
Autonomous Visual Navigation System Based on a Single Camera for Floor-Sweeping Robot


Abstract
1. Introduction
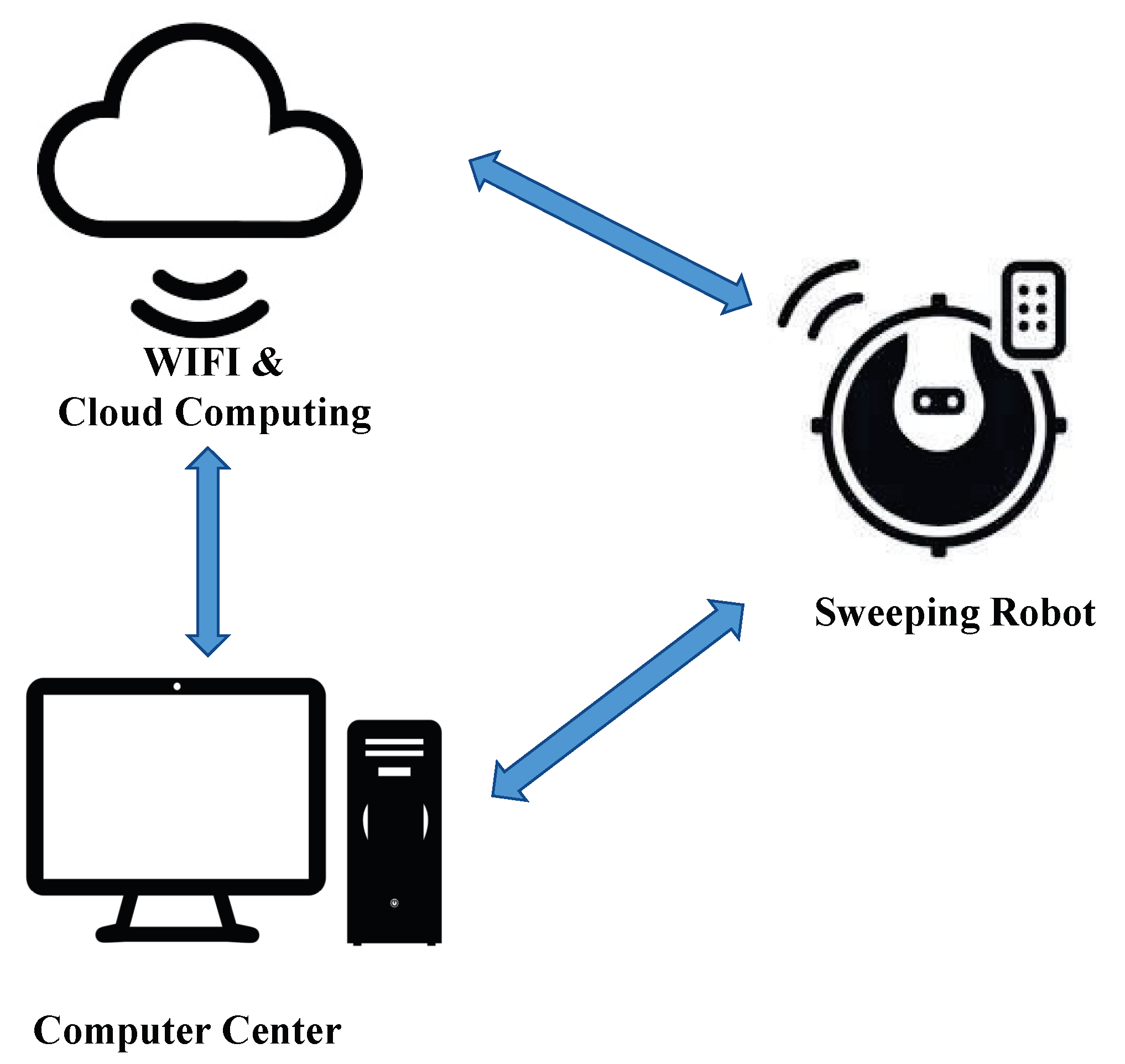
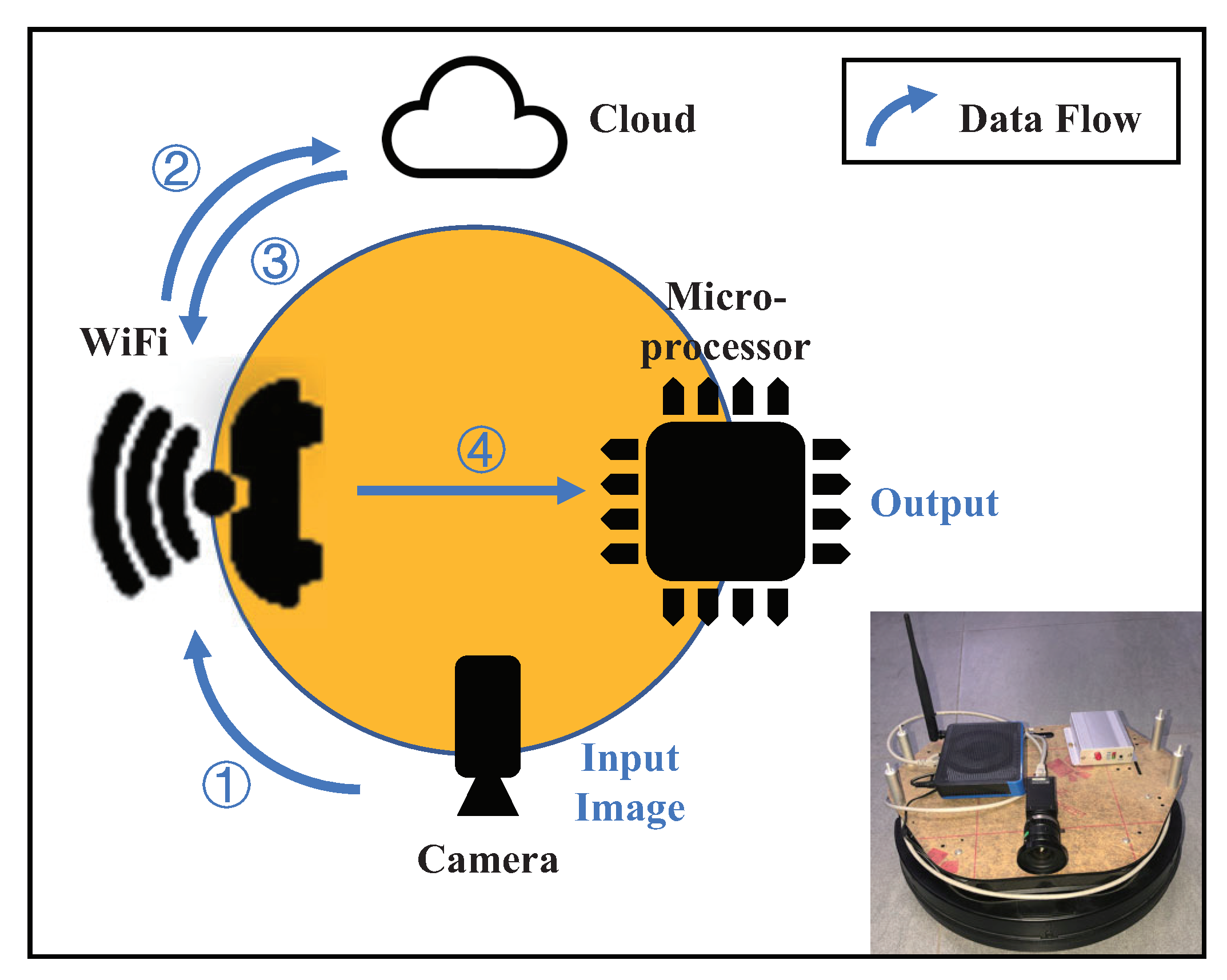
2. Framework of Autonomous Visual Navigation System
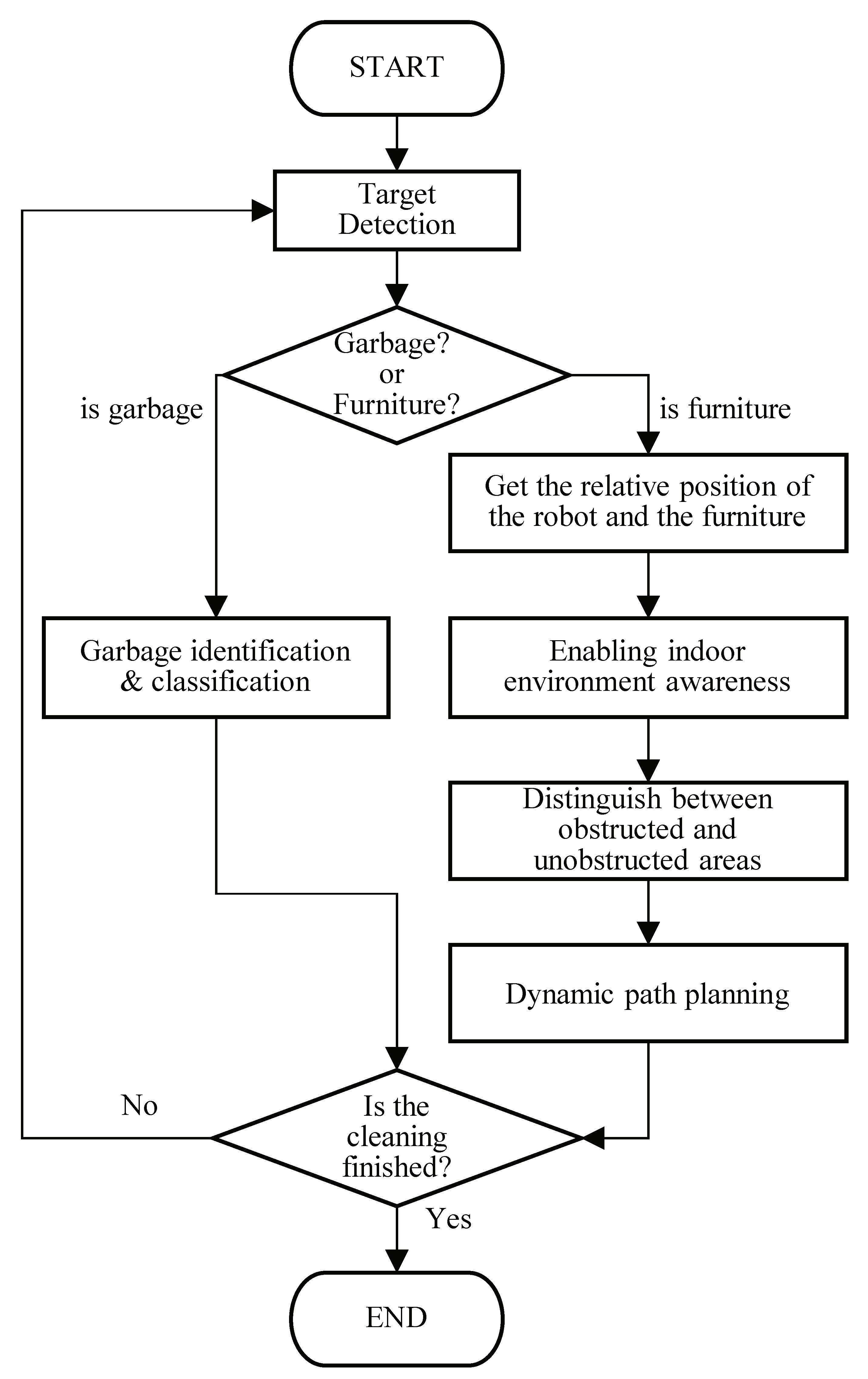
- (1)
- Garbage recognition can determine the relative orientation between the robot and the garbage.
- (2)
- Estimation of the distance between the robot and furniture under monocular vision can be used for indoor environment perception of the robot.
- (3)
- Distinguishing the obstacle areas from the clear areas forms the basis for dynamic local path planning.
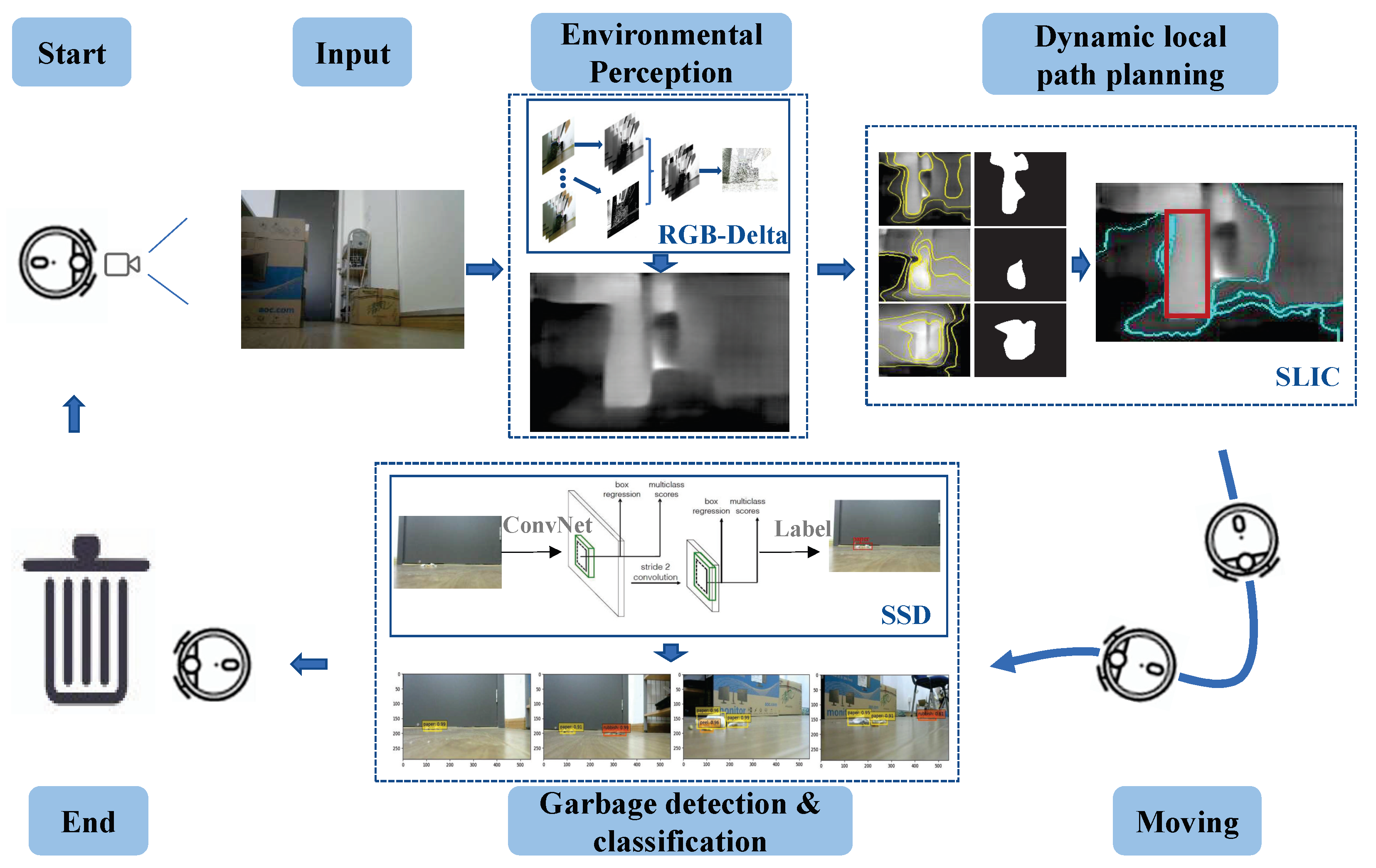
- (1)
- Inspection state. The robot rotates the direction randomly to sample images and detect garbage.
- (2)
- Targeting. After detecting the garbage, the robot adjusts its direction so that the cleaning target is in the robot’s view.
- (3)
- Environment perception. The robot performs environmental depth perception based on its position and calculates the distance from the robot to the obstacles and the distance from the robot to the targets.
- (4)
- Dynamic local path planning. The robot uses a superpixel image segment algorithm to process the image, determine the through and obstacle areas in the depth information map, and plan the way forward.
- (5)
- Directional calibration. As the robot moves forward, it continuously acquires images, re-plans the next step forward, and calibrates the forward direction in time.
3. Key Technologies
3.1. Garbage Identification and Target Detection
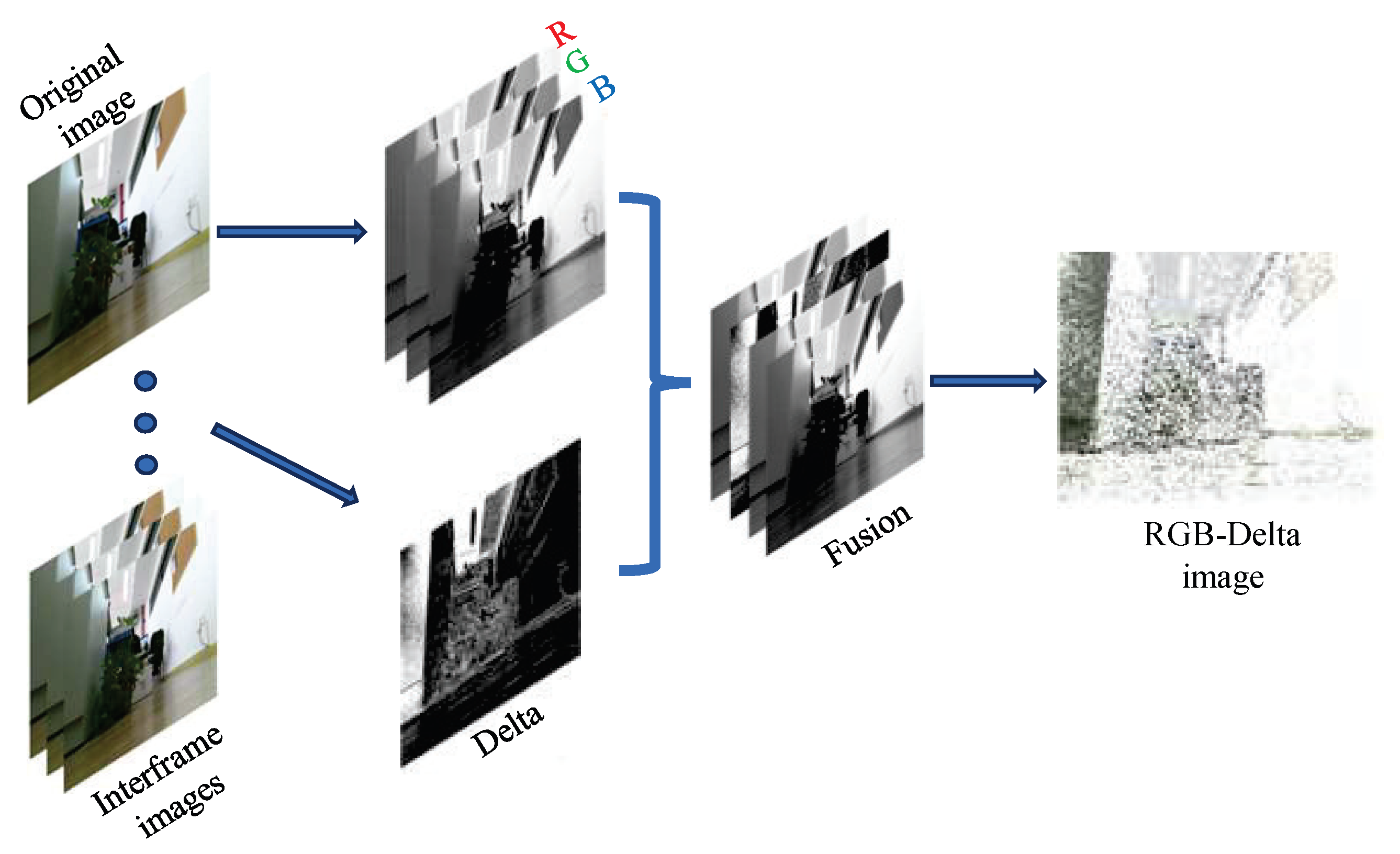
3.2. Environmental Depth Information Perception
| Algorithm 1: RGB-Delta image data fusion. |
| Require: |
| Ensure: |
|
3.3. Dynamic Local Path Planning Algorithm Based on Superpixel Segmentation
- (1)
- Obstacle areas have similar depth information performance due to their spatial relationship so that they can be fitted into superpixel blocks well after superpixel image segmentation.
- (2)
- Non-obstacle areas have the largest depth information values and are highly similar in terms of numerical relationships. Therefore, it is easy to cluster into the same superpixel block in superpixel segmentation processing.
- (3)
- Objects in different depth environments are divided into different superpixel blocks, and adjacent superpixel blocks are delimited clearly. The relative depth relationships of various objects match well when comparing the images captured in real environments.
4. Experiments
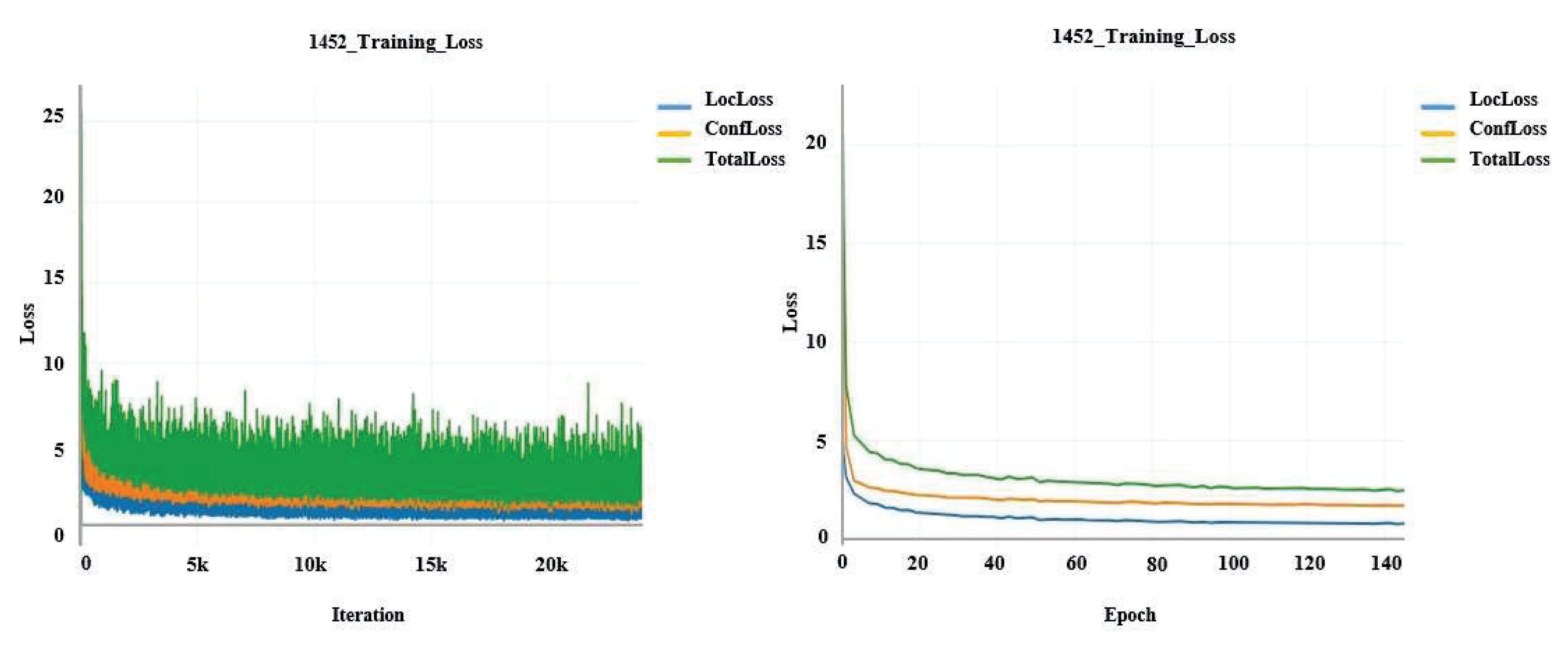
4.1. Garbage Target Detection Experiment
- (1)
- The garbage was subdivided into three types of labels, including paper, peel, and rubbish, to improve the accuracy of garbage identification.
- (2)
- There was a severe imbalance among the data sample classes, which affected the learning of the SSD model. We used horizontal flip and vertical flip to double the sample size of the images of the peel tag category so that we could balance the ratio of the samples with the other two types.
- (3)
- Data with a larger size can improve the neural network’s performance effectively, and we used random channel offset and random noise addition techniques to augment the data.
4.2. Indoor Depth Perception and Dynamic Local Path Planning Experiment
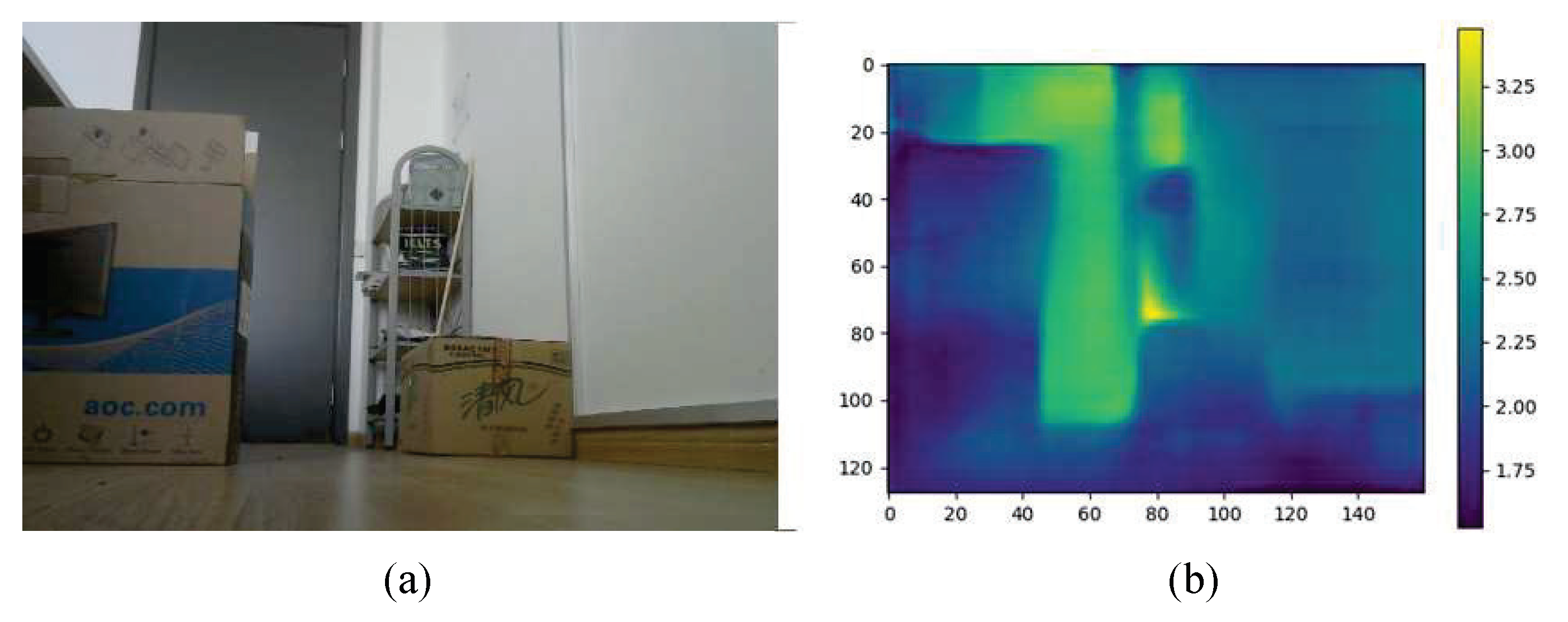
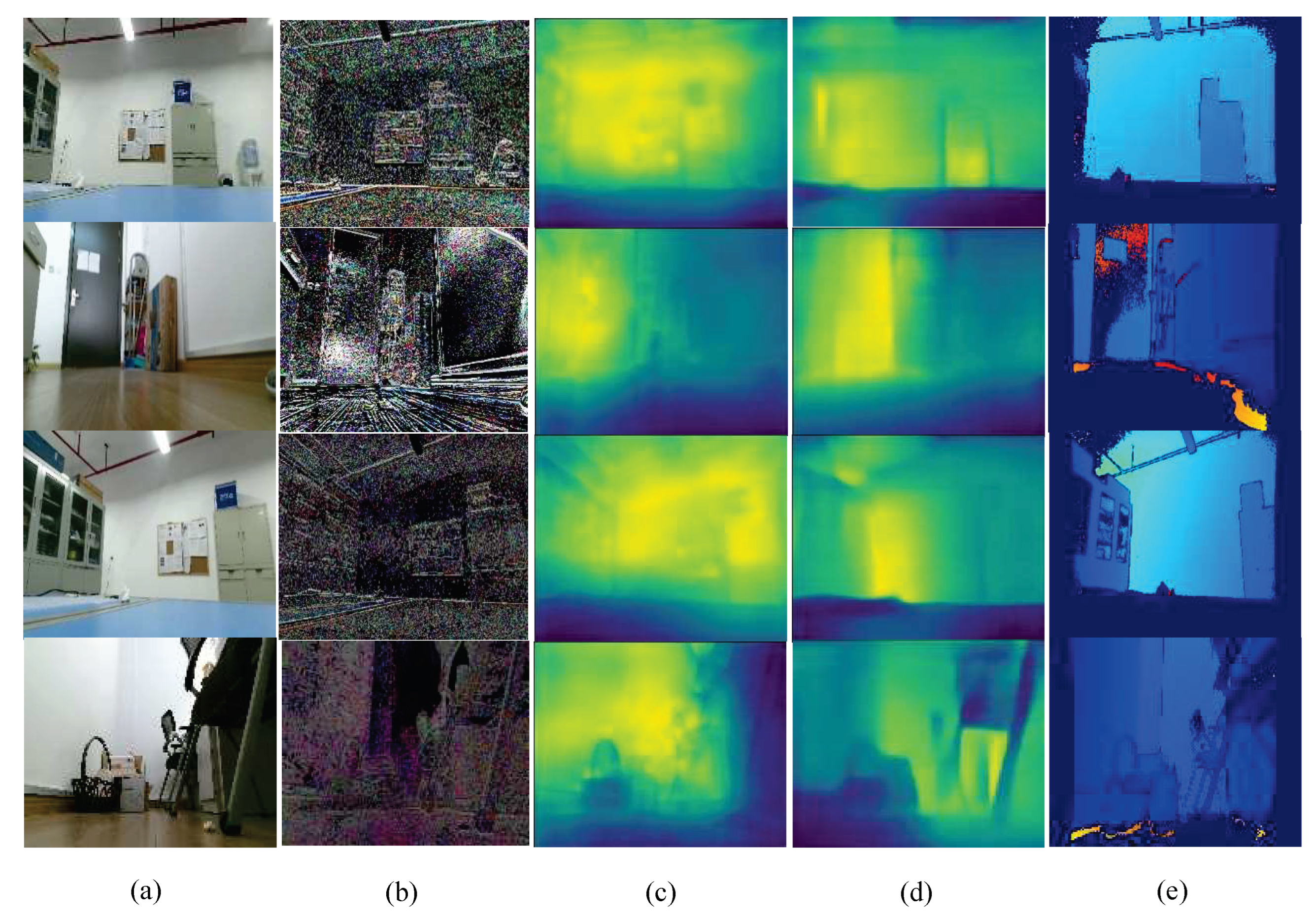
4.2.1. Indoor Depth Perception
4.2.2. Dynamic Local Path Planning
5. Conclusions and Outlook
- (1)
- The robot can realize the functions of garbage identification, environment depth information estimation, and superpixel dynamic local path planning.
- (2)
- Based on the SSD algorithm, the robot can actively identify three types of garbage, such as paper, fruit peel, and rubbish. Its mAP accuracy reaches 91.28%, which meets the high-performance requirement. The active identification of garbage avoids the blind work of traditional visual navigation and improves the working intelligence of the robot.
- (3)
- A modified method based on the self-encoder fully convolutional neural network is used to achieve monocular visual depth estimation. The depth information is used to solve the distance perception problem between the sweeping robot and the obstacles. The modified method improves the accuracy by about 3.1% when < 1.25 and lowers the average relative error Rel by about 10.4%.
- (4)
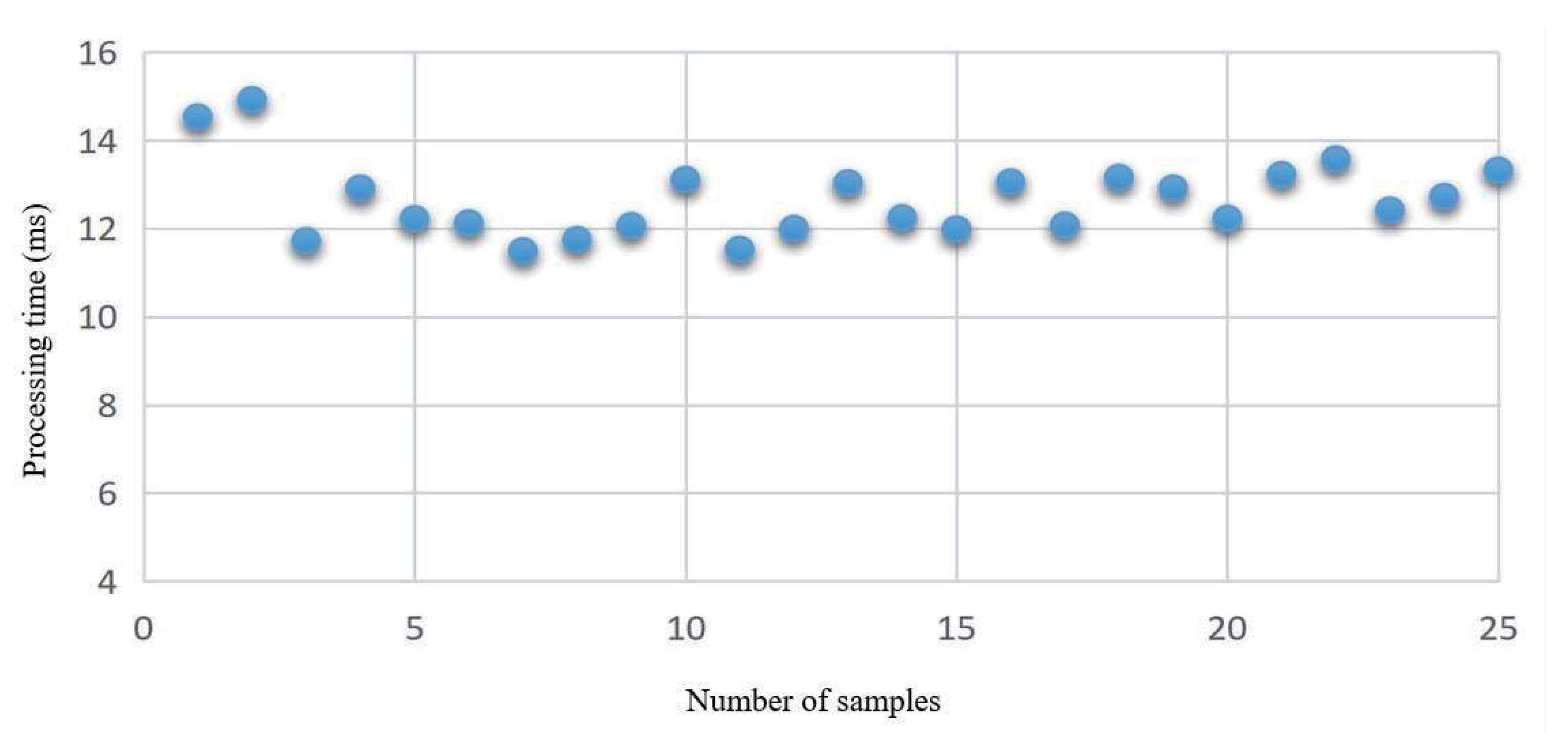
- We used the superpixel image segmentation algorithm to determine the obstacle area and the non-obstacle area. It takes only 12.554 ms to complete a single path planning, and the algorithm improves the efficiency of the navigation system and reduces the computational workload.
- (1)
- The sweeping robot we researched only conducted experiments on light garbage, such as paper, peels, and rubbish. In the future, we will research the effects of more types of garbage on the sweeping robot to improve environmental adaptability.
- (2)
- Our research avoided the drawback of over-reliance on environmental map modeling by traditional visual navigation techniques. However, there is still potential for improving the system stability, which can be optimized in the future to strengthen light anti-interference to make the path planning solution model more stable.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yi, L.; Le, A.V.; Hayat, A.A.; Borusu, C.S.C.S.; Mohan, R.E.; Nhan, N.H.K.; Kandasamy, P. Reconfiguration during locomotion by pavement sweeping robot with feedback control from vision system. IEEE Access 2020, 8, 113355–113370. Available online: https://ieeexplore.ieee.org/abstract/document/9120028 (accessed on 9 January 2023). [CrossRef]
- Zhou, Y.; Li, B.; Wang, D.; Mu, J. 2D Grid map for navigation based on LCSD-SLAM. In Proceedings of the 2021 11th International Conference on Information Science and Technology (ICIST), Chengdu, China, 21–23 May 2021; Available online: https://ieeexplore.ieee.org/document/9440650 (accessed on 9 January 2023).
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Deep learning based robot for automatically picking up garbage on the grass. IEEE Trans. Consum. Electron. 2018, 64, 382–389. Available online: https://ieeexplore.ieee.org/abstract/document/8419288/ (accessed on 9 January 2023). [CrossRef]
- Lakshmanan, A.K.; Mohan, R.E.; Ramalingam, B.; Le, A.V.; Veerajagadeshwar, P.; Tiwari, K.; Ilyas, M. Complete coverage path planning using reinforcement learning for tetromino based cleaning and maintenance robot. Autom. Constr. 2020, 112, 103078. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0926580519305813 (accessed on 9 January 2023). [CrossRef]
- Alshorman, A.M.; Alshorman, O.; Irfan, M.; Glowacz, A.; Muhammad, F.; Caesarendra, W. Fuzzy-based fault-tolerant control for omnidirectional mobile robot. Machines 2020, 8, 55. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Shi, H.; Sun, J.; Zhao, L.; Seah, H.S.; Quah, C.K.; Tandianus, B. Multi-channel convolutional neural network based 3D object detection for indoor robot environmental perception. Sensors 2019, 19, 893. Available online: https://www.mdpi.com/1424-8220/19/4/893 (accessed on 9 January 2023). [CrossRef] [PubMed]
- Cui, X.; Lu, C.; Wang, J. 3D semantic map construction using improved ORB-SLAM2 for mobile robot in edge computing environment. IEEE Access 2020, 8, 67179–67191. Available online: https://ieeexplore.ieee.org/abstract/document/9047931 (accessed on 9 January 2023). [CrossRef]
- Zhou, T.; Sun, C.; Chen, S. Monocular vision measurement system for the position and orientation of remote object. In Proceedings of the International Symposium on Photoelectronic Detection and Imaging 2007: Image Processing, Beijing, China, 9–12 September 2008; Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/6623/662311/Monocular-vision-measurement-system-for-the-position-and-orientation-of/10.1117/12.791428.short (accessed on 9 January 2023).
- Coffey, V.C. Machine Vision: The Eyes of Industry 4.0. Optics and Photonics News 2018, 29, 42–49. Available online: https://opg.optica.org/opn/viewmedia.cfm?uri=opn-29-7-42 (accessed on 9 January 2023). [CrossRef]
- Silva, R.L.; Rudek, M.; Szejka, A.L.; Junior, O.C. Machine vision systems for industrial quality control inspections. In Proceedings of the IFIP International Conference on Product Lifecycle Management, Turin, Italy, 2–4 July 2018; Available online: https://link.springer.com/chapter/10.1007/978-3-030-01614-2_58 (accessed on 9 January 2023).
- Kurabayashi, D.; Ota, J.; Arai, T.; Ichikawa, S.; Koga, S.; Asama, H.; Endo, I. Cooperative sweeping by multiple mobile robots with relocating portable obstacles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS’96, Osaka, Japan, 8 November 1996; Available online: https://ieeexplore.ieee.org/abstract/document/569008 (accessed on 9 January 2023).
- Luo, C.; Yang, S.X. A real-time cooperative sweeping strategy for multiple cleaning robots. In Proceedings of the IEEE Internatinal Symposium on Intelligent Control, Vancouver, BC, Canada, 30 October 2002; Available online: https://ieeexplore.ieee.org/abstract/document/1157841 (accessed on 9 January 2023).
- Xin, B.; Gao, G.-Q.; Ding, Y.-L.; Zhu, Y.-G.; Fang, H. Distributed multi-robot motion planning for cooperative multi-area coverage. In Proceedings of the 2017 13th IEEE International Conference on Control & Automation (ICCA), Ohrid, Macedonia, 3–6 July 2017; Available online: https://ieeexplore.ieee.org/abstract/document/8003087 (accessed on 9 January 2023).
- Altshuler, Y.; Pentland, A.; Bruckstein, A.M. Cooperative “swarm cleaning” of stationary domains. In Swarms and Network Intelligence in Search; Springer: Cham, Switzerland, 2018; pp. 15–49. Available online: https://link.springer.com/chapter/10.1007/978-3-319-63604-7_2 (accessed on 9 January 2023).
- Yu, T.; Deng, B.; Yao, W.; Zhu, X.; Gui, J. Market-Based Robots Cooperative Exploration In Unknown Indoor Environment. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; Available online: https://ieeexplore.ieee.org/abstract/document/9641421 (accessed on 9 January 2023).
- Matveev, A.; Konovalov, P. Distributed reactive motion control for dense cooperative sweep coverage of corridor environments by swarms of non-holonomic robots. Int. J. Control 2021, 1–14. Available online: https://www.tandfonline.com/doi/abs/10.1080/00207179.2021.2005258 (accessed on 9 January 2023). [CrossRef]
- Zhai, C.; Zhang, H.-T.; Xiao, G. Distributed Sweep Coverage Algorithm Using Workload Memory. In Cooperative Coverage Control of Multi-Agent Systems and its Applications; Springer: Singapore, 2021; pp. 63–80. Available online: https://link.springer.com/chapter/10.1007/978-981-16-7625-3_5 (accessed on 9 January 2023).
- Bangyal, W.H.; Nisar, K.; Ag. Ibrahim, A.A.B.; Haque, M.R.; Rodrigues, J.J.; Rawat, D.B. Comparative analysis of low discrepancy sequence-based initialization approaches using population-based algorithms for solving the global optimization problems. Appl. Sci. 2021, 11, 7591. Available online: https://www.mdpi.com/2076-3417/11/16/7591 (accessed on 9 January 2023). [CrossRef]
- Bangyal, W.H.; Ahmed, J.; Rauf, H.T. A modified bat algorithm with torus walk for solving global optimisation problems. Int. J.-Bio-Inspired Comput. 2020, 15, 1–13. Available online: https://www.inderscienceonline.com/doi/abs/10.1504/IJBIC.2020.105861 (accessed on 9 January 2023). [CrossRef]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Liu_High-Level_Semantic_Feature_Detection_A_New_Perspective_for_Pedestrian_Detection_CVPR_2019_paper.html (accessed on 9 January 2023).
- Mahankali, S.; Kabbin, S.V.; Nidagundi, S.; Srinath, R. Identification of illegal garbage dumping with video analytics. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; Available online: https://ieeexplore.ieee.org/abstract/document/8554678 (accessed on 9 January 2023).
- Liu, Y.; Ge, Z.; Lv, G.; Wang, S. Research on automatic garbage detection system based on deep learning and narrowband internet of things. In Proceedings of the Journal of Physics: Conference Series, Suzhou, China, 22–24 June 2018; p. 012032. Available online: https://iopscience.iop.org/article/10.1088/1742-6596/1069/1/012032/meta (accessed on 9 January 2023).
- Sousa, J.; Rebelo, A.; Cardoso, J.S. Automation of waste sorting with deep learning. In Proceedings of the 2019 XV Workshop de Visão Computacional (WVC), São Bernardo do Campo, Brazil, 9–11 September 2019; Available online: https://ieeexplore.ieee.org/abstract/document/8876924 (accessed on 9 January 2023).
- Setiawan, W.; Wahyudin, A.; Widianto, G. The use of scale invariant feature transform (SIFT) algorithms to identification garbage images based on product label. In Proceedings of the 2017 3rd International Conference on Science in Information Technology (ICSITech), Bandung, Indonesia, 25–26 October 2017; Available online: https://ieeexplore.ieee.org/abstract/document/8257135 (accessed on 9 January 2023).
- Yang, G.; Zheng, W.; Che, C.; Wang, W. Graph-based label propagation algorithm for community detection. Int. J. Mach. Learn. Cybern. 2020, 11, 1319–1329. Available online: https://link.springer.com/article/10.1007/s13042-019-01042-0 (accessed on 9 January 2023). [CrossRef]
- He, L.; Ren, X.; Gao, Q.; Zhao, X.; Yao, B.; Chao, Y. The connected-component labeling problem: A review of state-of-the-art algorithms. Pattern Recognit. 2017, 70, 25–43. Available online: https://www.sciencedirect.com/science/article/pii/S0031320317301693 (accessed on 9 January 2023). [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Gardiner, A.; Hare, J.; Atkinson, P.M. VPRS-based regional decision fusion of CNN and MRF classifications for very fine resolution remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4507–4521. Available online: https://ieeexplore.ieee.org/abstract/document/8345225/ (accessed on 9 January 2023). [CrossRef]
- Chen, X.; Zheng, C.; Yao, H.; Wang, B. Image segmentation using a unified Markov random field model. IET Image Process. 2017, 11, 860–869. Available online: https://ietresearch.onlinelibrary.wiley.com/doi/full/10.1049/iet-ipr.2016.1070 (accessed on 9 January 2023). [CrossRef]
- Kong, X.; Meng, Z.; Nojiri, N.; Iwahori, Y.; Meng, L.; Tomiyama, H. A HOG-SVM based fall detection IoT system for elderly persons using deep sensor. Procedia Comput. Sci. 2019, 147, 276–282. Available online: https://www.sciencedirect.com/science/article/pii/S187705091930287X (accessed on 9 January 2023). [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. Available online: https://ieeexplore.ieee.org/abstract/document/8627998/ (accessed on 9 January 2023). [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0925231220301430 (accessed on 9 January 2023). [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 9 January 2023).
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; Available online: https://ieeexplore.ieee.org/abstract/document/7785097 (accessed on 9 January 2023).
- Lin, X.; Wang, J.; Lin, C. Research on 3d reconstruction in binocular stereo vision based on feature point matching method. In Proceedings of the 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 27–29 September 2020; Available online: https://ieeexplore.ieee.org/abstract/document/9236889 (accessed on 9 January 2023).
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. Available online: https://ieeexplore.ieee.org/abstract/document/6205760 (accessed on 9 January 2023). [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. Available online: https://ieeexplore.ieee.org/abstract/document/888718 (accessed on 9 January 2023). [CrossRef]
- Vijayanagar, K.R.; Loghman, M.; Kim, J. Real-time refinement of kinect depth maps using multi-resolution anisotropic diffusion. Mob. Netw. Appl. 2014, 19, 414–425. Available online: https://link.springer.com/article/10.1007/s11036-013-0458-7 (accessed on 9 January 2023). [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processing Method | Precision | Accuracy | Data Requirements | Computational Resource Consumption |
|---|---|---|---|---|
| CCM 1 [25,26] | Low | Low | Low | Low |
| MRF [27,28] | Relatively low | General | Low | Low |
| HOG + SVM [29] | High | High | Relatively high | General |
| Deep Learning [30,31] | Relatively high | Relatively high | Very high | Very high |
| Hardware | Description |
|---|---|
| Wi-Fi | TP-LINK |
| Micro-processor | SZ02-232-2K, S202-NET-2K |
| Camera | Logitech C270c |
| GPU | NVIDIA GTX 1080TI Single video memory 11G, memory 32G |
| CPU | AMD Ryzen 5 5600X 6-Core Processor 3.70 GHz |
| Platform | Turtlebot2 |
| Software | Version |
|---|---|
| Operation System | Ubuntu 16.04 LTS, ROS Kinetic |
| Programming Language | Python 3.6.5 |
| Framework of Deep Learning | Tensorflow 1.13.0 |
| Dataset | Dataset Size | mAP (%) |
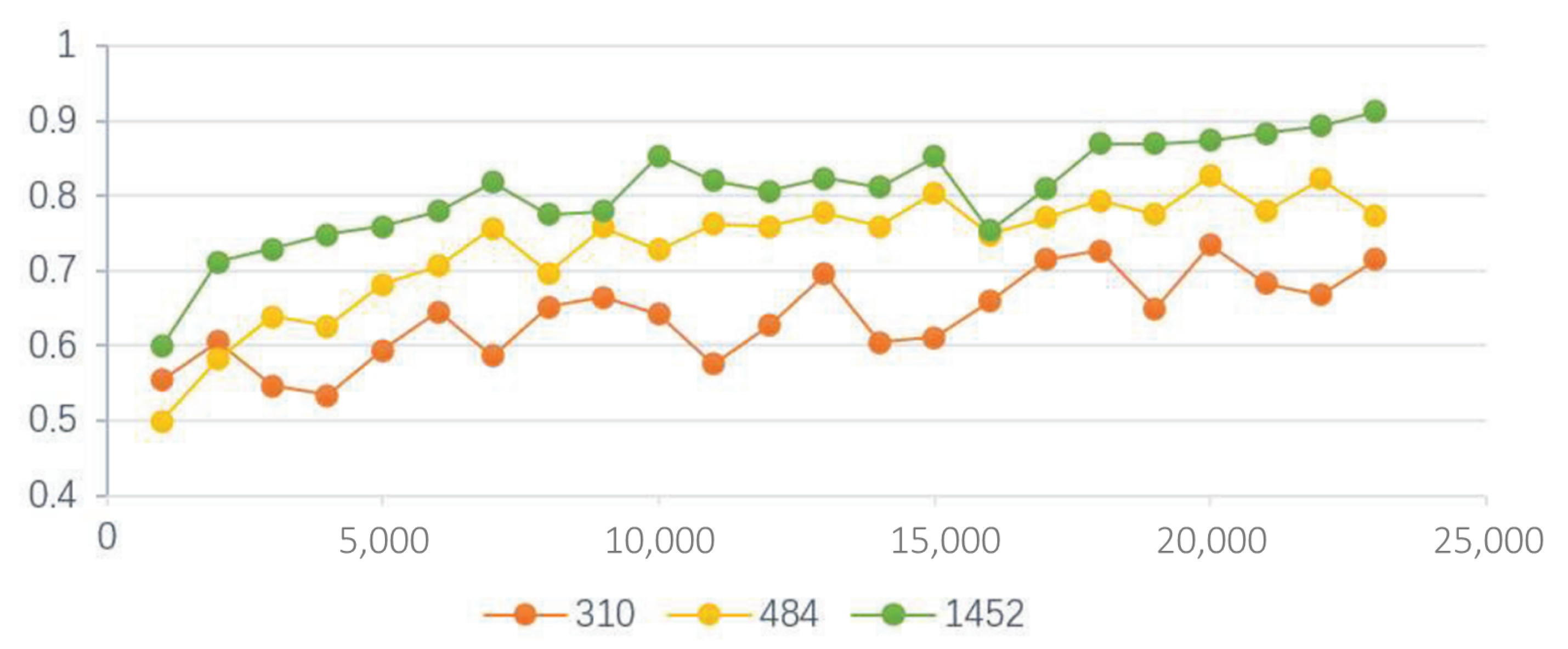
|---|---|---|
| Original dataset | 310 | 73.45 |
| Sample-balanced dataset | 484 | 85.29 |
| Data augmented dataset | 1452 | 91.28 |
| Parameters | Value |
|---|---|
| Learn rate | 0.001 |
| Bitch size | 4 |
| Momentum | 0.9 |
| Ratio | 6:2:2 |
| Method | Accuracy (Higher is Better) | Error (Lower is Better) | ||||
|---|---|---|---|---|---|---|
| RMS | Rel | log10 | ||||
| Laina’s [30] | 0.807 | 0.946 | 0.979 | 0.579 | 0.135 | 0.059 |
| Ours | 0.838 | 0.957 | 0.986 | 0.565 | 0.121 | 0.051 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, J.; Bian, H.; Xu, X.; Chen, J. Autonomous Visual Navigation System Based on a Single Camera for Floor-Sweeping Robot. Appl. Sci. 2023, 13, 1562. https://doi.org/10.3390/app13031562
Rao J, Bian H, Xu X, Chen J. Autonomous Visual Navigation System Based on a Single Camera for Floor-Sweeping Robot. Applied Sciences. 2023; 13(3):1562. https://doi.org/10.3390/app13031562
Chicago/Turabian StyleRao, Jinjun, Haoran Bian, Xiaoqiang Xu, and Jinbo Chen. 2023. "Autonomous Visual Navigation System Based on a Single Camera for Floor-Sweeping Robot" Applied Sciences 13, no. 3: 1562. https://doi.org/10.3390/app13031562
APA StyleRao, J., Bian, H., Xu, X., & Chen, J. (2023). Autonomous Visual Navigation System Based on a Single Camera for Floor-Sweeping Robot. Applied Sciences, 13(3), 1562. https://doi.org/10.3390/app13031562