1. Introduction
Isolation switches are critical components in power systems. Accurate and reliable determination of their operational status is essential for power grid security. With the rapid development of smart grids and the increasing prevalence of unmanned substations, there is a growing need for real-time monitoring and automatic identification of the operational status of isolation switches [
1]. Manual inspections traditionally consume both time and effort, while also facing challenges in maintaining accuracy and timeliness, particularly during unfavorable weather conditions. With the rise of automation and intelligent inspection technologies, computer vision and pattern recognition techniques are increasingly being applied in modern power systems to assist in monitoring the operational status of isolation switches [
2,
3,
4].
In the early stages, most research on visual isolation switch detection methods primarily focused on traditional machine learning methods. These methods first design feature descriptors for isolation switches, such as histogram of oriented gradients (HOG) and local binary patterns (LBP), to extract image feature information. Traditional machine learning classifiers, such as support vector machines (SVM) and random forests, are designed to determine the operational status of isolation switches [
5]. Compared to deep-learning-based methods, traditional machine learning methods do not necessitate large image datasets of isolation switches for model training and are comparatively easier to deploy on inspection robots. However, in complex power monitoring scenarios, the isolation switch state recognition results of traditional machine learning methods are susceptible to factors such as lighting variations, occlusions, and diverse viewpoints. The dual-layer cellular neural network (CNN) with a constant template proposed by P. Arena et al. [
6] is well-suited for generating self-organizing patterns and can simulate complex phenomena, offering a potential solution for detection in complex and dynamic power scenarios.
In recent years, the rise of deep learning has led to significant progress in the intelligent identification of power system equipment. Object detection algorithms based on deep learning, such as YOLO [
7], SSD [
8], and Faster R-CNN [
9], have been widely used to identify the status of power equipment. These algorithms have demonstrated exceptional performance in detecting objects with nonlinear and high-dimensional features. The accuracy and robustness of detection results have significantly improved. Currently, research on deep-learning-based methods for power equipment detection primarily focuses on the identification and fault detection of other types of power equipment, while little research focuses on isolation switch state detection.
Numerous recent studies on deep-learning-based power equipment recognition have concentrated on identifying electrical devices of various sizes in monitoring scenarios, particularly in environments such as substations. The diverse morphological differences in the equipment within these images pose a significant challenge for visual detection models in adapting to objects of different scales, often resulting in suboptimal recognition outcomes. Wu et al. [
10] proposed an enhanced YOLOv5-based visual fault detection algorithm for substation equipment, which adjusts the combination of multi-level features in the network through a floating adaptive weighted fusion strategy, enabling adaptive learning for objects of different scales. Similarly, Bi et al. [
11] introduced a YOLOX++ detector, based on YOLOX, which utilizes a multi-scale cross-stage partial network (MS-CSPNet) to fuse multi-scale feature information and expand the receptive field for objects through channel combinations, thereby optimizing the localization of small objects. The primary focus of these studies was to enhance the multi-scale fusion network in the neck of object detection models. By integrating feature maps of different sizes, these models enhance their ability to extract features at various scales, ultimately improving detection accuracy.
In the field of deep-learning-based visual detection for power equipment, significant efforts are being made to improve detection performance across a range of electrical devices. Ou et al. [
12] put forth a object detection model based on an improved faster R-CNN, tailored for the automatic detection of five types of power equipment in substations. This method involves modifying the feature extraction network and adjusting the aspect ratios of anchor boxes to elevate the accuracy when identifying elongated equipment. To tackle the challenges presented by the diverse shapes and sizes of distribution equipment, Hu et al. [
13] introduced a multi-device detection method for distribution line inspection based on YOLOx-s. This innovative approach enables the simultaneous recognition of multiple types of power equipment, thereby bolstering the intelligence of autonomous UAV inspections of distribution lines. These studies predominantly sought to address the visual detection challenges of electrical equipment with significant appearance variations. By proposing object detection algorithms, they aimed to refine the recognition accuracy of different types of electrical devices.
In the domain of deep-learning-based visual detection for power equipment, there has been a focus on creating lightweight detection models to improve real-time performance. Yu et al. [
14] introduced the RepVGG-YOLOv5 model, aimed at transmission line fault detection with drones, which enhances real-time detection without compromising accuracy by optimizing the weight distribution, adjusting single-branch inference, and improving the normalization performance. Similarly, Su et al. [
15] restructured the detection head and neck to develop a lightweight insulator defect detection method. This approach minimizes the number of parameters, while preserving robust feature extraction and perception abilities, thereby enhancing the accuracy of insulator defect detection. These studies typically achieve a light weight by modifying the backbone network and redesigning the detection head, thereby reducing model parameters, while preserving the detection accuracy. This research provides valuable insights for developing real-time object detection models in power system scenarios.
Overall, existing research has primarily focused on improving the accuracy, multi-scale detection, and real-time performance of power equipment detection models. These improvements can be summarized as follows: (1) Multi-scale fusion methods have been introduced to enhance a model’s ability to recognize objects of varying sizes; (2) Convolutional modules and attention mechanisms have been designed to strengthen feature extraction, thereby improving model accuracy; (3) Lighter network architectures have been proposed to accelerate model inference, thereby enhancing real-time performance.
It is important to note that isolation switch status detection differs from other electrical equipment detection tasks, due to its unique characteristics. First, compared to other electrical devices, isolation switches have a relatively elongated shape with a large length-to-width ratio. Second, the structure of isolation switches is variable; they exhibit significant visual differences between open and closed states, and may also appear in a separated state. Third, in monitoring scenarios, the scale of isolation switches can vary within the same image, due to differences in the distance from the monitoring equipment. Finally, power monitoring systems often generate large volumes of image data. To ensure faster system response and reduce data transmission delays, lightweight models must be deployed at the edge to process images in real time.
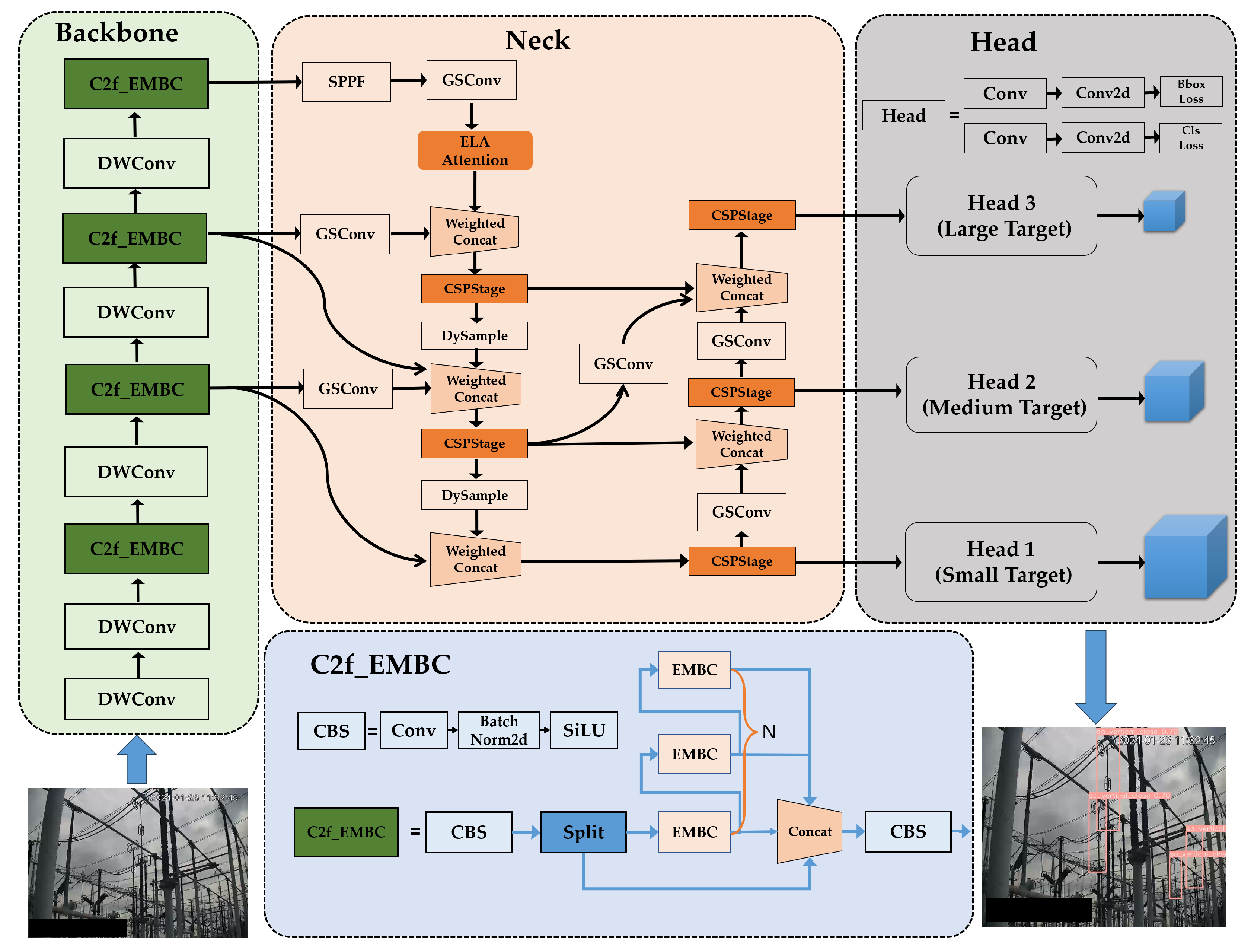
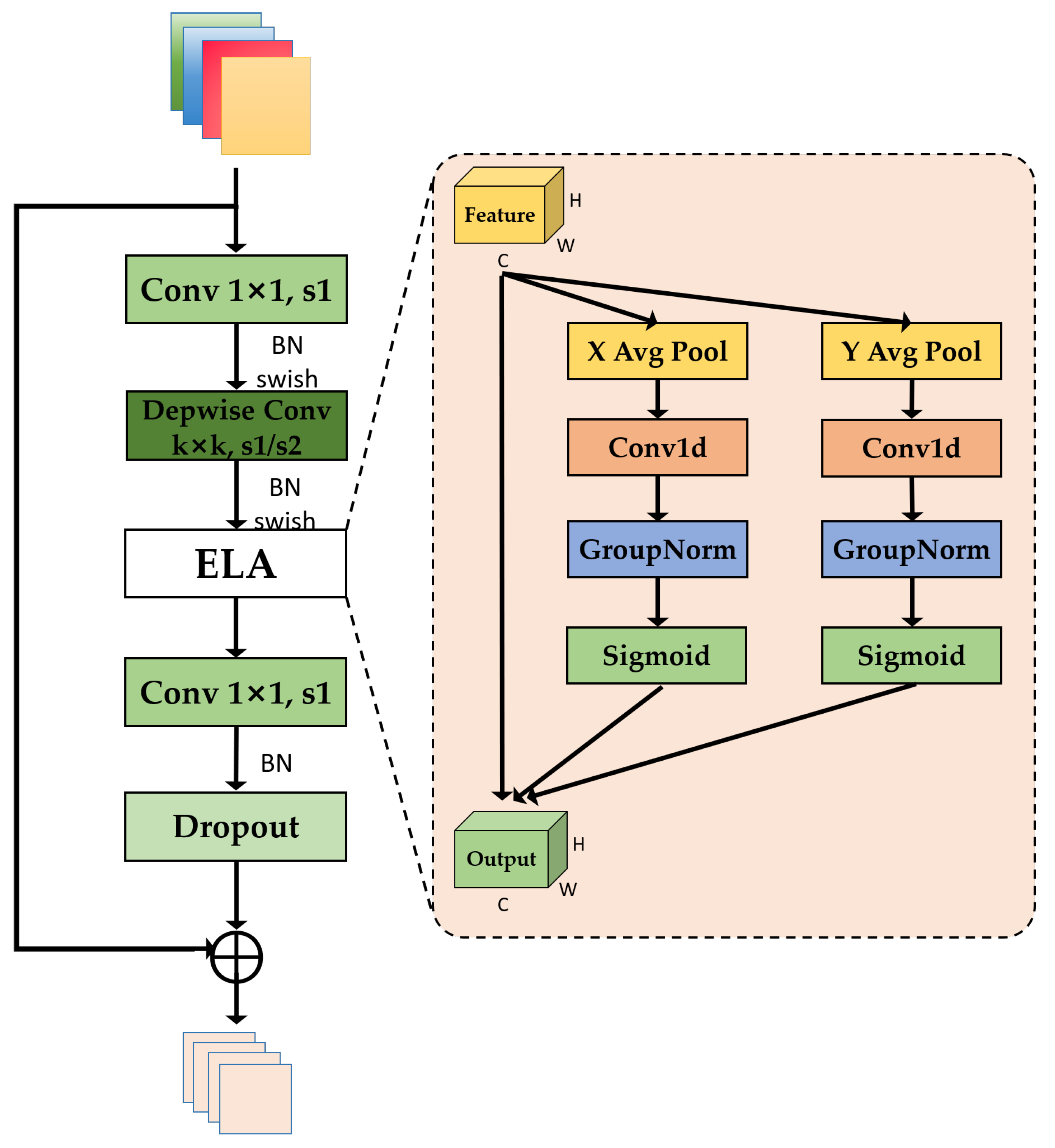
To address the aforementioned challenges, this paper first proposes an efficient mobile inverted bottleneck convolution (EMBC) module within the backbone network. This module leverages an ELA attention mechanism [
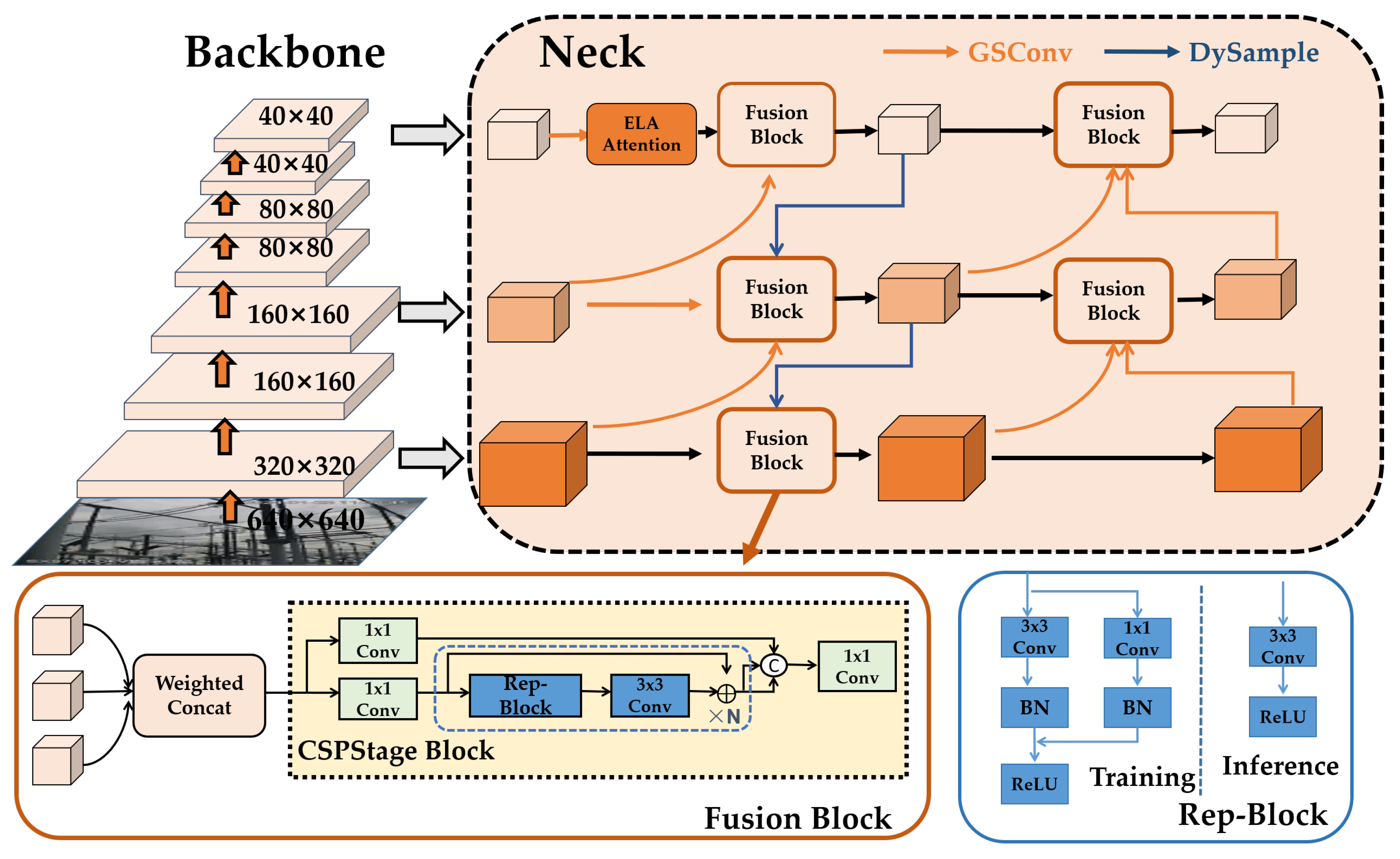
16] to enhance the feature extraction capability of the detection model for complex backgrounds. The ELA attention mechanism focuses on the spatial features of object positions in both the horizontal and vertical directions. By independently processing the feature vectors of each direction, it activates attention weights, guiding the model to focus on the location information of the isolation switch in different states. Second, an efficient-RepGDFPN feature fusion module is employed, which uses lightweight convolutional modules and a fast normalized fusion method to enhance the model’s multi-scale feature fusion capability. Finally, depthwise separable convolutions are used to replace the traditional convolutions, achieving a lightweight model for isolation switch detection and improving the real-time inference performance.
Compared to existing methods, the innovation of EMB-YOLO in the field of power monitoring mainly lies in its lightweight design and optimization for the specific object of isolator switches. Through the combination of the EMBC module and the efficient-RepGDFPN fusion network, we not only improved the computational efficiency of the model, but also addressed the instability issues of traditional methods in complex environments. These designs ensure that EMB-YOLO can provide a higher detection accuracy and real-time performance in practical applications within power monitoring scenarios.
The paper proposes a lightweight object detection algorithm, EMB-YOLO, for identifying the states of isolation switches. This algorithm ensures accurate detection of isolation switch states, even in complex background environments, while significantly reducing the computational overhead. It can be applied to intelligent power monitoring systems, enhancing the detection performance of isolation switch states, while maintaining the detection speed. The contributions of this paper are as follows:
To achieve timely and accurate detection with complex backgrounds, we modified the bottleneck in the original C2f module of YOLOv8 based on the characteristics of isolation switches. A more efficient EMBC-Module was designed, enhancing the model’s feature extraction capabilities to accurately capture isolation switch features from complex substation environments.
A novel feature fusion module, efficient-RepGDFPN, was developed. By utilizing the lightweight convolutional module GSconv and a fast normalized fusion method, this module efficiently extracts features of isolation switches at different scales. The capability of the proposed model for extracting multi-scale features is ultimately enhanced.
Considering the characteristics of horizontally and vertically extensible isolation switches, we integrated the ELA attention mechanism into the network. By employing strip pooling in the spatial dimension, the model effectively extracts feature vectors in both horizontal and vertical directions, capturing long-range dependencies. This approach is highly beneficial for handling global features in images, such as object shapes and positions.
We collected and processed surveillance images from various power operation sites to create a dataset for detecting the open and closed states of isolation switches. This dataset includes objects such as single-arm horizontal telescopic isolation switches, single-arm vertical telescopic isolation switches, and double-arm vertical telescopic isolation switches, in both their open and closed states.
2. Related Work
2.1. Vision-Based Object Detection for Fault and Anomaly Identification in Power Equipment
In the field of power system automation, the fault and anomaly detection of power equipment is a typical problem in monitoring the operational status of such equipment. With the widespread application of deep learning technologies, an increasing number of studies have employed automated analysis of image data from power equipment. By utilizing visual object detection methods, these studies swiftly identified faults and anomalies, enabling early warnings and timely interventions. This approach helps ensure the stable operation of power systems.
Zheng et al. [
17] employed an improved YOLOv4 model for detecting circuit breaker and insulation switch faults. Their approach achieved intelligent diagnosis of thermal faults by rapidly identifying and extracting device temperature features. Peng et al. [
18] proposed a defect recognition method called EDF-YOLOv5 based on YOLOv5s, which enhanced the accuracy of transmission line defect detection. Liu et al. [
19] introduced the CSPD-YOLO model for detecting insulation switch faults in complex background aerial images. Their method improved the detection accuracy by utilizing feature pyramid networks and an enhanced loss function. Zhao et al. [
20] developed a limited slip network (LSNet) for detecting minor defects in transmission line infrastructure. Li et al. [
21] proposed a lightweight power equipment detection network (PEDNet) based on YOLOv4-tiny, addressing challenges such as complex infrared backgrounds, low contrast in infrared images, and object rotation, resulting in improvements in both detection speed and accuracy.
In summary, while significant progress has been made in deep learning models for detecting power equipment faults, most research has focused on devices such as insulators and transmission lines, with relatively less attention given to the status recognition of isolation switches. Therefore, this paper proposes algorithmic optimizations specifically for the characteristics of isolation switches. The proposed approach achieves an effective balance between accuracy and model efficiency in isolation switch status detection, enhancing the practicality of the model for real-world applications.
2.2. Attention Mechanism
Attention mechanisms enable neural networks to focus exclusively on crucial features of an image, while disregarding less significant features. This capability has demonstrated substantial potential in enhancing the performance of deep convolutional neural networks. Consequently, attention mechanisms have been widely adopted across various object detection algorithms within the field of computer vision [
22].
Huang et al. [
23] proposed the cross-cross attention model, which introduced a cross-crossover attention mechanism to more efficiently capture global image dependencies, ultimately demonstrating advanced model performance across multiple benchmark datasets. Hu et al. [
24] introduced an effective channel attention mechanism known as squeeze-and-excitation (SE) attention, which enhances model detection accuracy by leveraging 2D global pooling and fully connected structures. Wang et al. [
25] designed an efficient channel attention (ECA) mechanism to better capture global information and reduce computational complexity. This mechanism improves the channel relationships in feature maps, thereby enhancing the performance of deep learning models. Woo et al. [
26] proposed a convolutional block attention module (CBAM), which integrates channel attention and spatial attention modules. By using average pooling and maximum pooling to aggregate features, the CBAM effectively enhances the feature representation capabilities of convolutional neural networks.
The introduction of attention mechanisms has been proven to significantly enhance both the accuracy and efficiency of detection tasks. This mechanism enables detection models to focus more precisely on critical regions within an image. In the context of detecting the open and closed states of isolation switches, incorporating attention mechanisms can strengthen a model’s ability to capture switch features and improve the detection performance. By leveraging attention mechanisms, a model can better interpret and analyze visual data, thereby achieving efficient and accurate detection of isolation switch states.
2.3. Lightweight Object Detection Algorithm
Lightweight object detection algorithms enhance model efficiency by reducing complexity, optimizing computational processes, and compressing parameters, while maintaining accuracy. To improve the detection efficiency for power equipment, the application of real-time lightweight algorithms in power systems is essential. Furthermore, efficiently running complex deep learning models on resource-constrained embedded systems and mobile devices has become a key focus of research.
Han et al. [
27] designed GhostNet, which enhances the model performance by extracting feature maps with reduced computational resources. Howard A G et al. [
28] developed MobileNets, which employs depthwise separable convolution to create lightweight models. MobileNetV2 [
29] introduces an inverted residual structure, while MobileNetV3 [
30] leverages AutoML techniques to improve the model performance, while reducing computational complexity. Zhang [
31] proposed ShuffleNet, which optimizes the information flow between different channel groups using channel shuffle operations. ShuffleNetV2 [
32] further refined the model design for improved compatibility with object hardware. Tan et al. [
33] developed EfficientNet through a neural architecture search, optimizing the width and depth ratios of the network to enhance efficiency. Ding et al. [
34] introduced RepVGG, which unifies different convolutional layer structures (such as standard and depthwise separable convolutions) during training, thereby achieving a higher inference efficiency by simplifying the network structure during inference.
In recent years, with the introduction of the ViT [
35] model, it has been demonstrated that transformers also hold great potential in the field of computer vision. Some researchers have focused on how to make ViT models more lightweight. LeViT [
36] proposed a multi-stage transformer architecture that uses an attention mechanism for downsampling, significantly improving the computational efficiency. MobileViT [
37], by introducing local convolution operations and a simplified transformer structure, retains the ViT’s advantage in capturing global information, while maintaining the efficiency of a lightweight network. EdgeViTs [
38] developed the transformer block and introduced a cost-effective bottleneck, achieving a better accuracy–latency balance. Additionally, DETRs [
39] have garnered widespread attention in academia for eliminating various handcrafted components. Recently, lightweight object detection models based on DETRs have also emerged. Lite-DETR [
40], specifically designed for efficiency, introduces an efficient encoder block, enhancing the model efficiency through optimizations to the architecture and computational requirements. RT-DETR [
41], developed by Baidu, leverages ViT to efficiently process multi-scale features, achieving real-time performance, while maintaining a high accuracy.
These models have achieved impressive performance with minimal FLOPs, ensuring high-performance object detection even under resource-constrained conditions, which is essential for practical applications in power equipment monitoring. To improve the real-time inference capability of the model, this study employs more lightweight convolutional modules to replace the standard convolutions, thereby maintaining a low parameter count and computational complexity, while still delivering effective detection results.
4. Results
4.1. Experimental Setting
The hardware environment for the experiments in this study included the Windows 10 operating system, a 2.10GHz Intel Xeon Silver 4110 CPU, and an NVIDIA GeForce RTX 2080 Ti GPU. The programming environment was based on Python 3.8.15, utilizing CUDA 11.3.1 and cuDNN 8.2.1 for deep learning acceleration, with PyTorch 1.13.0 serving as the deep learning framework. The neural network model was optimized using stochastic gradient descent (SGD) with a learning rate set to 0.01. The input image size was 640 × 640 pixels, and each batch contained 64 samples. To ensure thorough training, the model underwent 300 epochs of iterative training.
4.2. Experimental Data
Since there is currently no publicly available dataset for detecting the open and closed states of isolator switches, we needed to construct a dataset for algorithm training and evaluation. During the dataset construction process, we carried out a significant amount of work, including image collection, image augmentation, and annotation. In this paper, we obtained a set of isolator switch open and closed state images from actual substation operation and maintenance environments. The collected images were cleaned and annotated to create a dataset suitable for this study. The specific implementation was as follows:
Firstly, we collected a large number of high-voltage isolator switch images from real substations, totaling 1654 images. The images were captured using high-resolution cameras installed within the substations, with resolutions of 704 × 576 and 1280 × 720. Typically, the images were taken from a low-angle view. These images feature various types of isolator switches and cover a range of angles and distances, both near and far, as well as different sizes. The dataset includes images under various lighting conditions, weather environments, and times of day, including morning, noon, and evening. The weather conditions represented include cloudy, foggy, and sunny days, as shown in
Figure 6.
Secondly, we performed data cleaning and augmentation on the collected data, as some images were blurry, incomplete, or duplicated. Before annotation, we cleaned the dataset by removing invalid or unclear images. To enhance the robustness and generalization of the training algorithm and improve its performance under noise, environmental changes, and other anomalies, we applied data augmentation techniques during training. These techniques included the following: Scaling and flipping: By scaling and flipping the images, we generated new training samples. Lighting adjustments: We modified the hue and saturation of the images to simulate various lighting conditions, helping the model adapt to real-world changes in lighting. Blur effects: We added blurred images to improve the model’s robustness in noisy environments. Mosaic augmentation: We combined four training images into one, simulating different scene compositions and object interactions, thereby enhancing the model’s ability to recognize complex scenarios.
Finally, we used the LabelImg 1.8.6 software to annotate six objects in the power equipment dataset. These annotations covered three common types of isolator switches: single-arm horizontal telescopic isolator switches, single-arm vertical telescopic isolator switches, and double-arm vertical telescopic isolator switches. Each type of switch image was further divided into two states: open and closed. We annotated the images using rectangular bounding boxes, manually marking the position of the isolator switches and assigning corresponding labels based on their open or closed state. After augmenting the dataset, we obtained a total of 4962 images, with 3473 images selected as the training set, 992 as the validation set, and 497 as the test set.
Figure 6 shows a sample from the dataset. Specifically, the dataset was designed to detect the open and closed states of isolator switches.
4.3. Evaluation Indicators
4.3.1. Evaluation Metrics for Accuracy
The accuracy metrics used in this paper included precision, recall, and mean average precision (mAP). Precision refers to the ratio of correctly detected objects (true positives, TP) to the total number of detected objects, i.e., the ratio of TP to the sum of true positives (TP) and false positives (FP). The formula for calculating precision is provided in Equation (
9).
Recall refers to the ratio of correctly detected objects (true positives, TP) to the total number of actual objects, i.e., the ratio of TP to the sum of true positives (TP) and false negatives (FN). The formula for calculating recall is provided in Equation (
10).
Mean average precision (mAP) is a comprehensive metric commonly used in multi-class object detection tasks. To calculate mAP, the average precision (AP) for each object category must first be determined. Then, the mAP is obtained by averaging the AP values across all categories. The specific formula for calculating AP is provided in Equation (
11).
In this context,
represents the recall value corresponding to the first interpolated point on the precision–recall curve in ascending order, and
n denotes the number of recall values considered. After calculating the AP values for each object category, the mean average precision (mAP) is obtained by summing these AP values and taking the average. The formula for calculating mAP is shown in Equation (
12).
In this study, mAP@0.5 and mAP@.5:0.95 were used as accuracy evaluation metrics. Here, mAP@0.5 is the mAP value calculated at an intersection over union (IoU) threshold of 0.5, while mAP@.5:0.95 is a more comprehensive evaluation metric. It calculates mAP at 11 different IoU thresholds, ranging from 0.5 to 0.95, in increments of 0.05, and averages these mAP values to provide an overall assessment.
4.3.2. Evaluation Metrics for Lightweightness
In the design of lightweight object detection algorithms, it is essential, not only to evaluate the model’s performance, but also to pay special attention to its complexity. Therefore, this study introduced two commonly used evaluation metrics: floating point operations (FLOPs) and the total number of parameters (parameters) in the convolutional layers. These metrics were used to quantify the model’s computational load and parameter count, respectively. The formula for calculating FLOPs is provided in Equation (
13).
If the detection model includes
L convolutional layers, the total number of parameters (parameters) can be calculated using Equation (
14).
In addition, this paper introduced FPS (frames per second) as a metric to measure the actual performance of the model on embedded devices. It represents the number of images a model can detect per second, with the calculation formula shown in Equation (
15).
4.4. Comparison Experiment
To validate the performance of the proposed EMB-YOLO model in the task of isolation switch detection, we conducted a series of comparative experiments with various object detection models. Specifically, EMB-YOLO was compared with transformer-based object detection algorithms, such as RT-DETR [
41]. Additionally, it was evaluated against single-stage object detection algorithms including YOLOv5, YOLO8, YOLOX-tiny [
46], and YOLOv10 [
47]. Furthermore, we performed comparative experiments using the two-stage object detection algorithm faster-RCNN [
9]. The results of these comparative experiments on our custom isolation switch status dataset were as follows:
As shown in the
Table 1 and
Table 2, the proposed EMB-YOLO model outperformed the baseline model YOLOv8n of similar scale, with mAP@0.5 and mAP@.5:0.95 improving by 3.6% and 2.2%, respectively, while also reducing the computational complexity and parameter count. Compared to several well-known algorithms, such as RT-DETR-L (80.8), YOLOv5n (82.1), Faster-RCNN (84.2), and YOLOv10 (72.3), our EMB-YOLO achieved a significant improvement in mAP@0.5, increasing by 6.4%, 5.1%, 3%, and 14.9%, respectively. Additionally, EMB-YOLO demonstrated reductions in both parameter count and computational cost when compared with RT-DETR-L, YOLOv5s, YOLOv8, YOLOX-tiny, and faster-RCNN. Our EMB-YOLO achieved the highest F1 score, indicating that it strikes a good balance between precision and recall, resulting in a more stable performance. In terms of real-time capabilities, it was comparable to YOLOv5s and YOLOv8s, meeting the requirements for real-time detection. This performance advantage can be attributed to the use of the EMBC module in EMB-YOLO, which enhances positional information in both horizontal and vertical directions, captures long-range dependencies more effectively, and strengthens the model’s ability to detect isolation switch features, while reducing the number of parameters and computational complexity. This highlights the model’s outstanding lightweight performance.
To validate the effectiveness of the ELA attention module used in the EMB-YOLO detection model, we conducted experiments by replacing the ELA attention mechanism within the C2f module. Various comparative experiments were performed to demonstrate the superiority of the ELA attention module in EMB-YOLO. The results, as shown in
Table 3, indicated that the model incorporating the ELA attention module in the C2f module achieved a better performance for both mAP@0.5 and mAP@0.5:0.95 on the self-constructed isolation switch dataset. Specifically, compared to the CA attention, SE attention, CBAM attention, and EMA attention modules, the mAP@0.5 improved by 0.3%, 5.2%, 3.7%, and 0.4%, respectively. Additionally, in terms of model complexity, the computational load decreased compared to the EMA and CA attention modules, and the FPS reached 38.4, outperforming the CA attention, SE attention, and EMA attention modules.
We further visualized the training weights of the detection models by implementing five different attention modules (CA, SE, ECA, CBAM, ELA) on the custom isolation switch state detection dataset. The visualization results are presented in
Figure 7. It can be observed that, compared to other attention mechanisms, the ELA attention mechanism employed in this study allowed the model to focus more intensively on the elongated features of the isolation switch. This better concentrated and sensitive focus significantly aided the detection model in accurately identifying and localizing the isolation switch, thereby enhancing the model’s precision in detecting isolation switch objects.
4.5. Ablation Experiments
To validate the effect of the proposed optimization techniques on model performance, ablation experiments were conducted on the self-constructed dataset. As shown in
Table 4, ablation studies were performed on the EMB-YOLO series models by replacing the backbone and neck networks of YOLOv8n with those of EMB-YOLO, and experiments were conducted on the self-built isolation switch dataset. The results demonstrated improvements in mAP@0.5 and mAP@0.5:0.95 compared to the baseline model after introducing these techniques. Replacing the standard backbone network with the EMB-backbone improved the accuracy, especially in multi-scale object detection (mAP@0.5:0.95), increasing from 49.3% to 51.8%. This indicates that the EMB-backbone is more effective at feature extraction, reducing the computational overhead, while enhancing accuracy. When only the neck network was introduced, mAP@0.5 improved by 1.6%. By introducing both the backbone and neck networks, mAP@0.5 and mAP@0.5:0.95 increased by 3.6% and 2.2%, respectively. This shows that the combination of the EMB-backbone and EMB-neck more effectively extracts multi-scale features, while reducing the computational complexity.
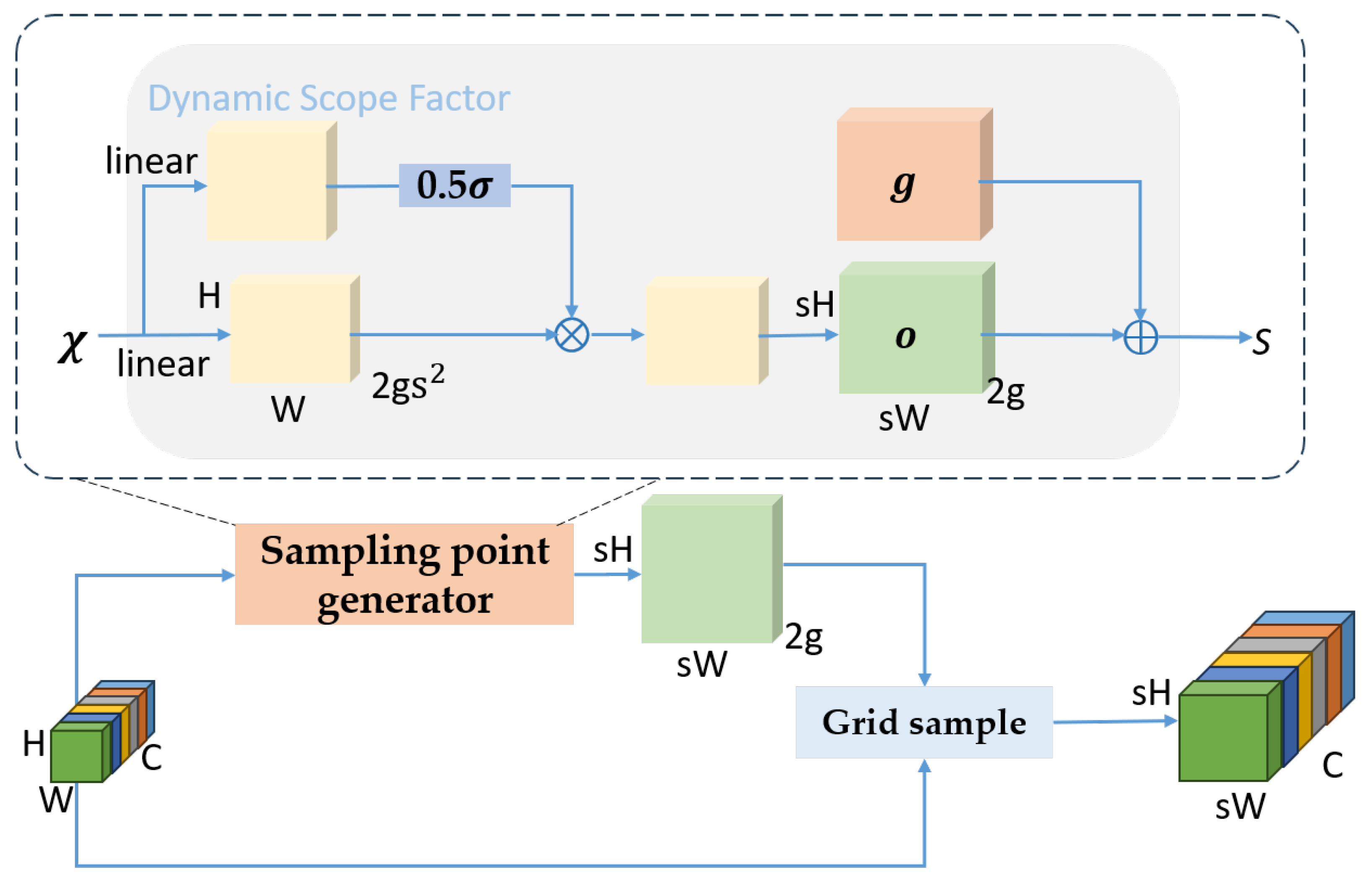
To evaluate the impact of different modules in the fusion network, the experiment progressively added key components from the neck network into the EMB-YOLO model, such as the efficient-RepGFPN fusion block, lightweight convolution GSConv, weighted feature fusion (Weighted Concat), DySample upsampling module, and more. The effect of each component on the performance of the fusion network was analyzed. After adding each module, the model was retrained and its performance on the validation set was recorded. The experimental results are shown in
Table 5.
The results indicate that with the unmodified fusion network, the mAP@0.5 and mAP@0.5:0.95 were only 81.5% and 48.9%, respectively. The inclusion of GSConv significantly improved the performance of the fusion network, especially for complex environments and multi-scale object detection, where mAP@0.5 and mAP@0.5:0.95 increased by 5.4% and 4.9%, respectively, while reducing the computational load and model size. After adding DySample, both mAP@0.5 and mAP@0.5:0.95 saw notable improvements, indicating that DySample improved the sampling accuracy and enhanced the model’s performance in multi-scale scenarios. Although the computational load slightly increased, the performance gains were substantial. The introduction of the weighted feature fusion (Weighted Concat) provided a limited mAP improvement. Our analysis suggests that the fast normalized fusion method used in this experiment trained relatively slowly, and its advantages in weight computation were not fully leveraged in this application. However, when combined with other techniques, it performed better overall.
6. Conclusions
In the recognizing the open and closed states of isolation switches, traditional visual detection methods often struggle with a low accuracy, poor adaptability, and insufficient robustness in complex environments. To address these challenges, we proposed a novel algorithm, EMB-YOLO, specifically designed for isolation switch state recognition. Given the characteristics of the isolation switch dataset, we designed an efficient mobile inverted bottleneck convolution module to extract features in complex environments, while reducing the computational costs. This module was specifically designed for isolator switch detection in complex environments. Its novelty lies in combining depthwise separable convolution with pointwise convolution and integrating the efficient local attention (ELA) mechanism. This enhances the model’s ability to extract key switch features along the vertical and horizontal axes, which is crucial for power equipment monitoring. The efficient-RepGDFPN fusion network was also utilized to integrate multi-scale features, effectively addressing the scale diversity problem in isolation switch images.
Our model can also be deployed on inspection robots or edge cameras, making it more convenient than traditional visual inspections. For power inspections, this reduces inspection time and labor costs. Especially in large-scale power equipment inspections, it enables automated processing, allowing inspection personnel to monitor the status of isolator switches at any time from a central control center. This reduces the workload and time required for manual inspections.
The EMB-YOLO algorithm mainly relies on the shape features of isolator switches and is relatively insensitive to the influence of texture and color. Therefore, it can even maintain good performance under poor lighting conditions. However, the model still encounters challenges in certain situations. Firstly, when the isolator switch is partially obscured by wires, structural components, or nearby equipment, the detection performance decreases significantly, especially when more than 70% of the switch is obscured. In such cases, the model may fail to detect the switch or misidentify its state. This is because the model relies on distinct vertical and horizontal features of the isolator switch, and severe occlusion greatly affects the detection accuracy. To address this issue, the training dataset could be expanded with more images containing occlusions, and more powerful attention mechanisms or context learning techniques could be introduced to enhance the model’s focus on local features, thereby reducing the detection errors in occluded situations.
Secondly, the issue of viewing angles is also a challenge. When the isolator switch is observed from a side angle, the model’s reliance on horizontal and vertical shape features can lead to changes in the switch’s appearance, thereby affecting the detection accuracy. To improve the model’s performance under different viewing angles, diverse angle data samples could be added, and multi-view learning methods could be incorporated to enhance the model’s detection ability across various perspectives.
Additionally, small object detection is also a challenge, especially when the isolator switch occupies a very small portion of the image or is captured at a long distance. In such cases, the model often struggles to capture key features, leading to detection failure. This is because small objects have fewer pixels, providing insufficient information for the model. To address this, the efficient-RepGDFPN fusion network could be optimized to enhance the detection capability for small objects, or the image resolution during training could be increased. Additionally, using super-resolution techniques could help to improve the detection accuracy for small objects.
Finally, in images with complex backgrounds, such as those containing many wires, transformers, or other electrical equipment, the model occasionally experiences missed detections or false positives. This is because substations contain many elongated or tubular objects similar in shape to isolator switches, which can cause confusion. To address this, the ELA attention mechanism could be further strengthened or combined with other deep learning techniques to help the model better distinguish isolator switches from other similar objects in complex backgrounds, thereby reducing the occurrence of false positives.
Additionally, we plan to adopt pruning and quantization methods in our future work, which will help reduce the model’s computational requirements and improve its detection speed. We will also develop and adjust loss functions to adapt to different types of switchgear. This approach will enhance the model’s generalization, making it more reliable in diverse power inspection environments, allowing for more accurate and faster real-time monitoring.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}