
YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection


Abstract
1. Introduction
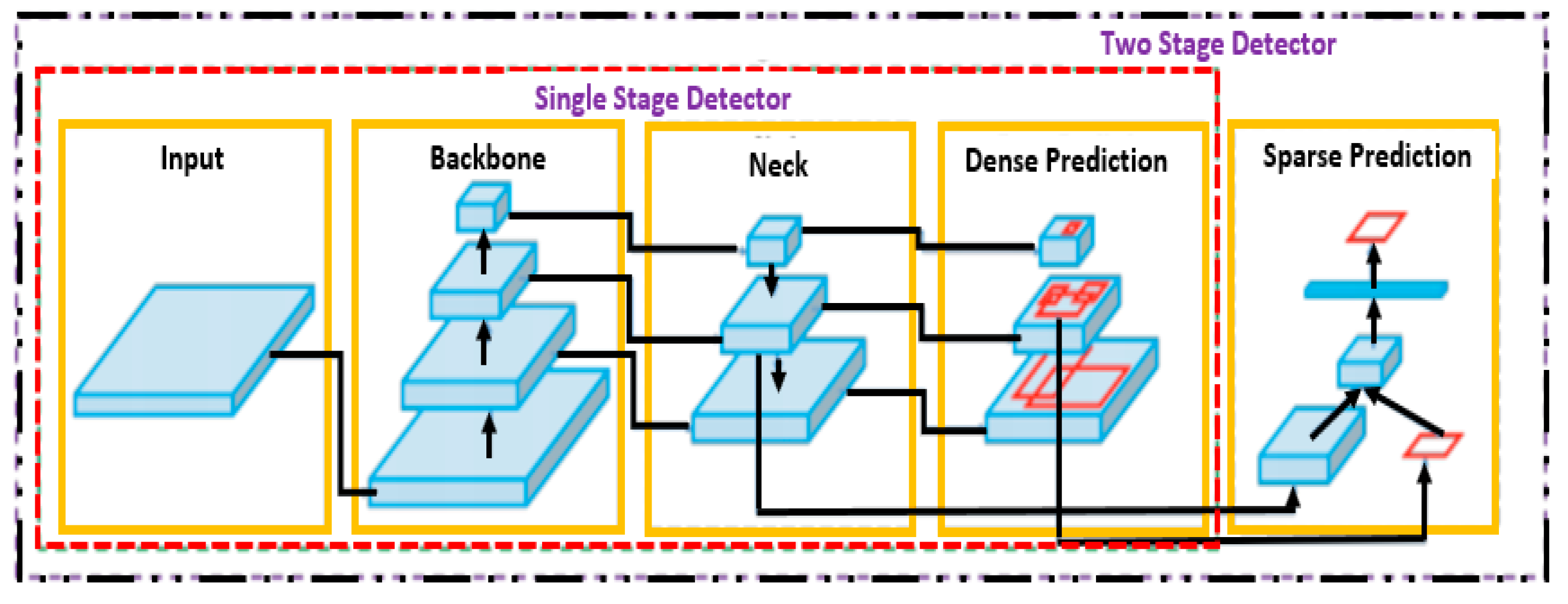
Object Detection
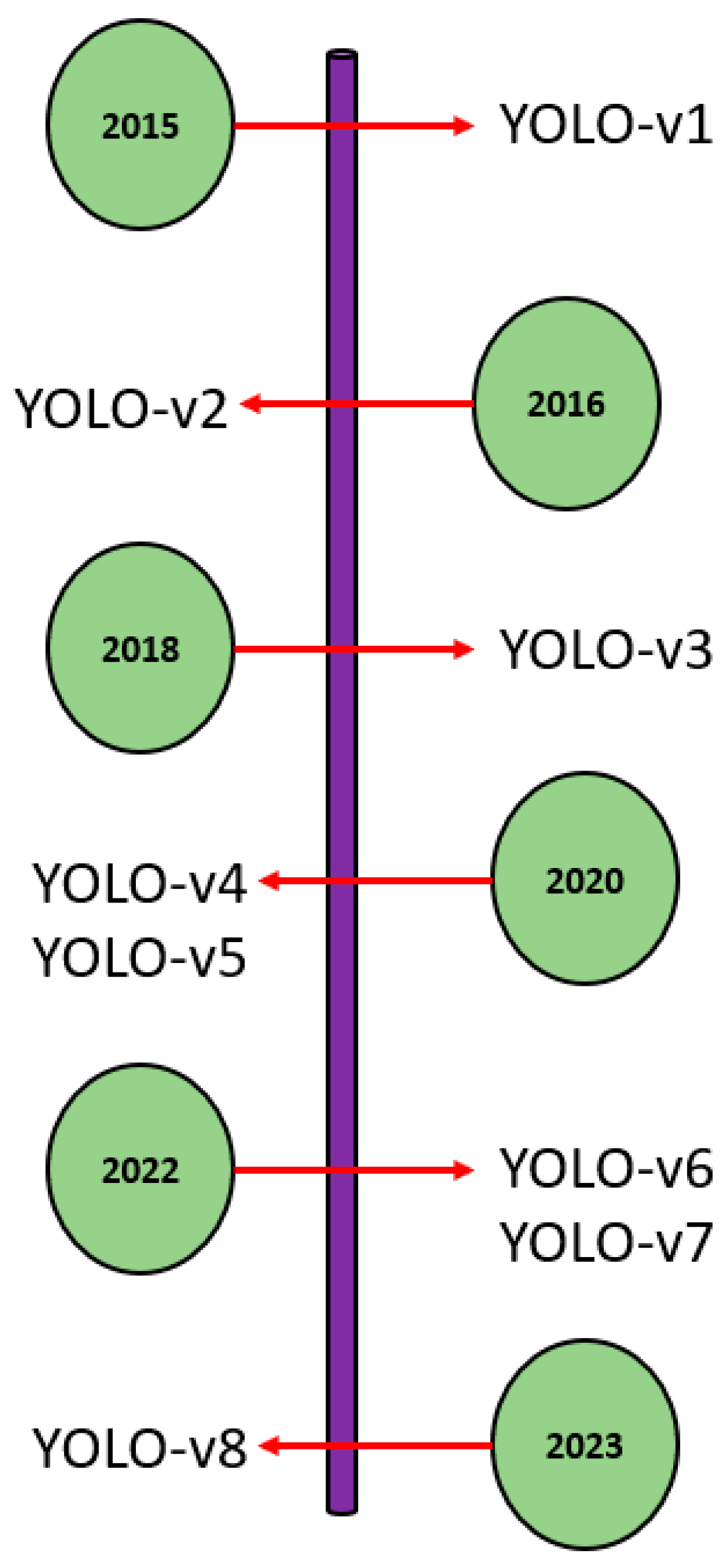
2. Original YOLO Algorithm
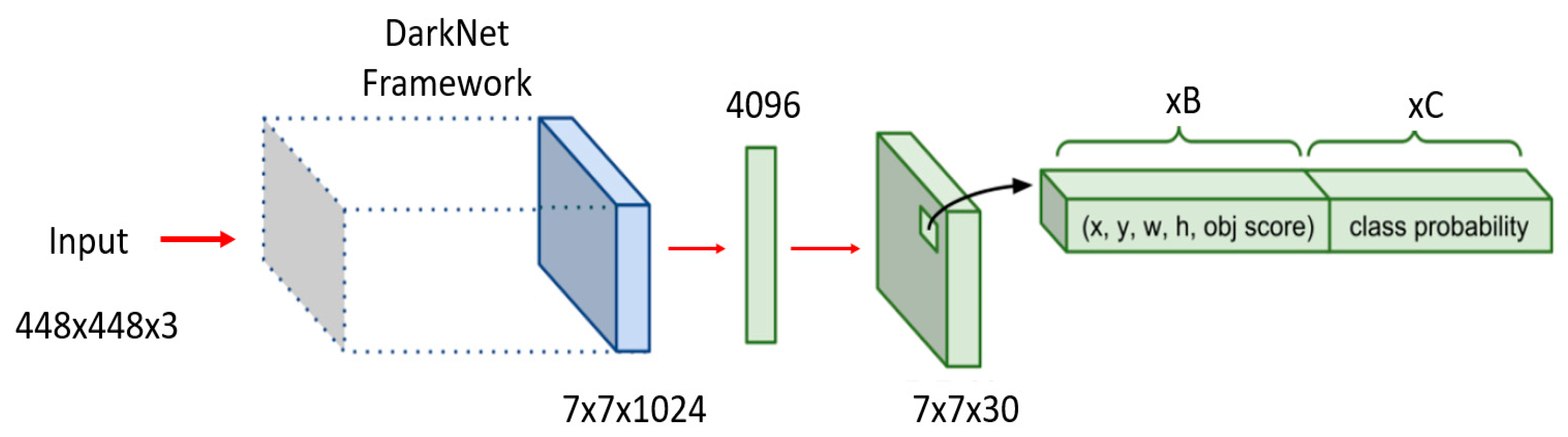
2.1. Original YOLO
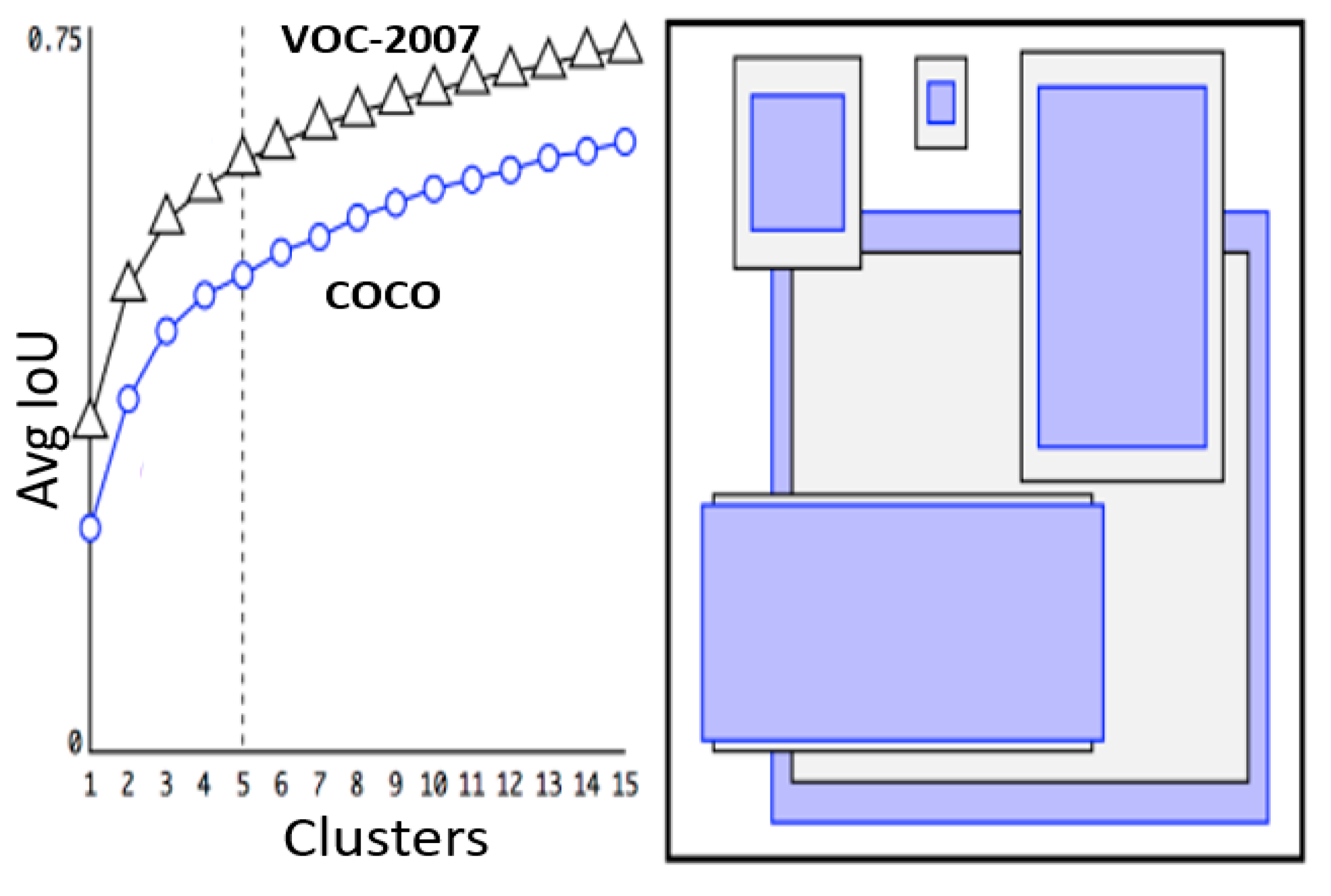
2.2. YOLO-v2/9000
2.3. YOLO-v3
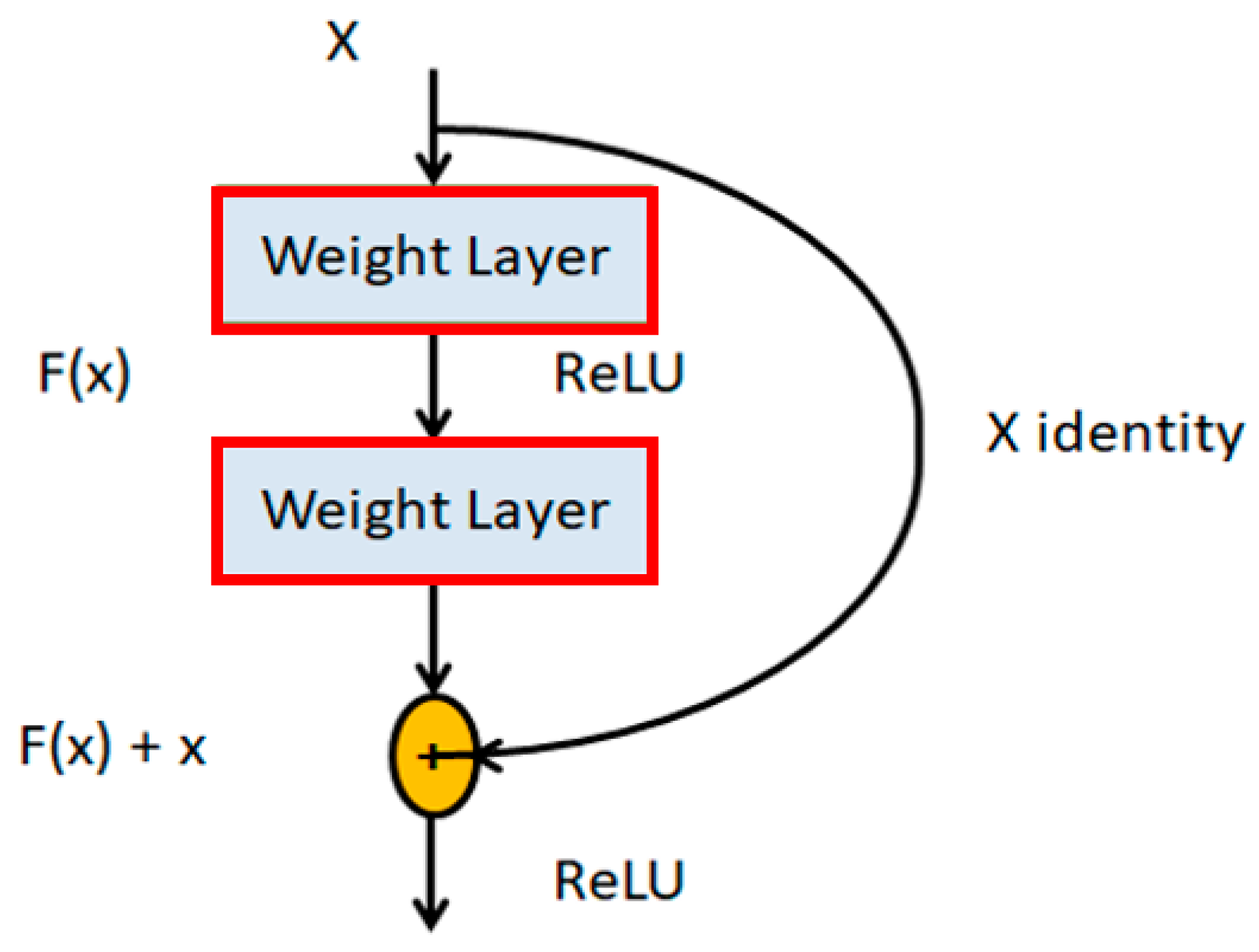
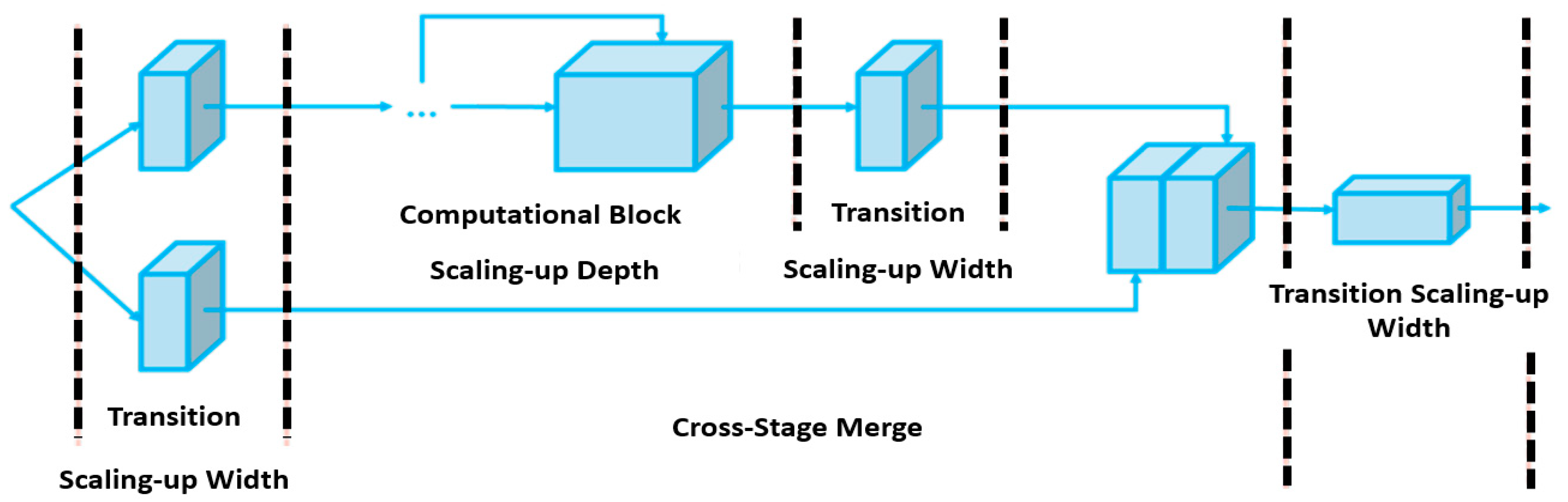
2.4. YOLO-v4
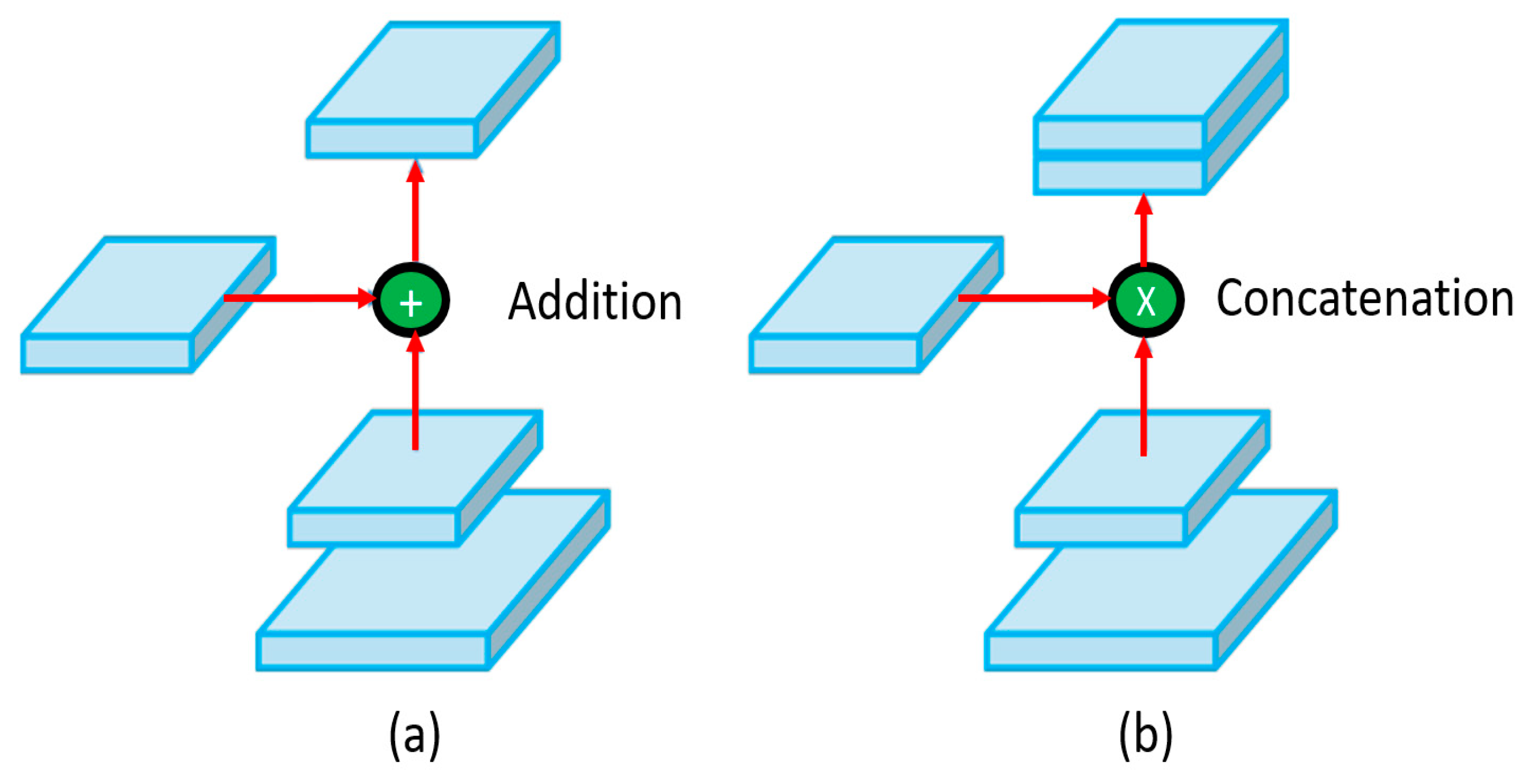
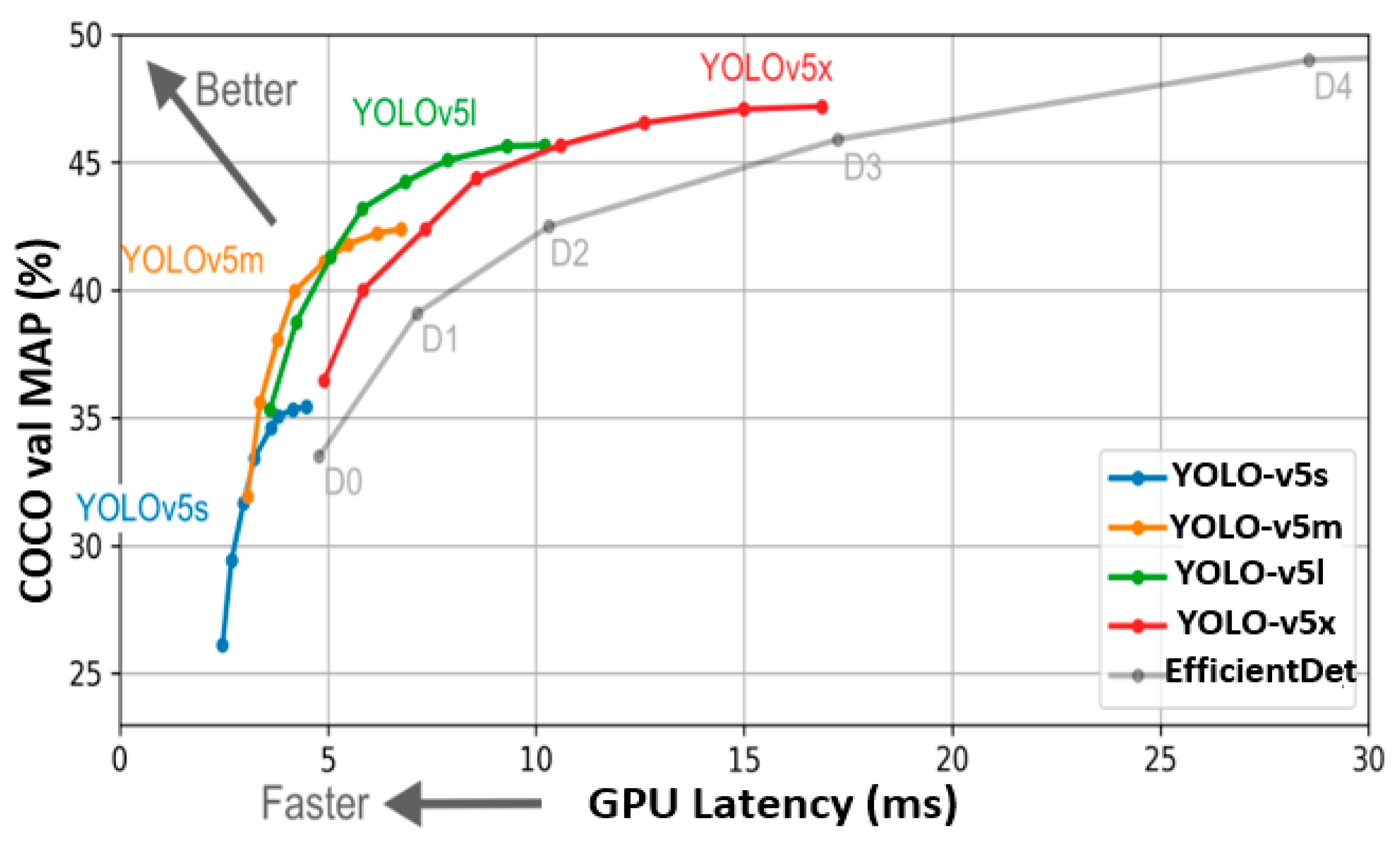
2.5. YOLO-v5
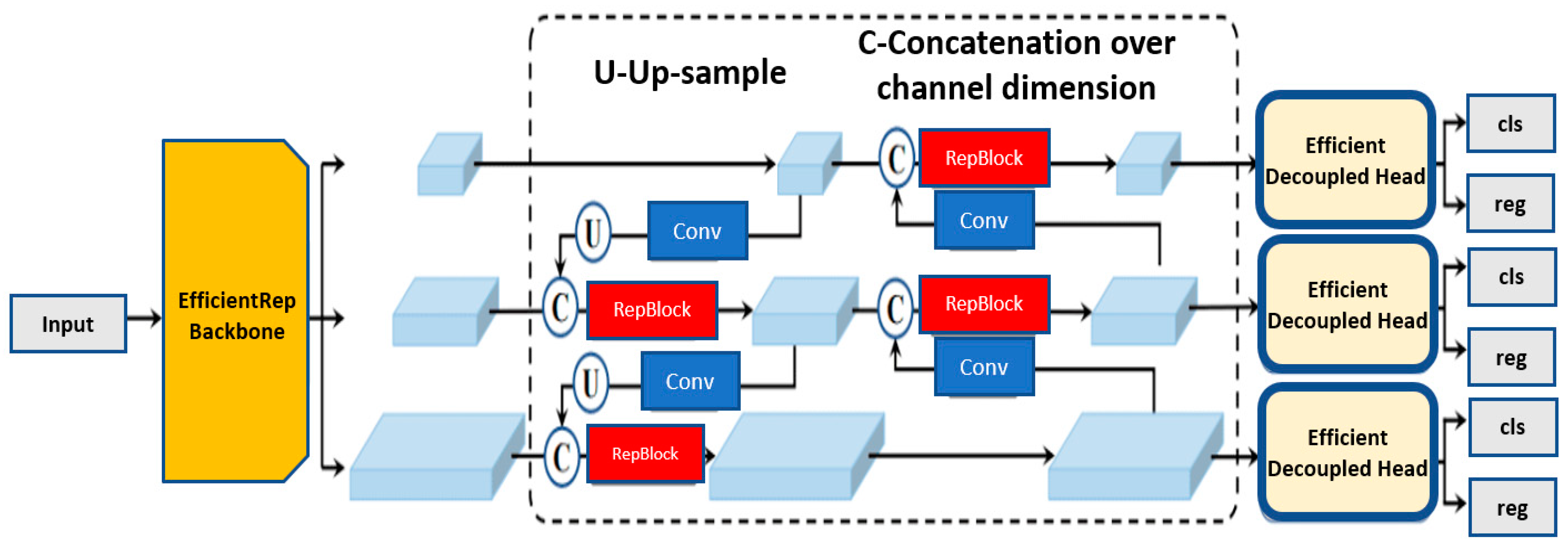
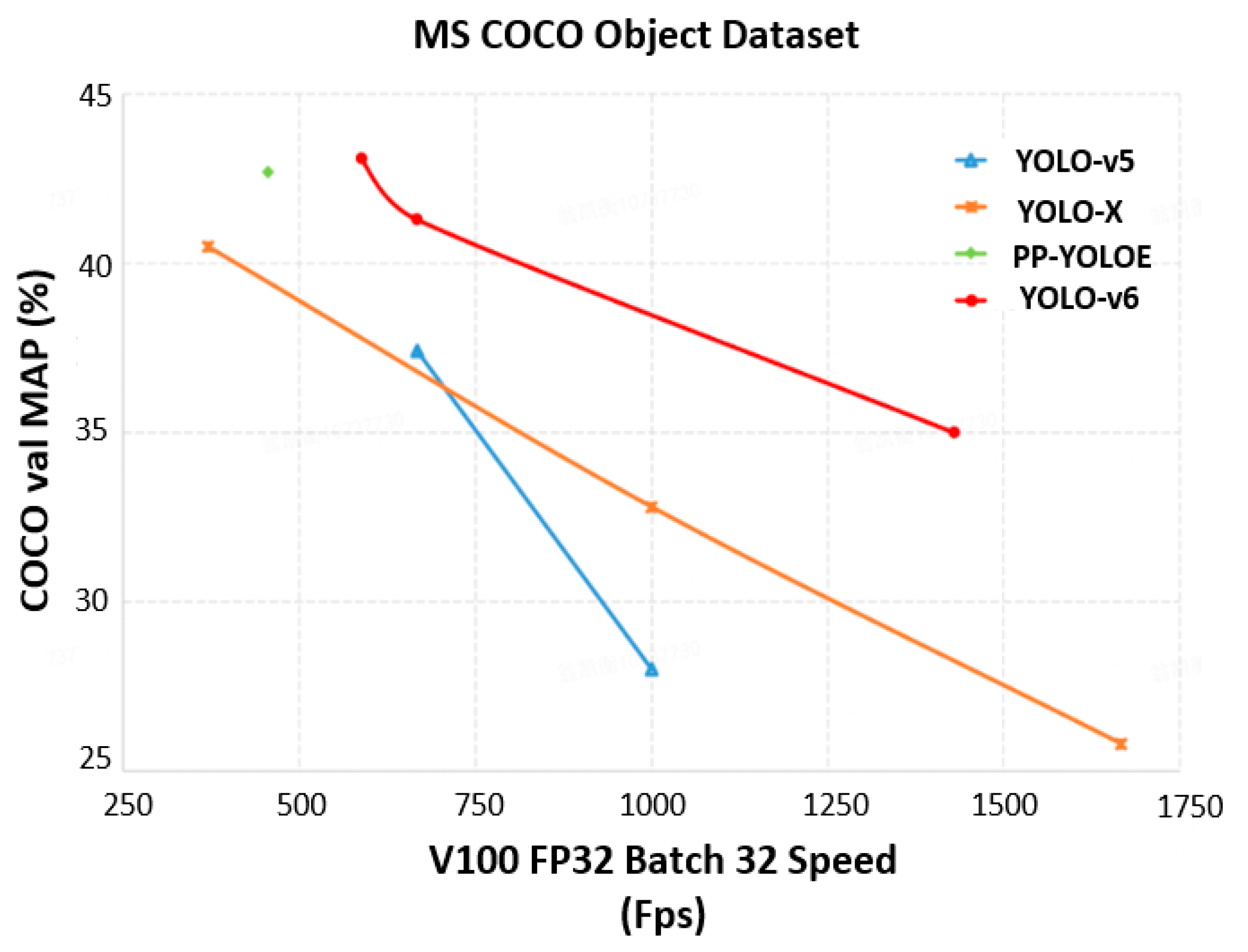
2.6. YOLO-v6
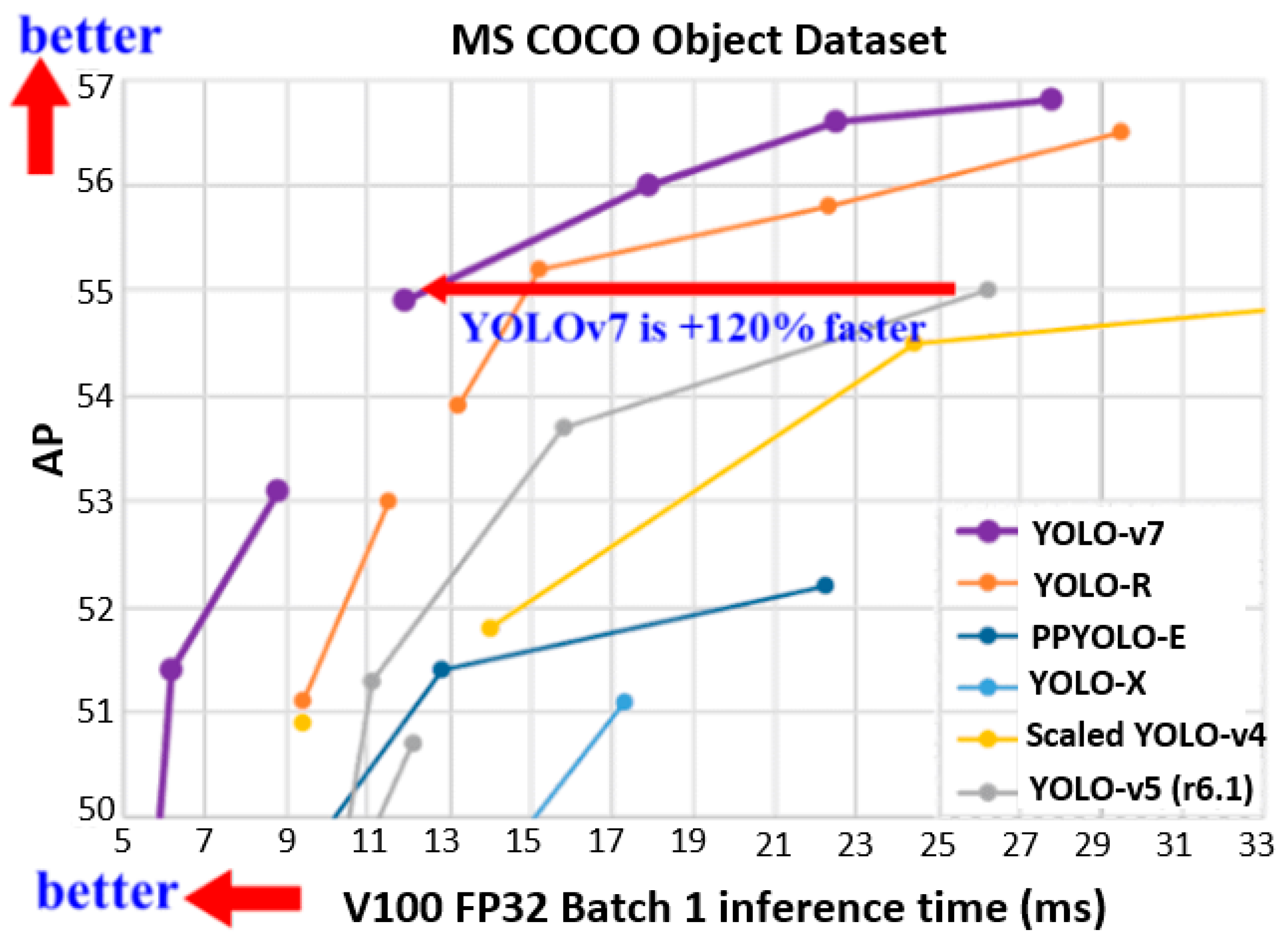
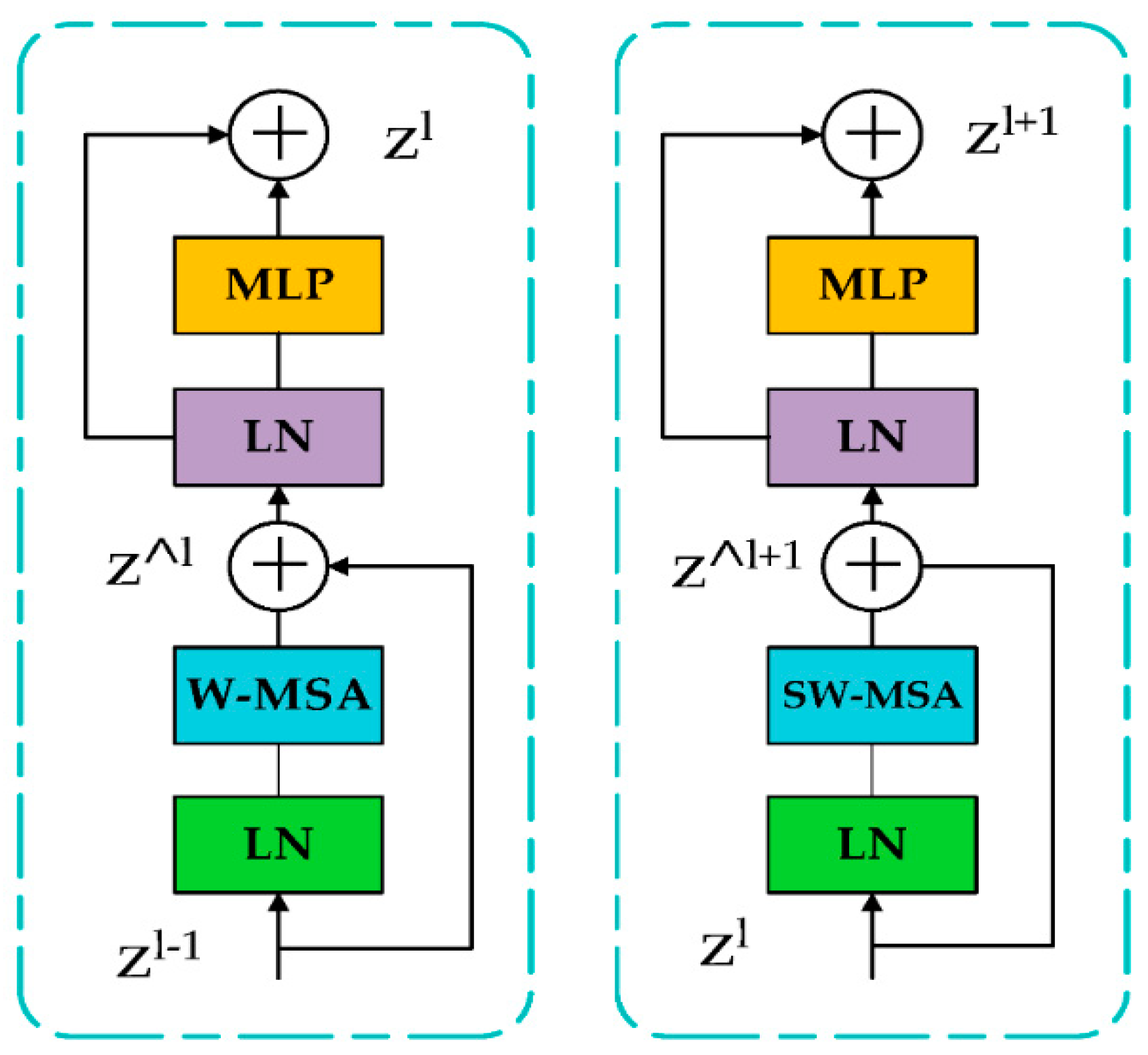
2.7. YOLO-v7
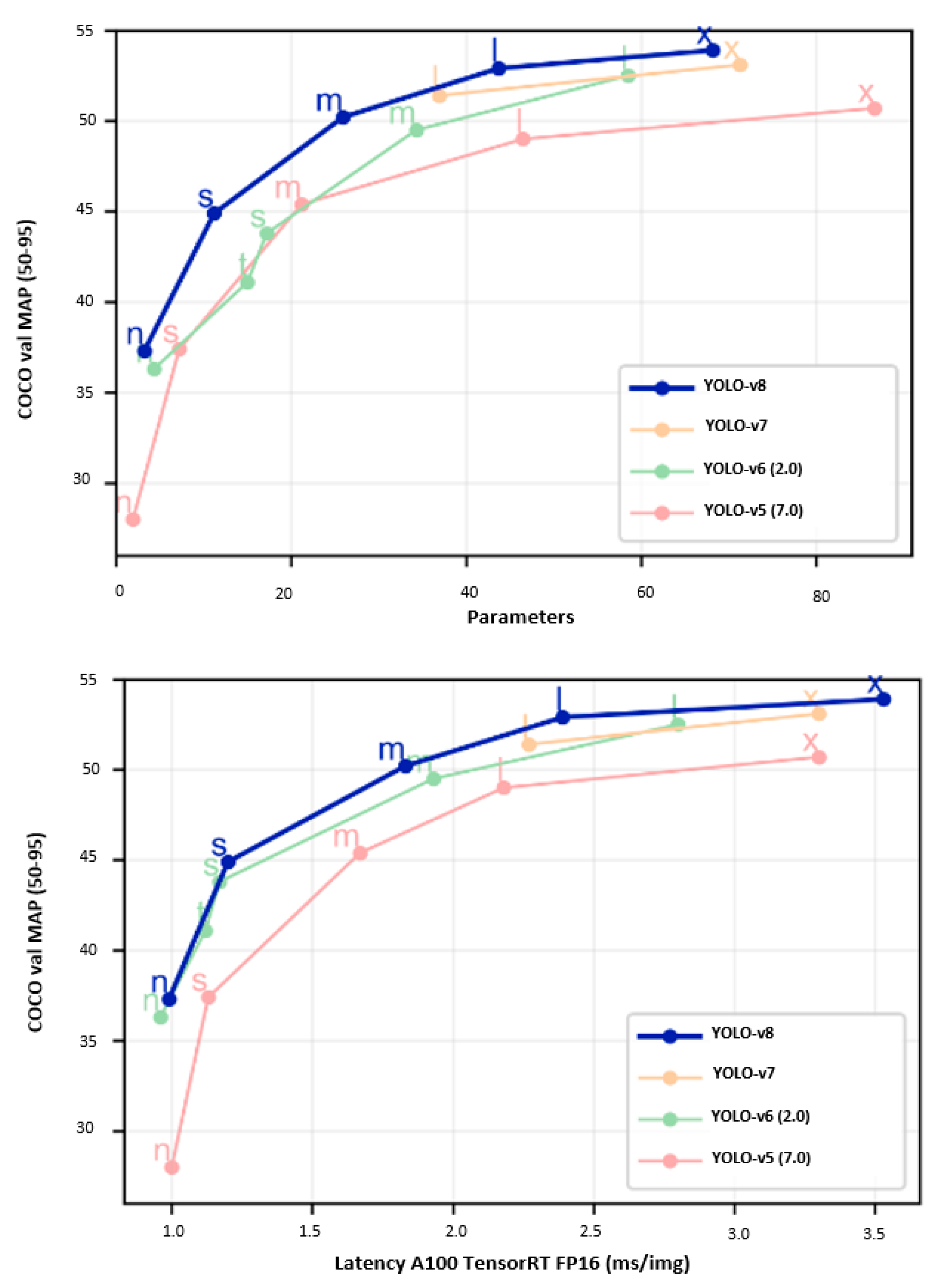
2.8. YOLO-v8
3. Industrial Defect Detection via YOLO
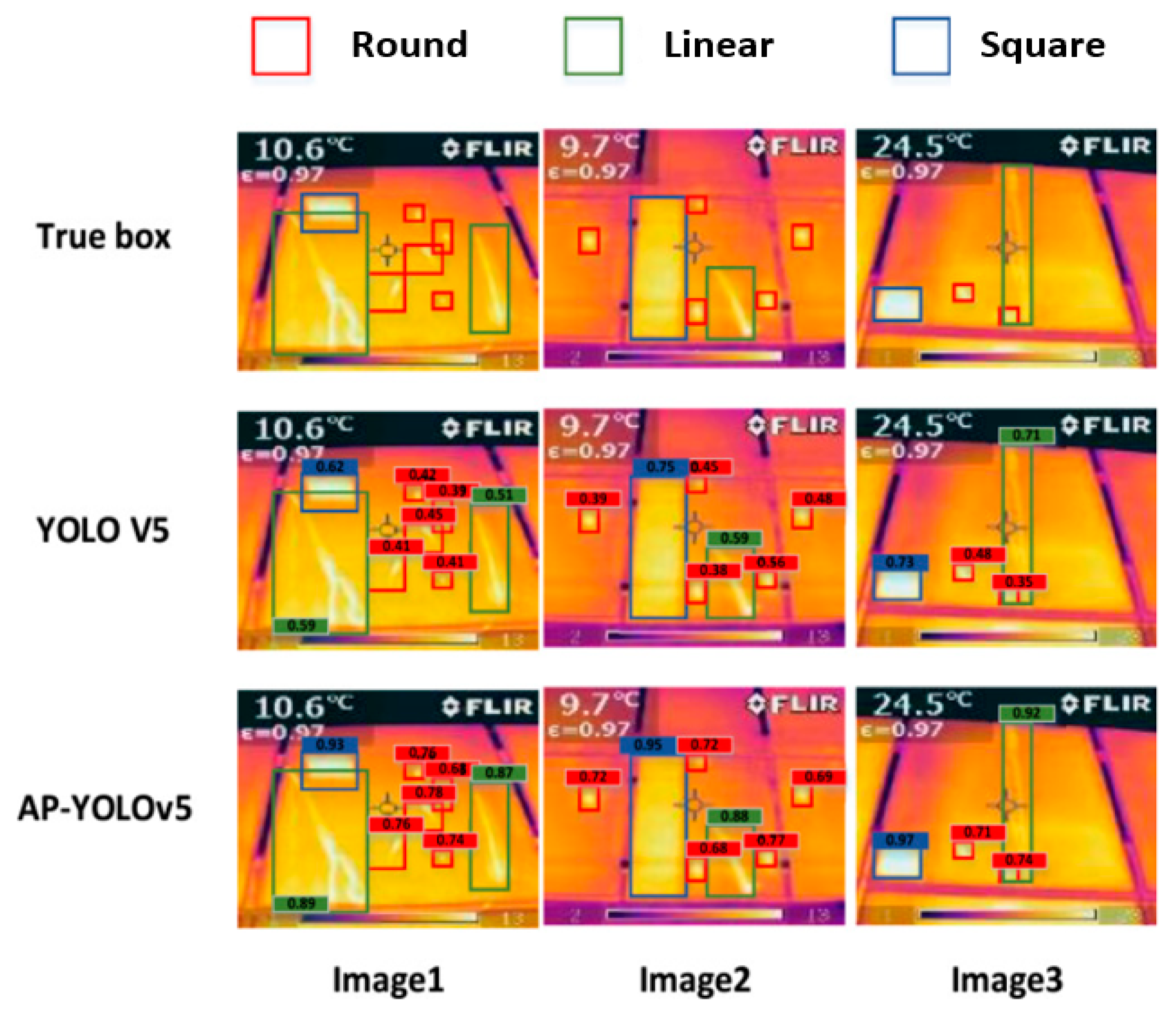
3.1. Industrial Fabric Defect Detection
3.2. Solar Cell Surface Defect Detection
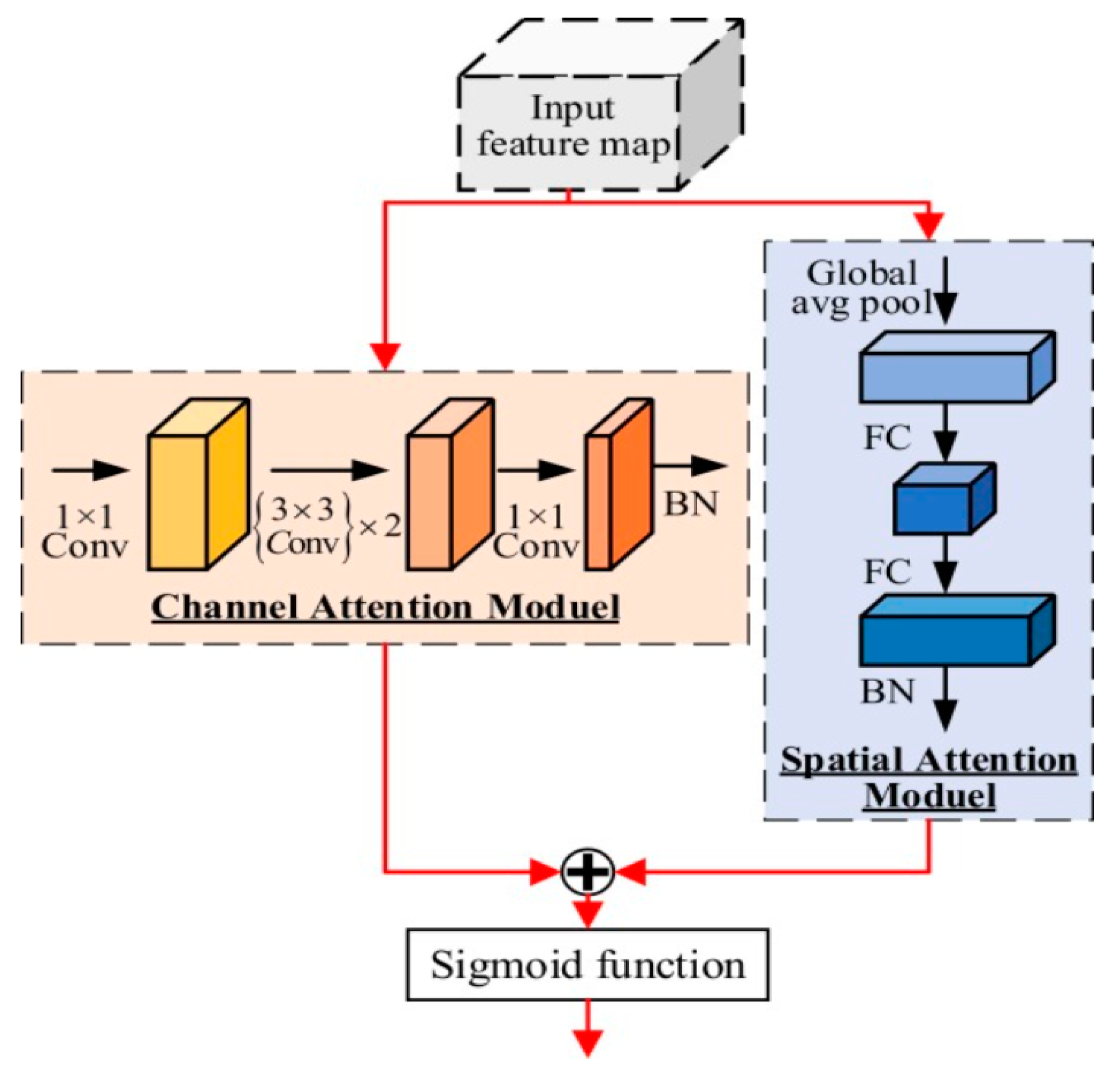
3.3. Steel Surface Defect Detection
3.4. Pallet Racking Defect Inspection
4. Discussion
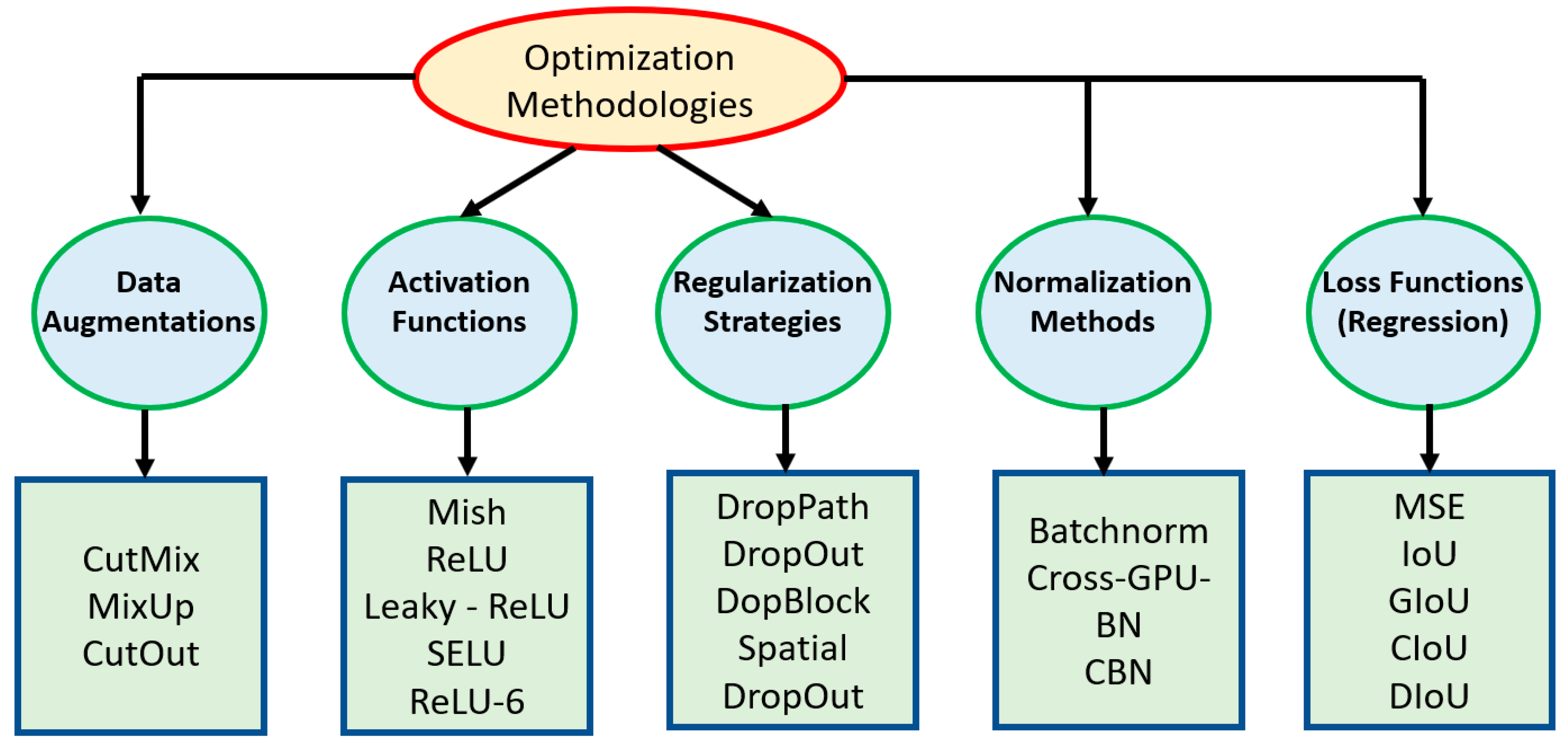
4.1. Reason for Rising Popularity
4.2. YOLO and Industrial Defect Detection
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, B.; Quan, C.; Ren, F. Study on CNN in the recognition of emotion in audio and images. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016. [Google Scholar] [CrossRef]
- Pollen, D.A. Explicit neural representations, recursive neural networks and conscious visual perception. Cereb. Cortex 2003, 13, 807–814. [Google Scholar] [CrossRef] [PubMed]
- Using artificial neural networks to understand the human brain. Res. Featur. 2022. [CrossRef]
- Improvement of Neural Networks Artificial Output. Int. J. Sci. Res. (IJSR) 2017, 6, 352–361. [CrossRef]
- Dodia, S.; Annappa, B.; Mahesh, P.A. Recent advancements in deep learning based lung cancer detection: A systematic review. Eng. Appl. Artif. Intell. 2022, 116, 105490. [Google Scholar] [CrossRef]
- Ojo, M.O.; Zahid, A. Deep Learning in Controlled Environment Agriculture: A Review of Recent Advancements, Challenges and Prospects. Sensors 2022, 22, 7965. [Google Scholar] [CrossRef] [PubMed]
- Jarvis, R.A. A Perspective on Range Finding Techniques for Computer Vision. IEEE Trans. Pattern Anal. Mach. Intell. 1983, PAMI-5, 122–139. [Google Scholar] [CrossRef]
- Hussain, M.; Bird, J.; Faria, D.R. A Study on CNN Transfer Learning for Image Classification. 11 August 2018. Available online: https://research.aston.ac.uk/en/publications/a-study-on-cnn-transfer-learning-for-image-classification (accessed on 1 January 2023).
- Yang, R.; Yu, Y. Artificial Convolutional Neural Network in Object Detection and Semantic Segmentation for Medical Imaging Analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef]
- Haupt, J.; Nowak, R. Compressive Sampling vs. Conventional Imaging. In Proceedings of the 2006 International Conference on Image Processing, Las Vegas, NV, USA, 26–29 June 2006; pp. 1269–1272. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Perez, H.; Tah, J.H.M.; Mosavi, A. Deep Learning for Detecting Building Defects Using Convolutional Neural Networks. Sensors 2019, 19, 3556. [Google Scholar] [CrossRef]
- Hussain, M.; Al-Aqrabi, H.; Hill, R. PV-CrackNet Architecture for Filter Induced Augmentation and Micro-Cracks Detection within a Photovoltaic Manufacturing Facility. Energies 2022, 15, 8667. [Google Scholar] [CrossRef]
- Hussain, M.; Dhimish, M.; Holmes, V.; Mather, P. Deployment of AI-based RBF network for photovoltaics fault detection procedure. AIMS Electron. Electr. Eng. 2020, 4, 1–18. [Google Scholar] [CrossRef]
- Hussain, M.; Al-Aqrabi, H.; Munawar, M.; Hill, R.; Parkinson, S. Exudate Regeneration for Automated Exudate Detection in Retinal Fundus Images. IEEE Access 2022. [Google Scholar] [CrossRef]
- Hussain, M.; Al-Aqrabi, H.; Hill, R. Statistical Analysis and Development of an Ensemble-Based Machine Learning Model for Photovoltaic Fault Detection. Energies 2022, 15, 5492. [Google Scholar] [CrossRef]
- Singh, S.A.; Desai, K.A. Automated surface defect detection framework using machine vision and convolutional neural networks. J. Intell. Manuf. 2022, 34, 1995–2011. [Google Scholar] [CrossRef]
- Weichert, D.; Link, P.; Stoll, A.; Rüping, S.; Ihlenfeldt, S.; Wrobel, S. A review of machine learning for the optimization of production processes. Int. J. Adv. Manuf. Technol. 2019, 104, 1889–1902. [Google Scholar] [CrossRef]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. CIRP Ann. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Kusiak, A. Smart manufacturing. Int. J. Prod. Res. 2017, 56, 508–517. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using Deep Learning to Detect Defects in Manufacturing: A Comprehensive Survey and Current Challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef]
- Soviany, P.; Ionescu, R.T. Optimizing the Trade-Off between Single-Stage and Two-Stage Deep Object Detectors using Image Difficulty Prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 20–23 September 2018. [Google Scholar] [CrossRef]
- Du, L.; Zhang, R.; Wang, X. Overview of two-stage object detection algorithms. J. Phys. Conf. Ser. 2020, 1544, 012033. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. A Review of Object Detection Models Based on Convolutional Neural Network. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; pp. 1–16. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Cheng, X.; Yu, J. RetinaNet with Difference Channel Attention and Adaptively Spatial Feature Fusion for Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2020, 70, 2503911. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Wang, Z.J.; Turko, R.; Shaikh, O.; Park, H.; Das, N.; Hohman, F.; Kahng, M.; Chau, D.H.P. CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1396–1406. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Vidyavani, A.; Dheeraj, K.; Reddy, M.R.M.; Kumar, K.N. Object Detection Method Based on YOLOv3 using Deep Learning Networks. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 1414–1417. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Shetty, S. Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset. arXiv 2016, arXiv:1607.03785. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef]
- Liao, Z.; Carneiro, G. On the importance of normalisation layers in deep learning with piecewise linear activation units. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), New York, NY, USA, 7–10 March 2016. [Google Scholar] [CrossRef]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. batch normalization: An empirical study of their impact to deep learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Li, G.; Jian, X.; Wen, Z.; AlSultan, J. Algorithm of overfitting avoidance in CNN based on maximum pooled and weight decay. Appl. Math. Nonlinear Sci. 2022, 7, 965–974. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Xue, J.; Cheng, F.; Li, Y.; Song, Y.; Mao, T. Detection of Farmland Obstacles Based on an Improved YOLOv5s Algorithm by Using CIoU and Anchor Box Scale Clustering. Sensors 2022, 22, 1790. [Google Scholar] [CrossRef]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means Algorithm: A Comprehensive Survey and Performance Evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013. Available online: https://pjreddie.com/darknet (accessed on 1 January 2023).
- Furusho, Y.; Ikeda, K. Theoretical analysis of skip connections and batch normalization from generalization and optimization perspectives. APSIPA Trans. Signal Inf. Process. 2020, 9, e9. [Google Scholar] [CrossRef]
- Machine-Learning System Tackles Speech and Object Recognition. Available online: https://news.mit.edu/machine-learning-image-object-recognition-918 (accessed on 1 January 2023).
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Misra, D. Mish: A self regularized nonmonotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-Iteration Batch Normalization. arXiv 2020, arXiv:2002.05712. [Google Scholar]
- Ultralytics. YOLOv5 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 January 2023).
- Jocher, G.; Stoken, A.; Borovec, J.; Christopher, S.T.A.N.; Laughing, L.C. Ultralytics/yolov5: v4.0-nn.SiLU() Activations, Weights & Biases Logging, PyTorch Hub Integration. Zenodo 2021. Available online: https://zenodo.org/record/4418161 (accessed on 5 January 2023).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Gevorgyan, Z. Siou loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 20221; pp. 5311–5320. [Google Scholar]
- Solawetz, J.; Nelson, J. What’s New in YOLOv6? 4 July 2022. Available online: https://blog.roboflow.com/yolov6/ (accessed on 1 January 2023).
- Wang, C.Y.; Bochkovskiy, A.; Liao HY, M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Wu, W.; Zhao, Y.; Xu, Y.; Tan, X.; He, D.; Zou, Z.; Ye, J.; Li, Y.; Yao, M.; Dong, Z.; et al. DSANet: Dynamic Segment AggrDSANet: Dynamic Segment Aggregation Network for Video-Level Representation Learning. In Proceedings of the MM ’21—29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021. [Google Scholar] [CrossRef]
- Li, C.; Tang, T.; Wang, G.; Peng, J.; Wang, B.; Liang, X.; Chang, X. BossNAS: Exploring Hybrid CNN-transformers with Block-wisely Self-supervised Neural Architecture Search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021. [Google Scholar] [CrossRef]
- Dollar, P.; Singh, M.; Girshick, R. Fast and accurate model scaling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 924–932. [Google Scholar]
- Guo, S.; Alvarez, J.M.; Salzmann, M. ExpandNets: Linear over-parameterization to train compact convolutional networks. Adv. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 1298–1310. [Google Scholar]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling up your kernels to 31 × 31: Revisiting large kernel design in CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. GitHub. 1 January 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 12 January 2023).
- Jin, R.; Niu, Q. Automatic Fabric Defect Detection Based on an Improved YOLOv5. Math. Probl. Eng. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- NVIDIA Jetson TX2: High Performance AI at the Edge, NVIDIA. Available online: https://www.nvidia.com/en-gb/autonomous-machines/embedded-systems/jetson-tx2/ (accessed on 30 January 2023).
- NVIDIA TensorRT. NVIDIA Developer. 18 July 2019. Available online: https://developer.nvidia.com/tensorrt (accessed on 5 January 2023).
- Dlamini, S.; Kao, C.-Y.; Su, S.-L.; Kuo, C.-F.J. Development of a real-time machine vision system for functional textile fabric defect detection using a deep YOLOv4 model. Text. Res. J. 2021, 92, 675–690. [Google Scholar] [CrossRef]
- Lin, G.; Liu, K.; Xia, X.; Yan, R. An Efficient and Intelligent Detection Method for Fabric Defects based on Improved YOLOv5. Sensors 2022, 23, 97. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Tan, Y.; He, Q.; Xiao, Y. SwinNet: Swin Transformer Drives Edge-Aware RGB-D and RGB-T Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4486–4497. [Google Scholar] [CrossRef]
- Zhang, M.; Yin, L. Solar Cell Surface Defect Detection Based on Improved YOLO v5. IEEE Access 2022, 10, 80804–80815. [Google Scholar] [CrossRef]
- Binomairah, A.; Abdullah, A.; Khoo, B.E.; Mahdavipour, Z.; Teo, T.W.; Noor, N.S.M.; Abdullah, M.Z. Detection of microcracks and dark spots in monocrystalline PERC cells using photoluminescene imaging and YOLO-based CNN with spatial pyramid pooling. EPJ Photovolt. 2022, 13, 27. [Google Scholar] [CrossRef]
- Sun, T.; Xing, H.; Cao, S.; Zhang, Y.; Fan, S.; Liu, P. A novel detection method for hot spots of photovoltaic (PV) panels using improved anchors and prediction heads of YOLOv5 network. Energy Rep. 2022, 8, 1219–1229. [Google Scholar] [CrossRef]
- Yang, D.; Cui, Y.; Yu, Z.; Yuan, H. Deep Learning Based Steel Pipe Weld Defect Detection. Appl. Artif. Intell. 2021, 35, 1237–1249. [Google Scholar] [CrossRef]
- Ma, Z.; Li, Y.; Huang, M.; Huang, Q.; Cheng, J.; Tang, S. A lightweight detector based on attention mechanism for aluminum strip surface defect detection. Comput. Ind. 2021, 136, 103585. [Google Scholar] [CrossRef]
- Shi, J.; Yang, J.; Zhang, Y. Research on Steel Surface Defect Detection Based on YOLOv5 with Attention Mechanism. Electronics 2022, 11, 3735. [Google Scholar] [CrossRef]
- CEP, F.A. 5 Insightful Statistics Related to Warehouse Safety. Available online: www.damotech.com (accessed on 11 January 2023).
- Armour, R. The Rack Group. Available online: https://therackgroup.com/product/rack-armour/ (accessed on 12 January 2023).
- Hussain, M.; Chen, T.; Hill, R. Moving toward Smart Manufacturing with an Autonomous Pallet Racking Inspection System Based on MobileNetV2. J. Manuf. Mater. Process. 2022, 6, 75. [Google Scholar] [CrossRef]
- Hussain, M.; Al-Aqrabi, H.; Munawar, M.; Hill, R.; Alsboui, T. Domain Feature Mapping with YOLOv7 for Automated Edge-Based Pallet Racking Inspections. Sensors 2022, 22, 6927. [Google Scholar] [CrossRef] [PubMed]
- Farahnakian, F.; Koivunen, L.; Makila, T.; Heikkonen, J. Towards Autonomous Industrial Warehouse Inspection. In Proceedings of the 2021 26th International Conference on Automation and Computing (ICAC), Portsmouth, UK, 2–4 September 2021. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Average Precision (@50) | Parameters | FLOPs |
|---|---|---|---|
| YOLO-v5s | 55.8% | 7.5 M | 13.2B |
| YOLO-v5m | 62.4% | 21.8 M | 39.4B |
| YOLO-v5l | 65.4% | 47.8 M | 88.1B |
| YOLO-v5x | 66.9% | 86.7 M | 205.7B |
| Variant | mAP 0.5:0.95 (COCO-val) | FPS Tesla T4 | Parameters (Million) |
|---|---|---|---|
| YOLO-v6-N | 35.9 (300 epochs) | 802 | 4.3 |
| YOLO-v6-T | 40.3 (300 epochs) | 449 | 15.0 |
| YOLO-v6-RepOpt | 43.3 (300 epochs) | 596 | 17.2 |
| YOLO-v6-S | 43.5 (300 epochs) | 495 | 17.2 |
| YOLO-v6-M | 49.7 | 233 | 34.3 |
| YOLO-v6-L-ReLU | 51.7 | 149 | 58.5 |
| Model | Size (Pixels) | mAP (@50) | Parameters | FLOPs |
|---|---|---|---|---|
| YOLO-v7-tiny | 640 | 52.8% | 6.2 M | 5.8G |
| YOLO-v7 | 640 | 69.7% | 36.9 M | 104.7G |
| YOLO-v7-X | 640 | 71.1% | 71.3 M | 189.9G |
| YOLO-v7-E6 | 1280 | 73.5% | 97.2 M | 515.2G |
| YOLO-v7-D6 | 1280 | 73.8% | 154.7 M | 806.8G |
| Research | Architecture | Dataset Size | Accuracy | FPS |
|---|---|---|---|---|
| [95] | MobileNet-V2 | 19,717 | 92.7% | ----- |
| [96] | YOLO-v7 | 2095 | 91.1% | 19 |
| [97] | Mask-RCNN | 75 | 93.45% | ----- |
| Variant | Framework | Backbone | AP (%) | Comments |
|---|---|---|---|---|
| V1 | Darknet | Darknet-24 | 63.4 | Only detect a maximum of two objects in the same grid. |
| V2 | Darknet | Darknet-24 | 63.4 | Introduced batch norm, k-means clustering for anchor boxes. Capable of detecting > 9000 categories. |
| V3 | Darknet | Darknet-53 | 36.2 | Utilized multi-scale predictions and spatial pyramid pooling leading to larger receptive field. |
| V4 | Darknet | CSPDarknet-53 | 43.5 | Presented bag-of-freebies including the use of CIoU loss. |
| V5 | PyTorch | Modified CSPv7 | 55.8 | First variant based in PyTorch, making it available to a wider audience. Incorporated the anchor selection processes into the YOLO-v5 pipeline. |
| V6 | PyTorch | EfficientRep | 52.5 | Focused on industrial settings, presented an anchor-free pipeline. Presented new loss determination mechanisms (VFL, DFL, and SIoU/GIoU). |
| V7 | PyTorch | RepConvN | 56.8 | Architectural introductions included E-ELAN for faster convergence along with a bag-of-freebies including RepConvN and reparameterization-planning. |
| V8 | PyTorch | YOLO-v8 | 53.9 | Anchor-free reducing the number of prediction boxes whilst speeding up non-maximum suppression. Pending paper for further architectural insights. |
| YOLO Variant | Stars (K) |
|---|---|
| V3 | 9.3 |
| V4 | 20.2 |
| V5 | 34.7 |
| V6 | 4.6 |
| V7 | 8.4 |
| V8 | 2.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. https://doi.org/10.3390/machines11070677
Hussain M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines. 2023; 11(7):677. https://doi.org/10.3390/machines11070677
Chicago/Turabian StyleHussain, Muhammad. 2023. "YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection" Machines 11, no. 7: 677. https://doi.org/10.3390/machines11070677
APA StyleHussain, M. (2023). YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines, 11(7), 677. https://doi.org/10.3390/machines11070677