
Knowledge Graph Completion Using a Pre-Trained Language Model Based on Categorical Information and Multi-Layer Residual Attention


Abstract
1. Introduction
- (1)
- Proposing a novel text-based contrastive learning model called CAKGC, which incorporates both entity category semantic information and textual descriptions to more accurately model entity embedding representations.
- (2)
- Design a new attention network called Multi-layer Residual Attention Network (MRAN), which combines MRAN with pre-trained language models. The multi-layer self-attention mechanism allows the model to iterate and propagate information between entities, better capturing the complex relationships between entities. By simultaneously learning multiple attention heads, the model can model different types of relationships in parallel, enhancing the representation capability for diverse relationships. Each attention head can focus on different relationship patterns, capturing finer-grained features of relationships.
2. Related Works
2.1. Structure-Based Approach
2.2. Text-Description-Based Approach
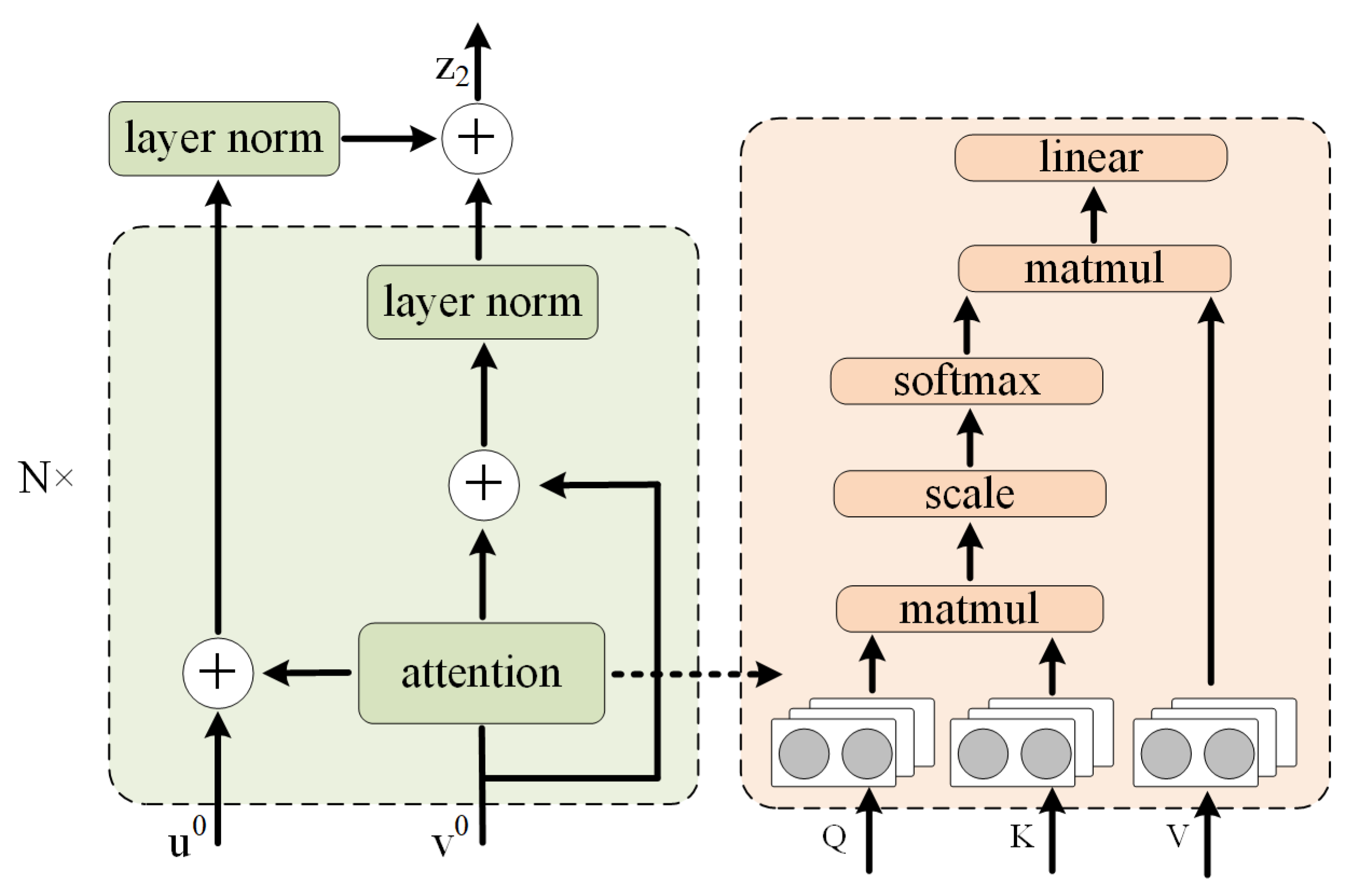
3. CAKGC
3.1. Encoder
3.2. Decoder
4. Experiment
4.1. Datasets
4.2. Experimental Setup and Evaluation Metrics
4.3. Comparison with Baseline Model Performance
4.4. Ablation Experiment
5. Discussion
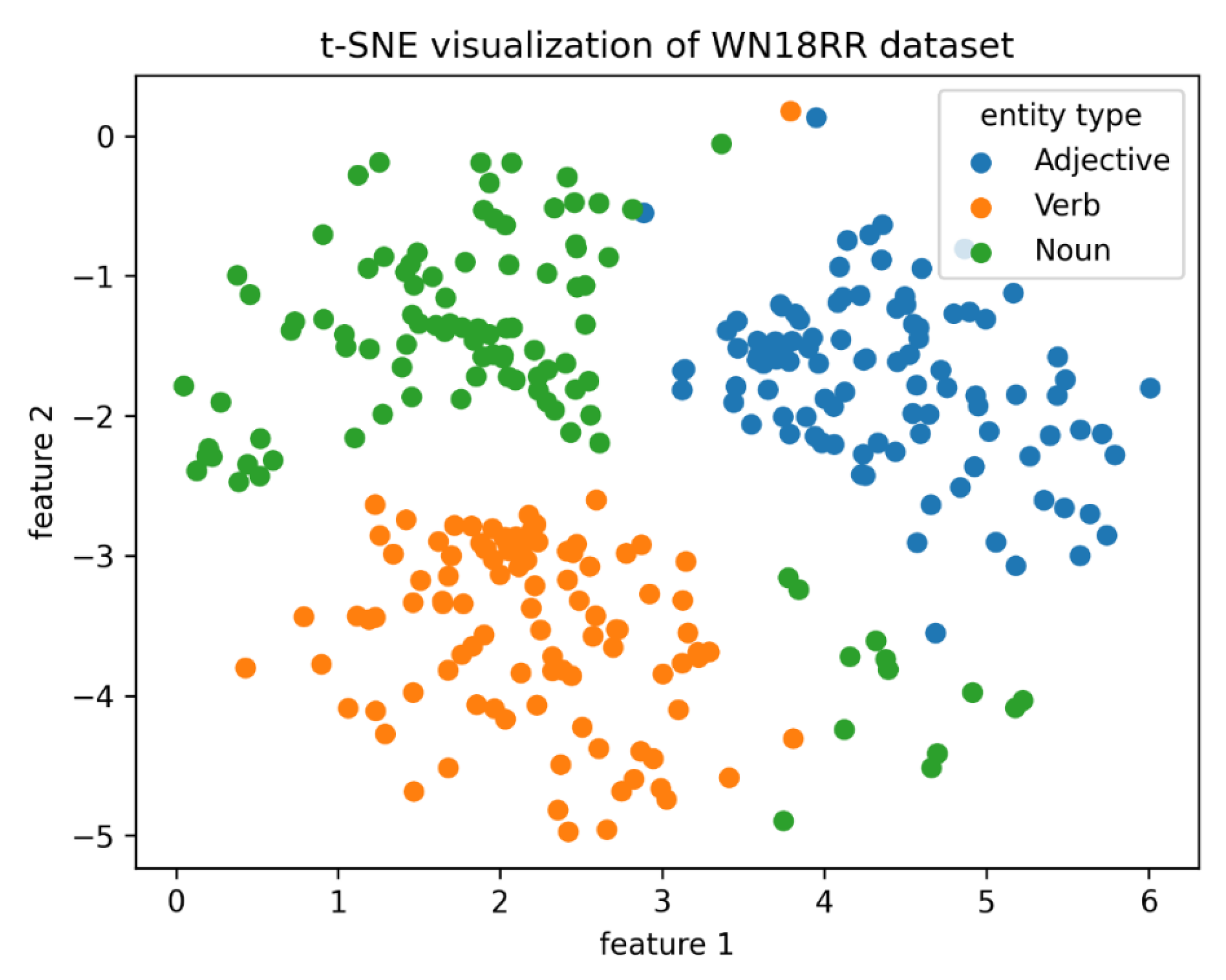
5.1. Entity Visualization
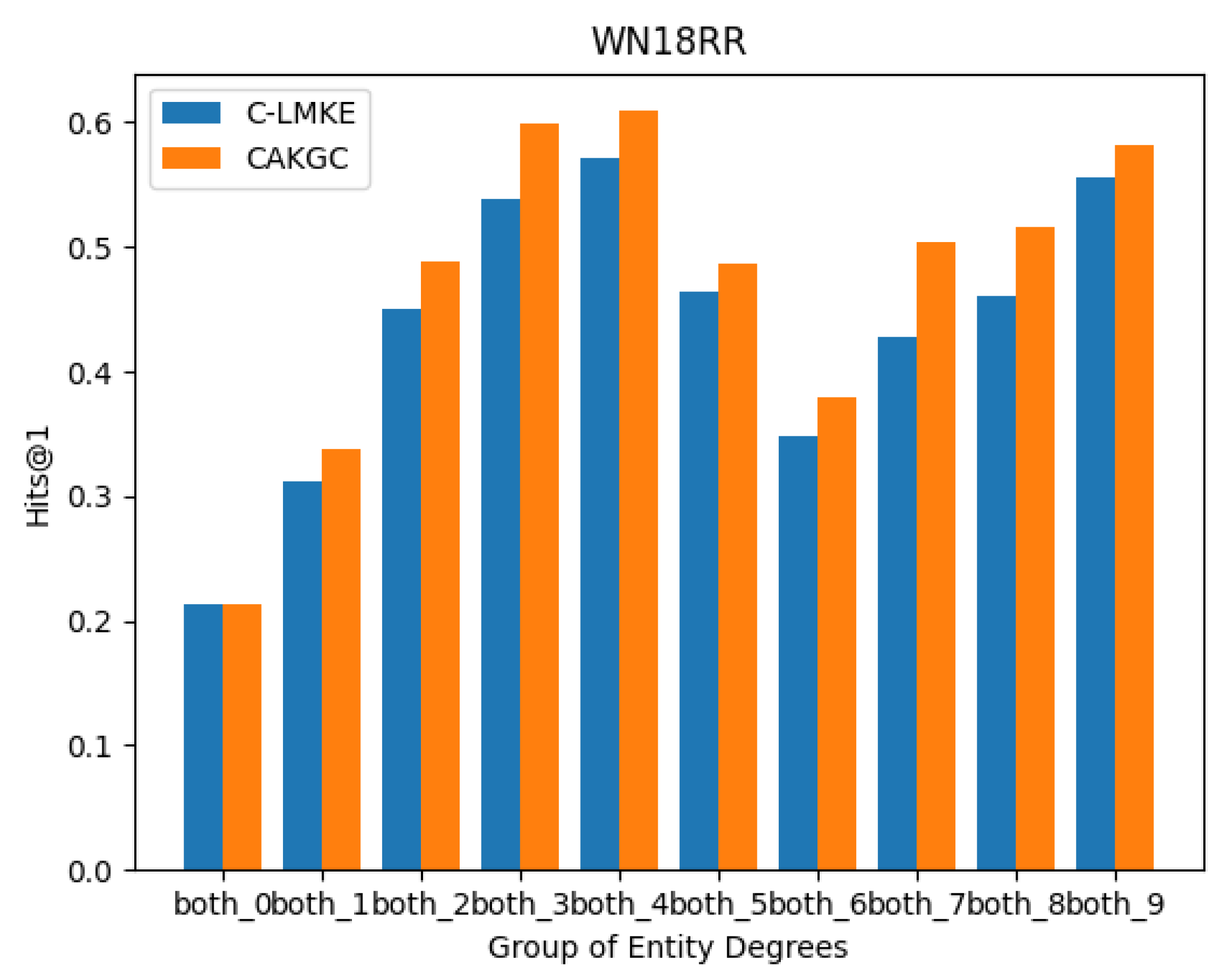
5.2. Sparse Entity Prediction
5.3. Attention Mechanism
6. Conclusions
6.1. Future Work
6.2. Limitations of the Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Advances in Neural Information Processing Systems 26, Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates, Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Wang, B.; Shen, T.; Long, G.; Zhou, T.; Wang, Y.; Chang, Y. Structure-Augmented Text Representation Learning for Efficient Knowledge Graph Completion. Proc. Web Conf. 2021, 2021, 1737–1748. [Google Scholar]
- Wang, X.; He, Q.; Liang, J.; Xiao, Y. Language Models as Knowledge Embeddings. In Proceedings of the International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Knowledge Graph Completion with Adaptive Sparse Transfer Matrix. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Chao, L.; He, J.; Wang, T.; Chu, W. PairRE: Knowledge graph embeddings via paired relation vectors. arXiv 2020, arXiv:2011.03798. [Google Scholar]
- Nickel, M.; Volker, T.; Hans-Peter, K. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, DC, USA, 28 June–2 July 2011. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Théo, T.; Johannes, W.; Sebastian, R.; Éric, G.; Guillaume, B. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic Embeddings of Knowledge Graphs. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Kazemi, S.; Poole, N. Simple embedding for link prediction in knowledge graphs. In Advances in Neural Information Processing Systems 31, Proceedings of the Annual Conference on Neural Information Processing Systems 2018, Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018. [Google Scholar]
- Zhang, Y.; Yao, Q.; Kwok, J.T. Bilinear Scoring Function Search for Knowledge Graph Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1458–1473. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of naacL-HLT, Minneapolis, MN, USA, 6–7 June 2019. [Google Scholar]
- Calderón-Suárez, R.; Ortega-Mendoza, R.M.; Montes-Gómez, M.; Toxqui-Quitl, C.; Márquez-Vera, M.A. Enhancing the Detection of Misogynistic Content in Social Media by Transferring Knowledge from Song Phrases. IEEE Access 2023, 11, 13179–13190. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, X.; Zhang, Y.; Su, Q.; Sun, X.; He, B. Pretrain-KGE: Learning knowledge representation from pretrained language models. In Findings of the Association for Computational Linguistics; Association for Computational Linguistics: Baltimore, MD, USA, 2020. [Google Scholar]
- Choi, B.; Jang, D.; Ko, Y. MEM-KGC: Masked entity model for knowledge graph completion with pre-trained language model. IEEE Access 2021, 9, 132025–132032. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, W.; Wei, Z.; Liu, J. SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Iulia Turc, T. Well-read students learn better: On the importance of pre-training compact models. arXiv 2019, arXiv:1908.08962. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Category | Key Innovations |
|---|---|
| Distance-based methods | Introduce various improvements to manage the semantic representation of relations, including translation operations, relation hyperplanes, relation-specific mapping matrices, and complex rotational operations to better handle symmetrical relationships. |
| Tensor decomposition-based methods | Focus on matrix factorization techniques that optimize computational efficiency and parameter count, addressing asymmetry in relations and automating the design of scoring functions. |
| Dataset | Entities | Relations | Train | Valid | Test |
|---|---|---|---|---|---|
| FB15k-237 | 14,151 | 237 | 272,115 | 17,535 | 20,466 |
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| Thangka | 1399 | 13 | 2793 | 399 | 399 |
| Method | FB15k-237 | WN18RR | ||||||
|---|---|---|---|---|---|---|---|---|
| MRR | Hits@1 | Hits@3 | Hits@10 | MRR | Hits@1 | Hits@3 | Hits@10 | |
| TransE | 0.279 | 0.198 | 0.376 | 0.441 | 0.243 | 0.043 | 0.441 | 0.532 |
| RotatE | 0.338 | 0.241 | 0.375 | 0.533 | 0.476 | 0.428 | 0.492 | 0.571 |
| DistMult | 0.241 | 0.155 | 0.263 | 0.419 | 0.430 | 0.390 | 0.440 | 0.490 |
| AutoBLM | 0.364 | 0.270 | - | 0.553 | 0.492 | 0.452 | - | 0.567 |
| Pretrain-KGE | 0.332 | - | - | 0.529 | 0.235 | 0.263 | 0.423 | 0.557 |
| KG-BERT | - | - | - | 0.420 | 0.216 | 0.041 | 0.302 | 0.524 |
| StAR | 0.296 | 0.205 | 0.322 | 0.482 | 0.401 | 0.243 | 0.491 | 0.709 |
| 0.346 | 0.253 | 0.381 | 0.531 | 0.557 | 0.475 | 0.604 | 0.704 | |
| 0.406 | 0.319 | 0.445 | 0.571 | 0.545 | 0.467 | 0.587 | 0.692 | |
| 0.404 | 0.324 | 0.439 | 0.556 | 0.598 | 0.480 | 0.675 | 0.806 | |
| SimKGC | 0.336 | 0.249 | 0.362 | 0.511 | 0.666 | 0.587 | 0.717 | 0.800 |
| 0.416 | 0.335 | 0.451 | 0.571 | 0.579 | 0.512 | 0.614 | 0.704 | |
| - | - | - | - | 0.636 | 0.544 | 0.698 | 0.795 | |
| Model | MRR | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|
| 0.593 | 0.534 | 0.623 | 0.683 | |
| 0.612 | 0.566 | 0.635 | 0.703 |
| Model | MRR | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|
| CAKGC | 0.579 | 0.512 | 0.614 | 0.704 |
| CAKGC (w/o type) | 0.571 | 0.502 | 0.606 | 0.698 |
| CAKGC (w/o attn) | 0.550 | 0.482 | 0.580 | 0.681 |
| CAKGC (w/o type and attn) | 0.545 | 0.467 | 0.587 | 0.692 |
| Model | MRR | Hits@1 | Hits@3 | Hits@10 |
|---|---|---|---|---|
| CAKGC (Pre-LN-Attention) | 0.568 | 0.499 | 0.602 | 0.693 |
| CAKGC (Post-LN-Attention) | 0.573 | 0.504 | 0.609 | 0.701 |
| CAKGC (ResiDual-Attention) | 0.579 | 0.512 | 0.614 | 0.704 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, Q.; Wang, T.; Guo, X.; Wang, K.; Yan, Y. Knowledge Graph Completion Using a Pre-Trained Language Model Based on Categorical Information and Multi-Layer Residual Attention. Appl. Sci. 2024, 14, 4453. https://doi.org/10.3390/app14114453
Rao Q, Wang T, Guo X, Wang K, Yan Y. Knowledge Graph Completion Using a Pre-Trained Language Model Based on Categorical Information and Multi-Layer Residual Attention. Applied Sciences. 2024; 14(11):4453. https://doi.org/10.3390/app14114453
Chicago/Turabian StyleRao, Qiang, Tiejun Wang, Xiaoran Guo, Kaijie Wang, and Yue Yan. 2024. "Knowledge Graph Completion Using a Pre-Trained Language Model Based on Categorical Information and Multi-Layer Residual Attention" Applied Sciences 14, no. 11: 4453. https://doi.org/10.3390/app14114453
APA StyleRao, Q., Wang, T., Guo, X., Wang, K., & Yan, Y. (2024). Knowledge Graph Completion Using a Pre-Trained Language Model Based on Categorical Information and Multi-Layer Residual Attention. Applied Sciences, 14(11), 4453. https://doi.org/10.3390/app14114453