
REACT: Relation Extraction Method Based on Entity Attention Network and Cascade Binary Tagging Framework


Abstract
1. Introduction
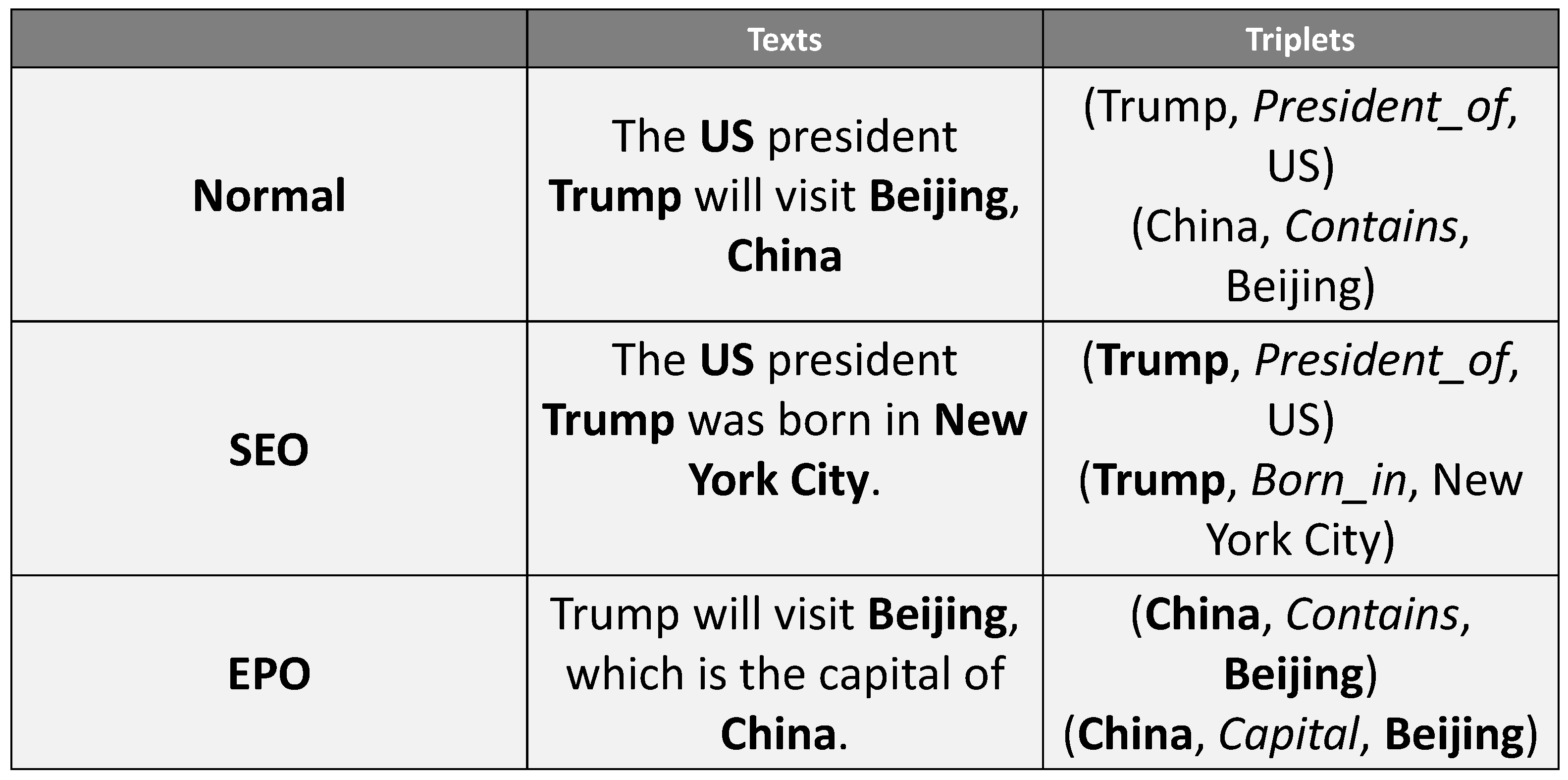
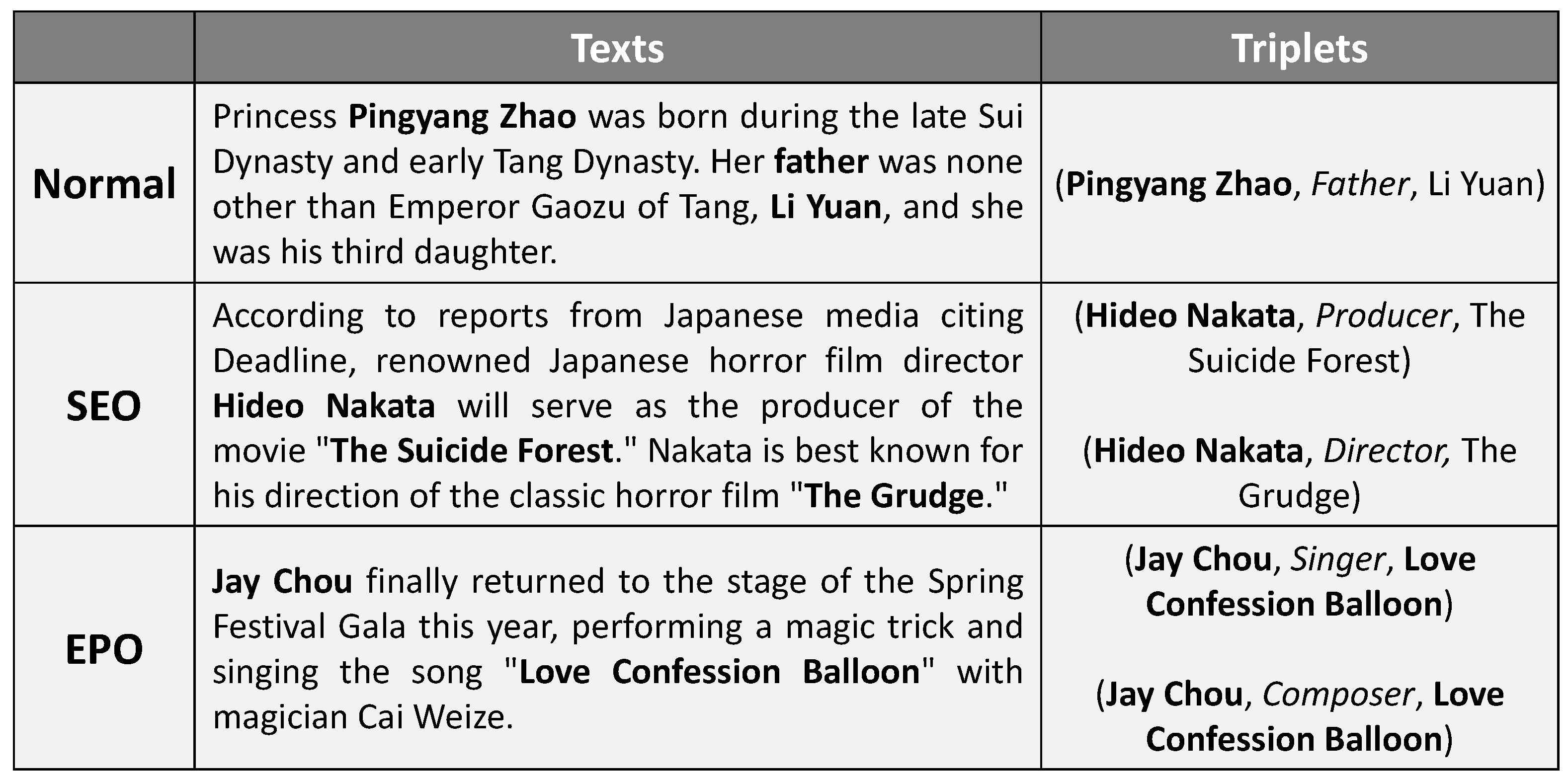
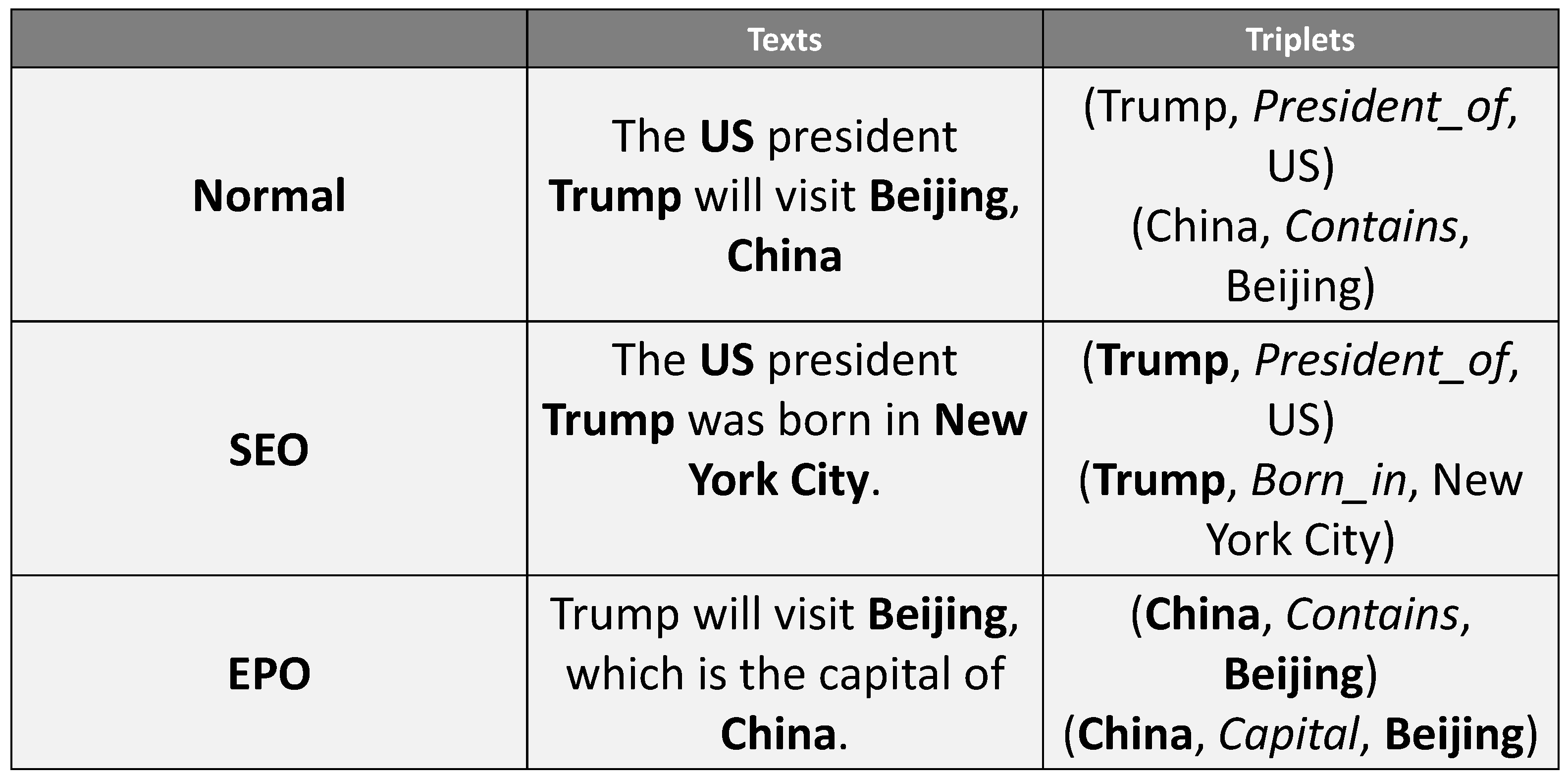
- Due to the current lack of Chinese datasets, we constructed a high-quality Chinese dataset with a high number of data with relation overlapping problems by optimizing the public Duie 2.0 entity-relation dataset;
- For the relation overlapping problem, we propose the Relation extraction method based on the Entity Attention network and Cascade binary Tagging framework;
- We conducted extensive experiments on a high-quality Chinese dataset to evaluate REACT and compared it with other baselines. The results demonstrate that REACT outperforms other baselines in handling relation overlapping problems.
2. Related Works
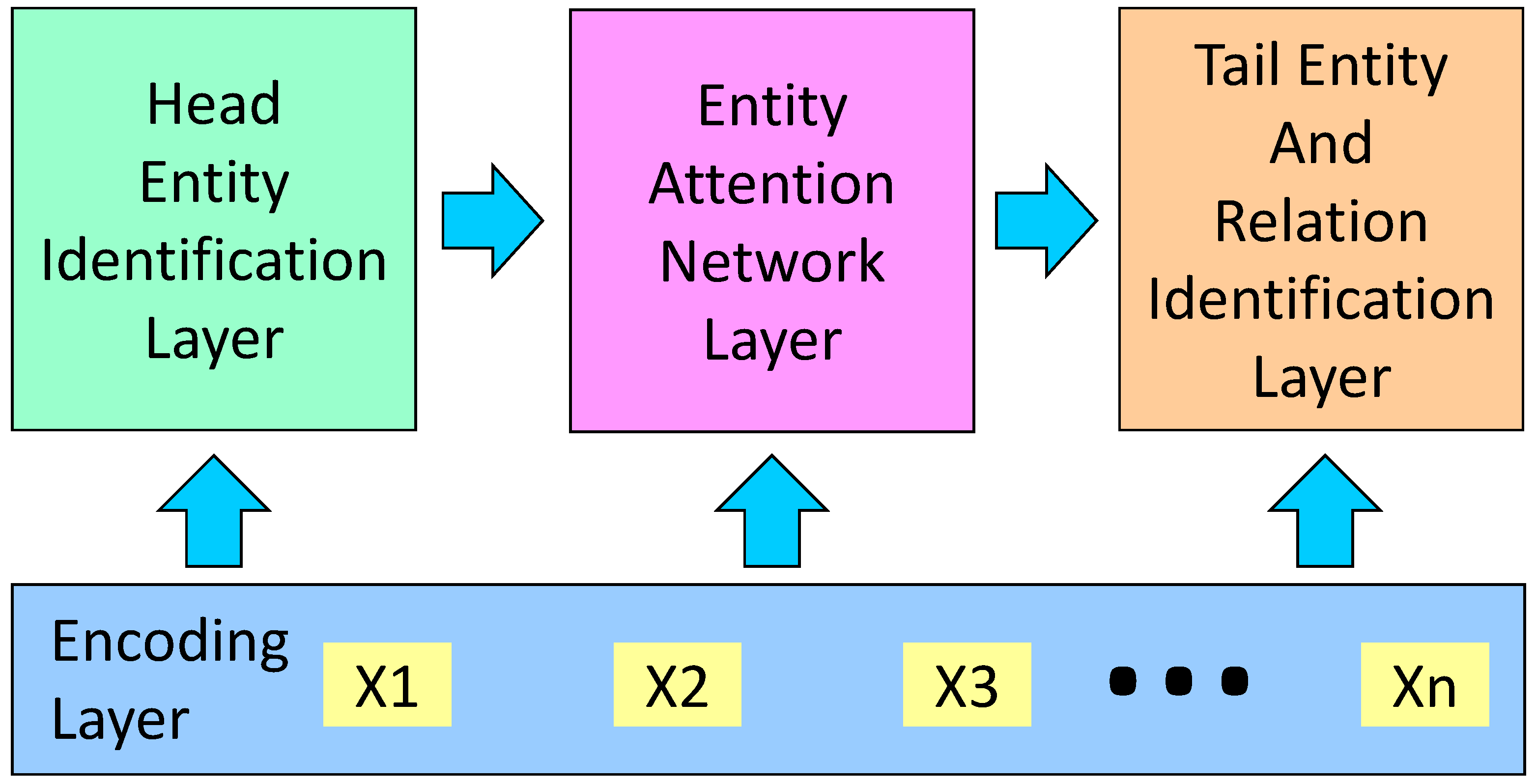
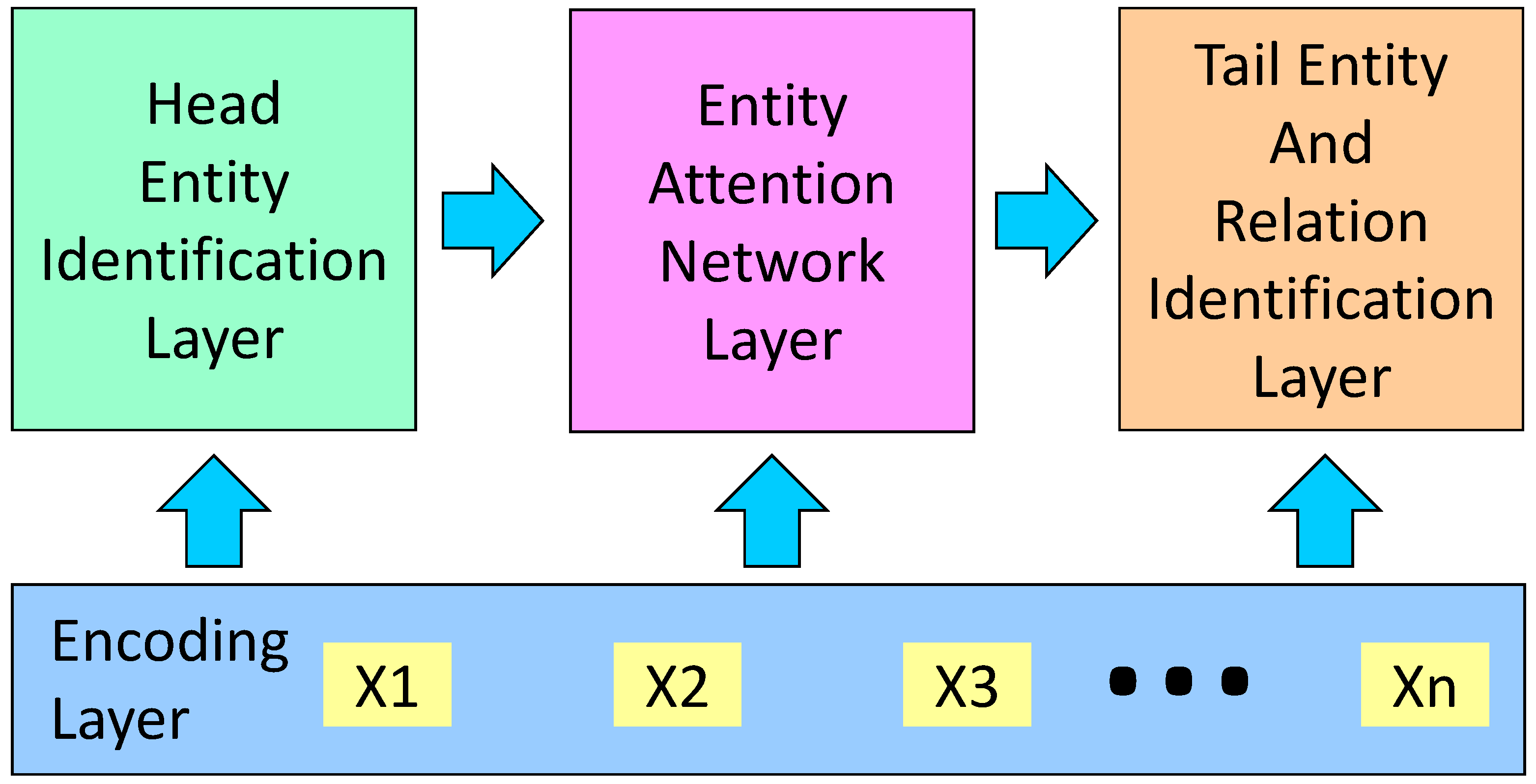
3. Methodology
3.1. Formalization of the Task
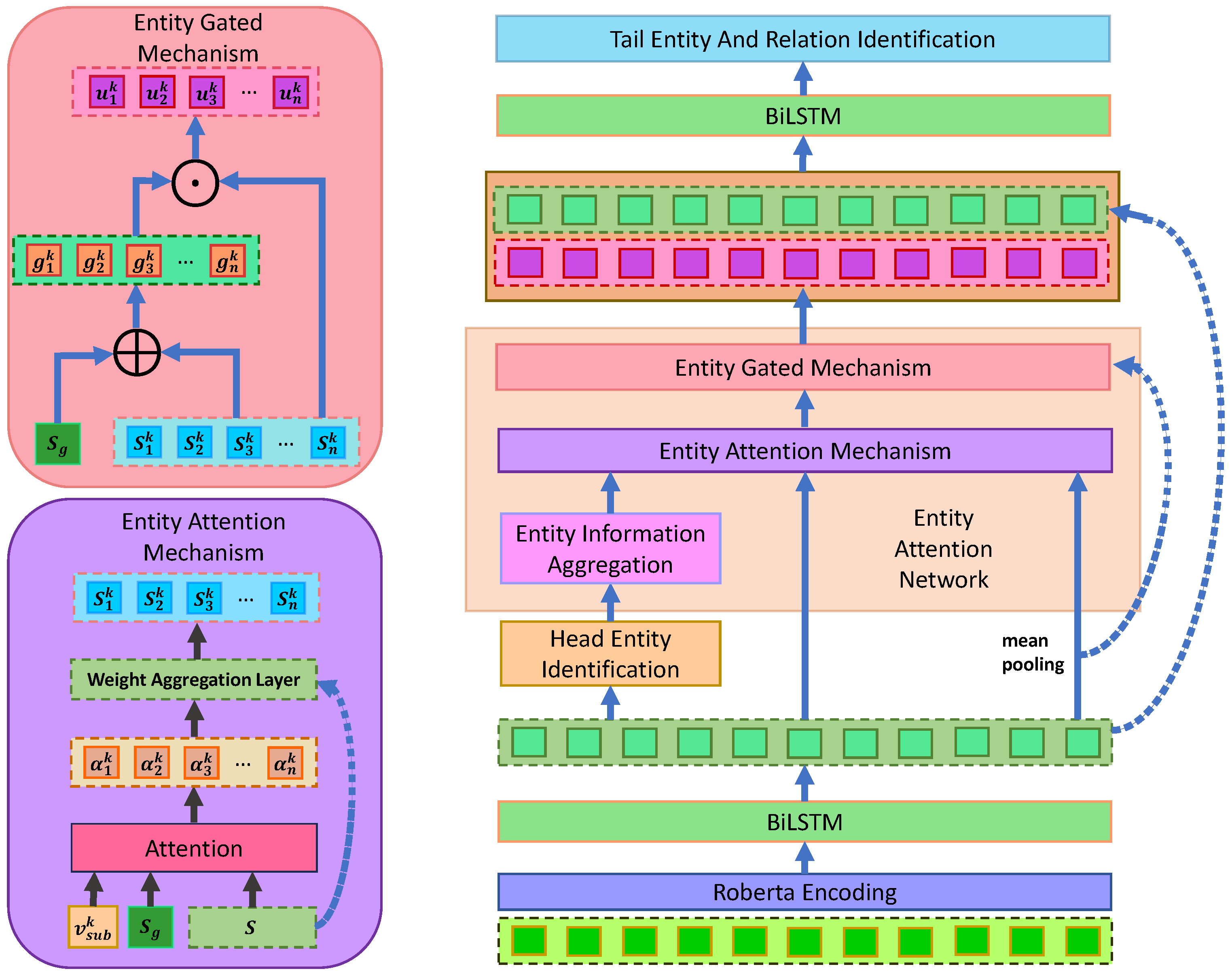
3.2. Encoding Layer
3.2.1. Roberta Layer
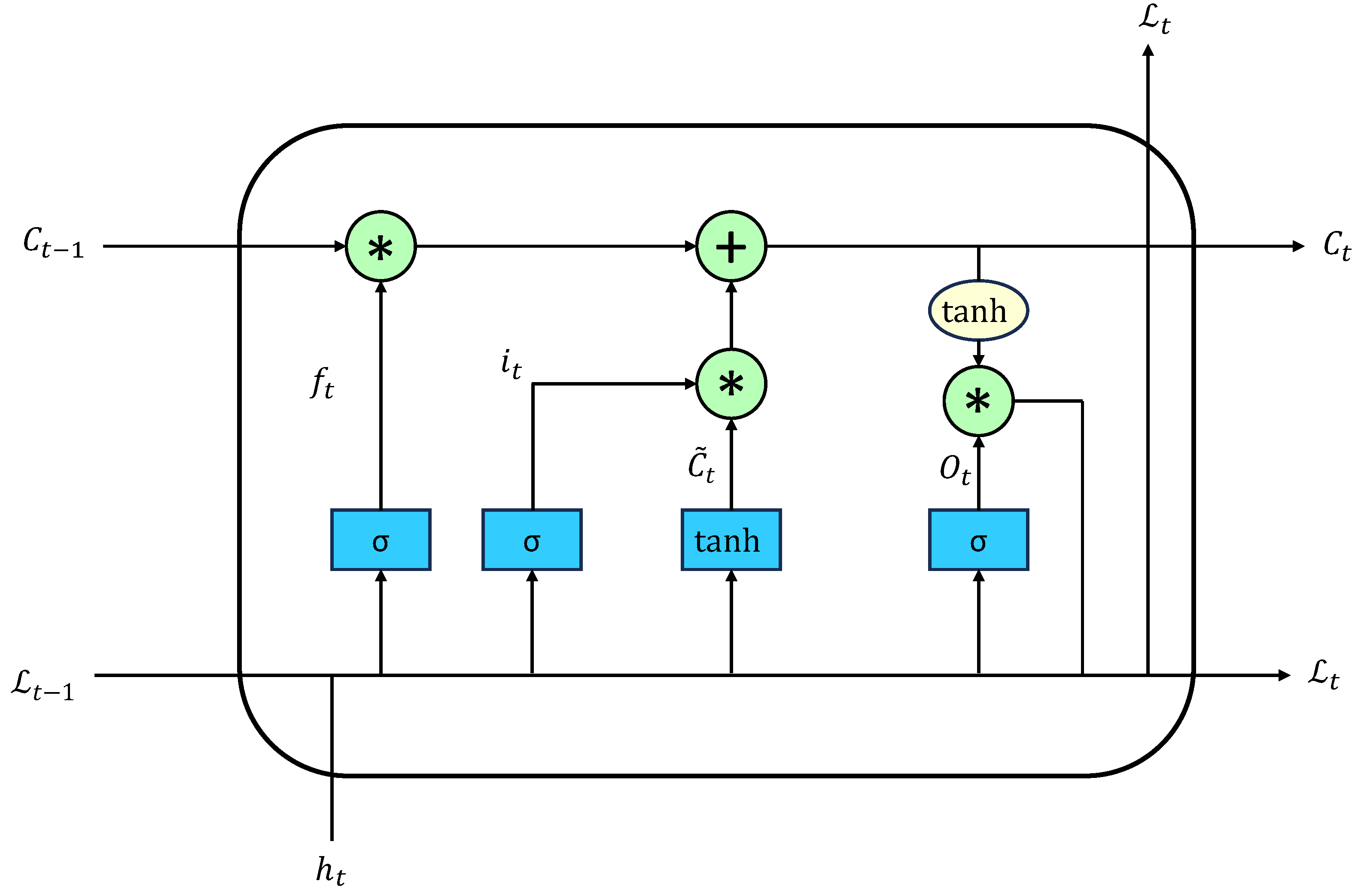
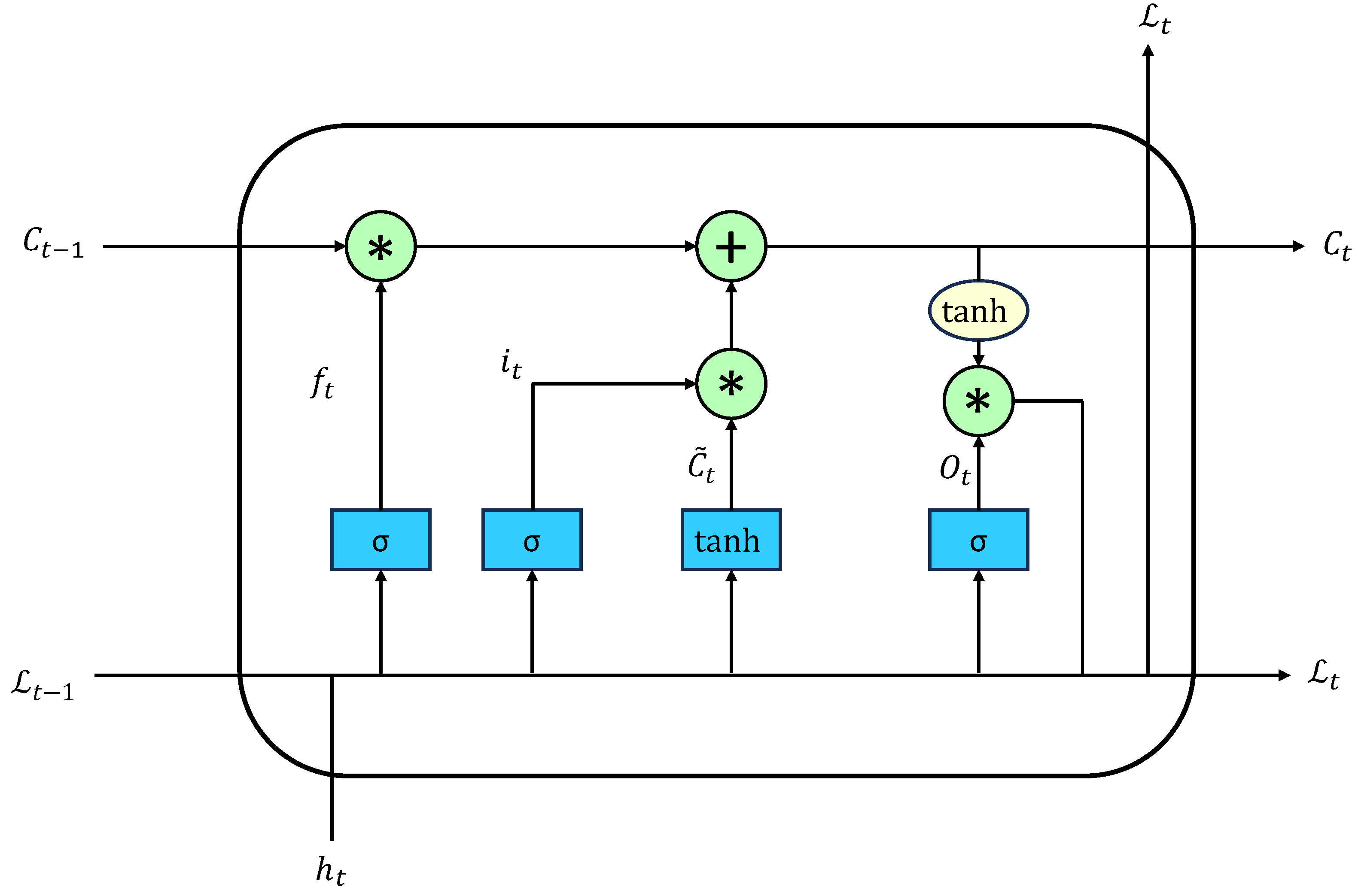
3.2.2. BiLSTM Layer
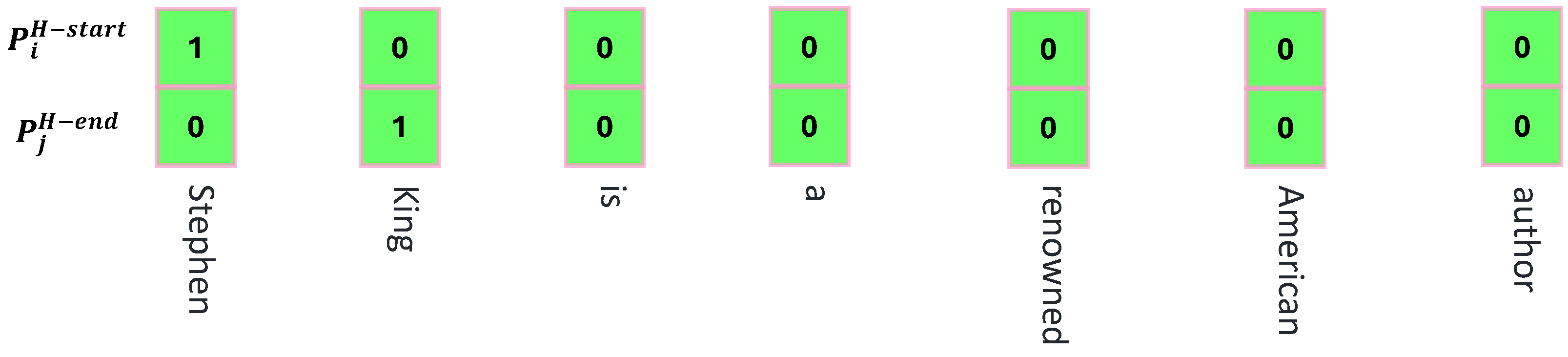
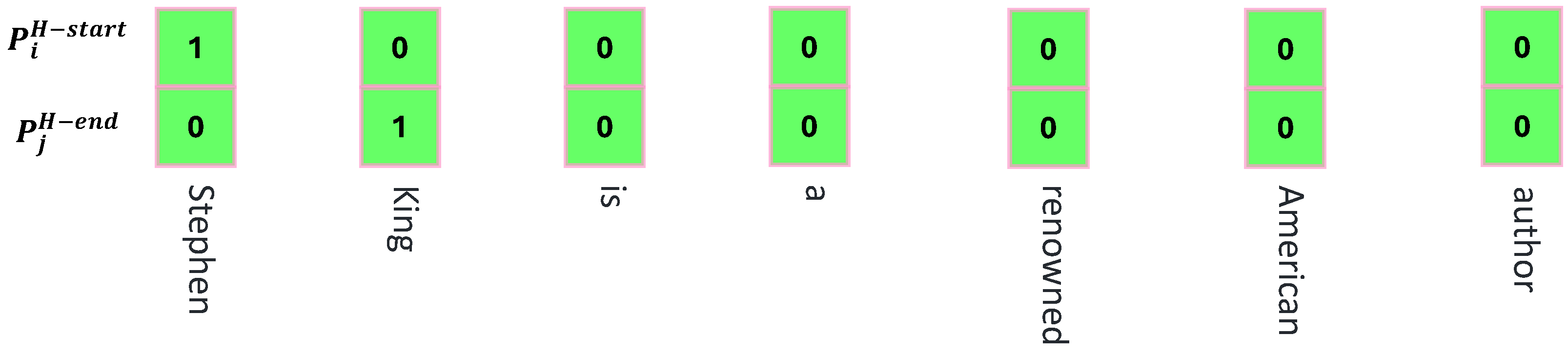
3.3. Head Entity Identification
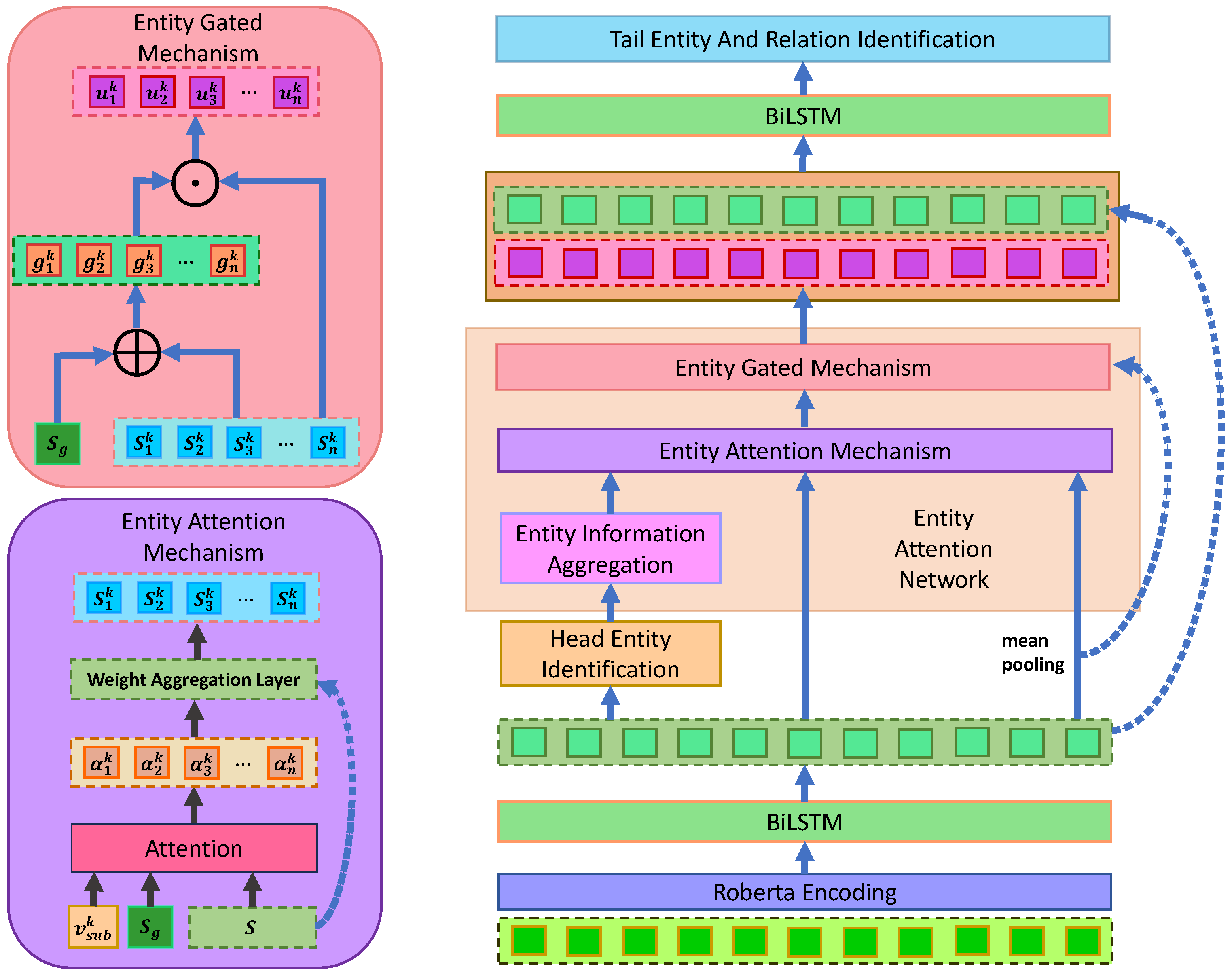
3.4. Entity Attention Network
3.4.1. Entity Information Aggregation
3.4.2. Entity Attention Mechanism
3.4.3. Entity Gated Mechanism
3.5. Tail Entity and Relation Identification
4. Experimental Section
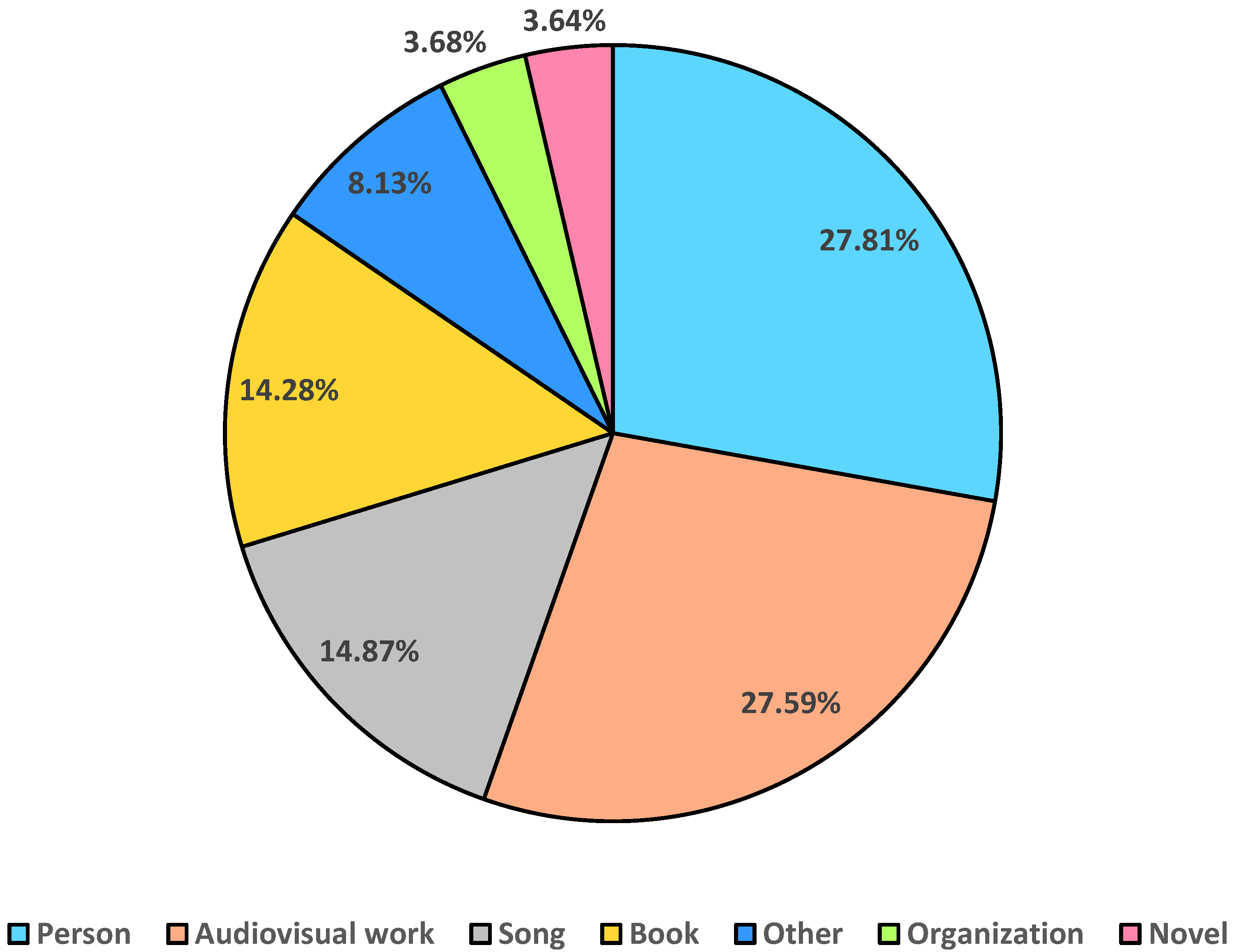
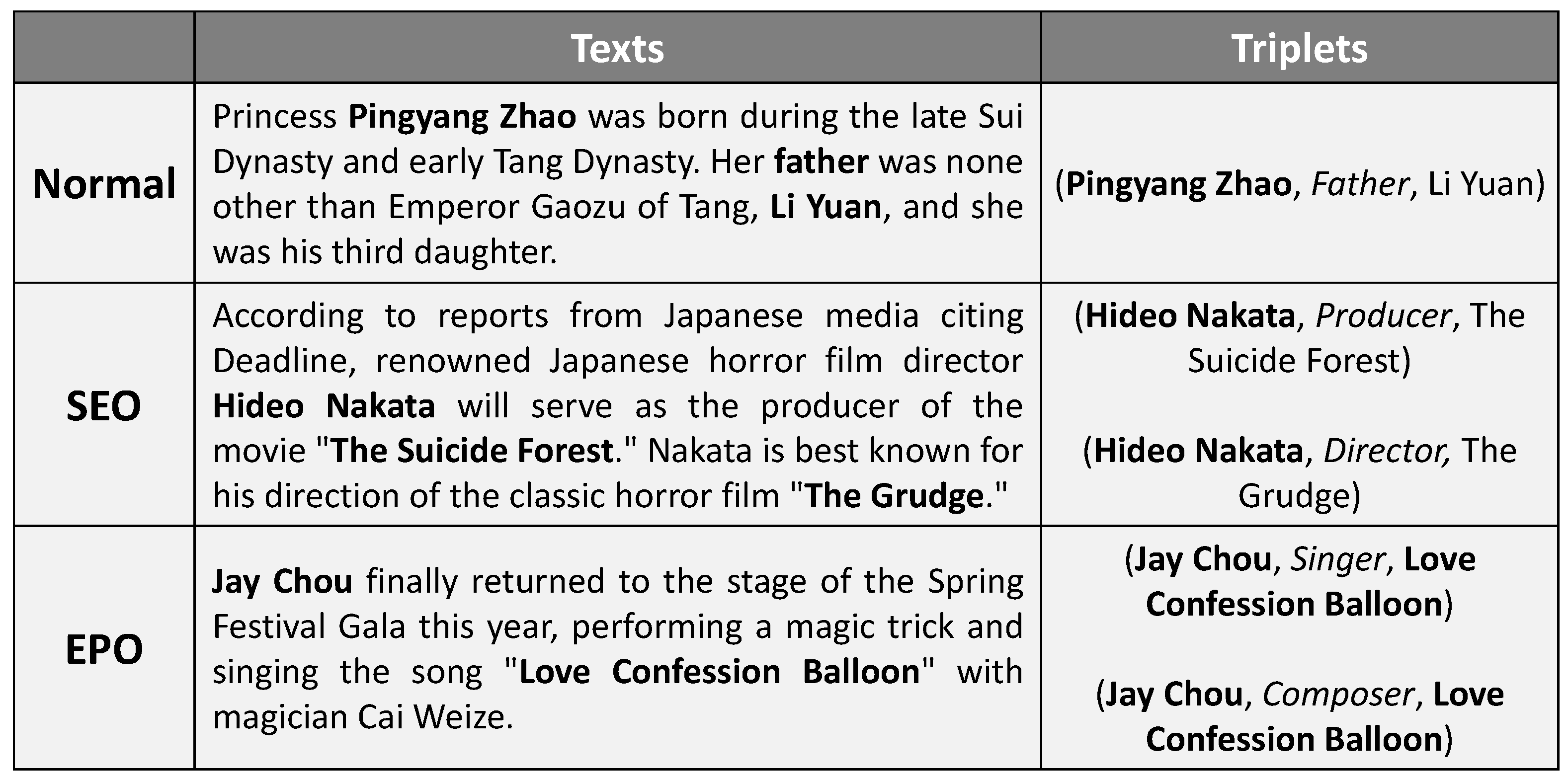
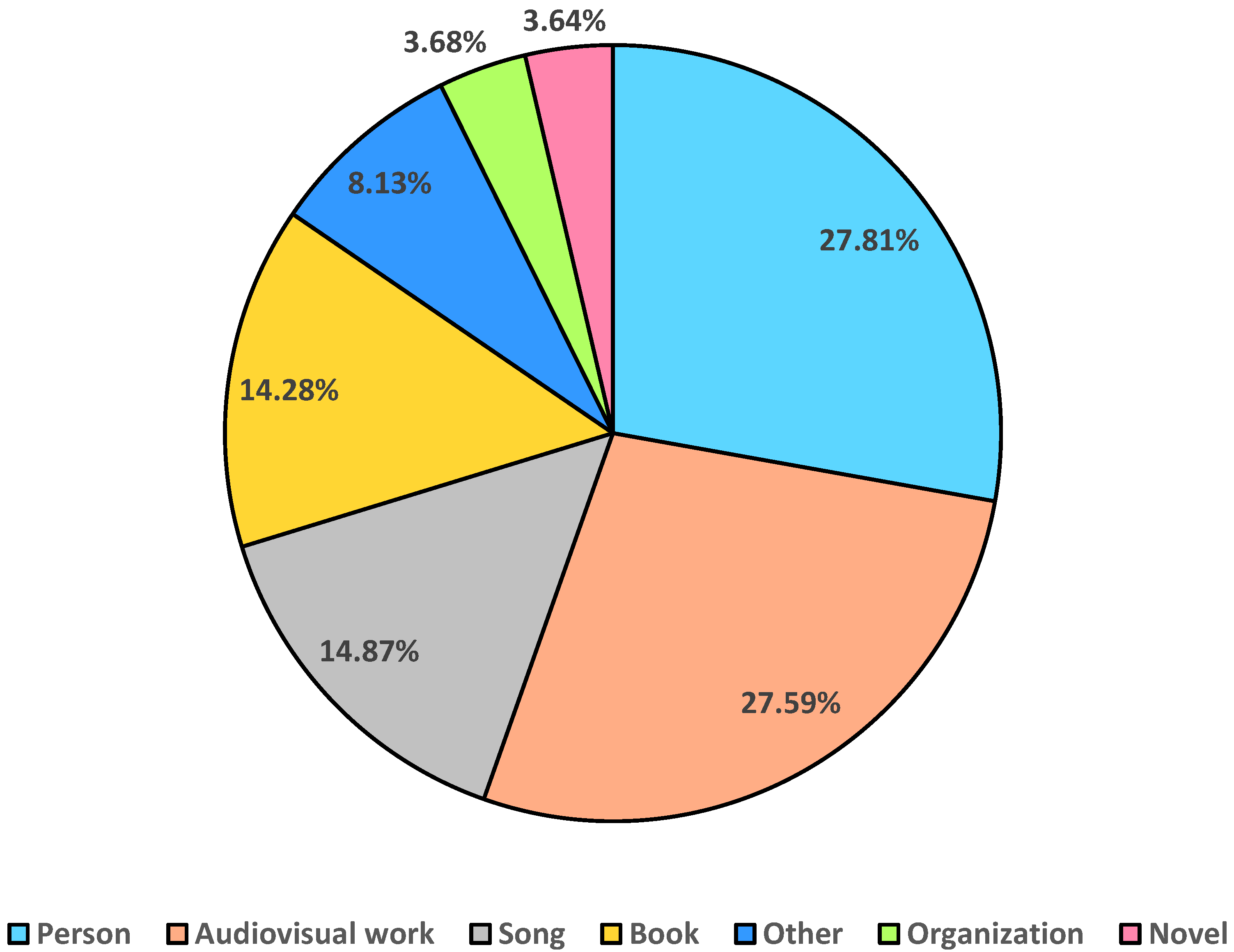
4.1. Balanced Chinese Dataset Construction
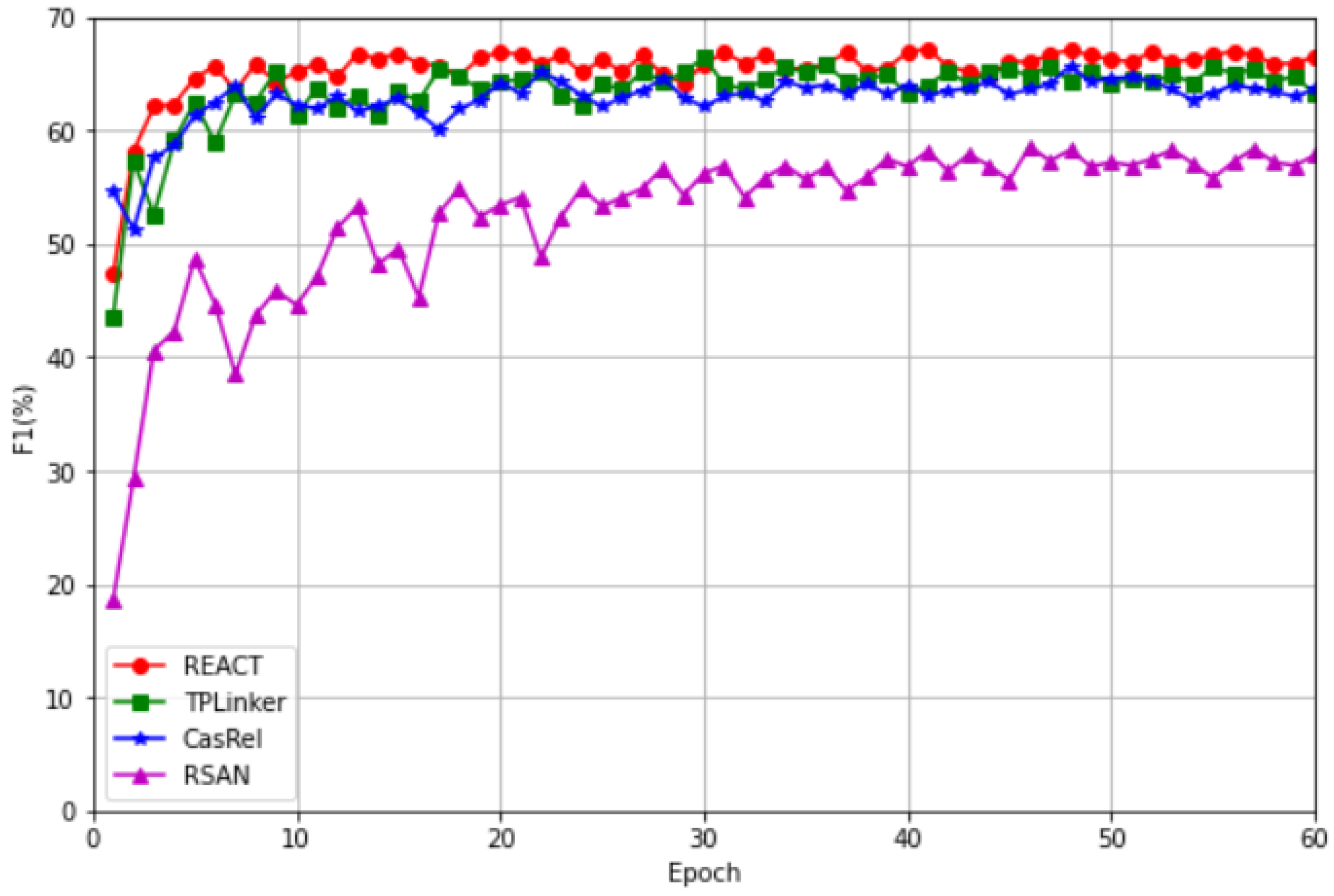
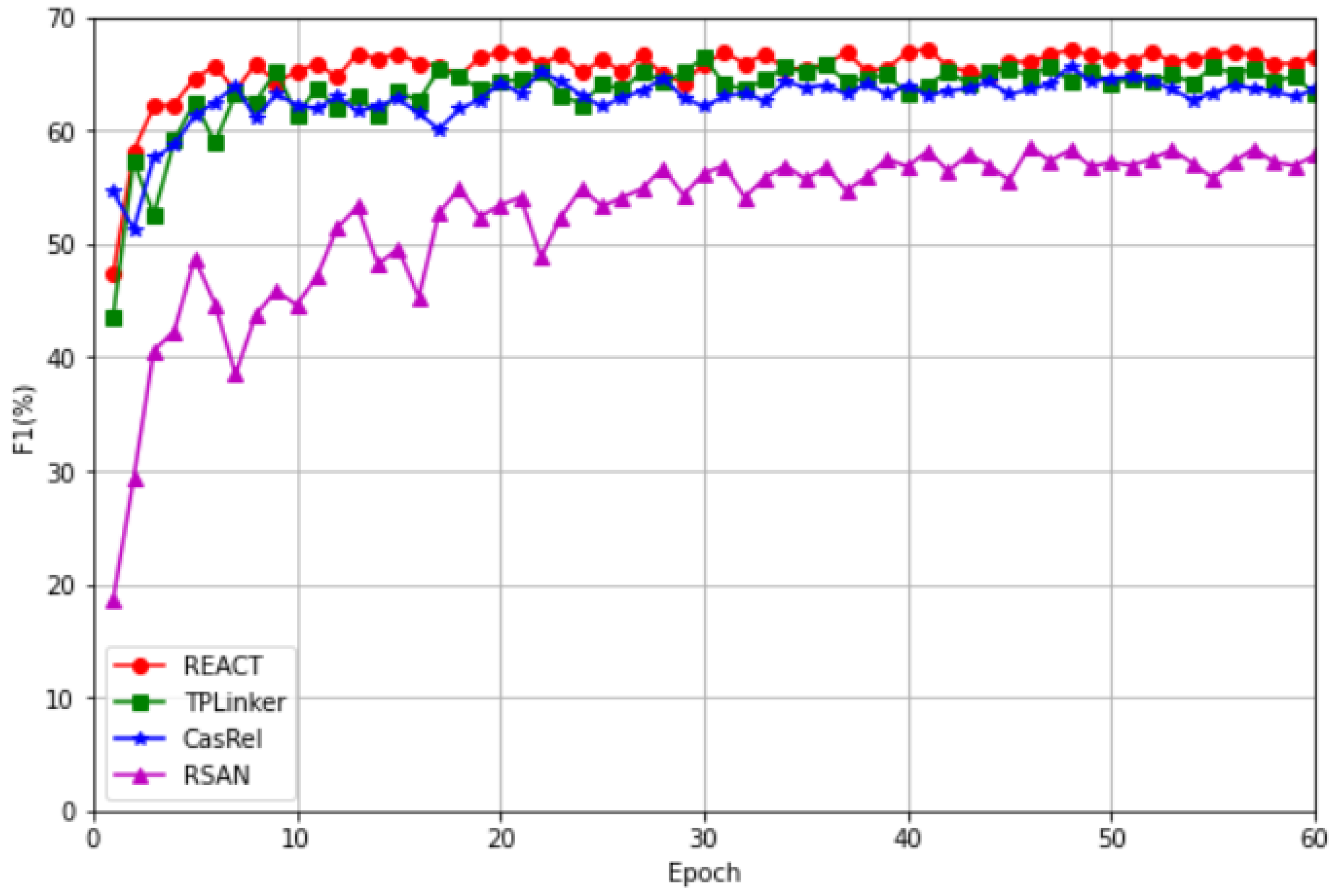
4.2. Baseline Comparison Experiment
4.3. Model Variants and Ablation Experiments
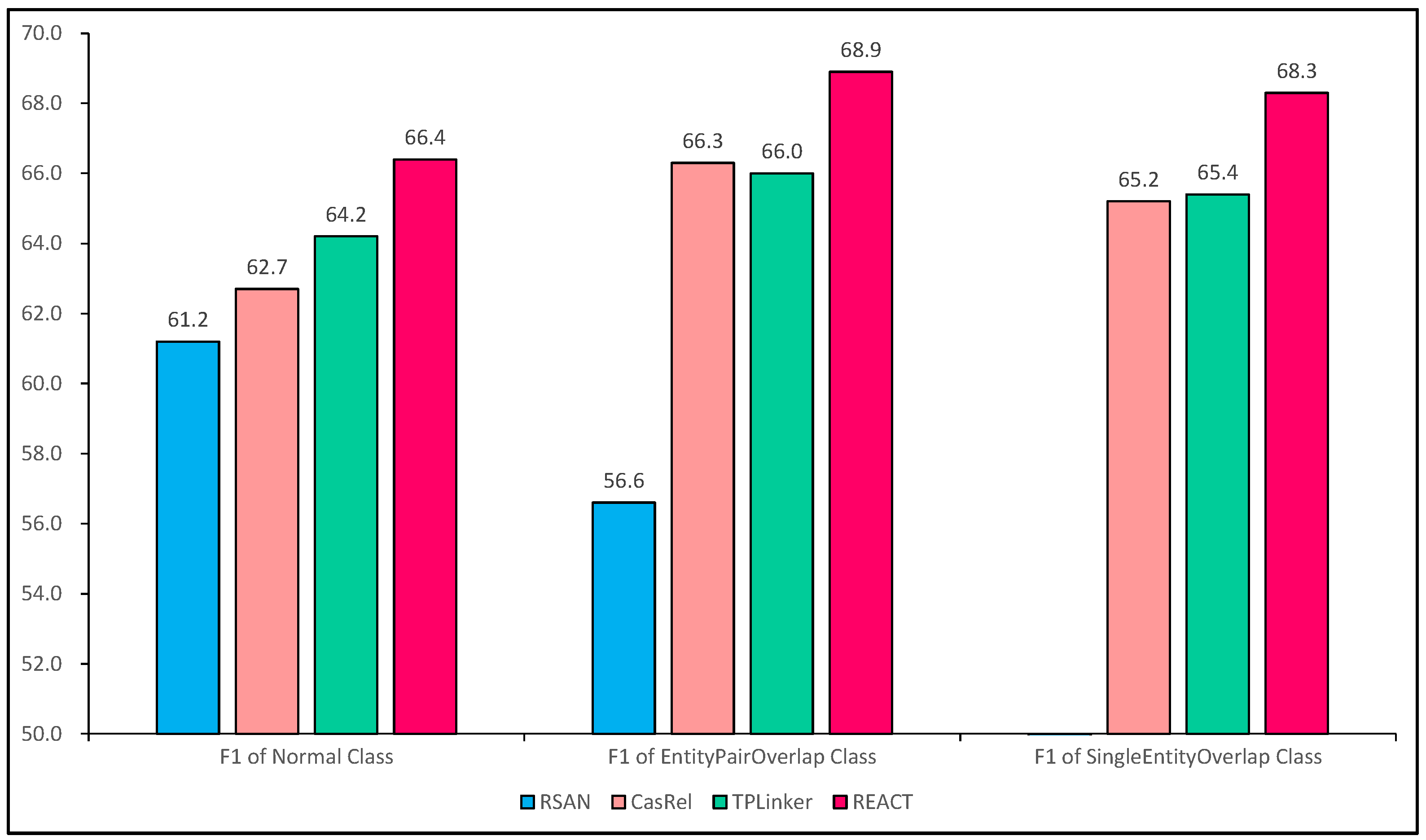
4.4. Detailed Results on Different Types of Sentences
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Golshan, P.N.; Dashti, H.R.; Azizi, S.; Safari, L. A study of recent contributions on information extraction. arXiv 2018, arXiv:1803.05667. [Google Scholar]
- Freitag, D. Machine learning for information extraction in informal domains. Mach. Learn. 2000, 39, 169–202. [Google Scholar] [CrossRef]
- Hahn, U.; Oleynik, M. Medical information extraction in the age of deep learning. Yearb. Med. Inform. 2020, 29, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Li, C.; Tian, Y. Downstream model design of pre-trained language model for relation extraction task. arXiv 2020, arXiv:2004.03786. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the CoNLL ’09: Proceedings of the Thirteenth Conference on Computational Natural Language Learning, Boulder, CO, USA, 4–5 June 2009. [Google Scholar]
- Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. arXiv 2003, arXiv:cs/0306050. [Google Scholar]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel methods for relation extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Bunescu, R.; Mooney, R. A shortest path dependency kernel for relation extraction. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 724–731. [Google Scholar]
- Zhou, Y.; Huang, L.; Guo, T.; Hu, S.; Han, J. An attention-based model for joint extraction of entities and relations with implicit entity features. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, Montreal, QC, Canada, 25–31 May 2019; pp. 729–737. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Zhou, G.; Su, J.; Zhang, J.; Zhang, M. Exploring various knowledge in relation extraction. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (acl’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 427–434. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 551–560. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Gormley, M.R.; Yu, M.; Dredze, M. Improved relation extraction with feature-rich compositional embedding models. arXiv 2015, arXiv:1505.02419. [Google Scholar]
- Yu, X.; Lam, W. Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach. In Proceedings of the Coling 2010: Posters, Beijing, China, 23–27 August 2010; pp. 1399–1407. [Google Scholar]
- Li, Q.; Ji, H. Incremental joint extraction of entity mentions and relations. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 23–25 June 2014; pp. 402–412. [Google Scholar]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Gupta, P.; Schütze, H.; Andrassy, B. Table filling multi-task recurrent neural network for joint entity and relation extraction. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–17 December 2016; pp. 2537–2547. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 917–928. [Google Scholar]
- Zhou, P.; Zheng, S.; Xu, J.; Qi, Z.; Bao, H.; Xu, B. Joint extraction of multiple relations and entities by using a hybrid neural network. In Proceedings of the Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data: 16th China National Conference, CCL 2017, and 5th International Symposium, NLP-NABD 2017, Nanjing, China, 13–15 October 2017; Proceedings 16. Springer: Berlin/Heidelberg, Germany, 2017; pp. 135–146. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. Graphrel: Modeling text as relational graphs for joint entity and relation extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Bai, F.; Ritter, A. Structured minimally supervised learning for neural relation extraction. arXiv 2019, arXiv:1904.00118. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Zeng, X.; He, S.; Zeng, D.; Liu, K.; Liu, S.; Zhao, J. Learning the extraction order of multiple relational facts in a sentence with reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 367–377. [Google Scholar]
- Yuan, Y.; Liu, L.; Tang, S.; Zhang, Z.; Zhuang, Y.; Pu, S.; Wu, F.; Ren, X. Cross-relation cross-bag attention for distantly-supervised relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 Januray–1 February 2019; Volume 33, pp. 419–426. [Google Scholar]
- Yuan, Y.; Zhou, X.; Pan, S.; Zhu, Q.; Song, Z.; Guo, L. A Relation-Specific Attention Network for Joint Entity and Relation Extraction. In Proceedings of the IJCAI, Yokohama, Janpan, 11–17 July 2020; Volume 2020, pp. 4054–4060. [Google Scholar]
- Yu, B.; Zhang, Z.; Shu, X.; Wang, Y.; Liu, T.; Wang, B.; Li, S. Joint extraction of entities and relations based on a novel decomposition strategy. arXiv 2019, arXiv:1909.04273. [Google Scholar]
- Li, X.; Yin, F.; Sun, Z.; Li, X.; Yuan, A.; Chai, D.; Zhou, M.; Li, J. Entity-relation extraction as multi-turn question answering. arXiv 2019, arXiv:1905.05529. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A unified MRC framework for named entity recognition. arXiv 2019, arXiv:1910.11476. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A novel cascade binary tagging framework for relational triple extraction. arXiv 2019, arXiv:1909.03227. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zhong, P.; Wang, D.; Miao, C. Knowledge-enriched transformer for emotion detection in textual conversations. arXiv 2019, arXiv:1909.10681. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Chen, N.; Liu, F.; You, C.; Zhou, P.; Zou, Y. Adaptive bi-directional attention: Exploring multi-granularity representations for machine reading comprehension. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7833–7837. [Google Scholar]
- Li, S.; He, W.; Shi, Y.; Jiang, W.; Liang, H.; Jiang, Y.; Zhang, Y.; Lyu, Y.; Zhu, Y. Duie: A large-scale chinese dataset for information extraction. In Proceedings of the Natural Language Processing and Chinese Computing: 8th CCF International Conference, NLPCC 2019, Dunhuang, China, 9–14 October 2019; Proceedings, Part II 8. Springer: Berlin/Heidelberg, Germany, 2019; pp. 791–800. [Google Scholar]
- Feng, J.; Huang, M.; Zhao, L.; Yang, Y.; Zhu, X. Reinforcement learning for relation classification from noisy data. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage joint extraction of entities and relations through token pair linking. arXiv 2020, arXiv:2010.13415. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting pre-trained models for Chinese natural language processing. arXiv 2020, arXiv:2004.13922. [Google Scholar]
- Liu, Y.; Wen, F.; Zong, T.; Li, T. Research on joint extraction method of entity and relation triples based on hierarchical cascade labeling. IEEE Access 2022, 11, 9789–9798. [Google Scholar] [CrossRef]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relation Number | DuIE2.0 Training Set | Uniform Sampling Training Set | DuIE2.0 Test Set | Uniform Sampling Test Set |
|---|---|---|---|---|
| 1 | 984 | 230 | 101 | 46 |
| 2 | 3159 | 230 | 302 | 46 |
| 3 | 1807 | 230 | 170 | 46 |
| 4 | 7188 | 230 | 639 | 46 |
| 5 | 8345 | 230 | 718 | 46 |
| 6 | 593 | 230 | 46 | 46 |
| 7 | 937 | 230 | 87 | 46 |
| 8 | 1849 | 230 | 101 | 46 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| 31 | 22 | 51 | 1 | 29 |
| ⋯ | ⋯ | ⋯ | ⋯ | 46 |
| 49 | 395 | 230 | 32 | 46 |
| Total number | 173,109 | 10,423 | 15,475 | 2012 |
| Module | Parameter | Value |
|---|---|---|
| Roberta | hidden_size | 768 |
| max_position_embedding | 512 | |
| num_attention_heads | 12 | |
| num_hidden_layers | 12 | |
| pooler_fc_size | 768 | |
| pooler_num_attention_heads | 12 | |
| pooler_num_fc_layers | 3 | |
| pooler_size_per_head | 128 | |
| vocab_size | 21,128 | |
| input_size | 768 | |
| BiLSTM | hidden_size | 64 |
| LSTM | hidden_size | 64 |
| dropout | 0.4 | |
| CNN | in_channels | 768 |
| out_channels | 128 | |
| kernel_size | 3 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| RSAN | 59.7 | 57.6 | 58.6 |
| CasRel | 65.7 | 64.2 | 64.9 |
| TPLinker | 65.3 | 66.4 | 65.8 |
| REACT | 68.5 | 66.0 | 67.2 |
| No. | Encoding Layer | Additional Modules |
|---|---|---|
| 1 | DE+CNN | EAM+EGM |
| 2 | DE+LSTM | EAM+EGM |
| 3 | DE+BiLSTM | EAM+EGM |
| 4 | BERT+CNN | EAM+EGM |
| 5 | BERT+LSTM | EAM+EGM |
| 6 | BERT+BiLSTM | NULL |
| 7 | BERT+BiLSTM | EAM+EGM |
| 8 | Roberta+CNN | EAM+EGM |
| 9 | Roberta+LSTM | NULL |
| 10 | Roberta+LSTM | EAM |
| 11 | Roberta+LSTM | EAM+EGM |
| 12 | Roberta+BiLSTM | NULL |
| 13 | Roberta+BiLSTM | EAM |
| 14 | Roberta+BiLSTM | EGM |
| 15 (REACT) | Roberta+BiLSTM | EAM+EGM |
| No. | Models | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | DE+CNN+EAM+EGM | 70.7 | 40.5 | 51.5 |
| 2 | DE+LSTM+EAM+EGM | 74.3 | 44.7 | 55.8 |
| 3 | DE+BiLSTM+EAM+EGM | 74.6 | 46.7 | 57.4 |
| 4 | BERT+CNN+EAM+EGM | 67.5 | 62.0 | 64.6 |
| 5 | BERT+LSTM+EAM+EGM | 68.3 | 63.7 | 65.9 |
| 6 | BERT+BiLSTM | 64.8 | 63.8 | 64.1 |
| 7 | BERT+BiLSTM+EAM+EGM | 69.0 | 64.3 | 66.5 |
| 8 | Roberta+CNN+EAM+EGM | 69.2 | 60.1 | 64.3 |
| 9 | Roberta+LSTM | 65.7 | 62.2 | 63.9 |
| 10 | Roberta+LSTM+EAM | 66.4 | 65.1 | 65.7 |
| 11 | Roberta+LSTM+EAM+EGM | 68.1 | 64.8 | 66.4 |
| 12 | Roberta+BiLSTM | 66.2 | 63.9 | 65.0 |
| 13 | Roberta+BiLSTM+EAM | 67.6 | 65.3 | 66.4 |
| 14 | Roberta+BiLSTM+EGM | 67.8 | 64.7 | 66.2 |
| 15 | (REACT) Roberta+BiLSTM+EAM+EGM | 68.5 | 66.0 | 67.2 |
| Model | N = 1 | N = 2 | N = 3 | N ≥ 4 |
|---|---|---|---|---|
| RSAN | 64.5 | 61.3 | 58.7 | 51.2 |
| CasRel | 62.9 | 65.0 | 68.6 | 63.4 |
| TPLinker | 65.7 | 67.6 | 68.4 | 61.5 |
| RANGE | 66.0 | 68.3 | 71.4 | 65.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, L.; Liu, S. REACT: Relation Extraction Method Based on Entity Attention Network and Cascade Binary Tagging Framework. Appl. Sci. 2024, 14, 2981. https://doi.org/10.3390/app14072981
Kong L, Liu S. REACT: Relation Extraction Method Based on Entity Attention Network and Cascade Binary Tagging Framework. Applied Sciences. 2024; 14(7):2981. https://doi.org/10.3390/app14072981
Chicago/Turabian StyleKong, Lingqi, and Shengquau Liu. 2024. "REACT: Relation Extraction Method Based on Entity Attention Network and Cascade Binary Tagging Framework" Applied Sciences 14, no. 7: 2981. https://doi.org/10.3390/app14072981
APA StyleKong, L., & Liu, S. (2024). REACT: Relation Extraction Method Based on Entity Attention Network and Cascade Binary Tagging Framework. Applied Sciences, 14(7), 2981. https://doi.org/10.3390/app14072981