Abstract
Robot autonomous navigation has become a vital area in the industrial development of minimizing labor-intensive tasks. Most of the recently developed robot navigation systems are based on perceiving geometrical features of the environment, utilizing sensory devices such as laser scanners, range-finders, and microwave radars to construct an environment map. However, in robot navigation, scene understanding has become essential for comprehending the area of interest and achieving improved navigation results. The semantic model of the indoor environment provides the robot with a representation that is closer to human perception, thereby enhancing the navigation task and human–robot interaction. However, semantic navigation systems require the utilization of multiple components, including geometry-based and vision-based systems. This paper presents a comprehensive review and critical analysis of recently developed robot semantic navigation systems in the context of their applications for semantic robot navigation in indoor environments. Additionally, we propose a set of evaluation metrics that can be considered to assess the efficiency of any robot semantic navigation system.
1. Introduction
In the near future, robots will undoubtedly require a deeper understanding of their operational environment and the world around them in order to explore and interact effectively. Autonomous mobile robots are being developed as solutions for various industries, including transportation, manufacturing, education, and defense [1]. These mobile robots have diverse applications, such as monitoring, material handling, search and rescue missions, and disaster assistance. Autonomous robot navigation is another crucial concept in industrial development aimed at reducing manual effort. Often, autonomous robots need to operate in unknown environments with potential obstacles in order to reach their intended destinations [2,3].
Mobile robots, also known as autonomous mobile robots, have been increasingly employed to automate logistics and manual operations. The successful implementation of autonomous mobile robots relies on the utilization of various sensing technologies, such as range-finders, vision systems, and inertial navigation modules. These technologies enable the robots to effectively move from one point to another and navigate the desired area [4].
The process by which a robot selects its own position, direction, and path to reach a destination is referred to as robot navigation. Mobile robots utilize a variety of sensors to scan the environment and gather geometric information about the area of interest [5]. The authors of [6] revealed that the creation or representation of a map is achieved through the simultaneous localization and mapping (SLAM) approach. Generally, there are two types of SLAM approaches: filter-based and graph-based. The former focuses on the temporal aspect of sensor measurements, while the latter maintains a graph of the robot’s entire trajectory along with landmark locations.
While grid maps are effective for facilitating the point-to-point navigation of mobile robots in small 2D environments, they fall short when it comes to navigating real domestic scenes. This is because grid maps lack semantic information, which makes it difficult for end users to clearly specify the navigation task at hand [7].
On the other hand, a novel concept called semantic navigation has emerged as a result of recent efforts in the field of mobile robotics to integrate semantic data into navigation tasks. Semantic information represents object classes in a way that allows the robot to understand its surrounding environment at a higher level beyond just geometry. Consequently, with the assistance of semantic information, mobile robots can achieve better results in various tasks, including path planning and human–robot interaction [8].
Robots that utilize semantic navigation exhibit a greater similarity to humans in terms of how they model and comprehend their surroundings and how they represent it. Connecting high-level qualities to the geometric details of the low-level metric map is crucial for semantic navigation. High-level information can be extracted from data collected by various sensors, enabling the identification of locations or objects. By adding semantic meaning to the aspects and relationships within a scene, robots can comprehend high-level instructions associated with human concepts [9].
As illustrated in Figure 1, the design and development of a robot semantic navigation system involve several functions: localization, which entails estimating the robot’s position; path planning, which involves determining the available paths in the navigation area; cognitive mapping, which encompasses constructing a map of the area of interest; motion control, which governs how the robot platform moves from one point to another; and object recognition, which involves identifying objects in the area of interest to build a semantic map [10,11].
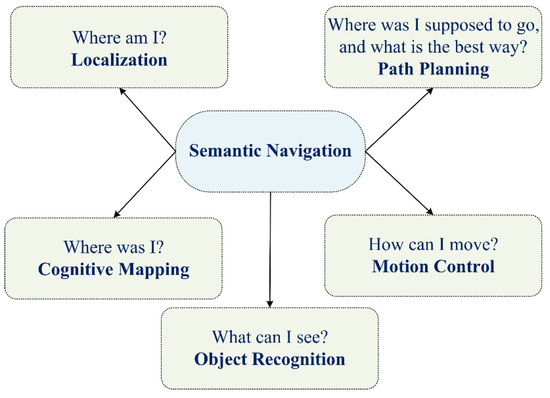
Figure 1.
Main components of robot semantic navigation.
The area of robot semantic navigation has received considerable attention recently, driven by the requirement to achieve high localization and path planning accuracy, with the ability to accurately recognize things (objects) in the navigation area. Recently, there have been several survey articles that have focused on various aspects of this field. For example, the work presented in [12] surveyed the use of reinforcement learning for autonomous driving, whereas the work discussed in [13] presented an overview of semantic mapping in mobile robotics, focusing on collaborative scenarios, where authors highlighted the importance of semantic maps in enabling robots to reason and make decisions based on the context of their environment. Additionally, the authors of [14] addressed the challenges involved in robot navigation in crowded public spaces, discussing both engineering and human factors that impede the seamless deployment of autonomous robots in such environments. Furthermore, the work presented in [9] explored the role of semantic information in improving robot navigation capabilities. The authors of [15] presented a comprehensive overview of semantic mapping in mobile robotics and highlighted its importance in facilitating communication and interaction between humans and robots.
Several methods and advancements in semantic mapping for mobile robots in indoor environments were discussed in [16], where the authors emphasized the importance of attaching semantic information to geometric maps to enable robots to interact with humans, perform complex tasks, and understand oral commands. On the other hand, the work discussed in [17] aimed to offer a comprehensive overview of semantic visual SLAM (VSLAM) and its potential to improve robot perception and adaptation in complex environments.
In addition, the authors of [18] presented an overview of the importance of semantic understanding for robots to effectively navigate and interact with their environment. The authors emphasized that semantics enable robots to comprehend the meaning and context of the world, enhancing their capabilities. Moreover, the work presented in [19] highlighted the recent advancements in applying semantic information to SLAM, focusing on the combination of semantic information and traditional visual SLAM for system localization and map construction.
As mentioned earlier, numerous research studies have surveyed the works that target the area of robot semantic navigation for indoor environments. Nevertheless, this paper distinguishes itself from existing works by specifically concentrating on semantic navigation systems designed for indoor settings. This paper goes on to categorize and discuss the various navigation technologies utilized, such as LiDAR, Vision, or Hybrid approaches. Additionally, it delves into the specific requirements for object recognition methods, considering factors such as the number of categorized objects, processing overhead, and memory requirements. Lastly, this paper introduces a set of evaluation metrics aimed at assessing the effectiveness and efficiency of different approaches to robot semantic navigation.
The remaining sections of this paper are organized as follows: Section 2 discusses the existing indoor robot semantic navigation systems, while Section 3 examines and compares the results obtained from these systems. Additionally, a list of evaluation metrics is presented. In Section 4, we discuss the lifecycle of developing an efficient robot semantic navigation system. Finally, Section 5 concludes the work presented in this paper.
2. Indoor Robot Semantic Navigation Systems
Recently, numerous robot navigation systems have been proposed in response to the need to automate various robot tasks by enabling robots to comprehend their surrounding environments. In general, robot navigation systems can be classified into two main categories: geometric-based and semantic-based navigation systems, as illustrated in Figure 2. Geometric-based navigation systems typically utilize LiDAR (light detection and ranging), RADAR (Radio Detection and Ranging), or range-finder modules to construct a map of the area based on distance measurements.
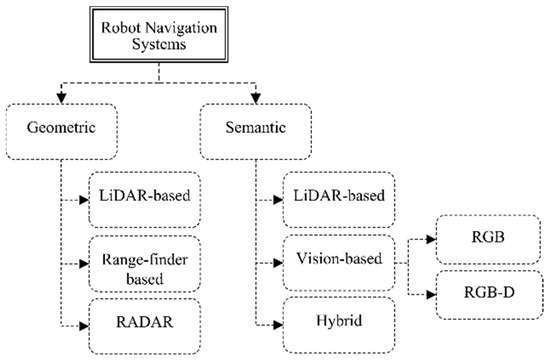
Figure 2.
Classification of robot navigation systems.
Geometric-based navigation systems utilize distance measurement technologies. For example, a LiDAR-based system employs a directed beam to estimate the distance between the LiDAR device and objects in its path, while a laser range-finder illuminates a larger area. In contrast, RADAR technology differs from LiDAR, as it uses wavelength signals instead of pulsed laser beams. However, this paper focuses on robot navigation systems that utilize semantic information specifically for indoor environments [20].
On the other hand, robot semantic navigation systems aim to construct maps with semantic information to assist mobile robots in navigation, recognition, and decision-making. Semantic navigation enables robots to understand the environment in a manner similar to humans. Scene understanding is one of the key tasks in robot semantic navigation, encompassing object detection and recognition, depth estimation, object tracking, and event classification. To achieve efficient robot semantic navigation, a mobile robot must comprehend both geometric and visual information [21].
As shown in Figure 2, robot semantic navigation can be further categorized into LiDAR-based, vision-based, and hybrid approaches. LiDAR-based systems gather information from LiDAR modules to categorize object types and structures, while vision-based systems employ sophisticated vision systems to recognize objects within the area of interest. Hybrid approaches combine both range-finder and vision systems. Therefore, this paper surveys, discusses, and analyzes recently developed robot semantic navigation systems for indoor environments.
The research method employed to acquire the newly developed robot semantic navigation systems adhered to a specific criterion, which is illustrated in Figure 3. The search process involved identifying pertinent research papers using the keywords “semantic navigation”, “robot”, and “indoor navigation”. Only papers published after 2010 were taken into account, with a specific emphasis on indoor robot semantic navigation systems. Research works that lacked simulation or real experiments were excluded.
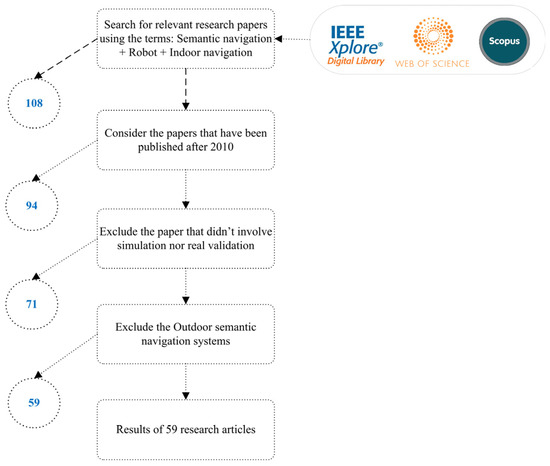
Figure 3.
Research methodology for surveying recently developed robot semantic navigation systems.
2.1. LiDAR Based Semantic Navigation Systems
These systems utilize data obtained from LiDAR sensors, which are processed, trained, and tested. LiDAR-based approaches aim to classify the environment type based on the LiDAR data, often performing pattern recognition for specific objects or places without relying on complex sensing technologies like vision systems. However, LiDAR-based semantic navigation has limitations in distinguishing between objects or places within the area of interest.
LiDAR technology has been employed in various semantic navigation robot systems. In [22], the authors developed a semantic mapping system to classify three different types of buildings: single-family, multiple-family, and non-residential buildings. Additionally, classification systems for forest environment characteristics were developed in [23,24]. In [25], an efficient classification system was proposed to continuously identify a person in a complex environment using LiDAR sensor information. Furthermore, [26] presented a method for the semantic classification of LiDAR data to distinguish between non-movable, movable, and dynamic objects.
The work presented in [27] focused on classifying four types of indoor environments, including doors, halls, corridors, and rooms, for the purpose of indoor semantic navigation. The developed system could distinguish between these different places and construct a map area with efficient classification accuracy for indoor spaces. However, the use of LiDAR sensors offers limited semantic information due to the nature of the sensed data.
A novel method for place recognition based on point clouds that were obtained from LiDAR scans was proposed by Xia et al. [28], where the authors presented CASSPR, which uses cross-attention transformers to integrate voxel- and point-based techniques. In order to extract and aggregate data at a lower resolution, CASSPR uses a sparse voxel branch, and to capture fine-grained local features, it uses a point-wise branch. Cross-attention links the two branches together so that they can share information and add to the point cloud’s global descriptor. Numerous datasets and extensive trials show that CASSPR achieves state-of-the-art performance in point-cloud place recognition tasks, outperforming earlier approaches by a large margin.
In [29], the authors employed a neural network named Vehicle Points Completion-Net (VPC-Net) to combine incomplete and sparse data from mobile laser scanning (MLS) systems to create complete and dense point clouds of cars. The network is made up of three modules: refiner, decoder, and encoder. Using a point feature improvement layer and a spatial transformer network, the encoder module extracts global features. The refiner module adds fine-grained information to the outputs while maintaining vehicle details, while the decoder module produces the first complete outputs. Using both synthetic and real-scan datasets, the proposed VPC-Net was validated and showed better results than the baseline techniques.
The employment of LiDAR data frames for the purpose of classifying the area of interest in indoor semantic navigation scenarios offers a fast, reliable, and low-overhead process approach. However, LiDAR-based semantic navigation systems offer a limited number of recognized objects (classes); this is due to the nature of the obtained data frames by the LiDAR perception unit.
2.2. Vision-Based Semantic Navigation Systems
Vision-based semantic navigation systems can be implemented using either RGB (Red Green Blue) cameras or RGB-D (RGB-Depth) cameras. RGB-based systems can recognize objects in the area of interest, while RGB-D-based systems can also measure the distance to recognized objects. RGB-D cameras are more useful for semantic navigation applications, as they provide better semantic information for indoor robot navigation.
2.2.1. RGB Based Systems
In [30], the authors developed a semantic segmentation network for an indoor robot navigation system. The system utilized a Residual Neural Network (RNN) and adopted ResNet-18 transfer learning to discriminate between the floor, walls, and obstacles such as furniture and boxes. Real experiments, using a robot platform, laptop, and webcam, were conducted to assess the classification accuracy of the developed system.
The work presented in [31] aimed to develop a visual navigation scheme based on a topological map, similar to the system used by humans. Additionally, a road-following scheme using a combination of image processing methods resulted in efficient semantic segmentation. The proposed system identifies a target point towards which the robot moves. Experimental results on a 500 m course on a university campus demonstrated that the robot controlled by the proposed approach could navigate the course adequately.
In [32], the authors created a vision-based framework for an indoor robot navigation system. The system leverages semantic segmentation and deep-learning techniques to achieve the precise and efficient mapping of indoor scenes. They introduced a path extraction scheme that utilizes deep convolutional neural networks (DCNNs) and transfer learning for semantic pixel-wise segmentation. The authors of [33] suggested using high-level semantic and contextual features included in the segmentation and detection masks and learning the navigation policy from observations. Furthermore, an optimal path-planning algorithm was employed as stronger supervision to estimate progress towards the goal point.
The work presented in [34] focused on semantic knowledge and how it can be effectively employed in robot task planning. The authors explored different ways in which semantic knowledge can be used for task planning in robot navigation. They also defined a well-founded semantic map that combines spatial knowledge.
In [35], the authors proposed a location and autonomous navigation system using entropic vision and the visual bug algorithm. The proposed navigation system was intended for emergency situations to help people find an exit door along a secure route. The algorithm employed a visual topological map to autonomously navigate the environment of interest. The implemented bug algorithm does not require knowledge about the robot’s coordinates, as the robot uses its own location method during navigation. Experimental results showed that the hybrid algorithm is highly robust when the robot navigates in unknown environments.
The work presented in [36] involved developing a method that effectively deals with simultaneous localization and mapping (SLAM) problems for scenarios with dynamic objects. The method utilizes semantic descriptors extracted from images with the assistance of a knowledge graph. The proposed system leverages the knowledge graph to build a priori movement relationship between entities and constructs high-level semantic information.
The authors of [37] developed a vision system to detect objects in natural environments using a real robot platform. They employed an SVM classification model to classify objects in the area of interest. The main concept is to capture real-time images in the navigation environment, process and extract features of the objects, and then employ an SVM classifier to recognize the objects.
The work presented in [38] involves a vision-based navigation control system for a wheeled robot traveling in outdoor environments. The proposed system includes the use of a deep CNN for pixel-wise segmentation to identify road regions. A fuzzy controller was designed to command the robot’s activities. Several experiments were conducted to verify the essential capabilities of the proposed navigation system using the deep architecture of CNN.
The authors of [39] discussed the process of establishing semantic maps, which are rich maps containing high-level features, and explained how to label entities in such maps. They also explored the use of semantic maps to enable context-aware navigation behaviors. Additionally, they presented a method for extracting metric goals from semantic map landmarks and planning human-aware paths that consider the personal spaces of people. They demonstrated context-aware navigation behaviors through a multi-modal interaction model for annotating semantic landmarks.
In [40], a three-layer perception approach based on transfer learning was proposed. The approach included a place recognition model used to recognize different regions in rooms and corridors, as well as a side recognition model to determine the robot’s rotation. Semantic navigation was performed using a single camera, and real indoor environment experiments were conducted to showcase the robustness and effectiveness of the perception approach.
The authors of [41] introduced a reinforcement learning-based local navigation approach that learns navigation behavior based on visual observations to handle dynamic environments. They developed an efficient simulator called ARENA2D, which generates highly randomized training environments and provides semantic information to train robot systems. The developed system was validated in terms of safety and robustness in highly dynamic environments.
The work presented In [42] focused on offering mobile robots the ability to detect objects for semantic navigation. Two different object detection methods were proposed: contour detection and a descriptor. By combining both methods, the system achieved efficient classification accuracy even in dynamic environments.
The aim of the work presented in [43] was to build a semantic map that investigated the semantic meanings of navigation elements, particularly place names. The developed system aimed to define place names inside a building where the robot navigated, to present corresponding facts and rules using predicate logic expressions, and to establish a conceptual system that is semantically relevant to humans. The proposed semantic map method utilized predicate logic to represent the building’s structure and link it with place names.
The system presented in [44] focused on semantic navigation without employing visual object detection. Instead, the system adopted path planning based on movable area extraction from input images using semantic navigation. The system utilized a novel dataset for semantic segmentation, and the results showed that it achieved more than 99% accuracy in extracting the movable area using ICNet.
The authors of [45] introduced a semantic region map model for complex environments. The developed system demonstrated how navigation points (semantic positions) could be deduced from the map using a semantic description of the environment. These semantic positions were then connected to form a graph, where the edges were labeled with robot actions based on the semantic description of the robot’s capabilities.
The work presented in [46] focused on semantic mapping and semantic-boosted navigation. The goal was to develop an intelligent robot system capable of real-time belief-based scene understanding. The system employed object detection and recognition methods, along with a path creation strategy based on semantic information. Scene understanding was achieved using a CNN model with multiple functions, and the results were transformed into robotic beliefs using Bayes filtering to ensure temporal coherence.
In [47], the authors discussed map building and the localization of mobile robot exploration tasks in planetary areas using semantic navigation maps. The semantic navigation map was generated from descent and landing imagery in a robotic exploration mission. The semantic navigation system was implemented using a virtual robotics testbed and utilized different localization algorithms.
Joo et al. [48] utilized ontology to integrate semantic information into robotic systems, providing the robot with mapping, recognizing, and planning abilities similar to those of a human. They established a Triplet Ontological Semantic Model (TOSM) based on ontology, inspired by recent developments in the employment of ontology in robot applications. They used a CNN model, specifically YOLOv3, as a recognition model for object and place detection. To facilitate navigation through multi-story buildings, they described a multi-layer hierarchical planning scheme that combined reinforcement learning, a traditional planner, and semantic information. The experiments demonstrated the practical usability of their system and showed that TOSM data could effortlessly fulfill navigation tasks in large and dynamic areas.
In a similar context of using ontology-based knowledge systems to enhance a basic robot’s intelligence, Riazuelo et al. [49] proposed a system that combined visual SLAM with a knowledge base to provide precise and continuous awareness of the surroundings, along with accurate object detection. They developed a semantic mapping technique based on scene geometry and item positions by combining visual SLAM and the RoboEarth ontology. The knowledge base approaches utilized prior knowledge of landmark locations in the semantic map to determine potential object locations and guide the robot’s direction when searching for specific objects.
In order to include the semantic information of the robot-navigated environment, the authors of [50] proposed using relational models, which included decision rules in the relational information. The provided design facilitates the integration of various object and room categorizations, encompassing both conceptual and physical aspects. This model empowers the robot to comprehend and interact with the environment, enabling it to perform navigation tasks effectively while also making inquiries about the surroundings.
It has been demonstrated that employing a database to implement the semantic model is a feasible and time-effective solution for handling the data. Results have shown the capability of achieving goals using user-provided semantic data, enabling a more natural relationship between humans and robots.
Adachi et al. [51] devised a unique navigation strategy that encompasses corner identification, road-following, and obstacle avoidance. These functionalities were integrated into the proposed method using visual data from a monocular camera. To achieve autonomous mobility, a route is selected based on information from a topological map. The output of semantic segmentation plays a crucial role in accomplishing these tasks. Road-following, a key component of this technology, involves the vehicle navigating while avoiding obstacles within the traversable area identified through semantic segmentation. This approach does not rely on precise environmental mapping or localization; instead, it utilizes repeated coarse localization based on landmarks and follows a road, similar to human behavior, to enhance reliability. Experimental results demonstrated the successful implementation of this strategy in indoor environments, where the robot was capable of traversing hallways, identifying corners, and making turns while effectively avoiding multiple obstacles.
A framework for robotic navigation without a global map was proposed by Posada et al. [52]. Their method used a collection of conventional classification modules, including Random Forest (RF) and SVM, to conduct object segmentation and detection given scene photos. They offered a semantic navigation method that could be parsed immediately from spoken language, such as “enter or leave the room” or “follow the corridor until the next door”, etc. Additionally, semantic (or cognitive) maps that include in-depth details about the environment, such as object types, functionalities, and their relationships, were provided.
OpenStreetMap (OSM) has limitations, which is somewhat counterintuitive for indoor robotic applications. OSM maintains data about roads, trails, railway stations, and much more all over the world, as well as basic interior architecture, like doors. Naik et al. [53] introduced a novel approach for indoor robotic applications, where they proposed the use of an occupancy grid map as a graph-based semantic mapping solution instead of relying on pre-existing maps. This approach adds robotic-specific, semantic, topological, and geometrical information to the OSM map. These maps have substantially less point-cloud data and rely on manually drawn maps with precise semantic elements (such as edges, corners, etc.) for localization and navigation. They provided models for fundamental building blocks that are semantically grouped into a network, such as walls, doors, and hallways. Then, it uses its hierarchical structure to enable precise navigation that is compatible with grid-based motion planning techniques. By incorporating the capability to query specific aspects, the models possess the capacity to identify task-relevant features within the immediate environment, thereby improving the performance of the robot planner.
Three-way decisions (3WD) and federated learning (FL) were applied in the research work [54] to improve mobile robot navigation (MRN) for Industry 5.0. The significance of MRN in promoting human–machine collaboration is emphasized. Authors proposed the employment of fuzzy sets (PFSs) to successfully handle information discrepancies and proposed the integration of FL to enable knowledge consolidation from various robots. Adjustable multi-granularity (MG) picture fuzzy (PF) probabilistic rough sets (PRSs) have been employed to construct an MRN technique based on FL and 3WD. To ascertain the ideal granularity of MG PF membership degrees, the CODAS technique has been utilized. A case study was carried out to verify the viability of their approach utilizing MRN data from the Kaggle database.
A solution to the problem of place recognition using point-cloud data was presented by Xia et al. [55]. A brand new network architecture dubbed SOE-Net has been employed, which used orientation encoding and self-attention to record point relationships and integrate distant context into local descriptors. Authors presented a self-attention unit to capture feature dependencies and a PointOE module to capture local information from various orientations. Moreover, authors proposed a novel loss function, the HPHN quadruplet loss, which performed better than the current metric learning losses. Experimental results on benchmark datasets showed that SOE-Net outperformed state-of-the-art techniques in terms of performance. On the Oxford RobotCar dataset, the suggested network attained a recall of 89.37% at top 1 retrieval.
The authors of [56] addressed the challenge of processing pixel-wise semantic segmentation in mobile robotic systems with limited computing resources. A light and efficient deep neural network architecture was proposed that can run in real-time on an embedded platform. The proposed model has the ability to segment navigable space in an image sequence, providing contextual awareness for autonomous vehicles based on machine vision. The study demonstrated the performance efficiency of the proposed architecture compared to existing models.
The authors of [57] presented MiniNet-v2, an enhanced version of MiniNet, which is a model that assists in semantic segmentation for robotic applications with comparable accuracy to state-of-the-art models while using less memory and computational resources. The proposed architecture was validated through comprehensive experiments on public benchmarks, demonstrating its benefits over prior work.
The work presented in [58] presented a method for performing semantic segmentation in indoor environments to aid robot navigation. The authors utilized deep-learning techniques to classify and segment various objects in real-time. The developed system was evaluated using a dataset of indoor images and demonstrated its effectiveness in accurately segmenting objects such as walls, floors, furniture, and doors.
The authors of [59] proposed an end-to-end vision-based autonomous navigation framework called Agronav for agricultural robots and vehicles. The framework utilizes semantic segmentation and semantic line detection models to accurately identify key components in the scene and detect boundary lines that separate the crops from the traversable ground. Unlike existing methods that rely on expensive equipment, like RTK-GNSS and LiDAR, Agronav is entirely vision-based, requiring only a single RGB camera.
Scene recognition is the main target of the algorithms proposed by the authors of [60]. The proposed algorithms are real-time algorithms for segmenting and detecting contrast objects in color images, aiming to provide stable segmentation components. The proposed techniques were based on the geometrized histogram method and were applied to analyze video sequences and identify visual landmarks for autonomous robot navigation. The proposed approach combines contour-based and region-based approaches and offers a vector description of contrast objects, enabling the fast evaluation of their shape and classification. Authors revealed that the proposed technique is especially useful for navigation in unknown environments, and it was applied to solve navigation problems for mobile robots in indoor environments.
Furuta et al. [61] proposed a framework for navigation in dynamic environments using semantic maps generated through deep-learning object segmentation. The challenge of using geometry-free representations for navigation in home environments has been addressed, where the environment can undergo dynamic changes. The developed system consists of a two-step approach: first, generating a deep-learning-enabled semantic map from annotated world representations, and second, performing object-based navigation using the learned semantic map representation. The developed framework allows robots to autonomously generate a dataset for deep learning and transfer existing geometric map-based task execution systems to a semantic map-based one that is invariant to changes in object location.
A real-time solution for extracting corridor scenes from a single image using a lightweight semantic segmentation model was proposed in [62]. The model combines an FCN decoder and MobilenetV2 encoder, allowing for high precision with minimized computation time. The study also introduced the use of the balance cross-entropy loss function to handle diverse datasets and incorporated various techniques, such as the Adam optimizer and Gaussian filters, to enhance segmentation performance. Experimental results demonstrated that the proposed model outperformed baseline models across different datasets and maintain consistent performance when applied to a real mobile robot, supporting optimal path planning and efficient obstacle avoidance.
The adoption of RGB-based methods with robot semantic navigation systems may enhance the navigation capability and reliability. In addition, RGB-based vision systems offer semantic information about the navigation environment, which are better than range-finder systems. However, the processing of RGB images is not a simple task in several scenarios, as the RGB images suffer from several problems, including low light and occlusion. In addition, the adoption of RGB-based vision systems lacks the geometry information obtained by the LiDAR-based systems.
2.2.2. RGB-D Based Systems
Drouilly et al. [63] showed how semantic information can be used to infer a path in an outdoor map, especially when there is no clear demarcation between various places in outdoor spaces. The proposed method was based on an automatically constructed object-based representation of the world made from spherical images taken by robots. The experimental study included a labeling layer that depends on an RF classifier and uses RGB-D information for semantic mapping. Moreover, this work presented a novel method for specifying pathways in terms of high-level robot activities. The authors conducted experimental studies using simulated and real-world data to show how their strategy can handle challenging large-scale outdoor environments while addressing labeling problems.
Gao et al. [64] presented a technique for the semantic dense reconstruction of the operating room scene using multiple RGB-D cameras connected to the da Vinci Xi surgical system, which were registered to it. They developed a unique SLAM (simultaneous localization and mapping) technique to track the robot’s attitude in dynamic OR environments and to achieve the dense reconstruction of the stationary objects on the OR table. To validate their proposed system, they collected data from a simulated OR laboratory, using optical tracking and manual labeling as the ground truth. The results indicated that their SLAM system, with its accurate trajectory estimation and semantic scene understanding, significantly improved the robotic perception of the OR environment. This technology has the potential to assist with robot setup, to assist with intraoperative navigation, and to enhance human–robot interaction within surgical procedures.
Song et al. [65] presented an innovative approach based on semantic segmentation to extract navigation lines in wheat fields. To accomplish this, they employed an RGB-D camera to construct a dataset that incorporated horizontal parallax, height, and grayscale information (HHG). The technique involves two main steps: firstly, utilizing a fully convolutional network (FCN) for semantic segmentation of the wheat, ground, and background, and secondly, fitting the navigation line within the camera coordinate system by leveraging the segmentation outcomes and the principle of camera pinhole imaging. By training and testing their segmentation model on a dataset of wheat field images, the researchers achieved remarkable accuracy in extracting navigation lines.
A novel control system for autonomous navigation in vineyards using deep semantic segmentation and edge AI techniques was proposed in [66]. The main objective was to achieve affordable and reliable navigation in vineyard rows without the need for expensive sensors or high computational workloads. The proposed system utilizes a custom-trained segmentation network and a low-range RGB-D camera to leverage semantic information and generate smooth trajectories and stable control. The segmentation maps produced by the control algorithm can also be used for the vegetative assessment of the crop status. The effectiveness and robustness of the methodology were demonstrated through extensive experiments and evaluations in real-world and simulated environments.
In general, RGB-D-based object detection approaches offer two functions: object classification capability and depth estimation for the detected (recognized) object. RGB-D vision systems offer more reliable semantic information for robot navigation than the RGB vision systems. However, RGB-D vision systems are more expensive than the traditional RGB vision systems and have the same limitations of the existing RGB vision systems (low light and occlusion). In addition, the processing of RGB-D images requires powerful processing capabilities.
2.3. Hybrid Based Semantic Navigation Systems
Hybrid-based approaches rely on the utilization of two main perception systems: LiDAR and vision-based (RGB cameras). The former is capable of building a geometry map, while the latter can recognize objects in the area of interest. The adoption of these two perception systems offers a semantic map with rich navigation information.
In [67], a new visual navigation method for mobile robots was introduced. The proposed method utilizes a combination of a sketched map and a semantic map for robot navigation. Unified tags were employed to aid in recognizing landmarks. By using a hand-drawn map, the robot could easily identify referenced objects against complex backgrounds and estimate the approximate distances between them based on the recently updated scale. This method proved effective for unknown and dynamic environments, offering robust recognition algorithms and eliminating the need for capturing photos in advance.
The research described in [68] introduced a semantic SLAM framework designed for rescue robots. The system is capable of generating geometric maps along with semantic labels derived from CNN semantic segmentation. To train the CNN model, an RGB-D dataset from the RoboCup Rescue-Robot-League (RRL) competition environment was utilized. By leveraging semantic information, the rescue robot can identify viable paths in intricate environments. The results obtained from the study demonstrated the effectiveness of the proposed semantic SLAM framework in creating a dense semantic map within complex RRL competition environments, thereby reducing the navigation time to reach desired destinations.
The work presented in [69] involved a language-driven navigation system for commanding mobile robots in unknown outdoor environments. The proposed system aims to facilitate natural interaction in human–robot teams. The approach addresses the problem of spatial navigation and relations using inverse optimal control to learn navigation modes and a Bayesian model to balance perception uncertainties with spatial constraints.
Semantic grid maps were suggested by Qi et al. [70] as a supplement to the occupancy grid map, incorporating the semantics of items and rooms. This enables robots to navigate safely using user-friendly modes. The authors employed fully convolutional region-based networks for object classification, including ten classes of objects. However, the proposed object detection subsystem was unable to differentiate between distinct manifestations of the same object. To address this issue, the authors employed various techniques, such as density-based grouping, item size, and grid map information. Consequently, the authors proposed using a high number of clusters and then utilizing the topological spaces of objects and domestic common sense to merge the cluster results. The experiments were conducted using the FABO robot, which is equipped with 13 sonar sensors and stereovision, in a homelike environment comprising three rooms and domestic objects. The findings of the experiment demonstrated that the mapping technique accurately represented the surroundings and enabled the robot to perform home navigation duties in a user-friendly manner.
In a similar context, Qi et al. [71] developed an object semantic grid-mapping system using 2D LiDAR and RGB-D sensors to incorporate semantic information into the occupied grid maps, allowing robots to select social goals and behave in a human-friendly manner. For the object detection task, the authors proposed using the well-known deep-learning algorithm called Mask R-CNN to obtain semantic labels, probability values, and bounding rectangles of six types of objects in the captured images. The Robot@Home dataset was used to test the proposed system, and the results demonstrated its satisfactory performance. The experimental results showed that the developed system achieved an average precision of 68.42% and an average recall of 65%.
In their work in [72], the authors introduced a modular system called “Goal-Oriented Semantic Exploration”, which aimed to create an episodic semantic map and utilize it for efficient world exploration based on a specific target object category. The proposed system incorporates top-down metric maps that explicitly encode semantic categories. Rather than starting from scratch with first-person predictions, the system leverages pre-trained models for object detection and semantic segmentation to construct semantic maps, which are then combined with differentiable geometric projections. Furthermore, the authors developed a goal-oriented semantic exploration policy that learns semantic priors to facilitate effective navigation, instead of relying solely on coverage-maximizing and goal-agnostic exploration policies based on obstacle maps. Empirical results obtained in visually accurate simulation settings demonstrated that the proposed model outperformed various baselines, including end-to-end learning-based methods and modular map-based methods. Notably, the model achieved the highest performance in the CVPR-2020 Habitat ObjectNav Challenge, making it the winning submission.
Wang et al. [73] replaced the use of the occupancy grid map generated by SLAM with another type of map called the Layout map. The Layout map displays structures and contains semantic data, enabling the robot to find a route from its current location to the desired location. A layout map always depicts the entire area comprehensively and accurately. However, the authors noted that the Layout map may be inaccurate in terms of resolution, which could reduce the precision and reliability of navigation. To address this, the authors proposed calibrating the Layout map using the occupancy grid map to enhance navigation performance. They achieved this by using visible light positioning landmarks to determine the robot’s location, reflecting location on the layout map as the robot underwent SLAM. Sensors were also used to locate the robot on the occupancy grid map. The experimental results demonstrated that the robot could navigate almost as well on calibrated floor maps as on calibrated building blueprints, and it performed better on calibrated layout maps than on sensor maps.
In [74], the authors presented a robot navigation system that can perform navigation tasks in unfamiliar environments using the same symbolic spatial information used by humans. This includes labels, signs, maps, planners, spoken directions, and navigational gestures. The developed navigation system utilizes adaptable spatial models for hidden spaces based on spatial symbols, employing a novel data structure called the abstract map. A robotic-oriented grammar, with manually crafted clauses, is used to express the spatial information conveyed by navigation cues. The robot then uses its sensorimotor perceptions to navigate towards symbolic goal areas within the unknown surroundings. Overall, the abstract map helped the robot complete tasks 5.3% more quickly, excluding two outlier human results, and 11.5% faster than human participants.
In their study [75], Borkowski et al. utilized laser scanner raw data to extract semantic features, enabling object classification and the creation of semantic maps for building interiors. They introduced a semantic navigation scheme based on hypergraphs, which employed multiple layers to represent different levels of abstraction within the investigated building. Semantic information was obtained from the digital model of the building, such as the building information model (BIM), which adheres to the architecture–engineering–construction (AEC) industry standard [76] and describes the building’s infrastructure. This semantic information facilitated robot navigation. The developed system incorporates advanced data processing techniques, including online updating of a 3D environment model, object classifiers based on rules and features, a path planner utilizing cellular neural networks, and other tools. The effectiveness of these solutions was validated through experiments conducted in real-life scenarios.
In their work in [77], Bersan et al. proposed a strategy based on semantic segmentation for detecting and identifying various object classes within an indoor environment. They employed a deep neural network model that integrated object detection and semantic classification in a visual-based perception framework. The system generated a 2D map of the environment, providing information about the semantic object classes and their respective locations. To gather the necessary data, multiple sensors were utilized, including odometers, an RGB-D camera, and LiDAR. The authors also employed a 3D model-based segmentation technique and a CNN-based object detection method called YOLO to accurately locate and classify different object classes within the scene.
In their research in [78], Martins et al. addressed the challenge of generating indoor environments with semantic information. They proposed a comprehensive framework for constructing an enhanced map representation of the environment that includes object-level data. This representation can be utilized in various applications, such as visual navigation, assistive robotics, human–robot interaction, and manipulation tasks. Their approach involved instance semantic segmentation, localization, identification, and tracking of multiple object classes within the scene. This was achieved using a CNN-based object detector (Yolo) and a 3D model-based segmentation technique. To track and position semantic classes accurately, a dictionary of Kalman filters was employed, which combined sensor measurements over time. The formulation also accounted for recognizing and disregarding dynamic objects to provide a map representation that remains invariant over the medium term. The proposed method was evaluated using RGB-D data sequences recorded in different interior scenes, which were made publicly available. The experimental results demonstrated the effectiveness of the technology in generating augmented semantic maps, with a particular emphasis on the inclusion of doors. The authors released the source code as ROS (robot operating system) packages and provided a dataset containing annotated object classes (doors, fire extinguishers, benches, and water fountains) and their corresponding locations for the benefit of the research community.
In [79], the authors emphasized the importance of autonomous robots adhering to prescribed travel paths, such as sidewalks or footpaths, while avoiding areas like grass and flowerbeds for safety and social reasons. They proposed a system that combines semantic segmentation from an RGB-D camera with LiDAR-based autonomous navigation for uncharted urban areas. Their method involved building a 3D map of the environment’s obstacles using the segmented picture mask and calculating the limits of the footpath. The proposed approach eliminated the need for a pre-built map and provided a 3D understanding of the safe region for movement, allowing the robot to plan any route along the footpath. Comparative experiments demonstrated significant performance improvements over existing methods, with success rates exceeding 91% outdoors and over 66% indoors when compared to LiDAR-only or semantic segmentation-only approaches, respectively. The suggested strategy reduced collisions and ensured that the robot always followed the safest path.
In [80], a human–robot interaction system for an indoor environment was proposed, utilizing visual and audio signals to create a grid–semantic map. The authors validated their work using four modules from the ROS development environment: the interaction module, control module, navigation module, and mapping module. The semantic map was generated through interaction between humans and robots using speech and visual signals. By having the robot follow the user and providing verbal commentary, a contextual topological map with semantic information was created. The technique resulted in a final map that combined spatial values and semantic names to provide the robot with detailed descriptions of specific locations. The robot then converted the grid map into a cost map, planned a route using Dijkstra’s algorithm, and reached the desired location. The proposed system was tested and evaluated in both virtual and real environments, including hallways and offices.
Joo et al. [81] presented a framework for real-time autonomous robot navigation in a dynamically changing environment, with a focus on human-like robot interaction and task planning. Their framework utilized cloud and on-demand databases and consisted of a robot mapping system that emulated the functioning of a human brain. This mapping system incorporated spatial data and performed 3D visual semantic SLAM (simultaneous localization and mapping) to enable autonomous navigation. The robot’s memory system was divided into long-term memory (LTM) and short-term memory (STM), which were connected to the autonomous navigation module, learning module, and behavior planner module, collectively forming the robot’s behavior and knowledge system. The proposed framework was evaluated using an RGB-D camera, a laser range finder, and a mobile robot simulated in the ROS (robot operating system)-based Gazebo environment. The simulation demonstrated the practical value and effectiveness of the suggested framework for autonomous robot navigation in a realistic indoor setting.
In [82], the researchers proposed a safe robot navigation system designed for outdoor and natural environments. The system focused on achieving safe navigation even in the presence of unknown obstacles. They developed a model that classified new sensory inputs into “known” and “unknown” terrain classes, enabling the robot to navigate safely. The best performance was achieved by combining RGB images, depth, and surface normal data as sensor modalities. This combination allowed robots to operate in environments with unexpected and infrequently occurring barriers, thanks to the researchers’ anomaly detection technology.
A novel visual navigation scheme for autonomous robots that utilizes only a monocular camera as an external sensor was proposed by Miyamoto et al. [83]. The key concept is to select a target point in an input image based on the results of semantic segmentation, allowing simultaneous road following and obstacle avoidance. The authors also introduced a scheme called virtual LiDAR, which estimates the robot’s orientation relative to the current path in a traversable area based on the semantic segmentation results. Experimental results from the Tsukuba Challenge 2019 demonstrated that the proposed scheme enabled a robot to navigate in a real environment with obstacles, such as humans and other robots, given accurate semantic segmentation results.
The integration of vision-based with the LiDAR-based methods enhances the robot navigation capabilities by providing both the geometry and semantic information. Therefore, hybrid-based approaches have received considerable attention due to their efficiency in obtaining reliable semantic navigation data.
As presented above, several robot semantic navigation systems have been recently proposed with varying levels of efficiency, accuracy, and complexity. The next section discusses the results obtained from existing approaches and defines a set of evaluation metrics that can be employed to assess the efficiency of any semantic navigation system.
3. Discussion
Understanding the environment is a crucial aspect of achieving high-level navigation. Semantic navigation, therefore, involves incorporating high-level concepts, such as objects, things, or places, into a navigation framework. Additionally, the relationships between these concepts are utilized, especially with respect to specific objects. By leveraging the knowledge derived from these concepts and their relationships, mobile robots can make inferences about the navigation environment, enabling better planning, localization, and decision-making.
As discussed in the previous section, existing robot semantic navigation systems can be categorized into three distinct types. Figure 4 illustrates the distribution of these systems across the categories. It should be noted that while LiDAR-based systems offer simplicity in terms of data processing tasks, they have limitations when it comes to object classification. Compared to vision-based systems, LiDAR systems have a more limited capacity for recognizing a wide range of labels. As a result, the development of technologies for robot semantic navigation systems that rely solely on LiDAR is less necessary.
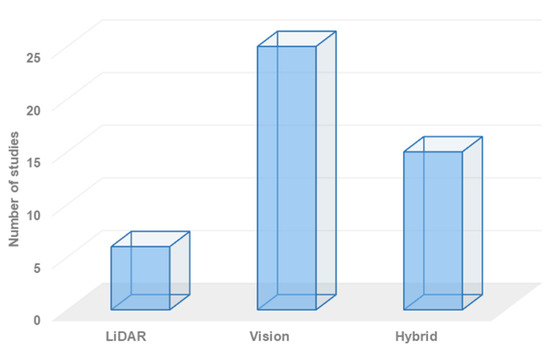
Figure 4.
The distribution of robot semantic navigation systems based on the employed technology.
On the one hand, vision-based approaches have gained significant attention in the field of robot navigation, particularly for building semantic navigation maps. However, these systems lack the geometry information that can be obtained from LiDAR sensor units. In contrast, hybrid-based approaches offer the best combination of geometry and semantic information, allowing for the creation of maps with rich details that include both geometry and object classification and localization.
Robot perception plays a crucial role in the functioning of autonomous robots, especially for navigation. To achieve efficient navigation capabilities, the robot system must possess accurate, reliable, and robust perception skills. Vision functions are employed to develop reliable semantic navigation systems, with the primary goal of processing and analyzing semantic information in a scene to provide scene understanding. Scene understanding goes beyond object detection and recognition, involving further analysis and interpretation of the data obtained from sensors. This concept of scene understanding has found practical applications in various domains, including self-driving cars, transportation, and robot navigation. Figure 4 demonstrates that vision-based semantic navigation is the most commonly employed technology in recently developed robot semantic navigation systems for indoor environments.
Semantic navigation systems require intensive processing capabilities. Therefore, it is crucial to employ an efficient processor unit to handle and process the data received from onboard sensors, including LiDAR and RGB camera units. Processing RGB and RGB-D images necessitates high processing capabilities for tasks such as object detection, recognition, and localization. Many researchers utilize personal computers integrated with the robot platform to perform these processing tasks. However, incorporating a computer (such as a laptop) onto the robot platform adds extra size, power consumption, cost, and complexity. Alternatively, some researchers have employed processors like Raspberry Pi, Jetson Nano, or Intel Galileo to handle the processing tasks. Figure 5 illustrates the distribution of existing robot semantic navigation systems based on the employed processor technology. Raspberry Pi computers are cost-efficient, adaptable, and compact, but they may struggle with complex processing tasks. Jetson Nano offers better specifications than Raspberry Pi but adds an additional cost to the overall robotic system.
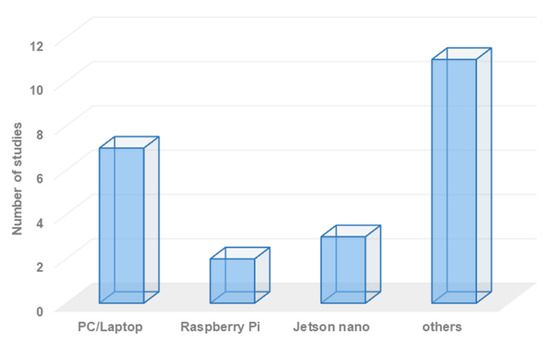
Figure 5.
Overall distribution of the existing research works based on employed processor technology.
Robot semantic navigation systems necessitate the use of object recognition models to classify various types of objects within the area of interest. Several object recognition models have been developed for this purpose. For example, many researchers choose to develop customized convolutional neural network (CNN) models to classify objects of interest. Others employ models such as YOLO, MobileNet, ResNet, and Inception. The choice of an object recognition model primarily depends on the processor and memory capabilities of the system. Figure 6 provides an overview of the employed object recognition approaches in recently developed semantic navigation systems, offering statistics on their usage.
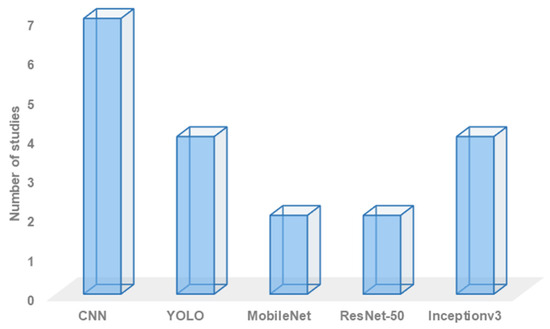
Figure 6.
Overall statistics on employed object recognition approach.
The adoption of object recognition models is fundamentally reliant on the availability of an object recognition dataset. Different datasets vary in terms of the number and type of objects classified within them. Therefore, it is crucial to select the most suitable dataset for a given robot semantic navigation scenario. Figure 7 illustrates the overall distribution of recently developed robot semantic navigation systems based on the employed object recognition dataset, providing an overview of the usage across different datasets.
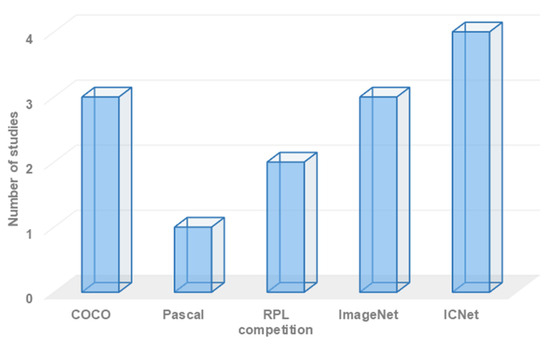
Figure 7.
Overall statistics on employed object recognition dataset.
The choice of sensing technology, or perception units, plays a significant role in obtaining an efficient semantic map. Various sensing technologies have been used to gather data about the surrounding environment. Most researchers have focused on using RGB cameras to build semantic maps. RGB cameras are effective for object detection and classification, but they cannot accurately estimate the distance to objects in the area of interest and do not provide geometry information. In contrast, RGB-D cameras offer better results as they can recognize objects and measure the distance to objects in the area of interest, leading to the construction of a more efficient semantic map.
Figure 8 provides an overview of the employed sensing technologies in recently developed systems, presenting statistics on their usage. On the other hand, semantic navigation systems that combine RGB cameras and LiDAR units have the potential to construct a semantic map with rich information. However, these technologies have received less attention due to the higher requirements in terms of processing capabilities, complexity, power consumption, and cost.
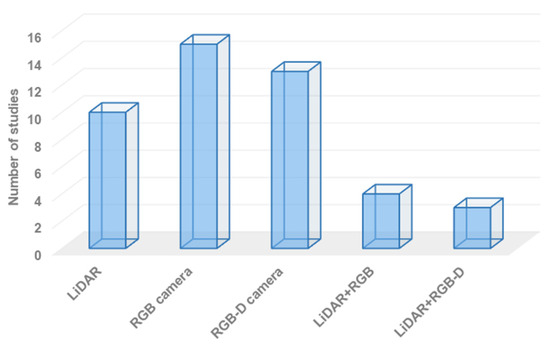
Figure 8.
Overall statistics on employed sensing technology.
For validation purposes, researchers have the option to employ various experimental testbed environments. Initially, researchers often build their concepts using theoretical models to validate the efficiency of their systems. However, for more reliable and confident results, researchers typically perform either simulation experiments or real-world experiments to validate the effectiveness of the proposed robot semantic navigation system. Figure 9 illustrates the distribution of existing robot semantic navigation systems based on the type of experiment testbed employed.
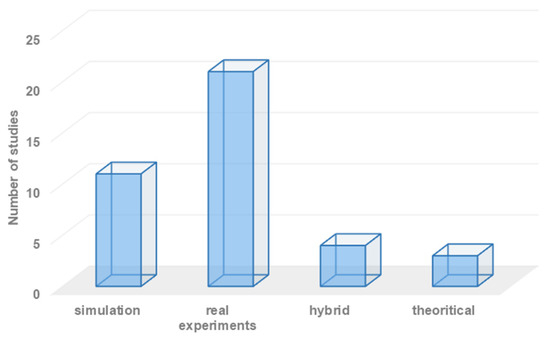
Figure 9.
Statistics on the employed development environments.
From our perspective, validating robot semantic navigation systems solely through simulation experiments can be challenging. This is because robots need to accurately recognize objects in the area of interest to build an efficient semantic map, and real-time geometry information may be difficult to replicate accurately in simulation environments. Consequently, a large number of researchers rely on real-world experiments for validation purposes, as they provide a more realistic and practical assessment of the system’s performance.
Recent research studies [71,75] have highlighted that the academic community has yet to establish a unified standard for the validation of semantic maps. As a result, there is currently no clear set of validation parameters for assessing the efficiency of robot semantic navigation systems. In light of this, after conducting various analyses and assessments of the validation metrics adopted in recently developed robot semantic navigation systems, we propose a set of validation metrics that can be used to assess the efficiency of any robot semantic navigation system. These metrics are as follows:
- Navigation algorithm: This metric refers to the navigation algorithm employed in the robot semantic navigation system. The SLAM (simultaneous localization and mapping) navigation approach is commonly used and can be divided into laser-based SLAM and vision-based SLAM. Laser-based SLAM establishes occupied grid maps, while vision-based SLAM creates feature maps. However, integrating both categories allows for constructing a rich semantic map.
- Array of sensors: This metric involves the list of sensors used in the robot semantic navigation system. Typically, a vision-based system and a LiDAR (light detection and ranging) sensor are required to establish a semantic navigation map. The integration of additional sensors may enhance semantic navigation capabilities, but it also introduces additional processing overhead, power consumption, and design complexity. Therefore, it is important to choose suitable perception units. Several robot semantic navigation systems have employed LiDAR- and vision-based sensors to obtain geometry information, visual information, and proximity information, and the fusion of these sensors has achieved better robustness compared to using individual LiDAR or camera subsystems.
- Vision subsystem: In most semantic navigation systems, the vision subsystem is crucial for achieving high-performance navigation capabilities. Objects can be detected and recognized using an object detection subsystem with a corresponding object detection algorithm. There are currently several object detection classifiers available, each with different accuracy scores, complexity, and memory requirements. Therefore, it is important to choose the most suitable object classification approach based on the specific requirements of the system.
- Employed dataset: For any object detection subsystem, an object classification dataset is required. However, available vision datasets differ in terms of the number of trained objects, size, and complexity. It is important to select a suitable vision dataset that aligns with the robot semantic application [84].
- Experiment testbed: This metric refers to the type of experiment conducted to assess the efficiency of the developed robot semantic navigation system. The system may be evaluated through simulation experiments or real-world experiments [85]. In general, semantic navigation systems require real-world experiments to realistically assess their efficiency.
- Robot semantic application: This metric refers to the type of application for which the developed system has been designed. It is important to determine the specific application in which the navigation system will be employed, since the vision-based system needs to be trained on a dataset that corresponds to the objects that may exist in the navigation environment. Additionally, the selection of suitable perception units largely depends on the structure of the navigation environment.
- Obtained results: This metric primarily concerns the results obtained from the developed robot semantic navigation system. As observed in the previous section, researchers have employed different sets of evaluation metrics to assess the efficiency of their systems. Therefore, it is necessary to adopt the right set of validation metrics to assess the efficiency of a developed robot semantic navigation system.
4. Indoor Semantic Navigation Lifecycle
With the advancement of deep neural network algorithms, semantic segmentation algorithms based on deep learning have become widely used. These algorithms contribute to faster and more accurate object recognition. Given the high demand for efficient robot semantic navigation systems across various applications, we list stages that need to be implemented when developing an indoor robot semantic navigation system. Figure 10 illustrates the lifecycle of developing an efficient robot semantic navigation approach.
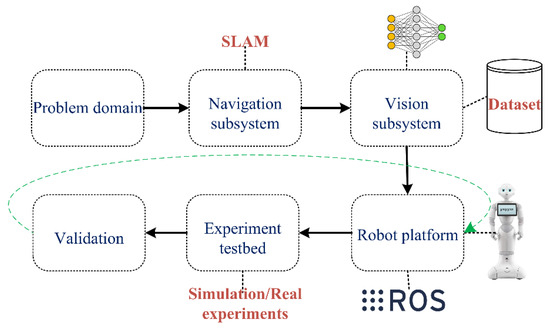
Figure 10.
Main phases for developing an efficient robot semantic navigation system.
The main phases that need to be addressed when developing an efficient robot semantic navigation system are as follows:
- Problem domain: The design and development of an efficient robot semantic navigation system depend on the specific problem domain [86]. The choice of perception units, robot design, processing unit, and navigation algorithm varies depending on the robot navigation application. Developing a robot semantic navigation system for domestic applications, for example, is different from developing one for industrial inspection. Therefore, it is significant to identify the problem domain prior to developing a robot semantic navigation system.
- Navigation subsystem: The navigation system aims to explore possible paths from an initial point to a destination point. SLAM is a widely used navigation approach for constructing maps in unknown environments [87]. However, several research works considered other navigation approaches, for instance, the Unscented Kalman Filter (UKF). Therefore, the need to adopt a reliable navigation system is a crucial task for the purpose of developing an efficient robot semantic navigation system.
- Vision subsystem: A robust robot semantic navigation system requires the use of an object detection and recognition approach to classify objects in the navigation area and obtain rich semantic map information [88]. There are several object recognition models available with different sets of classes, classification accuracy, processing speed, and memory requirements. However, choosing the most suitable object detection approach for the selected application is a critical task.
- Robot platform: This includes the robot platform (e.g., Pepper, NAO, Husky) and the development environment (e.g., ROS) used to develop an efficient robot navigation system. Recently, various numbers of robot platforms were made available in the market with several functionalities, capabilities, and prices. On the other hand, several development environments are available that allow developers to implement the robot system for semantic navigation (ROS 2, Matlab R2023b, Webots 2023b, … etc.). Hence, the selection of a suitable mobile robot platform and software environment area is a significant task.
- Experimental testbed: This refers to the experimental environment used to validate the efficiency of the developed robot semantic navigation system. In addition, the experiment testbed may include the array of sensors and actuators that are required to perform the task of robot semantic navigation.
- Validation: Assessing the efficiency of the developed robot semantic navigation system requires the adoption of evaluation metrics. As mentioned earlier, there is currently no academic standard for assessing the efficiency of any robot semantic navigation system. However, this paper presents a set of evaluation metrics that can be used to assess the efficiency of any robot semantic navigation approach.
5. Conclusions
The field of robot semantic navigation has gained significant attention in recent years due to the need for robots to understand their environment in order to perform various automated tasks accurately. This paper focused on categorizing and discussing the recently developed robot semantic navigation systems specifically designed for indoor environments.
Furthermore, this paper introduced a set of validation metrics that can be used to accurately assess the efficiency of indoor robot semantic navigation approaches. These metrics provide a standardized framework for evaluating the performance and effectiveness of such systems.
Lastly, this paper presented a comprehensive lifecycle of the design and development of efficient robot semantic navigation systems for indoor environments. This lifecycle encompasses the consideration of robot applications, navigation systems, object recognition approaches, development environments, experimental studies, and the validation process. By following this lifecycle, researchers and developers can effectively design and implement robust robot semantic navigation systems tailored to indoor environments.
Author Contributions
R.A. (Raghad Alqobali) and M.A. reviewed the recent developed vision-based robot semantic navigation systems, whereas A.R. and R.A. (Reem Alnasser) investigated the available LiDAR-based robot semantic navigation systems. O.M.A. discussed and compared the existing robot semantic navigation systems, whereas T.A. proposed a set of evaluation metrics for assessing the efficiency of any robotic semantic navigation system. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Alhmiedat, T.; Alotaibi, M. Design and evaluation of a personal Robot playing a self-management for Children with obesity. Electronics 2022, 11, 4000. [Google Scholar] [CrossRef]
- Gul, F.; Rahiman, W.; Nazli Alhady, S.S. A comprehensive study for robot navigation techniques. Cogent Eng. 2019, 6, 1632046. [Google Scholar] [CrossRef]
- Alhmiedat, T.; Marei, A.M.; Albelwi, S.; Bushnag, A.; Messoudi, W.; Elfaki, A.O. A Systematic Approach for Exploring Underground Environment Using LiDAR-Based System. CMES-Comput. Model. Eng. Sci. 2023, 136, 2321–2344. [Google Scholar] [CrossRef]
- García, F.; Jiménez, F.; Naranjo, J.E.; Zato, J.G.; Aparicio, F.; Armingol, J.M.; de la Escalera, A. Environment perception based on LIDAR sensors for real road applications. Robotica 2012, 30, 185–193. [Google Scholar] [CrossRef]
- Alhmiedat, T.; Marei, A.M.; Messoudi, W.; Albelwi, S.; Bushnag, A.; Bassfar, Z.; Alnajjar, F.; Elfaki, A.O. A SLAM-based localization and navigation system for social robots: The pepper robot case. Machines 2023, 11, 158. [Google Scholar] [CrossRef]
- Estrada, C.; Neira, J.; Tardós, J.D. Hierarchical SLAM: Real-time accurate mapping of large environments. IEEE Trans. Robot. 2005, 21, 588–596. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Dang, T.V.; Bui, N.T. Multi-scale fully convolutional network-based semantic segmentation for mobile robot navigation. Electronics 2023, 12, 533. [Google Scholar] [CrossRef]
- Crespo, J.; Castillo, J.C.; Mozos, O.M.; Barber, R. Semantic information for robot navigation: A survey. Appl. Sci. 2020, 10, 497. [Google Scholar] [CrossRef]
- Alamri, S.; Alamri, H.; Alshehri, W.; Alshehri, S.; Alaklabi, A.; Alhmiedat, T. An Autonomous Maze-Solving Robotic System Based on an Enhanced Wall-Follower Approach. Machines 2023, 11, 249. [Google Scholar] [CrossRef]
- Alhmiedat, T. Fingerprint-Based Localization Approach for WSN Using Machine Learning Models. Appl. Sci. 2023, 13, 3037. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Achour, A.; Al-Assaad, H.; Dupuis, Y.; El Zaher, M. Collaborative Mobile Robotics for Semantic Mapping: A Survey. Appl. Sci. 2022, 12, 10316. [Google Scholar] [CrossRef]
- Mavrogiannis, C.; Baldini, F.; Wang, A.; Zhao, D.; Trautman, P.; Steinfeld, A.; Oh, J. Core challenges of social robot navigation: A survey. ACM Trans. Hum.-Robot Interact. 2023, 12, 1–39. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Han, X.; Li, S.; Wang, X.; Zhou, W. Semantic mapping for mobile robots in indoor scenes: A survey. Information 2021, 12, 92. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, J.; Liu, J.; Tong, Q.; Liu, R.; Chen, S. Semantic Visual Simultaneous Localization and Mapping: A Survey. arXiv 2022, arXiv:2209.06428. [Google Scholar]
- Garg, S.; Sünderhauf, N.; Dayoub, F.; Morrison, D.; Cosgun, A.; Carneiro, G.; Wu, Q.; Chin, T.J.; Reid, I.; Gould, S.; et al. Semantics for robotic mapping, perception and interaction: A survey. Found. Trends® Robot. 2020, 8, 1–224. [Google Scholar] [CrossRef]
- Li, X.-Q.; He, W.; Zhu, S.-Q.; Li, Y.-H.; Xie, T. Survey of simultaneous localization and mapping based on environmental semantic information. Chin. J. Eng. 2021, 43, 754–767. [Google Scholar]
- Alamri, S.; Alshehri, S.; Alshehri, W.; Alamri, H.; Alaklabi, A.; Alhmiedat, T. Autonomous maze solving robotics: Algorithms and systems. Int. J. Mech. Eng. Robot. Res 2021, 10, 668–675. [Google Scholar] [CrossRef]
- Humblot-Renaux, G.; Marchegiani, L.; Moeslund, T.B.; Gade, R. Navigation-oriented scene understanding for robotic autonomy: Learning to segment driveability in egocentric images. IEEE Robot. Autom. Lett. 2022, 7, 2913–2920. [Google Scholar] [CrossRef]
- Lu, Z.; Im, J.; Rhee, J.; Hodgson, M. Building type classification using spatial and landscape attributes derived from LiDAR remote sensing data. Landsc. Urban Plan. 2014, 130, 134–148. [Google Scholar] [CrossRef]
- Hopkinson, C.; Chasmer, L.; Gynan, C.; Mahoney, C.; Sitar, M. Multisensor and multispectral lidar characterization and classification of a forest environment. Can. J. Remote Sens. 2016, 42, 501–520. [Google Scholar] [CrossRef]
- McDaniel, M.W.; Nishihata, T.; Brooks, C.A.; Iagnemma, K. Ground plane identification using LIDAR in forested environments. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–8 May 2010; pp. 3831–3836. [Google Scholar]
- Álvarez-Aparicio, C.; Guerrero-Higueras, A.M.; Rodríguez-Lera, F.J.; Ginés Clavero, J.; Martín Rico, F.; Matellán, V. People detection and tracking using LIDAR sensors. Robotics 2019, 8, 75. [Google Scholar] [CrossRef]
- Dewan, A.; Oliveira, G.L.; Burgard, W. Deep semantic classification for 3D LiDAR data. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3544–3549. [Google Scholar]
- Alenzi, Z.; Alenzi, E.; Alqasir, M.; Alruwaili, M.; Alhmiedat, T.; Alia, O.M. A Semantic Classification Approach for Indoor Robot Navigation. Electronics 2022, 11, 2063. [Google Scholar] [CrossRef]
- Xia, Y.; Gladkova, M.; Wang, R.; Li, Q.; Stilla, U.; Henriques, J.F.; Cremers, D. CASSP R: Cross Attention Single Scan Place Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 30 September–6 October 2023; pp. 8461–8472. [Google Scholar]
- Xia, Y.; Xu, Y.; Wang, C.; Stilla, U. VPC-Net: Completion of 3D vehicles from MLS point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 174, 166–181. [Google Scholar] [CrossRef]
- Teso-Fz-Betoño, D.; Zulueta, E.; Sánchez-Chica, A.; Fernandez-Gamiz, U.; Saenz-Aguirre, A. Semantic segmentation to develop an indoor navigation system for an autonomous mobile robot. Mathematics 2020, 8, 855. [Google Scholar] [CrossRef]
- Miyamoto, R.; Nakamura, Y.; Adachi, M.; Nakajima, T.; Ishida, H.; Kojima, K.; Aoki, R.; Oki, T.; Kobayashi, S. Vision-based road-following using results of semantic segmentation for autonomous navigation. In Proceedings of the 2019 IEEE 9th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 8–11 September 2019; pp. 174–179. [Google Scholar]
- Yeboah, Y.; Yanguang, C.; Wu, W.; Farisi, Z. Semantic scene segmentation for indoor robot navigation via deep learning. In Proceedings of the 3rd International Conference on Robotics, Control and Automation, Chengdu, China, 11–13 August 2018; pp. 112–118. [Google Scholar]
- Mousavian, A.; Toshev, A.; Fišer, M.; Košecká, J.; Wahid, A.; Davidson, J. Visual representations for semantic target driven navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8846–8852. [Google Scholar]
- Galindo, C.; Fernández-Madrigal, J.A.; González, J.; Saffiotti, A. Robot task planning using semantic maps. Robot. Auton. Syst. 2008, 56, 955–966. [Google Scholar] [CrossRef]
- Maravall, D.; De Lope, J.; Fuentes, J.P. Navigation and self-semantic location of drones in indoor environments by combining the visual bug algorithm and entropy-based vision. Front. Neurorobotics 2017, 11, 46. [Google Scholar] [CrossRef]
- Fang, B.; Mei, G.; Yuan, X.; Wang, L.; Wang, Z.; Wang, J. Visual SLAM for robot navigation in healthcare facility. Pattern Recognit. 2021, 113, 107822. [Google Scholar] [CrossRef]
- Hernández, A.C.; Gómez, C.; Crespo, J.; Barber, R. Object classification in natural environments for mobile robot navigation. In Proceedings of the IEEE 2016 International Conference on Autonomous Robot Systems and Competitions (ICARSC), Bragança, Portugal, 4–6 May 2016; pp. 217–222. [Google Scholar]
- Lin, J.; Wang, W.J.; Huang, S.K.; Chen, H.C. Learning based semantic segmentation for robot navigation in outdoor environment. In Proceedings of the 2017 Joint 17th World Congress of International Fuzzy Systems Association and 9th International Conference on Soft Computing and Intelligent Systems (IFSA-SCIS), Otsu, Japan, 27–30 June 2017; pp. 1–5. [Google Scholar]
- Cosgun, A.; Christensen, H.I. Context-aware robot navigation using interactively built semantic maps. Paladyn J. Behav. Robot. 2018, 9, 254–276. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, L.; Huo, G.; Li, R.; Hou, Z.; Luo, P.; Sun, Z.; Wang, K.; Yang, C. Visual semantic navigation based on deep learning for indoor mobile robots. Complexity 2018, 2018, 1627185. [Google Scholar] [CrossRef]
- Kästner, L.; Marx, C.; Lambrecht, J. Deep-reinforcement-learning-based semantic navigation of mobile robots in dynamic environments. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1110–1115. [Google Scholar]
- Astua, C.; Barber, R.; Crespo, J.; Jardon, A. Object detection techniques applied on mobile robot semantic navigation. Sensors 2014, 14, 6734–6757. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Ren, J. A semantic map for indoor robot navigation based on predicate logic. Int. J. Knowl. Syst. Sci. (IJKSS) 2020, 11, 1–21. [Google Scholar] [CrossRef]
- Miyamoto, R.; Adachi, M.; Nakamura, Y.; Nakajima, T.; Ishida, H.; Kobayashi, S. Accuracy improvement of semantic segmentation using appropriate datasets for robot navigation. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 1610–1615. [Google Scholar]
- Uhl, K.; Roennau, A.; Dillmann, R. From structure to actions: Semantic navigation planning in office environments. In Proceedings of the IROS 2011 Workshop on Perception and Navigation for Autonomous Vehicles in Human Environment (Cited on Page 24). 2011. Available online: https://www.researchgate.net/profile/Arne-Roennau/publication/256198760_From_Structure_to_Actions_Semantic_Navigation_Planning_in_Office_Environments/links/6038f20ea6fdcc37a85449ad/From-Structure-to-Actions-Semantic-Navigation-Planning-in-Office-Environments.pdf (accessed on 10 December 2023).
- Sun, H.; Meng, Z.; Ang, M.H. Semantic mapping and semantics-boosted navigation with path creation on a mobile robot. In Proceedings of the 2017 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Ningbo, China, 19–21 November 2017; pp. 207–212. [Google Scholar]
- Rossmann, J.; Jochmann, G.; Bluemel, F. Semantic navigation maps for mobile robot localization on planetary surfaces. In Proceedings of the 12th Symposium on Advanced Space Technologies in Robotics and Automation (ASTRA 2013), Noordwijk, The Netherlands, 15–17 May 2013; Volume 9, pp. 1–8. [Google Scholar]
- Joo, S.H.; Manzoor, S.; Rocha, Y.G.; Bae, S.H.; Lee, K.H.; Kuc, T.Y.; Kim, M. Autonomous navigation framework for intelligent robots based on a semantic environment modeling. Appl. Sci. 2020, 10, 3219. [Google Scholar] [CrossRef]
- Riazuelo, L.; Tenorth, M.; Di Marco, D.; Salas, M.; Gálvez-López, D.; Mösenlechner, L.; Kunze, L.; Beetz, M.; Tardós, J.D.; Montano, L.; et al. RoboEarth semantic mapping: A cloud enabled knowledge-based approach. IEEE Trans. Autom. Sci. Eng. 2015, 12, 432–443. [Google Scholar] [CrossRef]
- Crespo, J.; Barber, R.; Mozos, O.M. Relational model for robotic semantic navigation in indoor environments. J. Intell. Robot. Syst. 2017, 86, 617–639. [Google Scholar] [CrossRef]
- Adachi, M.; Shatari, S.; Miyamoto, R. Visual navigation using a webcam based on semantic segmentation for indoor robots. In Proceedings of the IEEE 2019 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorrento, Italy, 26–29 November 2019; pp. 15–21. [Google Scholar]
- Posada, L.F.; Hoffmann, F.; Bertram, T. Visual semantic robot navigation in indoor environments. In Proceedings of the ISR/Robotik 2014; 41st International Symposium on Robotics, Munich, Germany, 2–3 June 2014; pp. 1–7. [Google Scholar]
- Naik, L.; Blumenthal, S.; Huebel, N.; Bruyninckx, H.; Prassler, E. Semantic mapping extension for OpenStreetMap applied to indoor robot navigation. In Proceedings of the IEEE 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3839–3845. [Google Scholar]
- Zhang, C.; Hou, H.; Sangaiah, A.K.; Li, D.; Cao, F.; Wang, B. Efficient Mobile Robot Navigation Based on Federated Learning and Three-Way Decisions. In International Conference on Neural Information Processing; Springer Nature: Singapore, 2023; pp. 408–422. [Google Scholar]
- Xia, Y.; Xu, Y.; Li, S.; Wang, R.; Du, J.; Cremers, D.; Stilla, U. SOE-Net: A self-attention and orientation encoding network for point cloud based place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11348–11357. [Google Scholar]
- Asadi, K.; Chen, P.; Han, K.; Wu, T.; Lobaton, E. Real-time scene segmentation using a light deep neural network architecture for autonomous robot navigation on construction sites. In Proceedings of the ASCE International Conference on Computing in Civil Engineering, Atlanta, GA, USA, 17–19 June 2019; American Society of Civil Engineers: Reston, VA, USA, 2019; pp. 320–327. [Google Scholar]
- Alonso, I.; Riazuelo, L.; Murillo, A.C. Mininet: An efficient semantic segmentation convnet for real-time robotic applications. IEEE Trans. Robot. 2020, 36, 1340–1347. [Google Scholar] [CrossRef]
- Kim, W.; Seok, J. Indoor semantic segmentation for robot navigating on mobile. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018; pp. 22–25. [Google Scholar]
- Panda, S.K.; Lee, Y.; Jawed, M.K. Agronav: Autonomous Navigation Framework for Agricultural Robots and Vehicles using Semantic Segmentation and Semantic Line Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6271–6280. [Google Scholar]
- Kiy, K.I. Segmentation and detection of contrast objects and their application in robot navigation. Pattern Recognit. Image Anal. 2015, 25, 338–346. [Google Scholar] [CrossRef]
- Furuta, Y.; Wada, K.; Murooka, M.; Nozawa, S.; Kakiuchi, Y.; Okada, K.; Inaba, M. Transformable semantic map based navigation using autonomous deep learning object segmentation. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 614–620. [Google Scholar]
- Dang, T.V.; Tran, D.M.C.; Tan, P.X. IRDC-Net: Lightweight Semantic Segmentation Network Based on Monocular Camera for Mobile Robot Navigation. Sensors 2023, 23, 6907. [Google Scholar] [CrossRef]
- Drouilly, R.; Rives, P.; Morisset, B. Semantic representation for navigation in large-scale environments. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1106–1111. [Google Scholar]
- Gao, C.; Rabindran, D.; Mohareri, O. RGB-D Semantic SLAM for Surgical Robot Navigation in the Operating Room. arXiv 2022, arXiv:2204.05467. [Google Scholar]
- Song, Y.; Xu, F.; Yao, Q.; Liu, J.; Yang, S. Navigation algorithm based on semantic segmentation in wheat fields using an RGB-D camera. Inf. Process. Agric. 2023, 10, 475–490. [Google Scholar] [CrossRef]
- Aghi, D.; Cerrato, S.; Mazzia, V.; Chiaberge, M. Deep semantic segmentation at the edge for autonomous navigation in vineyard rows. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3421–3428. [Google Scholar]
- Li, X.; Zhang, X.; Zhu, B.; Dai, X. A visual navigation method of mobile robot using a sketched semantic map. Int. J. Adv. Robot. Syst. 2012, 9, 138. [Google Scholar] [CrossRef]
- Deng, W.; Huang, K.; Chen, X.; Zhou, Z.; Shi, C.; Guo, R.; Zhang, H. Semantic RGB-D SLAM for rescue robot navigation. IEEE Access 2020, 8, 221320–221329. [Google Scholar] [CrossRef]
- Boularias, A.; Duvallet, F.; Oh, J.; Stentz, A. Grounding spatial relations for outdoor robot navigation. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1976–1982. [Google Scholar]
- Qi, X.; Wang, W.; Yuan, M.; Wang, Y.; Li, M.; Xue, L.; Sun, Y. Building semantic grid maps for domestic robot navigation. Int. J. Adv. Robot. Syst. 2020, 17, 1729881419900066. [Google Scholar] [CrossRef]
- Qi, X.; Wang, W.; Liao, Z.; Zhang, X.; Yang, D.; Wei, R. Object semantic grid mapping with 2D LiDAR and RGB-D camera for domestic robot navigation. Appl. Sci. 2020, 10, 5782. [Google Scholar] [CrossRef]
- Chaplot, D.S.; Gandhi, D.P.; Gupta, A.; Salakhutdinov, R.R. Object goal navigation using goal-oriented semantic exploration. Adv. Neural Inf. Process. Syst. 2020, 33, 4247–4258. [Google Scholar]
- Wang, Y.; Hussain, B.; Yue, C.P. VLP Landmark and SLAM-Assisted Automatic Map Calibration for Robot Navigation with Semantic Information. Robotics 2022, 11, 84. [Google Scholar] [CrossRef]
- Talbot, B.; Dayoub, F.; Corke, P.; Wyeth, G. Robot navigation in unseen spaces using an abstract map. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 791–805. [Google Scholar] [CrossRef]
- Borkowski, A.; Siemiatkowska, B.; Szklarski, J. Towards semantic navigation in mobile robotics. In Graph Transformations and Model-Driven Engineering: Essays Dedicated to Manfred Nagl on the Occasion of His 65th Birthday; Springer: Berlin/Heidelberg, Germany, 2010; pp. 719–748. [Google Scholar]
- Bouchlaghem, D.; Shang, H.; Whyte, J.; Ganah, A. Visualization in architecture, engineering and construction (AEC). Autom. Constr. 2005, 14, 287–295. [Google Scholar] [CrossRef]
- Bersan, D.; Martins, R.; Campos, M.; Nascimento, E.R. Semantic map augmentation for robot navigation: A learning approach based on visual and depth data. In Proceedings of the 2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE), Joȧo Pessoa, Brazil, 6–10 November 2018; pp. 45–50. [Google Scholar]
- Martins, R.; Bersan, D.; Campos, M.F.; Nascimento, E.R. Extending maps with semantic and contextual object information for robot navigation: A learning-based framework using visual and depth cues. J. Intell. Robot. Syst. 2020, 99, 555–569. [Google Scholar] [CrossRef]
- Buckeridge, S.; Carreno-Medrano, P.; Cousgun, A.; Croft, E.; Chan, W.P. Autonomous social robot navigation in unknown urban environments using semantic segmentation. arXiv 2022, arXiv:2208.11903. [Google Scholar]
- Zhao, C.; Mei, W.; Pan, W. Building a grid-semantic map for the navigation of service robots through human–robot interaction. Digit. Commun. Netw. 2015, 1, 253–266. [Google Scholar] [CrossRef]
- Joo, S.H.; Manzoor, S.; Rocha, Y.G.; Lee, H.U.; Kuc, T.Y. A realtime autonomous robot navigation framework for human like high-level interaction and task planning in global dynamic environment. arXiv 2019, arXiv:1905.12942. [Google Scholar]
- Wellhausen, L.; Ranftl, R.; Hutter, M. Safe robot navigation via multi-modal anomaly detection. IEEE Robot. Autom. Lett. 2020, 5, 1326–1333. [Google Scholar] [CrossRef]
- Miyamoto, R.; Adachi, M.; Ishida, H.; Watanabe, T.; Matsutani, K.; Komatsuzaki, H.; Sakata, S.; Yokota, R.; Kobayashi, S. Visual navigation based on semantic segmentation using only a monocular camera as an external sensor. J. Robot. Mechatron. 2020, 32, 1137–1153. [Google Scholar] [CrossRef]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Alhmiedat, T.; Alotaibi, M. Employing Social Robots for Managing Diabetes Among Children: SARA. Wirel. Pers. Commun. 2023, 130, 449–468. [Google Scholar] [CrossRef]
- Dos Reis, D.H.; Welfer, D.; De Souza Leite Cuadros, M.A.; Gamarra, D.F.T. Mobile robot navigation using an object recognition software with RGBD images and the YOLO algorithm. Appl. Artif. Intell. 2019, 33, 1290–1305. [Google Scholar] [CrossRef]
- Alhmiedat, T.A.; Abutaleb, A.; Samara, G. A prototype navigation system for guiding blind people indoors using NXT Mindstorms. Int. J. Online Biomed. Eng. 2013, 9, 52–58. [Google Scholar] [CrossRef]
- Aftf, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. Indoor object c1assification for autonomous navigation assistance based on deep CNN model. In Proceedings of the 2019 IEEE International Symposium on Measurements & Networking (M&N), Catania, Italy, 8–10 July 2019; pp. 1–4. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).