1. Introduction
Sentence embedding learning has long been a core focus within the field of natural language processing, serving as a critical component in a wide array of downstream applications [
1,
2,
3,
4,
5,
6]. Researchers have been constructing sentence vector models through text-matching annotated datasets, where each sample is formatted as (Sentence A, Sentence B, Label). When comparing or ranking pairs of sentences for semantic similarity, we typically rely on the cosine value of the angle between sentence vectors for judgment, as shown in Equation (
1). Here, A and B represent sentence vectors, and cos(A, B) denotes the cosine value of the angle between them. This equation is based on a standard coordinate basis, where the cosine value of the angle between different basis vectors is 0. Due to the high-dimensional nature of sentence vectors, using the cosine value of the angle between vectors to measure semantic similarity offers the following advantages: (1) it is unaffected by scale; (2) it effectively captures angular information; (3) it exhibits high computational efficiency; and (4) it remains effective in high-dimensional spaces (whereas metrics based on vector norms are susceptible to the curse of dimensionality in high-dimensional spaces). Gao et al. [
7] discovered that the sentence vectors learned via Transformers exhibit anisotropy, a characteristic similarly identified in BERT and GPT-2 by Ethayarajh [
8]. “Anisotropy” refers to the phenomenon where word embeddings occupy a narrow conical region in the vector space, implying that the coordinate system of the sentence vectors is not a standard coordinate basis, rendering the equality in Equation (
1) invalid. Methods such as Bert-flow [
9], Bert-whitening [
10], IS-Bert [
11], CT-Bert [
12], and Simcse [
13] aim to eliminate or mitigate the anisotropy of the learned sentence vectors, thereby enabling more accurate semantic similarity judgments between sentence pairs.
In recent years, contrastive learning has seen successfully applied in sentence embedding learning [
13,
14,
15]. The goal of contrastive learning is to bring positive sample pairs closer together in the encoding space, while pushing negative samples further apart. Wang et al. [
16] introduced two key concepts for measuring the quality of contrastive learning: alignment and uniformity. For alignment, two samples forming a positive pair should be mapped to nearby features and thus be (mostly) invariant to unneeded noise factors. For uniformity, feature vectors should be roughly uniformly distributed on the unit hypersphere, preserving as much information from the data as possible. Therefore, constructing positive samples and selecting negative samples are crucial for enhancing the effectiveness of contrastive learning, among which SimCSE [
13] stands out as a representative method. SimCSE’s unsupervised model uses dropout [
17] as a form of data augmentation to construct positive samples with minimal noise. Specifically, SimCSE processes N sentences as a batch, where each sentence undergoes two independent rounds of dropout masking before being input into a pretrained BERT model. The resulting embeddings from the same sentence serve as positive pairs, whereas embeddings from different sentences are treated as negative pairs.
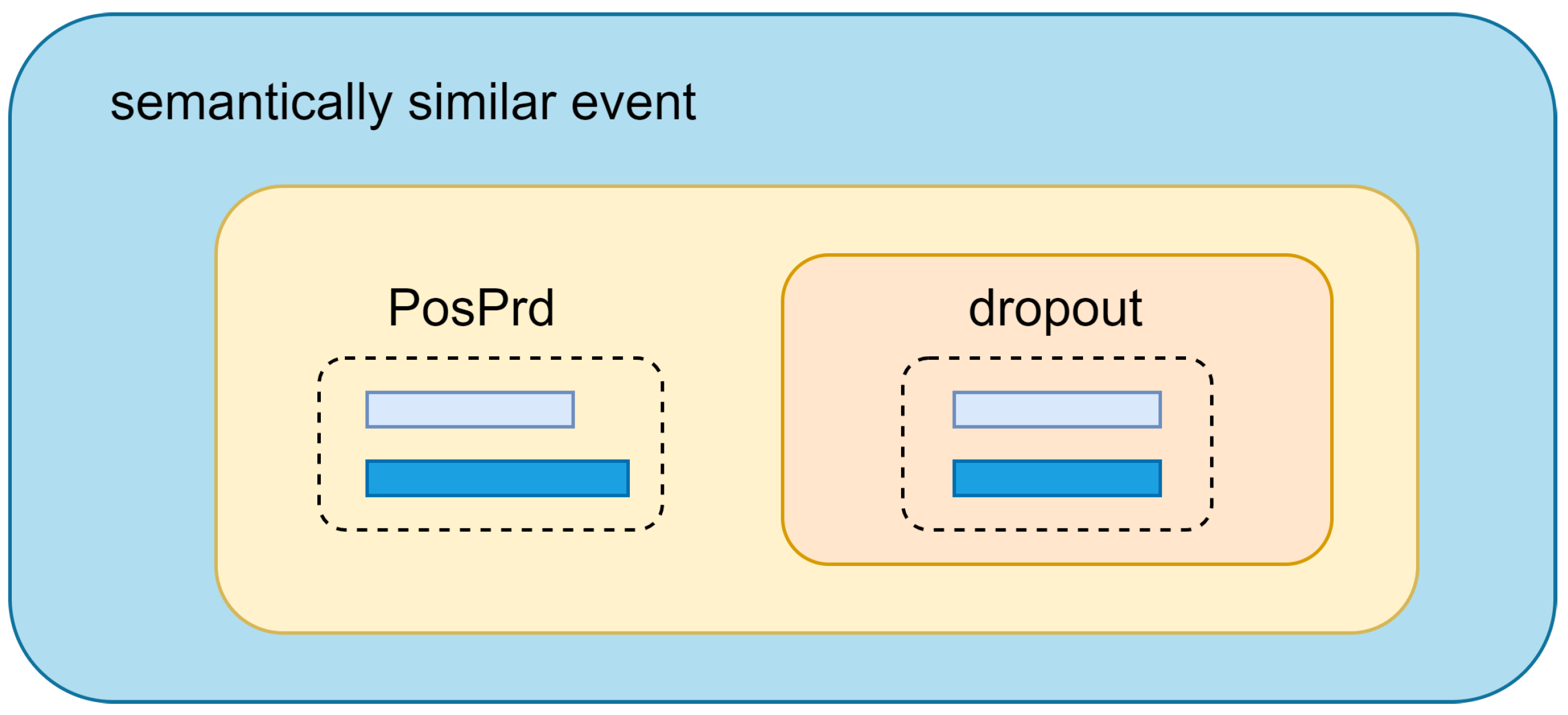
SimCSE assumes that dropout serves as the “minimal” form of data augmentation, but a crucial weakness is overlooked. Because dropout aims to retain as much information from the original sentence as possible, including the positional information of each token, this approach inadvertently leads to a misunderstanding: sentences of the same length are perceived to have a higher probability of being semantically similar. Conversely, the unsupervised version of SimCSE does not effectively differentiate between various negative examples. The supervised version of SimCSE, which uses a supervised natural language inference (NLI) dataset, constructs hard negative samples to further enhance the effect of contrastive learning. Wang et al. [
18] proposed SNCSE, which acquires word vectors through cue learning and syntactic parsing using spacy and constructs soft negative examples. Nishikawa et al. [
19] proposed Ease, which generates positive sample pairs by associating entities sourced from Wikipedia. Negative entities are constrained to be the same type as the positive ones and are excluded if they appear on the same Wikipedia page. Randomly selected candidate entities that meet these criteria are used as hard negative data to construct triplet data. However, these methods for distinguishing negative samples are limited to annotated datasets and are not applicable in unsupervised learning scenarios.
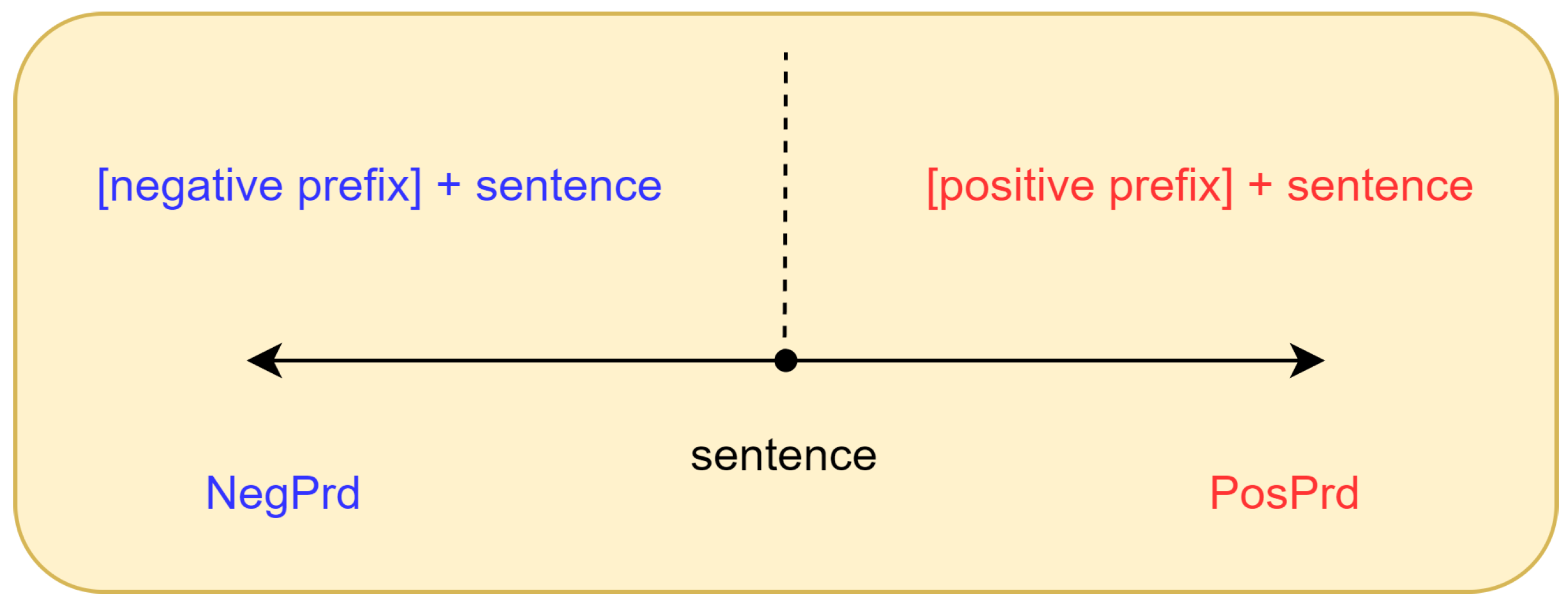
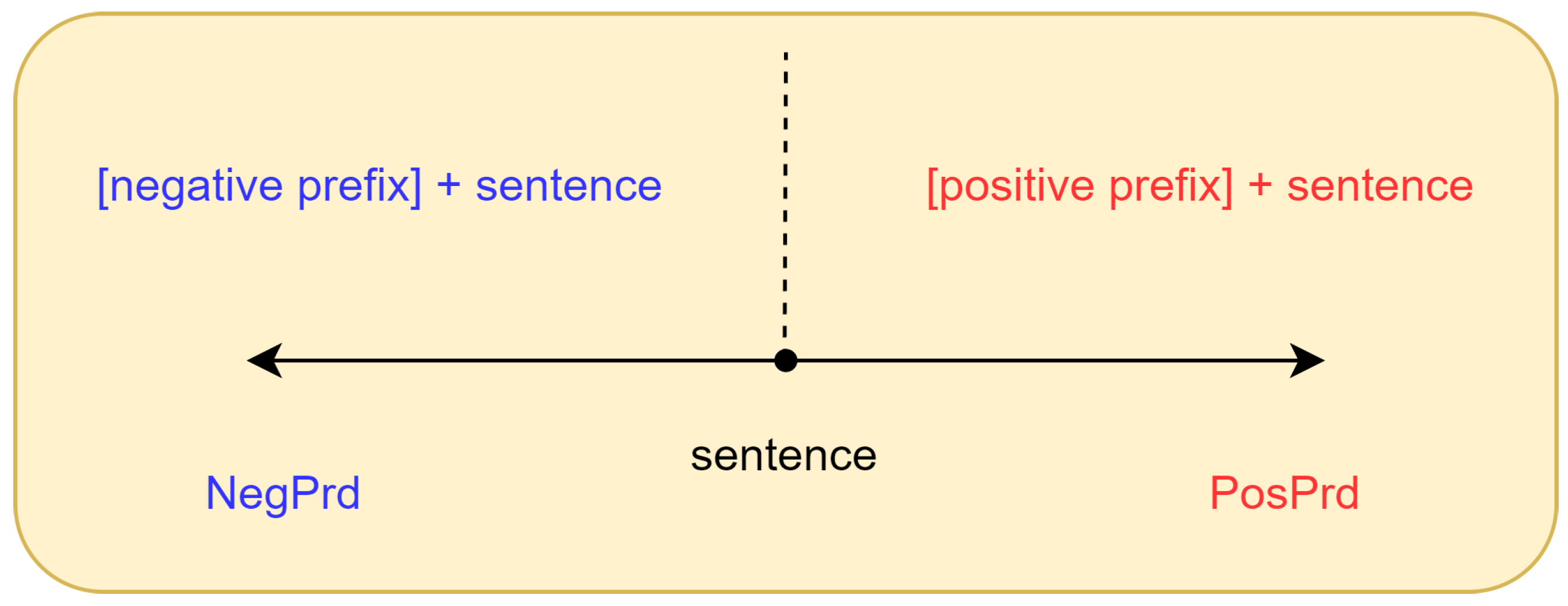
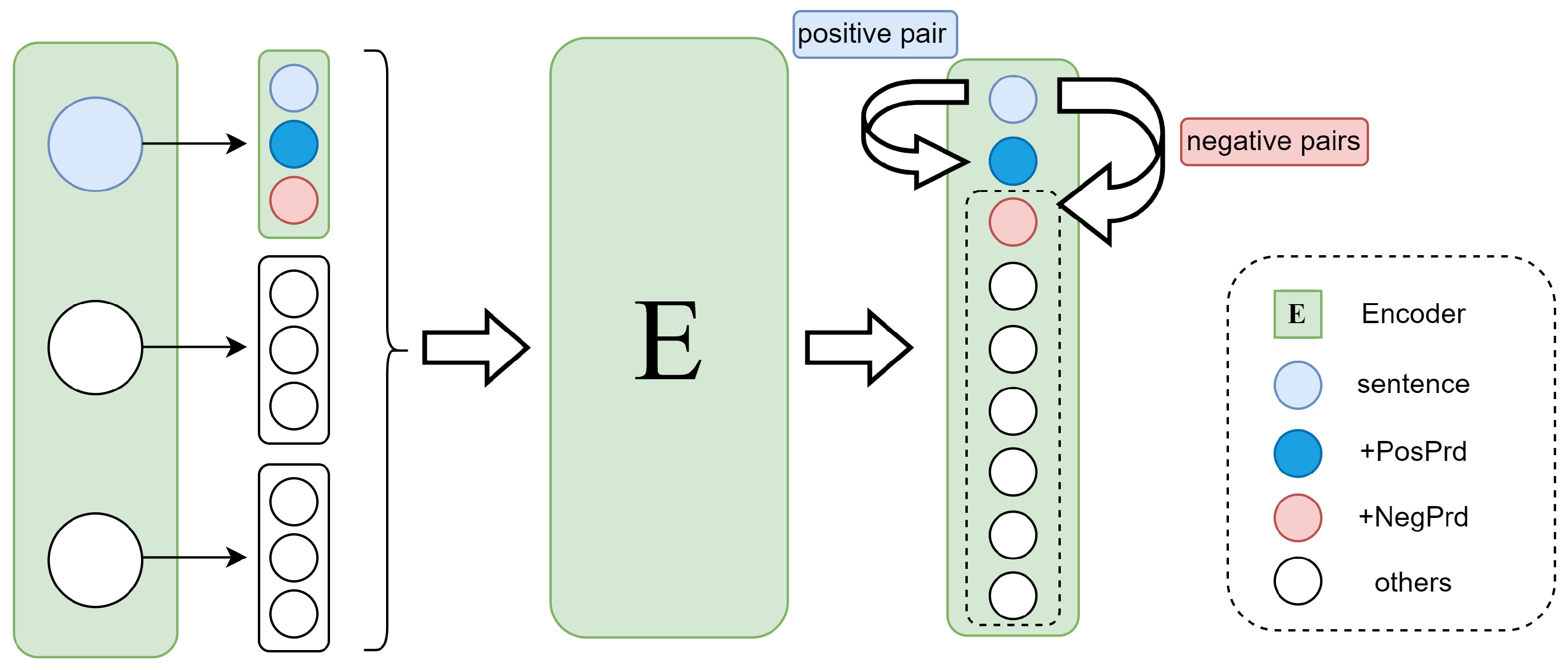
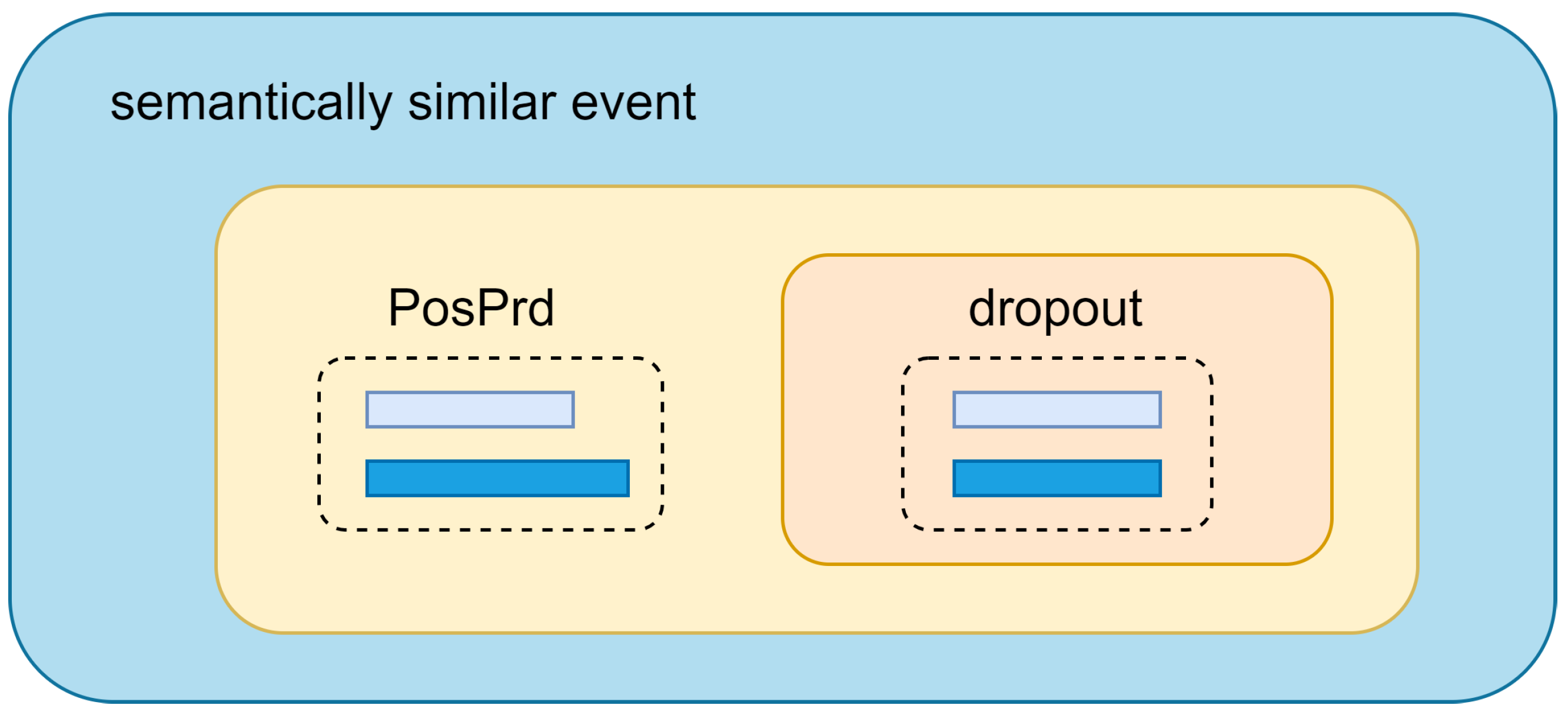
To address these aforementioned issues, we propose PrdSimCSE, an unsupervised contrastive learning framework based on prefix data augmentation. As illustrated in
Figure 1, PrdSimCSE uses prefix data augmentation (Prd) to construct positive samples and differentiate negative samples. Next,
Section 2 introduces the background knowledge on text augmentation, including the basic concepts of sentence embedding and contrastive learning.
Section 3 details the prefix data augmentation method, including how to determine positive and negative prefixes and their impact on the model.
Section 4 outlines the unsupervised PrdSimCSE, covering algorithm design, experimental environment setup, parameter settings, datasets, and baseline comparisons.
Section 5 describes the progress of prefix data augmentation determined through ablation studies, where we further discuss how to determine positive and negative prefixes and the semantic bias caused by prefix data augmentation.
Section 6 discusses the relationship between semantic similarity events and prefix data augmentation, including the advantages and roles of positive and negative prefixes.
Section 7 concludes the paper by providing the contributions of prefix data augmentation to unsupervised sentence embedding learning and directions for future research.
The contributions of this paper can be summarized as follows:
This paper introduces a novel text data augmentation method, prefix data augmentation. Positive samples are constructed using modal particle prefixes combined with dropout, thus preserving the original semantics as much as possible while altering the positional information of each token. This approach enhances and facilitates contrastive learning.
Prefix data augmentation can also be used to modify the original semantics. By constructing prompts that reverse the semantics and using them as prefixes, the modified sentences can serve as negative samples. This method allows for the creation of a richer set of negative samples from unsupervised corpora, thereby increasing the discriminability between different negative samples.
We developed a novel unsupervised sentence embedding learning approach, PrdSimCSE, which we used to construct both positive and negative samples through prefix data augmentation. Additionally, the approach treats other sentences within the same batch as negative samples.
We evaluated PrdSimCSE across various datasets, and the experimental results demonstrated that our proposed PrdSimCSE achieves superior performance in sentence representation compared with prior approaches. Furthermore, through ablation studies, we further examined the effectiveness of PrdSimCSE and discussed the advantages and limitations of our method in detail.
2. Background
Text Augmentation Text augmentation can be categorized into two main types based on the generation method: back-translation and adding noise. Back-translation is a simple and efficient text augmentation technique that generates more high-quality samples on the basis of existing datasets by translating and then retranslating the text in scenarios with few samples [
20,
21]. However, back-translation carries an implicit prior, whereas the model is presented with input texts that, despite having different linguistic expressions, share the same semantics. Adding noise involves directly performing operations such as the addition, deletion, or replacement of sentences. The easy data augmentation (EDA) technique proposed by Wei et al. [
22] is a compilation of such methods. EDA consists of four strategies: (1) synonym replacement (SR): randomly select nonstop words from a sentence and replace them with randomly chosen synonyms; (2) random insertion (RI): randomly identify a nonstop word in a sentence, find a synonym for it, and insert that synonym into a random position in the sentence; then, repeat this process n times; (3) in random swap (RS), two words in the sentence are randomly chosen, and their positions are swapped, repeating this process n times; and (4) random deletion (RD): each word in the sentence is randomly deleted with a probability p. Given that these methods involve random operations, a question arises: can the text’s label remain unchanged after EDA operations? To address this concern, Xie et al. [
23] proposed unsupervised data augmentation (UDA), where the core idea involves replacing a certain proportion of nonessential words in the text with unimportant words from a dictionary, thereby generating new texts. However, in the context of contrastive learning for sentence representation, using such text augmentation methods to construct positive samples for unsupervised learning typically results in lower performance compared with supervised models. SimCSE has achieved notable success in unsupervised learning, also demonstrating that dropout can serve as a “minimal” form of text data augmentation, offering an alternative to other text augmentation methods. However, dropout augmentation does not alter the positional information of words within a sentence, which can introduce new biases to the model. Inspired by SimCSE, we developed a text augmentation technique suitable for unsupervised learning: prefix data augmentation.
Sentence Embedding Sentence embedding learning aims to convert natural language text sequences into numerical sequences that machines can comprehend. Depending on whether the training corpus is labeled, sentence embedding learning processes can be categorized into supervised and unsupervised approaches. In this study, we primarily focused on unsupervised sentence embedding learning. Word2Vec [
24] was one of the earlier models developed for the unsupervised learning of semantic knowledge from large text corpora. Word2Vec proposed the CBOW and skip-gram methods. In CBOW, surrounding words are predicted based on the center word; in skip-gram, the center word is predicted based on surrounding words. BERT [
25] introduced the masked language model (MLM) and next sentence prediction (NSP) training methods, but the training data must be at the document level. Subsequent models such as CrossThought [
26] and CMLM [
27] face similar issues. SimCSE [
13] is an unsupervised contrastive learning framework, enabling direct sentence embedding learning using widely available short texts. SimCSE also adapts well to downstream tasks that primarily involve short texts.
Contrastive Learning In the context of sentence embedding learning, the aim of contrastive learning is to train an encoder that produces similar encodings for sentences of the same class within the same dataset, while ensuring the encoding results for sentences of different classes are as dissimilar as possible. Suppose we have a set of samples to be learned,
, where
serves as the anchor sample,
serves as the positive sample for
, and
serves as the negative sample for
. We drew inspiration from the infoNCE used in MoCo [
28] and adopted the SimCSE approach, using other samples within the same batch as negative samples. In a single batch, the contrastive learning objective for the anchor sample
is
where the batch size is denoted as
, where t is the temperature hyperparameter, and sim is the function used to compute the cosine similarity between two vectors. In our experiments, positive samples were generated only using PosPrd (positive prefix), represented as
m = 1 in the formula. For the selection of negative samples, in addition to using other samples within the batch as negative samples, we employed NegPrd (negative prefix). Subsequently, we used pretrained models such as BERT and RoBERTa [
29] and fine-tuned all parameters using the contrastive learning objective.
3. Prefix Data Augmentation
As the name suggests, prefix data augmentation involves changing text data by adding prefixes to augment the dataset. In theory, any text can serve as a prefix for other texts. However, from the perspective of constructing positive samples, we aimed for prefixes that did not alter the original sentence’s semantics. When constructing negative samples, we preferred prefixes that reversed or disrupted the semantics of the original sentence as much as possible. Through multiple experiments and trials, we found that modal particle prefixes are excellent positive prefixes, whereas prompts that reverse the semantics are effective as negative prefixes.
In the field of computer vision, various effective data augmentation methods are employed to construct positive examples for contrastive learning, such as cropping, rotation, and color adjustments. These methods are employed because the information in images is continuous [
30], and partial pixel blocks of an image can convey information. However, in natural language processing (NLP), the semantic information embedded in text data is discrete. As shown in
Table 1, text augmentation methods such as Random deletion, Word substitution, and Rearrangement substantially alter the semantics of the original sentence, resulting in decreased similarity between the modified and original sentences. However, the positive prefix preserves the original semantic information. SimCSE applies dropout as a method that effectively addresses the challenge posed by the discrete nature of semantics in text data. When using contrastive learning for sentence embeddings, dropout can serve as a “minimal” positive data augmentation method for constructing positive examples. However, the dropout method only deactivates certain positions in the sentence embeddings. Does constructing positive samples using this approach ensure the encoder is sensitive to the length and structure of sentences? To mitigate this issue, we introduced a simple meaningless prefix in PosPrd.
We found that specific semantic reversal prefixes can serve as negative data augmentation, used for constructing negative samples in contrastive learning. In the contrastive learning of sentence embeddings, a common approach involves using other sentences within the same batch as negative samples for the anchor sentence. This method is based on the assumption that in a rich training corpus, each sentence belongs to two semantically different categories. However, text data often contain a considerable amount of repetition. For instance, in restaurant reviews, many sentences may belong to the positive semantic category, whereas others belong to the negative semantic category. Consequently, during training, many negative samples may be “problematic”, where two semantically similar sentences are treated as negative pairs, which is detrimental to contrastive learning. By introducing manually crafted negative prefixes, we ensure the original sentence is augmented into a category with the opposite semantic meaning, thereby constructing higher-quality negative samples. This approach contributes to increasing the effectiveness of contrastive learning, enabling the model to more accurately capture semantic distinctions.
7. Conclusions
We developed a novel text augmentation method, prefix data augmentation. By using modal words as prefixes to construct positive samples, we avoided the positional information error that arises when SimCSE constructs positive samples. Constructing negative samples by employing specific semantic inversion prompts as prefixes effectively distinguishes negative samples. Based on these methods, we developed an unsupervised sentence embedding contrastive learning model enhanced using prefix data augmentation. The results of the experiments showed that compared with SimCSE, PrdSimCSE achieved comprehensive performance improvements on semantic similarity task sets, achieving a 2.01% increase on STS-B and a 1.08% increase on average.
We conducted a search on the form of prefixes. For positive prefixes, we found that as sentence length increases, adding more semantic word prefixes improves the model’s performance. For negative prefixes, we discovered that semantic inversion cue sentences are suitable choices, where the shorter the cue sentence, the larger the performance loss of the model. Additionally, we found that in some transfer tasks, PrdSimCSE’s understanding of short texts is not as strong as that of SimCSE. Through multiple ablation experiments, we observed that although PrdSimCSE avoids the semantic biases caused by positive samples of the same length, it loses some ability to comprehend short text. In summary, PrdSimCSE produced improvements compared with SimCSE on 16 tasks, also proving the feasibility and effectiveness of prefix data augmentation.
PrdSimCSE not only addresses the bias issues experienced with previous approaches but also provides a new approach to constructing negative samples for contrastive learning. We think that the method presented in this paper offers valuable references for researchers in the NLP field.





{kind=link}
{kind=link}
{kind=link}