
PPDD: Egocentric Crack Segmentation in the Port Pavement with Deep Learning-Based Methods



Abstract
1. Introduction
2. Related Work
2.1. Public Dataset for Crack Identification and Detection
2.2. Deep Learning-Based Segmentation
3. Materials and Methods
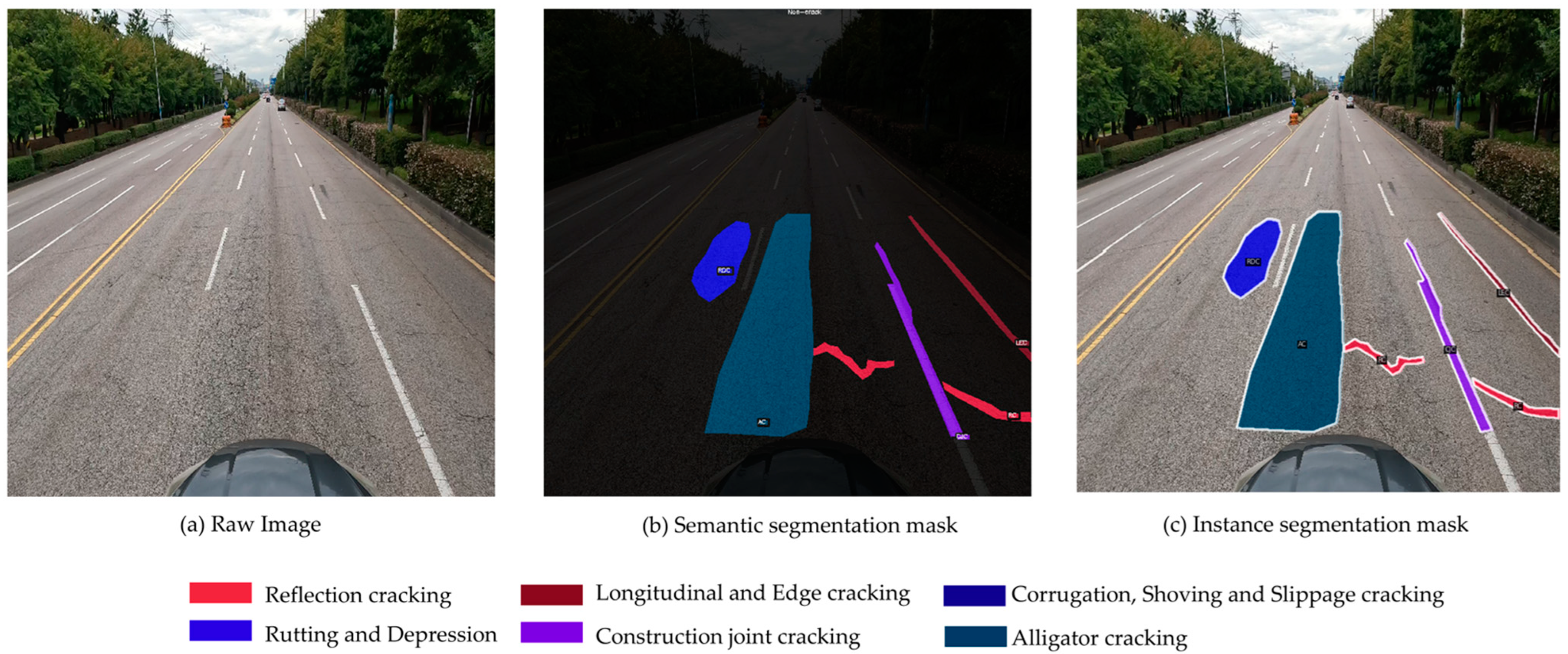
3.1. Port Pavement Distress Dataset (PPDD)
3.2. Baselines
4. Experiments
4.1. Experimental Setup
4.2. Experimental Results
4.2.1. Quantitative Evaluation
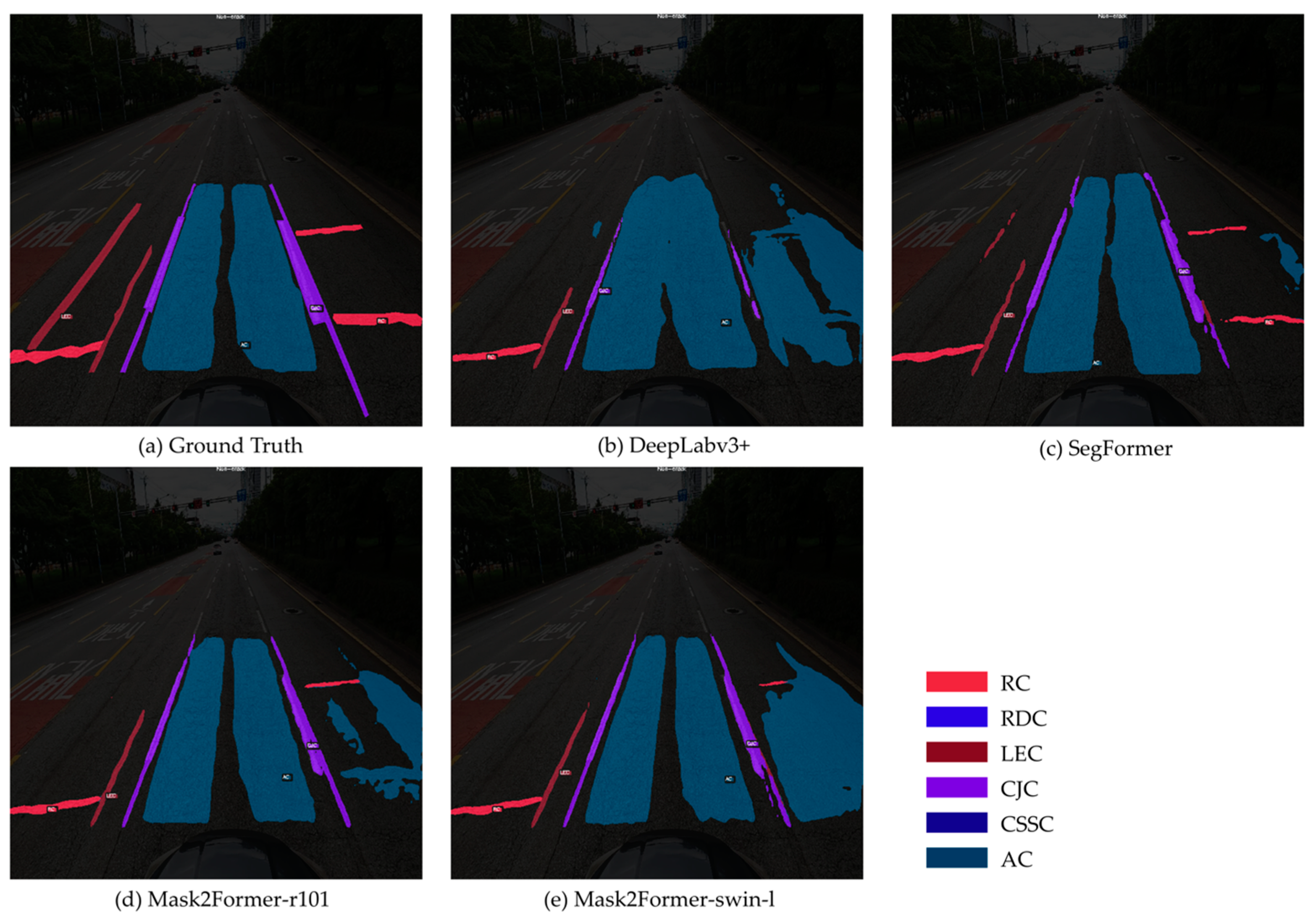
4.2.2. Qualitative Evaluation
5. Discussion
5.1. Road Crack Detection and Segmentation Dataset
5.2. Limitations and Opportunities
5.3. Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thompson, E.M.; Ranieri, A.; Biasotti, S.; Chicchon, M.; Sipiran, I.; Pham, M.-K.; Nguyen-Ho, T.-L.; Nguyen, H.-D.; Tran, M.-T. SHREC 2022: Pothole and crack detection in the road pavement using images and RGB-D data. Comput. Graph. 2022, 107, 161–171. [Google Scholar] [CrossRef]
- Kanwal, S.; Rasheed, M.I.; Pitafi, A.H.; Pitafi, A.; Ren, M. Road and transport infrastructure development and community support for tourism: The role of perceived benefits, and community satisfaction. Tour. Manag. 2020, 77, 104014. [Google Scholar] [CrossRef]
- Kanwal, S.; Pitafi, A.H.; Rasheed, M.I.; Pitafi, A.; Iqbal, J. Assessment of residents’ perceptions and support toward development projects: A study of the China–Pakistan Economic Corridor. Soc. Sci. J. 2022, 59, 102–118. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y. Transfer learning-based road damage detection for multiple countries. arXiv 2020, arXiv:2008.13101. [Google Scholar]
- Benz, C.; Rodehorst, V. Omnicrack30k: A benchmark for crack segmentation and the reasonable effectiveness of transfer learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 3876–3886. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Hedeya, M.A.; Samir, E.; El-Sayed, E.; El-Sharkawy, A.A.; Abdel-Kader, M.F.; Moussa, A.; Abdel-Kader, R.F. A low-cost multi-sensor deep learning system for pavement distress detection and severity classification. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications, Cairo, Egypt, 5–7 May 2022; pp. 21–33. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An annotated image dataset for automatic road damage detection using deep learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. A cost effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M.; Shirzad-Ghaleroudkhani, N. Towards smart cities: Crowdsensing-based monitoring of transportation infrastructure using in-traffic vehicles. J. Civ. Struct. Health Monit. 2020, 10, 653–665. [Google Scholar] [CrossRef]
- Chen, T.; Cai, Z.; Zhao, X.; Chen, C.; Liang, X.; Zou, T.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Omata, H.; Kashiyama, T.; Sekimoto, Y. Global road damage detection: State-of-the-art solutions. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5533–5539. [Google Scholar]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection using deep neural networks with images captured through a smartphone. arXiv 2018, arXiv:1801.09454. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. Oneformer: One transformer to rule universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2989–2998. [Google Scholar]
- Guo, F.; Qian, Y.; Liu, J.; Yu, H. Pavement crack detection based on transformer network. Autom. Constr. 2023, 145, 104646. [Google Scholar] [CrossRef]
- Faruk, A.N.; Liu, W.; Lee, S.I.; Naik, B.; Chen, D.H.; Walubita, L.F. Traffic volume and load data measurement using a portable weigh in motion system: A case study. Int. J. Pavement Res. Technol. 2016, 9, 202–213. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Computer Vision Annotation Tool (CVAT), Version 2.25.0. Available online: https://github.com/cvat-ai/cvat (accessed on 29 June 2018).
- OpenMMLab Detection Toolbox and Benchmark, Version 3.0.0. Available online: https://github.com/open-mmlab/mmdetection (accessed on 22 August 2018).
- OpenMMLab Semantic Segmentation Toolbox and Benchmark, Version 1.0.0. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 14 June 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Saltık, A.O.; Allmendinger, A.; Stein, A. Comparative analysis of yolov9, yolov10 and rt-detr for real-time weed detection. arXiv 2024, arXiv:2412.13490. [Google Scholar]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. Crackformer: Transformer network for fine-grained crack detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3783–3792. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2022: A multi-national image dataset for automatic road damage detection. Geosci. Data J. 2024, 11, 846–862. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Omata, H.; Kashiyama, T.; Sekimoto, Y. Crowdsensing-based road damage detection challenge (crddc’2022). In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 6378–6386. [Google Scholar]
- Arya, D.; Omata, H.; Maeda, H.; Sekimoto, Y. Orddc’2024: State of the art solutions for optimized road damage detection. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; pp. 8430–8438. [Google Scholar]
- Tang, K.; Niu, Y.; Huang, J.; Shi, J.; Zhang, H. Unbiased scene graph generation from biased training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3716–3725. [Google Scholar]
- Shin, S.-P.; Kim, K.; Le, T.H.M. Feasibility of advanced reflective cracking prediction and detection for pavement management systems using machine learning and image detection. Buildings 2024, 14, 1808. [Google Scholar] [CrossRef]
- Wang, C.; Liu, H.; An, X.; Gong, Z.; Deng, F. SwinCrack: Pavement crack detection using convolutional swin-transformer network. Digit. Signal Process. 2024, 145, 104297. [Google Scholar] [CrossRef]
- He, Z.; Su, C.; Deng, Y. A novel hybrid approach for concrete crack segmentation based on deformable oriented-YOLOv4 and image processing techniques. Appl. Sci. 2024, 14, 1892. [Google Scholar] [CrossRef]
- Ha, J.; Kim, D.; Kim, M. Assessing severity of road cracks using deep learning-based segmentation and detection. J. Supercomput. 2022, 78, 17721–17735. [Google Scholar] [CrossRef]
- Ochoa-Ruiz, G.; Angulo-Murillo, A.A.; Ochoa-Zezzatti, A.; Aguilar-Lobo, L.M.; Vega-Fernández, J.A.; Natraj, S. An asphalt damage dataset and detection system based on retinanet for road conditions assessment. Appl. Sci. 2020, 10, 3974. [Google Scholar] [CrossRef]
- Lin, C.-S.; Wang, C.-Y.; Wang, Y.-C.F.; Chen, M.-H. SemPLeS: Semantic prompt learning for weakly-supervised semantic segmentation. arXiv 2024, arXiv:2401.11791. [Google Scholar]
- Jo, S.; Pan, F.; Yu, I.-J.; Kim, K. DHR: Dual Features-Driven Hierarchical Rebalancing in Inter-and Intra-Class Regions for Weakly-Supervised Semantic Segmentation. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 231–248. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Q.; Li, Y.; Li, X. Allspark: Reborn labeled features from unlabeled in transformer for semi-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 3627–3636. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2030. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Image Type | Task | Number of Class | Dataset Size |
|---|---|---|---|---|
| Chen, T., et al. [17] | Patch | SEG | 1 | 10,000 (5000/2500/2500) |
| EdmCrack600 [16] | Ego-vehicle | SEG | 1 | 600 (420/60/120) |
| CPRID | Ego-vehicle | SEG | 1 | 2235 (2000/200/35) |
| RCDC [18] | Ego-vehicle | OD | 4 | 23,705 (18,930/2111/2664) |
| RDD [19] | Ego-vehicle | OD | 8 | 9053 (-) |
| Omicrack30k [6] | Patch | SEG | 1 | 30,017 (22,158/3277/4582) |
| PPDD (Ours) | Ego-vehicle | SEG | 6 | 204,839 (163,871/20,484/20,484) |
| (%) | RC | LEC | CSSC | RD | CJC | AC | Background | Total | |
|---|---|---|---|---|---|---|---|---|---|
| Mask2Former-r101 | |||||||||
| PA | 48.71 | 53.9 | 42.5 | 69.33 | 60.33 | 64.39 | 97.46 | 62.37 | |
| mIoU | 33.8 | 38.7 | 29.13 | 36.79 | 40.31 | 54.62 | 95.42 | 46.96 | |
| Mask2Former-swin-l | |||||||||
| PA | 48.45 | 56.03 | 40.67 | 64.75 | 62.9 | 65.84 | 97.98 | 62.37 | |
| mIoU | 34.36 | 41.82 | 34.92 | 39.89 | 41.76 | 56.19 | 95.90 | 49.26 | |
| SegFormer | |||||||||
| PA | 40.84 | 58.64 | 53.92 | 73.10 | 58.17 | 81.96 | 99.10 | 66.53 | |
| mIoU | 35.13 | 50.74 | 48.31 | 62.27 | 49.19 | 72.55 | 97.52 | 59.39 | |
| DeepLabv3+ | |||||||||
| PA | 39.76 | 48.67 | 36.29 | 46.54 | 46.45 | 68.38 | 98.70 | 54.97 | |
| mIoU | 31.95 | 38.14 | 27.05 | 37.86 | 36.93 | 57.18 | 96.19 | 46.47 | |
| (%) | RC | LEC | CSSC | RD | CJC | AC | Total | |
|---|---|---|---|---|---|---|---|---|
| Mask2Former-r101 | ||||||||
| 45.9 | 50.7 | 49.1 | 62.6 | 64.9 | 69.7 | 57.15 | ||
| 15.4 | 17.1 | 18.7 | 36.6 | 29.6 | 43.3 | 26.78 | ||
| Mask2Former-swin-s | ||||||||
| 51.9 | 56.5 | 57.6 | 66.7 | 70.10 | 76.3 | 63.18 | ||
| 18.5 | 20 | 22.7 | 41.4 | 34.6 | 49.4 | 31.10 | ||
| YOLOv7 | ||||||||
| 57.4 | 65.1 | 80.2 | 84 | 84.3 | 87.2 | 76.37 | ||
| 21.3 | 25.2 | 38.3 | 55.9 | 45.2 | 57.5 | 40.57 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, H.; Kim, H.-K.; Kim, S. PPDD: Egocentric Crack Segmentation in the Port Pavement with Deep Learning-Based Methods. Appl. Sci. 2025, 15, 5446. https://doi.org/10.3390/app15105446
Yoon H, Kim H-K, Kim S. PPDD: Egocentric Crack Segmentation in the Port Pavement with Deep Learning-Based Methods. Applied Sciences. 2025; 15(10):5446. https://doi.org/10.3390/app15105446
Chicago/Turabian StyleYoon, Hyemin, Hoe-Kyoung Kim, and Sangjin Kim. 2025. "PPDD: Egocentric Crack Segmentation in the Port Pavement with Deep Learning-Based Methods" Applied Sciences 15, no. 10: 5446. https://doi.org/10.3390/app15105446
APA StyleYoon, H., Kim, H.-K., & Kim, S. (2025). PPDD: Egocentric Crack Segmentation in the Port Pavement with Deep Learning-Based Methods. Applied Sciences, 15(10), 5446. https://doi.org/10.3390/app15105446