
Frequency-Separated Attention Network for Image Super-Resolution

Abstract
1. Introduction
- We introduce the novel deep convolutional neural network FSANet for image super-resolution tasks, utilizing a densely connected structure to leverage the powerful representational capability of deep CNNs and employing a parallel branching structure to separately process high- and low-frequency features.
- To further enhance the quality of the network’s output images, we incorporate attention mechanisms in the LFAB and HFAB to fully exploit informative features across both channel and spatial dimensions.
- Experimental results demonstrate that our proposed method achieves higher performance compared to state-of-the-art super-resolution methods.
2. Related Work
2.1. Image Super-Resolution Based on Deep Learning
2.2. Frequency-Separated Networks
2.3. Attention Networks
3. Method
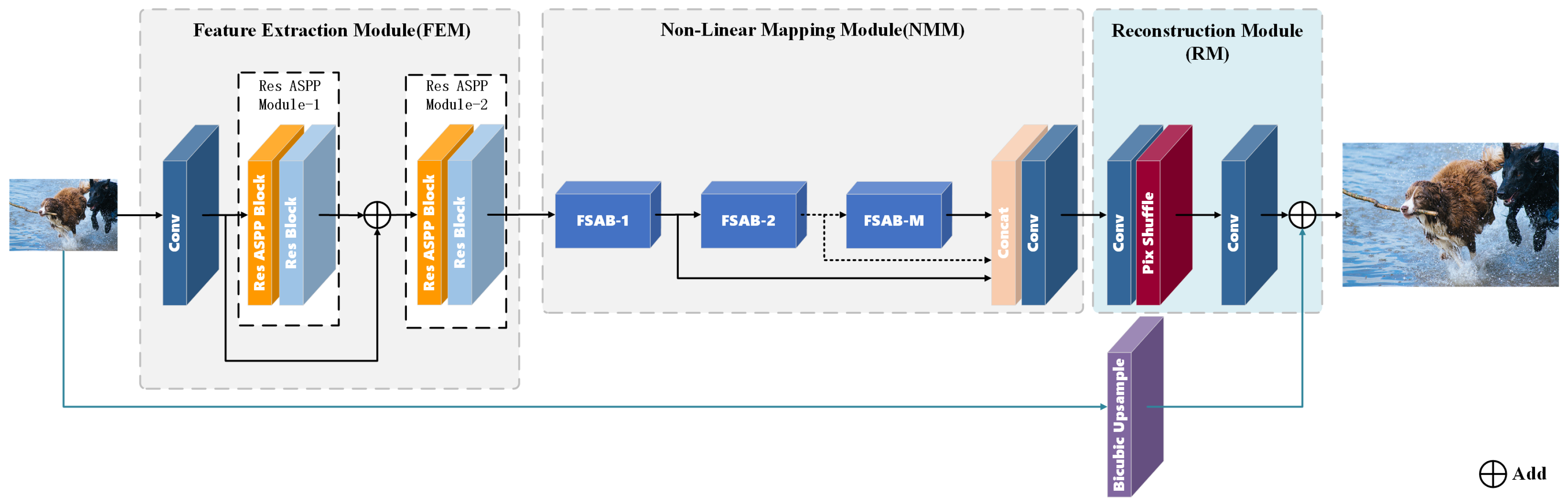
3.1. Network Architecture
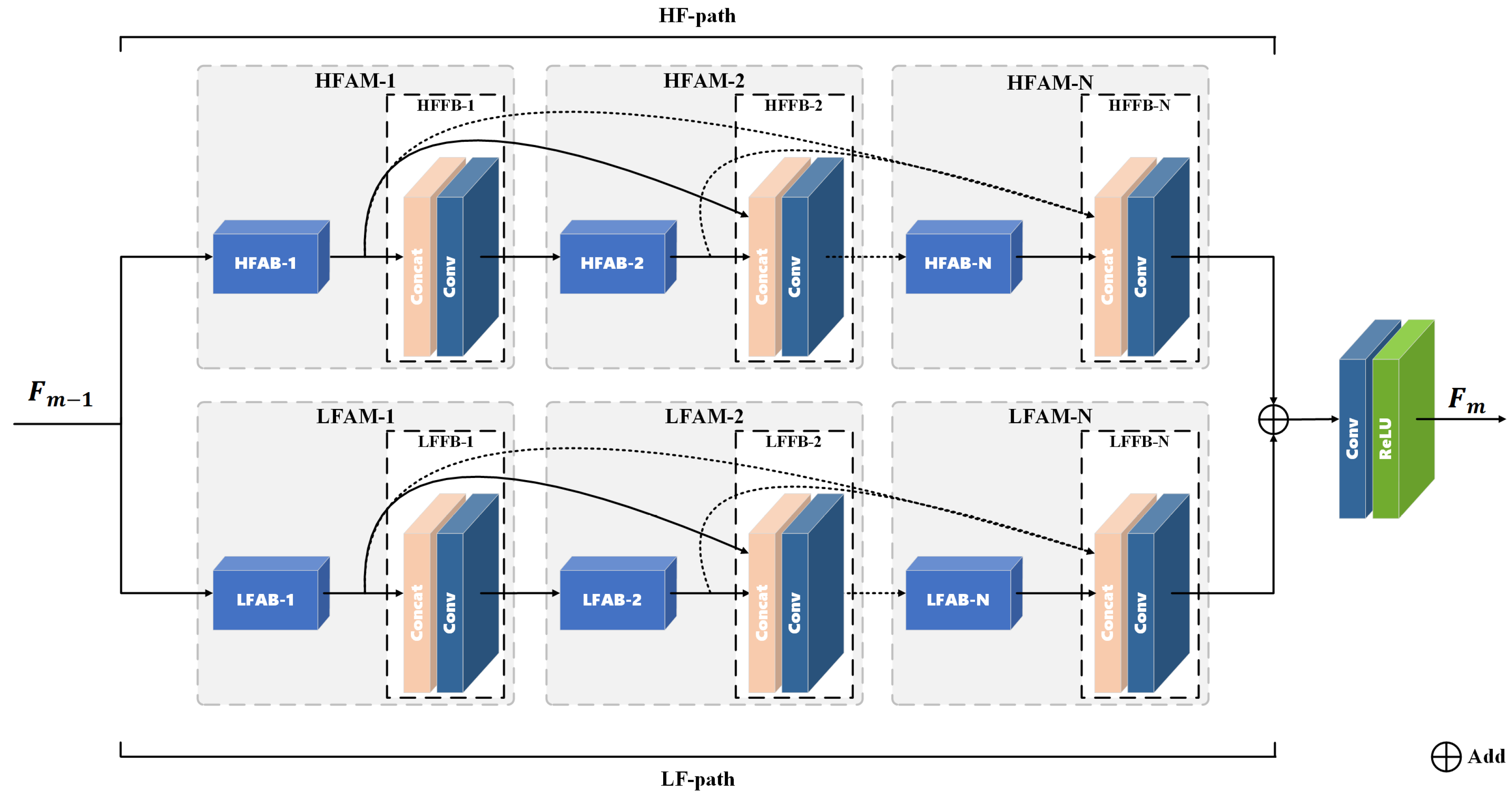
3.2. Frequency-Separated Attention Block
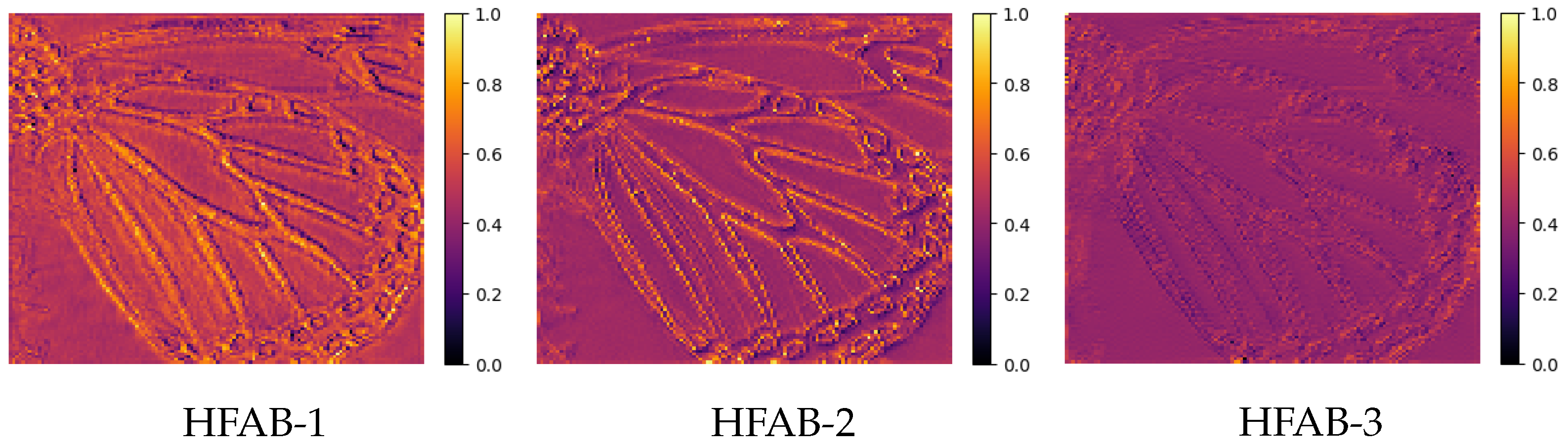
3.3. High-Frequency Attention Module
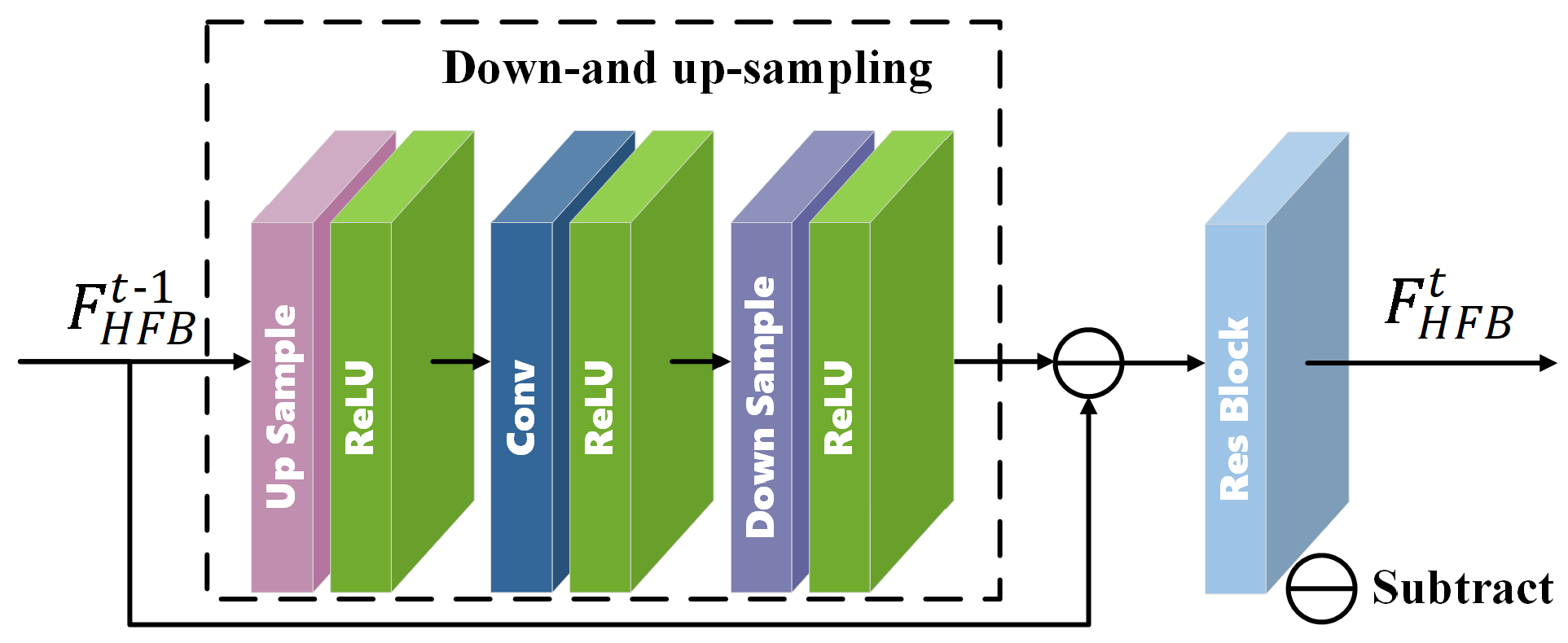
3.3.1. The Architecture of the HFAB
3.3.2. The Architecture of the HFB
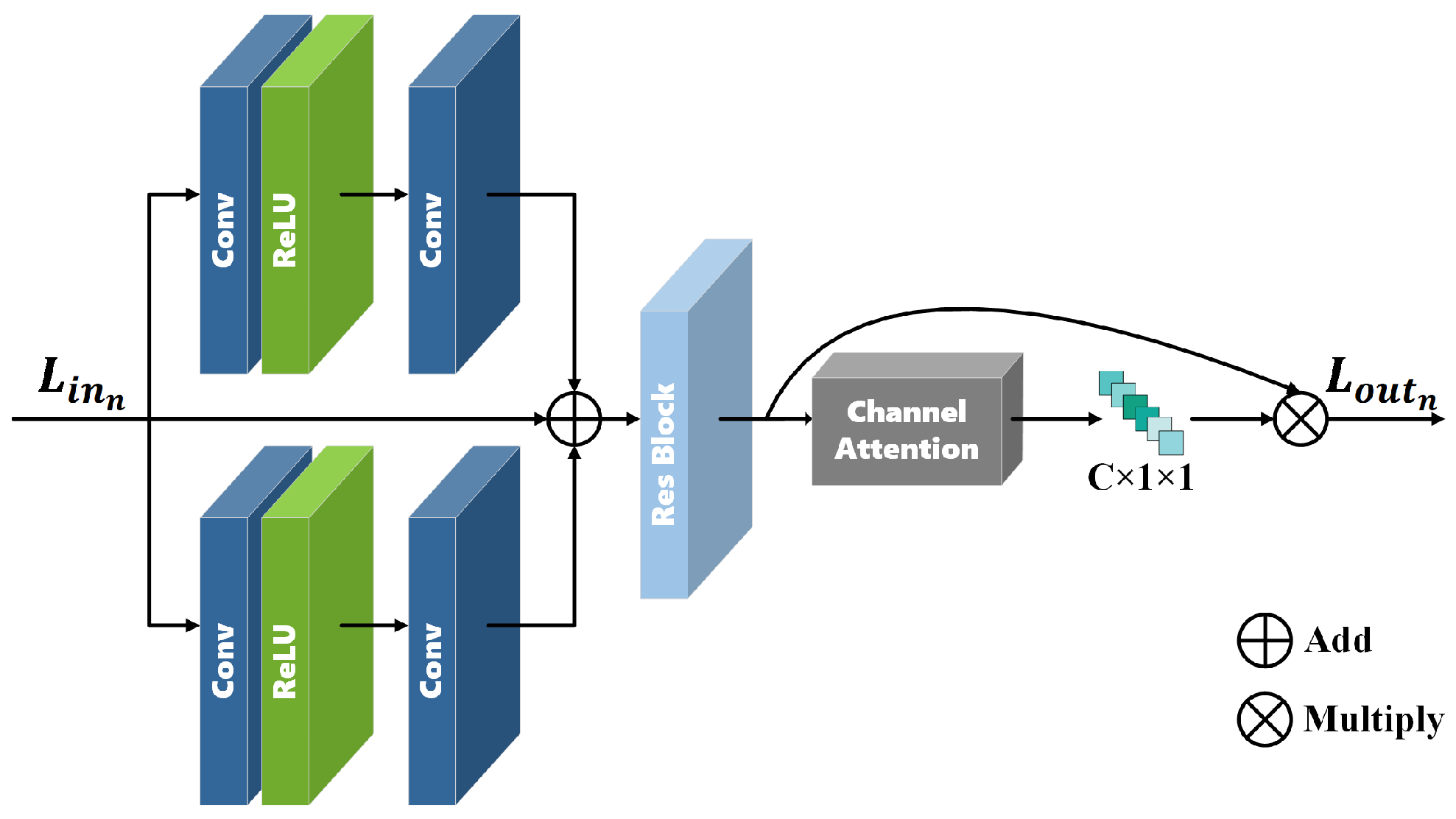
3.4. Low-Frequency Attention Module
4. Experiments
4.1. Settings
4.1.1. Datasets and Metrics
4.1.2. Implementation Details
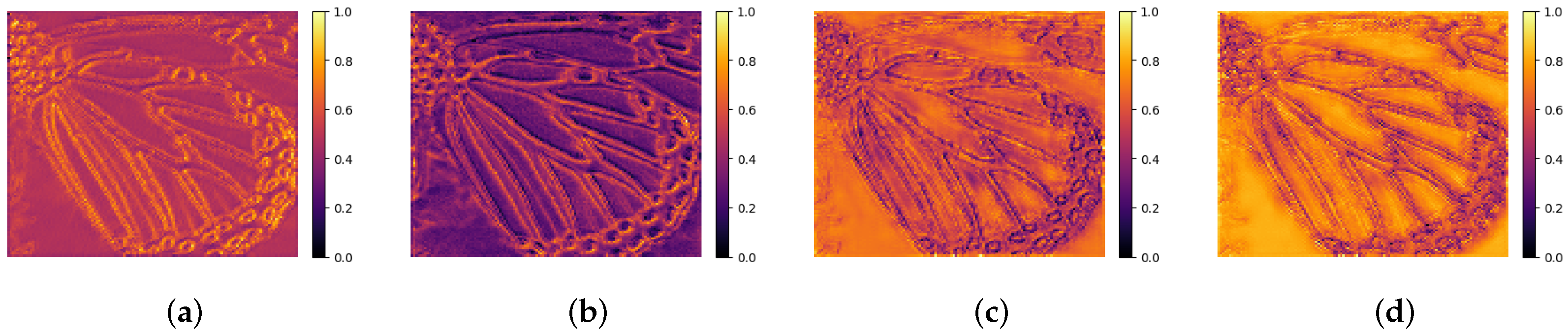
4.2. Ablation Study
4.2.1. The Effectiveness of Res ASPP Feature Extraction
4.2.2. The Effectiveness of Frequency-Separated Structures
4.2.3. The Effectiveness of Attention Mechanisms
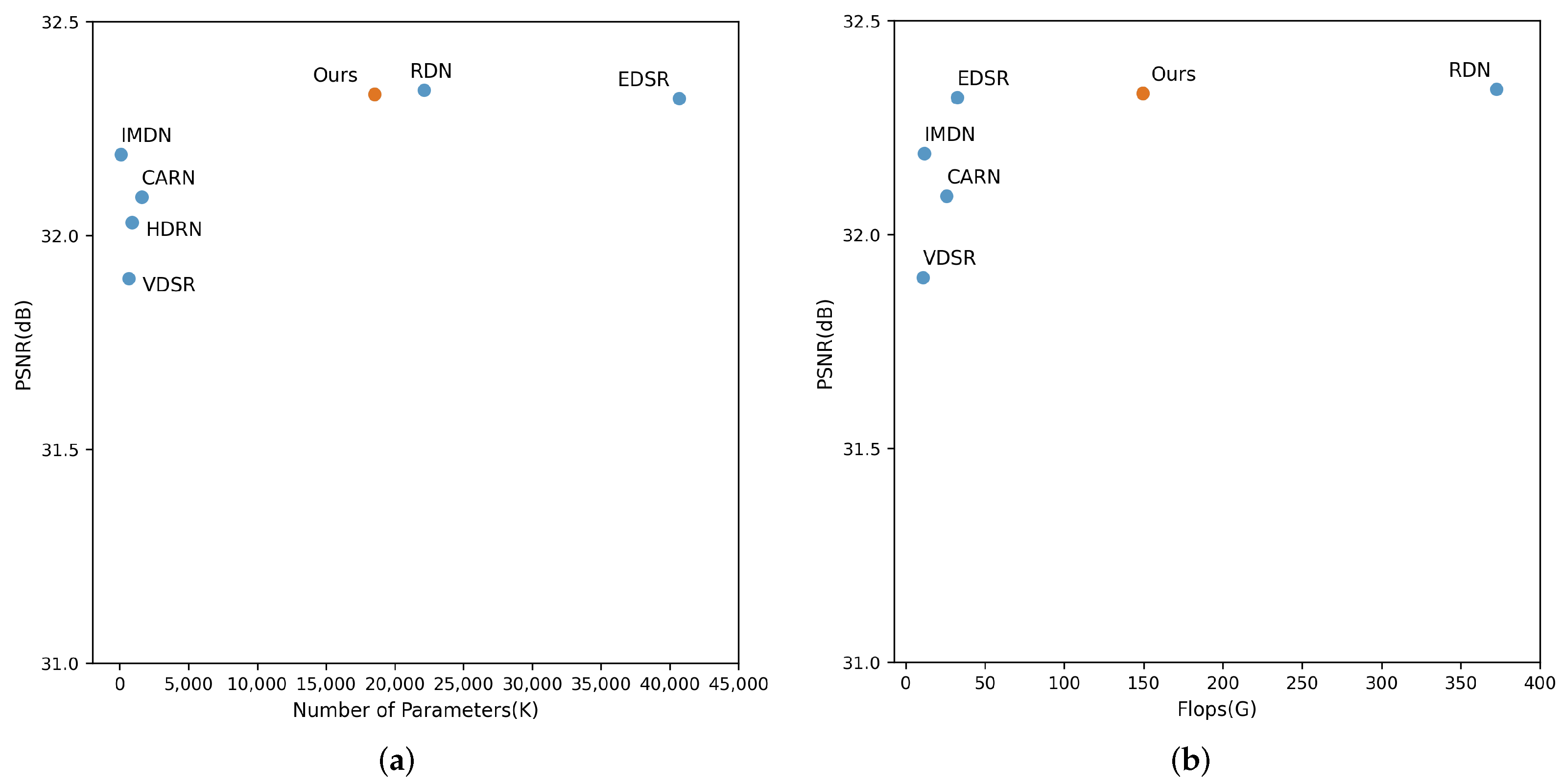
4.3. Comparison with State-of-the-Art Methods
4.3.1. Comparison and Visualization of PSNR and SSIM Results
4.3.2. Analysis of Model Comparisons
4.3.3. Comparison with Other Methods on Real-World Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, X.; Yuan, H.; Yan, P.; Yuan, Y.; Li, X. Geometry constrained sparse coding for single image super-resolution. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1648–1655. [Google Scholar]
- Gao, X.; Zhang, K.; Tao, D.; Li, X. Image super-resolution with sparse neighbor embedding. IEEE Trans. Image Process. 2012, 21, 3194–3205. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Wang, Z.; Wen, B.; Yang, J.; Han, W.; Huang, T.S. Robust single image super-resolution via deep networks with sparse prior. IEEE Trans. Image Process. 2016, 25, 3194–3207. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep networks for image super-resolution with sparse prior. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 370–378. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Dudczyk, J.; Rybak, Ł. Application of Data Particle Geometrical Divide Algorithms in the Process of Radar Signal Recognition. Sensors 2023, 23, 8183. [Google Scholar] [CrossRef]
- Rybak, Ł.; Dudczyk, J. Variant of data particle geometrical divide for imbalanced data sets classification by the example of occupancy detection. Appl. Sci. 2021, 11, 4970. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Zhao, M.; Cheng, C.; Zhang, Z.; Hao, X. Deep convolutional networks super-resolution method for reconstructing high frequency information of the single image. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 531–535. [Google Scholar]
- Zhou, F.; Li, X.; Li, Z. High-frequency details enhancing DenseNet for super-resolution. Neurocomputing 2018, 290, 34–42. [Google Scholar] [CrossRef]
- Liu, A.; Liu, Y.; Gu, J.; Qiao, Y.; Dong, C. Blind image super-resolution: A survey and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5461–5480. [Google Scholar] [CrossRef]
- Zamfir, E.; Conde, M.V.; Timofte, R. Towards real-time 4k image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1522–1532. [Google Scholar]
- Chen, J.; Li, B.; Xue, X. Scene text telescope: Text-focused scene image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12026–12035. [Google Scholar]
- Yue, Z.; Wang, J.; Loy, C.C. Resshift: Efficient diffusion model for image super-resolution by residual shifting. Adv. Neural Inf. Process. Syst. 2024, 13294–13307. [Google Scholar]
- Zhang, M.; Zhang, C.; Zhang, Q.; Guo, J.; Gao, X.; Zhang, J. Essaformer: Efficient transformer for hyperspectral image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 23073–23084. [Google Scholar]
- Lu, Y.; Wang, Z.; Liu, M.; Wang, H.; Wang, L. Learning spatial-temporal implicit neural representations for event-guided video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1557–1567. [Google Scholar]
- Turco, A.; Gheysens, O.; Nuyts, J.; Duchenne, J.; Voigt, J.U.; Claus, P.; Vunckx, K. Impact of CT-based attenuation correction on the registration between dual-gated cardiac PET and high-resolution CT. IEEE Trans. Nucl. Sci. 2016, 63, 180–192. [Google Scholar] [CrossRef]
- Tantawy, H.M.; Abdelhafez, Y.G.; Helal, N.L.; Kany, A.I.; Saad, I.E. Effect of correction methods on image resolution of myocardial perfusion imaging using single photon emission computed tomography combined with computed tomography hybrid systems. J. Phys. Commun. 2020, 4, 015011. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3867–3876. [Google Scholar]
- Li, S.; Cai, Q.; Li, H.; Cao, J.; Wang, L.; Li, Z. Frequency separation network for image super-resolution. IEEE Access 2020, 8, 33768–33777. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1664–1673. [Google Scholar]
- Yang, C.; Lu, G. Deeply recursive low-and high-frequency fusing networks for single image super-resolution. Sensors 2020, 20, 7268. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 714–722. [Google Scholar]
- Liu, Y.; Wang, Y.; Li, N.; Cheng, X.; Zhang, Y.; Huang, Y.; Lu, G. An attention-based approach for single image super resolution. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Beijing, China, 2018; pp. 2777–2784. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Lu, Y.; Zhou, Y.; Jiang, Z.; Guo, X.; Yang, Z. Channel attention and multi-level features fusion for single image super-resolution. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; IEEE: Taichung, Taiwan, 2018; pp. 1–4. [Google Scholar]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 3911–3927. [Google Scholar] [CrossRef]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution Based on Nonnegative Neighbor Embedding; BMVA Press: Durham, UK, 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7. Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, Y.; Liang, Z.; Lin, Z.; Yang, J.; An, W.; Guo, Y. Learning parallax attention for stereo image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12250–12259. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J. Hierarchical dense recursive network for image super-resolution. Pattern Recognit. 2020, 107, 107475. [Google Scholar] [CrossRef]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. Adv. Neural Inf. Process. Syst. 2020, 33, 20343–20355. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Wang, X.; Wang, Q.; Zhao, Y.; Yan, J.; Fan, L.; Chen, L. Lightweight single-image super-resolution network with attentive auxiliary feature learning. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Behjati, P.; Rodriguez, P.; Tena, C.F.; Mehri, A.; Roca, F.X.; Ozawa, S.; Gonzalez, J. Frequency-based enhancement network for efficient super-resolution. IEEE Access 2022, 10, 57383–57397. [Google Scholar] [CrossRef]
- Cai, J.; Zeng, H.; Yong, H.; Cao, Z.; Zhang, L. Toward real-world single image super-resolution: A new benchmark and a new model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3086–3095. [Google Scholar]
- Wei, P.; Xie, Z.; Lu, H.; Zhan, Z.; Ye, Q.; Zuo, W.; Lin, L. Component divide-and-conquer for real-world image super-resolution. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 101–117. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Deactivate Res ASPP Module PSNR/SSIM | Activate Res ASPP Module PSNR/SSIM |
|---|---|---|
| Set5 | 38.19/0.9610 | 38.20/0.9612 |
| Set14 | 33.79/0.9190 | 33.88/0.9200 |
| BSD100 | 32.29/0.9009 | 32.33/0.9016 |
| Urban100 | 32.69/0.9337 | 32.83/0.9351 |
| Manga109 | 39.03/0.9778 | 39.11/0.9781 |
| Dataset | LF Path PSNR/SSIM | HF Path PSNR/SSIM | LF Path and HF Path PSNR/SSIM |
|---|---|---|---|
| Set5 | 38.09/0.9608 | 38.15/0.9609 | 38.20/0.9612 |
| Set14 | 33.78/0.9192 | 33.73/0.9186 | 33.88/0.9200 |
| BSD100 | 32.24/0.9004 | 32.26/0.9005 | 32.33/0.9016 |
| Urban100 | 32.46/0.9315 | 32.57/0.9324 | 32.83/0.9351 |
| Manga109 | 38.91/0.9776 | 38.98/0.9777 | 39.11/0.9781 |
| Dataset | Deactivate Attention PSNR/SSIM | Activate Attention PSNR/SSIM |
|---|---|---|
| Set5 | 38.16/0.9609 | 38.20/0.9612 |
| Set14 | 33.78/0.9190 | 33.88/0.9200 |
| BSD100 | 32.28/0.9009 | 32.33/0.9016 |
| Urban100 | 32.68/0.933 | 32.83/0.9351 |
| Manga109 | 39.02/0.9779 | 39.11/0.9781 |
| Method | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| Bicubic | ×2 | 33.68/0.9304 | 30.24/0.8691 | 29.56/0.8453 | 26.88/0.8405 | 30.80/0.9399 |
| SelfExSR | ×2 | 36.50/0.9537 | 32.23/0.9036 | 31.18/0.8855 | 29.38/0.9032 | –/– |
| Laplacian | ×2 | 25.91/0.8200 | 24.31/0.7825 | 24.19/0.7653 | 22.10/0.7643 | 24.19/0.8422 |
| SRCNN | ×2 | 36.66/0.9542 | 32.45/0.9067 | 31.36/0.8879 | 29.51/0.8946 | 35.60/0.9663 |
| FSRCNN | ×2 | 36.98/0.9556 | 32.62/0.9087 | 31.50/0.8904 | 29.51/0.8946 | 35.67/0.9710 |
| VDSR | ×2 | 37.53/0.9587 | 33.05/0.9127 | 31.90/0.8904 | 30.77/0.9141 | 37.22/0.9750 |
| HDRN | ×2 | 37.75/0.9590 | 33.49/0.9150 | 32.03/0.8980 | 31.87/0.9250 | 38.07/0.9770 |
| CARN | ×2 | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | 38.36/0.9764 |
| MemNet | ×2 | 37.78/0.9597 | 33.28/0.9142 | 32.08/0.8978 | 31.31/0.9195 | 37.72/0.9740 |
| SRMD | ×2 | 37.79/0.9601 | 33.32/0.9159 | 32.05/0.8985 | 31.33/0.9204 | 38.07/0.9761 |
| IMDN | ×2 | 38.00/0.9605 | 33.63/0.9177 | 32.19/0.8996 | 32.17/0.9283 | 38.88/0.9774 |
| LAPAR-A | ×2 | 38.01/0.9605 | 33.62/0.9183 | 32.19/0.8999 | 32.10/0.9283 | 38.67/0.9772 |
| A2F-L | ×2 | 38.09/0.9607 | 33.78/0.9192 | 32.23/0.9002 | 32.46/0.9313 | 38.95/0.9772 |
| FENet | ×2 | 38.08/0.9608 | 33.70/0.9184 | 32.20/0.9001 | 32.18/0.9287 | 38.89/0.9775 |
| Ours | ×2 | 38.20/0.9612 | 33.88/0.9200 | 32.33/0.9016 | 32.83/0.9351 | 39.11/0.9781 |
| Bicubic | ×3 | 30.40/0.8686 | 27.54/0.7741 | 27.21/0.7389 | 24.46/0.7349 | 26.95/0.8556 |
| SelfExSR | ×3 | 32.62/0.9094 | 29.16/0.8197 | 28.30/0.7843 | –/– | –/– |
| Laplacian | ×3 | 25.29/0.7246 | 24.03/0.6718 | 24.02/0.6496 | 21.77/0.6485 | 23.77/0.7616 |
| SRCNN | ×3 | 32.75/0.9090 | 29.29/0.8215 | 28.41/0.7863 | 26.24/0.7991 | 30.48/0.9117 |
| FSRCNN | ×3 | 33.16/0.9140 | 29.42/0.8242 | 28.52/0.7893 | 26.41/0.8064 | 31.10/0.9210 |
| VDSR | ×3 | 33.66/0.9213 | 29.78/0.8318 | 28.83/0.7976 | 27.14/0.8279 | 32.01/0.9340 |
| HDRN | ×3 | 34.24/0.9240 | 30.23/0.8400 | 28.96/0.8040 | 27.93/0.8490 | 33.17/0.9420 |
| CARN | ×3 | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | 33.49/0.9440 |
| MemNet | ×3 | 34.09/0.9248 | 30.00/0.8350 | 28.96/0.8001 | 27.56/0.8376 | 32.51/0.9369 |
| SRMD | ×3 | 34.12/0.9254 | 30.04/0.8382 | 28.97/0.8025 | 27.57/0.8398 | 33.00/0.9403 |
| IMDN | ×3 | 34.36/0.9270 | 30.32/0.8417 | 29.09/0.8046 | 28.17/0.8519 | 33.61/0.9445 |
| LAPAR-A | ×3 | 34.36/0.9267 | 30.34/0.8421 | 29.11/0.8054 | 28.15/0.8523 | 33.51/0.9441 |
| A2F-L | ×3 | 34.54/0.9283 | 30.41/0.8436 | 29.14/0.8062 | 28.40/0.8574 | 33.83/0.9463 |
| FENet | ×3 | 34.40/0.9273 | 30.36/0.8422 | 29.12/0.8060 | 28.17/0.8524 | 33.52/0.9444 |
| Ours | ×3 | 34.64/0.9299 | 30.51/0.8456 | 29.21/0.8078 | 28.70/0.8633 | 34.04/0.9474 |
| Bicubic | ×4 | 28.43/0.8109 | 26.00/0.7023 | 25.96/0.6678 | 23.14/0.6574 | 24.89/0.7866 |
| SelfExSR | ×4 | 30.33/0.8623 | 27.40/0.7518 | 26.85/0.7108 | 24.82/0.7386 | –/– |
| Laplacian | ×4 | 27.22/0.7544 | 25.41/0.6772 | 25.46/0.6492 | 22.71/0.6358 | 24.44/0.7567 |
| SRCNN | ×4 | 30.48/0.8628 | 27.50/0.7513 | 26.90/0.7103 | 24.52/0.7226 | 27.58/0.8555 |
| FSRCNN | ×4 | 30.70/0.8657 | 27.59/0.7535 | 26.96/0.7128 | 24.60/0.7258 | 27.90/0.8610 |
| VDSR | ×4 | 31.25/0.8838 | 28.02/0.7678 | 27.29/0.7252 | 25.18/0.7525 | 28.83/0.8870 |
| HDRN | ×4 | 32.23/0.8960 | 28.58/0.7810 | 27.53/0.7370 | 26.09/0.7870 | 30.43/0.9080 |
| CARN | ×4 | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | 30.40/0.9082 |
| MemNet | ×4 | 31.74/0.8893 | 28.26/0.7723 | 27.40/0.7281 | 25.50/0.7630 | 29.42/0.8942 |
| SRMD | ×4 | 31.96/0.8925 | 28.35/0.7787 | 27.49/0.7337 | 25.68/0.7731 | 30.09/0.9024 |
| IMDN | ×4 | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 |
| LAPAR-A | ×4 | 32.15/0.8944 | 28.61/0.7818 | 27.61/0.7366 | 26.14/0.7871 | 30.42/0.9074 |
| A2F-L | ×4 | 32.32/0.8964 | 28.67/0.7839 | 27.62/0.7379 | 26.32/0.7931 | 30.72/0.9115 |
| FENet | ×4 | 32.24/0.8961 | 28.61/0.7818 | 27.63/0.7371 | 26.20/0.7890 | 30.46/0.9083 |
| Ours | ×4 | 32.37/0.8969 | 28.72/0.7842 | 27.66/0.7385 | 26.49/0.7977 | 30.80/0.9118 |
| Dataset | DRealSR PSNR/SSIM | RealSR PSNR/SSIM |
|---|---|---|
| Bicubic | 30.78/0.8468 | 27.30/0.7557 |
| SRCNN | 30.88/0.8490 | 27.65/0.7711 |
| FSRCNN | 30.79/0.8473 | 27.65/0.7692 |
| CRAN | 30.82/0.8474 | 27.66/0.7700 |
| VDSR | 30.82/0.8458 | 27.52/0.7554 |
| IMDN | 30.80/0.8489 | 27.66/0.7717 |
| Ours | 31.47/0.8580 | 27.77/0.7739 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, D.; Li, L.; Yao, R. Frequency-Separated Attention Network for Image Super-Resolution. Appl. Sci. 2024, 14, 4238. https://doi.org/10.3390/app14104238
Qu D, Li L, Yao R. Frequency-Separated Attention Network for Image Super-Resolution. Applied Sciences. 2024; 14(10):4238. https://doi.org/10.3390/app14104238
Chicago/Turabian StyleQu, Daokuan, Liulian Li, and Rui Yao. 2024. "Frequency-Separated Attention Network for Image Super-Resolution" Applied Sciences 14, no. 10: 4238. https://doi.org/10.3390/app14104238
APA StyleQu, D., Li, L., & Yao, R. (2024). Frequency-Separated Attention Network for Image Super-Resolution. Applied Sciences, 14(10), 4238. https://doi.org/10.3390/app14104238