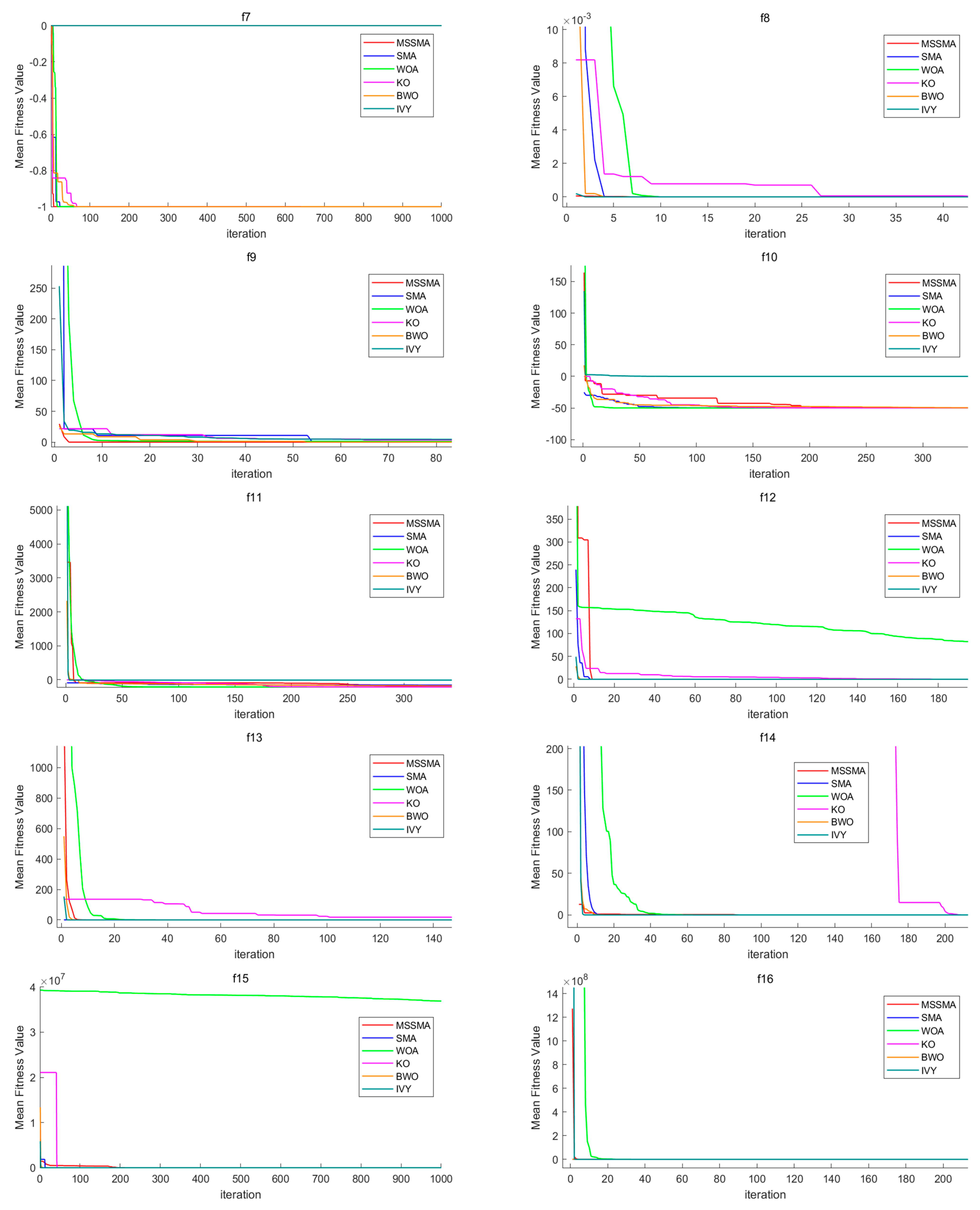
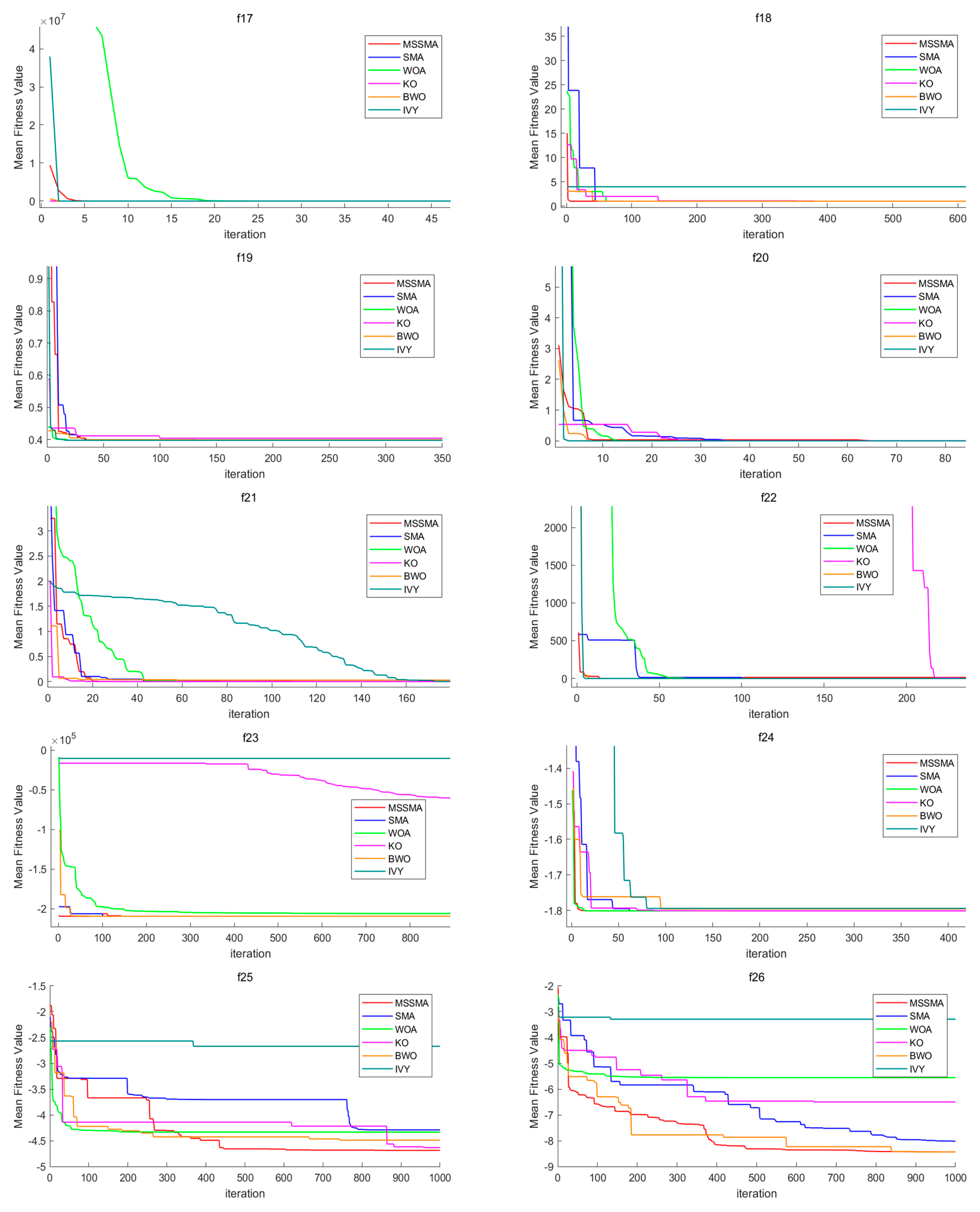
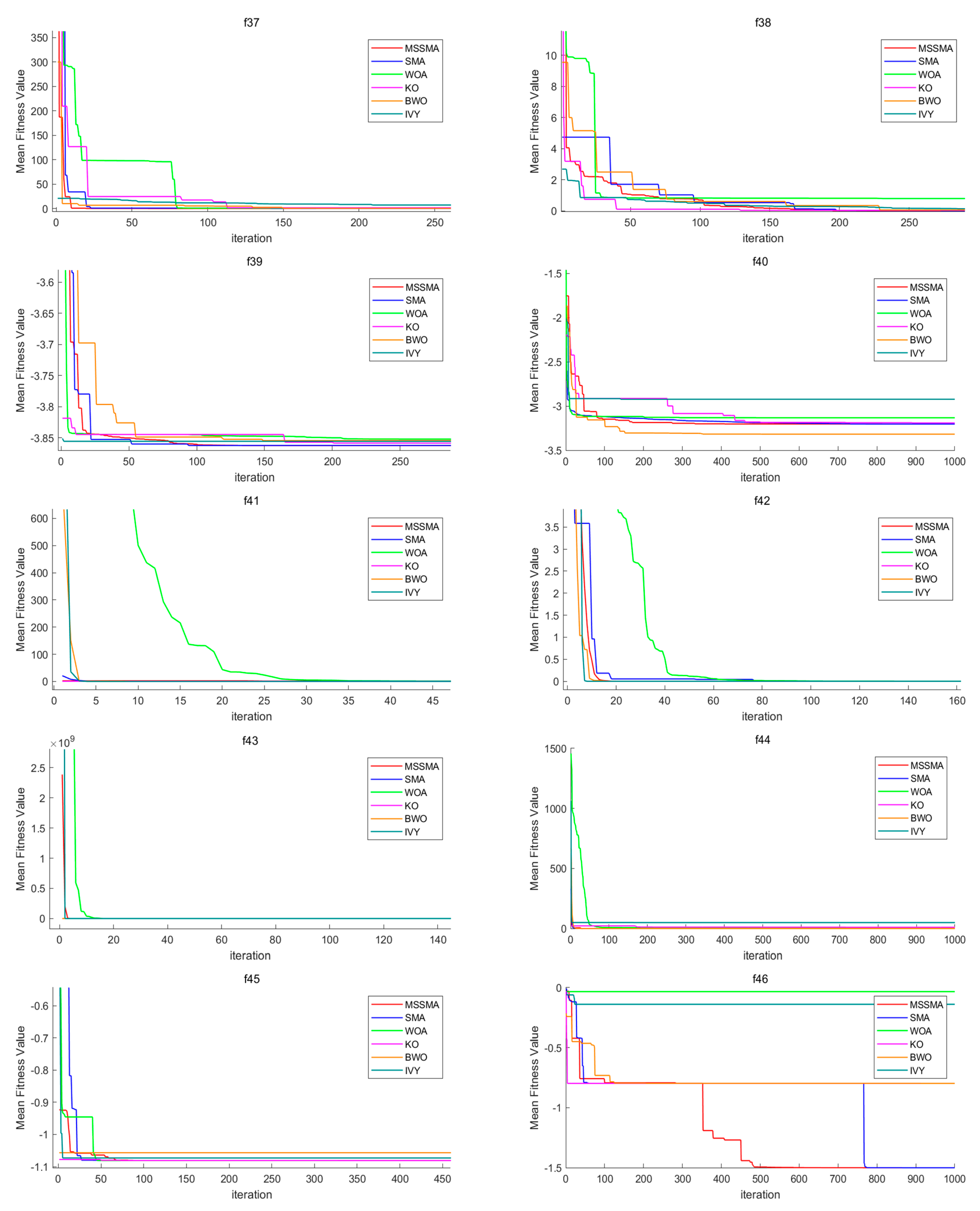
4.3. Comparison of Algorithm Performance
4.4. Collaborative Multi-UAV Path Planning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C | Function | D | Range | fopt |
|---|---|---|---|---|
| US | 5 | [−5.12, 5.12] | −5 | |
| US | 30 | [−100, 100] | 0 | |
| US | 30 | [−100, 100] | 0 | |
| US | 30 | [−10, 10] | 0 | |
| US | 30 | [−1.28, 1.28] | 0 | |
| UN | 5 | [−4.5, 4.5] | 0 | |
| UN | 2 | [−100, 100] | −1 | |
| UN | 2 | [−10, 10] | 0 | |
| UN | 4 | [−10, 10] | 0 | |
| UN | 6 | [−D2, D2] | −50 | |
| UN | 10 | [−D2, D2] | −210 | |
| UN | 10 | [−5, 10] | 0 | |
| UN | 24 | [−4, 5] | 0 | |
| UN | 30 | [−10, 10] | 0 | |
| UN | 30 | [−100, 100] | 0 | |
| UN | 30 | [−30, 30] | 0 | |
| UN | 30 | [−10, 10] | 0 | |
| MS | 2 | [−65.536, 65.536] | 0.998 | |
| MS | 2 | [−5, 10] × [0, 15] | 0.398 | |
| MS | 2 | [−100, 100] | 0 | |
| MS | 2 | [−10, 10] | 0 | |
| MS | 30 | [−5.12, 5.12] | 0 | |
| MS | 30 | [−500, 500] | −12,569.5 | |
| MS | 2 | [0, π] | −1.8013 | |
| MS | 5 | [0, π] | −4.6877 | |
| MS | 10 | [0, π] | −9.6602 | |
| MN | 2 | [−100, 100] | 0 | |
| MN | 2 | [−5, 5] | −1.03163 | |
| MN | 2 | [−100, 100] | 0 | |
| MN | 2 | [−100, 100] | 0 | |
| MN | 2 | [−10, 10] | −186.7309 | |
| MN | 2 | [−2, 2] | 3 | |
| MN | 4 | [−5, 5] | 0.00031 | |
| MN | 4 | [0, 10] | −10.1532 | |
| MN | 4 | [0, 10] | −10.4028 | |
| MN | 4 | [0, 10] | −10.5363 | |
| MN | 4 | [−D, D] | 0 | |
| MN | 4 | [0, D] | 0 | |
| MN | 3 | [0, 1] | −3.86 | |
| MN | 6 | [0, 1] | −3.32 | |
| MN | 30 | [−600, 600] | 0 | |
| MN | 30 | [−32, 32] | 0 | |
| MN | 30 | [−50, 50] | 0 | |
| MN | 30 | [−50, 50] | 0 | |
| MN | 2 | [0, 10] | −1.08 | |
| MN | 5 | [0, 10] | −1.5 | |
| MN | 10 | [0, 10] | –1.080938 | |
| MN | 2 | [−π, π] | 0 | |
| MN | 5 | [−π, π] | 0 | |
| MN | 10 | [−π, π] | 0 |
| ID | Index | L = 3 | L = 5 | L = 10 | L = 15 | L = 20 |
|---|---|---|---|---|---|---|
| F1 | Mean | −5.00 | −5.00 | −5.00 | −5.00 | −5.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F2 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F3 | Mean | 0.00 | 0.00 | 4.50 × 10−255 | 4.40 × 10−174 | 4.00 × 10−161 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F4 | Mean | 0.00 | 0.00 | 1.90 × 10−226 | 1.70 × 10−191 | 3.40 × 10−151 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 3.40 × 10−300 | |
| F5 | Mean | 5.47 × 10−49 | 2.23 × 10−3 | 2.34 × 10−3 | 3.28 × 10−3 | 2.83 × 10−3 |
| Std | 3.30 × 10−18 | 3.66 × 10−6 | 3.77 × 10−6 | 1.25 × 10−5 | 7.13 × 10−6 | |
| F6 | Mean | 6.75 × 10−10 | 1.21 × 10−10 | 2.06 × 10−10 | 1.85 × 10−10 | 3.96 × 10−10 |
| Std | 1.15 × 10−18 | 1.16 × 10−19 | 1.94 × 10−19 | 1.42 × 10−19 | 3.41 × 10−19 | |
| F7 | Mean | −1.00 | −9.99 × 10−1 | −9.97 × 10−1 | −9.98 × 10−1 | −9.97 × 10−1 |
| Std | 1.51 × 10−20 | 6.18 × 10−7 | 1.50 × 10−4 | 1.81 × 10−5 | 1.65 × 10−4 | |
| F8 | Mean | 0.00 | 0.00 | 0.00 | 5.20 × 10−262 | 2.40 × 10−214 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F9 | Mean | 4.81 × 10−7 | 8.63 × 10−5 | 5.16 × 10−5 | 7.49 × 10−5 | 4.84 × 10−5 |
| Std | 1.50 × 10−12 | 2.63 × 10−8 | 1.85 × 10−8 | 3.58 × 10−8 | 1.37 × 10−8 | |
| F10 | Mean | −5.00 × 101 | −4.99 × 101 | −4.99 × 101 | −4.99 × 101 | −4.99 × 101 |
| Std | 1.11 × 10−18 | 1.99 × 10−8 | 8.07 × 10−8 | 9.7 × 10−8 | 5.53 × 10−7 | |
| F11 | Mean | −2.10 × 102 | −2.10 × 102 | −2.10 × 102 | −2.10 × 102 | −2.10 × 102 |
| Std | 1.92 × 10−9 | 1.40 × 10−2 | 1.26 × 10−2 | 3.71 × 10−2 | 1.01 × 10−1 | |
| F12 | Mean | 0.00 | 0.00 | 4.90 × 10−160 | 9.70 × 10−115 | 7.91 × 10−86 |
| Std | 0.00 | 0.00 | 0.00 | 2.80 × 10−227 | 1.90 × 10−169 | |
| F13 | Mean | 0.00 | 0.00 | 1.70 × 10−223 | 4.80 × 10−115 | 2.10 × 10−116 |
| Std | 0.00 | 0.00 | 0.00 | 7.00 × 10−228 | 1.30 × 10−230 | |
| F14 | Mean | 0.00 | 9.98 × 10−94 | 2.99 × 10−67 | 2.09 × 10−36 | 1.59 × 10−35 |
| Std | 0.00 | 2.95 × 10−185 | 1.40 × 10−132 | 1.31 × 10−70 | 6.44 × 10−69 | |
| F15 | Mean | 0.00 | 2.79 × 101 | 6.41 × 101 | 6.47 × 101 | 4.94 × 101 |
| Std | 0.00 | 2.28 × 104 | 5.65 × 104 | 7.44 × 104 | 1.925 × 104 | |
| F16 | Mean | 2.28 × 10−8 | 1.51 | 2.22 | 1.27 | 1.90 |
| Std | 3.26 × 10−9 | 8.53 | 1.30 × 104 | 2.39 | 9.66 | |
| F17 | Mean | 3.46 × 10−4 | 5.64 × 10−1 | 5.80 × 10−1 | 6.00 × 10−1 | 5.80 × 10−1 |
| Std | 4.17 × 10−13 | 8.34 × 10−2 | 9.38 × 10−2 | 9.07 × 10−2 | 1.06 × 10−1 | |
| F18 | Mean | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 |
| Std | 1.86 × 10−26 | 4.14 × 10−25 | 2.66 × 10−25 | 1.21 × 10−24 | 8.70 × 10−24 | |
| F19 | Mean | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 |
| Std | 1.10 × 10−18 | 3.16 × 10−20 | 1.05 × 10−20 | 3.21 × 10−17 | 4.70 × 10−17 | |
| F20 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F21 | Mean | 9.58 × 10−11 | 9.50 × 10−12 | 2.26 × 10−11 | 1.31 × 10−11 | 1.89 × 10−11 |
| Std | 1.61 × 10−20 | 2.68- × 10−22 | 4.19 × 10−21 | 4.58 × 10−22 | 7.66 × 10−22 | |
| F22 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F23 | Mean | −1.59 × 105 | −1.88 × 105 | −2.01 × 105 | −2.29 × 105 | −2.03 × 105 |
| Std | 1.28 × 10−2 | 2.01 | 1.61 | 0.42 | 4.61 | |
| F24 | Mean | −1.80 | −1.80 | −1.80 | −1.80 | −1.80 |
| Std | 2.86 × 10−23 | 3.52 × 10−23 | 3.76 × 10−21 | 2.15 × 10−21 | 5.09 × 10−22 | |
| F25 | Mean | −4.58 | −4.46 | −4.42 | −4.58 | −4.54 |
| Std | 1.27 × 10−3 | 9.10 × 10−2 | 1.06 × 10−1 | 2.66 × 10−2 | 3.72 × 10−2 | |
| F26 | Mean | −8.57 | −7.28 | −7.45 | −7.61 | −7.68 |
| Std | 3.42 × 10−2 | 6.19 × 10−1 | 6.40 × 10−1 | 6.39 × 10−1 | 4.69 × 10−1 | |
| F27 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F28 | Mean | −1.03 | −1.03 | −1.03 | −1.03 | −1.03 |
| Std | 1.27 × 10−25 | 1.17 × 10−27 | 4.02 × 10−27 | 8.42 × 10−26 | 1.17 × 10−24 | |
| F29 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F30 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F31 | Mean | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 |
| Std | 4.01 × 10−14 | 6.43 × 10−16 | 8.26 × 10−14 | 2.38 × 10−14 | 1.19 × 10−14 | |
| F32 | Mean | 3.00 | 3.00 | 3.00 | 3.00 | 3.00 |
| Std | 1.23 × 10−26 | 1.75 × 10−24 | 1.07 × 10−23 | 1.8 × 10−22 | 3.07 × 10−22 | |
| F33 | Mean | 3.08 × 10−4 | 3.51 × 10−4 | 3.37 × 10−4 | 4.60 × 10−4 | 4.49 × 10−4 |
| Std | 5.99 × 10−14 | 2.83 × 10−8 | 5.00 × 10−9 | 5.99 × 10−8 | 6.12 × 10−8 | |
| F34 | Mean | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 |
| Std | 1.26 × 10−13 | 6.64 × 10−13 | 9.13 × 10−13 | 4.15 × 10−12 | 7.79 × 10−13 | |
| F35 | Mean | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 |
| Std | 4.05 × 10−12 | 3.84 × 10−13 | 2.28 × 10−12 | 8.58 × 10−12 | 1.36 × 10−11 | |
| F36 | Mean | −1.05 × 101 | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 |
| Std | 4.70 × 10−12 | 4.30 × 10−13 | 7.13 × 10−13 | 1.8 × 10−12 | 1.38 × 10−11 | |
| F37 | Mean | 9.26 × 10−2 | 6.75 × 10−2 | 2.18 × 10−2 | 5.75 × 10−2 | 5.59 × 10−2 |
| Std | 1.91 × 10−2 | 2.06 × 10−2 | 1.97 × 10−3 | 2.08 × 10−2 | 2.05 × 10−2 | |
| F38 | Mean | 9.57 × 10−4 | 3.30 × 10−4 | 5.58 × 10−4 | 7.98 × 10−4 | 7.19 × 10−4 |
| Std | 1.53 × 10−6 | 2.15 × 10−7 | 1.46 × 10−6 | 1.54 × 10−6 | 1.48 × 10−6 | |
| F39 | Mean | −3.86 | −3.86 | −3.86 | −3.86 | −3.86 |
| Std | 9.69 × 10−22 | 3.30 × 10−22 | 2.06 × 10−21 | 1.02 × 10−18 | 3.23 × 10−18 | |
| F40 | Mean | −3.28 | −3.20 | −3.21 | −3.20 | −3.21 |
| Std | 2.34 × 10−5 | 1.74 × 10−14 | 9.10 × 10−4 | 8.08 × 10−11 | 9.10 × 10−4 | |
| F41 | Mean | 0.00 | 1.10 × 10−4 | 0.00 | 0.00 | 2.33 × 10−10 |
| Std | 0.00 | 3.65 × 10−7 | 0.00 | 0.00 | 1.64 × 10−18 | |
| F42 | Mean | 3.89 × 10−16 | 4.44 × 10−16 | 4.47 × 10−16 | 4.59 × 10−16 | 4.87 × 10−16 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F43 | Mean | 2.36 × 10−8 | 3.45 × 10−5 | 2.20 × 10−5 | 4.07 × 10−5 | 2.73 × 10−5 |
| Std | 4.30 × 10−11 | 7.54 × 10−9 | 1.88 × 10−9 | 9.11 × 10−9 | 1.57 × 10−9 | |
| F44 | Mean | 1.07 × 10−3 | 6.93 × 10−3 | 8.26 × 10−3 | 8.50 × 10−3 | 7.13 × 10−3 |
| Std | 5.03 × 10−6 | 1.92 × 10−4 | 3.82 × 10−4 | 3.23 × 10−4 | 2.49 × 10−4 | |
| F45 | Mean | −1.08 | −1.08 | −1.08 | −1.08 | −1.08 |
| Std | 2.33 × 10−20 | 1.44 × 10−20 | 1.21 × 10−20 | 9.76 × 10−20 | 2.90 × 10−20 | |
| F46 | Mean | −1.40 | −1.09 | −1.18 | −1.26 | −1.17 |
| Std | 5.40 × 10−3 | 1.78 × 10−1 | 8.41 × 10−2 | 8.20 × 10−2 | 1.06 × 10−1 | |
| F47 | Mean | −9.40 × 10−1 | −3.17 × 10−1 | −2.88 × 10−1 | −2.78 × 10−1 | −2.07 × 10−1 |
| Std | 5.57 × 10−5 | 3.58 × 10−2 | 2.94 × 10−2 | 2.20 × 10−2 | 2.82 × 10−2 | |
| F48 | Mean | 2.85 × 10−9 | 1.78 × 10−9 | 3.39 × 10−9 | 5.97 × 10−9 | 8.15 × 10−9 |
| Std | 3.33 × 10−17 | 4.1810−18 | 1.29 × 10−17 | 6.24 × 10−17 | 1.99 × 10−16 | |
| F49 | Mean | 1.04 × 102 | 2.49 × 102 | 1.34 × 102 | 1.72 × 102 | 3.17 × 102 |
| Std | 2.45 × 105 | 3.56 × 105 | 8.26 × 105 | 8.88 × 105 | 4.06 × 105 | |
| F50 | Mean | 3.83 × 103 | 4.42 × 105 | 4.12 × 105 | 2.05 × 105 | 3.00 × 105 |
| Std | 4.86 × 106 | 4.38 × 107 | 1.20 × 107 | 7.48 × 106 | 2.23 × 107 |
| ID | Index | MSSMA | SMA | MSSMA-1 | MSSMA-2 | MSSMA-3 |
|---|---|---|---|---|---|---|
| F1 | Mean | −5.00 | −5.00 | −5.00 | −5.00 | −5.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F2 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F3 | Mean | 0.00 | 0.00 | 1.49 × 10−4 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 2.04 × 10−7 | 0.00 | 0.00 | |
| F4 | Mean | 0.00 | 0.00 | 1.13 × 10−2 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 8.73 × 10−4 | 0.00 | 0.00 | |
| F5 | Mean | 5.47 × 10−8 | 3.26 × 10−4 | 1.92 × 10−4 | 1.81 × 10−6 | 4.27 × 10−7 |
| Std | 3.30 × 10−18 | 5.45 × 10−8 | 2.11 × 10−6 | 1.84 × 10−8 | 8.01 × 10−8 | |
| F6 | Mean | 6.75 × 10−10 | 2.85 × 10−8 | 1.15 × 10−8 | 3.99 × 10−9 | 7.76 × 10−10 |
| Std | 1.15 × 10−18 | 2.80 × 10−14 | 9.29 × 10−14 | 9.26 × 10−23 | 3.25 × 10−18 | |
| F7 | Mean | −1.00 | −9.95 × 10−1 | −9.97 × 10−1 | −1.00 | −1.00 |
| Std | 1.51 × 10−20 | 5.76 × 10−4 | 2.06 × 10−10 | 6.15 × 10−24 | 4.92 × 10−19 | |
| F8 | Mean | 0.00 | 0.00 | 9.89 × 10−189 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F9 | Mean | 4.81 × 10−7 | 2.37 × 10−4 | 4.01 × 10−5 | 1.72 × 10−4 | 7.37 × 10−7 |
| Std | 1.50 × 10−12 | 2.34 × 10−7 | 1.52 × 10−9 | 7.91 × 10−8 | 2.53 × 10−12 | |
| F10 | Mean | −5.00 × 101 | −5.00 × 101 | −5.00 × 101 | −5.00 × 101 | −5.00 × 101 |
| Std | 1.11 × 10−18 | 8.08 × 10−9 | 3.63 × 10−9 | 8.15 × 10−10 | 4.53 × 10−15 | |
| F11 | Mean | −2.10 × 102 | −2.10 × 102 | −2.10 × 102 | −2.10 × 102 | −2.10 × 102 |
| Std | 1.92 × 10−9 | 2.39 × 10−4 | 6.81 × 10−4 | 1.15 × 10−8 | 3.25 × 10−9 | |
| F12 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F13 | Mean | 0.00 | 0.00 | 2.17 × 10−243 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F14 | Mean | 0.00 | 3.42 × 10−2 | 1.32 × 10−2 | 1.07 × 10−1 | 0.00 |
| Std | 0.00 | 1.06 × 10−2 | 1.78 × 10−1 | 2.82 × 10−1 | 0.00 | |
| F15 | Mean | 0.00 | 0.00 | 3.35 × 10−1 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 7.56 × 10−1 | 0.00 | 0.00 | |
| F16 | Mean | 2.28 × 10−6 | 6.85 × 101 | 21.04 | 1.03 | 2.33 × 10−4 |
| Std | 3.26 × 10−9 | 1.20 × 104 | 5.52 × 10−2 | 4.18 × 10−1 | 1.32 × 10−1 | |
| F17 | Mean | 3.46 × 10−4 | 8.12 × 10−1 | 3.51 × 10−1 | 5.95 × 10−1 | 3.07 × 10−3 |
| Std | 4.17 × 10−13 | 8.05 × 10−2 | 3.27 × 10−2 | 2.48 × 10−2 | 1.78 × 10−2 | |
| F18 | Mean | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 | 9.98 × 10−1 |
| Std | 1.86 × 10−26 | 3.00 × 10−23 | 3.04 × 10−24 | 3.27 × 10−26 | 1.96 × 10−26 | |
| F19 | Mean | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 |
| Std | 1.10 × 10−18 | 1.12 × 10−16 | 3.17 × 10−15 | 2.89 × 10−18 | 2.35 × 10−18 | |
| F20 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F21 | Mean | 9.58 × 10−11 | 3.30 × 10−10 | 3.46 × 10−10 | 4.62 × 10−10 | 1.04 × 10−10 |
| Std | 1.61 × 10−20 | 5.55 × 10−19 | 9.36 × 10−15 | 5.71 × 10−25 | 8.71 × 10−20 | |
| F22 | Mean | 0.00 | 0.00 | 5.04 × 10−4 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 1.87 × 10−16 | 0.00 | 0.00 | |
| F23 | Mean | −1.59 × 105 | −2.09 × 105 | −2.09 × 105 | −2.05 × 105 | −1.84 × 105 |
| Std | 1.28 × 10−2 | 1.18 × 102 | 1.22 × 10−2 | 3.69 × 10−2 | 1.98 × 10−2 | |
| F24 | Mean | −1.80 | −1.80 | −1.80 | −1.80 | −1.80 |
| Std | 2.86 × 10−23 | 1.67 × 10−17 | 5.81 × 10−19 | 5.15 × 10−20 | 7.81 × 10−23 | |
| F25 | Mean | −4.58 | −4.39 | −4.45 | −4.45 | −4.57 |
| Std | 1.27 × 10−3 | 8.90 × 10−2 | 3.24 × 10−2 | 1.15 × 10−2 | 1.29 × 10−2 | |
| F26 | Mean | −8.57 | −8.46 | −8.46 | −8.49 | −8.54 |
| Std | 3.42 × 10−2 | 5.28 × 10−1 | 5.03 × 10−1 | 5.39 × 10−1 | 3.32 × 10−1 | |
| F27 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F28 | Mean | −1.03 | −1.03 | −1.03 | −1.03 | −1.03 |
| Std | 1.27 × 10−25 | 9.65 × 10−22 | 1.23 × 10−22 | 3.48 × 10−24 | 5.12 × 10−25 | |
| F29 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F30 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F31 | Mean | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 |
| Std | 4.01 × 10−14 | 1.30 × 10−13 | 4.03 × 10−13 | 1.63 × 10−13 | 1.22 × 10−14 | |
| F32 | Mean | 3.00 | 3.00 | 3.00 | 3.00 | 3.00 |
| Std | 1.23 × 10−26 | 2.97 × 10−22 | 1.48 × 10−22 | 1.06 × 10−24 | 4.34 × 10−25 | |
| F33 | Mean | 3.08 × 10−4 | 4.44 × 10−4 | 3.86 × 10−4 | 3.10 × 10−4 | 3.09 × 10−4 |
| Std | 5.99 × 10−14 | 2.96 × 10−8 | 7.17 × 10−9 | 4.57 × 10−14 | 3.94 × 10−12 | |
| F34 | Mean | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 | −1.02 × 101 |
| Std | 1.26 × 10−13 | 2.04 × 10−9 | 1.35 × 10−9 | 8.18 × 10−10 | 2.28 × 10−12 | |
| F35 | Mean | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 | −1.04 × 101 |
| Std | 4.05 × 10−12 | 6.36 × 10−9 | 2.70 × 10−9 | 4.00 × 10−11 | 6.44 × 10−12 | |
| F36 | Mean | −1.05 × 101 | −1.05 × 101 | −1.05 × 101 | −1.05 × 101 | −1.05 × 101 |
| Std | 4.70 × 10−12 | 1.82 × 10−9 | 3.91 × 10−9 | 2.40 × 10−10 | 2.67 × 10−12 | |
| F37 | Mean | 9.26 × 10−2 | 1.38 × 10−1 | 1.02 × 10−1 | 9.58 × 10−2 | 9.43 × 10−2 |
| Std | 1.91 × 10−2 | 3.77 × 10−2 | 1.99 × 10−2 | 2.57 × 10−2 | 2.50 × 10−2 | |
| F38 | Mean | 9.57 × 10−4 | 7.85 × 10−3 | 6.75 × 10−3 | 2.56 × 10−3 | 1.61 × 10−3 |
| Std | 1.53 × 10−6 | 7.91 × 10−5 | 9.31 × 10−5 | 9.16 × 10−8 | 7.87 × 10−6 | |
| F39 | Mean | −3.86 | −3.86 | −3.86 | −3.86 | −3.86 |
| Std | 9.69 × 10−22 | 1.27 × 10−16 | 4.66 × 10−18 | 9.87 × 10−20 | 5.50 × 10−21 | |
| F40 | Mean | −3.28 | −3.24 | −3.21 | −3.24 | −3.26 |
| Std | 2.34 × 10−5 | 3.07 × 10−3 | 9.10 × 10−4 | 1.39 × 10−3 | 3.59 × 10−3 | |
| F41 | Mean | 0.00 | 0.00 | 7.73 × 10−7 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 1.20 × 10−11 | 0.00 | 0.00 | |
| F42 | Mean | 3.89 × 10−16 | 4.44 × 10−16 | 4.44 × 10−16 | 4.44 × 10−16 | 4.44 × 10−16 |
| Std | 0.00 | 2.07 × 10−32 | 6.50 × 10−9 | 0.00 | 0.00 | |
| F43 | Mean | 2.36 × 10−8 | 4.08 × 10−4 | 4.02 × 10−6 | 2.22 × 10−6 | 1.31 × 10−7 |
| Std | 4.30 × 10−11 | 1.05 × 10−6 | 1.20 × 10−12 | 9.67 × 10−8 | 6.30 × 10−11 | |
| F44 | Mean | 1.07 × 10−3 | 3.60 × 10−2 | 7.51 × 10−3 | 5.76 × 10−3 | 4.14 × 10−3 |
| Std | 5.03 × 10−6 | 2.28 × 10−3 | 3.05 × 10−7 | 7.46 × 10−7 | 1.61 × 10−6 | |
| F45 | Mean | −1.08 | −1.08 | −1.08 | −1.08 | −1.08 |
| Std | 2.33 × 10−20 | 4.35 × 10−17 | 1.15 × 10−18 | 3.86 × 10−19 | 4.51 × 10−20 | |
| F46 | Mean | −1.40 | −1.55 × 10−1 | −0.98 | −1.03 | −1.32 |
| Std | 5.40 × 10−3 | 9.16 × 10−2 | 1.41 × 10−2 | 1.04 × 10−2 | 7.12 × 10−2 | |
| F47 | Mean | −9.40 × 10−1 | −1.37 × 10−3 | −1.35 | −1.34 | −1.24 |
| Std | 5.57 × 10−5 | 3.32 × 10−4 | 1.94 × 10−4 | 6.4 × 10−3 | 4.52 × 10−4 | |
| F48 | Mean | 2.85 × 10−9 | 1.46 × 10−8 | 7.44 × 10−9 | 7.23 × 10−9 | 3.44 × 10−9 |
| Std | 3.33 × 10−17 | 3.24 × 10−16 | 9.31 × 10−11 | 9.72 × 10−21 | 3.08 × 10−17 | |
| F49 | Mean | 1.04 × 102 | 2.82 × 102 | 1.31 × 102 | 1.22 × 102 | 1.19 × 102 |
| Std | 2.45 × 105 | 5.67 × 105 | 1.87 × 105 | 5.18 × 105 | 6.53 × 105 | |
| F50 | Mean | 3.83 × 103 | 5.17 × 103 | 4.59 × 103 | 4.09 × 103 | 3.86 × 103 |
| Std | 4.86 × 106 | 6.29 × 106 | 2.58 × 106 | 5.41 × 106 | 7.82 × 106 |
| ID | Index | MSSMA | SMA | WOA | KO | BWO | IVY |
|---|---|---|---|---|---|---|---|
| F1 | Mean | −5.00 | −5.00 | 2.46 × 10−187 | −4.07 | −5.00 | −8.00 × 10−1 |
| Std | 0.00 | 0.00 | 0.00 | 3.40 × 10−1 | 0.00 | 1.82 | |
| F2 | Mean | 0.00 | 0.00 | 4.35 × 10−104 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 4.79 × 10−206 | 0.00 | 0.00 | 0.00 | |
| F3 | Mean | 0.00 | 0.00 | 2.76 × 107 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 4.76 × 10+13 | 0.00 | 0.00 | 0.00 | |
| F4 | Mean | 0.00 | 0.00 | 7.31 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 6.69 | 0.00 | 0.00 | 0.00 | |
| F5 | Mean | 5.47 × 10−8 | 3.26 × 10−4 | 4.13 × 10−6 | 1.26 × 10−4 | 3.19 × 10−5 | 1.86 × 10−5 |
| Std | 3.30 × 10−18 | 5.45 × 10−8 | 3.32 × 10−8 | 1.82 × 10−8 | 7.03 × 10−10 | 3.26 × 10−10 | |
| F6 | Mean | 6.75 × 10−10 | 2.85 × 10−8 | 0.00 | 8.46 × 10−7 | 4.58 × 10−4 | 6.78 × 10−18 |
| Std | 1.15 × 10−18 | 2.80 × 10−14 | 0.00 | 1.02 × 10−12 | 4.25 × 10−7 | 1.00 × 10−33 | |
| F7 | Mean | −1.00 | −9.95 × 10−1 | 1.95 × 10−4 | −1.00 | −1.00 | −2.16 × 10−1 |
| Std | 1.51 × 10−20 | 5.76 × 10−4 | 5.54 × 10−8 | 1.96 × 10−13 | 0.00 | 1.21 × 10−1 | |
| F8 | Mean | 0.00 | 0.00 | −7.89 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 3.19 × 10−17 | 0.00 | 0.00 | 0.00 | |
| F9 | Mean | 4.81 × 10−7 | 2.37 × 10−4 | 0.00 | 1.39 × 10−1 | 1.35 × 10−3 | 1.14 |
| Std | 1.50 × 10−12 | 2.34 × 10−7 | 0.00 | 4.16 × 10−2 | 2.35 × 10−6 | 3.01 | |
| F10 | Mean | −5.00 × 101 | −5.00 × 101 | 2.10 × 10−15 | −5.00 × 101 | −4.98 × 101 | −2.31 |
| Std | 1.11 × 10−18 | 8.08 × 10−9 | 4.12 × 10−30 | 1.48 × 10−7 | 7.13 × 10−3 | 1.65 × 101 | |
| F11 | Mean | −2.10 × 102 | −2.10 × 102 | 2.67 × 10−2 | −2.10 × 102 | −1.97 × 102 | −4.43 × 10−1 |
| Std | 1.92 × 10−9 | 2.39 × 10−4 | 2.86 × 10−3 | 1.66 × 10−4 | 2.50 × 101 | 4.99 | |
| F12 | Mean | 0.00 | 0.00 | 2.39 × 10−5 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 3.48 × 10−10 | 0.00 | 0.00 | 0.00 | |
| F13 | Mean | 0.00 | 0.00 | 1.21 × 10−2 | 2.40 × 10−63 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 1.79 × 10−4 | 1.72 × 10−124 | 0.00 | 0.00 | |
| F14 | Mean | 0.00 | 3.42 × 10−2 | 1.13 × 10−106 | 0.00 | 2.47 × 10−257 | 0.00 |
| Std | 0.00 | 1.06 × 10−2 | 1.56 × 10−211 | 0.00 | 0.00 | 0.00 | |
| F15 | Mean | 0.00 | 0.00 | 2.44 × 107 | 1.20 × 10−302 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 3.70 × 10+13 | 0.00 | 0.00 | 0.00 | |
| F16 | Mean | 2.28 × 10−6 | 6.85 × 101 | 4.95 × 102 | 4.95 × 102 | 2.68 × 10−3 | 4.94 × 102 |
| Std | 3.26 × 10−9 | 1.20 × 104 | 5.42 × 10−2 | 6.50 × 10−2 | 2.00 × 10−4 | 7.28 × 10−1 | |
| F17 | Mean | 3.46 × 10−4 | 8.12 × 10−1 | 6.67 × 10−1 | 6.67 × 10−1 | 2.50 × 10−1 | 6.67 × 10−1 |
| Std | 4.17 × 10−13 | 8.05 × 10−2 | 1.90 × 10−9 | 2.51 × 10−11 | 1.31 × 10−8 | 7.74 × 10−10 | |
| F18 | Mean | 9.98 × 10−1 | 9.98 × 10−1 | 1.52 | 9.98 × 10−1 | 9.98 × 10−1 | 9.52 |
| Std | 1.86 × 10−26 | 3.00 × 10−23 | 3.41 | 3.98 × 10−24 | 5.22 × 10−25 | 1.52 × 101 | |
| F19 | Mean | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 3.98 × 10−1 | 3.99 × 10−1 | 3.98 × 10−1 |
| Std | 1.10 × 10−18 | 1.12 × 10−16 | 9.64 × 10−15 | 1.65 × 10−7 | 1.85 × 10−6 | 3.98 × 10−15 | |
| F20 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F21 | Mean | 9.58 × 10−11 | 3.30 × 10−10 | 3.18 × 10−5 | 1.00 × 10−6 | 7.24 × 10−3 | 1.34 × 10−10 |
| Std | 1.61 × 10−20 | 5.55 × 10−19 | 9.44 × 10−10 | 7.12 × 10−13 | 2.96 × 10−5 | 1.42 × 10−19 | |
| F22 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F23 | Mean | −1.59 × 105 | −2.09 × 105 | −1.95 × 105 | −6.36 × 104 | −2.09 × 105 | −1.75 × 104 |
| Std | 1.28 × 10−2 | 1.18 × 102 | 4.61 × 108 | 1.16 × 108 | 8.76 × 10−22 | 4.68 × 106 | |
| F24 | Mean | −1.80 | −1.80 | −1.80 | −1.80 | −1.79 | −1.69 |
| Std | 2.86 × 10−23 | 1.67 × 10−17 | 2.28 × 10−16 | 1.65 × 10−11 | 6.16 × 10−5 | 5.61 × 10−2 | |
| F25 | Mean | −4.58 | −4.39 | −3.95 | −4.50 | −4.55 | −2.78 |
| Std | 1.27 × 10−3 | 8.90 × 10−2 | 2.95 × 10−1 | 3.09 × 10−2 | 4.03 × 10−3 | 1.89 × 10−1 | |
| F26 | Mean | −8.57 | −8.46 | −6.50 | −6.78 | −8.66 | −3.70 |
| Std | 3.42 × 10−2 | 5.28 × 10−1 | 7.59 × 10−1 | 7.92 × 10−1 | 3.28 × 10−2 | 3.10 × 10−1 | |
| F27 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F28 | Mean | −1.03 | −1.03 | −1.03 | −1.03 | −1.03 | −9.71 × 10−1 |
| Std | 1.27 × 10−25 | 9.65 × 10−22 | 8.25 × 10−23 | 1.41 × 10−12 | 5.45 × 10−9 | 3.55 × 10−2 | |
| F29 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F30 | Mean | 0.00 | 0.00 | 2.59 × 10−17 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 1.25 × 10−32 | 0.00 | 0.00 | 0.00 | |
| F31 | Mean | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.87 × 102 | −1.61 × 102 |
| Std | 4.01 × 10−14 | 1.30 × 10−13 | 1.75 × 10−10 | 1.59 × 10−2 | 4.72 × 10−11 | 1.02 × 103 | |
| F32 | Mean | 3.00 | 3.00 | 3.00 | 3.00 | 3.42 | 3.90 |
| Std | 1.23 × 10−26 | 2.97 × 10−22 | 1.12 × 10−11 | 9.53 × 10−10 | 1.88 × 10−1 | 2.43 × 101 | |
| F33 | Mean | 3.08 × 10−4 | 4.44 × 10−4 | 5.30 × 10−4 | 3.36 × 10−4 | 3.16 × 10−4 | 1.04 × 10−3 |
| Std | 5.99 × 10−14 | 2.96 × 10−8 | 8.88 × 10−8 | 4.19 × 10−9 | 1.91 × 10−10 | 1.34 × 10−5 | |
| F34 | Mean | −1.02 × 101 | −1.02 × 101 | −9.73 | −1.02 × 101 | −1.02 × 101 | −2.87 |
| Std | 1.26 × 10−13 | 2.04 × 10−9 | 2.66 | 4.70 × 10−7 | 3.64 × 10−12 | 4.09 | |
| F35 | Mean | −1.04 × 101 | −1.04 × 101 | −1.00 × 101 | −1.04 × 101 | −1.04 × 101 | −3.66 |
| Std | 4.05 × 10−12 | 6.36 × 10−9 | 1.82 | 2.25 × 10−7 | 7.32 × 10−12 | 2.73 | |
| F36 | Mean | −1.05 × 101 | −1.05 × 101 | −8.89 | −1.05 × 101 | −1.05 × 101 | −4.01 |
| Std | 4.70 × 10−12 | 1.82 × 10−9 | 8.04 | 2.29 × 10−7 | 1.92 × 10−11 | 3.00 | |
| F37 | Mean | 9.26 × 10−2 | 1.38 × 10−1 | 3.01 | 1.04 | 1.18 × 10−1 | 3.21 × 10−1 |
| Std | 1.91 × 10−2 | 3.77 × 10−2 | 1.13 × 101 | 9.11 × 10−1 | 8.40 × 10−3 | 4.14 × 10−1 | |
| F38 | Mean | 9.57 × 10−4 | 7.85 × 10−3 | 9.28 × 10−1 | 6.61 × 10−2 | 3.63 × 10−2 | 1.61 × 10−1 |
| Std | 1.53 × 10−6 | 7.91 × 10−5 | 1.32 | 2.59 × 10−3 | 7.03 × 10−4 | 1.09 × 10−1 | |
| F39 | Mean | −3.86 | −3.86 | −3.86 | −3.86 | −3.86 | −3.83 |
| Std | 9.69 × 10−22 | 1.27 × 10−16 | 3.31 × 10−6 | 3.20 × 10−9 | 6.68 × 10−6 | 1.93 × 10−3 | |
| F40 | Mean | −3.28 | −3.24 | −3.26 | −3.22 | −3.31 | −2.74 |
| Std | 2.34 × 10−5 | 3.07 × 10−3 | 8.16 × 10−3 | 3.86 × 10−3 | 4.56 × 10−4 | 1.50 × 10−1 | |
| F41 | Mean | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Std | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| F42 | Mean | 3.89 × 10−16 | 4.44 × 10−16 | 4.23 × 10−15 | 4.41 × 10−16 | 4.16 × 10−16 | 6.57 × 10−16 |
| Std | 0.00 | 2.07 × 10−32 | 7.78 × 10−30 | 1.07 × 10−28 | 9.74 × 10−36 | 3.86 × 10−19 | |
| F43 | Mean | 2.36 × 10−8 | 4.08 × 10−4 | 1.49 × 10−2 | 1.15 × 10−1 | 1.38 × 10−9 | 7.85 × 10−2 |
| Std | 4.30 × 10−11 | 1.05 × 10−6 | 1.64 × 10−5 | 2.99 × 10−4 | 4.75 × 10−8 | 3.28 × 10−4 | |
| F44 | Mean | 1.07 × 10−3 | 3.60 × 10−2 | 4.70 | 9.64 | 1.45 × 10−2 | 4.96 × 101 |
| Std | 5.03 × 10−6 | 2.28 × 10−3 | 2.20 | 7.87 | 6.12 × 10−5 | 9.75 × 10−4 | |
| F45 | Mean | −1.08 | −1.08 | −1.08 | −1.08 | −1.06 | −9.95 × 10−1 |
| Std | 2.33 × 10−20 | 4.35 × 10−17 | 8.42 × 10−6 | 1.03 × 10−13 | 3.65 × 10−4 | 3.00 × 10−2 | |
| F46 | Mean | −1.40 | −1.55 × 10−1 | −7.96 × 10−1 | −1.28 | −1.36 | −3.15 × 10−1 |
| Std | 5.40 × 10−3 | 9.16 × 10−2 | 8.55 × 10−2 | 4.83 × 10−3 | 3.92 × 10−2 | 2.32 × 10−2 | |
| F47 | Mean | −9.40 × 10−1 | −1.37 × 10−3 | −2.52 × 10−1 | −1.07 × 10−1 | −6.27 × 10−1 | −2.42 × 10−2 |
| Std | 5.57 × 10−5 | 3.32 × 10−4 | 2.75 × 10−2 | 1.91 × 10−1 | 3.01 × 10−2 | 5.90 × 10−3 | |
| F48 | Mean | 2.85 × 10−9 | 1.46 × 10−8 | 3.53 × 10−9 | 1.13 × 10−1 | 1.28 × 101 | 4.70 × 101 |
| Std | 3.33 × 10−17 | 3.24 × 10−16 | 3.24 × 10−17 | 1.17 × 10−2 | 1.87 × 102 | 3.20 × 104 | |
| F49 | Mean | 1.04 × 102 | 2.82 × 102 | 4.08 × 102 | 6.79 × 102 | 8.91 × 102 | 9.92 × 102 |
| Std | 2.45 × 105 | 5.67 × 105 | 6.34 × 105 | 6.96 × 101 | 5.06 × 103 | 2.96 × 106 | |
| F50 | Mean | 3.83 × 103 | 5.17 × 103 | 9.67 × 103 | 2.15 × 103 | 3.61 × 103 | 4.09 × 103 |
| Std | 4.86 × 106 | 6.29 × 106 | 1.61 × 108 | 1.05 × 107 | 6.90 × 105 | 3.05 × 107 |


References
- Shadravan, S.; Naji, H.R.; Bardsiri, V.K. The Sailfish Optimizer: A novel nature-inspired metaheuristic algorithm for solving constrained engineering optimization problems. Eng. Appl. Artif. Intell. 2019, 80, 20–34. [Google Scholar] [CrossRef]
- Wu, G. Across neighborhood search for numerical optimization. Inf. Sci. 2016, 329, 597–618. [Google Scholar] [CrossRef]
- Chou, J.-S.; Truong, D.-N. A novel metaheuristic optimizer inspired by behavior of jellyfish in ocean. Expert Syst. Appl. 2021, 165, 113702. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Z.; Yang, Y.; Zhang, P.; Fan, D. Time-optimal trajectory planning for robotic arms based on an improved tuna swarm algorithm. Comput. Integr. Manuf. Syst. 2024, 30, 4292–4301. [Google Scholar]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Chen, Y.; Pan, Z. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Jia, H.; Liu, Y.; Liu, Q.; Wang, S.; Zheng, R. A hybrid optimization algorithm combining slime mould and arithmetic with random opposition-based learning. J. Comput. Sci. Explor. 2022, 16, 1182–1192. [Google Scholar]
- Guo, Y.; Liu, S.; Zhang, L.; Huang, Q. An improved slime mould algorithm with elite opposition-based learning and quadratic interpolation. Comput. Appl. Res. 2021, 38, 3651–3656. [Google Scholar] [CrossRef]
- Huang, H.; Gao, Y.; Ru, F.; Yang, L.; Wang, H. Three-dimensional path planning for UAVs based on adaptive slime mould algorithm optimization. J. Shanghai Jiao Tong Univ. 2023, 57, 1282–1291. [Google Scholar] [CrossRef]
- Chen, L.F.; Cao, K.X.; Zhang, S.P.; Bai, H.R.; Han, Y.; Dai, Q. Recent advances in swarm intelligent optimization algorithms. Comput. Eng. Appl. 2024, 60, 46–67. [Google Scholar] [CrossRef]
- Maaranen, H.; Miettinen, K.; Mäkelä, M.M. Quasi-random initial population for genetic algorithms. Comput. Math. Appl. 2004, 47, 1885–1895. [Google Scholar] [CrossRef]
- Poles, S.; Fu, Y.; Rigoni, E. The effect of initial population sampling on the convergence of multi-objective genetic algorithms. In Multiobjective Programming and Goal Programming: Theoretical Results and Practical Applications; Springer: Berlin/Heidelberg, Germany, 2009; pp. 123–133. [Google Scholar]
- Ibada Ali, J.; Tüű-Szabó, B.; Kóczy, T.L. Effect of the initial population construction on the DBMEA algorithm searching for the optimal solution of the traveling salesman problem. Infocommunications J. 2022, 14, 72–78. [Google Scholar] [CrossRef]
- Li, J.W.; Cheng, Y.M.; Chen, K.Z. Chaotic particle swarm optimization algorithm based on adaptive inertia weight. In Proceedings of the 26th Chinese Control and Decision Conference (2014 CCDC), Changsha, China, 31 May–2 June 2014; pp. 1310–1315. [Google Scholar]
- Hui, L.C.; Chen, X.L.; Meng, Z.B. An improved sparrow search algorithm with multi-strategy hybridization. Comput. Eng. Appl. 2022, 58, 71–83. [Google Scholar]
- Ewees, A.A.; Abd Elaziz, M.; Houssein, E.H. Improved grasshopper optimization algorithm using opposition-based learning. Expert Syst. Appl. 2018, 112, 156–172. [Google Scholar] [CrossRef]
- Zhou, X.Y.; Yin, Z.Y.; Gao, W.F.; Tan, G.S.; Yi, Y.G. An adaptive multi-neighborhood artificial bee colony algorithm based on reinforcement learning. J. Comput. 2024, 47, 1521–1546. [Google Scholar]
- Wu, F.; Chen, K.; Wang, W.L. A review of computational intelligence based on parallel computing. J. Zhejiang Univ. (Eng. Ed.) 2025, 59, 27–38. [Google Scholar]
- Minh, H.L.; Sang-To, T.; Wahab, M.A.; Cuong-Le, T. A new metaheuristic optimization based on K-means clustering algorithm and its application to structural damage identification. Knowl. -Based Syst. 2022, 251, 109189. [Google Scholar] [CrossRef]
- Layeb, A. Tangent search algorithm for solving optimization problems. Neural Comput. Appl. 2022, 34, 8853–8884. [Google Scholar] [CrossRef]
- Tao, X.M.; Guo, W.J.; Li, X.K.; Chen, W.; Wu, Y.K. Dimensionally reset multiple swarm particle swarm algorithm based on density peaks. J. Softw. 2023, 34, 1850–1869. [Google Scholar] [CrossRef]
- Chen, Z.; Damian, Z.; Ziyun, X. A new species of the genus Pseudococcus (Coleoptera, Staphylinidae) from China. A symbiotic nonuniform Gaussian variational bottle sea squirt swarm algorithm for multisubgroups. J. Autom. 2011, 48, 1307–1317. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, L.; Mirjalili, S. Artificial hummingbird algorithm: A new bio-inspired optimizer with its engineering applications. Comput. Methods Appl. Mech. Eng. 2022, 388, 114194. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Zhong, C.; Li, G.; Meng, Z. Beluga whale optimization: A novel nature-inspired metaheuristic algorithm. Knowl.-Based Syst. 2022, 251, 109215. [Google Scholar] [CrossRef]
- Ghasemi, M.; Zare, M.; Trojovský, P.; Rao, R.V.; Trojovská, E.; Kandasamy, V. Optimization based on the smart behavior of plants with its engineering applications: Ivy algorithm. Knowl.-Based Syst. 2024, 295, 111850. [Google Scholar] [CrossRef]
- Michelon, G.K.; Assunção, W.K.; Grünbacher, P.; Egyed, A. Analysis and propagation of feature revisions in preprocessor-based software product lines. In Proceedings of the 2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Taipa, Macao, 21–24 March 2023; pp. 284–295. [Google Scholar]
- Schlosser, A.D.; Szabó, G.; Bertalan, L.; Varga, Z.; Enyedi, P.; Szabó, S. Building Extraction Using Orthophotos and Dense Point Cloud Derived from Visual Band Aerial Imagery Based on Machine Learning and Segmentation. Remote Sens. 2020, 12, 2397. [Google Scholar] [CrossRef]
- Shan, J.R. Research on Multi-AUV Task Assignment and Path Planning Based on Swarm Intelligence Algorithm. Master’s Thesis, Jilin University, Changchun, China, 2024. Available online: https://kns.cnki.net/kcms2/article/abstract?v=b41E60TuiN92yX80tKT_USqnbcSNTnxPQKhL4fFkW-XNZDWl1InNX-8Dcn9rpiwkepQv1v6478hR0Z6BX8foFcZYjotIkicM5EwiERYMp3b901hmdbSBul97a6VlBiwCki07dsMcghujyaacLzn4Uh8y0WGPTiPNv7OMzT7fHElTFXPJ2HPuvoPwch0OaM5cNNaUZ3GmvIuJbpDNVQlMNA==&uniplatform=NZKPT (accessed on 10 March 2025).
- Peng, H.; Zhang, J.; Li, H.; Hu, J. Cooperative UAV mission planning based on improved wolfpack algorithm. Comput. Eng. 2024, 50, 69–79. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, H.; Han, M.; Xing, L.N. Co-evolutionary mixed-variable multi-objective particle swarm optimization algorithm based on co-evolution for solving UAV cooperative multi-tasking problem. J. Comput. 2021, 44, 1967–1983. [Google Scholar]
- Liu, C.-A.; Wang, X.; Liu, C.; Wu, H. Three-dimensional trajectory planning for unmanned aerial vehicles based on improved gray wolf optimization algorithm. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2017, 45, 38–42. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, M.; Yao, M.; Li, K.H.; Wu, R. An improved ant algorithm for UAV multi-target 3D trajectory planning. J. Shenyang Univ. Technol. 2011, 33, 570–575. [Google Scholar]
- Zhou, R.; Huang, C.Q.; Wei, Z.L.; Zhao, K.X. Application of MP-GWO algorithm in multi-UCAV cooperative trajectory planning. J. Air Force Eng. Univ. (Nat. Sci. Ed.) 2017, 18, 24–29. [Google Scholar]



| ID | L = 3 | L = 5 | L = 10 | L = 15 | L = 20 |
|---|---|---|---|---|---|
| (W|T|L) | (40|6|4) | (20|26|4) | (11|35|4) | (8|32|10) | (7|24|19) |
| Ave | 1.56 | 2.88 | 3.54 | 3.40 | 3.62 |
| Rank | 1 | 2 | 3 | 4 | 5 |
| ID | MSSMA | SMA | MSSMA-1 | MSSMA-2 | MSSMA-3 |
|---|---|---|---|---|---|
| (W|T|L) | (49|1|0) | (14|9|27) | (7|31|12) | (15|35|0) | (17|33|0) |
| Ave | 1.68 | 3.20 | 3.54 | 3.40 | 3.14 |
| Rank | 1 | 3 | 5 | 4 | 2 |
| ID | MSSMA | SMA | WOA | KO | BWO | IVY |
|---|---|---|---|---|---|---|
| (W|T|L) | (43|7|0) | (14|31|5) | (7|32|11) | (13|35|2) | (7|40|3) | (14|16|20) |
| Ave | 1.86 | 2.88 | 3.22 | 3.94 | 4.58 | 4.52 |
| Rank | 1 | 2 | 3 | 4 | 6 | 5 |
| p-value | - | 0.0159 | 9.7 × 10−6 | 0.0013 | 0.0242 | 0.003 |
| ID | Minimum Cost | Mean Cost | Var |
|---|---|---|---|
| MSSMA | 53.641 | 103.123 | 74.996 |
| SMA | 127.708 | 143.431 | 106.813 |
| WOA | 183.296 | 247.842 | 245.518 |
| KO | 136.166 | 196.649 | 305.482 |
| BWO | 2350.998 | 2421.506 | 1558.914 |
| IVY | 213.893 | 265.483 | 81.260 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, D.; Tang, T.; Yan, Y. Multi-Strategy-Improvement-Based Slime Mould Algorithm. Appl. Sci. 2025, 15, 5456. https://doi.org/10.3390/app15105456
Huang D, Tang T, Yan Y. Multi-Strategy-Improvement-Based Slime Mould Algorithm. Applied Sciences. 2025; 15(10):5456. https://doi.org/10.3390/app15105456
Chicago/Turabian StyleHuang, Donghai, Tianbing Tang, and Yi Yan. 2025. "Multi-Strategy-Improvement-Based Slime Mould Algorithm" Applied Sciences 15, no. 10: 5456. https://doi.org/10.3390/app15105456
APA StyleHuang, D., Tang, T., & Yan, Y. (2025). Multi-Strategy-Improvement-Based Slime Mould Algorithm. Applied Sciences, 15(10), 5456. https://doi.org/10.3390/app15105456