

Enhancing Prospecting Target Prediction Precision: A Multi-Source Data Mining Approach in Gansu’s Beishan Area

Abstract
1. Introduction
2. Geology and Data
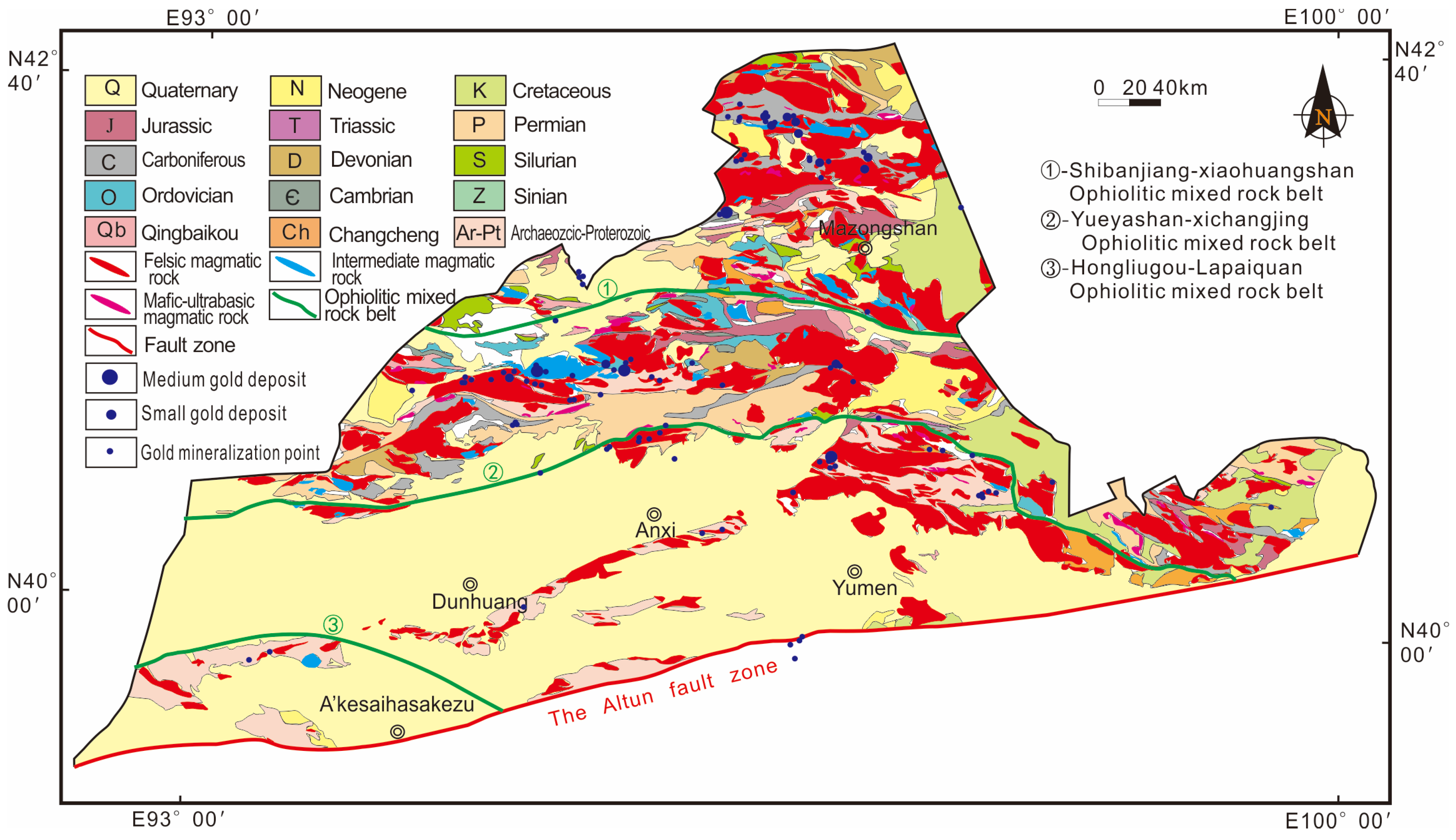
2.1. Geological Setting
2.2. Data Sources
3. Methodology
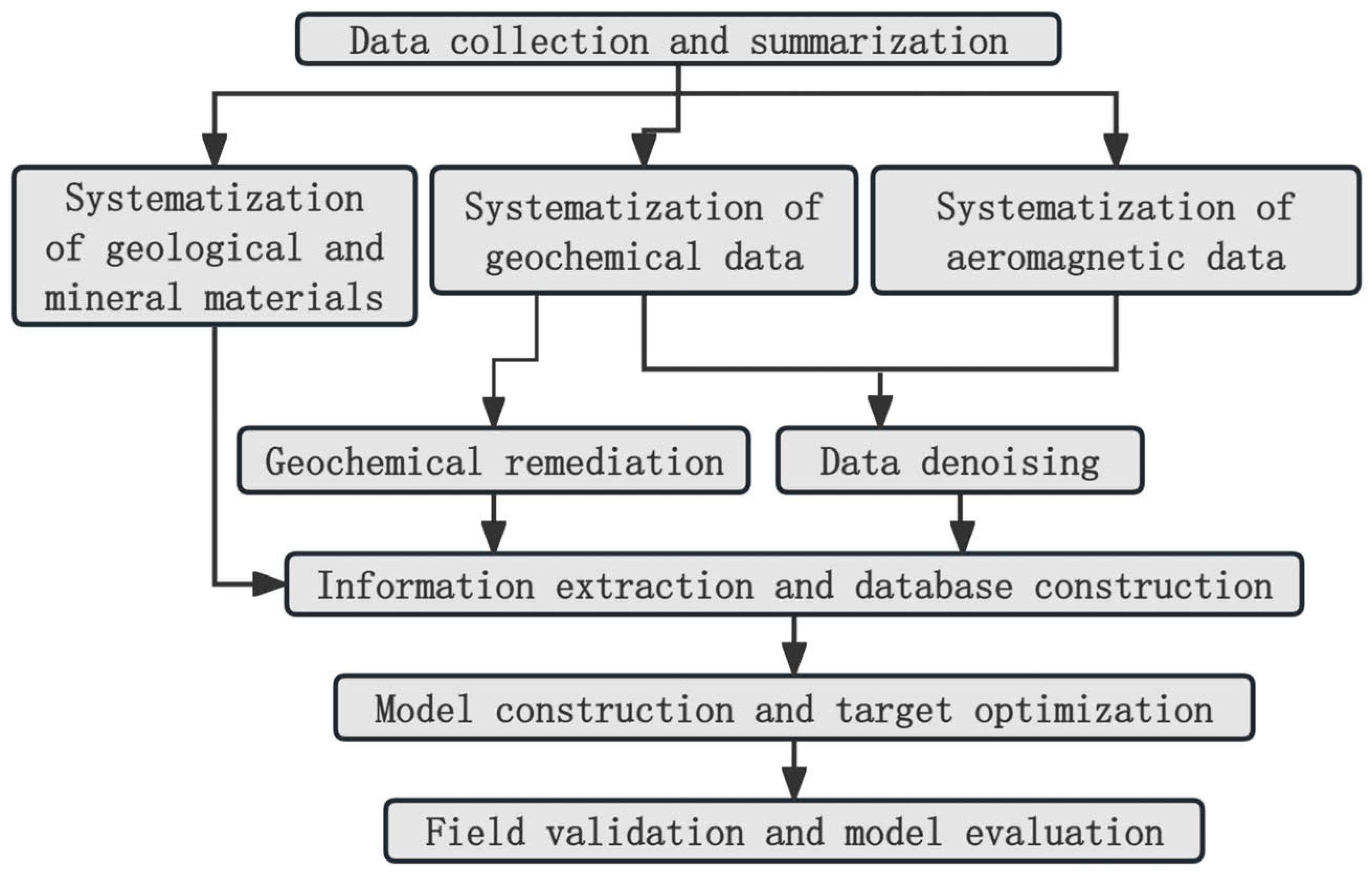
3.1. Research Ideas and Research Procedures
3.1.1. Research Ideas
3.1.2. Research Procedures
- The objective is to compile and categorize data related to regional and mineral surveys and mineral resources within the specified study area, at varying scales, including 1:50,000 and 1:200,000. These data must be organized and classified according to a standardized geological background information system. Subsequently, a database of information on the principal gold deposits (points) within the Beishan area should be established, based on statistical analysis.
- The geochemical data at a scale of 1:200,000 and aeromagnetic data of various scales were processed individually, leading to the creation of separate geochemical and aeromagnetic databases. These databases were then combined in readiness for mathematical modeling.
- A comprehensive investigation into the relationship between regional geophysical and geochemical exploration data and the Au deposits (points) previously identified in the study area is necessary. This will involve developing a conditional correlation model, associating predicted deposits (points) with geophysical and geochemical exploration units, and creating a database of optimal models that incorporate known ore-bearing units.
- SPSS Statistics Trial Version (20), which is the software provided by IBM China Headquarters located in Shanghai, China, was utilized to construct the quantitative preferred series model for the Au mine regional mineral exploration target area, employing specification units, sample units, and anomaly units, respectively.
- Utilizing the data from the optimal results, a map of optimal prospecting targets is constructed, providing comprehensive information on predicted mineral species within the study area. The relevant parameters undergo statistical analysis, and the target area is subsequently verified in the field to evaluate the effectiveness and optimization of the optimal model.
3.2. Raw Data Processing
3.2.1. Raw Data Noise Reduction Processing
3.2.2. Information Extraction
3.2.3. Restoration of Au Geochemical Information
3.2.4. Specification of Unit Division
4. Results and Discussion
4.1. Construction of a Quantitative Optimization Model for Prospecting Target Areas
- 1.
- Model I
- 2.
- Model II
- 3.
- Model III
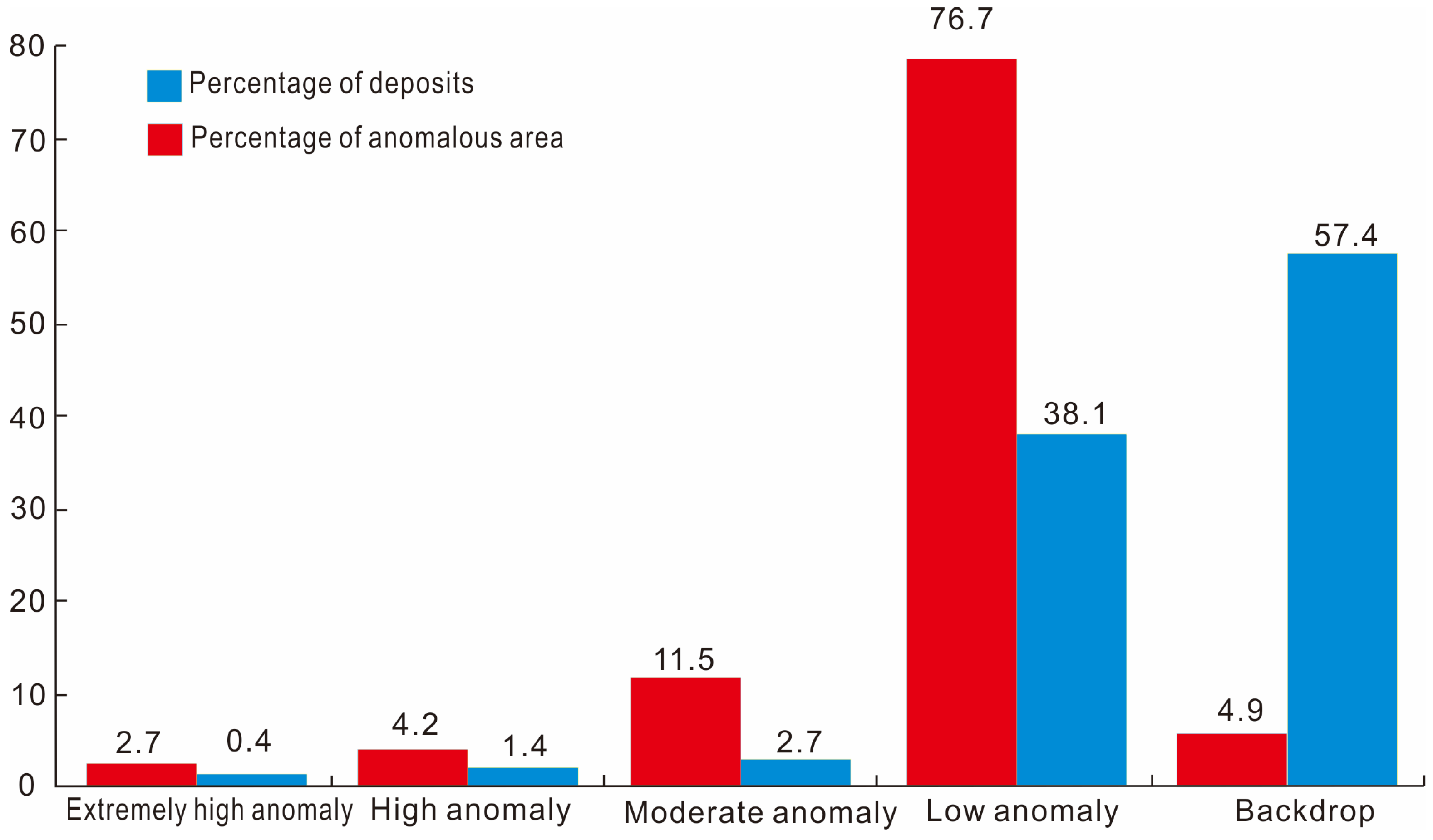
4.2. Discussion of the Model’s Validity
- 1.
- The effectiveness of optimal model I:
- 2.
- The effectiveness of optimal model II
- 3.
- The effectiveness of optimal model III
- 4.
- Discussion of a series of models for the optimization of prospecting target areas in the Au mining area
- 5.
- Discussion on the contribution of aeromagnetic data in the models
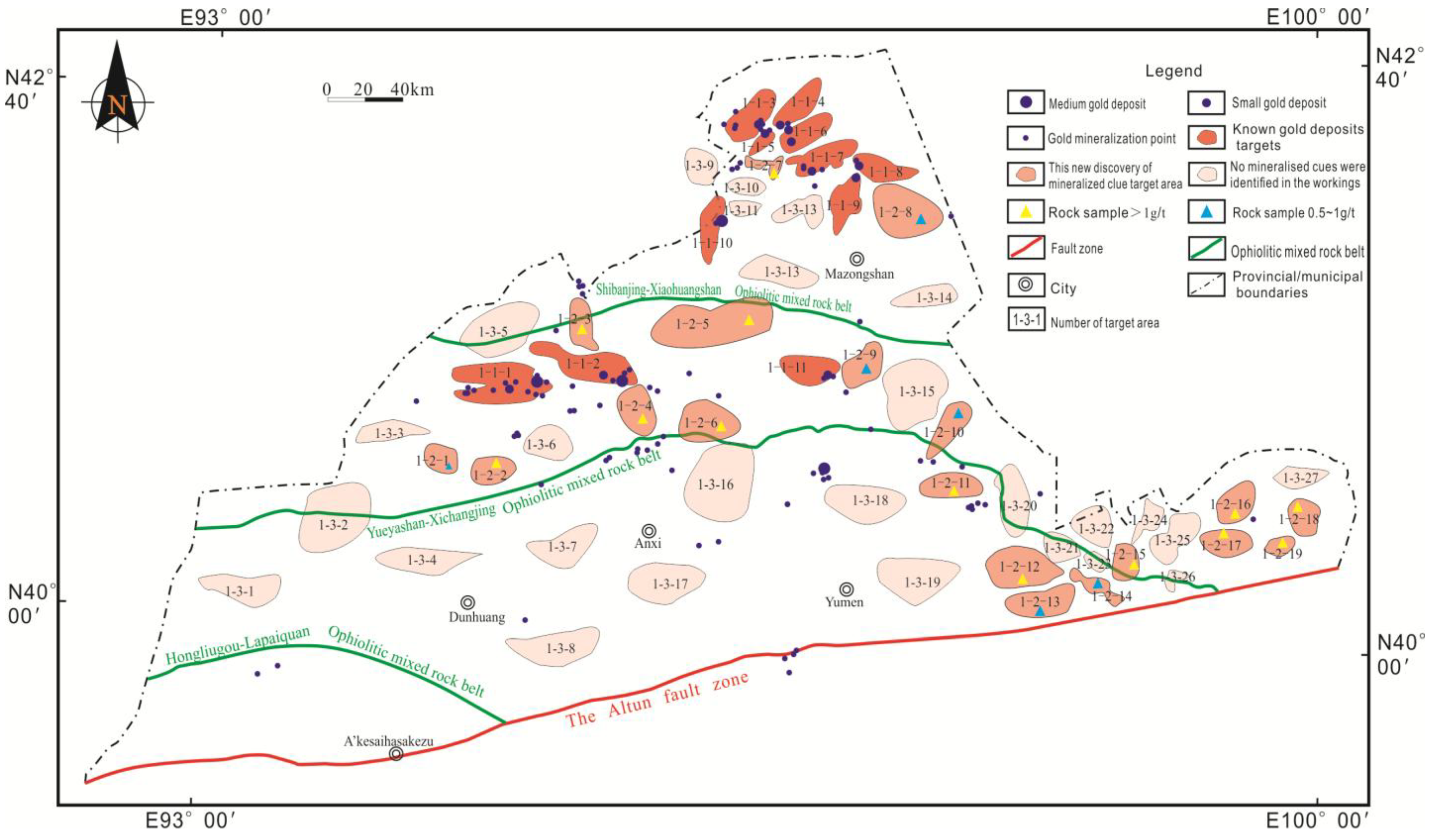
4.3. Results of Quantitative Target Selection Based on Geophysical and Geochemical Prospecting Information for Au Mining Region
4.4. Field Inspection to Verify the Situation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, J.M.; Wang, X.W.; Song, B.T.; Yang, Z.M.; Zhang, Q.; Zhao, Y.Q. Discussion on the method for quantitative classification of magmatic rocks: Taking it’s application in West Qinling of Gansu Province for example. Acta Petrol. Sin. 2018, 34, 326–332. [Google Scholar]
- Wang, C.; Ma, X.; Chen, J.; Chen, J. Information extraction and knowledge graph construction from geoscience literature. Comput. Geosci. 2018, 112, 112–120. [Google Scholar] [CrossRef]
- Enkhsaikhan, M.; Holden, E.J.; Duuring, P.; Liu, W. Understanding ore-forming conditions using machine reading of text. Ore Geol. Rev. 2021, 135, 104200. [Google Scholar] [CrossRef]
- Austin, J.R.; Blenkinsop, T.G. Local to regional scale structural controls on mineralization and the importance of a major lineament in the eastern Mount Isa Inlier. Australia: Review and analysis with autocorrelation and weights of evidence. Ore Geol. Rev. 2009, 35, 298–316. [Google Scholar] [CrossRef]
- Liu, C.; Ji, X.; Dong, Y.; He, M.; Yang, M.; Wang, Y. Chinese mineral question and answering system based on knowledge graph. Expert Syst. Appl. 2023, 231, 120841. [Google Scholar] [CrossRef]
- Zhuang, C.; Liu, C.; Zhu, H.; Ma, Y.; Shi, G.; Liu, Z.; Liu, B. Constraint information extraction for 3D geological modelling using a span-based joint entity and relation extraction model. Earth Sci. Inf. 2024, 17, 985–998. [Google Scholar] [CrossRef]
- Sobhana, N.V.; Mitra, P.; Ghosh, S.K. Conditional random field based named entity recognition in geological text. Int. J. Comput. Appl. 2010, 1, 143–147. [Google Scholar] [CrossRef]
- Qiu, Q.; Tian, M.; Huang, Z.; Xie, Z.; Ma, K.; Tao, L.; Xu, D. Chinese engineering geological named entity recognition by fusing multi-features and data enhancement using deep learning. Expert Syst. Appl. 2024, 238, 121925. [Google Scholar] [CrossRef]
- Zhou, Y.Z.; Chen, S.; Zhang, Q.; Xiao, F.; Wang, S.G.; Liu, Y.P.; Jiao, S.T. Advances and prospects of big data and mathematical geoscience. Acta Petrol. Sin. 2018, 34, 255–263. [Google Scholar]
- Zhou, Y.Z.; Xiao, F. Overview: A glimpse of the latest advances in artificial intelligence and big data geoscience research. Earth Sci. Front. 2024, 31, 1–6. [Google Scholar]
- Abbaszadeh, M.; Hezarkhani, A.; Soltani-Mohammadi, S. An SVM-based machine learning method for the separation of alteration zones in Sungun porphyry copper deposit. Geochemistry 2013, 73, 545–554. [Google Scholar] [CrossRef]
- Zuo, R.G. Identifying geochemical anomalies associated with Cu and Pb-Zn skarn mineralization using principal component analysis and spectrum-area fractal modeling in the Gangdese Belt, Tibet (China). J. Geochem. Explor. 2011, 111, 13–22. [Google Scholar] [CrossRef]
- Filzmoser, P.; Hron, K.; Reimann, C. Robust factor analysis for compositional data. Comput. Geosci. 2009, 35, 1854–1861. [Google Scholar] [CrossRef]
- Maepa, F.; Smith, R.S.; Tessema, A. Support vector machine and artificial neural network modelling of orogenic gold prospectivity mapping in the Swayze greenstone belt, Ontario, Canada. Ore Geol. Rev. 2021, 130, 103968. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, Q.; Han, S.; Zhang, J.; Yang, P.; Liu, X.; Lang, M. The metallogenic tectonic implication of the volcanic rocks of the Dahalajunshan Formation in the Early Carboniferous in the West Tianshan based on big data analytics. Arab. J. Geosci. 2022, 15, 1658. [Google Scholar] [CrossRef]
- Zhang, S.; Xiao, K.Y.; Carranza, E.J.M.; Yang, F. Maximum entropy and random forest modeling of mineral potential: Analysis of gold prospectivity in the Hezuo—Meiwu district west Qinling Orogen, China. Nat. Resour. Res. 2019, 28, 645–664. [Google Scholar] [CrossRef]
- Shabani, A.; Ziaii, M.; Monfared, M.S.; Shirazy, A.; Shirazi, A. Multi-Dimensional Data Fusion for Mineral Prospectivity Mapping (MPM) Using Fuzzy-AHP Decision-Making Method, Kodegan-Basiran Region. East Iran. Minerals 2022, 12, 1629. [Google Scholar] [CrossRef]
- Nti, I.K.; Quarcoo, J.A.; Aning, J.; Fosu, G.K. A mini-review of machine learning in big data analytics: Applications, challenges, and prospects. Big Data Min. Anal. 2022, 5, 81–97. [Google Scholar] [CrossRef]
- Zhang, S.; Carranza, E.J.M.; Xiao, K.Y.; Wei, H.T.; Yang, F. Mineral prospectivity mapping based on isolation forest and random forest: Implication for the existence of spatial signature of mineralization in Outliers. Nat. Resour. Res. 2023, 31, 1981–1999. [Google Scholar] [CrossRef]
- Qiu, Q.; Ma, K.; Lv, H.; Tao, L.; Xie, Z. Construction and application of a knowledge graph for iron deposits using text mining analytics and a deep learning algorithm. Math. Geosci. 2021, 55, 423–456. [Google Scholar] [CrossRef]
- Jean, G.E.; Bancroft, M. An XPS and SEM study of gold deposition at low temperatures on sulphide mineral surfaces: Concentration of gold by adsorption /reduction. Geochim. Cosmochim. Acta 1985, 49, 979–987. [Google Scholar] [CrossRef]
- Sadeghi, B.; Khalajmasoumi, M.; Afzal, P.; Moarefvand, P.; Yasrebi, A.B.; Wetherelt, A.; Foster, P.; Ziazarifi, A. Using ETM+ and ASTER sensors to identify iron occurrences in the Esfordi 1:100,000 mapping sheet of Central Iran. J. Afr. Earth Sci. 2013, 85, 103–114. [Google Scholar] [CrossRef]
- Hu, H.; Wen, Y.; Chua, T.S.; Li, X. Toward scalable systems for big data analytics: A technology tutorial. IEEE Access 2014, 2, 652–687. [Google Scholar] [CrossRef]
- Rodriguer-galiano, V.F.; Chica, O.M.; Chica, R.M. Predictive modelling of gold potential with the integration of multisource information based on random forest: Acase study on the Rodalquilar area Southern Spain. Int. J. Geogr. Inf. Sci. 2014, 28, 1336–1354. [Google Scholar] [CrossRef]
- Carranza, E.J.M.; Laborte, A.G. Random forest predictive modeling of mineral prospectivity with small number of prospects and data with missing values in Abra (Philippines). Comput. Geosci. 2015, 74, 60–70. [Google Scholar] [CrossRef]
- Rodgiguez, G.; Sanchez, C.; Chica, O.M.; Chica, R.M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks random forest regression trees and supportvector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar]
- Baumann, P.; Mazzetti, P.; Ungar, J.; Barbera, R.; Barboni, D.; Beccati, A.; Bigagli, L.; Boldrini, E.; Bruno, R.; Calanducci, A.; et al. Big data analytics for earth sciences: The Earth Server approach. Int. J. Digit. Earth 2016, 9, 3–29. [Google Scholar] [CrossRef]
- Li, T.F.; Xia, Q.L.; Zhao, M.Y.; Gui, Z.; Leng, S. Prospectivity mapping for tungsten polymetallic mineral resources Nanling Metallogenic Belt South China: Use of Random Forest Algorithm from a Perspective of Data Imbalance. Nat. Resour. Res. 2019, 29, 203–227. [Google Scholar] [CrossRef]
- Mohamed, A.; Najafabadi, M.K.; Wah, Y.B.; Zaman, E.A.K.; Maskat, R. The state of the art and taxonomy of big data analytics: View from new big data framework. Artif. Intell. Rev. 2020, 53, 989–1037. [Google Scholar] [CrossRef]
- Chen, G.X.; Huang, N.; Wu, G.P.; Luo, L.; Wang, D.T.; Cheng, Q.M. Mineral prospectivity mapping based on wavelet neural network and Monte Carlo simulations in the Nanling W-Sn metallogenic province. Ore Geol. Rev. 2022, 143, 104765. [Google Scholar] [CrossRef]
- Li, Y.S.; Peng, C.; Ran, X.J.; Xue, L.F.; Chai, S.L. Soil geochemical prospecting prediction method based on deep convolutional neural networks-Taking Daqiao Gold Deposit in Gansu Province, China as an example. China Geol. 2022, 5, 71–83. [Google Scholar]
- Ren, W.X.; Luo, J.M.; Sun, B.N.; Wang, H.T.; Wang, Y.X. Application of geochemical data in gold prospecting and target selecting: Taking the Yushishan area in Gansu Province as a case. Acta Petrol. Sin. 2018, 34, 3225–3234. [Google Scholar]
- Safari, S.; Ziaii, M.; Ghoorchi, M.; Sadeghi, M. Application of concentration gradient coefficients in mining geochemistry: A comparison of copper mineralization in Iran and Canada. J. Min. Environ. 2018, 9, 277–292. [Google Scholar]
- Zuo, R.; Xiong, Y. Big data analytics of identifying geochemical anomalies supported by machine learning methods. Nat. Resour. Res. 2018, 27, 5–13. [Google Scholar] [CrossRef]
- Ziaii, M.; Safari, S.; Timkin, T.; Voroshilov, V.; Yakich, T. Identification of geochemical anomalies of the porphyry-Cu deposits using concentration gradient modelling: Acase study Jebal-Barez area Iran. J. Geochem. Explor. 2019, 199, 16–30. [Google Scholar] [CrossRef]
- Huston, D.L.; Sie, S.H.; Suter, G.F.; Cooke, D.R. Both RATrace elements in sulfide minerals from Eastern Australian volcanic-hosted massive sulfide deposits: Part, I. Proton Microprobe analyses of pyrite, chalcopyrite, and sphalerite, and Part II. Selenium Levels in Pyrite: Comparison with δ34S values and implications for the source of sulfur in volcanogenic hydrothermal systems. Econ. Geol. 1995, 90, 1167–1196. [Google Scholar]
- Han, B.F.; Guo, Z.J.; Zhang, Z.C.; Zhang, L.; Chen, J.F.; Song, B. Age, geochemistry, and tectonic implications of a late Paleozoic stitching pluton in the North Tian Shan suture zone, Western China. Geol. Soc. Am. Bull. 2010, 122, 627–640. [Google Scholar] [CrossRef]
- Kwok, S.W.; Carter, C. Multiple decision trees. In Machine Intelligence and Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 1990; Volume 9, pp. 327–335. [Google Scholar]
- Kempe, U.; Seltmann, R.; Graupner, T.; Rodionov, N.; Sergeev, S.A.; Matukov, D.; Kremenetsky, A.A. Concordant U-Pb SHRIMP ages of U-rich zircon in granitoids from the Muruntau gold district (Uzbekistan): Timing of intrusion, alteration ages, or meaningless numbers. Ore Geol. Rev. 2015, 65, 308–326. [Google Scholar] [CrossRef]
- Feng, W.Y.; Zheng, J.H.; Shen, P. Petrology, mineralogy, and geochemistry of the Carboniferous Katbasu Au-Cu deposit, western Tianshan, Northwest China: Implications for petrogenesis, ore genesis, and tectonic setting. Ore Geol. Rev. 2023, 161, 105659. [Google Scholar] [CrossRef]
- Teng, C.; Dong, M.; Yang, X.; Xiao, D.; Shao, J.; Cao, J.; Su, Y.; Lu, W. Zircon U-Pb Geochronology and Geochemical Constraints of Tiancang Granites, Southern Beishan Orogenic Belt: Implications for Early Permian Magmatism and Tectonic Evolution. Minerals 2025, 15, 426. [Google Scholar] [CrossRef]
- Li, R.; Su, S.; Sun, H.; Liu, R.; Xia, Y. Petrogenesis and Tectonic Significance of Early Permian Intermediate–Felsic Rocks in the Southern Beishan Orogen, Northwest China: Geochronological and Geochemical Constraints. Minerals 2024, 14, 114. [Google Scholar] [CrossRef]
- Chen, B.; Shen, Y.; Liu, T. Ore-controlling factors and metallogenic models of gold deposits in the Beishan orogenic belt, NW China. Minerals 2021, 11, 345. [Google Scholar]
- Zhang, F.; Li, G. Geological characteristics and prospecting indicators of quartz vein-type gold deposits in the Beishan area. J. Geochem. Explor. 2022, 235, 106952. [Google Scholar]
- Lu, X. Metallogenic regularity and prospecting indicators of porphyry copper deposits in the Beishan area: A case study of the Gongpoquan deposit. Appl. Sci. 2023, 13, 5890. [Google Scholar]
- Shen, Z.; Zeng, Q. Tectonic evolution and its constraints on gold-copper mineralization in the Beishan orogenic belt. Ore Geol. Rev. 2020, 124, 103678. [Google Scholar]
- He, Z.; Zhan, G. Geochemical characteristics and metallogenic potential of sedimentary rock-hosted gold deposits in the Beishan area. J. Asian Earth Sci. 2021, 215, 104803. [Google Scholar]
- Laurent-Charvet, S.; Charvet, J.; Shu, L.S.; Ma, R.S.; Lu, H.F. Palaeozoic late collisional strike-slip deformations in Tianshan and Altay, Eastern Xinjiang, NW China. Terra Nova 2002, 14, 249–256. [Google Scholar] [CrossRef]
- Keith, M.; Smith, D.J.; Jenkin, G.R.T.; Holwell, D.A.; Dye, M.D. A review of Te and Se systematics in hydrothermal pyrite from precious metal deposits: Insights into ore-forming processes. Ore Geol. Rev. 2018, 96, 269–282. [Google Scholar] [CrossRef]
- Large, R.R.; Mukherjee, I.; Gregory, D.D.; Steadman, J.A.; Maslennikov, V.V.; Meffre, S. Ocean and atmosphere geochemical proxies derived from trace elements in marine pyrite: Implications for ore genesis in sedimentary basins. Econ. Geol. 2017, 112, 423–450. [Google Scholar] [CrossRef]
- Mao, Q.G.; Xiao, W.J.; Wang, H.; Ao, S.J.; Windley, B.; Song, D.F.; Sang, M.; Tan, Z.; Li, R.; Wang, M. Prolonged Late Mesoproterozoic to Late Triassic Tectonic Evolution of the Major Paleo-Asian Ocean in the Beishan Orogen (NW China) in the Southern Altaids. Front. Earth Sci. 2022, 9, 825852. [Google Scholar] [CrossRef]
- Kempe, U.; Graupner, T.; Seltmann, R.; Boorder, H.D.; Dolgopolova, A.; Zeylmans Van Emmichoven, M. The Muruntau gold deposit (Uzbekistan)- A unique ancient hydrothermal system in the southern Tien Shan. Geosci. Front. 2016, 7, 495–528. [Google Scholar] [CrossRef]
- Dong, L.L.; Wan, B.; Yang, W.Z.; Deng, C.; Chen, Z.; Yang, L.; Cai, K.D.; Xiao, W.J. Rb-Sr geochronology of single gold-bearing pyrite grains from the Katbasu gold deposit in the South Tianshan, China and its geological significance. Ore Geol. Rev. 2018, 100, 99–110. [Google Scholar] [CrossRef]
- Groves, D.I.; Foster, R.P. Archaean lode gold deposits. In Gold Metallogeny and Exploration; Foster, R.P., Ed.; Springer: Boston, MA, USA, 1991; pp. 63–103. [Google Scholar]
- Xu, X.W.; Ma, T.L.; Sun, L.Q. Characteristics and dynamic origin of the large−scale Jiaoluotage ductile compressional zone in the eastern Tianshan Mountains, China. J. Struct. Geol. 2003, 25, 1901–1915. [Google Scholar] [CrossRef]
- Yousefi, M.; Kreuzer, O.P.; Nykänen, V.; Hronsky, J.M.A. Exploration information systems-a proposal for the future use of GIS in mineral exploration targeting. Ore Geol. Rev. 2019, 111, 103005. [Google Scholar] [CrossRef]
- Xi, Y.Z.; Li, Y.B.; Liu, J.J.; Wu, S.; Lu, N.; Liao, G.X.; Wang, Q.L. Application of Analytic Hierarchy Process in Mineral Prospecting Prediction Based on an Integrated Geology-Aerogeophysics-Geochemistry Model. Minerals 2023, 13, 978. [Google Scholar] [CrossRef]
- Agterberg, F. New applications of the model of de Wijs in regional geochemistry. Math. Geol. 2007, 39, 1. [Google Scholar] [CrossRef]
- Parsa, M.; Maghsoudi, A. Assessing the effects of mineral systems-derived exploration targeting criteria for random Forests-based predictive mapping of mineral prospectivity in Ahar-Arasbaran area, Iran. Ore Geol. Rev. 2021, 138, 104399. [Google Scholar] [CrossRef]
- Allard, D.; Comunian, A.; Renard, P. Probability aggregation methods in geoscience. Math. Geosci. 2012, 44, 545–581. [Google Scholar] [CrossRef]
- Chhabra, A.B.; Sreenivasan, K.R. Negative dimensions: Theory, computation, and experiment. Phys. Rev. A 1991, 43, 1114. [Google Scholar] [CrossRef]
- Chen, Y.; Lu, L.; Li, X. Application of continuous restricted Boltzmann machine to identify multivariate geochemical anomaly. J. Geochem. Explor. 2014, 140, 56–63. [Google Scholar] [CrossRef]
- Enkhsaikhan, M.; Liu, W.; Holden, E.J.; Duuring, P. Auto-labelling entities in low-resource text: A geological case study. Knowl. Inf. Syst. 2021, 63, 695–715. [Google Scholar] [CrossRef]
- Abedini, M.; Ziaii, M.; Negahdarzadeh, Y.; Ghiasi-Freez, J. Porosity classification from thin sections using image analysis and neural networks including shallow and deep learning in Jahrum formation. J. Min. Environ. 2018, 9, 513–525. [Google Scholar]
- Parsa, M.; Maghsoudi, A.; Yousefi, M. Spatial analyses of exploration evidence data to model skarn-type copper prospectivity in the Varzaghan district, NW Iran. Ore Geol. Rev. 2018, 92, 97–112. [Google Scholar] [CrossRef]
- Shirazi, A.; Hezarkhani, A.; Beiranvand, P.A.A. Fusion of Lineament Factor (LF) Map Analysis and Multifractal Technique for Massive Sulfide Copper Exploration: The Sahlabad Area, East Iran. Minerals 2022, 12, 549. [Google Scholar] [CrossRef]
- Chorley, R.J.; Haggett, P. Trend-surface mapping in geographical research. Trans. Inst. Br. Geogr. 1965, 37, 47–67. [Google Scholar] [CrossRef]
- Journel, A.; Zhang, T. The necessity of a multiple-point prior model. Math. Geol. 2006, 38, 591–610. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variant | Constant | Bi | Pb | Cu | Zn | Sb | SiO2 | Y | K2O | B | La | Th |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Factor | 2.79 | 0.76 | 0.02 | 0.02 | −0.01 | 0.07 | 0.01 | 0.02 | −0.10 | 0.004 | −0.01 | 0.02 |
| Variant | Be | Na2O | Li | MgO | CaO | Au | Nb | U | Fe2O3 | Al2O3 | Mo | |
| Factor | −0.05 | −0.02 | −0.004 | −0.01 | 0.01 | 0.002 | −0.004 | −0.01 | −0.01 | 0.005 | −0.01 |
| Model No. | Variables and Parameters | Validity Check | Typical Deposits | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model I | Variable | constant | SiO2 | ΔTx | ΔTd | Al2O3 | Na2O | R0 = −1.98 Fp = 16.26 Mineral positive conviction rate, 82.2% Mineral-free positive conviction rate, 98.3% Ore-bearing units: 60 | The Xiaoxi Gong medium-sized gold deposit in Subei County and the Laojin Chang medium-sized gold deposit in Guazhou County |
| Parameter | −19.44 | 0.208 | 0.004 | −0.003 | 0.267 | 0.251 | |||
| Contribution | 32.645 | 22.784 | 16.283 | 7.904 | 4.466 | ||||
| Variable | Ti | Ba | Pb | V | Au | ||||
| Parameter | 0.001 | 0.001 | −0.034 | −0.014 | −0.043 | ||||
| Contribution | 2.652 | 2.594 | 2.473 | 1.869 | 1.838 | ||||
| Model II | Variable | constant | SiO2 | Au | Zr | CaO | Sr | R0 = −0.89 Fp = 6.45 Mineral positive conviction rate, 100% Mineral-free positive conviction rate, 88.1% Ore-bearing units: 78 | The Xiaocaohu small gold deposit in Anxi County and the Xinjinchang small gold deposit in Xihu Township, Anxi County |
| Parameter | −20.08 | 0.216 | −0.119 | 0.012 | 0.064 | 0.002 | |||
| Contribution | 25.092 | 18.628 | 16.981 | 7.465 | 6.778 | ||||
| Variable | MgO | Mn | ΔTd | ||||||
| Parameter | 0.153 | 0.001 | −0.002 | ||||||
| Contribution | 6.685 | 5.696 | 5.302 | ||||||
| Model III | Variable | constant | Auh | Y | Al2O3 | ΔTx | V | R0 = −1.41 Fp = 0.47 Mineral positive conviction rate, 85.7% Mineral-free positive conviction rate, 94.6% Ore-bearing units: 21 | Jinchanggou gold deposit in Subei County and the Jingoujing gold deposit in Anxi County |
| Parameter | 0.18 | −1.821 | −0.126 | 0.341 | 0.002 | 0.026 | |||
| Contribution | 15.260 | 13.269 | 10.611 | 6.122 | 5.327 | ||||
| Variable | B | CaO | Pb | Sr | Cu | ||||
| Parameter | 0.022 | 0.105 | −0.029 | −0.002 | 0.042 | ||||
| Contribution | 4.389 | 4.338 | 4.105 | 3.172 | 3.013 | ||||
| Class of Preferred Units | Number of Preferred Units | Ratio of Preferred Units to Total Projected Units | Number of Known Ore-Bearing Units | Ratio of Known Ore-Bearing Units to Preferred Units | Increase Multiplier for Proportion of Units with Minerals |
|---|---|---|---|---|---|
| Level I | 89 | 0.36% | 24 | 26.97% | 61.29 |
| Level II | 144 | 0.58% | 28 | 19.44% | 44.18 |
| Level III | 233 | 0.94% | 8 | 3.43% | 7.80 |
| Total | 467 | 1.88% | 60 | 12.85% | 29.20 |
| Class of Preferred Units | Number of Preferred Units | Ratio of Preferred Units to Total Projected Units | Number of Known Ore-Bearing Units | Ratio of Known Ore-Bearing Units to Preferred Units | Increase Multiplier for Proportion of Units with Minerals |
|---|---|---|---|---|---|
| Level I | 127 | 0.51% | 20 | 15.75% | 35.79 |
| Level II | 205 | 0.83% | 35 | 17.07% | 38.71 |
| Level III | 332 | 1.34% | 23 | 6.92% | 15.72 |
| Total | 665 | 2.68% | 78 | 11.73% | 26.66 |
| Class of Preferred Units | Number of Preferred Units | Ratio of Preferred Units to Total Projected Units | Number of Known Ore-Bearing Units | Ratio of Known Ore-Bearing Units to Preferred Units | Increase Multiplier for Proportion of Units with Minerals |
|---|---|---|---|---|---|
| Level I units | 105 | 0.42% | 6 | 5.71% | 12.98 |
| Level II units | 170 | 0.68% | 4 | 2.35% | 5.34 |
| Level III units | 275 | 1.11% | 11 | 4% | 9.09 |
| Total | 550 | 2.22% | 21 | 3.81% | 8.68 |
| Class of Target Areas | Number of Preferred Target Areas | Ratio of Preferred Target Areas to Total Projected Target Areas | Number of Known Ore-Bearing Target Areas | Ratio of Known Ore-Bearing Target Areas to Preferred Target Areas | Increase Multiplier for Proportion of Target Areas with Minerals |
|---|---|---|---|---|---|
| Level I | 57 | 0.23% | 11 | 19.29% | 43.85 |
| Level II | 93 | 0.37% | 11 | 11.82% | 26.88 |
| Level III | 150 | 0.60% | 5 | 3.33% | 7.57 |
| Total | 300 | 1.21% | 27 | 9.00% | 20.45 |
| Number of Target Area | Au (10−6) | Number of Target Area | Au (10−6) | Data Supplier |
|---|---|---|---|---|
| I-2-6 | 1.96–2.02 | I-2-9 | 0.63 | The Fourth Geological Survey Institute of Gansu Provincial Geology and Mining Bureau |
| I-2-10 | 0.57 | I-2-11 | 3.65 | |
| I-2-12 | 2.76–3.43 | I-2-13 | 0.97 | |
| I-2-14 | 0.51 | - | - | |
| I-2-7 | 1.42–1.71 | I-2-4 | 1.42 | Geological Survey of Gansu Province |
| I-2-8 | 0.86–0.93 | I-2-1 | 0.59 | |
| I-2-5 | 1.63–1.84 | I-2-2 | 2.34–3.78 | |
| I-2-3 | 1.16 | I-2-4 | 2.76–2.95 | |
| I-2-14 | 0.66 | I-2-15 | 1.74 | The Third Geological Survey Institute of Gansu Provincial Geology and Mining Bureau |
| I-2-16 | 1.52–2.13 | I-2-17 | 1.06–4.42 | |
| I-2-18 | 1.62–1.74 | I-2-19 | 2.85–5.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, L.; Han, R.; Zhang, Y.; Fu, H.; Luo, J.; Luo, Y. Enhancing Prospecting Target Prediction Precision: A Multi-Source Data Mining Approach in Gansu’s Beishan Area. Appl. Sci. 2025, 15, 5430. https://doi.org/10.3390/app15105430
Zhu L, Han R, Zhang Y, Fu H, Luo J, Luo Y. Enhancing Prospecting Target Prediction Precision: A Multi-Source Data Mining Approach in Gansu’s Beishan Area. Applied Sciences. 2025; 15(10):5430. https://doi.org/10.3390/app15105430
Chicago/Turabian StyleZhu, Lihui, Runsheng Han, Yan Zhang, Hao Fu, Jianmin Luo, and Yunzhi Luo. 2025. "Enhancing Prospecting Target Prediction Precision: A Multi-Source Data Mining Approach in Gansu’s Beishan Area" Applied Sciences 15, no. 10: 5430. https://doi.org/10.3390/app15105430
APA StyleZhu, L., Han, R., Zhang, Y., Fu, H., Luo, J., & Luo, Y. (2025). Enhancing Prospecting Target Prediction Precision: A Multi-Source Data Mining Approach in Gansu’s Beishan Area. Applied Sciences, 15(10), 5430. https://doi.org/10.3390/app15105430