
Skip-Gram and Transformer Model for Session-Based Recommendation


Abstract
1. Introduction
- We proposed the SkipGT model to identify users’ global and current interests, behavioral patterns, and critical preferences.
- We utilized skip-gram pre-training for the first time to generate session vector embeddings in session-based recommender systems.
- To the best of our knowledge, this is the first model in session-based recommendation systems that combines the skip-gram model and transformer in natural language processing.
- We introduced a model that captures bidirectional conversions in session-based subreddits and represents users with different interest patterns.
- The proposed model’s efficacy is substantiated through rigorous experimentation, where it is compared against contemporary benchmark models across three distinct datasets.
2. Related Work
2.1. Conventional Session-Based Recommendation Methods
2.2. RNN-Based Methods
2.3. SAN-Based Methods
2.4. GNN-Based Methods
3. Materials and Methods
3.1. Problem Definition
3.2. Overview of the Proposed Model
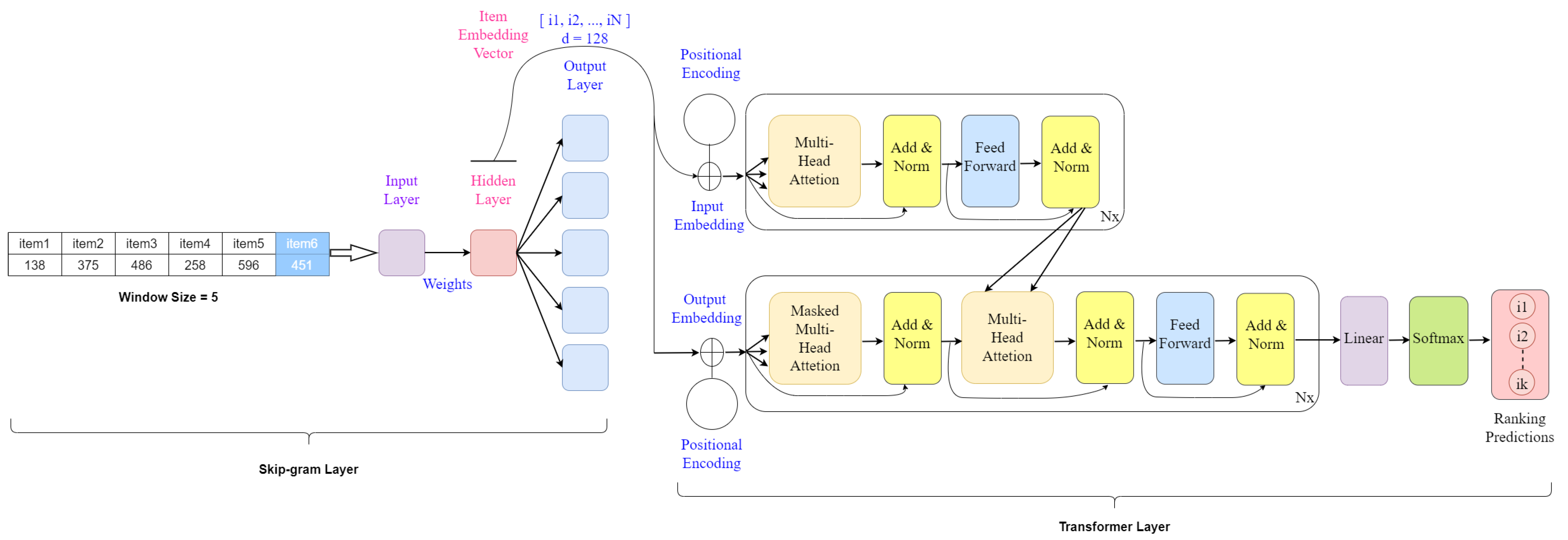
3.3. Skip-Gram Layer
3.4. Transformer Layer
3.5. Model Optimization
4. Experiments
- RQ1: Comparative Performance: How does the proposed model perform compared to existing state-of-the-art approaches?
- RQ2: Component Impact: To what degree do the individual components of the model influence its effectiveness? Does each significant module contribute to improved recommendation performance?
- RQ3: Transformer Parameterization: How do different parameter configurations within the transformer module affect the model’s performance?
- RQ4: Hyperparameter Influence: What is the impact of the main hyperparameters on the experimental outcomes?
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Baseline Methods
- Item-KNN [21] employs a nearest-neighbor approach based on cosine similarity to recommend items within a session.
- FPMC [12] leverages a combination of Markov chains and matrix decomposition for recommendation purposes.
- GRU4Rec [13] models user interest sequences and utilizes the final state for making recommendations.
- NARM [26] employs attention mechanisms and recurrent neural networks (RNNs) to capture users’ primary interests.
- STAMP [14] incorporates the user’s general intents from the current session and the most recent click.
- SASRec [30] utilizes multiple transformer layers to model user interests across session sequences.
- SR-GNN [16] leverages gated GNNs to learn complex interactions between items within session graphs.
- GC-SAN [37] employs GNNs to capture intricate item transformations and long-term dependencies within sessions while additionally incorporating self-attention networks (SANs).
- GCE-GNN [10] constructs two distinct graphs to capture local and global contextual information for recommendation purposes.
- DHCN [42] utilizes a hypergraph convolutional network to represent item-session-item relationships for recommendations.
- MTD [36] extracts intra-session and inter-session transformation relationships using a multi-tasking and multi-level network architecture.
- ICM-SR [43] retrieves representations of neighboring items while considering both a user’s general and recent preferences.
- CGL [44] integrates information from the current session with global information from all sessions to generate recommendations.
- DGS-MGNN [45] incorporates a dynamic global multi-channel GNN that models items at three levels: global, local, and consensus.
- LDGC-SR [46] utilizes an adaptive weight fusion mechanism to combine long-term dependencies with global contextual information.
- GCAN [33] employs graph-enhanced attention to capture user interest in item-specific subsequences and collaborative attention to model item representations across sessions.
- CSRM [23] leverages two parallel memory modules to incorporate both current session information and collaborative neighborhood data for session-based recommendation.
- FGNN [19] employs a weighted attention graph layer to learn item embeddings within a session and utilizes a readout function to obtain a session sequence embedding representing the current session’s intent.
- CTA [34] implements an attention-based sequential neural architecture that jointly models temporal and contextual information for sequential behavior modeling.
- SR-IEM [9] introduces an improved self-attention mechanism that more accurately estimates item importance, generating final recommendations by combining a user’s long-term preferences with their current interests.
- HG-GNN [47] cleverly combines information about current session preferences with valuable item-transition data extracted from other users’ historical sessions, leading to improved user preference inference.
- IGT [35] utilizes an interval-enhanced session graph along with a graph transformer with time intervals.
4.5. Results and Discussion
4.6. Ablation Study
- Transformer: model without skip-gram layer.
4.7. Sensitivity Analysis of the Hyperparameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gu, Y.; Song, J.; Liu, W.; Zou, L. HLGPS: A home location global positioning system in location-based social networks. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 901–906. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for YouTube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar] [CrossRef]
- Gu, Y.; Ding, Z.; Wang, S.; Yin, D. Hierarchical user profiling for e-commerce recommender systems. In Proceedings of the 13th International Conference on Web Search and Data Mining, Virtual Event, 10–13 July 2020; pp. 223–231. [Google Scholar] [CrossRef]
- Wu, L.; He, X.; Wang, X.; Zhang, K.; Wang, M. A survey on accuracy-oriented neural recommendation: From collaborative filtering to information-rich recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 4425–4445. [Google Scholar] [CrossRef]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph neural networks in recommender systems: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Q.; Hu, L.; Zhang, X.; Wang, Y.; Aggarwal, C. Sequential/session-based recommendations: Challenges, approaches, applications and opportunities. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11 July 2022; pp. 3425–3428. [Google Scholar] [CrossRef]
- Wang, S.; Cao, L.; Wang, Y.; Sheng, Q.Z.; Orgun, M.A.; Lian, D. A survey on session-based recommender systems. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Feng, C.; Shi, C.; Hao, S.; Zhang, Q.; Jiang, X.; Yu, D. Hierarchical social similarity-guided model with dual-mode attention for session-based recommendation. Knowl.-Based Syst. 2021, 230, 107380. [Google Scholar] [CrossRef]
- Pan, Z.; Cai, F.; Ling, Y.; de Rijke, M. Rethinking item importance in session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 1837–1840. [Google Scholar] [CrossRef]
- Wang, Z.; Wei, W.; Cong, G.; Li, X.L.; Mao, X.L.; Qiu, M. Global context enhanced graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 169–178. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar] [CrossRef]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2015, arXiv:1511.06939. [Google Scholar] [CrossRef]
- Liu, Q.; Zeng, Y.; Mokhosi, R.; Zhang, H. STAMP: Short-term attention/memory priority model for session-based recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1831–1839. [Google Scholar] [CrossRef]
- Khoali, M.; Tali, A.; Laaziz, Y. Advanced recommendation systems through deep learning. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security, Marrakech, Morocco, 31 March–2 April 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, S.; Tang, Y.; Zhu, Y.; Wang, L.; Xie, X.; Tan, T. Session-based recommendation with graph neural networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 346–353. [Google Scholar] [CrossRef]
- Agrawal, N.; Sirohi, A.K.; Kumar, S. No Prejudice! Fair Federated Graph Neural Networks for Personalized Recommendation. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 10775–10783. [Google Scholar] [CrossRef]
- Liu, L.; Wang, L.; Lian, T. CaSe4SR: Using category sequence graph to augment session-based recommendation. Knowl.-Based Syst. 2021, 212, 106558. [Google Scholar] [CrossRef]
- Qiu, R.; Li, J.; Huang, Z.; Yin, H. Rethinking the item order in session-based recommendation with graph neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 579–588. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar] [CrossRef]
- Ludewig, M.; Jannach, D. Evaluation of session-based recommendation algorithms. User Model.-User-Adapt. Interact. 2018, 28, 331–390. [Google Scholar] [CrossRef]
- Bonnin, G.; Jannach, D. Automated generation of music playlists: Survey and experiments. ACM Comput. Surv. 2014, 47, 1–35. [Google Scholar] [CrossRef]
- Wang, M.; Ren, P.; Mei, L.; Chen, Z.; Ma, J.; De Rijke, M. A collaborative session-based recommendation approach with parallel memory modules. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 345–354. [Google Scholar] [CrossRef]
- Tan, Y.K.; Xu, X.; Liu, Y. Improved recurrent neural networks for session-based recommendations. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 17–22. [Google Scholar] [CrossRef]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing session-based recommendations with hierarchical recurrent neural networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 130–137. [Google Scholar] [CrossRef]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Fan, Z.; Liu, Z.; Wang, Y.; Wang, A.; Nazari, Z.; Zheng, L.; Peng, H.; Yu, P.S. Sequential recommendation via stochastic self-attention. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2036–2047. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, P.; Zhao, L.; Liu, Y.; Sheng, V.S.; Zhou, X. Variational self-attention network for sequential recommendation. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1559–1570. [Google Scholar] [CrossRef]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar] [CrossRef]
- Luo, A.; Zhao, P.; Liu, Y.; Zhuang, F.; Wang, D.; Xu, J.; Fang, J.; Sheng, V.S. Collaborative Self-Attention Network for Session-based Recommendation. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI-20), Yokohama, Japan, 11–17 July 2020; pp. 2591–2597. [Google Scholar]
- Zhu, X.; Zhang, Y.; Wang, J.; Wang, G. Graph-enhanced and collaborative attention networks for session-based recommendation. Knowl.-Based Syst. 2024, 289, 111509. [Google Scholar] [CrossRef]
- Wu, J.; Cai, R.; Wang, H. Déjà vu: A contextualized temporal attention mechanism for sequential recommendation. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2199–2209. [Google Scholar] [CrossRef]
- Wang, H.; Zeng, Y.; Chen, J.; Han, N.; Chen, H. Interval-enhanced graph transformer solution for session-based recommendation. Expert Syst. Appl. 2023, 213, 118970. [Google Scholar] [CrossRef]
- Huang, C.; Chen, J.; Xia, L.; Xu, Y.; Dai, P.; Chen, Y.; Bo, L.; Zhao, J.; Huang, J.X. Graph-enhanced multi-task learning of multi-level transition dynamics for session-based recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 4123–4130. [Google Scholar] [CrossRef]
- Xu, C.; Zhao, P.; Liu, Y.; Sheng, V.S.; Xu, J.; Zhuang, F.; Fang, J.; Zhou, X. Graph contextualized self-attention network for session-based recommendation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, China, 10–16 August 2019; Volume 19, pp. 3940–3946. [Google Scholar]
- Luo, J.; He, M.; Pan, W.; Ming, Z. BGNN: Behavior-aware graph neural network for heterogeneous session-based recommendation. Front. Comput. Sci. 2023, 17, 175336. [Google Scholar] [CrossRef]
- Tang, G.; Zhu, X.; Guo, J.; Dietze, S. Time enhanced graph neural networks for session-based recommendation. Knowl.-Based Syst. 2022, 251, 109204. [Google Scholar] [CrossRef]
- Pan, Z.; Cai, F.; Chen, W.; Chen, H.; De Rijke, M. Star graph neural networks for session-based recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Galway, Ireland, 19–23 October 2020; pp. 1195–1204. [Google Scholar] [CrossRef]
- Chen, T.; Wong, R.C.W. Handling Information Loss of Graph Neural Networks for Session-based Recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 23–27 August July 2020; pp. 1172–1180. [Google Scholar] [CrossRef]
- Xia, X.; Yin, H.; Yu, J.; Wang, Q.; Cui, L.; Zhang, X. Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 4503–4511. [Google Scholar] [CrossRef]
- Pan, Z.; Cai, F.; Ling, Y.; de Rijke, M. An Intent-guided Collaborative Machine for Session-based Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, Xi’an, China, 25–30 July 2020; pp. 1833–1836. [Google Scholar] [CrossRef]
- Pan, Z.; Cai, F.; Chen, W.; Chen, C.; Chen, H. Collaborative Graph Learning for Session-based Recommendation. ACM Trans. Inf. Syst. 2022, 40, 1–26. [Google Scholar] [CrossRef]
- Zhu, X.; Tang, G.; Wang, P.; Li, C.; Guo, J.; Dietze, S. Dynamic global structure enhanced multi-channel graph neural network for session-based recommendation. Inf. Sci. 2023, 624, 324–343. [Google Scholar] [CrossRef]
- Qiu, N.; Gao, B.; Tu, H.; Huang, F.; Guan, Q.; Luo, W. LDGC-SR: Integrating long-range dependencies and global context information for session-based recommendation. Knowl.-Based Syst. 2022, 248, 108894. [Google Scholar] [CrossRef]
- Pang, Y.; Wu, L.; Shen, Q.; Zhang, Y.; Wei, Z.; Xu, F.; Chang, E.; Long, B.; Pei, J. Heterogeneous global graph neural networks for personalized session-based recommendation. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 775–783. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Session-Sequential | Loss Function | Methodology |
|---|---|---|---|
| Item-KNN [21] | Session | BPR | KNN |
| FPMC [12] | Session | S-BPR | LFM+Markov Chains |
| GRU4Rec [13] | Session | BPR, TOP1 | GRU |
| NARM [26] | Sequential | BCE | Attention |
| STAMP [14] | Session | BCE | Attention |
| SASRec [30] | Sequential | BCE | Transformer |
| SR-GNN [16] | Session | BCE | GNN |
| GC-SAN [37] | Sequential | BCE | GNN+Attention |
| GCE-GNN [10] | Session | BCE | GNN+Attention |
| DHCN [42] | Session | BCE | Graph Convolutional Network |
| MTD [36] | Sequential | BCE | Graph+Attention |
| ICM-SR [43] | Session | BCE | Graph+Collaborative |
| CGL [44] | Session | KLD | Graph+Collaborative |
| DGS-MGNN [45] | Session | BCE | GNN+Attention |
| LDGC-SR [46] | Session | BCE | Graph+Attention |
| GCAN [33] | Sequential | BCE | Graph+Collaborative |
| CSRM [23] | Session | BCE | Encoder+RNN |
| FGNN [19] | Session | BCE | GNN |
| CTA [34] | Sequential | NLL, BPR | Attention |
| SR-IEM [9] | Session | BCE | Attention |
| HG-GNN [47] | Sequential | BCE | GNN+Encoder |
| IGT [35] | Sequential | BCE | Graph+Transformer |
| SkipGT [Ours] | Both | BCE | Skip-gram+Transformer |
| Datasets | Diginetica | Yoochoose 1/64 | Yoochoose 1/4 |
|---|---|---|---|
| Items | 43,097 | 16,766 | 29,618 |
| Clicks | 982,961 | 557,248 | 8,326,407 |
| Training Sets | 719,470 | 369,895 | 5,917,745 |
| Testing Sets | 60,858 | 55,898 | 55,898 |
| Avg. Length | 5.12 | 6.16 | 5.71 |
| Methods | Diginetica | Yoochoose 1/64 | Yoochoose 1/4 | |||
|---|---|---|---|---|---|---|
| P@20 | MRR@20 | P@20 | MRR@20 | P@20 | MRR@20 | |
| Item-KNN | 35.75 | 11.57 | 51.60 | 21.81 | 52.31 | 21.70 |
| FPMC | 26.53 | 6.95 | 45.62 | 15.01 | - | - |
| GRU4Rec | 29.45 | 8.33 | 60.64 | 22.89 | 59.53 | 22.60 |
| NARM | 49.70 | 16.17 | 68.32 | 28.63 | 69.73 | 29.23 |
| STAMP | 45.64 | 14.32 | 68.74 | 29.67 | 70.44 | 30.00 |
| SASRec | 52.97 | 18.43 | 68.39 | 29.26 | 68.27 | 29.22 |
| SR-GNN | 50.73 | 17.59 | 70.57 | 30.94 | 71.36 | 31.89 |
| GC-SAN | 52.33 | 18.37 | 69.49 | 30.25 | 70.37 | 31.05 |
| GCE-GNN | 54.22 | 19.04 | 70.90 | 31.26 | 71.40 | 31.49 |
| DHCN | 53.18 | 18.44 | 70.74 | 31.05 | 71.58 | 31.72 |
| MTD | 53.18 | 18.33 | 71.12 | 31.28 | 71.83 | 30.83 |
| ICM-SR | 52.28 | 17.63 | 71.11 | 31.23 | - | - |
| CGL | 52.11 | 18.64 | 69.32 | 29.96 | 70.05 | 31.13 |
| DGS-MGNN | 54.13 | 19.02 | 72.62 | 32.49 | 73.10 | 33.55 |
| LDGC-SR | 54.38 | 18.96 | - | - | - | - |
| GCAN | 54.73 | 19.69 | - | - | - | - |
| CSRM | 49.63 | 16.47 | 69.20 | 29.18 | 69.61 | 29.64 |
| FGNN | 51.21 | 17.21 | 71.03 | 30.74 | 71.49 | 31.08 |
| CTA | 50.51 | 17.19 | 70.25 | 30.65 | 71.25 | 31.11 |
| SR-IEM | 50.35 | 17.06 | 70.03 | 30.16 | 70.45 | 30.11 |
| HG-GNN | 49.88 | 16.29 | 69.31 | 29.02 | 70.37 | 30.86 |
| IGT | 40.13 | 17.94 | 71.82 | 31.35 | 72.13 | 31.93 |
| SkipGT (Ours) | 55.72 | 20.69 | 76.78 | 34.59 | 77.32 | 35.29 |
| Improv. (%) | 1.8 | 5.1 | 5.73 | 6.46 | 5.77 | 5.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Celik, E.; Ilhan Omurca, S. Skip-Gram and Transformer Model for Session-Based Recommendation. Appl. Sci. 2024, 14, 6353. https://doi.org/10.3390/app14146353
Celik E, Ilhan Omurca S. Skip-Gram and Transformer Model for Session-Based Recommendation. Applied Sciences. 2024; 14(14):6353. https://doi.org/10.3390/app14146353
Chicago/Turabian StyleCelik, Enes, and Sevinc Ilhan Omurca. 2024. "Skip-Gram and Transformer Model for Session-Based Recommendation" Applied Sciences 14, no. 14: 6353. https://doi.org/10.3390/app14146353
APA StyleCelik, E., & Ilhan Omurca, S. (2024). Skip-Gram and Transformer Model for Session-Based Recommendation. Applied Sciences, 14(14), 6353. https://doi.org/10.3390/app14146353