1. Introduction
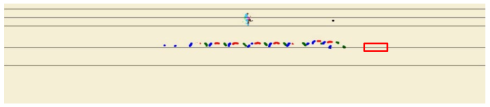
Rail tracks are one of the most critical infrastructure systems in the world. Repeated loads, the environment, and the quality of construction and material may introduce damage to rails, which could pose risks to their safe operation. One of the most concerning distresses is the internal defect of a rail (shown in
Figure 1), which is challenging to be identified through visual inspection. Various methods for detecting these internal defects have been developed in the past, and significant progress has been made in defect identification algorithms and systems.
Inspection methods have developed from early traditional manual inspection to automatic inspection. At present, rail non-destructive automatic inspection systems, such as ultrasonic, magnetic flux leakage, eddy current, and non-destructive inspection using video camera, are widely used.
With the advancement of camera systems and the maturity of computer vision and image processing algorithms, the traditional manual inspection method, which has low-efficiency and is costly and subjective, has been gradually replaced. Automated image-collection vehicles with high-speed digital cameras, as the substitution, are installed on track checking trains to detect railway defects efficiently. Li et al. [
1] proposed a real-time visual inspection system (VIS) to detect discrete rail surface defects, which can be detected in real time on a 216 km/h test train. Lee et al. [
2] and Gong et al. [
3] developed a system to acquire railway tunnel images using line scan cameras, which helped them realize the rapid detection of cracks in tunnel linings. Other studies [
4,
5,
6,
7], through extracting visual features based on the local spatial morphology of defects and through the use of texture analysis and intensity histogram analysis, detected rail surface defects automatically. However, the optical imagery caught by video camera may be prone to the illegibility of local information and a changing background due to shadow and light, and the images can only reflect the surface state of the rail, but not the internal state. As a result, other NDT (non-destructive testing) methods are also applied in this task, such as ultrasonic, eddy current, and magnetic flux leakage, and subsequently, intensive research has been directed to the field of defect assessment [
8,
9]. Sperry et al. [
10] developed a non-destructive testing system for rail inspection; its inspection method involved magnetic induction, which could identify defects in the rail according to perturbations in the field. However, this technique is often considered cumbersome and sensitive, as electromagnetic noise and the presence of special parts might result in false detections. Eddy current testing [
11] identifies defects using a magnetic field generated by eddy currents, and it has the common disadvantages of magnetic induction. The magnetic flux leakage (MFL) method is carried out through magnetic flux leaks from the rail wall in the location of a defect, which can be used for the evaluation of the rail’s health condition. However, one shortcoming of MFL is the necessity of a rather intense magnetizing field. For the longitudinal magnetization of the rail, the magnetizing field is not virtually changed along the guide. Therefore, the method is typically used in car flaw detectors [
12]. Compared with this, the ultrasonic method occupies a dominant position for rails in the field of rail inspection benefits from its excellent directivity, transmission, and reflection and refraction characteristics. Ultrasonic testing is reliable for detecting many deep surface-breaking cracks and internal defects in rails.
Based on ultrasonic testing, the existing methods are mainly used to detect rail defects through B-scan images acquired by an ultrasonic defect detector. The B-scan images could intuitively reflect the locations of the defects, which is beneficial for an operator to identify and locate them. Also, compared with optical imagery, ultrasonic B-scan images are not likely to be affected by light or shadows, and the resolution is fixed depending on the minimum scanning distance of the rail inspection vehicle, which avoids objects of the same category with different features due to different resolutions. Based on the characteristics of ultrasonic data, an SVM-based classification algorithm [
13,
14] was introduced to achieve the real-time detection and classification of rail defects. Li et al. [
15] used an array probe to send a linear equivalent modulation ultrasonic wave to a rail to detect internal defects, used the wavelet threshold to denoise the acquired signals, extracted features in the time domain and frequency domain, and used a support vector machine (SVM) to detect ultrasonic defects. Huang et al. [
16] provided a BP neural network-based ultrasonic defect pattern classification technique to identify four common types of defects, and the effectiveness of the algorithm was verified with the example of bolt hole cracks. These machine vision-based ultrasonic processing methods saved labor and achieved good results. However, they relied on a large amount of prior knowledge and engineering experience to design the features learned. Due to the complexity and diversity of rail defects in shapes and orientations, and poor distinction between various defects, it is difficult to manually design accurate and robust feature descriptors for all rail defects, leading to stagnation in detection accuracy. Furthermore, the B-scan image is susceptible to clutter interference generated by the operating instrument, bringing greater impediments to the accuracy and efficiency of detection in machine learning.
In recent years, deep convolutional neural networks (CNNs) have been introduced to automatically extract features with good abstraction, accuracy, and robustness, and are widely used for image classification and recognition. Hu et al. [
17] proposed an automatic classification method based on the ResNet-50 deep residual network for internal rail defects, which successfully classified four categories of defects in B-scan images. However, the category probability values as output were not intuitive. The method was unable to locate the defects from images and could not classify when multiple categories of defects appeared in one image. Benaissa et al. [
18] successfully calculated the severity and crack depth of cracked beams by using vibration sensors based on the Teaching-Learning-Based Optimization Algorithm. Luo et al. [
19] improved a new intelligent defect recognition system integrating deep learning and support vector machine, using a combination of deep separable convolution and selective search for target localization and support vector machine method for image classification, with the detection rate and accuracy of the ultrasonic B-scan image of defects higher than 95%. However, they used a combination of models that would increase the cost of (training and inference) time and cannot achieve end-to-end detection.
In pursuit of automating the localization and categorization of internal flaws in B-scan imagery, typically an object detection task, two primary framework types have emerged. The first is a dual-stage object detection approach, encompassing a region proposal network followed by a refined network. The alternative approach integrates object position regression with classification into a singular stage [
20]. Among the two-stage methods, Faster R-CNN has demonstrated commendable accuracy, albeit with room for improvement in inference speed. Among them, the YOLO network is summarized as extremely fast, highly robust for near distance targets or small targets, and easy to be deployed on the mobile side [
21]. Yuan et al. [
22] introduced a YOLOv2-based recognition method combined with the Otsu algorithm, effectively identifying loose screws in the connection plates of low and medium speed maglev contact rails. Similarly, Wang et al. [
20] conducted a comparative analysis of various one-stage deep learning methods for inspecting crucial railway track components such as rails, bolts, and clips, noting the YOLO models’ superior speed at equivalent accuracy levels. Sikora P et al. [
23] employed YOLO for the detection and classification of rail barriers at level crossings, including railway warnings and light signaling systems, achieving a mean average precision of 96.29%. Feng et al. [
24] proposed a detection network incorporating a MobileNet backbone and novel detection layers, attaining high-accuracy detection and localization of rail surface defects. However, the application of object detection networks in internal defect detection of rails remains scarce, primarily focusing on optical images with limited usage in B-scan data processing [
25,
26,
27]. The latest research [
28] describes the application of the YOLO series in wound detection, which provides a good idea for our research.
In summary, the following problems remain unsolved on the internal defect detection of the rail. (1) For the existing NDT methods, the optical imagery taken by video cameras cannot reflect the status of rail internal defects, and other NDT (such as Eddy Current and MFL) methods are sensitive and complex, which are unreliable in internal defect detection. (2) For the existing ultrasonic B-scan image processing algorithms, traditional machine vision-based algorithms (such as SVM) rely heavily on prior knowledge and engineering experience to design features, which is prone to accuracy stagnation; deep learning CNN-based methods, one is the classification algorithm cannot locate the defects, the second is the combinatorial algorithm would increase the inference time. (3) For object detection algorithm, most primarily used for processing optical images and very few was used for B-scan data. The latest research used it on B-scan images but has unclear classification criteria and no noise processing. To address the above issues, this paper based on YOLOv8, proposes to automatically classify and localize internal rail defects based on object detection models using B-scan images obtained by ultrasonic detector. The rest of this paper is organized as follows:
Section 2 introduces the preparation and processing of datasets. Firstly, it comes up with a defect image classification principle according to the features of the B-scan image channel’s color, morphology and relative location. Then, these images are pre-processed by denoising and data enhancement to establish an image dataset containing four categories of defects (head, bolt hole, web, base).
Section 3 simply indicates the features of YOLO series, SSD and Faster R-CNN detectors, and then sets the YOLOv8 as an example to introduce the structural composition and improvement methods (small tricks) in the model.
Section 4 transfer-learns four object detection networks and tests them on the test set, optimizes the parameter and validates generalization capability by adjusting hyperparameters and network details.
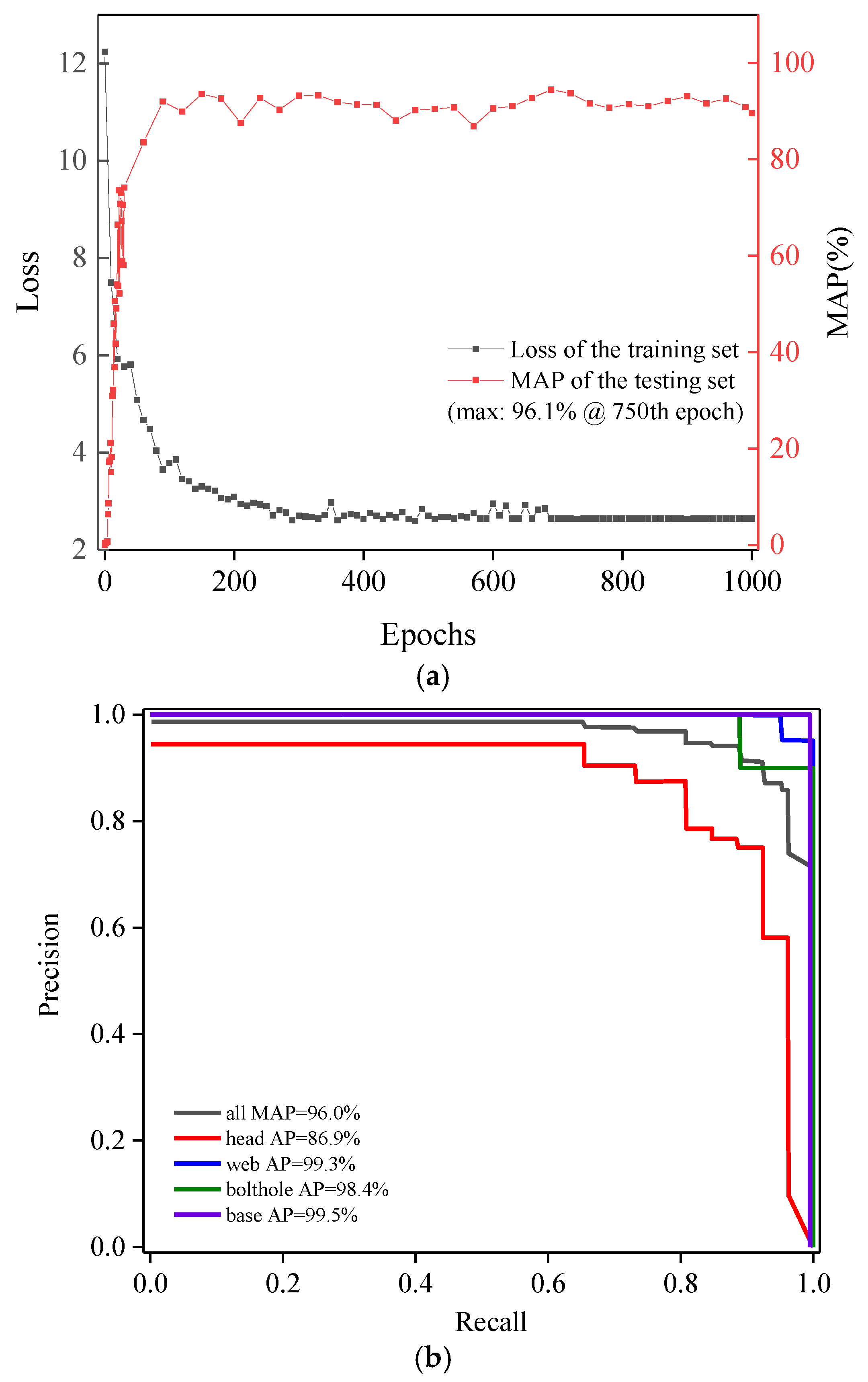
Section 5 investigates the suitability of the YOLOv8 method in the test set, and further compares it with Faster R-CNN, DETR (Detection Transformer), and YOLOv5 in terms of the mean average precision (mAP), IOU, the
F1 score, and inference time and discusses the results in different conditions, followed by the concluding remarks in
Section 6.
2. Data Preparation
The preparation and processing of the B-scan image dataset consists of three steps. Firstly, the data is acquired by the GCT-8C rail defect detector and further comes up with a defect image classification (labeling) principle according to the features of the B-scan image channel’s color, morphology and relative location. Then, these images are pre-processed to establish an image dataset containing four categories of defects (head, bolt hole, web, base).
2.1. Data Collection
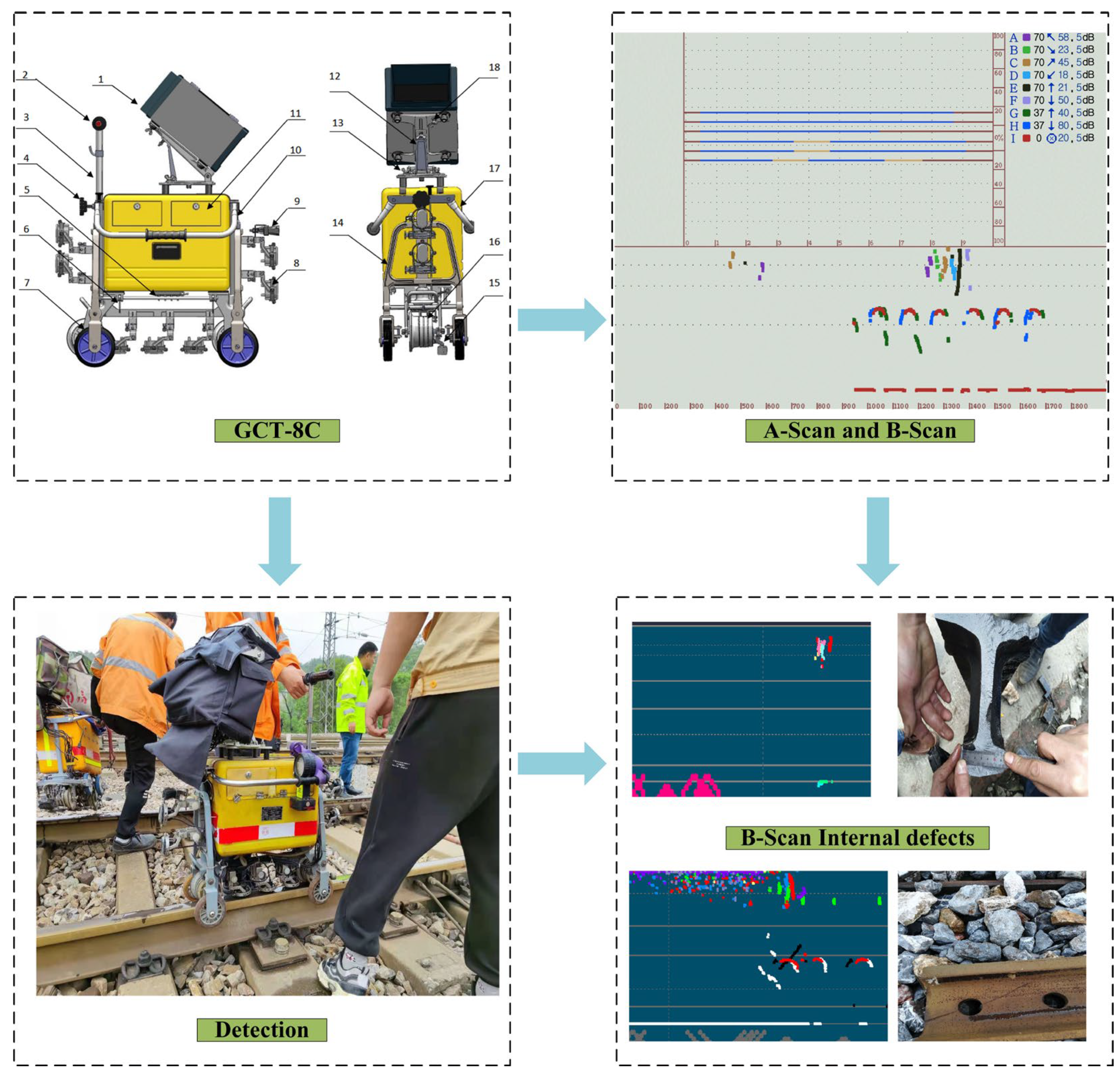
The internal defects dataset in this research comes from the inspection records of railway lines in Nanchang, China.
Figure 2 demonstrates how the rail defect detector was used to collect images of internal defects and the correspondence between B-scan images and actual defects.
For data processing, one of the most important conditions is acquisition devices and their parameters that determine the resulting quality. GCT-8C rail defect detector, a kind of small hand-pushed digital rail ultrasonic defect detector that has a total of nine detection channels: one 0° channel, two 37° channels, and six 70° channels ensuring sufficient view angle, used for detection. Each of the channels corresponds to a specific color (customized) and detection area, forming an image with complex colors but a regular layout. The main technical parameters of the instrument are shown in
Table 1, and the setting of color and detection area of different channels are shown in
Table 2. These channels run with a rate of 60 Hs per second along rail and display in 2 forms: ultrasonic A-scan image and B-scan image. In them, ultrasonic A-scan image is mainly used for on-site equipment status adjustment and monitoring due to the large data amount. In contrast, the ultrasonic B-scan image, which has a small amount of data, stores and further analyzes railway conditions. Furthermore, B-scan images could intuitively reflect the location of the defects, which is beneficial for the operator to identify and locate them. Also, compared with traditional images, ultrasonic B-scan images are not likely to be affected by light or shadows, and the resolution is fixed, depending on the minimum scanning distance of the rail inspection vehicle, which avoids objects of the same category with different features due to different resolutions. In this study, the collected continuous long B-scan images were cut and extracted to establish a dataset containing 200 samples, and each sample has a pixel size of 1325 pixels × 346 pixels.
However, the established B-scan image dataset has some drawbacks: the data is extremely sparse, lacks features, and is always noisy. Due to the characteristics of B-scan data, the corresponding image processing methods are also specific, and to address these drawbacks, pre-processing methods are introduced in the next steps.
2.2. Internal Defects Classification from Collected B-Scan Images
The ultrasonic B-scan image is a kind of continuous 2D image data that can display the cross-sectional image of the detected object. In B-scan images, the horizontal coordinates represent the probe movement distance, and the vertical coordinates represent the acoustic wave propagation time or distance. This intuitively reflects the detailed distribution in the probe detection range and the depth of the detected object from the detection surface.
Based on the ultrasonic special transmission, reflection, and refraction characteristics of ultrasonic, when encountering a discontinuous medium, the wave will reflect and represent different colors and morphological characteristics. These discontinuous structures that can reflect the ultrasonic wave and can be received by the echo sensor are called ultrasonic reflector. The ultrasonic reflector includes both normal rail structures, such as screw holes, conductor holes, and rail joints, and rail defects, such as fishbolt hole cracks, crescent-shaped fatigue cracks, and rail base transverse cracks. According to the wave distribution regular, rail defects were first picked out from the ultrasonic reflectors. Then, the selected rail defects are further subdivided. The ultrasonic defects were manually labeled to fully learn these ultrasonic B-scan rail defect image features in the following training stage. Due to the lack of features in the B-scan images dataset and because the morphology of different categories of defects B-scan images are similar, this paper proposes a three-step classification method: the first step is a coarse classification method based on the colors and morphological characteristics of the channels, the second step is a fine classification method based on geometrics moments, and the third step is to frame in auxiliary line information during the labeling process to add location features. The specific classification method based on B-scan image features is divided into three parts, which are as follows:
2.2.1. Distinction of Defects Based on Colors and Morphological Characteristics
The three boundary lines in the B-scan images divide the rail cross-section into three parts: rail head, rail web, and rail base, as shown in
Figure 3a. The corresponding area in the ultrasonic B-scan image is shown in
Figure 3b. When the reflectors appear in different parts, the channel displays different colors and morphological characteristics, which represent the category and extent of the defects: When reflectors are located in the rail head or rail fillet areas, channels of reflectors are shown as monochrome or multi-color. In this area, the reflectors are likely to belong to two situations: a weld joint which is a normal structure, and the other is rail head nuclear injury, which is a defect. The key to distinguishing these two situations is the channel color of the straight 70° probe; when the color appears, the reflector is nuclear injury; when reflectors are located in the rail web areas, channels show a monochrome or combination of red, green and blue. In this area, the reflectors will likely be normal bolt holes or the cracks around the hole. If there are cracks, the channels of the upper cracks and lower cracks of the hole are regularly shown as green and blue, respectively, and the horizontal crack is shown as red. When reflectors in the rail base area, channels show a monochrome or combination of red, green, and blue. If there are rail base transverse cracks, the channels of the horizontal crack of the rail base are blue and green, and the longitudinal crack are red. Through this way, the rail internal defects have been coarsely classified. The classification of rail defects and the representatives of B-scan images of each category are shown in
Table 3.
However, when reflectors are located in the rail web areas, the complex reflection might lead to a confusing distribution of channels, which cannot be easily distinguished by the above method.
2.2.2. Distinction of Defects Based on Geometric Moments
Holes including bolt holes, wire guide holes and structure holes, are normal ultrasonic reflectors. Its B-scan imaging is difficult to distinguish from that of holes surrounding cracks. It is shown in
Figure 4. Wu et al. [
29] analyzed and extracted features of every rail defect, including color features, distribution features, and contour features, and built the numerical constraint relationship of the different defect categories, which solved this problem. Based on color and distribution features, the B-scan image of a bolt hole is displayed by intersecting green-red-blue channels, and the channels of bolt hole cracks are located on both sides of that bolt hole. Generally, the channels represent the upper cracks of a bolt hole are typically positioned on either side of the bolt hole’s channel, with the green channel commonly situated to the right and the blue channel to the left of the bolt hole channel. When cracks adjacent to the bolt hole are absent, the channels of identical hues associated with the bolt holes exhibit a pattern of equidistant arrangement along the horizontal axis. Conversely, the presence of cracks in the vicinity of the bolt hole disrupts this equidistant channel distribution. Concerning the lower cracks of the bolt hole, they are categorized into two distinct formations, separated lower screw cracks and bonded lower screw cracks, which need numerical constraints. The contour moments are calculated by integrating over all pixel points on the contour boundary. For a
size of image, when its function is
, the calculation of
order geometric moment
is as follows:
Then, calculate the 0th-order moment and 1st-order moment of
, respectively. When the image is a binary image, the 0th-order moment gains the area of the image contour and the 1st-order moment gains the coordinates of the center of gravity of the image
). The specific calculation is as follows:
Based on contour features, the horizontal distance between the center of gravity of the upper crack channel and the center of gravity of the bolt hole channel is greater than its vertical distance, that is . And the rule for lower crack is the opposite, that is .
2.2.3. Label Division
The categories of rail defects are different, and the hazards and maintenance methods required are also different. Normally, the defects originate from the manufacturing process, cyclical loading, impact from rolling stock, rail wear, and plastic flow [
30]. Refer to the “Railway Defect Classification” (TB/T 1778-2010 [
31]). In this paper, the dataset is labeled into four categories of rail defects: crescent-shaped fatigue cracks (head), fishbolt hole cracks (bolt hole), rail web cracks (web) and rail base transverse cracks (base), and their counterparts, normal rail structure. Each image with a pixel size of 1325 pixels × 346 pixels usually contains one or more labels. According to the 9:1 principle of training set data and test set data, 20 images (containing 16 labels) are taken as the test set, and 180 images (containing 176 labels) are taken as the training set, as shown in
Table 4.
2.3. Data Pre-Processing
The dataset in this research has the problems of the data being sparse and the image scale of the four labels being uneven. Most of the rail defects are concentrated in the rail head area, with 96 and 79 images of crescent-shaped fatigue cracks and scaling, respectively. This paper uses data enhancement to expand the image set of the web and base area. The category of target defect in B-scan images is related to the position of the whole image, which limits the enhancement way. So, data enhancement mainly uses random mirror transformation (only left and right) and random miscut transformation to change each image while randomly maintaining the same pixel size. In this way, the sizes of the original image set of fishbolt hole cracks, rail web cracks, and rail base transverse crack expand three times, reaching a balance of all defect categories. It is conducive for the network to learn image feature information fully.
The last problem of the dataset is always noisy. Unlike the Gaussian white noise in ordinary images, the noise in ultrasonic B-scan images is influenced by complicated factors during the ultrasonic wave propagation process, including the state of the rail surface, water coupling, electronic noise, and impacts of detection parameters. A B-scan image is a two-dimensional image created by superimposing the pixel values on the corresponding position of the three-primary-color two-dimensional matrix. The pixel (echo) points of the same reflector are closely connected. This paper adopts the pixel subtraction method and eight-directional point finding denoising method, that is, starting from one-pixel point, using it as the starting point to find consecutive non-background color pixel points from each of the eight directions and add up these pixel points, and if the number of consecutive pixel points is less than or equal to 3, it will be regarded as a spurious wave, that is noise. This paper eliminates noise by setting the threshold of the echo points number as 3 to build a cleaner and clearer dataset.
Figure 5a shows the schematic diagram eight-point direction finding denoising method.
Figure 5b shows the comparison of B-scan images before and after denoising.
Finally, 20 images (containing 16 labels) were taken as the test set and 282 images (containing 336 labels) as the training set.
Table 5 shows the labels and quantity of the pre-processed B-scan image dataset.
3. Methodology
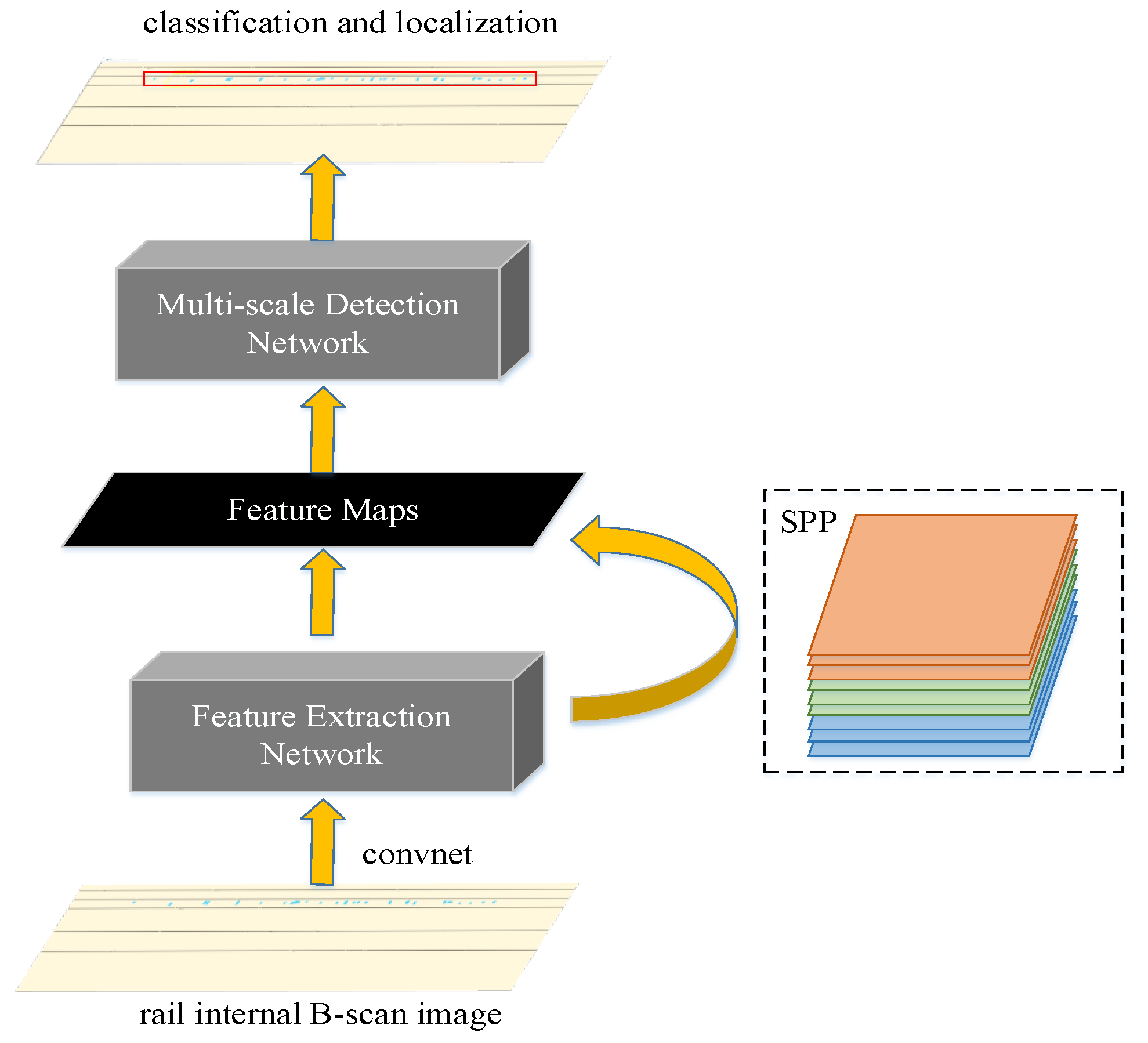
The objective of this study is to develop an automated methodology for the classification and precise localization of internal rail defects, leveraging advanced object detection algorithms applied to B-scan image datasets. The architecture of the object detection network is tripartite, encompassing the backbone, neck, and head components.
The backbone is a fundamental feature extractor, processing input images or videos to produce pertinent feature maps [
32]. The backbone selection is pivotal, emphasizing optimizing a balance among accuracy, computational speed, and operational efficiency. Sophisticated, highly interconnected backbones such as ResNet and DenseNet offer enhanced accuracy but at the expense of increased processing time. Conversely, streamlined architectures like MobileNet and EfficientNet are preferred for their efficiency and swifter processing capabilities, providing a pragmatic trade-off between speed and performance accuracy [
33]. The neck component of the network amalgamates diverse feature maps, with prominent examples including the Spatial Pyramid Pooling (SPP), Path Aggregation Network (PAN), and Feature Pyramid Network (FPN). The head component is responsible for the prediction phase, comprising two distinct types of detectors: the one-stage and the two-stage detectors. The two-stage detector incorporates a Regional Proposal Network (RPN) and a Region of Interest (RoI) pooling network. In this setup, the RPN layer forwards region proposals to a classifier and regressor for classification and bounding box regression. The one-stage detector, in contrast, eschews the region proposal phase, directly predicting bounding boxes from the input images and conflating location regression and classification into a singular, streamlined process. While two-stage networks such as Fast R-CNN and Faster R-CNN have achieved notable accuracy in localization and recognition, their application in real-time scenarios like pedestrian detection and video analysis is often limited by prolonged inference times [
34]. To address these limitations, one-stage networks like the YOLO series and SSD have been developed, characterized by their high inference speeds and aimed at establishing efficacious real-time object detection systems [
9].
3.1. YOLO Series Detectors
YOLO [
35] (you only look once), a seminal one-stage object detection model, was conceptualized by Redmon and colleagues. It stands out for its capability to directly ascertain bounding boxes, associated confidence levels, and class probabilities of objects within input images. Notably, YOLO generates a considerably reduced count of bounding boxes per image compared to Faster R-CNN, facilitating an end-to-end real-time detection process. An enhanced iteration, DETR [
36], has emerged as a prominent model, acclaimed for its exemplary balance of processing speed and detection accuracy, securing its position as one of the most prevalently utilized deep learning frameworks globally. The DETR algorithm represents another significant innovation in object detection, employing the Transformer architecture as opposed to the reliance on convolutional neural networks seen in models like YOLOv8. By utilizing self-attention mechanisms, DETR can process images holistically, achieving commendable results. However, a notable drawback of DETR, as evidenced in our computations, is its slower operational speed compared to CNN-based approaches such as YOLOv8. This aspect underscores the trade-off between the comprehensive contextual analysis afforded by the Transformer model and the expedited processing characteristic of CNN-based detectors.
The latest YOLO version, v8, has shown significant improvements in the accuracy and speed of deep learning for object detection, particularly in terms of accuracy and speed in defect detection [
37,
38]. YOLOv8, while maintaining a comparable parameter count, achieves higher throughput, signifying a substantial progression in deep learning applied to object detection. This development has propelled YOLOv8 to the forefront of this research, surpassing previous versions of YOLO.
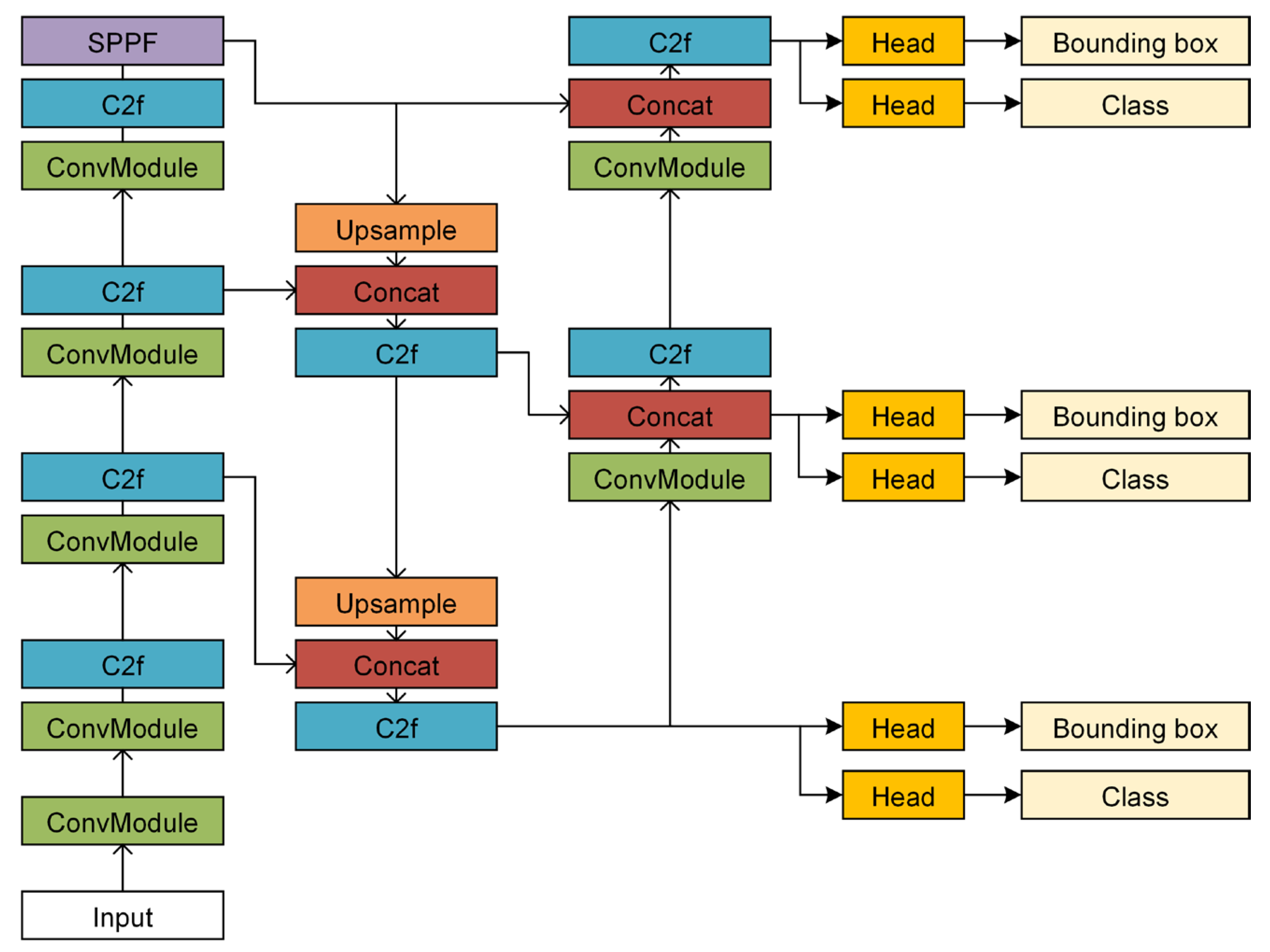
YOLOv8 inherits and enhances the core attributes of the YOLO series, including its capacity to directly predict bounding boxes, confidence levels, and class probabilities from input images. Compared to Faster R-CNN, YOLOv8 generates significantly fewer bounding boxes per image, facilitating an end-to-end real-time detection process. Moreover, YOLOv8 introduces innovations in structure and performance, employing a novel network architecture and advanced feature extraction methodologies. Notably, YOLOv8 adopts a new backbone network structure and an anchor-free detection head, leading to heightened detection precision, augmented multi-scale detection capabilities, and more efficient feature fusion. These improvements ensure the acquisition of rich semantic information while enhancing multi-scale detection ability and feature fusion effectiveness. YOLOv8 also incorporates new loss functions, including classification loss, bounding box regression loss, and IOU balance loss, optimizing model performance during training.
Recent advancements in YOLOv8 encompass training and network optimization techniques [
39], such as data augmentation, learning rate adjustments, and selecting activation functions, further enhancing the model’s performance across various scenarios. This is evident in the rail defect B-scan image inspection process depicted in
Figure 6 and
Figure 7 and the comprehensive architecture of YOLOv8.
3.2. Other Object Detectors
3.2.1. SSD
The Single Shot MultiBox Detector (SSD) [
40], represents an innovative one-stage detection framework capable of simultaneously identifying multiple categories. It uniquely determines categorical scores and offsets for bounding boxes across various scales. Predominantly, SSD utilizes the VGG-16 architecture [
41] as its backbone. Feature computation across individual image scales occurs independently within each feature map, from the highest to the lowest layers. During the training phase, anchor bounding boxes are aligned with corresponding ground truth boxes, classifying matches as positive instances and non-matches as negative. Empirical analyses demonstrate that SSD achieves robust performance metrics, particularly in the mean average precision (mAP) and processing speed.
3.2.2. Faster R-CNN
Faster R-CNN [
42] stands out as a particularly noteworthy model among the plethora of two-stage detectors. Typically employing ResNet50 [
43] or VGG16 as its backbone, Faster R-CNN processes the extracted feature maps in two stages. The region proposal network (RPN) generates candidate boxes across three scales and three aspect ratios. These anchors are then classified as positive or negative using a Softmax function, and their positions are refined through bounding box regression to yield precise proposals. In the subsequent stage, the RoIPool (Region of Interest Pooling) operation extracts input feature maps and proposals from each candidate box, facilitating the tasks of classification and bounding-box regression. The model then calculates the proximity between the predicted box and the corresponding ground truth, optimizing the predicted box’s location. Empirical results underscore that Faster R-CNN has significantly enhanced both accuracy and efficiency compared to its predecessors.
3.3. Object Detection Networks for Rail Defects Detection
Input B-scan images into the object detection network. In the training stage, the anchor bounding box (bbox) is used as the training sample, and find the anchor bbox, which has the largest IOU with each ground truth bbox, then use the label of the ground truth bbox as labeled of the anchor bbox, and then further calculates the offset of the anchor bbox relative to the ground truth bbox. The final purpose is to train the parameters of the anchor bbox to fit the ground truth bbox. Multiple anchor bboxes are first generated in the image in the prediction stage. Then, the category and offset of these anchor bboxes are predicted according to the trained model parameters to obtain the prediction bbox. The model will output the probability value of each category, and the category with the highest probability value is used as the category of the prediction bbox. In this way, the classification and localization of rail defects from the B-scan image dataset.
6. Conclusions
We proposed deep learning-based approaches (object detection) to process rail internal B-scan images obtained by ultrasonic detectors to automatically identify and localize rail internal defects. Instead of conventional artificial secondary replay recognition, the new technique reduces labor and time costs and also meets both detection speed and accuracy requirements.
In the context of rail defect detection, the methodology proposed in this paper serves as an efficacious complementary approach. It capitalizes on the data provided by the GCT-8C rail flaw detector, applying a series of processing techniques to these data. As a result, the approach achieves commendable outcomes in detecting rail damage. This method enhances the existing diagnostic capabilities by leveraging the strengths of the GCT-8C instrument’s data, which, when combined with the sophisticated data processing steps outlined in this study, significantly improves the accuracy and reliability of rail defect detection.
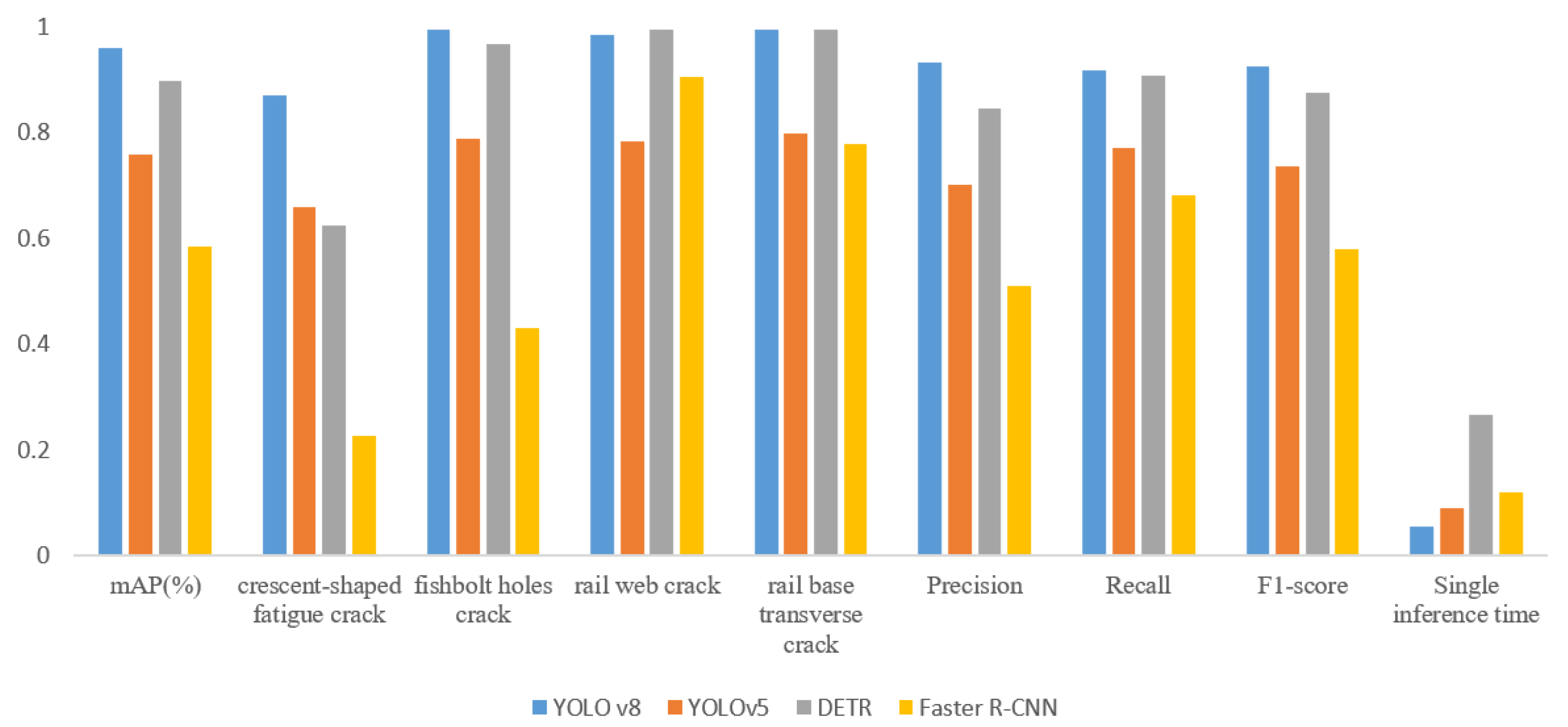
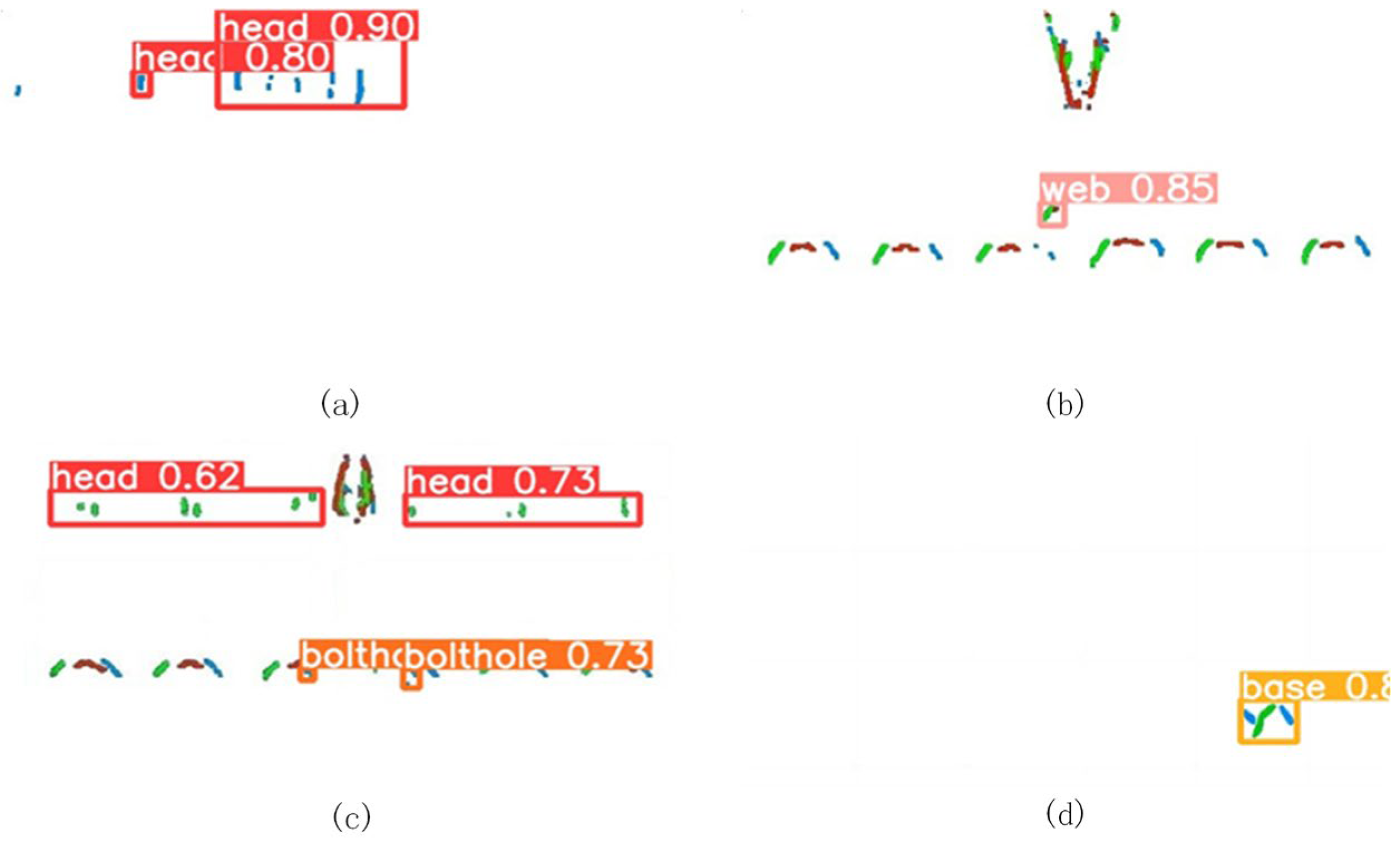
In this study, the representatives of one-stage deep learning networks, DETR, YOLOv5, and YOLOv8, and of two-stage deep learning networks, Faster R-CNN are proposed to detect four categories of internal defects, including crescent-shaped fatigue cracks (head), fishbolt hole cracks (bolt hole), rail web cracks (web) and rail base transverse cracks (base). After data pre-processing, these networks were transfer-learned based on B-scan images, the parameter was optimized, and the generalization capability was validated by adjusting hyperparameters and network details, then further tested and compared in different evaluation conditions. Compared to the Faster R-CNN model (mAP: 0.585, inference time: 0.125 IPS) with the problem of frequently missed and wrong detection, the YOLO series can detect almost all categories of defects in B-scan images. DETR demonstrates commendable performance across multiple metrics, including mAP, precision, recall, and the F1 score. Its overall performance closely approximates that of YOLOv8. However, in terms of single inference time, YOLOv8 (0.056 IPS) possesses a definitive advantage, evidencing superior efficiency in processing speed compared to DETR (0.267 IPS). There comes the first conclusion that the overall performance of YOLO series models is superior to that of Faster R-CNN on our datasets. Further, the YOLOv8 model further improves accuracy (mAP: 0.96 vs. 0.757 vs. 0.896) and inference time (0.056 IPS vs. 0.089 IPS vs. 0.067) over DETR and YOLOv5, and can accurately distinguish the interference items in B-scan images such as the image of bolt holes and surrounding cracks. There comes the second conclusion that the optimization algorithms (tricks) of YOLOv8 work well in our small dataset, finally achieving a balance between FPS and Precision. Last but not least, the two one-stage object detection networks are trained and tested at different input resolutions. YOLOv8 has a higher mAP value than our datasets. To conclude, the YOLOv8 model with input sizes of 608 pixels × 608 pixels, with the highest accuracy and fastest detection speed, is the most suitable model for real-time rail internal B-scan image analysis.
For future work, unnecessary convolution layer structures in the deep learning network are suggested to be removed to reduce the calculation volume for B-scan image identification, and the specific operations in the network affecting the effectiveness of detection must be further explored. In addition, the object detection model cannot evaluate defect severity. Future research should focus on quantitative and qualitative studies of these defects, and segmentation algorithms might be used in the future.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}