1. Introduction
In parallel with the intensification of human activities, the deterioration of water quality and the associated ecological damage have become more pronounced [
1]. As a result, one of the most important ways to protect water resources is through real-time water quality monitoring and wastewater treatment [
2]. In the last few years, a great deal of research has been conducted to monitor and forecast water quality parameters such as turbidity, transparency, potential of hydrogen (pH), chemical oxygen demand (COD), dissolved oxygen (DO), total phosphorus (TP), and others. Researchers have employed a variety of methodologies in their investigations [
3,
4,
5], with the objective of developing a rapid and accurate prediction of water quality parameters, which will enable water supply companies or water treatment companies to identify the trends of water quality deterioration and to implement timely treatments of abnormal water [
6].
Traditional mechanistic models and emerging, data-driven, non-mechanistic-based models are the main approaches for forecasting water quality parameters. However, traditional mechanistic modeling methods are very complex and less generalizable [
7], so non-mechanistic water quality forecasting models are now commonly used to forecast long-term and short-term trends in water quality parameters [
8]. Among the most frequently employed methodologies are the grey system model method, regression analysis method, time series domain analysis method, and machine learning (ML) forecasting method. For instance, Fan et al. [
9] aim to forecast the long-term effects of rapid population growth on the quality of a river water body in the near future using a deformed-derivative, cumulative, grey, multi-convolution model. In order to improve the accuracy of their model, they incorporated the accumulation of deformed derivatives. Research on the grey model has shown that the model is faster at forecasting small samples of data, yet the methodology employs a limited quantity of sample data, rendering it challenging to discern the long-term characteristics of the water quality parametric data. Huang et al. [
10] devised a method for assessing changes in water quality parameters and turning points in trends by integrating segmented regression and locally weighted polynomial regression methods. Good prediction results were obtained and the research records demonstrated that the method was efficient. Regression analysis is a highly scalable technique, but it does have a significant drawback: it necessitates the utilization of a substantial quantity of sample data, and it cannot be guaranteed that it will yield accurate results when forecasting long-term series [
11]. As a matter of fact, water quality parameters are a dynamically changing time series with historical characteristics, and their prediction process is progressive, with strong correlation between current and historical water quality parameters [
12]. Among time series domain forecasting methods, traditional methods such as the autoregressive integrated moving average (ARIMA) and modern machine learning methods such as the transformer each play their respective roles. A water quality prediction method combining ARIMA and clustering models was employed by Wu Jiang et al. [
13]. Their prediction object was selected to be the water quality TP index, and ARIMA was utilized for forecasting the water quality parameters, resulting in satisfactory water quality prediction outcomes. To enhance the accuracy and reliability of time series prediction, Sarkar et al. introduced an integrated learning model known as GATE [
14]. This model addresses overfitting in deep learning by optimizing parameters within the integrated structure. It utilizes sample loss and weight update functions, along with unsupervised learning strategies, to guide network output. Empirical findings demonstrate that the GATE model outperforms existing models when dealing with long-term prediction tasks.
Recent research findings have indicated that machine learning and deep learning models are significantly impacting the realm of time series prediction, particularly in the context of forecasting water quality parameters. Furthermore, the integration of machine learning and deep learning techniques with traditional methods to construct hybrid models has emerged as a prominent trend in advancing water quality prediction. By incorporating self-attention mechanisms and intricate network structures, these models excel at capturing long-term dependencies and complex patterns, making them well suited for handling high-dimensional and intricate time series data. Despite their increased computational requirements, these models typically outperform traditional methods in terms of predictive accuracy, particularly in scenarios involving long time series and high-dimensional data [
15,
16]. To forecast the quantity of detrimental cyanobacterial cells in a body of water, Ahn and colleagues integrated a convolutional neural network (CNN) and transformer algorithms to develop a consolidated predictive model [
17]. They utilized algal water quality data collected from 2012 to 2021 to train the model and compared the results with a temporal fusion transformer (TFT), and the efficacy of the approach was validated with data from 2022. As one of the important branches of machine learning and deep learning, artificial neural networks have obvious advantages in handling time series prediction problems. General recurrent neural networks (RNNs) are susceptible to the challenges of gradient vanishing and gradient explosion when utilized [
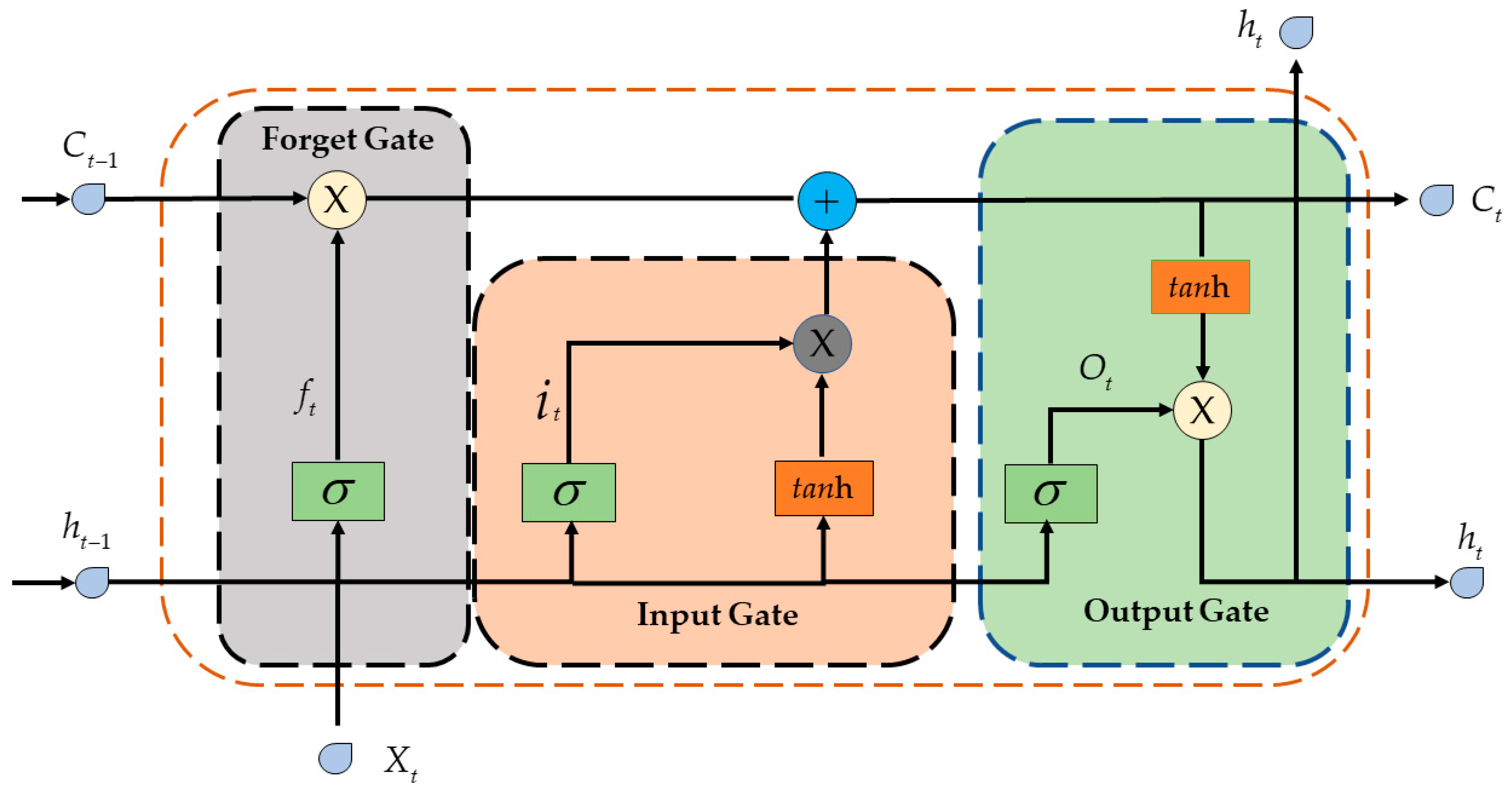
18]. To address these limitations, long short-term memory (LSTM) neural networks have been developed as potential solutions. Tan et al. [
19] constructed a fusion model of a CNN and LSTM model to forecast the dissolved oxygen parameters of water quality based on the seasonal and nonlinear characteristics of the water quality’s parametric variations. The CNN extracts local features from preprocessed water quality parametric data and feeds these sequences into an LSTM model for forecasting. This approach yields good prediction results. Peng et al. collected five-year historical monitoring data of chemical oxygen demand (COD) and ammonia nitrogen indicators in water bodies within the Fenjiang River Basin, China. They then established a single-factor water quality prediction model based on long short-term memory (LSTM) and utilized the wavelet packet denoising (WPD) technique for noise reduction in the dataset. The results of their study demonstrated that the model yield satisfactory resulted in predicting the impacts of COD and ammonia nitrogen indicators on the water quality of the river [
20]. In order to overcome the limitations associated with the conventional LSTM neural network in hyperparametric selection, a significant number of scholars have employed sophisticated optimization algorithms with the objective of identifying an optimal solution for hyperparameters and thereby achieving enhanced prediction outcomes [
21]. For instance, Liu et al. used an improved particle swarm optimization (PSO) algorithm to optimize the hyperparameters of the LSTM neural network [
22]. The mean absolute precision error (MAPE) metric of the optimized final model was reduced by 8.993% to 25.996%, while experimental outcomes indicated that hyperparametric optimization could enhance the network’s prediction performance. In order to improve model training efficiency and model performance while conserving computing power, numerous scholars have adopted the GRU neural network [
23,
24,
25], which exhibits comparable predictive capabilities to the LSTM neural network and a more streamlined structure. Moreover, the use of intelligent bionic optimization algorithms for adaptive optimization in the selection of hyperparameters for the GRU model is very helpful in improving the performance of the model [
26]. Yang et al. employed an improved whale optimization algorithm (IWOA) for the optimization of the GRU model in order to provide a reference for modeling water quality prediction models [
27]. The IWOA–GRU was then compared with other prediction models, including the random forest (RF) model, RNN model, CNN model, and LSTM model. The findings of their experiment demonstrated that the model’s predictive accuracy and generalization capabilities surpassed those of the comparison models. Among the above-mentioned optimization algorithms, the improved PSO algorithm emulates the foraging habits of a bird flock, considering each candidate solution as a particle. This algorithm features a straightforward structure and a rapid convergence rate, making it suitable for real-time applications. Nonetheless, with continuous iterations, particles may assimilate too much, thereby reducing their exploratory abilities. On the other hand, the IWOA algorithm models the search process based on the predatory behavior of whales and incorporates dynamic adjustment parameters to boost search efficacy. While this algorithm excels in high-dimensional and complex search spaces, it is computationally intensive and challenging to implement. The grey wolf optimizer (GWO) algorithm has been a focal point of interest among researchers in recent years because of its impressive convergence capabilities, minimal parametric requirements, and straightforward implementation. Its effectiveness in optimizing complex problems has made it a popular choice for academics and professionals alike [
28,
29].
In the field of water quality parametric prediction, the latest research results also include signal decomposition and noise reduction in unstable and noisy water quality parametric data to improve the accuracy of the established prediction model, especially the modal decomposition method for historical water quality parameters. After decomposing the data, a multi-modal component combination prediction model is established to significantly enhance the prediction effect [
30,
31]. Currently, the widely used signal decomposition algorithms are the empirical mode decomposition (EMD) algorithm [
32], principal component analysis [
33], wavelet transform (WT), etc. Zhang et al. [
34] combined a data preprocessing module based on EMD with a prediction model based on LSTM neural networks in order to improve the accuracy of their modeling approach. In order to address the limitations of existing EMD signal decomposition methods, which are prone to endpoint effects and modal overlap [
35], as well as the challenges associated with WT, which involve selecting an appropriate decomposition scale, Khadiri et al. proposed an EWT method that combines EMD and WT. The results verified the effectiveness of this method in removing noise and performed better than other denoising algorithms in locating different parts of abnormal biomedical signal data [
36]. Researchers have also completed a lot of work to improve EMD. Rezaiy et al. used ensemble empirical mode decomposition (EEMD) combined with the ARIMA method to establish a drought forecasting model, and their results showed that using the EEMD–ARIMA model significantly improved the accuracy of their drought forecast [
37]. Roushangar et al. used CEEMD combined with the LSTM method to establish a prediction model for the DO indicator of water pollution [
38]. The introduction of the CEEMDAN method increased their modeling accuracy by 35%. On the other hand, a variational mode decomposition (VMD) method that can also solve the shortcomings of EMD was proposed by Konstantin et al. The VMD is distinguished by its quasi-orthogonality, non-recursive properties, and strong auto-adaptive capability [
39]. Hu et al. introduced a technique for spectral sample generation utilizing variational mode decomposition in conjunction with a generative adversarial network [
40], and the method’s efficiency was assessed by constructing a regression model and forecasting the COD in real water samples. In order to improve the accuracy of water quality prediction, He et al. [
41] utilized the VMD to reduce noise in the datasets of total nitrogen and total phosphorus gathered from four online monitoring stations surrounding a lake. Through the implementation of this approach, accurate final data regarding water quality parameters for every element are successfully anticipated. Their evaluation yielded advantageous outcomes with regards to the forecasting of water quality.
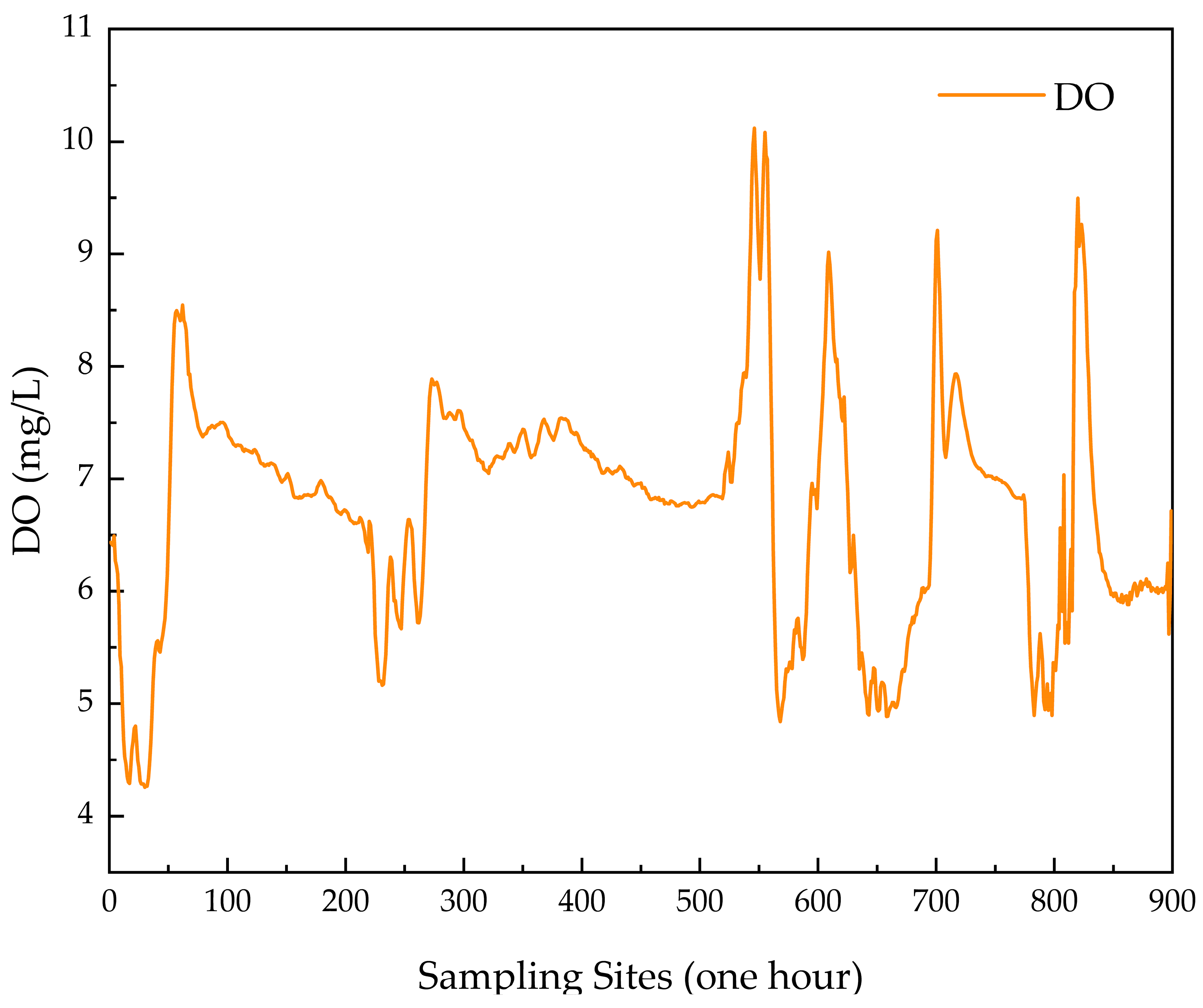
According to the research presented above, to thoroughly analyze the patterns of change over time in water quality parameter data and enhance the precision of the forecasting model, this study focuses on DO, a crucial water quality parameter. A novel hybrid model, named VMD–GWO–GRU, is proposed to forecast water quality parameters by employing the VMD technique for data feature extraction and signal denoising, along with the GWO to upgrade the conventional GRU model. Unlike conventional neural networks, this approach addresses the issue of challenging parameter tuning, aiming to boost the forecasting accuracy of water quality parameters. The findings of this research will facilitate the forecasting of important water quality metrics and provide essential assistance to water treatment organizations in improving their capacity to observe and regulate water quality.
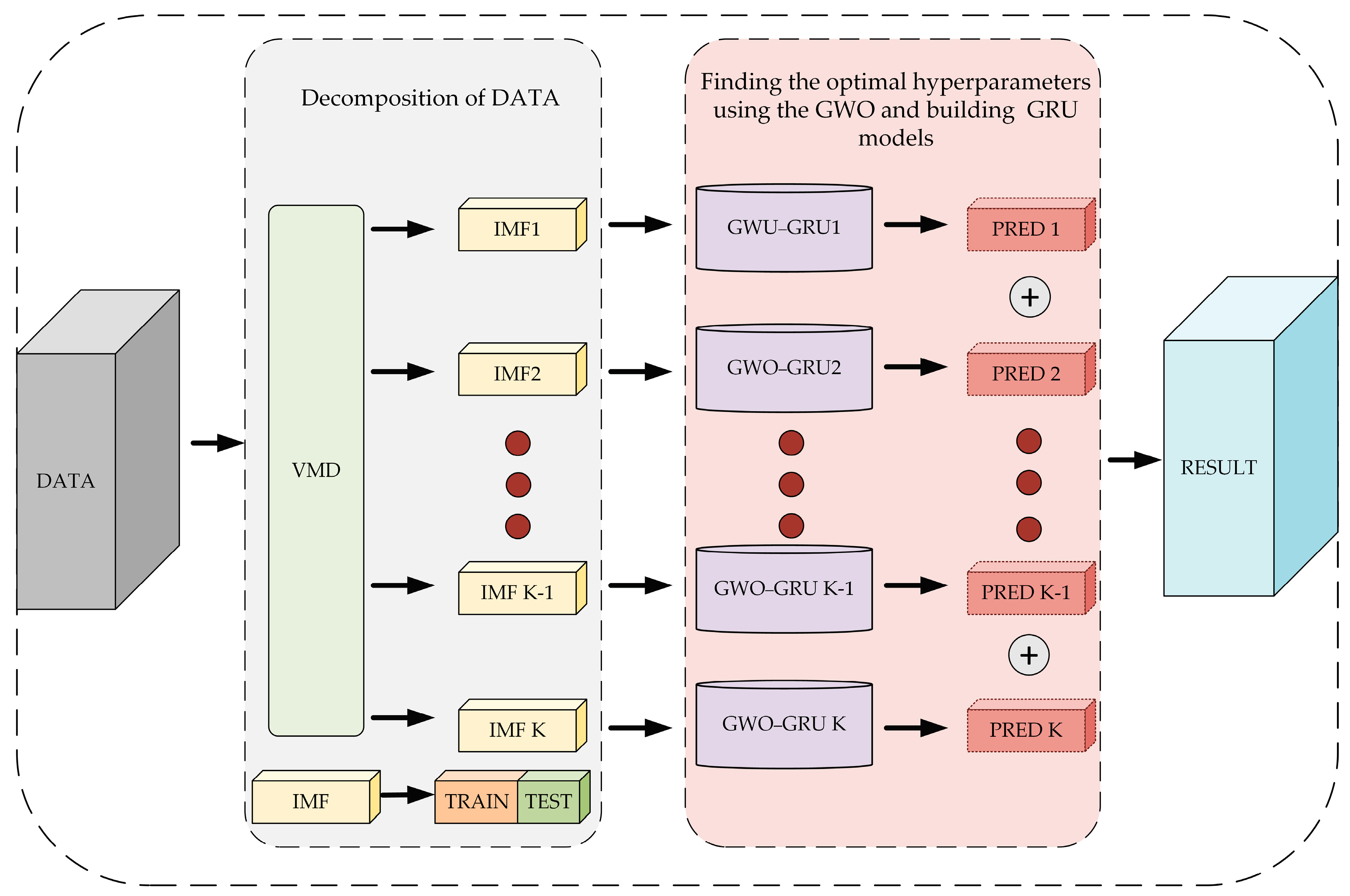
The experiment scheme of this study can be seen in
Figure 1. Initially, the raw data were processed in advance to obtain a dataset, which was then divided into K different modal components using the VMD technique, which are represented as intrinsic mode function (IMF)1 to IMF K in
Figure 1. Each modal component was divided into a training dataset and a test dataset. The training dataset was used to train the model, and the test dataset was used to evaluate the effectiveness of the model. After that, a GRU neural network was built for each component, and the parameters of each GRU model were adjusted using the GWO algorithm during the training process. These models are represented as GWO–GRU1 to GWO–GRU K in
Figure 1. Finally, the prediction results PRED 1 to PRED K of each part were superposed and calculated to obtain the final prediction result.
This paper is structured in a systematic manner to provide a comprehensive overview of the study conducted. The sources of water quality parametric data acquisition are discussed in
Section 2, along with the initial processing of the acquired data to ensure a quality dataset. Following this,
Section 3 delves into the methodology and theoretical basis used in this study, offering a detailed description of the approach taken. Moving on to
Section 4, the experimental procedure and results of the water quality parametric forecasting models are presented, accompanied by a comparison of the outcomes of each model. The effectiveness and reliability of the models were thus thoroughly analyzed and evaluated. Furthermore,
Section 5 examines the limitations of the research presented in this paper, while also highlighting potential avenues for future research and development in this field. Lastly, in
Section 6, a summary of the entire paper is provided, encapsulating the conclusions drawn from this study.
5. Discussion
The VMD–GWO–GRU model adopted in this paper integrates the GWO algorithm, VMD algorithm, and GRU neural network, which fully exploit the feature information hidden in the dissolved oxygen data and enhance the precision of water quality parametric prediction, but there are some aspects that need to be further discussed and improved.
In this paper, we employed the VMD decomposition technique to further break down dissolved oxygen data, thereby fully capturing the water quality parameters’ trends. The findings indicate that the VMD approach offers significant advantages in data decomposition, addressing the modal aliasing issue present in conventional signal decomposition algorithms, and enhancing the prediction accuracy of dissolved oxygen data. Additionally, we utilized the central frequency method to determine the number of decompositions, specifically eight. Future research can explore the use of intelligent optimization algorithms (such as PSO and GWO) to automatically adjust key parameters of the VMD algorithm, such as α and K, overcoming the difficulties of manual parameter tuning. By selecting appropriate objective functions as the basis for optimization, signal loss due to insufficient decomposition can be avoided, thereby enhancing the robustness and efficiency of VMD in practical applications.
Some hyperparameters of the GRU neural network were obtained by the grey wolf optimizer, and the experimental results showed that the GRU model established by applying the combination of these hyperparameters achieved a good predictive effect on the dissolved oxygen data. The number of experiments could be increased in future research to find better hyperparametric optimization intervals, reduce the number of iterations of GWO, and increase the speed of modeling. Meanwhile, the VMD–GWO–GRU model proposed in this paper currently focuses on predicting only one parameter, the DO level, with both model inputs and outputs being DO. Future research could explore the modeling prediction of more water quality parameters (including ammonia nitrogen level and pH) to improve the overall generalizability of the model. In addition, future studies should focus more on exploring the linkages between these water quality parameters, using more parameters as auxiliary variables for predicting a particular water quality parameter to improve the performance of the prediction model, and investigating the effectiveness of the model proposed in this paper in different regions and water body environments to provide a more reliable tool for water quality monitoring and treatment.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}